Künstliche Intelligenz
AI Act: Was im KI-Verhaltenskodex der EU für Anbieter steht
Die europäische KI-Verordnung (KI-VO, englisch AI Act) nimmt nicht nur verbotene und Hochrisiko-KI-Systeme in den Blick, sondern auch Anbieter sogenannter General-Purpose-AI-Modelle (GPAI). Die Pflichten für GPAI gelten seit dem 2. August 2025.
- Der KI-Verhaltenskodex der EU soll die Anforderungen der KI-Verordnung für General-Purpose-AI-Modelle konkretisieren und so den betroffenen Unternehmen die Umsetzung einfacher machen.
- Der Kodex behandelt die drei relevantesten Themen Transparenz, Urheberrechte sowie Sicherheit und Gefahrenabwehr und liefert einige Details zur Umsetzung.
- Neben den Konkretisierungen der Anforderungen enthält die Veröffentlichung auch Hinweise für GPAI-Modelle, insbesondere zum Geltungsbereich der Vorschriften.
- Zwar liefert der Verhaltenskodex konkrete technische Hilfestellungen, in einigen wichtigen Punkten, beispielsweise der Transparenz bei Trainingsdaten, bleibt er jedoch zu vage.
- Das Thema Sanktionen bleibt vollständig ausgespart.
Um die bislang teils vagen Vorgaben des AI Act zu GPAI zu konkretisieren, hat die EU-Kommission pünktlich vor dem Geltungsbeginn der neuen Vorgaben des AI Act einen „General-Purpose AI Code of Practice“ veröffentlicht und ihn am 1. August genehmigt. Dieser Verhaltenskodex soll der Industrie als Orientierungshilfe dienen, um die Anforderungen des AI Act praxisnah umzusetzen.


Christina Kiefer ist Rechtsanwältin und Senior Associate in der Digital Business Unit bei reuschlaw.

Moritz Schneider ist Rechtsanwalt und Associate bei reuschlaw in Saarbrücken. Dort berät er in der Digital Business Unit Unternehmen zu Datenschutz, Cybersicherheit und IT-Recht.
Der Kodex besteht aus konkretisierenden Kapiteln zu den neuen Anforderungen zu Transparenz, Urheberrecht, Sicherheit und Risikomanagement. Wir fassen die wichtigsten Punkte zusammen.
Das war die Leseprobe unseres heise-Plus-Artikels „AI Act: Was im KI-Verhaltenskodex der EU für Anbieter steht“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.










Künstliche Intelligenz
DeepSeek-OCR: Bilder vereinfachen Texte für große Sprachmodelle
Viele Unternehmensdokumente liegen zwar als PDFs vor, sind aber häufig gescannt. Obwohl es simpel klingt, können diese Dokumente oftmals nur unter großen Mühen in Text gewandelt werden, insbesondere wenn die Struktur der Dokumente komplexer ist und erhalten bleiben soll. Auch Bilder, Tabellen und Grafiken sind häufige Fehlerquellen. In den letzten Monaten gab es daher eine wahre Flut von OCR-Software, die auf großen Sprachmodelle (LLMs) setzt.
Weiterlesen nach der Anzeige
Auch der chinesische KI-Entwickler DeepSeek steigt nun in diesen Bereich ein und veröffentlicht nach dem Reasoning-Modell R1 ein experimentelles OCR-Modell unter MIT-Lizenz. Auf den ersten Blick mag das verblüffen, denn OCR schien bisher nicht die Kernkompetenz von DeepSeek zu sein. Und tatsächlich ist das neue Modell erstmal eine Technikdemo für einen neuen Ansatz in der Dokumentenverarbeitung von großen Sprachmodellen.

