Entwicklung & Code
Testing Unleashed: Aktuelle Herausforderungen für Tester
In dieser Episode seines englischsprachigen Podcasts „Testing Unleashed“ spricht Richard Seidl über die Bedeutung von Qualität als Haltung im Software Testing. Er zeigt, wie sich die Rolle des Testers in den letzten Jahrzehnten gewandelt hat.
Richard Seidl betont die Notwendigkeit, Qualität als integralen Bestandteil des gesamten Softwareentwicklungsprozesses zu betrachten. In Zeiten von Agile und DevOps sind neue Denkansätze gefragt, um den Herausforderungen der Softwarequalität zu begegnen.
Dieser Podcast betrachtet alles, was auf Softwarequalität einzahlt: von Agilität, KI, Testautomatisierung bis hin zu Architektur- oder Code-Reviews und Prozessoptimierungen. Alles mit dem Ziel, bessere Software zu entwickeln und die Teams zu stärken. Frei nach dem Podcast-Motto: Better Teams. Better Software. Better World.
Richard Seidl spricht dabei mit internationalen Gästen über modernes Software-Engineering und wie Testing und Qualität im Alltag gelebt werden können.
Die aktuelle Ausgabe ist auch auf Richard Seidls Blog verfügbar: „Testing Unleashed: Aktuelle Herausforderungen für Tester“ und steht auf YouTube bereit.
(mdo)









Entwicklung & Code
Cleverer Werbebetrug mit Android-Apps doch aufgeflogen
224 betrügerische Android-Apps hat Google aus seinem Play Store entfernt. Sie waren insgesamt 38 Millionen Mal installiert, von Android-Nutzern in 228 Ländern, und lösten täglich 2,3 Milliarden betrügerische Werbeanzeigen aus, die nie jemand zu Gesicht bekam. Klassischer Werbebetrug, aber besonders gut versteckt. Dennoch aufgedeckt haben ihn Sicherheitsforscher der Firma Human. Sie nennen den Fall „SlopAds“, in Anspielung an „AI Slop“, was KI-generierte Medieninhalte geringer Qualität bezeichnet.
Die betrügerischen Anwendungen hatten meist KI-Bezug und enthielten, so wie sie im Play Store eingereicht und zum Download angeboten wurden, keine Malware-Funktion im engeren Sinne. Erst nach erfolgter Installation wurde eine verschlüsselte Konfiguration mittels Firebase Remote Config nachgeladen. Darin enthalten waren Hyperlinks: eine Liste über 300 betrügerischer Webseiten, die der Bereitstellung der fremden Reklame dienten; ein Link zum Download eines Javascripts, das den heimlichen Abruf der Reklame über Webview steuerte; und ein Link zu vier PNG-Bilddateien.
In diesen Bildern war, steganografisch, weiterer Code versteckt. Die Apps bauten daraus die eigentliche Schadroutine, die Human „FatModule“ nennt. Diese Software prüfte zunächst, auf welchem Wege der Nutzer an die App gelangt war. Wurde sie mittels Suche im Play Store gefunden und installiert, arbeitete sie nur wie angepriesen, die Schadroutine wurde dann nie scharfgeschaltet.
Wer auf Werbung hereinfiel, wurde für Werbedownloads missbraucht
Allerdings hatten die Werbebetrüger auch selbst Werbung geschaltet, nämlich für ihre Apps. Klickte ein Nutzer auf solche Reklame, landete auf diesem Weg in Googles Play Store und installierte die App, wurde deren Betrugsmodus aktiviert. Das sollte Sicherheitsforscher ausschließen, die sich eher im Play Store direkt bedienen, anstatt irgendwelche Reklame zu klicken.
Zusätzlich suchten die Apps nach Hinweisen auf mögliche Ausführung durch Sicherheitsforscher, etwa ein gerootetes Betriebssystem, einen Emulator oder Debugging-Werkzeuge. Nur wenn nichts dergleichen gefunden wurde, begannen die heimlichen Downloads von Werbung in einem versteckten Webview-Prozess. Selbst dann wurden die Abrufe über mehrere Weiterleitungen geschickt, um dem Werbeserver keine verdächtigen Referrer zu liefern.

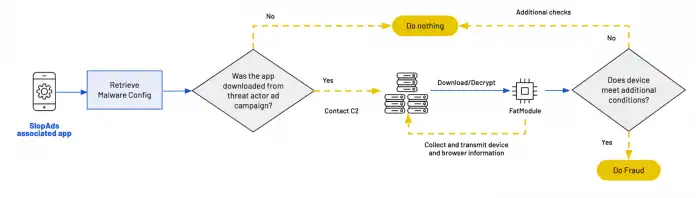
Workflow der nicht-immer-betrügerischen Apps
(Bild: Human)
Human hat Google informiert, dass die 224 bekannten Apps aus dem Play Store gelöscht wurden. Google Play wird jene Anwender, die solche Apps bereits installiert haben, zu deren Löschung von ihren Geräten auffordern.
Neuer Anlauf erwartet
Wie lange die Täter schon am Werk waren, ist nicht bekannt. Sie hatten es immerhin auf 38 Millionen Downloads gebracht. Und noch während der laufenden Untersuchung Humans sind weitere Apps hinzugekommen.
Die Forscher erwarten nicht, dass die Täter sich fortan redlichem Broterwerb widmen werden; wahrscheinlicher sei, dass sie bald neuen Anlauf nehmen, mit einer noch ausgefeilteren Werbebetrugsmasche. Opfer sind einerseits Werbetreibende, die für Werbung bezahlen, die nie ein Mensch würdigt, und andererseits die App-Nutzer, deren Bandbreite, Prozessorleistung und Akkuladung für systematischen Betrug vergeudet wird.
(ds)
Entwicklung & Code
Spiele-Engine Godot 4.5 bringt Screenreader-Support und Stencil Buffer
Das Godot-Entwicklungsteam hat Version 4.5 der quelloffenen Game-Engine für 2D- und 3D-Spiele veröffentlicht. Das Update ermöglicht Screenreader-Support für Teile des UI-Editors, eine Live-Preview des GUI in mehreren Sprachen und neue optische Spieleeffekte.
Überarbeitete Optik per Stencil Buffer
Für neue optische Möglichkeiten lassen sich nun Stencil Buffer verwenden: Mit ihnen lässt sich beispielsweise im Spiel ein Loch in eine Wand bohren, um zu sehen, was sich auf der anderen Seite befindet. Stencil Buffer ähneln den bestehenden Depth Buffern, sind jedoch flexibler und bieten mehr Kontrolle. Wie das aussehen kann, demonstriert ein Video in der Ankündigung.

Stencil Buffer in Aktion
(Bild: godotengine.org)
Neuerungen für Accessibility und Internationalisierung
Der Editor wird in Godot 4.5 barrierefreier: Screenreader können nun mit Control-Nodes umgehen und es sind Screenreader-Bindings vorhanden, um das Verhalten aller Node-Typen anzupassen. Das konnte das Godot-Team mithilfe des AccessKit umsetzen, einer Accessibility-Infrastruktur für UI-Toolkits.
Diese Änderungen sind derzeit als experimentell eingestuft und der Screenreader-Support für den Godot-Editor ist noch nicht vollständig. Er gilt derzeit lediglich für den Project Manager, Standard-UI-Nodes und den Inspector. In künftigen Updates soll die Accessibility weiter verbessert werden.
Auch an der Zugänglichkeit in verschiedenen Sprachen hat das Godot-Team gearbeitet: Das neue Feature „Internationalization Live Preview“ zeigt eine Echtzeitvorschau für Übersetzungen direkt im Editor-Viewport und soll das GUI-Testing in mehreren Sprachen vereinfachen.
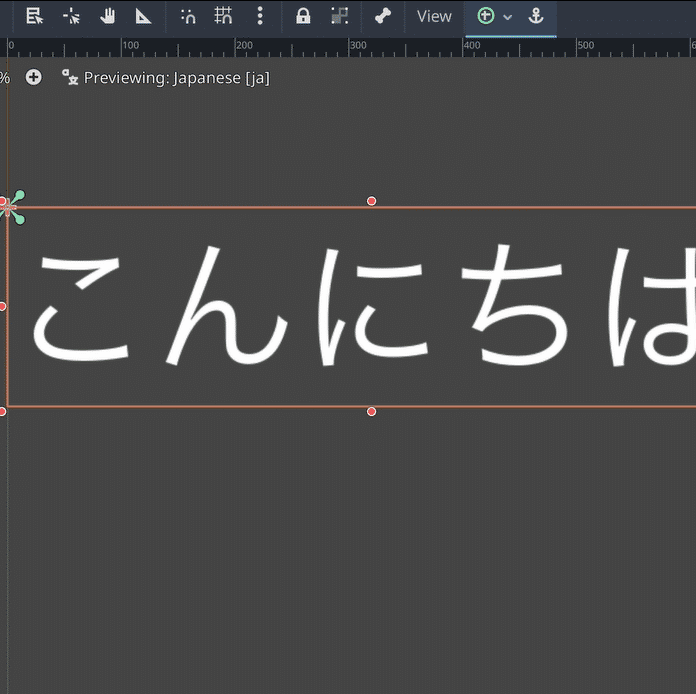
Live-Vorschau für Internationalisierung, hier am Beispiel Japanisch
(Bild: godotengine.org)
Zudem ist es im Editor nun möglich, die Sprache ohne Neustart zu ändern. Das soll beispielsweise beim Entwickeln von Editor-Plug-ins hilfreich sein, um Übersetzungen zu testen.
Weitere Editor-Updates
Zu den weiteren Neuerungen im Editor zählt unter anderem ein „Mute“-Button. Beim Debuggen kann es vorkommen, dass Entwicklerinnen und Entwickler wieder und wieder die gleiche Spielemusik hören. Um das zu vermeiden, ohne den Ton komplett ausschalten zu müssen, hat das Godot-Team in der Game View eine neue Option eingeführt. Der Ton lässt sich dort nun per Klick auf ein Lautsprecher-Icon ausschalten:
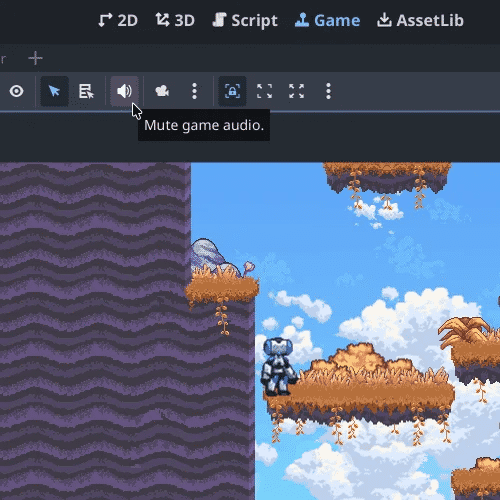
Ein Klick auf „Mute“, und schon haben Developer Ruhe beim Debugging.
(Bild: godotengine.org)
Ein anderes Editor-Update betrifft die Ansicht: Auf HiDPI-Bildschirmen konnten die Standard-Steuerelemente und das Editor-UI bisher unscharf aussehen. Auch hier hat das Entwicklungsteam nachgebessert und das Rendering überarbeitet, um die Elemente auf allen Monitoren scharf darzustellen.
Weitere Details zu allen Neuerungen in Version 4.5 präsentiert die detaillierte Ankündigung auf der Godot-Website.
(mai)
Entwicklung & Code
Die Produktwerker: Berufsbild von UX-Professionals
In dieser Folge berichtet Thomas Jackstädt, der Präsident der German UPA – dem Berufsverband für User Experience und Usability Professionals –, über die aktuelle Entwicklung des Berufsbilds von UX-Professionals: als Menschen, die Produkte und Services so gestalten, dass sie nutzbar, verständlich und erlebbar werden. Doch das Bild dieser Rolle ist in Bewegung. Unterschiedliche Titel wie UX-Designer, Service-Designer oder Strategic Designer machen es Teams schwer, den Mehrwert von UX-Professionals eindeutig zu greifen.
Berufsbild UX-Professional – im Wandel durch KI
Im Gespräch mit Dominique Winter erklärt Jackstädt, dass die German UPA daran arbeitet, Orientierung zu schaffen und das Berufsbild klarer zu definieren. Dabei geht es nicht um starre Festlegungen, sondern um Empfehlungen, die sowohl UX-Professionals selbst als auch Unternehmen, Hochschulen und Weiterbildungsanbieter nutzen können. Klarheit ist für die Zusammenarbeit im Team, für Recruiting und für die Ausgestaltung von Rollenprofilen entscheidend.
Ein (wenig überraschender) Treiber dieser Veränderungen ist die künstliche Intelligenz (KI). Während die Digitalisierung Informationen schnell verfügbar gemacht hat, verändert KI die Art, wie Inhalte und Designs überhaupt entstehen. UX-Professionals müssen lernen, diese Werkzeuge sinnvoll einzusetzen, ihre Qualität einzuschätzen und zu orchestrieren. So können sie den Freiraum nutzen, sich stärker auf die menschliche Erfahrung im Nutzungskontext zu konzentrieren.
Gleichzeitig bleibt die Unterscheidung zwischen Professionalität und Amateurarbeit wichtig. Professionalität bedeutet nicht automatisch bessere Ergebnisse, aber sie steht für Verlässlichkeit, methodisches Vorgehen und Orientierung an den Bedürfnissen der Nutzenden. UX-Professionals stellen sicher, dass Lösungen nicht irritieren, sondern verständlich sind und echten Mehrwert bringen.
Menschenzentrierte Gestaltung
Für Produktteams bedeutet diese Entwicklung, dass die Zusammenarbeit mit UX-Professionals an Bedeutung gewinnt. Product Owner, Product Manager oder Product Leads profitieren von Rollen, die Klarheit in der Gestaltung schaffen, auch wenn KI immer mehr Aufgaben übernimmt. Statt Spezialisierungen aufzulösen, entsteht ein neues Zusammenspiel von Generalisten, Tools und spezifischem Fachwissen. Entscheidend bleibt, dass Produkte menschenzentriert gestaltet werden; egal, wie stark Maschinen an ihrer Entstehung beteiligt sind.
(Bild: deagreez/123rf.com)

So geht Produktmanagement: Auf der Online-Konferenz Product Owner Day von dpunkt.verlag und iX am 13. November 2025 können Product Owner, Produktmanagerinnen und Service Request Manager ihren Methodenkoffer erweitern, sich vernetzen und von den Good Practices anderer Unternehmen inspirieren lassen.
Thomas Jackstädt denkt, dass UX-Professionals sich zu „KI-Natives“ entwickeln müssen, ohne ihren Kernauftrag zu verlieren: für Menschen zu gestalten. Die Rolle verändert sich, bleibt aber essenziell für den Erfolg von Produkten. Denn am Ende zählt nicht, wie schnell etwas produziert werden kann, sondern ob es verständlich, zugänglich und nützlich ist.
Die aktuelle Ausgabe des Podcasts steht auch im Blog der Produktwerker bereit: „Berufsbild von UX-Professionals„.
(mai)

KI-Bildbearbeitung im Vergleich: ChatGPT 5 und Gemini 2.5 Flash Image

Wir haben die Zweifler vom Gegenteil überzeugt

Marketing-Vorbilder: Das sind die 10 Kandidat:innen für den diesjährigen CMO of the Year

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 4 Wochen
UX/UI & Webdesignvor 4 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 3 Wochen
UX/UI & Webdesignvor 3 WochenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 4 Wochen
Social Mediavor 4 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Wochen
Entwicklung & Codevor 2 WochenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen