Entwicklung & Code
WebAssembly: Wasmer 7.0 bringt experimentellen Async-Support für Python
Die Open-Source-Runtime Wasmer ist in Version 7.0 mit neuen Funktionen für Python, RISC-V und zahlreichen Bugfixes erschienen. Insgesamt hat das Entwicklungsteam 200 Pull-Requests umgesetzt – davon 80, die sich auf Bugs oder seit Langem bestehende Limitierungen bezogen.
Weiterlesen nach der Anzeige
Das auf WebAssembly basierende Wasmer-Ökosystem ermöglicht das Ausführen von Anwendungen im Browser, eingebettet in eine Programmiersprache nach Wahl oder standalone auf dem Server.
Version 7.0 erweitert den Python-Support
In Wasmer 7.0 ist eine experimentelle Async-API mit an Bord, verfügbar in Wasmers nativen Backends singlepass, cranelift und llvm. Die API ermöglicht vollständigen Async-Support in Python unter Wasmer, was das Verwenden von Bibliotheken wie SQLAlchemy ermöglicht. Darüber hinaus bietet Wasmer 7.0 Support für dynamisches Linking in WASIX. Bislang war der Python-Support in Wasmer auf den Core Intepreter beschränkt, sodass sich viele native Libaries, beispielsweise NumPy, nicht nutzen ließen.
Weitere Updates betreffen unter anderem RISC-V: Die CPU-Befehlssatzarchitektur war in Wasmer bereits in LLVM und Cranelift verfügbar, doch nun besitzt auch Singlepass RISC-V-Support. Zudem ist das LLVM-Target RV32gc für eine erhöhte RISC-V-Abdeckung hinzugekommen.
Details zum neuen Release finden sich in der Ankündigung im Wasmer-Blog. Zusätzliche Informationen zu den neuen Python-Features sollen in weiteren Blogbeiträgen folgen.
Weiterlesen nach der Anzeige
(mai)












Entwicklung & Code
Developer-Häppchen fürs Wochenende – Kleinere News der Woche
In unserem leckeren Häppchen-Überblick servieren wir alles, was es zwar nicht in die News geschafft hat, wir aber dennoch für spannend halten:
Weiterlesen nach der Anzeige
- llamafile von Mozilla setzt ab Version 0.10 ein neues Build-System ein, das den Code zu den aktuellen Versionen von llama.cpp kompatibel macht. Damit lassen sich neuere Modelle einsetzen, aber einige der bisherigen Funktionen fehlen.
- Die PowerShell 7.6 ist nun allgemein verfügbar. Das Long-Term Release basiert auf .NET 10 und verbessert die Zuverlässigkeit der Engine, der Module und der Interaktivität.
- Webapps lassen sich in VS Code 1.112 jetzt debuggen, ohne den Editor verlassen zu müssen. Außerdem können Entwicklerinnen und Entwickler MCP-Server in einer Sandbox starten, um ihren Zugriff auf die Umgebung einzuschränken.
- Next.js 16.2 beschleunigt das Rendering zum einen beim Start des Entwicklungsservers
next devund zum anderen beim Deserialisieren von Server-Komponenten in JSON. Ein neues Aussehen hat die Standard-Fehlerseite 500 bekommen.

(Bild: NeuralStudio/Adobe Stock)

Die Online-Konferenz betterCode() ArchDoc am 20. Mai 2026 stellt leichtgewichtige Konzepte der Dokumentation vor, darunter den arc42-Canvas oder Docs-as-Code zum Arbeiten wie beim Programmieren. Auch KI unterstützt kräftig bei der Automatisierung der Doku. Jetzt Frühbucherrabatt sichern!
- Für Azure DevOps hat Microsoft einen MCP-Server vorgestellt. Er bietet dieselben Funktionen wie der DevOps-Server selbst, ist aber noch eine Preview-Version.
- Das in Rust geschriebene Observability-Tool Parseable tritt seit 2022 gegen die etablierte Konkurrenz an und liegt nun in Version 2.6 vor. Neben einer Reihe von Bugfixes wurde im neuen Release unter anderem auch die Tenant-ID der Metrikaggregation hinzugefügt. Parseable lässt sich lokal, in der Cloud oder über den verwalteten Dienst Parseable Cloud nutzen.
- Kubernetes-Plattformen einfach und schnell auf deklarativem Weg aufbauen – komplett inklusive vorkonfigurierter Komponenten wie Infrastruktur, Multi-Tenancy, GitOps, Observability, Secrets Management etc. – das verspricht das neue Open-Source-Framework Kubara. Das mit Unterstützung von Stackit entwickelte und in Go geschriebene CLI-Tool steht ab sofort frei zur Verfügung.
- Ein Nürnberger StartUp bietet mit kogiQA ein Testing-Tool, das komplett ohne Selektoren arbeitet. Stattdessen wählt es die Elemente zur Laufzeit deterministisch anhand ihrer semantischen Bedeutung aus. Dafür hat der Anbieter ein speziell trainiertes KI-Modell entwickelt.
- GitHub Enterprise Server 3.20 kommt mit einer überarbeiteten Seite für Pull Request, die einen besseren Überblick über den Status der Requests zeigt und das Mergen beschleunigt. So gibt es gruppierte Statusanzeigen und eine Liste fehlerhafter Checks.
- Die neue JFrog Agent Skills Registry unterstützt das NVIDIA Agent Toolkit inklusive OpenShell, einer Open-Source-Laufzeitumgebung für die Entwicklung und den Betrieb sicherer, autonomer und kontinuierlich arbeitender KI-Agenten.
Solltest du ein schmackhaftes Thema vermissen, freuen wir uns über deine Mail.
(who)
Entwicklung & Code
Next.js 16.2 bringt Updates für die Nutzung von KI-Agenten
Das Next.js-Team beim Hersteller Vercel hat Version 16.2 des React-Frameworks fertiggestellt. Next.js soll nun deutlich schneller sein, was die Time-to-URL während der Entwicklung und das Rendering in Anwendungen betrifft. Auch an der Performance des Bundlers Turbopack wurde geschraubt und für die KI-gestützte Softwareentwicklung hat Next.js ebenfalls Updates zu bieten.
Weiterlesen nach der Anzeige
(Bild: Stone Story / stock.adobe.com)

Webanwendungen mit KI anreichern, sodass sie wirklich besser werden? Der Online-Thementag enterJS Integrate AI am 28. April 2026 zeigt, wie das geht. Frühbuchertickets und Gruppenrabatte sind im Online-Ticketshop verfügbar.
Support für die KI-gestützte Entwicklung
In Next.js 16.2 ist in create-next-app standardmäßig eine AGENTS.md-Datei enthalten. Durch diese erhalten KI-Agenten Zugriff auf die Next.js-Dokumentation für die genutzte Version bereits zu Beginn eines Projekts. Das soll das Problem umgehen, dass KI-Agenten mit veralteten Daten trainiert werden und aktuelle APIs nicht kennen, woraus inkorrekter Code resultieren kann.
Als experimentelles CLI steht next-browser bereit. Es erlaubt KI-Agenten, eine laufende Next.js-Anwendung zu inspizieren. Zu den Daten, die next-browser den Agenten zugänglich macht, zählen solche auf dem Browser-Level wie Screenshots oder Netzwerkanfragen, ebenso wie Framework-spezifische Insights aus den React DevTools und dem Next.js Dev Overlay, darunter Props, Hooks, Partial Prerendering (PPR) Shells und Fehlermeldungen.
Um next-browser zu verwenden, installieren Entwicklerinnen und Entwickler es als Skill:
npx skills add vercel-labs/next-browser
Dann geben sie /next-browser in ihrem KI-Agenten ein, der mit Skills umgehen kann, beispielsweise Claude Code oder Cursor.
Weiterlesen nach der Anzeige
Weiterführende Hinweise zum Einsatz von next-browser sind im GitHub-Repository zu finden.
Turbopack-Updates für Performance und Security
Seit Version 16 nutzt Next.js den Bundler Turbopack als Standard. Das aktuelle Release bringt für Turbopack zahlreiche Performanceverbesserungen, Bugfixes und Kompatibilitäts-Updates – insgesamt sind über 200 Änderungen eingeflossen.
Eines der neuen Performance-Features betrifft das Neuladen von serverseitigem Code während der Entwicklung. Bisher wurde require.cache für ein geändertes Modul geleert, ebenso wie für alle anderen Module in seiner Import-Kette. Dadurch wurde oft mehr Code als notwendig neu geladen, beispielsweise unveränderte node_modules. In Next.js 16.2 wird nur noch der tatsächlich geänderte Code erneut geladen, was durch Turbopacks Kenntnis über den Module Graph ermöglicht wird. Das soll die Effizienz des serverseitigen Hot Reloading deutlich verbessern.
Das Next.js-Entwicklungsteam untermauert das mit Zahlen, die es in Echtzeitanwendungen beobachtet hat: 67 bis 100 Prozent schnelleres Anwendungs-Refresh und 400 bis 900 Prozent schnellere Kompilierungszeit in Next.js seien möglich.
Ein weiteres Update dreht sich um Security. Der Sicherheitsstandard Content Security Policy (CSP) dient dazu, Angriffe auf Webseiten wie das Cross-Site Scripting (XSS) zu verhindern. Die gängige nonce-basierte Methode erfordert, dass alle Webseiten dynamisch gerendert werden. Da dies die Performance einschränken kann, setzt das Next.js-Team auf die Alternative Subresource Integrity (SRI). Diese berechnet im Vorfeld einen Hash für jedes Skript und erlaubt dem Browser nur das Ausführen von Skripten mit genehmigten Hashes. In Next.js 16.2 besitzt Turbopack experimentellen Support für SRI.
Weitere Informationen zu den Updates in Next.js 16.2 sowie speziell in den Bereichen künstliche Intelligenz und Turbopack lassen sich dem Next.js-Blog entnehmen.
(mai)
Entwicklung & Code
Neu in .NET 10.0 [15]: Klasse Program und Main()-Methode in File-based Apps
Eine File-based App kann die in C# 9.0 (im Rahmen von .NET 5.0) eingeführten Top-Level Statements verwenden. Das wird der Regelfall sein, bei dem die Ausführung der Datei bei der ersten Zeile beginnt:
Weiterlesen nach der Anzeige
Console.WriteLine(System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription);
Console.WriteLine($"Kompilierungsmodus: {(System.Runtime.CompilerServices.RuntimeFeature.IsDynamicCodeSupported ? "JIT" : "AOT")}");

Start der File-based App mit Top-Level Statement (Abb. 1)
Neben der Verwendung von Top-Level Statements ist auch der klassische Stil mit class Program und Main()-Methode in den File-based Apps möglich:
class Program
{
static void Main(string[] args)
{
Console.WriteLine(System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription);
Console.WriteLine($"Kompilierungsmodus: {(System.Runtime.CompilerServices.RuntimeFeature.IsDynamicCodeSupported ? "JIT" : "AOT")}");
}
}
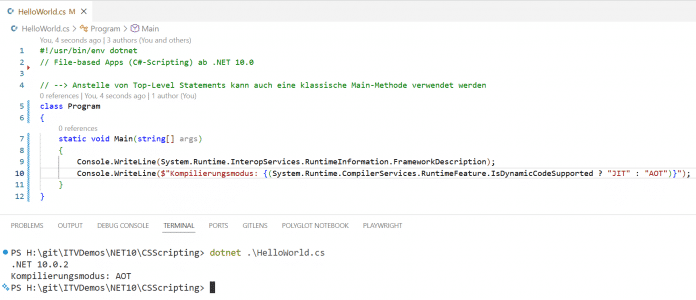
Die File-based App lässt sich auch mit der Main()-Methode in der Klasse Program starten (Abb. 2).
(rme)

Mercedes MB. Drive Assist Pro Level 2++ im CLA ausprobiert

US-Geschworene: Musk schädigte Twitter-Aktionäre bewusst

Platzt jetzt die KI-Blase? USA im freien Fall

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast

Community Management zwischen Reichweite und Verantwortung
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 3 Wochen
Social Mediavor 3 WochenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Social Mediavor 1 Monat
Social Mediavor 1 MonatCommunity Management zwischen Reichweite und Verantwortung
-
Künstliche Intelligenzvor 1 Monat
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenEindrucksvolle neue Identity für White Ribbon › PAGE online
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAumovio: neue Displaykonzepte und Zentralrechner mit NXP‑Prozessor
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenÜber 220 m³ Fläche: Neuer Satellit von AST SpaceMobile ist noch größer
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonateneHealth: iOS‑App zeigt Störungen in der Telematikinfrastruktur

