Entwicklung & Code
Bitte ohne KI: Sourcecode-Editor Zed bietet Ausschalter für KI-Funktionen
Wer den Sourcecode-Editor Zed verwendet, kann künftig mit einer Einstellung alle KI-Funktionen ausschalten. Damit reagieren die Projektverantwortlichen auf Wünsche aus der Community.
Das Team hinter dem Open-Source-Editor hatte im Mai 2025 in einem Blogbeitrag Zed zum schnellsten KI-Code-Editor erklärt. Zed ist von Grund auf in Rust geschrieben und seit Januar 2024 als Open-Source-Projekt unter GPL-Lizenz verfügbar. Seine Anfänge lagen auf macOS, im Juli 2024 folgte Linux und eine offizielle Windows-Version ist ebenfalls in Planung.
KI-Editor ohne KI
Auch wenn die oft nützlichen KI-Hilfen inzwischen für viele zum Alltag der Softwareentwicklung gehören, gibt es berechtigte Bedenken bezüglich der Codequalität und potenziell generierter Schwachstellen oder wegen der Daten und des Sourcecodes, die beim Einsatz der KI-Tools das Unternehmen verlassen.
Im GitHub-Repository des Editors finden sich bereits seit 2024 Diskussionen und Issues, die einen Ausschalter für KI-Funktionen wünschen.
Nun haben die Projektverantwortlichen reagiert und in der aktuellen Preview eine Einstellung in der settings.json-Datei eingeführt, die sämtliche KI-Funktionen deaktiviert:
{
"disable_ai": true
}
In Kürze ist zusätzlich ein Switch in den KI-Einstellungen innerhalb der UI des Editors geplant, der ebenfalls alle KI-Funktionen abschaltet.

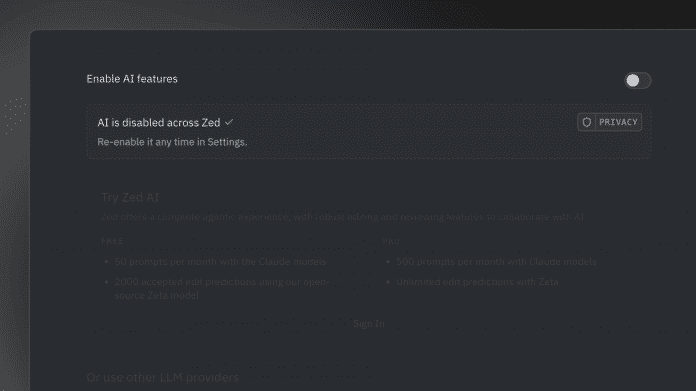
Ein einzelner Klick in den Settings genügt demnächst, um die KI-Unterstützung zu deaktivieren.
(Bild: Zed)
Datenschutz trotz KI
Der Blogbeitrag zum Deaktivieren der KI-Funktionen betont, dass diejenigen, die vor allem Bedenken bezüglich des Datenschutzes haben, die KI-Funktionen nicht unbedingt deaktivieren müssen.
Zed lässt bei der Auswahl des KI-Anbieters freie Wahl und ermöglicht auch den Einsatz lokaler KI-Modelle mittels Ollama, damit der Code und die Daten den Rechner nicht verlassen.
Weitere Details zu den Hintergründen lassen sich dem Zed-Blog entnehmen.
(rme)










Entwicklung & Code
Bestie statt for-Schleife: KI entwickelt Programmiersprache im Gen-Z-Slang
Damn, das ist cringe: Der Australier Geoffrey Huntley hat die Programmier-KI Claude Code von Anthropic drei Monate in Dauerschleife laufen lassen, um eine eigene Programmiersprache im Stile der verbreiteten Umgangssprache der Generation Z zu entwerfen. Und warum? Nun, weil er es kann, wie er in einem Blogpost darlegt.

Das Internet ist voll von heißen IT-News und abgestandenem Pr0n. Dazwischen finden sich auch immer wieder Perlen, die zu schade sind für /dev/null.
Tatsächlich habe ihn einfach die Möglichkeit gereizt, dass mithilfe generativer KI der Traum vom eigenen Compiler Gestalt annehmen kann, schreibt er. Das Ganze sei dann auch ein Lernexperiment gewesen. Der KI sei es dabei selbst überlassen worden, die Sprache jeweils weiter zu verbessern. Das Ergebnis hat er sogar auf einer eigenen Website zum Download bereitgestellt. Der Name der Programmiersprache: Cursed (auf deutsch: verflucht).
Der Compiler verfügt über zwei Modi. Er kann als Interpreter oder als Compiler eingesetzt werden und Binärdateien für macOS, Linux und Windows erstellen. Zudem gebe es halbfertige Erweiterungen für die Editoren VSCode, Emacs und Vim. Wer sich den Entstehungsprozess anschauen möchte, findet dazu entsprechende Videos bei YouTube.
Sprachlich darf man sich das so vorstellen, dass an die Stelle von bekannten Begriffen wie for oder case Wörter treten, die in der GenZ gerne benutzt werden, wie etwa bestie oder mood. Eine Roadmap zur Weiterentwicklung gebe es nicht, darüber soll die Community entscheiden.
Das kostete das Experiment
Der ursprüngliche Prompt lautete: „Hey, kannst du mir eine Programmiersprache wie Golang erstellen, bei der jedoch alle lexikalischen Schlüsselwörter ausgetauscht sind, sodass sie dem Slang der Generation Z entsprechen?“
Wer dem Beispiel von Huntley folgen möchte, sollte allerdings das nötige Kleingeld bereithalten. Der eigene Compiler koste einen etwa 5000 US-Dollar, schreibt er in einem Post auf X. Tatsächlich habe er mit 14.000 US-Dollar fast das Dreifache investieren müssen, da Cursed zunächst in C, dann in Rust und jetzt in Zig entwickelt wurde. Aber so gebe es jetzt eben auch drei Editionen des Compilers. Und am Ende sei das nur ein Vierzehntel des Gehalts eines Entwicklers in San Francisco, scherzt er.
(mki)
Entwicklung & Code
MCP Registry gestartet: Katalog für MCP-Server
Das Entwicklungsteam hinter dem Model Context Protocol (MCP) hat die MCP Registry als Preview eingeführt – einen offenen Katalog und eine API, um öffentlich verfügbare MCP-Server ausfindig zu machen und zu verwenden. Bei MCP handelt es sich um ein offenes Protokoll für den Zugriff von Large Language Models (LLMs) auf externe Datenquellen.
Öffentliche MCP-Server hinzufügen und finden
Bereits vor einigen Monaten teilte das MCP-Team auf GitHub mit, an einem zentralen Register für das MCP-Ökosystem zu arbeiten. Die nun veröffentlichte, quelloffene MCP Registry soll das Verfahren standardisieren, wie MCP-Server verteilt und entdeckt werden. Sie bietet Server-Maintainern die Möglichkeit, ihre Server hinzuzufügen, und Client-Maintainern, auf Serverdaten zuzugreifen.
Um der Registry einen Server hinzuzufügen, muss dieser auf einer Package Registry wie npm, PyPI oder DockerHub veröffentlicht sein. Eine detaillierte Anleitung findet sich auf GitHub. Dort erfahren Developer, wie sie eine server.json-Datei für ihren Server erstellen, Authentifizierung mit der Registry erreichen, ihren Server veröffentlichen und die Veröffentlichung verifizieren können.
Umgang mit Sub-Registries
Wie das MCP-Team betont, soll das zentrale Register als hauptsächliche Source of Truth für öffentlich verfügbare MCP-Server dienen, jedoch den bereits bestehenden Registries von Community und Unternehmen nicht im Weg stehen. Diese können in der MCP Registry öffentliche oder private Sub-Registries anlegen, wie das MCP-Team auf GitHub beschreibt.
Bereits existierende Sammlungen sind etwa eine lange, gepflegte Liste auf GitHub und ein Docker-Verzeichnis für MCP-Quellen.
Da es sich bei der MCP Registry derzeit um eine Preview handelt, gibt es keine Garantie für die Beständigkeit der darin enthaltenen Daten. Auch sind Breaking Changes möglich, bevor die Registry die allgemeine Verfügbarkeit erreicht.
Weitere Informationen sind auf dem MCP-Blog zu finden.
(mai)
Entwicklung & Code
KI-Überblick 4: Deep Learning – warum Tiefe den Unterschied macht
Die bisherigen Beiträge dieser Serie haben gezeigt, dass neuronale Netze aus einfachen Bausteinen bestehen. Erst die Kombination vieler dieser Bausteine in mehreren Schichten ermöglicht jedoch die Durchbrüche, die moderne KI-Systeme prägen. Genau hier setzt das Konzept „Deep Learning“ an: Es beschreibt maschinelles Lernen mit tiefen, also mehrschichtigen, neuronalen Netzen.

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Deser Beitrag klärt, was „tief“ im Kontext neuronaler Netze bedeutet, warum zusätzliche Schichten die Leistungsfähigkeit erhöhen und welche typischen Architekturen in der Praxis verwendet werden.
Was „deep“ wirklich heißt
Von Deep Learning spricht man, wenn ein neuronales Netz mehrere verborgene Schichten enthält – in der Regel deutlich mehr als zwei oder drei. Jede Schicht abstrahiert die Ausgaben der vorherigen Schicht und ermöglicht so, komplexe Funktionen zu modellieren. Während einfache Netze vor allem lineare und leicht nichtlineare Zusammenhänge erfassen, können tiefe Netze hochdimensionale Strukturen und Muster erkennen.
Die Entwicklung hin zu tieferen Netzen wurde erst durch drei Faktoren möglich:
- Stärkere Rechenleistung – insbesondere durch Grafikkarten (GPUs) und später spezialisierte Hardware wie TPUs.
- Größere Datenmengen, die zum Training genutzt werden können.
- Verbesserte Trainingsverfahren, darunter die Initialisierung von Gewichten, Regularisierungstechniken und optimierte Aktivierungsfunktionen.
Hierarchisches Lernen von Merkmalen
Ein Kernprinzip des Deep Learning ist die hierarchische Merkmalsextraktion. Jede Schicht eines tiefen Netzes lernt, auf einer höheren Abstraktionsebene zu arbeiten:
- Frühe Schichten erkennen einfache Strukturen, zum Beispiel Kanten in einem Bild.
- Mittlere Schichten kombinieren diese zu komplexeren Mustern, etwa Ecken oder Kurven.
- Späte Schichten identifizieren daraus ganze Objekte wie Gesichter, Autos oder Schriftzeichen.
Diese Hierarchiebildung entsteht automatisch aus den Trainingsdaten und macht Deep Learning besonders mächtig: Systeme können relevante Merkmale selbst entdecken, ohne dass Menschen sie mühsam vordefinieren müssen.
Typische Architekturen
Im Deep Learning haben sich verschiedene Architekturen etabliert, die für bestimmte Datenarten optimiert sind.
Convolutional Neural Networks (CNNs) sind spezialisiert auf Bild- und Videodaten. Sie verwenden Faltungsschichten („Convolutional Layers“), die lokale Bildbereiche analysieren und so translationinvariante Merkmale lernen. Ein CNN erkennt beispielsweise, dass ein Auge im Bild ein Auge bleibt, egal wo es sich befindet. CNNs sind der Standard in der Bildklassifikation und Objekterkennung.
Recurrent Neural Networks (RNNs) wurden entwickelt, um Sequenzen wie Text, Sprache oder Zeitreihen zu verarbeiten. Sie besitzen Rückkopplungen, durch die Informationen aus früheren Schritten in spätere einfließen. Damit können sie Zusammenhänge über mehrere Zeitschritte hinweg modellieren. Varianten wie LSTMs (Long Short-Term Memory) und GRUs (Gated Recurrent Units) beheben typische Probleme wie das Vergessen relevanter Informationen.
Autoencoder sind Netze, die Eingaben komprimieren und anschließend wieder rekonstruieren. Sie lernen dabei implizit eine verdichtete Repräsentation der Daten und werden etwa für Anomalieerkennung oder zur Vorverarbeitung genutzt. Erweiterte Varianten wie Variational Autoencoders (VAE) erlauben auch generative Anwendungen.
Diese Architekturen bilden die Grundlage vieler moderner KI-Anwendungen. Sie sind jedoch noch nicht der Endpunkt: In den letzten Jahren haben Transformer klassische RNNs in vielen Bereichen abgelöst, insbesondere in der Sprachverarbeitung. Darum wird es in einer späteren Folge dieser Serie gehen.
Herausforderungen des Deep Learning
Tiefe Netze sind leistungsfähig, bringen aber neue Herausforderungen mit sich:
- Großer Datenhunger: Ohne ausreichend Trainingsdaten tendieren tiefe Modelle zum Überfitting.
- Rechenintensiv: Training und Inferenz erfordern spezialisierte Hardware und hohe Energieaufwände.
- Schwer erklärbar: Mit wachsender Tiefe nimmt die Nachvollziehbarkeit weiter ab, was für viele Anwendungsbereiche problematisch ist.
Trotzdem hat sich Deep Learning als Schlüsseltechnologie für die meisten aktuellen KI-Durchbrüche etabliert.
Ausblick
Die nächste Folge widmet sich den Transformern – der Architektur, die Large Language Models und viele andere moderne Systeme ermöglicht. Sie erläutert, warum klassische RNNs an ihre Grenzen stießen und wie Self-Attention die Verarbeitung von Sprache revolutionierte.
(rme)

Abgespeckt: Apple schickt dünnes iPhone Air ins Rennen – eSIM only
: Maximale Kameras und Leistung im Cosmic Orange Unibody")
Apple iPhone 17 Pro (Max): Maximale Kameras und Leistung im Cosmic Orange Unibody

GirlsDoPorn: Extra lange Haftstrafe für Eigentümer

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

Der ultimative Guide für eine unvergessliche Customer Experience

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 UX/UI & Webdesignvor 3 Wochen
UX/UI & Webdesignvor 3 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenAdobe Firefly Boards › PAGE online
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
eine gute Nachricht ist")
eine gute Nachricht ist") Social Mediavor 3 Wochen
Social Mediavor 3 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 3 Wochen
Entwicklung & Codevor 3 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 7 Tagen
Entwicklung & Codevor 7 TagenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events