Entwicklung & Code
.NET 10.0 Preview 6 bringt persistierte Circuits und Passkeys für Blazor
.NET 10.0 Preview 6 steht zum Download auf der .NET-Downloadseite bereit. Von Visual Studio 2022 gab es nur ein Bugfixing-Update von Version 17.14.8 auf 17.14.9. Weiterhin ist .NET 10.0 nicht direkt über das Visual-Studio-Setupprogramm installierbar. Wenn das .NET 10.0 SDK getrennt installiert wurde, kann man aber „.NET 10.0 Preview“ in den Auswahlmasken finden.


Dr. Holger Schwichtenberg ist Chief Technology Expert bei der MAXIMAGO-Softwareentwicklung. Mit dem Expertenteam bei www.IT-Visions.de bietet er zudem Beratung und Schulungen im Umfeld von Microsoft-, Java- und Webtechniken an. Er hält Vorträge auf Fachkonferenzen und ist Autor zahlreicher Fachbücher.
Persistenz für Circuit-Zustände bei Blazor Server
Blazor Server besitzt für jeden per Websocket angeschlossenen Browser einen sogenannten Circuit mit dem HTML-Inhalt und den Werten aller Variablen aller aktiven Razor Components. Bisher ging der Circuit komplett verloren, wenn die Verbindung mehrere Sekunden abreißt oder der Browser die Anwendung schlafen legt (z. B. bei mobilen Geräten), denn der Webserver erwartet zum Beibehalten des Circuits eine regelmäßige kurze Keep-Alive-Nachricht über die Websocket-Verbindung.
(Bild: coffeemill/123rf.com)

Verbesserte Klassen in .NET 10.0, Native AOT mit Entity Framework Core 10.0 und mehr: Darüber informieren Dr. Holger Schwichtenberg und weitere Speaker der Online-Konferenz betterCode() .NET 10.0 am 18. November 2025. Nachgelagert gibt es sechs ganztägige Workshops zu Themen wie C# 14.0, KI-Einsatz und Web-APIs.
In .NET 10.0 Preview 6 können Entwicklerinnen und Entwickler nun erstmalig, was das Konkurrenzprodukt Wisej.NET schon lange kann: Zustände über solche Abbrüche hinweg persistieren. Während dies in Wisej.NET jedoch automatisch erfolgt, müssen sie bei Blazor Server selbst etwas implementieren.
Die Persistenz von Circuit-Zuständen bei Blazor Server erfolgt im Standard nur im RAM des Webservers, kann aber optional auch in getrennten Cache-Prozessen (z. B. Redis) oder in einem Datenbankmanagementsystem (z. B. Microsoft SQL Server) erfolgen.
Blazor Server persistiert dabei nicht den kompletten Circuit und auch nicht alle Variablen einer Razor Component, sondern nur diejenigen Werte, die explizit in den Persistent Component State gelegt werden. Den gibt es in Blazor schon länger, um Werte vom Pre-Rendering an das interaktive Rendering zu übergeben. Vor .NET 10.0 mussten Entwicklerinnen und Entwickler den Persistent Component State aufwendig per Code setzen und lesen. Seit .NET 10.0 Preview 3 können sie die zu persistierenden Variablen einfach mit [SupplyParameterFromPersistentComponentState] annotieren.
Lesen Sie auch
Das folgende Listing zeigt ein aussagekräftiges Beispiel. Die Razor Component „State.razor“ persistiert via [SupplyParameterFromPersistentComponentState] eine Instanz der eigenen Klasse PageState. Die Klasse PageState umfasst eine aus einem Datenbankmanagementsystem via Entity Framework Core in OnInitialized() geladene Menge von Flugdaten sowie die Anzahl der Flüge, die angezeigt werden sollen. Zudem gibt es auf der Seite eine laufend aktualisierte Zeitanzeige. Zu Demonstrationszwecken wird jeweils beim Aktualisieren der Zeit die aktuelle Zeit auch in die Browserkonsole geschrieben.
Für .NET 10.0 Preview 7 hat Microsoft angekündigt, [SupplyParameterFromPersistentComponentState] in [PersistentState] umzubenennen. Im gleichen Ankündigungskasten steht auch „Blazor.pauseCircuit will be renamed to Blazor.pause. Blazor.resumeCircuit will be renamed to Blazor.resume.“. Im Praxistest zeigt sich aber, dass die neuen Namen schon in Preview 6 gelten.
@page "/State"
@using BO.WWWings
@using ITVisions
@inject ITVisions.Blazor.BlazorUtil util
Counter
Aktuelle Uhrzeit: @currentTime.ToString("HH:mm:ss")
Anzahl Flüge: @pageState.CurrentCount
@if (this.pageState?.FlightSet != null)
{
@foreach (Flight f in this.pageState.FlightSet.Take(this.pageState.CurrentCount))
{
- Flug #@f.FlightNo @f.FlightDate.ToShortTimeString() @f.Departure ⟶ @f.Destination
}
}
@code {
[SupplyParameterFromPersistentComponentState] // NEU ab .NET 10.0
public PageState pageState { get; set; } = null;
private DateTime currentTime = DateTime.Now;
private System.Timers.Timer? timer;
private void IncrementCount()
{
if (pageState.CurrentCount < maxCount) pageState.CurrentCount++;
}
private void DecrementCount()
{
if (pageState.CurrentCount > 0) pageState.CurrentCount--;
}
int maxCount = 50; // > 58 Führt zum Absturz von Blazor Server (Stand Preview 5)
protected override void OnInitialized()
{
// Uhrzeit-Timer starten
timer = new System.Timers.Timer(1000);
timer.Elapsed += (s, e) => {
currentTime = DateTime.Now;
InvokeAsync(StateHasChanged);
util.Log(currentTime);
};
timer.Start();
if (pageState == null)
{
// Lade Daten
var renderMode = this.RendererInfo.Name;
var logMessage = "Lade bis zu " + maxCount + " Flugdatensätze im Blazor-Rendermode=" + renderMode;
DA.WWWings.WwwingsV1EnContext ctx = new();
var data = ctx.Flights.Take(maxCount).ToList(); // LINQ --> SQL
pageState = new()
{
FlightSet = data,
CurrentCount = 20,
Created = DateTime.Now
};
}
}
public void Dispose()
{
timer?.Dispose();
}
///
/// Beliebige eigene Klasse mit dem zu persistierenden Zustand der Seite.
///
public class PageState
{
public DateTime Created { get; set; }
public DateTime LastChange { get; set; }
public int _CurrentCount;
public int CurrentCount
{
get
{
return _CurrentCount;
}
set
{
_CurrentCount = value;
LastChange = DateTime.Now;
}
}
public List FlightSet { get; set; }
}
}
Listing: State.razor
In App.razor wird zudem der folgende JavaScript-Code hinterlegt, der dafür sorgt, dass Circuits und die zugehörige Websocket-Verbindung beendet werden, wann immer die Webanwendung nicht mehr sichtbar ist und eine Wiederherstellung des Circuits und der Websocket-Verbindung erfolgen, sobald die Webanwendung wieder sichtbar wird. Auf diese Weise kann man bei Blazor Server einige Ressourcen (RAM und Rechenzeit) auf dem Webserver sparen und damit die Skalierbarkeit verbessern.
Listing: Pausieren und Wiederaufnahme von Circuits und zugehöriger Websocket-Verbindung
Die folgende Abbildung zeigt das Verhalten der Razor Component, die für kurze Zeit unsichtbar gemacht wurde (z. B. durch Öffnen eines anderen Browser-Tags oder Minimieren des Browsers). Zunächst gibt es im Sekundentakt eine Ausgabe in die Browserkonsole, jeweils beim Aktualisieren der Uhrzeit auf dem Bildschirm. Sobald die Razor Component nicht mehr sichtbar ist, wird der Circuit-Zustand mit dem JavaScript-Aufruf blazor.pause() persistiert und die Websocket-Verbindung beendet. 23 Sekunden später wird die Webseite wieder sichtbar. Via Blazor.resume() in JavaScript wird ein neuer Circuit erstellt, der persistente Zustand des Circuits geladen und die Websocket-Verbindung wieder aufgebaut. Die Razor Component wird neu gerendert und macht aus Benutzersicht dort weiter, wo sie aufgehört hat: Sie besitzt noch die gleichen Flugdaten wie zuvor (ohne diese neu aus dem Datenbankmanagementsystem laden zu müssen) und zeigt die gleiche Anzahl von Flügen. Die Uhrzeitausgabe in der Webseite und der Browserkonsole läuft weiter. Dass die Uhrzeitausgabe in der Browserkonsole unterbrochen ist, beweist, dass die Webanwendung zwischenzeitlich tatsächlich inaktiv war.
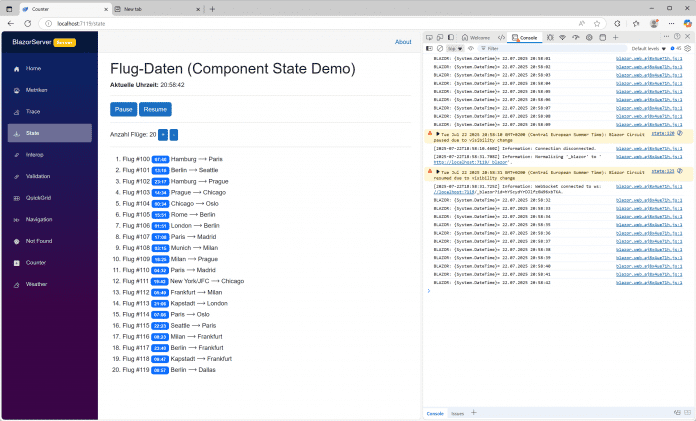
Persistierung eines Blazor-Server-Circuits
Im Startcode der Blazor-Server-Anwendung können Entwicklerinnen und Entwickler die Persistierung konfigurieren. Das folgende Listing zeigt die Festlegung der maximalen Anzahl der persistierten Circuits-Zustände auf 500 (Standard ist 1000), die Dauer der Persistierung im RAM auf 10 Sekunden (der Standard ist zwei Stunden) und die Dauer der Persistierung im Second-Level-Cache auf eine Stunde (der Standard ist zwei Stunden) sowie die Festlegung eines Microsoft SQL Servers als Second-Level-Cache zusätzlich zum RAM-Cache. Einen Hybrid Cache muss man dabei auch hinzufügen, denn Microsoft verwendet die Hybrid-Cache-Bibliothek (eingeführt in .NET 9.0) als Abstraktion.
Der Second-Level-Cache soll eine serverübergreifende Nutzung der persistierten Circuit-Daten erlauben, wenn man dem Tooltip der neuen Eigenschaft HybridPersistenceCache in der Klasse CircuitOptions glauben will: „Gets or sets the HybridCache instance to use for persisting circuit state across servers.“ Mangels Dokumentation zu dieser Aussage wurde die serverübergreifende Nutzung vom Autor dieses Beitrags aber bisher noch nicht getestet.
builder.Services.Configure(options =>
{
options.PersistedCircuitInMemoryMaxRetained = 500; // The maximum number of circuits to retain. The default is 1,000 circuits.
options.PersistedCircuitInMemoryRetentionPeriod = TimeSpan.FromSeconds(1); // The maximum retention period as a TimeSpan. The default is two hours.
options.PersistedCircuitDistributedRetentionPeriod = TimeSpan.FromSeconds(60); // The maximum retention period for distributed circuits. The default is two hours.
options.DetailedErrors = true;
});
// --------------------- Hybrid Cache konfigurieren
var hyb = builder.Services.AddHybridCache(options => // optionale Einstellungen
{
options.DefaultEntryOptions = new HybridCacheEntryOptions
{
Flags = HybridCacheEntryFlags.DisableCompression // nur als Beispiel für Einstellungen
};
});
// --------------------- Second-Level-Cache konfigurieren
builder.Services.AddDistributedSqlServerCache(options =>
{
options.ConnectionString = "Data Source=" + DB_SERVERNAME + ";Initial Catalog=NET_Cache;Integrated Security=True;Connect Timeout=30;Encrypt=False;Trust Server Certificate=True;Application Intent=ReadWrite;Multi Subnet Failover=False";
options.SchemaName = "dbo";
options.TableName = "Cache2";
});
Listing: Circuit-Zustandspersistenz konfigurieren
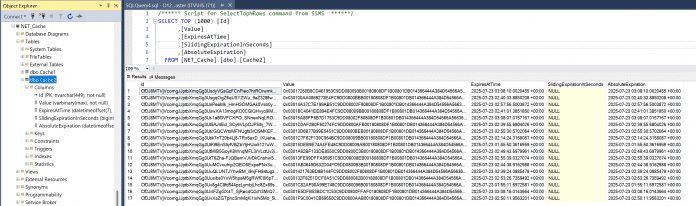
Persistierte Circuit-Zustände in einer Microsoft-SQL-Server-Tabelle, deren Aufbau durch den Distributed Cache Provider (SqlServerCache) vorgegeben ist.
Die hier beschriebene Persistenz funktioniert nur bei Blazor Server. Bei einem manuellen Browser-Refresh (Wisej.NET behält dabei den Zustand) oder manuellen Schließen des Browserfensters funktioniert die Persistenz nicht. Diese und weitere Einschränkungen dokumentiert Microsoft in den Release Notes. Dort findet man ebenso Hinweise, wie man Daten in per Dependency Injection injizierten Diensten (sofern es ein „Scoped Service“ ist) persistieren kann.
Validierung für Unterobjekte in Blazor
Die in Blazor eingebauten Eingabesteuerelemente (Company-Objekt ein Contact-Objekt und dieses wieder ein Address-Objekt enthält, wurden nur die Datenvalidierungsannotationen in der Klasse Company verwendet.
using System.ComponentModel.DataAnnotations;
using Microsoft.Extensions.Validation;
namespace NET10_BlazorServer.Model;
#pragma warning disable ASP0029 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
[ValidatableType]
#pragma warning restore ASP0029 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
public class Company
{
public int CompanyID { get; set; }
[Required(ErrorMessage = "Firmenname ist Pflichtfeld")]
public string CompanyName { get; set; }
[Required(ErrorMessage = "Gründungsdatum ist Pflichtfeld")]
[Range(typeof(DateTime), "01/01/1900", "31/12/2024", ErrorMessage = "Datum muss zwischen 1900 und 2024 liegen.")]
public DateTime Foundation { get; set; }
public Contact Contact { get; set; } = new Contact();
}
public class Contact
{
[Required(ErrorMessage = "Website ist Pflichtfeld")]
public string Website { get; set; }
[Required(ErrorMessage = "E-Mail ist Pflichtfeld")]
[EmailAddress(ErrorMessage = "Ungültige E-Mail-Adresse")]
public string Email { get; set; }
public Address Address { get; set; } = new Address();
}
public class Address
{
[Required(ErrorMessage = "Adresse ist Pflichtfeld")]
public string AddressText { get; set; }
}
Listing: Datenmodell Company mit Unterobjekt Contact
In dem im nächsten Listing gezeigten Formular wurde daher bisher nur geprüft, ob die Eingaben bei Firma und Gründungsdatum stimmen, nicht aber bei Website und E-Mail sowie Adresse.
@page "/Validation"
@using BO.WWWings
@using ITVisions
@using System.ComponentModel.DataAnnotations
@using NET10_BlazorServer.Model
@inject ITVisions.Blazor.BlazorUtil util
Eingabevalidierung für komplexe Objekte in Blazor 10.0
company.CompanyName)" />
company.Foundation)" />
company.Contact.Website)" />
company.Contact.Email)" />
company.Contact.Address.AddressText)" />
@code {
private Company company = new Company();
private EditContext editContext;
protected override void OnInitialized()
{
editContext = new EditContext(company);
}
void Submit()
{
if (editContext.Validate())
{
// Formular ist gültig
util.Log("Formular ist gültig!");
}
else
{
// Formular ist NICHT gültig
util.Log("Formular ist NICHT gültig!");
}
}
}
Listing: Eingabeformular für das obige Datenmodell
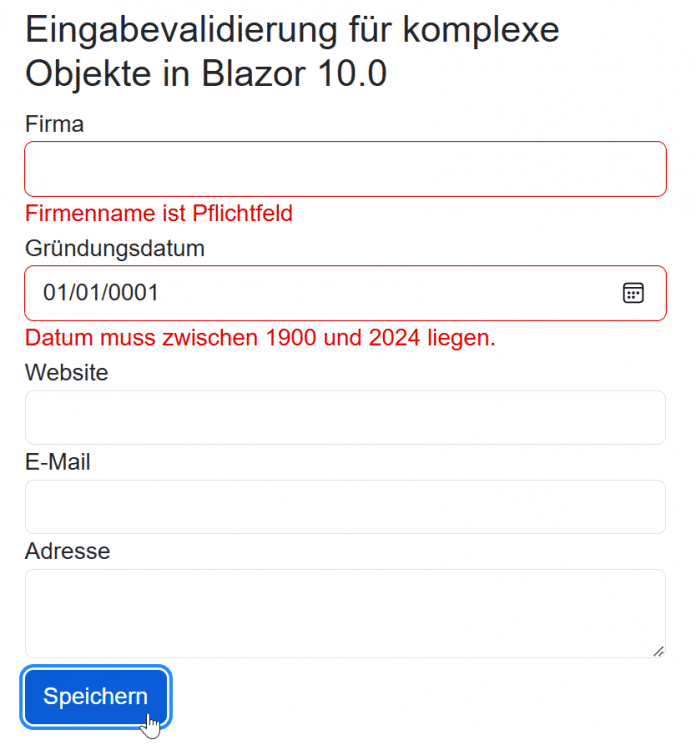
Die Validierung findet bei Blazor 9.0 nur auf der obersten Ebene in der Objekthierarchie statt.
Ab .NET 10.0 Preview 6 können nun auch Unterobjekte (komplexe Objekte bzw. Objekthierarchien) validiert werden. Blazor verwendet dabei die gleiche Implementierung wie ASP.NET Core Minimal WebAPIs seit .NET 10.0 Preview 3. Die Implementierung liegt seit Preview 6 im neuen NuGet-Paket „Microsoft.Extensions.Validation„.
Dazu müssen Entwicklerinnen und Entwickler zwei Dinge hinzufügen: erstens einen Aufruf von builder.Services.AddValidation() im Startcode der Anwendung in Program.cs und zweitens müssen sie diese Zeilen in der Datei ergänzen, in der die Modellklassen stehen, wobei dies eine .cs-Datei sein muss. Es funktioniert nicht, wenn die Modellklassen in .razor-Dateien liegen:
#pragma warning disable ASP0029 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
[ValidatableType]
#pragma warning restore ASP0029 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
Da ein Teil der Funktionen noch als „experimentell“ gilt, braucht man die Deaktivierung der Warnung.
Dies führt dazu, dass zur Entwicklungszeit ein Source Code Generator den Validierungscode erzeugt. Einsehen kann man den generierten Programmcode im Projekt im Ast „Dependencies/Analyzers/Microsoft.Extensions.Validation.ValidationsGenerator“.

In Blazor 10.0 können auch die Benutzereingaben für das Unterobjekt Contact validiert werden.
Passkeys in ASP.NET Core Identity
ASP.NET Core Identity ist eine von Microsoft vordefinierte Benutzerverwaltung mit Weboberfläche und REST-Diensten. Ab .NET 10.0 Preview 6 unterstützt ASP.NET Core Identity nun auch die Web Authentication (WebAuthn) API alias Passkeys.
Der einfachste Weg zur Passkey-Unterstützung führt über das Anlegen eines neuen Blazor-Projekts mit dem Authentifizierungstyp „Individual Accounts“. Man findet dann zusätzliche Dateien wie PasskeyOperation.cs, PasskeyInputModel.cs, Passkeys.razor und PasskeySubmit.razor im Projekt in den Ordnern /Component/Account, /Component/Account/Shared und /Component/Account/Pages/Manage. Diese Dateien kann man (wie bei ASP.NET Core üblich) an eigene Bedürfnisse anpassen. Die Passkey-Daten speichert ASP.NET Core Identity im Standard in seiner Microsoft-SQL-Server-Datenbank in der neuen Tabelle „AspNetUserPasskeys“.
Wie man bestehende Projekte und Datenbankschemata nachrüsten kann, will Microsoft laut „What’s new„-Dokument Mitte August 2025 zusammen mit .NET 10.0 Preview 7 veröffentlichen.
Die Passkey-Implementierung in .NET 10.0 unterstützt Resident Keys (Discoverable Credentials) und Non-Resident Keys, allerdings keine Attestation.

Anlegen eines neuen Blazor-Projekts mit dem Authentifizierungstyp „Individual Accounts“

Anlegen eines Passkeys innerhalb der Benutzerverwaltung
Man muss dem Passkey einen Namen geben.
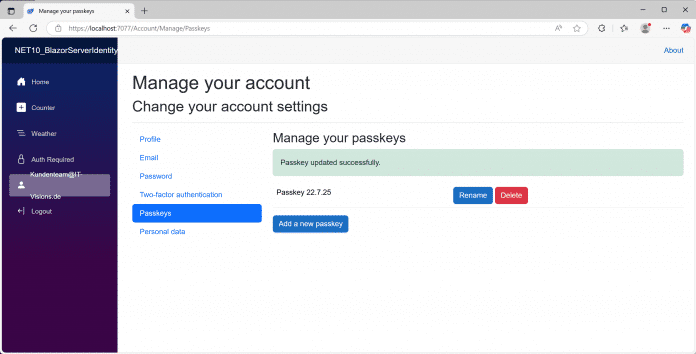
Der Passkey wurde gespeichert.
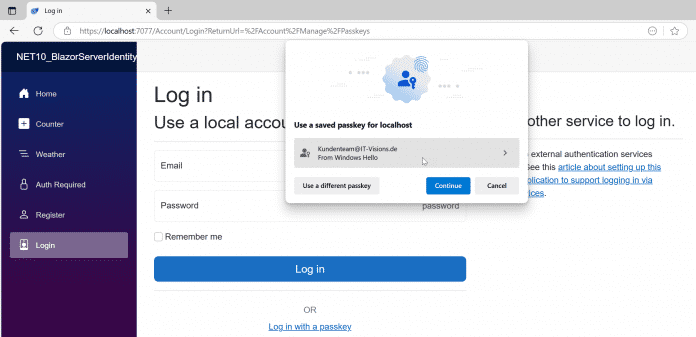
Mit dem gespeicherten Passkey kann man sich wieder anmelden.

Tabelle „AspNetUserPasskeys“ im Microsoft SQL Server












Entwicklung & Code
Visual Studio Code 1.104: Agent Mode bittet um Bestätigung
Das August-Update für Visual Studio Code steht bereit. Unter der Versionsnummer 1.104 hat Microsofts freier Sourcecode-Editor einige KI-Neuerungen an Bord, darunter die automatische Modellauswahl im GitHub Copilot Chat, eine neue Sicherheitsebene für den Agent Mode und die automatische Verwendung von AGENTS.md-Dateien. Zu den weiteren Updates zählen unter anderem farblich hervorgehobene Fensterumrandungen unter Windows und eine Vorschau für Git-Worktree-Änderungen.
Automatische LLM-Auswahl im Copilot Chat
Im GitHub Copilot Chat können Entwicklerinnen und Entwickler nun als Preview-Feature dasjenige Large Language Model (LLM) auswählen lassen, das eine optimale Performance und eine Reduzierung der Rate Limits bieten soll – denn manche Modelle weisen eine stärkere Nutzung auf. Diese Funktion soll zunächst die User mit individuellen Copilot-Abos erreichen und im Verlauf der nächsten Wochen an alle Copilot-Nutzerinnen und -Nutzer ausgespielt werden.
Um die automatische Modellauswahl zu aktivieren, ist im Model Picker die Option Auto anzuklicken. Dann fällt VS Code die Entscheidung zwischen Claude Sonnet 4, GPT-5, GPT-5 mini und GPT-4.1 – sofern das Unternehmen der Entwicklerinnen und Entwickler keines dieser Modelle blockiert hat. Der Name des ausgewählten Modells erscheint beim Hovern über der Antwort in der Chatansicht.

Per „Auto“-Option wählt VS Code automatisch ein Large Language Model aus.
(Bild: Microsoft)
Änderungsbestätigung für Agent Mode
Der Agent Mode in GitHub Copilot erhält derweil eine neue Sicherheitsebene: Er erfordert nun eine explizite Bestätigung, bevor er Änderungen an sensiblen Dateien („sensitive files“) vornimmt. Welche das sind, können Entwicklerinnen und Entwickler mit der Einstellung chat.tools.edits.autoApprove festlegen. Einige Dateien, wie solche außerhalb des Workspace, werden standardmäßig als sensible Dateien behandelt.
Als experimentelles Feature verwendet der Agent Mode zudem automatisch eine AGENTS.md-Datei – sofern diese im Workspace-Root vorhanden ist – als Kontext für Chatanfragen. Mit einer AGENTS.md-Datei lassen sich einem Agenten Kontext und Anweisungen vermitteln.
Updates abseits der KI
Windows-Nutzer können dank der neuen Einstellung window.border ihre VS-Code-Fenster nun mit einem farblich hervorgehobenen Rahmen versehen. Die Farben lassen sich je nach Workspace anpassen, sodass auf einen Blick sichtbar ist, welcher Workspace in welchem Fenster geöffnet ist:

Bunte Rahmen für Workspaces – je nach Workspace können Developer andere Farben vergeben.
(Bild: Microsoft)
Eine weitere Neuerung betrifft die Versionskontrolle: Eine Vorschau zeigt nun die Änderungen zwischen Worktree-Dateien und dem aktuellen Workspace. Dazu dient ein Rechtsklick auf eine Worktree-Datei, um das Kontextmenü in der Ansicht Source Control Changes zu öffnen. Dort lässt sich dann Compare with Workspace auswählen.

Das Feature „Compare with Workspaces“ zeigt die Änderungen zwischen Worktree-Dateien und aktuellem Workspace.
(Bild: Microsoft)
Nach Review der Änderungen können Entwicklerinnen und Entwickler dann den Befehl Migrate Worktree Changes… aus der Befehlspalette verwenden, um alle Änderungen aus einem Worktree in den aktuellen Workspace zu mergen. Das soll es vereinfachen, mit mehreren Worktrees zu arbeiten und Änderungen selektiv in das Haupt-Repository zu übernehmen.
Weitere Informationen zu diesen und zahlreichen anderen neuen Features lassen sich der offiziellen Ankündigung entnehmen.
(mai)
Entwicklung & Code
Genkit Go 1.0: Google bringt stabiles KI-Framework ins Go-Ökosystem
Google hat mit Genkit Go 1.0 die erste stabile Version seines Open-Source-Frameworks für KI-Entwicklung im Go-Ökosystem veröffentlicht. Entwicklerinnen und Entwickler können damit ab sofort produktionsreife KI-Anwendungen erstellen und deployen. Gleichzeitig bringt Google mit dem neuen CLI-Befehl genkit init:ai-tools eine direkte Integration für gängige KI-Coding-Assistenten.
Typsichere KI-Flows erstellen
Eine der spannendsten Neuerungen in Genkit Go 1.0 ist die Möglichkeit, typensichere KI-Flows mit Go-Structs und JSON-Schema-Validierung zu erstellen. Dadurch lassen sich Modellantworten offenbar zuverlässig strukturieren und einfacher testen.
Im folgenden Beispiel aus dem Ankündigungsbeitrag generiert ein Flow ein strukturiertes Rezept:
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/firebase/genkit/go/ai"
"github.com/firebase/genkit/go/genkit"
"github.com/firebase/genkit/go/plugins/googlegenai"
)
// Define your data structures
type RecipeInput struct {
Ingredient string `json:"ingredient" jsonschema:"description=Main ingredient or cuisine type"`
DietaryRestrictions string `json:"dietaryRestrictions,omitempty" jsonschema:"description=Any dietary restrictions"`
}
type Recipe struct {
Title string `json:"title"`
Description string `json:"description"`
PrepTime string `json:"prepTime"`
CookTime string `json:"cookTime"`
Servings int `json:"servings"`
Ingredients []string `json:"ingredients"`
Instructions []string `json:"instructions"`
Tips []string `json:"tips,omitempty"`
}
func main() {
ctx := context.Background()
// Initialize Genkit with plugins
g := genkit.Init(ctx,
genkit.WithPlugins(&googlegenai.GoogleAI{}),
genkit.WithDefaultModel("googleai/gemini-2.5-flash"),
)
// Define a type-safe flow
recipeFlow := genkit.DefineFlow(g, "recipeGeneratorFlow",
func(ctx context.Context, input *RecipeInput) (*Recipe, error) {
dietaryRestrictions := input.DietaryRestrictions
if dietaryRestrictions == "" {
dietaryRestrictions = "none"
}
prompt := fmt.Sprintf(`Create a recipe with the following requirements:
Main ingredient: %s
Dietary restrictions: %s`, input.Ingredient, dietaryRestrictions)
// Generate structured data with type safety
recipe, _, err := genkit.GenerateData[Recipe](ctx, g,
ai.WithPrompt(prompt),
)
if err != nil {
return nil, fmt.Errorf("failed to generate recipe: %w", err)
}
return recipe, nil
})
// Run the flow
recipe, err := recipeFlow.Run(ctx, &RecipeInput{
Ingredient: "avocado",
DietaryRestrictions: "vegetarian",
})
if err != nil {
log.Fatalf("could not generate recipe: %v", err)
}
// Print the structured recipe
recipeJSON, _ := json.MarshalIndent(recipe, "", " ")
fmt.Println("Sample recipe generated:")
fmt.Println(string(recipeJSON))
<-ctx.Done() // Used for local testing only
}
Hier wird ein Flow (recipeGeneratorFlow) definiert, der Rezepte auf Basis einer Hauptzutat und optionaler Ernährungsvorgaben wie „vegetarian“ generiert. Der Prompt wird dynamisch gebaut, ans KI-Modell (Google Gemini) übergeben und die Antwort in eine klar definierte Go-Datenstruktur (Recipe) zurückgeschrieben. Am Ende läuft der Flow mit der Eingabe „avocado, vegetarisch“ und gibt ein komplettes JSON-Rezept mit Zutaten, Kochzeit und Tipps zurück.
Anbindung an gängige Sprachmodelle
Darüber hinaus haben Developer mit Genkit Go 1.0 die Möglichkeit, externe APIs über Tool Calling einzubinden und Modelle von Google AI, Vertex AI, OpenAI, Anthropic und Ollama über eine einheitliche Schnittstelle zu nutzen. Die Bereitstellung soll unkompliziert als HTTP-Endpoint erfolgen. Eine Standalone-CLI sowie eine interaktive Developer UI unterstützen beim Schreiben von Tests, Debugging und Monitoring.
Der neue Befehl genkit init:ai-tools richtet automatisch KI-Assistenztools wie Gemini CLI, Firebase Studio, Claude Code und Cursor ein. Somit können Entwicklerinnen und Entwickler damit direkt die Genkit-Dokumentation durchsuchen, Flows testen, Debug-Traces ausführen und Go-Code nach Best Practices generieren.
(mdo)
Entwicklung & Code
Vorstellung Studie Cupra Tindaya: Betont unruhig
In den Weiten des Volkswagen-Konzerns darf sich kaum eine Marke optisch so weit vorwagen wie Cupra. Tatsächlich seriennah dürfte die Studie Tindaya kaum sein, und doch ist die spektakuläre Formgebung mehr als nur ein Blickfang auf der IAA. Der Name Tindaya, nach einem Vulkan auf der Insel Fuerteventura, ist dabei durchaus Programm.
Terramar, Tavascan, Formentor und auch noch der Ateca, dessen Produktion absehbar ausläuft: An SUVs mangelt es der Marke Cupra derzeit wahrlich nicht. Ist dort perspektivisch Platz für ein weiteres Modell mit rund 4,7 m Länge? Ja, befanden offenbar die Verantwortlichen. Die Studie Tindaya ist 4,72 m lang und ausschließlich auf batterieelektrische Antriebe ausgerichtet. Welche Plattform in einem Serienmodell genutzt werden würde, ist aktuell noch zweitrangig. Viel spricht dafür, dass es die Basis des kommenden VW ID.4 sein könnte.
23-Zoll-Felgen
Das kantig-faltige Design ist bewusst überzeichnet. Allein schon der gesetzliche Fußgängerschutz würde einem Serieneinsatz dieser Front vermutlich entgegenstehen. Riesige Radhäuser, in denen selbst 23-Zoll-Felgen samt Reifen mit geringer Flankenhöhe nicht übertrieben scheinen, haben da vermutlich bessere Chancen. Innen gibt es vier Einzelsitze, ein 24-Zoll-Display, ein Lenkrad im Gaming-Stil und eine Mittelkonsole, die an die 2023er-Studie des Lamborghini Lanzador erinnert. In der Mitte der bis in den Fond durchgehenden Konsole befindet sich ein Zentralknopf, mit dem sich verschiedene Funktionen ansteuern lassen.
250 kW Leistung im Spitzenmodell – mindestens
Ein aufregend gestaltetes Serienmodell würde sich bei den Antriebskomponenten vermutlich im Baukasten des Konzerns bedienen. Hinter- wie Allradantrieb wären damit möglich. Das Leistungsangebot dürfte sich zwischen 210 und 250 kW bewegen, wobei wir damit rechnen, dass sich Volkswagen irgendwann genötigt sehen könnte, in dieser Hinsicht nachzulegen. Ein Ende des Wettrüstens ist schließlich nicht abzusehen – ganz im Gegenteil: Der Umstieg auf Elektromobilität macht mehr Leistung vergleichsweise problemlos möglich, was eher Folgen für die Verkehrssicherheit haben wird als auf den Bedarf an Fahrenergie.

Cupra
)
Unter anderem Volkswagen hat mit dem E-Motor APP550 gezeigt, dass sich selbst 210 kW Spitzenleistung potenziell mitführen lassen, ohne beim Verbrauch dramatisch über dem zu liegen, was ein elektrischer Kleinwagen wie der Opel Corsa-e auch braucht. Auch in dieser Hinsicht unterscheiden sich Verbrenner und batterieelektrischer Antrieb enorm. Das Potenzial eines aufgeladenen V8 wird auch bei gemäßigter Fahrweise immer ein Stück weit zu füttern sein. Beim ungleich effizienteren E-Motor steigt der Verbrauch erst dann, wenn die Leistung abgerufen wird.
Ladeleistung: 200 kW plus X
Zweigeteilt ist die Welt bei Volkswagen hinsichtlich der Ladeleistung. Audi und Porsche haben schon Modelle mit 800 Volt Spannungsebene, was Ladeleistung von deutlich mehr als 200 kW an der gängigen, mit 500 Ampere abgesicherten Ladeinfrastruktur erlaubt. Marken wie Skoda, VW und eben auch Cupra nutzen derzeit ein 400-Volt-System. Damit ist an Ladesäulen mit 500 A bei 200 kW die Spitze erreicht. Mittelfristig werden auch andere Konzernmarken Elektroautos mit 800 Volt ins Sortiment aufnehmen. Ob ein Serienableger der Studie Tindaya dazu gehören könnte, ist ungewiss.
Lesen Sie mehr zur Marke Cupra
(mfz)

Studie zur Brennstoffzelle im Lkw: „Prinzipiell machbar“

Jetzt patchen! Attacken auf Android-Smartphones von Samsung beobachtet

„Nur teure Symbolpolitik“: 1Komma5°-Gründer über Reiches Energiepolitik

Der ultimative Guide für eine unvergessliche Customer Experience
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist

Adobe Firefly Boards › PAGE online
-
 UX/UI & Webdesignvor 4 Wochen
UX/UI & Webdesignvor 4 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
eine gute Nachricht ist") Social Mediavor 4 Wochen
Social Mediavor 4 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenAdobe Firefly Boards › PAGE online
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Wochen
Entwicklung & Codevor 2 WochenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen