Apps & Mobile Entwicklung
Wie AI das Internet „klaut“ und womöglich damit durchkommt
Dass nun auch Hollywood-Studios wie Disney und Universal gegen KI-Dienste vorgehen, verstärkt nochmals den Druck in den Copyright-Klagen. Die KI-Anbieter – von OpenAI über Meta bis Midjourney – rechtfertigen das Vorgehen mit den Fair-Use-Regeln. Auf was es bei den Verfahren ankommt, analysiert der Analyst Timothy B. Lee.
Wie viel Harry Potter kann AI zitieren?
Hintergrund ist eine Studie von Rechtswissenschaftlern der Universitäten von Stanford, Cornell und der West Virginia University vom Mai 2025, die Lee in seinem Newsletter Understanding AI aufgreift. Die Forschenden haben untersucht, inwieweit die Modelle auch urheberrechtlich geschützte Inhalte wiedergeben können. Stimmt der Output (nahezu) exakt mit den Trainingsdaten überein, spricht man von „Memorization“. Während die KI-Firmen wie OpenAI solche Inhalte nur als Ausnahmefälle beschreiben, sind sie zentraler Bestandteil von Copyright-Klagen wie der New York Times.
Bei den Verfahren geht es also auch um die Frage, wie häufig sich „Memorization“-Inhalte produzieren lassen. Um das zu analysieren, nutzen die Studien-Autoren den books3-Datensatz, der zum Teil urheberrechtlich geschützte Werke enthält. Und das Ergebnis war erstaunlich: je nach Modell und Buch unterscheidet sich zwar, wie häufig das Phänomen auftritt. In manchen Fällen war es jedoch sehr häufig. Das gilt etwa für den ersten Harry-Potter-Band Der Stein der Weisen und Metas Modell Llama 3.1 70B.
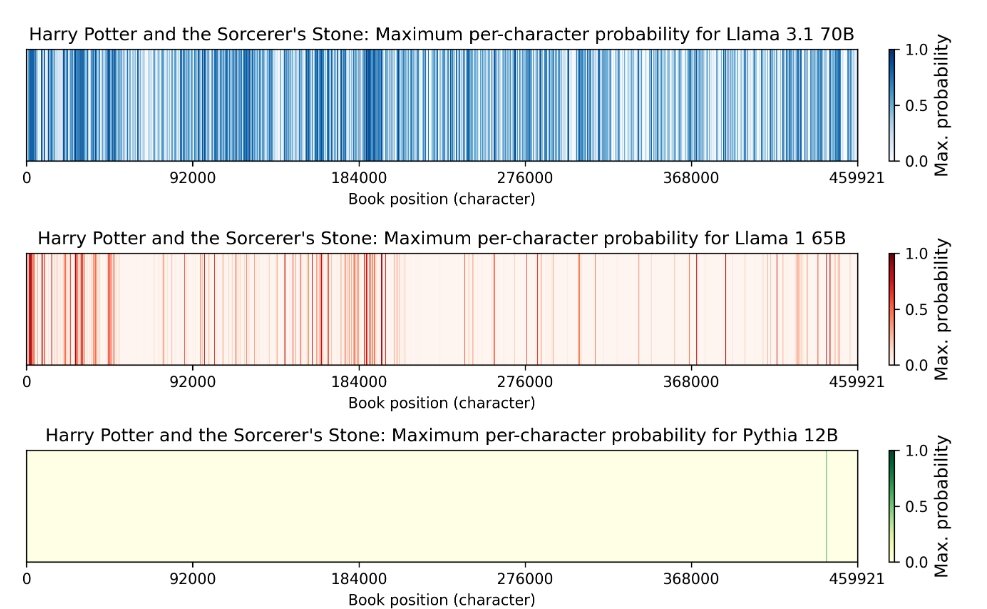
Wie Timothy B. Lee zusammenfasst, hat Llama 3.1 70B insgesamt 42 Prozent des Buches so gut „abgespeichert“, dass sich 50-Token-Auszüge in mindestens der Hälfte der Fälle reproduzieren lassen. Token sind die Wortbestandteile, die Large Language Models (LLM) nutzen, um Texte zu generieren. Der Befund besagt also: Man kann das Modell dazu bringen, regelmäßig Originalzitate aus dem Buch auszugeben.
Überrascht waren die Autoren vom Ausmaß. Man habe eher mit einer Größenordnung von ein bis zwei Prozent gerechnet, sagte der Studien-Mitautor Mark Lemey zu Lee. Es sind Werte, die sich auf die laufenden Copyright-Verfahren auswirken können.
Daten als zentraler Baustein für generative KI-Entwicklung
Die Klagen richten sich gegen praktisch alle prominenten KI-Firmen – selbst wenn die Studienergebnisse erst einmal Meta betreffen, können diese in weiteren Verfahren eine Rolle spielen. Und der Datenhunger ist ohnehin bei allen gleich.
Der Grund ist naheliegend: Um aktuelle Modelle zu entwickeln, benötigt man massenhaft Daten. Diese sind neben der Computing-Power und der Modellgröße einer der Bestandteile der Scaling-Formel, die maßgeblich für den Aufstieg der aktuellen KI-Modelle steht. Wer mehr und bessere Daten hat, kann leistungsfähigere Modelle entwickeln.
Wie groß so ein Trainingsdatensatz in der Praxis ist, schilderte OpenAI in einem GPT-3-Paper aus dem Jahr 2020 mit. Allein der CommonCrawl-Datensatz, der für rund 80 Prozent der Token im Modell-Training stand, umfasste 45 TB an komprimierter Klartext vor der Filterung und 570 GB nach der Filterung. Und das ist bereits fünf Jahre her. Die Branche ist mittlerweile deutlich verschlossener, die Menge dürfte nochmals deutlich gestiegen sein.
AI-Webcrawler bremsen das Netz aus
Um an die Daten zu kommen, gehen die KI-Firmen weite Wege. Die AI-Crawler grasen praktisch das komplette Web ab und sammeln damit nicht nur enorme Datenmengen, sondern bremsen das komplette Netz aus. Wikipedia verzeichnete deswegen im Jahr 2024 ein Traffic-Plus von über 50 Prozent, aktuell berichtet 404Media, dass die AI-Bots die Server von Museen, offenen Bibliotheken, Archiven und Galerien in die Knie gehen lassen. Auch über die Web-Crawler hinaus ist die Branche wenig zimperlich. Beispiele:
- Meta soll einen LibGen-Datensatz verwendet haben, berichtete The Atlantic. Dieser besteht also aus der illegalen Schattenbibliothek für geschützte Bücher und Artikel.
- Wie die New York Times (die selbst OpenAI verklagt) im letzten Jahr berichtete, transkribierte OpenAI massenhaft YouTube-Videos, um Material für das KI-Training zu erhalten.
„Um Daten zu erhalten, haben Tech-Unternehmen wie OpenAI, Google und Meta Abkürzungen genommen, Unternehmensrichtlinien ignoriert und diskutiert, das Gesetz zu beugen“, analysiert die New York Times in einem Bericht von 2024. Kurzum: Man hat wenig Skrupel und bewegte sich den Medienberichten zufolge völlig bewusst in Grauzonen – mindestens.
Wie Urheberrechtsverstöße möglich sind
Ob und wie genau das KI-Training mit geschützten Werken gegen das Urheberrecht verstoßen kann, ist aber noch strittig. Timothy B. Lee unterscheidet in dem aktuellen Newsletter zwischen drei Theorien:
- Generell stellt das KI-Training mit geschützten Werken ein Verstoß gegen das Urheberrecht dar, weil in dem Prozess eine digitale Kopie des Werks verwendet wird.
- Durch den Trainingsprozess werden Informationen aus den Trainingsdaten in das Modell übertragen, damit ist das Modell ein abgeleitetes Werk im Sinne des Urheberrechts.
- Verstöße finden dann statt, wenn Modelle (Teile) eines geschützten Werkes wiedergeben.
Viele Diskussionen drehen sich laut Lee bislang um den ersten Ansatz. Sollten Gerichte das KI-Training mit geschützten Inhalten als Urheberrechtsverstoß werten, wären die Konsequenzen am weitreichendsten. In diesem Fall wären praktisch alle aktuellen Modelle illegal.
Die KI-Firmen streiten die Vorwürfe stets ab. So sei etwa die Klage der New York Times haltlos, erklärte zuletzt erst wieder OpenAI. Der Standpunkt: Das Vorgehen der KI-Firmen ist durch die Fair-Use-Regeln gedeckt.
Man sammelt also praktisch das komplette Internet ein, trainiert damit Modelle, die komplette Branchen und Berufszweige umkrempeln können – und all das sei völlig legitim. Wie soll das gehen?
Wann greifen die Fair-Use-Regeln?
Die Antwort ist Fair Use. Ob ein Produkt oder eine Technologie unter die Fair-Use-Regeln fällt, lässt sich anhand von vier Faktoren bewerten. Wie Lee oder der amerikanische Rechtsprofessor James Grimmelmann bereits 2024 in einem Beitrag für Ars Technica beschrieben haben, sind vor allem zwei relevant: Einer ist zunächst die Art der Nutzung. Wahrscheinlicher ist der Fair-Use-Charakter, wenn die Nutzung geschützter Werke „transformativ“ ist – es muss sich also um etwas Neues handeln, das fundamental vom ursprünglichen Zweck und Charakter des Originals abweicht. Ein weiterer Faktor ist, wie das neue Produkt den Markt für das ursprüngliche Produkt beeinflusst.
Lee und Grimmelmann schildern diese Faktoren anhand von zwei Beispielen:
MP3.com: Digitale Kopien sind nicht mehr als ein digitaler Verkaufskanal
MP3.com startete im Jahr 2000 einen Dienst, mit dem Nutzer eine digitale Kopie von bereits gekaufter Musik abrufen konnten. Um Zugang zu erhalten, mussten sie zunächst die Original-CD einlegen, damit eine Urheberrechtsprüfung erfolgen konnte. War diese positiv, wurden die Songs in die Online-Bibliothek der Nutzer auf MP3.com hinzugefügt.
Die Betreiber rechtfertigten das Vorgehen mit Fair-Use-Regeln, immerhin würden Nutzer ausschließlich auf Musik zugreifen können, die sie ohnehin besitzen. Richter gingen bei dieser Argumentation nicht mit. Das Geschäftsmodell sei nicht transformativ, sondern im Prinzip nur ein neuer Verkaufskanal – an den Songs ändert sich nicht, das Angebot verfolge im Prinzip auch keinen anderen Zweck als der CD-Verkauf. Und hinzu kommt in diesem Fall: Nur weil das Kopieren geschützter Musik für den privaten Gebraucht legitim ist, gelte das dann nicht automatisch in dem Ausmaß, in dem es von MP3.com betrieben wurde.
Google Books: Eine Suchmaschine ist etwas anderes als ein Buch
Umfang beim Verarbeiten geschützter Werke ist damit aber kein Totschlagargument, wie der Fall Google Books zeigt. Die Bücher-Suchmaschine bietet eine Übersicht zahlloses Bücher. Beim Design war Google jedoch vorsichtig. Man zeigt etwa keine vollständigen Bücher an, sondern nur Ausschnitte von bestimmten Seiten, die je nach Suchanfrage variieren. Bei Wörterbüchern, Lexika oder Kochbüchern sind die Restriktionen noch schärfer, weil in solchen Werken schon einzelne Seiten ausreichen können, damit Nutzer sich das komplette Buch nicht kaufen müssen.
Festhalten lässt sich also laut Lee und Grimmelmann: Die Suche enthält urheberrechtlich geschützte Bücher, doch der Nutzungszweck einer Suchmaschine unterscheidet sich stark von der Funktion eines einzelnen Buchs – die Suche ist damit als transformativ im Sinne der Fair-Use-Regeln. Zudem stellt Google sicher, dass die Rechte der Autoren so gut es geht geschützt werden. Damit konnte Google sich dann 2015 in einem Gerichtsverfahren durchsetzen.
ChatGPT und Co.: Mehr als das Trainingsmaterial?
KI-Firmen wie OpenAI argumentieren nun ähnlich wie Google bei der Books-Suchmaschine. Bei KI-Training würden nicht geschützte Inhalte kopiert, sondern vielmehr Muster in den Werken erfasst, die zu den aktuellen Modellen führen. ChatGPT biete daher etwa wesentlich mehr, als das Wissen der New York Times abzurufen. Die Chatbots helfen den Nutzern, produktiver oder kreativer zu sein, sie haben einen Nutzungszweck, der weit über den einer Zeitung hinausgeht.
Hinzu kommen noch die Lizenzabkommen, die OpenAI mit zahlreichen Medien abgeschlossen hat. Ebenso arbeite man daran, Fehler wie das Memorization-Phänomen abzustellen. Man zeigt sich also bemüht. Und selbst bei der enormen Datenmenge, die KI-Firmen für das Training erfasst haben, könnte das Vorgehen also legitim sein.
They can point to the value that their AI systems provide to users, to the creative ways that generative AI builds on and remixes existing works, and to their ongoing efforts to reduce memorization.
Timothy B. Lee und James Grimmelmann
Umso heikler sind daher die Erkenntnisse aus der aktuellen Studie, erklärt Lee in dem aktuellen Understanding-AI-Newsletter. Google konnte technisch sicherstellen, dass nie mehr als kurze Ausschnitte aus Büchern angezeigt werden. 42 Prozent der Inhalte aus dem ersten Harry-Potter-Band sind aber mehr als einige Zeilen.
So lässt sich nur schwer die Verteidigung aufrechterhalten, in den Modellen stecken nur Wortmuster, erklärt der Studien-Mitautor Mark Lemley gegenüber Lee. Richter könnten nun zu der Erkenntnis kommen, dass der Trainingsprozess zwar unter Fair-Use-Regeln falle, die Modelle aber nicht, wenn sie geschützte Werke erhalten.
US-Gerichte verhandeln Dutzende AI-Copyright-Klagen
Relevant werden dürfte das im Verfahren zwischen dem New-York-Times-Verlag und OpenAI. Die Zeitung argumentiert in der Klageschrift, dass ChatGPT auch Originalartikel der Zeitung ausgibt. OpenAI bezeichnet den Vorwurf als haltlos, spricht von Tricks und beschreibt Memorization als seltenen Fehler. Inwieweit das zutrifft, will das Gericht nun selbst prüfen. So wurde OpenAI vor kurzem verpflichtet, sämtlichen Output der Chatbots dauerhaft zu speichern. Man will also sicherstellen, dass keine Beweise verloren gehen.
Das Verfahren ist aber nur eine der Dutzenden Copyright-Klagen, die Gerichte in den USA derzeit verhandeln. Sowohl Zeitungen und Zeitschriften als auch zahlreiche Autoren, Schauspieler, Bildagenturen und Filmkonzerne ziehen gegen die KI-Firmen. Zu den prominentesten Verfahren zählen:
- Die New York Times sowie wie zahlreiche Autoren und Nachrichtenseiten verklagen OpenAI und Microsoft, eingereicht wurde die Klage im Juli 2023. Der Vorwurf ist, dass OpenAIs Modelle mit geschütztem Material trainiert worden sind. Ein Beweis, den die New York Times – wie erwähnt – vorlegt hat: ChatGPT kann vollständige Originalartikel auswerfen.
- Autoren verklagen Meta, weil der Konzern massenhaft geschützte Inhalte für das KI-Training auswertet.
- Ebenfalls 2023 verklagte die Bilder-Datenbank Getty Images den Bildgenerator-Betreiber Stability AI, weil dieser zwölf Millionen Bilder aus der Getty-Datenbank samt Metadaten für das Modell-Training verwendet haben soll.
- Letzte Woche reichten die Hollywood-Konzerne Disney und Universal eine Klage gegen den KI-Bildgenerator Midjourney ein, weil sich mit diesem Inhalte erstellen lassen, die die Rechte von Marken wie Star Wars, Simpsons oder Cars verletzen.
- Schon 2020 hatte Thomson Reuters das Start-up Ross Intelligence verklagt, weil es Inhalte aus einer geschützten Juristen-Rechercheplattform nutzte. Thomson Reuters hatte den Fall bereits gewonnen. Weil Ross bereits 2021 aufgrund der Klage den Betrieb einstellte, hat das Urteil zunächst keine praktischen Konsequenzen.
Eine Übersicht der laufenden und abgeschlossenen Verfahren bietet Wired in einem Tracker.
Wie stehen die Chancen?
Wie die Verfahren ausgehen, lässt sich nur schwer abschätzen. Der Sieg von Thomson Reuter ist ein erster Fingerzeig. Zusätzlich kommt die Aussage des Bundesbezirksrichters Vince Chhabria bei einer Anhörung in einem der Meta-Verfahren. Er könne sich nicht vorstellen, wie das Vorgehen unter Fair-Use fallen soll. „Sie haben Unternehmen, die mit urheberrechtlich geschütztem Material ein Produkt erschaffen, das in der Lage ist, eine unendliche Anzahl von konkurrierenden Inhalten zu erstellen“, sagte er zu Metas Anwälten laut einem Bericht der Nachrichtenagentur Reuters.
Diese Inhalte könnten den Markt für die Kläger dramatisch verändern oder sogar auslöschen – und trotzdem würden die Anwälte behaupten, sie müssten „der Person nicht einmal Lizenzgebühren zahlen“, so Chhabria. Er verweist damit auf das Marktargument, das laut Lee und Grimmelmann einer der zentralen Faktoren ist, um ein Vorgehen als Fair-Use zu bewerten. Wesentliche Aufgabe von Metas Anwälten ist nun, diesen Aussagen etwas entgegenzusetzen.
- KI-Suchmaschinen: Wie Googles AI-Pläne das alte Internet töten
Eine schwierige Aufgabe, denn die öffentliche Diskussion geht eher in die andere Richtung. „Wie AI das alte Internet tötet“, ist seit Jahren ein Leitsatz, der durch Googles Umstieg auf KI-Suchmaschinen wieder Fahrt aufgenommen hat. Wenn Suchmaschinen in erster Linie keine Links mehr verteilen, sondern die KI-Dienste direkt die Antworten liefern, hat es unmittelbare Auswirkungen auf Geschäftsmodelle – und in diesem Fall betrifft es sogar unmittelbar Verlage.
Nun muss man bedenken: Die Fälle unterscheiden sich, was für die Google-Suche gilt, betrifft nicht unbedingt ChatGPT. Wie Lee und Grimmelmann in dem Ars-Technica-Beitrag beschreiben, bewerten Richter bei solchen Verfahren auch immer die Marktlage. Und inwieweit die KI-Firmen versuchen, die Copyright-Vorgaben einzuhalten. Selbst wenn es zu einer Verurteilung kommen würde, könnte der Eindruck dann darüber entscheiden, wie hoch die Strafe ausfällt.
Ultimately, the fate of these companies may depend on whether judges feel that the companies have made a good-faith effort to color inside the lines.
Timothy B. Lee und James Grimmelmann
So gesehen sind die KI-Firmen auch von der öffentlichen Meinung abhängig.
Politischer Lobbyismus als Ausweg für Tech-Konzerne
Neben den Gerichtsverfahren gibt es für die KI-Firmen aber noch einen Plan B: die Politik. OpenAI bringt sich bereits in Stellung. In einem Dokument für den AI Action Plan, den die Trump-Administration diesen Sommer noch beschließen will, argumentiert der Konzern für eine „Freiheit zum Lernen“. Das Training mit Copyright-Inhalten müsse legal bleiben, um Amerikas Vormachtstellung im KI-Sektor beizubehalten. Es gehe um Geopolitik, den Konflikt mit China und die nationale Sicherheit.
Dass die Copyright-Klagen scheitern, ist demnach also im nationalen Interesse der USA. Man sorgt für eine enorme Fallhöhe bei den Verfahren. Die eigentliche Kernbotschaft des Dokuments ist aber: Wenn man vor Gericht scheitert, soll Trump den Status Quo retten.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.












Apps & Mobile Entwicklung
MediaMarkt reduziert PS5 gewaltig – doch es ist Eile gefragt!
Wer ein Auge auf die PlayStation 5 geworfen hat, sollte hier schnell weiterlesen. MediaMarkt senkt die 1-TB-Variante der Digital Slim Edition jetzt nämlich ordentlich im Preis. Doch es herrscht Ausverkauf-Gefahr.
Die PlayStation 5 gehört nach wie vor zu den begehrtesten Konsolen auf dem Markt, und MediaMarkt hat derzeit ein Angebot, das für Aufsehen sorgt. Die PS5 Digital Edition Slim mit 1 Terabyte Speicher ist aktuell nämlich stark reduziert. Das Angebot ist dabei scheinbar so gut, dass die Konsole zu dem Preis fast wieder vergriffen ist.
Achtung: Fast ausverkauft!
Nachdem der durchschnittliche Preis der PlayStation 5 Digital Slim* zuletzt bei 439 Euro gelegen hatte, ist MediaMarkt jetzt mit einem Super-Angebot am Start. Dort könnt Ihr die Konsole momentan für nur 399 Euro ergattern, wohlgemerkt in der 1-TB-Variante. Ein absoluter Top-Preis, der im Netz derzeit unerreicht ist. Der einzige Haken: Laut der MediaMarkt-Produktseite ist die Sony-Konsole fast ausverkauft. Wer also noch zum Sonderpreis drankommen möchte, muss sich beeilen.
Falls Ihr zu langsam wart: Eine Top-Alternative
Wenn Ihr doch zu lange gewartet habt, dann habt Ihr hier noch die Chance, die PlayStation 5 mit 825 GB* Speicherplatz zu ergattern. Die bekommt Ihr momentan bei MediaMarkt für denselben Preis wie die 1‑TB-Version. Da ist der Deal zwar nicht so gut, wie zuvor, aber billiger bekommt Ihr die PlayStation 5 mit einem DualSense Wireless Controller kaum wo. Die technischen Spezifikationen unterscheiden sich nicht, abgesehen von der Speicherkapazität.
Flüssiges Zocken und riesiger Speicher
Technisch hat die PlayStation 5 Digital Edition einiges zu bieten. Herzstück ist ein AMD-Ryzen-Prozessor auf Basis der Zen-2-Architektur, kombiniert mit einer AMD-Radeon-GPU mit RDNA-2-Technologie. Diese Kombination sorgt für flüssiges Gaming in 4K-Auflösung bei stabilen Framerates. Dazu kommen 16 GB Arbeitsspeicher und eine schnelle Custom-SSD mit 1 Terabyte Speicher, welche die Ladezeiten spürbar reduziert. Wer viele große Spiele installieren möchte, kann den Speicher über einen Erweiterungsanschluss vergrößern.
Auch die Ausstattung kann sich sehen lassen: Im Lieferumfang enthalten sind ein DualSense Wireless-Controller, HDMI- und USB-Kabel, Netzteil, zwei horizontale Standfüße sowie das Spiel ASTRO’s Playroom, das bereits vorinstalliert ist. Bei den Anschlüssen stehen ein HDMI-Out-Port, ein USB-A-SuperSpeed-Port (10 Gbit/s) und zwei USB-C-Ports zur Verfügung. Wer ein Auge auf die PS5 geworfen hat, für den ist all das sicher nichts Neues. Wirklich beachtlich ist vor allem der aktuelle MediaMarkt-Preis.
Was haltet Ihr von dem Angebot? Habt Ihr ohnehin schon die Konsole Eurer Wahl im Wohnzimmer oder schlagt Ihr hier beim PS5-Angebot zu.
Apps & Mobile Entwicklung
Warum die Akkulaufzeit je nach Land unterschiedlich ist
Apple passt seine iPhones seit jeher an regionale Märkte an. Mal aus technischen, mal aus regulatorischen Gründen. In den USA gibt es etwa spezielle mmWave‑5G‑Antennen, in Japan war lange exklusiv ein FeliCa‑Chip für kontaktloses Bezahlen verbaut, in China gibt es Dual‑SIM‑Schächte. Auch Einschränkungen wie der nicht abschaltbare Kamera‑Ton in Japan oder deaktiviertes FaceTime Audio in den Vereinigten Arabischen Emiraten gehören dazu. Bisher betrafen diese Unterschiede jedoch nie die Akkulaufzeit, bis jetzt.
Erstes Redesign seit dem iPhone 12 Pro
Mit dem iPhone 17 Pro hat Apple den inneren Aufbau komplett überarbeitet. Das größere Kamera‑Element beherbergt nicht nur die Kameras selbst, sondern auch weitere Bauteile, um im unteren Bereich Platz für einen größeren Akku zu schaffen. Gleichzeitig plant Apple offenbar, den SIM‑Slot weltweit abzuschaffen. In Ländern, in denen das iPhone 17 Pro bereits ausschließlich mit eSIM verkauft wird, nutzt Apple den frei gewordenen Platz für eine größere Batterie. In Märkten mit physischem SIM‑Slot muss der Akku kleiner ausfallen.

Nur das Pro‑Modell betroffen
Diese Änderung betrifft ausschließlich das iPhone 17 Pro. Das iPhone Air wird weltweit ohne SIM‑Slot ausgeliefert, das reguläre iPhone 17 behält den bisherigen inneren Aufbau und dürfte, wie schon in den USA seit dem iPhone 14, dort wieder einen Kunststoff‑Platzhalter anstelle des SIM‑Slots haben.
Hier gibt es die längste Akkulaufzeit
Die eSIM‑only‑Versionen des iPhone 17 Pro verkauft Apple derzeit in: USA, Kanada, Mexiko, Japan, Guam, US‑Jungferninseln, Katar, Saudi‑Arabien, Oman, Kuwait, Bahrain und den Vereinigten Arabischen Emiraten. In diesen Ländern hält der Akku laut Apple beim Videostreaming rund zwei Stunden länger durch – ein Plus von etwa fünf Prozent.
In allen anderen Märkten, darunter Europa, gibt es weiterhin einen Nano‑SIM‑Slot. Die Akkulaufzeit fällt hier minimal kürzer aus, profitiert aber dennoch vom neuen Gehäusedesign, das generell größere Akkus ermöglicht. Im Vergleich zum iPhone 16 Pro steigt die Laufzeit in allen Regionen.
Lohnt sich der Kauf im Ausland?
Wer überlegt, ein iPhone 17 Pro aus einem eSIM‑only‑Land zu importieren, sollte vorher prüfen, ob das Modell alle in Deutschland genutzten Mobilfunkfrequenzen unterstützt. Auch regionale Besonderheiten, wie deaktivierte Funktionen, sind zu beachten. Zudem kann es sein, dass Apple die Garantie hierzulande nicht anerkennt und man sich im Problemfall an den Händler im Kaufland wenden muss.
Apps & Mobile Entwicklung
Datei-Manager: Multi-Commander 15.6 führt über 90 Änderungen ein

1986 führte Norton mit dem Norton Commander den ersten Datei-Manager mit Zwei-Fenster-Ansicht ein. Beinahe vier Jahrzehnte später erfreut sich dieses Konzept weiterhin großer Beliebtheit und hat zahlreiche Nachahmer gefunden – darunter der Multi-Commander für Windows, der nun in Version 15.6 mit zahlreichen Neuerungen erscheint.
Verbesserungen in vielen Bereichen
So wurde in der aktuellen Version mit VFG (Virtual Folder Group) eine neue Erweiterung des virtuellen Dateisystems integriert, durch die sich viele Ordner auf einem virtuellen Gerät gruppieren lassen. Darüber hinaus ist eine MultiScript-Funktion hinzugekommen, die den Umgang mit Unzip vereinfacht. Der Spracheditor kann nun einen Änderungsbericht auf Basis einer älteren Sprachpaketdatei erzeugen, zusätzlich erscheint künftig ein Dialog zum Entsperren des Geräts, wenn versucht wird, auf ein mit Bitlocker verschlüsseltes Laufwerk zuzugreifen.
Auch an die Nutzung von Mediendateien wurde gedacht: Mit dem neuen Audio-Werkzeug „MP3 Merger“ können mehrere mp3-Dateien zu einer großen Datei zusammengefügt werden. Wird gleichzeitig der Play-Audio-Button und die CTRL-Taste gedrückt, spielt das Programm einen kleinen Ausschnitt der jeweiligen Audio-Datei ab. Im Bildbetrachter lässt sich außerdem der Dateipfad nun direkt in die Zwischenablage kopieren.
Zahlreiche Fehler behoben
Zahlreiche Fehler wurden in der neuen Version ebenfalls behoben. So besitzt der Multi-Commander 15.6 nun eine verbesserte Fehlerbehandlung für den Fall, dass beim Kopieren oder Verschieben von Dateien als Administrator der Fehler „Zugriff verweigert“ auftritt. Zusätzlich wurden die AutoScaling-Optionen angepasst, um unter Windows 11 bessere Ergebnisse zu erzielen. Auch sollten bei der Sicherung der Konfiguration nun keine Konfigurationsdateien mehr fehlen.
Insgesamt sollen die detaillierten Release-Notes laut Entwickler Mathias Svensson über 90 Neuerungen und Verbesserungen umfassen.
Ab sofort erhältlich
Der kostenlose Multi-Commander 15.6 für Windows ist ab sofort über die Website des Entwicklers erhältlich. Alternativ kann der Datei-Manager auch bequem über den Link am Ende dieser Meldung aus dem Download-Bereich von ComputerBase bezogen werden.

Ausgezeichnete VR-Spiele gratis ausprobieren: VR Forever Fest startet auf Steam
 ohne Code")
So produziert ihr einen KI-Podcast in 5 Minuten (fast) ohne Code

Instagram-Algorithmus selbst steuern – so geht’s

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 3 Wochen
UX/UI & Webdesignvor 3 WochenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 1 Monat
Social Mediavor 1 MonatRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Wochen
Entwicklung & Codevor 2 WochenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 3 Tagen
UX/UI & Webdesignvor 3 TagenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier