Künstliche Intelligenz
DeepSeek-OCR: Bilder vereinfachen Texte für große Sprachmodelle
Viele Unternehmensdokumente liegen zwar als PDFs vor, sind aber häufig gescannt. Obwohl es simpel klingt, können diese Dokumente oftmals nur unter großen Mühen in Text gewandelt werden, insbesondere wenn die Struktur der Dokumente komplexer ist und erhalten bleiben soll. Auch Bilder, Tabellen und Grafiken sind häufige Fehlerquellen. In den letzten Monaten gab es daher eine wahre Flut von OCR-Software, die auf großen Sprachmodelle (LLMs) setzt.
Weiterlesen nach der Anzeige
Auch der chinesische KI-Entwickler DeepSeek steigt nun in diesen Bereich ein und veröffentlicht nach dem Reasoning-Modell R1 ein experimentelles OCR-Modell unter MIT-Lizenz. Auf den ersten Blick mag das verblüffen, denn OCR schien bisher nicht die Kernkompetenz von DeepSeek zu sein. Und tatsächlich ist das neue Modell erstmal eine Technikdemo für einen neuen Ansatz in der Dokumentenverarbeitung von großen Sprachmodellen.


Prof. Dr. Christian Winkler beschäftigt sich speziell mit der automatisierten Analyse natürlichsprachiger Texte (NLP). Als Professor an der TH Nürnberg konzentriert er sich bei seiner Forschung auf die Optimierung der User Experience.
DeepSeek versucht, lange Textkontexte in Bildern zu komprimieren, da sich hierdurch eine höhere Informationsdichte mit weniger Token darstellen lässt. DeepSeek legt die Messlatte für die Erwartungen hoch und berichtet, dass das Modell bei hohen Kompressionsraten (Faktor 10) noch eine Genauigkeit von 97 Prozent erreicht, bei einer noch stärkeren Kompression fällt zwar die Genauigkeit, bleibt dabei aber relativ hoch. Das alles soll schneller funktionieren als bei anderen OCR-Modellen und auf einer Nvidia A100-GPU bis zu 200.000 Seiten pro Tag verarbeiten.
Das Kontext-Problem
Large Language Models haben Speicherprobleme, wenn der Kontext von Prompts sehr groß wird. Das ist der Fall, wenn das Modell lange Texte oder mehrere Dokumente verarbeiten soll. Grund dafür ist der für effiziente Berechnungen wichtige Key-Value-Cache, der quadratisch mit der Kontextgröße wächst. Die Kosten der GPUs steigen stark mit dem Speicher, was dazu führt, dass lange Texte sehr teuer in der Verarbeitung sind. Auch das Training solcher Modelle ist aufwendig. Das liegt allerdings weniger am Speicherplatz, sondern auch an der quadratisch wachsenden Komplexität der Berechnungen. Daher forschen die LLM-Anbieter intensiv daran, wie sich man diesen Kontext effizienter darstellen kann.
Hier bringt DeepSeek die Idee ins Spiel, den Kontext als Bild darzustellen: Bilder haben eine hohe Informationsdichte und Vision Token zur optischen Kompression könnten einen langen Text durch weniger Token. Mit DeepSeek-OCR haben die Entwickler diese Grundidee überprüft – es ist also ein Experiment zu verstehen, das zeigen soll, wie gut die optische Kompression funktioniert.
Weiterlesen nach der Anzeige
Die Modellarchitektur
Der dazugehörige Preprint besteht aus drei Teilen: einer quantitativen Analyse, wie gut die optische Kompression funktioniert, einem neuen Encoder-Modell und dem eigentlichen OCR-Modell. Das Ergebnis der Analyse zeigt, dass kleine Sprachmodelle lernen können, wie sie komprimierte visuelle Darstellungen in Text umwandeln.
Dazu haben die Forscher mit DeepEncoder ein Modell entwickelt, das auch bei hochaufgelösten Bildern mit wenig Aktivierungen auskommt. Der Encoder nutzt eine Mischung aus Window und Global Attention verbunden mit einem Kompressor, der Konvolutionen einsetzt (Convolutional Compressor). Die schnellere Window Attention sieht nur einzelne Teile der Dokumente und bereitet die Daten vor, die langsamere Global Attention berücksichtigt den gesamten Kontext, arbeitet nur noch mit den komprimierten Daten. Die Konvolutionen reduzieren die Auflösung der Vision Token, wodurch sich der Speicherbedarf verringert.
DeepSeek-OCR kombiniert den DeepEncoder mit DeepSeek-3B-MoE. Dieses LLM setzt jeweils sechs von 64 Experten und zwei geteilte Experten ein, was sich zu 570 Millionen aktiven Parametern addiert. Im Gegensatz zu vielen anderen OCR-Modellen wie MinerU, docling, Nanonets, PaddleOCR kann DeepSeek-OCR auch Charts in Daten wandeln, chemische Formeln und geometrische Figuren erkennen. Mathematische Formeln beherrscht es ebenfalls, das funktioniert zum Teil aber auch mit den anderen Modellen.
Die DeepSeek-Entwickler betonen allerdings, dass es sich um eine vorläufige Analyse und um ebensolche Ergebnisse handelt. Es wird spannend, wie sich diese Technologie weiterentwickelt und wo sie überall zum Einsatz kommen kann. Das DeepSeek-OCR-Modell unterscheidet sich jedenfalls beträchtlich von allen anderen. Um zu wissen, wie gut und schnell es funktioniert, muss man das Modell jedoch selbst ausprobieren.
DeepSeek-OCR ausprobiert
Als Testobjekt dient eine Seite aus einer iX, die im JPEG-Format vorliegt. DeepSeek-OCR kann in unterschiedlichen Konfigurationen arbeiten: Gundam, Large und Tiny. Im Gundam-Modus findet ein automatisches Resizing statt. Im Moment funktioniert das noch etwas instabil, bringt man die Parameter durcheinander, produziert man CUDA-Kernel-Fehler und muss von vorne starten.
Möchte man den Text aus Dokumenten extrahieren, muss man das Modell geeignet prompten. DeepSeek empfiehlt dazu den Befehl

Im Gundam-Modus erkennt DeepSeek-OCR den gesamten Text und alle relevanten Elemente und kann auch Textfluss des Magazins rekonstruieren.
Den Text hat das Modell praktisch fehlerfrei erkannt und dazu auf einer RTX 4090 etwa 40 Sekunden benötigt. Das ist noch weit entfernt von den angepriesenen 200.000 Seiten pro Tag, allerdings verwendet Gundam auch nur ein Kompressionsfaktor von zwei: 791 Image Token entsprechen 1.580 Text Token. Immerhin erkennt das Modell den Textfluss im Artikel richtig. Das ist bei anderen Modellen ein gängiges Problem.
Mit etwa 50 Sekunden rechnet die Large-Variante nur wenig länger als Gundam, allerdings sind die Ergebnisse viel schlechter, was möglicherweise auch dem größeren Kompressionsfaktor geschuldet ist: 299 Image-Token entsprechen 2068 Text-Token. Im Bild verdeutlichen das die ungenauer erkannten Boxen um den Text – hier gibt es noch Optimierungsbedarf. Außerdem erkennt das Modell die Texte nicht sauber, teilweise erscheinen nur unleserliche Zeichen wie „¡ ¢“, was möglicherweise auf Kodierungsfehler und eigentlich chinesische Schriftzeichen hindeuten könnte.

Der Large-Modus komprimiert die Bilder stärker als Gundam, was zu einer ungenaueren Erkennung führt. Die Textboxen sind unschärfer abgegrenzt und es erscheinen unleserliche Zeichen, die auf eine fehlerhafte Kodierung hinweisen.
Fehler mit unleserlichen Zeichen gibt es beim Tiny-Modell nicht. Das rechnet mit einer Dauer von 40 Sekunden wieder etwas schneller und nutzt einen Kompressionsfaktor von 25,8 – 64 Image-Token entsprechen 1652 Text-Token. Durch die hohe Kompression halluziniert das Modell allerdings stark und erzeugt Text wie „Erweist, bei der Formulierung der Ab- fragen kann ein KI-Assistent helfen. Bis Start gilt es auf Caffès offiziell die Gewicht 50 Prozent der Früh-, der Prüfung und 50 Prozent für den Arzt- und NEUT und in Kürze folgen. (Spezielle)“. Das hat nichts mit dem Inhalt zu tun – auf diese Modellvariante kann man sich also nicht verlassen.

Die Tiny-Variante hat den höchsten Kompressionsfaktor für die Bilder und halluziniert bei der Text-Ausgabe stark. Hier sollte man sich also nicht auf die Ergebnisse verlassen.
Neben der Markdown-Konvertierung lässt DeepSeek-OCR auch ein Free OCR zu, das das Layout nicht berücksichtigt. Damit funktioniert das Modell sehr viel schneller und produziert auch in der Large-Version mit hoher Kompression noch gute Resultate. Diese Variante ist aber nur sinnvoll, wenn man weiß, dass es sich um Fließtexte ohne schwieriges Layout handelt.
Informationen aus Grafiken extrahieren
DeepSeek-OCR hat beim Parsing die im Artikel enthaltenen Bilder erkannt und separat abgelegt. Das Diagramm speichert das Modell dabei in einer schlecht lesbaren Auflösung.
Das mit Gundam extrahierte Diagramm ist verschwommen und lässt sich mit bloßem Auge nur noch schlecht entziffern.
Jetzt wird es spannend, denn DeepSeek-OCR soll aus diesem Diagramm auch Daten extrahieren können, das geht mit dem Prompt
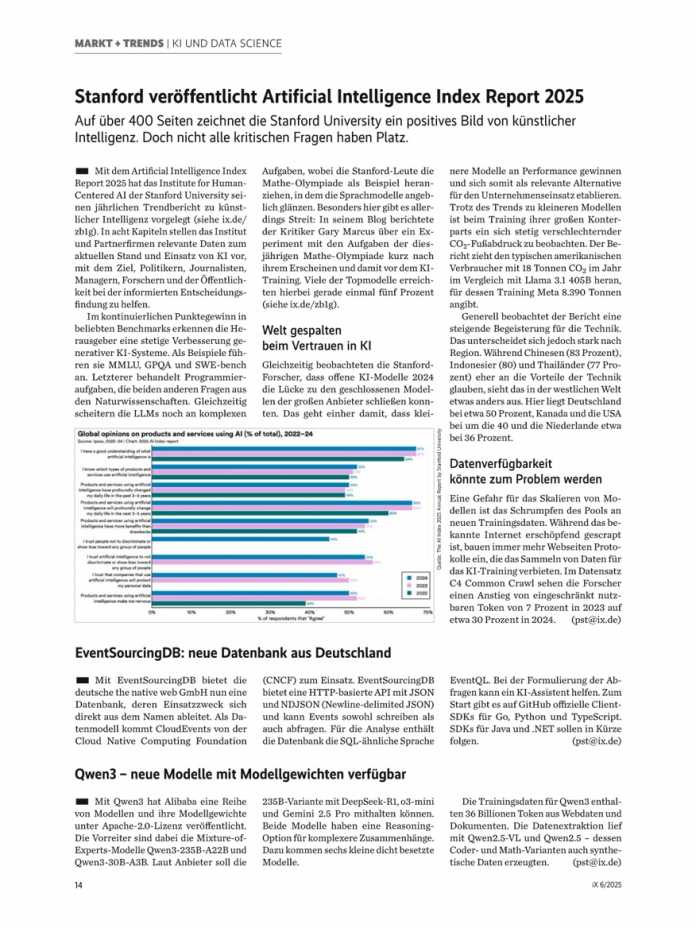
| 2024 | 2023 | 2022 | |
| I have a good understanding of what artificial intelligence is | 67% | 67% | 64% |
| I know which types of products and services use artificial intelligence | 52% | 51% | 50% |
| Products and services using artificial intelligence have profoundly changed my daily life in the past 3-5 years | 50% | 50% | 49% |
| Products and services using artificial intelligence will profoundly change my daily life in the next 3-5 years | 66% | 66% | 60% |
| Products and services using artificial intelligence have more benefits than drawbacks | 55% | 54% | 52% |
| I trust people not to discriminate or show bias toward any group of people | 45% | 45% | 44% |
| I trust artificial intelligence to not discriminate or show bias toward any group of people | 54% | 54% | 50% |
| I trust that companies that use artificial intelligence will protect my personal data | 47% | 50% | 50% |
| Products and services using artificial intelligence make me nervous | 39% | 39% | 39% |
Offenbar haben sich Fehler in die Tabelle eingeschlichen, aber zumindest hat das Modell den verwaschenen Text richtig erkannt. Hier zeigt sich die Stärke des Encoders, aber auch die englische Beschriftung vereinfacht den Prozess für das Modell. Die meisten Prozentwerte stimmen, ebenso die Struktur der Daten. Verwendet man eine höhere Auflösung, verbessern sich die Ergebnisse allerdings nur marginal.
Neben Diagrammen kann DeepSeek-OCR auch mathematische Formeln erkennen und sie in LaTeX-Syntax wandeln. Chemische Strukturformeln hat es auch im Repertoire und wandelt sie in das SMILES-Format.
Fazit
DeepSeek hat sich erneut einen spannenden technischen Ansatz ausgedacht und mit DeepSeek-OCR überzeugend demonstriert. Die Erkennung von Texten funktioniert besonders im Gundam-Modus schon gut, auch das Parsing der Diagramme ist überzeugend. Allerdings sind andere Modelle wie MinerU, Nanonets und PaddleOCR-VL besonders bei der reinen Texterkennung ebenfalls sehr gut und liefern teilweise sogar bessere Ergebnisse, da sie etwa getrennte Wörter zusammenführen. Besonders das ebenso nagelneue PaddleOCR-VL ist hervorzuheben, das Daten aus Diagrammen verlässlich extrahiert und in eigenen Tests sogar besser als DeepSeek-OCR funktionierte. Um OCR ist ein wahres Wettrennen entbrannt.
DeepSeek scheint mit dem Modell jedoch nicht nur auf OCR zu setzen, sondern möchte zeigen, dass die Vision Token eine gute Darstellung sind, um den Kontext in großen Sprachmodellen besonders kompakt zu speichern. Mit einer geringen Kompression funktioniert das schon gut, mit höherer Kompression leiden die Ergebnisse aber spürbar. Dieser Ansatz steht allerdings noch ganz am Anfang.
DeepSeek-OCR ist in allen Konfigurationen verhältnismäßig schnell. Experimente mit MinerU, Nanonets und PaddleOCR-VL waren alle mindestens 50 Prozent langsamer. Nanonets erzeugte immerhin eine Tabelle aus dem Diagramm, aber ohne die Jahreszahlen, dafür war der Fließtext sehr viel besser erkannt. Das nagelneue PaddleOCR-VL konnte das Diagramm sogar besser als DeepSeek-OCR erkennen, ist aber nicht auf chemische Strukturformeln und ähnliche Inhalte trainiert.
DeepSeek-OCR ist – wie von den Entwicklern deutlich vermerkt – eine Technologiedemonstration, die dafür schon äußerst gut funktioniert. Es bleibt abzuwarten, wie sich die Technologie in klassische LLMs integrieren lässt und dort zur effizienteren Verarbeitung von längeren Kontexten genutzt werden kann.
Weitere Informationen finden sich auf GitHub, Hugging Face und im arXiv-Preprint.
(pst)











Künstliche Intelligenz
Top 10: Der beste Wischsauger im Test – mit Dampf & Schaum gegen den Schmutz
Mit Akku-Wischsaugern geht Wischen so einfach und schnell wie Saugen. Wir haben über 20 Modelle getestet und zeigen hier die 10 besten.
Die Müslischale mit Milch ist übergeschwappt und die Hälfte ist auf den Küchenfliesen gelandet? Der Hund ist nach dem Gassigehen im Regen schön durch Schlammpfützen und anschließend über den Laminatboden gejagt? Oder sieht der Flur im Eingangsbereich im Herbst und Winter dank eingetrockneter Schmutzreste mal wieder furchtbar aus? Dann ist wohl Wischen angesagt.
Also Eimer, Wischlappen und Schrubber herausholen, dann Wasser in den Eimer, den Lappen auswringen, über den Schrubberkopf legen und wischen, was das Zeug hält – da kommt man schon beim Lesen ins Schwitzen. Aber es gibt eine wesentlich einfachere und deutlich weniger anstrengende Alternative: den Wischsauger mit Akku. Dieser vereinfacht dank moderner Technik und nützlicher Funktionen die sonst sehr mühselige Arbeit ungemein und kombiniert Staubsaugen und Wischen in einem Arbeitsschritt. In unserer Bestenliste zeigen wir die Top-Modelle aus unseren Tests und erklären, worauf es bei Wischsaugern ankommt.
Welcher ist der beste Akku-Wischsauger?
Unser Testsieger ist der Dreame H15 Pro Heat für 499 Euro. Er überzeugt mit seiner Heißwasser-Bodenreinigung, seiner starken Saugkraft von 22.000 Pa und der Abziehlippe, die für eine perfekte Kantenreinigung sorgt.
Als neuer Technologiesieger hat sich der Roborock F25 Ace Pro für 549 Euro herauskristallisiert. Mit seiner Schaumdüse kann er auch mit äußerst hartnäckigen Flecken und Verschmutzungen umgehen.
Unser Preis-Leistungs-Sieger ist der Mova X4 Pro für 349 Euro aus dem Hause Dreame. Per Knopfdruck sprüht er im Heißwasser-Modus 80 °C heißes Wasser vor sich auf den Boden, um hartnäckige Flecken zu entfernen. Zudem liefert er eine grundsolide Saug- und Wischleistung zu einem angenehmen Preis.
Der Dreame H15 Pro Heat für 499 Euro bietet zwei Alleinstellungsmerkmale: Die automatische Abziehlippe reinigt Kanten und Ecken perfekt, während 85 °C heißes Wischwasser selbst hartnäckige Verschmutzungen löst. Die Saugkraft von 22.000 Pa und das Tangle-Cut-System gegen verhedderte Haare machen ihn zum Kraftpaket. Wer maximale Reinigungsleistung und innovative Technik sucht, findet hier das aktuell beste Gesamtpaket am Markt.
- Heißwasser-Bodenreinigung mit bis zu 100 °C
- automatische Abziehlippe für perfekte Kantenreinigung
- starke Saugkraft von 22.000 Pa
- Tangle-Cut-System mit Messereinsatz gegen Haare
- teilweise billig wirkende Kunststoffteile
- sehr laute Selbstreinigung mit 77 dB(A)
- holprige App-Einrichtung mit Update-Problemen
- hoher Preis
Der Roborock F25 Ace Pro kann dank einer Schaumdüse auf Knopfdruck Reinigungskonzentrat in dichten Schaum verwandeln, um so auch hartnäckigere Flecken gründlicher entfernen zu können. Er ist zwar keine Wunderwaffe, erleichtert das Wischen in unserem Test aber durchaus. Der Wischsauger kostet 549 Euro.
- Schaumdüse nützlich, um hartnäckigere Flecken zu lösen
- zuverlässige Saugleistung
- unkomplizierte Handhabung
- kaum Neuerungen zu Vorgängermodellen
- Schmutzwassersieb wirkt etwas fragil
Der Mova X4 Pro vereint schlaues und hochwertig wirkendes Design mit einer soliden Saug- und Wischleistung zu einem guten Preis. Funktionen wie der Heißwassermodus sind nützlich, um hartnäckige Flecken zu entfernen. Die 100 °C heiße Selbstreinigung mit anschließender Trocknung überzeugt ebenfalls. Im Alltag weiß der Mova X4 Pro für 349 Euro größtenteils zu überzeugen, während ein etwas schwächelnder Saugmodus sowie die Schmutzansammlung an den Walzenseiten den Eindruck etwas schmälern.
- Sprühfunktion nützlich, um härtere Verschmutzungen zu lösen
- 100 °C heiße Selbstreinigung
- schlaues Design erleichtert Reinigung des Schmutzwassertanks
- solide Verarbeitung
- Sauger hat Schwierigkeiten mit größeren Objekten
- Wischwalze hinterlässt manchmal Staubfäden am Boden
- kein separates Fach für Reinigungskonzentrat
Ratgeber
Was ist ein Wischsauger?
Grundsätzlich gibt es Wischsauger mit Kabel zum Anschluss an die 230-Volt-Steckdose und mit Akku. Sie ersetzen Wassereimer, Schrubber und Wischtuch. Mit Akku ähneln sie vom Aufbau her Akkusaugern wie dem Dyson V15 Detect oder dem Samsung Bespoke Jet, doch es gibt entscheidende Unterschiede.
Denn statt eines Schmutzbehälters für Krümel und Sandkörner gibt es einen Schmutz- und Abwassertank, in dem nicht nur diese festen Partikel, sondern auch Flüssigkeiten abgesaugt werden. Hinzu kommt außerdem ein integrierter Behälter für frisches Wischwasser, der Wischeimer ist also immer mit dabei. Aus dem Frischwassertank wird die weiche Rollenbürste im Bürstenkopf des Gerätes und/oder (selten) der Boden davor mit Wasser befeuchtet. Die Absaugfunktion entfernt im gleichen Arbeitsschritt das schmutzige Wasser, Krümel und Staub und zieht die so entstehende Plörre in den Abwassertank. Über zu feuchtes Wischen und Beschädigung von teuren Holzböden wie Parkett muss man sich keine Sorgen machen, denn der dünne Feuchtigkeitsfilm trocknet schnell wieder ab.
Was bringen Wischsauger?
Dadurch, dass Frischwasser normalerweise in einem Schritt auf den Boden gegeben und direkt wieder als Abwasser abgesaugt wird, entfällt das lästige, regelmäßige Auswaschen und anschließende Auswringen des Wischtuches, wie man es beim manuellen Wischen hat. Das schont den Rücken und spart Zeit. Gleiches gilt für die Wischvorbereitung: Einfach den Akku-Wischsauger von der Ladestation nehmen und loslegen.
Minimaler Reinigungsaufwand entsteht nur nach dem Wischen, hier sollte der Abwassertank ausgespült und der Frischwassertank wieder aufgefüllt werden. Manche Wischsauger verlangen zudem den Ausbau der Wischrolle zum Trocknen. Die meisten aktuellen Modelle nehmen diesen Arbeitsschritt ab. Die Selbstreinigung geht schnell und mit nur einem Knopfdruck. Eine dafür nötige Dockingstation ist bei vielen Wischsaugern im Lieferumfang enthalten. Ist das Gerät angedockt, erhitzt es das Wasser aus dem Frischwassertank, um die Wischwalze damit gründlich zu reinigen. Viele Wischsauger haben zudem eine Trocknungsfunktion, die die gereinigte Wischwalze anschließend mit heißer Luft trocknet.

Die schnell drehende Wischrolle eines Wischsaugers ersetzt das anstrengende Schrubben, das Wischen wird so zum Kinderspiel. Die meisten modernen Wischsauger haben außerdem motorisierte Räder, die durch ihren Antrieb automatisch vorwärtsfahren und einen dadurch zusätzlich entlasten.
Selbst eingetrockneter Schmutz stellt normalerweise kein Problem dar, eventuell muss man mehrfach oder besonders langsam über hartnäckigen Schmutz wischen. Was dem Wischsauger an Anpressdruck fehlt, macht er durch die schnelle Drehung der Wischrolle wett. Top-Modelle sind auch in der Lage, das Wasser zum Wischen zu erhitzen oder per Dampf noch gründlicher zu reinigen.
Alternative: Wischsauger mit Stromkabel
Sind Wischsauger zu empfehlen?
Wischsauger kosten deutlich mehr als die herkömmliche Eimer-Schrubber-Lappen-Kombi. Die Zeitersparnis und die deutlich geringere Anstrengung während der Vor- und Nachbereitung sowie während des Putzens lohnen sich aber allemal.
Wer schon einmal über die Anschaffung von Saugroboter (Bestenliste) oder Akkusauger (Bestenliste) nachgedacht hat, hat eigentlich bereits den ersten richtigen Schritt gemacht und denkt über eine Vereinfachung der täglichen Arbeiten nach. Denn sowohl Saugroboter als auch Akkusauger erledigen die Bodenreinigung nicht ganz so gut wie ein herkömmlicher, kabelgebundener Sauger; sie bieten für sich betrachtet dennoch deutliche Vorteile. Genauso ist das mit Wischsaugern: Sie lösen ein Problem nicht vollständig, aber sie vereinfachen es enorm. Wischen wird damit zum Kinderspiel. Eine tolle Ergänzung sind Saugroboter mit ordentlicher Wischfunktion. Die fahren regelmäßig, der Wischsauger kommt dann nur sporadisch zum Einsatz.

Was sind die Nachteile von Wischsaugern?
Neben dem bereits erwähnten höheren Preis ist hauptsächlich die relative Unhandlichkeit ein Problem bei Wischsaugern. Sie müssen ausreichend große Frisch- und Abwassertanks aufnehmen. Dadurch entfällt ein frei stehendes, schlankes Saugrohr wie beim Akkusauger, mit dem man bequem unter die Möbel käme.
Der vergleichsweise klobige Korpus eines Wischsaugers verhindert daher häufig einfaches Wischen unter Möbeln, zumal bei den meisten Modellen der Wischkopf nicht bis 180 Grad gestreckt werden kann, sondern eher bis 140 Grad. Geht man mit dem Griff doch weiter runter, um etwa unter die Couch zu kommen, hebt sich der Wischkopf einfach ab und verliert dann seine Reinigungswirkung. Im Extremfall kann bei manchem Modell Wasser aus den Tanks auslaufen und sogar den Motor zerstören, beim normalen Wischen muss man davor aber keine Sorge haben. Mittlerweile gibt es jedoch auch diverse Modelle wie den Roborock F25 Ace oder den Mova X4 Pro, die sich komplett waagerecht auf den Boden legen und so problem- und gefahrlos unter Möbeln wischen und saugen können.
Wischsauger wiegen größtenteils 4 bis 5 Kilogramm und fühlen sich beim ersten Ausprobieren viel steifer an als ein Schrubber. Daran gewöhnt man sich aber schnell. Das Gewicht ist dann auch darum kein Nachteil mehr, weil die meisten Geräte durch die Rollendrehung oder angetriebene Räder wie von allein nach vorn gezogen werden. Ein weiterer Nachteil von Wischsaugern: Sie sind laut wie ein Akkusauger und verbrauchen Strom. Beides ist beim manuellen Wischen anders.

Können Wischsauger bis zum Rand wischen?
Es gibt noch einen Nachteil: Aktuell können viele Wischsauger nicht ganz bis an den Rand wischen. Wegen der Aufhängevorrichtungen, der Wischrolle und der Kunststoffabdeckung des Wischkopfes bleiben dann normalerweise 1 bis 2 Zentimeter bis zum Rand ungewischt. Es gibt aber auch Modelle wie den Roborock Dyad Pro und andere, die bis auf wenige Millimeter am Rand wischen können.

Kann man mit einem Wischsauger auch Teppich saugen?
Wischsauger sind für die Reinigung von Hartboden wie Fliesen, Beton, Laminat oder Parkett ausgelegt. Wie bei manuellem Wischen mit Eimer, Schrubber und Wischlappen ist von einem Reinigungsversuch auf dem Teppich abzusehen. Wer Teppiche reinigen möchte, sollte zu speziellen Teppich-Nasssaugern oder herkömmlichen (Akku‑)Staubsaugern greifen. Generell gilt: Kleine Krümelansammlungen oder etwas Sand kann ein Wischsauger aufnehmen, er ersetzt aber keinen Sauger. Dafür kommt er aber auch mit dem Haferflocken-Müsli oder Joghurt klar.
Für mehr trockenen Schmutz gibt es Kombimodelle wie den Dreame H12 Dual. Diese Modelle erlauben den einfachen Umbau vom Wischsauger zum Akkusauger. Das funktioniert schnell und unkompliziert mit wenigen Handgriffen. Alle benötigten Komponenten dafür sind im Lieferumfang enthalten. Allerdings sind diese Modelle teils mangels echter Borstenbürste dann trotzdem nur bedingt etwas für hochflorige Teppiche. Inzwischen gibt es aber auch Geräte mit solchen Motorbürsten.
Wie hygienisch sind Wischsauger?
Wischsauger verfügen normalerweise über HEPA-Filter, die die aufgesaugte Luft reinigen. Zudem geben viele Hersteller ihren Produkten spezielle Reinigungszusätze mit, die nicht nur gut riechen, sondern auch antibakteriell wirken. Erste Modelle ermöglichen zudem eine Sterilisierung des Wischwassers per Elektrolyse. Da in den meisten Varianten aber nur kaltes oder leicht warmes Wasser eingesetzt wird, kann eine Keimbildung letztlich nicht ganz ausgeschlossen werden – wie beim normalen Wischen von Hand auch. Im Gegensatz dazu wird bei Wischsaugern allerdings schmutziges Wasser nicht mehrfach oder über einen längeren Zeitraum verwendet, da es sofort wieder in den Abwassertank abgesaugt wird. Das sorgt für einen gleichbleibend hohen Sauberkeitslevel.

Die größten Probleme sehen wir bei der Wischrolle. Dabei geht es nicht um die Sauberkeit nach dem Wischen, denn dank automatischer Selbstreinigung in der Lade- und Reinigungsstation, die inzwischen fast jedes Gerät beherrscht, ist die ausreichend gewährleistet. Gelegentlich sollten Nutzer dennoch darüber nachdenken, die Wischrolle einmal richtig per Hand zu säubern. Wird die Rolle hingegen bei einfachen Modellen nicht ausgebaut und getrocknet, können hier durch die langsame Trocknung Bakterien und unangenehme Gerüche entstehen. Wer schon einmal eine Waschmaschinenladung in der Trommel vergessen hat, kennt das.
Inzwischen gibt es aber immer mehr Varianten, die zur Selbstreinigung auch zur anschließenden Trocknung durch Heißluft in der Lage sind. Das verhindert unserer Erfahrung nach Geruchs- und Bakterienbildung effektiv. Beides geht aber nicht geräuschlos vonstatten, es ist ein kontinuierliches Lüftergeräusch bis zum Abschluss der Trocknung zu hören. Weiterer Schwerpunkt: Der Abwassertank sollte nach jeder Verwendung des Wischsaugers geleert und gereinigt werden, um üble Gerüche zu vermeiden. Wir machen das bei unseren Modellen aber nicht jedes Mal sofort und haben damit bislang keine negativen Erfahrungen gemacht.
Wie lange hält der Akku bei einem Wischsauger?
Die meisten Hersteller geben Wischzeiten von 30 Minuten mit einer Ladung bei Akku-Wischsaugern an. Durch die Zeitersparnis der Geräte reicht das unserer Erfahrung nach locker für eine Etage eines normalen Einfamilienhauses oder einer Wohnung. Wer mehr benötigt, sollte auf die Möglichkeit zum Akkuwechsel achten und darauf, ob ein Ersatzakku im Lieferumfang enthalten ist. Das hilft außerdem, wenn es später zu Ermüdungserscheinungen beim Akku oder gar zu einem Defekt kommen sollte. Dann können die Energiespender einfach ausgetauscht werden. Die Akkus selbst sollten dank Lithium-Ionen-Technologie mehrere Jahre ohne spürbar nachlassende Leistung halten.
Fazit
Wischsauger lösen das Problem Wischen nicht komplett. Sie machen die Arbeit aber deutlich einfacher. Mit ihnen geht Wischen fast so schnell und bequem wie Staubsaugen. Die Frage nach einem weiteren Gerät für mehrere hundert Euro ist dennoch berechtigt. Wer jedoch bereits über einen Saugroboter oder einen Akkusauger nachgedacht hat, kennt den Wunsch nach mehr Komfort.
Genau hier setzen Wischsauger an. Sie sorgen spürbar für Entlastung im Alltag. Die Unterschiede zwischen den Modellen liegen primär im Funktionsumfang sowie in der Saug- und Wischleistung. Selbstreinigungsstationen mit anschließender Trocknung werden zunehmend zum Standard. Geräte wie der Tineco Floor One S9 Artist, der Dreame H15 Pro Heat, der Mova X4 Pro oder der Roborock F25 Ace Pro reinigen inzwischen sogar mit heißem Wasser und Schaum für bessere Ergebnisse.
Dreame H15 Pro Heat
Der Dreame H15 Pro Heat reinigt mit bis zu 85 °C heißem Wasser und automatischer Abziehlippe. Ob die Innovationen den Preis rechtfertigen, zeigt der Test.
- Heißwasser-Bodenreinigung mit bis zu 100 °C
- automatische Abziehlippe für perfekte Kantenreinigung
- starke Saugkraft von 22.000 Pa
- Tangle-Cut-System mit Messereinsatz gegen Haare
- teilweise billig wirkende Kunststoffteile
- sehr laute Selbstreinigung mit 77 dB(A)
- holprige App-Einrichtung mit Update-Problemen
- hoher Preis
Dreame H15 Pro Heat im Test: Wischsauger reinigt klasse mit heißem Wasser
Der Dreame H15 Pro Heat reinigt mit bis zu 85 °C heißem Wasser und automatischer Abziehlippe. Ob die Innovationen den Preis rechtfertigen, zeigt der Test.
Dreame setzt beim H15 Pro Heat auf zwei echte Innovationen: Als einer der ersten Wischsauger erhitzt er das Wischwasser auf bis zu 85 °C und nutzt es direkt zur Bodenreinigung. Die Konkurrenz verwendet heißes Wasser nur zum Auswaschen der Walze in der Station. Noch spannender ist die automatische Abziehlippe. Sie hebt und senkt sich automatisch, um Kanten und Ecken besonders gründlich zu reinigen. Beim Zurückziehen verhindert sie, dass Schmutz zurückbleibt. Diese Technologie gibt es aktuell bei keinem anderen Gerät.
Mit 22.000 Pa Saugkraft und verbesserter Gewichtsverteilung verspricht der Nachfolger des hervorragenden H14 Pro (Testbericht) deutliche Verbesserungen. Ob die Neuerungen den Aufpreis rechtfertigen, zeigt unser Test.
Achtung: Nur der Dreame H15 Pro Heat erhitzt das Wasser so stark – das Modell H15 Pro hingegen bietet dieses Feature nicht.
Lieferumfang: Welches Zubehör liegt beim Dreame H15 Pro Heat bei?
Im Karton finden sich neben dem Wischsauger die Lade- und Reinigungsstation, eine Reinigungsbürste für die Wartung, ein Fläschchen Reinigungsmittel-Konzentrat, ein Ersatz-HEPA-Filter und eine Ersatzwalze. Die Verpackung ist durchdacht, alle Teile sind sicher verstaut. Eine bebilderte Anleitung führt durch die erste Inbetriebnahme. Für die optionale App-Steuerung gibt es einen QR-Code. Der Lieferumfang ist komplett, weitere Anschaffungen sind nicht nötig.
Design: Wie gut ist die Verarbeitung des Dreame H15 Heat Pro?
Die Verarbeitung des H15 Heat Pro zeigt sich zwiespältig. Während die Technik hochwertig ist, wirken manche Kunststoffteile etwas billig. Der zweiteilige Schmutzwassertank mit getrennten Kammern für Wasser und feste Partikel ist clever konstruiert, zusätzlich gibt es einen Luftfilter. Allerdings erweist sich die Handhabung als tückisch: Beim Auseinandernehmen muss man das untere Teil festhalten, sonst schüttet man sich voll – was uns im Test prompt passierte.
Dreame H15 Pro – Bilderstrecke
Wischsauger Dreame H15 Pro im Test

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Dreame H15 Pro – Bilderstrecke

Die Gewichtsverteilung wurde verbessert: Der Frischwassertank sitzt jetzt im Bodenelement, was den Bedienwiderstand verringert. Mit 6,2 kg ist das Gerät schwer, liegt aber besser in der Hand als der Vorgänger. Die Station wirkt solide, nimmt aber mit ihren Maßen einigen Platz ein. Das schwarze Design ist zeitlos, allerdings auch unspektakulär. Die automatische Abziehlippe am Kopf ist das optische Highlight und macht einen robusten Eindruck. Im direkten Vergleich wirkt der Tineco Floor One S9 Artist (Testbericht) hochwertiger verarbeitet.
Einrichtung: Wie schnell ist der Dreame H15 Pro Heat betriebsbereit?
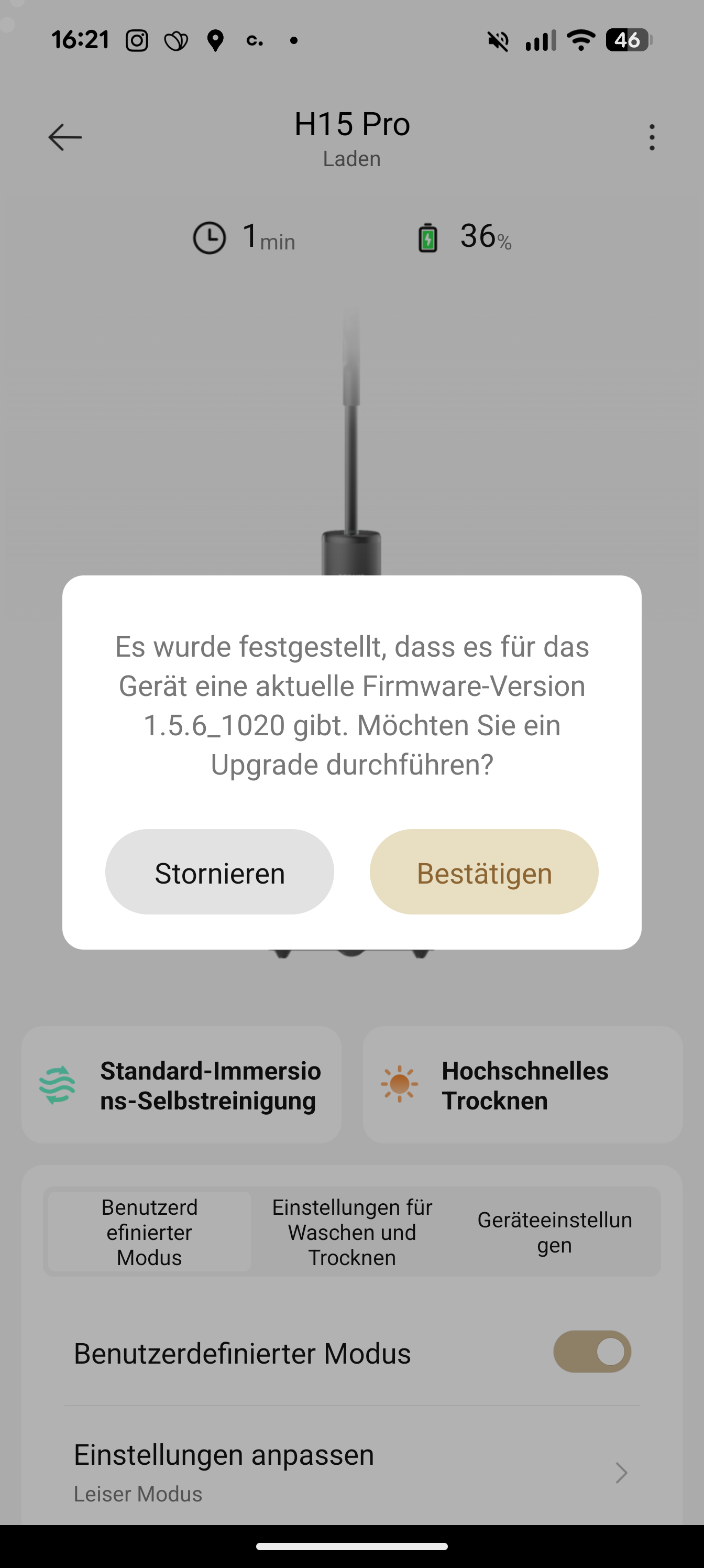
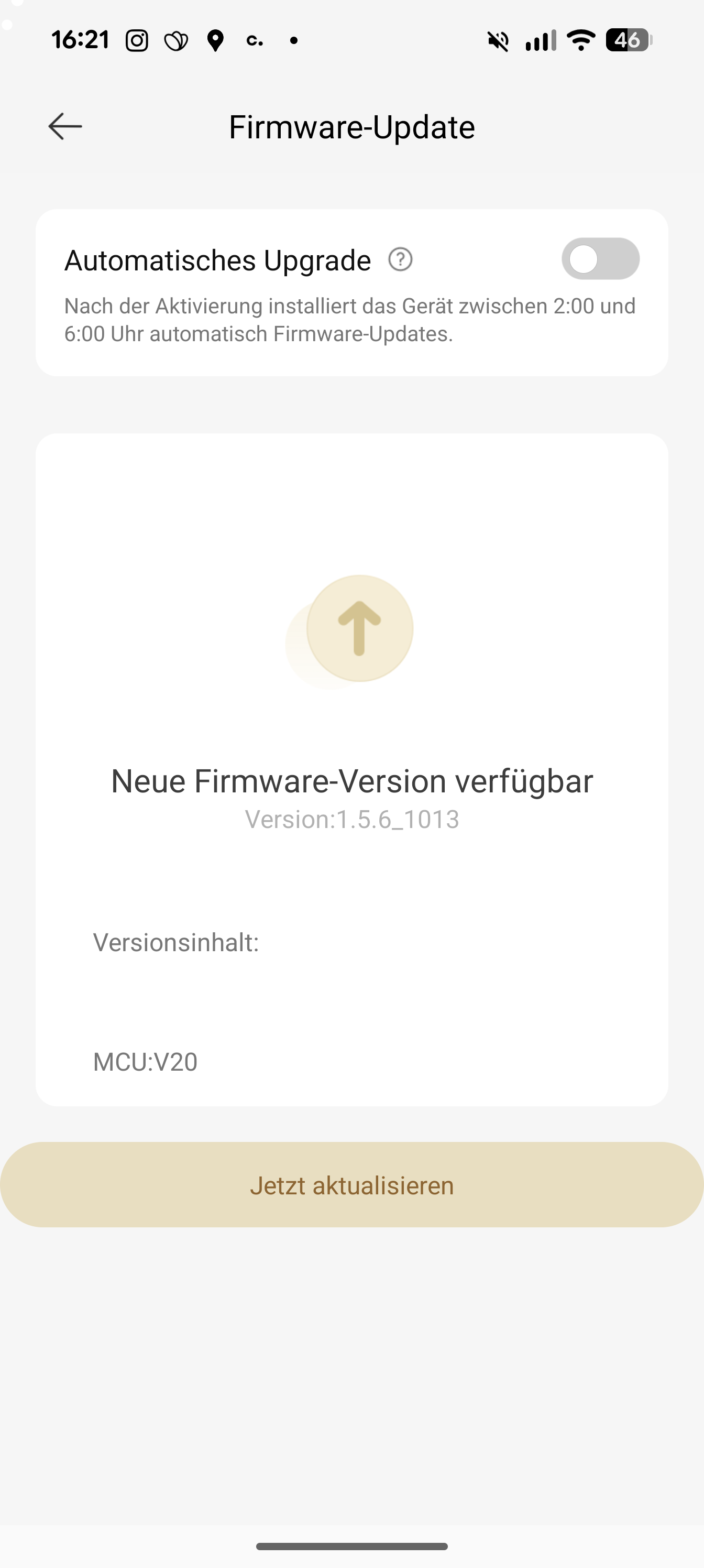
Die Inbetriebnahme des H15 Pro Heat gelingt insgesamt schnell: Haupteinheit und Griff werden zusammengesteckt, die Station mit Strom versorgt und der 800-ml-Frischwassertank befüllt sowie eingesetzt. Optional lässt sich die zugehörige App nutzen – sie ermöglicht Firmware-Updates und bietet zusätzliche Einstellungsmöglichkeiten, ist im Alltag jedoch nicht zwingend erforderlich. Viele Funktionen lassen sich direkt über die Tasten am Gerät steuern.
Zur Einrichtung der App dient ein versteckter Knopf auf der Rückseite des Wischsaugers, über den auch die Lautstärke der Sprachansagen angepasst werden kann. Die Dreamehome-App (Account erforderlich) erkennt das Gerät per Umgebungssuche. Nach Verbindung mit dem Geräte-Hotspot kann das WLAN eingerichtet werden.
Im Test war direkt ein App-Update verfügbar, dessen Installation jedoch auffällig lange dauerte und zunächst mit einer Fehlermeldung abbrach – obwohl es offenbar dennoch korrekt installiert wurde. Die App bietet weiterführende Optionen wie die Anpassung der Radunterstützung oder der Wasserzufuhr. Nach dem ersten Ladevorgang von etwa vier Stunden ist der H15 Pro vollständig einsatzbereit.
Dreame H15 Pro – App
Dreame H15 Pro – App

Dreame H15 Pro – App
Dreame H15 Pro – App
Dreame H15 Pro – App
Dreame H15 Pro – App
Dreame H15 Pro – App
Dreame H15 Pro – App
Steuerung: Wie ist das Handling des Dreame H15 Pro Heat?
Die Bedienung erfolgt über Tasten am Griff: Power, Modus-Wahl und Selbstreinigung. Die 4-stufige Leistungsregelung passt sich dem Verschmutzungsgrad an. Im Auto-Modus erkennt die Schmutzerkennung Verunreinigungen und regelt die Saugkraft sowie Wassermenge automatisch. Das Handling profitiert von der verbesserten Gewichtsverteilung, auch wenn der Tineco S9 Artist noch etwas besser in der Hand liegt.
Die angetriebenen Lenkrollen erleichtern die Bewegung trotz des hohen Gewichts. Das Flat-Reach-Design mit auf 180 Grad neigbarem Handteil ermöglicht flaches Wischen unter Möbeln. Die fehlende Front-LED des Vorgängers vermissen wir bei schlechten Lichtverhältnissen.
Reinigung: Wie gut saugt und wischt der Dreame H15 Pro Heat?
Die Reinigungsleistung des H15 Pro Heat überzeugt auf ganzer Linie. Das Thermo-Rinse-System mit bis zu 85 °C heißem Wischwasser ist ein echter Gamechanger. Während die Konkurrenz nur lauwarmes oder kaltes Wasser nutzt, löst der H15 Pro selbst hartnäckige Verschmutzungen. Im Test entfernte er eingetrocknete Kaffeeflecken, Ketchup und Cola meist mit einer Überfahrt. Die Saugkraft von 22.000 Pa (Unterdruck) packt groben Schmutz mühelos.
Das absolute Highlight ist die Gap-Free-Abziehlippe. Sie senkt sich automatisch an Kanten ab und reinigt bis in die Ecken. Beim Zurückziehen hebt sie sich und verhindert, dass Schmutz zurückbleibt. Auf Hartböden bleibt nichts zurück – genial!
Bei der Selbstreinigung in der Station arbeitet er mit 100 °C heißem Wasser statt der üblichen 60 °C. Das ist hygienischer und entfernt Bakterien zuverlässiger. Mit 77 dB(A) ist die Walzenwäsche sehr laut, die Heißlufttrocknung aber effektiv. Der zweiteilige Schmutzwassertank mit getrennten Kammern für Wasser und feste Partikel erleichtert die Reinigung. Dennoch sollte er schnell geleert werden – nach zwei Tagen entwickeln sich bereits unangenehme Gerüche. Die fehlende automatische Reinigungsmitteldosierung des Vorgängers vermissen wir nicht wirklich.
Akkulaufzeit: Wie lange arbeitet der Dreame H15 Pro?
Mit seinem 21,6V Li-Ionen-Akku (5.0Ah) schafft der H15 Pro bis zu 72 Minuten Laufzeit. Das reicht für etwa 200 m² Wohnfläche. Die tatsächliche Laufzeit hängt vom gewählten Modus ab: Im Auto-Modus mit variabler Leistung hält er länger durch als bei maximaler Stufe. Die Ladezeit von 4 Stunden ist marktüblich. Der Akkustand wird permanent am Display angezeigt. Für die meisten Haushalte reicht eine Akkuladung locker aus.
Preis
Der Dreame H15 Pro Heat kostet in der UVP 699 Euro. Seit dem Marktstart ist der Straßenpreis aber etwas gefallen und liegt inzwischen bei 499 Euro. Angesichts der einzigartigen Features wie Heißwasser-Bodenreinigung und automatischer Abziehlippe ist der Preis gerechtfertigt.
Vergleichbare Premiummodelle, wie etwa der Tineco Floor One S9 Artist (Testbericht), liegen in ähnlichen Preisregionen, bieten jedoch keine vergleichbaren Innovationen. Wer auf die Heißwasserfunktion verzichten kann, findet bereits günstigere Alternativen ab 400 Euro. Das Modell Dreame H15 Pro ohne Heizfunktion bekommt man bereits für 360 Euro.
Fazit
Der Dreame H15 Pro Heat setzt neue Maßstäbe im Bereich der Wischsauger. Die Heißwasser-Bodenreinigung mit bis zu 85 °C warmem Wasser sowie die automatische, lückenlose Abziehlippe („Gap-Free“) sind echte Alleinstellungsmerkmale. Die Reinigungsleistung überzeugt auf ganzer Linie: Auf Hartböden bleibt nichts zurück, selbst Kanten und Ecken werden gründlich gesäubert. Dazu kommen die gesteigerte Saugleistung von 22.000 Pa und das Tangle-Cut-System zur Vermeidung von Haarverwicklungen.
Schwächen zeigt das Gerät bei der Verarbeitung: Einige Kunststoffteile wirken wenig hochwertig, und der Schmutzwassertank ist trotz durchdachter Kammertrennung unpraktisch zu entleeren. Die App-Einrichtung verlief holprig – inklusive fehlschlagender Updates. Dass die LED-Beleuchtung und automatische Reinigungsmitteldosierung des Vorgängers fehlen, ist verschmerzbar. Mit 77 dB(A) fällt die Selbstreinigung allerdings sehr laut aus.
Dennoch: Wer maximale Reinigungsleistung und innovative Technik sucht, kommt am H15 Pro Heat kaum vorbei. Er rechtfertigt seinen Premium-Preis durch echte Alleinstellungsmerkmale.
Roborock F25 Ace Pro
Der F25 Ace Pro ist der neueste Wischsauger aus dem Hause Roborock. Er saugt mit 25.000 Pa und wischt mit Schaum.
- Schaumdüse nützlich, um hartnäckigere Flecken zu lösen
- zuverlässige Saugleistung
- unkomplizierte Handhabung
- kaum Neuerungen zu Vorgängermodellen
- Schmutzwassersieb wirkt etwas fragil
Roborock F25 Ace Pro im Test: Wischsauger, der auf Knopfdruck Schaum versprüht
Der F25 Ace Pro ist der neueste Wischsauger aus dem Hause Roborock. Er saugt mit 25.000 Pa und wischt mit Schaum.
Die neueste Iteration der Wischsauger aus dem Hause Roborock, der F25 Ace Pro, versprüht auf Knopfdruck gezielt Schaum für eine bessere Fleckenreinigung. Alles andere bleibt größtenteils beim Alten: Selbstreinigung und Trocknung per Ladestation, Einrichtung per App. Lohnt sich das Upgrade für den Schaum oder bleibt man besser beim Vorgängermodell? Wir haben den Roborock F25 Ace Pro getestet und klären auf. Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Zum Roborock F25 Ace Pro gibt es die Ladestation samt Stromkabel, die Wischwalze, ein Reinigungskonzentrat, einen Ersatz-HEPA-Filter und eine Handbürste für die Wartung. Selbstverständlich liegen auch ein Quick-Start-Guide sowie eine ausführlichere Betriebsanleitung bei. Alle Einzelteile sind dank Styroporeinlagen sicher verstaut. Der Quick-Start-Guide zeigt zudem visuell die Anordnung der einzelnen Komponenten innerhalb der Box, was für ein späteres Verstauen extrem hilfreich ist.
Design
Hier ändert sich nicht wirklich etwas. Wie bisher setzt Roborock mit dem F25 Ace Pro auf schlichtes Schwarz und viel Plastik. Der Wischsauger kommt mit den Maßen 265 x 1100 x 250 mm und wirkt äußerst robust. Alle Einzelteile klicken problemlos ineinander und sitzen fest. Das Auffangsieb aus Kunststoff wirkt allerdings etwas fragil. Das liegt hauptsächlich an den Verbindungsstücken, die sich durch Drücken an beiden Seiten vom Rest des Schmutzwasserfiltersystems lösen.
Roborock F25 Ace Pro – Bilder
Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Roborock F25 Ace Pro – Bilder

Die Ladestation ist kompakt und ebenfalls in unspektakulärem Schwarz gehalten. Das Stromkabel ist hingegen grau und bricht mit der sonst sehr einheitlichen Optik. Auch hier wirkt alles top verarbeitet.
Einrichtung
Die Einrichtung des Wischsaugers ist gewohnt einfach und schnell erledigt. Für die erste Inbetriebnahme muss man sämtliche Schutzfolien vom Gehäuse entfernen, die Wischwalze anbringen und den Griff in die dafür vorgesehene Öffnung stecken, bis er einrastet. Anschließend stellt man den F25 Ace Pro an die angeschlossene Ladestation, um den Akku aufzuladen. Zeitgleich kann die Koppelung mit der Roborock-App starten. Hinter dem Schmutzwassertank ist ein QR-Code versteckt, den man mit der Roborock-App einscannt, anschließend verbindet das Gerät mit dem heimischen WLAN. Etwaige anstehende Firmware-Updates können jetzt gestartet werden.
Für den ersten Einsatz steht zum Schluss noch das Auffüllen des Frischwassertanks und des Reinigungsmittelfachs an. Alles in allem ist die Einrichtung auch beim F25 Ace Pro super schnell und einfach erledigt.
Steuerung
Die Steuerung per App funktioniert erneut super. Man wechselt schnell zwischen den einzelnen Modi hin und her, justiert die Saugstärke und Wassermenge oder passt die Stärke der motorisierten Räder an. Auch die anschließende Selbstreinigung und Trocknung startet man bequem per App. Selbstverständlich steuert sich der Wischsauger auch über die Knöpfe am Gerät selbst.
Das LCD gibt Aufschluss über den gerade aktiven Modus sowie den derzeitigen Akkustand, wobei die Prozentanzeige der App aufschlussreicher ist als die Batterieanzeige auf dem Display.
Fester Bestandteil des Roborock F25 Ace Pro ist die Ansagerstimme, die jeden Moduswechsel und generell jede Zustandsänderung des Wischsaugers vertont. Uns stört das während des Tests nicht, auch wenn sie relativ laut ist. Das relativiert sich jedoch, sobald der Wischsauger in Betrieb ist. Die vertonten Informationen beschränken sich wirklich nur auf das Nötigste. Etwa der Wechsel in einen anderen Modus, die Information, dass der Ladevorgang beginnt oder die Aufforderung, dass man die Selbstreinigung starten soll. Man kann sie aber, wenn gewünscht, jederzeit leiser stellen oder auch ganz verstummen lassen. Es stehen neben Englisch und Deutsch auch viele andere Sprachausgaben, wie etwa Japanisch, Spanisch und Polnisch zur Auswahl. Beim
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Roborock F25 Ace Pro – Bilder App
Über den Trigger am Griffinneren aktiviert sich die Düse am Bürstenkopf und verwandelt einen Teil des Reinigungskonzentrats in Schaum, der vor dem Wischsauger verteilt wird. Die motorisierten Räder fahren mit einer angenehmen Beschleunigung, die in Kombination mit der 70-Grad-Schwenkung des Wischsaugers für eine super präzise und komfortable Steuerung sorgt.
Auch den Roborock F25 Ace Pro kann man für die Reinigung senkrecht auf den Boden legen. Die App dient dann als Fernbedienung, mit der man den Wischsauger auch unter Möbel fahren kann, ohne sich dabei verrenken zu müssen. Eine Kamera, um unter den Möbeln sehen zu können, wo der Sauger gerade lang fährt, fehlt leider. Generell bietet sich die Fernsteuerung per App nur für punktuelle Bewegungen an, da sie sehr verzögert und grob auf die Eingaben reagiert.
Reinigung
Bei der täglichen Reinigung macht der F25 Ace Pro eine durchaus gute Figur. Mit 25.000 Pa saugt er gröbere Schmutzpartikel problemlos auf, während die Wischfunktion im Automatikmodus ideal das Parkett befeuchtet. Wir beseitigen mit ihm problemlos eingetrocknete Kakaoflecken, aber auch Flüssigkeiten wie verschüttete Hafermilch sind keine Herausforderung.
Mit der Schaumfunktion bearbeiten wir hartnäckigere Flecken und zum Großteil bemerken wir, dass sich die Verschmutzung im Anschluss tatsächlich leichter löst. Ein Allheilmittel ist das allerdings nicht, denn auch der F25 Ace Pro kommt an seine Grenzen. Eine besonders hartnäckige und festgetretene Verschmutzung auf dem Parkettboden bekommt er auch mit Schaum und mehrmaligem Darüberfahren nicht ohne weiteres gelöst. Hier müssen wir von Hand reinigen.
Auf Fliesen kann er verhältnismäßig gut sauber machen, auch wenn er in erster Linie für Parkettböden gedacht ist. Er muss sich aber deutlich schneller mit Flecken geschlagen geben als auf dem Holzboden. Hier hilft ebenso der zusätzliche Schaum beim Lösen der Verschmutzungen. Mit dem Schaum die gewünschte Stelle zu treffen, erfordert ein, zwei Versuche, bis man den Sprühradius raus hat. Die Düse beginnt nämlich unmittelbar vor dem Bürstenkopf zu sprühen und verteilt den Schaum dann in etwa bis zu 15 cm nach vorne.
Die Selbstreinigung mit der Ladestation erfolgt mit 95 °C heißem Wasser und reinigt die Wischwalze während unseres Tests rundum zufriedenstellend innerhalb von fünf Minuten. Auch die anschließende Lufttrocknung findet bei 95 °C statt, wahlweise in fünfminütiger Schnelltrocknung oder in der deutlich entspannteren dreißigminütigen Trocknung. Wir entscheiden uns für letztere und begrüßen das leise, angenehme Surren während des Vorgangs.
Was die Lautstärke angeht, ist der Roborock F25 Ace Pro im Betrieb vollkommen in Ordnung. Im Automatik-Modus und Max-Modus arbeitet er mit 50 bis 60 dB(A), die wir per Smartphone-App direkt am Gerät messen. 60 dB(A) waren aber tatsächlich auch die Obergrenze, die wir hier feststellen konnten. Die Werte dienen selbstverständlich nur als Richtwert und sind nicht mit Messwerten von professionellem Equipment zu vergleichen.
Die Lautstärke der Selbstreinigung fährt ebenfalls bis auf 60 dB(A) hoch, bewegt sich aber überwiegend bei etwa 55 dB(A). Das leise Surren der dreißigminütigen Selbsttrocknung pegelt sich bei etwa 35 dB(A) unmittelbar an der Station ein, ist aber bei laufendem Fernseher oder Musik nicht mehr wirklich zu hören.
Die anschließende Reinigung des Schmutzwassertanks findet nach wie vor von Hand statt. Hier gibt es nichts zu beanstanden, denn das Auffangsieb löst sich mit nur einem Handgriff vom Tank und hinterlässt größtenteils nur Plörre. Der feste Schmutz bleibt am Sieb hängen und kann einfach in den Mülleimer verfrachtet werden. Anschließend noch den HEPA-Filter, das Sieb und den Tank durchspülen, abtrocknen und wieder einsetzen, und der F25 Ace Pro ist erneut einsatzbereit.
Akkulaufzeit
Roborock verspricht bis zu 60 Minuten Betrieb im Eco-Modus, 40 Minuten im Auto-Modus und 30 Minuten im Max-Modus mit dem F25 Ace Pro. Die Werte decken sich mit unseren Beobachtungen, denn nach etwa 15 Minuten im Auto-Modus mit mehrmaligem Wechsel in den Max-Modus verbleiben noch gut 60 Prozent Akkuladung. Das sollte ausreichen, um die meisten Wohnungen problemlos durchzuwischsaugen.
Preis
Die UVP des Roborock F25 Ace Pro liegt bei 649 Euro. Aktuell gibt es den Wischsauger für 549 Euro auf der Roborock-Website. Alternativ ist er zum gleichen Preis auch bei Amazon verfügbar.
Fazit
Für 549 Euro reinigt der Roborock F25 Ace Pro zuverlässig die meisten Verschmutzungen – sowohl durch Wischen als auch Saugen. Unterstützt wird er hierbei durch die neu hinzugekommene Schaumdüse, die in unserem Test einen guten Job macht und tatsächlich eine nützliche Ergänzung für die regelmäßige Putzaktion ist.
Mit 25.000 Pa hat er zwar auf dem Papier eine höhere Saugleistung als noch der F25 Ace, saugt für uns aber nicht merklich besser oder schlechter. Auch die restlichen Funktionen gleichen sich mehr oder weniger mit denen älterer Modelle. Für Besitzer eines aktuelleren Roborock-Saugwischers lohnt sich also ein Upgrade auf den F25 Ace Pro nicht wirklich, da hier die Schaumdüse die einzige tatsächliche Neuerung darstellt.
Wer noch keinen Wischsauger hat, bekommt mit dem Roborock F25 Ace Pro aber ein kompetentes Modell, das im Hinblick auf Reinigung, Verarbeitung und Handhabung überzeugt.
Dreame Mova X4 Pro
Der Wischsauger Mova X4 Pro versprüht heißes Wasser auf Knopfdruck und entfernt damit stärkere Verschmutzungen. Sich selbst reinigt er mit 100 °C heißem Wasser.
- Sprühfunktion nützlich, um härtere Verschmutzungen zu lösen
- 100 °C heiße Selbstreinigung
- schlaues Design erleichtert Reinigung des Schmutzwassertanks
- solide Verarbeitung
- Sauger hat Schwierigkeiten mit größeren Objekten
- Wischwalze hinterlässt manchmal Staubfäden am Boden
- kein separates Fach für Reinigungskonzentrat
Mova X4 Pro im Test: Wischsauger, der 80 °C heißes Wasser auf Knopfdruck sprüht
Der Wischsauger Mova X4 Pro versprüht heißes Wasser auf Knopfdruck und entfernt damit stärkere Verschmutzungen. Sich selbst reinigt er mit 100 °C heißem Wasser.
Der Wischsauger Mova X4 Pro liefert einen Heißwassermodus, mit dem man auf Knopfdruck zusätzlich Wasser versprühen kann, um hartnäckige Flecken zu entfernen. Außerdem erleichtert ein gut durchdachtes Design die Reinigung des Geräts ungemein. Wie es um seine Saug- und Wischleistung bestellt ist, zeigt der Test.
Lieferumfang
Zusammen mit dem Wischsauger erhält man eine Ersatzwischwalze, eine Flasche Reinigungskonzentrat, einen Ersatz-HEPA-Filter sowie eine Handbürste. Zudem liegt dem Paket auch eine Betriebsanleitung bei.
Design
Der Mova X4 Pro kommt im schlanken Design in silbern-schwarzer Optik daher. Das LCD ist zum Ende des Griffs hin platziert, wodurch eine einwandfreie Lesbarkeit während des Saugens garantiert ist. Es zeigt den Akkustand sowie den derzeit ausgewählten Modus an. An den Seiten des Rumpfs befinden sich zwei Lautsprecher, über die das Gerät verschiedene Statusmeldungen von sich gibt.
Der Wassertank ist unten am Fuß des Saugwischers auf der Rückseite angebracht. Diesen löst man durch Anheben eines Griffs. Schade: Der Wassertank ist nicht zweigeteilt. Das bedeutet, eine separate Zufuhr des Reinigungskonzentrats gibt es nicht. Stattdessen kippt man es zum Wischwasser dazu, wodurch etwa bei der Selbstreinigung auch das Konzentrat mit ausgeschüttet wird. Das lösen andere Hersteller besser und verzichten so auf eine unnötige Verschwendung.
Mova X4 Pro – Bilder
Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Mova X4 Pro – Bilder

Am Griff befinden sich mehrere Knöpfe. Ein An-/Aus-Schalter, ein Button, um den Reinigungsmodus zu wechseln, sowie ein Knopf auf der Innenseite des Griffs. Dieser sorgt für eine gezielte Zufuhr von heißem Wasser, wenn man den entsprechenden Modus verwendet. Die Öffnung dafür befindet sich vorn am Fuß. Unterstützend arbeitet hier eine grüne LED, die permanent leuchtet, wenn der Wischsauger in Betrieb ist. Sie zeigt den Bereich an, in welchem das heiße Wasser verteilt wird.
Der Schmutzwassertank löst sich problemlos vom Saugwischer und offenbart den runden HEPA-Filter, welcher oben auf dem Tank thront. Durch Hochziehen eines Griffs trennt man nun Auffangbehälter vom Schmutzwassertank. Das Ganze funktioniert unkompliziert und ist leicht verständlich. Das Herausnehmen des Filters erfordert jedoch etwas Kraft. Praktisch ist das herausfahrbare Sieb, welches die Reinigung im Anschluss an den Saugvorgang erheblich erleichtert.
Die Reinigungsstation ist so konzipiert, dass man mit dem Saugwischer einfach in sie hineinfährt und das Gerät dabei nicht anheben muss.
Einrichtung
Da es für den Mova X4 Pro keine App gibt, ist die Einrichtung superschnell erledigt. Nach dem Auspacken muss man die Plastikfolien am Gerät entfernen, den Griff mit dem Rumpf des X4 Pro verbinden sowie die Reinigungsstation mit der Steckdose verbinden. Während der Mova X4 Pro lädt, kann man schon einmal den Wassertank auffüllen und das Reinigungskonzentrat hinzugeben. Die Wischwalze ist bei der Lieferung bereits vorinstalliert.
Steuerung
Die Steuerung des Mova X4 Pro erfolgt ausschließlich über die Buttons am Saugwischer selbst. Das ist entspannt und unkompliziert. Man hat allerdings aufgrund einer fehlenden App keine Möglichkeit, das Saug- und Wischverhalten gezielt an die eigenen Bedürfnisse anzupassen. Hier müssen die vier vorprogrammierten Reinigungsmodi ausreichen.
Dank der motorisierten Räder fährt sich der Mova X4 Pro angenehm leicht und ohne großen Kraftaufwand. Da er um 60 Grad nach links und rechts schwenkbar ist, fährt er mit flüssigen Bewegungen um Gegenstände herum. Er ist zudem in der Lage, auch komplett flach auf dem Boden zu saugwischen und kommt somit gut unter Möbel. Hier muss man allerdings beachten, dass sich die maximale Füllmenge des Schmutzwassertanks ändert. Im Idealfall sollte man demnach zu Beginn der Putzaktion unter den Möbeln saugwischen.
Über einen Trigger auf der Innenseite des Griffs sprüht man im Heißwassermodus zusätzlich das auf 80 Grad aufgeheizte Wasser vor den Saugwischer auf den Boden. Der Trigger ist dabei gut verarbeitet und bietet genügend Widerstand, um nicht aus Versehen zu sprühen.
Reinigung
Der Mova X4 Pro arbeitet mit bis zu 20.000 Pa und hat vier verschiedene Reinigungsmodi zur Auswahl: Smart-, Ultra-, Suction- und Hot-Water-Mode. Im Smart-Mode reguliert das Gerät die Saugkraft von selbst in Abhängigkeit von der Verschmutzung am Boden. Der Modus ist für die tägliche Reinigung gedacht. Ultra-Mode dreht den X4 Pro komplett auf und ist für die Tiefenreinigung gedacht. Die hinzugeschaltete Leistung wirkt sich logischerweise auch stärker auf die Akkulaufzeit aus. Suction-Mode ist rein zum Aufsaugen von Wasser gedacht, da weder die Bürste vom Gerät befeuchtet noch frisches Wasser auf dem Boden verteilt wird. Der Hot-Water-Mode ist das für uns spannendste Reinigungsprofil. Das liegt primär daran, dass man punktuell durch die Düse am Bürstenkopf 80 °C heißes Wasser auf den Boden sprühen kann, um eingetrocknete Flecken besser zu beseitigen.
Während unseres Tests haben wir tatsächlich mit diesem Reinigungsprofil die beste Erfahrung gemacht, als es um die Entfernung hartnäckiger Flecken ging. Obwohl der Ultra-Mode auf dem Papier verspricht, die intensivste Reinigung hinzulegen, konnten die härtesten Flecken auf unserem Fliesenboden in der Küche nur durch den Hot-Water-Mode beseitigt werden. Im Laufe des Tests alternieren wir so zwischen Smart- und Heißwassermodus, um sowohl Parkett- als auch Fliesenböden zu säubern. Eine Möglichkeit, gänzlich ohne Wasser zu saugen, gibt es leider nicht.
Was die Saugleistung betrifft, überzeugt der Mova X4 Pro nicht auf ganzer Linie. Während er Haare, Krümel und Staub im Laufe des Tests problemlos aufsaugt, kämpft er mit größerem Dreck wie ungekochten Penne, die er nur nach mehrmaligem Drüberfahren aufsaugt.
Die anschließende Säuberung des Wischsaugers erfolgt über die Reinigungsstation. Dank der Auffahrrampe fährt man den Mova X4 Pro einfach in die Station, mit der er sich über die Kontakte auf der Unterseite des Rumpfs verbindet. Der Button oben am Griff startet den Reinigungsprozess. Drückt man ihn erneut unmittelbar nach der Sprachansage, startet indes der Intensivmodus. Dieser ist lauter, dafür aber auch deutlich schneller als der reguläre. Gereinigt wird mit 100 °C heißem Wasser. Die anschließende Trocknung findet mit 90 °C Heißluft statt. Das Ergebnis kann sich sehen lassen: Die Bürste ist frei von Haaren, Fusseln oder sonstigem Schmutz und zudem trocken.
Dank des schlau designten Auffangbehälters mit herausklappbarem Sieb ist auch die Reinigung des Schmutzwassertanks superschnell erledigt. Es gibt wenige Verwinkelungen und Spalten, in denen sich Schmutz festsetzen kann. So reicht ein einfaches Durchspülen mit heißem Wasser in unserem Fall aus, um sichtbaren Schmutz restlos zu entfernen. Mit Schwamm und Spüli schrubbt man einmal kurz drüber, um Gerüche zu vermeiden. Auch der Tank an sich ist schnell durchgespült und abgetrocknet.
Akkuleistung
Wie auch bei anderen Wischsaugern ist die Akkuleistung abhängig vom gewählten Modus. Am meisten holt man mit dem Smart-Mode heraus. Hier schafft der Akku bis zu 45 Minuten Laufzeit, bevor der X4 Pro wieder an die Station muss. Maximal 25 Minuten hält er im Hot-Water-Mode durch. Vorgesehen ist er für einen Einsatz auf bis zu 350 m². Während des Tests kommen wir mit der Akkukapazität gut aus, bemerken aber definitiv die unterschiedlich starke Beanspruchung der einzelnen Modi. Für die meisten täglichen Einsätze ist der Smart-Mode vollkommen ausreichend und bietet mit bis zu 45 Minuten genügend Ausdauer, um mehrere Räume zu saugwischen. Bedenkt man, dass der Hot-Water-Mode für den punktuellen Einsatz gedacht ist, sind auch die maximalen 25 Minuten Einsatzzeit komplett in Ordnung.
Preis
Die UVP des Mova X4 Pro liegt bei 499 Euro. Derzeit kostet er 349 Euro.
Fazit
Der Mova X4 Pro überzeugt durch einige gut durchdachte Funktionen in der Ausstattung und ein schickes Design. Neben nützlichen Funktionen wie dem Heißwassermodus mit Sprühfunktion und der 100 °C heißen Selbstreinigung stechen eine sinnvoll designte Ladestation und das praktische Auffangsieb hervor. Die Saug- und Wischleistung überzeugt größtenteils, weist aber auch Schwächen auf: Mit 20.000 Pa saugt der X4 Pro zwar kräftig, kämpft aber mit größeren Objekten. Die Wischwalze verteilt das Wasser gleichmäßig und größtenteils schlierenfrei, an den Seiten sammeln sich jedoch immer mal wieder Staubfäden. Diese lösen sich gelegentlich und bleiben dann auf dem ansonsten sauberen Boden liegen. Zusammenfassend bekommt man mit dem Mova X4 Pro einen soliden Wischsauger zu einem kompetitiven Preis, der im Alltag seinen Job gut erledigt, allerdings in bestimmten Situationen schwächelt.
Tineco Floor One S9 Artist
Der Tineco Floor One S9 Artist kombiniert Saugen und Wischen in einem eleganten Design. Wir haben getestet, ob der Premium-Wischsauger für 599 Euro sein Geld wert ist.
- hervorragende Saug- und Wischleistung
- angenehmes Handling
- automatische Selbstreinigung mit Warmwasser und Heißlufttrocknung
- hochwertig & ungewöhnliches Design mit Leuchteffekten
- relativ hoher Preis
- hohe Lautstärke bei Selbstreinigung
Gutes Handling und Top-Reinigung: Wischsauger Tineco Floor One S9 Artist im Test
Der Tineco Floor One S9 Artist kombiniert Saugen und Wischen in einem eleganten Design. Wir haben getestet, ob der Premium-Wischsauger für 599 Euro sein Geld wert ist.
Der Tineco Floor One S9 Artist spielt mit 499 Euro auf Ebay im oberen Preissegment der Wischsauger mit, bietet dafür aber auch einige Besonderheiten. Neben einer motorisierten Rollunterstützung für leichteres Handling verfügt er über eine Reinigungsstation, die die Wischwalze mit erwärmtem Wasser durchspült und anschließend mit heißer Luft trocknet. Wir haben getestet, wie gut der Wischsauger im Alltag funktioniert und ob er mit der Konkurrenz mithalten kann.
Lieferumfang: Welches Zubehör liegt dem Tineco Floor One S9 Artist bei?
Im Lieferumfang des Tineco Floor One S9 Artist befinden sich neben dem Wischsauger selbst die kombinierte Lade- und Reinigungsstation, ein Filter sowie zwei Bürstenrollen für die Wischfunktion. Zusätzlich liegt eine Flasche der wohlriechenden Reinigungslösung bei, die dem Frischwasser beigemischt werden kann. Zur einfachen Pflege des Geräts ist außerdem ein spezielles Reinigungswerkzeug enthalten, mit dem sich Haare und andere Verschmutzungen leicht aus der Bürstenrolle entfernen lassen. Die Ausstattung ist damit komplett und enthält alles, was für den sofortigen Einsatz und die regelmäßige Wartung des Wischsaugers benötigt wird.
Design: Wie gut ist die Verarbeitung des Tineco Floor One S9 Artist?
Der Tineco Floor One S9 Artist überzeugt mit einer hochwertigen Optik, die klar auf Design ausgerichtet ist. Besonders auffällig ist die schillernde Kunststofffront, über der je nach Betriebsstatus verschiedene Leuchteffekte erscheinen. Trotz der Verwendung von Kunststoff wirkt das Gerät hochwertig verarbeitet und macht einen soliden Eindruck. Die Optik ist dabei durchaus diskutabel und sorgt in der Redaktion für ein gespaltenes Meinungsbild.
Mit Abmessungen von 266 x 1100 x 233 mm und einem Gewicht von 5,3 kg ist der S9 Artist zwar kein Fliegengewicht. Der im Wischkopf integrierte Frischwassertank fasst 1 Liter und ermöglicht damit längere Reinigungszyklen ohne Nachfüllen. Besonders praktisch ist das Zwei-Kammer-System des Schmutzbehälters, das groben Schmutz und Schmutzwasser voneinander trennt. Das vereinfacht die Reinigung und verhindert Verstopfungen. Die Entleerung sollte allerdings zügig nach der Reinigung erfolgen, da sich sonst in Verbindung mit der Feuchtigkeit Gerüche und Schimmel bilden können.
Tineco Floor One S9 Artist – Bilderstrecke
Wischsauger Tineco Floor One S9 Artist im Test

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Tineco Floor One S9 Artist – Bilderstrecke

Das hochauflösende Farbdisplay im Handgriff zeigt wichtige Informationen wie den Akkustand, den aktuell verwendeten Modus sowie Statusmeldungen übersichtlich an. Insgesamt präsentiert sich der Tineco Floor One S9 Artist als durchdachtes Gerät mit einem gelungenen Mix aus Funktionalität und ansprechendem Design.
Einrichtung: Wie schnell ist der Tineco Floor One S9 Artist betriebsbereit?
Die Inbetriebnahme des Tineco Floor One S9 Artist gestaltet sich unkompliziert. Nach dem Auspacken muss man lediglich den Handgriff in die Basiseinheit stecken und den Akku vollständig aufladen, wobei er in unserem Fall bereits fast vollständig aufgeladen kommt. Abschließend muss man noch den Frischwassertank mit Leitungswasser befüllen; bei Bedarf kann man die mitgelieferte Reinigungslösung hinzufügen.
Für die Nutzung der App ist eine Installation auf dem Smartphone erforderlich. Dazu lädt man die App Tineco Life herunter und meldet sich mit seinem Tineco-Account an oder erstellt einen neuen. Anschließend muss man der App einige Berechtigungen erteilen. Alsdann kann man nach dem Wischsauger suchen und ihn in der App hinzufügen. Nach Angabe des WLAN-Netzwerks mit Passwort ist die Einrichtung abgeschlossen. Hier gab es im Test zunächst Probleme mit Android-Geräten, wo sich die App beim Download der Produktressourcen aufhing. Ein aktuelles App-Update hat dieses Problem jedoch behoben. Unter iOS funktioniert die App von Anfang an einwandfrei. Die App-Nutzung ist abgesehen davon optional, da alle wichtigen Funktionen auch direkt am Gerät gesteuert werden können.
Die Lade- und Reinigungsstation sollte an einem gut zugänglichen Ort mit Stromanschluss platziert werden. Nach der Reinigung wird der S9 Artist dort abgestellt, wo er automatisch auflädt und bei Bedarf die Selbstreinigungsfunktion durchführt.
Tineco Floor One S9 Artist – App
Tineco Floor One S9 Artist – App
Tineco Floor One S9 Artist – App
Tineco Floor One S9 Artist – App
Tineco Floor One S9 Artist – App
Tineco Floor One S9 Artist – App
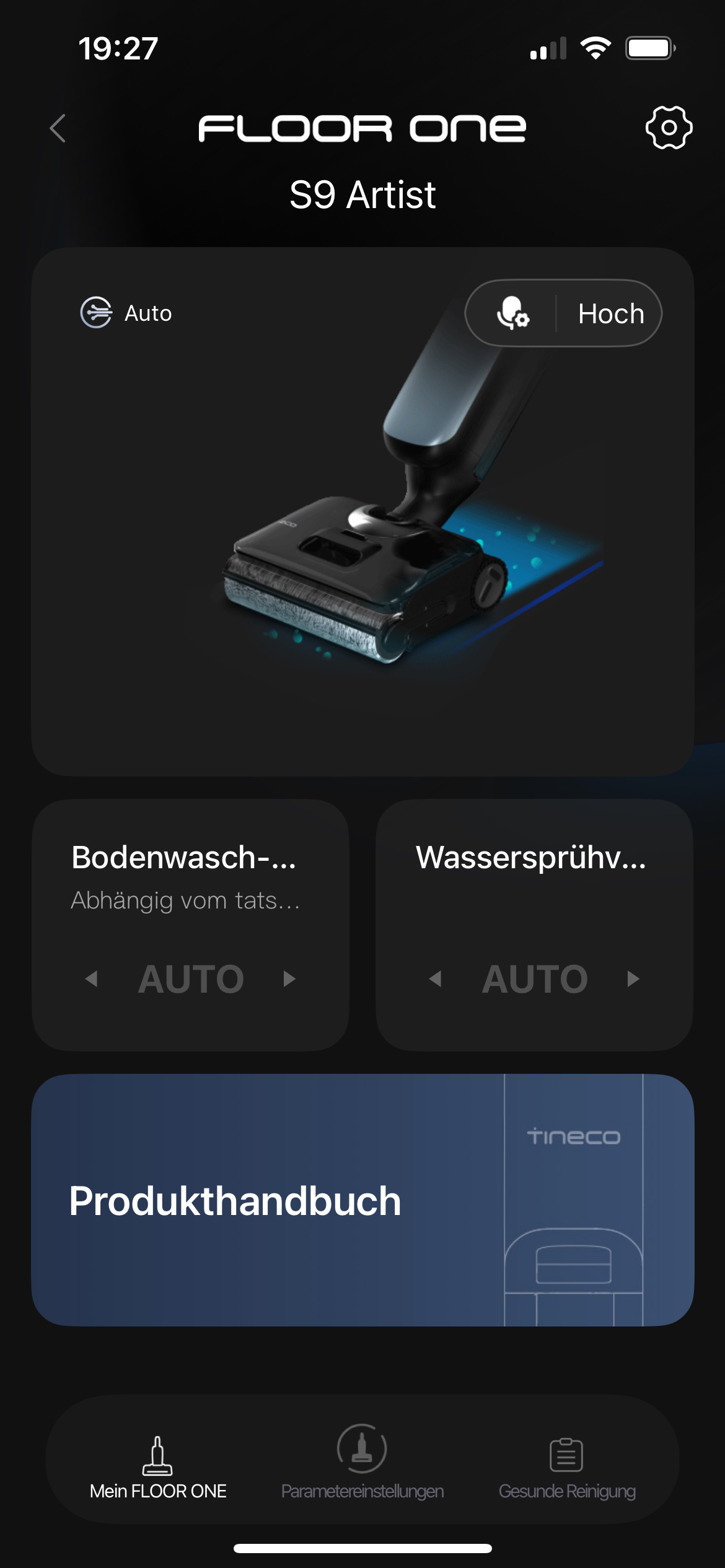
Steuerung: Wie ist das Handling des Tineco Floor One S9 Artist?
Das Handling des Tineco Floor One S9 Artist gestaltet sich im Test ausgesprochen angenehm und übertrifft in diesem Punkt nach unserem Gefühl sogar den Dreame H15 Pro (Test folgt in Kürze). Auch hier erweist sich die motorisierte Rollunterstützung als große Erleichterung, da sie das Schieben des 5,3 kg schweren Geräts deutlich angenehmer macht. Der Wischsauger gleitet fast von selbst über den Boden, was die Reinigung auch in größeren Räumen weniger anstrengend macht.
Die Bedienung erfolgt hauptsächlich über das hochauflösende Farbdisplay im Handgriff, das alle wichtigen Informationen übersichtlich anzeigt. Praktisch sind auch die Statusmeldungen, die auf dem Display angezeigt werden, wenn etwa der Frischwassertank leer ist oder der Schmutzbehälter geleert werden sollte. So behält man während der Reinigung stets den Überblick über den Zustand des Geräts.
Mit einem Knopfdruck kann zwischen den drei Reinigungsmodi Auto, Max und Leise (62 dB(A)) gewechselt werden. Der Auto-Modus passt die Saugleistung automatisch an den erkannten Verschmutzungsgrad an, was in den meisten Fällen die beste Wahl darstellt.
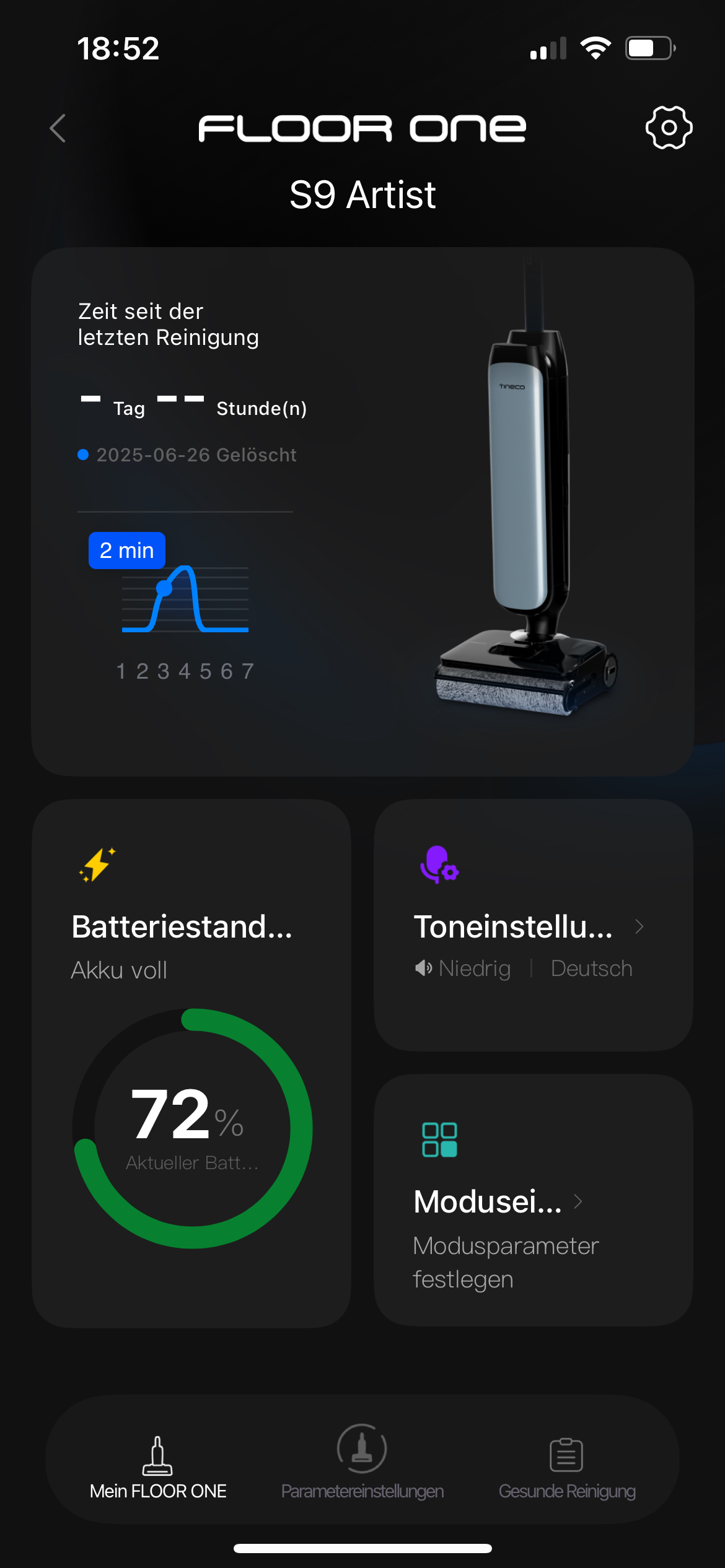
Die App bietet zwar zusätzliche Einstellungsmöglichkeiten, ist aber für den täglichen Gebrauch nicht zwingend erforderlich. Hier lassen sich neben den auch am Gerät wählbaren Betriebs-Modi auch die Selbstreinigung auslösen sowie die Laufgeschwindigkeit je nachdem, ob der Wischsauger gekippt ist oder flachliegt. Ebenso kann man seine Reinigungshäufigkeit sowie die durchschnittliche Verschmutzung der letzten sieben Tage einsehen.
Wen die durchaus penetranten Sprachansagen des S9 Artist stören, der kann diese sowohl per App als auch am Gerät selbst über einen eigens dafür vorhandenen Knopf deaktivieren. So ist insbesondere die Betonung der Aufforderung „Stellen Sie das Gerät auf die Ladestation“ in eindrücklicher Erinnerung geblieben.
Reinigung: Wie gut saugt und wischt der Tineco Floor One S9 Artist?
Der Tineco Floor One S9 Artist überzeugt im Test mit einer hohen Saugleistung von 22.000 Pa sowie einer guten Wischleistung durch die Wischwalze. Er bewältigt verschiedene Verschmutzungen wie Kaffeeflecken, Vogelfutter mit Haferflocken oder Mehl mühelos. Bei einem einzigen Durchgang werden bereits etwa 95 Prozent des Schmutzes entfernt – lediglich beim Mehl bleiben vereinzelt klumpig-klebrige Rückstände zurück, die einen zweiten Durchgang erfordern.

Die Lautstärke im Auto-Modus beträgt moderate 65 dB(A), in der höchsten Stufe erreicht sie 69 dB(A). Der leise Modus arbeitet mit angenehmeren 62 dB(A).
Nach der Reinigung empfiehlt sich die Nutzung der automatischen Selbstreinigungsfunktion in der Station. Dabei wird die Wischwalze mit erwärmtem Wasser durchgespült und anschließend mit 85 Grad heißer Luft getrocknet. Dieser Vorgang dauert etwa 5 Minuten und erreicht eine Lautstärke von 77 dB(A). Im Test zeigte sich, dass die Walze nach einem Durchgang noch nicht vollständig trocken war, weshalb ein zweiter Trocknungsvorgang sinnvoll sein kann. Ausgelöst wird die Selbstreinigung über einen eigens dafür im Handgriff integrierten Knopf.
Akkulaufzeit: Wie lange arbeitet der Tineco Floor One S9 Artist?
Der Tineco Floor One S9 Artist ist mit einem 3900-mAh-Akku ausgestattet. Damit erreicht er je nach Modus eine Betriebsdauer von bis zu 50 Minuten, was für die gründliche Reinigung auch größerer Wohnflächen ausreichend ist.
Das Aufladen des vollständig entleerten Akkus dauert etwa 4 bis 5 Stunden in der Ladestation. Eine praktische Ladezustandsanzeige im Display informiert jederzeit über die verbleibende Akkulaufzeit, sodass man die Reinigung entsprechend planen kann.
Preis: Was kostet der Tineco Floor One S9 Artist?
Der Tineco Floor One S9 Artist ist mit seinem Normalpreis von 699 Euro im oberen Preissegment der Wischsauger angesiedelt. Aktuell bekommt man den Premium-Wischsauger 100 Euro günstiger bei Ebay für 499 Euro.
Fazit: Lohnt sich der Kauf des Tineco Floor One S9 Artist?
Der Tineco Floor One S9 Artist überzeugt im Test als leistungsstarker und komfortabler Wischsauger. Mit seiner hervorragenden Saug- und Wischleistung entfernt er nahezu alle Arten von Verschmutzungen effektiv und gründlich. Besonders die motorisierte Rollunterstützung macht das Handling angenehm und hebt den S9 Artist positiv von manchen Konkurrenzprodukten ab.
Die Selbstreinigungsfunktion mit Warmwasser und Heißlufttrocknung sorgt für Hygiene und verlängert die Lebensdauer der Bürstenrollen, auch wenn ein zweiter Trocknungsvorgang manchmal notwendig sein kann. Das durchdachte Zwei-Kammer-System des Schmutzbehälters erleichtert die Entleerung und Reinigung.
Mit einer Akkulaufzeit von bis zu 50 Minuten ist der S9 Artist für die meisten Haushalte ausreichend dimensioniert. Die intuitive Bedienung direkt am Gerät macht die App zwar nicht zwingend erforderlich, bietet aber zusätzliche Einstellungsmöglichkeiten.
Zum Preis von 599 Euro ist der Tineco Floor One S9 Artist zwar kein Schnäppchen, bietet aber im Vergleich zur ähnlich positionierten Konkurrenz ein gutes Preis-Leistungs-Verhältnis. Für alle, die einen leistungsstarken Wischsauger mit komfortabler Handhabung und ansprechendem Design suchen, ist der S9 Artist eine empfehlenswerte Wahl.
Dreame H14 Pro
Der Dreame H14 Pro vereint alle Features, die bislang in einem Top-Saugwischer denkbar sind. Das prädestiniert ihn für den Titel „bester Saugwischer“ – aber ist er das auch wirklich? Wir haben das Modell ausführlich getestet.
- Elektrolyse zur Frischwasser-Desinfektion
- Heißwasserwäsche
- Schnelltrocknung
- sinnvolle App-Steuerung
- fast vollständige Randreinigung
- hervorragende Reinigungswirkung
- Auto-Dosierung von Reinigungskonzentrat
- angetriebene Räder
- recht teuer
- Schnelltrocknung sehr laut
Dreame H14 Pro im Test: Das ist der beste Saugwischer
Der Dreame H14 Pro vereint alle Features, die bislang in einem Top-Saugwischer denkbar sind. Das prädestiniert ihn für den Titel „bester Saugwischer“ – aber ist er das auch wirklich? Wir haben das Modell ausführlich getestet.
Dreame baut nicht nur tolle Saugroboter wie den L40 Ultra (Testbericht) oder gar den X40 Ultra (Testbericht), sondern auch hervorragende Wischsauger. Das zuletzt getestete Modell H13 Pro (Testbericht) überzeugte weitgehend, bei der neuesten H14-Generation will der Hersteller aber noch einmal eine Schippe nachlegen. So vereint der getestete H14 Pro alles, was derzeit in einem perfekten Saugwischer denkbar ist – zumindest auf dem Papier. Wir haben im Test überprüft, wie sich die überzeugenden technischen Daten auf den Alltag auswirken.
Highlights: Welche Stärken bietet der Dreame H14 Pro?
- beidseitige Kantenreinigung
- informatives Display
- starke Saugkraft von bis zu 18.000 Pa
- verschiedene Leistungsmodi inkl. DIY-Modus (per App)
- automatische Schmutzerkennung mit Leistungsanpassung
- bis auf den Boden absenkbar für Reinigung unter Möbeln
- automatische Reinigungsmitteldosierung
- Moppwäsche mit bis zu 60 °C heißem Wasser
- 5-minütige Schnelltrocknung der Wischwalze per Heißluft
- elektrolytische Desinfektion des Frischwassers
- praktische LED-Beleuchtung der Bodendüse
- angetriebene Räder für leichte Manövrierbarkeit
- App-Support
Aktuell ist der Dreame H14 Pro zum Bestpreis von 379 Euro erhältlich (UVP 699 Euro).
Lieferumfang: Was ist beim Dreame H14 Pro dabei?
Bereits beim Zusammenbau macht der Dreame H14 Pro einen robusten Eindruck. Das Gerät ist hochwertig verarbeitet, die einzelnen Komponenten lassen sich einfach zusammenstecken. Mit einem Gewicht von 5,7 kg ist der H14 Pro allerdings kein Leichtgewicht. Umso wichtiger, dass Dreame hier mit den angetriebenen „Glide-Wheel“-Rädern vorgesorgt hat.
Diese sorgen dank eines intelligenten Algorithmus für eine flüssige Vor- und Rückwärtsbewegung, sodass sich der H14 Pro trotz des hohen Gewichts überraschend leicht manövrieren lässt. Das macht die Reinigung wirklich komfortabel, zumal diese Unterstützung kaum merklich abläuft und sich daher nicht künstlich anfühlt. Auch die praktische Freistehfunktion erweist sich als sehr nützlich im Alltag, um den Sauger mal eben für eine kurze Pause abstellen zu können, ohne dass er umfällt. Dabei saugt der Wischer einige Sekunden lang noch einmal verstärkt Feuchtigkeit ab, um die Gefahr von Feuchtigkeitsschäden am Standort zu minimieren.
Alle Bilder zum Dreame H14 Pro im Test
Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Dreame H14 Pro

