Entwicklung & Code
GitLab 18.2: Duo Agent Platform für VS Code und JetBrains als Beta erschienen
GitLabs Juli-Release mit der Versionsnummer 18.2 steht bereit. Die Entwicklungsplattform legt den Fokus wie bereits in vergangenen Releases auf die KI-Nutzung und versieht die „Duo Agent Platform in the IDE“ mit dem Beta-Status. Daneben ist eine neue Merge-Request-Homepage erschienen und die Sicherheit in Bezug auf Container-Images soll sich durch unveränderliche Container-Tags erhöhen.
GitLab Duo Agent Platform in der IDE: Code-Interaktion mit natürlicher Sprache
Der KI-Dienst GitLab Duo Agent Platform für IDEs liegt nun als Beta-Version vor und ist für zahlende GitLab-Kunden verfügbar. Die Plattform bringt Agentic Chat und Agent Flows mit und lässt sich mittels Erweiterungen in Visual Studio Code sowie in JetBrains-Entwicklungsumgebungen verwenden. Dadurch können Entwicklerinnen und Entwickler in natürlicher Sprache mit ihren Codebasen und GitLab-Projekten interagieren.
Der Agentic Chat ist darauf ausgelegt, schnelle Aufgaben wie das Erstellen und Editieren von Dateien oder die Dateisuche in Codebasen mittels Pattern Matching und grep auszuführen. Dagegen sind Agent Flows dazu vorgesehen, mit größeren Implementierungen und Planungen umzugehen, um Ideen vom Konzept bis zur Architektur voranzubringen. Dazu nutzen die Agent Flows GitLab-Ressourcen wie Issues, Merge Requests, Commits, CI/CD-Pipelines und Informationen über Sicherheitslücken.
Zudem unterstützt die Duo Agent Platform das Model Context Protocol (MCP). Ein dedizierter Blogeintrag hält ausführliche Informationen zur Plattform bereit. In den kommenden Wochen sollen weitere Features hinzukommen, darunter die Integration in GitLab, Support für Visual Studio und ein KI-Katalog zur Auswahl spezialisierter Agenten und Flows:

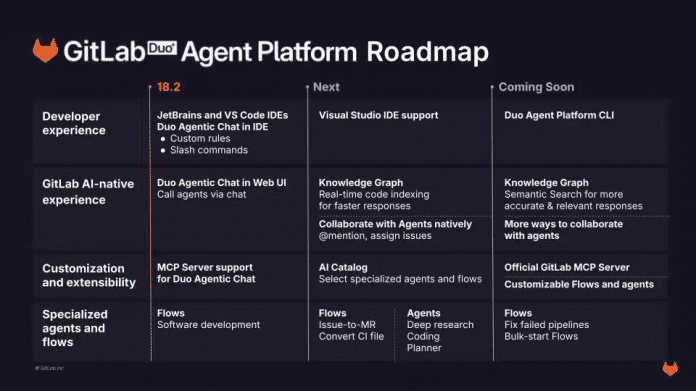
Roadmap der GitLab Duo Agent Platform
(Bild: GitLab)
Neue Homepage für Merge Requests und Security-Feature für Container
Für User aller GitLab-Editionen steht eine neue Merge-Request-Homepage bereit. Diese soll laut dem GitLab-Team intelligent priorisieren, welche Aspekte aktuell Aufmerksamkeit benötigen. Dazu stehen zwei Ansichten bereit: Die Workflow View organisiert Merge Requests nach ihrem Review-Status und gruppiert sie nach ihrer Stufe im Code-Review-Workflow. Die Role View gruppiert dagegen Merge Requests anhand dessen, ob der Betrachter oder die Betrachterin entweder Autor oder Reviewer ist.
Eines der weiteren Updates in GitLab 18.2 richtet sich ausschließlich an Ultimate-User und soll der erhöhten Sicherheit dienen: Sie können nun durch immutable (unveränderliche) Container-Tags ihre Container-Images vor ungewünschten Änderungen schützen. Nachdem ein Tag erstellt wurde, das einer Immutable-Regel entspricht, lässt sich das Container-Image durch niemanden mehr verändern. Dabei gibt es einige Einschränkungen, unter anderem lassen sich nur bis zu fünf Regeln pro Projekt einsetzen und die Next-Generation Container Registry (standardmäßig aktiviert auf GitLab.com) wird vorausgesetzt.
Weitere Informationen zu diesen und anderen neuen Features in GitLab 18.2 bietet der GitLab-Blog. Insgesamt sind über 30 Neuerungen in das Release eingezogen.
(mai)










Entwicklung & Code
KI-Überblick 4: Deep Learning – warum Tiefe den Unterschied macht
Die bisherigen Beiträge dieser Serie haben gezeigt, dass neuronale Netze aus einfachen Bausteinen bestehen. Erst die Kombination vieler dieser Bausteine in mehreren Schichten ermöglicht jedoch die Durchbrüche, die moderne KI-Systeme prägen. Genau hier setzt das Konzept „Deep Learning“ an: Es beschreibt maschinelles Lernen mit tiefen, also mehrschichtigen, neuronalen Netzen.

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Deser Beitrag klärt, was „tief“ im Kontext neuronaler Netze bedeutet, warum zusätzliche Schichten die Leistungsfähigkeit erhöhen und welche typischen Architekturen in der Praxis verwendet werden.
Was „deep“ wirklich heißt
Von Deep Learning spricht man, wenn ein neuronales Netz mehrere verborgene Schichten enthält – in der Regel deutlich mehr als zwei oder drei. Jede Schicht abstrahiert die Ausgaben der vorherigen Schicht und ermöglicht so, komplexe Funktionen zu modellieren. Während einfache Netze vor allem lineare und leicht nichtlineare Zusammenhänge erfassen, können tiefe Netze hochdimensionale Strukturen und Muster erkennen.
Die Entwicklung hin zu tieferen Netzen wurde erst durch drei Faktoren möglich:
- Stärkere Rechenleistung – insbesondere durch Grafikkarten (GPUs) und später spezialisierte Hardware wie TPUs.
- Größere Datenmengen, die zum Training genutzt werden können.
- Verbesserte Trainingsverfahren, darunter die Initialisierung von Gewichten, Regularisierungstechniken und optimierte Aktivierungsfunktionen.
Hierarchisches Lernen von Merkmalen
Ein Kernprinzip des Deep Learning ist die hierarchische Merkmalsextraktion. Jede Schicht eines tiefen Netzes lernt, auf einer höheren Abstraktionsebene zu arbeiten:
- Frühe Schichten erkennen einfache Strukturen, zum Beispiel Kanten in einem Bild.
- Mittlere Schichten kombinieren diese zu komplexeren Mustern, etwa Ecken oder Kurven.
- Späte Schichten identifizieren daraus ganze Objekte wie Gesichter, Autos oder Schriftzeichen.
Diese Hierarchiebildung entsteht automatisch aus den Trainingsdaten und macht Deep Learning besonders mächtig: Systeme können relevante Merkmale selbst entdecken, ohne dass Menschen sie mühsam vordefinieren müssen.
Typische Architekturen
Im Deep Learning haben sich verschiedene Architekturen etabliert, die für bestimmte Datenarten optimiert sind.
Convolutional Neural Networks (CNNs) sind spezialisiert auf Bild- und Videodaten. Sie verwenden Faltungsschichten („Convolutional Layers“), die lokale Bildbereiche analysieren und so translationinvariante Merkmale lernen. Ein CNN erkennt beispielsweise, dass ein Auge im Bild ein Auge bleibt, egal wo es sich befindet. CNNs sind der Standard in der Bildklassifikation und Objekterkennung.
Recurrent Neural Networks (RNNs) wurden entwickelt, um Sequenzen wie Text, Sprache oder Zeitreihen zu verarbeiten. Sie besitzen Rückkopplungen, durch die Informationen aus früheren Schritten in spätere einfließen. Damit können sie Zusammenhänge über mehrere Zeitschritte hinweg modellieren. Varianten wie LSTMs (Long Short-Term Memory) und GRUs (Gated Recurrent Units) beheben typische Probleme wie das Vergessen relevanter Informationen.
Autoencoder sind Netze, die Eingaben komprimieren und anschließend wieder rekonstruieren. Sie lernen dabei implizit eine verdichtete Repräsentation der Daten und werden etwa für Anomalieerkennung oder zur Vorverarbeitung genutzt. Erweiterte Varianten wie Variational Autoencoders (VAE) erlauben auch generative Anwendungen.
Diese Architekturen bilden die Grundlage vieler moderner KI-Anwendungen. Sie sind jedoch noch nicht der Endpunkt: In den letzten Jahren haben Transformer klassische RNNs in vielen Bereichen abgelöst, insbesondere in der Sprachverarbeitung. Darum wird es in einer späteren Folge dieser Serie gehen.
Herausforderungen des Deep Learning
Tiefe Netze sind leistungsfähig, bringen aber neue Herausforderungen mit sich:
- Großer Datenhunger: Ohne ausreichend Trainingsdaten tendieren tiefe Modelle zum Überfitting.
- Rechenintensiv: Training und Inferenz erfordern spezialisierte Hardware und hohe Energieaufwände.
- Schwer erklärbar: Mit wachsender Tiefe nimmt die Nachvollziehbarkeit weiter ab, was für viele Anwendungsbereiche problematisch ist.
Trotzdem hat sich Deep Learning als Schlüsseltechnologie für die meisten aktuellen KI-Durchbrüche etabliert.
Ausblick
Die nächste Folge widmet sich den Transformern – der Architektur, die Large Language Models und viele andere moderne Systeme ermöglicht. Sie erläutert, warum klassische RNNs an ihre Grenzen stießen und wie Self-Attention die Verarbeitung von Sprache revolutionierte.
(rme)
Entwicklung & Code
Die Produktwerker: Sprintziele etablieren, die wirklich helfen
Sprintziele gehören zu den stärksten Werkzeugen im Scrum-Framework. In dieser Folge diskutieren Dominique Winter und Oliver Winter, wie es Teams gelingt, Sprintziele so zu etablieren, dass sie Orientierung geben, Wirkung entfalten und Vertrauen schaffen. Ein Sprintziel ist schließlich mehr als eine Pflichtübung im Sprint Planning. Richtig eingesetzt, schafft es Klarheit über das „Warum“ der nächsten Iteration und verbindet die tägliche Arbeit mit der Produktvision.
Schwierigkeiten mit Sprintzielen
Vielen Teams fällt die Nutzung von Sprintzielen jedoch schwer. Häufig gibt es gar kein Ziel oder es bleibt auf der Ebene von Aufgabenlisten stecken. Statt echter Wirkung wird dann nur Output gemessen. Die Folge: wenig Fokus, kaum Begeisterung bei Stakeholdern und sinkendes Vertrauen in den Wert von Sprintzielen.
(Bild: deagreez/123rf.com)

So geht Produktmanagement: Auf der Online-Konferenz Product Owner Day von dpunkt.verlag und iX am 13. November 2025 können Product Owner, Produktmanagerinnen und Service Request Manager ihren Methodenkoffer erweitern, sich vernetzen und von den Good Practices anderer Unternehmen inspirieren lassen.
Gute Sprintziele: Outcome-orientiert und im Alltag präsent
Doch gerade hier liegt der Hebel. Ein gut formuliertes Sprintziel richtet die Arbeit am Outcome aus. Es beantwortet die Frage, welchen Mehrwert das Team in den kommenden zwei Wochen schaffen will, und gibt damit eine klare Orientierung für Entscheidungen im Sprint. Statt einer Sammlung von Backlog-Items entsteht ein gemeinsamer Fokus. Im Daily oder im Review lässt sich damit jederzeit prüfen, ob die Arbeit noch auf das eigentliche Ziel einzahlt.
Dominique Winter und Oliver Winter machen aber auch deutlich, dass Sprintziele eben nicht im stillen Kämmerlein entstehen sollten. Entscheidend ist die gemeinsame Gestaltung mit den Developern. Wer das Ziel aktiv mitformuliert, wird es auch eher als eigenes Commitment ansehen. So entsteht nicht nur mehr Akzeptanz, sondern auch die Bereitschaft, externe Einflüsse auszuhalten und das Ziel zu verteidigen. Product Owner bringen dabei den strategischen Rahmen ein – etwa Vision, Roadmap oder Product Goal – und öffnen einen Raum, in dem das Team das nächste sinnvolle Ziel bestimmen kann.
Ein gutes Sprintziel ist aber auch sichtbar und im Alltag präsent: in Dailys, in Gesprächen mit Stakeholdern und sogar in der spontanen Antwort auf die Frage „Woran arbeitet ihr gerade?“. Nur so werden sie zu einem lebendigen Orientierungspunkt statt zu einem Protokolleintrag. Wenn ein Team das gemeinsam vereinbarte Sprintziel erreicht, gilt es, diesen Erfolg sichtbar zu feiern; nicht die Anzahl der erledigten Backlog-Items, sondern den erzielten Mehrwert. Gerade im Sprint Review eröffnet das die Chance, Stakeholder zu begeistern und ihnen zu zeigen, warum sich die investierte Arbeit gelohnt hat. So wird das Konzept Sprintziele gestärkt und gewinnt wieder Vertrauen.
Zusammengefasst helfen Sprintziele Teams dabei, sich auf das Wesentliche zu konzentrieren, Entscheidungen leichter zu treffen und Stakeholder einzubeziehen. Wer sie konsequent auf Outcome ausrichtet, gemeinsam gestaltet und sichtbar macht, etabliert ein Instrument, das weit mehr ist als eine Formalität. Es ist ein Kompass, der Produktteams eine gemeinsame, wertvolle Richtung gibt.
Die aktuelle Ausgabe des Podcasts steht auch im Blog der Produktwerker bereit: „So etablierst du Sprintziele, die wirklich helfen„.
(mai)
Entwicklung & Code
Flexibel und pflegeleicht: Testing ohne Mocks
Robuste, automatisierte Tests sind feste Bestandteile der agilen Softwareentwicklung. Da Anforderungen und Rahmenbedingungen sich stetig ändern, müssen Entwicklerinnen und Entwickler kontinuierlich in der Lage sein, ihre Architektur anzupassen. Ihr Code muss wachsen und sich weiterentwickeln können. Sie müssen laufend bestehende Features erweitern, anpassen, umsortieren, zusammenführen oder aufteilen. Dazu benötigen sie die Unterstützung einer schnellen, verlässlichen und robusten Testsuite, die bestehende Funktionen der Software nicht beeinträchtigt.

Martin Grandrath ist Software-Developer und entwickelt seit über 15 Jahren Applikationen mit Web-Technologien. Seine Schwerpunkte sind neben Frontend-Architektur vor allem Software-Craftsmanship und testgetriebene Entwicklung. Seit 2023 arbeitet er als Senior IT-Consultant bei codecentric.
Auf Mocks basierende Tests verursachen häufig zusätzlichen Pflegeaufwand beim Refaktorieren, also Änderungen an der Codestruktur, die die Arbeit mit dem Code insgesamt vereinfachen, das Verhalten des Systems aber nicht verändern. Die Art und Weise, wie Mocks in der Praxis meist zum Einsatz kommen, führt zu einer Kopplung von Tests und Implementierungsdetails. Änderungen an diesen Details erfordern Anpassungen der Tests, was zulasten der Entwicklungsgeschwindigkeit geht.
Dieser Artikel zeigt auf, welche Kompromisse mit auf Mocks basierenden Tests verbunden sind und stellt mit dem Nullable-Entwurfsmuster von James Shore eine Alternative vor.
Isolierte, interaktionsbasierte Tests
Mock-Objekte oder kurz Mocks (englisch für „Attrappe“) sind eine Unterkategorie der Test-Doubles, die in Unit Tests als Platzhalter für Produktionsobjekte dienen. Der Begriff Test-Double ist angelehnt an das Stunt-Double in Filmen. Weitere Arten von Test-Doubles sind Stubs, Spies oder Fakes.
Mocks zeichnen während eines Testlaufs auf, wie die Software mit ihnen interagiert: Welche ihrer Methoden ruft die Anwendung in welcher Reihenfolge und mit welchen Argumenten auf? Anschließend verifiziert der Unit-Test, ob die beobachteten Interaktionen mit den erwarteten übereinstimmen. Auf diese Weise werden die Interaktionen zwischen den Objekten zu einem integralen Bestandteil der Implementierung und der Tests. Diese Art von Tests wird als Interaction-based bezeichnet.
Gleichzeitig isolieren Mocks das zu testende Objekt von seinen Abhängigkeiten. Während des Tests wird also nur der Code eines einzelnen Objekts ausgeführt, während alle Interaktionspartner durch Mocks ersetzt werden. Tests, die Objekte in Isolation testen, nennt man solitary.
Auch wenn Solitary Interaction-based Tests ihre Vorzüge haben und sich im Laufe der Zeit zum Standard entwickelt haben, sind sie nicht frei von Nachteilen. Dass Tests an die Interaktionen zwischen Objekten gekoppelt sind, erschwert Refaktorierungen. Diese sind jedoch ein unverzichtbares Werkzeug, um die Qualität der Codebasis dauerhaft aufrechtzuerhalten.
Refaktorierungen, die die Interaktionen zwischen Objekten verändern, können zu False Positives führen: Tests schlagen fehl, obwohl das Programm als Ganzes keine Fehler enthält. Lediglich die Objektinteraktionen weichen von den Erwartungen der Tests ab. Eine Suite aus Interaction-based Tests macht die Codebasis dadurch insgesamt weniger flexibel, da die Tests die Implementierungsdetails fixieren.
Zudem kann es vorkommen, dass Solitary Tests Fehler nicht erkennen, wenn zwar alle Objekte in Isolation erwartungsgemäß arbeiten, es aber im Zusammenspiel der Objekte zu unerwünschtem Verhalten kommt. Um dem vorzubeugen, sind neben den Unit Tests zusätzliche Integrationstests erforderlich, die gezielt das Zusammenspiel mehrerer Objekte testen.
Eine Alternative stellen Sociable, State-based Tests dar.
Echte Abhängigkeiten und sichtbares Verhalten
In Sociable Tests interagiert das zu testende Objekt nicht mit Test-Doubles, sondern mit den echten Abhängigkeiten, die auch im Produktivbetrieb existieren. Fehler, die durch die Interaktion zwischen den Objekten entstehen, fallen im Test sofort auf. Separate Integrationstests sind nicht erforderlich.
State-based Tests verifizieren das sichtbare Verhalten von Objekten und ignorieren die darunter liegenden Interaktionen. Diese Tests reagieren daher sehr viel robuster gegenüber Refactorings, da sie sich nur für das Endergebnis interessieren und nicht für die Implementierungsdetails.
Der Elefant im Raum
Die echten Produktionsobjekte in den Tests zu verwenden, statt sie durch Mocks zu ersetzen, führt zunächst zu einem Problem: Der zu testende Code muss mit APIs, Datenbanken oder dem Dateisystem kommunizieren. Diese Nebenwirkungen (Side Effects) würden zu nicht deterministischen Tests führen, da sie vom globalen Zustand abhängig sind, unter anderem von Drittsystemen. So könnte etwa ein Test fehlschlagen, weil eine Fremd-API mit anderen Daten antwortet, als es der Test erwartet.
Ein weiteres Problem sind die Auswirkungen, die API-Aufrufe haben können. Dass jede Ausführung der Warenkorbtests eine Kreditkarte belastet, ist nicht wünschenswert. Darüber hinaus muss es möglich sein, zu testen, wie sich ein Programm verhält, wenn eine Dritt-API mit unterschiedlichen Formaten, mit Fehlern oder gar nicht antwortet. Und schließlich verlangsamt die API-Anbindung die Tests.
Integrationstests sind zwar für den Übergang des zu implementierenden Systems mit der Außenwelt notwendig, aber die Nebenwirkungen sind für die Tests innerhalb des Systems unerwünscht.

Weg von Windows 11: Gaming unter Linux mit Bazzite im Selbstversuch

Stuttgarter Autobauer: So lässt Mercedes auf der IAA Mobility die Marke strahlen

Google AI Overviews: Wenn sich die KI auf KI als Quelle beruft

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

Der ultimative Guide für eine unvergessliche Customer Experience

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 UX/UI & Webdesignvor 3 Wochen
UX/UI & Webdesignvor 3 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-

 UX/UI & Webdesignvor 1 Woche
UX/UI & Webdesignvor 1 WocheAdobe Firefly Boards › PAGE online
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
eine gute Nachricht ist")
eine gute Nachricht ist") Social Mediavor 3 Wochen
Social Mediavor 3 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 3 Wochen
Entwicklung & Codevor 3 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 5 Tagen
Entwicklung & Codevor 5 TagenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events