Prof. Dr. Christian Winkler beschäftigt sich speziell mit der automatisierten Analyse natürlichsprachiger Texte (NLP). Als Professor an der TH Nürnberg konzentriert er sich bei seiner Forschung auf die Optimierung der User Experience.
DeepSeek versucht, lange Textkontexte in Bildern zu komprimieren, da sich hierdurch eine höhere Informationsdichte mit weniger Token darstellen lässt. DeepSeek legt die Messlatte für die Erwartungen hoch und berichtet, dass das Modell bei hohen Kompressionsraten (Faktor 10) noch eine Genauigkeit von 97 Prozent erreicht, bei einer noch stärkeren Kompression fällt zwar die Genauigkeit, bleibt dabei aber relativ hoch. Das alles soll schneller funktionieren als bei anderen OCR-Modellen und auf einer Nvidia A100-GPU bis zu 200.000 Seiten pro Tag verarbeiten.
Das Kontext-Problem
Large Language Models haben Speicherprobleme, wenn der Kontext von Prompts sehr groß wird. Das ist der Fall, wenn das Modell lange Texte oder mehrere Dokumente verarbeiten soll. Grund dafür ist der für effiziente Berechnungen wichtige Key-Value-Cache, der quadratisch mit der Kontextgröße wächst. Die Kosten der GPUs steigen stark mit dem Speicher, was dazu führt, dass lange Texte sehr teuer in der Verarbeitung sind. Auch das Training solcher Modelle ist aufwendig. Das liegt allerdings weniger am Speicherplatz, sondern auch an der quadratisch wachsenden Komplexität der Berechnungen. Daher forschen die LLM-Anbieter intensiv daran, wie sich man diesen Kontext effizienter darstellen kann.
Hier bringt DeepSeek die Idee ins Spiel, den Kontext als Bild darzustellen: Bilder haben eine hohe Informationsdichte und Vision Token zur optischen Kompression könnten einen langen Text durch weniger Token. Mit DeepSeek-OCR haben die Entwickler diese Grundidee überprüft – es ist also ein Experiment zu verstehen, das zeigen soll, wie gut die optische Kompression funktioniert.
Weiterlesen nach der Anzeige
Die Modellarchitektur
Der dazugehörige Preprint besteht aus drei Teilen: einer quantitativen Analyse, wie gut die optische Kompression funktioniert, einem neuen Encoder-Modell und dem eigentlichen OCR-Modell. Das Ergebnis der Analyse zeigt, dass kleine Sprachmodelle lernen können, wie sie komprimierte visuelle Darstellungen in Text umwandeln.
Dazu haben die Forscher mit DeepEncoder ein Modell entwickelt, das auch bei hochaufgelösten Bildern mit wenig Aktivierungen auskommt. Der Encoder nutzt eine Mischung aus Window und Global Attention verbunden mit einem Kompressor, der Konvolutionen einsetzt (Convolutional Compressor). Die schnellere Window Attention sieht nur einzelne Teile der Dokumente und bereitet die Daten vor, die langsamere Global Attention berücksichtigt den gesamten Kontext, arbeitet nur noch mit den komprimierten Daten. Die Konvolutionen reduzieren die Auflösung der Vision Token, wodurch sich der Speicherbedarf verringert.
DeepSeek-OCR kombiniert den DeepEncoder mit DeepSeek-3B-MoE. Dieses LLM setzt jeweils sechs von 64 Experten und zwei geteilte Experten ein, was sich zu 570 Millionen aktiven Parametern addiert. Im Gegensatz zu vielen anderen OCR-Modellen wie MinerU, docling, Nanonets, PaddleOCR kann DeepSeek-OCR auch Charts in Daten wandeln, chemische Formeln und geometrische Figuren erkennen. Mathematische Formeln beherrscht es ebenfalls, das funktioniert zum Teil aber auch mit den anderen Modellen.
Die DeepSeek-Entwickler betonen allerdings, dass es sich um eine vorläufige Analyse und um ebensolche Ergebnisse handelt. Es wird spannend, wie sich diese Technologie weiterentwickelt und wo sie überall zum Einsatz kommen kann. Das DeepSeek-OCR-Modell unterscheidet sich jedenfalls beträchtlich von allen anderen. Um zu wissen, wie gut und schnell es funktioniert, muss man das Modell jedoch selbst ausprobieren.
DeepSeek-OCR ausprobiert
Als Testobjekt dient eine Seite aus einer iX, die im JPEG-Format vorliegt. DeepSeek-OCR kann in unterschiedlichen Konfigurationen arbeiten: Gundam, Large und Tiny. Im Gundam-Modus findet ein automatisches Resizing statt. Im Moment funktioniert das noch etwas instabil, bringt man die Parameter durcheinander, produziert man CUDA-Kernel-Fehler und muss von vorne starten.
Möchte man den Text aus Dokumenten extrahieren, muss man das Modell geeignet prompten. DeepSeek empfiehlt dazu den Befehl