Eines der Highlights ist sicherlich die Möglichkeit, den H14 Pro so weit abzusenken, dass er komplett flach auf dem Boden liegt. Das können nur wenige Konkurrenten, da die Gefahr besteht, dass der Saugwischer ausläuft. Das sorgt dann unter Umständen nicht nur für eine ungebetene Sauerei, sondern kann auch zur Beschädigung der Technik führen. Mit einer Gesamthöhe von nur 14 cm im liegenden Zustand kommt man damit einwandfrei unter die meisten Möbelstücke und kann auch diese Bereiche mühelos reinigen. Damit der Korpus des Gerätes dabei nicht verkratzt und auch empfindliche Holzböden nicht beschädigt werden, verfügt der H14 Pro auf der Rückseite über eine kleine Laufrolle. So kratzt der Saugwischer nicht über den Boden, sondern rollt auch liegend.
Der Dreame H14 Pro kommt gut geschützt in einem Karton zum Kunden. Zum Lieferumfang gehören neben der Sauger-Haupteinheit mit Wischwalze eine Ersatzwalze, Ladestation, Netzteil, Reinigungsbürste, Ersatzfilter, Reinigungsmittel-Konzentrat und eine Bedienungsanleitung.
Steuerung: Wie ist das Handling des Dreame H14 Pro?
Gesteuert wird der Dreame H14 Pro über vier Tasten und einen Schalter am Griff: Power-Taste zum Ein- und Ausschalten, Modus-Taste zum Wechseln der Reinigungsmodi, Reinigungs-Taste für Walzenreinigung auf der Station und den Schalter für Reinigungsmittelzufuhr. Auf der Oberseite des Korpus befindet sich ein schickes Display, das neben dem Akkustand und dem gewählten Reinigungsmodus auch per Farbindikatoren Auskunft über den Verschmutzungsgrad des Bodens gibt. Der Inhalt des Screens dreht sich in Abhängigkeit davon, ob das Gerät ladend in der Station steht oder in Gebrauch ist. So müssen sich Nutzer nie den Hals verrenken, um den Inhalt richtig herum ablesen zu können.
Der Auto-Modus erkennt Verschmutzung und passt die Saugleistung automatisch an. Im Ultra-Modus wird die elektrolytische Desinfektion des Frischwassers aktiviert, um Bakterien weitestgehend zu eliminieren. Der Nur-Saugen-Modus stoppt den Wasserzufluss und saugt Flüssigkeiten auf – etwa, um die Dusche trocken zu bekommen. Der DIY-Modus ist in der App individuell einstellbar und erlaubt so direkten Eingriff auf Parameter wie Saugleistung, Wasserzuführung und Elektrolyse.
App: Was kann man alles einstellen?
Bislang waren Apps für Saugwischer eher nettes Gimmick als sinnvolles Feature. Beim Dreame H14 Pro ist das etwas anders. Eine tolle Neuerung ist etwa die automatische Dosierung des Reinigungsmittels. Über eine kleine Klappe auf der Vorderseite lässt sich der Dosierer mit jeglicher Art von Reinigungsflüssigkeit-Konzentrat befüllen. Diese wird dann je nach Verschmutzungsgrad des Bodens automatisch dem Wischwasser in einem Mischverhältnis von 1:200 bis 1:30 zugegeben. Eine wirklich praktische Funktion, die dem Nutzer Arbeit abnimmt und in der App auf „kraftvolle Fleckentfernung“ umgestellt werden kann.
Zudem darf der Nutzer in der App die Antriebsstärke der Räder wählen, das LED-Licht des Wischkopfes deaktivieren und die Sprache sowie Lautstärke bestimmen. Außerdem gibt es hier Einblick auf Reinigungsverläufe, den Zustand der Verbrauchsmaterialien und Firmware-Updates können angestoßen werden – sofern Updates nicht automatisch bezogen werden sollen. Auch gibt es Schnellzugriffe für Reinigung und Trocknung: Von 5 Minuten Schnelltrocknung können Nutzer auf die deutlich leisere 1-Stunden-Trocknung wechseln. Dann gibt es auch noch den bereits erwähnten DIY-Modus, der in der App eingerichtet werden kann. Auch wenn längst nicht alle Funktionen wirklich eine App rechtfertigen, sind doch einige dabei, die den Umgang mit dem Dreame H14 Pro erleichtern.
Reinigung: Wie gut wischt der Dreame H14 Pro?
Doch kommen wir zum wichtigsten Punkt: Wie gut reinigt der Dreame H14 Pro? Um das herauszufinden, haben wir ihn diversen Härtetests unterzogen – mit beeindruckenden Ergebnissen. In unserem Test entfernte der Saugwischer Kaffeeflecken, Ketchup, verschüttete Haferflocken mit Milch und eingetrocknetem Schlamm bereits nach wenigen, meist schon nach nur einer Überfahrt rückstandslos. Hartnäckige Verunreinigungen wie eingetrockneter Ketchup benötigen zwar mehrere Überfahrten, das ist aber bei der Konkurrenz genauso.
Auch hinsichtlich der Randreinigung macht der H14 Pro eine ausgezeichnete, wenn auch keine perfekte Figur. Mit der beidseitigen Kantenreinigung kommt er bis auf wenige Millimeter, aber eben nicht ganz an Sockelleisten und Ecken heran. Ein Nacharbeiten ist hier aber insgesamt kaum nötig.
Absolut überzeugend schneidet der Dreame H14 Pro auch beim Thema Wischwalzenreinigung ab. Mit bis zu 60 °C heißem Wasser und rotierenden Vor- und Rückwärtsbewegungen der Walze entfernt die Selbstreinigung der Basisstation selbst festsitzende Verschmutzungen effektiv. Nach der Reinigung wird die Walze dank eines speziellen Heißluftverfahrens innerhalb von nur 5 Minuten nahezu komplett getrocknet. Das ist allerdings sehr laut, wir haben in einem Meter Abstand satte 64 dB gemessen. Das entspricht in etwa dem Akkustaubsauger Dyson V15 Detect (Testbericht) im Normalbetrieb. Dafür ist das eben schnell wieder vorbei. Die deutlich leisere Trocknungsmethode kam im Test auf etwa 39 dB, dauert dafür aber eine Stunde.
Heißwasserwäsche, Heißlufttrocknung und die Elektrolyse des Frischwassers sind ein echter Komfort-, Hygiene- und Zeitgewinn. Damit hebt sich der Dreame H14 Pro positiv von der Konkurrenz ab, denn die meisten Modelle bieten eine oder zwei dieser Funktionen, selten aber alle drei.
Preis: Was kostet der Dreame H14 Pro?
Aktuell ist der Dreame H14 Pro zum Bestpreis von 349 Euro erhältlich (UVP 699 Euro).
Fazit: Lohnt sich der Kauf des Dreame H14 Pro?
Der Dreame H14 Pro bietet ein echtes Rundum-sorglos-Paket. Exzellente Reinigungsleistung, ausgereifte Funktionen zur Selbstreinigung und Trocknung der Walzen, hohe Flexibilität dank flachem Wischen und leichte Handhabung durch die angetriebenen Räder machen den H14 Pro zum neuen Spitzenreiter unter den Saugwischern. Das Gerät lässt kaum Wünsche offen und setzt in vielen Bereichen Maßstäbe. Das hat natürlich mit stolzen 699 Euro in der UVP des Herstellers seinen Preis, in Relation zu ähnlich teuren Modellen ist er das aber auch wert.
Dreame H12 Dual
Ein Saugwischer wischt primär, ein Akkusauger saugt – warum nicht beides in Einem? Geht – und zwar beim Dreame H12 Dual. Er ist beides: vollwertiger Wischer und Sauger. Wie das klappt, zeigt der Test.
- wischt sehr gut
- saugt auf Hartboden ebenfalls sehr gut
- Motorbürste bleibt auch auf Teppich nicht stehen
- 2 Geräte in einem: Saugwischer und Akkusauger
- Trocknung mit Warmluft
- Filter als Akkusauger umständlich zu entleeren
Dreame H12 Dual im Test: Sehr guter Saugwischer und Akkusauger in einem
Ein Saugwischer wischt primär, ein Akkusauger saugt – warum nicht beides in Einem? Geht – und zwar beim Dreame H12 Dual. Er ist beides: vollwertiger Wischer und Sauger. Wie das klappt, zeigt der Test.
Ein Saugwischer kostet locker 300 Euro, ein ordentlicher Akkusauger auch. Anschließend kann man zwar gut Wischen und Saugen, allerdings stehen auch immer zwei Geräte rum. Dreame findet das offenbar auch überflüssig und bringt mit dem Dreame H12 Dual ein Modell auf den Markt, das wie der Roborock Dyad pro Combo (Testbericht) beides in Einem ist: vollwertiger Saugwischer und Akkusauger. Wir haben im Test überprüft, wie gut das tatsächlich klappt. Alle Saugwischer-Tests findet man in unserer Themenwelt Saugwischer.
Lieferumfang
Der Lieferumfang fällt beim Dreame H12 Dual zwangsläufig etwas umfangreicher als bei einem „einfachen“ Saugwischer aus. Denn zusätzlich zum Gerät selbst und der passenden Lade- und Reinigungsstation befinden sich darin zusätzlich ein Aufbewahrungsständer sowie das darauf zu lagernde Zubehör, das aus dem Saugwischer einen reinrassigen Akkusauger macht. Dazu gehört ein zusätzlicher Staubbehälter, Saugrohr, Bürstenkopf, eine kleine Motorbürste für Polster und ein Reinigungszusatz zum Wischen. Hinzu kommen eine zweite Wischrolle mit Stoffbezug sowie eine Fugendüse, mit der man etwa in Sofaritzen kommt. Aufbewahrung für Saugwischer und Akkusauger-Zubehör sind nicht miteinander verbunden und können daher theoretisch auch separat aufgestellt werden.
Design
Beim Design setzt Dreame auf den nahezu gleichen monolithischen Korpus wie beim Dreame H11 Max (Testbericht) oder dem Nachfolger H12 Pro. Entsprechend wirkt der H12 Dual wieder ziemlich wuchtig und ist das genaue Gegenteil des filigranen Jimmy HW9 (Testbericht). Trotzdem hat das Design des Dreame-Modells seinen Reiz und uns gefällt der Mix aus grauem und schwarzem Kunststoff sowie durchsichtigen Elementen gut. Oben installiert der Hersteller wieder ein Display, das sich um 180 Grad dreht. So können Nutzer sowohl beim Laden in der Station als auch während des Betriebs Inhalte ablesen, ohne sich den Hals verrenken zu müssen. Abweichend vom Vorgänger verfügt der HW12 Dual nun über einen zusätzlichen Tragegriff am oberen Bereich des Korpus, direkt unter dem Display.
Er dient als Griff, wenn der Saugwischer zum reinen Akkusauger umgebaut wird. Dafür lässt sich dieser Teil samt Motor, Display und Akku abnehmen, der Staubbehälter für den Akkusauger andocken und Saugrohr samt Bürstenkopf anschließen. Praktisch: Das Zubehör findet zusammen wie bereits angedeutet auf einem eigenen Aufbewahrungsständer Platz, nur die Reinigungsflüssigkeit zum Wischen passt nirgendwo hin und muss daher komplett separat aufbewahrt werden. Gut gefallen hat uns übrigens auch die Verarbeitung des HW12 Dual, hier klappert oder wackelt nichts.
Im Betrieb
Eine App gibt es für den Dreame H12 Dual nicht, entsprechend entfällt ein Abschnitt dazu. Schlimm ist das nicht, denn beim Roborock Dyad Pro Combo (Testbericht) lassen sich darin zwar durchaus sinnvolle Dinge einstellen, zwingend nötig ist aber auch dort die App nicht. Auch so wirkt das Dreame-Modell ausreichend „digital“: Das gut ablesbare Display informiert umfassend über Modi, Akkustand und Fehler, hinzu kommt eine (auf Wunsch deaktivierbare) Sprachausgabe, die auch auf Deutsch verfügbar ist. Im Betrieb wirkt der Saugwischer wie die meisten Modelle leicht steif, wenn es um Richtungswechsel geht. Das sorgt im Gegenzug für einen guten Geradeauslauf, außerdem ist der Kraftaufwand, um Kurven zu fahren, minimal. Für die Bewegung nach vorn muss überhaupt keine Kraft aufgewendet werden, da der H12 Dual durch die drehende Wischrolle selbst für Vortrieb sorgt. Das Roborock-Modell ist hier dank der beiden gegenläufigen Rollen neutral, trotzdem aber mit genauso wenig Kraft zu bewegen.
Alle Bilder zum Dreame H12 Dual im Test
Dreame H12 Dual

Dreame H12 Dual
Dreame H12 Dual

Dreame H12 Dual

Dreame H12 Dual

Dreame H12 Dual

Dreame H12 Dual

Dreame H12 Dual

Dreame H12 Dual

Dreame H12 Dual

Dreame H12 Dual

Dreame H12 Dual

Außerdem hat der Dyad Pro (Combo) beim Randwischen leicht die Nase vorn. Während beim Dreame-Modell an der Fußleiste trotz angepriesenem randlosem Wischen etwa ein halber Zentimeter trocken bleibt, ist es beim Dyad Pro (Combo) noch etwas weniger. Schlussendlich schneidet hier der H12 Dual aber auch nicht schlecht ab. Der Rest ist in etwa wie bei der Oberklasse-Konkurrenz. Vollständiges Ablegen, um unter flache Möbel zu kommen, ist mit dem Saugwischer H12 Dual nicht möglich, da er sonst auslaufen könnte. Beim Wischen sorgt der Saugwischer nach kurzer Anfangsphase für einen gleichmäßigen, feuchten Flüssigkeitsfilm, der schnell abtrocknet. Sorge um teuren Parkettfußboden muss man sich da nicht machen. Dennoch ist die Reinigungsleistung gut, das oft in der Werbung verschüttete Müsli mit Haferflocken nimmt der H12 Dual im Wischmodus tatsächlich nach wenigen Wischbewegungen restlos auf. Gleiches gilt für sonstige Flüssigkeiten und meist auch eingetrockneten Schmutz wie Kaffee. Dabei regelt der H12 Dual die Saugleistung zuverlässig selbst. Den Ultra-Modus der neuen H12-Reihe, bei dem vor der Reinigung auf Knopfdruck das Wischwasser per Elektrolyse sterilisiert wird, gibt es beim H12 Dual nicht.
Nach der Reinigung wird der H12 Dual zur Selbstreinigung auf die Ladestation gestellt. Dabei spült der Saugwischer die Stoffrolle ordentlich durch und säubert sie, anschließend trocknet die Station sie für 20 Minuten mit 55 Grad warmer Luft. Dabei dreht der Sauger die Wischrolle kontinuierlich, damit sie von allen Seiten gleichmäßig getrocknet wird. Das geht mit einer gewissen Lautstärke einher, da die Drehzahl der Rolle für unseren Geschmack einfach zu hoch angesetzt ist. Im Schrank im Hauswirtschaftsraum stehend ist davon nebenan aber nichts mehr zu hören.
Zum Akkusauger umgebaut zeigen sich im Wesentlichen die gleichen Vor- und Nachteile wie beim Roborock Dyad Pro Combo. Der Zusammenbau geht schnell vonstatten, nachdem man sich anfangs kurz damit beschäftigt hat. Ohne Umbau geht es aber auch hier nicht, entsprechend braucht es einige Handgriffe und etwas Zeit vor dem Saugen. Danach klappt alles ordentlich. Der Bürstenkopf mit der stoffbesetzten Rolle für Hartböden wirkt anfangs etwas labil, sodass ein ordentlicher Geradeauslauf schwerfällt. Nach kurzer Eingewöhnungszeit macht das aber keine Probleme mehr und stattdessen kommt ein großer Vorteil im Vergleich zum Roborock-Modell zum Tragen: Die motorbetriebene Rolle kommt auch auf hohen Teppichen nicht zum Stillstand. Zwar dreht sie dort sicht- und hörbar langsamer, allerdings kämpft sie sich tapfer weiter. Damit schlägt sich das Kombi-Modell Dreame H12 Dual zumindest in diesem Punkt beim Saugen sogar besser als teilweise sehr hochpreisige Akkusauger. Klar ist aber auch, dass die Stoffbürste eigentlich eher für kurze Auslegeware und Hartböden gedacht ist. Für eine echte Tiefenwirkung fehlt es an längeren Borsten und die ansonsten gute Saugkraft von bis zu 16.000 Pa reicht nicht aus, um tief sitzenden Schmutz aus hochflorigen Teppichen zu entfernen.
Der Akku hält beim Wischen bis zu 35 Minuten, beim Saugen sind es im Normalmodus sogar bis zu 60 Minuten. Im Test konnten wir damit das Erdgeschoss des Testhauses mit rund 140 m² problemlos komplett reinigen. Anschließend lädt der H12 Dual in rund 4 – 5 Stunden wieder komplett auf.
Preis
Die UVP des Dreame H12 Dual liegt bei 280 Euro auf Ebay, günstiger war das Modell zum Testzeitpunkt nicht zu bekommen.
Fazit
Mit einem Saugwischer kann man auch nur saugen, entsprechend verfügt der Dreame H12 Dual ebenfalls über einen „nur-saugen-Modus“. Als Saugwischer ist das Modell aber insgesamt mit etwas über 5 kg recht schwer und unhandlich, außerdem bietet ein Akkusauger situativ auch weitere Aufsätze wie eine Polsterbürste oder Fugendüse. Daher sind sowohl Saugwischer als auch Akkusauger absolut sinnvoll. Oder man kauft ein Kombi-Gerät wie den H12 Dual.
Denn der bietet für 500 Euro Saugwischer und Akkusauger in einem und in beiden Funktionen liefert er gute Leistung. Nur, wer viele hochflorige Teppiche hat, wird mit dem H12 Dual nicht glücklich. Denn dort kämpft sich die Motorbürste zwar im Gegensatz zum direkten Konkurrenten Roborock Dyad Pro Combo (Testbericht) tapfer durch und bleibt nicht stecken. Aufgrund der Beschaffenheit der Hauptbürste bleibt die Teppichreinigung aber eher oberflächlich.
Kernaufgabe ist entsprechend das Wischen und Saugen von Hartboden. Wer ohnehin mehr Wert aufs Wischen legt, sollte sich den Roborock Dyad Pro (Testbericht) ohne „Combo“ im Namen oder den von uns noch nicht getesteten, aber weitgehend baugleichen Dreame H12 Pro anschauen. Die Wischfunktion finden wir ansonsten beim Roborock-Combo-Gerät minimal besser, die Saugfunktion bei Dreame.
Dreame H12 Pro Ultra
Der Dreame H12 Pro Ultra präsentiert sich als vielseitiger Nass- und Trockensauger, der mit einer beeindruckenden Reinigungsleistung und praktischen Funktionen aufwartet. Wir beleuchten die Stärken und Schwächen des Geräts und klären, für wen sich die Investition lohnt.
- Selbstreinigung mit heißem Wasser
- Trocknung mit warmer Luft (30 Minuten)
- gute Reinigungsleistung
- starker Akku
- gutes Preis-Leistungs-Verhältnis
- kein LED-Licht
- nicht flach ablegbar
Dreame H12 Pro Ultra im Test: Überzeugender Saugwischer für 450 Euro
Der Dreame H12 Pro Ultra präsentiert sich als vielseitiger Nass- und Trockensauger, der mit einer beeindruckenden Reinigungsleistung und praktischen Funktionen aufwartet. Wir beleuchten die Stärken und Schwächen des Geräts und klären, für wen sich die Investition lohnt.
Aktuell ist die H14-Serie von Dreame, gerade erst haben wir den H14 Pro (Testbericht) einem ausführlichen Test unterzogen. Und doch bringt der Hersteller ein neues Modell der H12-Reihe an Wischsaugern auf den Markt? Tatsache: Das neue Pro-Ultra-Modell dürfte allerdings auch das letzte Modell der Reihe sein und markiert damit die Krönung der H12-Modelle. Grund dürfte die Preispolitik sein: Die H12-Serie ist schon älter, da kann man als Hersteller selbst solche nachgeschobenen neuen Modelle wie den H12 Pro Ultra im Vergleich deutlich günstiger anbieten und so Kunden ansprechen, die keine 800 Euro für ein Gerät ausgeben wollen. Ob sich der Kauf lohnt, haben wir im Test überprüft.
Highlights
- Selbstreinigungsfunktion mit 60 Grad heißem Wasser
- beidseitige Kantenreinigung
- Anti-Haaraufwicklung
- Heißlufttrocknung in 30 Minuten
Wie ist das Design des Dreame H12 Pro Ultra?
Der Dreame H12 Pro Ultra bietet das typische durchdachte Design der Dreame-Saugwischer, das sowohl funktional als auch durch sein monolithisches Äußeres ästhetisch ansprechend ist. Der Aufbau des Geräts ist unkompliziert: Die Führungsstange wird einfach mit dem Handgriff in den Korpus gesteckt, die Basisstation aufgestellt und mit dem Stromnetz verbunden. Rollenbürste und Filter sind bereits installiert, was den Start erleichtert. Ersatzrolle, Ersatzfilter, Reinigungsbürste und eine Flasche mit Reinigungsmittel sind im Lieferumfang enthalten.
Zwar besteht das Gerät wie fast alle Wettbewerber aus Kunststoff, der fühlt sich aber ausreichend hochwertig an und ist außerdem tadellos verarbeitet. Angst vor vorzeitigem Ausfall muss man beim H14 Pro Ultra wohl nicht haben. Der Griff mit den Steuertasten liegt gut in der Hand und ermöglicht eine intuitive Bedienung.
Ein Merkmal des Dreame H12 Pro Ultra ist der große Wassertank, der 900 ml fasst. Dieser wird mit 10 ml Reinigungsflüssigkeit befüllt, um die Reinigungsleistung zu optimieren. Der Tank sitzt schlank am Gerät und lässt sich leicht entnehmen und wieder einsetzen. Es wird empfohlen, keine handelsüblichen Bodenreiniger zu verwenden, da diese angeblich den Motor beschädigen könnten.
Alle Bilder zum Dreame H12 Pro Ultra im Test
Dreame H12 Pro Ultra

Dreame H12 Pro Ultra

Dreame H12 Pro Ultra

Dreame H12 Pro Ultra

Dreame H12 Pro Ultra

Dreame H12 Pro Ultra

Dreame H12 Pro Ultra

Dreame H12 Pro Ultra

Wie gut ist das Handling beim Dreame H14 Pro Ultra?
Alle Bedienelemente des Dreame H12 Pro Ultra sind am Handgriff angebracht, was eine einfache Steuerung ermöglicht. Der Ein-/Ausschalter aktiviert den Automatikmodus, der für die meisten Reinigungsaufgaben geeignet ist. Bei besonders hartnäckigen Verschmutzungen kann in den Ultra-Modus gewechselt werden, der die maximale Saugleistung von 16.000 Pa bereitstellt. Ein reiner Saugmodus steht ebenfalls zur Verfügung, um größere Flüssigkeitsmengen aufzunehmen. Damit bekommt man etwa die Dusche trocken, zum reinen Saugen ist das eigentlich nicht gedacht.
Die vorwärts drehende Rolle zieht den 4,9 kg schweren Sauger automatisch nach vorn, was die Handhabung erleichtert. Der Dreame H12 Pro Ultra lässt sich mühelos an Kanten entlangführen und erfordert nur minimalen Kraftaufwand. Im Gegensatz zu teureren Modellen wie dem Dreame H14 Pro (Testbericht) verfügt er jedoch nicht über motorisierte Räder zum Zurückziehen und kann nicht flach auf den Boden gelegt werden, um unter Möbel zu gelangen. Auch das LED-Licht, mit dem man Verschmutzungen vor dem Wischkopf besser erkennt, haben wir vermisst.
Das große, gut ablesbare Display des Dreame H12 Pro Ultra informiert über die Restlaufzeit des Akkus, den eingestellten Modus und den Verschmutzungsgrad des Bodens. Zusätzlich gibt es Sprachansagen, die den Nutzer über den Status des Geräts informieren. Ab Werk ist die Sprache auf Englisch eingestellt, kann jedoch über einen Knopf hinten am Gehäuse auf Deutsch umgestellt werden.
Wie gut wischt der Dreame H14 Pro Ultra?
Der Dreame H12 Pro Ultra bietet ordentliche Reinigungsleistung, die sowohl nasse als auch trockene Verschmutzungen effektiv beseitigt. Im Automatikmodus erkennt ein Sensor den Verschmutzungsgrad des Bodens und passt die Leistung entsprechend an. Dies funktionierte im Test zuverlässig. Die Randreinigung ist zwar nicht ganz randlos, es bleiben noch einige Millimeter ungewischt. Für die meisten Nutzer dürfte dies aber kein Problem darstellen. Die Flüssigkeitszufuhr ist gleichmäßig und stark. Da direkt nach dem Aufbringen das Wasser in einem Schritt wieder angesaugt wird, sind hier trotzdem keine Beschädigungen von empfindlichem Boden zu befürchten. Wir nutzen ähnlich funktionierende Saugwischer schon seit Jahren bei Laminat und hatten bislang keinerlei Probleme damit.
Wie immer bei einem ordentlichen Saugwischer mit dabei: die Selbstreinigungsfunktion. Nach der Reinigung wird die Rollenbürste mit bis zu 60 Grad heißem Wasser gespült, wobei sich zwischendurch die Drehrichtung ändert und die Bürste am Ende hochtourig läuft, um möglichst viel Wasser herauszuschleudern. Anschließend wird die Bürste mit warmer Luft getrocknet, dieser Vorgang ist nach rund 30 Minuten erfolgreich abgeschlossen. Diese Funktion sorgt dafür, dass die Bürste stets sauber bleibt und keine Bakterien und dadurch unangenehmen Gerüche entstehen.
Wie lange hält der Akku des Dreame H12 Pro Ultra?
Der Akku des H12 Pro Ultra benötigt etwa vier Stunden, um vollständig aufgeladen zu werden, und bietet im Automatikmodus eine Laufzeit von bis zu 30 Minuten. Diese Ausdauer reicht aus, um eine beträchtliche Fläche am Stück zu reinigen – bei uns rund 140 m² (brutto). Zeit- und kraftraubende Zwischenschritte wie Erneuern des Wassers, Schrubben und Auswringen entfallen schließlich. Bei Bedarf kann das Gerät in den Stand-by-Modus versetzt werden, indem die Führungsstange aufrecht gestellt wird. Ein einfaches Kippen des Griffs aktiviert den Sauger erneut.
Preis: Wie viel kostet der Dreame H12 Pro Ultra?
Der Dreame H12 Pro Ultra kostet 449 Euro laut der UVP. Im Online-Handel bekommt man das Modell schon ab 349 Euro.
Fazit
Der Dreame H12 Pro Ultra überzeugt mit starker Reinigungsleistung, durchdachter Selbstreinigungsfunktion und benutzerfreundlicher Handhabung. Der große Wassertank und die gute Akkulaufzeit machen ihn zu einem zuverlässigen Partner im Kampf gegen verschmutzte Böden. Auch die Heiß-Wasser-Reinigung und die schnelle Trocknung mit heißer Luft sind wichtige Punkte. Wer auf der Suche nach einem vielseitigen Nass- und Trockensauger ist, der sowohl nasse als auch trockene Verschmutzungen effektiv beseitigt, wird mit dem Dreame H12 Pro Ultra zufrieden sein.
Die fehlende Möglichkeit, das Gerät flach auf den Boden zu legen, und das Fehlen von LED-Licht sind jedoch Punkte, die bei der Kaufentscheidung berücksichtigt werden sollten. Dafür ist das Modell aber auch deutlich günstiger als Geräte mit diesen Features. Insgesamt bietet der Dreame H12 Pro Ultra gute Leistung zu einem fairen Preis und ist eine empfehlenswerte Wahl für alle, die Wert auf gründliche und einfache feuchte Reinigung legen.
Roborock F25 Ace
Als Wischsauger wartet der Roborock F25 Ace mit einer Fernsteuerung per App auf, um auch unter Möbeln zu kommen. Er saugt dabei mit 20.000 Pa.
- Fernsteuerung praktisch für schwer erreichbare Stellen
- solide Verarbeitung
- Selbstreinigungsprozess ist zügig und gründlich
- Saugt zuverlässig groben und feinen Schmutz restlos auf
- Reinigungskonzentrat ist sehr ergiebig
- Schwierigkeiten mit hartnäckigen Flecken
- Akku je nach Modus relativ schnell leer
- Fehlende Kameraansicht bei Fernsteuerung
Roborock F25 Ace im Test: Per App unter Möbeln fernsteuerbarer Wischsauger
Als Wischsauger wartet der Roborock F25 Ace mit einer Fernsteuerung per App auf, um auch unter Möbeln zu kommen. Er saugt dabei mit 20.000 Pa.
Der Roborock F25 Ace hat neben den für Wischsauger mittlerweile zum Standard gehörenden Funktionen auch eine manuelle Fernsteuerung per App. Vergleichbares kennt man bislang nur von Saugrobotern. Wie sinnvoll das ist und welche Figur der Roborock F25 Ace sowohl beim Saugen als auch beim Wischen macht, zeigen wir im Test.
Lieferumfang
Zum Saugwischer gibt es die Lade- und Selbstreinigungsstation, eine Handbürste, um etwa den Schmutzwassertank zu säubern, ein Fläschchen Reinigungsmittel-Konzentrat, einen HEPA-Ersatzfilter sowie eine Kurzanleitung für die erste Inbetriebnahme des Geräts.
Design
Der Roborock F25 Ace wirkt direkt beim Auspacken hochwertig und gut verarbeitet. Alle Einzelteile klicken sauber ineinander und lassen sich ebenso sauber wieder voneinander trennen. Der zweigeteilte Schmutzwassertank, der Flüssigkeiten und festen Schmutz voneinander trennt, ist praktisch. Auch die Reinigungsstation wirkt einwandfrei verarbeitet und robust.
Alles sitzt fest und wackelt nicht. Der Wassertank am Fuß des Geräts ist zweigeteilt, wobei auf der linken Seite das Reinigungskonzentrat eingefüllt wird und auf der rechten das frische Wasser. Eine Markierung für die Füllgrenze gibt es allerdings nicht.
Roborock F25 Ace – Bilder
Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Roborock F25 Ace – Bilder

Am Griff befinden sich mehrere Buttons zur Steuerung des Geräts sowie ein Rädchen, um den Wischsauger auch flach am Boden zu verwenden. Die Bedienung erfolgt dann über die Smartphone-App.
Das LCD befindet sich oben am Wischsauger, sodass man problemlos darauf schauen kann, wenn man ihn am Griff hält. In gut beleuchteten Räumen ist die Anzeige problemlos sichtbar. Eine Möglichkeit, die Helligkeit des Displays anzupassen, gibt es jedoch nicht.
Einrichtung
Die Einrichtung ist dankbar unkompliziert. Neben dem Griff, den man mit dem Rumpf des Geräts verbindet, müssen die Wischrolle eingesetzt und das Stromkabel an der Reinigungsstation angebracht werden. Anschließend stellt man den Saugwischer auf die Reinigungsstation, damit dieser auflädt. Über den QR-Code des Quickstart-Guides lässt sich die App des Wischsaugers auf das Smartphone laden. Das sollte man im Idealfall auch tun, da diese prompt ein Firmware-Update für das Gerät bereithält. Der Update-Prozess dauert ein paar Minuten. Dessen Beendigung verkündet der Roborock F25 Ace dann lautstark durch die integrierte Stimmbenachrichtigung. Diese kann man übrigens in der App leiser stellen.
Steuerung
Steuerbar ist der Roborock F25 Ace entweder über die Buttons am Griff oder über die Smartphone-App. Im Hub der App gibt es Einstellungen zu den Reinigungsmodi sowie zur Selbstreinigung des Wischsaugers. Insgesamt gibt es vier verschiedene Reinigungsprofile: Auto, Floor Drying, Eco und Sponge. Wobei Auto der einzige Modus ist, bei dem man manuell Saugkraft und Wasserzufuhr regulieren kann. Einen Modus gänzlich ohne Wasser gibt es nicht.
Die Motoren am Fuß des Roborock F25 Ace sorgen für eine durchgehende Zugkraft, der Saugwischer fährt also permanent nach vorn, wenn er saugt. Das ist, wenn man bisher nur mit regulären Staubsaugern hantiert hat, etwas gewöhnungsbedürftig. Im Gegensatz zu normalen Staubsaugern ohne motorisierte Räder entsteht der Kraftaufwand hier nur beim Zurückziehen des Saugers. Die Stärke des Motors legt man über die Einstellung Adaptive Drive Wheel fest.
Roborock F25 Ace – Bilder App
Roborock F25 Ace – Bilder App
Roborock F25 Ace – Bilder App
Roborock F25 Ace – Bilder App
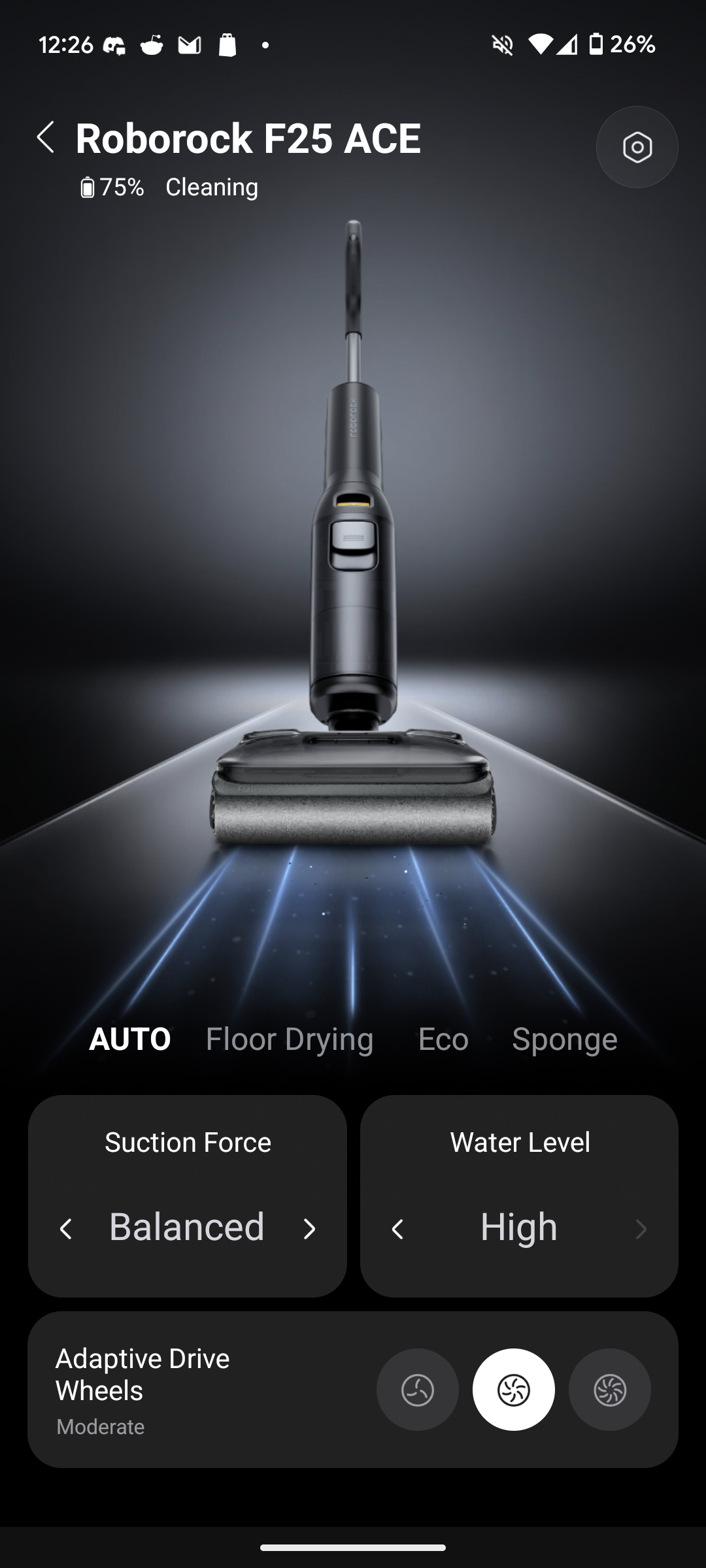
Roborock F25 Ace – Bilder App
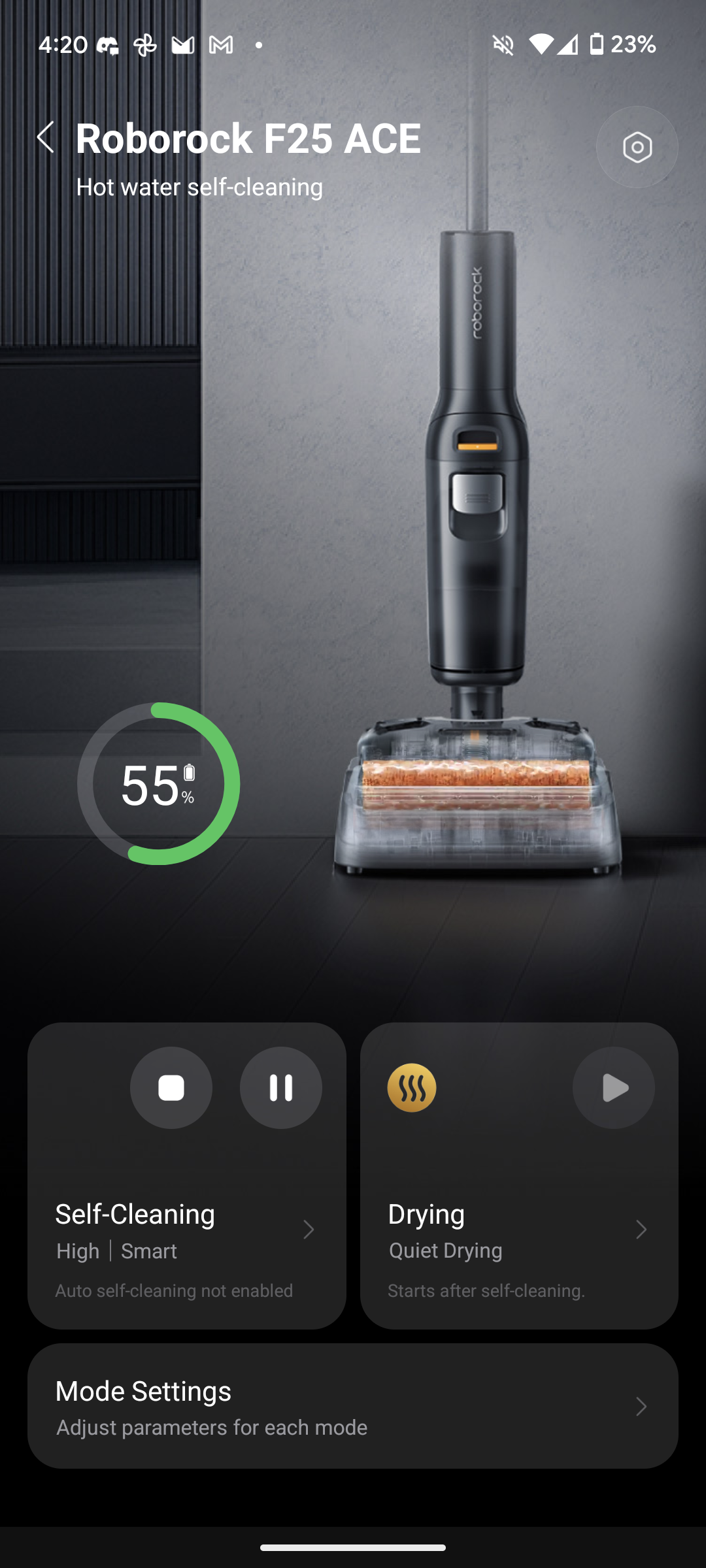
Roborock F25 Ace – Bilder App
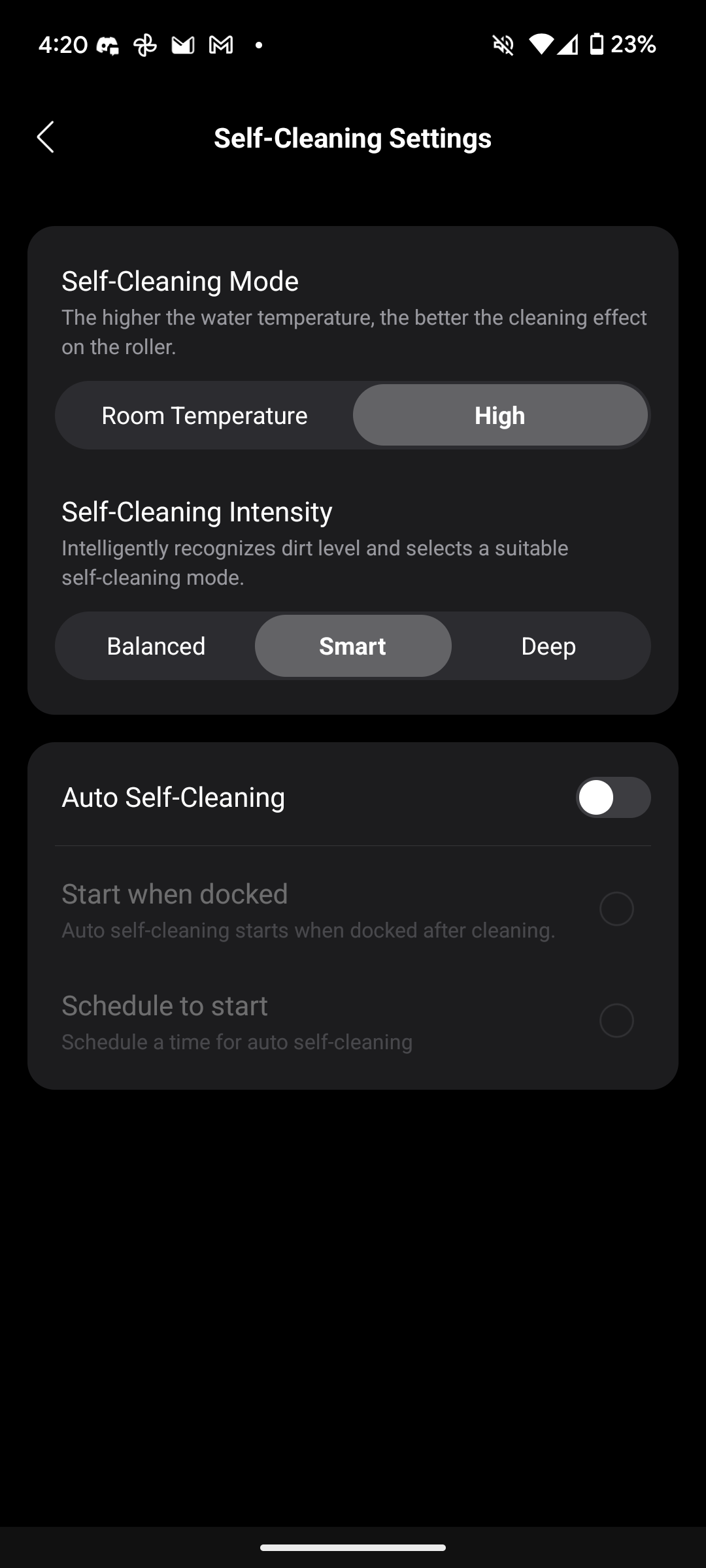
Roborock F25 Ace – Bilder App
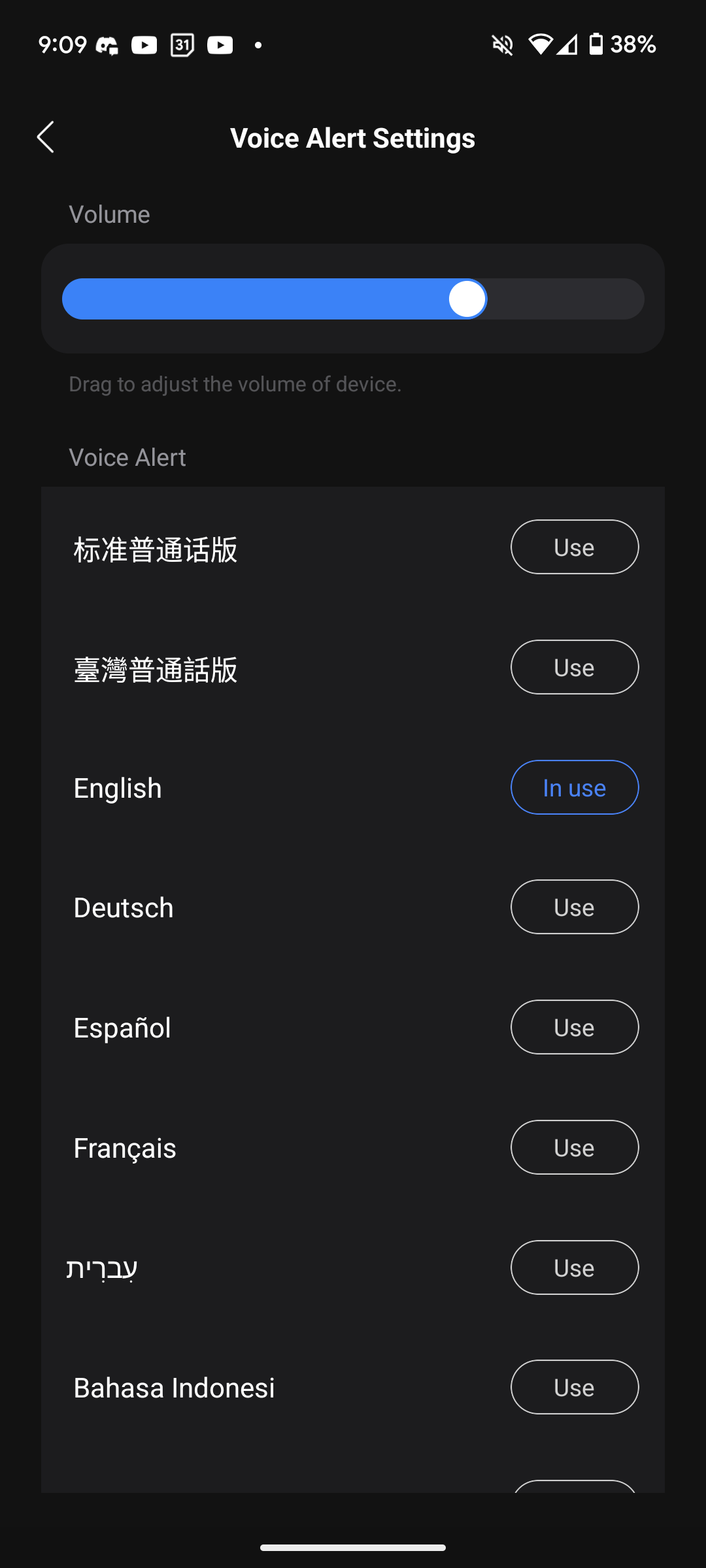
Roborock F25 Ace – Bilder App
Spannend ist zudem die Steuerung per Fernbedienung. Dabei legt man den Wischsauger horizontal auf den Boden. Anschließend steuert man ihn manuell über die App. Hauptsächlich ist der Modus für schwer zu erreichende Stellen gedacht, etwa unter der Couch oder unter Schränken, bei denen man sich ansonsten verrenken oder die Möbel verschieben müsste. Für die reguläre Bodenreinigung ist die Steuerung allerdings nicht zu gebrauchen. Das liegt unter anderem an der Verzögerung zwischen gesendetem Signal und Reaktion des Wischsaugers sowie der sehr grobmotorischen Bewegung des F25 Ace.
Reinigung
Der Wischsauger Roborock F25 Ace reinigt mit 20.000 Pa und ist vom Hersteller für eine Fläche von bis zu 410 m² ausgelegt. In unserem Test saugen wir sowohl auf Parkettboden als auch auf Fliesen. In beiden Fällen saugt er Schmutz wie Krümel, Katzenstreu und Staub problemlos und restlos auf. Dank der Wischrolle entstehen auch keine Schlieren auf dem Boden. Auch Weinflecken bekommt er restlos von Fliesen entfernt. Bei stärkeren Verschmutzungen wie eingetrockneten Flecken kommt der F25 Ace jedoch an seine Grenzen. Egal, welchen Modus wir anwenden – die hartnäckigen Flecken bleiben bestehen. Diese muss man gegebenenfalls vorbehandeln oder direkt zu einem vollwertigen Nasswischer greifen. Er ist zwar hauptsächlich für harte Böden wie Parkett und Fliesen ausgelegt, wir lassen ihn dennoch testweise über unseren kurzflor Polypropylen-Teppich fahren. Feine Katzenhaare sowie Krümel vom Frühstück nimmt er hier problemlos mit.
Der Wechsel zur Fernsteuerung per App klappt gut. Hat man den Wischsauger waagerecht auf den Boden gelegt und per App bestätigt, wechselt die App in die Steuerungsansicht. Dank des schlau platzierten Stützrads am Griffende gleitet der Roborock F25 Ace problemlos auf dem Boden hin und her. Wie bereits erwähnt, funktioniert die Steuerung so zwar, ist aber alles andere als präzise und responsiv. Für die punktuelle Reinigung an schwer zugänglichen Stellen ist sie vollkommen ausreichend. Für eine flächendeckende Reinigung der ganzen Wohnung würde sie uns aber auf Dauer in den Wahnsinn treiben. Eine fehlende Kameraansicht sorgt zudem dafür, dass man mehr oder weniger blind unter den Möbeln hin- und herfährt.
Die anschließende Selbstreinigung liefert zufriedenstellende Ergebnisse. Der Prozess ist dabei in zwei Schritte unterteilt. Zuerst erfolgt die Reinigung, dann die Trocknung von Wischwalze und Sauger. Die Intensität der Reinigung ist über die App konfigurierbar, genauso wie die Wassertemperatur. Auch eine automatische Selbstreinigung ist möglich. Dann entweder, sobald der Sauger zurück in die Station gestellt wird, oder zu festen Zeiten, die man im Vorfeld einrichtet. Für die anschließende Trocknung hat man die Wahl, einen etwa fünf Minuten langen, dafür mit ungefähr 60 dB(A) etwas lauteren Trocknungsvorgang zu starten, oder auf eine leise Trocknung mit rund 40 dB(A) umzusteigen. Diese dauert dann ungefähr 20 Minuten. Die Lautstärke ist mit maximal 60 dB(A) allerdings noch völlig im Rahmen des Erträglichen.
Nach der Selbstreinigung mit heißem Wasser und anschließender schneller Trocknung (beides bei 90° C) sind die Wischwalze sauber und der Wassertank nur noch minimal gefüllt. Diesen sollte man entleeren, wenn man den Wischsauger fürs Erste nicht mehr benutzt. Anschließend muss noch der Schmutzwassertank gereinigt werden. Dank des zweigeteilten Designs gießt man problemlos den Großteil der schmutzigen Plörre ab, während feste Bestandteile im Tank bleiben. Nachdem man die zwei Kammern voneinander gelöst und den HEPA-Filter herausgenommen hat, lassen sich die groben Schmutzpartikel einfach in den Mülleimer verfrachten – zur Not hilft man mit der inkludierten Handbürste nach. Schlussendlich reinigt man noch den Auffangbehälter und den Filter, bevor man sie wieder zusammensetzt. Eine Erkenntnis, die wir durch unseren Test gewonnen haben: Man sollte mit einem Wischsauger wie dem Roborock F25 Ace kein Katzenstreu aufsaugen. Dieses verklumpt, setzt sich in Ecken ab und verstopft zudem die Rohre des Tanks, wodurch die Handreinigung deutlich länger dauert.
Akkulaufzeit
Die Akkulaufzeit ist abhängig vom gewählten Modus, wobei der Eco-Mode aufgrund reduzierter Leistung sparsamer im Stromverbrauch ist. Wir saugwischen überwiegend im Auto-Modus, der den Akku relativ zügig entleert. Nach gut zehn Minuten Saugen attestiert uns die App rund 70 Prozent Akkuladung, nach weiteren fünf Minuten zeigt sie uns 60 Prozent an. Je nach Modus schätzen wir so die Laufzeit im Schnitt auf 35 bis 45 Minuten, bis man das Gerät zurück zur Ladestation bringen muss. Etwas nervig ist, dass das Display keine Prozentzahl anzeigt, sondern den Akkustand in Form von Strichen abbildet.
Preis
Die UVP des Roborock F25 Ace liegt bei 549 Euro. Aktuell gibt es ihn für 547 Euro.
Fazit
Der Roborock F25 Ace überzeugt durch eine gute Saugleistung, die sowohl kleinteiligem als auch gröberem Schmutz gewachsen ist. Er wischt dabei gleichmäßig und je nach Modus unterschiedlich stark den Boden mit Wasser. Mit den meisten Verschmutzungen, darunter etwa Weinflecken, kommt er klar, macht allerdings bei angetrockneten, hartnäckigen Flecken schlapp. Die Selbstreinigung überzeugt mit Gründlichkeit und Effizienz. Die Wischwalze ist nach wenigen Minuten sauber und trocken. Für 547 Euro bekommt man mit dem Roborock F25 Ace einen grundsoliden Wischsauger, der in den meisten Fällen eine gute Figur macht und durch seine Reinigungsleistung überzeugt.
Dreame H13 Pro
Der Dreame H13 Pro ist ein leistungsstarker Saugwischer, der durch seine Selbstreinigungsfunktionen mit 60 Grad heißem Wasser und hoher Saugkraft überzeugt. Wir haben den Sauger auf Herz und Nieren geprüft.
- motorisierte Räder
- ordentliche Wischleistung
- LED vorn an Wischkopf
- gut ablesbares Display
- Selbstreinigung mit heißem Wasser
- schnelle Trocknung mit Heißluft
- recht teuer
- wenig Neuerungen zum Vorgänger
Dreame H13 Pro im Test: Dieser Wischsauger ist idiotensicher & hygienisch
Der Dreame H13 Pro ist ein leistungsstarker Saugwischer, der durch seine Selbstreinigungsfunktionen mit 60 Grad heißem Wasser und hoher Saugkraft überzeugt. Wir haben den Sauger auf Herz und Nieren geprüft.
Was sind die Highlights am Dreame H13 Pro?
- hohe Saugkraft von 18.000 Pa
- Selbstreinigung mit heißem Wasser
- LED-Beleuchtung für bessere Sicht
- Bequeme Bedienung und Sprachansagen
- Rand- und Eckenreinigung
- angetriebene Räder
Design: Wie sieht der Dreame H13 Pro aus?
Der Dreame H13 Pro hinterlässt einen hochwertigen Eindruck. Das Gerät ist in elegantem Schwarz und gedecktem (Silber)Grau gehalten und wirkt durch seine robuste Verarbeitung sehr stabil. Beim Design setzt Dreame wie gewohnt auf sein zylindrisches Design, das sieht ebenfalls schick und hochwertig aus. Der Sauger kommt mit einem 900-ml-Frischwassertank hinten und einem 700-ml-Schmutzwassertank vorn, die beide leicht zugänglich und einfach zu befüllen oder zu entleeren sind. Interessant ist die Möglichkeit, einen Schmutzsammler in den Abwassertank einzubauen. Der ist allerdings nicht vorinstalliert – wir fragen uns, warum das so ist, schließlich scheint er keine Nach-, sondern nur Vorteile zu bieten. Dem Namen entsprechend sammelt er größere Schmutzpartikel, die dann nicht im flüssigen Abwasser landen, sondern schon vorher abgefangen werden. Das erleichtert unter Umständen die Reinigung.
Die Bedienelemente sind am Griff angebracht und ermöglichen eine einfache Steuerung des Geräts. Das LED-Display zeigt den aktuellen Reinigungsmodus und den Akkustand an. Praktisch: Der Inhalt der Anzeige wird gedreht – bei Nutzung und der Sicht von oben ist sie also „richtig herum“ und in der Ladestation, wenn man von vor dem Gerät draufschaut, ebenfalls. Die LED-Beleuchtung an der Bürste sorgt dafür, dass auch dunkle Bereiche gut ausgeleuchtet werden, sodass keine Verschmutzung übersehen wird. Außerdem sieht die komplett weiß illuminierte Wischrolle ziemlich stylish aus. Die Ladestation dient wie von der Konkurrenz gewohnt gleichzeitig der Selbstreinigung. Auffällig ist hier nur der Metallstreifen vorn unter der Wischrolle. Er wird erhitzt und sorgt für mehr Hygiene während des Trocknungsvorgangs. Ersatzrolle und Reinigungslösung liegen dem Lieferumfang übrigens sogar bei.
Alle Bilder zum Dreame H13 Pro im Test
Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Dreame H13 Pro

Reinigungsleistung: Wie gut wischt der Dreame H13 Pro?
Der Dreame H13 Pro beeindruckt mit einer Saugkraft von 18.000 Pa und 520 Umdrehungen der Wischrolle pro Minute. In unserem Test konnte der Sauger flüssige Verunreinigungen nach nur einer Durchfahrt vollständig entfernen. Auch hartnäckige, eingetrocknete Verunreinigungen wurden nach vier oder fünf Durchfahrten beseitigt. Noch härtere Verschmutzungen können auch mal mehr Fahrten nötig machen, das ist bei der Konkurrenz nicht anders. Der Automatik-Modus passt die Reinigungsleistung direkt an die Verschmutzung an, zeigte jedoch gelegentlich eine Verzögerung bei der Erkennung stärkerer Verunreinigungen.
Bei der Reinigung von Holzböden ist es wichtig, dass nicht zu feucht gewischt wird, um Schäden zu vermeiden. Das klappt beim Dreame H13 Pro ganz ordentlich. Er gibt immer ausreichend Wasser ab, sodass am Ende keine Wischspuren zurückblieben, aber der Boden wird nicht zu nass. Dennoch sollte man bei teurem, empfindlichem Boden vorsichtig mit der Reinigung beginnen und sich langsam herantasten. Auf Fliesen oder PVC ist solche Vorsicht hingegen unbegründet. Für Teppich ist der Saugwischer nicht gedacht – auch wenn es einen dedizierten Saugmodus gibt. Der ist dafür da, etwa die feuchte Dusche trockenzusaugen.
Die Leisten- und Kantenreinigung des Dreame H13 Pro hat uns überzeugt. Das Gerät kommt sehr nah an die Kanten heran und entfernt Schmutz zuverlässig. Ein Nachwischen ist nicht nötig, da die Eckenreinigung so gründlich ist, dass alle Rückstände vollständig beseitigt werden.
Bedienung: Wie ist das Handling des Dreame H13 Pro?
Der Dreame H13 Pro punktet mit seinen angetriebenen Rädern, die die Bewegung unterstützen und die Reinigung besonders komfortabel und mühelos machen. Die Zeitverzögerung, die beim Wechsel von nach vorn schieben und nach hinten ziehen bei manchem Konkurrenten auftritt, ist hier nur minimal zu spüren. Stattdessen unterstützt der Antrieb den Nutzer angenehm und hilft ihm dabei, konstante Reinigungsgeschwindigkeit für konstante Reinigungsergebnisse zu erzielen. Damit ist der H13 Pro zusammen mit der vorderen LED, die Zusammenstöße auch in dunklen Ecken zu verhindern hilft, quasi idiotensicher.
Das Gerät liegt gut in der Hand und lässt sich insgesamt angenehm führen. Es ist nicht zu schwer, was es auch für längere Reinigungsarbeiten geeignet macht. Allerdings kann der Sauger nicht komplett flach gemacht werden, was die Erreichbarkeit bestimmter Bereiche – etwa unter Möbeln – erschwert. Das machen aber nur wenige Konkurrenten besser.
Selbstreinigung: Wie gut ist die Basisstation?
Ein herausragendes Alleinstellungsmerkmal des Dreame H13 Pro ist die Fähigkeit, die Walze mit heißem Wasser zu reinigen und anschließend mit Wärme und aktiver Luftzufuhr zu trocknen. Beide Funktionen tragen zur Hygiene bei, da der Großteil der Bakterien, die beim langsamen Trocknen bei Zimmertemperatur und ohne aktive Luftzufuhr entstehen und für unangenehmen Geruch sorgen, abgetötet werden. Während der Trocknung ist ein konstantes Lüftergeräusch zu hören, das wie bei der Konkurrenz deutlich hörbar, aber im Nebenraum nicht störend ist. Dafür dauert das beim Dreame-Modell nur 30 Minuten.
In vielen Haushalten mit Haustieren stellen Haare ein großes Problem dar. Der Dreame H13 Pro hat in unseren Tests gezeigt, dass er Haare sehr gut aufsaugen kann, ohne dass sich diese in den Walzen verfangen. Die Walzen werden dank einer speziellen Lippe und einem Kamm gut von der Rolle entfernt und anschließend abgesaugt.
Die Wartung des Dreame H13 Pro gestaltet sich erfreulich einfach und benutzerfreundlich. Die Bürstenrolle lässt sich mit wenigen Handgriffen entnehmen, was die regelmäßige Reinigung und den Austausch der Rolle erleichtert. Eine Ersatzrolle liegt dem Lieferumfang sogar bei. Alle Teile inklusive des Frischwassertanks sind gut zugänglich und stellen beim Entleeren keine Probleme dar.
Akkulaufzeit: Wie lange kann man mit dem Dreame H13 Pro am Stück reinigen?
Der Dreame H13 Pro ist mit einem 4900 mAh starken Akku ausgestattet. Im Auto-Modus konnten wir den Boden 25 bis 40 Minuten reinigen, bevor der Sauger wieder an die Ladestation musste. Die Ladezeit beträgt etwa vier Stunden.
Preis: Wie viel kostet der Dreame H13 Pro?
Der Dreame H13 Pro kostet knapp 280 Euro auf Ebay. Das ist auf den ersten Blick nicht wenig, aber dafür erhält man viele neue Funktionen, die lästige Arbeiten abnehmen.
Fazit
Der Dreame H13 Pro ist ein Premium-Saugwischer, der durch seine starke Reinigungsleistung, Benutzerfreundlichkeit und vielseitige Anwendungsmöglichkeiten überzeugt. Trotz kleinerer Schwächen bei den Reinigungsmodi und der Lautstärke bietet der H13 Pro ein wirklich gutes Gesamtpaket. Wer einen leistungsstarken Wischsauger sucht, ist mit dem Dreame H13 Pro bestens bedient.
Dyson V16 Piston Animal Submarine 2.0
Der Dyson V16 Piston Animal Submarine ist in erster Linie ein Akkustaubsauger mit zusätzlicher Wischfunktion, die durch einen Aufsatz ermöglicht wird.
- gute Saugleistung
- Entleerung nach dem Saugen super bequem
- verhältnismäßig leise für einen Staubsauger
- platzsparendes Design
- keine Selbstreinigung & Selbsttrocknung
- Wischfunktion nur per zusätzlichem Aufsatz
- teilweise Verbindungsprobleme zum Smartphone
- teuer
Dyson V16 Piston Animal Submarine im Test: Akku-Staubsauger mit Wischaufsatz
Der Dyson V16 Piston Animal Submarine ist in erster Linie ein Akkustaubsauger mit zusätzlicher Wischfunktion, die durch einen Aufsatz ermöglicht wird.
Mit dem V16 Piston Animal Submarine zeigt Dyson einen Akkustaubsauger, der nicht nur Staub und Schmutz aufsaugt, sondern dank Wischwalzenaufsatz auch Flüssigkeiten vom Boden aufwischt. Was ihn sonst noch von regulären Wischsaugern, die gleichzeitig saugen und wischen, unterscheidet und ob er dabei eine gute Figur macht, zeigen wir im Test.
Dieser Test betrachtet den Dyson V16 Piston Animal Submarine unter den Gesichtspunkten eines Saugwischers. Da das Produkt auch ohne den Wischaufsatz Submarine 2.0 angeboten wird, folgt in Kürze ein separater Test, in dem wir den V16 Piston Animal als reinen Staubsauger testen und bewerten.
Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Der Dyson V16 Piston Animal im Submarine-2.0-Paket enthält neben dem Staubsauger-Set, welches aus Handstaubsauger, Akku, Ladegerät sowie Boden-, Haar-, Kombi- und Fugendüse besteht, auch den Submarine-2.0-Bodenaufsatz, der den Akkustaubsauger zu einem Wischsauger umwandelt. Im Akkustaubsauger befindet sich zudem ein auswaschbarer Hepa-Filter. Zusätzlich gibt es noch einen Quick-Start-Guide sowie eine Wandhalterung, um den Dyson V16 bei Bedarf aufzuhängen.
Design
Wie von Dyson-Produkten gewohnt, hat auch der V16 Piston Animal Submarine einen futuristischen Look. Farblich dominieren Bronze und Schwarz das Gehäuse des Saugers. Die Bürsten der Aufsätze sind in Rot und Blau gehalten, während rote Knöpfe und Hebel Akzente am Gehäuse setzen. Ebenso gewohnt sind die schlanken Maße des leistungsstarken Saugers: 125 cm x 25 cm x 25,9 cm. Der Handstaubsauger mitsamt Akku bringt rund 2,15 kg auf die Waage, in voller Montur (mit angeschlossenem Rohr, Akku und Bodendüse) sind es 3,4 kg.
Dyson V16 Piston Animal Submarine – Bilder
Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Dyson V16 Piston Animal Submarine – Bilder

Das Gehäuse besteht mit Ausnahme des Aluminium-Saugrohrs aus Plastik. Die Verarbeitung kann sich aber sehen lassen: Die einzelnen Komponenten klicken problemlos ineinander, sitzen fest und fühlen sich robust an. Das Design wirkt größtenteils durchdacht und wartet mit praktischen Funktionen auf. Der 1,3-l-Auffangkorb des Dyson V16 Piston Animal ist mit zwei Hebeln ausgestattet, die das anschließende Entsorgen des aufgesaugten Schmutzes erleichtern. Über den silbernen Hebel öffnet sich der Deckel des Auffangkorbs, während der rote Hebel den angesammelten Staub zusammenpresst und diesen bei geöffnetem Deckel auch zur Öffnung hinausschiebt. Der Auffangkorb lässt sich für eine gründlichere Reinigung zudem vollständig vom Handstaubsauger lösen. Ähnlich sieht es bei der durchsichtigen Plastikabdeckung der Bodendüsen aus. Diese löst sich in wenigen Handgriffen und gibt die darunterliegenden Bürsten frei, damit man sie von Hand reinigen kann.
Der Submarine-2.0-Bodenaufsatz kommt bereits vollständig montiert, erfordert aber logischerweise vor dem ersten Einsatz das Auffüllen des Wassertanks. Beim Auseinandernehmen und Zusammenbauen des Aufsatzes stört uns allerdings die Auffangrinne. Da man den Wischaufsatz hochkant hinstellen muss, um den Tank zu befüllen, löst sich die Auffangrinne sehr leicht aus ihrer Halterung. Uns ist sie so mehrmals ins Spülbecken gefallen.
Das oben auf dem Handstaubsauger eingelassene Display wird von zwei Buttons flankiert. Der rote Button oberhalb des Bildschirms startet den Saugvorgang, der silberne unterhalb dient dazu, zwischen verschiedenen Saugstärken zu wechseln und bei ausgeschaltetem Motor durch die Systemeinstellungen zu navigieren.
Einrichtung
Mit der My-Dyson-App richtet man den V16 Piston Animal unkompliziert und innerhalb weniger Minuten ein. Das Ganze dann entweder direkt über die Gerätesuche in der App oder durch Scannen des QR-Codes, den der Bildschirm des Piston Animal anzeigt. Zuvor sollte man jedoch den Akku aufladen, bzw. den Sauger mit angeschlossenem Akku an das Ladekabel hängen, da man sonst ausstehende Firmware-Updates des V16 nicht durchführen kann.
Dyson V16 Piston Animal Submarine – Bilder App
Dyson V16 Piston Animal Submarine – Bilder App
Dyson V16 Piston Animal Submarine – Bilder App
Dyson V16 Piston Animal Submarine – Bilder App
Dyson V16 Piston Animal Submarine – Bilder App

Dyson V16 Piston Animal Submarine – Bilder App

Dyson V16 Piston Animal Submarine – Bilder App
Dyson V16 Piston Animal Submarine – Bilder App
Dyson V16 Piston Animal Submarine – Bilder App
Dyson V16 Piston Animal Submarine – Bilder App
Dyson V16 Piston Animal Submarine – Bilder App
Die App führt einen Schritt für Schritt durch den Prozess, und die Verknüpfung zwischen App und Akkusauger klappt für uns reibungslos. Hierbei richtet man auch zugleich den Sauger an sich ein, hauptsächlich die bevorzugte Systemsprache. Anschließend gab es ein Firmware-Update, für das man, etwas unpraktisch, die App auf dem Smartphone geöffnet lassen muss und das Handy idealerweise währenddessen nicht verwendet. Die Installation der neuen Firmware dauerte knapp 2 Minuten, was vollkommen in Ordnung ist.
Anschließend ist der Akkustaubsauger einsatzbereit.
Steuerung
Der Dyson V16 Piston Animal Submarine 2.0 erkennt anhand der angebrachten Düse automatisch, um welche Art der Reinigung es sich handelt. Bei der normalen Bodendüse startet er den regulären Saugmodus, während der Submarine-2.0-Bodenaufsatz den V16 Piston Animal in den Wischmodus versetzt.
Die Steuerung erfolgt entweder über die zwei Buttons am Staubsauger oder, in Teilen, über die App. Im Saugmodus wechselt man zwischen den Saugstärken Auto, Eco und Boost. Eco steht hier wie bei vielen anderen Herstellern für eine schwächere und somit stromsparende Saugleistung. Der Auto-Modus passt indes die Saugkraft entsprechend der vom System registrierten Verschmutzung und in Abhängigkeit vom Untergrund an. Im Wischmodus wechselt man zwischen regulärer Nässe und maximaler Zufuhr von Wasser.
Während unseres Tests hatte der V16 öfter mal Schwierigkeiten, sich mit der App auf unserem Smartphone (Google Pixel 7, Android 16) zu verbinden. Wir mussten mehrmals die gespeicherte Bluetooth-Verbindung löschen und erneut einrichten, damit der Sauger wieder vollständig in der App abgebildet wurde. Er lässt sich zwar auch problemlos ohne App im vollen Umfang nutzen, für ein Produkt dieser Preisklasse darf man allerdings eine rundum reibungslose Erfahrung erwarten.
Reinigung
Beim Dyson V16 Piston Animal Submarine 2.0 handelt es sich nicht um einen traditionellen Saugwischer, der Staubsaugen und Nasswischen in einem Durchgang erledigt, sondern um einen Staubsauger mit zusätzlichem Wischaufsatz. Das bringt sowohl Vor- als auch Nachteile für die Reinigungsleistung mit sich.
Direkt vornweg: Gleichzeitiges Staubsaugen und Wischen ist nicht möglich, da es keinen Schmutzwasserbehälter gibt. Der Submarine-2.0-Aufsatz hat einen kleinen Frischwassertank, der die Wischwalze befeuchtet und so den Boden benässt. In diesen gibt man auch noch ein Reinigungsmittel hinzu, denn getrennte Fächer gibt es nicht. Verschüttete Flüssigkeiten auf dem Boden nimmt die Wischwalze in sich auf, etwaiger gröberer Schmutz wird jedoch nicht eingesaugt und bleibt auf dem Boden liegen. Das bedeutet, dass man immer zuerst den Boden saugen sollte, bevor man mit dem Wischaufsatz arbeitet. Das Wasser wird anders als bei vielen Saugwischern hier zudem auch nicht erhitzt. Die Räder des Wischaufsatzes fahren motorisiert, was die Wischerei ein Stück weit angenehmer macht. Zwei verschiedene Reinigungsmodi decken reguläre und hartnäckigere Verschmutzungen auf Hartböden ab. Auf dem Hartboden macht der Wischaufsatz eine gute Figur und entfernt sowohl frisch verschüttete Flüssigkeiten als auch eingetrocknete Flecken problemlos. Wir testen ihn zudem auf den Fliesen in der Küche. Mit diesen kommt er schlecht klar und beseitigt nur sehr leichte Verschmutzungen. Da er aber ohnehin hauptsächlich für Hartböden ausgelegt ist, ist das vollkommen in Ordnung.
Dank des fehlenden Schmutzwasserbehälters entfällt zwar das Wegkippen der angesammelten Plörre, Wischwalze und Auffangrinne wollen jedoch trotzdem gereinigt werden. Denn über eine Selbstreinigungsfunktion verfügt der Dyson V16 Piston Animal Submarine 2.0 nicht. Der Aufsatz lässt sich zum Glück leicht auseinandernehmen. Die Wischwalze halten wir zur Reinigung unter dem laufenden Wasserhahn und entfernen so gröberen Schmutz. Auch die Auffangrinne machen wir so sauber. Der Nachteil einer fehlenden Selbstreinigungsstation ist auch, dass eine anschließende intelligente Trocknung der Wischwalze ebenfalls entfällt und man diese dann auf ganz altmodische Art und Weise trocknen muss.
Als Staubsauger leistet der Dyson V16 Piston Animal ganze Arbeit: Mit einer Saugkraft von 315 AW und einem 900-W-Motor ausgestattet, saugt er Staub, Krümel und Haare problemlos von Hartböden und Fliesen auf. Tierbesitzer dürften sich über die inkludierte Haardüse freuen, die Tierhaare von Polstermöbeln und aus dem Teppich hervorragend entfernt. Aber auch ohne Tiere in der Wohnung ist sie ideal, um Teppiche gründlich abzusaugen. Die grüne LED, die vorn am regulären Bürstenkopf angebracht ist, macht den Staub am Boden hervorragend sichtbar. Das ist vor allem dann praktisch, wenn man etwa unter dem Bett oder dem Tisch saugt, wo Licht normalerweise nur schlecht gut hinkommt. Während des Saugens zeigt der Staubsauger zeitgleich auf dem Bildschirm die Beschaffenheit des Staubs an und unterteilt ihn visuell per Balken in verschiedene Kategorien – von sehr fein bis grob. Unpraktisch ist hingegen die Form des Bürstenkopfs. Dieser ist nicht rechteckig, sondern zur Mitte hin länger. Das führt dazu, dass man mit dem Aufsatz nicht nahtlos an Ränder und Kanten kommt, sondern den Bürstenkopf angewinkelt heranfahren muss.
Im Auto-Modus erreicht der Staubsauger Lautstärken von bis zu 63 dB (A), hält sich aber im Schnitt bei 58 dB (A) auf. Im Boost-Modus steigen die dB auf 65 an. Beim Wischen gibt nur die Wischwalze ein hörbares Surren von sich, da das Gebläse des Akkustaubsaugers nicht aktiv ist und siedelt sich in unseren Messungen per Smartphone-App bei etwa 43 dB (A) an.
Akkuleistung
Dyson verspricht bis zu 70 Stunden Akkulaufzeit und bezieht sich dabei auf die Nutzung im Eco-Modus auf Hartböden. Wir verwenden den Dyson V16 Piston Animal Submarine 2.0 sowohl zum Saugen als auch Wischen. Beim Saugen verlassen wir uns auf den Auto-Modus, der die Saugkraft von allein reguliert. Mit voll aufgeladenem Akku prognostiziert uns die Anzeige gut 45 Minuten Einsatzbereitschaft. Das ist mehr als genug, um die Wohnung durchzusaugen. Beim Wischen reduziert sich der Verbrauch stark, sodass wir nach gut 10 Minuten Wischens immer noch bei vollen 100 Prozent Akku liegen. Hier sollte also mehr als genug Saft vorhanden sein, um die Wohnung gründlich wischen zu können. Je nach Restakkustand benötigt die anschließende Aufladung bis zu viereinhalb Stunden.
Insgesamt sind wir mit der Leistung des Akkus vollkommen zufrieden.
Preis
Die UVP des Dyson V16 Piston Animal Submarine liegt bei 999 Euro. Aktuell gibt es das Paket mit Wischaufsatz für 889 Euro.
Fazit
Der Dyson V16 Piston Animal Submarine ist im Gegensatz zu regulären Wischsaugern nur mittels des Submarine-2.0-Aufsatzes in der Lage, Flüssigkeiten aufzusaugen und zu wischen. Während ein fast fließender Übergang zwischen Staubsaugen und Wischen zwar möglich ist, kann er mit den günstigeren Kombilösungen anderer Hersteller hier nicht mithalten. Eine fehlende Selbstreinigungsfunktion samt anschließender Trocknung machen den Wischvorgang um einiges mühseliger. Die klare Trennung zwischen Staubsaugen und Wischen bedeutet zudem, dass die zu wischende Fläche zuvor immer erst abgesaugt werden muss. Denn die Wischwalze nimmt nur Flüssigkeiten und Verschmutzungen wie Flecken in sich auf, gröberer Schmutz bleibt liegen, da nicht aktiv gesaugt wird.
Die reine Saugleistung und der Komfort während und nach dem Saugen sind dafür spitze – hier zeigt der V16 Piston Animal, wo seine Stärken liegen. Eine unkomplizierte Entleerung des angesammelten Staubs gepaart mit einer für Staubsauger angenehmen Lautstärke und nützlichen Aufsätzen macht das regelmäßige Saugen mit dem Akkustaubsauger zur Freude. Leider konnte die App nur bedingt überzeugen, da die Verbindung zwischen Staubsauger und App nicht immer reibungslos möglich war.
Wer einen reinen Saugwischer sucht, der beide Funktionen kompetent in einem Gerät verbindet, ist mit günstigeren Modellen von Anbietern wie Dreame, Roborock und Co. deutlich besser bedient. Möchte man einen guten Akkustaubsauger, der für gelegentliches Wischen ausgerüstet ist, bekommt man ihn mit dem Dyson V16 Piston Animal Submarine – vorausgesetzt man ist bereit, 889 Euro dafür zu bezahlen.
ZUSÄTZLICH GETESTET
Dreame H11 Max
Dreame H11 Max
Saugen klappt inzwischen auch kabellos hervorragend – oder gleich komplett autonom als Roboter. Und wischen? Der neue Dreame H11 Max zeigt, wie das perfekt funktioniert und so zum Kinderspiel wird.
- Schick und modern
- richtig gute Wischleistung dank aut. Schmutzerkennung
- gute Bedienbarkeit und großes Display
- Randreinigung nur eingeschränkt möglich
Dreame H11 Max im Test: Akkusauger mit richtig guter Wischfunktion
Saugen klappt inzwischen auch kabellos hervorragend – oder gleich komplett autonom als Roboter. Und wischen? Der neue Dreame H11 Max zeigt, wie das perfekt funktioniert und so zum Kinderspiel wird.
Bei Saugrobotern hat uns der chinesische Hersteller Dreame mit Modellen wie unserem Allzeit-Favoriten D9 (Testbericht) überzeugt, ebenfalls bei Wischrobotern wie dem Dreame Bot W10 (Testbericht). Wer lieber noch etwas selbst Hand beim Wischen anlegt, ohne dabei aber ins Schwitzen geraten zu wollen, für den hat der Hersteller nun auch etwas im Angebot: den Dreame H11 Max.
Dieser akkubetriebene Wischsauger ist im Prinzip ein Akkusauger mit zusätzlicher Wischfunktion wie etwa der Jimmy PowerWash HW8 Pro (Testbericht) und verfügt ebenfalls über je einen Frisch- und Abwassertank. In letzteren saugt der H11 Max das schmutzige Wasser gleich wieder vom Boden auf, statt es wie die meisten Roboter nur zu verteilen. Dabei sieht er schick und modern aus – reicht das, um ein guter Haushaltshelfer zu sein?
Lieferumfang
Der Lieferumfang ist vollständig: Es gibt den Wischsauger, bei dem der separate Handgriff nach der Entnahme aus dem Lieferkarton Werkzeug-frei aufgesteckt werden muss, ein Ladegerät mit deutschem Stecker, die Ladeschale, in die der Wischsauger zum Laden und Säubern gestellt wird, außerdem Ersatzrolle, Reinigungsbürste und ein Handbuch, das auch deutsche Instruktionen bereitstellt. Zudem packt der Hersteller einen Reinigungszusatz in den Lieferkarton, der angenehm frisch riecht. Der scheint aber nicht immer mit dabei zu sein, wie einige andere Tester berichten. Ersatzrolle und Reinigungsbürste lassen sich in der Ladeschale aufbewahren, sie stehen dort etwas wackelig in eigenen Aufbewahrungsröhrchen.
Design
Im Gegensatz zum Jimmy-Modell, das wir optisch eher altbacken finden, orientiert sich der Dreame H11 Pro an der neuen Generation an Wischsaugern, die Konkurrenten wie Tineco und Roborock auf den Markt gebracht haben. Entsprechend packt der Hersteller Frischwassertank, Abwassertank und Motor in eine zylindrische Form, die einerseits moderner, andererseits durch ihre monolithische Anmutung wuchtiger als der Jimmy H8 Pro daherkommt.
Insgesamt gefällt uns diese Formensprache deutlich besser, zumal das Gerät dadurch auch insgesamt funktionaler bleibt. So werden die großen Tanks (Frischwasser 900 ml und Abwasser 500 ml) einfach nach vorne entnommen und oben auf dem zylinderförmigen Korpus installiert Dreame ein großes, gut ablesbares Display.
Alle Bilder zum Akku-Wischsauger Dreame H11 Max im Test
Dreame H11 Max

Dreame H11 Max

Dreame H11 Max

Dreame H11 Max

Dreame H11 Max

Dreame H11 Max

Dreame H11 Max

Dreame H11 Max

Dreame H11 Max

Dreame H11 Max

Der zwar modern, aber auch etwas unergonomisch wirkende Handgriff mit drei Knöpfen für Selbstreinigung, Automatik und Absaugfunktion erfüllt seine Aufgabe ebenfalls deutlich besser, als die Formensprache suggeriert. Die Verarbeitungsqualität ist dabei insgesamt sehr gut, alles wirkt so, als würde es die nächsten Jahre Nutzung problemlos überstehen.
Funktion und Reinigungsleistung
Wie bei den meisten Wischsaugern gilt: Hinlegen ist nicht, dann könnte Wasser auslaufen. Stattdessen steht der Sauger nicht nur in der Ladeschale, sondern auch außerhalb selbstständig, sobald man den Wischkopf in 90-Grad-Stellung zum Korpus bringt. Dann läuft im Betrieb zwar der eigentliche Motor weiter, die Wischbürste bleibt aber stehen. Sie könnte sonst den Sauger aufrecht durchs Zimmer ziehen – an dieser Stelle ungewollt, beim Wischen selbst hilft dieser Vorwärtsdrang allerdings ungemein.
Denn übermäßig handlich ist der Dreame H11 Max mit seinem Gesamtgewicht von fast 4,7 kg (inklusive Wasser) nicht. Der beständige Zug nach vorn macht das Gewicht aber schnell vergessen. Durch das leichtgängige Gelenk zwischen Saugkopf und Korpus lässt sich der Wischsauger zudem gut lenken. Probleme gibt es bestenfalls, wenn man unter Möbeln wie Bett oder Sofa wischen will. Hier macht der wuchtige Körper des Dreame H11 Max einen Strich durch die Rechnung – je nach akrobatischer Übung des Nutzers sind hier nur einige wenige Zentimeter Unterfahrt möglich. Auch an den Rand wie an Möbelstücke oder die Fußbodenleiste kommt man nicht ganz heran. Bauartbedingt sorgt die seitliche Halterung der Wischrolle dafür, dass an beiden Seiten rund 1 Zentimeter zum Rand trocken bleibt.
Die beiden Wasserbehälter lassen sich leicht mit einem Knopfdruck entfernen und ebenso leicht wieder einsetzen. Sie verfügen beide über Sensoren, die den Wischsauger erkennen lassen, wann der eine voll oder der andere leer ist. Dann zeigt der H11 Max entsprechende Symbole auf seinem großen Display und verweigert die Arbeit. Dank Ventilen laufen die Behälter auch außerhalb des Gerätes nicht aus.
Das Display zeigt neben diversen Fehlermeldungen in erster Linie zentral den Ladestand des Akkus an, außerdem einen farbigen Kreis ringsherum. Der zeigt in grün, gelb und rot die aufgewendete Saugleistung des Wischsaugers. Der erkennt Verschmutzung nämlich selbstständig und passt die Leistung entsprechend an – einer der großen Unterschiede zum Dreame H11 ohne Max im Namen, der zudem weniger Saugleistung und einen schwächeren Akku hat.
Das Display ist kein Touchscreen, einstellen kann man darauf also nichts. Etwas schade ist der Umstand, dass das Display ausschließlich auf den Nutzer ausgerichtet ist. Während sich der Wischsauger in der Ladeschale befindet, die im Normalfall in einer Raumecke oder zumindest an einer Wand stehen dürfte, ist der Ladezustand dadurch „auf dem Kopf“ dargestellt. Eine Drehung wie bei den Akkusaugern Roborock H6 Adapt (Testbericht) oder H7 (Testbericht) wäre hier das Tüpfelchen auf dem i gewesen. Als weitere Informationsquelle verwendet der Dreame H11 Max zudem Sprachansagen. Die lassen sich anhand eines kleinen gummierten Knopfes durch langes und kurzes Drücken auf der Rückseite des Gerätes von Englisch auf Deutsch umstellen, außerdem darf hier auch die Sprachlautstärke justiert werden. Ob man nun tatsächlich von seinem Akkusauger vollgequatscht werden will, bleibt dabei jedem selbst überlassen – auch komplettes Abstellen der Sprachaussage ist möglich.
Die Reinigungsleistung des Dreame H11 Max empfanden wir im Test als hervorragend. Natürlich erreicht man mit Schrubber und Wischlappen mehr – bei Bedarf können Nutzer hier punktuell einfach deutlich mehr Kraft aufbringen. In Verbindung mit der automatischen Schmutzerkennung und der entsprechenden Anhebung der Reinigungskraft konnten wir eingetrockneten und flüssigen Schmutz problemlos entfernen. Manchmal ist es dafür allerdings notwendig, ein zweites Mal oder einfach langsamer über eingetrocknete Stellen zu fahren. Ansonsten fehlt es einfach an Anpressdruck. Ganz perfekt arbeitet die Schmutzerkennung für unseren Geschmack dabei nicht, was wegen des Fehlens manueller Eingriffsmöglichkeiten bisweilen etwas nervt. Zudem kommt hin und wieder der bereits angesprochene Umstand zum Tragen, dass wegen der Halterung der Reinigungsbürstenrolle Wischen bis ganz an den Rand nicht möglich ist – das war auch beim Jimmy H8 Pro (Testbericht) so. Im Gegensatz zu dem führt der Dreame H11 Max dem Boden allerdings beständig und vor allem selbständig innerhalb des Saugkopfes Flüssigkeit zu, anstatt sie manuell vor den Kopf sprühen zu müssen. Insgesamt ist der H11 Max daher der bessere Wischer.
Der Akku mit seinen 4000 mAh hält nach Angaben des Herstellers „nur“ 36 Minuten am Stück durch. Selbst bei großer Wohnfläche sollte das aber nicht erreicht werden, wir brauchten für rund 80 Quadratmeter reine Wischfläche normalerweise nicht mehr als 20 Minuten. Die Dimensionierung der Wasserbehälter ist für 36 Minuten gut gewählt, Strom und Wasser gehen in etwa gleichzeitig zur Neige.
Zur Reinigung des Wischsaugers will der H11 Max in die Ladestation gestellt werden, daran erinnert er per Sprache. Anschließend startet ein längerer Druck auf die oberste Taste am Handgriff die Autoreinigung. Dabei füllt der Wischsauger die Ladeschale immer wieder mit Frischwasser aus dem Tank des Gerätes und spült so die Rolle sauber. Im Test kam es vor, dass hinterher etwas Wasser zurückblieb, was die Trocknung der Rolle verzögerte. Wichtig ist es außerdem, den Abwassertank nach jedem Gebrauch zu leeren und auszuspülen, da es sonst zu Geruchsbelästigung kommen kann. Das gilt auch für den Filter, der im Abwasserbehälter installiert ist.
Preis
Der Dreame H11 Max kostet ursprünglich um 500 Euro, inzwischen ist er deutlich günstiger zu haben.
Fazit
Muss ein Akku-Wischsauger wirklich sein? Wer sich diese Frage stellt, gehört vermutlich nicht zur Zielgruppe. Die hat am besten große Hartboden-Flächen im Haus, vielleicht schon einen guten Saug- und/oder Wischroboter und möchte – wenn es schon sein muss – so einfach und schnell wie möglich wischen. Das klappt mit dem Dreame H11 Max hervorragend.
Das Gerät ist ausreichend handlich, sieht schick aus, ist äußerst praktisch und erledigt seine Aufgabe, nämlich das Wischen, gut, ohne dem Nutzer Schweißperlen auf die Stirn zu zaubern. Leichte Abzüge in der B-Note gibt es nur für das Display, das im Ladeständer „auf dem Kopf“ steht, die schmalen, unerreichbaren Streifen an Raumecken und die fehlende manuelle Eingriffsmöglichkeit, wenn der Automatikmodus gerade doch nicht wie erwartet die Leistung anhebt. Insgesamt ist der H11 Max ein richtig gutes Gerät.
Proscenic Washvac F20
Proscenic Washvac F20
Der Wischsauger Proscenic Washvac F20 bietet große Tanks, einen wechselbaren Akku, er trocknet die Wischrolle nach Gebrauch und desinfiziert angeblich auch noch – wir erklären im Test, wie gut das funktioniert.
- wechselbarer Akku
- Trocknungsfunktion
- gutes Gesamtpaket
- etwas nerviges Motorgeräusch
Proscenic Washvac F20 im Test: Guter Saugwischer mit austauschbarem Akku und App
Der Wischsauger Proscenic Washvac F20 bietet große Tanks, einen wechselbaren Akku, er trocknet die Wischrolle nach Gebrauch und desinfiziert angeblich auch noch – wir erklären im Test, wie gut das funktioniert.
Proscenic bietet schon länger viel Technik für vergleichsweise wenig Geld, etwa Saugroboter und auch akkubetriebene Wischsauger. Das soll beim neuen Washvac F20 nicht anders sein. Der Wischsauger punktet mit großen Wassertanks, bietet als eines von sehr wenigen Modellen auf dem Markt einen wechselbaren Akku, hat eine Trocknungsfunktion für die Wischrolle und nutzt nicht nur LEDs zur Desinfizierung der Rolle während der Trocknung, sondern „stellt eine Sterilisationslösung her“, um damit anschließend zu wischen – so steht es zumindest im Handbuch. Was davon funktioniert und wie gut, klären wir im Test.
Lieferumfang
Der Saugwischer ist im Lieferkarton zweigeteilt, der Griff muss wie bei den Konkurrenten einmalig eingesteckt werden. Ansonsten gibt es die Lade- und Reinigungsschale samt separatem Netzteil, in dem ein zugekaufter Ersatzakku parallel geladen werden kann. Im Lieferumfang befindet sich aber nur ein Akku. Weiterhin gibt es eine Ersatz-Wischrolle und ein Reinigungswerkzeug, beides findet in der Ladestation Platz. Zudem sind zwei Ersatz-HEPA-Filter und eine wohlriechende Reinigungsflüssigkeit im Lieferumfang.
Design und Verarbeitung
Proscenic mag es düster: Der F20 ist aus schwarzem Kunststoff mit zylindrischem, aber „zusammengedrücktem“ Korpus, der von oben betrachtet oval aussieht. Dort ist entsprechend kein rundes, sondern ein mehr oder weniger ovales LCD zur Angabe wichtiger Informationen wie Akkustand und gewähltem Modus eingebaut.
Aufgelockert wird das schwarze Gehäuse durch transparenten Kunststoff für Frisch- und Abwassertank vorn und hinten sowie einige hellgraue Elemente. Vorn steht zudem eine Art Griff aus dem Korpus hervor, mit dessen Hilfe der Abwassertank leicht entfernt werden kann. Der Akku wird auf der Rückseite zwischen Griffstück und Frischwassertank in das Gerät gesteckt und fügt sich dort nahtlos ein. Hinten gibt es zudem einen Knopf, über den die Sprache der Sprachausgabe eingestellt werden kann, alternativ lässt sich der Wischsauger auch ganz stumm schalten.
Der Handgriff ist größentechnisch nicht ganz so ausladend wie bei der Konkurrenz, fasst sich aber nicht schlechter an und bietet die gleichen Tasten wie bei vielen Wettbewerbern: An/Aus, Selbstreinigung und Moduswahl. Positiv ist der Bürstenkopf zu erwähnen. Er ist einige Millimeter niedriger als bei anderen Wischsaugern, dadurch kam er im Testhaushalt unter einige Möbel, unter die andere Geräte nicht kamen.
Die generelle Verarbeitung ist ordentlich, allerdings fiel uns beim ersten Befüllen des Frischwassertanks die Dichtung des Verschlusses entgegen und musste von uns eingesetzt werden. Ganz dicht ist der Tank dann aber auch nicht, wie bei den meisten Konkurrenten darf man den Wischsauger darum nicht zu weit nach unten in die Horizontale neigen. Die nicht richtig aufgebrachte Dichtung lässt uns allerdings an der Aussage auf einem Aufkleber zweifeln, dass alle Geräte vor Auslieferung getestet werden – das wäre dann nämlich sofort aufgefallen.
Alle Bilder zum Proscenic Washvac F20 im Test
Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Proscenic Washvac F20

Funktion und Reinigungsleistung
Ein kurzer Druck auf den Power-Button und die wilde Fahrt geht los. Der F20 zieht sich dank der Rollenbewegung selbst vorwärts, allerdings ist dieser Vorwärtsdrang weniger ausgeprägt als bei manchem Wettbewerber. Wir finden das angenehm – er entlastet den Nutzer, ohne dass der den Wischsauger krampfhaft im Zaum halten muss.
Im Betrieb finden wir allerdings das Geräusch des Gebläsemotors nicht ganz so angenehm wie bei manchem Konkurrenten, es ähnelt eher einem hohen Pfeifen, ohne jedoch störend zu sein. Auffällig ist der Umstand, dass der F20 schon deutlich vor vollem Aufrichten die Rolle anhält und die Absaugleistung erhöht, weil er davon ausgeht, gleich abgestellt zu werden. Das machen anderen Modelle erst, wenn ein spürbarer Widerstand beim Aufstellen überwunden wurde. Außerdem wirkt der F20 in Bezug auf Richtungswechsel nicht ganz so leichtfüßig wie einige Konkurrenten, bleibt aber trotzdem gut handhabbar. An die Wand kommt er bauartbedingt nicht ganz heran, einen schmalen Bereich von 8 Millimeter zum Rand wischt er nicht. Das ist allerdings bei den meisten Modellen so, seltene Ausnahme ist hier etwa der Roborock Dyad (Testbericht).
Der Proscenic Washvac F20 bietet mehrere Wischmodi: Der Smart-Modus regelt Wasserzufuhr und Saugleistung eigenständig, der Max-Modus maximiert beides, im Wasserabsorptionsmodus saugt der F20 ausschließlich Flüssigkeit auf und im Sterilisationsmodus wird es ganz wild. Hierzu schreibt der Hersteller: „Im Sterilisationsmodus stellt dieses Gerät eine Sterilisationslösung her und arbeitet dann im Smart-Modus“. Wie genau das geht, verrät Proscenic nicht, entsprechend halten wir das bestenfalls für einen Übersetzungsfehler oder Marketing-Gewäsch. Die unterschiedlichen Wischmodi werden auf dem gut ablesbaren Display angezeigt.
Frisch- und Abwassertank sind beim F20 mit je einem Liter im Vergleich zu den Wettbewerbern ziemlich groß. Nicht gefallen hat uns allerdings die Einfüll-Öffnung des Frischwassertanks, die ein fast horizontales Halten des langgezogenen Tanks unter dem Wasserhahn erfordert. Der Abwassertank wird hingegen oben geöffnet und trennt Flüssigkeit ausreichend effektiv von festen aufgesaugten Bestandteilen. Allerdings wird der abnehmbare obere Teil des Tanks zum Entleeren nur von einer Gummidichtung gehalten. Bei unserem Testgerät war sie anfangs aufgrund längerer Nichtnutzung „festgeklebt“ und ließ sich nur mit viel Kraft entfernen. Kaputtgegangen ist dabei aber nichts.
Die Selbstreinigung funktioniert wie bei fast allen Wischsaugern mit demselben Feature: Gerät in Ladeschale stellen, entsprechenden Knopf drücken und der F20 legt los. Der Wassertank sollte dazu ausreichend gefüllt sein, der Abwassertank ausreichend leer. Der Wischsauger spitzt Frischwasser in die Ladeschale und säubert anschließend die Rolle durch Drehung in diesem Wasserbecken. Die trübe Brühe, die sich nach dem Absaugen im Abwassertank sammelt, ist ein deutliches Zeichen für die Wirksamkeit des Wisch- und Reinigungsvorgangs. Anschließend trocknet der F20 die Rolle mit eingeblasener kalter Luft und „sterilisiert“ sie gleichzeitig mit vier UV-LEDs. Ob das wirklich viel bringt, konnten wir im Test nicht überprüfen, allerdings zweifeln wir das stark an. Denn die LEDs leuchten nur eine Seite der Rolle an, die beim Trocknungsvorgang offenbar nicht gedreht wird.
Die Wischleistung des Proscenic Washvac F20 bewegt sich auf dem Niveau der anderen bislang getesteten Wischsauger mit einer Wischrolle. Die verwendete Wassermenge ist dabei unauffällig – man sieht einen deutlichen Feuchtigkeitsfilm, der aber schnell wieder abtrocknet und so auch auf empfindlichem Laminat oder Parkettboden keine Beschädigungen verursachen sollte.
Als Akkulaufzeit gibt der Hersteller 20 bis 45 Minuten an, die komplette Reinigung einer Wohnfläche von rund 140 Quadratmetern sollte erfahrungsgemäß im Smart-Modus kein Problem sein. Zu sehr sollte man den Akku nicht entleeren, da dann anschließend keine Selbstreinigung mehr durchgeführt werden kann. Ein Ersatzakku kostete zum Testzeitpunkt etwa 50 Euro, ein zweiter Akku kann in der Ladestation parallel geladen werden. So lässt sich nicht nur die Laufzeit verdoppeln, sondern außerdem später ein defekter oder ermüdeter Akku problemlos austauschen.
Der Proscenic Washvac F20 lässt sich mit der aktuellen Proscenic-App verbinden, über die auch aktuelle Saugroboter des Herstellers gesteuert werden. Die Verbindung ist einfach und funktionierte direkt. Allerdings sind wir von der Sinnhaftigkeit einer App für einen Wischsauger wie schon beim Tineco Floor One S3 (Testbericht) mäßig überzeugt. Denn in der App sieht der Nutzer in erster Linie den „Zustand“ von Tanks und Wischrolle, überdies den Akkuladestand. Aktivieren lässt sich darüber noch die Selbstreinigungsfunktion – warum man das allerdings hier und nicht direkt nach dem Wischvorgang am Gerät tun sollte, erschließt sich uns nicht. Da halten wir eine Nutzungsübersicht für sinnvoller, wenngleich auch alles andere als notwendig.
Preis
Der Proscenic Washvac F20 war ganz zu Anfang der Verfügbarkeit mit diversen Rabattcodes offenbar für unter 300 Euro erhältlich, inzwischen kostet er bei großen Händlern um 400 Euro.
Fazit
Der Proscenic Washvac F20 überzeugt im Test mit viel Ausstattung und guter Funktion, auch wenn nicht alles glaubhaft erscheint. So vermuten wir, dass die UV-LEDs bei der Trocknung der Wischrolle nur bedingt effektiv gegen Bakterien ist und die Funktion, bei der der F20 angeblich eine Sterilisationslösung „herstellt“, zweifeln wir stark an.
Der Rest ist vorbildlich: Design und Verarbeitung gefallen uns, die Wischleistung ist gut und die Akkuleistung ebenfalls. Besonders positiv finden wir den Wechselakku samt Möglichkeit, einen Zweiten in der Station zu laden. Schade, dass keiner im Lieferumfang dabei ist. Auch die Trocknung der Wischrolle per Luftstrom finden wir praktisch, auch wenn sie recht laut und auf Dauer nervig ist. Die App ist hingegen eher eine Spielerei. Dennoch schlägt sich der F20 gut und ist eine Bereicherung für den Haushalt – wie alle bislang von uns getesteten Wischsauger.
Jashen F16
Jashen F16
Wischsauger reinigen selbstständig die Wischrolle, die Trocknung übernimmt aber die Zeit. Beim Jashen F16 wird das deutlich beschleunigt, das Modell kommt mit Trocknungsfunktion und mehr.
- Wechselakku und 2. Akku im Lieferumfang
- Trocknungsfunktion
- gute Wischleistung
- kommt nicht ganz bis an Rand
Saugwischer Jashen F16 im Test: Einfach durchwischen mit Akku für 350 Euro
Wischsauger reinigen selbstständig die Wischrolle, die Trocknung übernimmt aber die Zeit. Beim Jashen F16 wird das deutlich beschleunigt, das Modell kommt mit Trocknungsfunktion und mehr.
Akku-Saugwischer sind zwar noch weitestgehend unbekannt, aber extrem hilfreich. Denn wer „mal eben schnell“ durchwischen oder ein verschüttetes Malheur feucht entfernen will, muss nicht mehr Eimer, Wischlappen und Schrubber bemühen, sondern wischt auf Knopfdruck. Ganz von allein und dadurch noch einfacher geht das nur mit dedizierten Wischrobotern wie dem sehr guten Dreame Bot W10 (Testbericht). Dafür ist man mit einem Wischsauger schneller, das Tempo bestimmt in erster Linie der eigene Einsatz.
Vermutlich noch unbekannter als Wischsauger dürfte in Deutschland der chinesische Hersteller Jashen sein. Der kurz F16 benannte Akku-Saugwischer des Herstellers bietet neben den typischen, teilweise oben beschriebenen Vorteilen eines Wischsaugers zwei Highlights: Einen Zweitakku zum Wechseln im Lieferumfang und eine Trocknungsfunktion, die Geruchsbildung vorbeugt und das Gerät hygienischer als die Konkurrenz machen soll. Wir haben das im Test überprüft.
Lieferumfang
Der Saugwischer selbst muss noch durch Einstecken des Griffs komplettiert werden, anders hätte er nicht in den Lieferkarton gepasst. Hinzu kommt die typische Lade- und Selbstreinigungsschale, in der der Wischsauger nach Gebrauch aufrecht steht. Als Dreingaben gibt es einen Zweitakku, Reinigungsflüssigkeit und eine Reinigungsbürste, die wie eine Flaschenbürste geformt ist.
An die Ladestation lässt sich eine Aufbewahrungs- und Ladeschale für den Zweitakku andocken, außerdem eine „Halterung“ für die Bürste. Letztere Aufnahme ist aber für ihre Funktion völlig ungeeignet, weshalb die Bürste vermutlich früher oder später verloren gehen wird. Schade, denn neben Bürstenfunktion beherbergt sie im Inneren des Griffs noch Werkzeug zur Haarentfernung.
Design
Hersteller Jashen entscheidet sich für fast ausschließlich schwarzen Kunststoff beim F16, der lediglich oben um die Akkus herum und unten an der Rollenbürste durch blau eloxierte Akzente aufgelockert wird. Zudem ist die Innenseite des Handgriffes im gleichen Hellgrau ausgeführt, wie die Hersteller-Schriftzüge sowie die Funktionsbeschriftungen auf den Bedienknöpfen des Gerätes. Beim grundsätzlichen Aufbau sowie bei der Form des Handgriffs wählt Jashen das gleiche Design wie fast alle Konkurrenzprodukte, darunter etwa Dreame H11 Max (Testbericht) oder Tineco Floor One S3 (Testbericht). Im Gegensatz zum H11 Max ist der Korpus aber weniger monolithisch, stattdessen wird das Gehäuse mit integriertem Frisch- (800 ml) und Abwassertank (600 ml) in der Mitte dicker.
Der restliche Aufbau ist weitestgehend gleich: Die Tanks werden nach vorn entnommen und verfügen dafür über die gleichen Mechanismen wie die Konkurrenz, zudem sind die Tanks mit Sieb und Filter ausgestattet, damit das Innenleben des Wischsaugers nicht beschädigt wird.
Alle Bilder zum Saugwischer Jashen F16 im Test
Jashen F16

Jashen F16

Jashen F16

Jashen F16

Jashen F16
Jashen F16
Jashen F16

Jashen F16

Jashen F16

Jashen F16

Jashen F16

Jashen F16

Jashen F16

Jashen F16

Jashen F16

Jashen F16

Ein wichtiger Unterschied betrifft den Akku: Er bildet mit dem wie bei den Wettbewerbern nach oben gerichteten Display eine Einheit und lässt sich mit einem Knopfdruck tauschen. Bei der Konkurrenz sind die Akkupacks fest eingebaut. Zwar dürfte ein Ersatzakku wegen des integrierten Displays teuer sein, aber immerhin ist ein Wechsel bei einem Defekt oder altersbedingter Ermüdung möglich. Die Verarbeitungsqualität bietet trotz der fast ausschließlichen Verwendung von Kunststoff keinen Grund zur Beanstandung.
Funktion und Reinigungsleistung
Wie die anderen bislang von uns getesteten Akku-Wischsauger abgesehen vom Roborock Dyad (Testbericht) steht auch der Jashen F16 von allein, sobald man einen kleinen Widerstand im unteren Saugkopf-Gelenk überwunden hat und das Gerät aufrecht ausrichtet. Die Rolle, die beim Wischen durch ihre Drehbewegung für leichten Vorwärtsdrang sorgt, steht dann still. Nachdem der Saugmotor kurz deutlich hörbar sie Leistung erhöht, geht er aus und will anschließend erst wieder manuell aktiviert werden. Ein entsprechender Warnhinweis zum Abbruch des Wischvorgangs beim Aufstellen befindet sich in Form eines Aufklebers am Handgriff. Hinlegen darf man auch den Jashen F16 wie die Konkurrenzprodukte nicht, da Wasser auslaufen könnte.
Wer bislang nur einen Handwischer gewohnt war, wird sich anfangs über das etwas steife Handling des fast 5 kg schweren Akku-Wischmops wundern. Zudem kommt man mit dem F16 wegen des im Vergleich zum ansonsten vielleicht gewohnten Saugrohr eines Bodenstaubsaugers dicken Gehäuses kaum unter Möbel. Erschwerend kommt hinzu, dass der Bürstenkopf nur maximal 65 Grad angewinkelt werden kann und danach einfach den Kontakt zum Boden verliert. Sowohl Handlichkeit als auch die Einschränkung beim Wischen unter Möbeln ist derzeit allerdings allen Akku-Wischsaugern gemein und kann daher dem F16 nicht zum Vorwurf gemacht werden. Ebenfalls wie bei fast allen anderen Wischsaugern auf dem Markt: Die Wischrolle kommt wegen ihres Halterungsmechanismus nicht bis an den Rand. Stattdessen muss man mit einem trockenen (und ungewischten) Bereich von 1 bis 2 Zentimeter am Rand leben. Derzeit macht das nur der Roborock Dyad (Testbericht) mit seinen zwei Rollenreihen besser.
Die gesamte Bedienung des Jashen F16 ist mit den Modellen der Konkurrenz weitgehend identisch. Eine Sprachansage des Wischsaugers gibt es allerdings nicht, was wir auch nicht vermisst haben. Etwas mager ist das LCD ausgestattet. Es zeigt die verbleibende Akkuleistung nur in drei Schritten an, außerdem gibt es Anzeigen für die Bürstentrocknung, den Turbomodus, leeren Frisch- oder vollen Abwassertank sowie ein Fehlerhinweis bei Problemen mit der Wischrolle. Etwas erschreckend: Die Entnahme eines der beiden Tanks im laufenden Betrieb bemerkt der Wischsauger nicht – das kann schnell zu einer Sauerei führen.
Die Selbstreinigung nach dem Wischen funktioniert wie bei anderen Wischsaugern auf Knopfdruck. Dann spült der Jashen F16 die schmutzige Wischrolle mit Frischwasser in der Ladeschale durch. Das dauert rund 2 Minuten. Anschließend springt die Lufttrocknung der Rolle an. Zu hören ist ein konstantes Rauschen, was aufgrund seiner Frequenz nicht wirklich nervig ist, aber wegen der Lautstärke doch störend sein kann. Zu allem Überfluss startet diese rund 3 Stunden dauernde Prozedur auch dann, wenn der Wischsauger nur kurz ohne Gebrauch aus der Ladeschale gehoben und direkt wieder zurückgestellt wurde. Abbrechen lässt sich diese Funktion ebenfalls nicht – zieht man den Stecker und steckt ihn danach wieder ein, beginnt die Lüftung von vorn. Den Abwassertank sollte man nach einem gründlichen Wischdurchgang händisch ausspülen, um Geruchsbelästigung zu vermeiden.
Die Wischleistung des Jashen F16 bewegt sich auf dem Niveau der anderen bislang getesteten Wischsauger mit einer Wischrolle. Die verwendete Wassermenge ist dabei in Ordnung – man sieht einen deutlichen Feuchtigkeitsfilm, der aber schnell wieder abtrocknet und so auch auf empfindlichem Parkettboden keine Beschädigungen verursachen sollte. Wer hier auf Nummer sicher gehen will, aktiviert den Turbo-Modus mit stärkerer Saugleistung. Auffällig ist vor allem die langsam hochtourende Wischrolle. Das erinnert an das Hochlaufen eines Triebwerks und es dauert über 15 Sekunden, bis die normale Umdrehungsgeschwindigkeit erreicht ist. Gewisse Parallelen zu einer Turbine ergeben sich auch bei der Lautstärke im Betrieb. Anfänglich bewegt die sich bei rund 66 Dezibel in 1 Meter Abstand, sie wächst im Normalbetrieb auf über 68 Dezibel an. Im Turbobetrieb, bei dem die Absaugleistung erhöht wird, haben wir 72 Dezibel gemessen. Die Angabe von bis zu 78 Dezibel konnten wir zum Glück nicht verifizieren. Das schlafende Kind weckt man damit – wie mit einem Akkusauger oder anderen Wischsaugern auch – trotzdem auf.
Der Akku des Jashen F16 leistet 2500 mAh, das ist im Vergleich zu anderen Modellen der Konkurrenz ziemlich wenig. Dennoch verspricht der Hersteller bis zu 35 Minuten Reinigungszeit, die dank des beiliegenden Zweitakkus verdoppelt werden kann. Im Test geht vor dem Akku der Frischwassertank zuneige, der Akku hielt tatsächlich über 25 Minuten durch. Damit wischt man problemlos ein ganzes Haus. Wer mit zwei Akkus nicht auskommt, wohnt vermutlich in einem Schloss.
Die meisten werden sogar mit einem Akku auskommen und können daher auch zum Jashen F12 greifen. Neben dem Zweitakku fehlt dem allerdings auch die Trocknungsfunktion.
Preis
Der Jashen F16 wird hierzulande für 349 Euro verkauft.
Fazit
Mit zwei Wechselakkus und der Trocknungsfunktion bietet der Jashen F16 echten Mehrwert. Denn die Möglichkeit zum Akkutausch bei gleichzeitiger Ladung in der Ladeschale verdoppelt nicht nur die Reinigungszeit, sondern ist auch im Falle von Defekten oder Ermüdungserscheinung des Stromspenders hilfreich.
Das gilt auch für die Trocknungsfunktion. Sie sorgt dafür, dass die Wischrolle bereits nach rund 1,5 Stunden trocken ist und nicht stundenlang vor sich „hingammelt“ – das beugt Bakterien und damit Geruchsbildung vor. Etwas nervig ist hier allerdings die Tatsache, dass diese Funktion nicht ab- oder unterbrochen werden kann – jedes Entfernen des Wischsaugers sorgt nach dem Wiedereinstellen für den Start der dreistündigen Prozedur, die durchaus hörbar ist.
Die Wischleistung ist auf dem Niveau der Konkurrenz – mit allen beschriebenen Vor- und Nachteilen. Der F16 ist eine gute Wahl – vor allem, wenn die Wischfläche groß ist. Alternativen sind der bereits erwähnte Dreame H11 Max (Testbericht) oder der Tineco Floor One S3 (Testbericht) mit App – beide Modelle sind minimal günstiger, natürlich ohne Zweitakku.
Dyson V15s Detect Submarine
Sauger mit Wischaufsatz
Dyson V15s Detect Submarine
Dyson ist berühmt für seine guten Akkusauger, das Thema Wischen hat das Unternehmen bislang ausgeklammert. Der erste Versuch heißt Submarine – ob der untergeht oder einschlägt, verrät der Test.
- hervorragender Akkusauger
- viel Zubehör für Sauger
- gute Akkuausdauer beim Wischen
- Wischaufsatz sehr teuer, da nur mit Sauger zu kaufen
- keine Selbstreinigung
- keine Saugfunktion für Flüssigkeiten
- nur für kleine Mengen Schmutz
- keine Selbsttrocknung
Dyson V15s Detect Submarine: Dieser Wischaufsatz geht im Test unter
Dyson ist berühmt für seine guten Akkusauger, das Thema Wischen hat das Unternehmen bislang ausgeklammert. Der erste Versuch heißt Submarine – ob der untergeht oder einschlägt, verrät der Test.
Bei den Akkusaugern ist der Dyson V15 Detect (Testbericht) das Topmodell. In unserer Top 5 der besten Akkusauger ist das Gerät auf dem ersten Platz gelandet. Wischen war hingegen nicht das Thema des Unternehmens, dabei sind die besten elektrischen Akkuwischer eine echte Arbeitserleichterung. Was liegt da also näher, als das Topmodell V15 mit einem neuen Wischaufsatz zu kombinieren? Das scheint sich zumindest Dyson gedacht zu haben und wir wollen im Test wissen, ob das nur in der Theorie oder auch in der Praxis wirklich eine so gute Idee ist.
Highlights: Was sind die Stärken des Dyson V15s Detect Submarine?
- Wischen und Saugen mit einem Gerät möglich
- Wischaufsatz mit eigenem Frisch- und Schmutzwassertank
- starke Akkulaufzeit beim Wischen
- sehr flexibel dank Gelenk am Wischaufsatz
Den Submarine-Wischaufsatz gibt es nicht einzeln zu kaufen. Stattdessen kostet die Kombi aus dem bekannten Dyson-Akkusauger und dem Aufsatz als V15s Detect Submarine derzeit mit dem Code POWEREBAY3 ab knapp 747 Euro.
Aufbau & Lieferumfang: Wie funktioniert der Dyson V15s Detect Submarine?
Es wurde bereits angedeutet: Beim Dyson V15s Submarine handelt es sich um den sehr guten Akkusauger Dyson V15 Detect (Testbericht), der um einen Wischaufsatz erweitert wurde. Auf den Sauger gehen wir daher in diesem Test nur teilweise ein, wer mehr dazu wissen will, sollte einen Blick in den Einzeltest werfen. Stattdessen schauen wir uns die relevanten Dinge am V15s-Paket an.
Das Wichtigste zuerst: Den Wischaufsatz gibt es nicht einzeln zu kaufen, sondern nur im Paket mit dem Akkusauger als V15s Detect Submarine. Entsprechend liegt im Paket alles, was man zum Staubsaugen und eben Wischen benötigt. Neben dem Akkusauger selbst sind das zwei Bodendüsen, eine Fugendüse, eine 2-in-1-Bürste, eine Haar-/Milbenbürste, ein Netzkabel, die Ladestation sowie die Aufbewahrungsschale für den Wischaufsatz und der Aufsatz selbst.
Der ist exklusiv für den V15s entwickelt worden und funktioniert nicht mit anderen V15-Modellen. Dyson begründet das mit einer speziell angepassten Software. Aber man wird den Verdacht nicht los, dass da vielleicht doch eher monetäre Gründe im Vordergrundstehen – ein komplett neuer Sauger bringt natürlich deutlich mehr Geld als ein einzelner Wischaufsatz … Fakt ist, dass der Wischaufsatz nicht am herkömmlichen V15 funktioniert. Er lässt sich dort zwar mechanisch problemlos anbringen, allerdings schaltet der normale V15 die Saugleistung nicht ab und meldet sofort eine „verstopfte Düse“. Montiert man den Aufsatz hingegen wie angedacht an den V15s, zeigt das Display ein entsprechendes Symbol und die Saugleistung wird abgeschaltet und lässt sich auch nicht mehr regulieren.
Saugen: Wie gut saugt der V15s Detect ohne Wischaufsatz?
In aller Kürze: Beim Staubsaugen überzeugt der V15s auf ganzer Linie, schließlich steckt in ihm die Technik des sehr guten V15 Detect (Testbericht). Die praktische Bodendüse mit grünem „Laserlicht“ zur besseren Stauberkennung sowie die hohe Saugleistung sind auch hier mit an Bord.
Leider hat Dyson keine weiteren Verbesserungen am V15 vorgenommen. Nach wie vor muss beim Saugen die Abzugstaste durchgehend gedrückt werden und die nicht gerade elegante Wandhalterung wurde ebenfalls vom V15 übernommen.

Wischen: Wie gut wischt der Submarine-Aufsatz?
Der namensgebende Wischaufsatz des V15s Submarine ist ein in sich geschlossenes System. Es gibt keine Saugkraft vom Sauger, sondern der versorgt die motorgetriebene Wischrolle lediglich mit Strom. Die drehende Wischbürste wird dann kontinuierlich mit Frischwasser aus dem in den Aufsatz integrierten Tank benetzt, während Schmutz und überschüssige Flüssigkeit von der rotierenden Walze in den Auffangbehälter befördert werden.
Durch dieses einfache System ist die Akkulaufzeit beim Wischen deutlich länger als beim Saugen. Der Nachteil: Vor dem Wischen sollte auf jeden Fall gesaugt werden, da die Wischbürste nur sehr leichte Verschmutzungen aufnimmt, schwere Partikel werden einfach zur Seite geschoben. Hartnäckige Verschmutzung löst der Wischaufsatz von Dyson nur widerwillig. Helfen könnte die Verwendung von Reinigungsmitteln. Hierzu macht Dyson aber keine konkreten Angaben, in welcher Dosierung dies möglich wäre. Außerdem sollte man grobe Verschmutzungen besser per Hand entfernen, bevor man mit dem V15s wischt.
Die Reinigungsleistung des Wischaufsatzes geht insgesamt in Ordnung. Leichte und frische Verschmutzungen nimmt er zuverlässig auf, bei eingetrockneten Flecken muss man mehrmals über die Stelle wischen. Schwierig wird es bei größeren Mengen Schmutz. Wer mal eben das verschüttete Müsli mit Haferflocken aufwischen will, bekommt schnell die Grenzen des Submarine-Aufsatzes aufgezeigt. Denn die Wischrolle bleibt dann mangels Kraft einfach stehen, da der Schmutz nicht in den Abwassertank befördert werden kann.
Da überschüssige Feuchtigkeit generell nicht abgesaugt wird, trocknet der Boden nur langsam. Das könnte auf Holzboden problematisch sein und macht ein vollwertiger Saugwischer deutlich besser – sowohl bei der Reinigungsleistung als auch bei der Wassermenge. Unpraktisch ist zudem die Reinigung des Wischaufsatzes. Der Schmutzwassertank ist offen und kann bei zu hektischer Bewegung theoretisch überschwappen, die Rolle muss von Hand ausgewaschen und der komplette Aufsatz inklusive Rolle vor dem Zusammenbau getrocknet werden. Das ist nach jedem Wischen ein nicht unerheblicher Aufwand. Auch hier sind gute Saugwischer wesentlich unkomplizierter. Positiv: Der Dyson V15a Detect Submarine ist etwas handlicher als die meisten Saugwischer und mit ihm kommt man auch unter Möbel, da er sich fast ganz ablegen lässt, ohne dass sich der Wischkopf vom Boden abhebt.
Alle Bilder zum Dyson V15s Detect Submarine im Test
Dyson V15s Detect Submarine

Dyson V15s Detect Submarine

Dyson V15s Detect Submarine

Dyson V15s Detect Submarine

Dyson V15s Detect Submarine

Dyson V15s Detect Submarine

Dyson V15s Detect Submarine

Dyson V15s Detect Submarine
Dyson V15s Detect Submarine

Preis: Wie viel kostet der Dyson V15s Detect Submarine?
Den Submarine-Wischaufsatz gibt es nicht einzeln zu kaufen. Stattdessen kostet die Kombi aus dem bekannten Dyson-Akkusauger und dem Aufsatz als V15s Detect Submarine mit dem Code POWEREBAY3 derzeit knapp 750 Euro. Bei iBood ist das Modell aktuell für 699 Euro erhältlich.
Fazit
Der Dyson V15s Detect Submarine ist in erster Linie ein sehr guter kabelloser Staubsauger, der zusätzlich halbwegs akzeptabel wischen kann. Der spezielle Wischaufsatz ist für einfaches Staubwischen oder die regelmäßige Feuchtreinigung geeignet, da dann nur wenig Schmutz aufkommen sollte. Mit hartnäckigen Flecken wird er aber nur bedingt fertig, mit größeren Mengen Schmutz gar nicht.
Für regelmäßige Nutzung ist aber die Handhabung des Wischaufsatzes zu umständlich. Er muss nach jedem Einsatz aufwendig zerlegt, gereinigt und getrocknet werden. Praktische Features wie ein geschlossener Schmutzwassertank oder eine Absaugung überschüssiger Feuchtigkeit fehlen. Einen vollwertigen Kombi-Nass-Trockensauger ersetzt der V15s Detect Submarine also nicht, zum Wischen ist man mit einem spezialisierten Gerät, das Schmutzwasser einsaugt und über praktische Features wie eine Absaugstation mit aktiver Trocknungsfunktion verfügt, deutlich besser bedient.
Wer also Dyson will, sollte sich aufs Saugen beschränken und für rund 588 Euro den „normalen“ V15 Detect (Testbericht) kaufen und sich nach einem ordentlichen, zusätzlichen Saugwischer umschauen. Die fast 200 Euro Aufpreis für den Wischaufsatz sind unserer Meinung nach nicht gerechtfertigt.
Tineco Floor One S5 Combo
Tineco Floor One S5 Combo
Der Tineco Floor One S5 Combo ist ein multifunktionaler Akkuwischsauger, der sowohl als Nass-Trocken-Sauger als auch als Handstaubsauger verwendet werden kann. In unserem umfassenden Test haben wir das Gerät auf Herz und Nieren geprüft.
- Handstaubsauger und Saugwischer in einem Gerät
- sehr gute Wischleistung
- viel Ausstattung
- mit App
- keine aktive Trocknungsfunktion
- Akku als Wischsauger mittelmäßig
- App überflüssig
Tineco Floor One S5 Combo im Test: Handstaubsauger und Wischsauger mit Akku
Der Tineco Floor One S5 Combo ist ein multifunktionaler Akkuwischsauger, der sowohl als Nass-Trocken-Sauger als auch als Handstaubsauger verwendet werden kann. In unserem umfassenden Test haben wir das Gerät auf Herz und Nieren geprüft.
Hersteller wie Dreame oder Roborock haben es längst geschafft, sich hierzulande einen Namen zu machen. Neben Saugrobotern (Bestenliste) bieten sie auch Akkusauger (Bestenliste) und Saugwischer mit Akku (Bestenliste) an. Tineco setzt ebenfalls auf eine Vielzahl an Produkten und die tauchen teilweise ebenfalls in unseren Bestenlisten auf, allerdings ist dieser Hersteller in Deutschland immer noch weniger bekannt. Zu Unrecht, wie unser Test des Tineco Floor One S5 Combo zeigt.
Was sind die Highlights am Tineco Floor One S5 Combo?
- vielseitige Anwendung als Wisch- und Handstaubsauger
- randlose Reinigung dank neuer Bürstenwalze
- benutzerfreundliches Design, einfacher Umbau und intuitive Handhabung
- Selbstreinigungsfunktion minimiert Wartungsaufwand
- App-Unterstützung, Überwachung und Steuerung per Smartphone
Der Tineco Floor One S5 Combo ist für rund 370 Euro im Handel zu bekommen.
Design: Wie gut ist die Verarbeitung des Tineco Floor One S5 Combo?
Der Tineco Floor One S5 Combo wirkt modern und hochwertig verarbeitet. Die Dichtungen und Verbindungen sind gut verarbeitet und robust. Der Tineco Floor One S5 Combo misst vom Boden bis zur Oberseite des Griffs 110 cm. Das Gewicht beträgt 3,8 kg, was durch die Bauweise des Geräts und die praktischen Rollen an der Unterseite kaum ins Gewicht fällt.
Das Gerät ist mit einem modernen LED-Display ausgestattet, das den Reinigungsprozess überwacht. Es zeigt Informationen wie Ladestand, Akkustand, Saugstufe und Reinigungsstatus an. Ein farbiger Ring gibt Auskunft über den Verschmutzungsgrad des Bodens. Der Display-Inhalt wird leider in Betrieb und auf der Ladestation nicht gedreht, sodass beim Laden die Angaben „auf dem Kopf stehen“. Zusätzlich verfügt der Tineco Floor One S5 Combo über eine Sprachausgabe, die den Nutzer über anstehende Wartungsaufgaben informiert.
Der Lieferumfang des Tineco Floor One S5 Combo ist umfangreich und enthält alles, was man für die Reinigung benötigt:
- Tineco Floor One S5 Combo
- Ladestation mit Halterung für das Zubehör
- Ersatz-Bürstenwalze
- Reinigungsbürste für die Bürstenwalze
- Ersatz-HEPA-Filter
- Reinigungsmittel
- Zubehör für den Umbau zum Handsauger (Staubbehälter, 2-in-1 Kombidüse, Fugendüse)
Alle Bilder zum Tineco Floor One S5 Combo im Test
Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Tineco Floor One S5 Combo

Wie einfach ist der Umbau zum Handsauger?
Der Tineco Floor One S5 Combo ist einfach in Betrieb zu nehmen. Der Griff wird in die dafür vorgesehene Öffnung gesteckt und der Wassertank aufgefüllt. Schon kann die Reinigung beginnen. Ein besonderes Highlight des Tineco Floor One S5 Combo ist die Möglichkeit, ihn in einen kompakten Handsauger umzubauen. Dies geht schnell und einfach in wenigen Handgriffen. Anfangs kann das etwas hakelig sein, mit etwas Übung klappt der Umbau aber problemlos. Als Handsauger überzeugte das Gerät im Test durchaus. Mit dem entsprechenden Aufsatz wie etwa der Fugendüse lässt sich Schmutz normalerweise ausreichend gut aus schwer zugänglichen Stellen entfernen. An einen echten Staubsauger mit Motorbürste kommt der Handsauger natürlich nicht heran.
Wie gut reinigt der Tineco Floor One S5 Combo?
Der Power-Knopf wird entgegen Dyson-Modellen automatisch festgestellt, sodass er nicht ständig gedrückt gehalten werden muss. Das Gerät lässt sich leicht und handlich durch den Raum bewegen und hat dabei durch die Wischrollendrehung einen leichten Zug nach vorn. Unter Möbel kommt man mit dem Tineco-Modell wie beim Großteil der Konkurrenz nur bedingt, da Wischkopf und Korpus nicht komplett gerade zueinander ausgestreckt werden können. Senkt man den Griff am Korpus zu weit ab, hebt sich entsprechend der Wischkopf vom Boden. Praktisch ist hingegen das gut ablesbare Display, das wichtige Informationen wie Akkuladung und Modus anzeigt. Die Tineco-App ist in unseren Augen hingegen eine nette, aber überflüssige Spielerei. Ihr größter Nutzen liegt darin, den Akkustand aus der Ferne abfragen zu können. Die Steuerung des Geräts per Smartphone halten wir hingegen für unpraktisch und daher unsinnig.
In unserem Test muss der Tineco Floor One S5 Combo eine Vielzahl von Verschmutzungen auf unterschiedlichen Bodenbelägen bewältigen. Dabei handelt es sich um trockenen Schmutz wie Sand, Haferflocken sowie feuchten Schmutz wie Ketchup, Ei und Müsli mit Milch auf Fliesen und Laminat. Das Gerät verfügt über einen Automatikmodus und einen Max-Modus. Im Automatikmodus erkennt der Wischsauger den Verschmutzungsgrad und passt die Saugleistung entsprechend an.
Der Akkuwischsauger entfernt im Test trockenen Schmutz wie Haferflocken oder Sand ohne Probleme. Auch flüssige Verschmutzungen stellen den Tineco Floor One S5 Combo vor keine Probleme. Sowohl feuchter Schmutz als auch eingetrocknete Flecken wurden mühelos entfernt, nach wenigen Durchgängen glänzte der Boden wie neu.
Dank der im Vergleich zum Vorgänger verbesserten Bodenwalze, die nahezu bis in die Ecken reicht, erzielt der Tineco Floor One S5 Combo auch entlang der Kanten sehr gute Ergebnisse. In unserem Test erreicht der Tineco Floor One S5 Combo eine Lautstärke von etwa 75 Dezibel, was in etwa der Lautstärke einer Waschmaschine entspricht und ähnlich wie bei der Konkurrenz ist.
Die Wartung des Tineco Floor One S5 Combo ist unkompliziert. Nach der Reinigung sollten Wassertanks gespült, Filter gewaschen und die Bürstenwalze gereinigt werden. Das Gerät verfügt über eine Selbstreinigungsfunktion, die den Wartungsaufwand minimiert. Was uns fehlt, ist eine aktive Trocknungsfunktion. Dadurch wird ein Ausbau und Wechsel der genutzten Wischrolle gegen die Ersatzrolle aus dem Lieferkarton fast schon zwingend nötig, da sonst Keime und unangenehme Gerüche entstehen.
Wie ist die Akkulaufzeit des Tineco Floor One S5 Combo?
Die Laufzeit des Akku-Wischsaugers beträgt rund 20 Minuten, was für kleinere Wohnungen ausreichend ist. Hier ist die Konkurrenz im Schnitt stärker. Im Max-Modus verringert sich die Laufzeit sogar auf unter 15 Minuten. Als Handsauger liegt die Akkulaufzeit hingegen bei etwa 25 bis 50 Minuten, was ein ordentlicher Wert ist. Die Ladezeit beträgt etwa 3 Stunden.
Preis
Der Tineco Floor One S5 Combo ist ein Gerät der Premium-Klasse und hat mit einer UVP von 450 Euro seinen Preis. Der Tineco Floor One S5 Combo ist für rund 370 Euro im Handel zu bekommen.
Fazit
Der Tineco Floor One S5 Combo überzeugt durch seine Vielseitigkeit und gute Reinigungsleistung. Sowohl trockener Schmutz als auch Flüssigkeiten und eingetrocknete Flecken werden mühelos entfernt. Die einfache Handhabung und die umfangreichen Reinigungsfeatures machen das Gerät zu einem praktischen Helfer im Haushalt. Lediglich die Akkulaufzeit könnte bei größeren Wohnungen problematisch sein und auch ein anderes Feature haben wir schmerzlich vermisst: Es gibt keine aktive Trocknungsfunktion, was einen Ausbau der Wischwalze nach getaner Arbeit empfehlenswert macht, um Gerüche zu vermeiden.
Tineco Floor One S3
Tineco Floor One S3
Wischsauger sind praktisch und erleichtern den Alltag. Hersteller Tineco hat mit dem Floor One S3 ein besonders smartes Exemplar mit App-Anbindung im Sortiment.
- Schickes Design
- App-Anbindung
- gute Reinigungsleistung
- Randreinigung nur eingeschränkt möglich
- etwas „steif“ in der Handhabung
Tineco Floor One S3 im Test: Akku-Wischsauger mit App
Wischsauger sind praktisch und erleichtern den Alltag. Hersteller Tineco hat mit dem Floor One S3 ein besonders smartes Exemplar mit App-Anbindung im Sortiment.
Akku-Wischsauger, also kabellose Staubsauger, die gleichzeitig (und in erster Linie) wischen, liegen gerade im Trend. Ganz neu sind diese Geräte aber nicht, tatsächlich wurde der Tineco Floor One S3 bereits 2020 vorgestellt und räumte damals Preise ab. Dass das Modell nach wie vor verkauft wird, spricht für das Produkt. Wer Tineco als Marke nicht kennt, sollte sich davon nicht abschrecken lassen. Tineco gehört zu Ecovacs, das hierzulande primär für seine Saugroboter bekannt ist – genügend Know-how ist also offensichtlich vorhanden.
Lieferumfang
Der Lieferumfang des Tineco Floor One S3 ist üppig. Enthalten ist die Ladeschale, die dem Sauger als Abstellort und Selbstreinigungsgefäß dient und zudem Aufbewahrungsort für weiteres Zubehör ist: zweite Wischwalze, zweiter HEPA-Filter und ein Reinigungsinstrument. Zudem packt Tineco eine spezielle Reinigungsflüssigkeit in den Lieferkarton, die nicht nur optisch, sondern auch geruchstechnisch für Frische sorgt.
Design
Optisch sieht der Tineco Floor One S3 wie eine Mischung aus Roborock Dyad (Testbericht) und Dreame H11 Max (Testbericht) aus – wobei hier die anderen beiden Firmen wegen des früheren Erscheinungsdatums des Tineco-Modells wohl eher beim S3 abgekupfert haben dürften. So ähnelt der Korpus des Floor S3 mit seiner monolithischen Aufmachung eher an den H11 Max. Farblich ist Roborock näher am Tineco-Modell, wobei sich der Hersteller beim S3 ausschließlich auf Schwarz und Weiß konzentriert, während Roborock sein Modell noch mit weiteren Farbtupfern garniert hat.
Tineco verpasst seinem Wischsauger wie Dreame ein sehr großes Display, das wesentliche Funktionen wie Saugleitung, Akkustand und diverse Fehler meldet. Zudem wird hier angezeigt, ob das Gerät eine WLAN-Verbindung hat – denn im Gegensatz zu seinen Konkurrenten bietet der Floor One S3 eine App-Anbindung. Die Qualitätsanmutung des Gerätes ist wie bei den Modellen von Roborock und Dreame sehr gut.
Funktion und Reinigungsleistung
Im Gegensatz zu den Konkurrenten ohne App steht beim Tineco Floor One S3 als Erstes die Verbindung mit dem Smartphone an. Nach dem Herunterladen der Tineco-App sucht man das hinzuzufügende Modell, anschließend muss der Wischsauger aus der Ladeschale genommen und angeschaltet werden. Anders als bei den Modellen von Roborock und Dreame führt das nicht dazu, dass der Motor anläuft. Anschließend folgt man der Anweisung auf dem Smartphone-Display. Bei uns gab es anfangs Probleme, eine Verbindung mit dem Wischsauger herzustellen, da der dazu benötigte Hotspot nicht aufgebaut wurde. Obwohl der Hersteller nicht darauf hinweist, scheint hier ein Ladestand des Akkus über 50 Prozent nötig zu sein, alternativ kann auch längeres Warten von ein paar Minuten dazu geführt haben, dass der Tineco-Hotspot plötzlich in den WLAN-Einstellungen des Smartphones auftauchte. Anschließend klappte die Verbindungsaufnahme reibungslos.
Alle Bilder zum Wischsauger Tineco Floor One S3 im Test
Tineco Floor One S3

Tineco Floor One S3

Tineco Floor One S3

Tineco Floor One S3

Tineco Floor One S3

Tineco Floor One S3

Tineco Floor One S3
Tineco Floor One S3

Tineco Floor One S3

Tineco Floor One S3

In der App wird die Sauberkeit des Wischsaugers generell, der Akkustand und der Zustand von Abwasser- und Frischwassertank angezeigt. Außerdem ist hier ersichtlich, welche Saug- und Wischstufe (Auto oder Maximum) eingestellt ist. Zudem lässt sich die Sprachausgabe des Gerätes deaktivieren und die Selbstreinigung starten. Braucht man das wirklich, gibt es tatsächlich Nutzer, die während des Wischens in der anderen Hand noch mit dem Smartphone herumrennen, um Einstellungen am Wischer vorzunehmen? Wohl kaum, dennoch gibt es ein paar sinnvolle Anwendungsbeispiele. So zeigt die App nicht nur den Akkustand, sondern auch die verbleibende Ladezeit in Minuten an. Zudem lassen sich über die Kontoeinstellungen Firmware-Updates anschubsen oder die Sprache Sprache geändert werden, etwa auf Deutsch. Ist das essenziell? Auch das darf wohl verneint werden – eher nice to have, zumal manches davon bei den anderen Anbietern teilweise über Bedienknöpfe zu machen ist. Moderner ist das natürlich per Smartphone…
Einer der größten Kritikpunkte am Roborock Dyad (Testbericht) war die fehlende Möglichkeit, den Wischsauger „ohne Krücke“ außerhalb der Ladeschale abzustellen. Beim Tineco-Modell klappt das wie etwa beim Dreame H11 Max (Testbericht) problemlos, sobald der Korpus etwas mehr als 90 Grad aufgerichtet und etwas weiter nach vorn geklappt wird. Im Gegensatz zu den anderen Modellen stellt sich der Wischsauger dann sogar aus, statt nur die motorgetriebene Wischwalze zu stoppen. Der Rest erinnert stark an den Dreame: Die Wasserbehälter (Abwasser 500 ml, Frischwasser 600 ml) sind zwar etwas kleiner, weisen aber in etwa die gleiche Form und Mechanik auf. Das Display ist ähnlich groß und zeigt die gleiche Darstellungsart mit rings um den großen Screen verlaufendem Farbband und zentraler Akkustandsanzeige, zeigt aber die Saugkraft etwas anders an und bietet zusätzlich eine WLAN-Anzeige. In der Ladeschale, die in den meisten Haushalten wohl an einer Wand oder in einer Zimmerecke stehen dürfte, steht diese Anzeige von vorn betrachtet quasi „auf dem Kopf“.
Die deutsche Sprachansage klingt freundlicher als die voreingestellte englische. Wer nicht von seinem Wischsauger vollgequatscht werden will, darf sie auch komplett deaktivieren. Dabei gehen Gespräche mit dem Tineco Floor One S3 theoretisch sogar in beide Richtungen – wenn auch mit dem Umweg über Amazon Alexa. Die gibt auf Anfrage Infos, etwa zum Akkustand. Auch hier dürfte gelten: Nett, aber nicht zwingend nötig. Die eigentliche Aufgabe, das Wischen, muss hingegen auf jeden Fall gut funktionieren – und das tut sich auch. Wie bei den beiden Modellen von Roborock und Dreame wird die Motorwalze im Bürstenkopf des Wischsaugers automatisch mit Frischwasser versorgt, während das Schmutzwasser in den entsprechenden Tank abgesaugt wird. Die Reinigungsleistung ist damit ebenfalls hervorragend, Flüssigkeiten, trockener oder sonstiger Schmutz lassen sich damit gut entfernen – bei hartnäckiger Verschmutzung zumindest beim zweiten Drüberwischen. Die Saugkraft wird dabei wie bei den anderen Modellen automatisch geregelt, alternativ darf der Nutzer sie manuell auf das Maximum erhöhen.
Insgesamt ist der Tineco Flor One S3 in der Handhabung steifer als die Modelle von Roborock und Dreame. Das merken Nutzer, sobald sie unter Möbeln wischen wollen – abgesehen davon, dass der Korpus des Wischsaugers wie bei den Konkurrenten dabei im Weg wäre, lässt sich das Gerät nicht gerade ausstrecken. Es bleibt immer ein Winkel von rund 45 Grad zwischen Bürstenkopf und Rest des Akkusaugers. Zudem lässt sich beim Wischen die Richtung nur mit etwas Kraft korrigieren. Die ist nicht so groß, dass es störend wäre, aber weit vom leichtfüßigen Handling von Roborock Dyad (Testbericht) und Dreame H11 Max (Testbericht) entfernt.
Der Akku leistet wie beim Dreame-Modell 4000 mAh und erlaubt damit nach Herstellerangaben eine maximale Reinigungszeit von 35 Minuten. Das reicht locker für 100 Quadratmeter reiner Wischfläche am Stück, anschließend lädt der Wischsauger über 4 Stunden lang. Die Restzeitangabe in der App ist hier hilfreich. Über die Reinigung muss man sich beim Tineco Floor One S3 keine Gedanken machen. Wie bei der Konkurrenz verfügt der Wischsauger über eine Selbstreinigungsfunktion, bei der die Wischwalze kräftig durchgespült wird. Ob das nötig ist, verrät das Gerät per Sprachansage oder Nachricht in der App. Grundsätzlich sollte die Selbstreinigung regelmäßig genutzt und der Abwassertank sollte sogar nach jedem Gebrauch geleert und gereinigt werden, um Geruchsbildung vorzubeugen. Dank zweiter Walze und zweitem, auswaschbarem HEPA-Filter im Lieferumfang können beide Gegenstände sogar für intensivere Reinigung gewechselt werden und dann „an der frischen Luft“ trocknen.
Preis
Der Tineco Floor One S3 kostet in der UVP des Herstellers 399 Euro – und das ist ziemlich genau der Preis, der auch zum Testzeitpunkt noch aufgerufen wurde.
Fazit
Natürlich sind akkubetriebene Wischsauger Luxusartikel, denn sie vereinfachen eine Arbeit, die auch ohne technische Hilfe gut und genau genommen sogar noch besser funktioniert. Aber sie nehmen Nutzern die Anstrengung, die mit dem Wischen größerer Flächen verbunden ist.
Das macht der Tineco Floor One S3 definitiv, er bietet schickes Design, ein tolles Display, gute Laufzeit mit passend dimensionierten Tanks und eine gute Reinigungsleistung. Randlos kann er nicht reinigen, wer das möchte, der sollte sich den Roborock Dyad (Testbericht) anschauen.
Tineco Floor One Switch S7
Tineco Floor One Switch S7
Der neue Tineco Floor One Switch S7 will mit App, Schnelltrocknung und dank seiner Auslegung als Kombi-Gerät sowohl als Akkusauger als auch als Saugwischer überzeugen. Wir haben uns angeschaut, ob das klappt.
- Akkusauger und Saugwischer in einem
- Reinigungsleistung in beiden Fällen gut
- Schnelltrocknung der Wischrolle
- Motorunterstützung der Rollen beim Wischen
- LED-Licht beim Saugen und Wischen
- Preis hoch
- App mit wenig Mehrwert
Tineco Floor One Switch S7 im Test: Top-Saugwischer & Akku-Staubsauger in einem
Der neue Tineco Floor One Switch S7 will mit App, Schnelltrocknung und dank seiner Auslegung als Kombi-Gerät sowohl als Akkusauger als auch als Saugwischer überzeugen. Wir haben uns angeschaut, ob das klappt.
Kabellos Saugen? Akkusauger sind inzwischen schon relativ weitverbreitet und unsere Top 5: Akkusauger (Bestenliste) zeigt die besten Modelle. Auch Saugwischer sind mehr und mehr im Kommen, schließlich versprechen sie, das kräftezehrende Wischen einfach wie nie zu machen. Die besten Modelle haben wir in unserer Top 10: Die besten Saugwischer mit Akku (Bestenliste) zusammengetragen. Eines ist aber beiden Gerätschaften gemein: Gute Modelle sind meist teuer. Der Tineco Floor One Switch S7 versucht daher, beides in einem zu sein: Akkusauger und Saugwischer. Das kostet zwar immer noch eine Stange Geld, spart aber unterm Strich trotzdem – und zwar Geld und Platz. Im Test haben wir überprüft, ob das Gerät hält, was es verspricht.

Der Tineco Floor One Switch S7 kostet in der UVP des Herstellers stolze 899 Euro, bei Amazon kostete er zum Testzeitpunkt exakt diese 899 Euro.
Was ist im Lieferumfang des Tineco Floor One Switch S7?
Beim Auspacken des Tineco Floor One Switch S7 fällt sofort der umfangreiche Lieferumfang auf. Das Gerät kommt mit zahlreichen Zubehörteilen, die alle einzeln in Plastikfolien verpackt sind. Das sorgt für einen erheblichen Müllberg. Nach dem Entfernen der Plastikverpackungen zeigt sich jedoch, dass Tineco an alles gedacht hat. Der Lieferumfang umfasst verschiedene Aufsätze und Bürsten, die eine gründliche Reinigung in allen Ecken und Winkeln ermöglichen. Auch ein Reinigungsmittel ist im Lieferumfang, zudem Reinigungswerkzeug und Ersatzfilter.
Wie schwer ist der Aufbau des Tineco Floor One Switch S7?
Der Aufbau des Tineco Floor One Switch S7 ist dank des einfachen Stecksystems ein Kinderspiel. Alles passt perfekt und lässt sich kinderleicht zusammenstecken und auseinandernehmen. Griff und Motor müssen am Bodenwischer montiert werden, während Saugrohr und Bürste am Sauger befestigt werden. Beide Geräte haben Platz in der Dockingstation, wobei der Akku nur in den Wischer eingelegt geladen wird. Der Sauger trägt in dieser Zeit nur einen Akku-Dummy – das sieht sicherlich schicker aus, ist aber eigentlich überflüssig. Das Stromkabel misst 1,5 Meter, weshalb eine Steckdose in relativer Nähe des Abstellortes erforderlich ist.
Der Ladestand des Switch-Pro-Motors wird auf dem großen und gut ablesbaren Display des Akkus angezeigt. Einziger Wermutstropfen hier: Die Anzeige dreht sich nicht auf den Kopf, wenn der Wischer in der Ladestation steht. Dafür lässt er sich durch Drücken einer Entriegelungstaste einfach entnehmen. Auch die beiden Tanks (Frischwasser hinten, Schmutzwasser vorn am Gerät) sind enorm einfach entnehmbar und finden anschließend wieder problemlos ihren Weg in den Saugwischer. Der Frischwassertank darf nur bis zur Max-Linie befüllt werden. Wasser kann dabei warm, aber nicht heißer als 60 Grad sein. Für hartnäckige Verschmutzungen kann eine Kappe der beiliegenden Reinigungslösung hinzugefügt werden.
Toll an der Ladestation: Sie nimmt nicht nur die Sauger-Teile seitlich auf, sondern bietet auch eine eigene Schale für den vorderen Teil mit der Wischrolle des Saugwischers. Sie darf zur Reinigung ganz einfach entnommen werden. Außerdem umfasst sie bei der Selbstreinigung die Rolle so, dass kein Wasser nach außen spritzt.
Alle Bilder zum Tineco Floor One Switch S7 im Test
Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7
Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Tineco Floor One Switch S7

Wie gut ist der Tineco Floor One Switch S7 als Staubsauger?
Als Kombi-Gerät dürfen Besitzer den Tineco Floor One Switch S7 je nach Bedarf als Akkusauger oder als Saugwischer verwenden. Für gröberen, trockenen Schmutz dürften viele Interessenten zur Akkusauger-Konfiguration greifen. Der Switch-Pro-Motor wird dafür vom Bodenwischer gelöst und an das andere Gerät angeschlossen. Der Staubsauger liegt gut in der Hand, ist aber aufgrund des starken Akkus kein Leichtgewicht. Über einen Abzug am Griff wird das Gerät gestartet. Dabei reicht ein kurzer Druck, der Motor bleibt anschließend bis zu einem weiteren Druck an. LED-Licht an der Turbodüse sorgt dafür, dass kein Staubkorn übersehen wird. Die Anti-Verhedderungs-Bürste hält, was sie verspricht: Haare von Mensch und Tier verfangen sich nicht und landen direkt im beutellosen Staubbehälter.
Die Saugleistung darf der Nutzer zwischen Eco und Max variieren. Sie ist im Max-Modus sehr gut, jeglicher Staub und grobe Verschmutzungen werden erfolgreich entfernt. Leider klappt das in erster Linie, wenn der Nutzer den Sauger nach vorn schiebt. Beim Zurückziehen befördert der Tineco Floor One Switch S7 immer etwas Schmutz hinter sich, der dann anschließend umkurvt und in einer Vorwärtsbewegung aufgesaugt werden muss. Die gute Saugleistung gilt ansonsten nicht nur für Hartboden, sondern selbst auf Teppich macht das Kombi-Gerät eine ordentliche Figur. Bei regelmäßiger Nutzung reicht der Tineco Floor One Switch S7 als alleiniger Akkusauger in den meisten Fällen absolut aus. Dabei bleibt die Motorbürste weit später als etwa beim Dyson V15 (Testbericht) stecken.
Im Eco-Modus ist das Gerät zwar leiser und verbraucht weniger Strom, aber dafür wird der Schmutz nicht so zuverlässig aufgenommen. Für leichte Krümmel wie Katzenstreu reicht es aber trotzdem. Als Sauger kommt der Tineco Floor One Switch S7 übrigens problemlos unter tiefe Möbel wie ein Bett – zumindest bis zum Akku.
Die verschiedenen Aufsätze aus dem Lieferumfang sind praktisch. Mit der 2-in-1-Staubbürste mit Fugendüse lassen sich Ritzen, Ecken und andere enge Stellen von Staub befreien. Auch um Spinnenweben an der Decke zu entfernen oder andere hoch gelegene Stellen zu reinigen, eignet sich der Aufsatz hervorragend. Um Polstermöbel oder Matratzen von Haaren zu säubern, kommt die Mini-Turbobürste zum Einsatz. Das Saugrohr wird dafür bei Bedarf entfernt und die Bürste direkt mit dem Gerät verbunden, sodass der Tineco Floor One Switch S7 zum Handstaubsauger wird. Kissen und Couch werden im Max-Modus sofort von Tierhaaren befreit, während der Eco-Modus hier weniger hilfreich ist. Im Max-Modus hält der Akku rund 20 Minuten.
Was taugt der Tineco Floor One Switch S7 als Wischer?
Nachdem der Boden vom groben Schmutz befreit ist, kommt der Bodenwischer zum Einsatz. Der Switch-Pro-Motor wird dafür wieder gewechselt und bei ausreichend gefülltem Frischwassertank (und leerem Abwassertank) kann es losgehen. Ansonsten beschwert sich der Saugwischer per entsprechendem Icon auf dem Display und Sprache. Zunächst wird nur das Display des Akkus aktiviert. Zum eigentlichen Start muss der Saugwischer aus dem Stand nach hinten „geknickt“ werden. Dann starten Motor und Wischrolle, außerdem werden die Räder, auf denen ein guter Teil des Gewichts des Tineco Floor One Switch S7 lagert, aktiv. Sie werden bei Vor- und Rückwärtsbewegungen angetrieben und minimieren so den Kraftaufwand des Nutzers – praktisch!
Im Betrieb stehen vier Reinigungsmodi zur Verfügung. Der Auto-Modus erkennt den Verschmutzungsgrad von allein und passt die Dosierung von Frischwasser und Saugleistung an. Der Max-Modus eignet sich für sehr hartnäckige Verschmutzungen, da hier die volle Saugleistung zum Einsatz kommt. Für nasse Flächen oder zum reinen Saugen ist der Suction-Modus die richtige Wahl. Mit dem Custom-Modus können die Parameter Saugleistung und Wasserzufuhr selbst bestimmt werden, das geschieht in der App.
Handhabung und Führung des Geräts sind sehr gut. Egal, ob Fliesen- oder Holzboden, das Ergebnis ist ausgezeichnet. Grober Schmutz wird aufgesaugt und Flecken werden problemlos beseitigt. Das gilt sogar für eingetrocknete Flecken, auch wenn Nutzer hier unter Umständen mehrfach drüberwischen müssen. Als Bodenwischer hat der Tineco Floor One Switch S7 übrigens dasselbe Problem wie der Großteil der Konkurrenz: Das Reinigen unter niedrigen Möbeln ist nur bedingt möglich. Denn einen Neigungswinkel von 148 Grad sollte man nicht überschreiten, da sonst Wasser aus den Tanks auslaufen könnte. Ganz randlos wischen kann der Tineco Floor One Switch S7 übrigens nicht, einige Millimeter bleiben hier bauartbedingt am Rand immer trocken. Wer randlos wischen möchte, sollte sich Modelle wie den Roborock Dyad Pro Combo (Testbericht), ebenfalls ein Kombi-Modell, anschauen.
Wischen ist mit einer Akkuladung im Turbo-Modus rund 30 Minuten lang möglich. Danach wird der Wischer wieder in der Station platziert und die Selbstreinigung über das Wassertropfen-Symbol am Handgriff eingeleitet. Dabei wird das schmutzige Wasser in den entsprechenden Behälter abgepumpt und die Bürstenrolle mit Frischwasser aus dem Tank des Geräts gereinigt. Dieser Vorgang dauert einige Minuten. Darin enthalten ist allerdings auch die Schnelltrocknung der Wischrolle. Der Tineco Floor One Switch S7 trocknet diese dank dauerhafter Drehbewegung und Warmluft in nur etwa 5 Minuten – kein anderer Saugwischer ist dabei derart schnell! Danach sollte der Schmutzwasserbehälter gereinigt werden, um unangenehme Gerüche zu vermeiden.
Was kann man beim Tineco Floor One Switch S7 in der App einstellen?
Wie so oft ist die App bei Wischsaugern eher ein netter Gag, das ist auch beim Tineco Floor One Switch S7 nicht viel anders. In erster Linie sieht man hier den Ladestand, ohne zum Gerät laufen zu müssen. Außerdem erhält man bei Problemen Hilfestellung mithilfe grafischer Animationen, kann Firmware-Updates machen und Sprache sowie Lautstärke einstellen. Letzteres ist daher interessant, da die voreingestellte Lautstärke für unseren Geschmack zu laut und scheppernd ist. Wer die Motorunterstützung der Laufrollen beim Wischen nicht mag, darf sie hier deaktivieren.
Preis
Der Tineco Floor One Switch S7 kostet in der UVP des Herstellers stolze 899 Euro, bei Amazon kostete er zum Testzeitpunkt exakt diese 899 Euro.
Fazit
Der Tineco Floor One Switch S7 ist eine hervorragende Hilfe im Haushalt. Dabei ersetzt er Akkusauger und Saugwischer in einem Gerät. Das spart Platz und – trotz des hohen Preises des Switch S7 – unter Umständen sogar Geld. Kabel- und beutellos ist die Reinigung sehr angenehm. Staub, Haare, grobe Verunreinigungen, Flecken und sogar Flüssigkeiten beseitigt er effizient. Der Eco-Modus reicht allerdings nicht immer aus, abseits davon geht der Akku allerdings wie bei der Konkurrenz schnell zur Neige. Für eine durchschnittliche Wohnungs- oder Etagengröße reicht das aber normalerweise locker.
Auch wenn der Tineco Floor One Switch S7 in den einzelnen Disziplinen als Saugwischer und Akkusauger stellenweise noch etwas Luft nach oben hat, handelt es sich um ein richtig gutes Gesamtpaket. Die Fülle an Zubehör rundet das Ganze ab. Besonders wenn es mal schnell gehen soll, kann die Geräte-Kombi punkten und liefert gute Ergebnisse.
Jimmy HW9
Jimmy HW9
Der Jimmy HW9 möchte genauso einfach wischen, wie saugen. Er kommt mit Reinigungsstation und spritzt auf Knopfdruck Wasser fächerartig vor sich, wenn es benötigt wird. Reicht das heute noch?
- saugt Hartböden trocken und wischt auf Knopfdruck gut
- schickes Design
- darf komplett abgelegt werden, ohne auszulaufen
- keine automatische Wischfunktion
- bringt punktuell sehr viel Wasser auf den Boden
- keine aktive Warmlufttrocknung
Saugwischer Jimmy HW9 im Test: Spuckt auf Kommando und wischt gut
Der Jimmy HW9 möchte genauso einfach wischen, wie saugen. Er kommt mit Reinigungsstation und spritzt auf Knopfdruck Wasser fächerartig vor sich, wenn es benötigt wird. Reicht das heute noch?
Saugwischer sind inzwischen im Markt angekommen und erfreuen sich wachsender Beliebtheit. Entsprechend hat Hersteller Jimmy ein Nachfolgemodell des HW8 Pro (Testbericht) veröffentlicht, den HW 9. Er unterscheidet sich in einigen Belangen von anderen Modellen im Handel und wir wollten im Test wissen, ob das gut oder schlecht ist.
Lieferumfang
Der Lieferumfang enthält neben dem Saugwischer und der entsprechenden Lade- und Reinigungsstation eine Handbürste zur Reinigung sowie Handbuch und Reinigungszusatz.
Design
Im Gegensatz zum bauchigen Vorgänger setzt Jimmy beim HW9 auf ein sehr schlankes Design, das viel mehr an eine filigrane Röhre als bei der Konkurrenz erinnert. Modelle wie der Dreame H11 Max (Testbericht) kommen wesentlich massiver daher. Möglich macht das dünne Design mit weiter nach unten verjüngender Form der Umstand, dass Jimmy nur Abwassertank, Akku und Motor in den Korpus integriert. Der Frischwassertank ist hingegen in den Wischkopf gewandert, der dadurch aber nicht wesentlich größer geworden ist. Er soll jetzt durch „eingebautes Silberionenmaterial“ stromlos das Wischwasser sterilisieren.
Ansonsten bleibt Jimmy beim gewohnten Design, so setzt etwa der Handgriff auf die für diese Geräteart typische geschwungene Form. Praktisch ist der Akku, der oben auf den Korpus aufgesetzt wird und entsprechend später bei einem Defekt oder Alterserscheinungen problemlos ausgetauscht werden kann. Dafür bleibt das Display, das Informationen zu Dingen wie Ladezustand und Fehlern bereithält, wie beim Vorgänger vorn am Gerät. Da ist es im Betrieb nicht so gut wie bei anderen Modellen ablesbar, allerdings dreht der HW9 es jetzt im Betrieb auf den Kopf. Dadurch ist es sowohl von vorn in der Ladestation als auch im Betrieb richtig herum abzulesen.
Neu ist zudem eine Schiene, die vorn an der Wischrolle rund 2 cm runter oder auch wieder raufgeschoben werden kann. Bei der Selbstreinigung und beim normalen Wischen soll sie oben sein, auf Teppich (!) unten. Damit wird vermutlich auf Teppich die Saugwirkung verstärkt. Tatsächlich erklärt die Bedienungsanleitung zu diesem Thema, dass der Nutzer zum Saugen von Teppich die Wischrolle entfernen und die Teppichrolle einlegen sollte. Das Entfernen klappt auch recht einfach – allerdings befindet sich im Lieferumfang keine Teppichrolle, obwohl die Ladestation dafür eine Aufbewahrungsmöglichkeit bietet. Grundsätzlich klingt die separate Verwendung als Sauger und Wischer sinnvoll, schließlich befeuchtet der HW9 wie schon beim Vorgänger HW8 Pro (Testbericht) die Wischrolle nicht automatisch, sondern nur auf Knopfdruck. Allerdings wäre dann eine Teppichrolle im Lieferumfang zwingend nötig gewesen.
Ein weiteres Manko: Die Selbstreinigungsfunktion funktioniert zwar wie bei allen Saugwischern gut und erfordert nach der Initiierung auch kein weiteres Eingreifen, allerdings verfügt der Jimmy HW9 über keine aktive Trocknungsfunktion mit Warmluft. Entsprechend muss der Nutzer nach der Selbstreinigung nicht nur die Tanks leeren oder füllen, sondern eigentlich die Wischrolle entfernen und zum Trocknen separat aufbewahren. Das ist nicht mehr zeitgemäß. Als letzte Negativpunkt möchten wir die Materialanmutung ansprechen. Während Verarbeitung und Design ordentlich sind, gefällt uns besonders der glänzende Kunststoff mit den billig wirkenden, hellgrauen Tasten des Handstücks nicht. Er wirkt im Gegensatz zum Rest billig.
Betrieb
Auch wenn im Vergleich zum Vorgänger die Leistung mit angegebenen 300 Watt gleichgeblieben ist, spricht der Hersteller von 30 Prozent verbesserter Saugleistung. Erreicht werden könnte das durch das neue Wischkopf-Design mit herunterziehbarer Frontlippe. Zudem soll der Motor allein rund 35 Prozent leichter als zuvor sein, was sich in einem etwas niedrigeren Gesamtgewicht niederschlägt. Ansonsten hat sich im Vergleich zum HW8 Pro (Testbericht) wenig getan.
Erstaunt waren wir vom starken Vorwärtsdrang, den der Saugwischer durch die Drehbewegung der Wischrolle entwickelt. Hier gilt es beinahe, mehr Kraft für die Zügelung der Bewegung, als für die Wischbewegung an sich aufzubringen. Suboptimal gelöst finden wir in diesem Zusammenhang, dass der Saugwischer noch eine kurze Zeit lang die Rolle aktiviert lässt, wenn das Gerät senkrecht aufgestellt wird. Dadurch will er immer noch kurz weiter vorwärtsfahren, bevor er dann nach der Erhöhung der Saugleistung abschaltet. Außerdem geht das Aufrechtstellen für unseren Geschmack zu hakelig und schwer vonstatten.
Auch das „Kurvenverhalten“ ist etwas steif, in Richtungswechsel muss der HW9 fast schon gezwungen werden. Das macht mancher Konkurrent besser. Dafür darf der Jimmy-Wischsauger zum Reinigen unter dem Sofa sogar flach abgelegt werden, ohne dass Frisch- oder Abwasser ausläuft. Die meisten anderen Saugwischer dürfen nicht über einen gewissen Punkt gekippt werden, da sie sonst lecken. Ansonsten gilt wie beim Vorgänger: Randloses Reinigen gibt es nicht, an Möbeln und Fußleisten bleibt immer ein schmaler Streifen ungewischt, da die Wischrolle nicht ganz bis an den Rand kommt. Das ist aber beim Großteil der Konkurrenz auch so – eine Ausnahme ist etwa der Roborock Dyad Pro Combo (Testbericht), der im Gegensatz zum Jimmy HW9 auch tatsächlich Sauger und Wischer in einem ist.
Die Wischfunktion an sich ist ordentlich, allerdings birgt sie im Gegensatz zu Konkurrenzmodellen auch Gefahren. Ohne Zutun des Nutzers ist der HW9 grundsätzlich erst einmal nur ein Hartbodensauger. Sollen dort Flecken entfernt werden, muss der Nutzer einen Knopf am Handgriff drücken, anschließend wird fächerartig Flüssigkeit aus dem Frischwassertank im Wischkopf vor den Saugwischer gesprüht. Das sorgt dafür, dass kurzzeitig recht viel Flüssigkeit auf den Boden kommt. Gerade bei hochwertigem Boden wie Parkett finden wir das nicht besonders vertrauenerweckend, zumal der Nutzer auch einen Teil des Wassers übersehen könnte. Dann müsste es von allein abtrocknen und könnte ins Holz einziehen – fatal. Bei der Konkurrenz wird den Wischrollen kontinuierlich Wasser zugeführt und direkt wieder abgesaugt, das ist wesentlich praktischer und sicherer.
Alle Bilder zum Jimmy HW9 im Test
Jimmy HW9

Jimmy HW9

Jimmy HW9

Jimmy HW9

Jimmy HW9

Jimmy HW9

Jimmy HW9

Jimmy HW9

Jimmy HW9

Jimmy HW9

Der Frischwassertank im Wischkopf ist hingegen kein Problem. Lediglich beim Befüllen müssen Nutzer etwas aufpassen. Da er sehr flach, dafür aber breit ist, läuft dieser Tank schnell über und ist je nach Haltung trotzdem nicht voll. Nach dem feuchten Wischen haben wir eine aktive Lufttrocknung mit warmer Luft und Gebläse vermisst. Wer hier nicht direkt die Rolle ausbaut und reinigt oder gar aktiv selbst zu trocknen versucht, wird durch die zu langsame Trocknung an der frischen Luft früher oder später ekelhaften Stockgestank feststellen. Das ist unhygienisch und passt nicht mehr ins Jahr 2023.
Der Akku ist nicht übermäßig groß dimensioniert. Der Hersteller gibt für Hartboden 30 Minuten, auf Teppich (das ist die höhere Saugstufe) 20 Minuten an. Im Test hat sich das knapp bewahrheitet. Das ist nicht übermäßig lang, sollte aber bei normalen Wohnungsgrößen problemlos reichen. Anschließend lädt der HW9 mit 4 bis 5 Stunden eher gemächlich.
Preis & Alternativen
Die UVP des Jimmy HW9 liegt bei 249 Euro, im Handel ist das Modell derzeit bei Geekmaxi mit dem Rabatt-Code JIMMYHW9TS für rund 180 Euro zu bekommen.
Fazit
Der Jimmy HW9 ist im Prinzip ein Hartbodensauger, der auf Knopfdruck zum Saugwischer werden soll. Die manuelle Wasserzufuhr wäre aber nur dann wirklich sinnvoll, wenn das Gerät tatsächlich als vollwertiger Akkusauger, also auch für Teppich, verwendet werden könnte. Aber auch wenn das Handbuch entsprechendes andeutet, fehlt eine entsprechende Teppichbürste im Lieferumfang. Der Lieferumfang selbst ist laut Handbuch aber ohne Bürste vollständig. Das passt nicht zusammen, so ist die manuelle Wasserzufuhr über einen Extraknopf einfach nur veraltet. Gleiches gilt für das Fehlen einer schnellen, aktiven Trocknung per warmer Luft, die Schimmelbildung unterbindet – das geht im Jahr 2023 gar nicht mehr.
Mit dem Wischergebnis kann man unter den genannten Umständen leben, hier ist allerdings der Preis entscheidend. Wir finden, dass der mit einer UVP von 249 Euro für das Gebotene einfach zu hoch ist. Bessere Alternativen wurden bereits im Test genannt, zusammengefasst haben wir sie in unserer Topliste der besten Saugwischer aufgeführt.
Jimmy PowerWash HW8 Pro
Jimmy PowerWash HW8 Pro
Saugen kann man elektrisch – warum nicht auch nass wischen? Der neue Jimmy PowerWash HW8 Pro bietet separaten Frisch- und Abwassertank und wischt, schrubbt und poliert Hartböden ganz ohne Anstrengung.
Xiaomi Jimmy PowerWash HW8 Pro im Test: Wischen so einfach wie Saugen
Saugen kann man elektrisch – warum nicht auch nass wischen? Der neue Jimmy PowerWash HW8 Pro bietet separaten Frisch- und Abwassertank und wischt, schrubbt und poliert Hartböden ganz ohne Anstrengung.
Wischen ist anstrengend: Wischer und Tuch wollen sinnvoll kombiniert werden, ohne dass das Tuch sich ständig verselbständigt, außerdem muss der Wassereimer ständig umgesetzt und das Wischwasser regelmäßig ersetzt werden. Flecken gehen zudem nur mit Mühe und Kraft weg. Das alles soll der neue Xiaomi Jimmy PowerWash HW8 Pro viel einfacher gestalten. Er ist quasi Wischer, Wassereimer und Kraftprotz in einem und spart so nicht nur Kraft, sondern auch Zeit beim Reinigen. Wir haben getestet, ob das Konzept wirklich aufgeht.
Lieferumfang
Im Lieferkarton befinden sich eine Ersatz-Bodenwisch-Rolle, der Sauger selbst, ein Aufbewahrungskörbchen und etwas Lesestoff – die Anleitung ist auch auf Deutsch, wenngleich bisweilen etwas plump übersetzt. Vor der ersten Inbetriebnahme muss die Griffstange noch am Sauger arretiert werden, was mit einfachem Einrasten gelingt. Der Bürstenkopf samt integrierter Sprühvorrichtung ist fest am Korpus des Saugwischers installiert. In einem Standfuß mit Kunststoffunterlage (daran wird das Körbchen befestigt) kann, der Akku-Saugwischer auch mit feuchter Rolle abgestellt werden, ohne den Boden darunter auf Dauer zu schädigen. Außerdem lädt er darauf auch gleich, sofern das beiliegende Netzteil an dem Fuß eingesteckt ist. Ein austauschbarer Lithium-Ionen-Akku mit 3000 mAh befindet sich im Lieferumfang, außerdem ein alkohol- und chlorfreier Reinigungszusatz gegen Bakterien (500 ml) und ein Werkzeug zum Reinigen, das man in ähnlicher Form auch von Saugrobotern kennt.
Design
Das Aussehen des Jimmy HW8 Pro dürfte Geschmackssache sein. Wir finden die Form recht altbacken – so ähnlich sahen vor zwei oder drei Jahrzehnten herkömmliche Staubsauger aus, bevor irgendwann Korpus und die Saugbürste an einem langen Saugrohr voneinander getrennt wurden und man den eigentlichen Staubsauger nur noch hinter sich herzog. Dem aus unserer Sicht altmodischen Aussehen setzt der Hersteller sein typisches Lila als Akzentfarbe entgegen, außerdem integriert er auf der Vorderseite ein einfaches, aber informatives LED-Display. Aufgrund der überwiegenden Verwendung von grauem Kunststoff wirkt der Wischsauger allerdings in Kombination mit dem altbackenen Design nicht übermäßig hochwertig.
Die Verarbeitungsqualität geht insgesamt in Ordnung, der HW 8 Pro wirkt nicht so, als ob er nach einmaliger Benutzung auseinanderfällt. Der Kunststoff sorgt aber auch beim Thema (gefühlte) Langlebigkeit nicht gerade für Begeisterungsstürme. Während des Testzeitraums gab es hier aber nichts zu bemängeln.
Alle Bilder zum Xiaomi Jimmy HW 8 Pro im Test
Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Jimmy HW 8 Pro

Funktion
Der Jimmy HW 8 Pro steht selbstständig, er muss (und sollte) nirgends angelehnt oder gar hingelegt werden, wenn man ihn gerade nicht in die Ladeschale stellt. Gerade Hinlegen kann dazu führen, dass das Abwasser aus dem Behälter läuft – unschön, aber leicht vermeidbar. Der separate Abwasserbehälter befindet sich vorn unten am Gerät. Direkt unterhalb des bereits angesprochenen Displays platziert Jimmy zum Entnehmen des Tanks eine Lila eingefärbte Taste, nach deren Betätigung der Abwassertank nach vorne entnommen werden kann. Der Tank verfügt über Sieb- und Schaumstofffilter und man sollte das Gerät nach Herstellerangabe nach jeder Nutzung reinigen, um Gerüchen vorzubeugen. Tatsächlich riecht der Filter ohne den regelmäßigen Reinigungsvorgang leicht, aber nur, wenn man direkt die Nase dranhält. Im Abwasserbehälter befindet sich ein Schwimmer, mittels dessen Hilfe der HW 8 Pro weiß, wann er voll ist. Dann meldet der Sauger das auf dem Display.
Der Frischwassertank befindet sich ebenfalls unten am Gerät, allerdings auf der Rückseite. Auch er wird mittels eines lilafarbenen Druckknopfes aus dem Gehäuse gelöst und kann dann zum Befüllen entnommen werden. Das geschieht auf dem Kopf stehend, eine Fülllinie auf dem durchsichtigen Tank zeigt die maximale Füllmenge an. Dafür, dass der Tank im Betrieb nicht ausläuft, sorgt ein Ventil. Oben auf der Vorderseite ist das bereits mehrfach angesprochene Display platziert. Es ist groß und recht hell, sodass es grundsätzlich gut ablesbar ist. Angezeigt wird der Ladezustand des Akkus in Prozent und ein Saugstärkebalken, der halbrund um die Prozentzahl angeordnet ist. Darunter gibt es Symbole für einen vollen Abwassertank, einen leeren Frischwassertank und einen aktiven Selbstreinigungsmodus. Außerdem werden hier potenzielle Fehlercodes angezeigt, was im Testbetrieb aber nicht vorkam.
Auf der Rückseite ist oben das Akkufach untergebracht. Nimmt man die Abdeckung ab, lässt sich hier sehr einfach der beiliegende Akku einlegen oder entfernen – bei einem Defekt des Akkus muss so nicht der ganze Wischsauger entsorgt oder zur Reparatur eingeschickt werden. Unten an der Saug- und Wischbürste gibt es ein weiteres lila Akzentstück, über das die obere Abdeckung der weichen Wischbürste entfernt werden kann. Das wirkt etwas fragil, ermöglicht aber den Wechsel der bereits eingelegten Rolle. Am Handgriff befinden sich auf der Oberseite zwei Knöpfe: ein Ein/Aus-Schalter und ein Button, um eine von zwei Saugstufen auszuwählen. Außerdem löst der Nutzer mit einem innenliegenden Wasser-Sprühknopf per Zeigefinger die Düse aus, die dann zur besseren Reinigung Flüssigkeit aus dem Frischwasserbehälter vor die Wischbürste spritzt.
Betrieb
Ein Klick auf den Powerbutton erweckt den bürstenlosen Digitalmotor des Jimmy HW8 Pro zum Leben. Der Wischsauger ist im Betrieb mit 65 bis 68,5 Dezibel in rund einem Meter Abstand deutlich hörbar, aber nicht störender als ein herkömmlicher Staubsauger. Die Rollenbürste pausiert, wenn der Sauger aufgestellt wird und wird automatisch aktiviert, wenn das Gerät zum Wischen aus seiner aufrechten Position verlagert wird. Dann zieht die Rollendrehung den rund 5,5 Kilogramm schweren Akku-Wischsauger fast von allein nach vorn, sodass das Gewicht des Saugers kaum eine Rolle spielt. Die Saugkraft des HW 8 Pro gibt Jimmy mit 300 Watt und 15 kPa an. Genau überprüfen lässt sich so etwas kaum, wichtiger ist daher das Ergebnis im Alltag. Und dort liefert der Jimmy HW 8 Pro ein ziemlich gutes Bild ab.
Wir haben den Staubsauger mit Wischfunktion ausschließlich auf Hartboden getestet, schließlich ist zumindest die Wischfunktion nur dafür ausgelegt. Erfahrungsgemäß funktionieren weiche Flauschbürsten auf Teppich aber auch nicht so gut, mehr Schmutz aus Auslegeware bekommen Modelle mit Borstenrollen wie etwa ein Roborock H6 Adapt (Vergleich) oder dessen Facelift, der Roborock H7 (Testbericht), heraus. Auf Hartboden reichen beim Saugen hingegen sowohl die Saugleistung als auch die Filzbürste, um typische leichte Verunreinigungen aus dem Haushalt wie Sand oder Krümmel zu entfernen.
Wichtiger ist aber die Wischfunktion, denn die ist das, was den Akku-Wischsauger HW8 Pro von reinen Akkusaugern wie Jimmy H8, H8 Pro oder H9 Pro (Vergleich) unterscheidet. Für ihre Nutzung muss der Wischsauger angeschaltet werden, außerdem müssen Nutzer immer wieder mit dem Zeigefinger-Knopf am Handgriff Frischwasser auf den Bereich vor die Wischbürste sprühen und anschließend einfach mit dem HW8 Pro darüberfahren. Die Dosierung ist dabei etwas schwierig, selbst ein kurzer Druck sprüht schon einen ordentlichen Stoß Flüssigkeit auf den Boden vor das Gerät, langes Gedrückthalten sprüht dauerhaft. Das mag Besitzern von Laminat oder Parket etwas aufstoßen, schließlich ist der Boden dann an dieser Stelle recht nass. Wer direkt danach über die Flüssigkeit fährt, sollte aber wohl keine Beschädigung durch Aufquellen fürchten müssen.
Anschließend geht alles wie von Zauberhand: Selbst eingetrocknete Flecken werden zuvor eingesprüht schnell gelöst und verschwinden zusammen mit dem Abwasser im Schmutzwassertank. Besonders hartnäckige Flecken benötigen selten mal ein erneutes Vor- und Zurück mit dem Wischsauger, dann sind die aber normalerweise auch entfernt. Größter Zugewinn ist die komfortable Handhabung und der Zeitgewinn: Kein Wischeimer herauskramen, kein Wischtuch auswringen – einfach loslegen und fertig. Die Reinigung der Bürste übernimmt der Sauger nach dem Wischen selbst. Dafür muss er lediglich in die Ladestation gestellt und danach die Wahlmodustaste (normales/starke Saugleistung) für drei Sekunden gedrückt werden. Anschließend sprüht der Sauger Wasser in die Ladeschale, lässt die Bürste darin für zwei Minuten rotieren und saugt hinterher alles wieder ab – fertig. Die Wirksamkeit lässt sich im Schmutzwasserbehälter sehen, das Wasser der Reinigung ist nach einem Durchgang genauso dreckig wie das Wasser während der Wohnflächenreinigung.
Kleine Einschränkung der Nutzbarkeit: Das Display vorn auf dem Akku-Wischsauger ist für den Nutzer auf dem Kopf und daher im Betrieb nur eingeschränkt ablesbar. Außerdem ist – wie bei jedem Staubsauger – die Reinigungsleistung nicht ganz bis an den Rand gegeben. Hier hat ein herkömmliches Wischtuch Vorteile.
Akku
Der Li-Ion-Akku leistet 3000 mAh, er lädt rund 5 Stunden. Die Akku-Laufzeit beträgt gut 30 Minuten auf normaler Saugstufe, dann muss der Wischsauger an den Strom. Der Akku-Betrieb reicht grundsätzlich für etwa 80 Quadratmeter. Für richtig große Flächen ist das nichts, zumindest nicht ohne Ersatzakku.
Preis
Der Hersteller will für den Jimmy HW 8 Pro in Deutschland 335 Euro in der UVP. Zubehör wie etwa einen Ersatzakku bietet der Hersteller derzeit nicht an. Der Verkauf startet am 3. August. Zum Start gibt es den Wischsauger Jimmy HW 8 Pro bei Geekmaxi mit dem Code QVpe9iF4 für 229,99 Euro, also deutlich unter der UVP.
Fazit
335 Euro sind eine Menge Geld für etwas, was man auch deutlich günstiger machen kann: nass Wischen. Andererseits benutzen wir Waschmaschinen statt Waschbretter, Geschirrspülmaschinen statt Handwäsche und Rasenmäher statt Sense – das ist eben Fortschritt. Warum also nicht? Der Jimmy HW 8 Pro ist sicherlich nicht perfekt. Das Display bietet im Betrieb weniger Info als erhofft, da es dann quasi auf dem Kopf steht. Außerdem kommt man bauartbedingt nie bis ganz an den Rand – das macht ein herkömmliches Wischtuch besser.
Aber dafür muss man bis auf das gelegentliche Auffüllen des Frischwasserbehälters oder das Leeren des Abwassertanks kaum Vorbereitungen treffen und das kräfteraubende Auswringen des Wischtuches und Schrubben bei Flecken entfällt. Stattdessen ist Wischen mit dem Jimmy so einfach wie Saugen. Gerade zum Startpreis von 230 Euro erscheint das zu Recht verlockend.
Wer sich (mehr oder weniger) eigenhändiges Wischen gleich ganz sparen will, sollte einen Blick auf den Boden-Wischsauger Hobot Legee 7 (Testbericht) werfen. Ein vollautomatischer Staubsauger-Roboter mit richtig gutem Wischmodus für gründliche Reinigung und saubere Böden ist hingegen der Roborock S7 (Testbericht).
Mova M50 Ultra
Mova M50 Ultra
Mit einem verstellbaren Griff erleichtert der Wischsauger Mova M50 Ultra das Erreichen schwer zugänglicher Stellen und erweist sich im Einsatz als flexibel.
- Flexibilität durch klapp- & herausziehbaren Griff
- unkomplizierte Einrichtung
- einfache Reinigung des Schmutzwassertanks
- Reinigung im Smart-Mode wirkt willkürlich
- etwas teurer als Produkte mit vergleichbarem Funktionsumfang
Wischsauger Mova M50 Ultra im Test: kommt dank verstellbaren Griffs unter Möbel
Mit einem verstellbaren Griff erleichtert der Wischsauger Mova M50 Ultra das Erreichen schwer zugänglicher Stellen und erweist sich im Einsatz als flexibel.
Als Wischsauger sticht der Mova M50 Ultra in erster Linie aufgrund seines extrem praktischen Designs hervor. Während Schlagwörter wie 22.000 Pa Saugleistung, Selbstreinigungsstation und intelligente Schmutzerkennung heutzutage kaum noch jemanden hinter dem Ofen hervorholen, überzeugt der Mova M50 Ultra mit einem intelligenten und vor allem nützlichen Design. Denn der Griff des 429 Euro kostenden Saugwischers lässt sich per Knopfdruck ausfahren und abknicken. Inwiefern das Sinn macht und wie es um den Rest des Gesamtpakets bestellt ist, klären wir im Test auf.
Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Mit dem Mova M50 Ultra erhält man eine Ersatzwischrolle, eine Handbürste, eine 500-ml-Flasche Reinigungskonzentrat sowie einen HEPA-Ersatzfilter. Zusätzlich liegen dem Wischsauger noch Betriebsanleitung und Quickstart-Guide bei. Zur Selbstreinigung des Wischsaugers dient die Reinigungsstation, die ebenfalls im Paket enthalten ist.
Design
Der M50 Ultra ist in schlichtem Schwarz gehalten mit grauen Akzenten, wobei der Tragegriff am Rumpf dezent mit Glitter durchzogen ist. Der Lenkarm lässt sich bei Bedarf verlängern, was vor allem dann praktisch ist, wenn man diesen durch Ziehen des Triggers am Griff abknickt. So kann man mit dem Mova M50 Ultra relativ bequem unter Tische, Schränke und andere Möbel kommen, für die man sich sonst weit nach vorn beugen muss oder anderweitig verrenkt. Der Wischsauger ist zudem mit den Maßen 256 x 275 x 1180 mm verhältnismäßig kompakt. Auf die Waage bringt er gut 5,8 kg, wobei man davon beim Einsatz effektiv etwas mehr als 600 g spürt.
Der LCD-Bildschirm direkt am Griff zeigt sowohl den Akkustand als auch den derzeitigen Reinigungsmodus per Icons an. Über ein Wi-Fi-Symbol signalisiert der Wischsauger zudem, dass er mit dem Internet verbunden ist.
Mova M50 Ultra – Bilder
Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Mova M50 Ultra – Bilder

Die Bedienelemente befinden sich allesamt am Griff. Neben dem bereits erwähnten Trigger am Inneren des Griffs sitzen oben am LCD-Bildschirm der Ein-/Aus-Button und der Reinigungs-Button, um zwischen den verschiedenen Reinigungsmodi zu wechseln. Die Taste, um den Selbstreinigungsprozess zu starten, befindet sich oben auf dem Griff. Hinten am Griff sitzt der Voice-Button. Dieser stellt die Sprachbenachrichtigungen des Wischsaugers stumm oder reaktiviert sie.
Den Frischwassertank am Fuß des Wischsaugers löst man durch gleichzeitiges Drücken der seitlichen Knöpfe. Die Einfüllöffnung offenbart sich durch Hochziehen des Verschlusses. Mova setzt hier zum Glück auf eine zweigeteilte Lösung, um Wasser und Reinigungskonzentrat einzufüllen. Der Gummistopfen ist allerdings etwas widerspenstig und will nicht immer sofort glatt sitzen. Durch etwas darauf herumdrücken fügt er sich dann jedoch. Aufgrund der Anschlüsse auf der Unterseite des Wassertanks sitzt dieser nicht gerade auf einer flachen Oberfläche, sondern wippt unter Umständen etwas hin und her. Das hat zur Folge, dass grobmotorische Menschen wie der Tester das Reinigungskonzentrat durch die spitz zulaufende Flaschenöffnung mehrfach an der Öffnung des Tanks vorbeischießen und eine Sauerei auf dem Wohnzimmertisch veranstalten.
Den Schmutzwassertank löst man problemlos von der Rückseite des Saugwischers durch Herunterdrücken der entsprechenden Taste. Obendrauf sitzt wie gewohnt der HEPA-Filter, welchen man ganz einfach herauszieht. Um die Auffangeinheit vom Tank zu lösen, zieht man den mit „Open“ beschrifteten Griff nach oben.
Einrichtung
Die Ersteinrichtung des Mova M50 Ultra ist in wenigen Minuten erledigt. Der Quickstart-Guide gibt hierzu eine gute Übersicht. Griff und Rumpf verbindet man zuerst, anschließend gilt es, sämtliche Plastikfolien vom Gerät zu entfernen. Die Selbstreinigungsstation ist direkt einsatzbereit und erfordert nur das Anstecken an die Steckdose.
Über die Mova-Home-App geht der Einrichtungsprozess dann weiter. Die App erfordert diverse Zugriffserlaubnisse (WLAN, GPS, Bluetooth), um sich mit dem heimischen Internet und dem Mova M50 Ultra zu verbinden. Am besten hat man hier direkt das WLAN-Passwort parat, um es auf dem Smartphone einzutippen. Durch gedrückt halten des Voice-Buttons für drei Sekunden wechselt der M50 Ultra in den WLAN-Suchmodus, um sich in das Netz einzuwählen. Anschließend möchte die App sich mit dem Wischsauger verbinden. Dazu scannt man entweder den QR-Code, der sich hinter dem Abwassertank versteckt, ein oder wählt das Gerät manuell aus einer Liste aus. Nach erfolgreicher Verbindung steht natürlich erst einmal ein Firmware-Update an. Die Installation ist schnell erledigt. Anschließend kann das Saugwischen auch direkt losgehen.
Steuerung
Über die App lassen sich Einstellungen zum Reinigungsverhalten vornehmen, wie die bevorzugte Stärke im Smart-Modus oder den verwendeten Selbstreinigungsmodus (Smart Self-Cleaning oder Deep Self-Cleaning). Auch die Selbstreinigung und Trocknung kann man über die App starten – vorausgesetzt, der Mova M50 Ultra befindet sich in der Reinigungsstation. Praktisch ist auch, dass die App einem anzeigt, ab wann man Verschleißteile wie die Wischwalze und den HEPA-Filter austauschen sollte.
Mova M50 Ultra – Bilder App
Mova M50 Ultra – Bilder App
Mova M50 Ultra – Bilder App
Mova M50 Ultra – Bilder App
Mova M50 Ultra – Bilder App
Mova M50 Ultra – Bilder App
Mova M50 Ultra – Bilder App
Das Gerät selbst bedient man erwartungsgemäß über die Steuerelemente am Griff und Display. Hauptsächlich dann über die gummierten Knöpfe am Display. Bei jeder Betätigung, etwa wenn man den Reinigungsmodus wechselt, ertönt die Sprachbenachrichtigung des M50 Ultra. Das Problem: Ist der Wischsauger ausgeschaltet, ist die Sprachbenachrichtigung ohrenbetäubend laut. Ist er hingegen in Betrieb, versteht man sie teilweise kaum – trotz bis zum Anschlag gestelltem Lautstärkeregler. Selbstverständlich lässt sich die Lautstärke auch reduzieren oder ganz stumm schalten.
Die motorisierten Räder des Bürstenkopfs sorgen wie auch bei anderen Saugwischern dafür, dass der Mova M50 Ultra gewollt vor einem davonfährt. So muss man ihn nur noch zurückziehen und hat zumindest ein Stück weit weniger Anstrengung bei der ohnehin schon ungeliebten Putzaktion.
Reinigung
Für die Reinigung stehen drei Modi zur Auswahl: Smart-Mode, Auto-Solution-Mode und Suction-Mode. Im Smart-Mode regelt der M50 Ultra alles augenscheinlich selbst. In der Praxis bedeutet das, dass der Saugwischer die Intensität der Reinigung an die von ihm erkannte Verschmutzung anpasst. In unserem Test fährt er dann hörbar mehrmals die Leistung hoch, visuell erkennbar an der farblich kodierten Linie, die am Rand des LCD eingeblendet ist. Grün bedeutet sanfter Betrieb, gelb steht für neutral und rot für intensiv. Wann er zwischen den Stufen hin und her wechselt, wirkt für uns jedoch recht willkürlich. An Stellen, an denen wir gewollt hätten, dass er die Leistung erhöht, passiert nichts und an Stellen, die augenscheinlich sauber sind, gibt er auf einmal Gas.
Im Auto-Solution-Mode verdünnt der Saugwischer das Reinigungskonzentrat intelligent. Inwiefern sich die Saug- und Wischleistung zu den anderen beiden Modi unterscheiden, ist jedoch nicht ersichtlich und wird auch in der Betriebsanleitung nicht näher erläutert. Der Suction-Mode ist schlussendlich dafür da, Wasser vom Boden aufzusaugen und besonders praktisch, wenn man etwas verschüttet hat.
Generell muss man sagen, dass der M50 Ultra bei hartnäckigeren Verschmutzungen an seine Grenzen kommt. Vor allem mit angetrockneten Flecken auf den Fliesen in der Küche hat er zu kämpfen. Das ist allerdings ein Problem, das die meisten Saugwischer haben. Hier sollte man entweder die betreffende Stelle vorbehandeln oder sie direkt per Hand entfernen. Die reguläre Flecken- und Schmutzbeseitigung auf den Fliesen klappt mit dem Mova M50 Ultra aber einwandfrei.
Auf dem Parkett macht er auf Anhieb eine gute Figur. Hier saugt und wischt er zufriedenstellend und passt Reinigungsleistung und Wasserzufuhr an, wenn man zuvor in den Parkett-Modus wechselt. Dieser aktiviert sich durch gedrückt halten der Modus-Taste für drei Sekunden.
Die Saugleistung des kompakten Mova M50 Ultra beträgt 22.000 Pa. Auf dem Parkett kommt er in unserem Test problemlos mit Staub, Krümeln und kleinen Laubblättern, die von draußen reingeweht wurden, klar. Auf den Fliesen in der Küche saugt er zufriedenstellend heruntergefallene trockene Reiskörner und Mehl ohne Rückstände auf. Mit im Schnitt 59 dB(A), gemessen per Smartphone-App, befindet er sich voll im Rahmen des Erträglichen. Unter Volllast kommt er kurzzeitig etwas über 60 dB(A).
Die Selbstreinigung gibt es in zwei Einstellungen: Smart und Deep Self-Cleaning. Erstere benötigt um die 30 Minuten und reguliert die Intensität des Reinigungsprozesses anhand der wahrgenommenen Verschmutzung der Wischwalze. Die Reinigung betrug in unserem Test etwa 5 Minuten, während die anschließende Trocknung der Wischwalze den Rest der Zeit in Anspruch nahm. Während der Selbstreinigung steigt die Lautstärke auf im Schnitt 50 dB(A) an. Die anschließende Trocknung gibt dann nur noch ein leises Surren von sich, das bei laufendem Fernseher oder Radio kaum bis gar nicht wahrnehmbar ist. Bei besonders starker Beanspruchung der Wischwalze gibt es den Deep-Self-Cleaning-Modus. Hier erhitzt das Wasser auf 100 Grad für eine intensivere Reinigung. Das Ganze dauert dann um die zwölf Minuten anstatt 30.
Akkuleistung
Verbaut ist ein 4000-mAh-Akku. In unserem Test kommen wir nach knapp 14 Minuten Dauereinsatz auf 55 Prozent Restakku. Dabei wechseln wir mehrmals zwischen den drei Modi hin und her. Bei gemischter Nutzung sind so zwischen 30 und 35 Minuten machbar, bis der Akku vollends entladen ist. Das sollte für die meisten Alltagssituationen und Putzaktionen reichen. Achtung: Um die Selbstreinigung nutzen zu können, muss noch mindestens 25 Prozent Akkuladung vorhanden sein, da das Gerät währenddessen nicht über die Station auflädt.
Preis
Die UVP des Mova M50 Ultra liegt bei 599 Euro. Derzeit kostet er 429 Euro auf Amazon.
Fazit
Der Mova M50 Ultra punktet neben einer zufriedenstellenden Reinigungsleistung vor allem durch sein praktisches Design, das eine Reinigung der schwer zu erreichenden Stellen in der Wohnung ungemein erleichtert. Das Setup per App geht schnell und unkompliziert von der Hand, wenngleich wir uns ein paar mehr Einstellungsmöglichkeiten in Bezug auf die Reinigungsmodi gewünscht hätten. Dafür punktet die App mit einer praktischen Verschleißanzeige für austauschbare Komponenten wie den HEPA-Filter oder die Wischwalze.
Auch nach dem Einsatz überzeugt der Mova M50 Ultra durch sein Design: Der Schmutzwassertank lässt sich problemlos und vor allem schnell säubern und wieder zusammensetzen und auch die Selbstreinigung lässt kaum Wünsche offen.
Während die Reinigung im Großen und Ganzen überzeugt, könnte der Smart-Mode vom ein oder anderen Software-Update profitieren. Die intelligente Schmutzerkennung griff während unseres Tests mehrmals daneben und ignorierte deutlich sichtbare Verschmutzungen gekonnt, während der Saugwischer an sauberen Stellen Vollgas gab.
Zusammengefasst bekommt man mit dem Mova M50 Ultra einen soliden Saugwischer, der sich vor allem durch sein praktisches Design von der Konkurrenz abhebt. Wer bereits einen guten Saugwischer sein Eigen nennt, hat nicht wirklich einen Grund zum Neukauf. Für Neukunden bietet das Gesamtpaket aber genügend praktische Funktionen und liefert zufriedenstellende Ergebnisse.
Roborock Dyad Air
Roborock Dyad Air
Roborock verkauft schon länger Saugwischer und hat damit inzwischen gute Geräte hervorgebracht. Der Dyad Air ist einfacher, aber günstiger – aber ist er auch gut?
- sehr gutes Reinigungsergebnis
- starker Akku
- Randreinigung
- Warmlufttrocknung
Saugwischer Roborock Dyad Air im Test: Wischt randlos und gut für nur 260 Euro
Roborock verkauft schon länger Saugwischer und hat damit inzwischen gute Geräte hervorgebracht. Der Dyad Air ist einfacher, aber günstiger – aber ist er auch gut?
Saugwischer erleichtern das Wischen enorm. Statt Eimer, Lappen und Schrubber zu verwenden, reicht ein einfacher Knopfdruck und die Akkusauger mit Wischfunktion sind bereit. Dass die Gemeinsamkeiten vorhandene Unterschiede überwiegen, zeigen Mischformen wie der Roborock Dyad Pro Combo (Testbericht), der alle Vorteile des Saugwischers Roborock Dyad Pro (Testbericht) bietet, mit weniger Handgriffen aber auch zum reinen Akkusauger mutiert.
Der Roborock Dyad Air geht einen anderen Weg. Während seine Geschwistermodelle teure Alleskönner sind, konzentriert sich Roborock beim Air auf die Grundfunktionen und heftet ihm ein vergleichsweise günstiges Preisschild an. So verzichtet der Air als erster Saugwischer der Dyad-Reihe auf die typische Doppelrolle und hat auch keinen Zusatztank für Reinigungsmittel mehr, behält aber die Fähigkeit, randlos wischen zu können und trocknet die Wischrolle nach erledigter Arbeit mit warmer Luft. Wir haben uns im Test angeschaut, wie gut der Dyad Air tatsächlich ist.
Was sind die Highlights des Roborock Dyad Air?
- Saugkraft von 17.000 Pa für trockenen und nassen Schmutz
- Dirtect-Sensor zur automatischen Anpassung an Verschmutzungsgrad
- Selbstreinigung und -trocknung der Bürste in der Station
- 50 Minuten Laufzeit für eine Reinigungsfläche von bis zu 140 m²
- randloses Wischen (rechts)
Design: Wie sieht der Roborock Dyad Air aus?
Der Roborock Dyad Air präsentiert sich in stilvollem, kompaktem Design, das in modernen Haushalten eine gute Figur macht. Mit nur 4,1 kg Gewicht ist er leichter als andere Modelle und lässt sich dank seines wendigen Körpers mühelos manövrieren. Die Ähnlichkeit zu den anderen Modellen der Dyad-Reihe ist dabei nicht von der Hand zu weisen. Das Gerät verfügt über einen 900 ml Frischwassertank, der nun wieder oben vorn im Korpus untergebracht ist, darüber gibt ein Display Informationen zum Status des Gerätes.
Einen Schmutzwassertank mit 770 ml ist ebenfalls vorn zu entnehmen und unterhalb des Frischwassertanks positioniert. Anstelle der zwei Bürsten des höherpreisigen Dyad Pro setzt der Dyad Air auf eine breite Einzelbürste mit recht flauschigen Fasern für die effektive Schmutzaufnahme. Sie ist so installiert, dass auf der rechten Seite nahezu kein Platz zum Rand bleibt, links hingegen wegen der Aufhängung der Rolle schon.
Wie ist die Reinigungsleistung des Roborock Dyad Air?
Der Motor des Roborock Dyad Air bietet eine Saugkraft von beeindruckenden 17.000 Pa. Damit meistert er sowohl trockenen Staub und Krümel als auch feuchten und flüssigen Schmutz. Unterstützt wird die Reinigung durch den sogenannten Dirtect-Sensor. Dieser erkennt den Verschmutzungsgrad des Bodens und passt Saugleistung, Bürstenrotation und Wassermenge automatisch an. Über das Display lässt sich der Verschmutzungsgrad in Echtzeit ablesen, im Automatikmodus muss der Nutzer aber nicht selbst einschreiten.
In unserem Test wurden flüssige und dickflüssige Verschmutzungen bereits mit einer Überfahrt sehr gut beseitigt. Bei eingetrockneten Flecken benötigte der Dyad Air zwar mehr Durchgänge, zeigte aber auch hier gute Reinigungsergebnisse. Erstaunlich: Der Unterschied zu den Dyad-Modellen mit zwei gegenläufig rotierenden Wischrollen ist nicht wirklich auszumachen.
Die Kantenreinigung klappt wegen der beschriebenen Aufhängung der Wischrolle nur an der rechten Seite gut, links bleiben einige Zentimeter Platz. Im Alltag sollte das aber selten zu Problemen führen. Gut gefallen hat uns die Akkuleistung des Dyad Air. Im Test kam der Saugwischer auf der manuell eingestellten höchsten Stufe auf rund 25 Minuten Laufzeit, im Alltag und im Automatikmodus reinigt der Air auch gut 45 Minuten am Stück. Eine Etage mit etwa 140 m² (brutto) in einem Durchgang ist damit kein Problem.
Wie die meisten Saugwischer ist auch der Robrock Dyad Air zwar bei der Nutzung grundsätzlich sehr beweglich und verlangt kaum Kraftaufwand, allerdings kommt man mit ihm kaum unter Möbel. Das Gerät erlaubt keine Senkung des Korpus über etwa 45 Grad hinaus. Wer sich mit dem Handgriff dem Boden weiter nähert, um unter Möbel zu kommen, hebt daher automatisch den Bürstenkopf vom Boden ab. Außerdem kann zu tiefes Neigen des Korpus dazu führen, dass Wasser ausläuft.
Alle Bilder zum Roborock Dyad Air im Test
Roborock Dyad Air

Roborock Dyad Air

Roborock Dyad Air

Roborock Dyad Air

Roborock Dyad Air

Roborock Dyad Air

Roborock Dyad Air

Roborock Dyad Air

Roborock Dyad Air

Roborock Dyad Air

Hat der Roborock Dyad Air eine App?
Der Roborock Dyad Air punktet mit einer Reihe von Komfortfunktionen, die die Reinigung erleichtern. Per Knopfdruck auf dem Griff lässt sich zwischen verschiedenen Modi wie Auto, Max, Nur-Saugen und Eco wechseln. Ist der Wassertank leer oder der Schmutzwassertank voll, informiert das Gerät per Sprachausgabe darüber. Erstaunlich ist, dass Roborock unbeirrbar kontinuierlich miese Lautsprecher für derartige Äußerungen in seine Dyad-Modelle einbaut. Die beiliegende App bietet zudem Einstellungsmöglichkeiten für die Reinigung und Wartung. Sie ist nett, aber wie bei der Konkurrenz nicht wirklich zwingend erforderlich.
Praktisch ist die Möglichkeit, den Sauger im Betrieb kurz hinzustellen, ohne dass Wasser austritt. Das war beim ersten Roborock Dyad (Testbericht) noch anders. Nach getaner Arbeit lässt sich die Bürste durch Einsetzen in die Station automatisch reinigen und anschließend mit Heißluft trocknen. Dadurch werden Bakterien und Gerüche vermieden.
Preis
Den Roborock Dyad Air gibt es aktuell für 400 Euro.
Fazit
Mit dem Roborock Dyad Air bekommt man einen leistungsstarken und vielseitigen Wischsauger zu einem attraktiven Preis. Für Hartböden ist er dank hoher Saugleistung und intelligentem Sensor eine effiziente Hilfe. Einfache Handhabung, durchdachte Ausstattung und praktische Selbstreinigung machen den Dyad Air zu einem empfehlenswerten Haushaltshelfer. Zwar verzichtet man gegenüber dem Dyad Pro auf Extras wie Dosiereinheit und Doppelbürste, doch im Kern überzeugt der günstige Verwandte mit solider Technik und gutem Reinigungsergebnis sowie guter Akkuausdauer.
Roborock F25 Ultra
Roborock F25 Ultra
Der Roborock F25 Ultra ist der erste Roborock-Wischsauger, der mit einer Dampffunktion ausgestattet ist, die 180 °C heißen Dampf zum Reinigen nutzt.
- saugt und wischt sehr gut
- Dampftechnik tatsächlich hilfreich
- lässt sich einfach manövrieren
- top Verarbeitung
Roborock F25 Ultra im Test: Dieser Wischsauger reinigt sogar mit heißem Dampf
Der Roborock F25 Ultra ist der erste Roborock-Wischsauger, der mit einer Dampffunktion ausgestattet ist, die 180 °C heißen Dampf zum Reinigen nutzt.
Die alljährliche Verbesserungsorgie hat beim Hersteller Roborock dieses Jahr die Dimension einer echten Revolution, statt nur einer behäbigen Evolution: Der neue F25 Ultra bringt statt nur minimal erhöhter Saugkraft und einer verbesserten Wischwalze nun eine Dampffunktion, die bei der Reinigung 180 °C heißen Dampf ausstößt. Das soll helfen, auch hartnäckige Flecken und andere Verschmutzungen besser beseitigen zu können. Ob die Funktion auch in der Praxis der echte Bringer ist und wie sich der Roborock F25 Ultra insgesamt schlägt, zeigt unser Test.
Das Testgerät hat uns der Hersteller zur Verfügung gestellt.
Lieferumfang
Der Roborock F25 Ultra kommt mit dem für Roborock üblichen Packungsinhalt bestehend aus Saugwischer, der Dockingstation, einer Flasche Reinigungskonzentrat, dem zusätzlichen HEPA-Filter, einer Handbürste sowie der Betriebsanleitung und dem Quick-Start-Guide.
Die Wischwalze und der Griff des F25 Ultra müssen vor der ersten Inbetriebnahme montiert werden und liegen ebenfalls bei.
Design
Das Design fügt sich ebenfalls in die bisherige Produktpalette ein: Schwarz und dunkles Grau zieren die 265 x 1096 x 246 mm des Akkuwischsaugers und verleihen ihm eine edle Optik. Wirkliche Abweichungen zu den Vorgängermodellen gibt es nicht. Die Platzierung der Buttons, die Form des Griffs sowie die von Frisch- und Schmutzwassertank bleiben gleich. Die Verarbeitung ist tadellos: Alle Komponenten sitzen fest, fühlen sich robust und wertig an und offenbaren keine groben Spaltmaße.
Auch die Dockingstation ist schwarz. Leider hat sie keine Auffahrrampe, was bedeutet, dass man den gut 5,6 kg schweren Saugwischer jedes Mal anheben muss, um ihn in die Station zu stellen oder herauszunehmen. Gerade körperlich eingeschränkte Menschen könnten damit zu kämpfen haben.
Roborock F25 Ultra – Bilder
Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Roborock F25 Ultra – Bilder

Der Frischwassertank befindet sich direkt am Fuß des Saugwischers und löst sich durch Ziehen eines Griffs. Neben der Öffnung für das Wasser gibt es ein separates Fach für das Reinigungskonzentrat, welches während des Putzvorgangs dem Wasser zugeführt wird. Der aufgesaugte Schmutz landet im Abwassertank, welcher über der Saugeinheit im unteren Teil des Korpus angebracht ist. Dieser löst sich ebenfalls durch Ziehen eines Griffs vom Rumpf.
Auf dem Tank sitzt ein austauschbarer und auswaschbarer HEPA-Filter. Mittels des etwas darunter platzierten Hebels löst man das Auffangsieb vom Tank, um die festen Substanzen in den Müll schmeißen zu können. Achtung: Auch wenn das Sieb das Gros an Haaren und Dreck auffängt, befinden sich in der Plörre im Abwassertank gerne mal feste Substanzen, die am Sieb vorbeihuschen. Diese können im Abfluss oder Rohrsystem verfangen und im schlimmsten Fall für eine Verstopfung sorgen. Es lohnt sich daher immer, ein Sieb im Abfluss zu haben oder eins ins Spülbecken zu stellen, bevor man das Abwasser wegkippt. Die mitgelieferte Handbürste hilft hier, das Auffangsieb und den Abwassertank anschließend sauber zu schrubben. Eine regelmäßige Reinigung, im besten Falle jedes Mal nach Verwendung, ist ratsam, um Gerüche zu vermeiden – auf dem Abwasser bildet sich innerhalb weniger Tage bereits ein stinkender Biofilm.
Einrichtung
Die Einrichtung des Saugwischers ist schnell und unkompliziert erledigt. Stromkabel an die Dockingstation anschließen und mit der Steckdose verbinden, den Griff sowie die Wischwalze des F25 Ultra anbringen und ihn in die Dockingstation zum Laden stellen. Während das Gerät fröhlich vor sich hin lädt, kann man schon einmal die Roborock-App auf dem Smartphone installieren, um den F25 Ultra mit ihr zu verknüpfen. Am schnellsten geht das über den QR-Code, der sich hinter dem Schmutzwassertank befindet. Nachdem sich App und Saugwischer miteinander verknüpft haben, steht direkt ein Firmware-Update bereit.
Sind die Updates installiert und der Akku aufgeladen, muss man zum Schluss nur noch den Frischwassertank befüllen und kann bei Bedarf Reinigungskonzentrat in das separate Fach hinzugeben.
Steuerung
Der Roborock F25 Ultra lässt sich sowohl per App als auch über die Buttons am Griff steuern. Er legt los, sobald man ihn durch das zu sich Ziehen aus der Arretierung löst. Auf dem Display zeigt er dann den Akkustand sowie den aktuell gewählten Modus per Icon an. Per Button wechselt man durch die vier verschiedenen Modi Auto, Steam, Hot-Water und Sponge oder nutzt direkt die App dafür. Der Vorteil daran: zusätzliche Einstellungsmöglichkeiten wie die Saugkraft, die Menge an Wasser oder wie stark die Räder motorisieren. Fester Bestandteil eines jeden Roborock-Wischsaugers ist zudem die Ansagerstimme, die Informationen zum Gerät weitergibt. Darunter der aktuell gewählte Modus oder ob das Gerät auf der Station zu laden beginnt. Lautstärke und Sprachausgabe lassen sich über die App verwalten, was gut ist, denn ab Werk ist uns die Stimme zu laut. Bei Ansagen hält sie sich vergleichsweise kurz, was angenehm ist. Möchte man keine Tipps oder Hinweise von der Roboterstimme erhalten, kann man diese jedoch auch gänzlich abschalten.
Roborock F25 Ultra – Bilder App
Roborock F25 Ultra – Bilder App
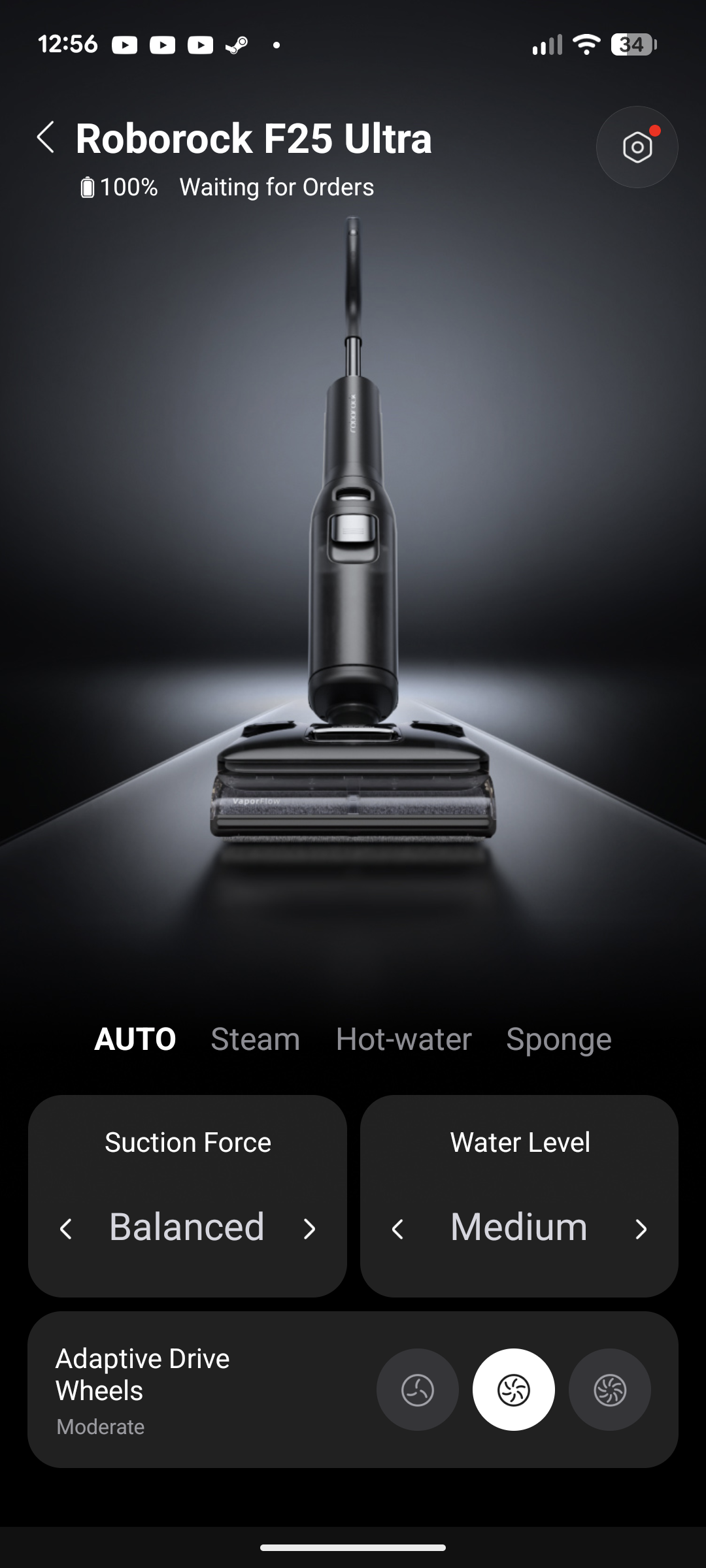
Roborock F25 Ultra – Bilder App
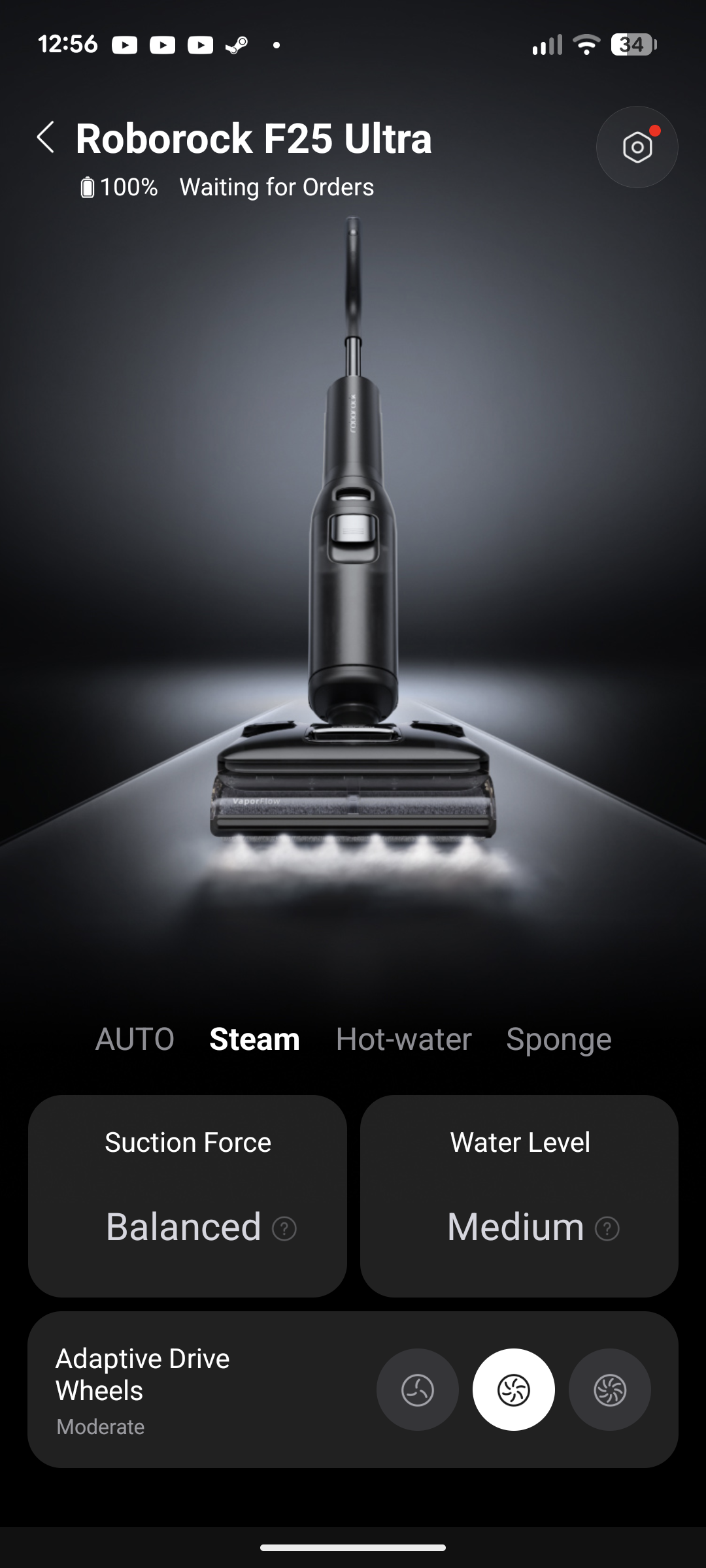
Roborock F25 Ultra – Bilder App
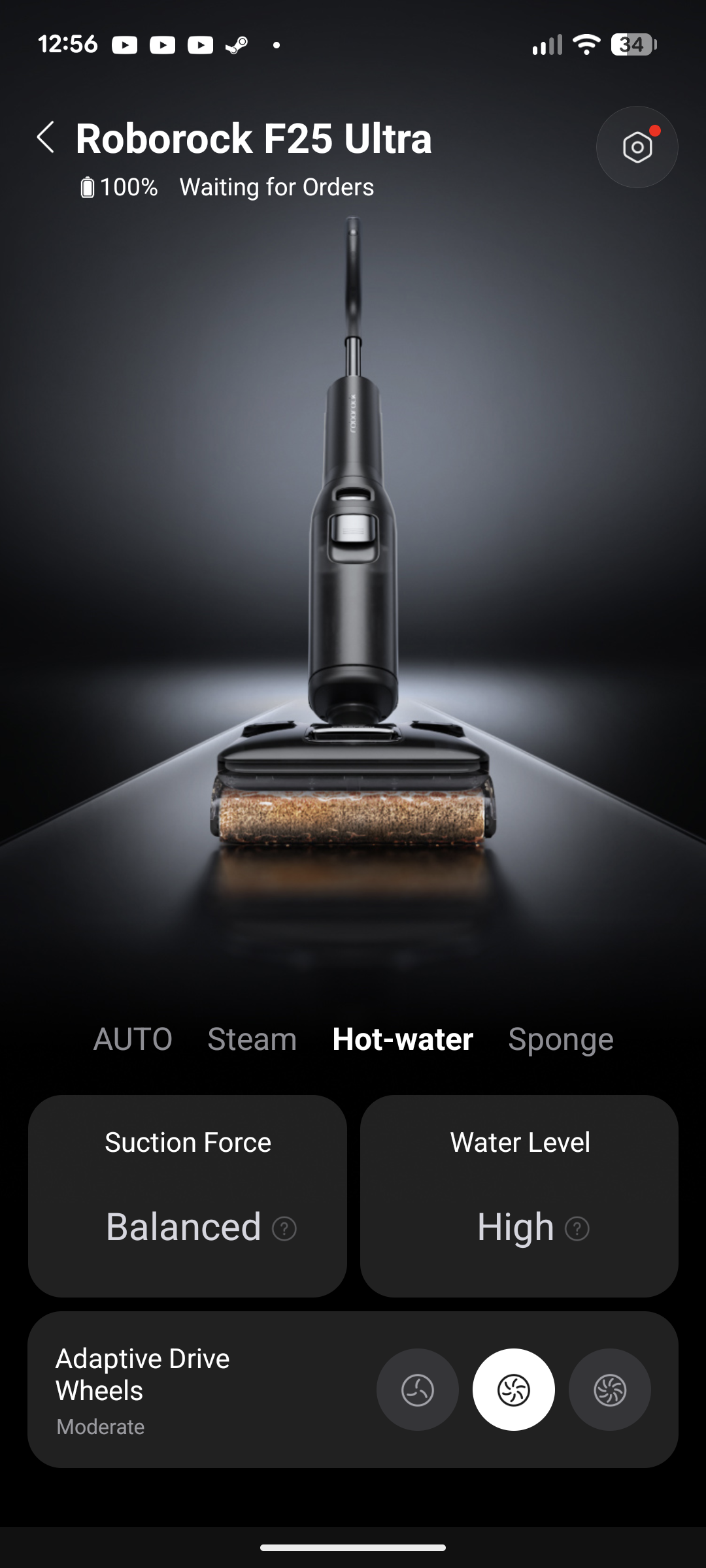
Roborock F25 Ultra – Bilder App
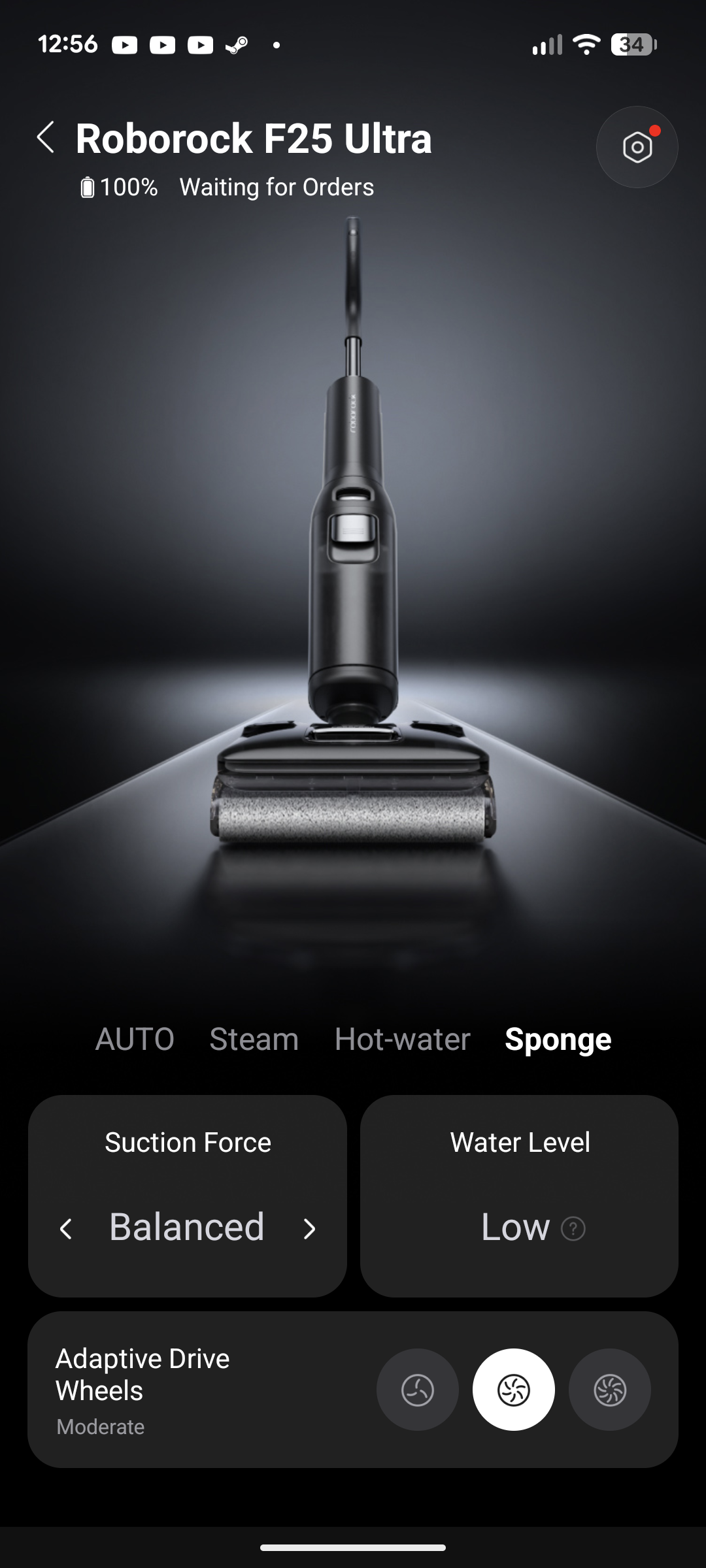
Roborock F25 Ultra – Bilder App
Roborock F25 Ultra – Bilder App
Roborock F25 Ultra – Bilder App
Wie bei manch anderen Roborock-Wischsaugern kann auch der F25 Ultra über die App aus der Ferne gesteuert werden. Dafür muss man ihn flach auf den Boden legen. Drückt man in der App dann die jeweilige Pfeilrichtung, fährt er mit etwas Verzögerung dorthin. Besonders praktisch, um unter schwer erreichbare Stellen zu kommen, ohne dafür Bett oder Couch verschieben zu müssen. Die Steuerung ist jedoch relativ schwerfällig und nur für den punktuellen Einsatz zu gebrauchen.
Reinigung
Der F25 Ultra ist wie bereits erwähnt mit vier unterschiedlichen Reinigungsmodi ausgestattet. Wir verwenden ihn hauptsächlich im Auto-Modus und wechseln gezielt zu den Modi Hot-Water und Steam. Unser Einsatzgebiet beschränkt sich auf eine Küche mit Fliesen, einen Parkettboden sowie eine kurze Fahrt über einen Teppich. In der Küche verwenden wir zuerst den Auto-Modus. Der F25 Ultra saugt mit maximal 22.000 Pa und reguliert Saug- und Wischverhalten in Abhängigkeit der Oberfläche und des Verschmutzungsgrades. Er ist am Bürstenkopf zusätzlich mit einer weiß leuchtenden LED ausgestattet, die den Boden unmittelbar vor ihm ausleuchtet. Bei unseren weißen Fliesen in der Küche ist das nicht nötig, da sieht man (leider) bereits mit bloßem Auge jedweden Fleck. Bei dunkleren oder schlecht beleuchteten Oberflächen ist das Licht allerdings eine große Hilfe. Im Auto-Modus saugt der F25 Ultra zuverlässig kleinere Krümel auf, kommt aber auch mit größeren Dingen wie heruntergefallenen Zwiebelschalen problemlos klar. Aufgrund des relativ hohen Bürstenkopfs kann es sein, dass man je nach Küche nicht bis ganz an den Rand kommt. Hier muss man dann mit einem regulären Staubsauger nacharbeiten, um auch den Staub, der sich dort angesammelt hat, zu beseitigen.
In einem zweiten Durchgang widmen wir uns dann den eingetrockneten Flecken auf den Fliesen. Hier wechseln wir zuerst zum Hot-Water-Modus, da der Auto-Modus diese in unserem Fall nicht entfernen kann. Nach dem Wechsel muss man kurz warten, bis sich das Wasser aufgeheizt hat. Mit heißem Wasser läuft es schon besser, für die hartnäckigsten Flecken müssen wir jedoch den Dampfer anschmeißen. Auch der Steam-Modus erfordert etwas Geduld, da der F25 Ultra kurz aufheizen muss. Das LED-Display zeigt hier den Fortschritt an (0 bis 100). Bei 100 angekommen, stößt vorne an der Wischwalze heißer Dampf aus. Damit bekommen wir auf den Fliesen auch die hartnäckigeren Flecken größtenteils in den Griff. An zwei Stellen müssen wir kleinere Rückstände am Ende noch kurz von Hand mit dem Schwamm entfernen. Die konnte der Saugwischer auch nach mehrmaligem Drüberfahren nicht mitnehmen.
Auf dem Parkett macht er ebenfalls eine gute Figur. Hier saugt er Staub, Krümel und einzelne trockene Laubblätter, die beim letzten Lüften ihren Weg in das Wohnzimmer gefunden haben, anstandslos auf. Im Auto-Modus verteilt er zudem nicht zu viel Wasser, wodurch der Holzboden befeuchtet, aber nicht triefend nass wird. Auf dem Parkett hat der F25 Ultra dann aber tatsächlich seine Nemesis gefunden: ein festgetretener Obstaufkleber. Diesen konnte er weder mit 86 °C heißem Wasser noch 180 °C heißem Dampf vom Boden lösen. Mit alltäglichem Schmutz kommt er auf dem Parkett allerdings prima klar.
Zu guter Letzt machen wir mit dem Roborock F25 Ultra einen Ausflug auf unseren Kurzflor-Polypropylen-Teppich. Als Hartboden-Saugwischer ist er für Teppiche zwar nicht ausgelegt – uns interessiert aber trotzdem, wie er mit diesen klarkommt. Selbstredend hat seine Performance hier keine Auswirkungen auf die endgültige Bewertung. Er schafft es erstaunlicherweise relativ einfach vom Parkettboden auf den Teppich und saugt souverän die heruntergefallenen Krümel vom Frühstück auf. Auch auf dem Teppich machen wir den Dampf-Test und widmen uns einem eingetrockneten Soßen-Fleck. Hier muss sich der F25 Ultra dann geschlagen geben, denn auch nach etwa einer Minute der Dampfbehandlung bleibt der Fleck hartnäckig. Beim Herunterfahren vom Teppich bleibt er dann am Rand hängen und benötigt einen beherzigten Schubs unsererseits, um wieder auf das Parkett zu kommen.
Während der Reinigungsaktion über die verschiedenen Modi hinweg erreicht der Saugwischer eine Lautstärke von maximal 63 dB(A), die wir mit einer Smartphone-App messen. Im Schnitt bewegt sich seine Lautstärke bei knapp 57 dB(A).
Nach getaner Arbeit geht es für den Roborock F25 Ultra zurück auf die Dockingstation, um die Selbstreinigung zu starten. Dies geschieht entweder über den Button am Griff oder über die App. Wir entscheiden uns für die App und starten so die fünfminütige Selbstreinigung, die im Schnitt mit 53 dB(A) ackert. Die neue 180 °C heiße Dampftechnik ist ebenfalls Bestandteil des Reinigungsprozesses und befreit die Wischwalze in Kombination mit 90 °C heißem Wasser von Schmutz. Die anschließende Selbsttrocknung bei 95 °C findet standardmäßig im dreißigminütigen, langsamen Modus statt. Eine Schnelltrocknung innerhalb von fünf Minuten ist aber auch möglich. Wir entscheiden uns für die langsame Trocknung, die auch wirklich so ziemlich genau 30 Minuten dauert und dabei im Schnitt nur 43 dB(A) an Lautstärke erzeugt. Die Wischwalze ist im Anschluss anstandslos sauber und trocken.
Akkuleistung
Nach 18 Minuten im Dauerbetrieb und unter Verwendung des Auto-, Hot-Water- und Steam-Modus liegt der Akkustand bei 40 Prozent. Es ist naheliegend, dass das Aufheizen des Wassers mehr Strom verbraucht und die Akkuleistung beeinträchtigt. Wer hier hauptsächlich mit dem Auto-Modus arbeitet, holt sicherlich noch etwas mehr aus dem Akku raus. Eine Ladung sollte also durchaus ausreichen, um mehrere Zimmer zu saugwischen. Beim Aufladen schafft er es, von 40 Prozent auf 100 Prozent in knapp unter zwei Stunden zu kommen und lässt sich somit auch problemlos mehrmals am Tag einsetzen.
Preis
Die UVP liegt bei 799 Euro. Aktuell ist der Roborock F25 Ultra fast überall ausverkauft, kann aber über Alza für 599 Euro mit Code ALZADAYS25DE vorbestellt werden. Wer nicht warten möchte, bekommt ihn auch für 779 Euro direkt.
Fazit
Der Roborock F25 Ultra für 599 Euro (Code ALZADAYS25DE) punktet mit einer soliden Reinigung auf Hartböden. Er kommt sowohl beim Saugen als auch beim Wischen mit dem meisten Schmutz klar und auch besonders hartnäckigen Flecken macht er größtenteils den Gar aus. Er ist der erste Roborock-Saugwischer, der mit Dampftechnik bestückt ist und setzt diese in unserem Test auch gewinnbringend ein. Als Besitzer eines Vorgängermodells muss man sich jedoch die Frage stellen, ob sich ein Upgrade auf den F25 Ultra lohnt. Denn mit einer UVP von 799 Euro kostet er relativ viel Geld und bringt in erster Linie nur die Dampffunktion als wirkliches Novum mit sich. Der restliche Funktionsumfang ist beinahe identisch zu älteren und mittlerweile auch günstigeren Modellen.
Für Neueinsteiger liefert Roborock hier aber ein stimmiges Gesamtpaket, an dem es nur wenig auszusetzen gibt und das mit den meisten Verschmutzungen im Alltag klarkommt.
Roborock Dyad Pro Combo
Sauger und Wischer
Roborock Dyad Pro Combo
Es gibt Akkusauger und es gibt Wischsauger mit Akku – aber selten beides in einem. Beim Roborock Dyad Pro Combo ist das anders und noch dazu ist der Preis fair. Kann das Gerät auch was?
- Saugwischer und Akkusauger in einem
- beides funktioniert richtig gut
- Preis für 2 vollwertige Geräte fair
- Laufzeit als Akkusauger könnte länger sein
Roborock Dyad Pro Combo im Test: Überzeugend als Saugwischer und Akkusauger
Es gibt Akkusauger und es gibt Wischsauger mit Akku – aber selten beides in einem. Beim Roborock Dyad Pro Combo ist das anders und noch dazu ist der Preis fair. Kann das Gerät auch was?
Roborock ist in erster Linie für seine guten Saugroboter (Themenwelt) bekannt, hier landet das Unternehmen bei uns in Bestenlisten (Top 10 Saugroboter) immer auf den ersten Plätzen. Aber auch bei anderen Haushaltsgeräten liefert der Hersteller richtig gute Leistung ab, wie er zuletzt mit dem Wischsauger Roborock Dyad Pro (Testbericht) oder dem Akkusauger Roborock H7 (Testbericht) bewiesen hat. Nun geht Roborock noch einen Schritt weiter und bringt mit dem Dyad Pro Combo ein Modell auf den Markt, das Wischsauger und Akkusauger in sich vereint. Der Clou dabei: Bei Einzelpreisen für die beiden Geräte, die schnell mal 300, 400 oder sogar 500 Euro überschreiten und dann zusammen mal eben einen vierstelligen Gesamtbetrag kosten, verlangt Roborock für den Combo nur 600 Euro. Das klingt fair – zumindest, wenn die Leistung für Wischen und Saugen gleichermaßen stimmt. Ob das so ist, überprüfen wir im Test.
Design und Verarbeitung
Auf den ersten Blick ist der Unterschied vom reinen Wischsauger Dyad Pro zum neuen 2-in-1-Gerät Dyad Pro Combo gar nicht groß. Als Wischsauger setzt er auf den gleichen großen Hauptbürstenkopf mit zwei hintereinander liegenden Wischrollen, wobei die vordere zweigeteilt ist und durch ihre besondere Konstruktion bis an den Rand kommt. Im Gegensatz zu anderen Modellen ist daher auch mit dem Dyad Pro Combo randloses Wischen möglich. Erneut gibt es den kleinen Zusatztank für Reinigungsmittel oben auf dem Hauptbürstenkopf und auch sonst hat sich am grundsätzlichen Aufbau wenig geändert. So wartet vorn unten am Korpus wieder der Abwassertank auf Entnahme, darüber sitzt die Motoreinheit mit oben angebrachtem, rundem Display. Hinten sitzt der Frischwassertank, darüber ragt der typische Griff mit Bedienelementen hervor. Das alles ist in schickes Schwarz-Weiß getaucht und gelegentlich kommen einige wenige graue Akzente hinzu.
Neu ist hingegen der zusätzliche Griff an der Motoreinheit und die Tatsache, dass diese Einheit vom Rest separiert werden kann. Zusammen mit einem zusätzlichen Filtereinsatz mit Schmutzbehälter, einem langen Saugrohr und einer Motorbürste für Hart- und Teppichboden wird daraus dann der Akkusauger – praktisch. Ebenfalls praktisch: All das Zubehör – gerade benötigtes, aber auch nicht benötigtes – wird in der schon vom Dyad Pro bekannten Reinigungs- und Aufbewahrungsschale mit warmer Lufttrocknungsfunktion aufbewahrt. Die wurde dafür mit einer Erweiterung versehen, die an die bekannte Schale angeklipst werden kann. Das ist alles ordentlich und auch gut verarbeitet. Einziger Wermutstropfen: Das Stromkabel ist hellgrau, Ladeschale und Aufbewahrungsständer schwarz – das passt nicht so recht, ist aber auch nicht weiter schlimm.
Einbindung und App
Die Verbindungsaufnahme klappt genauso gut und direkt wie beim Dyad Pro (Testbericht). Da sich an der App, in der auch die Roboter des Herstellers bedient werden, nichts geändert hat, verweisen wir an dieser Stelle auf den entsprechenden Passus beim Dyad Pro.
Alle Bilder zum Roborock Dyad Pro Combo im Test
Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo
Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Roborock Dyad Pro Combo

Reinigungsleistung und Handhabung
Auch in diesem Abschnitt kommen wir nicht ohne Vergleich zum sehr guten Saugwischer Roborock Dyad Pro (Testbericht) hin. Denn als Wischsauger profitiert der von all den Fortschritten, den der Pro gegenüber dem älteren Roborock Dyad ohne Pro-Namenszusatz (Testbericht) mit sich brachte. So ist die Handhabung mit dem Pro Combo wieder sehr angenehm. Kraft muss man nicht aufwenden, der Hauptbürstenkopf mit seinen beiden gegenläufig drehenden Rollen schwebt geradezu fast widerstandslos nach vorn und zurück und bleibt dabei problemlos in seiner Bahn. Das ist ein großer Fortschritt im Vergleich zum ersten Dyad, dessen Hauptbürstenkopf geradezu labil wirkte, wodurch eine gerade Bahnenführung durch den Nutzer zum Geduldspiel wurde. Im Gegenzug ist das Zirkeln um enge Kurven etwas schwieriger, bleibt aber im Rahmen.
Nach wie vor lässt sich der Pro Combo nicht weiter als etwa 45 Grad abwinkeln, unter Möbel kommt man so nur bedingt. Weiteres Ablegen hebt zwingend den Wischkopf an und kann zudem zum Auslaufen der Wassertanks führen. Ebenfalls gleichgeblieben: Der Pro Combo kann auch außerhalb der Aufbewahrungsschale aufrecht hingestellt werden. In der App lässt sich dann etwa einstellen, ob es nach dem Abklappen automatisch weitergehen soll, oder ob der Nutzer dafür erst wieder einen Knopf drücken muss. Alles andere ist ebenfalls gleich – leider auch der Lautsprecher, über den der Dyad Pro Combo mit dem Nutzer in per App einstellbaren Sprachen kommuniziert. Das ist grundsätzlich hilfreich und gut, klingt aber bei unserem Testgerät wieder, als ob die Sprach-Samples unter Wasser aufgenommen wurden. Die Trocknung der Wischrollen, die – auch wieder in der App einstellbar – automatisch beim Zurückstellen des Pro Combo oder auf Knopfdruck ausgeführt und schnell oder intensiv ausfallen darf, ist wieder von 2 bis 6 Stunden einstellbar und geschieht mit warmer Luft. Dabei dreht das Gerät die Rollen alle paar Minuten etwas weiter, damit die Luft alle Seiten gleich gut erreicht.
Beim Saugwischer Dyad Pro Combo ist also alles gleich, in der neu hinzugekommenen Saugfunktion unterscheidet sich das Modell aber deutlich vom Vorgänger. So darf der Nutzer wie eingangs erwähnt aus dem reinen Saugwischer einen lupenreinen Akkusauger machen. Dafür muss er allerdings zuerst etwas „basteln“. Denn mittels eines kleinen Knopfes am Korpus muss die Motoreinheit am neuen Zusatzgriff entnommen, daran der Schutzbehälter mit Filter angedockt und das lange Saugrohr mit der Motorbürste für Teppich und Hartboden angeschlossen werden. Das sind letztlich nur wenige Handgriffe, anfangs dauert das aber doch rund eine Minute, weil man schon genau hinschauen muss, damit alles richtig sitzt.
Danach geht es los mit dem Saugen und der Dyad Pro Combo verhält sich fast wie jeder andere Akkusauger auch. Dabei ist allerdings der Haltegriff für große Hände etwas knapp ausgefallen, geht aber noch in Ordnung. Auch die Positionierung der Tasten für An/Aus und Saugleistung sind nicht ganz optimal zu erreichen, auch das geht aber noch. Die Motorbürste mit ihrer harten und weichen, spiralförmig gedrehten Borstenreihe ist zumindest auf Hartboden etwas laut. Außerdem auffällig: Zum Ausleeren muss immer zuerst der Filter entnommen werden, außerdem quittierte unser Testgerät beim Saugen auf Teppich schnell den Dienst, weil der Bürstenmotor zu schwach ist.
Und wie ist jetzt die Reinigungsleistung? Die ist beim Wischen in etwa genauso gut, wie beim Dyad Pro (Testbericht) – und das bedeutet in Kurzform: Nur anstrengendes händisches Wischen ist noch effektiver, aber selbst eingetrockneter Dreck geht mit dem Pro Combo im Wischmodus weg. Zur Not muss der Nutzer zwei- oder dreimal über die Schmutzstelle gehen. Und Saugen? Hier schlägt sich das Combimodell nicht ganz so souverän, zumindest nicht auf Teppich. Denn während auf Hartboden kein Unterschied zu Konkurrenz-Akkusaugern auszumachen ist, kommt der Roborock-Transformer als Sauger auf hochflorigem Teppich hier nicht mehr mit und kapituliert aufgrund des zu schwachen Bürstenmotors. Auf kurzer Auslegeware hingegen ist das Ergebnis ordentlich, die angepriesenen 17.000 Pa Saugkraft reichen durchaus noch aus, um Schmutz aus den Tiefen zu ziehen. Allerdings soll hier generell nicht verschwiegen werden, dass Akkusauger in solchen Szenarios ohnehin schnell an ihre Grenzen kommen. Denn dann kann die Motorbürste die im Vergleich zu kabelgebundenen Saugern geringere Saugkraft einfach nicht mehr ausgleichen. Bedenkt man, dass mit dem Dyad Pro Combo Sauger und Wischer in einem kommen, ist die Gesamtleistung also trotzdem sehr gut.
Beim Akku hat sich nicht viel getan, beim Wischen reicht er immer noch für etwa 25 Minuten auf höchster Saugstufe und damit für 150 bis 180 Quadratmeter Wohnfläche. Die Leistungsaufnahme beim Saugen ist höher, entsprechend ist der Sauger eher für kurze Einsätze bis 10 oder 12 Minuten gedacht. Die mögliche Reinigungsfläche fällt daher deutlich geringer aus – aber für Hartboden kann man dann ja einfach auch gleich wischen.
Preis
Die UPV des Roborock Dyad Pro Combo liegt mit 599 Euro ein gutes Stück höher als noch beim Dyad Pro, dafür ist das neue Modell auch für die ganze Wohnung geeignet. Zum Testzeitpunkt kostet der Dyad Pro Combo in Deutschland rund 500 Euro (Preisvergleich), bei Amazon ist er etwas teurer. Unterboten wird dieser Preis von Geekbuying, hier kostet das Exemplar nur 479 Euro.
Fazit
600 Euro sind viel Geld. Führt man sich allerdings vor Augen, dass man dafür zwei vollwertige Geräte in einem bekommt, ist das gar nicht so teuer – zumal der Preis zum Testzeitpunkt bei „nur“ etwa 500 Euro lag. Tatsächlich müssen Nutzer hier so gut wie keine Kompromisse eingehen. Sie bekommen einen vollwertigen Dyad Pro (Testbericht) mit der besten randlosen Wischfunktion auf dem Markt und zusätzlich einen insgesamt guten Akkusauger mit dazu. Der kann es zwar nicht mit 700-Euro-Geräten wie einem Dyson V15 Detect Absolut (Testbericht) aufnehmen, schlägt sich aber vor allem auf Hartboden und kurzflorigem Teppich doch sehr gut.
Roborock Dyad
Roborock Dyad
Erst Akkusauger, dann Akku-Wischsauger: Wischen wird so zum Kinderspiel, aber gerade randlos klappt das mit kaum einem Gerät. Das soll beim Roborock Dyad anders sein, aber es gibt einen Haken.
- hervorragende Wischleistung dank 2 Walzen
- gute Verarbeitungsqualität
- „randlos“ Wischen möglich
- kann nicht allein aufrecht stehen
- Wischkopf klobig und polternd beim Wischen
Roborock Dyad im Test: Fast perfekter Wischsauger mit kleinem Haken
Erst Akkusauger, dann Akku-Wischsauger: Wischen wird so zum Kinderspiel, aber gerade randlos klappt das mit kaum einem Gerät. Das soll beim Roborock Dyad anders sein, aber es gibt einen Haken.
Wer hin und wieder größere Verschmutzungen aufwischen muss, weiß, wie schweißtreibend das ist. Wischmopp in den Wischeimer tauchen, Auswringen, Schrubben und das ganz wieder von vorn – etliche Male für ein paar Quadratmeter. Elektronikhersteller haben dafür eine Lösung: Wischsauger. Diese Akku-betriebenen Staubsauger verfügen zusätzlich über Frisch- und Abwassertank sowie Stoffrollen, mit denen sie Hartböden feucht polieren und das Schmutzwasser sofort wieder absaugen.
Als Resultat soll Wischen so einfach wie Saugen sein – versprechen die Hersteller. Dabei gibt es aber oft Kleinigkeiten wie bauartbedingte Probleme mit der Randreinigung und einiges mehr. Das war auch beim ansonsten sehr guten Dreame H11 Max (Testbericht) so. Ob das beim neuen Roborock Dyad besser klappt?
Lieferumfang
Roborock ist zwar bekannt für hervorragende Produkte, nicht aber unbedingt für einen umfangreichen Lieferumfang. Das bestätigt sich beim neuen Roborock Dyad . Im großen Karton warten neben dem Wischsauger, bei dem der separate Handgriff noch in den Korpus des Gerätes eingesteckt werden muss, lediglich die typische Ladestation, Reinigungsbürste, Ersatzfilter und ein unter anderem deutschsprachiges Handbuch. Ersatzwischrollen oder gar einen Reinigungszusatz gibt es nicht – obwohl einer von Anbieter Unilever auf der Seite von Roborock beworben wird.
Design
Beim Design orientiert sich Roborock an anderen aktuellen Geräten. So gibt es einen vergleichsweise große Reinigungskopf und Frischwassertank, Gebläse und Abwassertank sind in einem groß, mehr oder weniger zylindrischen Korpus untergebracht. Im Gegensatz zum monolithisch anmutenden Dreame H11 Max (Testbericht) setzt Roborock auf deutlich mehr Rundungen, harte Kanten gibt es nicht.
Das Display, oben auf dem Korpus des Wischsaugers angebracht, ist deutlich kleiner als beim direkten Konkurrenten aus (mehr oder weniger) gleichem Hause, zeigt aber ebenfalls Akkustand, Saugleistung durch einen farbigen LED-Kreis und diverse Fehlermeldungen an. Trotz etwas reduzierter Größe ist die Ablesbarkeit sehr gut – aus Sicht des Nutzers. Auf der Ladestation und an einer Wand stehend bleibt der Inhalt unverändert auf dem Kopf stehen. Das ist schade, zumal Roborock bei seinem Akkusauger Roborock H7 (Testbericht) ein kleines OLED-Display verwendet, das die Darstellung beim Laden oder während der Nutzung je um 180 Grad dreht.
Alle Bilder zum Wischsauger Roborock Dyad
Roborock Dyad

Roborock Dyad

Roborock Dyad

Roborock Dyad
Roborock Dyad

Roborock Dyad

Roborock Dyad

Roborock Dyad

Roborock Dyad

Roborock Dyad

Roborock Dyad

Roborock Dyad

Roborock Dyad

Der Saug- und Wischkopf wirkt nicht ohne Grund deutlich ausladender. Statt wie bei den meisten anderen Geräten nur eine Wischrolle zu beherbergen, stecken beim Dyad gleich zwei oder eigentlich sogar drei Rollen im Gehäuse – eine durchgehende vorn und eine zweigeteilte dahinter. Diese beiden kleineren Rollen reichen im Gegensatz zur großen vorderen Rolle bis direkt an den Rand, eine sichtbare Halterung dafür an den Seiten sieht man nicht. Damit löst Roborock auf dem Papier eines der Probleme bisheriger Wischsauger, bei denen beim Entlangfahren an der Fußbodenleiste immer ein Zentimeter trocken blieb.
Dafür schafft Roborock ein neues Problem: Der Dyad kann im Gegensatz zu nahezu allen anderen Wischsaugern nicht von allein aufrecht stehen. Als „Lösung“ baut der Hersteller auf der Rückseite eine Art ausklappbaren „Seitenständer“ ein, der bei Bedarf ausgeklappt werden kann. Dann steht der Wischsauger etwa im 45-Grad-Winkel, läuft nicht aus und fällt auch nicht um.
An der Verarbeitung gibt es indes nichts zu meckern. Alles sitzt fest und wirkt langlebig. Uns persönlich gefiel allerdings die Farbwahl des Modells mit weißem Korpus, schwarzen, blauen, silbernen und roten Akzenten nicht so gut, den silbernen Dreame H11 Max (Testbericht) finden wir schlicht stimmiger. Das ist aber Geschmackssache.
Funktion und Reinigung
Dyad, also englisch für Diade, bezeichnet im Prinzip eine enge Zweierbeziehung. Zugegeben: Namen sind Schall und Rauch, auf unserem Lieferkarton war der ursprüngliche Name „Washstick“ mit einem einfachen „Dyad“-Aufkleber überklebt. Und auch wenn wir „Dyad“ nur bedingt gut finden (immerhin trägt das Modell nicht einfach nur eine kryptische Buchstaben-Ziffern-Kombination als Bezeichnung), so findet man mit etwas Fantasie eine passende Bedeutung. So könnte der Name ein Hinweis auf die innige Beziehung zwischen Wischsauger und Nutzer oder – wahrscheinlicher – ein Fingerzeig auf eine der Besonderheiten des Dyad geben: Die zwei Wischrollen. Wobei – eigentlich sind es ja drei, denn die hintere Walze ist wie oben erwähnt zweigeteilt. Dadurch schafft der Roborock Dyad das, was andere Wischsauger nicht können: (fast) randlose Reinigung.
Tatsächlich bleibt nur ein sehr schmaler Bereich von ein oder zwei Millimeter auch für den Dyad unerreichbar und selbst der wird von einzelnen Fusseln der kurzhaarigen Bürsten teilweise noch erwischt – vorbildlich. Die zwei Walzenreihen haben aber noch einen ganz anderen Vorteil: Sie rotieren gegeneinander und negieren dadurch den typischen „Vorwärtsdrang“ von Modelle mit rotierenden Einzelwalzen. Durch die gegenläufige Rotationsbewegung soll der Roborock Dyad zudem Schmutz noch besser aufnehmen – und tatsächlich: das klappt! Waren wir von der Reinigungswirkung von Modellen wie dem Jimmy PowerWash HW8 Pro (Testbericht) oder Dreame H11 Max (Testbericht) schon sehr angetan, so ist die Reinigungskraft des Dyad noch einmal besser. Neben der doppelten Walzenzahl könnte das zumindest zum Teil auch am Verhältnis zwischen Frisch- und Abwassertank liegen. Während das etwa beim Dreame-Modell bei 900 zu 500 ml liegt, sind die Tanks beim Roborock-Modell 850 und 620 ml groß. Das könnte darauf hindeuten, dass hier etwas mehr Frischwasser aufgebracht wird, weil mehr abgesaugt werden kann. Optisch konnten wir allerdings keine Unterschiede bei der verwendeten Wassermenge, etwa zum Dreame-Modell, erkennen. So oder so: Die Reinigungsleistung empfanden wir als besser als bei allen anderen bislang von uns getesteten Wischsaugern.
Dabei passt der Dyad die Reinigungsleistung automatisch an die Verschmutzung an und stellt das entsprechend durch verschiedenfarbige LEDs in Kreisform auf dem Display dar. Sollte der im Test gut funktionierende Verschmutzungssensor im Alltag doch mal danebenliegen, bietet der Dyad die Möglichkeit, die Saugleistung per Knopfdruck manuell zu erhöhen – ebenfalls ein Vorteil im Vergleich zu Modellen mit einer ausschließlichen Automatikfunktion.
Die Tastenanordnung ist wie beim Dreame H11 Max, allerdings gibt es Unterschiede bei der Belegung bzw. der Auslösung bestimmter Vorgänge. Während man beim Dreame-Modell etwa die Autoreinigungstaste oben auf dem Handgriff im Dock länger drücken muss, langt bei Roborock ein kurzer Druck, um die gut ein bis zwei Minuten lange Prozedur auszulösen. Stattdessen muss man die vordere untere Modus-Wahltaste drei Sekunden gedrückt halten, um in den Bodentrocknungsmodus zu wechseln, bei dem nur Flüssigkeit aufgesaugt statt auch zugeführt wird. Wir halten das anders herum wie bei Dreame für sinnvoller. Dort gibt es zudem einen Extra-Knopf für die Sprachwahl. Bei Roborock muss man die Modus-Taste 10 Sekunden lang drücken, um in den Sprachwahl-Modus zu gelangen, in dem man den Dyad von englischer Sprachausgabe unter anderem auf Deutsch umstellen kann. Ohne Handbuch dürften darauf nur die wenigsten Nutzer kommen.
Im Betrieb wirkt der Wischsauger übrigens auch ohne den typischen Zug durch die rotierende Rolle erstaunlich handlich und beweglich. Das Gelenk, an dem der Wischkopf hängt, lässt sich dabei ohne großen Kraftaufwand bewegen. So kann man problemlos auch um 90 Grad gedreht wischen, um in eine schmalere Lücke zu gelangen. Nur unter Möbel kommt man mit dem Dyad noch weniger, als schon mit den meisten anderen Wischsaugern. Beim Roborock-Modell liegt das neben dem ohnehin raumgreifenden Korpus zusätzlich auch an der besonders hohen Wischbürste, bei der gleich zwei Walzenreihen motorbetrieben werden müssen. Das scheint sich auch im Betriebsgeräusch niederzuschlagen, der Roborock Dyad ist lauter und etwas schriller als der Dreame H11 Max. Zudem rumpelt der Wischkopf deutlich lauter über Fliesenfugen, das klingt etwas plastikartig und billig.
Die selbständige Reinigungsfunktion wurde bereits angedeutet. Nach jedem Wischvorgang sollten Nutzer das Gerät in die Ladeschale stellen, die Aufbewahrungsort und Waschbecken für den Sauger in einem ist. Ein kurzer Druck auf den obersten Knopf am Handgriff sorgt anschließend dafür, dass der Wischsauger seine beiden Wischwalzen ordentlich durchspült und so reinigt. Zudem sollten Nutzer auf jeden Fall den Abwassertank leeren und reinigen, damit es nicht zu einer Geruchsbelästigung kommt. Roborock versieht den Abwassertank im Gegensatz zu manchem Konkurrenten zusätzlich mit einem Sieb als Grobfilter für größere Schmutzpartikel oder Haare – gerade für Tierbesitzer ist das hilfreich. Ebenfalls abweichend vom Mainstream, ansonsten aber ohne Vorteil: Der Frischwassertank wird “von unten“ befüllt, muss also auf den Kopf gedreht werden. Außerdem gibt es keine maximale Füllstandlinie.
Beim Thema Akkuleistung macht sich die zusätzliche motorengetriebene Walzenreihe negativ bemerkbar, allerdings gleicht Roborock den erhöhten Stromverbrauch mit einem stärkeren Akku aus. Dadurch schafft der Dyad mit seinem 5000 mAh starken Akku die nahezu identische Reinigungszeit wie der Dreame-Wischsauger mit 4000 mAh: 35 statt 36 Minuten. Das klingt auf den ersten Blick wenig, ist tatsächlich aber mehr als genug, um locker 100 Quadratmeter und mehr zu reinigen. An die vom Hersteller angegebenen 280 Quadratmeter glauben wir nicht, bei 180 dürfte Schluss sein, solange man nicht durch die Räume hetzen will.
Größter Kritikpunkt bleibt für uns der ebenfalls schon angesprochene, ausklappbare Ständer. Wer mal eben etwas wegräumen will, um anschließend dort zu wischen, muss den immer erst ausklappen, um den Dyad dann im 45-Grad-Winkel hinzu“stellen“ – das nervt! In unseren Augen ist das nur eine Notlösung, die immer einen Extrahandgriff benötigt. Außerdem muss man sich zum Ausklappen und später zum Aufnehmen des Gerätes ständig bücken – unnötig, die Konkurrenz macht das besser. Warum nicht eine eigene Standfestigkeit wie bei nahezu jedem anderen Wischsauger-Modell?
Preis
Der Roborock Dyad kostet in der UVP 449 Euro. Zum Marktstart gab es von Roborock und später von anderen Händlern immer wieder Angebote für 350 Euro. Zum Testzeitpunkt kostete der Wischsauger bei Geekmaxi mit dem Coupon-Code L78TN8WR nur 369,00 Euro mit kostenlosem Versand aus europäischem Lager.
Fazit
Der Roborock Dyad ist ein richtig guter Wischsauger. Vorteile sind die hochwertige Verarbeitung, das informative Display, der „randlose“ Betrieb auch direkt an Möbeln oder Fußbodenleisten und vor allem die beste bislang von uns getestete Wischfunktion. Nachteile sind die höhere Lautstärke, das wie bei anderen Modellen „auf dem Kopf“ befindliche Display, wenn der Sauger lädt und vor allem die mangelnde „Standhaftigkeit“. Den ausklappbaren Ständer sehen wir eher als Notlösung. Das Design ist Geschmackssache.
Xiaomi Truclean W10 Pro
Xiaomi Truclean W10 Pro
Xiaomi hat mit den Truclean-W10-Modellen seine ersten Wischsauger auf den Markt gebracht. Wir haben uns im Test den günstigeren W10 Pro angeschaut – für schlappe 600 Euro.
- sehr gute Reinigungsleistung dank Tuch statt Rolle
- so gut wie randlose Reinigung
- sehr handlich und flexibel
- keine aktive Trocknung
- hoher Preis
Besser wischen: Saugwischer Xiaomi W10 Pro im Test setzt auf Tuch statt Rolle
Xiaomi hat mit den Truclean-W10-Modellen seine ersten Wischsauger auf den Markt gebracht. Wir haben uns im Test den günstigeren W10 Pro angeschaut – für schlappe 600 Euro.
Saugwischer sind praktisch, denn sie erleichtern und beschleunigen das feuchte Säubern von Hartböden im Vergleich zum händischen Wischen enorm. Das ist auch Xiaomi klar, entsprechend hat das Unternehmen inzwischen seine ersten beiden Wischsauger auf den Markt gebracht. Die unterscheiden sich nicht nur preislich, sondern auch ausstattungstechnisch. Wir haben uns in diesem Test den Xiaomi Truclean W10 Pro angeschaut, das Ultra-Modell folgt zu einem späteren Zeitpunkt.
Lieferumfang
Im Lieferkarton befinden sich neben dem Saugwischer selbst eine Reinigungs- und Ladestation sowie eine seitlich ansteckbare Halterung für eine mitgelieferte Reinigungsbürste. Weitere Zugaben wie eine geeignete Reinigungsflüssigkeit gibt es nicht.
Design und Verarbeitung
Der Xiaomi Trueclean W10 Pro sieht auf den ersten Blick wie viele seiner Wettbewerber aus. Er kommt mit dem gleichen, auffällig geformten Handgriff mit drei Tasten, hat einen zylindrischen Korpus und unten den Bürstenkopf. Als Farben wählt Xiaomi für sein Modell wie fast immer überwiegend Weiß und kombiniert das mit etwas Schwarz, Grau und Silber. Schwarz gibt es beim Display, das oben auf den Korpus aufgesetzt ist und somit im Betrieb gut vom Nutzer einzusehen ist, Grau bei einigen Bedienelementen wie den erwähnten Knöpfen und der Wischbürste und Silber beim Verlängerungsrohr vom Korpus zum Handgriff. Insgesamt sieht das stimmig und wertig aus, auch wenn wie immer bei solchen Produkten Kunststoff ganz oben auf der Werkstoffliste steht. Dennoch wackelt hier vergleichsweise wenig.
Es gibt aber auch Unterschiede zu den Wettbewerbern. So ist der weitgehend zylindrische Korpus von oben aufs Display geschaut eher oval zu nennen, die größten Abweichungen gibt es aber beim Bürstenkopf. Denn das ist eigentlich kein Bürstenkopf, es werkelt darin keine Bürste oder Rolle, sondern ein breites Tuch. Das wird im Prinzip um zwei mit leichtem Abstand zueinander installierten Umlenkrollen geführt, sodass das Tuch nicht nur wenige Millimeter Auflagefläche wie bei einer runden Rollenbürste bietet, sondern rund 10 Zentimeter. Das dürfte der Reinigungsleistung zugutekommen. Außerdem bietet die Verwendung eines Tuches noch einen Vorteil: Der Xiaomi Trueclean W10 Pro reinigt nahezu randlos. Das konnten bislang nur ganz wenige Modelle wie der Roborock Dyad (Testbericht).
Demgegenüber hat das Xiaomi-Modell aber zwei große Vorteile: Der Wischkopf ist nicht nur viel flacher als beim sehr hoch aufbauenden Kopf des Dyad und allen anderen Modellen mit Rollen, zusätzlich kann der W10 Pro selbstständig und ohne Hilfsmittel aufrecht hingestellt werden. Das ging beim Dyad nur mit einer „Krücke“, was einer unserer größten Kritikpunkte war und beim Nachfolger Dyad Pro (Testbericht) auch abgestellt wurde. Und es gibt noch einen Vorteil im Vergleich zu fast allen anderen Wischsaugern. Der Xiaomi Trueclean W10 Pro darf sogar ausgestreckt auf den Boden gelegt werden, ohne dass Frisch- oder Abwasser aus dem vorderen oder hinteren Tank ausläuft. So kommen Nutzer sogar unter Schränke oder hohe Sofas. Damit weder Saugwischer noch Boden Kratzer davontragen, installiert Xiaomi auf der Rückseite ein Rädchen. So schrappt der Korpus „in tiefster Gangart“ nicht über den Boden, sondern rollt.
Eigentlich hat das alles nicht Xiaomi, sondern Shunzao gemacht. Denn sowohl der W10 Pro in diesem Test als auch der W10 Ultra, den wir ebenfalls bald testen werden, werden von dem Partnerunternehmen Shunzao gefertigt, dessen Produkte ebenfalls in Europa verkauft werden – unter dem Namen Osotek. Der W10 Pro entspricht dabei dem Osotek Horizon (H200), der W10 Ultra dem Osotek Hotwave.
Alle Bilder zum Xiaomi Truclean W10 Pro im Test
Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Xiaomi Truclean W10 Pro

Funktion und Reinigungsleistung
Im Betrieb stellt der Xiaomi Trueclean W10 Pro seine Nutzer nicht vor Rätsel. Die Bedienung ist wie bei anderen Vertretern seiner Gattung: Einen Knopf zum Ein- und Ausschalten, einer für die automatische Selbstreinigung nach getaner Arbeit und einer für die Moduswahl. Letzteres übernimmt der Saugwischer allerdings auch von allein, wobei der Automatikmodus nicht immer Flecken so erkennt, wie sich der Mensch das vorstellt. Im Betrieb zieht das Gerät sich fast wie von selbst durch die Drehbewegung des Wischtuches nach vorn, der Nutzer muss hier eher Kraft zum Zügeln des W10 Pro als zum Anschieben aufbringen. Insgesamt geht die Arbeit dadurch leicht von der Hand, zumal das Gerät ausreichend handlich und flink ist. Eine gewisse Steifheit ist den meisten Saugwischern zu eigen, die das „Lenken“ meist nur mit etwas Kraft umsetzen – so auch beim W10 Pro. Der bereits angesprochene Roborock Dyad (Testbericht) ist davon das genaue Gegenteil, er ist sogar zu locker und lässt daher eine gewisse „Spurtreue“ vermissen.
Die bereits angesprochene Fähigkeit, mit dem Handgriff im Betrieb bis auf den Boden hinabzugehen, um auch unter manchen Möbeln wischen zu können, ist ein großer Pluspunkt des Xiaomi Trueclean W10 Pro. Fast alle Saugwischer können nur bis zu einem gewissen Grad „abgeknickt“ werden, da die Wassertanks im Gerät sonst auslaufen können. Zusammen mit dem vorn sehr flachen Wischkopf kommt man so deutlich weiter unter Möbel als mit der Konkurrenz. Ebenfalls toll: die Reinigung bis fast an den Rand. Die meisten anderen Saugwischer lassen hier gern einen Zentimeter und mehr zu Möbeln oder Fußbodenleisten ungewischt, Ausnahme ist hier wieder der bereits genannte Dyad von Roborock.
Das Display bietet übersichtlich Informationen zum Zustand des Gerätes an – inklusive eventueller Fehlermeldungen. Der Clou: Für noch bessere Ablesbarkeit dreht der Screen zumindest die Ladeanzeige, sobald das Gerät in der Ladeschale steht. Dann können Nutzer sie vor dem Saugwischer stehend ohne Halsverdrehung ablesen – clever, schließlich wird das Modell beim Laden vor einer Wand oder in einem Schrank stehen. Zusätzlich zur visuellen Information kommentiert der W10 Pro die meisten Aktionen auch verbal, die Sprache dafür lässt sich mittels eines kleinen Knopfes auf der Rückseite des Gerätes ein- oder ganz ausstellen.
Bei der Reinigungsleistung haben wir das Konkurrenzmodell von Roborock bislang auf dem ersten Platz gesehen, seine Doppelrolle nimmt einfach mehr Schmutz auf als die einzelne Rolle bei der Konkurrenz. Der Xiaomi Trueclean W10 Pro ist da anders. Durch seine große Auflagefläche des umgelenkten Wischtuches ist er auf Augenhöhe mit dem Roborock-Modell. Auch eingetrocknete Flecken lassen sich damit schneller als bei anderen Saugwischern entfernen, eventuell muss man mehrfach darüberfahren. Einmal komplett befeuchtet wischt das Gerät zudem streifenfrei. Durch die direkt hinter dem Wischtuch installierten Räder, die das Gewicht des W10 Pro tragen, entstehen aber immer kleine „Fahrspuren“, die allerdings nach dem Trocknen nicht mehr zu sehen sind. Bei der reinen Wischleistung ist der W10 Pro also richtig gut.
Kritikpunkte haben wir aber auch, genaugenommen abgesehen vom recht hohen Preis eigentlich nur einen: die fehlende Trocknungsfunktion. Während Saugwischer wie Proscenic Washvac F20 (Testbericht) und Jashen F16 (Testbericht) trotz niedrigerem Preis eine aktive Kaltlufttrocknung mittels Gebläse haben und manche Saug/Wischroboter sogar warme Luft auf die Wischmopps pusten, überlässt Xiaomi/Shunzao das der Natur. Das merkt und riecht man leider. Zumindest, wenn man den Wischkopf nicht optimalerweise nach jedem Wischvorgang auseinandernimmt und reinigt. Dann dauert der Trocknungsvorgang schon Stunden oder gar Tage und das sorgt schnell dafür, dass die Tuchrolle stockt und anfängt zu stinken. Das ist unangenehm und unhygienisch. Wir fragen uns, wie Xiaomi das Pro-Modell überhaupt ohne solch eine Trocknungsfunktion anbieten kann – „Pro“ ist das nun wirklich nicht. Außerdem verdreckt der W10 Pro innen schnell – so wie jeder Saugwischer. Regelmäßige Reinigung ist daher auch bei dem Xiaomi-Modell unabdingbar. Zum Glück klappt das wegen der einfachen Zerlegung des Wischkopfes schnell und ohne Werkzeug.
Hilfreich ist darüber hinaus die einfache Entnahme von Frisch- (750 ml) und Abwassertank (640 ml), für die es nur eines einfachen Knopfdrucks bedarf. Der Abwassertank bietet zudem ein einfaches Mehrkammersystem, bei dem gröberer Schmutz vom feineren Schmutz und Abwasser getrennt wird. Das erleichtert die Reinigung und das Innenleben des Wischsaugers dürfte so weniger schnell verstopfen.
Preis
Knapp 600 Euro kostet der Xiaomi Truclean W10 Pro in der UVP, der Straßenpreis ist schon wenige Wochen nach dem Marktstart bereits auf rund 475 Euro gefallen und das Gerät inzwischen für um 370 Euro zu haben. Das Osotech-Pendant lag hierzulande deutlich höher, inzwischen ist es aber preislich sogar unter dem Xiaomi-Pendant angesiedelt.
Fazit
Der Xiaomi Truclean W10 Pro ist insgesamt ein tolles Paket und wer einen Saugwischer sucht, macht hier nichts falsch. Zumindest dann nicht, wenn man etwas Extra-Arbeit in Kauf nimmt, die durch das regelmäßige Zerlegen des Wischkopfes inklusive Reinigung entsteht. Denn auch wenn Verarbeitung, Design, Display, Akkulaufzeit und vor allem auch die Reinigungsleistung dank niedrigem Wischkopf, Abklappbarkeit im Betrieb und die Konstruktion mit dem umlaufenden Tuch richtig klasse sind, patzt Xiaomi beim Thema Trocknung.
Das haben wir bei günstigeren und vor allem älteren Modellen in der Vergangenheit nicht so deutlich gerügt, bei einem Modell, das Ende 2022 auf den Markt gekommen ist, halten wir das Weglassen der aktiven Trocknungsfunktion allerdings für unverzeihlich. Vor allem zu dem Preis – 600 Euro in der UVP, das ist heftig. Hier müssen Interessen also abwägen, was ihnen wichtiger ist: die genannten Vorteile, oder der Nachteil in Kombination mit dem hohen Preis, wobei letzterer inzwischen kein Thema mehr ist.
Jimmy PW11 Pro Max
Jimmy PW11 Pro Max
Der Jimmy PW11 Pro Max will vollwertiger Staubsauger und Wischsauger in einem sein. Wir haben das Gerät ausführlich getestet und zeigen, wie es sich im Alltag schlägt.
- Akkusauger und Saugwischer in einem Gerät
- guter Saugwischer
- aktive Trocknung
- sehr laute aktive Trocknung
Jimmy PW11 Pro Max im Test: Wischsauger, Akkustaubsauger, Alleskönner
Der Jimmy PW11 Pro Max will vollwertiger Staubsauger und Wischsauger in einem sein. Wir haben das Gerät ausführlich getestet und zeigen, wie es sich im Alltag schlägt.
Der Jimmy PW11 Pro Max ist ein hochwertiger Akkuwischsauger, der dank verschiedener Aufsätze zum 5-in-1 Multitalent wird. Mit starker Saugleistung, bidirektionaler Wischfunktion und praktischem Zubehör verspricht er eine gründliche Reinigung für Hartböden, Teppiche und mehr. Wir haben das Gerät ausführlich getestet.
Was sind die Highlights des Jimmy PW11 Pro Max?
- Staubsauger, Handstaubsauger und Wischsauger in einem
- hohe Saugkraft von 21.000 Pa
- umfangreicher Lieferumfang mit verschiedenen Aufsätzen
- Selbstreinigung und aktive Walzentrocknung
- LED-Display mit Echtzeitinformationen
Der Jimmy PW11 Pro Max ist zum Artikelzeitpunkt bei Amazon für etwa 599 Euro zu bekommen. Geekmaxi bietet das Modell mit dem Code PX6E4EMG für 499 Euro an.
Design und Aufbau: Wie sieht der Jimmy PW11 Pro Max aus?
Der Jimmy PW11 Pro Max kommt in einer kompakten Verpackung mit praktischem Tragegriff. Der Lieferumfang ist beachtlich und umfasst:
- Motoreinheit mit eingebautem Staubbehälter
- herausnehmbarer Akku
- Bodendüse mit Frischwassertank
- Wascheinheit mit Schmutzwassertank
- Verlängerungsrohr
- motorisierte Polsterbürste
- zwei Aufsätze für manuelle Polster-Reinigung
- Basisstation zum Laden und Reinigen
- Reinigungsmittel
- Reinigungstool
- Bedienungsanleitung
Das klingt nicht nur beeindruckend, sondern ist es auch. Dabei gehören einige Teile des Puzzles für die Nutzung zusammen – das erklärt sich entweder nach kurzem Nachdenken oder mittels der umfangreichen, wenn auch nicht immer in ganz fehlerfreiem Deutsch verfassten Anleitung.
Das Design des Jimmy PW11 Pro Max ist modern und funktional. Auffällig ist die schlanke Form, die unter anderem dadurch realisiert werden kann, dass nur der Abwassertank im Korpus ist, während der Frischwassertank im Wischkopf steckt. Außerdem sind (Hand-)Staubsauger und der Teil mit dem Abwassertank voneinander getrennt und lassen sich voneinander abnehmen. Dann wandert der obere Bedienteil mit dem Staubsaugmotor an das Saugrohr samt motorisierter Bodenbürste, andernfalls steckt er auf dem Abwassertank, um als Saugwischer zu fungieren.
Der zusätzliche Staubsauger besteht aus dunkelgrauem und silbernem Kunststoff und wirkt stabil und langlebig. Der D-förmige Handgriff liegt gut in der Hand und ist mit zwei Bedienknöpfen ausgestattet, die während der Nutzung leicht erreichbar sind. Ein LED-Display an der Motoreinheit zeigt wichtige Informationen wie den Akkustand und den Verschmutzungsgrad des Bodens an.
Die Basisstation des Jimmy PW11 Pro Max dient nicht nur zum Laden des Geräts, sondern auch zur automatischen Reinigung der Walzen. Ein integrierter Ventilator trocknet die Walzen nach der Reinigung mit warmer Luft, um Bakterienbildung und Gerüche zu verhindern. Die Station bietet zudem Platz für die Aufsätze und das Reinigungsmittel.
Alle Bilder zum Jimmy PW11 Pro Max im Test
Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Jimmy PW11 Pro Max

Gewicht und Ergonomie
Der Staubsaugerkörper wiegt etwa 1,5 kg, im Wischsaugermodus wiegt das ganze Gerät rund 4,6 kg. Trotz des höheren Gewichts lässt sich der Staubsauger dank der Antriebsunterstützung der Walzen mühelos über den Boden bewegen. Der ergonomisch gestaltete Griff und die gut erreichbaren Bedienelemente tragen zur einfachen Handhabung bei.
Die Bedienung des Jimmy PW11 Pro Max ist intuitiv. Über die Bedientasten am Handgriff lassen sich das Gerät ein- und ausschalten sowie der Modus wechseln. Zur Auswahl stehen zwei Leistungsstufen für Hartböden und Teppiche sowie ein Automodus, der die Saugleistung automatisch an den Verschmutzungsgrad anpasst.
Die Wischeinheit des Jimmy PW11 Pro Max besteht aus zwei Teilen: Schmutzwassertank und Wischkopf. Der Frischwassertank befindet sich an der Oberseite der Walzeneinheit und lässt sich problemlos von oben befüllen. Dafür darf er mit einem leichten Ruck samt oberer Walzenabdeckung abgenommen und mit zum Wasserhahn genommen werden. Die Walzen drehen sich in entgegengesetzte Richtungen, um hartnäckigen Schmutz zu entfernen. Eine Düse an der Front besprüht in solchen Fällen und auf Geheiß des Nutzers den Boden zusätzlich mit Wasser, während die Walzen selbstständig befeuchtet werden.
Saugleistung: Wie gut saugt der Jimmy PW11 Pro Max?
Der Jimmy PW11 Pro Max überzeugt mit einer Saugleistung von 21.000 Pa. Staub, Haare und andere Partikel werden effizient aufgenommen. Der Automodus passt die Saugleistung automatisch an die Menge des erkannten Schmutzes an, was besonders bei wechselnden Untergründen nützlich ist. Alternativ klappt das mit der Modustaste am Handgriff. Dank der Motorbürste werden auch Teppiche gut gesaugt, sofern sie nicht zu hochflorig sind. Bei einem kurzen Teppich missfiel uns allerdings das „Hoppeln“ der Bürste, wenn wir den Teppich gegen den Strich saugten.
Haustierbesitzer oder Nutzer mit langen Haaren sollten zudem beachten, dass sich Haare in der Bürste verheddern können. Die müssen später manuell und mithilfe des beigelegten Reinigungswerkzeugs manuell entfernt werden. Außerdem ist das Entleeren des beutellosen Staubbehälters etwas umständlich. Zwar ist das Lösen des Behälters einfach, allerdings muss dann erst der Vorfilter abgenommen werden, bevor der Schmutz entleert werden kann. Praktisch: Während der Arbeit dreht sich die Anzeige, sodass der Nutzer sie sowohl dann als auch stehend auf der Ladestation ohne Halsverdrehen ablesen kann. Sie zeigt im Betrieb die verbleibenden Minuten, beim Laden hingegen den Ladestand in Prozent an.
Wischen: Wie gut ist die Nassreinigung des Jimmy PW11 Pro Max?
Die Nassreinigungsfunktion des Jimmy PW11 Pro Max ist das eigentliche Highlight des Geräts. Der Wischsauger kann verschüttete Flüssigkeiten aufnehmen und Flecken auf Hartböden effektiv entfernen. Bei eingetrockneten Flecken kommt das Gerät jedoch wie die meisten Konkurrenzprodukte an seine Grenzen. Hier hilft mehrfaches Drüberwischen und die Betätigung der „Sprühen-Taste“ am Handgriff. Durch diese zusätzliche Flüssigkeit, die in einem schmalen Fächer vor die eigentliche Wischfläche gesprüht wird, löst sich Schmutz noch besser. Etwas unpassend ist die Bezeichnung für die beiden Leistungsstufen neben dem Automatikmodus. Die werden nämlich wie beim Saugen als Floor und Carpet angezeigt – beim Wischen sollte aber wohl niemand Teppich wischen wollen.
Ansonsten macht der Jimmy-Saugwischer seine Sache sehr ordentlich. Der Feuchtigkeitsfilm ist gleichmäßig und satt, nur gelegentlich bleibt ein Tropfen übrig. Das Handling ist dabei angenehm, der PW11 Pro Max fühlt sich schön leichtgängig und beweglich an. Im Gegensatz zur Konkurrenz kommt der PW11 Pro Max auch unter Möbel, da der Korpus des Geräts sehr schmal und eine Anwinklung des Wischkopfes bis 180 Grad möglich wird, wobei der Saugwischer ausgestreckt auf dem Boden liegt. Ausgelaufen ist uns dabei der Abwassertank nicht. Ganz randlos wischt der Jimmy nicht, an der rechten Seite bleiben aber kaum drei oder vier Millimeter ungewischt. Auf der linken Seite des Wischkopfes sind es eher 3 Zentimeter.
Etwas enttäuscht sind wir von der aktiven Reinigung mit Luft in Zimmertemperatur. Sie ist zwar effektiv, da sie alle paar Minuten die Rollen von hörbarem Knacken begleitet weiterbewegt, aber erschreckend laut. Ein Saugroboter ist in Betrieb nicht lauter. Grund dürfte sein, dass beim Jimmy dafür ebenfalls der Saugmotor zum Einsatz kommt.
Akku: Wie ist die Akkulaufzeit des Jimmy PW11 Pro Max?
Der Jimmy PW11 Pro Max wird mit einem wechselbaren Akku mit 4600 mAh geliefert, der eine Laufzeit von bis zu 80 Minuten im Handstaubsaugermodus ermöglicht. Beim Einsatz als Bodensauger beträgt die Laufzeit bis zu 40 Minuten, im Teppichmodus etwa 30 Minuten. Die Ladezeit liegt bei etwa 4 bis 5 Stunden.
Preis: Wie viel kostet der Jimmy PW11 Pro Max
Der Jimmy PW11 Pro Max ist für etwa 599 Euro bei Amazon erhältlich. Geekmaxi bietet das Modell mit dem Code PX6E4EMG für 499 Euro an. Alternativen in derselben Preisklasse sind der Dreame Dual H12 und der Tineco Floor One S7. Beide Modelle bieten ähnliche Funktionen, jedoch mit einigen Unterschieden in der Ausstattung und Leistung.
Fazit
Der Jimmy PW11 Pro Max ist ein vielseitiger Akkuwischsauger mit guter Reinigungsleistung. Besonders die Nassreinigungsfunktion und die Selbstreinigung der Walzen überzeugen. Die hohe Saugkraft und der umfangreiche Lieferumfang machen das Gerät zu einer guten Wahl für Haushalte mit Hartböden und Teppichen. Einige Schwächen wie die Verhedderung von Haaren und die etwas umständliche Basisstation trüben das Gesamtbild jedoch leicht. Insgesamt ist der Jimmy PW11 Pro Max eine empfehlenswerte Option für alle, die ein vielseitiges Kombigerät suchen.
Selbst saugen und zumindest bei den teureren Modellen auch ordentlich wischen können Saugroboter:
Roborock Dyad Pro
Roborock Dyad Pro
Das Erstlingswerk Roborock Dyad war gut, der Wischsauger konnte aber nicht voll überzeugen. Das neue Pro-Modell verspricht Besserung – zu Recht?
- tolles Handling
- sehr gute Wischleistung
- praktische App
- zahlreiche Verbesserungen im Vergleich zum Vorgänger
- Trocknungsfunktion
- kann immer noch nicht unter Möbeln saugen
- Lautsprecher mies
Roborock Dyad Pro im Test: Das ist der beste Saugwischer
Das Erstlingswerk Roborock Dyad war gut, der Wischsauger konnte aber nicht voll überzeugen. Das neue Pro-Modell verspricht Besserung – zu Recht?
Saugwischer sind enorm praktisch, denn sie erleichtern und beschleunigen das anstrengende Wischen des Bodens per Hand. Das hat Roborock bereits im vergangenen Jahr erkannt und sein Erstlingswerk Dyad (Testbericht) auf den Markt gebracht. Vorteil des Modells ist die nahezu nahtlose Randreinigung und die gute Reinigungsleistung dank Doppelrolle, allerdings gibt es auch mehr als nur einen Haken. So lässt sich das Dyad-Modell nicht ohne Hilfsmittel hinstellen, sondern benötigt eine ausklappbare Stütze. Beim Nachfolger Roborock Dyad Pro hat der Hersteller kräftig an den Details gefeilt – auf den ersten Blick hat sich nicht viel getan, allerdings ist das Pro-Modell tatsächlich ein deutlich besserer Saugwischer.
Design und Verarbeitung
Am grundsätzlichen Design des Korpus hat Roborock wenig geändert. Der aus Kunststoff bestehende und mehr oder weniger zylindrische Hauptteil des Roborock Dyad Pro unterteilt sich wieder in den großen Abwassertank vorne unten sowie den kleineren Wischwassertank oben. Letzterer ist dabei im Vergleich zum Vorgänger etwas größer.
Erneut installiert Roborock ein Display, das oben auf dem zylindrischen Korpus sitzt, die wichtigsten Information für die Nutzung bietet und im Betrieb gut ablesbar ist. An eine automatische Drehung des Inhaltes, damit das Display auch in der Station stehend von vorn ohne Halsverrenkungen ablesbar bleibt, hat der Hersteller leider wieder nicht gedacht. Am Griff mit den typischen drei Bedienknöpfen hat sich ebenfalls nichts geändert.
Die größte Überarbeitung hat der Saug- und Wischkopf erfahren. Wirkte der beim Vorgänger durch seine kurze, aber hohe und unregelmäßige Bauweise noch ziemlich unförmig und erschwerte das Wischen unter Möbeln enorm, so bessert Roborock beim Pro-Modell deutlich nach. Der überarbeitete Kopf ist nun deutlich länger, niedriger und gleichmäßig hoch, sodass er mehr den Saug- und Wischköpfen der Konkurrenz entspricht. Weiterhin enthalten ist allerdings die Doppelrollen-Konstruktion, die bessere und randlose Reinigung garantieren soll. Nach wie vor verwendet Roborock eine durchgehende und eine zweigeteilte Rolle, die gegenläufig arbeiten. Allerdings tauscht das Unternehmen beide Rollen aus: Die zweigeteilte Rolle zur nahtlosen Randreinigung ist jetzt vorn platziert, so gelangt der Nutzer besser in Ecken.
Der Wischkopf enthält neuerdings einen kleinen Zusatztank für Reinigungsflüssigkeit, der für bis zu 20 Füllungen des Frischwassertanks reichen soll und ganz einfach zum Nachfüllen entnommen werden kann. Etwas ärgerlich für ein hochwertiges Produkt: Reinigungsmittel legt Roborock nicht bei, Nutzer sollten hier auf nicht schäumende Mittel achten. Neu ist auch die Lade- und Reinigungsstation des Dyad Pro. Sie ähnelt vom Aufbau her zwar der des Vorgängers, allerdings verfügt sie jetzt über eine Trocknungsfunktion mit Luft. Die wird hinter der Station durch ein kleines Gebläse angesaugt und zwischen die beiden Wischrollen geblasen. Alle paar Minuten drehen sich die Rollen dann ein Stück weiter, damit sie von allen Seiten getrocknet werden – hervorragend!
Mindestens genauso gut ist der Umstand, dass der Roborock Dyad Pro nun ohne Hilfsmittel selbständig und sicher stehen kann. Dafür muss der Nutzer wie bei fast allen anderen Geräten lediglich den Korpus des Saugwischers so weit aufrichten, bis er ein leichtes Einrasten verspürt – das Gerät schaltet sich dann nach einem Extra-Absaugvorgang ab. Wegen der feuchten Wischrollen sollte man den Dyad Pro aber nicht länger auf Holzböden stehen lassen, außerdem schaltet das Gerät abseits der Ladestation irgendwann die WLAN-Verbindung ab.
Die Geschwindigkeit der Trocknung lässt sich in der nächsten Neuerung anpassen: der App. Im Gegensatz zum Vorgänger ermöglicht Roborock jetzt, einige Einstellungen am Saugwischer per Smartphone vorzunehmen. Ein Punkt ist dann die Wahl zwischen einer deutlich hörbaren Schnelltrocknung und der leiseren, von zwei bis sechs Stunden wählbaren, deutlich leiseren normalen Trocknung.
Einbindung und App
Die Verbindung zwischen Smartphone und Roborock Dyad Pro gelingt mit der Roborock-App fast von allein. Nach der Kopplung stehen dem Nutzer Schnellzugriffe für ausgeglichene und intensive Selbstreinigung sowie leises und lautes Trocknen zur Verfügung. Zentral zeigt die App zudem eine grafische Darstellung des Wischsaugers sowie den Ladezustand des Akkus. Zusätzlich gibt es weitere Einstellungsmöglichkeiten. Normalerweise läuft das Gerät im Automatikmodus, der Saugkraft und Wasserzufuhr selbständig regelt. Der Nutzer darf darauf allerdings auch manuell zugreifen, zudem hat er Einfluss auf die Rollendrehgeschwindigkeit.
Endlich implementiert ein Hersteller zudem die Möglichkeit zur Selbstbestimmung, ob der Saugwischer nach jedem Gebrauch beim Zurückstellen die Selbstreinigung startet. Gerade, wenn man lediglich „mal eben“ einen Wasserfleck weggewischt hat, benötigt man keine Vollreinigung des Gerätes. Zudem erlaubt die App die Festlegung, ob der Dyad Pro beim Abknicken nach dem Aufstellen des Gerätes automatisch und ohne zusätzlichen Knopfdruck wieder die Arbeit aufnehmen soll.
Die Dauer des leisen Trocknungsvorgangs kann jetzt von zwei bis sechs Stunden eingestellt werden und es gibt typische Menüpunkte wie einen Nicht-Stören-Modus, es wird der Reinigungsverlauf angezeigt und es gibt eine Wartungsanzeige – fast wie bei einem Saugroboter. Zugriff auf ein Nutzerhandbuch hat man hier ebenfalls und die Sprachausgabe lässt sich ebenfalls anpassen. Diese klingt übrigens zumindest bei unserem Testgerät matschig und undeutlich wie bei einem Unterwassertelefonat.
Alle Bilder zum Roborock Dyad Pro im Test
Roborock Dyad Pro

Roborock Dyad Pro

Roborock Dyad Pro

Roborock Dyad Pro

Roborock Dyad Pro

Roborock Dyad Pro

Roborock Dyad Pro

Roborock Dyad Pro

Roborock Dyad Pro

Roborock Dyad Pro

Reinigungsleistung und Handhabung
Beim Handling des Roborock Dyad Pro gibt es im Vergleich zum Vorgänger Roborock Dyad (Testbericht) einen großen Schritt nach vorn. War der Vorgänger noch extrem labil und dadurch zwar leicht ums Eck zu zirkeln, aber auch schwierig auf gerade Bahnen zu bringen, findet der Hersteller beim neuen Modell nun die nahezu perfekte Balance zwischen angenehm weicher und dennoch straffer „Lenkung“. Das Dirigieren des Saugwischers ist daher jetzt exakt und einfach und auch der Richtungswechsel gelingt spielend. Dabei zieht der Wischsauger durch die Bewegung der Wischrollen dezent nach vorn, was das Handling weiter erleichtert. Das deutliche Rumpeln des Vorgängers bei Fugen gibt es mit dem neuen Reinigungskopf nicht mehr.
Durch den längeren Saug- und Wischkopf kommt man indessen etwas besser unter Möbel, zumindest am Rand. Denn nach wie vor lässt sich der Roborock um etwa 45 Grad abwinkeln, dann blockiert das Gelenk am Kopf. Außerdem können die Tanks bei mehr Tiefgang auslaufen. Zudem ist der Rollenkopf trotz der auferlegten Schrumpfkur nach wie vor höher als bei der Konkurrenz. Besser als zuvor ist das aber allemal.
An der Reinigungsleistung gibt es ebenfalls nichts auszusetzen, sie wurde weiter verbessert. Die Saugkraft wurde im Vergleich zum Vorgänger erhöht, überdies gibt es zur mechanischen Dosierung nun eine Klappe vorn am Saug- und Wischkopf. Insgesamt hatten wir den Eindruck, dass sich dadurch die Wischleistung weiter verbessert hat, wodurch der Roborock Dyad Pro wieder die Spitze in dieser Disziplin zurückerobert.
Neben der Automatik, bei der der Saugwischer selbständig die Saugleistung bei erkannter Verschmutzung erhöht, darf der Nutzer weiterhin selbst von Eco bis Turbo bestimmen, wie stark die Absaugung sein soll. Die Automatik regelt immer mal wieder hoch und runter – wie beim Vorgänger ist das nicht immer nachvollziehbar. Auf sichtbare Verschmutzung reagiert das Pro-Modell aber korrekt mit Anhebung der Saugkraft. Die Lufttrocknung nach der Selbstreinigung ist als Schnelltrocknung fast so laut wie ein leiser Föhn, im Normalmodus eher wie ein typischer PC. Ins Schlafzimmer würden wir den Dyad Pro entsprechend nachts auf keinen Fall stellen. Dafür verhindert die aktive Trocknung effizient Stockbildung und Gerüche, sofern der Abwassertank regelmäßig gereinigt wird.
Beim Akku bleibt das neue Modell unverändert, zumindest im Automatikmodus. Wegen der höheren maximalen Saugleistung sinkt die Laufzeit im Turbomodus allerdings um mehrere Minuten im direkten Vergleich – rund 20 statt 25 Minuten. Wer den Sauger selbst entscheiden lässt, kommt aber auf ähnliche Laufzeiten wie beim ersten Dyad und sollte damit gut einen Wohnbereich von 150 bis 180 Quadratmetern am Stück reinigen.
Preis
Der neue Roborock Dyad Pro kostet 479 Euro laut UVP des Herstellers. Bei Amazon kostet der Saugwischer 279 Euro.
Fazit
Der Roborock Dyad Pro ist derzeit einer der besten – wenn nicht gar der beste – Saugwischer auf dem Markt, auch wenn selbst er nicht ohne Kompromisse auskommt. Auf der Habenseite steht ein jetzt optimales Handling, noch bessere Reinigungsleistung mit verbesserter Randreinigung, ein niedrigerer und besser geformter Saug- und Wischkopf, der zusätzliche Reinigungsmittel-Tank und die neue Trocknungsfunktion. Zudem steht der Saugwischer nun selbständig auf der Stelle – ein nicht zu unterschätzender Pluspunkt. Das Gerät lässt sich einfach über die optional verwendbare App steuern, man kommt aber auch ohne aus.
Zu den erwähnten Kompromissen gehört der nach wie vor eher klobigere Reinigungskopf und die weiterhin eingeschränkte Möglichkeit, unter Möbeln zu wischen. Der Preis ist außerdem recht hoch, da wirkt es ziemlich knauserig, dass Roborock nicht einmal Reinigungsmittel in den Lieferumfang packt. Obendrein ist der Lautsprecher für die Sprachansage so schlecht, dass wir eigentlich von einem Fehler unseres Testgerätes ausgehen. Sollte das auch bei anderen Modellen der Fall sein, müsste sich Roborock die Frage gefallen lassen, ob das wirklich zu einem Spitzenmodell passt.
Zu guter Letzt fühlt sich der Dyad Pro eher wie eine Überarbeitung des ersten Dyad-Modells an, statt nach einem komplett neuen Gerät. Böse Zungen könnten behaupten, dass das Pro-Modell letztlich nur das ist, was das erste Dyad-Gerät hätte sein sollen – und sie haben recht. Das ändert aber nichts daran, dass der Roborock Dyad Pro deutlich besser als der Vorgänger und derzeit vermutlich auch besser als die Saugwischer-Konkurrenz ist.
Das sind die beliebtesten Hartbodenreiniger mit Akku aus unserem Preisvergleich:
Künstliche Intelligenz
Einführung von Starterpacks: X kopiert Bluesky
Der US-Kurznachrichtendienst X führt die von Bluesky bekannte Funktion der sogenannten Starter Packs ein. Das gab Produktchef Nikita Bier jetzt in einem Beitrag auf X bekannt. Dass sich X dabei am Funktionsumfang des Konkurrenzdienstes Bluesky bedient, macht das US-Unternehmen unverblümt deutlich. Die neue Funktion heißt Starterpacks und soll in den kommenden Wochen für alle X-Nutzer eingeführt werden.
Weiterlesen nach der Anzeige
Starter Packs sind ursprünglich von Bluesky Mitte 2024 eingeführt worden und erfreuten sich schnell großer Beliebtheit. Die von Nutzern kuratierten Accountsammlungen, denen man mit einem Klick folgen kann, helfen vor allem neuen Anwendern, sich auf der Plattform zurechtzufinden. Das soll das als „cold start“ bekannte Problem eines Wechsels auf eine neue Plattform mildern. Bedeutsam wurden die Listen mit vorgeschlagenen Accounts vor allem während der zweiten Abwanderungswelle von X nach dem Wahlsieg von Donald Trump in den USA.
X gibt Kuration nicht ab
Im Gegensatz zu den Starter Packs auf Bluesky basieren die Starterpacks von X nicht auf Nutzervorschlägen. X-Nutzer können keine eigenen Starterpacks erstellen und mit anderen teilen. Vielmehr gibt X intern erstellte, eigene Listen vor. Die sollen neuen X-Nutzern helfen, ihren Interessen entsprechende Konten zu finden, schreibt Bier auf X.
Die X-Starterpacks sind thematisch sortiert und enthalten sowohl unbekannte als auch bekannte Accounts aus den Bereichen Nachrichten, Politik, Mode, Technologie, Business, Gesundheit und Fitness, Gaming, Aktien, Memes und mehr. Für deren Erstellung habe das Unternehmen die eigene Plattform durchforstet, um die Top-X-Nutzer jeder thematischen Nische ausfindig zu machen.
Keine neue Idee
X ist nicht das einzige soziale Netzwerk, das die Funktion der Starter Packs von Bluesky kopiert. Metas Threads testet seit Dezember 2024 eine eigene Version der Vorschlagslisten, die aber ähnlich wie bei Bluesky von Nutzern erstellt werden. Auch das dezentrale soziale Netzwerk Mastodon plant, kuratierte Accountsammlungen offiziell einzuführen. Bislang sind die Mastodon-Startpakete nur inoffiziell verfügbar.
Weiterlesen nach der Anzeige
(rah)
Künstliche Intelligenz
Digitaler Befreiungsschlag: EU-Parlament fordert Loslösung von US-Tech-Riesen
Das EU-Parlament hat am Donnerstag einen Bericht über technologische Souveränität und digitale Infrastruktur mit einer großen, fraktionsübergreifenden Mehrheit von EVP, Sozialdemokraten, Liberalen und Grünen angenommen. Das breite Bündnis signalisiert die Entschlossenheit der Abgeordneten, die europäische Abhängigkeit von US-Technologien drastisch zu reduzieren und eigene Kapazitäten massiv auszubauen.
Weiterlesen nach der Anzeige
Die Volksvertreter fordern mit der Resolution von der EU-Kommission mutige Reformen, insbesondere einen ambitionierten „Cloud and AI Development Act“. Ein politisches Ausrufezeichen setzt die Verabschiedung eines Zusatzes, mit dem das Parlament das Recht der EU zur Durchsetzung eigener Gesetze wie dem Digital Services Act (DSA) bekräftigt und US-Einreiseverbote gegen zivilgesellschaftliche Akteure wie die Spitze der zivilgesellschaftlichen Organisation HateAid scharf verurteilt.
Inhaltlich setzt der Bericht auf eine strategische Neuausrichtung der öffentlichen Beschaffung und der Infrastruktur. Die verabschiedete Kompromisslinie sieht vor, dass Mitgliedstaaten europäische Tech-Anbieter in strategischen Sektoren bevorzugen können, um die technologische Kapazität der Gemeinschaft systematisch zu stärken. Die Grünen forderten hier sogar eine noch strengere Regelung, bei der die Nutzung von Produkten „Made in EU“ zur Regel werden sollte und Ausnahmen explizit begründet werden müssten. Auch bei der Cloud-Infrastruktur drängten sie auf eine Definition, die eine vollständige EU-Jurisdiktion ohne Abhängigkeiten von Drittstaaten vorsieht.
Weiche hin zu Open Source
Mit dem Beschluss wollen die Abgeordneten den Grundstein für eine europäische digitale öffentliche Infrastruktur legen, die auf offenen Standards und Interoperabilität basiert. Dabei wird das Prinzip Public Money, Public Code als strategisches Fundament verankert, um die Abhängigkeit von einzelnen Anbietern zu verringern. Software, die mit Steuergeldern speziell für die Verwaltung entwickelt wird, soll demnach unter freien Lizenzen für alle bereitgestellt werden. Zur Finanzierung setzt das Parlament auf den Ausbau von öffentlich-privaten Investitionen. Im Gespräch war vorab etwa ein mit zehn Milliarden Euro dotierter „European Sovereign Tech Fund“, um gezielt strategische Infrastrukturen zu errichten, die der Markt allein nicht bereitstellt.
Die Schattenberichterstatterin für die Grünen, Alexandra Geese, sieht Europa mit dem Votum bereit, die Kontrolle über seine digitale Zukunft zu übernehmen. Solange europäische Daten von US-Anbietern gehalten würden, die Gesetzen wie dem Cloud Act unterliegen, sei die Sicherheit in Europa nicht gewährleistet.
GI für „European Tech First“
Weiterlesen nach der Anzeige
Die Dringlichkeit der parlamentarischen Forderungen bestätigt eine Analyse der Gesellschaft für Informatik (GI). Experten wie Harald Wehnes und Julian Kunkel warnen, dass 2025 einen tiefen Einschnitt markiere: Die neue nationale Sicherheitsstrategie der USA definiere digitale Infrastrukturen explizit als nationale Sicherheitsgüter. In dem Papier der Trump-Regierung werde ein „digitaler Imperialismus“ deutlich, der Europa nur noch als reinen Absatzmarkt und Territorium für strategische Abhängigkeiten sehe. Wenn US-Monopolstellungen als Machtmittel instrumentalisiert würden, drohe Europa zu einem politisch entmündigten Gebiet zu verkommen.
Die GI-Autoren weisen darauf hin, dass das Dienstleistungsbilanzdefizit der EU gegenüber den USA bereits 2024 einen Rekordwert von 148 Milliarden Euro erreichte. Diese enorme Summe fließe direkt in die technologische Dominanz der Gegenseite. Angesichts dieser Bedrohung drängen sie auf eine radikale Kehrtwende in der öffentlichen IT-Beschaffung. Der Ansatz „European Tech First“ sei kein blinder Protektionismus, sondern Notwehr zur Sicherung der Handlungsfähigkeit.
Besonders kritisch sehen die Informatiker „Souveränitäts-Washing“: Angebote von US-Hyperscalern für „souveräne Clouds“ seien oft Scheinlösungen, da die finale technologische Kontrolle in den USA verbleibe. Stattdessen brauche es eine konsequente Bevorzugung von Open-Source-Lösungen aus dem europäischen Wirtschaftsraum. Der Beschluss des Parlaments bietet die Chance, diesen Appellen politisches Gewicht zu verleihen. Die Abgeordneten wollen damit den Weg für ein eigenständiges, werteorientiertes digitales Europa freimachen, das sich nicht länger durch algorithmische Kontrolle von außen steuern lässt.
(mho)

Top 10: Der beste Wischsauger im Test – mit Dampf & Schaum gegen den Schmutz

KI-Experte warnt Politiker: „Wir sind erst am Anfang der Dystopie“

Doch nicht kostenpflichtig: Samsung macht Rückzieher
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenArndt Benedikt rebranded GreatVita › PAGE online
-

 Künstliche Intelligenzvor 3 Wochen
Künstliche Intelligenzvor 3 WochenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-

 Entwicklung & Codevor 1 Monat
Entwicklung & Codevor 1 MonatKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGoogle „Broadwing“: 400-MW-Gaskraftwerk speichert CO₂ tief unter der Erde
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenFast 5 GB pro mm²: Sandisk und Kioxia kommen mit höchster Bitdichte zum ISSCC