APT- und Cybercrime-Gangs: Was der Namensabgleich durch die Hersteller bringt
close notice
This article is also available in
English.
It was translated with technical assistance and editorially reviewed before publication.
.
„Brass Typhoon“ ist „Wicked Panda“, und „Ghost Blizzard“ entspricht „Berserk Bear“: Diese und weitere eindeutige Namenszuordnungen von APT- und Cybercrime-Gruppen sind das erste sichtbare Resultat einer frisch ins Leben gerufenen Zusammenarbeit von Microsoft und CrowdStrike.
Ziel der Bemühungen ist ein vollständiger und in Bezug auf neue Bedrohungen jeweils möglichst zeitnaher Taxonomie-Abgleich der beiden Hersteller. Auch Googles Mandiant-Team sowie Palo Altos Unit 42 wollen sich laut Microsofts Ankündigung in Zukunft an der Kooperation beteiligen.
So weit der Plan. Aber was bringt der Abgleich eigentlich in der Praxis, und was können Sicherheitsverantwortliche mit den resultierenden Taxonomie-Mappings konkret anfangen? Wir ordnen die aktuelle Entwicklung ein, schauen uns den bisherigen Zwischenstand des Namensabgleichs an und checken, wie nützlich er bis hierhin ist.
Mehrwert: Verlässlichere Zuordnungen…
Zunächst einmal ist festzuhalten, dass die Zusammenarbeit zwischen Microsoft und CrowdStrike nur auf einen systematischen Namensabgleich abzielt; an der unterschiedlichen Benennung der Cybercrime-Akteure durch die Firmen ändert sich auch in Zukunft nichts.
Dennoch stellt die Tatsache, dass sich zwei Hersteller zusammentun, um auf Basis gesammelter Bedrohungsinformationen gemeinsam klare Zuordnungen zu treffen, einen echten Fortschritt beim Entwirren des Cybercrime-Namenschaos dar. Denn bislang erfolgten Mappings der Herstellerbezeichnungen primär „von außen“ – etwa durch das BSI oder im Rahmen der Wissensdatenbank MITRE ATT&CK. Offiziell von den betreffenden Unternehmen abgesegnet sind die Gleichsetzungen nicht. Deren Kooperation und der direkte Austausch lässt nun auf verlässlichere – und vor allem verbindliche – Namenszuordnungen hoffen.
… und übertragbare Bedrohungsinformationen
Derlei verbindliche Zuordnungen können bei Sicherheitsvorfällen wertvolle Zeit sparen helfen. Ein Beispiel: Ein von einem APT-Angriff betroffenes Unternehmen will gefährdete Geschäftspartner warnen. Die nutzen möglicherweise andere Sicherheitssoftware – und profitieren von dem Wissen um verlässliche alternative Herstellerbezeichnungen für die betreffende Bedrohung.
Ein weiterer Mehrwert des Taxonomie-Abgleichs: Er verbessert die Zugänglichkeit von Informationen zu den jeweiligen APT- oder Cybercrime-Gruppen. Denn wenn kooperierende Hersteller-Teams unterschiedlich benannte Gruppen als identisch anerkennen, sind logischerweise auch die ihnen zugeordneten Bedrohungsdaten übertragbar.
Das hilft bei der Informationsrecherche. Warnt etwa der unternehmensinterne CrowdStrike-Schutz plötzlich vor „Vanguard Panda“, kann eine zusätzliche Online-Suche nach Microsofts Entsprechung „Volt Typhoon“ weitere Hinweise auf geeignete Abwehr-, Bereinigungs- oder Präventivmaßnahmen liefern.
Von Microsoft identifizierte typische Kompromittierungsindikatoren (Indicators of Compromise, IoC) einer konkreten Cybercrime-Gruppe gelten auch für das CrowdStrike-Pendant und sind somit direkt nutzbar, um sie etwa für einen Systemscan an den IoC-Scanner Thor Lite zu verfüttern. Gleiches gilt für vorhandene YARA-Regeln oder Threat-Intelligence-Feeds. Somit müssen Sicherheitsverantwortliche das Rad nicht ständig neu erfinden.
Zwischenstand: (Noch) nicht wirklich praktisch
Fällt einem nun wie beschrieben Vanguard Panda vor die Füße, will man die Resultate des Namensabgleichs natürlich möglichst zügig abzurufen.
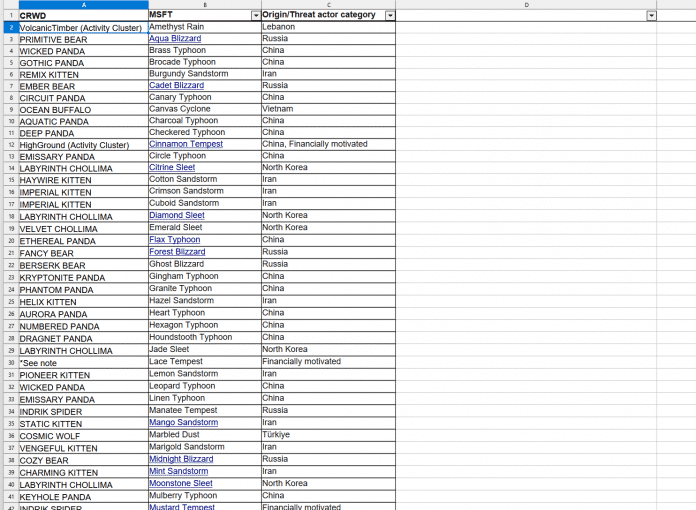
Genau das ist bislang aber nicht wirklich möglich. Der bisherige Zwischenstand der Hersteller-Bemühungen – etwas über 80 Zuordnungen von CrowdStrikes zu Microsofts Gruppenbezeichnungen – steht auf der CrowdStrike-Website bislang lediglich als gezippte Excel-Tabelle (!) bereit. Im Bedrohungsfall müsste man die erst einmal herunterladen und auspacken, um dann das Dokument manuell zu durchsuchen und ganz unten auf Volt Typhoon zu stoßen. Online-Suchinterfaces oder dergleichen gibt es (zumindest noch) nicht.
Informativ, aber umständlich: CrowdStrikes Excel-Dokument mit Namenszuordnungen.
(Bild: Screenshot)
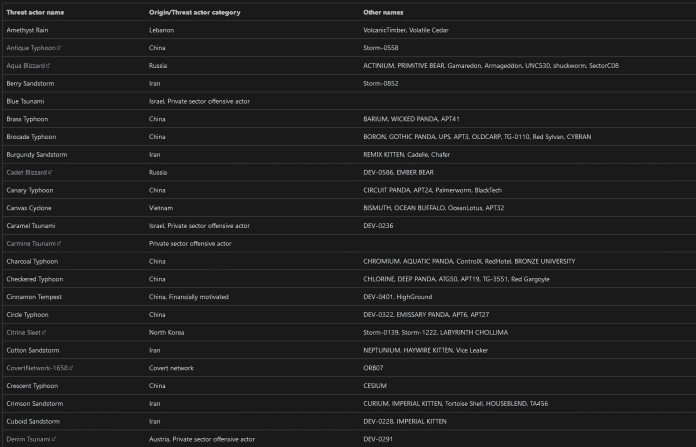
Microsoft wiederum hat neben einer – wiederum nur manuell durchforstbaren – Online-Tabelle mit Zuordnungen auch noch eine Fassung im JSON-Format bei GitHub veröffentlicht. Zusätzlich verweist das Unternehmen in einem Blogeintrag auf die Möglichkeit, Namensinformationen mittels eines speziellen Queries unter anderem aus Sentinel, Microsoft 365 Defender und Azure Data Explorer abrufen.
Blick ins Taxonomie-Mapping: Zusätzlich zu CrowdStrike-Aliases listet Microsoft für manche Gruppen unsortierte Bezeichnungen weiterer Hersteller auf.
Auch hier lässt sich festhalten: Einfache, schnelle Suchmöglichkeiten sehen anders aus. An Microsofts Tabelle verwirrt zudem, dass neben CrowdStrikes Gruppen-Aliases zusätzlich auch noch Bezeichnungen weiterer Hersteller darin auftauchen. Eine klare Zuordnung zwischen diesen Bezeichnungen zu konkreten Firmen fehlt. Auch bleibt offen, ob auch diese Zusatzinformationen das Ergebnis eines direkten inhaltlichen Austauschs mit anderen Sicherheitsteams sind oder ob sie einzig auf Microsofts Einschätzung basieren. Microsoft listet etwa den verballhornten „Laundry Bear“ (Waschbär?) des niederländischen Geheimdienstes auf, der aber bei Crowdstrike nicht auftaucht.
Gute Idee mit viel Luft nach oben
Unsere Beispiele zeigen, dass der von Microsoft und CrowdStrike initiierte Namensabgleich ein in vielerlei Hinsicht lohnendes Projekt darstellt. Die öffentliche Zugänglichkeit und Durchsuchbarkeit der Informationen ist allerdings noch stark ausbaufähig – zumal vor dem Hintergrund, dass die Taxonomie-Mappings in Zukunft kontinuierlich gepflegt und erweitert werden sollen.
Zu wünschen bleibt außerdem, dass sich künftig mehr Firmen an den Abgleichen beteiligen, damit Aussagekraft und inhaltlicher Nutzen weiter zunehmen. Und dass die Beteiligten im Austausch miteinander sorgfältig und gewissenhaft vorgehen. Denn so gut die Idee der Zusammenarbeit auch ist, hätten falsche Zuordnungen umgekehrt auch das Potenzial, großen Schaden anzurichten.
Einem Beitrag von CrowdStrike ist zu entnehmen, dass Vorbereitungen für weitere Kooperationen laufen: Man wolle mit einer „kleinen, fokussierten Gruppe Beitragender“, geleitet von Microsoft und CrowdStrike, beginnen. Die von Microsoft erwähnten Firmen Google/Mandiant und Palo Alto haben sich indes noch nicht selbst geäußert. Bis es soweit ist, bietet unter anderem das vom Sicherheitsforscher Florian Roth gepflegte Spreadsheet „APT Groups and Operations“ eine sehr umfangreiche und in der Security-Community beliebte Referenz für die Zuordnung von Namen.
Die Woche, in der sich die Überwachungspläne bei uns stapelten
Fraktal, generiert mit MandelBrowser von Tomasz Śmigielski
Liebe Leser*innen,
in Berlin ist zwar die Ferienzeit angebrochen. Sommerliche Ruhe will aber nicht so recht einkehren. Denn auf unseren Schreibtischen stapeln sich die neuen Gesetzesentwürfe der Bundesregierung. Und die haben’s in sich.
Beispiele gefällig?
Staatstrojaner: Künftig soll die Bundespolizei zur „Gefahrenabwehr“ Personen präventiv hacken und überwachen dürfen, auch wenn „noch kein Tatverdacht begründet ist“.
Biometrische Überwachung: Bundeskriminalamt, Bundespolizei und das Bundesamt für Migration und Flüchtlinge sollen Personen anhand biometrischer Daten im Internet suchen dürfen. Auch Gesichter-Suchmaschinen wie Clearview AI oder PimEyes können sie dann nutzen.
Palantir: Bundeskriminalamt und Bundespolizei sollen Datenbestände zusammenführen und automatisiert analysieren dürfen. Das riecht gewaltig nach Palantir – was das Innenministerium in dieser Woche bestätigt hat.
Auch in vielen Bundesländern wird über Palantir diskutiert. In Baden-Württemberg sind die Grünen soeben umgekippt. Keine gewagte Prognose: Andere werden ihre Vorsätze auch noch über Bord werfen.
Die gute Nachricht: In allen drei Bundesländern, die Palantir einsetzen – Bayern, Hessen und Nordrhein-Westfalen -, sind jeweils Verfassungsbeschwerden gegen die Polizeigesetze anhängig. Und auch die Überwachungspläne der Bundesregierung verstoßen ziemlich sicher gegen Grundgesetz und EU-Recht. Wir bleiben dran.
Martin, Sebastian und Chris im Studio. – CC-BY-NC-SA 4.0 netzpolitik.org
Diese Recherche hat für enorm viel Aufsehen gesorgt: Über Monate hinweg hat sich Martin damit beschäftigt, wie Polizeibehörden, Banken und Unternehmen unser Bargeld verfolgen und was sie über die Geldströme wissen. Die Ergebnisse überraschten auch uns, denn sie räumen mit gängigen Vorstellungen über das vermeintlich anonyme Zahlungsmittel auf. Die Aufregung um diese Recherche rührt vielleicht auch daher, dass Behörden nicht gerne darüber sprechen, wie sie Bargeld tracken. Martin selbst spricht von einer der zähsten Recherchen seines Arbeitslebens.
Außerdem erfahrt ihr, wie wir solche Beiträge auf Sendung-mit-der-Maus-Niveau bringen und warum man aus technischen Gründen besser Münzen als Scheine rauben sollte. Wir sprechen darüber, wie wir trotz schlechter Nachrichten zuversichtlich bleiben und warum wir weitere Wände im Büro einziehen. Viel Spaß beim Zuhören!
Und falls wir es in dieser Podcast-Folge noch nicht oft genug erwähnt haben sollten: Wir freuen uns über Feedback, zum Beispiel per Mail an podcast@netzpolitik.org oder in den Ergänzungen auf unserer Website.
In dieser Folge: Martin Schwarzbeck, Sebastian Meineck und Chris Köver. Produktion: Serafin Dinges. Titelmusik: Trummerschlunk.
Hier ist die MP3 zum Download. Wie gewohnt gibt es den Podcast auch im offenen ogg-Format. Ein maschinell erstelltes Transkript gibt es im txt-Format.
Unseren Podcast könnt ihr auf vielen Wegen hören. Der einfachste: in dem Player hier auf der Seite auf Play drücken. Ihr findet uns aber ebenso bei Apple Podcasts, Spotify und Deezer oder mit dem Podcatcher eures Vertrauens, die URL lautet dann netzpolitik.org/podcast.
Wir freuen uns auch über Kritik, Lob, Ideen und Fragen entweder hier in den Kommentaren oder per E-Mail an podcast@netzpolitik.org.
Sicherheitsupdates: IBM Db2 über verschiedene Wege angreifbar
close notice
This article is also available in
English.
It was translated with technical assistance and editorially reviewed before publication.
.
Aufgrund von mehreren Softwareschwachstellen können Angreifer IBM Db2 attackieren und Instanzen im schlimmsten Fall vollständig kompromittieren. Um dem vorzubeugen, sollten Admins die abgesicherten Versionen installieren.
Schadcode-Schlupfloch
Am gefährlichsten gilt eine Sicherheitslücke (CVE-2025-33092 „hoch„), durch die Schadcode schlüpfen kann. Die Basis für solche Attacken ist ein von Angreifern ausgelöster Speicherfehler. Wie ein solcher Angriff konkret ablaufen könnten, ist bislang unklar. Davon sind einer Warnmeldung zufolge die Client- und Server-Editionen von Db2 bedroht. Das betrifft die Db2-Versionen 11.5.0 bis einschließlich 11.5.9 und 12.1.0 bis einschließlich 12.1.2.
Eine weitere Schwachstelle (CVE-2025-24970) ist mit dem Bedrohungsgrad „hoch“ eingestuft. Sie betrifft das Application Framework Netty. An dieser Stelle können Angreifer Abstürze provozieren. Auch hier soll ein Special Build Abhilfe schaffen.
Weitere Gefahren
Die verbleibenden Schwachstellen sind mit dem Bedrohungsgrad „mittel“ versehen. An diesen Stellen können Angreifer meist ohne Authentifizierung DoS-Zustände erzeugen, was Abstürze nach sich zieht. Die dagegen gerüsteten Versionen finden Admins in den verlinkten Warnmeldungen (nach Bedrohungsgrad absteigend sortiert):