Entwicklung & Code
Neuerungen in C++26: Datenparallele Datentypen (SIMD)
Die SIMD-Bibliothek bietet in C++26 portable Typen zur expliziten Angabe von Datenparallelität und zur Strukturierung von Daten für einen effizienteren SIMD-Zugriff. Bevor wir uns im Detail mit der neuen Bibliothek befassen, möchte ich kurz ein paar allgemeine Anmerkungen zu SIMD (Single Instruction, Multiple Data) voranschicken.


Rainer Grimm ist seit vielen Jahren als Softwarearchitekt, Team- und Schulungsleiter tätig. Er schreibt gerne Artikel zu den Programmiersprachen C++, Python und Haskell, spricht aber auch gerne und häufig auf Fachkonferenzen. Auf seinem Blog Modernes C++ beschäftigt er sich intensiv mit seiner Leidenschaft C++.
SIMD – Single Instruction, Multiple Data
Vektorisierung bezieht sich auf die SIMD-Erweiterungen (Single Instruction, Multiple Data) des Befehlssatzes moderner Prozessoren. SIMD ermöglicht es dem Prozessor, eine Operation parallel auf mehrere Daten anzuwenden.
Ein einfaches Beispiel: Ob ein Algorithmus parallel und vektorisiert ausgeführt wird, hängt von vielen Faktoren ab – unter anderem davon, ob die CPU und das Betriebssystem SIMD-Befehle unterstützen. Außerdem kommt es auf den Compiler und den Optimierungsgrad an, der zum Kompilieren des Codes eingesetzt wird.
// SIMD.cpp
const int SIZE= 8;
int vec[]={1,2,3,4,5,6,7,8};
int res[SIZE]={0,};
int main(){
for (int i= 0; i < SIZE; ++i) {
res[i]= vec[i]+5; // (1)
}
}
Zeile 1 ist die Schlüsselzeile in dem kleinen Programm. Dank des Compiler Explorers ist es recht einfach, die Assemblerbefehle für Clang 3.6 mit und ohne maximale Optimierung (-O3) zu generieren.
Ohne Optimierung
Obwohl meine Zeit, in der ich mit Assemblerbefehlen herumgespielt habe, lange vorbei ist, ist es offensichtlich, dass alles sequenziell ausgeführt wird:

(Bild: Rainer Grimm)
Mit maximaler Optimierung
Durch die Verwendung der maximalen Optimierung erhalte ich Befehle, die parallel auf mehreren Datensätzen ausgeführt werden:

(Bild: Rainer Grimm)
Die Move-Operation (movdqa) und die Add-Operation (paddd) verwenden die speziellen Register xmm0 und xmm1. Beide Register sind sogenannte SSE-Register mit einer Breite von 128 Bit. Damit können 4 ints auf einmal verarbeitet werden. SSE steht für Streaming SIMD Extensions. Leider sind Vektorbefehle stark von der eingesetzten Architektur abhängig. Weder die Befehle noch die Registerbreiten sind einheitlich.
Moderne Intel-Architekturen unterstützen meist AVX2 oder sogar AVX-512. Dies ermöglicht 256-Bit- oder 512-Bit-Operationen. Damit können 8 oder 16 ints parallel verarbeitet werden. AVX steht für Advanced Vector Extension.
Genau hier kommen die neuen datenparallelen Datentypen der Bibliothek ins Spiel, die eine einheitliche Schnittstelle zu Vektorbefehlen bieten.
Datenparallele Typen (SIMD)
Bevor ich mich mit der neuen Bibliothek beschäftige, sind einige Definitionen erforderlich. Diese Definitionen beziehen sich auf den Proposal P1928R15. Insgesamt umfasst die neue Bibliothek sechs Proposals.

(Bild: Rainer Grimm)
Die Menge der vektorisierbaren Typen umfasst alle Standard-Ganzzahltypen, Zeichentypen sowie die Typen float und double. Darüber hinaus sind std::float16_t, std::float32_t und std::float64_t vektorisierbare Typen, sofern sie definiert sind.
Der Begriff datenparallel bezieht sich auf alle aktivierten Spezialisierungen der Klassen-Templates basic_simd und basic_simd_mask. Ein datenparalleles Objekt ist ein Objekt vom datenparallelen Typ.
Ein datenparalleler Typ besteht aus einem oder mehreren Elementen eines zugrunde liegenden vektorisierbaren Typs, der als Elementtyp bezeichnet wird. Die Anzahl der Elemente ist für jeden datenparallelen Typ eine Konstante und wird als Breite dieses Typs bezeichnet. Die Elemente in einem datenparallelen Typ werden von 0 bis Breite −1 indiziert.
Eine elementweise Operation wendet eine bestimmte Operation auf die Elemente eines oder mehrerer datenparalleler Objekte an. Jede solche Anwendung ist in Bezug auf die anderen nicht sequenziell. Eine unäre elementweise Operation ist eine elementweise Operation, die eine unäre Operation auf jedes Element eines datenparallelen Objekts anwendet. Eine binäre elementweise Operation ist eine elementweise Operation, die eine binäre Operation auf entsprechende Elemente zweier datenparallelisierter Objekte anwendet.
Nach so viel Theorie möchte ich nun ein kleines Beispiel zeigen. Es stammt von Matthias Kretz, Autor des Proposals P1928R15. Das Beispiel aus seiner Präsentation auf der CppCon 2023 zeigt eine Funktion f, die einen Vektor entgegennimmt und dessen Elemente auf ihre Sinuswerte abbildet:
void f(std::vector& data) {
using floatv = std::simd;
for (auto it = data.begin(); it < data.end(); it += floatv::size()) {
floatv v(it);
v = std::sin(v);
v.copy_to(it);
}
}
Die Funktion f nimmt einen Vektor von Floats (data) als Referenz. Sie definiert floatv als SIMD-Vektor von Floats unter Verwendung von std::simd. f durchläuft den Vektor in Blöcken, wobei jeder Block die Größe des SIMD-Vektors hat.
Für jeden Block gilt:
- Lädt den Block in einen SIMD-Vektor (
floatv v(it);). - Wendet die Sinusfunktion gleichzeitig auf alle Elemente im SIMD-Vektor an (
v = std::sin(v);). - Schreibt die Ergebnisse zurück in den ursprünglichen Vektor (
v.copy_to(it);).
Die Behandlung von SIMD-Anweisungen wird besonders elegant, wenn der Proposal P0350R4 in C++26 implementiert wird. SIMD kann dann beispielsweise als neue Execution Policy in Algorithmen verwendet werden:
void f(std::vector& data) {
std::for_each(std::execution::simd, data.begin(), data.end(), [](auto& v) {
v = std::sin(v);
});
}
Wie geht es weiter?
In meinem nächsten Artikel werde ich mich näher mit der neuen SIMD-Bibliothek befassen.
(map)









Entwicklung & Code
Spiele-Engine Godot 4.5 bringt Screenreader-Support und Stencil Buffer
Das Godot-Entwicklungsteam hat Version 4.5 der quelloffenen Game-Engine für 2D- und 3D-Spiele veröffentlicht. Das Update ermöglicht Screenreader-Support für Teile des UI-Editors, eine Live-Preview des GUI in mehreren Sprachen und neue optische Spieleeffekte.
Überarbeitete Optik per Stencil Buffer
Für neue optische Möglichkeiten lassen sich nun Stencil Buffer verwenden: Mit ihnen lässt sich beispielsweise im Spiel ein Loch in eine Wand bohren, um zu sehen, was sich auf der anderen Seite befindet. Stencil Buffer ähneln den bestehenden Depth Buffern, sind jedoch flexibler und bieten mehr Kontrolle. Wie das aussehen kann, demonstriert ein Video in der Ankündigung.

Stencil Buffer in Aktion
(Bild: godotengine.org)
Neuerungen für Accessibility und Internationalisierung
Der Editor wird in Godot 4.5 barrierefreier: Screenreader können nun mit Control-Nodes umgehen und es sind Screenreader-Bindings vorhanden, um das Verhalten aller Node-Typen anzupassen. Das konnte das Godot-Team mithilfe des AccessKit umsetzen, einer Accessibility-Infrastruktur für UI-Toolkits.
Diese Änderungen sind derzeit als experimentell eingestuft und der Screenreader-Support für den Godot-Editor ist noch nicht vollständig. Er gilt derzeit lediglich für den Project Manager, Standard-UI-Nodes und den Inspector. In künftigen Updates soll die Accessibility weiter verbessert werden.
Auch an der Zugänglichkeit in verschiedenen Sprachen hat das Godot-Team gearbeitet: Das neue Feature „Internationalization Live Preview“ zeigt eine Echtzeitvorschau für Übersetzungen direkt im Editor-Viewport und soll das GUI-Testing in mehreren Sprachen vereinfachen.
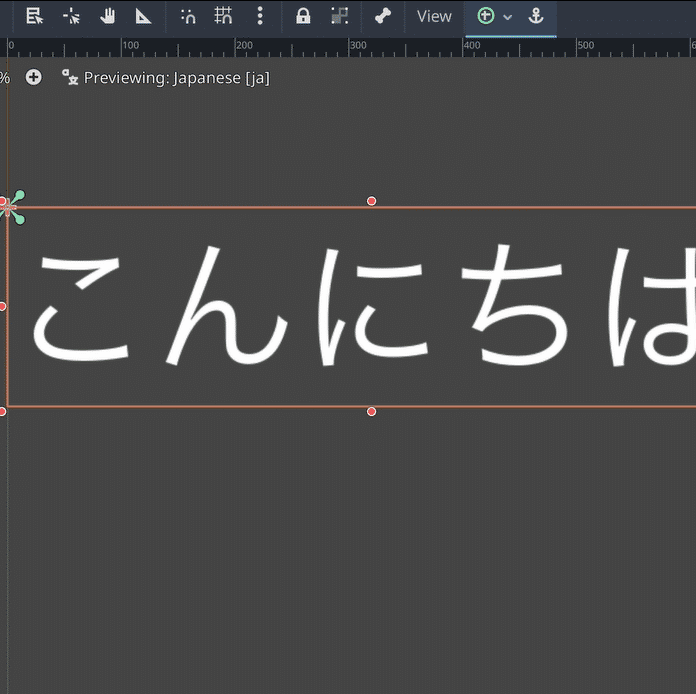
Live-Vorschau für Internationalisierung, hier am Beispiel Japanisch
(Bild: godotengine.org)
Zudem ist es im Editor nun möglich, die Sprache ohne Neustart zu ändern. Das soll beispielsweise beim Entwickeln von Editor-Plug-ins hilfreich sein, um Übersetzungen zu testen.
Weitere Editor-Updates
Zu den weiteren Neuerungen im Editor zählt unter anderem ein „Mute“-Button. Beim Debuggen kann es vorkommen, dass Entwicklerinnen und Entwickler wieder und wieder die gleiche Spielemusik hören. Um das zu vermeiden, ohne den Ton komplett ausschalten zu müssen, hat das Godot-Team in der Game View eine neue Option eingeführt. Der Ton lässt sich dort nun per Klick auf ein Lautsprecher-Icon ausschalten:
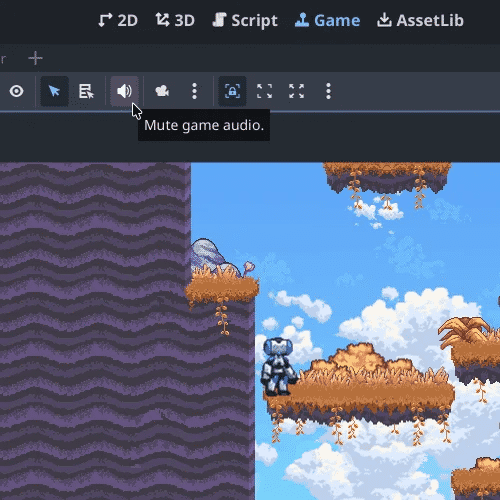
Ein Klick auf „Mute“, und schon haben Developer Ruhe beim Debugging.
(Bild: godotengine.org)
Ein anderes Editor-Update betrifft die Ansicht: Auf HiDPI-Bildschirmen konnten die Standard-Steuerelemente und das Editor-UI bisher unscharf aussehen. Auch hier hat das Entwicklungsteam nachgebessert und das Rendering überarbeitet, um die Elemente auf allen Monitoren scharf darzustellen.
Weitere Details zu allen Neuerungen in Version 4.5 präsentiert die detaillierte Ankündigung auf der Godot-Website.
(mai)
Entwicklung & Code
Die Produktwerker: Berufsbild von UX-Professionals
