Entwicklung & Code
Software Testing: Testen und Qualitätssicherung bei Start-ups
In dieser Episode spricht Richard Seidl mit Daniel Krauss, dem Gründer von Flix, und Florian Fieber, aktiv im German Testing Board e.V. (GTB), über Qualität und Testen in Start-ups. Sie vergleichen B2C und B2B, diskutieren schnelle Lieferzyklen, knappe Budgets und warum Qualität kein Selbstzweck ist. Ausfälle kosten mehr als gutes Testen, Coverage ist Mittel, nicht Ziel.
Weiterlesen nach der Anzeige
Über Daniel Krauss und Florian Fieber
Als Chief Information Officer (CIO) und Chief HR Officer (CHRO) bei Flix ist Daniel Krauss für die Bereiche Technologie und Personal des Unternehmens verantwortlich. Zusammen mit seinen Mitbegründern hat er Flix zu einem internationalen Transportdienstleister ausgebaut. Daniel Krauss ist außerdem Investor und Beiratsmitglied in Unternehmen wie BabyOne, Unity und GWF. Er ist überzeugt, dass Bildung, Unternehmertum und Innovation die Gesellschaft maßgeblich voranbringen können.
Florian Fieber studierte Medieninformatik und Information Systems, danach war er als Softwareentwickler und wissenschaftlicher Mitarbeiter tätig. Sein Fachgebiet umfasst heute alle Aspekte der Qualitätssicherung im Softwarelebenszyklus, mit einem Schwerpunkt auf Testmanagement und Prozessverbesserung. Seit 2018 ist er aktiv im German Testing Board e. V. (GTB), wo er unter anderem als Leiter der Arbeitsgruppe Acceptance Testing fungiert und seit 2022 als Vorsitzender des GTB dient.
Bei diesem Podcast dreht sich alles um Softwarequalität: Ob Testautomatisierung, Qualität in agilen Projekten, Testdaten oder Testteams – Richard Seidl und seine Gäste schauen sich Dinge an, die mehr Qualität in die Softwareentwicklung bringen.
Die aktuelle Ausgabe ist auch auf Richard Seidls Blog verfügbar: „Testen und Qualitätssicherung bei Start-ups – Daniel Krauss, Florian Fieber“ und steht auf YouTube bereit.
Weiterlesen nach der Anzeige
(mdo)









Entwicklung & Code
Next.js 16.2 bringt Updates für die Nutzung von KI-Agenten
Das Next.js-Team beim Hersteller Vercel hat Version 16.2 des React-Frameworks fertiggestellt. Next.js soll nun deutlich schneller sein, was die Time-to-URL während der Entwicklung und das Rendering in Anwendungen betrifft. Auch an der Performance des Bundlers Turbopack wurde geschraubt und für die KI-gestützte Softwareentwicklung hat Next.js ebenfalls Updates zu bieten.
Weiterlesen nach der Anzeige

(Bild: Stone Story / stock.adobe.com)

Webanwendungen mit KI anreichern, sodass sie wirklich besser werden? Der Online-Thementag enterJS Integrate AI am 28. April 2026 zeigt, wie das geht. Frühbuchertickets und Gruppenrabatte sind im Online-Ticketshop verfügbar.
Support für die KI-gestützte Entwicklung
In Next.js 16.2 ist in create-next-app standardmäßig eine AGENTS.md-Datei enthalten. Durch diese erhalten KI-Agenten Zugriff auf die Next.js-Dokumentation für die genutzte Version bereits zu Beginn eines Projekts. Das soll das Problem umgehen, dass KI-Agenten mit veralteten Daten trainiert werden und aktuelle APIs nicht kennen, woraus inkorrekter Code resultieren kann.
Als experimentelles CLI steht next-browser bereit. Es erlaubt KI-Agenten, eine laufende Next.js-Anwendung zu inspizieren. Zu den Daten, die next-browser den Agenten zugänglich macht, zählen solche auf dem Browser-Level wie Screenshots oder Netzwerkanfragen, ebenso wie Framework-spezifische Insights aus den React DevTools und dem Next.js Dev Overlay, darunter Props, Hooks, Partial Prerendering (PPR) Shells und Fehlermeldungen.
Um next-browser zu verwenden, installieren Entwicklerinnen und Entwickler es als Skill:
npx skills add vercel-labs/next-browser
Dann geben sie /next-browser in ihrem KI-Agenten ein, der mit Skills umgehen kann, beispielsweise Claude Code oder Cursor.
Weiterlesen nach der Anzeige
Weiterführende Hinweise zum Einsatz von next-browser sind im GitHub-Repository zu finden.
Turbopack-Updates für Performance und Security
Seit Version 16 nutzt Next.js den Bundler Turbopack als Standard. Das aktuelle Release bringt für Turbopack zahlreiche Performanceverbesserungen, Bugfixes und Kompatibilitäts-Updates – insgesamt sind über 200 Änderungen eingeflossen.
Eines der neuen Performance-Features betrifft das Neuladen von serverseitigem Code während der Entwicklung. Bisher wurde require.cache für ein geändertes Modul geleert, ebenso wie für alle anderen Module in seiner Import-Kette. Dadurch wurde oft mehr Code als notwendig neu geladen, beispielsweise unveränderte node_modules. In Next.js 16.2 wird nur noch der tatsächlich geänderte Code erneut geladen, was durch Turbopacks Kenntnis über den Module Graph ermöglicht wird. Das soll die Effizienz des serverseitigen Hot Reloading deutlich verbessern.
Das Next.js-Entwicklungsteam untermauert das mit Zahlen, die es in Echtzeitanwendungen beobachtet hat: 67 bis 100 Prozent schnelleres Anwendungs-Refresh und 400 bis 900 Prozent schnellere Kompilierungszeit in Next.js seien möglich.
Ein weiteres Update dreht sich um Security. Der Sicherheitsstandard Content Security Policy (CSP) dient dazu, Angriffe auf Webseiten wie das Cross-Site Scripting (XSS) zu verhindern. Die gängige nonce-basierte Methode erfordert, dass alle Webseiten dynamisch gerendert werden. Da dies die Performance einschränken kann, setzt das Next.js-Team auf die Alternative Subresource Integrity (SRI). Diese berechnet im Vorfeld einen Hash für jedes Skript und erlaubt dem Browser nur das Ausführen von Skripten mit genehmigten Hashes. In Next.js 16.2 besitzt Turbopack experimentellen Support für SRI.
Weitere Informationen zu den Updates in Next.js 16.2 sowie speziell in den Bereichen künstliche Intelligenz und Turbopack lassen sich dem Next.js-Blog entnehmen.
(mai)
Entwicklung & Code
Neu in .NET 10.0 [15]: Klasse Program und Main()-Methode in File-based Apps
Eine File-based App kann die in C# 9.0 (im Rahmen von .NET 5.0) eingeführten Top-Level Statements verwenden. Das wird der Regelfall sein, bei dem die Ausführung der Datei bei der ersten Zeile beginnt:
Weiterlesen nach der Anzeige
Console.WriteLine(System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription);
Console.WriteLine($"Kompilierungsmodus: {(System.Runtime.CompilerServices.RuntimeFeature.IsDynamicCodeSupported ? "JIT" : "AOT")}");

Start der File-based App mit Top-Level Statement (Abb. 1)
Neben der Verwendung von Top-Level Statements ist auch der klassische Stil mit class Program und Main()-Methode in den File-based Apps möglich:
class Program
{
static void Main(string[] args)
{
Console.WriteLine(System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription);
Console.WriteLine($"Kompilierungsmodus: {(System.Runtime.CompilerServices.RuntimeFeature.IsDynamicCodeSupported ? "JIT" : "AOT")}");
}
}
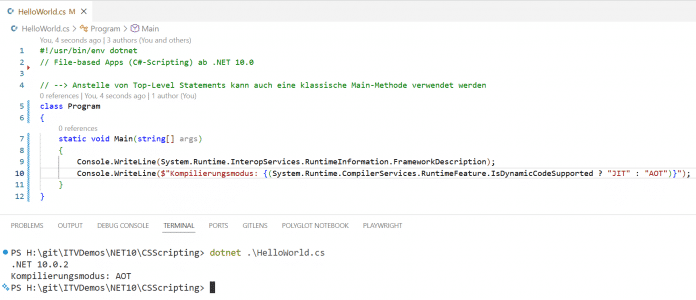
Die File-based App lässt sich auch mit der Main()-Methode in der Klasse Program starten (Abb. 2).
(rme)
Entwicklung & Code
Apple blockiert Updates für Vibe-Coding-Apps
Gegen Vibe-Coding fürs iPhone hat Apple erklärtermaßen keine Einwände. Wer aber auf diese Weise Web-Apps am App Store vorbei entwickeln lässt, geht dem iPhone-Hersteller offenbar zu weit: Dies haben jetzt zwei Anbieter von Vibe-Coding-Apps zu spüren bekommen, deren geplante Updates von Apples App-Store-Kontrolle abgelehnt wurden. Das Unternehmen selbst verweist auf Verstöße gegen die Regeln und zeigt einen möglichen Lösungsweg auf.
Weiterlesen nach der Anzeige
Erst vor kurzem hat Apple selbst einen großen Vorstoß in Richtung Vibe-Coding unternommen. Mit der Einführung von agentischer KI in Apples Entwicklungsumgebung Xcode ist es seit Version 26.3 so einfach wie noch nie, ohne Kenntnis von Programmiersprachen ganze Apps entwickeln zu lassen. Dennoch nimmt die Entwicklung dort ihren klassischen Weg, wie Apple ihn seit Anbeginn des App Stores einfordert: Die Entwicklung findet am Mac statt und die fertige App kann der Entwickler sich wahlweise lokal zum Testen installieren, per TestFlight an größere Testerkreise verteilen oder dem App Review zur Prüfung vorlegen, um sie im App Store zu veröffentlichen.
Maßgeschneiderte Apps im Browser
Die beiden Vibe-Coding-Apps Replit und Vibecode gehen einen anderen Weg. Sie dienen weniger dazu, Apps zu erstellen, die auch andere nutzen. Stattdessen werben die Anbieter damit, dass Nutzer sich ohne Programmierkenntnisse maßgeschneiderte Web-Apps erstellen lassen können. Gibt es also keine passende App im App Store, die den Wünschen gerecht wird, können sich Nutzer per Vibe-Coding einfach eine eigene erstellen lassen. Allerdings besteht dadurch je nach Funktionsumfang auch die Möglichkeit, Alternativen zu Kauf- oder Abo-Apps erschaffen zu lassen. Und dann gehen nicht nur deren Entwickler leer aus, sondern auch Apple als Ladenbetreiber, der pro Verkauf eine Provision bekommt.
Aus Apples Sicht sei der Grund für das Blockieren der Updates allerdings ein ganz anderer, berichtet das Apple-Blog 9to5Mac. So gehe es dem Hüter des App Stores in Wirklichkeit darum, dass es Apps untersagt sei, Code nachzuladen oder auszuführen, der ihre Funktionalität verändere. Dies ist eigentlich eine Vorschrift, die Fake-Apps verhindern soll, die etwa im Gewand einer harmlosen App im App Store erscheinen, dann jedoch in Wirklichkeit Inhalte nachladen, die gegen die Regeln verstoßen. Apple wendet die entsprechenden Paragrafen der Nutzungsbedingungen des Entwicklerprogramms nunmehr auch auf Vibe-Coding-Apps an. Konkret beruft sich Apple dabei auf App Store Guideline 2.5.2 sowie Abschnitt 3.3.1(B) des Developer Program License. Dies berichtete zuvor bereits The Information.
Unversöhnlich gibt sich Apple allerdings nicht. In drei Telefongesprächen in zwei Monaten habe man den betroffenen Entwicklern mögliche Lösungswege aufgezeigt. Einer soll sein, dass App-Vorschauen im Browser angezeigt werden, anstatt sie innerhalb der App zu generieren. Diesen Umstand dürften die Anbieter der Vibe-Coding-Apps aber eher als unnötige Mühsal für ihre Nutzer ansehen, weil diese dann ständig zwischen zwei verschiedenen Apps – Browser und Vibe-Coding-App – wechseln müssten.
Lesen Sie auch
(mki)
Xiaomi Tag im Test: Günstig aber einfach gehalten

Make Football My Only Job › PAGE online

Schluchten und Horizonte: Die Bilder der Woche 12

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Community Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast

Community Management zwischen Reichweite und Verantwortung
-
 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Social Mediavor 3 Wochen
Social Mediavor 3 WochenCommunity Management und Zielgruppen-Analyse: Die besten Insights aus Blog und Podcast
-
 Social Mediavor 1 Monat
Social Mediavor 1 MonatCommunity Management zwischen Reichweite und Verantwortung
-
Künstliche Intelligenzvor 1 Monat
Top 10: Die beste kabellose Überwachungskamera im Test – Akku, WLAN, LTE & Solar
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenEindrucksvolle neue Identity für White Ribbon › PAGE online
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAumovio: neue Displaykonzepte und Zentralrechner mit NXP‑Prozessor
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenÜber 220 m³ Fläche: Neuer Satellit von AST SpaceMobile ist noch größer
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonateneHealth: iOS‑App zeigt Störungen in der Telematikinfrastruktur

