Online Marketing & SEO
OmniAvatar: So realistisch ist Alibabas neues KI-Videomodell
Ein Bild, eine Stimme, ein Prompt – mehr braucht OmniAvatar nicht für hyper-realistische KI-Videos mit Körpersprache. Das Modell ist zudem frei verfügbar als Open Source.
Digitale Avatare erhalten ein realistisches Update: Mit OmniAvatar hat die Alibaba Group gemeinsam mit der Zhejiang-Universität ein Open-Source-Modell veröffentlicht, das sprachgesteuerte, ganzkörperanimierte Videos generiert. Anders als viele bestehende Ansätze beschränkt sich die Technologie nicht auf die Synchronisation von Lippenbewegungen, sondern erlaubt komplexe Körpersprache, Emotionen und sogar Objektinteraktionen. Das KI-Tool markiert damit einen neuen Standard für automatisierte Videoproduktion. Auf der Projektseite demonstriert ein Video, welches kreative und technische Potenzial das Modell für die KI-Videoproduktion bietet.

Nach DeepSeek:
Jetzt bringt auch Alibaba neue Super-KI

Vom Sprachsignal zur Körpersprache: So funktioniert OmniAvatar
Im Zentrum von OmniAvatar steht ein multimodales KI-System, das Audiodaten, Bilder und Text-Prompts miteinander verknüpft. Das Audio wird mit einem Wav2Vec-Modell analysiert, das Sprachmerkmale auf Frame-Ebene extrahiert. Diese Merkmale werden in ein latentes Raumformat übertragen und mit visuellen Informationen aus einem Referenzbild kombiniert. Ein LoRA-basiertes Training erlaubt es dem Modell, zusätzliche Steuerungspunkte wie Emotionen, Gesten oder Blickrichtungen präzise zu integrieren – bei gleichzeitiger Effizienz und Wiederverwendbarkeit.

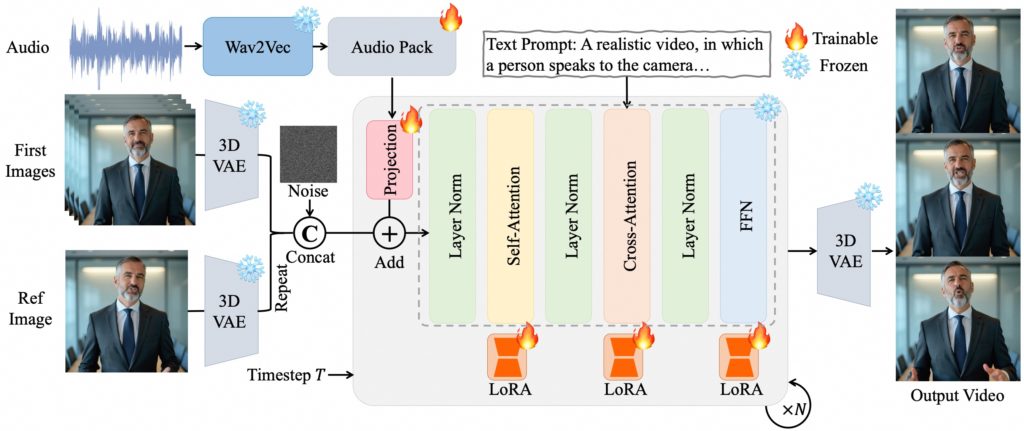
Die präzise Steuerung ist laut den Entwickler:innen durch eine pixelweise, multihierarchische Audioeinbettung möglich. Diese trägt entscheidend zur exakten Lippensynchronisation bei und verbessert laut der Veröffentlichung sogar die Generalisierungsfähigkeit über verschiedene Szenen hinweg. Einen praktischen Eindruck vermitteln Demos wie ein Beispiel für eine natürliche Präsentation oder ein Avatar in freier Gestikulation.
Regiefunktion per Prompt: OmniAvatar als Baukasten für Videokommunikation
Besonders bemerkenswert an OmniAvatar ist die intuitive Steuerung über einfache Texteingaben. Nutzer:innen können per Prompt bestimmen, ob der Avatar lächeln, überrascht oder wütend wirken soll – oder ob die Szene etwa in einem Cybercafé oder unter einem Zitronenbaum spielt. In diesem Beispielvideo erscheint die Figur in einer natürlichen Umgebung, während die Kamera langsam herauszoomt.
Diese Steuerungslogik macht OmniAvatar besonders interessant für den Einsatz in Marketing, Medienproduktion oder im Bildungsbereich. Laut einem Post von AI-Entwickler luokai sei die Steuerung so intuitiv, dass sich Anwendungen wie Podcast-Moderationen, virtuelle Präsentationen oder gesungene Performances in hoher Qualität realisieren lassen – ohne klassisches Motion Capturing.
Bemerkenswert ist auch die Offenheit der Technologie: OmniAvatar wurde als Open-Source-Modell auf GitHub veröffentlicht und ist somit frei zugänglich. Damit setzt Alibaba einen klaren Impuls in Richtung kollaborative Forschung und dezentrale Content-Produktion. Auch andere Entwicklungen der Alibaba Cloud AI Labs – wie Qwen 2.5‑Max, Anfang 2025 veröffentlicht, und inzwischen auch das jüngste Qwen 3‑Modell – zeigen, dass das Unternehmen zunehmend eigene technologische Standards setzt.
Videokommunikation neu gedacht
OmniAvatar hebt die Möglichkeiten generativer KI für Bewegtbildinhalte auf ein neues Niveau. Durch die Kombination aus präziser Lippensynchronisation, adaptiver Körpersprache und intuitiver Prompt-Steuerung entstehen realistische, ganzkörperanimierte Avatare, ganz ohne Studio, Schauspiel oder Green Screen. Für Marketing und Content Teams entstehen dadurch neue Möglichkeiten, etwa:
- personalisierte Avatarvideos für Social Media oder E-Mail-Kampagnen,
- skalierbare Content-Formate für Präsentationen, Podcasts oder Tutorials,
- KI-basierte Brand Ambassadors mit glaubwürdiger Mimik und Gestik,
- virtuelle Figuren für Events, Plattformen oder interne Schulungen.
Statt statischer Talking Heads ermöglichen solche Avatare eine neue Form automatisierter, aber dennoch glaubhafter Kommunikation – mit Ausdruck, Dynamik und Kontextbezug.
Auch strategisch kann OmniAvatar für Unternehmen relevant sein: Die Open-Source-Architektur erlaubt es, eigene virtuelle Sprecher:innen oder Assistent:innen zu entwickeln und zu skalieren. Besonders in internationalen Märkten, in denen Inhalte zunehmend automatisiert lokalisiert und ausgespielt werden, könnte das Modell neue Standards setzen.
Neue Qualität für skalierbare Videokommunikation
OmniAvatar erweitert das Potenzial generativer KI deutlich. Durch die Kombination aus präziser Lippensynchronisation, adaptiver Körpersprache und textbasierter Steuerung wird eine neue Stufe visueller Ausdruckskraft erreicht – ohne hohen Produktionsaufwand. Für Marketing und Content Teams eröffnet das Modell neue Wege für automatisierte, aber dennoch glaubwürdige digitale Kommunikation.