In dieser Folge berichtet Thomas Jackstädt, der Präsident der German UPA – dem Berufsverband für User Experience und Usability Professionals –, über die aktuelle Entwicklung des Berufsbilds von UX-Professionals: als Menschen, die Produkte und Services so gestalten, dass sie nutzbar, verständlich und erlebbar werden. Doch das Bild dieser Rolle ist in Bewegung. Unterschiedliche Titel wie UX-Designer, Service-Designer oder Strategic Designer machen es Teams schwer, den Mehrwert von UX-Professionals eindeutig zu greifen.
Berufsbild UX-Professional – im Wandel durch KI
Im Gespräch mit Dominique Winter erklärt Jackstädt, dass die German UPA daran arbeitet, Orientierung zu schaffen und das Berufsbild klarer zu definieren. Dabei geht es nicht um starre Festlegungen, sondern um Empfehlungen, die sowohl UX-Professionals selbst als auch Unternehmen, Hochschulen und Weiterbildungsanbieter nutzen können. Klarheit ist für die Zusammenarbeit im Team, für Recruiting und für die Ausgestaltung von Rollenprofilen entscheidend.
Ein (wenig überraschender) Treiber dieser Veränderungen ist die künstliche Intelligenz (KI). Während die Digitalisierung Informationen schnell verfügbar gemacht hat, verändert KI die Art, wie Inhalte und Designs überhaupt entstehen. UX-Professionals müssen lernen, diese Werkzeuge sinnvoll einzusetzen, ihre Qualität einzuschätzen und zu orchestrieren. So können sie den Freiraum nutzen, sich stärker auf die menschliche Erfahrung im Nutzungskontext zu konzentrieren.
Gleichzeitig bleibt die Unterscheidung zwischen Professionalität und Amateurarbeit wichtig. Professionalität bedeutet nicht automatisch bessere Ergebnisse, aber sie steht für Verlässlichkeit, methodisches Vorgehen und Orientierung an den Bedürfnissen der Nutzenden. UX-Professionals stellen sicher, dass Lösungen nicht irritieren, sondern verständlich sind und echten Mehrwert bringen.
Menschenzentrierte Gestaltung
Für Produktteams bedeutet diese Entwicklung, dass die Zusammenarbeit mit UX-Professionals an Bedeutung gewinnt. Product Owner, Product Manager oder Product Leads profitieren von Rollen, die Klarheit in der Gestaltung schaffen, auch wenn KI immer mehr Aufgaben übernimmt. Statt Spezialisierungen aufzulösen, entsteht ein neues Zusammenspiel von Generalisten, Tools und spezifischem Fachwissen. Entscheidend bleibt, dass Produkte menschenzentriert gestaltet werden; egal, wie stark Maschinen an ihrer Entstehung beteiligt sind.
(Bild: deagreez/123rf.com)

So geht Produktmanagement: Auf der Online-Konferenz Product Owner Day von dpunkt.verlag und iX am 13. November 2025 können Product Owner, Produktmanagerinnen und Service Request Manager ihren Methodenkoffer erweitern, sich vernetzen und von den Good Practices anderer Unternehmen inspirieren lassen.
Thomas Jackstädt denkt, dass UX-Professionals sich zu „KI-Natives“ entwickeln müssen, ohne ihren Kernauftrag zu verlieren: für Menschen zu gestalten. Die Rolle verändert sich, bleibt aber essenziell für den Erfolg von Produkten. Denn am Ende zählt nicht, wie schnell etwas produziert werden kann, sondern ob es verständlich, zugänglich und nützlich ist.
Die aktuelle Ausgabe des Podcasts steht auch im Blog der Produktwerker bereit: „Berufsbild von UX-Professionals„.
(mai)
Entwicklung & Code
KI-Überblick 5: Transformer – Self-Attention verändert die Sprachverarbeitung
Lange galten Recurrent Neural Networks (RNNs) als der Goldstandard für das Verarbeiten von Sprache. Sie waren dafür gemacht, Sequenzen schrittweise zu verarbeiten und dabei frühere Informationen im Gedächtnis zu behalten. Doch sie hatten Grenzen – insbesondere bei langen Texten, komplexen Abhängigkeiten und paralleler Verarbeitung.

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Mit dem Aufkommen der Transformer-Architektur hat sich das grundlegend geändert. Sie hat sich nicht nur als leistungsfähiger erwiesen, sondern auch als effizienter, skalierbarer und flexibler. Inzwischen ist sie die dominierende Grundlage für viele KI-Systeme, darunter BERT, GPT, T5 und viele mehr.
In diesem Beitrag zeige ich Ihnen, was Transformer-Modelle auszeichnet, warum Self-Attention der entscheidende Mechanismus ist und wie diese Architektur das maschinelle Lernen verändert hat.
Die Grenzen rekurrenter Netze
Recurrent Neural Networks verarbeiten Texte sequenziell – Wort für Wort oder Zeichen für Zeichen. Dabei führen sie ein internes Gedächtnis mit, das bei jedem Schritt aktualisiert wird. Dieses Prinzip funktioniert gut für kurze Eingaben, stößt jedoch bei längeren Sequenzen an mehrere Grenzen:
- Langfristige Abhängigkeiten gehen verloren: Frühere Informationen verblassen über die Zeit.
- Keine echte Parallelisierung möglich: Da jedes Wort auf dem vorherigen basiert, kann nicht gleichzeitig verarbeitet werden.
- Begrenzter Zugriff auf den Kontext: Jedes Element sieht nur den bisherigen Verlauf, nicht den gesamten Zusammenhang.
Diese strukturellen Schwächen führten dazu, dass selbst mit Verbesserungen wie LSTM oder GRU viele Sprachaufgaben schwer zu lösen blieben.
Die Grundidee des Transformer
Die Transformer-Architektur wurde 2017 in dem Paper „Attention Is All You Need“ vorgestellt. Der zentrale Gedanke: Statt Informationen sequenziell zu verarbeiten, sollen alle Teile eines Textes gleichzeitig betrachtet werden – mithilfe eines Mechanismus namens „Self-Attention“.
Transformer-Modelle bestehen nicht mehr aus rekursiven Schleifen, sondern aus einem Stapel gleichartiger Schichten, die Eingaben parallel verarbeiten. Jede Schicht analysiert dabei, welche Teile der Eingabe wie stark miteinander in Beziehung stehen – unabhängig von der Position.
Dieses Prinzip erlaubt es dem Modell:
- Kontext über beliebige Distanzen hinweg zu berücksichtigen,
- Ein- und Ausgaben gleichzeitig zu verarbeiten und
- die gesamte Eingabe als Ganzes zu analysieren.
Self-Attention: Kontext ohne Reihenfolge
Der Self-Attention-Mechanismus bewertet für jedes Element in einer Eingabesequenz, wie stark es auf alle anderen Elemente achten sollte. Vereinfacht gesagt:
- Jedes Wort erzeugt eine gewichtete Kombination aller anderen Wörter.
- Diese Gewichtung ergibt sich aus der inhaltlichen Ähnlichkeit.
- So kann zum Beispiel das Wort „sie“ korrekt auf „die Frau“ zurückverweisen, auch wenn diese am Satzanfang steht.
Mathematisch geschieht das über sogenannte Query-, Key– und Value-Vektoren, die aus den Eingabedaten erzeugt werden. Diese werden paarweise miteinander kombiniert, um zu bestimmen, wie viel Aufmerksamkeit jedes Token auf andere richten soll. Die resultierenden Gewichte fließen dann in die nächste Repräsentation ein.
Der Effekt: Das Modell kann flexibel entscheiden, welche Informationen an welcher Stelle wichtig sind – unabhängig von der linearen Reihenfolge.
Positionale Kodierung
Da Transformer-Modelle die Reihenfolge der Eingaben ignorieren können, benötigen sie eine zusätzliche Komponente, nämlich die positionale Kodierung. Sie sorgt dafür, dass die relative und absolute Position von Wörtern im Satz erhalten bleibt. Ohne diesen Schritt wäre ein Satz wie „Die Katze jagt die Maus“ nicht von „Die Maus jagt die Katze“ zu unterscheiden.
Die Positionsinformation wird meist als Vektor addiert oder eingebettet und fließt gemeinsam mit dem Inhalt in die Berechnung der Aufmerksamkeit ein.
Skalierung und Architektur
Ein vollständiger Transformer besteht typischerweise aus mehreren aufeinanderfolgenden Encoder- und/oder Decoder-Schichten, je nach Anwendungsfall:
- Encoder-only-Modelle (zum Beispiel BERT) analysieren Texte, etwa für Klassifikation oder Fragebeantwortung.
- Decoder-only-Modelle (zum Beispiel GPT) erzeugen Texte, etwa beim Autovervollständigen.
- Encoder-Decoder-Modelle (zum Beispiel T5) übersetzen oder transformieren Texte zwischen Formaten.
Die Fähigkeit, diese Architekturen effizient auf große Datenmengen und Modellgrößen zu skalieren, hat den Siegeszug der Transformer entscheidend geprägt. Moderne Modelle enthalten Milliarden von Parametern und lernen auf Datenmengen, die frühere Verfahren unvorstellbar überfordert hätten.
Warum Transformer so erfolgreich sind
Transformer-Modelle verdanken ihren Erfolg mehreren Faktoren:
- Sie verarbeiten Sprache kontextsensitiv und global, nicht lokal und sequenziell.
- Sie lassen sich hochgradig parallelisieren, was das Training beschleunigt.
- Sie sind modular und lassen sich flexibel für unterschiedliche Aufgaben anpassen.
- Sie eignen sich nicht nur für Sprache, sondern auch für Bilder, Videos, Molekülstrukturen und vieles mehr.
Dadurch haben sie sich zum universellen Baukasten moderner KI entwickelt.
Ausblick
Der nächste Teil befasst sich mit Large Language Models wie GPT, BERT oder Claude. Er wird zeigen, was diese Modelle von klassischen Sprachverarbeitungsansätzen unterscheidet, wie sie trainiert werden und warum sie so viele Aufgaben scheinbar mühelos lösen – obwohl sie kein echtes Verständnis besitzen.
(rme)

Hochdruckreiniger von Kärcher für günstige 99,99 Euro

Spiele-Engine Godot 4.5 bringt Screenreader-Support und Stencil Buffer
Eichenblatt statt Indianerfeder – Apache Software Foundation ändert Logo

Der ultimative Guide für eine unvergessliche Customer Experience
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist

Adobe Firefly Boards › PAGE online
-
 UX/UI & Webdesignvor 4 Wochen
UX/UI & Webdesignvor 4 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
eine gute Nachricht ist") Social Mediavor 4 Wochen
Social Mediavor 4 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenAdobe Firefly Boards › PAGE online
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Wochen
Entwicklung & Codevor 2 WochenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen