Entwicklung & Code
Microsoft wirft Windows PowerShell 2.0 über Bord
Ein neuer Eintrag hat sich auf die Liste der abgekündigten Windows-Features gemogelt. Windows PowerShell 2.0 wird aus Windows herausfliegen. Die Erinnerung erfolgt rund acht Jahre nach der ersten Ankündigung.

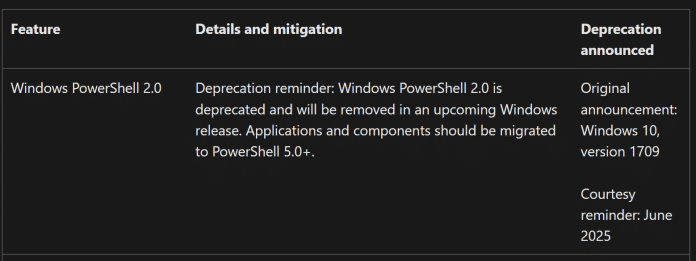
Ein neuer Eintrag auf der Deprecated-Feature-Liste weist auf das nahende Ende von Windows PowerShell 2.0 hin.
(Bild: Screenshot / dmk)
Auf der von Microsoft gepflegten Liste der abgekündigten Funktionen, der „Deprecated Features List“, erklärt der Hersteller: „Abkündigungserinnerung: Windows PowerShell 2.0 ist abgekündigt und wird in einer künftigen Windows-Version entfernt. Anwendungen und Komponenten sollten zu PowerShell 5.0+ migriert werden“. Ursprünglich hat Microsoft erstmals das Ende von PowerShell 2.0 zum Release von Windows 10 Build 1709, also im Jahr 2017, verkündet.
Gut abgehangene PowerShell-Version
Ursprünglich angekündigt hatte Microsoft die PowerShell 2.0 Ende 2008. Der damalige Chef-Architekt Jeffrey Snover kündigte dort die Integration in Windows 7, Windows 2008 R2 und auch Windows Server Core 2008 R2 an. Sie war für Windows XP, Vista und Server 2008 zudem als Add-on verfügbar. Nach nunmehr 17 Jahren will Microsoft die alte PowerShell-Version jetzt abräumen.
Die Entwicklung an PowerShell selbst hingegen geht munter weiter. Aktuell ist die Fassung 5.1 auf vielen Windows-Systemen, aber auch PowerShell 7 steht seit dem Jahr 2020 bereit – als Open Source. Beide Fassungen lassen sich parallel betreiben. Seit Anfang des Jahres entwickeln Microsofts Programmierer mit der Community hier an Version 7.6, die bislang als „preview.2“ verfügbar ist.
Für die Migration alter Skripte für PowerShell 2.0 auf die aktuelle Fassung des Administratorwerkzeugs stehen keine offensichtlichen Anleitungen von Microsoft bereit. Admins sollten sich jedoch langsam an die Anpassung und Tests der bisher genutzten Skripte an die neuen Versionen machen. Zumindest für den Umzug von PowerShell 5.1 zu PowerShell 7.x liefert Microsoft in einem Support-Artikel Informationen zu den Änderungen unter anderem auch in den Methoden und Funktionen.
(dmk)










Entwicklung & Code
Software Testing: Qualität ist kein Zufall
In dieser Episode sprechen Richard Seidl und Florian Fieber über den besonderen Anlass, dass Seidl mit dem Deutschen Preis für Softwarequalität ausgezeichnet wurde. Diese Auszeichnung bietet den Rahmen, um über die Rolle des Menschen in der Technologieentwicklung nachzudenken. Richard Seidl teilt seine Sichtweise, dass Qualität weit über Testdaten und Skripte hinausgeht und dass es darum geht, ein Umfeld zu schaffen, in dem Teams Qualität aktiv leben.
Seidl und Fieber diskutieren auch die zukünftigen Herausforderungen und Möglichkeiten, die sich durch die Integration von KI im Bereich Testing ergeben.
„Wenn ein Team wirklich Qualität lebt und nicht nur Testfälle schrubbt, dann ist das ganze Thema auf einem völlig anderen Level angekommen.“ – Richard Seidl
Bei diesem Podcast dreht sich alles um Softwarequalität: Ob Testautomatisierung, Qualität in agilen Projekten, Testdaten oder Testteams – Richard Seidl und seine Gäste schauen sich Dinge an, die mehr Qualität in die Softwareentwicklung bringen.
Die aktuelle Ausgabe ist auch auf Richard Seidls Blog verfügbar: „Qualität ist kein Zufall – Richard Seidl“ und steht auf YouTube bereit.
(mai)
Entwicklung & Code
Apple übernimmt Entwickler des Open Policy Agents
Open Policy Agent (OPA) ist eine Software, die Regeln (formuliert in der Sprache Rego) und Datenobjekte entgegennimmt und auf dieser Grundlage Entscheidungen trifft – Haupteinsatzgebiet sind Autorisierungsregeln, die die Frage beantworten, ob ein Nutzer eine Aktion ausführen darf. Weil OPA Open-Source-Software ist (Apache License 2.0) und vergleichsweise leicht in andere Anwendungen integriert werden kann, erfreut er sich großer Beliebtheit in der Cloud-Native-Community: OPA wird unter anderem genutzt, um über Anfragen ans Kubernetes-API zu entscheiden, trifft in Banken aber auch Entscheidungen, wer welche Anfragen an interne Systeme stellen darf.
Erfunden wurde OPA vom Unternehmen Styra, das mit Zusatzprodukten und Dienstleistungen rund um OPA Geld verdient hat. Auf der Homepage findet man die Logos von Zalando, CapitalOne und dem Europäischen Patentamt. Auch Goldman Sachs und Netflix gehört zu den OPA-Nutzern. Der Code von OPA selbst liegt aber nicht mehr in der Hand von Styra: 2018 wurde OPA als Incubating-Projekt von der CNCF (Cloud Native Computing Foundation) akzeptiert, seit 2021 hat es den höchsten Status „Graduated“ erreicht und hat insgesamt 485 Contributors.
Jetzt steht der nächste Umbruch an: Die Erfinder von Open Policy Agent sowie weitere Mitarbeiter des Unternehmens Styra wechseln den Arbeitgeber: Apple, ebenfalls OPA-Nutzer, übernimmt Styra-CTO Tim Hinrichs und weitere Entwickler. Das hat Hinrichs im OPA-Blog verkündet. „Apple ist ein enthusiastischer OPA-Nutzer, der es als zentrale Komponente seiner Autorisationsinfrastruktur nutzt, um ein großes Portfolio globaler Clouddienste zu verwalten.“
Mehr Open Source
Weil der Code bereits in der Hand der CNCF liegt, ändert sich das Open-Source-Projekt nichts. Der Code bleibt Open Source und wird wie zuvor von der CNCF verwaltet. Auch die Liste der Maintainer soll sich nicht ändern. Neu ist vielmehr, dass Zusatzprodukte aus dem Styra-Portfolio ebenfalls Open Source werden und ins öffentliche Repository umziehen: die kommerzielle OPA-Distribution EOPA, die Verwaltungsoberfläche „OPA Control Plane“, mehrere SDKs sowie der Rego-Linter namens Regal.
Website und Rego-Playground (eine Website, um Rego-Regeln zu testen) sollen wie gewohnt weiterlaufen und auch die Entwicklung soll weitergehen. Unklar hingegen ist, in welcher Form das Unternehmen Styra weiterarbeiten wird. Dazu macht der Blogpost keine Angaben. Große Organisationen, die gehofft haben, bei Styra die Autorisierungsexpertise und Beratung von Tim Hinrichs und den anderen OPA-Kernentwicklern einkaufen zu können, gehen leer aus: Diese Expertise nutzt jetzt Apple.
(jam)
Entwicklung & Code
software-architektur.tv: Netflix ohne Bounded Contexts
In der Softwarearchitektur gilt: Systeme lassen sich besser warten und flexibler gestalten, wenn man sie in mehrere Bounded Contexts aufteilt – und das ist gerade bei Microservices-Systemen entscheidend. Doch nun hat ausgerechnet Netflix, ein Pionier der Microservices-Bewegung, einen Blogpost veröffentlicht, der einen ganz anderen Weg propagiert: „Model Once, Represent Everywhere: UDA (Unified Data Architecture)„.
In dieser Episode nimmt Eberhard Wolff den Ansatz von Netflix genauer unter die Lupe und diskutiert, ob die Zeit gekommen ist, die Idee klar getrennter Bounded Contexts infrage zu stellen – und stattdessen auf ein zentrales Modell zu setzen.
Lisa Maria Schäfer malt dieses Mal keine Sketchnotes.
Livestream am 22. August
Die Ausstrahlung findet live am Freitag, 22. August 2025, 13 bis 14 Uhr statt. Die Folge steht im Anschluss als Aufzeichnung bereit. Während des Livestreams können Interessierte Fragen via Twitch-Chat, YouTube-Chat, Bluesky, Mastodon, Slack-Workspace oder anonym über das Formular auf der Videocast-Seite einbringen.
software-architektur.tv ist ein Videocast von Eberhard Wolff, Blogger sowie Podcaster auf iX und bekannter Softwarearchitekt, der als Head of Architecture bei SWAGLab arbeitet. Seit Juni 2020 sind über 250 Folgen entstanden, die unterschiedliche Bereiche der Softwarearchitektur beleuchten – mal mit Gästen, mal Wolff solo. Seit mittlerweile mehr als zwei Jahren bindet iX (heise Developer) die über YouTube gestreamten Episoden im Online-Channel ein, sodass Zuschauer dem Videocast aus den Heise Medien heraus folgen können.
Weitere Informationen zur Folge finden sich auf der Videocast-Seite.
(mdo)

Fugaku Next: Japans nächster Vorzeige-Supercomputer kommt mit Nvidia-GPUs

„Waifu Edition“ für GPUs und mehr: MSI präsentiert MLG-Serie mit eigenem Manga-Charakter

Trump inside: Intel teilverstaatlicht | heise online

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen

TikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Online Marketing & SEOvor 2 Monaten
Online Marketing & SEOvor 2 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-

 UX/UI & Webdesignvor 4 Tagen
UX/UI & Webdesignvor 4 TagenDer ultimative Guide für eine unvergessliche Customer Experience
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Entwicklung & Codevor 3 Tagen
Entwicklung & Codevor 3 TagenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenPhilip Bürli › PAGE online
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenAktuelle Trends, Studien und Statistiken