Künstliche Intelligenz
IT-Modernisierung: Unternehmen müssen ihren Legacy-Anwendungen zu Leibe rücken
In deutschen Firmen herrscht dringender IT-Modernisierungsbedarf, wie aus einer Studie der Beratungsgesellschaft Lünendonk hervorgeht. Demnach haben 62 Prozent der befragten Unternehmen angegeben, dass Teile ihrer geschäftskritischen Anwendungen bereits so veraltet sind, dass sie nicht mehr heutigen Anforderungen entsprechen und erneuert werden müssen. Bei der Hälfte seien auch Betrieb, Pflege und Weiterentwicklung der Altsysteme mittel- und langfristig nicht sichergestellt. Etwas über drei Viertel gehen davon aus, dass mindestens 20 Prozent aller geschäftskritischen Kernapplikationen in den nächsten fünf Jahren Modernisierungsbedarf haben.
Entsprechend planen 83 Prozent der Unternehmen, ihr IT-Modernisierungsbudget im Jahr 2026 zu erhöhen. Bei fast einem Fünftel soll das Budget um mehr als fünf Prozent steigen. Für die Studie hat Lünendonk eigenen Angaben nach über 150 IT- und Business-Verantwortliche mittelständischer und großer Unternehmen verschiedener Branchen befragt. Treiber für die steigenden Ausgaben sind vor allem steigende regulatorische Anforderungen an die Cybersicherheit, aber auch die Sorge vor Sicherheitsangriffen.

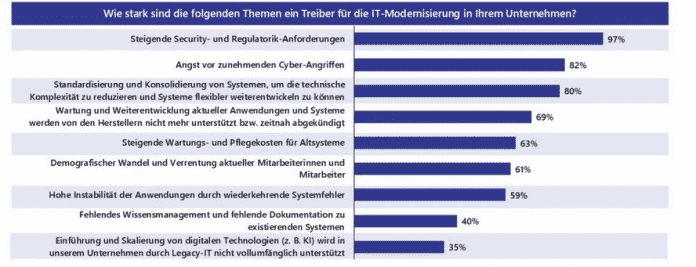
Vor allem Sicherheitsbedenken treiben die IT-Modernisierung an.
(Bild: Lünendonk)
Auf in die Cloud
Bei den Modernisierungsstrategien spielt wenig überraschend der Weg in die Cloud eine große Rolle. So wollen bis 2028 bereits neun von zehn befragten Unternehmen mehr IT-als 40 Prozent ihrer Anwendungen cloudbasiert betreiben. Aktuell täten das nur vier von zehn. Lünendonk geht davon aus, dass diese Verknüpfung verschiedener Betreibermodelle die IT-Landschaften zunehmend hybrider macht.
Dabei verfolgen die Unternehmen unterschiedliche Ansätze. 74 Prozent setzten auf Replatforming, also die Umstellung der Legacy-Anwendungen auf eine neue Plattform, 64 Prozent auf Refactoring. 72 Prozent wiederum wechselten komplett auf On-Premises- oder Private-Cloud-basierte Standardlösungen. Nur 47 Prozent entschieden sich für den Weg einer kompletten Neuentwicklung.
SaaS und KI spielen nur Nebenrolle
Software-as-a-Service (SaaS) kommt vorwiegend bei weniger kritischen Anwendungen infrage. Bei geschäftskritischen Anwendungen herrscht hier laut Lünendonk noch Skepsis vor. Insgesamt setzten 43 Prozent auf SaaS, um sich ihrer Legacy-Anwendungen zu entledigen.
Beim Bewältigen ihres Modernisierungsstaus setzen die Unternehmen auch große Hoffnungen auf KI – wobei es allerdings an praktischen Erfahrungen mangelt, wie hilfreich sie wirklich dabei ist. 74 Prozent erwarten demnach, dass KI in der Lage sein wird, Sicherheitslücken in Altsystemen aufzudecken und zumindest teilweise selbstständig zu beheben. 69 Prozent erhoffen sich außerdem ein besseres Verständnis der Programmier- und Codestrukturen. Allerdings verfügen nur acht Prozent der Unternehmen über fortgeschrittene Ansätze zur automatisierten Codeanalyse mittels KI. 22 Prozent nutzen KI immerhin bereits im Bereich der Dokumentation.
(axk)











Künstliche Intelligenz
„Animal Crossing“: Entwickler verpasst dem Kultspiel dynamische KI-Dialoge
Das Gamecube-Spiel „Animal Crossing“ (2001) ist längst Kult – auch wegen seiner immer gleichen, einstudierten Dialogzeilen, die die virtuellen Dorfbewohner von sich geben.
Genau das wollte Entwickler Josh Fonseca ändern: Wie er auf seinem Blog und in einem Youtube-Video detailliert festhält, hat er es geschafft, dass die NSCs in Echtzeit mithilfe einer Art KI-Gehirn sprechen können. Und das ganz ohne den alten Spielcode umzuschreiben. Stattdessen baute er eine Art Brücke zwischen dem Emulator, in dem das Spiel läuft, und einer KI in der Cloud. So können die Figuren plötzlich über aktuelle Ereignisse plaudern oder sich mit neuen Charakterzügen präsentieren.
Kreativer Hack: Dialoge kommen von externem Speicher
Das Hauptproblem, mit dem sich der Tüftler konfrontiert sah: Der Gamecube hat zu wenig Speicherkapazität und keine Internetverbindung, was die Kopplung mit jedwedem Large Language Model (LLM) zunächst unmöglich erscheinen lässt.
Die kreative Lösung: Fonseca hat das Spiel so umgeleitet, dass es seine Texte nicht mehr nur aus dem Speicher liest, sondern auch von einer externen „Mailbox“. Dort schreibt ein kleines Zusatzprogramm die Antworten der KI hinein.
Für das Spiel sieht es dann so aus, als kämen die Wörter direkt aus seiner eigenen Datenbank – dabei stammen sie aus einer modernen Sprach-KI. Das Ergebnis: Die Tiere reden nicht mehr in festen Phrasen, sondern reagieren flexibler und persönlicher.
„Animal Crossing“-Hack: Ein Dorf, das plötzlich lebt
Damit die Gespräche glaubwürdig wirken, hat Fonseca jeder Spielfigur ein eigenes „Profil“ gegeben – also typische Eigenschaften, Interessen und Macken, die er aus Fan-Wikis übernommen hat.
Eine KI schreibt die Texte, eine zweite sorgt als „Director“ dafür, dass sie wie im Originalspiel aussehen und klingen – mit Emotes, kleinen Pausen und Tonspielereien. Diese Arbeitsteilung sorgt dafür, dass die Bewohner nicht beliebig plappern, sondern wie ihre bekannten Charaktere wirken.
Besonders spannend: Die Dorfbewohner können sogar aktuelle Nachrichten aufgreifen. Fonseca hat eine kleine News-Quelle angeschlossen, sodass plötzlich ein tierischer Nachbar beiläufig eine Schlagzeile kommentiert. Außerdem erinnern sich die Figuren an bestimmte Gespräche untereinander – was dazu führt, dass sie auch zum Beispiel auch mal anfangen, über andere Spielfiguren wie Tom Nook zu lästern. Dadurch wirkt das Dorf lebendiger, manchmal sogar unheimlich echt. Für Interessierte stellt Fonseca seinen Code auf GitHub bereit.
Hack lässt erahnen, was mit KI in Games möglich sein könnte
Technisch ließe sich das Projekt auch auf echter Gamecube-Hardware ausprobieren – über einen alten Netzwerkadapter. Das wäre aber deutlich komplizierter, weil „Animal Crossing“ selbst keine Online-Funktion hat. Für den Emulator ist Fonsecas Lösung dagegen elegant und stabil.
Der Einfluss von künstlicher Intelligenz auf die Spielebranche ist für die Spieler selbst bisher noch kaum spürbar. Der Hack zeigt, wie nostalgische Spiele mit moderner KI plötzlich ein zweites Leben bekommen können – und gibt eine Vorahnung darauf, was noch alles möglich sein könnte, wenn Figuren in neueren Games plötzlich anfangen, Dialoge zu improvisieren.
Dieser Beitrag ist zuerst auf t3n.de erschienen.
(jle)
Künstliche Intelligenz
iX-Workshop IT-Sicherheit: Angriffstechniken verstehen und erfolgreich abwehren
Der iX-Workshop IT-Sicherheit: Aktuelle Angriffstechniken und ihre Abwehr beschäftigt sich mit aktuellen Angriffstechniken und den sich daraus ergebenden notwendigen Schutzmaßnahmen für Ihre IT-Systeme vor potenziellen Angriffen. Ausgehend von der aktuellen Bedrohungslage im Bereich der IT-Sicherheit lernen Sie praktische Strategien und Techniken zur Abwehr häufig auftretender Angriffe kennen. In einer Laborumgebung demonstriert Referent Oliver Ripka typische Angriffstechniken und stellt nützliche Tools vor, mit denen Sie selbst Angriffe erkennen und abwehren können.
Am Ende des Workshops haben Sie ein Verständnis dafür entwickelt, wie Angreifer vorgehen und welche konkreten Schutzmaßnahmen Sie ergreifen können, um Ihre Systeme sicherzumachen. Auf Basis dieses Wissens lernen Sie, die Schwachstellen und Angriffsmöglichkeiten Ihrer eigenen IT-Infrastruktur zu bewerten und die Wirksamkeit der eingesetzten Sicherheitsmaßnahmen einzuschätzen.
Ihr Trainer Oliver Ripka ist ein erfahrener Sicherheitsberater und Trainer bei Söldner Consult. Als Experte für Netzwerksicherheit liegen seine fachlichen Schwerpunkte in den Bereichen offensive Sicherheit und Netzwerkanalyse.
Der nächste Sicherheitsworkshop findet am 08. und 09. Oktober 2025 statt und richtet sich an IT-Administratoren, die ihren Blick für IT-Sicherheit schärfen wollen, sowie an Interessierte, die einen Überblick über die Funktionsweise von Cyberangriffen erhalten möchten.

(ilk)
Künstliche Intelligenz
Gravitationswellen: Schwarzes Loch nach Kollision auf 180.000 km/h beschleunigt
Ein internationales Forschungsteam hat zum ersten Mal Geschwindigkeit und Richtung des Rückstoßes ermittelt, mit dem ein Schwarzes Loch nach der Kollision zweier Vorläufer aus seiner Umgebung geschleudert wurde. Das hat die Universität Santiago de Compostela öffentlich gemacht, wo die Arbeit geleitet wurde. Gelungen ist das auf Basis der Gravitationswellen, die wir überhaupt erst seit 10 Jahren vermessen können. Das 2019 mit den Detektoren Advanced LIGO und Virgo beobachtete Signal GW190412 stammt demnach von der Verschmelzung zweier Schwarzer Löcher, deren Endprodukt auf 180.000 km/h katapultiert wurde. Das habe gereicht, um es aus seinem Kugelsternhaufen zu schleudern.
Hilfreich für die klassischere Astronomie
Gravitationswellen sind geringfügige Verformungen des Raum-Zeit-Gefüges, vorhergesagt wurden sie von Albert Einsteins Allgemeiner Relativitätstheorie. Der Physiker war aber davon ausgegangen, dass sie nie nachweisbar sein würden. Dank hochsensibler Messinstrumente ist das aber nun doch möglich – am 14. September 2015 wurden mit dem Gravitationswellen-Observatorium Ligo (Laser Interferometer Gravitation Wave Observatory) in den USA erstmals Gravitationswellen nachgewiesen. Schon zwei Jahre später gab es für diesen experimentellen Nachweis den Physik-Nobelpreis. Die spanische Universität erklärt jetzt, dass der Rückstoß zweier kollidierender Schwarzer Löcher zu den dramatischsten Elementen der zugrundeliegenden Ereignisse gehört, den habe man bislang aber nicht beobachten können.
Die jetzt eingesetzte Methode hat die Gruppe um den Physiker Juan Calderon-Bustillo demnach schon 2018 entwickelt. Sie beruht darauf, dass Gravitationswellen aus unterschiedlichen Richtungen unterschiedlich aussehen. Vor allem bei Kollisionen zweier besonders ungleicher Objekte könnte man deshalb den Rückstoß ermitteln, war sich die Gruppe sicher. Genau das wurde dann Mitte April 2019 beobachtet, die Gravitationswellen stammten vom Zusammenstoß zweier Schwarzer Löcher mit sehr unterschiedlicher Masse. Eines hatte etwa die achtfache Masse unserer Sonne, das andere kam auf die 30-fache Sonnenmasse. In akribischer Darstellung habe man eine dreidimensionale Darstellung des Ereignisses ermitteln können. Vorgestellt wird das im Fachmagazin Nature Astronomy.
Wenn man den Rückstoß und dessen Richtung künftig schneller ermitteln kann, könne das dabei helfen, auch andere Signale solcher Ereignisse zu finden, erklärt das Forschungsteam noch. Denn wenn ein so entstandenes Schwarzes Loch mit hoher Geschwindigkeit durch eine vergleichsweise dichte Umgebung wie einen Galaxienkern rast, könne es zu Signalblitzen kommen. Ob man die von der Erde aus nachweisen kann, hänge aber von der Richtung ab, in die das Schwarze Loch rast. Wenn man die kennt, könne man also echte Signale solch eines Ereignisses von zufälligen unterscheiden, die aus der gleichen Gegend am Nachthimmel kommen. Die Gravitationswellenastronomie wird damit also potenziell noch leistungsfähiger.
(mho)

„Animal Crossing“: Entwickler verpasst dem Kultspiel dynamische KI-Dialoge

CMC PRINT-MAILING-STUDIE 2025: Wie B2B-Unternehmen mit Print-Mailings ihre Kunden aktivieren

Asus ProArt: 162-Zoll-MicroLED-Display und ein OLED-Monitor für Profis

Der ultimative Guide für eine unvergessliche Customer Experience
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist

Adobe Firefly Boards › PAGE online
-
 UX/UI & Webdesignvor 4 Wochen
UX/UI & Webdesignvor 4 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
eine gute Nachricht ist") Social Mediavor 4 Wochen
Social Mediavor 4 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenAdobe Firefly Boards › PAGE online
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Wochen
Entwicklung & Codevor 2 WochenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen