Entwicklung & Code
Deep Dive Spring Modulith Teil 1: Fachliche Module im Fokus
Mit Spring Modulith ist es möglich, Spring-Boot-Anwendungen in fachliche Module aufzuteilen, die über klare Schnittstellen verfügen, per Events kommunizieren und sich isoliert testen lassen. Die Architektur der Module lässt sich automatisiert überwachen und dokumentieren. Diese Artikelserie stellt Spring Modulith, dessen Version 2.0 im November 2025 erschien, in zwei Teilen vor. Der erste Teil zeigt die Grundlagen der Modul- und Event-basierten Architektur. Teil 2 wirft unter anderem einen Blick auf die Testmöglichkeiten der Module.
Weiterlesen nach der Anzeige


Nils Hartmann ist freiberuflicher Softwareentwickler und Coach mit den Schwerpunkten Java im Backend und React im Frontend, wozu er auch Workshops und Trainings gibt.
Von klassischen Architekturen zum modularen Monolithen
Spring Boot ist eine typische Wahl bei der Entwicklung von Java-basierten Anwendungen. Um den damit entwickelten Code auch langfristig beherrschbar zu halten, werden oft Architekturmuster wie Schichten-, Hexagonal- oder Onion-Architektur angewendet. Diese Muster teilen die Anwendung aber oft nur in eher technische Bestandteile auf, um beispielsweise eine Entkopplung von eingesetzten Datenbanken oder anderen externen Systemen zu ermöglichen. In der klassischen Layer-Architektur greifen beispielsweise Controller auf Services und Services auf Repositorys zu, nicht aber Repositorys auf Services oder Controller.
In der Hexagonal-Architektur werden einzelne Komponenten wie UI- und Persistenzschicht sowie der fachliche Anwendungskern über „Ports“ und „Adapter“ voneinander separiert. Das soll die Domain-Logik von technischen Details, wie der Anbindung an eine konkrete Datenbank, trennen. Außerdem sollen diese Architekturstile ermöglichen, dass einzelne Teile der Anwendung isoliert testbar und jederzeit austauschbar sind, etwa beim Wechsel der Datenbank. Spring Modulith geht einen anderen Weg.
Modulith ist ein Kofferwort aus „modularer Monolith“. Die Anwendung wird als Monolith entwickelt, ist aber intern nach streng fachlichen Modulen (auch Slices genannt) aufgeteilt. Der potenziell komplexe fachliche Kern einer Anwendung soll so in beherrschbare kleinere Einheiten zerteilt werden, die in sich abgeschlossen mit klaren Schnittstellen versehen sind und alles enthalten, was zur Umsetzung der jeweiligen Fachlichkeit nötig ist. Änderungen an fachlichen Anforderungen haben somit im besten Fall nur Auswirkungen auf genau ein Modul. Die Module einer Anwendung können nach den oben genannten Architekturstilen implementiert werden, müssen es aber nicht. Ähnlich wie bei Microservices kann auch hier pro Modul – jedenfalls in einem gewissen Rahmen – die jeweils passende Architektur gewählt werden.
Dieser Artikel stellt Spring Modulith anhand der Beispielanwendung „Plantify“ vor. Plantify bietet die Möglichkeit, dass Kunden ihre Pflanzen pflegen lassen. Dazu registrieren sie zunächst ihre Pflanzen. Plantify legt für jede Pflanze Pflegeaufgaben an, die dann ein Dienstleister abarbeitet. Für die durchgeführten Aufgaben schickt Plantify regelmäßig eine Rechnung an die Kunden. Die Kommunikation mit der Anwendung findet über eine HTTP-API statt. Der Sourcecode der Beispielanwendung ist auf GitHub zu finden.
(Bild: buraratn/123rf)

Bei der Online-Konferenz betterCode() Spring stehen am Vormittag sichere Anwendungen mit Spring Security und die Integration von KI mit Spring AI im Fokus. Der Nachmittag widmet sich Spring Boot und zeigt die Neuerungen von Version 4 im Zusammenspiel mit Java 25, Tipps zur Integration von Containern sowie in der Praxis bewährte Spring Boot Hacks.
Application Module mit Spring Modulith
Weiterlesen nach der Anzeige
Um Spring Modulith in der eigenen Anwendung zu verwenden, fügt man dessen Starter-Paket in der eigenen Maven- oder Gradle-Konfiguration hinzu. Das reicht schon aus, damit Spring Modulith die Packages in der Anwendung unterschiedlich klassifiziert und behandelt. Alle Packages, die sich direkt unterhalb des Root-Packages befinden (das ist das Package mit der Klasse SpringBootApplication), betrachtet Spring Modulith als „Application Module“. Technisch bleiben es zwar weiterhin normale Java-Packages, aber Spring Modulith legt der Verwendung dieser Application Modules einige Regeln auf. Zum Beispiel darf es zwischen den Application Modules nicht zu direkten oder indirekten zirkulären Abhängigkeiten kommen.
In der Plantify-Anwendung gibt es etwa direkt unterhalb des Root-Packages nh.plantify drei Packages plant, care und billing. Diese drei Packages interpretiert Spring Modulith als Application Modules. In der Anwendung greift das Application Module plant auf care zu (z. B. um die Pflegeaufgaben einer neuen Pflanze anzulegen). Außerdem greift care auf billing zu, um die Einrichtungsgebühr zu berechnen. Diese Abhängigkeiten sind erlaubt, denn sie zeigen nur in eine Richtung. Würde die Anwendung aber erweitert, sodass eine Klasse aus dem billing-Modul auf das plant-Modul zugreifen würde, ergäbe sich daraus eine zirkuläre Abhängigkeit. Diese erkennt und verbietet Spring Modulith, da diese Art der Abhängigkeit oft zu Problemen in der weiteren Entwicklung führt.
Das Einhalten der Regeln lässt sich mit Spring Modulith auf mehreren Wegen kontrollieren und sicherstellen. Zum einen kann Spring Modulith sie bei jedem Start der Anwendung prüfen und bei Verstößen Fehler ausgeben. Das kostet allerdings Zeit und findet im Entwicklungsprozess erst spät statt. Alternativ lässt sich ein JUnit-Test implementieren, der die Regel überprüft. Ein entsprechendes Beispiel findet sich in Listing 1.
class PlantifyModuleTest {
static ApplicationModules modules = ApplicationModules.of(PlantifyApplication.class);
@Test
void verifyModules() {
modules.verify();
}
@Test
void writeDocumentationSnippets() {
new Documenter(modules)
.writeModulesAsPlantUml();
}
}
Listing 1: Die Modulstruktur wird im JUnit-Test überprüft und visualisiert
Die Klasse ApplicationModules repräsentiert die erkannten Application Modules im übergebenen Paket. Die verify-Methode stellt innerhalb des Tests sicher, dass alle Regeln eingehalten werden. Bei Verstößen schlägt der Test mit einer ausführlichen Fehlermeldung fehl (siehe Abbildung 1).

Der Unit-Test deckt Regelverstöße (zirkuläre Abhängigkeiten) auf (Abb. 1).
Diese Tests werden mit allen anderen „normalen“ Tests einer Anwendung kontinuierlich ausgeführt, sodass Probleme schnell auffallen. Die ApplicationModules-Klasse kann außerdem die Modulstruktur als C4-Diagramm ausgeben, aus der auch die Art der Verwendungen eines Moduls hervorgeht (dazu später mehr). Die Visualisierung der Plantify-Module zu diesem Zeitpunkt ist in Abbildung 2 zu sehen.
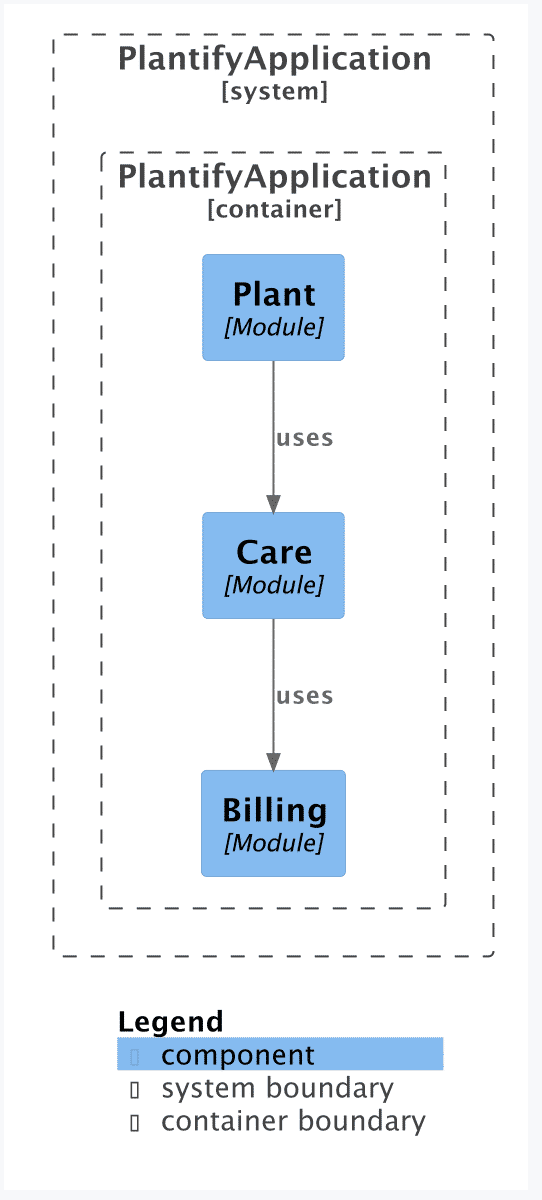
Die initiale Modulstruktur, visualisiert von Spring Modulith (Abb. 2).
Interne Module
Neben dem Verbot zirkulärer Abhängigkeiten wendet Spring Modulith noch eine andere Regel von Haus aus an: Alle Unterpakete in einem Application Module gelten als „intern“. Klassen daraus dürfen zwar innerhalb des Application Module beliebig verwendet werden, allerdings ist der Zugriff darauf aus anderen Modulen verboten. Mit anderen Worten: Das Root-Package eines Application Module ist dessen öffentliche API. Nur die Public-Klassen stehen anderen Modulen zur Verfügung. Der oben gezeigte Test Case prüft auch die Einhaltung dieser Regel. Zusätzlich können IDEs wie IntelliJ, Eclipse oder VS Code mit den entsprechenden Plug-ins diese Regeln prüfen und direkt im Quellcode anzeigen. Abbildung 3 zeigt ein entsprechendes Beispiel in Eclipse mit den Spring Tools.

Die Verwendung interner Klassen zeigt Eclipse mit den Spring Tools als Fehler an (Abb. 3).
Hier wird aus dem CareTaskService, der sich im Modul care befindet, auf die Klasse InvoiceGenerator zugegriffen, die sich in dem Unterpaket invoice des billing-Moduls befindet. Ohne Spring Modulith wäre der Zugriff aus Java-Sicht regelkonform, da die Klasse InvoiceGenerator public ist, und somit von allen Packages aus verwendet werden darf.











Entwicklung & Code
DeerFlow: Super-Agenten-Framework von ByteDance | heise online
OpenClaw hat es vorgemacht und gezeigt, zu welchen Leistungen LLMs schon in der Lage sind, wenn Agenten sie richtig nutzen. Allerdings sind die damit verbundenen Gefahren nicht nur groß, sondern sogar unüberschaubar: In manchen Fällen klaute OpenClaw Kreditkarten oder übernahm gleich den ganzen Computer. Dennoch steckt in der Technologie ein enormes Potenzial, was einige Nachahmer gefunden hat, die versuchen, die Schwächen zu korrigieren.
Weiterlesen nach der Anzeige
ByteDance legt vor
Einer der ersten Player, der sich aus der Deckung wagt, ist ByteDance, die Muttergesellschaft von TikTok, mit dem Tool DeerFlow (Deep Exploration and Efficient Research Flow). Nachdem das Projekt bereits über 56.000 Sterne auf GitHub erhalten hat, lohnt es sich, einen genaueren Blick darauf zu werfen.
ByteDance möchte, dass man für die Nutzung ein Coding-Abo abschließt, notwendig ist der aber nicht: DeerFlow lässt sich genauso mit lokalen Modellen verwenden. Etwas schwieriger wird es bei lokaler Nutzung allerdings, wenn das Framework selbstständig Websuchen durchführen soll. Das ist außerordentlich sinnvoll, denn der Knowledge Cutoff der meisten LLMs liegt beträchtlich in der Vergangenheit und sie sind über neue Entwicklungen nicht informiert. Hier kann man zum Beispiel die Search-Engine Tavily hinzufügen, für die es eine freie Variante gibt, mit der sich tausend Suchanfragen pro Monat durchführen lassen. Die gibt es auch bei InfoQuest, das ByteDance proprietär anbietet. Allerdings ist die Anzahl der Anfragen insgesamt auf tausend pro Account limitiert, Preise für weitere sind nicht direkt zu finden. Interessanterweise bietet ByteDance diesen Dienst in China selbst gar nicht an, möglicherweise auch aus Zensurgründen.
Alle lassen sich lokal installieren und konfigurieren. Die ausführliche Anleitung dazu findet sich auf GitHub. Zunächst muss man eine Konfigurationsdatei im YAML-Format anpassen. Anschließend lassen sich Docker-Container starten, in denen das System dann läuft. Die Container öffnen einen Port (2026, ob das Zufall ist?) auf dem Host-System. Das Ganze funktioniert ziemlich unproblematisch, wenn man alle Environment-Variablen in .env schreibt, die Variablen der Shell verwendet das System nämlich nicht. Das Ergebnis sieht dem Playground von DeerFlow sehr ähnlich, aber es lässt sich mit neuen Chats ergänzen.
Spielt man mit dem Playground, merkt man dem Tool auch seine Herkunft aus dem Deep Research an. Komplexe Themen kann der Agent selbst recherchieren und kommt zu guten Ergebnissen, die auch neue Entwicklungen beinhalten. Die Vorschläge für den heise-Verlag (siehe Abbildung 1) sind wie von anderen Agenten gewohnt sehr umfangreich und klingen auch sinnvoll. Allerdings ist das bei Weitem noch nicht alles.

Beispiel-Konversation mit DeerFlow mit der Frage, wie der heise-Verlag sein Geschäftsmodell ergänzen könnte (Abb. 1).
Von Deep Research zu Super-Agenten
Weiterlesen nach der Anzeige
Intern baut DeerFlow auf LangChain und LangGraph und ist damit hervorragend erweiterbar. Genau das betont auch ByteDance und bezeichnet das Framework als „Super Agent Harness“ – also ein Framework, das sich ausgezeichnet erweitern lässt. Angeblich haben die ByteDance-Developer DeerFlow neu konzipiert, als sie genau diese Erweiterungsfähigkeit von LangChain als einen entscheidenden Punkt erkannt haben.
Derartige Erweiterungen können auf unterschiedlicher Ebene erfolgen. Zentral dafür sind Skills und Tools, in denen Anwender über Markdown-Files Workflows definieren. Auch der im Beispiel der Abbildung benutzte Research-Workflow basiert auf einem solchen Skill. Von Anwendern bereitgestellte Skills lädt DeerFlow bei Bedarf nach, wenn sie benötigt werden. Das spart Speicher und Rechenzeit und erlaubt eine dynamische Erweiterung des Systems zur Laufzeit. Tools sind etwas fortgeschrittener und erledigen komplexe Aufgaben wie beispielsweise die Websuche, können aber auch Bash-Skript oder Python-Programme in einer Sandbox sicher ausführen.
ByteDance hat erkannt, dass komplexe Aufgaben sich nur schlecht in einem einzigen Durchlauf erledigen lassen. Daher stammt das Konzept der Sub-Agenten, die ihren eigenen Kontext, eigene Tools und Abschlussbedingungen haben. Das erlaubt, sie parallel zueinander laufen zu lassen und damit Zeit zu sparen.
Die Sandbox funktioniert in DeerFlow wie ein eigener Computer. Jeder Prozess erhält eine eigene Umgebung mit einem separaten Filesystem, in dem sich wiederum Skills usw. befinden können. Durch diese Isolation können die Prozesse unabhängig voneinander agieren.
Großen Wert legt ByteDance auf die Isolation von Kontexten. Jeder Agent verfügt über einen eigenen Kontext und wird nicht von anderen Agenten gestört. Nebenbei erlaubt das die schon angesprochene Parallelisierung von Agenten. Um den Kontext möglichst klein zu halten (und damit Speicher bzw. Token im LLM zu sparen), findet ständig eine Zusammenfassung statt.
DeerFlow hat ein Langzeitgedächtnis und merkt sich Inhalte auch über eine Unterhaltung hinaus. Es fungiert somit als Wissensspeicher und passt sich den Wünschen der Benutzer immer besser an. Diese Daten speichert es alle lokal. Mit Empfehlungen und Apps, auf die man nicht mehr verzichten möchte, kennt sich ByteDance ja bestens aus. Im Gegensatz zu TikTok entsteht bei DeerFlow aber ein echter Mehrwert.
DeerFlow bringt neue Ideen
ByteDance veröffentlicht mit DeerFlow ein Agenten-Framework mit vielen neuen Ideen und zeigt damit, wie sich Agenten zukünftig entwickeln könnten. Besonders spannend sind dabei die einfach zu implementierenden Skills, die Isolation und Parallelisierung sowie die Sandboxen, die gefährliche Situationen wie bei OpenClaw vermeiden sollen.
Agentische KI beschäftigt Forscher gerade sehr intensiv. Noch weiß niemand ganz genau, wie sich das Feld entfalten wird. Alternative Tools wie n8n oder Dify sind hier noch deutlich statischer als DeerFlow, aber möglicherweise ergeben sich für sie nun auch neue Richtungen. Umso spannender wird es zu beobachten, wie sich das DeerFlow-Framework weiterentwickelt.
(who)
Entwicklung & Code
Konsistenz ist eine fachliche Entscheidung
Im Deutschen hat sich eine Übersetzung eingebürgert, die das Denken über verteilte Systeme in eine falsche Richtung lenkt. „Eventual Consistency“ wird häufig als „eventuell konsistent“ wiedergegeben. Eventuell, also möglicherweise. Eine Datenbank, die möglicherweise konsistent ist, klingt nach einem System, dem man besser nicht vertraut. Kein Wunder, dass viele Entwicklerinnen und Entwickler reflexartig nach stärkeren Garantien greifen, sobald der Begriff fällt.
Weiterlesen nach der Anzeige

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Die englische Bedeutung von „eventual“ ist jedoch eine andere. Sie meint „letztendlich“ oder „am Ende“. Eventual Consistency bedeutet also nicht, dass Konsistenz vielleicht eintritt. Sie bedeutet, dass Konsistenz verlässlich eintritt, nur nicht sofort. Die Frage ist nicht, ob, sondern wann. Und diese Frage ist keine technische, sondern eine fachliche. Das war sie schon immer.
Ein besseres mentales Modell als „möglicherweise inkonsistent“ ist das der veralteten Daten. In jedem Moment kann irgendein Teil eines Systems auf Daten zugreifen, die den allerletzten Stand nicht widerspiegeln. Die Daten sind nicht falsch. Sie sind nur nicht aktuell. Sie waren vor einem Moment korrekt. Sie werden in einem Moment wieder korrekt sein. Gerade eben sind sie veraltet. Jedes System hat irgendwo veraltete Daten. Die Frage ist nicht, ob Daten veraltet sein können, sondern wie veraltet akzeptabel ist. Millisekunden? Sekunden? Minuten? Stunden? Die Antwort hängt vom Anwendungsfall ab, und sie lautet selten „niemals“.
Die bequeme Lüge der starken Konsistenz
Es gibt noch etwas, das sich in der Softwareentwicklung hartnäckig hält: Die Behauptung, eine relationale Datenbank sei immer konsistent. Transaktionen garantieren es. ACID garantiert es. Nach dem Commit sind die Daten da, und jeder sieht sie. Das stimmt allerdings nur innerhalb einer einzelnen Datenbankinstanz, für eine einzelne Abfrage, in einem einzelnen Moment. So funktionieren reale Systeme nicht.
Wer Read-Replicas einsetzt, akzeptiert bereits, dass Leseoperationen veraltete Daten liefern können. Wer einen Cache verwendet, akzeptiert, dass die gecachten Daten zum Zeitpunkt des Lesens nicht mehr aktuell sein müssen. Wer eine mobile App betreibt, akzeptiert, dass die Anzeige auf dem Gerät den Stand der letzten Synchronisation zeigt, nicht den aktuellen. Und wer HTML serverseitig rendert, akzeptiert, dass die Seite zum Zeitpunkt der Auslieferung bereits veraltet sein kann.
In dem Moment, in dem Daten die Datenbank verlassen, beginnen sie zu altern. Bis sie den Bildschirm einer Nutzerin oder eines Nutzers erreichen, sind sie bereits ein Schnappschuss der Vergangenheit. Die Kundin sieht „Bestellung bestätigt“, aber das Lagersystem hat den Auftrag noch nicht verarbeitet. Der Kunde sieht „3 Stück auf Lager“, aber jemand anders hat gerade zwei davon in den Warenkorb gelegt. Das ist kein Fehler. Das ist die Funktionsweise verteilter Systeme. Und jedes System mit einer Bedienoberfläche ist ein verteiltes System, denn das Endgerät ist ein eigener Knoten, das Netzwerk ist unzuverlässig, und zwischen Anfrage und Antwort vergeht Zeit.
Weiterlesen nach der Anzeige
Ich begegne in meiner Beratungsarbeit regelmäßig Teams, die überzeugt sind, ihre Systeme seien stark konsistent. Bei genauerem Hinsehen zeigt sich fast immer, dass die Konsistenz an der Datenbankgrenze endet. Dahinter beginnt eine Welt aus Caches, Replikas, Message-Queues und gerenderten Oberflächen, in der Daten bereits veraltet sind, bevor sie ankommen. Das System ist längst eventually consistent. Es gibt nur niemanden, der das ausspricht.
Konsistenz vor dem Computer
Eventual Consistency ist kein Phänomen, das mit verteilten Softwaresystemen entstanden ist. Sie ist ein Grundproblem der physischen Welt, und Unternehmen haben seit Jahrhunderten Wege gefunden, damit umzugehen.
Man stelle sich eine Firma mit zwei Vertriebsbüros in verschiedenen Städten vor, zu einer Zeit, als das Telefon das schnellste Kommunikationsmittel war. Beide Büros verkaufen aus demselben Lagerbestand. Eine Kundin in München möchte die letzte Einheit eines Produkts kaufen. Ein Kunde in Hamburg möchte dieselbe Einheit kaufen. Keiner der beiden Vertriebsmitarbeiter weiß, was der andere gerade macht.
Wie haben Unternehmen dieses Problem gelöst? Nicht durch perfekte Echtzeitsynchronisation. Sie haben akzeptiert, dass Konflikte auftreten werden, und Prozesse entwickelt, um sie zu behandeln. Sie haben überbucht und sich entschuldigt. Sie haben Sicherheitsbestände geführt. Sie haben im Lager angerufen, bevor sie eine Lieferung zugesagt haben. Sie haben enttäuschte Kundinnen und Kunden kompensiert. Sie haben Risiken gemanagt, nicht Konsistenz.
Das gleiche Produkt, das gleiche Problem, nur mit Stift und Papier statt mit Datenbanken. Keine Technologie der Welt kann diese grundlegende Herausforderung eliminieren: zwei Personen, zwei Orte, eine Ressource, unvollständige Information. Die Naturgesetze garantieren, dass Information Zeit braucht, um sich auszubreiten. Perfekte Synchronisation ist nicht nur schwierig. Sie ist unmöglich.
Das Interessante daran ist, dass diese analogen Prozesse oft erstaunlich gut funktioniert haben. Nicht weil sie Inkonsistenzen verhindert hätten, sondern weil sie Strategien für den Umgang mit ihnen entwickelt hatten. Die Buchhaltung glich am Ende des Tages die Bestände ab. Der Vertrieb rief im Zweifelsfall im Lager an. Und wenn doch einmal zwei Kunden dasselbe Produkt zugesagt bekamen, gab es ein Gespräch, eine Entschuldigung und eine Lösung. Der Geschäftsprozess war auf Konflikte vorbereitet, weil niemand auf die Idee gekommen wäre, sie für unmöglich zu erklären.
Wenn ich mit Teams über Eventual Consistency spreche, hilft dieser historische Blick oft mehr als jedes Architekturdiagramm. Er verschiebt das Problem aus der technischen Ecke in die geschäftliche, wo es hingehört. Die Frage lautet nicht: Wie verhindern wir Inkonsistenz? Sie lautet: Wie gehen wir mit ihr um?
Die richtigen Fragen stellen
Wenn Entwicklerinnen und Entwickler über Eventual Consistency diskutieren, stellen sie häufig die falsche Frage. Sie fragen: Ist Eventual Consistency hier akzeptabel? Das rahmt Konsistenz als binäre Eigenschaft, als hätte man sie oder hätte sie nicht.
Die richtigen Fragen sind anders: Wie häufig tritt ein Konflikt tatsächlich auf? Wenn zwei Nutzerinnen oder Nutzer gleichzeitig den letzten Artikel kaufen wollen: Passiert das einmal am Tag? Einmal im Monat? Einmal im Jahr? Die Häufigkeit entscheidet darüber, ob ein Konflikt ein reales Problem ist oder eine theoretische Sorge. Was kostet ein Konflikt? Ist die Konsequenz eine enttäuschte Kundin? Eine Rückerstattung? Ein manueller Eingriff? Ein rechtliches Problem? Die Kosten bestimmen, wie viel Aufwand die Vermeidung rechtfertigt. Und was kostet die Vermeidung? Stärkere Konsistenzgarantien sind nicht kostenlos. Sie erfordern Koordination, also Latenz. Sie erfordern Sperren, also geringeren Durchsatz. Sie erfordern Infrastruktur, also Geld.
Das sind betriebswirtschaftliche Fragen, keine Ingenieursfragen. Das Entwicklungsteam kann erklären, was technisch möglich ist und was jede Option kostet. Aber die Entscheidung über das akzeptable Risiko gehört ins Business. Ein Bezahlsystem und ein Social-Media-Feed haben unterschiedliche Toleranzen. Eine Patientenakte und ein Warenkorb haben unterschiedliche Anforderungen. Der Kontext bestimmt die Antwort.
Genau deshalb gehören Diskussionen über Eventual Consistency nicht ausschließlich in Technik-Meetings. Das Team mag starke Meinungen über technische Korrektheit haben, weiß aber vielleicht nicht, dass die Fachabteilung eine Verzögerung von einer Sekunde bereitwillig akzeptieren würde, wenn dafür die Infrastrukturkosten sinken. Oder es weiß nicht, dass ein bestimmter Anwendungsfall regulatorische Anforderungen hat, die stärkere Garantien verlangen. Das Gespräch braucht beide Perspektiven.
Alltagsbeispiele zeigen, wie selbstverständlich Eventual Consistency bereits ist. Paketverfolgung zeigt einen Status, der vor Stunden erfasst wurde. Das Paket wurde gescannt, als es das Sortierzentrum verlassen hat. Seitdem ist es unterwegs, möglicherweise bereits zugestellt. Die angezeigte Information ist veraltet, und das stört niemanden, weil ein ungefährer Überblick über den Fortschritt ausreicht. Bestandsanzeigen in Online-Shops sind ein ähnlicher Fall. „Nur noch 3 auf Lager“ war korrekt, als die Seite gerendert wurde. Inzwischen hat vielleicht jemand eines gekauft. Vielleicht hat jemand eines in den Warenkorb gelegt, ohne zu bestellen. Die Zahl ist ein Hinweis, keine Garantie. Und das ist akzeptabel, weil der Checkout-Prozess den Grenzfall abfängt, in dem der Artikel tatsächlich vergriffen ist.
Besonders aufschlussreich ist das Beispiel der Fluggesellschaften. Airlines überbuchen bewusst, weil sie wissen, dass ein Teil der Passagiere nicht erscheinen wird. Das Buchungssystem akzeptiert mehr Reservierungen, als Sitzplätze vorhanden sind. Wenn doch alle erscheinen, wird das Problem am Gate gelöst: Kompensation, Umbuchung, Upgrade. Das System ist darauf ausgelegt, Konflikte zu akzeptieren und sie nachträglich zu lösen. Das ist kein Versagen der Konsistenz. Es ist eine Geschäftsstrategie, die jedes Jahr Millionen von Flügen mit freien Sitzen füllt, die sonst leer geblieben wären.
All diese Systeme funktionieren. Ihre Nutzerinnen und Nutzer beschweren sich nicht, weil das Konsistenzfenster kurz genug ist oder weil der Geschäftsprozess die Ausnahmen elegant abfängt. Das Ziel war nie perfekte Konsistenz. Das Ziel war ausreichende Konsistenz.
Der Geldautomat, der weiterarbeitete
Unter den vielen Beispielen, die ich in Gesprächen über Eventual Consistency verwende, ist eines besonders aufschlussreich, weil es die Perspektive komplett umdreht.
Geldautomaten sind normalerweise online und mit den Systemen der Bank in Echtzeit verbunden. Bei einer Abhebung prüft der Automat den Kontostand, verifiziert die Deckung und gibt das Geld aus. Einfach und konsistent. Doch was passiert, wenn die Netzwerkverbindung ausfällt und der Automat offline geht?
Die meisten Entwicklerinnen und Entwickler, denen ich diese Frage stelle, antworten: „Der Automat muss den Betrieb einstellen. Keine Verbindung bedeutet keine Kontostandsprüfung. Keine Prüfung bedeutet mögliche Überziehungen. Also abschalten, bis die Verbindung wiederhergestellt ist.“ Das ist die naheliegende, die sichere, die technisch korrekte Antwort. Es ist aber auch die falsche.
Man stelle sich einen prominenten Millionär vor, der an einem Geldautomaten steht und 50 Euro abheben möchte, nur um zu erfahren, dass der Automat außer Betrieb ist. Die Schlagzeile am nächsten Tag: „Bank lässt Topkunden wegen Netzwerkproblem im Regen stehen.“ Das ist keine Schlagzeile, die eine Bank gebrauchen kann. Der Reputationsschaden übersteigt jedes Überziehungsrisiko bei einer Kleinbetragabhebung um ein Vielfaches.
Was machen Banken also tatsächlich? Der Automat arbeitet weiter, auch offline. Aber mit intelligentem Risikomanagement. Die meisten Ausfälle sind kurz: Die Verbindung bricht für wenige Minuten ab und stellt sich dann von selbst wieder her. Bis jemand etwas bemerkt, hat sich das Problem bereits gelöst. Die meisten Menschen heben zudem nur Geld ab, wenn sie wissen, dass sie es haben. Niemand möchte die Peinlichkeit erleben, an einem Geldautomaten mit einer Schlange hinter sich abgelehnt zu werden. Diese Selbstselektion reduziert das Überziehungsrisiko erheblich. Und für den Fall, dass die Verbindung länger ausfällt, begrenzt die Bank den maximalen Abhebungsbetrag im Offline-Modus.
Doch der eigentlich interessante Punkt liegt woanders. Wenn jemand im Offline-Modus sein Konto tatsächlich überzieht, hat die Bank zwei Möglichkeiten, die Situation zu rahmen. Erste Variante: „Kunde nutzte Systemschwachstelle während Netzwerkausfall.“ Das klingt nach einem Sicherheitsvorfall. Zweite Variante: „Bank zeigte Flexibilität und half Kunden trotz technischer Schwierigkeiten.“ Das klingt nach exzellentem Kundenservice. Und nebenbei: Die Bank berechnet Überziehungszinsen. Der Kunde, der 50 Euro abgehoben hat, die er nicht hatte, zahlt sie zurück, mit Aufschlag. Die Bank hat eine technische Einschränkung in eine Einnahmequelle verwandelt.
Das ist es, was fachliches Denken über Konsistenz bedeutet. Die Entwicklerin sieht ein Konsistenzproblem und will es um jeden Preis verhindern. Die Geschäftsseite sieht eine Risiko-Ertrags-Rechnung und findet eine Lösung, die besser ist als sowohl „immer konsistent“ als auch „immer verfügbar“. Die beste Antwort lag nicht im Engineering-Meeting. Sie lag im Business-Meeting.
Das Verstecken ist das eigentliche Risiko
Die Gefahr liegt nicht in Eventual Consistency. Sie liegt darin, so zu tun, als gäbe es sie nicht.
Wer sein System für stark konsistent hält, entwirft keine Kompensationslogik. Wer keine Konflikte erwartet, baut keine Konfliktbehandlung. Wer keine veralteten Daten einplant, gestaltet keine Benutzererfahrung, die damit umgehen kann. Und wenn dann die Race Condition doch eintritt, wenn der Cache im falschen Moment veraltete Daten liefert, wenn die Replica-Verzögerung zu einer sichtbaren Inkonsistenz führt, gibt es keinen Plan. Das System versagt auf eine Weise, die niemand vorhergesehen hat, weil sich niemand die Mühe gemacht hat, sie vorherzusehen.
Wer Eventual Consistency dagegen anerkennt, entwirft dafür. Man denkt darüber nach, was passiert, wenn Daten veraltet sind. Man baut idempotente Operationen, die gefahrlos wiederholt werden können. Man schafft Kompensationsmechanismen für den Fall, dass etwas schiefgeht. Man kommuniziert Unsicherheit gegenüber Nutzerinnen und Nutzern, statt falsche Sicherheit zu vermitteln.
In der Praxis bedeutet das konkrete Entwurfsentscheidungen. Statt „Bestellung erfolgreich“ anzuzeigen, wenn die Bestellung lediglich angenommen wurde, zeigt man „Bestellung wird verarbeitet“ und aktualisiert den Status, sobald die Verarbeitung abgeschlossen ist. Statt eine Schaltfläche nach dem Klick zu deaktivieren und auf Konsistenz zu hoffen, gestaltet man die Operation idempotent, sodass ein doppelter Klick keinen Schaden anrichtet. Statt einen Fehler zu zeigen, wenn ein Artikel zwischen Warenkorb und Checkout vergriffen ist, bietet man eine Alternative an. Das sind keine technischen Notlösungen. Das sind durchdachte Benutzererlebnisse, die auf einer ehrlichen Einschätzung der Systemrealität basieren.
Die deutsche Fehlübersetzung ist dabei versehentlich tiefgründig. „Eventuell konsistent“ klingt bedrohlich, weil Unsicherheit bedrohlich klingt. Aber Unsicherheit ist die Realität verteilter Systeme. Die Wahl besteht nicht zwischen Sicherheit und Unsicherheit. Sie besteht zwischen eingestandener und versteckter Unsicherheit. Das eine führt zu robusten Systemen. Das andere führt zu Überraschungen.
Eventual Consistency ist keine Einschränkung, die es zu überwinden gilt. Sie ist eine Realität, für die es zu entwerfen gilt. Ihre Systeme sind bereits eventually consistent. Die Frage ist, ob Sie für diese Realität entwerfen oder so tun, als existiere sie nicht. Und diese Frage ist keine, die ein Engineering-Team allein beantworten sollte. Sie ist eine fachliche Entscheidung. Das war sie schon immer.
(rme)
Entwicklung & Code
Programmiersprache C++: Was reinterpret_cast nicht tut
Im heutigen Beitrag werde ich eine der größten Fallstricke von C++ erläutern: reinterpret_cast. Ein anderer Titel für diesen Beitrag könnte lauten: „Das ist nicht der Cast, den du suchst!“
Weiterlesen nach der Anzeige

Andreas Fertig ist erfahrener C++-Trainer und Berater, der weltweit Präsenz- sowie Remote-Kurse anbietet. Er engagiert sich im C++-Standardisierungskomitee und spricht regelmäßig auf internationalen Konferenzen. Mit C++ Insights ( hat er ein international anerkanntes Tool entwickelt, das C++-Programmierenden hilft, C++ noch besser zu verstehen.
Meine Motivation für diesen Blogbeitrag stammt aus mehreren Schulungen und einigen Vorträgen, die ich gehalten habe. Seit C++23 gibt es in der Standardbibliothek eine neue Funktion: std::start_lifetime_as. Wenn ich Kurse mit Schwerpunkt auf eingebetteten Umgebungen unterrichte oder Vorträge mit diesem Schwerpunkt halte, habe ich begonnen, std::start_lifetime_as in das Material aufzunehmen. Mit einem interessanten Ergebnis.
Das Feedback, das ich bekomme, lautet in etwa:
- Warum benötige ich
std::start_lifetime_as, ich habe doch schonreinterpret_cast? - Warum kann ich
reinterpret_castnicht verwenden?
Wer noch nie von start_lifetime_as gehört hat, findet weitere Informationen in meinem englischen Artikel „The correct way to do type punning in C++ – The second act“. Ich verwende folgendes Beispiel daraus:
struct ConfigValues {
uint32_t chksum;
std::array values;
};
bool ProcessData(std::span bytes)
{
if(bytes.size() < sizeof(ConfigValues)) { return false; }
// #A
ConfigValues* cfgValues = reinterpret_cast(bytes.data());
return HandleConfigValues(cfgValues);
}
Die Idee hier ist, eine Reihe von rohen Bytes in eine bekannte Struktur umzuwandeln – hier mit dem Namen ConfigValues. Zusammen mit start_lifetime_as gerate ich immer öfter in Gespräche, in denen mir Leute sagen, dass der Name reinterpret impliziert, dass solcher Code wie erwartet funktionieren sollte. Die Erwartung ist, dass solcher Code frei von undefiniertem Verhalten ist und tatsächlich einen Zeiger auf ein ConfigValues-Objekt zurückgibt.
Weiterlesen nach der Anzeige
Zwar kann ich einer solchen Erwartung aufgrund des Wortlauts des Standards und des C++-Objektmodells nicht widersprechen, doch eine solche Erwartung führt zu undefiniertem Verhalten. In einer typsicheren Sprache kann ein Objekt nicht in ein anderes, nicht verwandtes Objekt konvertiert werden.
Der wichtigste Wortlaut ist [expr.reinterpret.cast § 7], der besagt:
An object pointer can be explicitly converted to an object pointer of a different type. When a prvalue v of object pointer type is converted to the object pointer type “pointer to cv T”, the result is static_cast
Zunächst einmal handelt dieser ganze Absatz von Zeigern auf Objekte und nicht von Objekten selbst. Es heißt, dass du ein ConfigValues in einen void* oder einen beliebigen anderen Datentyp konvertieren kannst, der ein Objekttyp ist. Ein Objekttyp ist alles außer einem Funktionstyp, einem Referenztyp und void.
Weiter unten in der Anmerkung bestätigt der Standard ausdrücklich, dass du einen Rundlauf durchführen kannst. Zum Beispiel:
ConfigValues cfg{};
ConfigValues* val{&cfg};
void* typeErased = reinterpret_cast(val);
ConfigValues* roundTripBackToVal = reinterpret_cast(typeErased);
Dies ermöglicht Konstrukte, die sogenannte Typlöschung (Type Erasure) nutzen, wie std::any. Du kannst einen Alias eines anderen Zeigertyps erhalten.
Konvertierung nur für den Zeiger
In diesem Absatz ist von einer Konvertierung des Objekts selbst keine Rede. Nur den Zeiger kann man konvertieren.
Im Sinne des C++-Objektmodells muss eine Anwendung ein gültiges Objekt erstellen (und später zerstören). Aber alles, was jemals erstellt wurde, ist ein ConfigValues-Objekt. reinterpret_cast ist ein Werkzeug, das es ermöglicht, einen Zeiger eines anderen Typs zu speichern. Sobald du ihn verwenden möchtest, musst du den Zeiger wieder in seinen ursprünglichen Typ zurückkonvertieren.
Nehmen wir einmal an, reinterpret_cast würde so funktionieren, wie manche Leute es erwarten:
struct Apple {
int x;
};
struct Orange {
int y;
};
Apple* grannySmith{new Apple{4}};
Orange* bali{reinterpret_cast(grannySmith)}; // #A
int y = bali->y;
int x = grannySmith->x;
Nach den Regeln von C++ muss ein Objekt erstellt und zerstört werden. Wenn #A ein Objekt erstellen würde, müsste es das grannySmith-Objekt zerstören. Was überraschend wäre. Dann hättest du keine Möglichkeit, eine Typlöschung wie std::any zu implementieren, da das Speichern eines gelöschten Typs void* das ursprüngliche Objekt aus Sicht der abstrakten Maschinerie von C++ zerstören würde. Das würde dem Compiler ermöglichen, verschiedene andere Optimierungen vorzunehmen, die das Programm zum Absturz bringen würden.
Mit reinterpret_cast hast du eine Möglichkeit, ein Objekt A als einen anderen Typ B zu aliasieren, jedoch ohne das Recht, jemals über diesen Zeiger auf ein B-Objekt zuzugreifen. Andererseits erstellt start_lifetime_as implizit ein B-Objekt am Zielort des Zeigers A, während gleichzeitig die Lebensdauer von A beendet wird.
Ein Objekt ins Leben rufen
Meist will man in diesen Situationen ein Objekt eines anderen Typs zum Leben erwecken. Und genau dafür ist std::start_lifetime_as gedacht.
Wenn du std::start_lifetime_as auf einen Zeiger anwendest, versteht die abstrakte Maschine, dass du ein neues Objekt dieses Typs erstellst. Im Gegensatz zu einem Aufruf von new oder einem Stack-Objekt wird kein Konstruktor ausgeführt. Alles geschieht nur innerhalb des C++-Objektmodells.
Es gibt noch eine weitere Funktion von std::start_lifetime_as: Wenn es die Lebensdauer eines neuen Objekts startet, wird die Lebensdauer der Quelle automatisch beendet, wiederum ohne einen tatsächlichen Destruktor aufzurufen. Das ist hier entscheidend.
Wenn ich std::start_lifetime_as auf mein vorheriges Beispiel anwende, sieht die korrekte Implementierung wie folgt aus:
struct Apple {
int x;
};
struct Orange {
int y;
};
Apple* grannySmith{new Apple{4}};
Orange* bali{std::start_lifetime_as(grannySmith)}; // #A
int y = bali->y;
grannySmith = std::start_lifetime_as(bali); // #B
int x = grannySmith->x;
Der Code in #B startet die Lebensdauer des Zeigers erneut als Apple-Objekt.
Wichtigste Erkenntnisse
Mit reinterpret_cast erhältst du nur eine Zeigerkonvertierung. Du darfst diesen neuen Zeiger nicht verwenden, um auf ein Objekt des Typs zuzugreifen.
Wenn du die Lebensdauer eines Objekts starten möchtest, um auf Daten als neuen Typ zuzugreifen, benötigst du std::start_lifetime_as.
(rme)

Googles March 2026 Core Update ist vorbei: Erste Auswirkungen

Design-Erneuerung: Warum Microsoft die Systemsteuerung in Windows 11 nicht los wird

Ausgerechnet jetzt: Sündteure 8-Terabyte-Version der Samsung SSD 870 Evo

Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast

Community Management zwischen Reichweite und Verantwortung
-
Künstliche Intelligenzvor 2 Monaten
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-
 Social Mediavor 1 Monat
Social Mediavor 1 MonatCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenCommunity Management zwischen Reichweite und Verantwortung
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenEindrucksvolle neue Identity für White Ribbon › PAGE online
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonateneHealth: iOS‑App zeigt Störungen in der Telematikinfrastruktur
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenCommunity-Protest erfolgreich: Galera bleibt Open Source in MariaDB
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommentar: Entwickler, wacht auf – oder verliert euren Job
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenInterview: Massiver Anstieg der AU‑Fälle nicht durch die Telefon‑AU erklärbar
