Künstliche Intelligenz
Gegen die Cookie-Banner-Flut: Erster „Einwilligungsagent“ geht an den Start
Surfen im Web gleicht für viele Nutzer einem Hindernislauf durch ein Dickicht aus Pop-ups und Klick-Labyrinthen. Wer seine Privatsphäre schützen will, muss sich oft mühsam durch kryptische Menüs für Cookies arbeiten. Wer nur schnell an Inhalten kommen will, klickt oft entnervt auf „Alle akzeptieren“ bei den Browser-Dateien. Diesem Zustand der „Einwilligungsmüdigkeit“ will die Berliner Legal-Tech-Firma Law & Innovation Technology nun ein Ende setzen. Vor wenigen Tagen hat das Unternehmen den „Consenter“ veröffentlicht: ein Werkzeug, das die Bundesdatenschutzbehörde als ersten Dienst zur Verwaltung von Cookie-Einwilligungen im Einklang mit den gesetzlichen Vorgaben offiziell anerkannt hat.
Weiterlesen nach der Anzeige
Der Startschuss erfolgte zunächst diskret: Die Projektverantwortlichen haben das Browser-Plugin im Rahmen eines sogenannten Silent Release verfügbar gemacht. Aktuell ist der Einwilligungsagent über einen speziellen, nicht öffentlich gelisteten Link im Chrome Store für Googles Browser zu finden. Doch dabei soll es nicht bleiben.
Während Versionen für Safari und Firefox bereits in der Pipeline sind, bereiten die Entwickler die große Bühne vor: Zur offiziellen Veröffentlichungsfeier am 26. Januar in Berlin soll der Dienst öffentlich gelistet und in den darauffolgenden Monaten sukzessive ausgebaut werden.
Consenter versteht sich als „Trust-Plattform“ mit dem Ziel, die digitale Selbstbestimmung aus der Theorie in die Praxis zu führen. Maximilian von Grafenstein, Professor für dieses Thema an der Universität der Künste Berlin (UdK) und Initiator des Projekts, sieht darin eine Brücke zwischen Endnutzern und Webseitenbetreibern.
Der Agent soll es ermöglichen, informierte Entscheidungen über die Datennutzung zentral zu verwalten, ohne dass bei jedem Seitenaufruf ein neues Banner den Lesefluss stört. Einmal in der Browser-Erweiterung festgelegt, werden die Präferenzen automatisch an die besuchten Webseiten übermittelt. Daraufhin verschwinden die lästigen Banner im Idealfall.
Eigener Consent-Banner nötig
Der Weg zur behördlichen Anerkennung war von regulatorischen Hürden geprägt. Von Grafenstein sagte heise medien, dass der Agent aktuell mit einem eigens entwickelten Cookie-Banner zusammenarbeiten müsse. Grund dafür sei eine Diskrepanz in der Rechtsauffassung: Während das höherrangige Recht im Paragraph 26 des Telekommunikation-Digitale-Dienste-Datenschutz-Gesetzes (TDDDG) vorschreibe, dass Webseiten solche Signale berücksichtigen müssten, habe das damalige Ministerium für Verkehr und Digitales in seiner Ausführungsverordnung die Freiwilligkeit betont.
Weiterlesen nach der Anzeige
Da klassische Consent Management Platforms (CMPs) die Signale kaum freiwillig implementieren, sah sich das Team gezwungen, eine eigene Lösung für die Betreiberseite zu bauen. Der Erfolg des Systems hängt daher massiv davon ab, dass nicht nur Nutzer die Browser-Extension installieren, sondern auch Webseitenbetreiber das entsprechende Banner implementieren.
Dabei bringt der Consenter Betreibern Vorteile. Statt rechtlicher Grauzonen und Nutzerfrust soll ein transparentes Datenschutzniveau als Wettbewerbsvorteil dienen. Das System basiert auf einem interdisziplinären Forschungsprozess, an dem Institutionen wie das Alexander von Humboldt Institut für Internet und Gesellschaft (HIIG) sowie das Einstein Center Digital Future (ECDF) der UdK beteiligt waren.
Der Dienst, den das Bundesforschungsministerium gefördert hat, bietet eine automatisierte Risikobewertung für Drittanbieter-Technologien. Diese fungiert als eine Art unabhängige Datenschutzfolgenabschätzung, die es Betreibern erlaubt, ihr Schutzniveau glaubhaft zu kommunizieren. Das soll das Vertrauen der Besucher stärken.
Mit begleitender empirischer Forschung will das Consenter-Team zudem den Beweis erbringen, dass echte Transparenz tatsächlich die Einwilligungsraten erhöhen kann. Für die Zukunft haben die Entwickler auch ehrgeizige Pläne: Consenter soll etwa in die digitale EU-Brieftasche (EUDI-Wallet) integriert werden. Gemeinsam mit einem europäischen Netzwerk aus Forschung und Regulierung wollen sie die digitale Souveränität stärken und Compliance von einer lästigen Pflicht in einen strategischen Marktvorteil verwandeln.
(wpl)











Künstliche Intelligenz
Vibe-Coding nach dem Tiktok-Prinzip: So funktioniert Gizmo
Dank Vibe-Coding können auch Menschen ohne Programmierkenntnisse vollständige Apps erstellen. Möglich wird das durch den Einsatz von KI, die Ideen direkt in funktionierende Anwendungen umsetzt. Ein US-Start-up geht jetzt mit seiner App Gizmo noch einen Schritt weiter: Es hat eine eigene Plattform für den Vibe-Coding-Trend entwickelt, auf der sich interaktive Mini-Anwendungen direkt erstellen, liken und teilen lassen.
Weiterlesen nach der Anzeige
Gizmo bietet App-Entwicklung im Tiktok-Fomat
Nutzer können interaktive Inhalte aus Text, Fotos, Ton und Berührungen erstellen. Diese erscheinen – ähnlich wie bei Tiktok oder Instagram-Reels – in einem vertikalen Feed. Im Gegensatz zu klassischen Kurzvideos können Nutzer die Inhalte hier aber nicht nur ansehen, sondern auch aktiv nutzen.
Je nach Art des jeweiligen „Gizmos” können Nutzer den Bildschirm antippen, wischen, zeichnen oder Elemente bewegen, um mit der Mini-App zu interagieren. Zum Angebot zählen unter anderem Rätsel, Memes und Animationen. Die Anwendungen lassen sich liken und kommentieren. Außerdem können Nutzer auch hier einen Remix aus bestehenden „Gizmos” erstellen.
Wie beim Vibe-Coding üblich beschreiben Nutzer in natürlicher Sprache, welche Anwendung sie erstellen möchten. Eine KI setzt diese Beschreibung in Quellcode um und erstellt eine funktionsfähige Mini-Anwendung. Den Begriff Vibe-Coding prägte Anfang 2025 Andrej Karpathy, der zuvor unter anderem die KI-Abteilung von Tesla leitete.
Gizmo unterstützt auch bei der Visualisierung, damit die Idee möglichst korrekt funktioniert und stabil läuft. Zusätzlich überprüft das Unternehmen die Inhalte mithilfe von KI sowie menschlichen Moderatoren, um die Sicherheit der Nutzer zu gewährleisten. Die Gizmo-App ist für iOS und Android verfügbar.
Die bisherigen Downloadzahlen sprechen für sich
Weiterlesen nach der Anzeige
Das New Yorker Start-up Atma Sciences hat Gizmo entwickelt. Zum Team gehören unter anderem Rudd Fawcett, Brandon Francis, CEO Josh Siegel und CTO Daniel Amitay. Im vergangenen Jahr sammelte das Unternehmen in einer Seed-Finanzierungsrunde rund 5,5 Millionen US-Dollar von First Round Capital und weiteren Investoren ein. Die App erschien im Sommer 2025. Laut einer Analyse von Appfigures verzeichnet Gizmo inzwischen rund 600.000 Downloads. Etwa die Hälfte davon entfällt auf die USA. Allein im Dezember wurde sie rund 235.000 Mal heruntergeladen, was etwa 39 Prozent der Gesamtdownloads entspricht.
Dieser Beitrag ist zuerst auf t3n.de erschienen.
(jle)
Künstliche Intelligenz
Nextcloud schaltet den ADA-Turbo: Deutliche Performance-Verbesserungen kommen
Nextcloud hat mit der ADA-Engine (Accelerated Direct Access) eine grundlegend überarbeitete Datenzugriffsarchitektur vorgestellt. Die in PHP, Go und Rust implementierte Engine soll die Skalierbarkeit der freien Kollaborationsplattform auf ein neues Niveau heben. Die Neuentwicklung ist als Hommage an Ada Lovelace benannt, die erste Computerprogrammiererin der Geschichte.
Weiterlesen nach der Anzeige
Die ADA-Engine berechnet Zugriffsdaten und Berechtigungen vorab, speichert sie im Cache und ermöglicht direkten Dateizugriff. Zudem pusht sie Daten aktiv zu Clients, um die Navigation responsiver zu gestalten.
Konkrete Leistungssprünge in Nextcloud Hub 26 Winter
In Aktion können Anwender die neue ADA-Engine erstmals mit Nextcloud Hub 26 Winter erleben, das am 18. Februar 2026 erscheinen soll. Die neue Version trennt Previews aus dem File Cache und reduziert so die Größe der File-Cache-Tabelle um 56 Prozent. Diese Metadaten-Abstraktionsschicht ist oft die größte Datenbanktabelle in Nextcloud-Installationen. Previews erhalten eine eigene Tabelle mit Ablaufmechanismus für ungenutzte Dateien.
Authoritative Mount Points beschleunigen das Laden von Ordnern mit Shares um 30 Prozent, im Beispiel von Nextcloud von 1,9 auf 1,3 Sekunden. Das Lean File System Setup verbessert die Shared-Folder-Retrieval um 60 Prozent, von 1,39 auf 0,44 Sekunden. Direkte S3-Downloads reduzieren die Serverlast massiv und beschleunigen das Laden von Thumbnails um den Faktor 2 bis 10.
Snowflake-IDs und Sharding für große Installationen
Eine zentrale Innovation sind Snowflake-IDs, ursprünglich von Twitter entwickelt. Diese 64-Bit-Identifikatoren lassen sich dezentral ohne Datenbankabfragen generieren und enthalten einen Zeitstempel mit Millisekundenpräzision, eine Server-ID und ein CLI-Flag. Sie ermöglichen Sharding, also die Aufteilung von Tabellen nach Benutzer- oder Datei-IDs über mehrere Nodes hinweg, was Wartezeiten reduziert. Die Snowflake-IDs sind bereits im Preview-Provider und External Sharing im Einsatz.
Für Installationen mit Millionen Nutzern implementiert Nextcloud zudem das Generator-Pattern zum Streaming großer Listen. Statt komplette Listen in den Speicher zu laden, was zu Out-of-Memory-Fehlern führen kann, werden die Daten schrittweise verarbeitet. Eine neue Mount-Points-Tabelle ersetzt die bisherigen Per-User-Caches und ermöglicht direkte Provider-Queries. Die Architektur ist ideal für geclusterte und Cloud-native Deployments wie Kubernetes geeignet.
Weiterlesen nach der Anzeige
High-Performance-Backends für Files und Talk
Die in Rust und Go entwickelten High-Performance-Backends erhalten ebenfalls Updates. Das HPB Files 2.0 reduziert die PROPFIND-Anfragen für Updates um 80 Prozent durch gestaffelte Benachrichtigungen bei Multi-User-Änderungen und detailliertere Informationen für selective Sync. Das HPB Talk 2.0 führt Chat-Relay ein und senkt die Datenbanklast für große Räume und Anrufe. Bei mehr als 100 Teilnehmern sinken die Chat-bezogenen Anfragen um bis zu 80 Prozent.
Direkte S3-Downloads sind bereits im aktualisierten Desktop-Client implementiert. Clients laden dabei Token-geschützt direkt aus S3-kompatiblen Speichern und umgehen den Application-Server. Für die Web-Oberfläche und Previews folgen entsprechende Funktionen in späteren Releases. Die Speicherabstraktion bleibt dabei erhalten und unterstützt weiterhin POSIX, S3, IBM, FTP, WebDAV, Samba, NFS und SharePoint.
Sicherheit und Open-Source-Charakter bleiben erhalten
Trotz der tiefgreifenden Änderungen bleiben alle Sicherheitsfeatures erhalten oder werden verbessert: Server- und End-to-End-Verschlüsselung, ACLs, Passwort- und Ablaufmechanismen sowie Video-Verifikation. Auch KI-gestützte Erkennung verdächtiger Logins, Brute-Force-Schutz, Rate-Limiting, Audit-Logging, Erkennung sensibler Dateien und Smart Locking funktionieren weiterhin. Die ADA-Engine sorgt für konsistente Berechtigungen über alle Features hinweg, von Files über Talk bis zu Tasks. Detaillierte Informationen zu allen Änderungen finden sich im Nextcloud-Blog.
Und natürlich bleibt der Open-Source-Charakter von Nextcloud unangetastet, es handelt sich nicht um ein kommerzielles Pro-Feature. Die erste Beta von Nextcloud Hub 26 Winter ist seit Januar 2026 verfügbar. Nextcloud verspricht, dass weitere Anpassungen in kommenden Releases folgen, wobei die größten Auswirkungen bei großen Installationen zu erwarten sind. Geografisch verteilte Speicherlösungen sind mit ADA technisch machbar, erfordern aber noch erheblichen Entwicklungsaufwand.
(fo)
Künstliche Intelligenz
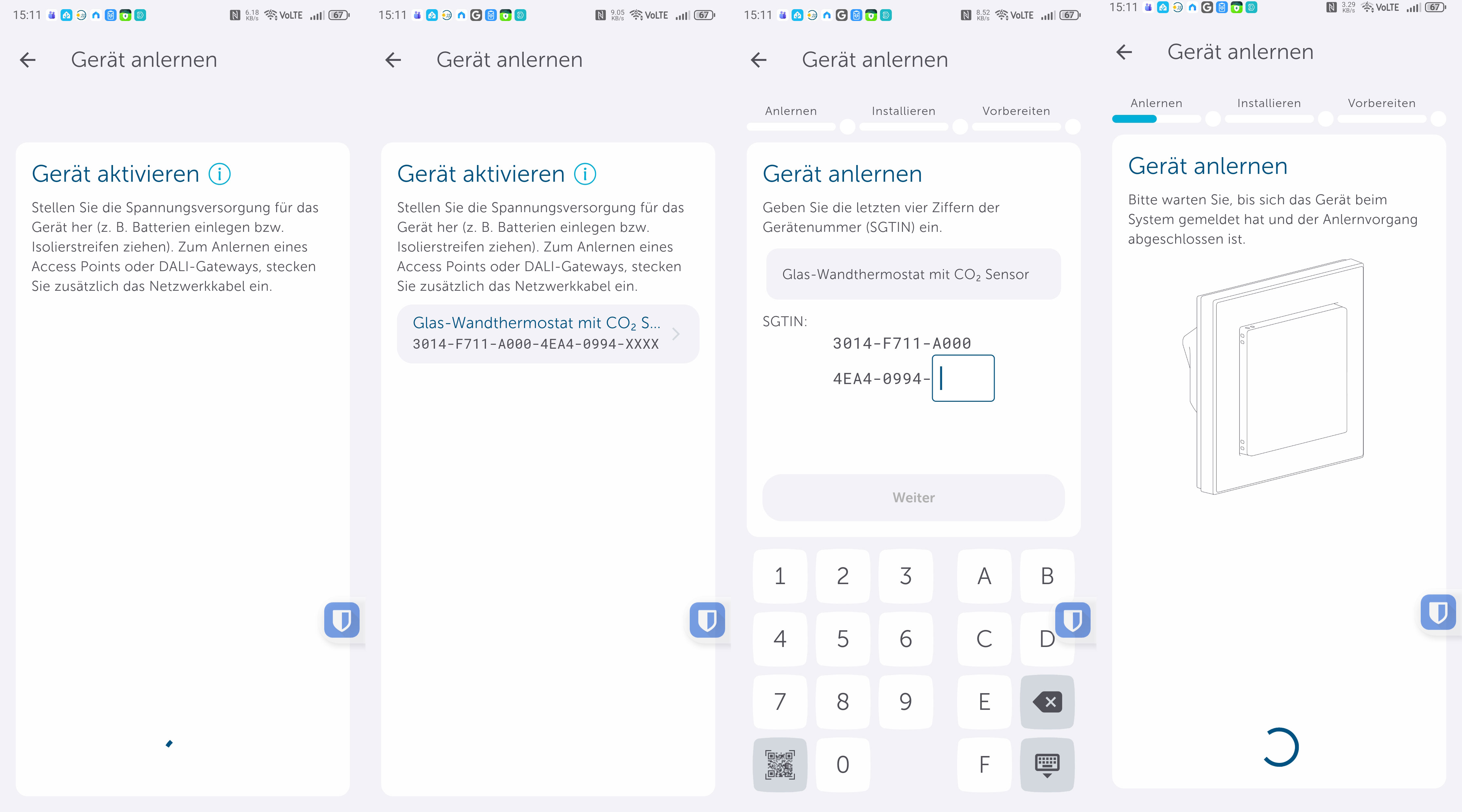
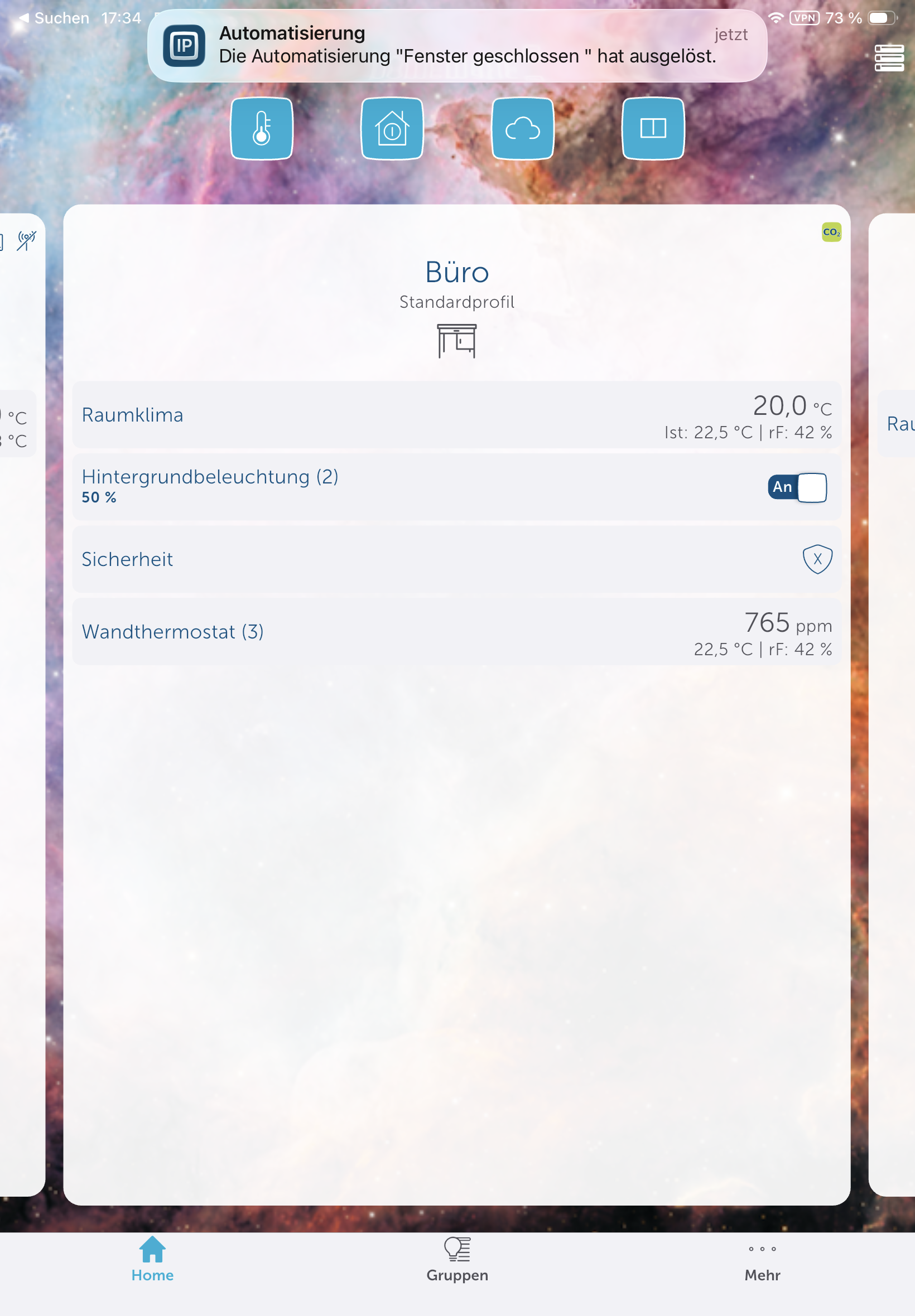
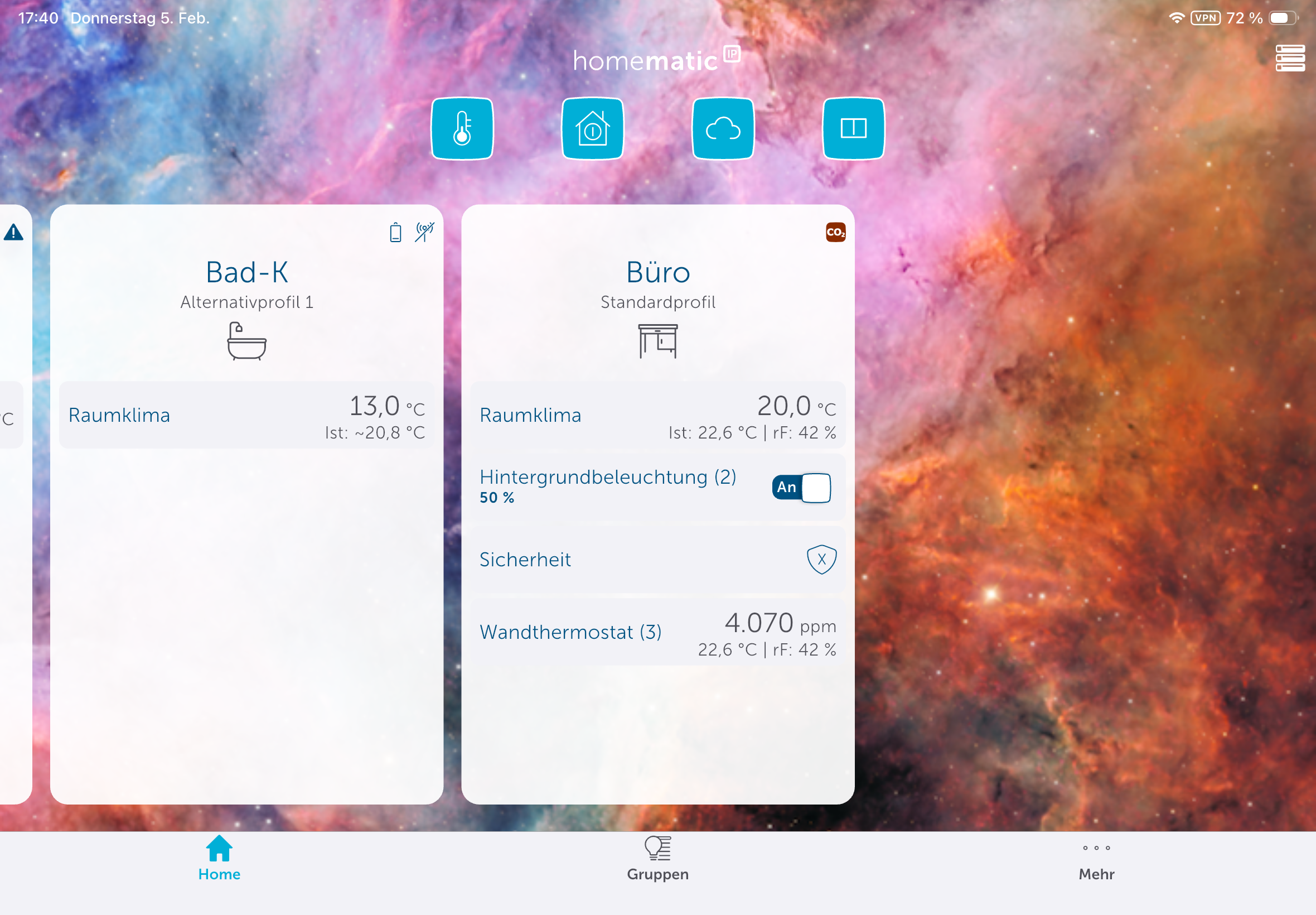
Fußbodenheizung: Homematic IP Glas-Wandthermostat mit CO₂-Sensor im Test
Neben einer smarten Temperaturregelung für Fußbodenheizungen zeigt das Homematic IP Glas-Wandthermostat auch die CO₂-Konzentration und die Luftfeuchtigkeit an.
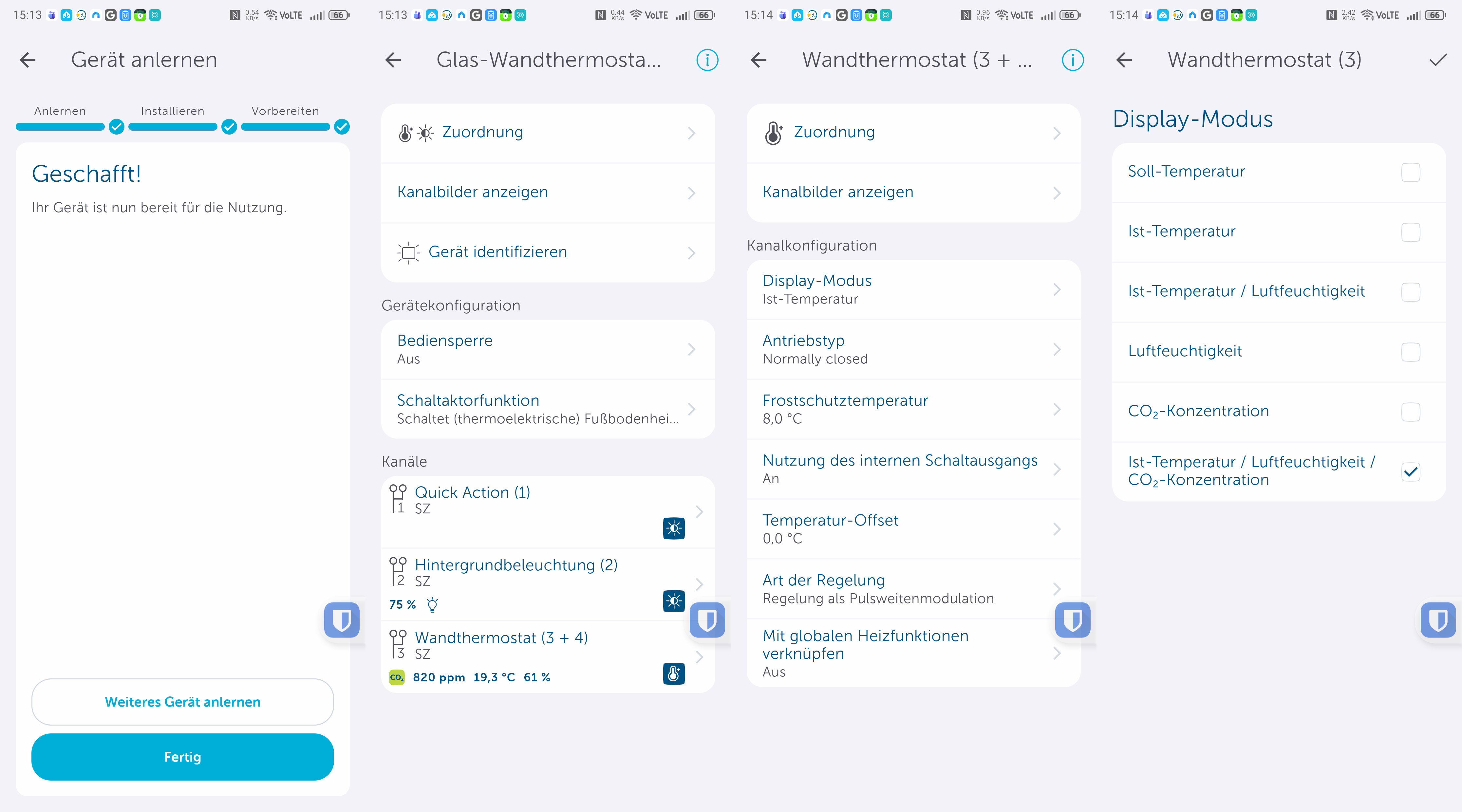
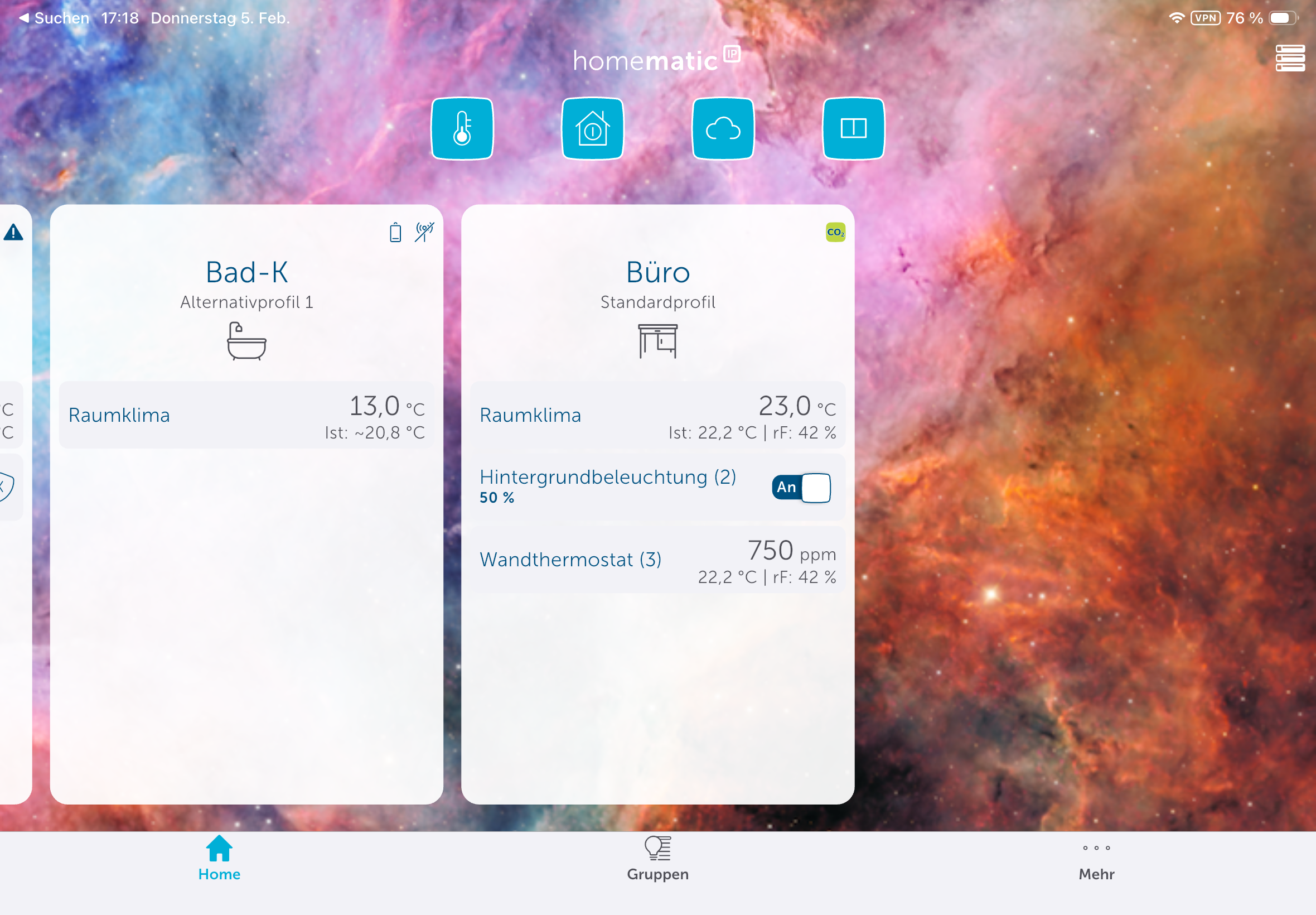
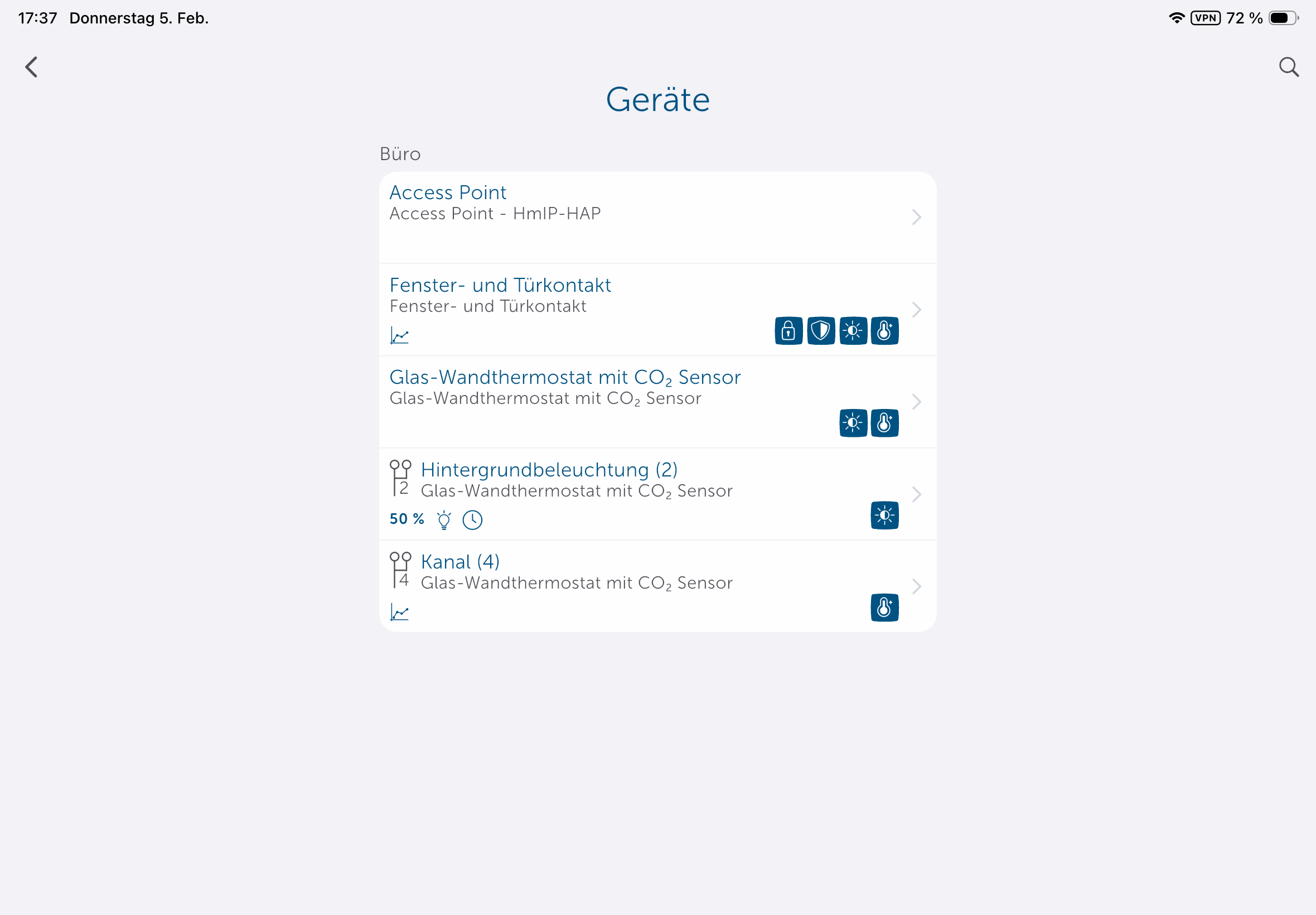
Das Homematic IP Glas-Wandthermostat des deutschen Herstellers eQ-3 bietet nicht nur eine smarte Regelung der Fußbodenheizung, sondern integriert auch einen CO₂-Sensor. Die Glasabdeckung in Schwarz oder Weiß sieht edel aus und kann Temperatur, CO₂-Konzentration sowie Luftfeuchte anzeigen. Für den Betrieb ist ein Homematic IP Access Point nötig, der mit der Homematic-IP-Cloud kommuniziert und darüber das Thermostat steuert. Eine lokale Steuerung ohne Cloud ist mithilfe der eQ-3 Home Control Unit oder mit der älteren CCU3 möglich. In beiden Fällen ist auch eine Integration in Home Assistant möglich.
Wie gut das Homematic IP Glas-Wandthermostat in der Praxis funktioniert und wie eine Integration in Home Assistant gelingt, zeigt der Testbericht.

Verarbeitung, Design, Bedienung und weitere Funktionen
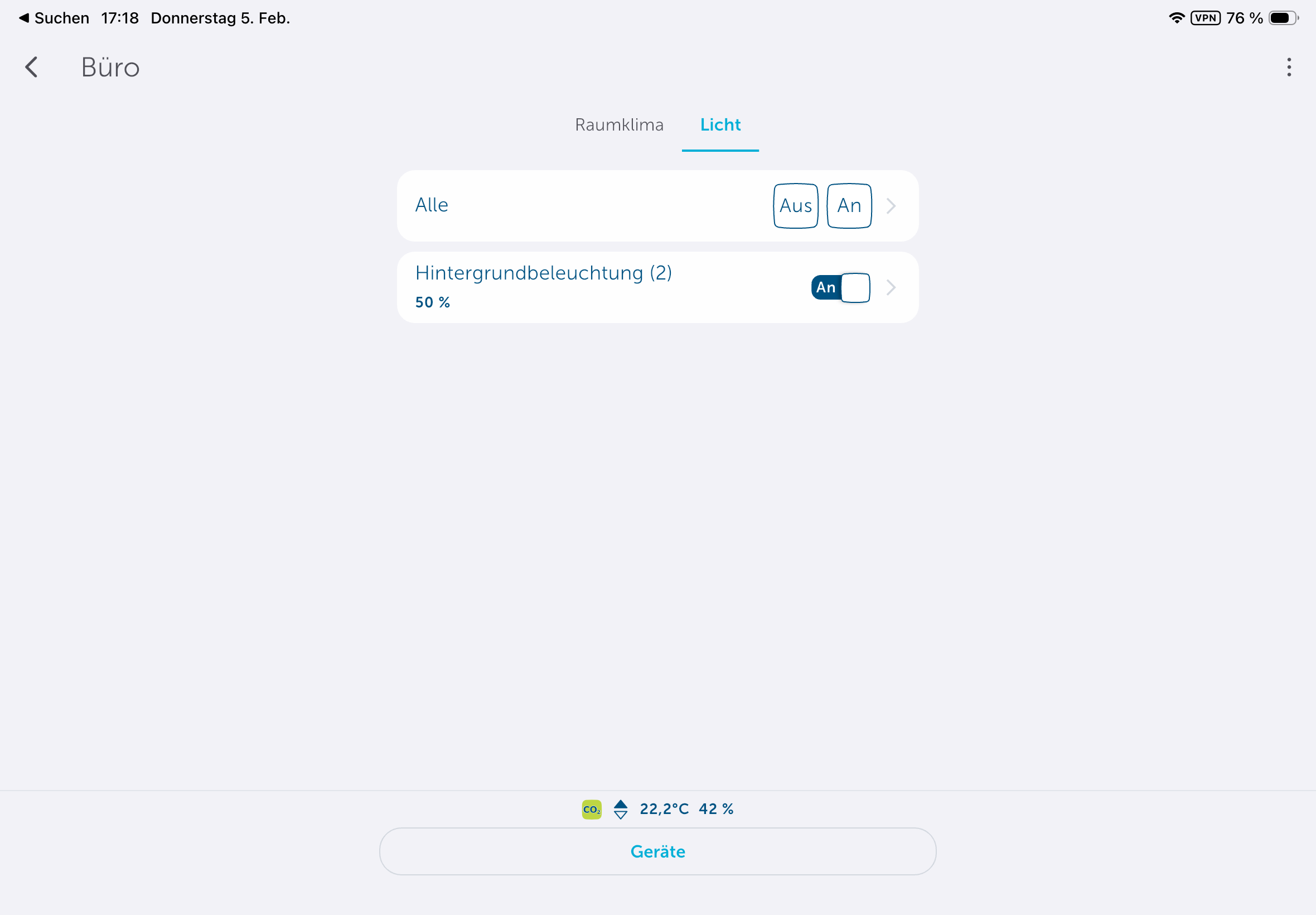
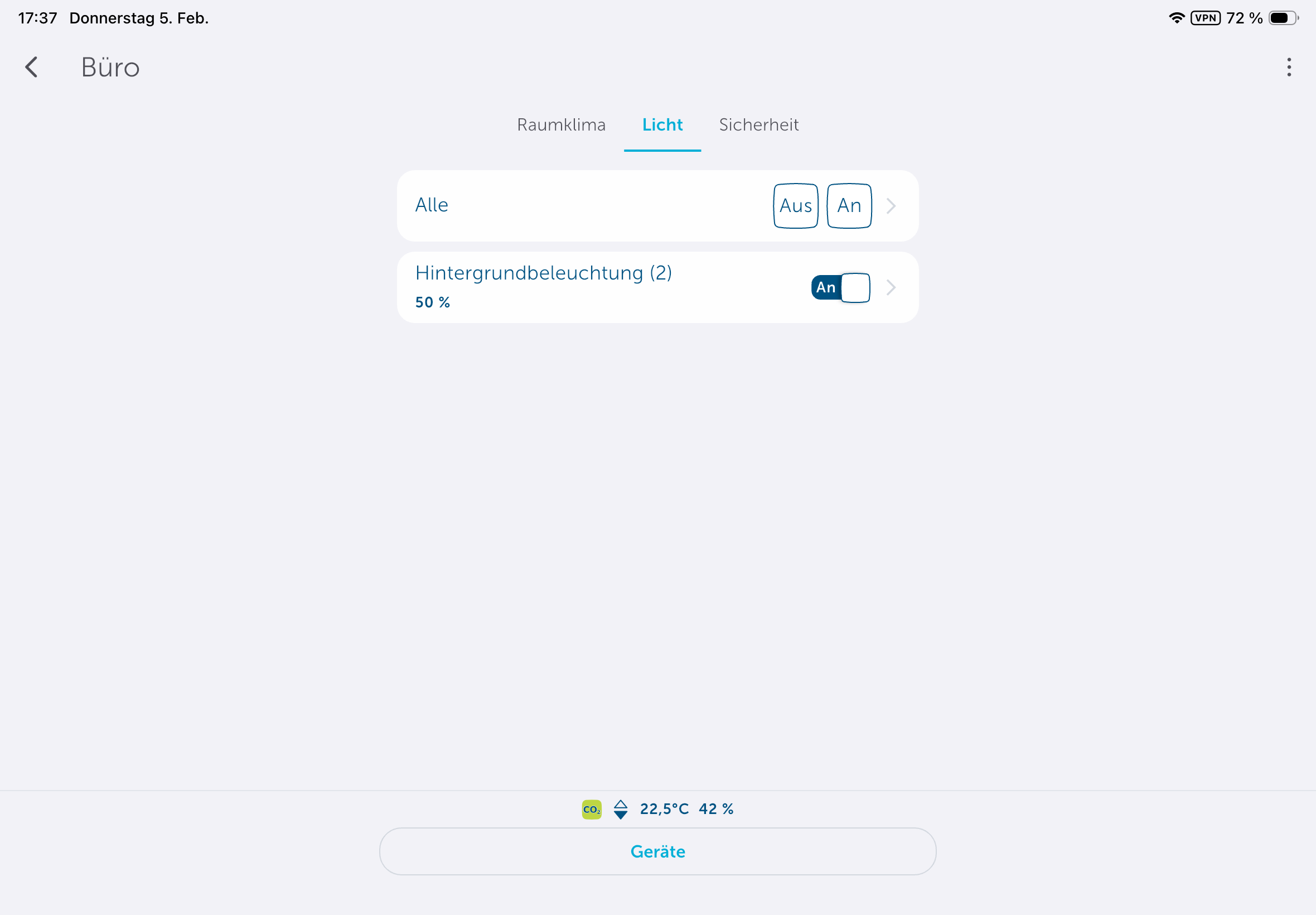
Das Homematic IP Glas-Wandthermostat für Fußbodenheizungen ist hochwertig verarbeitet. Die Glasoberfläche mit darunterliegenden LEDs sorgt haptisch wie visuell für einen ausgezeichneten Eindruck. Auch im Betrieb bleibt dieser Eindruck erhalten. So ist etwa die Anzeige von Raumtemperatur, Luftfeuchtigkeit und CO₂-Konzentration aus jedem Blickwinkel gut ablesbar. Außerdem bietet es noch zwei Touchflächen zur Bedienung. Zudem erlaubt es auch eine Sprachsteuerung über Amazon Alexa und Google Assistant.
Durch das standardisierte 55er-Rahmenmaß ist nicht nur die Installation in viele Schalterprogramme möglich, sondern die Montage in einer Unterputzdose unproblematisch. Somit ist es auch als Nachrüstlösung bestens geeignet.
Inbetriebnahme
Für die Inbetriebnahme ist eine Steuereinheit von eQ-3 nötig. Das kann ein an die Cloud des Herstellers gekoppelter Access Point, eine Zentrale wie die Home Control Unit oder die CCU3 sein. Letztere unterstützen die lokale Ansteuerung ohne Cloud.
Die Einrichtung erfolgt mit der Homematic-IP-App, die es für iOS und Android gibt und die auch für Tablets optimiert ist, sodass man von der größeren Darstellung, etwa eines iPads, profitiert. Die Inbetriebnahme ist dank klarer Benutzerführung in wenigen Minuten erledigt (siehe auch Bildergalerie).
Bilder: Homematic IP Glas-Wandthermostat mit CO₂-Sensor
Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.
Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor gibt es in Schwarz oder Weiß. Auf seinem Glas-Display kann es Temperatur, Luftfeuchte und CO₂-Konzentration abwechselnd anzeigen.

Inbetriebnahme mit Homematic-IP-App
Inbetriebnahme mit Homematic-IP-App
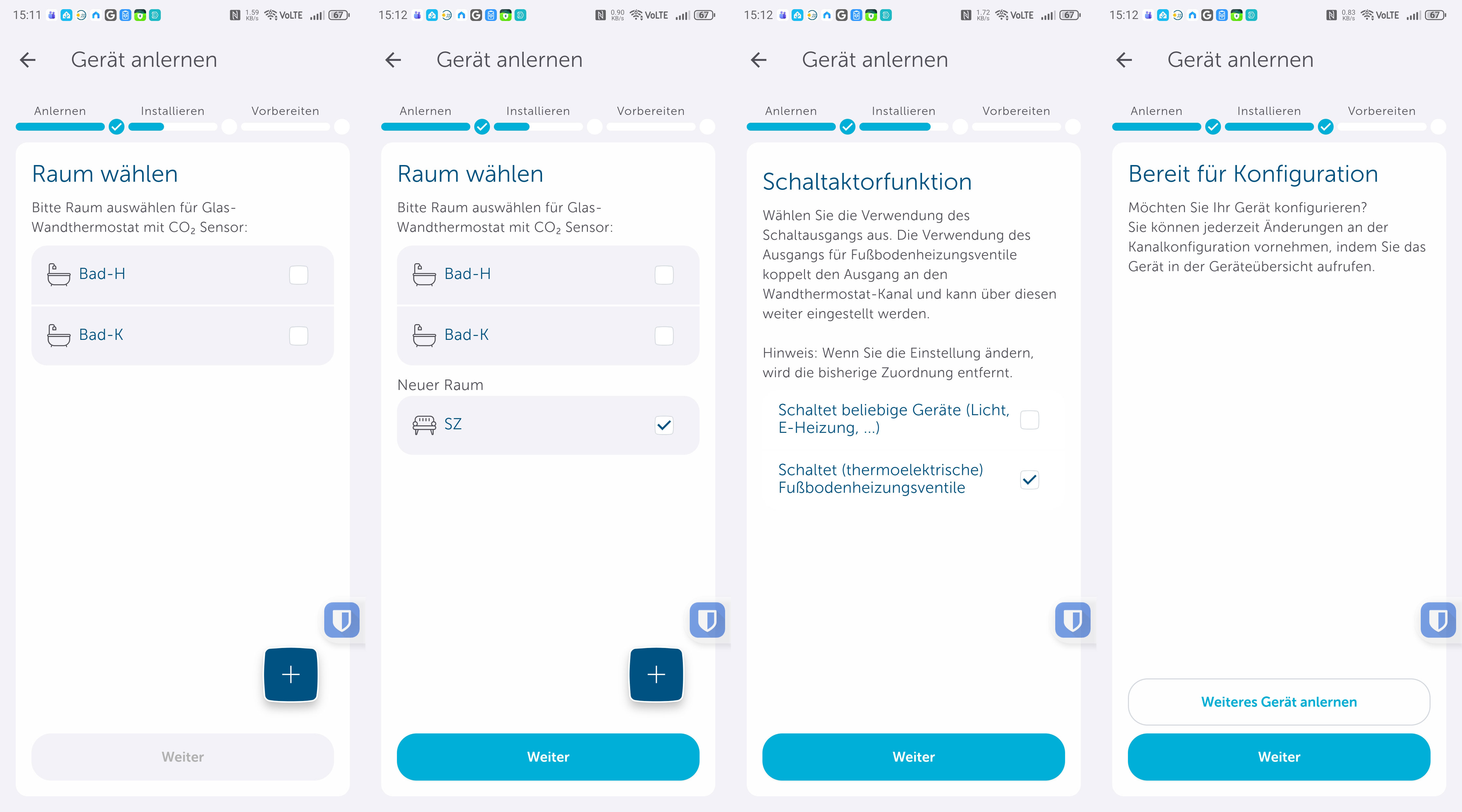
Inbetriebnahme mit Homematic-IP-App
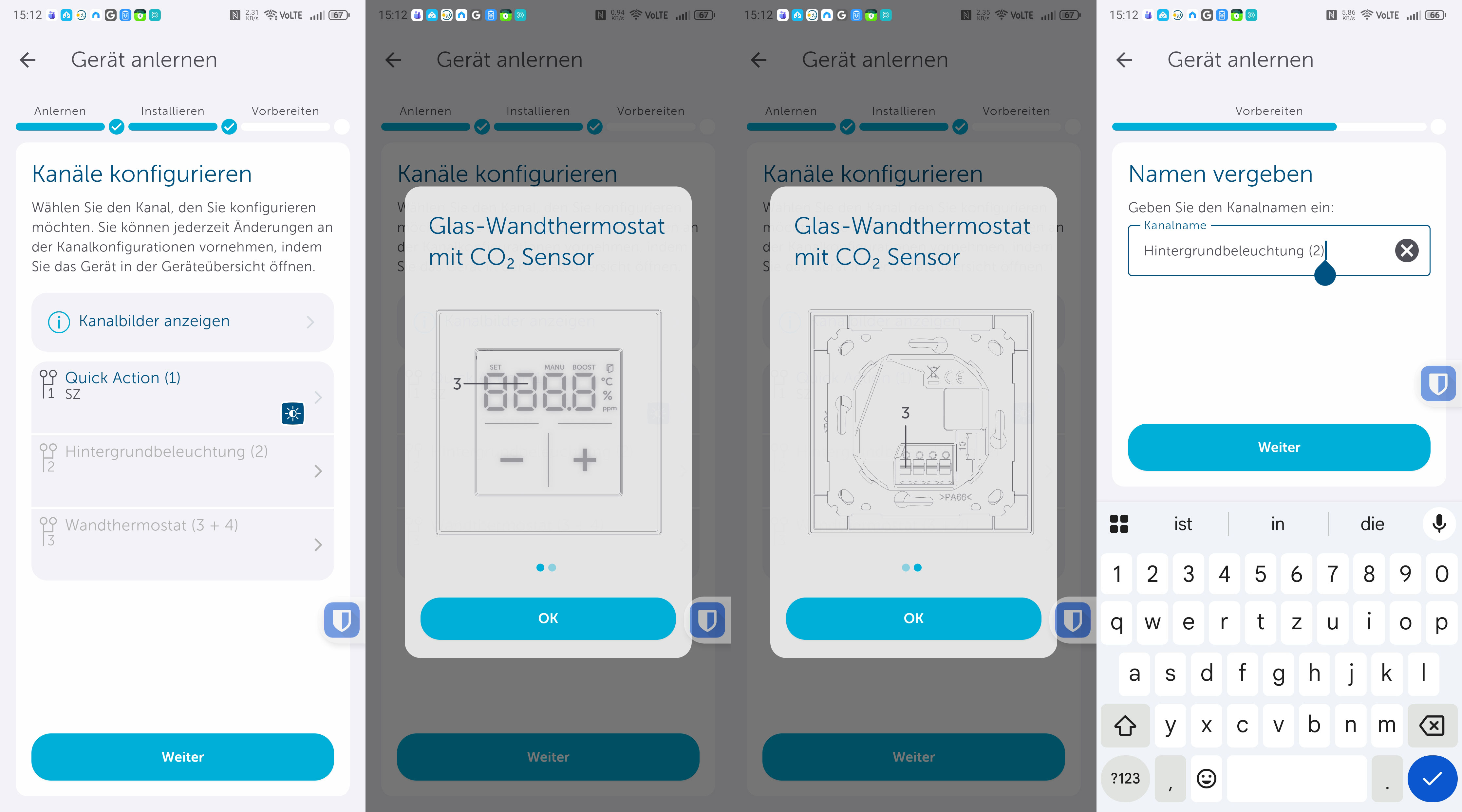
Inbetriebnahme mit Homematic-IP-App
Inbetriebnahme mit Homematic-IP-App
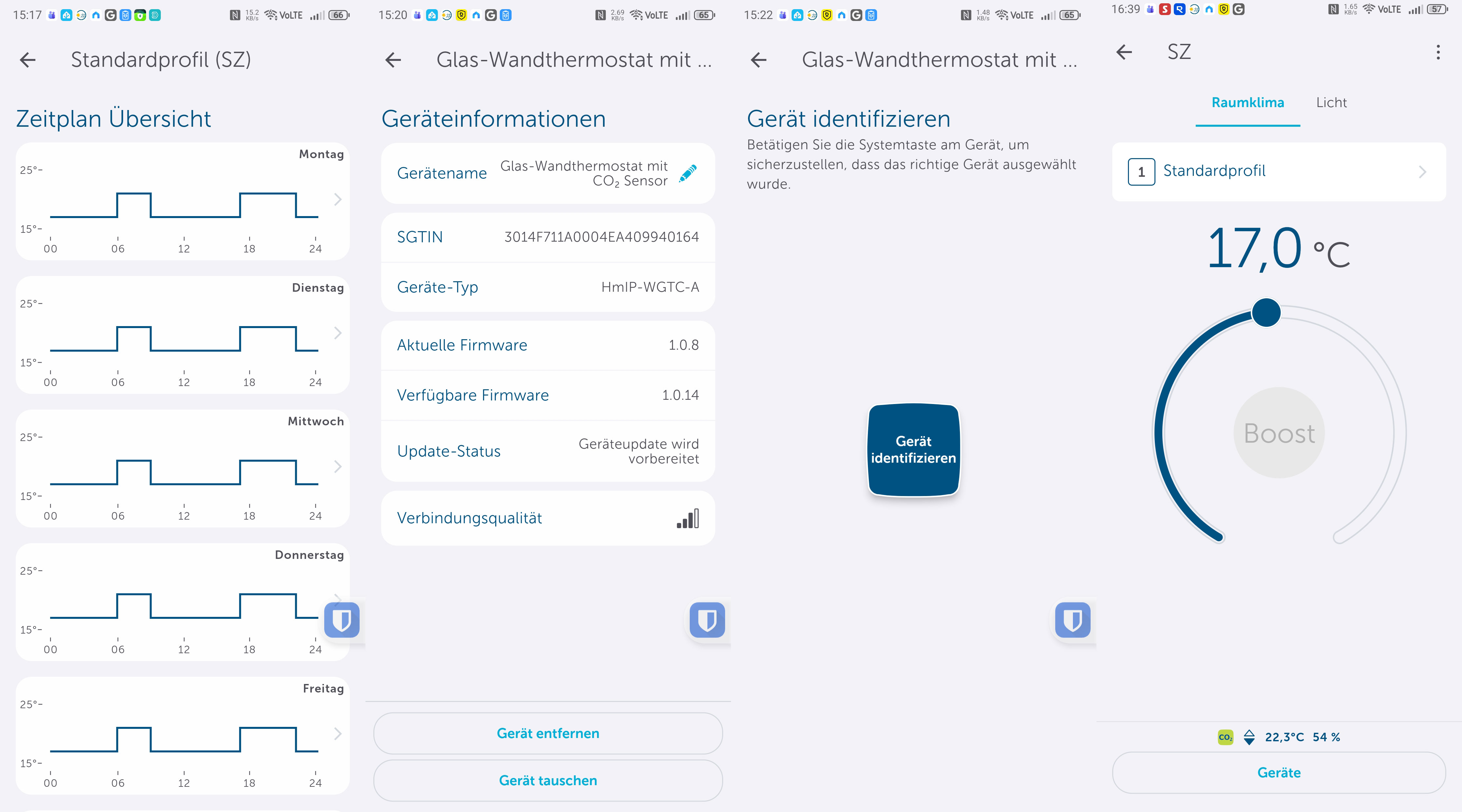
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.

Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
Die Homematic-IP-App ist auch für Tablets optimiert.
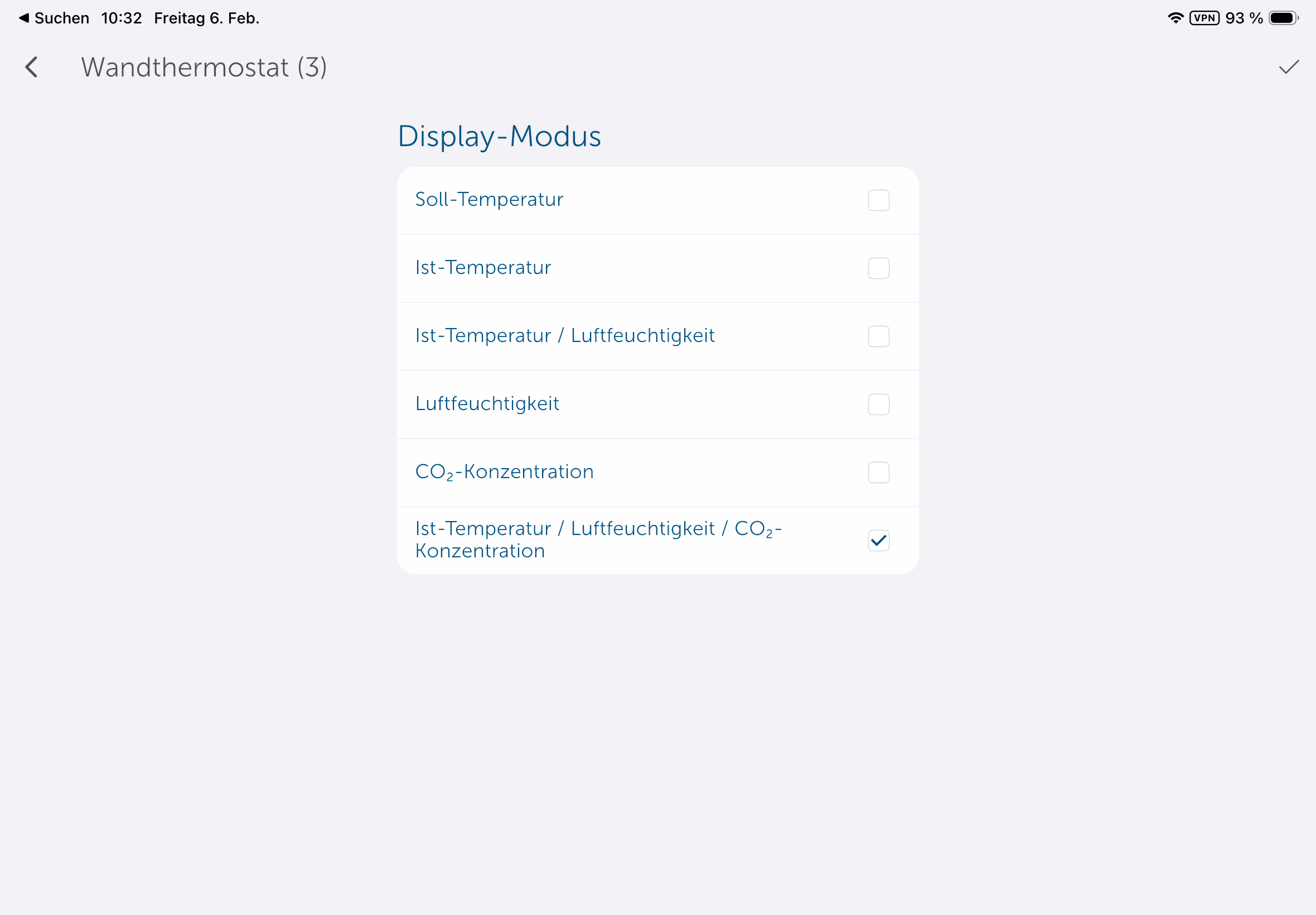
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.
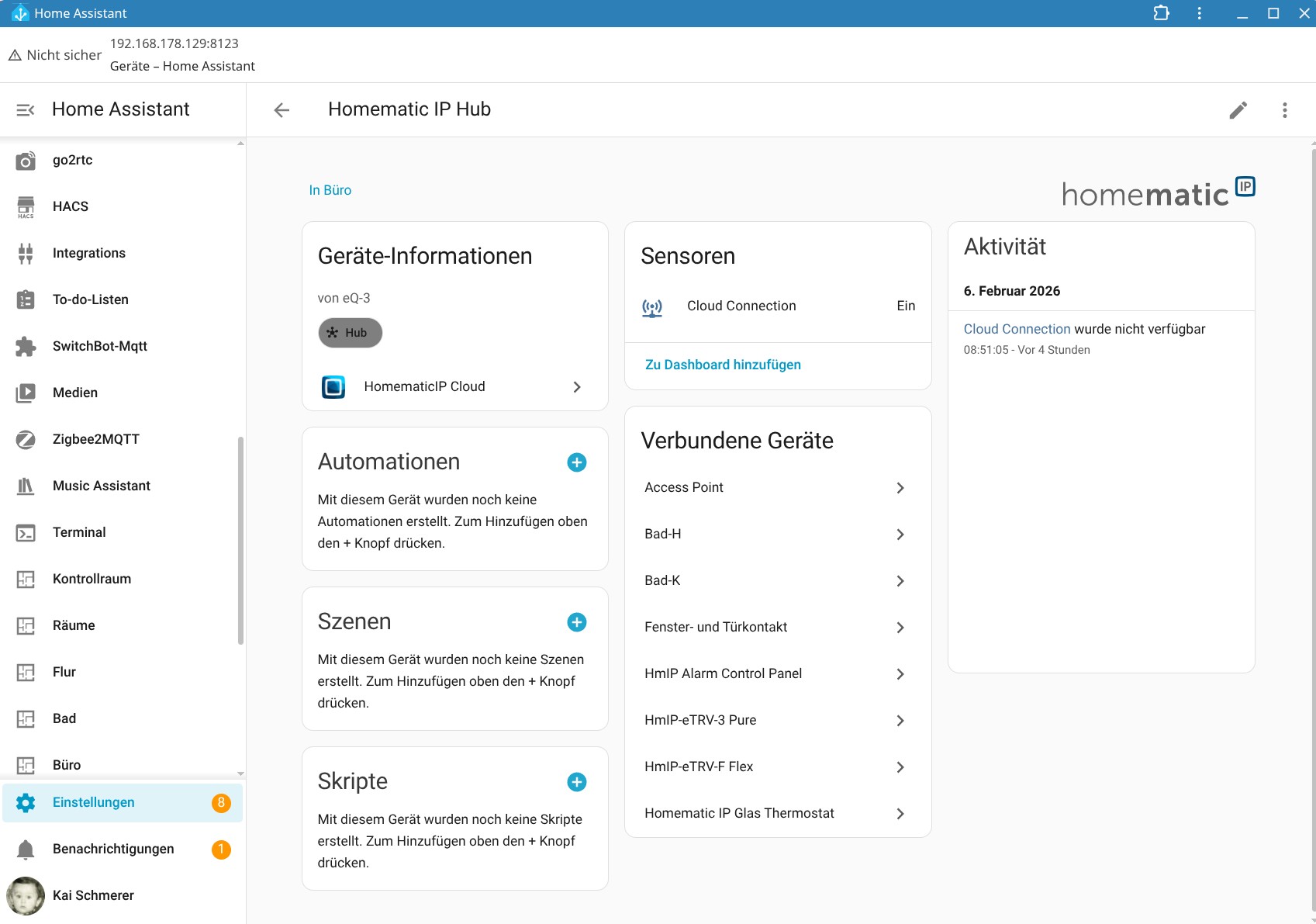
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.
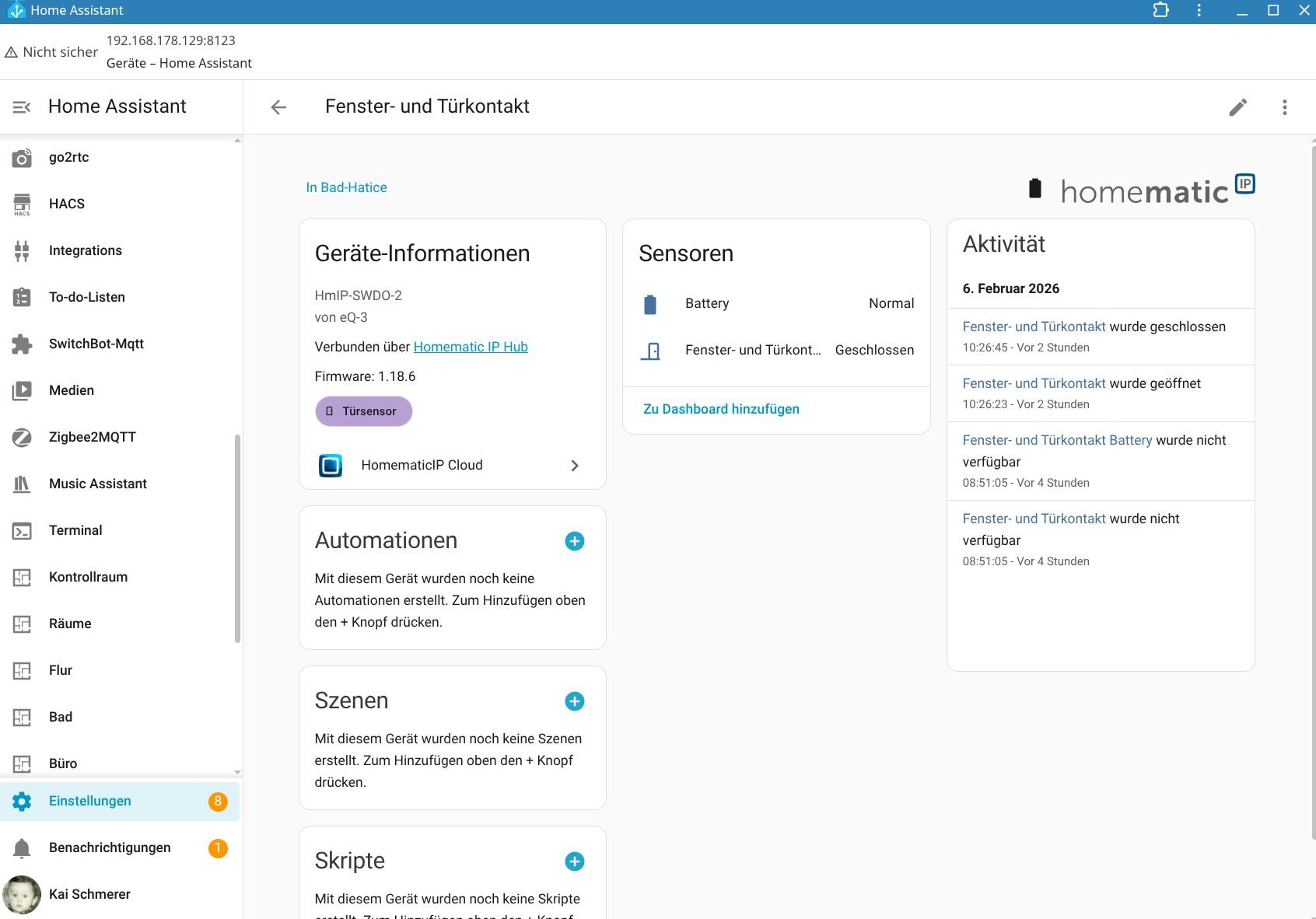
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.
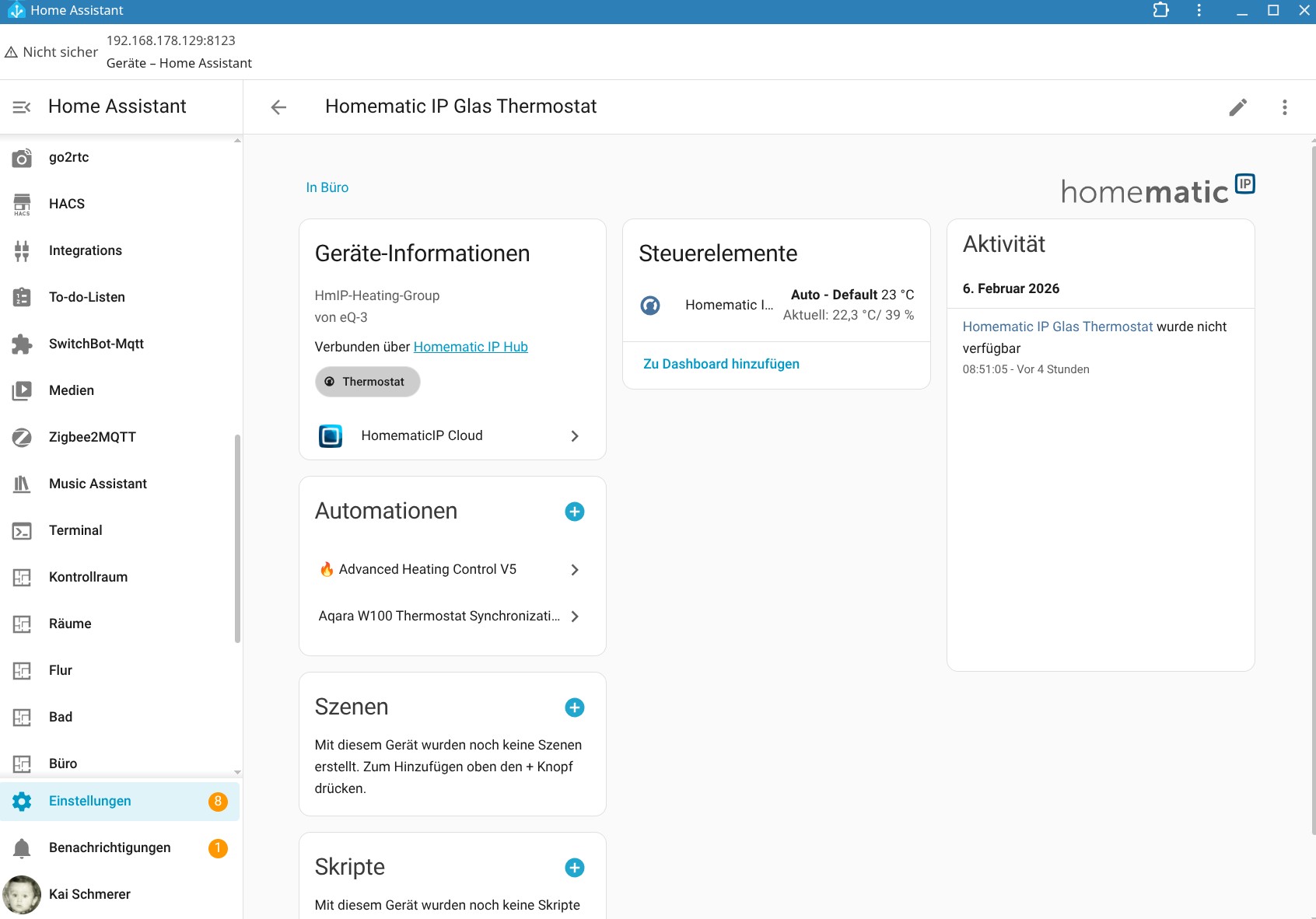
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.
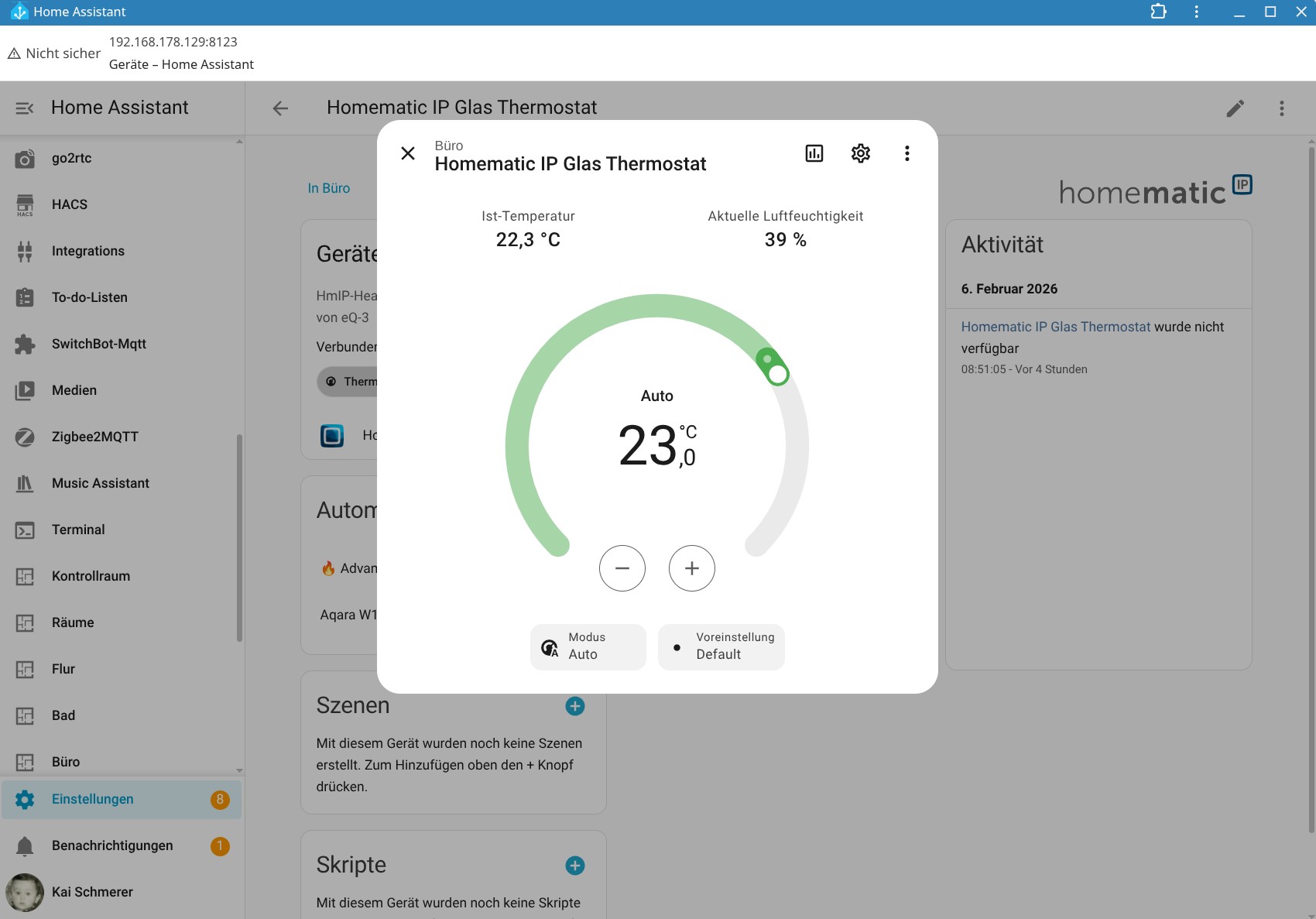
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.

Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.
Eine Integration des Homematic IP Glas-Wandthermostats in Home Assistant ist möglich, bietet allerdings nicht sehr viele Funktionen, sodass manuelle Anpassungen nötig sind. Dank KI-Tools hält sich der Aufwand dafür allerdings in Grenzen.

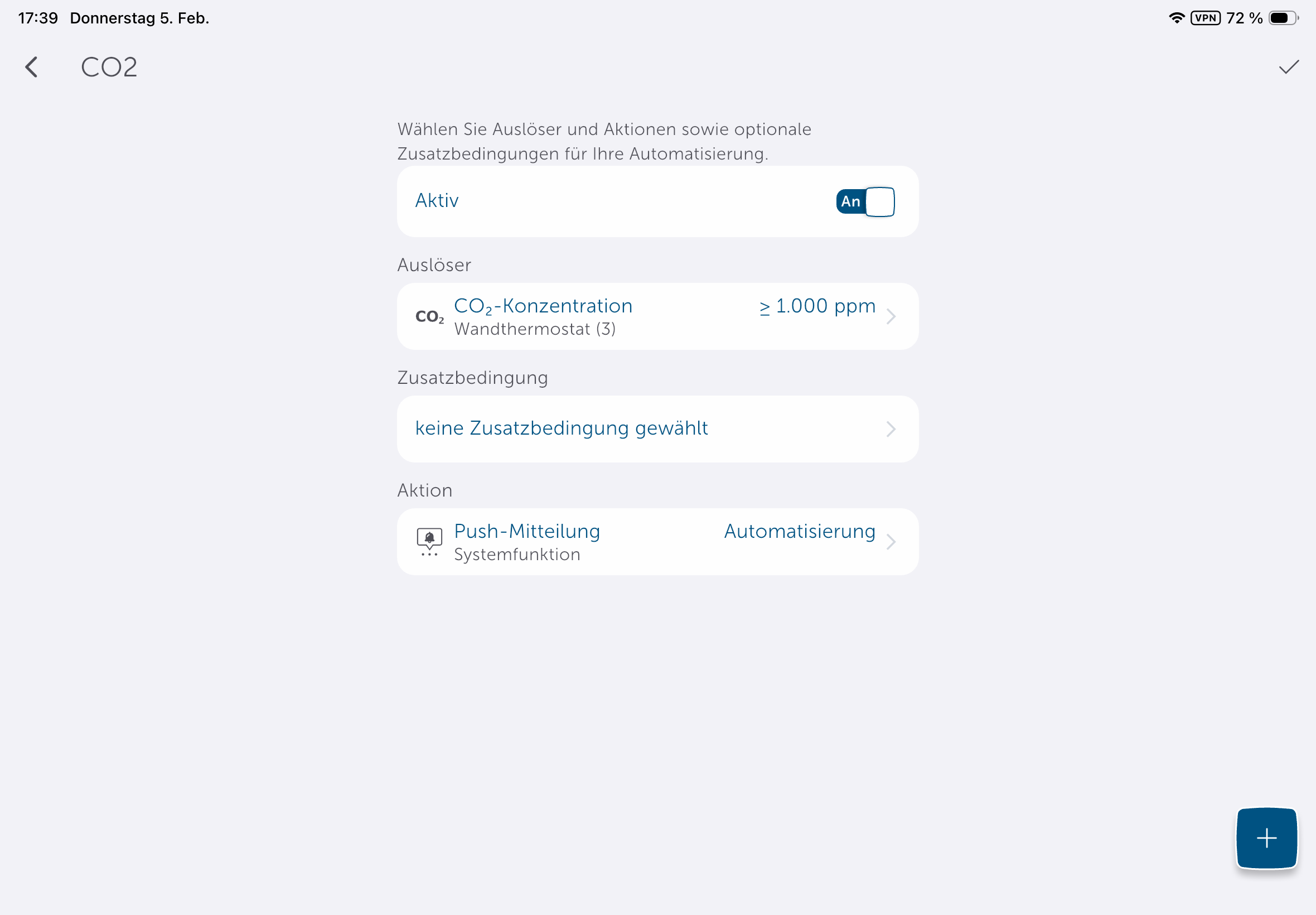
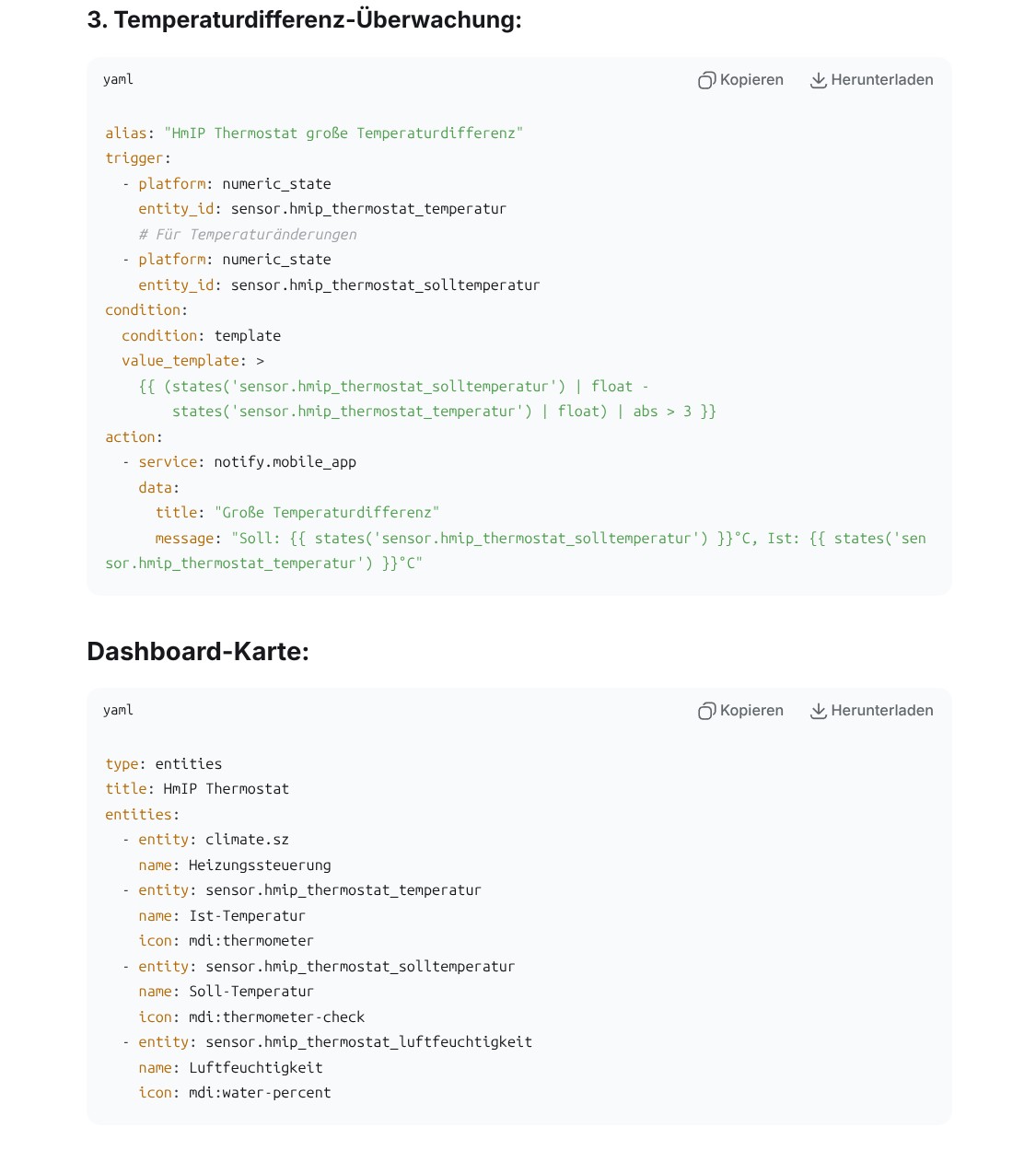
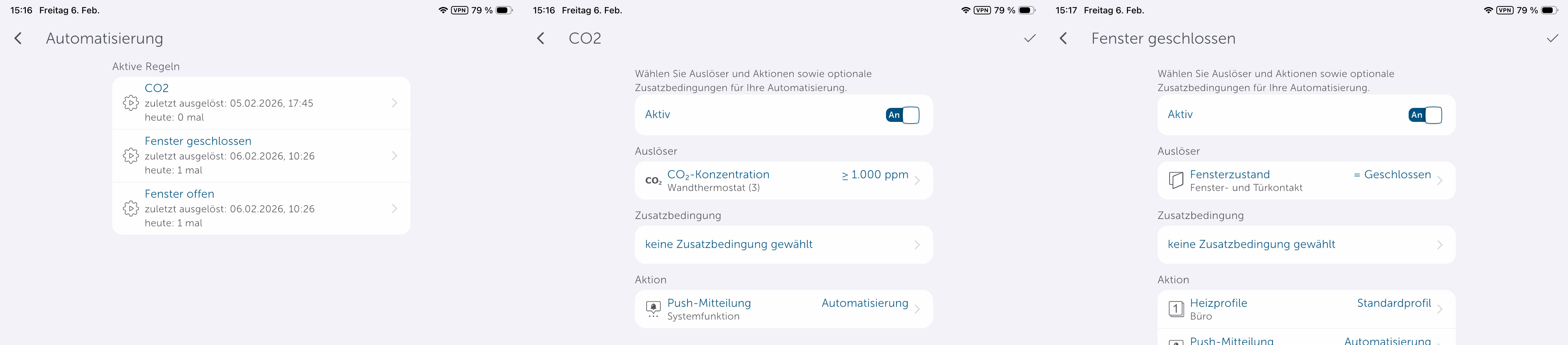
Unter Automatisierung können Anwender Regeln definieren. So wird etwa bei einem geöffneten Fenster ein anderes Heizprofil geladen, sodass wenig Energie verschwendet wird. Auch Benachrichtigungen über eine erhöhte CO₂-Konzentration kann man in diesem Abschnitt definieren.
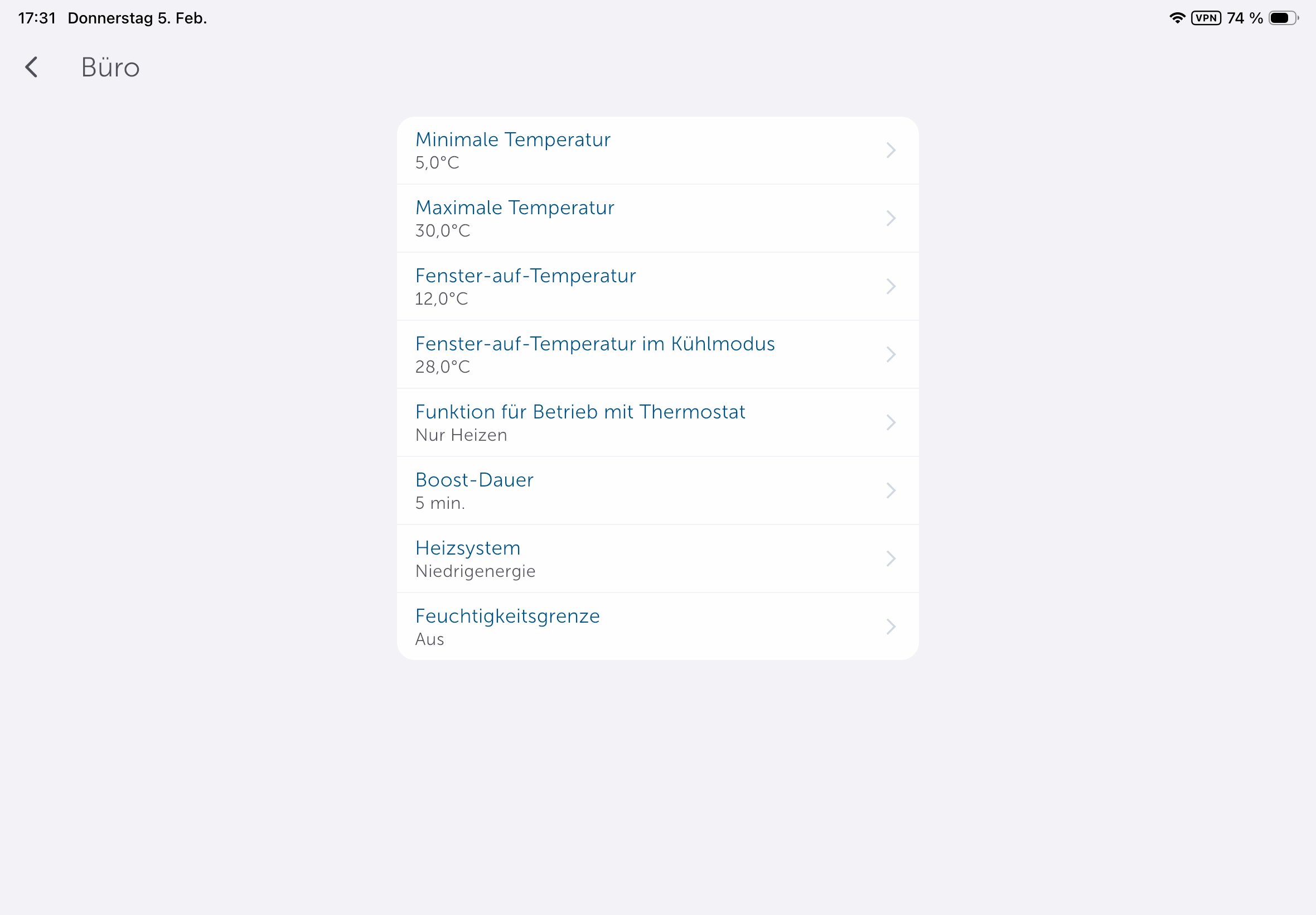
Steuerung mit der App
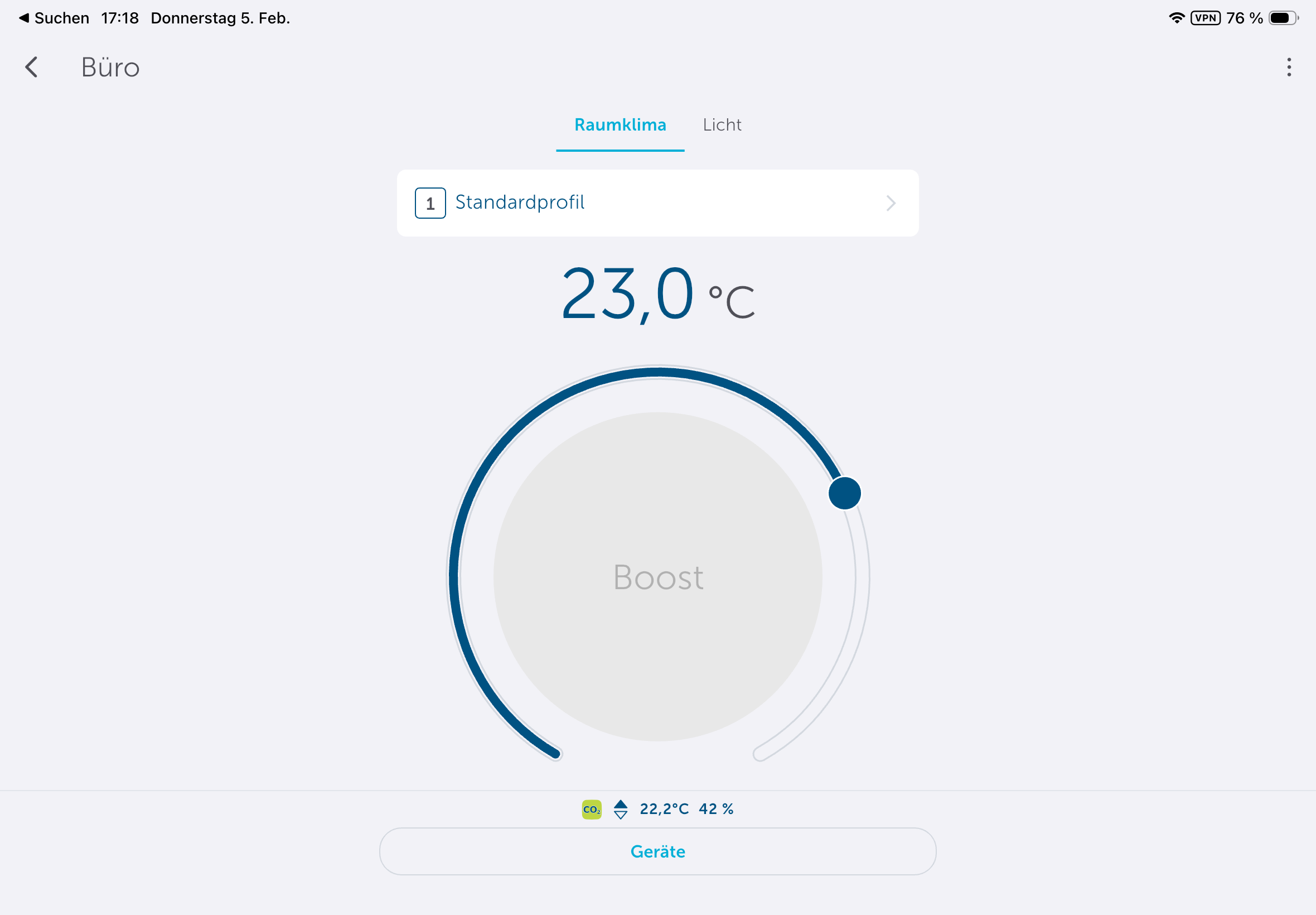
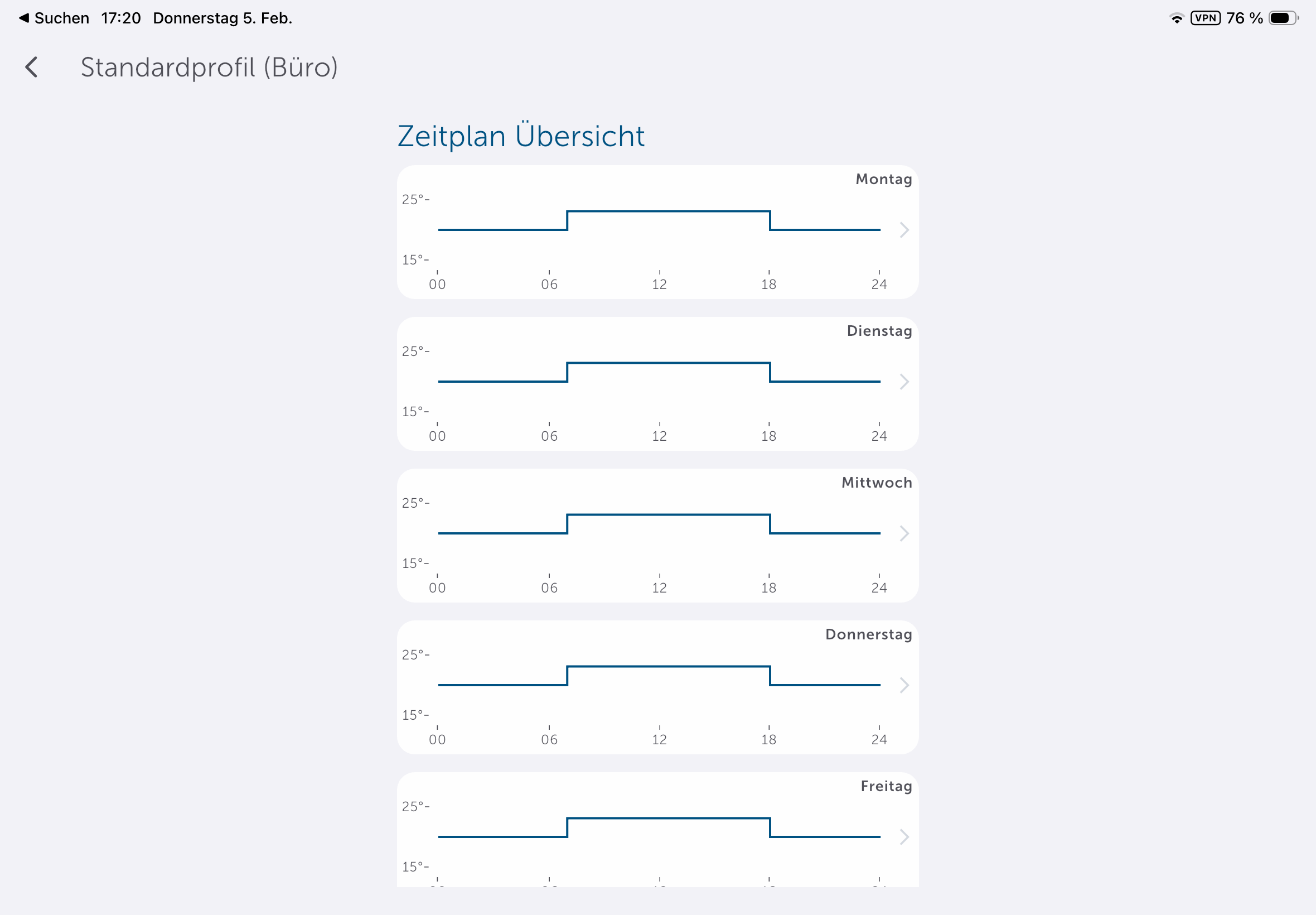
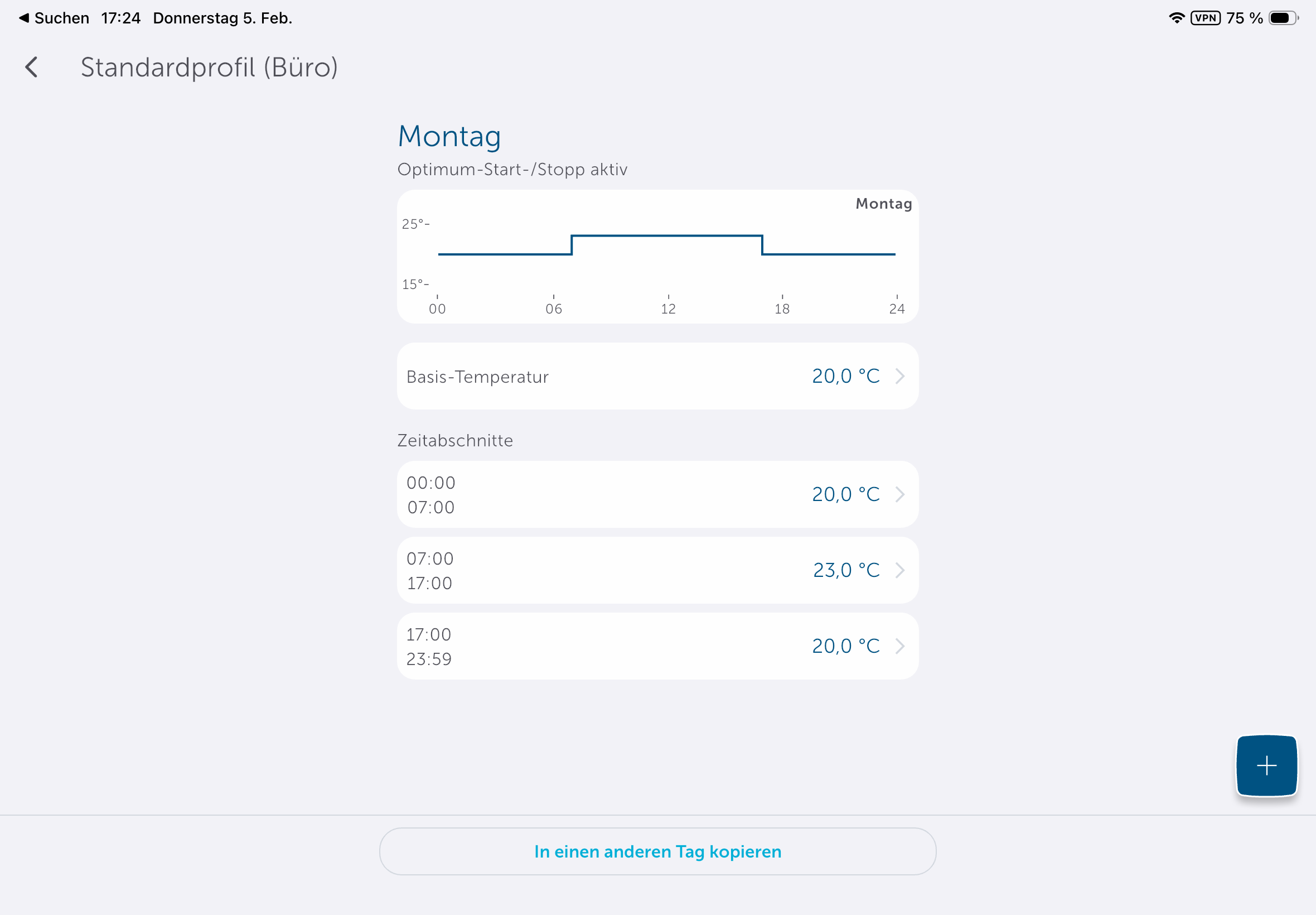
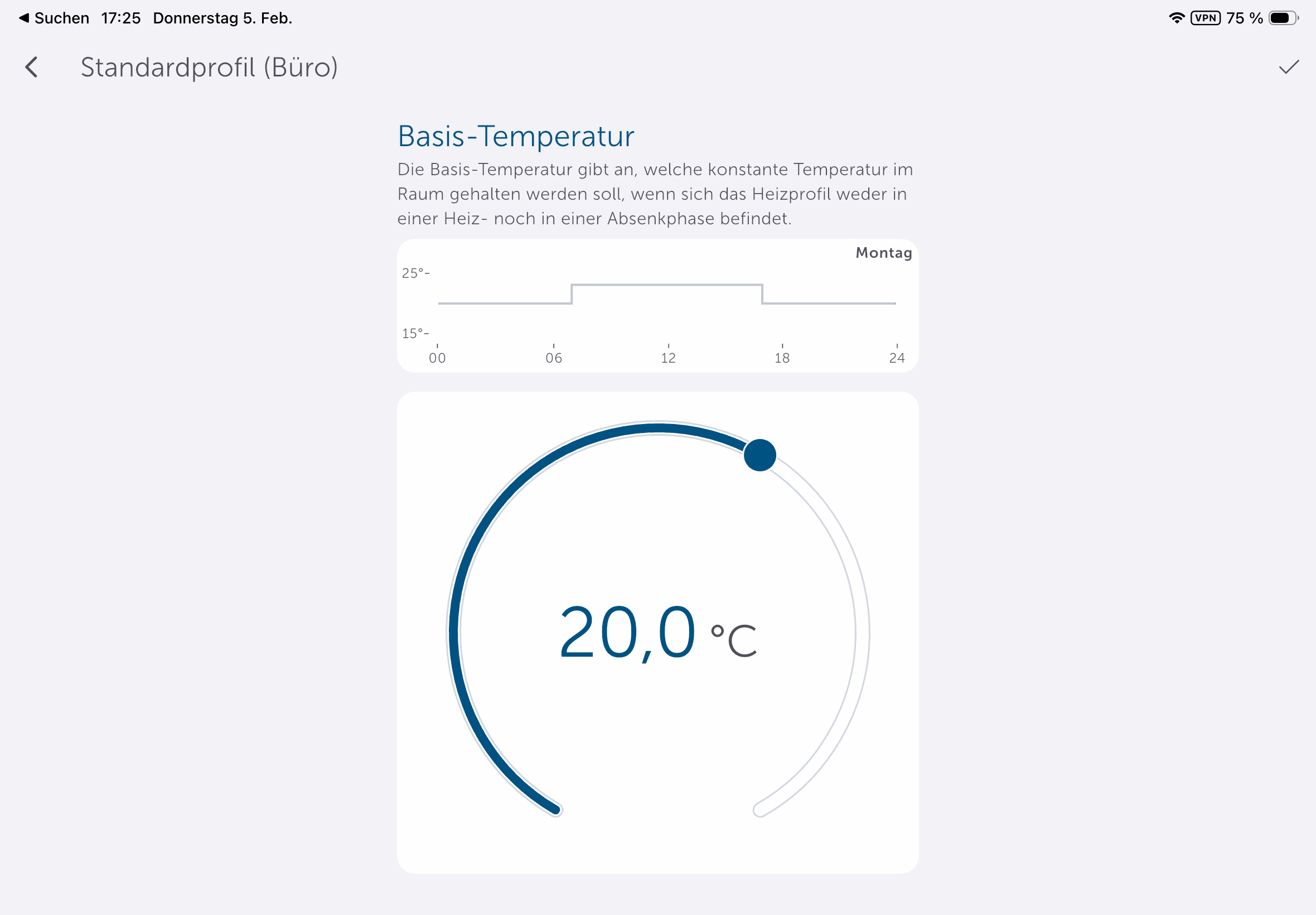
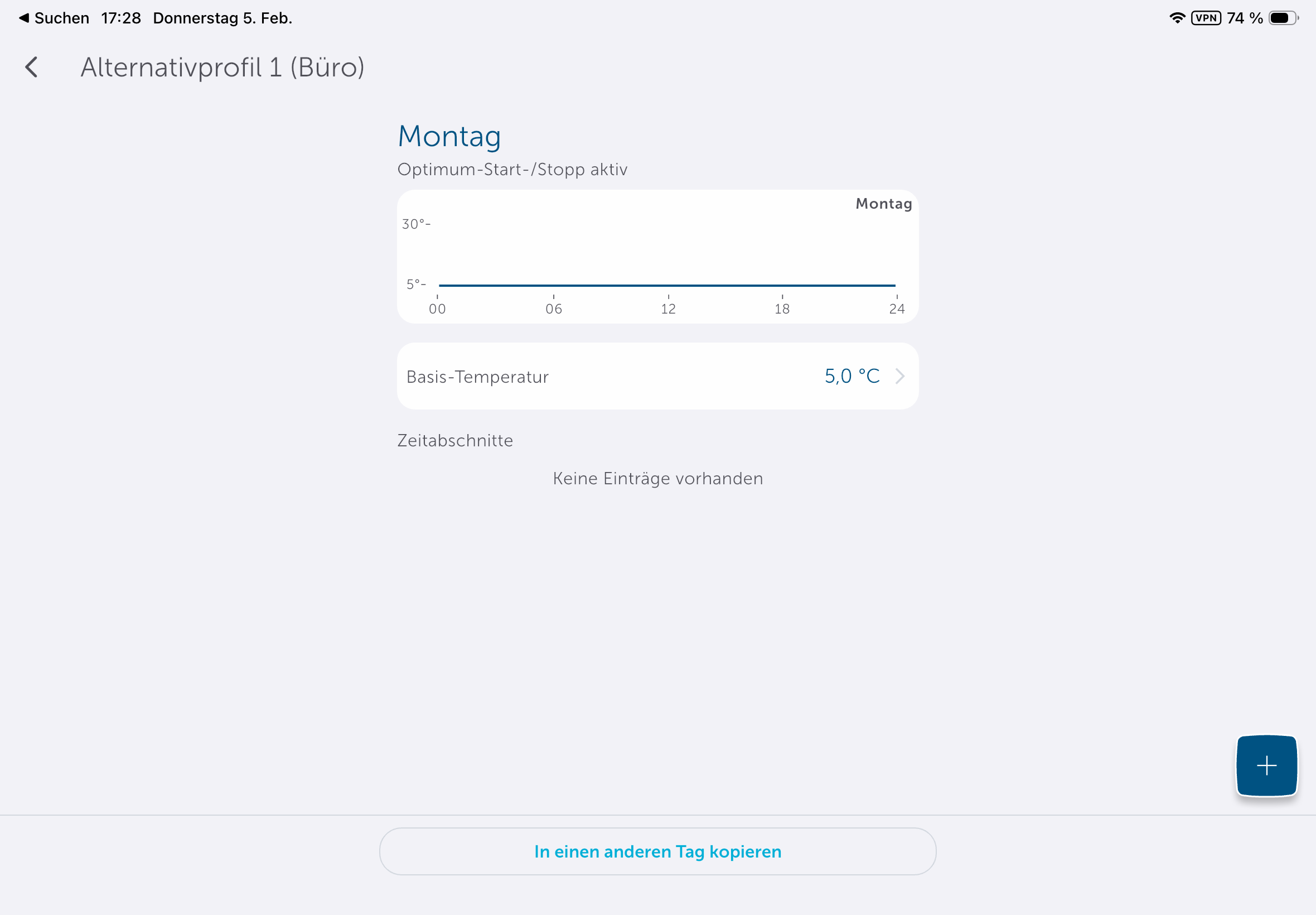
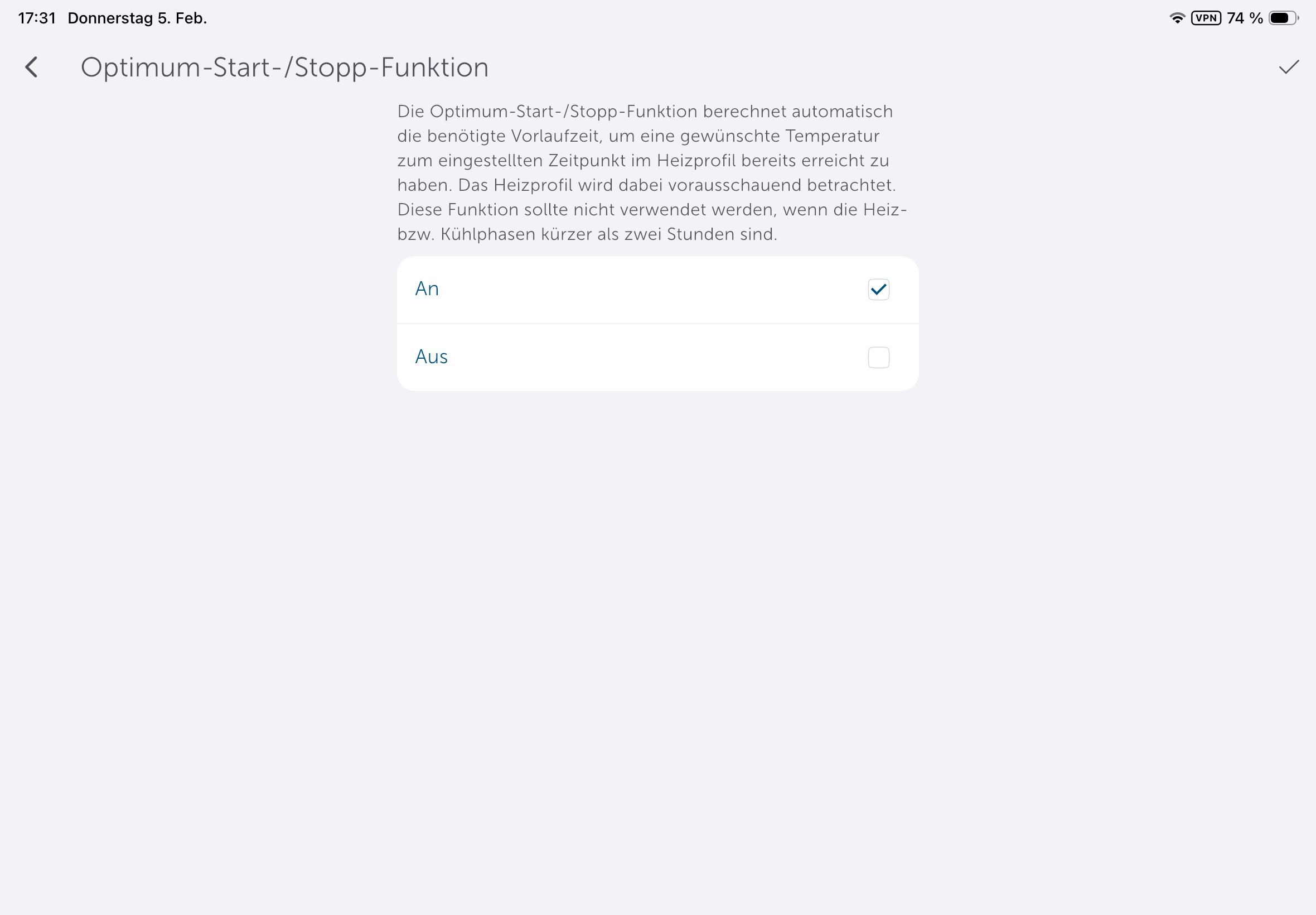
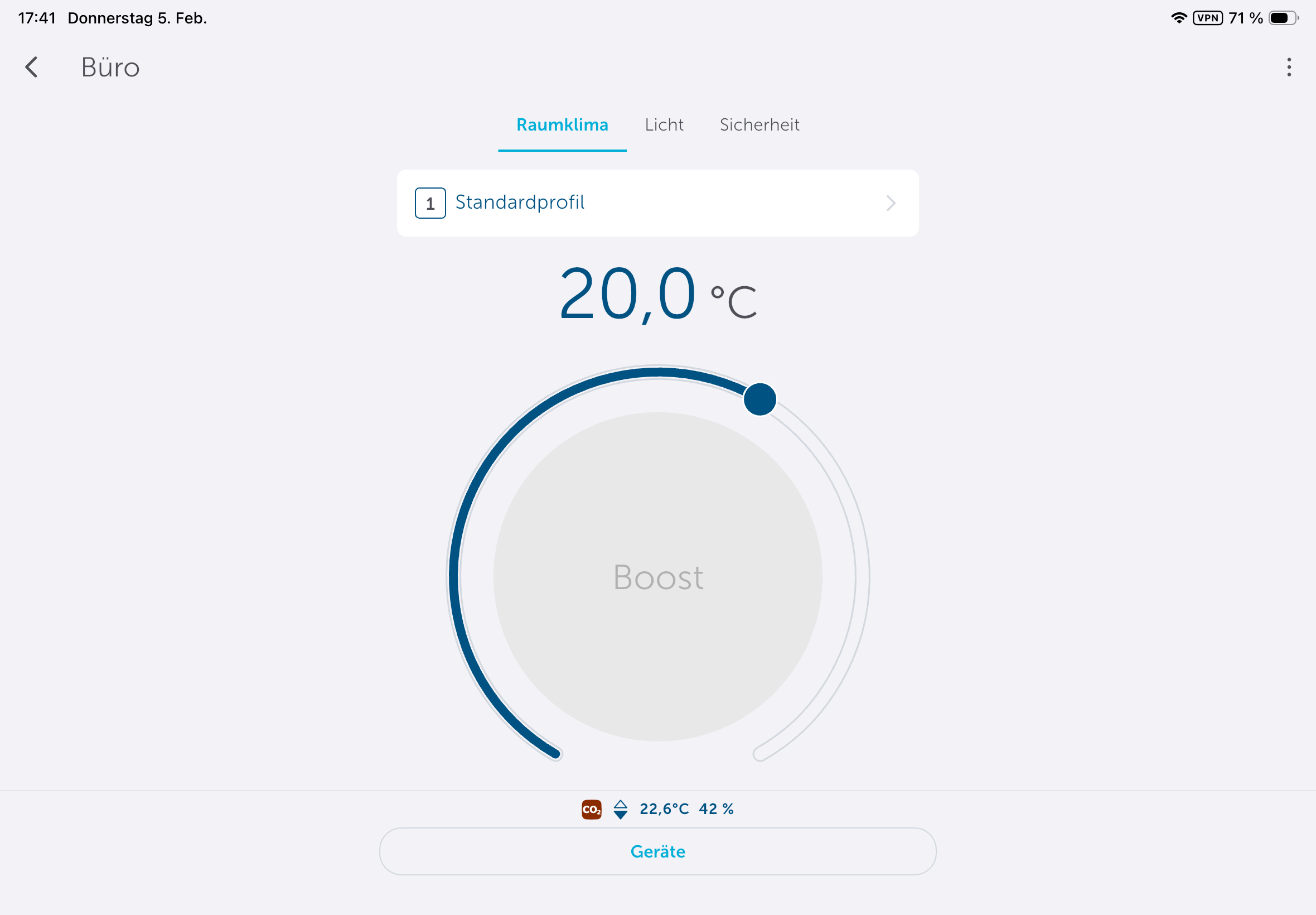
Die App könnte etwas intuitiver sein, da man Heizpläne nicht direkt in den Geräteeinstellungen anlegen kann, sondern unter Raumklima. Dort stehen mit Heizprofile und Raumklimakonfiguration zwei Abschnitte zur Steuerung parat. Passend zur Trägheit einer Fußbodenheizung sorgt die Aktivierung der Optimum-Start-/Stop-Funktion für ein Erreichen der im Heizprofil hinterlegten Temperatur zu einem bestimmten Zeitpunkt. Wer diese deaktiviert, muss beim Anlegen des Heizplans die Trägheit der Fußbodenheizung in Betracht ziehen. Anders ausgedrückt: Wer es um 8:22 Uhr °C warm haben will, sollte, wenn die Funktion deaktiviert ist, besser 7:30 Uhr oder 7 Uhr im Heizplan einstellen.
Wie gut ist die Smart-Home-Anbindung?
Homematic IP bietet eine Reihe von Smart-Home-Komponenten, die nahezu jeden Anwendungsfall abdecken. In Verbindung mit einem Thermostat ist etwa der Einsatz eines Tür-/Fenstersensors empfehlenswert, sodass man die Raumtemperatur absenken kann, sobald der Sensor ein geöffnetes Fenster signalisiert und den Heizvorgang wieder aktiviert, sobald das Fenster geschlossen ist. Entsprechende Regeln können Anwender unter Automatisierung erstellen. Benachrichtigungen, etwa über eine erhöhte CO₂-Konzentration, sind darüber auch realisierbar.
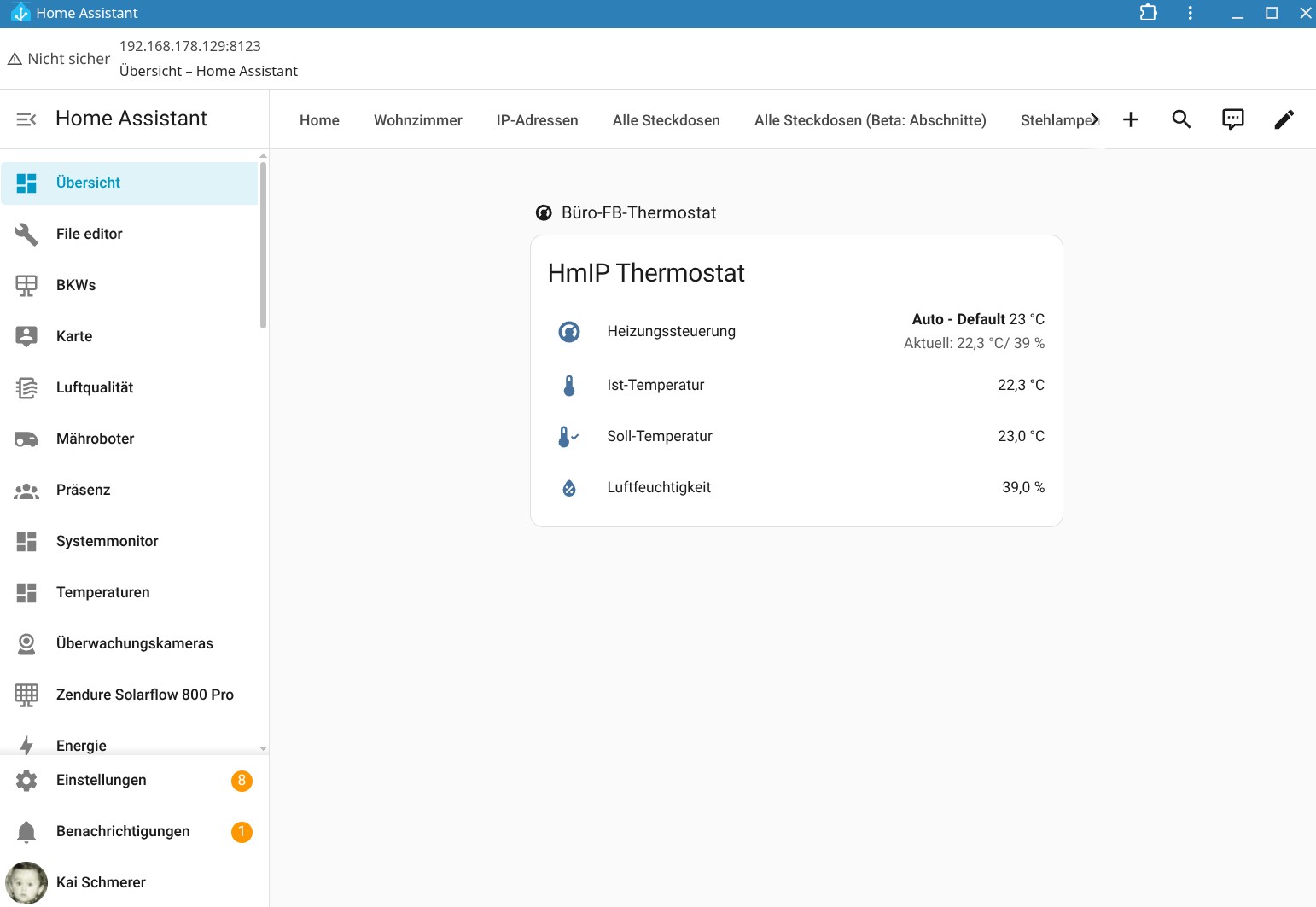
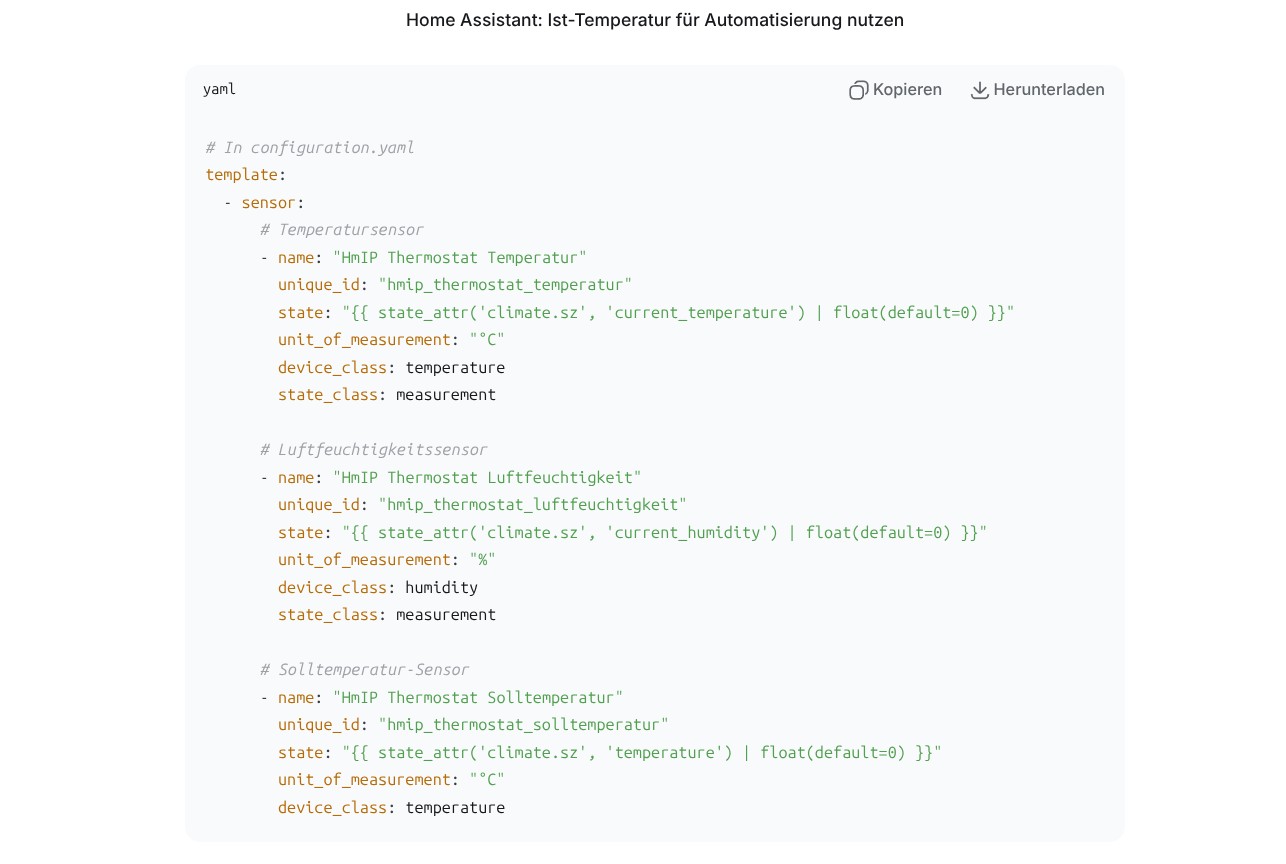
Die Integration in Home Assistant ist hingegen nur rudimentärer Natur. Man kann zwar die Heizung damit manuell steuern. Eine Automatisierung ist aber erst nach einer manuellen Anpassung möglich, mit der über ein Template die aktuelle Temperatur des Thermostats, die Zieltemperatur sowie die Luftfeuchte als Entitäten integriert werden.
Dank der Hilfe von KI-Tools hält sich diese Anpassung allerdings in Grenzen. Neben einem klassischen Heizplan kann man unter Home Assistant auch eine Fenster-Offen-Erkennung auf Basis eines Temperaturabfalls realisieren. Ein externer Sensor arbeitet natürlich exakter. Eine Integration des im Thermostat integrierten CO₂-Sensors ist hingegen nicht möglich. Schade.
Eine Sprachsteuerung mit Amazon Alexa und Google Assistant ist ebenfalls möglich.
Preis
Das Homematic IP Glas-Wandthermostat mit CO₂-Sensor kostet regulär knapp 180 Euro. Der bislang erreichte Tiefstpreis lag bei 155 Euro. Ohne CO₂-Sensor kostet das Thermostat rund 150 Euro. Bei Ebay ist es gerade für 143 Euro im Angebot.
Dazu muss man noch Kosten für einen Glasrahmen in Höhe von etwa 30 Euro und mindestens für einen Access Point von knapp 60 Euro kalkulieren. Wer eine lokale Ansteuerung wünscht, kann auch zu einer Home Control Unit für knapp 300 Euro oder zur CCU3-Zentrale für etwa 175 Euro greifen. Für den Einsatz weiterer Taster von Homematic IP, etwa zur Lichtsteuerung, stehen Glasrahmen mit zwei oder drei Montageplätzen zur Verfügung.
Lohnt sich eine smarte Fußbodenheizung?
Die Wirtschaftlichkeit der Heizung wird maßgeblich durch die Art des Heizsystems sowie die individuellen Nutzungsgewohnheiten bestimmt. Bei wassergeführten Fußbodenheizungen ist aufgrund ihrer hohen thermischen Trägheit zu beachten, dass kurze, starke Temperaturabsenkungen in der Nacht häufig unwirtschaftlich sind. Der Energieaufwand, um die ausgekühlten Räume am Morgen wieder aufzuheizen, kann die nächtliche Energieeinsparung übersteigen.
Deutlich sinnvoller sind Absenkungen bei längerer Abwesenheit. Beispielsweise muss ein Büro über das Wochenende nicht auf Komforttemperatur gehalten werden. Eine Reduzierung von etwa 23 °C auf 20 °C oder der Betrieb in der Frostschutzstellung kann hier bereits zu spürbaren Kosteneinsparungen führen.
Fazit
Mit dem Homematic IP Glas-Wandthermostat bietet eQ-3 ein hochwertiges Thermostat für Fußbodenheizungen, das höchsten ästhetischen Ansprüchen genügt. Die Variante mit integriertem CO₂-Sensor sorgt nicht nur für eine smarte Regelung der Fußbodenheizung, sondern informiert über das aus jedem Blickwinkel gut ablesbare Glas-Display über Temperatur, Luftfeuchte und CO₂-Konzentration.
Eine Integration in Home Assistant ist zwar möglich, doch diese bedarf des Feintunings, will man das Thermostat möglichst umfassend steuern. Immerhin sind die nötigen manuellen Eingriffe dank KI-Tools relativ überschaubar. Die Werte des CO₂-Sensors werden hingegen nicht unter Home Assistant angezeigt.
Der Preis samt passendem Glasrahmen von über 200 Euro dürfte den Kundenkreis stark einschränken. Zudem gesellen sich noch Kosten für einen Homematic IP Access Point oder für eine Homematic Control Unit respektive CCU3-Zentrale.

Vibe-Coding nach dem Tiktok-Prinzip: So funktioniert Gizmo

Nextcloud schaltet den ADA-Turbo: Deutliche Performance-Verbesserungen kommen

LibreOffice 26.2: Freie Büro-Software lernt Markdown und wird schneller

Kommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Huawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-
 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-
 Künstliche Intelligenzvor 1 Monat
Künstliche Intelligenzvor 1 MonatSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenFast 5 GB pro mm²: Sandisk und Kioxia kommen mit höchster Bitdichte zum ISSCC
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenWeiter billig Tanken und Heizen: Koalition will CO₂-Preis für 2027 nicht erhöhen