Entwicklung & Code
Bewölkte Aussichten: Nur noch Cloud-Lizenzen bei Atlassian
Der Softwareanbieter Atlassian stellt den Verkauf seiner Data-Center-Produkte ein. Dazu gehören die Wiki-Software Confluence oder das Projektmanagement-Tool Jira. Ab März 2026 wird es für Neukunden nur noch Cloud-Lizenzen geben.
Den Schritt begründet Atlassian damit, dass sich inzwischen nahezu alle Neukunden für die Cloud entscheiden. Mit dem Wechsel auf die Cloud-Plattform würde auch eine deutliche Verbesserung der Teamarbeit einhergehen. Den Verkauf von Serverlizenzen seiner Produkte hat Atlassian bereits im Jahr 2021 eingestellt.
Cloud-Umzug innerhalb von drei Jahren
Die Cloud-Umstellung führt Atlassian schrittweise über einen Zeitraum von drei Jahren durch. Ab dem 16. Dezember 2025 nimmt die Firma neue Marketplace-Apps für Data Center nicht mehr an. Am 30. März 2026 endet dann der Verkauf von Data-Center-Abonnements und Marketplace-Apps für Neukunden. Bestandskunden können noch bis zum 30. März 2028 neue Lizenzen erwerben.

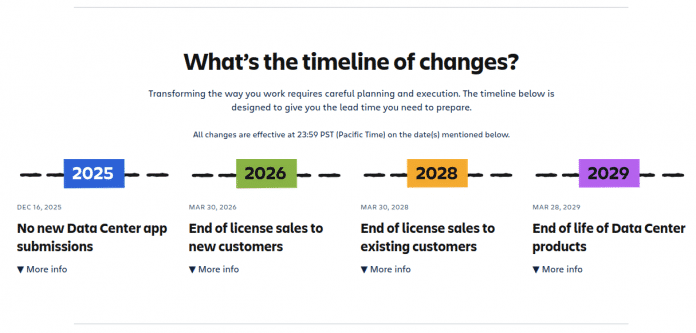
Zeitplan: Atlassian migriert seine Data Center-Produkte ab Dezember 2025 schrittweise in die Cloud. Bis 2029 soll der Umzug vollständig durchgeführt sein.
(Bild: Atlassian)
Abgesehen von zwei Ausnahmen laufen alle Lizenzen dann am 28. März 2029 ab. Die Versionsverwaltung Bitbucket Data Center wird weiterhin über eine neue Hybridlizenz verfügbar sein, die Kunden gleichermaßen Zugriff auf Bitbucket Data Center und Bitbucket Cloud gewährt. Des Weiteren bietet Atlassian für bestimmte Rechenzentrumskunden auch nach dem 28. März 2029 noch eine erweiterte Wartung an, um sie beim Umzug in die Cloud zu unterstützen.
Verschiedene Migrationstools
Den Umstieg in die Cloud begleitet der Hersteller mit seinem neuen Programm Atlassian Acend, das Kunden den Wechsel möglichst leicht machen will, etwa durch Live-Webinare und individuellen Support. Je nach Unternehmensgröße stehen unterschiedliche Cloud-Migrationstools zur Verfügung.
Kunden mit weniger als tausend Benutzerinnen und Benutzern verweist der Anbieter auf seine Self-Service-Tools. Größeren Organisationen offeriert Atlassian das FastShift-Programm. Dabei handelt es sich um eine kostenlose strategische Partnerschaft, mit der sich die Cloud-Migration drastisch verkürzen lassen soll. Kunden mit mehr als 5000 Benutzern lässt Atlassian mit dem Solution Design Acceleration-Programm, das auf die Geschäftsziele des Unternehmens abgestimmt ist, die breiteste Unterstützung zukommen.
Atlassian will seine Cloud-Plattform künftig weiter ausbauen, etwa über eine Partnerschaft mit Google Cloud zur Entwicklung einer Multi-Cloud. Welche Updates geplant sind, lässt sich in der öffentlichen Roadmap im Detail einsehen.
(who)











Entwicklung & Code
Red Hat integriert Nvidia CUDA in Enterprise-Linux und OpenShift
Red Hat und Nvidia haben eine erweiterte Partnerschaft angekündigt, die das CUDA-Toolkit direkt in Red Hats Produktportfolio integriert. Entwickler können künftig über die offiziellen Repositories von Red Hat Enterprise Linux (RHEL), OpenShift und Red Hat AI auf die essenziellen Werkzeuge für GPU-beschleunigte Anwendungen zugreifen. Das soll die Installation vereinfachen und Abhängigkeiten automatisch auflösen.
Weiterlesen nach der Anzeige
Die Integration adressiert eine zentrale Herausforderung beim Einsatz von KI-Systemen in Unternehmensumgebungen: die operative Komplexität beim Zusammenspiel verschiedener Komponenten. Entwickler müssen bislang einigen Aufwand betreiben, um kompatible Treiber zu identifizieren, Abhängigkeiten zu managen und Workloads zuverlässig auf unterschiedlichen Systemen zum Laufen zu bringen. Durch die direkte Distribution über Red Hats Plattformen entfällt dieser Integrationsaufwand weitgehend.
Das CUDA-Toolkit umfasst Compiler, Bibliotheken und Entwicklerwerkzeuge für die Programmierung auf Nvidia-GPUs. Die Bereitstellung erfolgt nun über einen einheitlichen, getesteten Software-Stack, der laut Red Hat eine konsistente Umgebung für KI-Workloads bietet – unabhängig davon, ob diese lokal, in Public Clouds oder am Edge betrieben werden. Dieser Ansatz entspricht Red Hats bisheriger Hybrid-Cloud-Strategie.
Red Hat betont den Open-Source-Charakter der Zusammenarbeit. Das Unternehmen positioniert sich als Brücke zwischen der Open-Hybrid-Cloud und Nvidias KI-Plattform, ohne dabei ein geschlossenes Ökosystem aufzubauen. Die Integration soll Unternehmen die Wahlfreiheit bei Tools und Technologien erhalten, während gleichzeitig eine stabile und sichere Plattform bereitgestellt wird.
Details zur Verfügbarkeit und zum genauen Zeitplan der Integration nannte Red Hat in der Ankündigung nicht.
(fo)
Entwicklung & Code
Eclipse ADL: Standardisierte Sprache für Entwurf und Steuerung von KI-Agenten
Die Eclipse Foundation hat eine offene, dezidierte Beschreibungssprache für die Planung, die Definition von Verhaltensmustern und die Steuerung von KI-Agentensystemen vorgestellt. Agent Definition Language (ADL) beschreibt Agentensysteme in einfachen, standardisierten Kategorien und Begrifflichkeiten, die ein strukturiertes Deployment und einen geregelten Betrieb ermöglichen sollen.
Weiterlesen nach der Anzeige
Laut der Ankündigung von Eclipse ist ein solcher offener und transparenter Standard im Markt bisher nicht vorhanden, der es Unternehmen ermöglicht, hersteller- und modellunabhängige Agentensysteme einzuführen und zu unterhalten.
Sprachlich gelenkte Anwendungsfälle
Im Konzept trennt ADL die Definition von Agentensystemen vom konkreten Prompting, wobei der Entwurf mit ADL in den Fachabteilungen geschieht, während im Idealfall ein Compiler die Umsetzung automatisiert in Prompts vollzieht und für die Lösung der Aufgabe benötigte Tools einbindet.
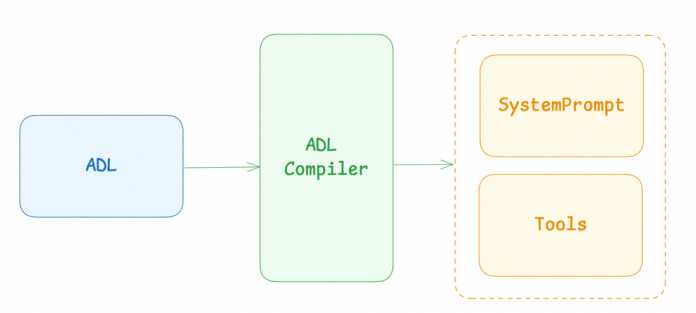
ADL trennt die Beschreibung von Agenten vom Prompting, das ein Compiler umsetzt.
Begrifflich gliedert die Sprache die Agenten in Use Cases ein, innerhalb derer sich verschiedene Szenarien ereignen. Hier agieren Nutzer mit Agenten oder Agenten untereinander. Die formalen Definitionen umfassen dabei:
- UseCase Name: Eine prägnante, beschreibende Kennung, die den Anwendungsfall eindeutig identifiziert.
- Description: Eine detaillierte Erläuterung der Situation oder Anfragen der Nutzerinnen und Nutzer.
- Steps (optional): Eine Abfolge von Schritten, die der Agent ausführen muss, bevor er die endgültige Lösung bereitstellt.
- Solution: Die empfohlene Lösung, um die Anfrage zu erfüllen.
- Alternative Solution (optional): Eine alternative Lösung, die der Agent ausprobieren sollte, wenn der erste Vorschlag scheitert.
- Fallback Solution (optional): Diese finale Ausweichmöglichkeit soll verhindern, dass der Agent in einer Schleife hängen bleibt, in der er immer wieder dieselben Vorschläge anbietet.
- Examples (optional): Dieser Abschnitt stellt zusätzlichen Kontext bereit.
Weiterlesen nach der Anzeige
Im Code:
### UseCase: password_reset
#### Description
Customer has forgotten their password and needs to reset it.
#### Steps
- Ask the customer for their registered email address.
- Send a password reset link to the provided email address.
#### Solution
Guide the customer through the password reset process defined on the webpage
#### Fallback Solution
If the customer cannot access their email, escalate the issue to a higher tier of support.
#### Examples
- I forgot my password.
Weitere Elemente sind beispielsweise Flow Options, mit denen Anwenderinnen und Anwender Entscheidungsbäume implementieren:
[option 1] command[option 2] command 2
Zum Ausprobieren bietet Eclipse einen Playground, in dem bereits ein erster Use Case „Automobile Example“ hinterlegt ist. Tiefergehende Infos finden sich in der technischen Doku.

Der Playground enthält bereits ein Beispiel für eine Anwendung mit ADL.
Teil einer offenen Agentenplattform
ADL bettet sich als Konzept in die Eclipse-Agentenplattform Language Model Operating System (LMOS), die zwei weitere Komponenten enthält: das ARC Agent Framework und die LMOS-Plattform. ARC bietet ein JVM-natives Framework mit Kotlin-Laufzeitumgebung zum Entwickeln, Testen und Erweitern von KI-Agenten mit visueller Schnittstelle. Diese hat ADL bereits implementiert.
Die LMOS-Plattform befindet sich noch im Alphastadium und soll als offene Orchestrierungsschicht für die Infrastruktur dienen und basiert auf den Open-Source-Tools aus dem Ökosystem der CNCF (Cloud Native Computing Foundation). LMOS ist bereits bei der Telekom als Basis für den Chatbot „Frag Magenta“ im Einsatz.
(who)
Entwicklung & Code
programmier.bar: Call for Papers mit Mirjam Aulbach
Der Call for Papers – oder Proposals/Participation – (CfP) entscheidet, welche Stimmen auf einer Konferenz gehört werden und welche nicht. Was passiert zwischen Einreichung und Entscheidung? Wer trifft die Auswahl und nach welchen Kriterien?
Weiterlesen nach der Anzeige
Mirjam Aulbach kennt den CfP aus beiden Perspektiven: von der Bühne und aus dem Programmbeirat, etwa bei der enterJS. Sie hat auf unzähligen Konferenzen präsentiert und war unter den Entscheiderinnen und Entscheidern diverser Konferenzen. Sie erklärt, warum ein CfP so wichtig ist und welche sonstigen Wege es für die Speaker-Akquise gibt. Gemeinsam mit Garrelt Mock und Jan Gregor Emge-Triebel spricht sie über die Herausforderung, faire Prozesse zu gestalten und warum am Ende trotzdem Kompromisse nötig sind.
(Bild: jaboy/123rf.com)

Call for Proposals für die enterJS 2026 am 16. und 17. Juni in Mannheim: Die Veranstalter iX und dpunkt.verlag suchen nach Vorträgen und Workshops rund um JavaScript und TypeScript, Frameworks, Tools und Bibliotheken, Security, UX und mehr. Seit 2021 ist Mirjam Aulbach im Programmbeirat.
Zum Abschluss teilt Mirjam Aulbach ihre besten Tipps für alle, die schon länger mit dem Gedanken spielen, selbst einen Talk bei einer Konferenz einzureichen, und noch auf den richtigen Moment gewartet haben.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externer Inhalt geladen.
Die aktuelle Ausgabe des Podcasts steht auch im Blog der programmier.bar bereit: „Call for Papers mit Mirjam Aulbach„. Fragen und Anregungen gerne per Mail oder via Mastodon, Bluesky, LinkedIn oder Instagram.
(mai)

„Flekst0re“: Alternativer iOS-Marktplatz verändert bekannte Apps

Jetzt patchen! Attacken auf DELMIA Apriso beobachtet

Diese Promis investieren 60 Millionen in Longevity-Guru Bryan Johnson

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenIllustrierte Reise nach New York City › PAGE online
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets