Künstliche Intelligenz
Leuchtstarker OLED-Fernseher ohne Spiegelungen: Samsung QE65S95F im Test
QD-OLED-TVs sind für satte Farben und helle Bilder mit hohen Kontrasten bekannt. Samsungs QD-OLED-Panel im aktuellen TV-Topmodell QE65S95F nutzt ein neues elektrolumineszentes Material und fünf organische Schichten für die OLED-Lichtquelle. Das soll die Lichtausbeute um 30 Prozent verbessern. Zudem setzt Samsung wie im Jahr 2024 auf eine matte Bildschirmoberfläche, eine Alleinstellung unter den OLED-Fernsehern. Die Mattierung hat der Hersteller weiter verbessert und setzt sie nun auch in den 4K- und 8K-LCDs der teuren Neo-QLED-Modelle ein. Damit stören Reflexionen von Lichtquellen den Filmgenuss weniger.
Alle organischen Displays mit Quantenpunkten (Quantum Dot OLEDs) verwenden blaue OLED-Schichten als flächige Lichtquelle, in zwei Subpixeln wandeln Quantenpunkte das blaue Licht in rotes und grünes um, das blaue Pixel leuchtet direkt. Die RGB-Subpixel sitzen dabei nicht wie in Flüssigkristalldisplays (LCD) nebeneinander, sondern sind im Dreieck angeordnet.
Pflicht scheint im Jahr 2025 ein Hinweis auf künstliche Intelligenz: Der NQ4 AI Gen3 Prozessor steigert die Anzahl der neuronalen Netzwerke von 20 auf 128 und soll die automatische Bildverarbeitung per „Samsung Vision AI“ verbessern. Was das bringt, prüfen wir in unserem Test. Die Tizen-Oberfläche des Smart-TVs hat Samsung leicht überarbeitet, die von den Smartphones des Herstellers bekannte One-UI-Oberfläche hält Einzug.
Das war die Leseprobe unseres heise-Plus-Artikels „Leuchtstarker OLED-Fernseher ohne Spiegelungen: Samsung QE65S95F im Test“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.










Künstliche Intelligenz
Support für Samsung-Smartwatches mit Tizen endet in vier Wochen
Bereits 2021 haben Samsung und Google ihre Betriebssysteme Tizen und Wear OS verschmolzen. Tizen wird seitdem nur noch für andere Geräte wie Smart-TVs weiterentwickelt. Neue Galaxy-Smartwatches von Samsung erscheinen seit vier Jahren nur noch mit Wear OS, der Support für Tizen auf den Uhren wird abgewickelt. Und in vier Wochen ist dann endgültig Schluss: Der Tizen-Store schließt, die Installation von Apps auf der Smartwatch über die entsprechende App auf dem gekoppelten Smartphone ist dann nicht mehr möglich.
Der Stichtag ist der 30. September 2025, wie aus einem Support-Dokument von Samsung hervorgeht. Bis dahin kann man den Store noch nutzen, um dort schon einmal bezogene Apps und andere Inhalte wie Zifferblätter auf die Smartwatch zu befördern. Bereits seit dem 25. Juni 2025 vertreibt der Tizen-Store keine Gratis-Inhalte mehr, was unter anderem die vielen von Benutzern erstellten Zifferblätter betreffen dürfte. Ende September können dann aber auch keine gekauften Apps, die vorher von der Uhr gelöscht wurden, erneut auf dieser installiert werden. Die Uhren funktionieren weiter, Updates für Tizen wie auch die Apps gibt es aber nicht mehr.
Betroffene Geräte und Abhilfe
Laut Android Authority wurden die Smartwatches Galaxy Gear, Gear 2, Gear Live, Gear S, Gear S2, Gear S3, Gear Sport, Galaxy Watch, Galaxy Watch Active, Galaxy Watch Active 2, und Galaxy Watch 3 mit Tizen ausgeliefert. Um beispielsweise nach einem Werksreset durch einen Akkutausch noch Apps auf die Uhr zu befördern, gibt es mehrere Möglichkeiten. In diesem Sub-Reddit werden einige Verfahren aufgezeigt, für die teils Root-Zugriff auf dem Smartphone nötig ist. Im Forum von XDA wird eine Methode ohne Root für die Galaxy Watch Active 2 beschrieben. Und ebenda, in einem anderen Thread, gibt es Anleitungen für Gear S2 und S3. In jenem Thread findet sich auch eine Liste mit App-Packages und Zifferblättern, die bereits aus dem Store gesichert wurden, samt der damaligen Beschreibungen im Store.
(nie)
Künstliche Intelligenz
Top 10: Balkonkraftwerk mit Speicher im Test – nachrüsten oder im Set
Testsieger
Zendure Solarflow 800 Pro
Zendure Solarflow 800 Pro kommt mit integriertem Speicher und vier MPP-Trackern. Wie gut das Balkonkraftwerk in der Praxis funktioniert, zeigt der Test.
- effizienter Wechselrichter mit vier MPP-Tracker und 1,92-kWh-Speicher
- Nulleinspeisung über Smart Meter wie Shelly Pro 3EM
- bidirektionales Laden (sinnvoll bei Nutzung dynamischer Stromtarife)
- Lokale API und Home-Assistant-Support
- Standardmäßig von Cloud abhängig
- App teilweise unübersichtlich
Zendure Solarflow 800 Pro im Test
Zendure Solarflow 800 Pro kommt mit integriertem Speicher und vier MPP-Trackern. Wie gut das Balkonkraftwerk in der Praxis funktioniert, zeigt der Test.
Zendure bietet mit Solarflow 800 Pro ein Balkonkraftwerk mit integriertem 1,92-kWh-Speicher. Es zielt vor allem auf Power-User, die sämtliche Vorteile eines BKWs nutzen möchten – inklusive Nulleinspeisung auf Basis von Smart Metern wie Shelly Pro 3EM und der Nutzung dynamischer Stromtarife wie von Tibber oder Rabot Energy.
Wie der Stromspeicher Anker Solix Solarbank 3 (Testbericht) unterstützt Zendure Solarflow 800 Pro den Anschluss von bis zu vier Solarpanel. Im Angebot bei Zendure lässt sich das Steckersolargerät mit bis zu vier 500-Watt-Panels konfigurieren. Damit schöpft die Anlage die gesetzlichen Bestimmungen, die eine maximale Solarleistung von 2000 Watt für BKWs erlauben, voll aus.
Solarflow 800 Pro kommt mit einem integrierten Speicher mit 1,92 kWh vom Typ AB2000X und kostet mit vier 500-Watt-Panels inklusive Halterung 1417 Euro. Der neue Akku bietet gegenüber dem Vorgänger AB2000S eine höhere Ausgangsleistung (1680 Watt statt 1200 Watt, beim Einsatz von zwei Batterien sind es sogar 1920 Watt) und erlaubt eine Erweiterung mit insgesamt sechs Einheiten auf bis zu 11,52 kWh. Mit der AB2000S lag die Obergrenze bei vier Einheiten und 7,68 kWh.
Zendure verkauft Solarflow 800 Pro für 799 Euro auch einzeln ohne Solarpanels, sodass die Lösung auch als Nachrüstoption für ein bestehendes Balkonkraftwerk infrage kommt.
Eine Notstromsteckdose mit 1000 Watt bietet Zendure Solarflow 800 Pro ebenfalls, sodass man bei einem Stromausfall Geräte wie eine Gefrierkombination mit Energie versorgen kann.
Wie die Lösung für den Anschluss von zwei Solarmodulen, Zendure Solarflow 800, bietet die Pro-Variante noch zwei weitere Besonderheiten: Mit einer Eingangsspannung von 14 Volt wandelt sie schon früher Sonnenenergie in Strom um als Modelle, die erst bei 16 Volt oder höher die Energiegewinnung starten. Außerdem unterstützt der Wechselrichter bidirektionales Laden. Man kann also die mit Solarflow 800 Pro verbundenen Batterien auch mit Strom aus der Steckdose betanken. Das ist wegen Umwandlungsverlusten aber nur bei Nutzung von dynamischen Stromtarifen sinnvoll: Wenn etwa zu bestimmten Zeiten der Bezug von Strom günstig ist, lädt man den Akku per Netzstrom und wenn der Strom teuer ist, entlädt man die Batterie und kann dadurch die Stromkosten etwas senken. Das ist vor allem im Winter interessant, wenn sich die Sonne rar macht und man die Akkus meist nicht per Sonnenenergie vollgeladen bekommt.
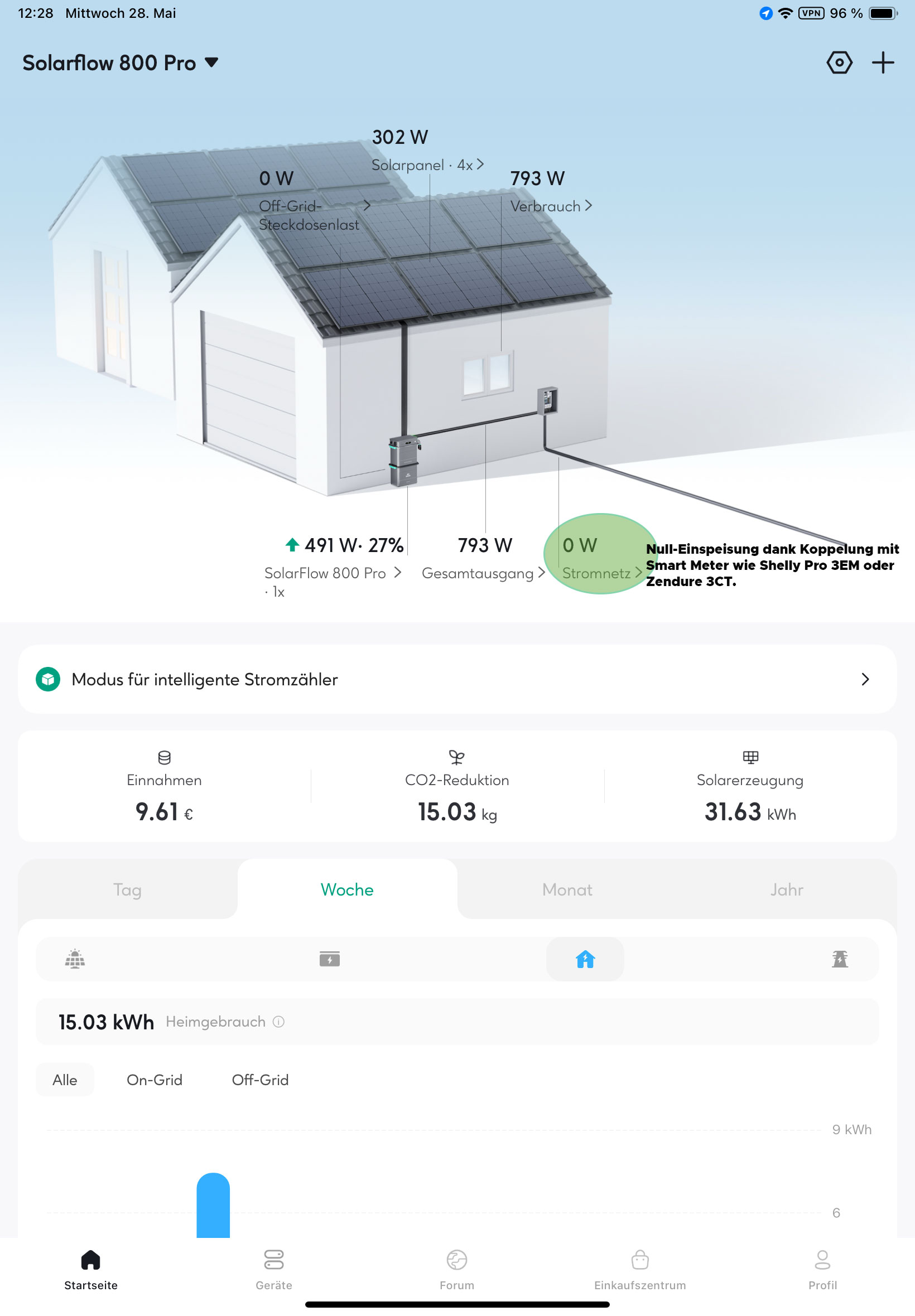
Bei Zendure fast schon Standard, ist die Möglichkeit, die Einspeiseleistung über einen Smart Meter wie Shelly Pro 3EM oder Eco Tracker an den tatsächlichen Bedarf zu knüpfen. Mit einer sogenannten Nulleinspeisung (Ratgeber) wird der selbst produzierte Strom effizient im eigenen Haushalt genutzt und landet nicht unvergütet im Netz des Lieferanten.
Wie gut Zendure Solarflow 800 Pro mit Speicher und Nulleinspeisung funktioniert, zeigt der Test.
Solarflow 800 Pro: Aufbau und Einrichtung
Der Aufstellort der Solarpanels entscheidet darüber, ob die im Lieferumfang befindlichen Anschlusskabel ausreichend dimensioniert sind. Erfolgt die Montage an einem Balkongeländer und ist die Steckdose nicht weit entfernt, kann man Solarflow 800 Pro mit integriertem Speicher in der Nähe der Solarpanels aufstellen, sodass die relativ kurzen Kabel der Panels und das 3,2 Meter lange Schuko-Kabel zur Inbetriebnahme ausreichen.
Werden die Solarpanels im Garten aufgestellt oder an einem Zaun montiert, benötigt man entweder ein Verlängerungskabel für die Steckdose oder entsprechend lange MC4-Verlängerungen für die Solarpanels, Solarflow 800 Pro inklusive Speicher und Erweiterungsbatterien weiter entfernt von den Solarpanels aufgestellt werden sollen. Zwar sind die Komponenten wasserdicht, man sollte sie aber dennoch an einem vor Wettereinflüssen geschützten Ort aufstellen. Und das nicht nur wegen der Feuchtigkeit, sondern auch um sie vor direkter Sonneneinstrahlung zu schützen. Auf einen schattigen Aufstellort verweist auch das Handbuch (PDF).
Die Montage ist wie bei allen Balkonkraftwerken sehr einfach. Man kann im Grunde nichts falsch machen: Wir schließen vier Solarpanels an die vier MPP-Tracker und das Schuko-Kabel an den dafür vorgesehenen Ausgang an und verbinden letzteres mit der Steckdose auf unserer Terrasse. Fertig.

Null-Einspeisung mithilfe von Smart Meter
Nicht ganz so einfach ist die Installation des Smart Meters Shelly Pro 3EM. Dieser wird in der Hausverteilung montiert und misst anhand dreier Induktionsspulen den Strombedarf. Die Installation sollte nur von qualifiziertem Personal wie einem Elektriker durchgeführt werden. Das gilt auch für den Zendure-Smart-Meter 3CT, der lediglich einen Aufpreis von 30 Euro verursacht. Wer also noch keinen Shelly hat, der mit 82 Euro deutlich teurer ist, sollte das Zendure-Angebot wahrnehmen, wenn eine Nulleinspeisung erwünscht ist.
Der alternativ unterstützte Smart Meter Everhome Eco Tracker wird hingegen nicht in der Stromverteilung installiert, sondern am Hausanschluss. Da sich dieser meist im Keller befindet, sollte am Installationsort überprüft werden, ob eine Verbindung zum Funknetzwerk vorhanden ist. Diese mag in Eigenheimen noch realisierbar sein, doch in Miet- oder Eigentumswohnungen dürfte eine Funkverbindung in den meisten Fällen nicht bis in den Keller des Gebäudes reichen. Für letzteres Szenario kommen also nur die Shelly-Smart-Meter oder das Zendure-Pendant infrage, wenn eine dynamische Einspeisung gewünscht ist.
Wer keinen Smart Meter von Shelly im Einsatz hat, kann die Einspeiseleistung auch mithilfe von smarten Steckdosen von Shelly oder Zendure optimieren, indem man sie für starke Verbraucher wie Heissluftfriteuse, Wasserkocher, Fernseher, Waschmaschine und Föhn installiert. Infrage kommen auch Herd und Kochfeld, wenn diese mit 230 Volt betrieben werden. Shelly-Plugs gibt es ab etwa 20 Euro. Wer sie im 5er-Set kauft, zahlt aktuell pro Stück knapp 18 Euro (Bestpreis-Link).
Inbetriebnahme mit der Zendure-App
Sind Balkonkraftwerk und Smart Meter oder smarte Steckdosen einsatzbereit, nimmt man die Anlage mit der Zendure-App in Betrieb. Dafür muss man sich allerdings bei Zendure registrieren. Um den Kopplungsmodus zu aktiveren, drücken wir drei Sekunden lang auf die Einschalttaste. Die blinkende IOT-LED am Solarflow 800 Pro signalisiert, dass sich die Lösung im Kopplungsmodus befindet. Über das Plus-Zeichen in der App fügen wir anschließend den Solarflow 800 Pro hinzu. Für die Koppelung muss Bluetooth am Smartphone oder Tablet eingeschaltet sein. Anschließend wird Solarflow 800 Pro mit dem heimischen WLAN über ein 2,4-GHz-Netz verbunden. Kommt eine Verbindung nicht zustande, könnte das daran liegen, dass der WLAN-Router über eine SSID 2,4- und 5-GHz-Netze bereitstellt. Da eine SSID für unterschiedliche Netze häufig die Ursache für Verbindungsprobleme für Smart-Home-Komponenten ist, sollte man die unterschiedlichen Netze mit eigenen SSIDs betreiben oder für die Inbetriebnahme das 5-GHz-Netz des Routers deaktivieren.
Bevor der Smart Meter Shelly Pro 3EM in der Zendure-App hinzugefügt werden kann, muss dieser mit der Shelly-App in Betrieb genommen und die Shelly-Cloud aktiviert werden. Anschließend klickt man in der Zendure-App unter Geräte verwalten – Zähler hinzufügen und anschließend auf Shelly Pro 3EM und authentifiziert sich in der Shelly-Cloud.
Die App informiert auf der Startseite über alle relevanten Betriebsparameter: Dazu zählen die aktuelle Solarleistung der Panels, den Stromverbrauch, den Füllstand der Batterie, wie viel Strom in der Batterie gespeichert wird, die Einspeiseleistung und ob das Stromnetz gerade etwas liefert oder Strom abfließt.
Zendure-App: Energiepläne respektive Betriebsmodi
Die Zendure-App bietet für den Solarflow 800 Pro mehrere Betriebsmodi. An erster Stelle steht Zenki, das neue Energiemanagement auf Basis von künstlicher Intelligenz. Zenki verwaltet die Anlage mithilfe unterschiedlicher Datenquellen, wie dem Stromverbrauch im Haushalt, verfügbaren Stromtarifen, der Wetterlage und dem aktuellen Ladezustand der Batterien. Auf Basis dieser Informationen soll Zenki die Anlage optimal verwalten, um das größtmögliche Sparpotential zu erschließen. Wir nutzen derzeit noch keinen dynamischen Stromtarif. Dieser ist bestellt und soll ab Juni zur Verfügung stehen. Später soll dann dafür noch eine intelligente Messeinrichtung am Stromanschluss im Keller verbaut werden. Erfahrungswerte zu Zenki werden wir in einem späteren Artikel nachliefern. Zenki ist zunächst sechs Monate kostenlos, danach ist eine Abo-Gebühr fällig. Wie hoch diese ausfällt, ist derzeit unbekannt. Wie uns Zendure mitgeteilt hat, soll, anders als in der App dargestellt, Zenki nun doch kostenlos bleiben.
Neben Zenki gibt es zudem einen Automatik-Modus, der einen der folgenden Betriebsmodi auswählt:
- Modus für intelligenten Stromzähler (passt die Einspeiseleistung basierend auf Smart Metern wie dem Shelly Pro 3EM an)
- Modus für smarte Steckdosen (passt die Einspeiseleistung basierend auf verbundenen Steckdosen von Shelly oder Zendure an)
- Grundlastmodus (passt die Einspeiseleistung auf Basis von Zeitplänen an)
- Stromtarifmodus (Für Anwender mit dynamischen Stromtarifen. Informiert über zuvor festgelegte Unter- und Obergrenzen von Strompreisen. Optional ist bei Erreichen der Untergrenze ein automatisches Laden der Batterie mit bis zu 800 Watt möglich.)
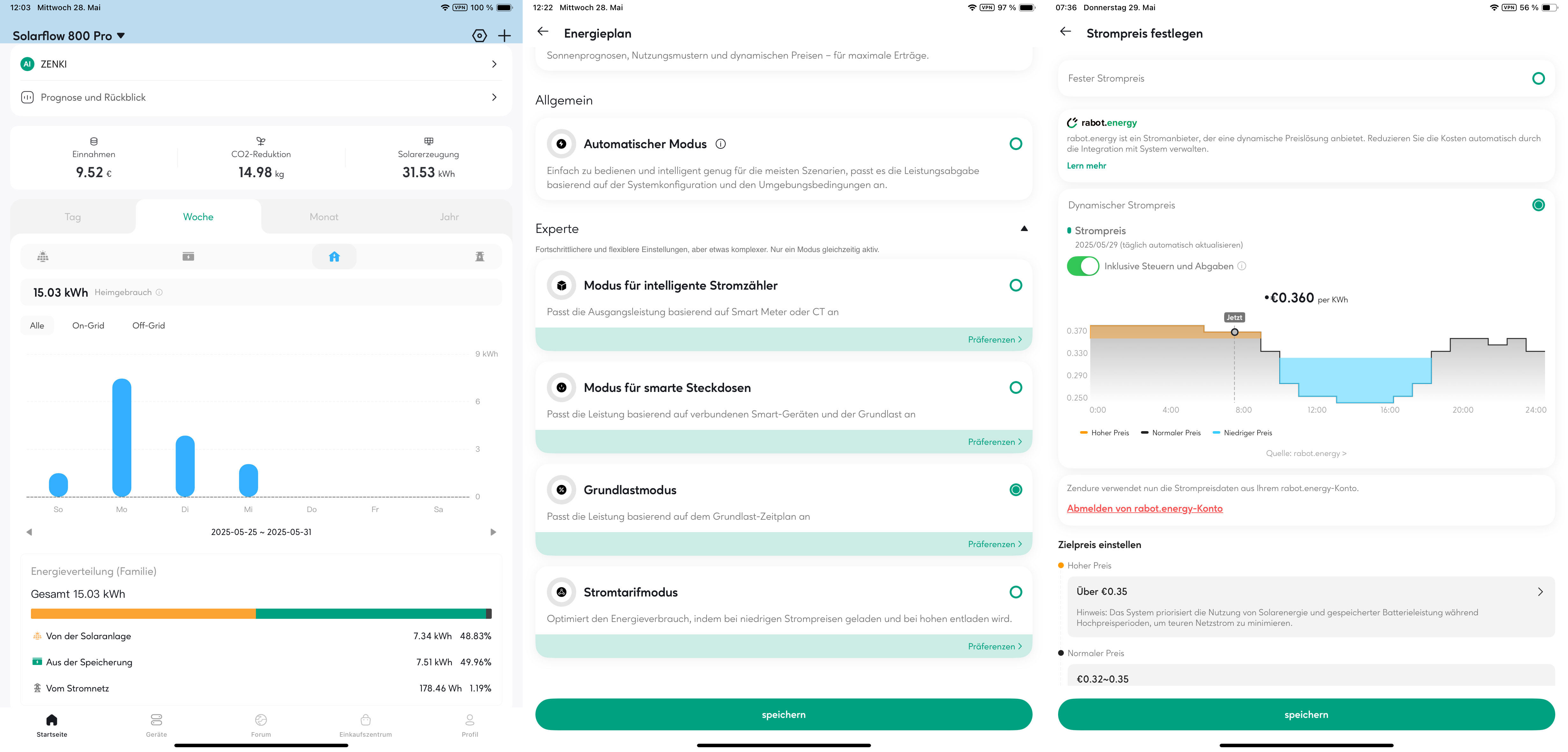
Wie zuverlässig funktioniert die dynamische Einspeisung?
Für unseren Test verwenden wir den Modus für intelligente Stromzähler auf Basis des Shelly Pro 3EM. Das dürfte für die meisten Anwender der relevanteste Betriebsmodus sein. Damit ist eine Nulleinspeisung möglich, da der Solarflow 800 Pro den vom Shelly ermittelten Strombedarf als Wert für die Einspeiseleistung verwendet.
Die Reaktion von Solarflow 800 Pro auf die vom Smart Meter Shelly Pro 3EM erfassten Stromverbrauchswerte dauert zwischen 3 und 5 Sekunden. Eine exakte Nulleinspeisung ist allerdings nur selten der Fall. Meist zeigt der Shelly einen Verbrauch von etwas über 0 Watt an bis maximal 5 Watt. Auch passiert es, dass der Solarflow Pro minimal zu viel Strom abgibt, sodass der Shelly Minus-Werte von wenigen Watt anzeigt. Dieses Verhalten haben wir allerdings auch bei anderen Lösungen beobachtet.
Wie groß sollte der Speicher sein?
In einem Ein-Personen-Test-Haushalt mit einem niedrigen Strombedarf von täglich 2 bis 3,5 kWh ist die Kapazität von knapp 2 kWh der in Solarflow 800 Pro integrierten Batterie AB2000X ausreichend. Hier würden bereits zwei Solarmodule ausreichen, um diesen an einem sonnigen Tag zu füllen. Für dieses Szenario reicht aber schon der kleine Bruder Solarflow 800 (Testbericht).
Wer jedoch wie wir im Test vier Solarmodule verwendet, um damit einen höheren Strombedarf zu decken, sollte mindestens eine weitere Batterie vom Typ AB2000 verwenden, sodass die Speicherkapazität auf 3,84 kWh steigt.
Und wer dynamische Stromtarife nutzt, kann je nach Strombedarf gerne weitere Akkus bis zur maximalen Ausbaustufe von 11,54 kWh verwenden. Die bekommt man mit vier 500-Watt-Modulen zwar selbst im Sommer nicht geladen, doch bei Nutzung eines dynamischen Stromtarifs kann eine so hohe Kapazität dennoch sinnvoll sein.
Im Tagesgang ist der Preisunterschied zwischen hohem und niedrigem Preis oft größer als die Umwandlungsverluste von etwa 18 Prozent, die durch das AC-Laden entstehen. Rabot Energy meldet etwa heute einen Höchstpreis von 36 Cent pro kWh, während der Tiefstpreis bei 25 Cent pro kWh liegt. Ein Preisunterschied von mehr als 30 Prozent. Somit lohnt sich das Laden der Akkus zu diesem Tarif, sodass man etwas Geld spart. Allerdings sollte man auch die Effizienzwerte (siehe folgenden Abschnitt) im Blick haben. Mehr Informationen zu dynamischen Stromtarifen finde sich weiter unten unter „Sparpotenzial erschließen: günstigere Stromtarife“ weiter unten.
Wie effizient arbeitet Zendure Solarflow 800 Pro?
Von den 1920 Wh des Akkus haben wir im Durchschnitt etwa 1880 Watt entnommen, was einer ausgezeichneten Effizienz von knapp 98 Prozent entspricht. Beim Laden des Speichers über die Steckdose muss der Strom allerdings zweimal umgewandelt werden. Dabei haben wir Ladeverluste von etwa 18 Prozent gemessen. Wer also einen dynamischen Stromtarif nutzt, sollte das Laden der Batterie per Steckdose nur dann nutzen, wenn der Preisunterschied zwischen hohem und niedrigem Tarif größer als 20 Prozent ausfällt.
Zudem sollte man die Effizienzwerte im Auge behalten. Die Effizienz bei der Einspeisung ist wie üblich abhängig von der Höhe der Einspeiseleistung. Wenn Zendure Solarflow Pro mit der maximal möglichen Leistung in Höhe von 800 Watt einspeist, kommen im Stromnetz 779 Watt an. Das entspricht einer Effizienz von über 97 Prozent, was ein ausgezeichneter Wert ist. Zum Vergleich: Der Growatt-Speicher im BKW Solakon On Basic (Testbericht) erreicht bei 800 Watt Leistungsabgabe eine Effizienz von 94 Prozent.
Wird weniger eingespeist, sinkt die Effizienz. Bis zu einer Einspeiseleistung von 500 Watt liegt sie aber noch über 96 Prozent. Mit 200 Watt sind es aber nur noch 91,5 Prozent und mit 150 Watt noch knapp 89 Prozent, während sie bei 100 Watt nur noch knapp 82 Prozent beträgt. Speist man hingegen nur mit 75 Watt ein, sinkt die Effizienz auf 77,6 Prozent und bei 50 Watt Einspeisung kommen im Stromnetz nur noch 33,5 Watt an, was einer Effizienz von nur 67 Prozent entspricht. Beim Growatt-Speicher fällt die Effizienz bei einer Einspeisung mit 50 Watt sogar unter die 50-Prozent-Marke.
Die Effizienzwerte sollte man also bedenken, wenn der Speicher per AC geladen wird, und man durch Nutzung eines dynamischen Stromtarifs davon profitieren möchte. Denn die Verluste bei der Einspeisung addieren sich zu den Umwandlungsverlusten von AC zu DC. Oder anders ausgedrückt. Bei einem Ein-Personen-Haushalt mit einer durchschnittlichen Leistungsabgabe von 100 Watt pro Stunde dürfte sich das Laden per Netzstrom kaum lohnen, da die Umwandlungsverluste insgesamt größer sind als der Unterschied zwischen günstigstem und teuerstem Preis pro kWh.
Preis: Was kostet Zendure Solarflow 800 Pro und welche Alternativen gibt es?
Der Wechselrichter mit integriertem 1,92-kWh-Speicher Solarflow 800 Pro kostet ohne Solarpanels regulär 799 Euro, mit einer Zusatz-Batterie und einer Gesamtkapazität von 3,84 kWh sind es 1398 Euro und mit zwei Batterien und einer Gesamtkapazität von 5,76 kWh sind es 1997 Euro. Diese Angebote sind vor allem für BKW-Nutzer interessant, die über ein Speicher-Upgrade nachdenken.
Wer hingegen noch kein Balkonkraftwerk im Einsatz hat, kann zu den Komplettangeboten von Zendure greifen. Diese umfassen für einen Aufpreis von aktuell nur 30 Euro auch einen Smart Meter von Zendure (3CT) und kosten mit vier 500-Watt-Panels 1398 Euro (1,92 kWh), 1997 Euro (3,84 kWh, 1 AB2000S zusätzlich auswählen) und 2596 Euro (5,76 kWh, 2 AB2000S auswählen).
Zendure gewährt auf den Solarflow 800 Pro eine Garantie von 10 Jahren. Auch für die Akkus gibt es 10 Jahre Garantie. Nach 6000 Zyklen sollen diese noch eine Kapazität von über 70 Prozent bieten.
Eine gleichwertige Alternative ist die Solix Solarbank 3. Wie Zendure Solarflow 800 Pro bietet die Anker-Lösung vier MPP-Tracker, einen integrierten Speicher, der allerdings mit 2,68 kWh größer ausfällt, sowie eine Not-Stromsteckdose mit 1200 Watt Leistung. In Kombination mit vier 500-Watt-Solarpanels kostet das BKW bei Kleines Kraftwerk inklusive Smart Meter 1399 Euro.
Inzwischen verkauft Zendure Solarflow 800 Pro auch über Amazon.
- Solarflow 800 Pro mit integriertem 1,92-kWh-Speicher für 735 Euro
- Zusatzakku AB2000X für aktuell 541 Euro (reduzierter Preis wird erst an der Kasse angezeigt) mit einer Gesamtkapazität von 3,84 kWh für 1276 Euro
- Solarflow 800 Pro mit integriertem 1,92-kWh-Speicher und vier 430-Watt-Solarmodule (1720 Watt) für 1103 Euro
- Solarflow 800 Pro mit vier 500-Watt-Modulen, integrierter 1,92-kWh-Speicher plus Zusatz-Akku AB2000X mit 1,92 kWh, mit einer Gesamtkapazität von 3,84 kWh für 1746 Euro
Die angegebenen Preise werden größtenteils erst an der Kasse angezeigt.
Integration in Smart-Home-Systeme
Zendure hat eine API und zusammen mit der Community eine Integration für Home Assistant veröffentlicht. Damit ist es möglich, das Zendure-System lokal ohne die Cloud anzusteuern.
Aktuell werden folgende Lösungen unterstützt:
- Ace 1500
- AIO 2400
- Hyper 2000
- Hub 1200
- Hub 2000
- Solarflow 800
- Solarflow 800 Pro
- Solarflow 2400 AC
- SuperBase V6400
Günstige Stromtarife: Sparpotenzial erschließen
Wer ein Balkonkraftwerk nutzt, möchte Stromkosten sparen. Ein weiteres Einsparpotenzial sollte man außerdem durch die Wahl des günstigsten Stromanbieters erschließen. Spätestens wenn man Post vom Stromlieferanten über eine Preiserhöhung erhält, lohnt sich ein Wechsel. Neutarife sind meist wesentlich günstiger. Gleiches gilt für Gastarife. Auch hierfür bieten wir ein entsprechendes Vergleichsangebot im heise Tarifvergleich.
Wer sich nicht selbst um günstige Preise und Anbieterwechsel kümmern will, kann zu Wechselservices wie Remind.me gehen. Der Anbieter bietet kostenlose Wechsel zwischen Strom- und Gasanbietern an. Dabei erhält der Kunde vorab eine Empfehlung und kann sich dann für oder gegen das jeweilige Angebot entscheiden. Vorteil: Remind.me vergleicht über 12.000 Tarife und meldet sich automatisch, wenn man einen Vertrag wechseln kann.
Wer sich für einen Stromspeicher mit bidirektionaler Lademöglichkeit entscheidet, kann diesen bei Nutzung eines dynamischen Stromtarifs, etwa von Rabot Energy (mit Code RABOT120 erhält man 120 Euro nach einem Jahr ausgezahlt, bei sechs Monaten sind es mit dem Code RABOT60 60 Euro) oder von Tibber, besonders profitabel einsetzen. So ist es möglich, diesen etwa während der Dunkelflaute über die Wintermonate oder bei schlechtem Wetter bei günstigen Konditionen, wenn etwa die Windkraft für billigen Strom sorgt, zu laden und ihn bei teuren Strompreisen zu entladen. Wegen der doppelten Stromumwandlung sollte der Preisunterschied aber deutlich über 20 Prozent liegen, damit sich das lohnt.
Fazit
Zendure Solarflow 800 Pro arbeitet im Test in Verbindung mit dem Smart Meter Shelly Pro 3EM zuverlässig und effizient. Mit dem integrierten Speicher, der auf bis zu 11,54 kWh erweitert werden kann, richtet sich die Lösung vor allem an Power-User, die mit vier Solarpanels, Smart Meter und dynamischen Stromtarifen das Maximum aus einem Balkonkraftwerk herausholen möchten.
Wie sich die integrierte KI Zenki in der Praxis schlägt, können wir aufgrund der kurzen Testdauer bisher nicht beurteilen. Wenn überhaupt, lohnt sich der Dienst nur in Verbindung mit einem dynamischen Stromtarif. Um eine Nulleinspeisung zu realisieren, reicht der Automatik-Modus völlig aus.
Positiv ist, dass Zendure eine API zur lokalen Ansteuerung und eine zusammen mit der Community entwickelte Integration für Home Assistant vorgestellt hat. Das könnte für viele Anwender Grund genug sein, auf die Zendure-Lösung zu setzen. Denn damit ist man im Vergleich zu anderen Lösungen wie Anker Solix Solarbank nicht länger von der Cloud abhängig.
Der Testbericht erschien am 29.5. Hinweis 30.5.: Angaben zur lokalen API und Support für Home Assistant ergänzt. Hinweis 10.6.: Preise bei Amazon mit 8 Prozent Rabatt eingefügt.
Künstliche Intelligenz
Digitalministerium: Bayerische Kommunen führen bei digitaler Verwaltung
Nirgendwo in Deutschland lassen sich nach Angaben des bayerischen Digitalministeriums so viele Behördensachen online erledigen wie in vielen bayerischen Kommunen. In einem bundesweiten Vergleich der Verwaltungsdigitalisierung liegen ausschließlich bayerische Kommunen auf den ersten 50 Plätzen. Erst auf Rang 51 folge mit Köln die erste Kommune außerhalb des Freistaats.
Nach aktuellen Zahlen des sogenannten Dashboards Digitale Verwaltung des Bundesdigitalministeriums wird die Liste von Augsburg mit 1890 digitalen Verwaltungsleistungen angeführt, gefolgt von Fürth, Ingolstadt und Erlangen. Online erledigt werden können beispielsweise Anträge für Geburtsurkunden oder Ummeldungen. Die Liste berücksichtigt nach Angaben eines Sprechers des bayerischen Digitalministeriums neben Leistungen von Ländern und Kommunen auch die vom Bund.
Laut dem Dashboard waren in diesem August überall in Bayern mindestens für 1.303 Verwaltungsleistungen Onlinedienste verfügbar – davon 815 bundesweite, 488 landesweite und für 892 auf kommunaler Ebene. Dabei liegt Bayern insgesamt auf Platz zwei hinter Hamburg, wo flächendeckend 1.548 Verwaltungsakte sich online erledigen lassen.
Lesen Sie auch
(nie)

Support für Samsung-Smartwatches mit Tizen endet in vier Wochen

Intel Arrow Lake: Taugt der Core Ultra 7 für die Steam Machine?

Top 10: Balkonkraftwerk mit Speicher im Test – nachrüsten oder im Set

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

Der ultimative Guide für eine unvergessliche Customer Experience

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
eine gute Nachricht ist")
eine gute Nachricht ist") Social Mediavor 2 Wochen
Social Mediavor 2 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 1 Woche
Entwicklung & Codevor 1 WochePosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenPhilip Bürli › PAGE online