Entwicklung & Code
LLM-Betreiber sammeln umfangreich persönlich Daten und geben diese weiter
Laut einer Studie der Datenschutzfirma Incogni geht der französische KI-Anbieter Mistral mit Le Chat am sorgfältigsten mit den privaten Daten von Anwenderinnen und Anwendern um (9,8 Punkte). Es folgen ChatGPT von OpenAI (9,9 Punkte) und Grok von xAI (11,2 Punkte). Am schlechtesten schneidet Meta.ai mit 15,7 Punkten ab, wobei mehr Punkte eine stärkere Verletzung der Privatsphäre bedeuten.

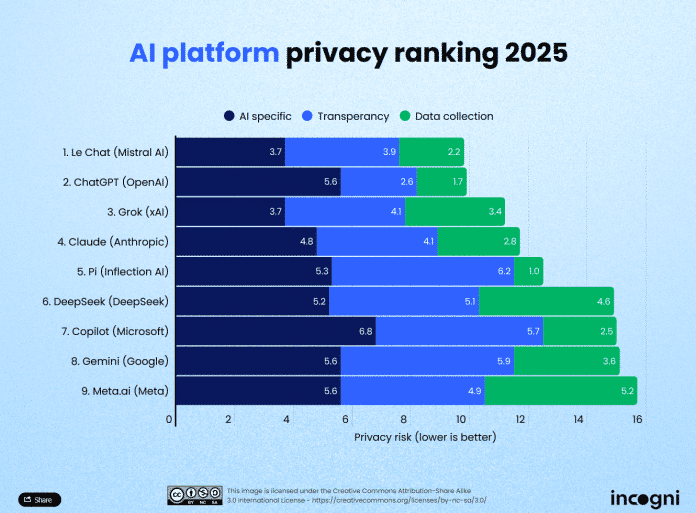
Le Chat von Mistral führt im Privatsphäre-Ranking von ChatGPT und Grok. An letzter Stelle steht Meta.ai.
(Bild: incogni)
Die Herausgeber der Studie kritisieren insgesamt den mangelnden Schutz der Privatsphäre bei KI-Anwendungen: „Das Potenzial für das unautorisierte Teilen von Daten, deren Missbrauch und das Bloßstellen persönlicher Daten hat schneller zugenommen, als dass die Wächter der Privatsphäre oder Untersuchungen mithalten könnten.“ Einfache Anwender können Praktiken der KI-Firmen und die damit einhergehenden Risiken nicht einschätzen: Sie würden die Trainingsdaten benötigen und Informationen über „laufende Interaktionen“, um festzustellen, ob ihre persönlichen Daten bloßgestellt wurden.
Modell-Training immer mit persönlichen Daten
Ein guter Teil der Incogni-Analyse befasst sich mit den Trainingsdaten und stellt lapidar fest, dass „alle Plattformen direkt oder indirekt angeben, Feedback der Anwender und öffentlich zugängliche private Daten für das Training ihrer Modelle zu verwenden.“
Ob die Betreiber auch User-Eingaben zum Training nutzen, ist oft nicht leicht festzustellen. Laut Bericht sagt nur Anthropic für seine Claude-Modelle, prinzipiell auf Daten über User-Eingaben zu verzichten. Eine Opt-out-Möglichkeit bieten ChatGPT, Copilot, Mistral und Grok. Dies gilt aber nur für die Prompts, ein Schützen der eigenen persönlichen Daten, die beispielsweise aus Social-Media-Quellen stammen, ist bei keinem der untersuchten KI-Anbieter möglich. Im Gegenteil: Incogni verweist auf Berichte, dass das Modell-Training Schranken, wie solche in robots.txt, schlichtweg ignoriert.
Als Quellen für persönliche Daten dient den KI-Betreibern jedoch nicht nur das Web, sondern auch:
- „Security Partners“ (ChatGPT, Gemini und DeepSeek)
- Marketing-Partner (Gemini und Meta)
- Finanzinstitute (Copilot)
- Nicht näher spezifizierte Datenbanken (Claude)
- Nicht näher spezifizierte Datenbroker (Microsoft)
Nur Inflection AI gibt für Pi an, persönliche Daten nur aus „öffentlich zugänglichen Quellen“ einzubinden.
Datenschutzerklärungen oft verwirrend
Wichtig für die Betroffenen – also fast jeden, denn über kaum jemanden finden sich keine persönlichen Daten irgendwo im Web – ist, wie transparent die KI-Betreiber sagen, was sie machen. Hier lobt der Bericht Anthropic, OpenAI, Mistral und xAI, die diese Transparenzinformationen leicht auffindbar machen und lesbar darbieten. Das Gegenteil beklagt die Studie bei Google, Meta und Microsoft, bei denen sich nicht einmal eine einheitliche Datenschutzerklärung für die KI-Produkte findet.
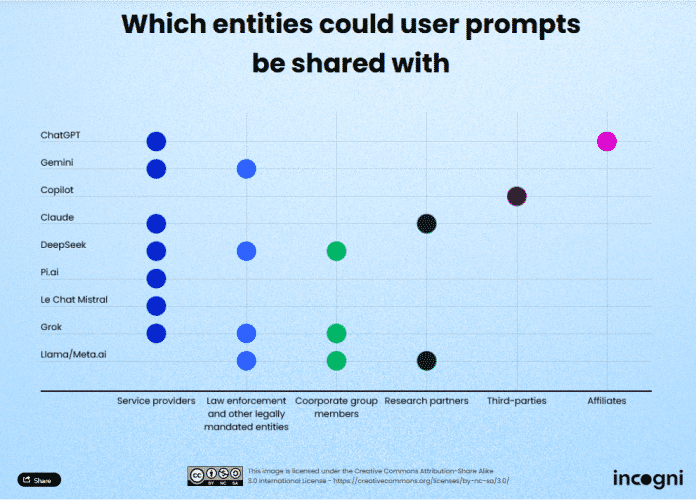
ChatGPT und MS Copilot geben Prompt-Daten auch an Werbepartner oder „Dritte“ weiter.
(Bild: incogni)
Auch welche Daten die KI-Firmen weitergeben, hat Incogni aus den jeweiligen Privacy Policies herausgelesen. Microsoft teilt Nutzer-Prompts beispielsweise mit „Dritten, die Online-Werbung für Microsoft ausführen oder Microsoft-Technologie dafür verwenden.“ Fast alle teilen die Prompts mit „Service-Providern“ und viele explizit mit „Strafverfolgungsbehörden“ (DeepSeek, Gemini, Grok und Meta).
App: Telefonnummern und Standortdaten
Bei der Nutzung der KI-Apps ergeben sich noch persönlichere Sammelmöglichkeiten für die datenhungrigen Betreiber:
- Präzise Standortdaten und Adressen (Gemini und Meta)
- Telefonnummern (DeepSeek, Gemini und Pi)
- Fotos (Grok, auch mit Dritten geteilt)
- App-Interaktionen (Claude, Grok ebenfalls mit Dritten geteilt)
Microsoft behauptet laut Bericht, bei der Android-App keine Daten zu sammeln, bei iOS jedoch schon. Die Analysten haben sich dafür entschieden, die Firma anhand der iOS-App zu bewerten.
(who)










Entwicklung & Code
KI-Überblick 1: Was hinter dem Begriff „Künstliche Intelligenz“ wirklich steckt
Kaum ein Begriff wird derzeit so häufig verwendet wie „Künstliche Intelligenz“. Ob in Nachrichten, Marketingbroschüren oder Strategiepapieren – „KI“ soll Unternehmen effizienter, Produkte smarter und ganze Branchen zukunftsfähig machen. Allerdings bleibt oft unklar, was damit konkret gemeint ist. Viele Personen verbinden den Begriff mit futuristischen Vorstellungen von Maschinen, die denken oder gar fühlen können. In der Realität beschreibt „Künstliche Intelligenz“ jedoch ein breites Spektrum an Verfahren und Technologien, die weit weniger mystisch sind.

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Diese neunteilige Blogserie widmet sich unterschiedlichen Aspekten von KI. Im ersten Beitrag möchte ich den Begriff KI systematisch aufdröseln, seine Entwicklung nachzeichnen und eine erste Einordnung geben, die die Grundlage für die weiteren Folgen der Serie bildet.
KI, ML, DL – was bedeutet das eigentlich?
Wenn von „KI“ gesprochen wird, ist häufig eine ganze Familie von Verfahren gemeint. Die gebräuchlichsten Abkürzungen sind dabei:
- KI (Künstliche Intelligenz) ist ein Oberbegriff, der alle Ansätze umfasst, Maschinen so zu gestalten, dass sie Aufgaben übernehmen können, die gemeinhin als „intelligent“ gelten. Dazu zählen etwa Sprache verstehen, Probleme lösen, lernen und planen.
- ML (Machine Learning) ist ein Teilbereich der KI, der sich darauf fokussiert, dass Maschinen auf Basis von Daten Muster erkennen und daraus Vorhersagen oder Entscheidungen ableiten.
- DL (Deep Learning) ist wiederum ein Teilbereich des Machine Learning, der komplexe neuronale Netze verwendet, um besonders tiefgehende Muster in Daten zu erkennen.
Maschinelles Lernen und Deep Learning sind also Unterkategorien der Künstlichen Intelligenz. In vielen Diskussionen werden diese Begriffe jedoch unscharf verwendet, was Missverständnisse begünstigt.
Von Expertensystemen zu lernenden Maschinen
Historisch begann die Forschung an Künstlicher Intelligenz nicht mit maschinellem Lernen, sondern mit sogenannten symbolischen Ansätzen. In den 1950er- und 1960er-Jahren entstanden Programme, die Wissen in Form von Regeln und Fakten speicherten. Daraus entwickelten sich später Expertensysteme, die etwa in der medizinischen Diagnose oder technischen Fehleranalyse eingesetzt wurden. Diese Systeme arbeiteten mit klar formulierten Wenn-Dann-Regeln. Ihr Vorteil war, dass ihre Entscheidungen transparent und nachvollziehbar waren. Ihr Nachteil bestand darin, dass sie nicht selbstständig lernen konnten und bei unvollständigem oder unscharfem Wissen schnell an ihre Grenzen stießen.
In den 1980er- und 1990er-Jahren rückte deshalb das maschinelle Lernen stärker in den Vordergrund. Statt einer Maschine explizit zu sagen, wie sie zu entscheiden hat, begann man, ihr Daten zu geben, aus denen sie selbst Regeln ableiten konnte. Damit wurden Systeme möglich, die flexibler auf neue Situationen reagieren konnten.
Ein einfaches Beispiel ist die Spam-Erkennung in E-Mails. Während ein Expertensystem vielleicht nur nach festen Schlüsselwörtern sucht, lernt ein Spam-Filter auf Basis vieler Beispiele von Spam- und Nicht-Spam-Nachrichten, typische Muster zu erkennen. Das erlaubt es, auch neue Formen von Spam zu identifizieren, ohne dass jemand manuell Regeln dafür hinterlegen muss.
Warum „Künstliche Intelligenz“ oft in die Irre führt
Der Begriff „Künstliche Intelligenz“ weckt häufig leicht falsche Assoziationen. Menschen neigen dazu, Maschinen Eigenschaften zuzuschreiben, die diese gar nicht besitzen. Ein Chatbot, der in flüssigen Sätzen antwortet, wirkt schnell so, als „wüsste“ er etwas. Tatsächlich basiert er jedoch lediglich auf komplexen statistischen Modellen, die aus unzähligen Beispielen gelernt haben, welche Wortfolgen wahrscheinlich aufeinanderfolgen.
Auch Programme, die Brettspiele meistern oder Bilder erkennen, verfügen nicht über ein Verständnis im menschlichen Sinne. Sie optimieren ihre Entscheidungen auf der Basis von Mustern in den Daten, ohne dass sie deren Bedeutung begreifen. Daher sprechen manche Fachleute lieber von „statistischer Mustererkennung“ statt von Intelligenz. Das mag sperrig klingen, trifft jedoch den Kern wesentlich besser.
Warum der Hype trotzdem berechtigt ist
Trotz dieser Einschränkungen hat Künstliche Intelligenz in den vergangenen Jahren beeindruckende Fortschritte gemacht. Rechnerische Ressourcen, größere Datenmengen und neue Algorithmen haben dazu geführt, dass Maschinen heute Aufgaben bewältigen können, die vor wenigen Jahren noch als Domäne des Menschen galten. Sprachmodelle wie GPT-4 formulieren Texte, Bildgeneratoren erschaffen fotorealistische Szenen und Algorithmen analysieren in Sekunden medizinische Aufnahmen.
Diese Erfolge beruhen jedoch nicht auf Magie, sondern auf systematischen Verfahren. Wenn Sie verstehen, was hinter Begriffen wie „Machine Learning“ und „Deep Learning“ steckt, können Sie besser einschätzen, was KI-Systeme tatsächlich leisten können – und wo ihre Grenzen liegen. Genau das soll diese Serie leisten.
Wohin die Reise geht
In den folgenden Beiträgen werden wir die verschiedenen Teilgebiete schrittweise vertiefen. Wir werden uns ansehen, wie Maschinen lernen, was neuronale Netze auszeichnet und warum Deep Learning „deep“ ist. Zudem werden wir beleuchten, wie Transformer-Architekturen die Sprachverarbeitung revolutioniert haben und was Large Language Models von früheren Ansätzen unterscheidet.
Das Ziel ist, dass Sie am Ende dieser Serie nicht nur einzelne Schlagworte einordnen können, sondern ein Gesamtverständnis dafür entwickeln, wie die verschiedenen Konzepte zusammenhängen. Damit können Sie fundierter entscheiden, ob und wie Künstliche Intelligenz für Ihre Projekte oder Ihr Unternehmen sinnvoll sein könnte.
Ergänzend zu dieser Serie seien an dieser Stelle die Blogposts von Michael Stal über den Aufbau von Neuronalen Netzen empfohlen.
(rme)
Entwicklung & Code
JetBrains Rider 2025.2: KI-Coding-Agent Junie läuft schneller und nutzt MCP
Das Softwareunternehmen JetBrains hat seine .NET- und Spieleentwicklungs-IDE Rider mit Version 2025.2 ausgestattet, ebenso wie die Visual-Studio-Erweiterung ReSharper und die .NET-Tools. In Rider steht damit eine schnellere Version des KI-Coding-Agenten Junie als Beta bereit, während ReSharper nun unter anderem den Out-of-Process-Modus ermöglicht.
(Bild: coffeemill/123rf.com)

Verbesserte Klassen in .NET 10.0, Native AOT mit Entity Framework Core 10.0 und mehr: Darüber informiert die Online-Konferenz betterCode() .NET 10.0 am 18. November 2025. Nachgelagert gibt es sechs ganztägige Workshops zu Themen wie C# 14.0, KI-Einsatz und Web-APIs.
Coding mit KI für .NET-Developer
Im neuen Release soll der KI-Coding-Agent Junie um bis zu 30 Prozent schneller sein, mit Remote-Entwicklung umgehen können und dank Model Context Protocol (MCP) ein tiefergehendes Kontextbewusstsein besitzen. Darüber hinaus können Entwickler im Early-Access-Programm Junie mit GitHub verbinden, um Pull Requests zu verwalten, ohne die IDE öffnen zu müssen.
Junie ist laut JetBrains für komplexe Entwicklungsaufgaben geeignet. Der „Ask“-Modus erlaubt High-Level-Brainstorming, der „Code“-Modus ist für die Hands-on-Implementierung zuständig. Dabei kann Junie Code schreiben und refaktorieren, Dateien generieren und Tests ausführen. Die Entwicklerinnen und Entwickler sollen dabei jedoch die Kontrolle behalten.
Details zu diesen und weiteren Änderungen in Rider 2025.2 hält der JetBrains-Blog bereit.
ReSharper erlaubt Out-of-Process Mode
Eines der Highlights in ReSharper 2025.2 ist der Out-of-Process-(OOP)-Modus. Das bedeutet, ReSharper kann in einem von Visual Studio separaten Prozess laufen, was die Stabilität erhöhen und den Weg für zukünftige Performanceverbesserungen ebnen soll.
Entwicklerinnen und Entwickler wechseln zum OOP-Modus, indem sie in ReSharper Options | Environment | Products & Features aufrufen und dort die Option „Run ReSharper in separate process“ aktivieren. Ein Klick auf den Button Save and restart übernimmt die Änderung.
Zudem soll ReSharper merkliche Performanceverbesserungen bringen, unter anderem beim Rename– und Inline-Refactoring sowie bei der Razor/Blazor-Verarbeitung. Auch Support für die neuesten Features der Sprachversion C# 14.0, die Microsoft voraussichtlich im November 2025 veröffentlichen wird, ist nun enthalten.
Weitere Informationen zu den Updates in ReSharper sowie in den .NET-Tools dotTrace, dotMemory und dotCover in Version 2025.2 bietet der JetBrains-Blog.
(mai)
Entwicklung & Code
Firebird: DoS-Schwachstellen in Datenbank, möglicherweise unbefugte Zugriffe
In der relationalen SQL-Datenbank Firebird haben die Entwickler zwei Sicherheitslücken geschlossen. Die ermöglichten Angreifern, Server mit manipulierten Anfragen lahmzulegen – oder unter Umständen sogar unbefugten Zugriff auf eigentlich verschlüsselte Daten.
Die schwerwiegendere Schwachstelle betrifft den Pool externer Verbindungen (ExtConnPool). Ist der aktiv, werden darin gespeicherte Verbindungen nicht erneut überprüft, ob die bei ihrer Erstellung verwendeten CryptCallback-APIs tatsächlich noch vorhanden und geeignet sind. Dadurch können Zugriffe auf verschlüsselte Datenbanken erfolgen, wenn externe SQL-Anweisungen ausgeführt werden, auf die später mit Attachments zugegriffen wird, denen ein Schlüssel zur Datenbank fehlt. Bei derartigen verketteten Execute-Statements kann zudem ein Segfault auftreten, auch auf unverschlüsselten Datenbanken, und damit die Serverprozesse lahmlegen (Denial of Service). Die Schwachstelle hat den CVE-Eintrag CVE-2025-24975 / EUVD-2025-25030 mit einem CVSS-Wert von 7.1 und der Risikoeinschätzung „hoch“ erhalten.
Davon ist FIrebirdSQL bis einschließlich 5.0.3 sowie 4.0.7 betroffen. Die Fehler korrigieren die Schnappschüsse 6.0.0.609, 5.0.2.1610 sowie 4.0.6.3183 und jeweils neuere.
Zweite Sicherheitslücke in Firebird
Vor den Versionen 5.0.3, 4.0.6 und 3.0.13 können beim Verarbeiten von XDR-Nachrichten NULL-Pointer-Derefenzierungen auftreten, also bereits freigegebene Ressourcen erneut freigegeben werden. Das mündet in einem Prozess-Absturz, also einem Denial-of-Service (CVE-2025-54989 / EUVD-2025-25032, CVSS 5.3, Risiko „mittel„).
IT-Verantwortliche sollten sicherstellen, die Firebird-Versionen auf die aktualisierten Stände zu bringen. Auf Github stehen die aktualisierten Quellcodes dafür bereit. Etwa die fehlerkorrigierte Fassung 5.0.3 ist seit Mitte Juli für diverse Betriebssysteme verfügbar. Die CVE-Einträge zu dem damit geschlossenen Sicherheitslücken wurden jedoch erst jetzt veröffentlicht.
(dmk)

„TouristDigiPay“: Thailand beginnt Umtausch von Kryptowährungen in Baht

Nvidia: GeForce Now erhält RTX 5080, höhere Bildqualität und mehr

„Stargate Project“: Foxconn und Softbank bauen zusammen KI-Server

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen

TikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Online Marketing & SEOvor 2 Monaten
Online Marketing & SEOvor 2 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenPhilip Bürli › PAGE online
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenAktuelle Trends, Studien und Statistiken
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen