Künstliche Intelligenz
Apple erweitert Passwörter-App-Unterstützung für Windows
Apple ist es offenbar endlich gelungen, eine Firefox-Erweiterung für seine Passwörter-App unter Windows zum Laufen zu bringen. Das berichten Nutzer auf Reddit. Allerdings scheint dies nur bei bestimmten Konfigurationen zu funktionieren.
Erweiterung da, doch der Support kam später
Apple hatte mit iOS 18, macOS 15 und iPadOS 18 im September letzten Jahres eine frische Anwendung zur Passwortverwaltung auf den Markt gebracht. Diese erlaubt auch eine Synchronisierung via iCloud. Um auch unter Windows an seine Passwörter direkt im Browser zu gelangen, führte Apple neben der Integration von Passwörtern in der offiziellen PC-iCloud-App auch eigene Extensions für verschiedene Windows-Browser ein.
Dies waren anfangs allerdings nur Google Chrome und Microsoft Edge. Dann tauchte einige Monate später auch eine offizielle Firefox-Erweiterung auf. Allerdings funktionierte diese zunächst nicht – bis zu dieser Woche. Offenbar hatte Apple zwar die Firefox-Erweiterung publiziert, jedoch passende Routinen in der iCloud-für-Windows-App nicht implementiert. Das wurde nun mit dem jüngsten Update nachgeholt. Ein Management der Passwörter erfolgt wie gehabt nicht im Browser, sondern in der iCloud-Anwendung. Eine rein Browser-basierte Passwortverwaltung im Stil von 1Password und anderen Konkurrenten scheint Apple nicht implementieren zu wollen.
Windows 10 vs. Windows 11
Ein Problem scheint es noch zu geben, wenn man auf seinem PC das mittlerweile veraltete Windows 10 nutzt. Userberichten zufolge funktioniert die Firefox-Erweiterung für Apples Passwörter-App auf PCs nämlich erst ab Windows 11. Apple hat allerdings keine Angaben dazu gemacht, ob sich das noch ändert. Unter Windows 10 scheinen mögliche Optionen für Firefox gar nicht erst aufzutauchen.
Apples Passwörter-App wird in den letzten Jahren immer wichtiger, denn sie beherrscht auch die Nutzung von Passkeys. Diese Form der biometrischen Authentifizierung ist derzeit noch schwer exportierbar, weshalb Nutzer nach Start der Verwendung in einer Kennwortanwendung festhängen. Allerdings hat Apple sich entschieden, Passkeys künftig exportierbar zu machen. So soll es ab Herbst erstmals möglich, die im iCloud-Schlüsselbund respektive in Apples Passwörter-App gespeicherten Passkeys in eine andere Passwortverwaltung umzuziehen. Das Exportieren von Passwörtern und Einmal-Codes wird dabei obendrein unterstützt, so Apple, ebenso wie ein Import.
(bsc)










Künstliche Intelligenz
Über den Chat hinaus: Mit LLMs echte Nutzerprobleme lösen
Seit dem Erscheinen von ChatGPT ist das Chat-Fenster das zentrale User-Interface für die Interaktion mit künstlicher Intelligenz. Doch ist ein Chat tatsächlich die optimale Möglichkeit zur Interaktion – oder gibt es möglicherweise besser geeignete Wege, KI in Anwendungen zu integrieren?


Sascha Lehmann war mit seinem ersten PC schon klar, in welche Richtung die Reise geht. Durch Desktop- und Backend-Entwicklung im .NET-Umfeld fand er über die Jahre hinweg zu seiner wahren Leidenschaft, der Webentwicklung. Als Experte im Angular- und im UI/UX-Umfeld hilft er bei der Thinktecture AG in Karlsruhe tagtäglich Kunden bei ihren Herausforderungen und Vorhaben.
In den vergangenen Jahren haben KI-Werkzeuge die Welt im Sturm erobert. KI-Funktionen hielten Einzug in alltäglich genutzte Software – sei es in Entwicklungsumgebungen (IDEs), Office-Programmen oder sogar bei der Erstellung der Steuererklärung. Und fast überall kann man mit der Software chatten. Doch warum eigentlich?
Warum Chat als Interface so gut funktioniert
Die Stärken großer Sprachmodelle liegen insbesondere darin, unterschiedlichste Arten von Informationen zu verarbeiten und in natürlicher Sprache mit Nutzerinnen und Nutzern zu kommunizieren. Dafür benötigen sie Eingaben – ebenfalls in natürlicher Sprache. Was läge also näher, als per Texteingabe mit ihnen zu interagieren?
Auch aus Sicht der User-Experience (UX) bietet sich der Chat als Interface zunächst an. Nahezu jede und jeder kennt dieses mentale Modell – also die grundsätzliche Funktionsweise und das Erscheinungsbild eines Chatfensters – und kann es intuitiv nutzen, ohne vorherige Schulung. Gerade diese Niedrigschwelligkeit war einer der entscheidenden Faktoren für den durchschlagenden Erfolg von ChatGPT und vergleichbaren Anwendungen.
Mehrwert statt Selbstzweck: Was gute KI-Features ausmacht
Bei genauerer Betrachtung kann das Interaktionsmodell „Chat“ jedoch nicht ohne Weiteres ebenso erfolgreich auf andere Einsatzbereiche übertragen werden. So hilfreich es sein kann, beliebige Fragestellungen in einem offenen Chat mit einer KI zu diskutieren, umso schneller verliert dieses Modell seinen Reiz, sobald es in einem klar definierten Anwendungskontext zum Einsatz kommt. Der Rahmen ist dort meist deutlich enger gesteckt, was neue Herausforderungen aufwirft – beispielsweise:
- Wie kann ein Chat sinnvoll in den Anwendungskontext integriert werden?
- Welchen konkreten Mehrwert bietet die KI-Funktion gegenüber etablierten Arbeitsabläufen?
- Wie können fachspezifische Informationen kontextbezogen eingebunden werden?
Ohne gezielte Unterstützung – etwa Hinweise zu möglichen Interaktionen oder zum verfügbaren Domänenwissen und dessen Nutzung im Chat – fühlen sich viele Nutzerinnen und Nutzer schnell überfordert. Bleiben erste Interaktionen zudem erfolglos, führt das häufig zu Frustration – und das beworbene KI-Feature wird nur noch zögerlich oder gar nicht mehr verwendet. Es entsteht der Eindruck, die neue Technologie sei lediglich um ihrer selbst willen integriert worden.
Ein solches Nutzungserlebnis gilt es unbedingt zu vermeiden. KI-Funktionen – wie auch alle anderen Features – müssen einen klaren Mehrwert bieten. Sei es durch eine Erweiterung des Funktionsumfangs oder durch die Vereinfachung zuvor mühsamer Aufgaben.
UX-Patterns gegen kognitive Überforderung
Ein blanker Chat erzeugt – ähnlich wie die berüchtigte leere Seite beim Schreiben einer Hausarbeit – eine zu hohe kognitive Last, also eine Art Überforderungs- oder Lähmungszustand. Um dem entgegenzuwirken, können Vorschläge (Suggestions), hilfreich sein: kleine Container mit konkreten Prompt-Hinweisen.

