Künstliche Intelligenz
ChatGPT als Arzt-Ersatz? Studie zeigt ernüchternde Ergebnisse
Große Sprachmodelle wie GPT-4o erreichen bei medizinischen Wissenstests inzwischen nahezu perfekte Ergebnisse. Sie bestehen die US-Ärzte-Zulassungsprüfung, fassen Patientenakten zusammen und können Symptome einordnen. Gesundheitsbehörden weltweit prüfen deshalb, ob KI-Chatbots als erste Anlaufstelle für Patienten dienen könnten – eine Art „neue Eingangstür zum Gesundheitssystem“, wie es in einem Strategiepapier des britischen NHS heißt.
Weiterlesen nach der Anzeige
Doch die Studie „Reliability of LLMs as medical assistants for the general public: a randomized preregistered study“ von Forschern der Universität Oxford dämpft diese Hoffnungen erheblich. Die Arbeit erscheint im Fachjournal Nature Medicine, eine Vorabversion ist auf arXiv verfügbar. Das zentrale Ergebnis: Das klinische Wissen der Modelle lässt sich nicht auf die Interaktion mit echten Menschen übertragen.
1298 Teilnehmer, zehn medizinische Szenarien
Für die randomisierte, kontrollierte Studie rekrutierten die Forscher 1298 Teilnehmer aus Großbritannien. Jeder Proband erhielt eines von zehn alltagsnahen medizinischen Szenarien – etwa plötzliche starke Kopfschmerzen, Brustschmerzen in der Schwangerschaft oder blutigen Durchfall. Die Aufgabe: Einschätzen, welche Erkrankung vorliegen könnte und ob ein Arztbesuch, die Notaufnahme oder gar ein Krankenwagen nötig ist.
Die Teilnehmer wurden zufällig in vier Gruppen eingeteilt. Drei Gruppen erhielten Zugang zu je einem KI-Modell, das zu Studienbeginn aktuell war – GPT-4o, Llama 3 oder Command R+. Die Kontrollgruppe durfte beliebige Hilfsmittel nutzen, etwa eine Internetsuche.
KI allein brilliert – mit Menschen versagt sie
Weiterlesen nach der Anzeige
Die Ergebnisse offenbaren eine bemerkenswerte Diskrepanz. Ohne menschliche Beteiligung identifizierten selbst die inzwischen nicht mehr aktuellen Sprachmodelle in 94,9 Prozent der Fälle mindestens eine relevante Erkrankung. Bei der Frage nach der richtigen Handlungsempfehlung – Selbstbehandlung, Hausarzt, Notaufnahme oder Rettungswagen – lagen sie im Schnitt in 56,3 Prozent der Fälle richtig.
Sobald jedoch echte Menschen die Modelle befragten, brachen die Werte ein. Teilnehmer mit KI-Unterstützung erkannten relevante Erkrankungen nur in maximal 34,5 Prozent der Fälle – signifikant schlechter als die Kontrollgruppe mit 47 Prozent. Bei der Wahl der richtigen Handlung schnitten alle Gruppen gleich ab: rund 43 Prozent Trefferquote, unabhängig davon, ob ein Chatbot half oder nicht.
Doppeltes Kommunikationsversagen
Die Forscher analysierten die Chat-Protokolle zwischen Nutzern und KI-Modellen, um die Ursachen zu verstehen. Sie identifizierten zwei zentrale Schwachstellen: Erstens gaben die Teilnehmer den Modellen oft unvollständige Informationen. Zweitens verstanden die Nutzer die Antworten der KI nicht richtig – obwohl die Modelle in 65 bis 73 Prozent der Fälle mindestens eine korrekte Diagnose nannten, übernahmen die Teilnehmer diese nicht zuverlässig.
Dr. Anne Reinhardt von der LMU München sieht hier eine grundsätzliche Schere: „Viele Menschen vertrauen KI-Antworten auf Gesundheitsfragen schnell, weil sie leicht zugänglich sind. Sie klingen auch sprachlich sehr überzeugend – selbst dann, wenn der Inhalt eigentlich medizinisch absolut falsch ist.“
Benchmarks führen in die Irre
Die Forscher verglichen die Leistung der Modelle auf dem MedQA-Benchmark – einem Standardtest mit Fragen aus Ärzte-Prüfungen – mit den Ergebnissen der Nutzerstudie. In 26 von 30 Fällen schnitten die Modelle bei den Multiple-Choice-Fragen besser ab als bei der Interaktion mit echten Menschen. Selbst Benchmark-Werte von über 80 Prozent korrespondierten teilweise mit Nutzer-Ergebnissen unter 20 Prozent.
Prof. Ute Schmid von der Universität Bamberg ordnet die hohe Leistung der Modelle „allein“ kritisch ein: „Etwas irreführend finde ich die Aussage, dass die Performanz der Sprachmodelle ‚alleine‘ deutlich höher ist als bei den Nutzenden. In diesem Fall wurden die Anfragen vermutlich von fachlich und mit LLMs erfahrenen Personen formuliert.“
Was müsste ein medizinischer Chatbot können?
Die Experten sind sich einig, dass spezialisierte medizinische Chatbots anders gestaltet werden müssten als heutige Allzweck-Modelle. Prof. Kerstin Denecke von der Berner Fachhochschule formuliert die Anforderungen: „Ein medizinisch spezialisierter Chatbot müsste evidenzbasierte, aktuelle Informationen bieten. Außerdem müsste er Notfallsituationen zuverlässig erkennen, individuelle Risikofaktoren berücksichtigen und transparent seine Grenzen kommunizieren. Er sollte eine strukturierte Anamnese erheben, um zuverlässig triagieren zu können. Und er sollte sich nicht dazu hinreißen lassen, eine Diagnose zu stellen.“
Die Hürden für einen solchen Einsatz seien allerdings erheblich, so Denecke: „Große Hürden sind zum einen die Regulierung – je nach Funktion als Medizinprodukt oder Hochrisiko-KI. Zum anderen sind es die Haftung, der Datenschutz sowie die technische Integration in Versorgungsprozesse.“
Tests mit echten Nutzern unerlässlich
Die Schlussfolgerung der Oxford-Forscher ist eindeutig: Bevor KI-Systeme im Gesundheitswesen eingesetzt werden, müssten sie mit echten Nutzern getestet werden – nicht nur mit Prüfungsfragen oder simulierten Gesprächen. Schmid plädiert für einen differenzierten Ansatz: „Qualitätsgeprüfte Chatbots könnten beispielsweise über die gesetzlichen Krankenkassen angeboten und von Hausarztpraxen als Erstzugang empfohlen werden. Allerdings sollten Menschen nicht gezwungen werden, diese Angebote zu nutzen.“
(mack)












Künstliche Intelligenz
Die Polizei im Nacken: Bayern jagt Verkehrsrowdys mit „Action-Cam“
Pünktlich zum Start der Motorradsaison, in der Kurvenstrecken in den Mittelgebirgen wieder tausende Zweiradfahrer anlocken, rüstet die bayerische Polizei technisch auf. An der B47 bei Amorbach, einer bei Anwohnern und Touristen gleichermaßen für ihre Lärmbelastung berüchtigten Route, präsentierte Innenstaatssekretär Sandro Kirchner (CSU) am Donnerstag das neueste Einsatzwerkzeug des Polizeipräsidiums Unterfranken: das Action-Kamera-System (AKS). Was für Hobby-Blogger und Urlauber ein nettes Gadget zur Dokumentation der eigenen Tour ist, wird in den Händen der Beamten zur Waffe gegen Verkehrsverstöße.
Weiterlesen nach der Anzeige
Das Projekt setzt laut dem bayerischen Innenministerium auf Diskretion und Unmittelbarkeit. Ein ziviles Polizeimotorrad auf Basis der BMW S 1000 XR mischt sich unter den fließenden Verkehr. Darauf sitzen geschulte Beamte, die ein Auge für riskante Fahrmanöver und manipulierte Auspuffanlagen haben sollen. Bei Verstößen aktiviert der nicht als solcher erkennbare Polizist eine angebrachte GoPro-Kamera. Die Aufzeichnung läuft ab diesem Moment kontinuierlich mit und dokumentiert das gesamte Fahrverhalten des Verdächtigen, bis er gestoppt wird.
Damit soll das System ein lückenloses digitales Protokoll liefern, das im späteren Gerichtsverfahren als objektives Beweismittel dienen könnte. Kirchner zufolge hat sich die Technik in mehrjährigen Testphasen bewährt. Sie führe zu einer deutlich realistischeren Beurteilung der Situation durch die Justiz.
Beweissicherung vs. informationelle Selbstbestimmung
Doch wo Kameras im öffentlichen Raum zum Einsatz kommen, ist die Debatte über den Datenschutz und die Verhältnismäßigkeit nicht weit. Die bayerische Polizei betont zwar, dass die Kamera erst bei einem konkreten Verdacht eingeschaltet wird. Dennoch bewegt sich das System in einem sensiblen Bereich der permanenten Überwachungsmöglichkeit.
Kritiker geben zu bedenken, dass die Grenzen zwischen einer anlassbezogenen Aufnahme und einer verdachtsunabhängigen Vorratsdatenspeicherung auf dem Asphalt verschwimmen könnten. Die Polizei hebt auch den „verkehrserzieherischen Effekt“ hervor: Dem Fahrer wird das Fehlverhalten direkt bei der Kontrolle auf dem Display bildlich vor Augen geführt. Doch für Datenschützer kommt die Einführung solcher Systeme einem weiteren Puzzlestück auf dem Weg zum gläsernen Fahrer gleich.
Die rechtlichen Hürden für solches Dashcam-Material sind in Deutschland traditionell hoch. Grundsätzlich kollidiert die permanente Aufzeichnung mit dem Recht auf informationelle Selbstbestimmung. Private Dashcams dürfen daher oft nur kurzzeitige, anlassbezogene Aufnahmen erstellen. Auch die Polizei muss sicherstellen, dass AKS strengen rechtsstaatlichen Vorgaben folgt.
Ein Beweisverwertungsverbot droht, wenn Aufnahmen ohne hinreichenden Tatverdacht oder unter Verletzung des Verhältnismäßigkeitsprinzips entstanden sind. Die bayerische Lösung versucht, diesen Spagat hinzubekommen, indem die Beamten die Aufnahme manuell starten. Das soll den Eingriff in die Grundrechte unbeteiligter Dritter minimieren.
Weiterlesen nach der Anzeige
Hohe Investitionen für die Verkehrssicherheit
Die Kosten für ein AKS-Motorrad von BMW sind mit rund 48.000 Euro beachtlich. Allein das Kamerasystem schlägt dabei mit etwa 10.000 Euro zu Buche. Die Politik rechtfertigt diesen finanziellen Aufwand mit der Notwendigkeit, die Unfallzahlen zu senken. Allein im Jahr 2025 wurden in Bayern über 5170 Motorradfahrer verletzt, 96 Unfälle endeten tödlich. Das AKS-Motorrad soll dabei helfen, „Rowdys“ aus dem Verkehr zu ziehen. Diese gefährden durch riskante Überholmanöver oder illegale Umbauten an der Maschine nicht nur sich selbst und Dritte, sondern sorgen auch für eine massive Lärmbelästigung.
Kirchner hob zugleich hervor, dass Politik und Polizei keine pauschale Kriminalisierung aller Biker anstrebten. Vielmehr gehe es darum, durch gezielte Einzelmaßnahmen harte Sanktionen wie Beschlagnahmungen oder Fahrverbote durchzusetzen, ohne die rücksichtsvolle Mehrheit durch Streckensperrungen zu bestrafen.
(mma)
Künstliche Intelligenz
Gehirn-Computer-Schnittstellen: Zwischen Durchbruch und ethischem Dilemma
Gedanken lesen, speichern, zurückspielen – was klingt wie Science-Fiction, ist in ersten Anwendungen bereits Realität. Brain-Computer-Interfaces, kurz BCIs, können Gehirnsignale auslesen, in digitale Daten übersetzen und in das Gehirn zurückspielen. Gelähmte Patientinnen und Patienten bedienen damit virtuelle Tastaturen allein durch die Kraft ihrer Gedanken. Menschen, die vollständig eingeschlossen in ihrem Körper gefangen waren, können plötzlich wieder kommunizieren.
Weiterlesen nach der Anzeige
Der Pathologe Dr. Jochen Lennerz hat diese Entwicklungen auf dem Digital Health Innovation Forum des Hasso-Plattner-Instituts eindrücklich beschrieben und zugleich unmissverständlich vor den Folgen gewarnt. Denn die Technologie wirft Fragen auf, für die Gesellschaft, Politik und Regulatorik bisher kaum Antworten haben. „Wenn man den Begriff funktional definiert: beispielsweise als Steuerung eines Cursors oder einer Auswahlbewegung, dann sind solche Anwendungen bereits heute möglich“, sagte Lennerz gegenüber heise online.
Lennerz zufolge könnten BCIs nicht nur therapeutische Chancen bieten, sondern das Verhältnis zwischen Mensch und Technologie grundlegend verändern. Perspektivisch sei es denkbar, Erfahrungen direkt zu teilen oder Wahrnehmungen auszulesen. Damit rücke die Technologie in die Nähe dessen, was bisher als Science-Fiction galt. „Das Potenzial der Technologie ist deutlich größer als der aktuelle Stand, aber wir befinden uns noch in einer frühen Entwicklungsphase“, sagte Lennerz.
Lennerz zufolge ließen sich Szenarien denken, in denen Soldaten Drohnen oder robotische Systeme direkt per Gedanken steuern. Ebenso könne es möglich werden, visuelle Informationen aus dem Gehirn zu extrahieren – also Wahrnehmungen zu analysieren, die dem Menschen selbst womöglich gar nicht bewusst seien.
Damit könnten sich neue Formen militärischer Aufklärung und Steuerung ergeben, die weit über heutige Technologien hinausgingen. BCIs würden nicht nur verlorene Fähigkeiten wiederherstellen, sondern könnten auch menschliche Leistungsfähigkeit gezielt erweitern. Daraus könnte sich ein globaler Wettbewerb entwickeln, bei dem Staaten versuchten, sich frühzeitig Zugriff auf diese Technologien zu sichern.
Rohdaten erhalten viele Informationen
Ein besonders sensibles Feld sei dabei der Umgang mit Hirndaten. Anders als klassische medizinische Daten enthielten sogenannte Neurodaten potenziell weit mehr Informationen, als aktuell genutzt werde. Systeme griffen oft nur auf einen kleinen Teil zu – etwa zur Steuerung eines Cursors. „Dabei enthalten die Rohdaten häufig deutlich mehr Information, als für die jeweilige Anwendung genutzt wird […] Diese latente Information wirft Fragen zur Sekundärnutzung auf, weil nicht immer klar ist, welche Inhalte potenziell aus den Daten abgeleitet werden könnten.“
Weiterlesen nach der Anzeige
„Ein weiterer offener Punkt betrifft“ laut Lennerz „den Datenschutz über den Tod hinaus.“ Hirndaten gelten als hochpersönlich. Nach geltendem Datenschutzrecht erlischt der unmittelbare Schutz personenbezogener Daten mit dem Tod, während spezifische Regelungen für neurobezogene Daten bislang fehlen. Dadurch entsteht eine rechtliche Grauzone, in der insbesondere Nutzung, Weitergabe und sekundäre Auswertung solcher Daten unklar bleiben.
Auch auf individueller Ebene zeigten sich Risiken. In einem Fall habe eine Patientin nach der Implantation eines solchen Systems eine starke emotionale Bindung an das Gerät entwickelt. Nach dessen Entfernung habe sie von einem massiven Verlustgefühl berichtet.
„Tendenz, Probleme mit Technik zu lösen“
Der Chemnitzer Psychologieprofessor Bertolt Meyer, der selbst eine bionische Prothese trägt, ordnete BCIs in der Anhörung des Deutschen Ethikrats „Neue Neurotechnologien – Ethik, Recht und Gesellschaft“ als sogenannte „Human Augmentation Technologies“ ein, die zu den invasiven gerätebasierten Technologien zur Erweiterung menschlicher Fähigkeiten zählen. Als Beispiel zeigte er unter anderem Neuralinks Pong-spielenden Affen. Die gesellschaftliche Akzeptanz hänge entscheidend davon ab, ob eine Technologie zur Wiederherstellung von Fähigkeiten oder der Leistungssteigerung diene. Hinzu kommt das Risiko der Stigmatisierung und eine zunehmende Tendenz, gesellschaftliche Probleme primär mit Technik lösen zu wollen.
Warnung vor Nutzungsdruck bei Neurotechnologien
Zudem warnte Dr. med. Philipp Kellmeyer, Juniorprofessor für Responsible AI und Digital Health an der Universität Mannheim, in der Anhörung vor neuen Formen von Nutzungsdruck, Selbstmodifikation und einer wachsenden Abhängigkeit durch verbraucherorientierte Neurotechnologien. Er plädiert dafür, mentale Integrität als eigenständiges Schutzgut ernst zu nehmen und partizipative Verfahren systematisch in Entwicklungs- und Regulierungsprozesse zu integrieren. Kellmeyer und weitere Forscher haben zudem ein Moratorium gefordert: keine implantierbaren nicht-medizinischen BCIs, solange deren Wirkung auf den menschlichen Geist nicht hinreichend verstanden sei. Der an der Forderung nach dem Moratorium beteiligte Rechtswissenschaftler Dr. Christoph Bublitz von der Universität Hamburg, wies auch auf unbeantwortete Fragen zu den psychischen Auswirkungen und der Gedankenfreiheit hin.
Besonders kritisch sei die mögliche militärische Nutzung. Laut Prof. Marcello Ienca, Professor für Ethik der Künstlichen Intelligenz und Neurowissenschaften an der TU München, wurden erste BCIs in den 1970er und 1980er Jahren ursprünglich für militärische Zwecke entwickelt. Ienca zufolge baut China seit 2023 spezialisierte Strukturen für kognitive Kriegsführung auf, zu denen auch Neurotechnologien gehören.
Wettbewerber arbeiten zusammen
Auch die Rolle großer Industrieakteure wie Neuralink, dessen BCI bereits bei über einem Dutzend Menschen implantiert wurde (Ende Januar 2026 waren es 21 Personen), ordnet Lennerz auf Nachfrage ein. „Neuralink ist, wie die anderen Industrieakteure, Teil unserer Collaborative Community.“ Dort arbeiteten Wettbewerber bewusst zusammen, um gemeinsame Grundlagen zu schaffen, „weil sie erkennen, dass bestimmte Herausforderungen gemeinsam leichter zu lösen sind.“
Lennerz zufolge könnten Brain-Computer-Interfaces zu einer der prägendsten Technologien des 21. Jahrhunderts werden – mit Auswirkungen weit über die Medizin hinaus. Die entscheidende Frage sei nicht mehr, ob sie kommen, sondern wie ihre Nutzung gestaltet, reguliert und kontrolliert wird.
Lesen Sie auch
(mack)
Künstliche Intelligenz
Top 10: Die beste Wärmebildkamera im Test – gut für Heim & Hobby ab 149 Euro
Wärmebildkameras helfen, Wärmebrücken und versteckte Tiere aufzuspüren. Wir stellen günstige Modelle für den Heimgebrauch vor.
Wärmebildkameras sind längst nicht mehr nur etwas für Profis aus Feuerwehr, Militär oder Industrie. Zunehmend finden sie auch im Alltag Verwendung – etwa bei der Haussanierung, auf der Jagd, beim Camping oder zur Überprüfung elektronischer Geräte. Die Technik macht Wärmestrahlung sichtbar und hilft dabei, Energieverluste im Gebäude aufzudecken oder Tiere in der Dunkelheit zu erkennen.
Die Unterschiede zwischen preiswerten Einsteigermodellen und hochpreisigen Profikameras sind dabei oftmals erheblich. Faktoren wie Bildauflösung, Temperaturgenauigkeit, Reichweite und Zusatzfunktionen variieren deutlich. Wir erklären, worauf es beim Kauf ankommt, und zeigen die besten günstigen Wärmebildkameras.
Anmerkung: Die hier vorgestellten Modelle richten sich an Amateure und Heimwerker – eine exakte Kalibrierung ist teilweise nicht möglich oder nur im Autokalibrierungsmodus. Für professionelle Anwendungen eignen sich eher teurere Modelle, die nicht Gegenstand dieser Bestenliste sind.
Welche Wärmebildkamera ist die beste?
Anmerkung: Beim Direktkauf über asiatische Plattformen oder Hersteller in China greifen weder EU-Gewährleistungsrechte noch der übliche Käuferschutz. Reklamationen lassen sich schwer durchsetzen. Deshalb sollte man nur mit sicheren Zahlungsarten (Kreditkarte, Paypal) bestellen und die Garantie- sowie Rückgabebedingungen genau prüfen.
Die Thermal Master THOR002 ist der derzeitige Testsieger – sie überzeugt mit hoher Auflösung, großem Messbereich und präziser Genauigkeit. Ergänzt wird das durch ihre ergonomische Pistolenform und die besonders einfache Bedienung.
Beim Hersteller kostet die Wärmebildkamera knapp 351 Euro (Code TMTHOR002)
- hohe native Auflösung von 256 × 192 Pixel
- großer Temperaturmessbereich (–20 bis 550 °C)
- Pistolenform mit stabilem Griff
- integriertes 3,5-Zoll-IPS-Display
- mehrere Bildmodi (IR, Fusion, PiP, Visual)
- keine Makrolinse im Lieferumfang
- wenige Custom-Messpunkte
- keine Software für Mac OS
Die Hikmicro B10S erweist sich im Test als gelungene Wärmebildkamera mit robuster Verarbeitung, guter Bildqualität und Extras wie der Makro-Funktion. Für Heimwerker und kleine Betriebe bietet sie eine zuverlässige Lösung. Sie liefert eine solide Ausstattung zum fairen Preis von 350 Euro.
- günstig
- intuitive Bedienung
- großes Display
- Wasser- und staubgeschützt nach IP54
- keine App-Anbindung
- nur Menü-Bedienung gewöhnungsbedürftig
Die Hikmicro D01 ist eine praktische, preiswerte und überraschend leistungsfähige Wärmebildkamera für Haus, Werkstatt und Alltag. Sie liefert solide Bilder im Nahbereich, startet schnell, ist kinderleicht zu bedienen und überzeugt mit extrem langer Akkulaufzeit.
Für Einsteiger und alle, die schnell und unkompliziert thermische Auffälligkeiten entdecken wollen, ist die D01 ein empfehlenswerter und sehr zugänglicher Einstieg in die Wärmebildtechnik. Ab 149 Euro geht es bei Amazon los.
- Sehr lange Akkulaufzeit (bis ca. 11 Stunden)
- Eigenständiges Gerät mit Display und internem Speicher
- Hot-/Cold-Spot-Anzeige für schnelle Orientierung
- Nativer Sensor nur 96 × 96 Pixel
- Schwächen auf größere Distanz
- Kunststoffgehäuse wirkt billig
- Keine Video-Funktion
Ratgeber
Wie wichtig ist die Auflösung wirklich?
Die Auflösung gehört zu den entscheidenden Faktoren. Einsteigergeräte bieten meist 80 × 60 oder 160 × 120 Pixel. Das ist ausreichend für einfache Temperaturprüfungen im Haushalt, etwa zur Kontrolle von Heizkörpern oder zum Aufspüren undichter Fenster. Für größere Distanzen, wie bei der Jagd oder der Gebäudethermografie, empfiehlt sich dagegen mindestens 320 × 240 Pixel. Profimodelle erreichen 640 × 480 Pixel oder mehr, das ist ausreichend für das Einsatzfeld eines Handwerkers.
Wichtig: Anders als bei Digitalkameras lassen sich Wärmebilder nicht verlustfrei hochskalieren. Eine zu geringe Auflösung führt dazu, dass Objekte verschwimmen und wichtige Details verloren gehen.
Welchen Temperaturbereich benötige ich?
Nicht jede Wärmebildkamera deckt denselben Temperaturbereich ab. Für Heimwerker genügt größtenteils ein Bereich von –20 bis 250 °C. Für industrielle Anwendungen – etwa bei der Inspektion von Maschinen – sind hingegen Bereiche bis 650 °C oder höher erforderlich.
Ebenso wichtig ist die thermische Empfindlichkeit (NETD, Noise Equivalent Temperature Difference). Sie bestimmt, ab welcher Temperaturdifferenz die Kamera Unterschiede darstellen kann. Werte von ≤ 0,1 °C gelten als gut, Profimodelle erreichen sogar ≤ 0,05 °C.

Welches Sichtfeld ist ideal?
Das Sichtfeld (Field of View, FOV) bestimmt, wie viel Umgebung eine Wärmebildkamera erfasst. Ein großer Bildwinkel von 90 bis 120 Grad eignet sich besonders für enge Räume oder wenn schnell größere Flächen untersucht werden sollen – etwa in der Gebäudethermografie oder bei Heizungsprüfungen. Wärmebrücken und undichte Stellen lassen sich so direkt auf einen Blick erkennen.
Für Distanzbeobachtungen empfiehlt sich dagegen ein engeres Sichtfeld zwischen 15 und 40 Grad. Damit steigt die Reichweite, und Objekte erscheinen klarer – etwa Wildtiere in der Nacht oder feine technische Details. Einige Modelle verfügen über Zoomfunktionen oder wechselbare Objektive, wodurch sich das Einsatzspektrum deutlich erweitert. Profi-Geräte kombinieren teils Weitwinkel- und Teleobjektive, was für flexible Anwendungen sorgt, den Preis aber spürbar erhöht.

Warum sind Display und Bedienung entscheidend?
Ein gutes Display erleichtert die Interpretation der Wärmebilder erheblich. Wichtig sind eine helle, kontrastreiche Darstellung und eine intuitive Menüführung. Viele Modelle bieten zudem verschiedene Farbpaletten – etwa „Iron“, „Rainbow“ oder Schwarzweiß –, die je nach Einsatzzweck Vorteile haben. Praktisch ist auch ein schneller Zugriff auf Fotos und Videos, insbesondere wenn die Aufnahmen später dokumentiert werden sollen.
Welche Rolle spielen Speicher und Schnittstellen?
Nahezu alle Geräte speichern Fotos, viele unterstützen auch Videoaufnahmen. Schnittstellen wie WLAN, Bluetooth oder ein USB-C-Anschluss sind besonders interessant, da sie eine direkte Übertragung aufs Smartphone oder in die Cloud ermöglichen. Einige Hersteller liefern begleitende Apps, die zusätzliche Analysefunktionen bereitstellen. Gerade im professionellen Einsatz erleichtert dies eine saubere und standardisierte Dokumentation.
Wie robust und ausdauernd sollte eine Wärmebildkamera sein?
Da Wärmebildkameras häufig im Freien oder in anspruchsvoller Umgebung genutzt werden, ist die Robustheit entscheidend. Empfehlenswert sind Geräte mit Staub- und Spritzwasserschutz nach IP54 oder höher. Gummierte Gehäuse erhöhen die Stoßfestigkeit. Die Akkulaufzeit variiert je nach Modell zwischen zwei und acht Stunden. Für längere Einsätze ist ein austauschbarer Li-Ionen-Akku oder die Möglichkeit zum Nachladen via USB-C-Anschluss sinnvoll.
Was kosten Wärmebildkameras?
- Unter 300 Euro: Vor allem einfache Smartphone-Adapter, die sich für Hobbyzwecke und gelegentliche Kontrollen eignen, sowie preiswerte Handheld-Modelle.
- 300 bis 1000 Euro: Solide Handgeräte mit brauchbarer Auflösung, ideal für Hausbesitzer oder den Outdoor-Einsatz.
- Über 1000 Euro: Hochwertige Profikameras mit hoher Auflösung, großem Temperaturbereich und zahlreichen Zusatzfunktionen – vorwiegend interessant für Energieberater, Handwerker oder ambitionierte Jäger.
Sind Smartphone-Adapter eine Alternative?
Für den Einstieg eignen sich Adapter, die per USB-C oder Lightning direkt an ein Android-Smartphone oder iPhone angeschlossen werden. Diese kompakten Lösungen nutzen die Rechenleistung und den Bildschirm des Handys und sind besonders handlich.

Die Vorteile liegen in niedrigen Kosten, kleinem Format und einfacher Bedienung über eine App. Zudem lassen sich Bilder und Videos direkt auf dem Smartphone speichern und sofort teilen. Nachteile sind die Abhängigkeit vom Handy-Akku, eine geringere Robustheit, eingeschränkte thermische Empfindlichkeit und in der Regel ein fixes Sichtfeld ohne Wechseloption.
Modelle von Flir, Hikmicro, Thermal Master oder Seek Thermal sind ab etwa 200 Euro erhältlich. Sie bieten Auflösungen von 80 × 60 bis 206 × 156 Pixeln. Für einfache Aufgaben – etwa die Überprüfung einer Fußbodenheizung, das Auffinden undichter Fenster oder die Kontrolle von Elektrogeräten – reicht das aus.
Für gelegentliche Checks sind solche Adapter daher eine interessante Lösung. Wer jedoch regelmäßig im Außenbereich arbeitet oder Tiere bei Nacht über größere Distanzen beobachten möchte, stößt schnell an Grenzen und sollte besser zu einem eigenständigen Handgerät greifen.
Fazit
Welche Wärmebildkamera die richtige ist, hängt stark vom Einsatzzweck ab. Für schnelle Kontrollen am Haus reicht oft ein günstiges Modell mit niedriger Auflösung. Wer dagegen Wildtiere auf Distanz beobachten oder eine präzise Gebäudethermografie durchführen möchte, benötigt mehr Pixel, höhere Empfindlichkeit und zusätzliche Funktionen. Ebenso wichtig sind Robustheit, Bedienkomfort und Konnektivität. Kurz gesagt: Vor dem Kauf genau den Verwendungszweck klären – das spart Kosten und beugt Enttäuschungen vor.
Weitere interessante Artikel für Hobby-Bastler und Outdoor-Fans:
Thermal Master THOR002
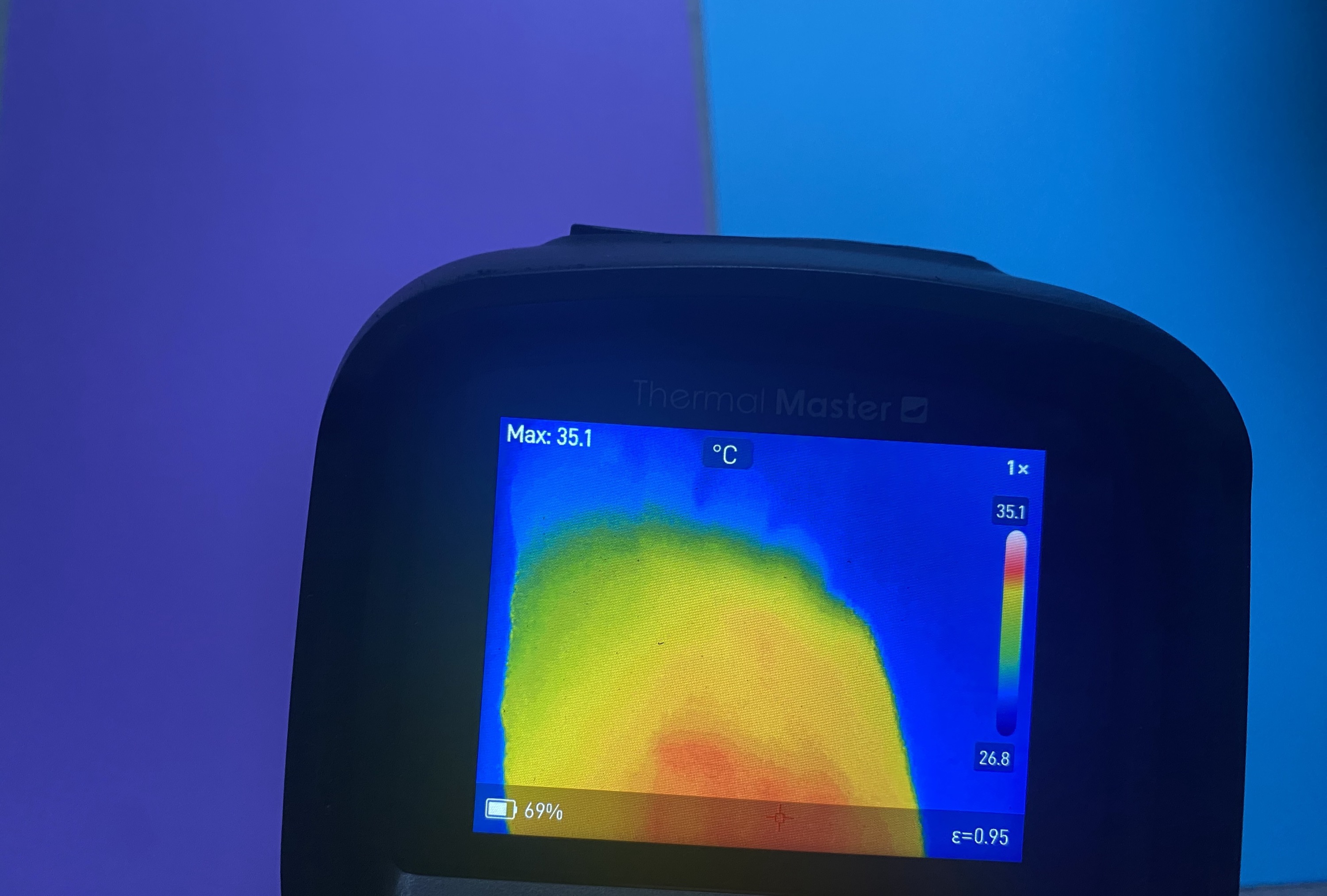
Der Thermal Master THOR002 misst präzise von –20 °C bis 550 °C. Wie gut die preiswerte Wärmebildkamera für Hand- und Heimwerker ist, zeigt der Test.
- hohe native Auflösung von 256 × 192 Pixel
- großer Temperaturmessbereich (–20 bis 550 °C)
- Pistolenform mit stabilem Griff
- integriertes 3,5-Zoll-IPS-Display
- mehrere Bildmodi (IR, Fusion, PiP, Visual)
- keine Makrolinse im Lieferumfang
- wenige Custom-Messpunkte
- keine Software für Mac OS
Thermal Master THOR002 im Test: Präzise Wärmebildkamera zum fairen Preis
Der Thermal Master THOR002 misst präzise von –20 °C bis 550 °C. Wie gut die preiswerte Wärmebildkamera für Hand- und Heimwerker ist, zeigt der Test.
Die Thermal Master THOR002 ist eine autarke Wärmebildkamera im Pistolenformat mit 3,5-Zoll-Display, IR-Sensor (256 × 192 Pixel) und zusätzlicher 2-Megapixel-Kamera. Sie wiegt etwa 500 g, bietet robustes Design mit gummiertem Griff sowie Objektivschutz und kann bei Bedarf auch mit dem Smartphone verbunden werden. Damit eignet sie sich ideal für Handwerker, Techniker und anspruchsvolle Heimwerker, die zuverlässige Temperaturmessungen benötigen.
Design & Display
Die THOR002 präsentiert sich im klassischen Pistolen-Design, wie es bei vielen tragbaren Wärmebildkameras üblich ist. Die Konstruktion wirkt robust und liegt sicher in der Hand. Auf der Rückseite dominiert das 3,5-Zoll-IPS-Display mit einer Auflösung von 640 × 480 Pixeln, das eine scharfe Darstellung bietet. Eine umlaufende Blende sorgt dafür, dass das Display beim Ablegen nicht direkt den Untergrund berührt.
An der Vorderseite sitzen die Infrarotlinse mit 4,3 mm Brennweite sowie die Digitalkamera. Zum besseren Anvisieren ist ein roter Laserpointer verbaut. Alternativ lässt sich eine helle LED zuschalten, um das Umfeld auszuleuchten. Ein integriertes Stativgewinde erlaubt stationäre Messungen – praktisch bei längeren Einsätzen. Die Infrarotoptik wird durch einen mechanischen Linsenschutz vor Beschädigungen bewahrt. Wünschenswert wäre allerdings ein vollständiger Frontschutz gewesen.
Zum Lieferumfang gehören ein USB-C-Kabel, die erwähnte microSD-Karte, ein schlagfester Transportkoffer sowie eine schriftliche Dokumentation inklusive Konformitäts- und Kalibrierzertifikat. Dank IP54-Schutzklasse ist das Gerät gegen Spritzwasser geschützt. Laut Hersteller übersteht es auch Stürze aus bis zu zwei Metern Höhe.
Thermal Master THOR002 – Bilder
Thermal Master THOR002

Thermal Master THOR002
Thermal Master THOR002

Thermal Master THOR002

Thermal Master THOR002

Thermal Master THOR002

Thermal Master THOR002

Thermal Master THOR002

Thermal Master THOR002

Thermal Master THOR002

Thermal Master THOR002

Thermal Master THOR002

Funktionen & Bedienung
Die THOR002 wird direkt über gummierte Navigationstasten bedient, die auch mit dünnen Handschuhen gut zu ertasten sind. Eine separate App ist nicht erforderlich. Nutzer mit dickeren Handschuhen könnten jedoch wegen des geringen Tastenabstands gelegentlich unbeabsichtigt mehrere Tasten drücken. Ausgelöst wird die Messung über den Pistolengriff, der einen klar definierten Druckpunkt bietet. Wird dieser länger gehalten, startet die Videoaufnahme.
Das unserer Ansicht nach sehr intuitive Menüsystem ermöglicht schnellen Zugriff auf alle wichtigen Funktionen; das Benutzerinterface ist zudem in deutscher Sprache verfügbar. Das Hauptmenü gliedert sich in vier Bereiche: Messfunktionen, Bildmodi, Farbpaletten und Einstellungen. Innerhalb der Messfunktionen lassen sich Mittelpunkt-, Heiß- und Kaltpunkt-Tracking sowie bis zu drei benutzerdefinierte Messpunkte aktivieren.
Zur besseren Unterscheidung der Wärmeverteilung stehen mehrere Bildmodi zur Verfügung: Der reine IR-Modus zeigt das klassische Wärmebild. Der PIP-Modus (Picture-in-Picture) blendet das Wärmebild teilweise in das Sichtbild ein, während der Visual-Modus ausschließlich das normale Bild der integrierten 2-Megapixel-Kamera darstellt.
Neben Einzelbildern kann die Kamera auch Videos samt Ton aufzeichnen. Für Fotos lassen sich im Nachhinein Sprachkommentare hinzufügen – zum Beispiel zur Dokumentation oder Analyse. Die Daten speichert das Gerät auf einer microSD-Karte; eine 32-GB-Karte liegt bei. Zur weiteren Ausstattung gehört ein USB-C-Anschluss zum Laden des Akkus, der laut Hersteller bis zu acht Stunden durchhält.
Ein zentrales Highlight ist die Fusion-Imaging-Funktion: Dabei werden die Infrarot- und Echtbildaufnahmen übereinandergelegt, wobei sich der Transparenzgrad individuell einstellen lässt. Das erleichtert insbesondere bei komplexen Strukturen mit vielen unterschiedlichen Temperaturzonen die Orientierung. Zur weiteren Differenzierung von Temperaturverteilungen können sieben verschiedene Farbpaletten ausgewählt werden.
Die Wärmebildkamera lässt sich per integriertem WLAN-Hotspot mit dem Smartphone verbinden. Dafür ist lediglich die App des Herstellers erforderlich. Das mobile Gerät fungiert dann als zweiter Bildschirm – nützlich etwa bei schwer zugänglichen Messpunkten oder zur Teamarbeit. Die App erlaubt zudem das Speichern von Bildern und Videos auf dem Smartphone oder Tablet.
Für Windows-Nutzer steht eine kostenlose PC-Software zur Verfügung, die über USB-C das Live-Streaming und eine Datenanalyse ermöglicht. Eine entsprechende Anwendung für Mac OS gibt es derzeit nicht.
Bildqualität
Die Infrarotkamera liefert eine native Auflösung von 256 × 192 Pixeln bei einer Bildfrequenz von 25 Hz. Das entspricht rund 49.000 Messpunkten pro Bild und sollte für sehr viele Anwendungen ausreichen. Der Bereich, in dem die Temperaturen gemessen werden können, reicht von –20 °C bis 550 °C, was den Einsatz sowohl im Innen- als auch im Außenbereich erlaubt.
Die Messgenauigkeit liegt laut Hersteller bei ± 2 °C oder ±2 % des Messwerts. Die thermische Empfindlichkeit (NETD) beträgt weniger als 40 Millikelvin (mK), was eine gute Auflösung von Temperaturunterschieden ermöglicht. Je niedriger dieser Wert, desto besser können Unterschiede erkannt werden.
Das Objektiv bietet ein Sichtfeld von 40° × 30°. Es gibt nur einen digitalen 4-fach-Zoom und bei diesem Modell auch keine Makro-Einstellung. Der Hersteller hat noch einen Modus für eine künstlich erhöhte Auflösung eingebaut, die X³IR SuperIR-Resolution genannt wird und bei 512 × 384 Pixeln liegt. Die sieht zwar gut aus, doch letztlich werden die fehlenden Pixel nur hinzugerechnet.
Technische Daten
| IR-Auflösung | 256 × 192 Pixel |
| Bildfrequenz | 25 Hz |
| Temperaturbereich | -20°C bis 550°C |
| Messgenauigkeit | ±2°C oder ±2% |
| Display | 3,5″ IPS (640 x 480) |
| Digitalkamera | 2 Megapixel |
| Akkulaufzeit | 8 Stunden |
| Ladezeit | 4 Stunden |
| Schutzklasse | IP54 |
| Gewicht | ca. 500g |
| Sichtfeld (FOV) | 40° x 30° |
Preis
Die Thermal Master THOR002 ist als professionelle Einstiegslösung positioniert und kostet aktuell 362 Euro statt 399 Euro (UVP). Für den Preis erhält man eine vollwertige Wärmebildkamera mit solidem Funktionsumfang und professioneller Ausstattung.
Direkt beim Hersteller bekommt man die Wärmebildkamera mit dem Code TMTHOR002 für knapp 351 Euro. Der Versand erfolgt aus Lagerbeständen in Deutschland binnen acht Tagen. Da der Hersteller in China ansässig ist, gelten dann aber die gewohnten Käuferschutzbestimmungen der EU nicht. Thermal Master gewährt allerdings ein 30-tägiges Rückgaberecht und eine Gewährleistung von zwei Jahren.
Beim Kauf der Kamera direkt über den chinesischen Store von Thermal Master müssen Käufer mit längeren Lieferzeiten, Importkosten sowie eingeschränktem Garantie- und Serviceumfang rechnen.
Fazit
Die Thermal Master THOR002 ist eine durchdachte Wärmebildkamera mit professioneller Ausstattung zu einem fairen Preis. Sie überzeugt mit hoher Auflösung, präziser Messgenauigkeit und großem Temperaturbereich. Dank ergonomischer Pistolenform und verschiedener Bildmodi lässt sie sich komfortabel bedienen und flexibel einsetzen.
Einschränkungen gibt es bei der fehlenden Makrolinse – im Gegensatz zum Schwestermodell THOR001 – sowie bei den nur drei frei wählbaren Messpunkten. Für die meisten Anwendungen ist die Ausstattung jedoch vollkommen ausreichend.
Hikmicro B10S
Robustes Design, klares Display und IP54: Die Hikmicro B10S ist eine kompakte Wärmebildkamera für den flexiblen Einsatz im Innen- und Außenbereich.
- günstig
- intuitive Bedienung
- großes Display
- Wasser- und staubgeschützt nach IP54
- keine App-Anbindung
- nur Menü-Bedienung gewöhnungsbedürftig
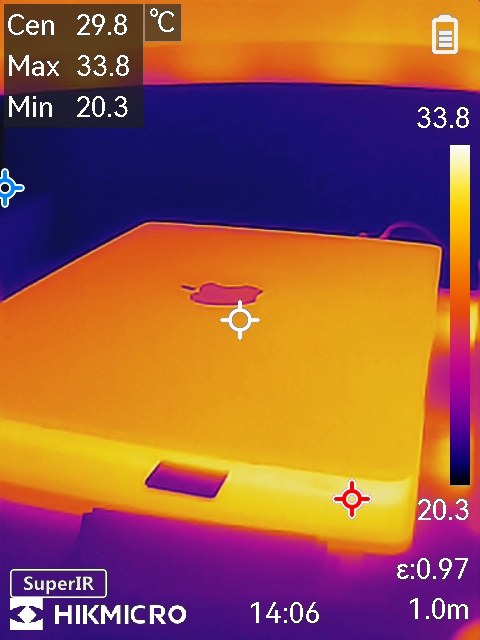
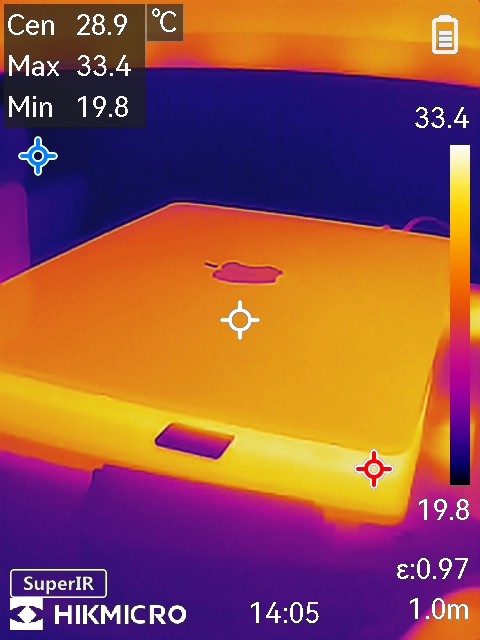
Hikmicro B10S im Test: Handliche Wärmebildkamera für 399 Euro überzeugt
Robustes Design, klares Display und IP54: Die Hikmicro B10S ist eine kompakte Wärmebildkamera für den flexiblen Einsatz im Innen- und Außenbereich.
Die Hikmicro B10S ist eine handliche Wärmebildkamera, die sich durch ihre kompakte Bauweise und ein attraktives Preis-Leistungs-Verhältnis hervorhebt. Ob zur Inspektion von elektrischen Anlagen, zur Lecksuche in Gebäuden oder zur Überprüfung von Heizsystemen – die B10S soll dabei helfen, Wärmequellen sichtbar zu machen und potenzielle Probleme frühzeitig zu erkennen. Die Kamera verspricht dabei eine einfache Bedienung und praktische Zusatzfunktionen, die den Arbeitsalltag erleichtern sollen.
Design & Display
Die Hikmicro B10S präsentiert sich im klassischen Handheld-Design mit ergonomischem Griff, der eine komfortable Handhabung ermöglicht – vergleichbar mit einem Handscanner im Supermarkt. Mit einem Gewicht von rund 380 g liegt sie gut in der Hand und ist auch für längere Einsätze geeignet.
Das 3,2 Zoll große Farb-LCD liefert eine klare Darstellung der Wärmebilder. Dank Schutzklasse IP54 ist die Kamera gegen Staub und Spritzwasser geschützt – ideal für den Einsatz im Außenbereich.
Zum Lieferumfang gehören neben der Kamera ein USB-C-Kabel mit USB-A-Adapter zum Laden, ein Befestigungsband sowie eine Kurzanleitung. Ein Netzteil ist hingegen nicht enthalten, was für manche Nutzer unpraktisch sein könnte.
Hikmicro B10S Wärmebildkamera – Bilder
Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera
Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera

Funktionen & Bedienung
Die B10S verfügt über mehrere Bildmodi wie Thermal, Fusion, PIP (Bild-in-Bild) und visuell, die eine flexible Analyse ermöglichen. Die Bedienung erfolgt über ein einfaches Menüsystem mit Tastensteuerung. Nach einer kurzen Eingewöhnungszeit lassen sich die Funktionen gut erschließen und sicher bedienen. Etwas gewöhnungsbedürftig ist, dass Eingaben im Menü mit der Power-Taste bestätigt werden müssen. Für Fotoaufnahmen steht eine separate Taste auf der Rückseite zur Verfügung, die sich wie ein Handscanner komfortabel bedienen lässt.
Die Kamera speichert die aufgenommenen Bilder intern. Laut Hersteller ist Platz für bis zu 35.000 Aufnahmen vorhanden. Auf Bluetooth oder WLAN muss man allerdings verzichten – eine App-Anbindung gibt es nicht, und die Übertragung der Bilder auf den Computer erfolgt ausschließlich per Kabel.
Die Hikmicro B10S eignet sich für eine Vielzahl von Einsatzbereichen. Im Handwerk hilft sie, Wärmeverluste schnell aufzuspüren – etwa an Fenstern, Türen oder Leitungen. Auch im Hausbau und in der Haustechnik ist sie ein nützliches Werkzeug zur Inspektion von Heizungsanlagen, Dämmungen und Rohrleitungen.
Techniker und Elektroniker profitieren von präzisen Temperaturmessungen zur Fehlerdiagnose an elektronischen Bauteilen. Nicht zuletzt ist die B10S auch für Hobbyanwender interessant, die ihre Umgebung oder Fahrzeuge auf Wärmequellen und undichte Stellen überprüfen möchten.
Bildqualität & Kamera
Die B10S ist mit einem IR-Detektor mit 256 × 192 Pixeln ausgestattet, was für die meisten Anwendungen im Heimwerkbereich ausreichend ist. Die Wärmebildkamera erlaubt eine Temperaturmessung im Bereich von –20 °C bis 550 °C mit einer Genauigkeit von ±2 °C oder ±2 %. Der NETD-Wert (Noise Equivalent Temperature Difference) liegt unter 40 mK, was eine gute Sensitivität bedeutet. Er erkennt daher schon kleine Schwankungen und kann diese sichtbar machen.
Das kleine LCD ist mit 640 × 480 Pixeln aufgelöst und lässt ausreichend Details erkennen. Grundsätzlich sind auch mittels integrierter Kamera normale Fotoaufnahmen (zwei Megapixel) möglich, aber diese sind nur bedingt zu verwerten. Auf dem Display werden zudem die höchsten und niedrigsten gemessenen Temperaturen angezeigt, während der wärmste Punkt mit einem Punkt markiert wird.
Die Kamera bietet eine Bildwiederholrate von 25 Hz, was für eine ausreichend flüssige Darstellung sorgt. Auch eine visuelle Alarmfunktion bei Überschreitung bestimmter Temperaturgrenzen, was die Sicherheit erhöht. Ein akustisches Signal ist als Warnung möglich. Praxisnahe Extras wie eine Makro-Funktion runden die Ausstattung ab.
Hikmicro B10S Wärmebildkamera – Aufnahmen
Hikmicro B10S Wärmebildkamera
Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera
Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera

Hikmicro B10S Wärmebildkamera
Hikmicro B10S Wärmebildkamera

Technische Daten
| Display-Auflösung | 640 x 480 Pixel |
| IR-Auflösung | 256 x 192 Pixel |
| Thermische Empfindlichkeit | < 0,04 °C |
| Genauigkeit | Max (±2 °C, ±2 %), für Umgebungstemperatur 15 °C bis 35 °C und Objekttemperatur über 0 °C |
| NETD-Wert | 40 mK |
| Visuelle Kamera | 2 Megapixel |
| Bildfrequenz | 25 Hz |
| Schutzart | IP54 |
Preis
Mit einer unverbindlichen Preisempfehlung von rund 400 Euro positioniert sich die Hikmicro B10S im mittleren Preissegment für Wärmebildkameras. Aktuell ist sie für etwa 350 Euro erhältlich. Im Vergleich zu etablierten Marken bietet das Modell vergleichbare Funktionen zu einem deutlich günstigeren Preis. Damit eignet sich die B10S besonders für Anwender, die eine preiswerte Thermografie-Lösung suchen, ohne auf zentrale Ausstattungsmerkmale verzichten zu wollen.
Fazit
Die Hikmicro B10S erweist sich im Test als gelungene Wärmebildkamera mit einem ordentlichen Funktionsumfang für ihre Preisklasse. Sie punktet mit guter Bildqualität, robuster Verarbeitung und praxisnahen Extras wie einer Makro-Funktion. Für Heimwerker, Techniker und kleine Handwerksbetriebe, die eine zuverlässige und preisgünstige Thermografie-Lösung suchen, ist die B10S eine empfehlenswerte Option.
Hikmicro D01
Die Hikmicro D01 liefert Aufnahmen wie eine große Wärmebildkamera, bleibt dabei aber kompakt und preiswert – so zumindest das Versprechen des Herstellers. Doch kann die Wärmebildkamera das einhalten?
- Sehr lange Akkulaufzeit (bis ca. 11 Stunden)
- Eigenständiges Gerät mit Display und internem Speicher
- Hot-/Cold-Spot-Anzeige für schnelle Orientierung
- Nativer Sensor nur 96 × 96 Pixel
- Schwächen auf größere Distanz
- Kunststoffgehäuse wirkt billig
- Keine Video-Funktion
Hikmicro D01 im Test: Günstige Wärmebildkamera für Haus & Werkstatt überrascht
Die Hikmicro D01 liefert Aufnahmen wie eine große Wärmebildkamera, bleibt dabei aber kompakt und preiswert – so zumindest das Versprechen des Herstellers. Doch kann die Wärmebildkamera das einhalten?
Wärmebildkameras sind längst nicht mehr nur Werkzeug für Profis. Auch private Nutzer kommen mittlerweile zu erschwinglichen Geräten, mit denen man Wärmebrücken entdeckt, Elektrobauteile überprüft oder Heizungsanlagen kontrolliert.
Die Hikmicro D01 gehört genau in dieses Segment: ein handliches Gerät mit Display, Akku und Speicher. Sie ist innerhalb weniger Sekunden einsatzbereit, benötigt kein Smartphone und richtet sich klar an Einsteiger, die schnell Ergebnisse sehen möchten. Im Test zeigt sie sich als überraschend leistungsfähig – mit klaren Stärken im Nahbereich und spürbaren Grenzen bei Detailtiefe und Reichweite.
Design
Die Hikmicro D01 setzt auf ein klassisches Wärmebildkamera-Format: ein kompaktes Handgerät mit integriertem Bildschirm und wenigen Bedienknöpfen. Das Gerät besteht aus Kunststoff und fühlt sich auch so an – etwas billig. Das Kunststoffgehäuse wirkt insgesamt funktional und ausreichend robust für typische Haus- und Werkstattaufgaben, aber für anspruchsvollere Aufgaben würden wir es nicht empfehlen.
Dafür liegt es aber gut in der Hand und ist leicht. Jedoch wurde auf eine leichte Schutzschicht wie eine Gummierung verzichtet, sodass es sich bei Nässe etwas rutschig anfühlt. Dank IP54-Zertifizierung übersteht es zumindest Spritzwasser.
Auf der Oberseite ist ein USB-C-Port angebracht. Damit kann man die D01 aufladen oder zur Datenübertragung mit einem PC oder Mac verbinden. Am unteren Ende ist hingegen ein Stativgewinde integriert, um das Handgerät auch stationär zu verwenden. Direkt daneben kann die mitgelieferte Handschlaufe angebracht werden.
Leider verzichtet Hikmicro auf einen Schutz für die Wärmebildlinse und auch eine Hülle oder Ähnliches ist nicht vorhanden. Wer also das Handheld-Gerät in den Werkzeugkoffer legen möchte, sollte daher aufpassen.
Bilderstrecke: Hikmicro D01
Hikmicro D01

Hikmicro D01

Hikmicro D01

Hikmicro D01

Hikmicro D01

Hikmicro D01

Hikmicro D01

Hikmicro D01

Hikmicro D01

Hikmicro D01

Hikmicro D01

Steuerung & Bedienung
Die Bedienung ist einer der größten Pluspunkte der D01. Nach dem Einschalten dauert es nur wenige Sekunden, bis das Wärmebild erscheint. Die Menüstruktur ist bewusst einfach gehalten: Szenen wechseln, SuperIR aktivieren, Entfernungen anpassen – alles funktioniert intuitiv und ohne umfangreiche Vorkenntnisse.
Für viele Anwender reicht das völlig aus. Die automatische Anzeige des heißesten, kältesten und mittleren Messpunkts hilft enorm bei schnellen Diagnosen: Überhitzte Bauteile im Sicherungskasten, kalte Fugen an Fenstern oder Unterschiede in Heizkreisen lassen sich sofort lokalisieren.
Die interne Foto-Funktion eignet sich gut zur Dokumentation. Zwar gibt es keinen Videomodus, doch für typische Anwendungen wie Hausinspektionen, Heizungschecks oder Renovierungsarbeiten ist das verschmerzbar. Die sehr lange Akkulaufzeit – bis zu elf Stunden – macht die Kamera besonders praktisch für längere Rundgänge oder Arbeitstage ohne permanente Stromversorgung.
Grenzen zeigt das Bedienkonzept bei professionellen Aufgaben: Die Menüs sind einfach, Emissionswerte nur begrenzt anpassbar, und komplexe Analysewerkzeuge fehlen. Wer anspruchsvolle thermografische Auswertungen oder industrielle Prozesskontrollen plant, wird hier nicht fündig. Für den Alltag bietet die D01 jedoch genau die richtige Mischung aus Einfachheit und Funktion.
Kamera & Bildqualität
Das Herzstück der Wärmebildkamera ist natürlich der Infrarot-Sensor: Er arbeitet mit 96 × 96 Pixeln, der durch die SuperIR-Optimierung auf 240 × 240 Pixel hochgerechnet wird. Das sorgt für ein deutlich besseres Bild, als die Basisauflösung vermuten lässt. Für Haus- und Werkstattanwendungen ist die Bildqualität überraschend brauchbar: Wärmebrücken an Fenstern, Unterschiede in Fußbodenheizungen, Dämmfehler oder überhitzte Elektrobauteile lassen sich klar erkennen, aber dennoch erkennt man den Unterschied zu nativ höher aufgelösten Sensoren.
Damit eignet sich die Hikmicro D01 besonders für den Nah- und Mittelbereich. Bis zu einigen Metern Abstand liefert sie verwertbare Bilder. Der Temperaturbereich von –20 °C bis 400 °C deckt typische Kontrollaufgaben ab – von Heizsystemen bis zu elektrischen Verteilungen. Andere Modelle sind auch für höhere Temperaturen ausgelegt, kosten aber in der Regel auch einiges mehr.
Die Hot-/Cold-Spot-Anzeige erleichtert schnelle Analysen, und verschiedene Farbpaletten sorgen für ausreichend Kontrast, je nach Einsatzgebiet.
Auf größere Entfernung zeigt der Sensor jedoch seine Grenzen. Gebäudeansichten, feine Strukturen oder kleine Komponenten werden schnell zu grob dargestellt. Für die Preisklasse liefert die D01 jedoch überzeugende und vor allem praxisnahe Ergebnisse.
Preis
Die Wärmebildkamera Hikmicro D01 ist ab 149 Euro erhältlich. Damit zählt sie zu den günstigsten eigenständigen Wärmebildkameras und bietet ein sehr gutes Preis-Leistungs-Verhältnis für Einsteiger.
Fazit
Die Hikmicro D01 ist eine praktische, preiswerte und überraschend leistungsfähige Wärmebildkamera für Haus, Werkstatt und Alltag. Sie liefert solide Bilder im Nahbereich, startet schnell, ist kinderleicht zu bedienen und überzeugt mit extrem langer Akkulaufzeit. Ihre Grenzen liegen bei Detailtiefe, Reichweite und professionellen Analysefunktionen. Für Einsteiger und alle, die schnell und unkompliziert thermische Auffälligkeiten entdecken wollen, ist die D01 ein empfehlenswerter und sehr zugänglicher Einstieg in die Wärmebildtechnik.
Hikmicro E01
Die Hikmicro E01 ist eine günstige und handliche Wärmebildkamera mit langer Akkulaufzeit. Wir klären, ob sie sich für Einsteiger und Gelegenheitsnutzer lohnt.
- gute Akkulaufzeit (8 Stunden)
- Temperaturbereich bis 400 °C
- kompakte, robuste Bauweise
- zuverlässige Tastenbedienung
- integrierter Laserpointer
- niedrige native Auflösung (96 × 96 Pixel)
- kleines 2,4-Zoll-Display
- keine optische Kamera/Fusionsmodus
- kein WLAN oder Bluetooth
Hikmicro E01 im Test: Günstige Wärmebildkamera für 199 Euro
Die Hikmicro E01 ist eine günstige und handliche Wärmebildkamera mit langer Akkulaufzeit. Wir klären, ob sie sich für Einsteiger und Gelegenheitsnutzer lohnt.
Wer eine Wärmebildkamera ohne Smartphone-Anbindung sucht, sollte sich die Hikmicro E01 ansehen. Sie ist kompakt, nach IP54 gegen Staub und Spritzwasser geschützt und verfügt über ein 2,4-Zoll-Display mit 240 × 320 Pixeln. Der Sensor liefert 96 × 96 Pixel, die per Super-IR-Technologie auf 240 × 240 Pixel hochgerechnet werden.
Die Kamera deckt einen großen Temperaturbereich ab, bietet verschiedene Farbpaletten und integriert einen Laserpointer zur exakten Messung. In unserem Test zeigen wir, wie gut die Wärmebildkamera in der Praxis ist.
Design & Display
Die Hikmicro E01 ist mit einem 2,4-Zoll-LCD ausgestattet, das allerdings recht dunkel wirkt. Die Kamera misst 196 × 117 × 59 mm und bringt rund 290 g auf die Waage. Durch ihr kompaktes Format passt die E01 problemlos in die Werkzeugtasche – praktisch für Hobbyhandwerker. Die Hikmicro E01 ist zudem nach IP54 zertifiziert und damit staubgeschützt sowie gegen Spritzwasser aus allen Richtungen abgesichert.
Das LCD ist kleiner als bei teureren Modellen. Dadurch wirkt die Wärmebildkamera mit Pistolengriff weniger sperrig. Ein Nachteil: Es gibt keinen Blendschutz, wodurch Spiegelungen unter bestimmten Lichtbedingungen unvermeidlich sind.
Die Display-Auflösung von 240 × 320 Pixeln reicht für die Darstellung der Wärmebilder aus, auch wenn Details schwerer zu erkennen sind als auf größeren Bildschirmen. Die Bildwiederholfrequenz liegt bei 20 Hz und damit unter dem Niveau vieler Konkurrenten. Für statische Szenen und ruhiges Arbeiten reicht das jedoch in der Praxis meist aus.
Die Kamera bedient man über vier physische Tasten – einen Touchscreen gibt es nicht. Das macht sie robuster und zuverlässiger, allerdings ist die Navigation durch die Menüs etwas aufwendiger und weniger intuitiv. Vorteilhaft: Die Tasten lassen sich auch mit dünnen Handschuhen bedienen. Die Bildaufnahme erfolgt über einen Abzug an der Vorderseite, der mit dem Zeigefinger betätigt wird.
An der Front sitzen der Infrarotsensor und ein Laserpointer. Letzterer hilft, Messpunkte exakt zu lokalisieren. Er zielt in die Bildmitte, wo die Temperaturwerte standardmäßig eingeblendet werden. Allerdings ist der Sensor so verbaut, dass die Kamera leicht nach unten gekippt werden muss, um ein Objekt ins Bildzentrum zu rücken – das ist nicht sonderlich ergonomisch.
Hikmicro E01 – Bilderstrecke
Hikmicro E01

Hikmicro E01

Hikmicro E01

Hikmicro E01

Hikmicro E01

Hikmicro E01

Funktionen
Die E01 konzentriert sich auf ihre Kernfunktion: reine Wärmebildaufnahmen ohne Zusatzfunktionen. Eine zusätzliche optische Kamera zur Anzeige von überlappten Bildern fehlt. Die E01 ist ein reines Wärmebildgerät – für viele Anwendungen ist das aber auch nicht nötig.
Die interne Software erlaubt das Einstellen verschiedener Farbpaletten, um je nach Einsatzbereich optimale Kontraste zu erzeugen. Zudem helfen automatische Temperaturmesspunkte (Zentrum, Hot, Cold) bei einer schnellen Analyse der Wärmebilder. Einen frei wählbaren Messpunkt kann die Kamera allerdings nicht setzen.
Der interne Speicher fasst 4 GB und reicht laut Hersteller für mehr als 30.000 Aufnahmen. Eine Erweiterung per Speicherkarte ist nicht vorgesehen. Die Datenübertragung erfolgt ausschließlich per USB-Kabel. WLAN oder Bluetooth fehlen. Am Windows-PC oder Mac meldet sich die Kamera als Wechseldatenträger.
Der integrierte Lithium-Ionen-Akku reicht im Idealfall für bis zu 8 Stunden Dauerbetrieb, sofern die Display-Helligkeit reduziert wird. Aufgeladen wird über eine USB-C-Buchse hinter einer Gummiklappe. Über dieselbe Schnittstelle lassen sich die gespeicherten Bilder auch auf den PC oder Mac übertragen.
Bildqualität
Mit einer nativen Auflösung von 96 × 96 Pixeln bewegt sich die E01 am unteren Ende des Marktes. Allerdings sollte man beachten: Schon etwas höhere Auflösungen verdoppeln schnell den Preis.
Die thermische Empfindlichkeit gibt der Hersteller mit < 50 mK an – ein überraschend guter Wert in dieser Preisklasse. Im Einsatz deckt die Wärmebildkamera einen Temperaturbereich von –20 bis 400 Grad Celsius ab. Zur besseren Darstellung der Messwerte stehen verschiedene Farbpaletten zur Auswahl.
Die Super-IR-Technologie interpoliert die nativen 96 × 96 Pixel auf 240 × 240 Pixel. Das funktioniert überraschend gut und sorgt für deutlich schärfere Darstellungen, als es die Rohauflösung erwarten lässt.
Technische Daten
| IR-Auflösung | 96 x 96 Pixel (nativ) |
| Interpolierte Auflösung | 240 x 240 Pixel |
| Bildfrequenz | 20 Hz |
| Temperaturbereich | -20°C bis 400°C |
| Display | 2,4″ LCD |
| Akkulaufzeit | 8 Stunden |
| Speicher | 4 GB intern |
| Konnektivität | USB (kein WLAN/Bluetooth) |
Preis
Die Hikmicro E01 ist derzeit reduziert und kostet bei Amazon nur rund 180 Euro und richtet sich klar an Einsteiger sowie Gelegenheitsnutzer. Für diese Zielgruppe ist das Preis-Leistungs-Verhältnis attraktiv. Anspruchsvollere Anwender könnten allerdings Funktionen wie eine integrierte Digitalkamera vermissen.
Fazit
Die Hikmicro E01 ist eine solide Einsteiger-Wärmebildkamera ohne überladene Ausstattung. Der Hersteller konzentriert sich auf das Wesentliche: zuverlässige Thermoaufnahmen bei langer Akkulaufzeit. Für die meisten Anforderungen von Hobby- und Gelegenheitsnutzern genügt das vollkommen. Die niedrige native Auflösung bleibt jedoch ein klarer Schwachpunkt – auch wenn die Super-IR-Interpolation das Ergebnis sichtbar verbessert.
Hikmicro E03
Die kompakte Wärmebildkamera Hikmicro E03 kombiniert Wärme- mit Sichtbildern per Fusion-Funktion. Dabei ist sie erfreulich kompakt und günstig.
- NETD von < 50mK
- Fusion-Technik
- leicht und kompakt
- LED-Arbeitslicht und USB-C
- Schnelle Ladezeit (2,5 h)
- unzuverlässige Touchscreen-Bedienung
- Hardware-Auslöser funktioniert unzuverlässig
- niedrige native IR-Auflösung (96 × 96)
- kein WLAN oder Bluetooth
Hikmicro E03 im Test: Kompakte und günstige Wärmebildkamera
Die kompakte Wärmebildkamera Hikmicro E03 kombiniert Wärme- mit Sichtbildern per Fusion-Funktion. Dabei ist sie erfreulich kompakt und günstig.
Die Hikmicro E03 ist eine handliche Wärmebildkamera im Kompaktformat, die Temperaturen von -20 bis 350 Grad Celsius misst. Mit ihrer Fusion-Funktion, die Wärme- und Sichtbilder überlagert, erleichtert sie die Orientierung – etwa beim Aufspüren von Wärmequellen oder Kältebrücken.
Für rund 210 Euro richtet sie sich an Einsteiger, die eine mobile und alltagstaugliche Lösung für Gebäudediagnose, Elektrocheck oder einfache Reparaturarbeiten suchen. Wir haben im Test geprüft, ob die günstige Einsteigerkamera im Alltag überzeugt.
Design & Display
Die Thermalkamera bringt 218 g auf die Waage und misst 138 × 85 × 24 mm. Die Kamera ist kompakt, angenehm leicht und damit gut transportabel. Zum Lieferumfang gehören neben einem USB-C-Kabel auch eine einfache Tasche mit Clip, sodass sich die Thermokamera sicher am Gürtel oder an der Kleidung befestigen lässt.
Der 3,5-Zoll-Touchscreen bietet lediglich eine Auflösung von 320 × 240 Pixeln – klassische Digitalkameras liefern hier deutlich mehr. Angesichts der insgesamt niedrigen Systemauflösung fällt das jedoch kaum ins Gewicht. Problematisch ist eher die Hintergrundbeleuchtung: Im Freien ist das Display nicht hell genug, bei direkter Sonne lässt es sich kaum ablesen.
Die Bedienung erfolgt fast ausschließlich über den Touchscreen, ergänzt um einen Power-Knopf sowie den Auslöser für Foto- und Videoaufnahmen. Das Menü ist logisch genug aufgebaut, allerdings fehlen physische Tasten fast vollständig. Zudem reagiert der Touchscreen mitunter etwas träge.
Auch der Auslöser überzeugt nicht: Ein klarer Druckpunkt fehlt, und da der recht breite Knopf ins Gehäuse eingelassen ist, gestaltet sich das Auslösen unnötig fummelig. Mit Handschuhen ist die Bedienung praktisch unmöglich – weder Touchscreen noch Auslöser lassen sich sinnvoll nutzen. Erschwerend kommt hinzu, dass das eher kantige Gehäuse nicht ergonomisch geformt ist, sodass längeres Arbeiten anstrengend wird. Hochkant-Aufnahmen sind ebenfalls nicht möglich, da sich das Display-Bild nicht automatisch dreht.
Das Gehäuse ist nach IP54 spritzwasser- und staubgeschützt. Untergetaucht werden darf die Kamera aber nicht.
Hikmicro E03 – Bilder
Hikmicro E03

Hikmicro E03

Hikmicro E03

Hikmicro E03

Hikmicro E03

Funktionen & Bedienung
Die E03 bietet drei Bildmodi, zwischen denen je nach Anwendung gewechselt werden kann: einen klassischen Infrarot-Modus, einen Sichtlicht-Modus über die integrierte Digitalkamera sowie einen Fusion-Modus, der beide Ansichten kombiniert. Zur Hervorhebung von Temperaturunterschieden stehen sechs Farbpaletten bereit – darunter White Hot, Black Hot, Rainbow, Ironbow, Rain und Blue Red.
Im Gerät steckt ein nicht austauschbarer 4‑GB-Speicher, der Platz für rund 30.000 Wärmebilder oder etwa 20 Stunden Videoaufzeichnung bietet. Einen Speicherkartenslot gibt es nicht, der Datenaustausch erfolgt daher ausschließlich per Kabel. Praktisch: Die Thermokamera wird am PC oder Mac ohne zusätzliche Software wie ein externes Laufwerk erkannt und lässt sich direkt auslesen.
Die Akkulaufzeit liegt bei ungefähr 4 Stunden bei durchschnittlich hell eingestelltem Display. Der nicht wechselbare Lithium-Ionen-Akku wird über ein USB-C-Kabel in etwa 2,5 Stunden wieder aufgeladen. Ein Netzteil liegt nicht bei, doch mittlerweile dürfte praktisch jeder, der ein Handy besitzt, auch ein USB-C-Netzteil haben.
Ein kleines LED-Licht an der Vorderseite dient zur Ausleuchtung des Messfelds, reicht aber nur bis etwa einen Meter. Auf einen Laserpointer zum gezielten Anvisieren verzichtet die Kamera, dafür steht ein digitaler Vierfachzoom zur Verfügung. Außerdem erscheinen im Sucherbild automatisch drei Messpunkte: Center Spot zeigt die Temperatur in der Bildmitte an, Hot Spot markiert die wärmste Stelle, Cold Spot die kälteste.
So erkennt die E03 kritische Bereiche von selbst und verschafft dem Nutzer schnell einen Überblick über die Temperaturverteilung – etwa um Wärmequellen, Überhitzungen oder Kältebrücken zu identifizieren.
Etwas störend fällt die automatische Kalibrierung auf: In Abständen von ein bis zwei Sekunden friert das Bild kurz ein und ein leises Klicken ist zu hören. Dabei wird der IR-Sensor abgedunkelt, um das System neu zu justieren. Das erhöht zwar die Messgenauigkeit, unterbricht jedoch regelmäßig den Beobachtungsfluss.
Bildqualität
Die Hikmicro E03 liefert eine native Infrarot-Auflösung von 96 × 96 Pixeln, die intern auf 240 × 240 Pixel hochskaliert wird, um Details besser erkennbar zu machen. Das Sichtfeld beträgt 50 × 50 Grad. Der Messbereich reicht von –20 bis 350 Grad Celsius. Die thermische Empfindlichkeit (NETD) unter 50 mK bei 25 °C ist für diese Preisklasse ordentlich – teurere Modelle erreichen Werte unterhalb von 40 mK, Spitzenmodelle sogar deutlich darunter. Beim NETD handelt es sich um ein Maß für Empfindlichkeit – je kleiner, desto besser.
Zusätzlich ist eine 0,3-Megapixel-Digitalkamera integriert, mit der sich Fusion-Aufnahmen erstellen lassen: Dabei werden Wärmebild und Sichtbild überlagert, was die Orientierung deutlich erleichtert. Für typische Anwendungen wie das Auffinden von Kältebrücken, Überhitzungen oder Temperaturverteilungen reicht die Leistung der Hikmicro E03 völlig aus. Damit ist sie geeignet zum schnellen Check von Heizungsrohren, Schaltschränken oder Dachdämmung.
Die Messgenauigkeit gibt der Hersteller mit ±2 °C an – ein üblicher Wert. Damit eignet sich die Kamera nicht nur für den privaten Einsatz, sondern auch für einfache professionelle Anwendungen. Einschränkend wirkt allerdings das Fehlen einer Makro-Funktion: Feinere Temperaturunterschiede, etwa auf Leiterplatten, lassen sich so nur schwer erfassen.
Technische Daten
| Native IR-Auflösung | 96 x 96 Pixel (9.216 Bildpunkte) |
| SuperIR-Auflösung | 240 x 240 Pixel (57.600 Bildpunkte) |
| Bildfrequenz | 25 Hz |
| NETD | < 50 mK (bei 25°C) |
| Display | 3,5 Zoll-LCD-Touch (320 x 240 Pixel) |
| Digitalkamera | 640 x 480 Pixel |
| Arbeitstemperatur | -10°C bis 50°C |
| Gewicht | 218 g |
| Speicher | 4 GByte |
| Schnittstelle | USB-C |
Preis
Die Hikmicro E03 richtet sich als kompakte Wärmebildkamera an Einsteiger und bietet mit einem Preis von rund 210 Euro ein überzeugendes Preis-Leistungs-Verhältnis.
Fazit
Die Hikmicro E03 punktet mit praktischen Funktionen wie der Fusion-Technik und einem handlichen Formfaktor, der sie deutlich alltagstauglicher macht als klassische Wärmebildkameras. Den Gesamteindruck schmälern allerdings die träge Touchscreen-Bedienung und die häufig klackernde Kalibrierung.
Topdon TC004 Mini
Die Topdon TC004 Mini bringt Wärmebildtechnik in kompakter Form für Hausinspektionen, Technik‑Checks oder den mobilen Einsatz – Kompromisse sind allerdings vorprogrammiert.
- kompakte Bauform, sehr leicht
- großer Temperaturbereich von rund -20 °C bis +450 °C
- sehr lange Akkulaufzeit (bis 15 Stunden)
- automatische Hot-/Cold-Spot-Erkennung
- Schutz nach IP54 und sturzfest bis 2 Meter
- Detailtiefe auf Distanz begrenzt
- Grundauflösung nur 128 × 128 Pixel
- Keine Videoaufnahme, nur Fotos
- Menüführung sehr einfach gehalten
- Wenig geeignet für anspruchsvolle Profi-Analysen
Topdon TC004 Mini im Test: Günstige und handliche Wärmebildkamera
Die Topdon TC004 Mini bringt Wärmebildtechnik in kompakter Form für Hausinspektionen, Technik‑Checks oder den mobilen Einsatz – Kompromisse sind allerdings vorprogrammiert.
Wärmebildkameras waren lange Zeit teures Spezialwerkzeug, doch inzwischen findet man auch handliche und erschwingliche Modelle, die für viele Alltagsaufgaben völlig ausreichen. Die Topdon TC004 Mini ist genau so ein Gerät: kompakt, leicht und für schnelle Temperaturanalysen gedacht – ob an der Heizung, an elektrischen Bauteilen oder beim Prüfen von Wärmebrücken am Haus.
Im Test zeigt sich schnell, dass die Kamera im Nah- und Mittelbereich überzeugt und sich besonders für schnelle Arbeitskontrollen eignet. Gleichzeitig wird klar: Wer maximale Auflösung oder große Reichweiten erwartet, sollte die Grenzen dieses Einsteigermodells für rund 160 Euro kennen.
Design
Die Topdon TC004 Mini setzt auf ein handliches Pistolenformat, das gut ausbalanciert in der Hand liegt. Der 2,4-Zoll-Bildschirm zeigt alle Informationen klar an, darunter befinden sich wenige, aber leicht verständliche Tasten zur Navigation. Das Gehäuse besteht aus einem robusten Kunststoff, der nach IP54 vor Staub und Spritzwasser schützt. Zusätzlich ist es nach Herstellerangaben sturzfest bis in eine hähe von rund zwei Metern – ein Vorteil für Baustelle, Werkstatt und Haushalt.
Mit ihrem geringen Gewicht eignet sich die TC004 Mini besonders für mobile Einsätze. Sie passt problemlos in den Werkzeugkoffer, die mitgelieferte Handschlaufe macht den Transport zusätzlich sicherer. Zubehör wie ein Hartschalenetui oder zusätzliche Objektive gibt es nicht, was in dieser Preisklasse nicht überrascht. Etwas kritisch ist jedoch, dass kein Kameraschutz beiliegt – hier ist Vorsicht geboten.
Ein kleines Detail versteckt sich auf der Unterseite: Wie auch andere Handgeräte verfügt die TC004 Mini über ein 1/4-Gewinde, sodass man die Kamera einfach auf ein Stativ schrauben und dadurch auch stationär nutzen kann. Auf der Oberseite ist hingegen der Lade- und Datenport zu finden. Für den USB-C-Anschluss liegt auch ein entsprechendes Ladekabel bei.
Bilderstrecke: Topdon TC004 Mini
Topon TC004 mini

Topon TC004 mini

Topon TC004 mini

Topon TC004 mini

Topon TC004 mini

Topon TC004 mini

Topon TC004 mini

Steuerung & Bedienung
Die Bedienung der TC004 Mini ist bewusst simpel gehalten und weitestgehend selbsterklärend. Ein längerer Druck auf den Einschaltknopf genügt – nach kurzer Initialisierung erscheint das Wärmebild auf dem Display. Dort startet man in einer Standardansicht, die die minimale sowie maximale Temperatur im Bildbereich mittels einer blauen und roten Markierung anzeigt und diese oben links nochmals als genauen Messwert ausgibt. Die Farbpalette kann man über die Oben- und Unten-Taste wechseln.
Über einen Druck auf die OK-Taste gelangt man in das Menü. Dieses ist übersichtlich und bietet die wichtigsten Funktionen: Temperaturwarnungen aktivieren, Messmodi ändern sowie grundlegende Einstellungen wie Temperatureinheit oder Messdistanz anpassen.
Die Bildfrequenz von 25 Hz sorgt für ein flüssiges Livebild, sodass man auch bewegte Szenen gut beurteilen kann.
Die ergonomische Form ist ein Pluspunkt. Der Pistolengriff liegt angenehm in der Hand, auch bei längerer Nutzung. Für stationäre Aufgaben lässt sich die Kamera dank Gewinde auf einem Stativ befestigen. Fotos können mittels Triggertaste direkt auf den internen Speicher aufgenommen und später per USB-C übertragen werden. Die Akkulaufzeit ist in dieser Klasse sehr solide: Man kann das Gerät mehrere Stunden verwenden – das ist genug für mehrere Inspektionen ohne Nachladen.
Allerdings bleibt die Bedienung funktional und eher einfach. Tiefergehende Analysefunktionen oder einen Video-Modus bietet die TC004 Mini nicht. Auch die Verbindung zur Datenübertragung mit einem Mac klappt leider nicht vollkommen reibungslos. Um Bilder zu übertragen, mussten wir daher auf einen Windows-PC zurückgreifen.
Kamera & Bildqualität
Im Kern arbeitet die Topdon TC004 Mini mit einem Infrarotsensor mit 128 × 128 Pixeln. Durch interne Optimierung wird das Bild auf 240 × 240 Pixel hochgerechnet, was für deutlich mehr Struktur sorgt, aber natürlich keine echte optische Detailsteigerung bedeutet. Der Temperaturmessbereich reicht von etwa –20 °C bis +450 °C, die Sensitivität liegt bei unter 40 mK – genug, um selbst kleine Temperaturunterschiede sichtbar zu machen.
Im Nah- und Mittelbereich liefert die Kamera sehr brauchbare Ergebnisse. Wärmebrücken an Fenstern, undichte Stellen oder Leitungen einer Fußbodenheizung werden klar dargestellt. Elektrische Bauteile lassen sich gut beurteilen, und auch in der Werkstatt zeigt die Kamera zuverlässig Temperaturverläufe.
Die verschiedenen Farbpaletten – etwa White Hot, Black Hot, Iron oder Rainbow – helfen dabei, je nach Situation den besten Kontrast herauszuholen. Die Hot-/Cold-Spot-Anzeige erleichtert schnelle Entscheidungen, da kritische Stellen sofort auffallen.
Ab einer Entfernung von etwa drei Metern wird jedoch deutlich, dass der Sensor nur 128 × 128 Pixel liefert. Feine Details gehen verloren, und der digitale Zoom bringt erwartungsgemäß keine echte zusätzliche Schärfe. Für Wildbeobachtung oder anspruchsvolle Industrieprüfungen ist die Auflösung daher zu gering. Für typische Heimwerker-Aufgaben, Leckage- und Heizungsprüfungen sowie elektrische Diagnosen liefert die TC004 Mini dagegen absolut solide Bilder und Messwerte.
Testaufnahmen Topdon TC004 Mini
Testaufnahmen Topdon TC004 Mini
Testaufnahmen Topdon TC004 Mini

Testaufnahmen Topdon TC004 Mini
Testaufnahmen Topdon TC004 Mini
Testaufnahmen Topdon TC004 Mini
Testaufnahmen Topdon TC004 Mini

Testaufnahmen Topdon TC004 Mini
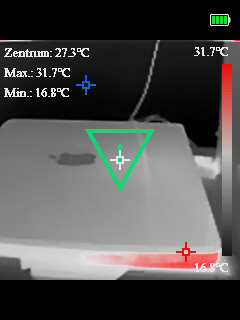
Testaufnahmen Topdon TC004 Mini

Testaufnahmen Topdon TC004 Mini
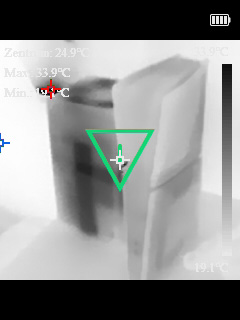
Preis
Die Topdon TC004 Mini kostet regulär rund 199 Euro. Im Handel ist sie teils auch etwas günstiger zu finden. So ist das Modell aktuell bei Amazon auf 160 Euro reduziert. Für eine eigenständige Wärmebildkamera mit solider Ausstattung ist das ein attraktiver Preis.
Fazit
Die Topdon TC004 Mini ist eine solide Einsteigerlösung für alle, die eine handliche Wärmebildkamera ohne komplexe Menüs suchen, aber auch keinen Smartphone-Adapter wollen. Sie liefert im Nah- und Mittelbereich ordentliche Ergebnisse, bietet eine lange Akkulaufzeit und ist robust genug für den Alltag.
Die Grenzen der Wärmebildkamera liegen klar bei der Auflösung, der fehlenden Videoaufnahme und eingeschränkter Detailtiefe auf Distanz. Für Hausinspektionen, Technikchecks und schnelle Kontrollen ist sie jedoch eine ausgezeichnete und preislich attraktive Wahl.
Hikmicro Eco Lite
Die Hikmicro Eco Lite sieht der teureren D01 zum Verwechseln ähnlich – doch unter der Haube gibt es entscheidende Unterschiede.
- sehr lange Akkulaufzeit (bis ca. 11 Stunden)
- eigenständiges Gerät mit Display und internem Speicher
- Hot-/Cold-Spot-Anzeige für schnelle Orientierung
- günstiger Einstiegspreis
- nur 96 × 96 Pixel ohne Bildoptimierung
- deutlich unscharfes Bild
- schwächen bereits im mittleren Entfernungsbereich
- Kunststoffgehäuse wirkt billig
- keine Video-Funktion
Hikmicro Eco Lite im Test: Günstige Wärmebildkamera für Einsteiger mit Top-Akku
Die Hikmicro Eco Lite sieht der teureren D01 zum Verwechseln ähnlich – doch unter der Haube gibt es entscheidende Unterschiede.
Wärmebildkameras sind längst nicht mehr nur Werkzeuge für Profis. Auch private Nutzer finden mittlerweile erschwingliche Geräte, mit denen sich Wärmebrücken aufspüren, Elektrobauteile überprüfen oder Heizungsanlagen kontrollieren lassen.
Die Hikmicro Eco Lite gehört genau in dieses Segment: ein handliches Gerät mit Display, Akku und Speicher. Sie ist innerhalb weniger Sekunden einsatzbereit, benötigt kein Smartphone und richtet sich klar an Einsteiger, die schnell Ergebnisse sehen wollen. Im Test zeigt sie sich als überraschend leistungsfähig – mit klaren Stärken im Nahbereich und spürbaren Grenzen bei Detailtiefe und Reichweite.
Design
Optisch ist die Hikmicro Eco Lite nicht von der Hikmicro D01 (Testbericht) zu unterscheiden. Das kompakte Handgerät besteht vollständig aus Kunststoff und vermittelt haptisch keinen besonders hochwertigen Eindruck. Die Oberfläche ist glatt und ohne Gummierung – bei Nässe wird das Gerät spürbar rutschig.
Für einfache Haus- und Werkstattaufgaben reicht die Verarbeitung aus, für anspruchsvollere Einsätze in rauer Umgebung wirkt das Gehäuse jedoch wenig vertrauenserweckend. Positiv bleibt die Ergonomie: Die Kamera liegt gut in der Hand und ist angenehm leicht.
Hikmicro Eco Lite – Bilder
Hikmicro Eco-Lite – Bilder

Hikmicro Eco-Lite – Bilder

Hikmicro Eco-Lite – Bilder

Hikmicro Eco-Lite – Bilder

Auf der Oberseite befindet sich der USB-C-Port zum Laden und für die Datenübertragung. Am unteren Ende ist ein Stativgewinde integriert, daneben lässt sich die mitgelieferte Handschlaufe befestigen. Wie schon bei der D01 fehlen allerdings ein Objektivschutz und eine Transporthülle. Wer das Gerät im Werkzeugkoffer transportieren möchte, sollte entsprechend vorsichtig sein.
Steuerung & Bedienung
Die Bedienung entspricht nahezu vollständig der des Schwestermodells D01 – und das ist ein Pluspunkt. Nach dem Einschalten ist die Kamera innerhalb weniger Sekunden einsatzbereit. Die Menüführung gibt sich schlicht und übersichtlich: Szenenwechsel, Farbpaletten und Messpunkte lassen sich bequem über das Menü anpassen.
Die automatische Anzeige des heißesten, kältesten und mittleren Messpunkts erleichtert schnelle Diagnosen erheblich. Für einfache Anwendungen – etwa das Prüfen von Heizkörpern, elektrischen Bauteilen oder Fensterdichtungen – genügt das vollkommen.
Auch die Akkulaufzeit von bis zu elf Stunden ist ein echtes Plus. Damit eignet sich die Eco Lite für längere Inspektionsrundgänge, ohne dass man ständig nachladen muss. Fotos lassen sich direkt auf dem Gerät speichern; ein Videomodus fehlt allerdings.
Grenzen zeigen sich bei den erweiterten Einstellungen: Der Emissionsgrad lässt sich nur eingeschränkt anpassen, professionelle Analysefunktionen fehlen komplett. Das Bedienkonzept richtet sich klar an Einsteigerinnen und Einsteiger – schnell verständlich, aber ohne Tiefgang.
Kamera & Bildqualität
Hier liegt der entscheidende Unterschied zur D01. Während die D01 das 96 × 96 Pixel große Sensorsignal per Super IR auf 240 × 240 Pixel hochrechnet, bleibt die Eco Lite bei der nativen Auflösung. Und das sieht man sofort.
Das Bild wirkt deutlich grober und unschärfer. Konturen verlaufen unsauber, feine Details gehen verloren und Strukturen erscheinen verpixelt. Im direkten Vergleich zur D01 fällt der Unterschied stärker aus, als es die bloße Zahl vermuten lässt.
Im Nahbereich – etwa beim Prüfen von Heizkörpern oder klar abgegrenzten Wärmequellen – liefert die Eco Lite dennoch brauchbare Ergebnisse. Temperaturunterschiede sind erkennbar, Warm- sowie Kaltstellen zeigt sie zuverlässig an.
Sobald jedoch mehr Distanz ins Spiel kommt oder feinere Strukturen betrachtet werden sollen, stößt der Sensor schnell an seine Grenzen. Gebäudeansichten, kleine Bauteile oder detaillierte Dämmprüfungen wirken grob und wenig präzise.
Der Temperaturbereich von –20 °C bis 400 °C deckt typische Haushaltsanwendungen ab. Für einfache Checks reicht das aus. Wer jedoch Wert auf eine klarere Darstellung legt, merkt schnell, dass die fehlende Bildoptimierung der Eco Lite spürbar ins Gewicht fällt.
Preis
Die Hikmicro Eco Lite gibt es aktuell für 100 Euro bei Amazon. Die UVP liegt bei 139 Euro.
Fazit
Die Hikmicro Eco Lite ist ein sehr günstiger Einstieg in die Wärmebildtechnik – allerdings mit klaren Abstrichen bei der Bildqualität. Das identische Gehäuse zur D01 täuscht darüber hinweg, dass unter der Haube deutlich weniger geboten wird. Für einfache Nahbereich-Checks reicht die Leistung aus. Wer jedoch ein klareres, schärferes Bild möchte, sollte den kleinen Aufpreis zur D01 investieren.
Yourealstar YXI96 Pro
Die Yourealstar YXI96 Pro ist robust und leicht zu bedienen. Damit ist sie eine günstige Wärmebildkamera für Einsteiger.
- Handheld-Gerät
- Fairer Preis
- Integrierte Taschenlampe
- Geringe Auflösung
- Geringe Sensor-Empfindlichkeit
- Keine App
Günstige Wärmebildkamera für Einsteiger ab 83 €: Yourealstar YXI96 Pro im Test
Die Yourealstar YXI96 Pro ist robust und leicht zu bedienen. Damit ist sie eine günstige Wärmebildkamera für Einsteiger.
Mit der YXI96 Pro bietet Yourealstar ein Handheld-Gerät, das sich vorwiegend an Einsteiger richtet. Anders als kompakte Smartphone-Adapter kommt hier ein eigenständiges Gerät mit Display und Bedienelementen zum Einsatz. Die Kamera verzichtet zwar auf High-End-Technik, liefert aber solide Ergebnisse für den schnellen Check von Temperaturunterschieden im Alltag.
Die YXI96 Pro ist deutlich größer als die winzigen Adapter des Herstellers. Mit 231 × 79,2 × 84,9 Millimetern und einem Gewicht von 303 Gramm liegt sie angenehm in der Hand und erinnert eher an ein kleines Werkzeug als an ein Gadget. Das Gehäuse besteht aus Kunststoff, wirkt robust und ist für den Außeneinsatz ausreichend stabil. Die Linse ist durch eine Kunststoffabdeckung geschützt, die den empfindlichen Sensor vor Staub und Kratzern bewahrt.
Die Bedienung erfolgt direkt am Gerät, sodass keine App oder Smartphone-Verbindung erforderlich ist. Damit eignet sich die Kamera besonders für Anwender, die eine unkomplizierte Standalone-Lösung bevorzugen. Auch für Nutzer, die ungern Software von Drittanbietern installieren, ist dies ein Pluspunkt. Aktuell kostet die Wärmebildkamera bei Banggood nur 83 Euro.
Lieferumfang
Der Lieferumfang ist spartanisch: Neben der Kamera selbst liegt nur ein USB-A-auf-USB-C-Kabel zum Laden im Karton. Immerhin lässt sich der Speicher per microSD-Karte erweitern, um Bilder und Messungen dauerhaft zu sichern. Allerdings ist sie schwer zu wechseln, da die umliegende Öffnung nur sehr klein ist. Weitere Extras oder Zubehörteile liefert der Hersteller nicht mit, was in dieser Preisklasse aber keine Seltenheit ist.
Bilderstrecke: Yourealstar YXI96 Pro
Yourealstar YXI96 Pro

Yourealstar YXI96 Pro

Yourealstar YXI96 Pro

Yourealstar YXI96 Pro

Display & Bedienung
Das 2,4-Zoll-Display löst mit 240 × 240 Pixeln auf und zeigt das Wärmebild in Farbe an. Für Innenräume ist es ausreichend hell. Die Menüführung ist einfach gehalten und beschränkt sich auf das Wesentliche. Mit wenigen Tasten navigieren Nutzer durch die Menüs, wechseln Farbprofile oder aktivieren die Taschenlampe. Die Kamera ist damit auch für Einsteiger ohne Vorkenntnisse schnell verständlich.
Eine App-Anbindung gibt es nicht – was den Funktionsumfang zwar einschränkt, gleichzeitig aber die Nutzung unkompliziert macht, da keine zusätzliche Installation notwendig ist. Wer einfach nur ein Gerät einschalten und sofort Ergebnisse sehen möchte, dürfte die YXI96 Pro als angenehm unkompliziert empfinden.
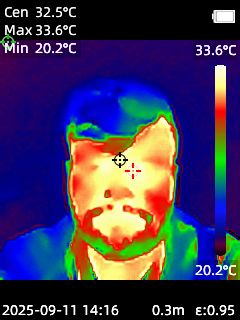
Funktionen & Bildqualität
Der verbaute Infrarotsensor löst mit 96 × 96 Pixeln auf – ein klarer Einsteigerwert, der für grundlegende Temperaturkontrollen im Nahbereich jedoch ausreicht. Der Temperaturbereich reicht von –20 °C bis 550 °C, sodass die Kamera sowohl für den Haushalt als auch für technische Anwendungen im Handwerk nutzbar ist.
Die thermische Empfindlichkeit von ≤ 60 mK ist solide und erlaubt die Darstellung von gängigen Temperaturunterschieden, wenn auch weniger präzise als bei höherwertigen Modellen. Zur Auswahl stehen fünf Farbprofile, mit denen sich die Temperaturdifferenzen optisch hervorheben lassen. Eine kleine Taschenlampe ist integriert und erweist sich bei Einsätzen in schlecht beleuchteten Räumen als nützliches Extra.
Für einfache visuelle Checks reicht die Auflösung aus, allerdings sind die Grenzen schnell erreicht: Feine Risse in der Dämmung oder kleine Kabelbrüche lassen sich nicht zuverlässig erkennen. Auf größere Distanzen verliert das Bild zudem stark an Schärfe, sodass die Kamera wirklich für den Nahbereich gedacht ist.
Praxistest
In der Praxis eignet sich die YXI96 Pro gut für einfache Checks im Haushalt: Ist ein Heizkörper gleichmäßig warm? Entweicht die Wärme durch ein Fenster? Wird ein Ladegerät übermäßig heiß? Solche Fragen beantwortet die Kamera zuverlässig.
Dank der eigenständigen Bauweise braucht es kein Smartphone, keine App und keine Internetverbindung – ein klarer Vorteil für Nutzer, die ein unkompliziertes Gerät suchen. Einschränkungen zeigen sich bei der Bildschärfe: Mit 96 × 96 Pixeln ist die Detailgenauigkeit sehr gering, kleine Objekte oder feine Strukturen lassen sich kaum unterscheiden. Für präzisere Messungen oder professionelle Anwendungen ist die Kamera daher nicht geeignet.
Im Alltag überzeugte die einfache Bedienung: einschalten, Motiv anvisieren, Farbprofil wählen und messen. Gerade für Gelegenheitsnutzer, die schnell eine grobe Einschätzung benötigen, ist dieser unkomplizierte Workflow angenehm. Wer dagegen regelmäßig arbeiten möchte, etwa im Handwerk oder in der Gebäudediagnose, wird die Limitierungen sehr schnell bemerken.
Technische Daten
| 256 × 192 Pixel |
| ±2 °C |
| 25 Hz |
| 50° x 37.2° |
| ≤40mK |
| -20 ℃ bis 550 ℃ |
| 35,3 × 26 × 19,2 mm |
| 15,6 g |
| keine |
Preis
Regulär kostet die Yourealstar YXI96 Wärmebildkamera knapp 100 Euro. Aktuell ist das Modell bei Banggood für 83 Euro zu haben.
Hinweis: Beim Kauf in China-Shops gilt kein EU-Käuferschutz. Es drohen lange Lieferzeiten, zusätzliche Zoll- und Steuerkosten sowie Probleme bei der Garantie und Rückgabe. Bei sicherheitsrelevanten Produkten besteht zudem das Risiko, dass sie nicht europäischen Standards entsprechen.
Fazit
Die Yourealstar YXI96 Pro ist eine einfache und robuste Wärmebildkamera für Einsteiger, die mit eigenem Display und intuitiver Bedienung punktet. Sie ist leicht zu handhaben, sofort einsatzbereit und deckt mit –20 °C bis 550 °C einen breiten Temperaturbereich ab. Die Erweiterung per SD-Karte und die integrierte Taschenlampe erhöhen die Praxistauglichkeit.
Auf der anderen Seite sind die Auflösung von 96 × 96 Pixeln und die Empfindlichkeit von ≤ 60 mK klar begrenzend. Für schnelle Kontrollen im Haushalt oder gelegentliche Hobbyanwendungen ist die Kamera vollkommen ausreichend. Wer jedoch detailliertere Wärmebilder benötigt, sollte zu einem höher auflösenden Modell greifen.
Insgesamt ist die YXI96 Pro ein Gerät, das primär durch seine Schlichtheit und sofortige Einsatzbereitschaft überzeugt. Für den Einstieg in die Welt der Thermografie ist sie brauchbar, für ambitionierte Nutzer jedoch eher ein Zwischenschritt. Wer einmal die Möglichkeiten höher auflösender Geräte kennengelernt hat, wird den Mehrwert schnell zu schätzen wissen.
Mustool MT15S Pro
Wer mit Elektronik arbeitet, benötigt oft eine Vielzahl an Messgeräten. Das Mustool MT15S Pro kombiniert ein Digitalmultimeter mit einer Wärmebildkamera und reduziert so den Gerätepark.
- Multimeter und Wärmebildkamera in einem
- ausreichende Auflösung für detaillierte Darstellung
- günstig
- kurze Akkulaufzeit
- Firmware-Updates schwer durchzuführen
- langsame Boot-Zeit
Mustool MT15S Pro im Test: Multimeter mit Wärmebildkamera
Wer mit Elektronik arbeitet, benötigt oft eine Vielzahl an Messgeräten. Das Mustool MT15S Pro kombiniert ein Digitalmultimeter mit einer Wärmebildkamera und reduziert so den Gerätepark.
Die Wärmebildkamera bietet eine Auflösung von 256 × 192 Pixeln. Damit lassen sich thermische Probleme an Leiterplatten, elektrischen Anlagen oder Fußbodenheizungen sowie Wärmelecks aufspüren. Das Multimeter misst Spannung, Strom, Widerstand und Kapazität. Zudem sind Durchgangsprüfung, Diodentests, Frequenzmessung, Temperaturmessung und eine berührungslose Spannungserkennung möglich.
Nutzer profitieren vom Mustool MT15S Pro vorwiegend bei der Fehlersuche an elektrischen und elektronischen Geräten, bei Wartungsarbeiten und Gebäudeinspektionen. Das Gerät erfasst nicht nur thermische Probleme, sondern misst gleichzeitig auch elektrische Parameter. Die Pro-Version verfügt zusätzlich über eine Makrolinse für den Sensor, die detaillierte Temperaturaufnahmen erlaubt – nützlich etwa zur Analyse feiner Strukturen auf Leiterplatten. Das Gerät hat uns Banggood für den Test zur Verfügung gestellt.
Design & Display
Das Mustool MT15S Pro steckt in einem robust wirkenden Kunststoffgehäuse mit leicht abgerundeten Kanten und liegt gut in der Hand. Es misst 134 × 64 × 28 mm und wiegt rund 200 g.
Trotz der Doppelfunktion bleibt die typische Multimeter-Form erhalten. Die Vorderseite dominiert ein 3,5-Zoll-Farbdisplay, das sowohl Messwerte als auch Wärmebilder anzeigt – jedoch ohne Touchfunktion. Stattdessen erfolgt die Bedienung über physische Tasten an den Seiten und oben. Diese lassen sich auch mit Handschuhen gut nutzen, während ein Touchscreen eine schnellere Menüführung ermöglichen würde.
An der Oberseite sitzen die standardmäßigen Multimeter-Buchsen für die Messleitungen sowie vier gummierte Bedientasten. Die Prüfspitzen der Messleitungen sind nicht vergoldet. Das Gerät wird über einen seitlichen Schalter ein- und ausgeschaltet. Ein USB-C-Anschluss dient zum Laden der austauschbaren 18650-Lithium-Ionen-Zelle. Der mitgelieferte 2000-mAh-Akku reicht für etwa acht Stunden Betrieb und kann durch ein Modell mit höherer Kapazität ersetzt werden. Unterwegs ist das Aufladen per Powerbank möglich.
Zur Beleuchtung der Messumgebung ist eine LED-Taschenlampe integriert. Auf der Rückseite befindet sich eine ausklappbare Halterung zum Aufstellen des Geräts. Zusätzlich verfügt die Unterseite über ein Stativgewinde für eine feste Montage. Zum Lieferumfang gehört eine kleine Transporttasche für das Gerät und Zubehör – die Anleitung passt allerdings nicht hinein.
Mustool MT15S Pro – Bilder
Mustool MT15S Pro

Mustool MT15S Pro

Mustool MT15S Pro

Mustool MT15S Pro
Funktionen & Anwendung
Nach dem Einschalten startet das Gerät im kombinierten Modus: Das Wärmebild nimmt den Hauptteil des Bildschirmes ein, während die Multimeterwerte im unteren Bereich angezeigt werden. Die Wärmebildkamera kann deaktiviert werden, um das gesamte Display für größere Messwerte und Graphen zu nutzen. In der Praxis erweist sich die geteilte Anzeige als nützlich, um thermische und elektrische Parameter gleichzeitig im Blick zu behalten.
Der Messmodus des Multimeters wird über die seitlichen Tasten gewechselt oder – bei Strommessungen – automatisch durch Einstecken der Messleitung in die entsprechende Buchse aktiviert.
Die Modi des Mustool MT15S Pro werden über die seitlichen Tasten umgeschaltet. Ein kurzer Druck wechselt zwischen Hauptfunktionen wie Spannung, Strom, Widerstand, Kapazität und Non-Contact-Voltage (NCV). Mit der Funktionstaste auf der Oberseite lassen sich Unterfunktionen steuern: Ein kurzer Druck wechselt zwischen AC und DC, ein langes Drücken öffnet das Einstellungsmenü.
Die NCV-Funktion erkennt Wechselspannung berührungslos. Dazu wird das Gerät in der Nähe eines Leiters, einer Steckdose oder einer elektrischen Leitung gehalten. Erkennt es eine Spannung, gibt es eine Warnung auf dem Display und einen durchdringenden Signalton aus.
Messwerte und Wärmebilder lassen sich durch langes Drücken der Speichertaste lokal sichern. Eine microSD-Karte kann intern eingesetzt werden, ist aber umständlich zu entnehmen und einzusetzen.
Ein praktischer Nachteil ist die lange Boot-Zeit von etwa 12 Sekunden, was spontane Messungen erschwert. Viele Nutzer werden daher den Stand-by-Modus nutzen, der jedoch die Akkulaufzeit verringert.
Das Multimeter kann nicht nur aktuelle Messwerte anzeigen, sondern auch Daten aufzeichnen und für spätere Analysen speichern. Ein kurzer Druck auf die Hold/Save-Taste friert den aktuellen Messwert auf dem Display ein. Im Wärmebildmodus speichert ein langes Drücken der Taste das aktuelle Bild auf der Speicherkarte. Im Multimeter-Modus ermöglicht dieselbe Funktion die Aufzeichnung von Wellenformen und Graphen zur Analyse zeitabhängiger Signale.
Gespeicherte Daten lassen sich direkt auf dem Display oder am PC ansehen. Über die USB-C-Buchse kann das Gerät als Wechseldatenträger genutzt werden, alternativ kann die microSD-Karte ausgelesen werden.
Ein Software-Tool von Mustool ist nicht bekannt. Die Anleitung erwähnt zwar Firmware-Updates, doch eine offizielle Hersteller-Website konnten wir nicht finden. Die angegebene URL führt auf einen nicht mehr erreichbaren Server.
Bildqualität & Genauigkeit
Laut Bedienungsanleitung hat die Wärmebildkamera eine Genauigkeit von ±2 °C an – ein Wert, der mit vielen Wärmebildkameras im mittleren Preissegment vergleichbar ist. Die Messauflösung beträgt 0,1 °C, die maximale Temperatur liegt bei 550 °C.
Die Genauigkeit des Multimeters entspricht der mittleren Geräteklasse, ohne an die Präzision spezialisierter Labormessgeräte heranzureichen.
- Spannungsmessung (AC/DC): Die Genauigkeit beträgt 1 % des Messwerts plus 3 Digits. Eine Messung von 100 V kann also real zwischen 98,7 V und 101,3 V liegen.
- Strommessung (AC/DC): Ebenfalls mit 1 % des Messwerts plus 3 Digits spezifiziert – ausreichend für die meisten Anwendungen.
- Widerstandsmessung: mit 0,5 % des Messwerts plus 3 Digits genauer als die Spannungs- und Strommessung.
- Kapazitätsmessung: 2 % des Messwerts plus 5 Digits bis 1999,9 µF, für höhere Werte bis 199,99 mF steigt die Abweichung auf 5 % plus 5 Digits.
- Diodentest: Mit einer Genauigkeit von 10 % eher für eine qualitative Beurteilung als für präzise Spannungsmessungen geeignet.
Preis
Bei Banggood kostet das Mustool MT15S Pro normalerweise rund 200 Euro, ist aber derzeit vergriffen. Baugleich mit dem Modell von Mustool ist die Tooltop ET15S bei Aliexpress für rund 227 Euro.
Fazit
Das Mustool MT15S Pro kombiniert eine hochauflösende Wärmebildkamera mit einem Digitalmultimeter in einem kompakten Gerät und richtet sich an Techniker, Elektroniker und Hobbyanwender, die beide Funktionen regelmäßig nutzen.
Die Kombination spart Zeit und Platz, hat aber einen Nachteil: Fällt das Gerät aus, sind beide Funktionen gleichzeitig unbrauchbar. Die Wärmebildkamera mit 256 × 192 Pixeln liefert detaillierte Aufnahmen, die für viele Anwendungen ausreichen. Dank der integrierten Makrolinse lassen sich auch kleine elektronische Bauteile analysieren. Das Multimeter beherrscht die gängigen Messfunktionen: Spannung, Strom, Widerstand, Kapazität und Frequenz.
Allerdings gibt es einige Einschränkungen, die potenzielle Käufer kennen sollten. Die Boot-Zeit von rund 12 Sekunden ist vergleichsweise lang. Die Navigation über physische Tasten ist weniger intuitiv als ein Touchscreen. Mit etwa acht Stunden Akkulaufzeit ist das Gerät für lange Einsätze knapp dimensioniert, der austauschbare Standardakku gleicht das teilweise aus. Ein weiteres Manko: Firmware-Updates scheinen mangels offizieller Hersteller-Website kaum möglich. Auch eine deutschsprachige Anleitung konnten wir nicht finden. Der Preis ist angesichts der gebotenen Funktionalität allerdings angemessen.
Kaiweets KTI-W01
Wärmebildkameras müssen nicht teuer sein. Die Kaiweets KTI-W01 ist ein kompaktes und günstiges Modell für den semiprofessionellen Einsatz.
- Dual-Light-Fusion-Technik
- integrierter 32-GB-Speicher
- lange Akkulaufzeit
- kompaktes & leichtes Design
- automatische Farbskalierung kann verwirren
- keine Mac-Software verfügbar
- fester Fokus ohne Makro-Einstellung
Kaiweets KTI-W01 im Test: Günstige Wärmebildkamera mit Bildüberlagerung
Wärmebildkameras müssen nicht teuer sein. Die Kaiweets KTI-W01 ist ein kompaktes und günstiges Modell für den semiprofessionellen Einsatz.
Mit der KTI-W01 bietet Kaiweets ein kompaktes und günstiges Modell im Pistolen-Design, das sich durch Bildüberlagerung mittels Dual-Light-Fusion, IP54-Schutz und lange Akkulaufzeit als vielseitige Lösung empfiehlt. Ob bei der Gebäudediagnose, bei Elektroinstallationen oder für Tierbeobachtungen – Wärmebildkameras sind längst nicht mehr nur teuren Profigeräten vorbehalten. Wie sich die Wärmebildkamera in der Praxis schlägt, zeigt unser Test.
Design & Display
Das 3,2-Zoll-Display der KTI-W01 löst mit 640 × 480 Pixeln auf – für die Darstellung von Wärmebildern ist das vollkommen ausreichend. Mit Abmessungen von rund 90 × 105 × 223 mm bleibt das Gerät trotz des Displays angenehm kompakt. Eine kleine Transporttasche gehört zum Lieferumfang.
Die gummierten Tasten lassen sich auch mit dünnen Handschuhen zuverlässig bedienen. Unpraktisch ist jedoch, dass die Bestätigungstaste nicht mittig im Steuerkreuz sitzt, sondern darüber. Eine blinde Bedienung ist so schwer möglich und erfordert eine gewisse Eingewöhnung. Im Test landeten unsere Fingertipps daher häufig in der Mitte des Kreuzes.
Auf der Vorderseite sitzen sowohl die Infrarot- als auch die Digitalkamera, die für die Fusion-Funktion zusammenarbeiten. Abgedeckt werden sie von einer fest montierten Schutzklappe. Eine Makrofunktion oder ein Hilfslicht bietet die KTI-W01 nicht.
Kaiweets KTI-W01 – Bilderstrecke
Kaiweets KTI-W01

Kaiweets KTI-W01

Kaiweets KTI-W01

Kaiweets KTI-W01
Kaiweets KTI-W01

Kaiweets KTI-W01

Kaiweets KTI-W01

Funktionen
Die KTI-W01 bietet drei Bildmodi, die sie von günstigen Konkurrenzgeräten abheben: Im klassischen Infrarotmodus zeigt sie ausschließlich das Wärmebild, der Sichtlichtmodus nutzt nur die integrierte Digitalkamera. Im Dual-Light-Fusion-Modus werden beide Aufnahmen in drei wählbaren Transparenzstufen übereinandergelegt. Diese Technik erleichtert die räumliche Orientierung bei komplexen Wärmebildern. In der Praxis wird jedoch meist der reine Thermalmodus bevorzugt, da er eine ausreichend hohe Auflösung liefert.
Während der Messung verfolgt die Kamera automatisch die höchste, niedrigste und zentrale Temperatur im Bild und markiert diese sichtbar. Zusätzlich lassen sich fünf verschiedene Farbpaletten auswählen, um Temperaturverteilungen besser unterscheiden zu können.
Weniger überzeugend ist die Umsetzung der automatischen Kalibrierung: Alle ein bis zwei Sekunden friert das Bild kurz ein, begleitet von einem leisen Klicken. In diesem Moment wird der IR-Sensor abgeschottet, um sich neu zu justieren – was zwar die Messgenauigkeit erhöht, im Gebrauch aber stört.
Der 3500-mAh-Akku ermöglicht eine Laufzeit von 6 bis 8 Stunden, abhängig von der Display-Helligkeit. Aufgeladen wird er per USB-C. Grundsätzlich austauschbar, ist er jedoch verlötet und damit nur mit technischem Know-how wechselbar.
Zur Ausstattung zählen eine automatische Abschaltfunktion, Spritzwasser- und Staubschutz nach IP54 sowie ein interner Speicher von 32 GB – ein Speicherkartenslot fehlt allerdings. Damit eignet sich die Kamera auch für den robusteren Außeneinsatz, bleibt bei der Speichererweiterung aber eingeschränkt.
Für die Nachbearbeitung stellt der Hersteller auf dem internen Speicher eine Windows-Software bereit, die Analysen, Echtzeit-Streaming und Datenauswertung über die USB-C-Verbindung ermöglicht. Eine Mac-OS-Version ist bislang nicht verfügbar.
Bildqualität
Die Infrarotkamera der Kaiweets KTI-W01 liefert eine native Auflösung von 256 × 192 Pixeln bei 25 Hz und damit rund 49.000 Messpunkten. Der Temperaturmessbereich reicht von –20 bis 550 °C bei einer Auflösung von 0,1 °C. Die thermische Empfindlichkeit (NETD) liegt bei ≤ 50 mK bei 25 °C, wodurch Temperaturunterschiede zuverlässig erkennbar sind. Teurere Geräte erreichen unter 40 mK, doch die KTI-W01 reicht für die meisten Anwendungen aus – nur bei Regen oder Schneefall stößt sie an Grenzen.
Weniger gelungen ist die automatische Anpassung des Farbspektrums: Die Kamera richtet die Farbskala permanent an den minimal und maximal erfassten Temperaturen aus. Das führt dazu, dass identische Temperaturen in unterschiedlichen Kontexten verschieden eingefärbt erscheinen – was besonders erfahrenen Anwendern die Orientierung erschwert.
Technische Daten
| IR-Auflösung | 256 x 192 Pixel |
| Bildfrequenz | 25 Hz |
| Temperaturbereich | -20 Grad Celsius bis 550 Grad Celsius |
| Thermische Empfindlichkeit | ≤50mK |
| Display | 3,2″ (640×480 Pixel) |
| Digitalkamera | eingebaut |
| Akkulaufzeit | 6-8 Stunden |
| Schutzklasse | IP54 |
| Gewicht | 417g |
| Sichtfeld (FOV) | 56° x 42° |
| Speicher | 32 GB eMMC |
Preis
Die KTI-W01 wurde uns von Kaiweets zur Verfügung gestellt. Mit dem Rabatt-Code KTIW01 gibt es einen Nachlass von 25 Prozent, die Wärmebildkamera ist derzeit aber vergriffen. Auch bei Amazon ist sie ausverkauft. Zu haben ist sie noch bei Aliexpress für 235 Euro.
Da der Händler seinen Sitz in China hat, greifen EU-Käuferschutzregeln nur eingeschränkt bei Kaum über Kaiweets. Der Hersteller verspricht jedoch 30 Tage Rückgaberecht und drei Jahre Garantie.
Fazit
Die Kaiweets KTI-W01 zeigt, dass eine Wärmebildkamera mit nützlichen Profi-Funktionen nicht teuer sein muss. Stärken wie Dual-Light-Fusion, der 32-GB-Speicher und die lange Akkulaufzeit sprechen für das Modell. Die automatische Farbskalierung, das regelmäßige Rekalibrieren und die fehlende Mac-OS-Software sind jedoch klare Schwächen. Wer eine erschwingliche, robuste und vielseitige Wärmebildkamera sucht, erhält hier ein überzeugendes Gesamtpaket.

Exynos 2600 im Benchmark: Samsungs 2-nm-SoC gegen den Snapdragon 8 Elite Gen 5

Die Polizei im Nacken: Bayern jagt Verkehrsrowdys mit „Action-Cam“

Geringe Smart-Meter-Quote: Bundesnetzagentur geht gegen fast 80 Stromanbieter vor

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast

Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 4 Wochen
Social Mediavor 4 WochenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
Künstliche Intelligenzvor 1 Monat
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatCommunity Management zwischen Reichweite und Verantwortung
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenEindrucksvolle neue Identity für White Ribbon › PAGE online
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenAumovio: neue Displaykonzepte und Zentralrechner mit NXP‑Prozessor
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenÜber 220 m³ Fläche: Neuer Satellit von AST SpaceMobile ist noch größer
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateneHealth: iOS‑App zeigt Störungen in der Telematikinfrastruktur