Im Gundam-Modus erkennt DeepSeek-OCR den gesamten Text und alle relevanten Elemente und kann auch Textfluss des Magazins rekonstruieren.
Den Text hat das Modell praktisch fehlerfrei erkannt und dazu auf einer RTX 4090 etwa 40 Sekunden benötigt. Das ist noch weit entfernt von den angepriesenen 200.000 Seiten pro Tag, allerdings verwendet Gundam auch nur ein Kompressionsfaktor von zwei: 791 Image Token entsprechen 1.580 Text Token. Immerhin erkennt das Modell den Textfluss im Artikel richtig. Das ist bei anderen Modellen ein gängiges Problem.
Mit etwa 50 Sekunden rechnet die Large-Variante nur wenig länger als Gundam, allerdings sind die Ergebnisse viel schlechter, was möglicherweise auch dem größeren Kompressionsfaktor geschuldet ist: 299 Image-Token entsprechen 2068 Text-Token. Im Bild verdeutlichen das die ungenauer erkannten Boxen um den Text – hier gibt es noch Optimierungsbedarf. Außerdem erkennt das Modell die Texte nicht sauber, teilweise erscheinen nur unleserliche Zeichen wie „¡ ¢“, was möglicherweise auf Kodierungsfehler und eigentlich chinesische Schriftzeichen hindeuten könnte.

Der Large-Modus komprimiert die Bilder stärker als Gundam, was zu einer ungenaueren Erkennung führt. Die Textboxen sind unschärfer abgegrenzt und es erscheinen unleserliche Zeichen, die auf eine fehlerhafte Kodierung hinweisen.
Fehler mit unleserlichen Zeichen gibt es beim Tiny-Modell nicht. Das rechnet mit einer Dauer von 40 Sekunden wieder etwas schneller und nutzt einen Kompressionsfaktor von 25,8 – 64 Image-Token entsprechen 1652 Text-Token. Durch die hohe Kompression halluziniert das Modell allerdings stark und erzeugt Text wie „Erweist, bei der Formulierung der Ab- fragen kann ein KI-Assistent helfen. Bis Start gilt es auf Caffès offiziell die Gewicht 50 Prozent der Früh-, der Prüfung und 50 Prozent für den Arzt- und NEUT und in Kürze folgen. (Spezielle)“. Das hat nichts mit dem Inhalt zu tun – auf diese Modellvariante kann man sich also nicht verlassen.

Die Tiny-Variante hat den höchsten Kompressionsfaktor für die Bilder und halluziniert bei der Text-Ausgabe stark. Hier sollte man sich also nicht auf die Ergebnisse verlassen.
Neben der Markdown-Konvertierung lässt DeepSeek-OCR auch ein Free OCR zu, das das Layout nicht berücksichtigt. Damit funktioniert das Modell sehr viel schneller und produziert auch in der Large-Version mit hoher Kompression noch gute Resultate. Diese Variante ist aber nur sinnvoll, wenn man weiß, dass es sich um Fließtexte ohne schwieriges Layout handelt.
Informationen aus Grafiken extrahieren
DeepSeek-OCR hat beim Parsing die im Artikel enthaltenen Bilder erkannt und separat abgelegt. Das Diagramm speichert das Modell dabei in einer schlecht lesbaren Auflösung.
Das mit Gundam extrahierte Diagramm ist verschwommen und lässt sich mit bloßem Auge nur noch schlecht entziffern.
Jetzt wird es spannend, denn DeepSeek-OCR soll aus diesem Diagramm auch Daten extrahieren können, das geht mit dem Prompt
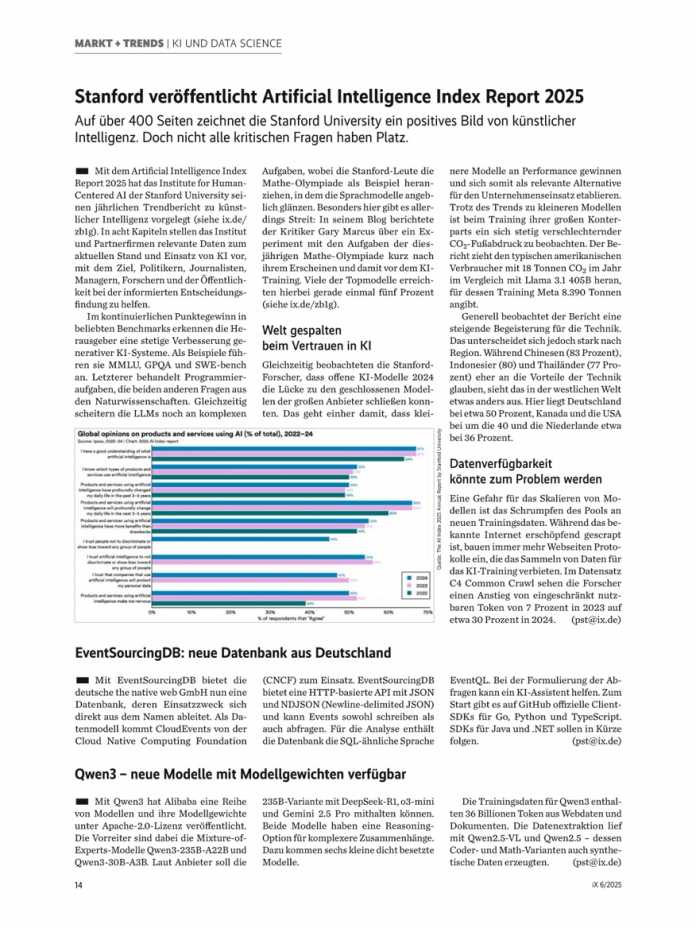
| 2024 | 2023 | 2022 | |
| I have a good understanding of what artificial intelligence is | 67% | 67% | 64% |
| I know which types of products and services use artificial intelligence | 52% | 51% | 50% |
| Products and services using artificial intelligence have profoundly changed my daily life in the past 3-5 years | 50% | 50% | 49% |
| Products and services using artificial intelligence will profoundly change my daily life in the next 3-5 years | 66% | 66% | 60% |
| Products and services using artificial intelligence have more benefits than drawbacks | 55% | 54% | 52% |
| I trust people not to discriminate or show bias toward any group of people | 45% | 45% | 44% |
| I trust artificial intelligence to not discriminate or show bias toward any group of people | 54% | 54% | 50% |
| I trust that companies that use artificial intelligence will protect my personal data | 47% | 50% | 50% |
| Products and services using artificial intelligence make me nervous | 39% | 39% | 39% |
Offenbar haben sich Fehler in die Tabelle eingeschlichen, aber zumindest hat das Modell den verwaschenen Text richtig erkannt. Hier zeigt sich die Stärke des Encoders, aber auch die englische Beschriftung vereinfacht den Prozess für das Modell. Die meisten Prozentwerte stimmen, ebenso die Struktur der Daten. Verwendet man eine höhere Auflösung, verbessern sich die Ergebnisse allerdings nur marginal.
Neben Diagrammen kann DeepSeek-OCR auch mathematische Formeln erkennen und sie in LaTeX-Syntax wandeln. Chemische Strukturformeln hat es auch im Repertoire und wandelt sie in das SMILES-Format.
Fazit
DeepSeek hat sich erneut einen spannenden technischen Ansatz ausgedacht und mit DeepSeek-OCR überzeugend demonstriert. Die Erkennung von Texten funktioniert besonders im Gundam-Modus schon gut, auch das Parsing der Diagramme ist überzeugend. Allerdings sind andere Modelle wie MinerU, Nanonets und PaddleOCR-VL besonders bei der reinen Texterkennung ebenfalls sehr gut und liefern teilweise sogar bessere Ergebnisse, da sie etwa getrennte Wörter zusammenführen. Besonders das ebenso nagelneue PaddleOCR-VL ist hervorzuheben, das Daten aus Diagrammen verlässlich extrahiert und in eigenen Tests sogar besser als DeepSeek-OCR funktionierte. Um OCR ist ein wahres Wettrennen entbrannt.
DeepSeek scheint mit dem Modell jedoch nicht nur auf OCR zu setzen, sondern möchte zeigen, dass die Vision Token eine gute Darstellung sind, um den Kontext in großen Sprachmodellen besonders kompakt zu speichern. Mit einer geringen Kompression funktioniert das schon gut, mit höherer Kompression leiden die Ergebnisse aber spürbar. Dieser Ansatz steht allerdings noch ganz am Anfang.
DeepSeek-OCR ist in allen Konfigurationen verhältnismäßig schnell. Experimente mit MinerU, Nanonets und PaddleOCR-VL waren alle mindestens 50 Prozent langsamer. Nanonets erzeugte immerhin eine Tabelle aus dem Diagramm, aber ohne die Jahreszahlen, dafür war der Fließtext sehr viel besser erkannt. Das nagelneue PaddleOCR-VL konnte das Diagramm sogar besser als DeepSeek-OCR erkennen, ist aber nicht auf chemische Strukturformeln und ähnliche Inhalte trainiert.
DeepSeek-OCR ist – wie von den Entwicklern deutlich vermerkt – eine Technologiedemonstration, die dafür schon äußerst gut funktioniert. Es bleibt abzuwarten, wie sich die Technologie in klassische LLMs integrieren lässt und dort zur effizienteren Verarbeitung von längeren Kontexten genutzt werden kann.
Weitere Informationen finden sich auf GitHub, Hugging Face und im arXiv-Preprint.
(pst)
Künstliche Intelligenz
Google „Broadwing“: 400-MW-Gaskraftwerk speichert CO₂ tief unter der Erde
Google beabsichtigt, im Projekt Broadwing ein 400-MW-Gaskraftwerk mit Carbon Capture and Storage (CCS) in Decatur im US-Bundesstaat Illinois zu errichten und zu betreiben. Das teilte Google am Donnerstag in seinem Blog mit. Das bei der Gasverbrennung entstehende CO₂ soll dabei zu etwa 90 Prozent abgeschieden und über eine Meile (etwa 1,6 km) tief unter der Erde dauerhaft gespeichert werden. Google will mit dem in seinem ersten CCS-Gaskraftwerk Broadwing Energy produzierten Strom vornehmlich seine eigenen Rechenzentren vor Ort mit nach eigenen Angaben sauberer Energie betreiben.
Weiterlesen nach der Anzeige
Entstehen soll Broadwing Energy in einer Industrieanlage von Archer Daniels Midland (ADM) in Decatur. Verantwortlich für die Projektentwicklung ist das Unternehmen Low Carbon Infrastructure (LCI). ADM verfüge bereits über Erfahrung mit der Speicherung von CO₂ aus der Ethanolproduktion, schreibt Google. Für Broadwing Energy werden zugelassene Klasse-IV-Sequestrierungsanlagen von ADM genutzt, um das bei der Gasverbrennung entstehende CO₂ zu binden und dann in einer Tiefe von mehr als einer Meile unter der Erde zu speichern.
CO₂-Bindung und Speicherung
Das dabei angewendete Verfahren funktioniert in drei Stufen: Absorption, Regeneration sowie Kompression und Speicherung. In der Absorptionsstufe strömt das durch Gasverbrennung entstehende Rauchgas durch eine große Absorbersäule, in der es mit einer Amin-Wasser-Lösung in Kontakt kommt. Das Amin, organische Verbindungen von Ammoniak, reagiert chemisch mit dem CO₂ im Rauchgas und verbindet sich mit dem CO₂ zu einer stabilen Verbindung, sodass kaum noch CO₂ enthalten ist.
In der Absorptionsphase wird die CO₂-haltige Aminlösung in einem Regenerator mit Dampf erhitzt. Die Hitze bricht die chemische Verbindung zwischen dem CO₂ und dem Amin auf, sodass reines CO₂-Gas freigesetzt wird. Die Aminlösung, die nun kaum noch CO₂ enthält, wird gekühlt und in den Absorber zurückgeführt, um erneut CO₂ binden zu können.
In der dritten Phase des Prozesses wird das CO₂-Gas abgekühlt und in flüssiger Form komprimiert. Dann wird es dauerhaft in geologischen Formationen unter der Erde gespeichert. Konkret geschieht das in Illinois in der Mount-Simon-Formation, ein Sandsteinreservoir in mehr als einer Meile Tiefe, das in der Lage ist, große Mengen an Flüssigkeit aufzunehmen und ideal für die Speicherung der CO₂-Flüssigkeit sein soll.
Rund 90 Prozent des durch die Gasverbrennung entstehenden CO₂ soll so gebunden werden können, was eine erhebliche Reduzierung von CO₂-Emissionen im Vergleich zu herkömmlichen Gaskraftwerken bedeutet. Kritiker der auf fossiler Verbrennung beruhenden Stromproduktion bemängeln jedoch, dass dadurch der Umstieg auf Formen erneuerbarer Energien hinausgezögert wird.
Bis Broadwing Energy umgesetzt ist, dauert es aber noch ein paar Jahre: 2025 sollen zunächst die erforderlichen behördlichen Genehmigungen eingeholt werden. 2026 könne dann der Bau der Anlage beginnen, die bis Ende 2029 einsatzbereit sein soll. Anfang 2030 soll die Anlage dann ihren Betrieb aufnehmen.
Weiterlesen nach der Anzeige
(olb)
Künstliche Intelligenz
Sonos-Soundbar Arc Ultra im Test
Ab Herbst zieht es manche wieder verstärkt ins Heimkino. Gerade rechtzeitig hat Sonos seinen im Frühjahr vorgestellten TV-Lautsprecher Arc Ultra per Softwareupdate aufgeschlaut. Von künstlicher Intelligenz trainierte Algorithmen sollen Dialoge von anderen Tönen im Center-Kanal trennen, damit Sprache besser zu verstehen ist. Bei drei einstellbaren Stufen soll das gelingen, ohne die Lautstärke etwa der Hintergrundmusik oder Geräusche der Filmhandlung zu verfälschen. Zwei weitere Stufen nehmen darauf keine Rücksicht und lassen Sprache zugunsten von Menschen mit Hörproblemen dominieren.
Unter der Abdeckung stecken im Vergleich zum vorherigen Modell Arc nun erstmals ein Tieftöner sowie sieben statt drei Hochtöner und sechs statt acht Mitteltöner. Das soll außer der Stimmklarheit auch einem volleren Bass zugutekommen. Der neue Tieftöner stammt vom aufgekauften Start-up Mayht und lässt einander gegenüberliegende Treibermembranen synchron bewegen. Im Vergleich zu herkömmlichen Bauweisen spart dies Platz, erklärte Hardwaremanager Naphur van Apeldoorn während eines Mediengesprächs im Europa-Hauptquartier von Sonos nahe Amsterdam.
Dadurch belegt der Ultra trotz mehr Lautsprechern nahezu die gleiche Stellfläche wie der Arc ohne „Ultra“-Siegel. Der Neuzugang ist etwa 3,6 Zentimeter breiter, aber 1,2 Zentimeter flacher und 0,6 Zentimeter schlanker. Im Test fiel jedoch negativ auf, dass die Sensortastenleiste nach hinten gerückt ist. Direkt unter der Kante eines TV-Geräts lässt sich die Soundbar also nicht platzieren. Man muss sie etwas nach vorn rücken, was einen Blick auf den Kabelsalat an der Rückseite freigibt.
Das war die Leseprobe unseres heise-Plus-Artikels „Sonos-Soundbar Arc Ultra im Test“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.

Länger leben: Frank Thelen investiert in den Jungbrunnen aus der Biotech-Küche

KI-Bearbeitung für Stories: Instagram bringt Restyle

Datensicherung: Duplicati 2.2.0.0 führt nicht nur neue Oberfläche ein

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 UX/UI & Webdesignvor 6 Tagen
UX/UI & Webdesignvor 6 TagenIllustrierte Reise nach New York City › PAGE online
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatSchluss mit FOMO im Social Media Marketing – Welche Trends und Features sind für Social Media Manager*innen wirklich relevant?