„Vorschlagskarten“ (hier für Chat-GPT) helfen, die anfängliche Überforderung zu reduzieren und Interaktionshinweise zu geben.
(Bild: Shape of AI)
Diese Suggestions sind Teil einer Sammlung von UX-Patterns (Shape of AI) rund um den Einsatz von KI- und Chat-Integrationen. Da künstliche Intelligenz nach wie vor ein junges Themenfeld ist, werden in den kommenden Jahren zunehmend weitere dieser Gestaltungsmuster entstehen, auf die Entwicklerinnen und Entwickler bei der Konzeption und Entwicklung zurückgreifen können. Dennoch empfiehlt es sich, bereits heute solche Patterns zu nutzen, um Usern einen einfachen und intuitiven Einstieg zu ermöglichen.
Tu, was ich will – nicht, was ich sage
Die kognitive Last ist nicht die einzige Schwachstelle von Chat-basierten Interfaces. Bei längeren Konversationen kann es dazu kommen, dass das Kontextfenster – sozusagen das Kurzzeitgedächtnis des LLM, um Informationen der Konversation zu halten – des aktuell verwendeten Sprachmodells ausgeschöpft ist. In solchen Fällen müssen User auf einen neuen Chat ausweichen. Da LLMs jedoch über kein dauerhaftes Gedächtnis verfügen, ist es notwendig, bei diesem Wechsel eine Zusammenfassung des bisher Gesagten mitzugeben – nur so kann an vorherige Ergebnisse angeknüpft werden.
Zudem neigen LLMs in Konversationen gelegentlich zu Halluzinationen oder verlieren sich bei unpräzisen Eingaben in einem ineffizienten Hin und Her. Besonders problematisch wird das, wenn die Nutzerin oder der Nutzer bereits eine klare Vorstellung vom gewünschten Ergebnis hat. Die Herausforderung liegt darin, die eigene Intention so klar zu formulieren, dass das Modell sie korrekt interpretiert – ganz nach dem Motto: „Tu, was ich will – nicht, was ich sage.“
Formulare automatisch verstehen und ausfüllen
Gibt es also jenseits des klassischen Chat-Interfaces klügere Wege, Nutzerinnen und Nutzern KI-Funktionen zugänglich zu machen – möglichst in kleinen, leicht verdaulichen Einheiten, sodass Überforderung gar nicht erst entsteht?
Ein genauer Blick auf die Stärken großer Sprachmodelle zeigt Fähigkeiten, die im Alltag besonders hilfreich sein können:
- Verständnis und Verarbeitung natürlicher Sprache
- umfangreiches Weltwissen
- vielfältige Einsatzgebiete und enorme Anpassbarkeit
- Multimodalität – Verarbeitung von Text-, Audio- und Bilddaten (ohne Modellwechsel)
- Echtzeitsprachverarbeitung
- Erkennung und Analyse von Patterns
Immer wieder gibt es Anwendungsszenarien, in denen Daten aus Dokumenten, Bildern oder Videos zu extrahieren und in strukturierter Form weiterzuverarbeiten sind – etwa bei Formularen. Das Ausfüllen langer Formulare zählt in der Regel nicht zu den beliebtesten Aufgaben im Alltag.
Gerade hier besteht deutliches Potenzial zur Verbesserung der User-Experience. Doch wie könnte ein optimierter „Befüllungs-Workflow“ konkret aussehen?
Von Text zu JSON: Daten intelligent befüllen
Für die Arbeit mit Formularen stehen im Web und in etablierten Frameworks umfangreiche Schnittstellen (Application Programming Interfaces, APIs) zur Verfügung. Die zugrunde liegende Struktur eines Formulars wird dabei häufig in Form eines JSON-Objekts (JavaScript Object Notation) definiert.
Das Listing zeigt eine exemplarische Deklaration einer FormGroup (inklusive Validatoren) innerhalb einer Angular-Anwendung.
personalData: this.fb.group({
firstName: ['', Validators.required],
lastName: ['', Validators.required],
street: ['', Validators.required],
zipCode: ['', Validators.required],
location: ['', Validators.required],
insuranceId: ['', Validators.required],
dateOfBirth: [null as Date | null, Validators.required],
telephone: ['', Validators.required],
email: ['', [Validators.required, Validators.email]],
licensePlate: ['', Validators.required],
}),
Dieses JSON-Objekt stellt den ersten Baustein des Workflows dar und definiert zugleich die Zielstruktur, in die das System die extrahierten Informationen überführt. Den zweiten Baustein bilden die Quelldaten in Form von Text, Bildern oder Audio. Zur vereinfachten Darstellung liegen sie im folgenden Szenario in Textform vor und sollen über die Zwischenablage in das System übertragen werden.
Bleibt noch ein dritter Aspekt: Entwicklerinnen und Entwickler müssen das Sprachmodell instruieren – sie müssen ihm eine präzise Aufgabenbeschreibung geben, um den gewünschten Verarbeitungsschritt korrekt durchzuführen. Diese Instruktion erfolgt im Hintergrund, vor dem User versteckt.
Versteckte Prompts: KI steuern ohne Chatfenster
Auch wenn Entwicklerinnen und Entwickler bewusst auf ein Chat-Interface verzichten, arbeiten Sprachmodelle weiterhin auf Basis von Instruktionen in natürlicher Sprache. Um Usern die Formulierungs- und Eingrenzungsarbeit abzunehmen, können diese Anweisungen vorab als sogenannte System-Messages oder System-Prompts im Programmcode hinterlegt werden.
Der Vorteil dieses Ansatzes liegt darin, dass die Befehle standardisiert und in konsistenter Qualität an das LLM übermittelt werden können. Zudem ist es möglich, diese Prompts mit Guards zu versehen – ergänzenden Anweisungen, die Halluzinationen vorbeugen oder potenziellem Missbrauch entgegenwirken sollen.
Nachfolgend eine exemplarische Darstellung eines System Prompt mit einer gezielten Aufgabe für das LLM:
Each response line must follow this format:
FIELD identifier^^^value
Provide a response consisting only of the following lines and values derived from USER_DATA:
${fieldString}END_RESPONSE
Do not explain how the values are determined.
For fields without corresponding information in USER_DATA, use the value NO_DATA.
For fields of type number, use only digits and an optional decimal separator.
In modernen Frontend-Applikationen ist es üblich, dass Schnittstellen ihre Antworten im JSON-Format liefern, da diese Datenstruktur leicht weiterverarbeitet werden kann.
Für möglichst präzise und verlässliche Ergebnisse kann die erwartete Zielstruktur mithilfe des JSON Mode definiert werden – in Form eines JSON-Schemas. Es beschreibt die Felder nicht nur strukturell, sondern auch mit genauen Typinformationen. Das erspart ausführliche textuelle Erläuterungen und erleichtert die Verarbeitung der Ergebnisse im Frontend.
Um Typsicherheit in der Anwendung sicherzustellen, kommt häufig Zod zum Einsatz – eine auf TypeScript ausgerichtete Validierungsbibliothek, mit der Datenstrukturen, von einfachen Strings bis hin zu komplexen geschachtelten Objekten, deklarativ definiert und zuverlässig geprüft werden können.
Das folgende Listing von OpenAI zeigt einen exemplarischen Aufruf der OpenAI-API, um Daten in einem bestimmten JSON Format zu extrahieren.
import OpenAI from "openai";
import { zodTextFormat } from "openai/helpers/zod";
import { z } from "zod";
const openai = new OpenAI();
// JSON-Schema-Definition mithilfe von Zod
const CalendarEvent = z.object({
name: z.string(),
date: z.string(),
participants: z.array(z.string()),
});
const response = await openai.responses.parse({
model: "gpt-4o-2024-08-06",
input: [
{ role: "system", content: "Extract the event information." },
{
role: "user",
content: "Alice and Bob are going to a science fair on Friday.",
},
],
text: {
format: zodTextFormat(CalendarEvent, "event"),
},
});
const event = response.output_parsed;
So kommunizieren Anwendungen mit dem LLM
Um System-Prompts und Quelldaten an ein LLM zu übermitteln, stehen je nach Anbieter verschiedene SDKs (Software Development Kits) zur Verfügung. Das obige Listing zeigt beispielsweise die Verwendung des OpenAI-SDK. Weitere Beispiele führender Anbieter sind Anthropic und Google. Sie bieten jeweils umfangreiche Funktionen, hohe Performance und eine benutzerfreundliche Developer-Experience, die den Einsatz der SDKs erleichtert.
Selbstverständlich ist die Nutzung von KI-Modellen nicht auf webbasierte Angebote großer Anbieter beschränkt. Wer mit kleineren Modellen für seine Aufgaben auskommt, kann ebenso lokal laufende Modelle verwenden oder auf im Browser integrierte Modelle wie WebLLM zurückgreifen.
Nach der erfolgreichen Implementierung und Abstraktion der SDK-Aufrufe genügt bereits ein Dreizeiler für das vollständige Parsing.
Es folgt eine exemplarische Darstellung des Ablaufs eines Extraktionsvorgangs anhand einer in Angular definierten FormGroup:
/* User Message – Datenquelle, aus der Daten zum Befüllen des Formulars extrahiert werden sollen. Diese werden in die Zwischenablage kopiert
Max Mustermann
77777 Musterstadt
Kfz-Kennzeichen: KA-SL-1234
Versicherungsnummer: VL-123456
*/
// Angular FormGroup zum Erfassen persönlicher Daten
personalData: this.fb.group({
firstName: ['', Validators.required],
lastName: ['', Validators.required],
street: ['', Validators.required],
zipCode: ['', Validators.required],
location: ['', Validators.required],
insuranceId: ['', Validators.required],
dateOfBirth: [null as Date | null, Validators.required],
telephone: ['', Validators.required],
email: ['', [Validators.required, Validators.email]],
licensePlate: ['', Validators.required],
}),
// JSON-Schema, das mit Zod anhand der FormGroup erstellt wurde
{
"firstName": {
"type": "string"
},
"lastName": {
"type": "string"
},
"street": {
"type": "string"
},
"zipCode": {
"type": "string"
},
"location": {
"type": "string"
},
"insuranceId": {
"type": "string"
},
"dateOfBirth": {
"type": "object"
},
"telephone": {
"type": "string"
},
"email": {
"type": "string"
},
"licensePlate": {
"type": "string"
}
}
// Antwort des LLM
[
{
"key": "firstName",
"value": "Max"
},
{
"key": "lastName",
"value": "Mustermann"
},
{
"key": "location",
"value": "Musterstadt"
},
{
"key": "zipCode",
"value": "77777"
},
{
"key": "licensePlate",
"value": "KA-SL-1234"
},
{
"key": "insuranceId",
"value": "VL-123456"
}
]
// Befüllen des Formulars mit den Ergebnissen (hier eine Angular FormGroup --> personalData)
try {
const text = await navigator.clipboard.readText();
const completions = await this.openAiBackend.getCompletions(fields, text);
completions.forEach(({ key, value }) => this.personalData.get(key)?.setValue(value));
} catch (err) {
console.error(err);
}
Aufwendige Ausfüllarbeiten gehören von nun an der Vergangenheit an und können dank geschickt eingesetzter KI-Unterstützung mühelos erledigt werden.
Dieses Beispiel zeigt einen ausgeführten Extraktionsvorgang: Zunächst wird der Text mit Informationen in die Zwischenablage kopiert, dann der Extraktionsvorgang gestartet, und schließlich stehen automatisch befüllte Formularfelder anhand der Textinformation bereit.

Darstellung des Ablaufs eines Extraktionsvorgangs aus Sicht der User (in drei Schritten, von oben nach unten).
Mehr Transparenz bei KI-generierten Inhalten
Diese Integration allein verbessert die UX enorm. Bei genauerer Betrachtung fallen aus UX-Designer-Sicht allerdings noch weitere Möglichkeiten auf:
Wie steht es etwa um die Nachvollziehbarkeit? Aktuell werden anhand des übermittelten Textes oder Bildes die Felder des Formulars automatisch befüllt. Zudem kann der Nutzer oder die Nutzerin das Formular nach Belieben selbst anpassen und editieren. Das mag in den meisten Fällen ausreichend und unproblematisch sein. Doch in bestimmten Kontexten reicht das allein nicht aus – beispielsweise bei rechtlich verbindlichen Themen wie Versicherungen oder Banking. Hier muss unter Umständen ersichtlich sein, welche Felder von einem Menschen und welche mithilfe von KI-Unterstützung befüllt wurden. Aus UX-Gründen ist es außerdem sinnvoll, Nutzern transparent zu vermitteln, wie einzelne Feldwerte zustande gekommen sind.
Nachvollziehbarkeit sichtbar machen
Ein Blick auf die großen Player zeigt: Wenn es um die Visualisierung von KI-generierten Inhalten geht, kommen oftmals Farbverläufe, Leucht- und Glitzereffekte zum Einsatz. Die folgenden Beispiele zeigen die visuelle Gestaltung von KI-Inhalten anhand der Designsprache von Apple und Google.

Beispiele für die Designsprachen von Apple (oben) und Google (unten) in Bezug auf deren AI-Produkte.
Warum also nicht dieses Pattern aufgreifen und für eigene Integrationen nutzen? Die großen Anbieter verfügen über UI/UX-Research-Budgets, von denen kleinere Unternehmen nur träumen können. Es liegt nahe, sich hier inspirieren zu lassen, zumal die hohe Reichweite bereits neue visuelle Standards prägt – Nutzer sind mit derartigen Darstellungen zunehmend vertraut.
Eine exemplarische Umsetzung im gezeigten Formularszenario könnte darin bestehen, automatisch befüllte Felder mit einem leuchtenden Rahmen (Glow-Effekt) zu versehen. Diese einfache Maßnahme schafft eine klare visuelle Unterscheidbarkeit – und verbessert gleichzeitig die User-Experience.

Automatisch befüllte Felder sind durch einen leuchtenden Rahmen (Glow-Effekt) hervorgehoben.
Um die Nachvollziehbarkeit weiter zu verbessern, können Entwickler eine History-Funktion einbauen: Sie zeigt, welche automatischen Extraktionen wann passiert sind – inklusive der genutzten Quellen (Texte, Sprache oder Bilder). So haben User jederzeit den Überblick und können bei Bedarf einfach per Undo/Redo zu einem früheren Zustand zurückspringen.
Künstliche Intelligenz
Android: Google verpasst der Telefon-App iPhone-ähnliche „Kontaktposter“
Google arbeitet weiter an der Bedienoberfläche von Android und verpasst seinen eigenen Apps nach und nach die im Mai angekündigte, polarisierende Designsprache Material 3 Expressive. Nun ergänzt der Konzern seine bereits überarbeitete Telefon-App um eine weitere Funktion, die ein wenig an Apples mit iOS 17 eingeführte Kontaktposter erinnert.
Das Auge telefoniert mit
Die neue Anruferansicht, so die offizielle Bezeichnung, ist nicht nur für Pixel-Smartphones und Android 16 bestimmt, sondern sollte alle aktuellen Android-Smartphones erreichen, auf denen Googles Telefon-App standardmäßig vorinstalliert ist. So steht die Funktion etwa auch auf einem Xiaomi-Smartphone mit Android 14 bereit.

Sobald die Funktion nutzbar ist, erscheint ein Hinweis in der Telefon-App.
(Bild: heise medien)
Diese Anruferansicht oder auch „Calling Cards“ sind erstmals Anfang des Monats in den Beta-Versionen der „Kontakte“- und „Telefon“-Apps von Google aufgetaucht. Mit Version 188 der Telefon-App bringt der Konzern die neue bildschirmfüllende Funktion für alle Nutzer. Laut Google soll das Feature weltweit verfügbar sein und „schrittweise“ verteilt werden, sodass es eine Weile dauern kann, bis es auf allen Geräten landet.
Sobald die Funktion verfügbar ist, erscheint in der Telefon-App im oberen Teil der Hinweis: „Anpassen, wie Anrufer angezeigt werden.“ Durch einen Tap auf „Jetzt starten“ gelangt man zur Kontaktübersicht, man kann die Einstellung aber auch in den einzelnen Kontakten erreichen. Hier können Nutzer für jeden Kontakt eine Art Kontaktposter erstellen, das angezeigt wird, wenn man die Person anruft oder von ihr angerufen wird.
Nur für das eigene Telefon
Hierfür kann ein Bild aus der Kamera, der Galerie oder Google-Fotos erstellt oder ausgewählt werden. Zudem können für den Kontaktnamen eine eigene Schriftart und -Farbe festgelegt werden. Die neue Funktion ist optional und muss nicht genutzt werden. Für Menschen, die solche Individualisierungen schätzen und ihren Geräten einen zusätzlichen eigenen Anstrich verpassen möchten, dürfte es eine willkommene und je nach Umfang der Kontakte eine arbeitsaufwendige Spielerei sein.
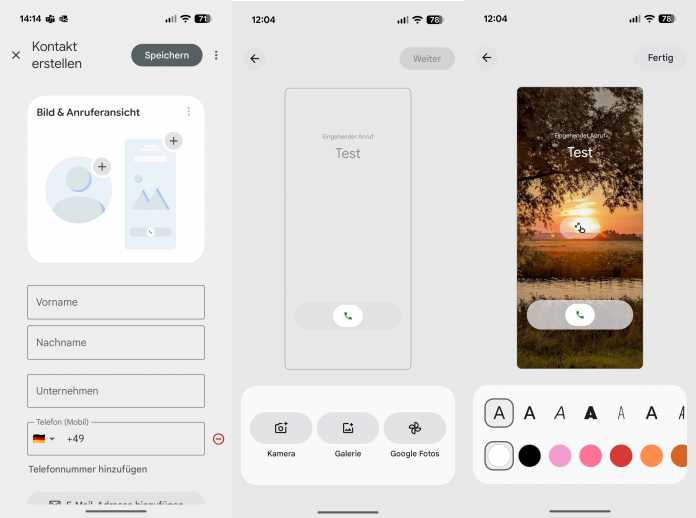
In den Einstellungen der Anruferansicht können Nutzer das Erscheinungsbild ihrer Kontakte anpassen.
(Bild: heise medien)
Trotz einer gewissen Ähnlichkeit zu Apples Kontaktpostern unter iOS können Android-Nutzer keine eigene Visitenkarte erstellen, die Kontakten angezeigt wird, wenn sie angerufen werden. Googles Lösung dient nur zur Aufhübschung der eigenen Kontakte auf dem persönlichen Gerät. Das Teilen dieser Kontaktposter ist aktuell offenbar nicht vorgesehen.
(afl)
Künstliche Intelligenz
Die Technik moderner Datenträger: SSDs, Festplatten und mehr | c’t uplink
Man könnte meinen, die klassische Festplatte sei eine tote Technologie, doch dem ist keineswegs so. Hersteller tüfteln nach wie vor an Methoden, die Speicherdichte zu verbessern und stopfen inzwischen bis zu elf Magnetscheiben in die rund 25 Millimeter flachen Gehäuse von 3,5″-Platten. Die Folge: Festplatten sind nach wie vor das Medium der Wahl, wenn es nicht um Megabyte pro Sekunde geht, sondern um Gigabyte pro Euro.

Den wöchentlichen c’t-Podcast c’t uplink gibt es …
Im c’t uplink sprechen wir aber auch über andere aktuelle Arten von Speichermedien – allen voran natürlich SSDs –, warum SD-Karten so viel langsamer und USB-Sticks fast schon ein Abfallprodukt sind, und: Gibt es eigentlich noch Bandlaufwerke?
Zu Gast im Studio: Lutz Labs, Christof Windeck
Host: Jan Schüßler
Produktion: Ralf Taschke
► Unseren Leitfaden zu Speichermedien lesen Sie bei heise+
► sowie in c’t 18/2025
In unserem WhatsApp-Kanal sortieren Torsten und Jan aus der Chefredaktion das Geschehen in der IT-Welt, fassen das Wichtigste zusammen und werfen einen Blick auf das, was unsere Kollegen gerade so vorbereiten.
► c’t Magazin
► c’t auf Mastodon
► c’t auf Instagram
► c’t auf Facebook
► c’t auf Bluesky
► c’t auf Threads
► c’t auf Papier: überall, wo es Zeitschriften gibt!
(jss)

Über den Chat hinaus: Mit LLMs echte Nutzerprobleme lösen

TP-Link M8550 im Test: Mobiles Highspeed-WLAN für unterwegs

Das Indiecon Festival 2025 › PAGE online

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

Der ultimative Guide für eine unvergessliche Customer Experience

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
eine gute Nachricht ist")
eine gute Nachricht ist") Social Mediavor 2 Wochen
Social Mediavor 2 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 1 Woche
Entwicklung & Codevor 1 WochePosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenPhilip Bürli › PAGE online