Datenschutz & Sicherheit
Biometrische Gangerkennung: Zeige mir, wie du gehst, und ich sage dir, wer du bist
Biometrische Gangerkennung soll Menschen aus der Ferne identifizieren können, selbst wenn sie ihr Gesicht verhüllen. Unser Überblick zeigt, wie die Technologie funktioniert und wo sie bereits eingesetzt wird. Menschenrechtler*innen fordern ein Verbot.

Unser Gang ist besonders. Wir unterscheiden uns zum Beispiel darin, wie wir unsere Füße aufsetzen, unsere Arme beim Gehen schlenkern lassen oder wie lange unsere Schritte dauern. Solche Merkmale sind individuell und potenziell auch verräterisch, denn sie werden wie beiläufig bei der Videoüberwachung mit aufgezeichnet. Und anders als bei der biometrischen Gesichtserkennung kann man nicht einfach eine Maske aufsetzen, um den eigenen Gang zu verschleiern.
Wenn man Menschen auch von Weitem anhand ihrer Körpermerkmale erkennt, nennt man das biometrische Fernidentifizierung. In der öffentlichen Debatte darüber geht es meist um Gesichtserkennung. Dabei gibt es noch weitere Möglichkeiten, Menschen biometrisch zu erkennen. Eine solche Methode ist die biometrische Gangerkennung.
Verboten ist der Einsatz der Technologie in der EU nicht, im Gegenteil. Dort, wo die KI-Verordnung (AI Act) den Staaten Spielraum für biometrische Gesichtserkennung lässt, können Behörden auch andere biometrische Technologien einsetzen – auch wenn darüber selten diskutiert wird.
Dieser Artikel erklärt, was Gangerkennung bereits kann, und wo sie schon angewandt wird. Die Organisationen Amnesty International und AlgorithmWatch warnen vor der Technologie – die beispielsweise die Polizei bereits auf dem Schirm hat. Und im Auftrag der Europäischen Union erkunden Forscher*innen in Österreich ihren Einsatz an der EU-Grenze.
- Wie funktioniert Gangerkennung?
- Wie korrekt ist Gangerkennung?
- Deutschland: Polizei bildet sich zu Gangerkennung weiter
- Deutschland: Erkennung gehender Personen im Supermarkt
- EU: Forschung an Gangerkennung für die Grenze
- China und Russland: Gangerkennung über 50 Meter Entfernung
- Grundrechte in Gefahr: Menschenrechtler*innen fordern Verbot
Wie funktioniert Gangerkennung?
Auch Menschen können andere Personen anhand ihres Gang identifizieren. Unter anderem in Großbritannien werden dafür Sachverständige vor Gerichte geladen, um etwa die Identität eines Tatverdächtigen festzumachen. Einer Studie über diese forensische Gangerkennung aus dem Jahr 2018 zufolge würden solche Gang-Expert*innen allerdings noch wenig mit Software arbeiten.
Inzwischen gibt es zunehmend technisch gestützte Methoden für Gangerkennung, die gemeinhin als „KI“ bezeichnet werden. Einer der Menschen, der dazu forscht, ist Simon Hanisch. „Gangerkennung funktioniert mittlerweile sehr gut mithilfe von Deep Learning und Objekterkennung“, erklärt der Forscher, der am Karlsruher Institut für Technologie zur Anonymisierung biometrischer Daten arbeitet.
Im Gespräch mit netzpolitik.org beschreibt er eine Art, wie Gangerkennung per Software heutzutage funktionieren kann: Zuerst zerlegt die Software das Video einer laufenden Person in einzelne Frames, also Momentaufnahmen. So lassen sich etwa die Phasen eines Schritts nachvollziehen, die Bewegungen von Armen und Beinen. Danach stellt die Software die Umrisse der Person frei. Sie sieht dann so ähnlich aus wie ein Ampelmännchen. Schließlich legt die Software die Umrisse aus mehreren Frames in Graustufen übereinander. Das sieht dann aus wie ein Ampelmännchen mit vielen Armen und Beinen.
Auf diese Weise sollen möglichst einzigartige Profile entstehen, anhand derer sich Menschen voneinander unterscheiden lassen – und wiedererkennen.
Wie korrekt ist Gangerkennung?
Zu Gangerkennung sind in den vergangenen Jahren viele Studien erschienen. Sie beschreiben mehrere Verfahren, die verschieden genau sind. Manche Forschende verweisen auf äußere Faktoren, die Einfluss auf unseren Gang haben und deshalb die Wiedererkennung erschweren würden. Zum Beispiel könnten Schuhe, die Beschaffenheit des Bodens oder Taschen das Gangprofil verändern.
So stellten auch die Autor*innen der oben erwähnten Studie zur forensischen Gangerkennung fest: Der Beweiswert eines menschlichen Gang-Gutachtens vor Gericht sei relativ niedrig. Das war jedoch im Jahr 2018. Mittlerweile sind die technischen Mittel ausgereift genug, um Personen auch trotz sich ändernder Bedingungen zu identifizieren, wie Simon Hanisch erklärt. Die Software könnte auch Veränderungen des Gangs einbeziehen.
Eine KI ist jedoch nur so gut wie die Daten, mit denen sie trainiert wurde. „Für das Training benötigt man viele Daten“, sagt Hanisch, „die entsprechenden Datensätze gibt es aber heute schon“. Um nur eine einzelne Person anhand ihres Gangs über mehrere Überwachungskameras hinweg zu verfolgen, brauche es nicht sehr viele Daten, so der Forscher. Zur Identifikation würden bereits einige Beispiele genügen, die zeigen, wie diese Person geht.
Anders sehe es aus, wenn eine beliebige Person in einem Video eindeutig identifiziert werden soll, erklärt Hanisch. Dafür „wäre eine große Datenbank erforderlich, in der Gangbeispiele aller Personen vorhanden sind – analog zu einer Datenbank mit Gesichtsbildern oder Fingerabdrücken.“ Im Moment gibt es allerdings keine Anzeichen dafür, dass in Deutschland größere Datenbanken mit biometrischen Gangprofilen existieren.
Eine wichtige Komponente könne auch die Zeitspanne sein. Wie verändert sich der Gang eines Menschen über Jahrzehnte? Es gibt „noch nicht genug Forschung, um sagen zu können, wie gut die Gangerkennung über die Zeit funktioniert“, sagt Hanisch. „Wahrscheinlich wird es einen großen Einfluss haben; allerdings sind mir keine Studien bekannt, die das wirklich gut untersucht haben.“
Für eine realistische Anwendung von Gangerkennung brauche es noch mehr Forschung. „Meiner allgemeinen Vermutung nach würde die Gangerkennung in einem realistischen Setting außerhalb des Labors wahrscheinlich eher mäßig gut funktionieren.“
Trotzdem warnt Hanisch vor der Technologie: „Man sollte nicht vergessen, dass sich biometrische Merkmale kombinieren lassen, um bessere Ergebnisse zu erzielen, beispielsweise Gangerkennung mit Gesichtserkennung.“ Das Potenzial für staatliche Überwachung sieht Hanisch durchaus. Besonders sei es für Behörden vorteilhaft, Gangerkennung einzusetzen, weil „man seinen Gang nur schwer verstecken kann“.
Deutschland: Polizei bildet sich zu Gangerkennung weiter
Wir haben bei deutschen Polizeibehörden nachgefragt, ob sie biometrische Gangerkennung einsetzen oder sich zumindest damit beschäftigen. Die Landeskriminalämter (LKAs) aus 16 Bundesländern sowie das Bundeskriminalamt (BKA) haben den Einsatz computergestützter biometrischer Gangerkennung verneint.
Laut der Pressestelle des LKA Hessen „fehlt es an einer Datenbank, gegen die ein solches System Daten abgleichen könnte“. Gangerkennung hätten die Beamt*innen in Hessen allerdings auf dem Schirm. „Denkbar wären 1:1 Vergleiche, beispielsweise den Gang einer unbekannten Person mit dem Gang einer bekannten Person abzugleichen“, schreibt die Pressestelle. Dies könne „als Sachbeweis in einem laufenden Ermittlungsverfahren herangezogen werden“.
Das LKA Berlin hat sich ebenso mit Gangerkennung beschäftigt, allerdings nicht computerbasiert. Stattdessen würden Gutachten des kriminaltechnischen Instituts (KTI) des LKA Berlin „nach der Methode der beobachtenden Gangbildanalyse erstellt, wie sie auch in der Medizin und der Sportwissenschaft angewandt wird“. Auch das LKA Rheinland-Pfalz wende sich für solche Gutachten an das LKA Berlin.
Das LKA Saarland hat sich nach eigenen Angaben bereits mit biometrischer Gangerkennung beschäftigt, und zwar im Rahmen einer Fortbildung durch das BKA. Das BKA wiederum teilt mit, die angesprochene Fortbildung sei eine Online-Vortragsreihe der Deutschen Hochschule der Polizei gewesen. Dort habe man Vertreter*innen der Polizeien von Bund und Ländern über aktuelle Entwicklungen in der Kriminaltechnik informiert.
Deutschland: Erkennung gehender Personen im Supermarkt
Gangerkennung findet wohl auch Verwendung in der freien Wirtschaft. Bereits 2024 berichtete netzpolitik.org von einem Rewe-Supermarkt in Berlin, der seine Besucher*innen mit hunderten Überwachungskameras durch den Laden verfolgt, die mitgenommenen Waren erkennt und dann an der Kasse abrechnet. Dabei arbeitet Rewe mit der israelischen Firma Trigo zusammen, die es sich zur Mission gemacht hat, den Einzelhandel mit sogenannter KI zu optimieren.
Im Rewe-Supermarkt soll es allerdings keine Gesichtserkennung geben, wie Rewe und Trigo betonten. Stattdessen würden Kameras die schematische Darstellung des Knochenbaus der Besucher*innen erfassen, um sie voneinander zu unterscheiden. Auch das kann eine Form biometrischer Gangerkennung sein, wie sie etwa in einer Studie der TU München beschrieben wird. Demnach könne Gangerkennung per Skelettmodell sogar besser funktionieren als über die Silhouette. Die Strichmännchen mit Knotenpunkten an den Gelenken aus der Münchner Studie ähneln optisch dem Pressematerial von Trigo.

Auf Anfrage von netzpolitik.org verneint Trigo allerdings den Einsatz von Gangerkennung: „Unser System unterscheidet zwischen Käufer*innen mittels computerbasiertem Sehen (‚computer vision‘)“, schreibt die Pressestelle. „Aus wettbewerbstechnischen Gründen können wir nicht tiefer auf technologische Details eingehen, aber wir nutzen keine Gangerkennung oder biometrische Identifikation.“
Ohne die technologischen Details, die Trigo vorenthält, lässt sich die Technologie nicht abschließend bewerten. Bereits 2024 hatten wir den Biometrie-Experten Jan Krissler (alias starbug) um eine Einschätzung gebeten. Er sagte mit Blick auf Trigo: „Körpermerkmale erfassen ist der Inbegriff von Biometrie – und das passiert hier.“
Die Technologie, deren Details das Unternehmen geheimhalten will, wird nach Angaben von Trigo schon in mehreren europäischen Länder eingesetzt. Wo genau? Auch hierzu verweigert die Pressestelle eine Antwort, wieder mit Verweis auf Wettbewerber*innen.
EU: Forschung an Gangerkennung für die Grenze
Die EU erforscht den Einsatz von Gangerkennung an der Grenze, Projektname: PopEye. Das Projekt läuft von Oktober 2024 bis September 2027. Auf der Projektwebsite gibt es beim Klick auf „Ergebnisse“ noch nichts zu sehen. In der dazugehörigen Beschreibung heißt es auf Englisch: „Das von der EU geförderte Projekt PopEye zielt darauf ab, die Sicherheit an den EU-Grenzen durch den Einsatz fortschrittlicher biometrischer Technologien zur Identitätsüberprüfung in Bewegung zu erhöhen“. Eine dieser Technologien ist Gangerkennung.
Die Grenzagentur Frontex listet PopEye als eines von mehreren Forschungsprojekten auf der eigenen Website auf. Bereits 2022 hatte Frontex Gangerkennung in einer Studie über biometrische Technologien beschrieben. Demnach benötige Gangerkennung „keine Kooperation der betreffenden Person und kann aus mittlerer Entfernung zum Subjekt funktionieren“. In der Studie schätzt Frontex: Bis biometrische Gangerkennung im Alltag ankommt, würden noch mindestens zehn Jahre vergehen.
Frontex ist auch an illegalen Pushbacks beteiligt. Das heißt, Beamt*innen verhindern, dass schutzsuchende Menschen an der EU-Grenze Hilfe bekommen. Auf Anfrage von netzpolitik.org will sich Frontex nicht zu PopEye äußern und verweist auf das AIT, das Austrian Institute of Technology. Das Institut aus Österreich koordiniert das Projekt im Auftrag der EU.
Das AIT wiederum erklärt auf Anfrage, selbst nicht im Bereich Gangerkennung zu arbeiten. Allerdings sei Gangerkennung eines von mehreren biometrischen Verfahren, die im Rahmen von PopEye erforscht würden. In dem Projekt würden biometrische Methoden entwickelt, die auch dann funktionieren, wenn sich eine Person bewegt und etwas entfernt ist. Kurzum: Man will Menschen identifizieren können, auch wenn sie gerade nicht aktiv ihr Gesicht vor eine Kamera halten oder ihren Finger auf einen Sensor legen. Das könne etwa die Wartezeit von Reisenden verkürzen, so das AIT.
Weiter erklärt das AIT, man wolle die Technologie verstehen, ihre Einschränkungen und Risiken. Ohne, dass wir ausdrücklich danach gefragt hätten, betont das AIT mehrfach, nichts Verbotenes zu tun. „Wir verpflichten uns, alle geltenden Vorschriften einzuhalten und die Werte der EU sowie die Grundrechte zu fördern und zu wahren.“ Sollte das nicht selbstverständlich sein?
Die gemeinnützige Organisation AlgorithmWatch kritisiert Gangerkennung an der Grenze, gerade mit Blick auf einen möglichen Einsatz bei Geflüchteten. „Wie so häufig wird also die Entwicklung digitaler Überwachungstools an Menschen auf der Flucht getestet, die sich kaum dagegen wehren können“, schreibt Referentin Pia Sombetzki auf Anfrage.
China und Russland: Gangerkennung über 50 Meter Entfernung
Die chinesische Regierung treibt Forschung zu Gangerkennung voran. Einer der größeren Datensätze mit Gangprofilen ist Gait3D, der auf Videodaten aus einem Supermarkt basiert. Das im Jahr 2022 veröffentliche Projekt hat China mit staatlichen Mitteln gefördert.
Nach Berichten der Agentur AP News soll China bereits 2018 Überwachung per Gangerkennung eingeführt haben, und zwar durch Polizeibehörden in Beijing und Shanghai. Die Technologie komme von der chinesischen Überwachungsfirma Watrix. Nach Angaben des CEOs gegenüber AP News könne das System Personen aus bis zu 50 Metern Entfernung identifizieren. Das System lasse sich angeblich nicht täuschen, etwa durch Humpeln.
In einer Spiegel-Reportage aus dem Jahr 2019 erklärte eine Pressesprecherin von Watrix, das System würde weitere Informationen nutzen, um Menschen zu identifizieren, etwa Körpergröße und Statur. Angeblich erkenne die Software Menschen in einer Sekunde. „Zwei Schritte reichen.“ Auch in Gruppen von bis zu 100 Leuten könne die Software Menschen erkennen, deren Gangprofil dem System bekannt sei. Es ist üblich, dass Überwachungsfirmen die Fähigkeiten ihrer Produkte überhöhen. Auf unsere Fragen hat Watrix nicht reagiert.
Auch das russische Regime soll biometrische Gangerkennung einsetzen. Im Jahr 2020 berichtete das russische Exilmedium Meduza von entsprechenden Plänen für das Folgejahr. Die Technologie sollte demnach Teil der staatlichen Kameraüberwachung in Moskau werden. Im Jahr 2021 schreib das staatliche Propaganda-Medium Rossiyskaya Gazeta von einem solchen Überwachungssystem im Auftrag des Innenministeriums. Angeblich könne die Gangerkennung eine Person aus einer Entfernung von bis zu 50 Metern identifizieren. Es fehlt allerdings eine unabhängige Prüfung, um festzustellen, viel davon Einschüchterung ist und wie viel korrekt.
Grundrechte in Gefahr: Menschenrechtler*innen fordern Verbot
Menschenrechtsorganisationen betrachten Gangerkennung schon länger kritisch. Privacy International warnte bereits 2021 vor den Gefahren von Gangerkennung bei Protesten. Auch Amnesty International beschäftigt sich damit. Gangerkennung funktioniere aus der Ferne und bleibe dadurch unbemerkt, schreibt Lena Rohrbach auf Anfrage von netzpolitik.org. Sie ist Referentin für Menschenrechte im digitalen Zeitalter bei Amnesty International in Deutschland.
Behörden könnten Gangerkennung etwa ergänzend zu Gesichtserkennung einsetzen, um Menschen auch auf Distanz zu identifizieren. „Überwachung durch Gangerkennung ist ein tiefgreifender Eingriff in Menschenrechte und geht mit umfassenden Risiken einher“, warnt Rohrbach. „Jede Form biometrischer Fernidentifizierung ist potenziell geeignet, zur Repression genutzt zu werden und die freie und unbeobachtete Bewegung im öffentlichen Raum vollständig zu beenden.“
Amnesty International setze sich deshalb für ein umfassendes Verbot biometrischer Fernidentifizierung zur Überwachung des öffentlichen Raums ein – inklusive Gangerkennung. Die EU hat die Gelegenheit verpasst, ein solches Verbot im Rahmen der KI-Verordnung zu beschließen.
In Deutschland befasst sich die Organisation AlgorithmWatch mit den Auswirkungen sogenannter KI auf Menschenrechte. Auf Anfrage vergleicht Referentin Pia Sombetzki Gangerkennung mit Gesichtserkennung. „Die Anonymität im öffentlichen Raum wird effektiv aufgehoben, und Menschen dürften es sich tendenziell eher zweimal überlegen, an welcher Versammlung sie noch teilnehmen“, schreibt sie. Neben Demonstrierenden könnten zum Beispiel auch Obdachlose oder Suchtkranke beobachtet werden.
Das Problem betreffe grundsätzlich alle, die sich in der Öffentlichkeit frei bewegen wollten. Rufe nach mehr KI in der Polizeiarbeit könnten in eine Sackgasse führen, warnt Sombetzki. „Denn je mehr die Freiheitsrechte auch hierzulande eingeschränkt werden, desto weniger bleibt von der demokratischen Gesellschaft übrig, die es eigentlich zu schützen gilt.“
Die Arbeit von netzpolitik.org finanziert sich zu fast 100% aus den Spenden unserer Leser:innen.
Werde Teil dieser einzigartigen Community und unterstütze auch Du unseren gemeinwohlorientierten, werbe- und trackingfreien Journalismus jetzt mit einer Spende.












Datenschutz & Sicherheit
Die Mehrheit folgt dem Hype nicht
Ich öffne mein Bahn-Ticket. “Dieses Dokument scheint lang zu sein. Spare Zeit und lies eine Zusammenfassung”, empfiehlt mir prompt mein PDF-Reader. Ein Paradebeispiel dafür, wie immer mehr Anwendungen den Nutzer*innen KI-Tools aufdrängen, in den meisten Fällen, ohne dass sich ein Nutzen daraus ergibt.
Weltweit versuchen Regierungen und große IT-Firmen, sich im KI-Wettbewerb zu überbieten. Dabei benötigen die zugrunde liegenden Systeme immer mehr Rechenleistung, für die irgendwo Computer laufen müssen, die Strom und Wasser verbrauchen. Doch während das Thema Rechenzentren längst in der politischen Debatte und bei Fachleuten angekommen ist, wusste man bislang kaum etwas darüber, wie die Bevölkerung diese Entwicklung einschätzt.

Aus diesem Grund hat AlgorithmWatch in mehreren europäischen Ländern eine repräsentative Umfrage zu Rechenzentren und ihren Auswirkungen durchführen lassen. Gemeinsam mit internationalen Partnerorganisationen wie der spanischen Initiative Tu Nube Seca mi Rio, Friends of the Earth Ireland und der europäischen Klimaschutzallianz Beyond Fossil Fuels wurden Menschen in Deutschland, der Schweiz, Spanien, Irland und dem Vereinigen Königreich befragt.
Wunsch nach mehr Transparenz und mehr Regulierung
Die Ergebnisse sind überraschend deutlich: In allen beteiligten Ländern spricht sich jeweils eine große Mehrheit der Befragten für eine stärkere Regulierung und mehr Transparenz von Rechenzentren aus. In einigen Ländern ist die Zustimmung dabei besonders hoch, so zum Beispiel in Spanien und Irland. Dort ist der Wasser- beziehungsweise Stromverbrauch der KI- und Cloud-Fabriken schon länger Gegenstand öffentlicher Diskussionen und Proteste. Denn sowohl im grünen Irland als auch im trockenen Spanien wirken sich die Rechenzentren bereits spürbar auf Energiepreise und Wasserverfügbarkeit aus. In Spanien befürchten knapp 90 Prozent der Befragten, dass der Wasserverbrauch der Einrichtungen ihre eigene Versorgung beeinträchtigen könnten.
Auch beim Blick auf die Gesamtergebnisse sprechen die Zahlen eine eindeutige Sprache: Drei Viertel der Befragten aller Länder sorgen sich, dass der Wasserverbrauch die umliegenden Ökosysteme beeinträchtigen könnte. Fast genauso viele befürchten Auswirkungen auf den eigenen Wasserverbrauch und immerhin nahezu zwei Drittel denken, dass der Energieverbrauch von Rechenzentren bereits heute einen relevanten Anteil des Stromverbrauchs in den jeweiligen Ländern ausmacht.
Groß ist aber nicht nur der Anteil derer, die sich Sorgen machen, sondern auch die Unterstützung für politische Forderungen, die Betreiber stärker in die Verantwortung nehmen. Mehr als sieben von zehn Befragten wollen, dass der Bau neuer Rechenzentren nur dann erlaubt ist, wenn der zusätzliche Strombedarf durch zusätzliche Kapazitäten an erneuerbaren Energien gedeckt wird. Ebenso viele wollen klare Kriterien, nach denen Energie verteilt wird – wobei die Befragten Rechenzentren und KI-Modelle konsequent als unwichtig bewerten.
Bei der Verteilung der Energie sollten gemäß der Umfrage vor allem die Sektoren priorisiert werden, die erneuerbare Energien zur Umstellung auf eine klimafreundliche Produktion benötigen. Rechenzentren gehören nicht dazu – ihr Stromverbrauch entsteht ja gerade zusätzlich. Häufig werden diese aktuell direkt mit Strom aus fossilen Brennstoffen betrieben. Vielerorts werden sogar Gaskraftwerke neu errichtet, um den Bedarf zu decken. Aber selbst wenn neue Rechenzentren mit erneuerbaren Energien betrieben werden, wie es in Deutschland ab 2027 für größere Einrichtungen vorgeschrieben ist, fehlt ohne weiteren Ausbau diese Energie dann in anderen Sektoren und verlangsamt dort die Dekarbonisierung. Ob direkt oder indirekt: Der Strombedarf für Rechenzentren und KI-Anwendungen gefährdet die Klimaziele.
Wir sind ein spendenfinanziertes Medium
Unterstütze auch Du unsere Arbeit mit einer Spende.
Verbräuche steigen an, verlässliche Zahlen fehlen
Der Blick auf die Zahlen zeigt: Die in der Umfrage deutlich werdenden Sorgen sind mehr als berechtigt. In Irland verbrauchen Rechenzentren mittlerweile 22 Prozent des gesamten Stroms und tragen erheblich zu den teils enormen Strompreissteigerungen bei. Auch in Deutschland entfallen aktuell mehr als vier Prozent des gesamten Stromverbrauchs auf Rechenzentren. Schätzungen zufolge sind es in Frankfurt am Main bereits jetzt 40 Prozent des Stromverbrauchs, in Dublin sogar 80 Prozent. In der gesamten EU sind es mehr als drei Prozent – Tendenz stark steigend.
Hinzu kommt das für die Kühlung benötigte Wasser: In Spanien werden die größten KI-Fabriken ausgerechnet in den trockensten Regionen gebaut. Auch in Deutschland könnte laut einer Studie der Gesellschaft für Informatik der Wasserverbrauch von Rechenzentren zu Problemen führen – beispielsweise im Rhein-Main-Gebiet und in Brandenburg.
Während die Politik und Betreiberunternehmen offensiv für einen starken Ausbau von Rechenzentren und KI-Infrastruktur werben, mehren sich die Proteste der lokalen Bevölkerung. In Deutschland konzentrieren sich diese bislang vor allem auf Frankfurt und Umgebung. In Irland oder Spanien, wo bereits länger protestiert wird, sind die Bürgerinitiativen weiter verbreitet und dauerhafter organisiert, beispielsweise in der Initiative Tu Nube Seca Mi Rio – “Deine Cloud trocknet meinen Fluss aus”.
Vielerorts ist die mangelnde Transparenz ein großes Problem. Selbst offizielle Stellen müssen größtenteils auf Schätzungen zurückgreifen, wie viel Wasser und Strom die Rechenzentren tatsächlich verbrauchen. Sind valide Daten vorhanden, bleiben diese meist geheim. Zwar sollen Betreiber größerer Rechenzentren die Verbräuche mittlerweile an nationale Stellen wie dem deutschen Energieeffizienzregister für Rechenzentren und die EU melden – aber auch diese Daten werden nur aggregiert veröffentlicht. Hinzu kommt der Unwillen der Betreiber, diese Informationen bereitzustellen. Ein aktueller Bericht der Europäischen Kommission schätzt für das Jahr 2024, dass nur gut ein Drittel aller Rechenzentren in der gesamten EU dies tun. Selbst die Gesamtzahl aller Rechenzentren kann sie dabei nur mutmaßen.
Ein ähnliches Bild zeigt sich auch in Deutschland
In der Bundesrepublik wird der Strom- und Wasserverbrauch von Rechenzentren erst in der jüngsten Zeit stärker thematisiert. Hier liegt der Anteil der Menschen, die sich Sorgen machen, noch etwas niedriger als in anderen europäischen Ländern. Die Betonung liegt hier auf dem „noch“, denn auch in Deutschland nimmt die Zahl der Rechenzentren stark zu – und soll nach dem Willen der Bundesregierung noch stärker wachsen.
Wie drastisch die Entwicklungen sind, zeigen beispielsweise die Zahlen der Bundesnetzagentur. Diese hatte erst vor kurzem die Schätzungen bezüglich des zukünftigen Stromverbrauchs stark nach oben korrigiert: Die im April 2025 veröffentlichten Szenarien gehen davon aus, dass bis zum Jahr 2037 Rechenzentren 78 bis 116 Terawattstunde (TWh) Strom verbrauchen – doppelt bis viermal so viel, wie es die ursprünglichen Abfragen ergeben hatten. Zur Einordnung: Der gesamte Bruttostromverbrauch lag in Deutschland im Jahr 2023 bei gut 550 TWh.
Da die Bundesnetzagentur nur die Rechenzentren berücksichtigt, die sich aktuell in der Planung befinden, könnten die tatsächlichen Zahlen sogar noch weiter ansteigen. Damit würde der Gesamtbedarf der Rechenzentren 2037 nicht nur bis zu 10 Prozent des deutschen Stromverbrauchs betragen. Der Zuwachs an Rechenzentren sorgt vor allem dafür, dass große Mengen Strom zusätzlich bereitgestellt werden müssen, dass fossile Kraftwerke länger laufen und dass wahrscheinlich auch die Strompreise steigen.
Angesichts dieser Zahlen überraschen die Umfrageergebnisse in Deutschland nicht: Auch hier unterstützen zwei Drittel der Befragten die Auflage, dass Rechenzentren nur gebaut werden dürfen, wenn dafür entsprechend auch weitere Kapazitäten erneuerbarer Energien geschaffen werden. Mehr als drei Viertel der Befragten fordern, dass Betreiber von Rechenzentren ihren Energieverbrauch (76 Prozent), ihre Energiequellen (77 Prozent) und ihre Umweltauswirkungen (81 Prozent) offenlegen.
Die Umfrageergebnisse offenbaren damit auch eine Kluft zwischen der Mehrheitsmeinung in der Bevölkerung und dem Kurs der Bundesregierung. Digitalminister Karsten Wildberger (CDU) hatte erst Ende September gegenüber der Süddeutschen Zeitung angegeben, dass es für ihn “erst einmal primär um das Rechnen” gehe und Nachhaltigkeit demgegenüber nachrangig sei. Die Mehrheit der Befragten sieht das offensichtlich anders.
Und noch eines wird deutlich: Es reicht nicht aus, nur etwas an der Effizienz zu schrauben oder die Nutzung der Abwärme zu optimieren. Angesichts der Größe des erwarteten Wachstums muss es auch darum gehen, den Verbrauch von Rechenzentren absolut zu begrenzen – und dort, wo er unvermeidbar ist, durch zusätzliche erneuerbare Energien zu decken.
KI-Hype begrenzen – Rechenzentren nachhaltig gestalten
Rechenzentren sind zweifelsfrei wichtige Infrastrukturen und werden in Zukunft weiter an Bedeutung gewinnen. Umso wichtiger ist es, diese Infrastruktur nachhaltig zu gestalten und die Fehler der Vergangenheit nicht zu wiederholen. Dazu gehört auch die Frage: Wie viele solcher Rechenzentren brauchen wir eigentlich? Welche der neuerdings überall eingebauten KI-Anwendungen haben einen gesellschaftlichen Nutzen – und welche nicht?
Wie auch in anderen Bereichen darf sich die Debatte um den nachhaltigen Einsatz von KI nicht in erster Linie auf der Ebene von individuellen Konsum- beziehungsweise Nutzungsentscheidungen abspielen. Es braucht vielmehr eine politische Diskussion und Regulierung.
Aktuell wird einem bei jeder noch so kleinen PDF-Datei eine algorithmische Zusammenfassung aufgedrängt, führt jede Google-Anfrage zum Aufruf von Sprachmodellen und soll auch die staatliche Verwaltung nach dem Willen der Bundesregierung an so vielen Stellen wie möglich KI-Systeme benutzen. Hier bringt es wenig, nur an das Individuum zu appellieren. Stattdessen braucht es politische Entscheidungen, die sowohl bei KI-Systemen als auch bei Rechenzentren die ökologischen Folgen mitdenken. Statt der „KI-Nation“, zu der sich Deutschland laut dem Koalitionsvertrag entwickeln soll, braucht es – wenn man schon von Nation sprechen will – eine „KI-sensible Nation“, die neben dem Nutzen auch die Nebenwirkungen und häufig leeren Versprechungen solcher Anwendungen im Auge behält.
Mein Bahnticket jedenfalls drucke ich mir weder aus, noch lasse ich es mir zusammenfassen. Gar nicht so selten ist der Nicht-Einsatz von KI nämlich ihr bester Einsatz.
Julian Bothe ist als Senior Policy Manager bei der gemeinnützigen NGO AlgorithmWatch verantwortlich für das Thema „KI und Klimaschutz“. An der Schnittstelle von Digital- und Energiepolitik arbeitet er daran, den Ressourcenverbrauch und den Klimaschaden des aktuellen KI-Booms in Grenzen zu halten. Promoviert hat er zur Akzeptanz der Energiewende.
Datenschutz & Sicherheit
Die Woche, in der die Bundesregierung ihre KI-Agenda hyped
Liebe Leser:innen,
Deutschland soll wieder „Innovationsführer“ werden. Das forderte Bundeskanzler Friedrich Merz am Mittwoch auf einer Auftaktveranstaltung zur Hightech Agenda Deutschland. Es ging dort viel um Aufbruch, Wettbewerbsfähigkeit und Wertschöpfung. Und um sogenannte Künstliche Intelligenz. Bis 2030 sollen zehn Prozent der deutschen Wirtschaftsleistung „KI-basiert“ erwirtschaftet werden.
All diese Buzzwords lassen mich etwas ratlos zurück. Ein solcher Event-Zirkus soll wohl vor allem Entschlossenheit und Tatkraft demonstrieren. Schaut her, wir krempeln die Ärmel hoch und packens an! Die Tagesschau ist auch vor Ort.
Dieses Mal wirkte das Schauspiel noch bizarrer als sonst. Denn alle Welt warnt derzeit vor einer wachsenden KI-Blase. Ökonom:innen ziehen Vergleiche zum Dotcom-Crash vor 25 Jahren. Es läuft wohl auf „eine reale, schmerzhafte Disruption“ für uns alle hinaus, schreibt der „Atlantic“. Doomsday is coming, wenn auch anders als gedacht.
Die Regierung verliert dazu kein Wort. Stattdessen will sie die Umsetzung der europäischen KI-Regulierung hinauszögern, wie meine Kollegin Anna Ströbele Romero schreibt. Sie gibt damit dem Druck der Industrieverbände nach. Alles für die angebliche Wettbewerbsfähigkeit – und zulasten der Verbraucher:innen.
Wenig überraschend interessiert Schwarz-Rot auch die ökologische Frage nur am Rande. Dabei ist der Ressourcenhunger von KI immens. Mancherorts wird bereits das Trinkwasser knapp, weil es KI-Rechenzentren kühlt. Tech-Konzerne reaktivieren stillgelegte Atomkraftwerke, selbst fossile Energieträger sind wieder stark gefragt.
Einer Mehrheit der Bevölkerung bereitet diese Rolle rückwärts offenbar große Sorgen, wie Julian Bothe von AlgorithmWatch für uns in einem Gastbeitrag darlegt. Die NGO hat dafür eine repräsentative Umfrage in mehreren europäischen Ländern durchführen lassen. Demnach wünscht sich eine Mehrheit auch strengere Regulierung beim Bau neuer Rechenzentren.
Statt zu bizarren KI-Events einzuladen wäre die Bundesregierung gut beraten, solchen Bedenken Gehör zu schenken.
Habt ein schönes Wochenende
Daniel
Datenschutz & Sicherheit
Docker Image Security – Teil 3: Minimale, sichere Container-Images selbst bauen
Minimale Container-Images verzichten auf Komponenten wie Shells oder Paketmanager, die zur Laufzeit normalerweise nicht gebraucht werden. Sie sind auch als „distroless“ oder „chiseled“ Images bekannt. Weil weniger Komponenten weniger Schwachstellen bedeuten, reduzieren diese Images die Angriffsfläche und erhöhen dadurch die Sicherheit.
Weiterlesen nach der Anzeige


Dr. Marius Shekow war über 10 Jahre als Forscher und Softwareentwickler bei Fraunhofer tätig. Seit 2022 ist er Lead DevOps- & Cloud-Engineer bei SprintEins in Bonn. Dort baut er für Konzerne und KMUs individuelle Cloud-Umgebungen, inkl. CI/CD-Automatisierung, Observability und Security-Absicherung.
Schlüsselfertige Images für ein Basis-Linux sowie die Sprachen PHP, Python, Java, C# und Node.js hat Teil 2 der Artikelserie vorgestellt. Diese vorkonfektionierten Images passen jedoch nicht immer zu den eigenen Anforderungen und es kann notwendig sein, eigene zu erstellen. Dieser Artikel zeigt, wie Softwareentwicklerinnen und -entwickler eigene minimale Images basierend auf den Angeboten Ubuntu Chiseled, Chainguard/WolfiOS und Azure Linux bauen (siehe die folgende Tabelle).
| Drei Anbieter minimaler Images im Vergleich | |||
| Bewertungskriterium | Ubuntu Chiseled | WolfiOS / Chainguard | Azure Linux |
| Verfügbare Pakete | ~500 | ~3000 | ~3000 |
| Qualität der Dokumentation / Schwierigkeit der Nutzung | ➕➕ | ➕➕➕ | ➕ |
| Integrationsgeschwindigkeit von Paket-Versionsupdates (Upstream) | Langsam | Schnell | Mittel |
| Reproduzierbare Image-Builds / Pinnen der zu installierenden Paket-Versionen | ❌ | ✅ | ❌ |
| Kommerzieller Support | ✅ | ✅ | ❌ |
Bauen von Ubuntu Chiseled Images
Canonical verwendet die Bezeichnung „Chiseled“ für minimale, Ubuntu-basierte Images. Ein Blogbeitrag stellt das Chisel-CLI von Ubuntu vor. Chisel ist ein Build-Tool, das Entwickler mit der gewünschten Ubuntu-Version (beispielsweise „24.04“) und einer Liste von „Slices“ aufrufen, die Chisel zu einem neuen Root-Filesystem zusammenbaut. Dieses Filesystem kopiert man anschließend in ein leeres scratch-Image, wie der Ablaufplan in Abbildung 1 verdeutlicht:
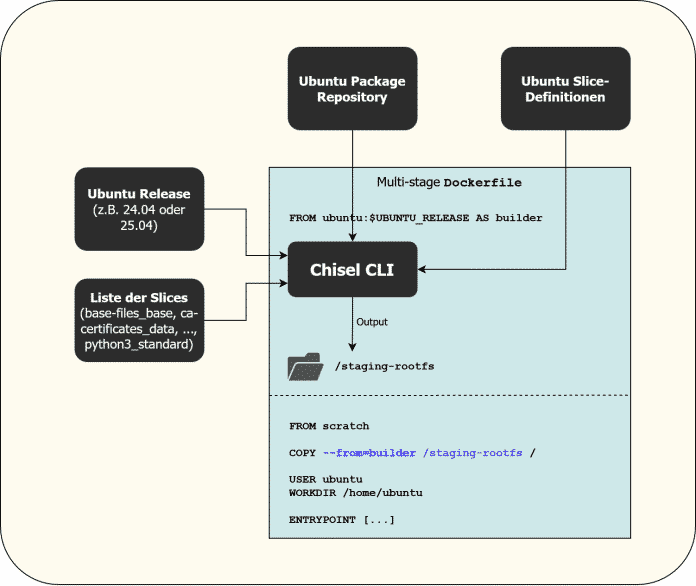
Bau eines Chiseled-Image via Multi-Stage Dockerfile (Abb.1)
Das Ubuntu-Team hat einige (jedoch nicht alle) der offiziellen Ubuntu-Pakete in mehrere Slices aufgeteilt und diese auf GitHub veröffentlicht. Falls Slices für ein gewünschtes Paket fehlen, sollte man auf andere im Artikel erwähnte Ansätze wechseln. Denn bestehende GitHub Issues zeigen, dass reine Feature-Requests lange oder gänzlich ignoriert werden, und der Zeitinvest für die Einarbeitung für eigene Pull Requests (PRs) hoch ist.
Weiterlesen nach der Anzeige
Aufbauend auf Chisel stellt Canonical zudem das Rockcraft-Tool zur Verfügung, das auf einer höheren Abstraktionsebene arbeitet.
Verwenden des Chisel CLI
Bevor Entwickler tiefer in den Build-Prozess von Ubuntu Chiseled-Images einsteigen, sollten sie sich der folgenden zwei Einschränkungen bewusst sein:
- Es lassen sich nur Pakete installieren, für die das Ubuntu-Team bereits Slice-Definitionen erstellt hat. Die Slices unterscheiden sich je nach Ubuntu-Version (beispielsweise hat 22.04 andere Slices als 24.04). Das ist insbesondere beim Erstellen eines Image für einen Interpreter einer Programmiersprache wie Java, Node.js oder Python relevant. Dabei stehen lediglich die in der jeweiligen Distro-Version mitgelieferten Interpreter-Versionen zur Verfügung. So gibt es bei Python im neuesten Ubuntu-LTS-Release (24.04) nur Python 3.12.3. Neuere 3.12-Versionen (oder 3.13) fehlen. Für Python 3.12.3 hat Ubuntu jedoch zumindest die seit dieser Version 3.12.3 bekannt gewordenen Schwachstellen behoben (sogenannte „Backports“).
- Es ist nicht möglich, die Versionen der Pakete oder Slices zu pinnen! Das Chisel CLI installiert immer die aktuelle Version des Pakets, die zum Zeitpunkt der Chisel-Ausführung im offiziellen Ubuntu-Repo verfügbar ist.
Der einfachste Weg, ein Chiseled-Image zu erstellen, ist ein Docker Multi-Stage Build. Wie man für ein Python-Image (mit Python 3.12.3) auf Basis von Ubuntu 24.04 vorgeht, erklärt das offizielle Chisel-Tutorial.
Da Schwachstellenscanner wie Trivy oder Grype die Pakete im frisch gebauten Image leider nicht korrekt identifizieren können, sind weitere Anpassungen am Dockerfile nötig. Der Grund dafür, warum die Scanner relevante Schwachstellen übersehen, geht aus einem GitHub Issue hervor: Ubuntu hat entschieden, für Chisel-Images ein eigenes proprietäres Paket-Manifest-Format zu erfinden, das Scanner wie Trivy bisher nicht verstehen.
Ubuntu versucht daher mit Scanner-Anbietern zusammenzuarbeiten, wie beispielsweise eine GitHub-Diskussion zu Trivy zeigt. Bis es so weit ist, können Entwickler einen Workaround nutzen: Das chisel-wrapper-Skript generiert Metadaten im Standard-Debian-Paket-Format, das Scanner wie Trivy verstehen. Dazu sind im Dockerfile des Multi-Stage-Builds (vom offiziellen Tutorial) folgende Änderungen vorzunehmen:
# Einfügen der folgenden 3 RUN-Zeilen, irgendwo vor dem "chisel cut" Befehl des Tutorials:
# "file" wird vom chisel-wrapper script benötigt
RUN apt-get update && apt-get install -y git file
RUN git clone --depth 1 -b main /rocks-toolbox && mv /rocks-toolbox/chisel-wrapper /usr/local/bin/ && rm -rf /rocks-toolbox
RUN mkdir -p /staging-rootfs/var/lib/dpkg
# Ersetzen der RUN-Zeile, die den "chisel cut" Befehl ausführt, mit folgender Zeile:
RUN chisel-wrapper --generate-dpkg-status /staging-rootfs/var/lib/dpkg/status -- --release "ubuntu-$UBUNTU_RELEASE" --root /staging-rootfs
Ein vollständiges Beispiel für Python 3 liegt im GitHub-Repository des Autors öffentlich parat. Es veranschaulicht den Build einer Flask-basierten Demo-Anwendung. Zudem demonstriert es, wie man ein Problem löst, das dadurch entsteht, dass der Python-Interpreter im Chiseled Basis-Image an einem anderen Pfad liegt als beim python-Image, das in der Build-Stage verwendet wird. Ein weiteres GitHub-Gist des Autors zeigt, wie man ein Chiseled Java JRE-Image erstellt und darin die Springboot-Petclinic-Anwendung ausführt.
Verwendung des Rockcraft CLIs
Ein weiterer Ansatz, Ubuntu Chiseled Images zu erstellen, ist das Rockcraft-CLI, das auf einer höheren Abstraktionsebene als Chisel arbeitet.
Rockcraft greift intern auf Chisel zurück, um das Root-Filesystem zu erstellen. Über eine von Rockcraft eingelesene YAML-Datei legt man deklarativ die folgenden Aspekte fest:
- Die Ubuntu-Version, deren Slices verwendet werden sollen
- Die Liste der zu installierenden Slices
- Die CPU-Architekturen, für die Rockcraft das Image erstellen soll (für Multiplattform-Builds)
- Welcher Nicht-Root-Linux-User erstellt und automatisch beim Image-Start verwendet werden soll
- Welche Linux-Services zum Image-Start mit dem Pebble Service-Manager gestartet werden sollen (Pebble ist eine Alternative zu systemd)
Mit Rockcraft erstellte, vorgefertigte Images lassen sich mit dem Suchbegriff „chisel“ in der Canonical GitHub-Organisation finden, beispielsweise:
Die größten Nachteile von Rockcraft sind:
- Rockcraft macht den Build-Prozess durch zusätzliches Tooling komplexer (verglichen mit einem direkten Chisel-CLI-Aufruf).
- Es erzwingt die Nutzung des Pebble Service Managers, der als
ENTRYPOINTfür das Image gesetzt wird. Dies ist unnötig, denn im Gegensatz zur Vorgehensweise bei virtuellen Maschinen (VMs) sind Service-Manager bei Containern nicht üblich. In diesen Umgebungen ist es gewollt, dass der gesamte Container beendet wird, wenn das imENTRYPOINTfestgelegte Programm abstürzt. Denn Container Runtimes wie Docker Compose oder Kubernetes überwachen den Container-Status und starten ihn dann neu. Zudem finden Schwachstellenscanner wie Trivy im Pebble-Binary häufig CVEs. Diese stellen zwar meistens keine Bedrohung dar, verursachen allerdings unnötigen Diagnose-Aufwand. - Die von Rockcraft generierten Images verwenden den chisel-wrapper-Trick für Schwachstellenscanner nicht. Folglich können diese die im Image installierten Komponenten nicht korrekt identifizieren und keine Schwachstellen melden.
Um sichere, minimale Images zu erstellen, ist es daher empfehlenswert, direkt das Chisel-CLI statt Rockcraft zu verwenden. Dennoch lohnt sich ein Blick in die stage-packages-Einträge der rockcraft.yaml-Dateien in den oben gelisteten Repositorys (beispielsweise für Python), um eine Idee dafür zu bekommen, welche Slices im eigenen Image sinnvoll sind.

China bestätigt Pause bei Kontrollen auf Seltene Erden, Forderung an die EU

Last Call: c’t-Webinar – Sprachmodelle verstehen statt nur verwenden

Samsung macht Kühlschrank-Displays zur Werbefläche

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenIllustrierte Reise nach New York City › PAGE online
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online