Entwicklung & Code
Die oberste Direktive und ihre praktischen Konsequenzen für Softwareteams
Moin.

(Bild: Stefan Mintert )
Stefan Mintert arbeitet mit seinen Kunden daran, die Unternehmenskultur in der Softwareentwicklung zu verbessern. Das derzeit größte Potenzial sieht er in der Leadership; unabhängig von einer Hierarchieebene.
Die Aufgabe, dieses Potenzial zu heben, hat er sich nach einem beruflichen Weg mit einigen Kurswechseln gegeben. Ursprünglich aus der Informatik kommend, mit mehreren Jahren Consulting-Erfahrung, hatte er zunächst eine eigene Softwareentwicklungsfirma gegründet. Dabei stellte er fest, dass Führung gelernt sein will und gute Vorbilder selten sind.
Es zeichnete sich ab, dass der größte Unterstützungsbedarf bei seinen Kunden in der Softwareentwicklung nicht im Produzieren von Code liegt, sondern in der Führung. So war es für ihn klar, wohin die Reise mit seiner Firma Kutura geht: Führung verbessern, damit die Menschen, die die Produkte entwickeln, sich selbst entwickeln und wachsen können.
Für Heise schreibt Stefan als langjähriger, freier Mitarbeiter der iX seit 1994.
Die oberste Direktive für Retrospektiven hat Norman Kerth 2001 in seinem Buch „Project Retrospectives“ formuliert:
„Regardless of what we discover, we must understand and truly believe that everyone did the best job he or she could, given what was known at the time, his or her skills and abilities, the resources available, and the situation at hand.“
„Unabhängig davon, was wir herausfinden, müssen wir verstehen und wirklich glauben, dass jeder das Beste getan hat, was er oder sie in Anbetracht der damaligen Kenntnisse, seiner oder ihrer Fähigkeiten und Fertigkeiten, der verfügbaren Ressourcen und der gegebenen Situation tun konnte.“
Die oberste Direktive ist insbesondere im Bereich agiler Softwareentwicklung bekannt geworden. Das ist bemerkenswert, weil in Kerths Buch die Worte „agil“ oder „Scrum“ nicht vorkommen.
Ich habe die Direktive oftmals in eine erste Retrospektive eingebracht, die ich mit einem neuen Team durchgeführt habe. Die Reaktionen fielen in den Teams sehr unterschiedlich aus. Da war auch schon einmal jemand dabei, der verächtlich schnaubte. Darauf angesprochen bekam ich manchmal als Antwort eine rhetorische Frage der Art: „Das meinst Du doch nicht ernst, oder?“ Darin schwingt eine klare Aussage mit: Die Leistung einer anderen Person ist nicht ausreichend.
In so einem Moment lasse ich mich nicht auf eine Diskussion über die Leistung anderer ein. Vielmehr halte ich folgende Fragen mit entgegengesetzten Aussagen für weiterführend:
- Angenommen, die fragliche Person hat ihre beste Leistung geliefert, und ich bin mit dem Ergebnis nicht zufrieden. Was folgt für mich daraus?
- Angenommen, die fragliche Person hat nicht ihre beste Leistung geliefert. Wie gehe ich damit um?
Fangen wir mit dem zweiten Punkt an: Jemand bringt nicht seine beste Leistung. Welche Gründe fallen mir ein?
Erstens: Die Kollegin oder der Kollege ist krank, hat irgendwelche persönlichen Probleme oder ist aus einem anderen Grund nicht in der Lage, seinen Fertigkeiten entsprechend zu arbeiten. In einem „gesunden“ Team ist die eigene Reaktion ganz einfach: Ich spreche die Person an und biete ggf. Hilfe an.
Zweitens: Die Kollegin oder der Kollege arbeitet absichtlich schlecht. Dafür gibt es ein Wort: Sabotage. Das ist einer der äußerst seltenen Fälle, in denen ich disziplinarische Maßnahmen für sinnvoll halte.
Damit komme ich zurück zum ersten Punkt: Wer seine beste Leistung liefert, kann dafür nicht kritisiert werden. Worin sollte die Kritik bestehen? Wenn ein Kleinkind nicht Rad fahren kann, gibt es daran nichts zu beanstanden. Wenn ein 95-jähriger Mensch keinen Marathon laufen kann, wer will es ihm verübeln (am Rande: wie viele 20-Jährige schaffen die Strecke?). Wer krank ist oder private Probleme hat, wird nicht seine (theoretischen) 100 Prozent leisten können.
Wenn sich das negativ auf das Teamergebnis auswirkt, sehe ich alle Mitglieder gemeinsam in der Verantwortung – und in der Pflicht, konstruktiv dagegen vorzugehen. Teaminterne Kritik an einzelnen Personen gehört nicht dazu. Stattdessen sehe ich Folgendes als vernünftige Leitlinie an:
- Wenn ich als Entwickler feststelle, dass ein anvisiertes Ziel wie das Sprintziel in Gefahr gerät, spreche ich es offen an, sobald ich es erkenne.
- Ich vermeide Schuldzuweisungen (Blaming and Finger-Pointing).
- Wenn ich selbst nicht über die Fertigkeiten verfüge, das Defizit zu behandeln, weil es beispielsweise Probleme in einer Komponente gibt, die in einer Programmiersprache geschrieben ist, die ich nicht beherrsche, geht eins immer: Ich biete Hilfe an. Dabei kann es sich um Pair Programming handeln, oder ich stelle mich als Sparringspartner zur Verfügung.
Im Endeffekt kann man alles auf zwei Punkte zurückführen. Aus der obersten Direktive folgt für die Zusammenarbeit im Team:
- Ich verzichte auf Schuldzuweisungen. Die Suche nach Problemursachen ist natürlich notwendig, sowohl um eine geeignete Lösung zu finden, als auch um zukünftige Probleme der gleichen Art zu vermeiden oder früher behandeln zu können.
- Ich biete Hilfe an, um Lösungen zu finden. Dabei spielen Zuständigkeiten keine Rolle. Ein Team erreicht oder verfehlt Ergebnisse und Ziele gemeinsam.
Nach einem Problem oder Scheitern die handelnde Person zu benennen und das nicht als Blaming oder Finger-Pointing zu verstehen, ist für die meisten Teams schwierig. Genau in solchen Fällen hilft es, im Team offen über die oberste Direktive zu sprechen.
Erst lesen, dann hören
Im Podcast Escape the Feature Factory greife ich ausgewählte Themen des Blogs auf und diskutiere sie (meist) mit einem Gast. Durch den Austausch lerne ich eine zweite Perspektive kennen. Zur obersten Direktive habe ich gleich zwei Podcast-Folgen im Angebot; im ersten Beitrag gehe ich kurz darauf ein, was jeder selbst tun kann, wenn es an anderer Stelle im Team klemmt; im zweiten Beitrag gehe ich mit einem Gast in die Tiefen der obersten Direktive. Wer auch daran interessiert ist, findet den Podcast bei Spotify, Deezer, Amazon Music, Apple Podcasts und auf kutura.digital. Dort finden sich auch Workshops, die sich den Themen des Blogs widmen.
(rme)











Entwicklung & Code
Angular Signals: Elegante Reaktivität als Architekturfalle
Mit Angular 17 hielten Signals 2023 offiziell Einzug in das Framework. Sie versprechen eine modernere, klarere Reaktivität: weniger Boilerplate-Code, bessere Performance. Gerade im Template- und Komponentenbereich lösen sie viele Probleme eleganter als klassische Observable-basierte Ansätze.

Nicolai Wolko ist Softwarearchitekt, Consultant und Mitgründer der WBK Consulting AG. Er unterstützt Unternehmen bei komplexen Web- und Cloudprojekten und wirkt als Sparringspartner sowie Gutachter für CTOs. Fachbeiträge zur modernen Softwarearchitektur veröffentlicht er regelmäßig in Fachmedien und auf seinem Blog.
Statt Subscriptions, pipe() und komplexen Streams genügen nun wenige Zeilen mit signal(), computed() und effect(). Der Code wirkt schlanker, intuitiver und näher am User Interface (UI).
Da liegt die Idee nahe: Wenn Signals im UI überzeugen, warum nicht auch in der Applikationslogik? Warum nicht RxJS vollständig ersetzen? Ein Application Store ohne Actions, Meta-Framework und Observable: direkt, deklarativ, minimalistisch.
Ein Ansatz, der im Folgenden anhand eines konkreten Fallbeispiels analysiert und kritisch hinterfragt wird. Anschließend wird behandelt, in welchen Kontexten sich Signals sinnvoll einsetzen lassen.
Aufbau des Fallbeispiels
Auf den ersten Blick besitzt dieses Beispiel einen klar strukturierten Architekturansatz. Doch der Wandel beginnt unauffällig. RxJS bleibt zunächst außen vor. Das UI reagiert flüssig, der Code bleibt übersichtlich. Komplexe Streams, verschachtelte Operatoren oder eigenes Subscription Handling entfallen. Stattdessen kommen Signals zum Einsatz. Es liegt nahe, diese unkomplizierte Herangehensweise auch für die Applikationslogik zu übernehmen. Im folgenden Beispiel übernimmt ein ProductStore die Zustandslogik. Signals organisieren Kategorien, Filter und Produktdaten – reaktiv und direkt.
@Injectable({ providedIn: 'root' })
export class ProductStore {
private allProducts = signal([]);
readonly selectedCategory = signal('Bücher');
readonly onlyAvailable = signal(false);
readonly productList = computed(() => {
return this.allProducts().filter(p =>
this.onlyAvailable() ? p.available : true
);
});
selectCategory(category: string) {
this.selectedCategory.set(category);
}
toggleAvailabilityFilter() {
this.onlyAvailable.set(!this.onlyAvailable());
}
constructor(private api: ProductApiService) {
effect(() => {
const category = this.selectedCategory();
const onlyAvailable = this.onlyAvailable();
this.api.getProducts(category, onlyAvailable).then(products => {
this.allProducts.set(products);
});
});
}
}
Die Struktur überzeugt zunächst durch Klarheit. Die Komponente konsumiert productList direkt, ohne eigene Logik. Der Store verwaltet den Zustand, Signals sorgen für die Weitergabe von Änderungen.
Doch mit der nächsten Anforderung ändert sich das Bild: Bestimmte Produkte sollen zwar im Katalog verbleiben, aber im UI nicht mehr erscheinen. Da auch andere Systeme die bestehende API verwenden, ist eine Anpassung nicht möglich. Stattdessen liefert das Backend eine Liste freigegebener Produkt-IDs, anhand derer das UI filtert.
@Injectable({ providedIn: 'root' })
export class ProductStore {
// [...]
readonly backendEnabledProductIds = signal>(new Set());
readonly productList = computed(() => {
return this.allProducts().filter(p =>
this.onlyAvailable() ? p.available : true
).filter(p => this.backendEnabledProductIds().has(p.id));
});
constructor(private api: ProductApiService) {
effect(() => {
const category = this.selectedCategory();
const onlyAvailable = this.onlyAvailable();
this.api.getProducts(category, onlyAvailable).then(products => {
this.allProducts.set(products);
});
});
effect(() => {
this.api.getEnabledProductIds().then(ids => {
this.backendEnabledProductIds.set(new Set(ids));
});
});
}
// [...]
}
Nach außen bleibt die Architektur zunächst unverändert. Die Komponente enthält weiterhin keine eigene Logik, Subscriptions sind nicht notwendig, und die Reaktivität scheint erhalten zu bleiben. Im Service jedoch nimmt die Zahl der effect()s zu, Abhängigkeiten werden vielfältiger, und die Übersichtlichkeit leidet.
Nach und nach wandert Logik in verteilte effect()s, bis ihre Zuständigkeiten kaum noch greifbar sind. Aus einem überschaubaren ViewModel entsteht ein Gebilde mit immer mehr impliziten Reaktionen – eine Entwicklung, die ein waches Auge für Architektur erfordert.
Wenn reaktive Systeme entgleisen
Das Setup wirkt zunächst unspektakulär. Die Produktliste wird über ein computed() erstellt, gefiltert nach Verfügbarkeit und den vom Backend freigegebenen IDs. Zwei effect()s laden die Daten.
Der Code wirkt aufgeräumt und lässt sich modular erweitern. Doch der nächste Feature-Wunsch stellt das System auf die Probe: Die Stakeholder möchten wissen, wie oft bestimmte Kategorien angesehen werden. Die Entwicklerinnen und Entwickler entscheiden sich für einen naheliegenden Ansatz. Eine Änderung der Kategorie löst ein Tracking-Event aus. Ein effect() scheint dafür perfekt geeignet – unkompliziert und ohne erkennbare Nebenwirkungen:
effect(() => {
const category = this.selectedCategory();
this.analytics.trackCategoryView(category);
});
Schnell eingebaut, kein zusätzlicher State, keine neue Subscription. Eine Reaktion auf das bestehende Signal, unkompliziert und ohne erkennbare Nebenwirkungen. Doch damit verlässt der Code den Bereich kontrollierter Reaktivität.
Der Kipppunkt
Die Annahme ist klar: Ändert sich die Kategorie, wird ein Tracking ausgelöst. Was dabei leicht zu übersehen ist: Signals reagieren nicht auf Bedeutung, sondern auf jede Mutation. Auch wenn set() denselben Wert schreibt oder zwei Komponenten nacheinander dieselbe Auswahl treffen, passiert zwar technisch etwas, semantisch aber nicht. Das Ergebnis sind doppelte Events und verzerrte Metriken, ohne dass der Code einen Hinweis darauf gibt. Alles sieht korrekt aus.
Das Tracking erfolgt unmittelbar im selben Ausführungstakt (Tick), ohne Möglichkeit zur Entkopplung. Wenn parallel ein weiterer effect() ausgelöst wird – etwa durch ein zweites Signal –, fehlt jegliche Koordination.
Die Reihenfolge ist nicht vorhersehbar, und das UI kann in einen inkonsistenten Zustand geraten: Daten werden mehrfach geladen, Reaktionen überschneiden sich, Seiteneffekte sind nicht mehr eindeutig zuzuordnen. Mit jedem zusätzlichen effect() steigt die Zahl impliziter Wechselwirkungen. Was wie ein reagierendes System wirkt, ist längst nicht mehr entscheidungsfähig.
In einem Kundenprojekt führte genau dieser Zustand dazu, dass ein effect() mehrfach pro Sekunde auslöste. Nicht wegen einer echten Änderung, sondern weil derselbe Wert mehrfach gesetzt wurde. Das UI zeigte korrekte Daten, aber das Backend war mit redundanten Anfragen überlastet.
Das Missverständnis
effect() wirkt wie ein deklarativer Controller: „Wenn sich X ändert, tue Y.“ Doch in Wirklichkeit ist es ein reaktiver Spion. Er beobachtet jedes Signal, das gelesen wird, unabhängig von der semantischen Bedeutung. Er feuert sogar dann, wenn niemand es erwartet. Und er ist nicht koordiniert. Jeder effect() lebt in seiner eigenen Welt, ohne zentrale Regie.
Was als architektonische Vereinfachung begann, endet in einer Blackbox aus Zuständen, Reaktionen und Nebenwirkungen. Mit jedem weiteren Feature wächst diese Komplexität. Es gibt keinen großen Knall, aber eine zuvor elegant erscheinende Struktur driftet leise auseinander.
Entwicklung & Code
KubeSphere entfernt Open-Source-Dateien und stellt Support ein
Die chinesische Kubernetes-Plattform KubeSphere hat auf GitHub angekündigt, die Open-Source-Version des Produkts zurückzuziehen und den kostenlosen Support einzustellen: „Ab dem Datum dieser Ankündigung werden die Download-Links für die Open-Source-Version von KubeSphere deaktiviert und der kostenlose technische Support eingestellt.“
Das Kernprojekt von KubeSphere auf GitHub bleibt jedoch Open Source unter Apache-2-Lizenz. Als Grund für den Wechsel nennt der Hersteller die Änderung der Digitalisierung mit Gen AI, wodurch auch die Infrastruktur-Branche tiefgreifende Veränderungen erfahren hat. „Um sich an die neue Ära anzupassen, die Produktkapazitäten und die Servicequalität weiter zu verbessern und sich auf die Forschung und Entwicklung von Kerntechnologien sowie die Optimierung kommerzieller Lösungen zu konzentrieren, hat das Unternehmen nach mehrjähriger Planung und sorgfältiger Prüfung beschlossen, die folgenden Anpassungen am Open-Source-Projekt KubeSphere vorzunehmen.“ Es folgt die oben genannte Ankündigung.
Welche aktuellen oder künftigen Produkte konkret nicht mehr Open Source sind, ist der Ankündigung nicht zu entnehmen. Auf der Webseite weist der Hersteller derzeit sogar noch auf die CNCF-Zertifizierung hin. Nutzern von KubeSphere rät der Diskussionsbeitrag, sich für eine kommerzielle Version an den Support zu wenden.
Der Beitrag ist auf Chinesisch, darunter findet sich eine englische Übersetzung. Wir haben mit KI-Hilfe direkt aus dem Chinesischen übersetzt.
(who)
Entwicklung & Code
JetBrains: Preissprung bei Entwicklungsumgebungen ab 1. Oktober
Das tschechische Softwareunternehmen JetBrains hat angekündigt, seine Preise am 1. Oktober 2025 anzuziehen. Nach drei Jahren der Preisstabilität sieht sich der Hersteller beliebter Entwicklungsumgebungen (Integrated Development Environments, IDEs) aufgrund der Inflation gezwungen, die Preise für Abonnements zu erhöhen. Wer im Voraus zahlt, kann die bisherigen Preise noch für eine begrenzte Zeitdauer über den 1. Oktober hinaus beibehalten.
Preissteigerungen für IDEs, .NET-Tools, dotUltimate und All Products Pack
Betroffen sind die Abos für die JetBrains-Entwicklungsumgebungen – wie IntelliJ IDEA, WebStorm oder PhpStorm –, die .NET-Tools, das .NET-Toolkit dotUltimate und die IDE-Sammlung All Products Pack. Auf einer Webseite informiert JetBrains über die Preisänderungen. Beispielsweise erhöhen sich die Kosten der IDE IntelliJ IDEA Ultimate für den individuellen Einsatz bei jährlicher Zahlweise von 169 Euro auf 199 Euro (plus Mehrwertsteuer), bei monatlicher Zahlung von 16,90 Euro auf 19,90 Euro – jeweils auf das erste Nutzungsjahr bezogen. Für Unternehmen fallen die Steigerungen happiger aus: Das gleiche Produkt kostet pro User und Jahr derzeit 599 Euro (oder 59,90 Euro monatlich), ab dem 1. Oktober 719 Euro (oder 71,90 Euro monatlich) – eine Erhöhung um rund 20 Prozent.

Kosten für IntelliJ IDEA Ultimate für die individuelle Nutzung
(Bild: JetBrains)
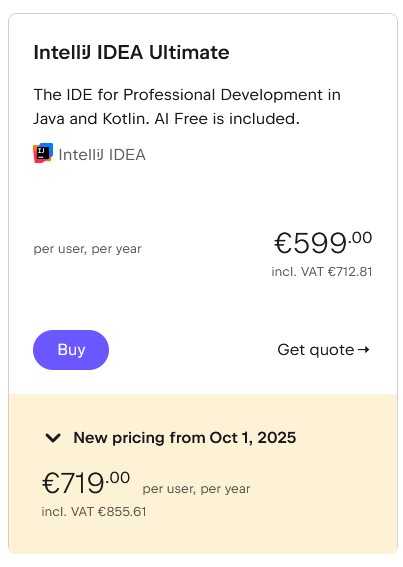
Kosten für IntelliJ IDEA Ultimate für Unternehmen
(Bild: JetBrains)
Beim All Products Pack, das aus elf Entwicklungsumgebungen und weiteren Inhalten besteht, steigen die Preise für den individuellen Einsatz von 289 Euro auf 299 Euro pro Jahr an, für den Einsatz in Unternehmen pro Jahr und User von 779 Euro auf 979 Euro.
Für bestimmte Nutzergruppen wie Lehrkräfte, Schülerinnen und Schüler oder Core Maintainer von Open-Source-Projekten sind weiterhin kostenfreie Angebote aufgeführt.
Alternative: Im Voraus bezahlen und sparen
JetBrains bietet seinen bestehenden sowie neuen Kundinnen und Kunden die Möglichkeit, im Voraus noch zu den derzeitigen Preisen zu bezahlen: Für individuelle Abos gilt dieser dann bis zu drei Jahre lang, für kommerzielle bis zu zwei Jahre. Dann wird die entsprechende Zahlung jedoch auf einen Schlag vor dem 1. Oktober 2025 fällig.
Weitere Details bieten der JetBrains-Blog und die Preisübersichtsseite.
(mai)

UniFi OS: Ubiquiti bringt Netzwerkbetriebssystem für den eigenen Server

Ultra-Kapazitätsnetz: Telekom verdichtet Mobilfunknetz um 100 neue Standorte

Anfang 2026 sind Nokia-Smartphones wohl endgültig Geschichte

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

TikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 Online Marketing & SEOvor 2 Monaten
Online Marketing & SEOvor 2 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenPhilip Bürli › PAGE online
-

 Digital Business & Startupsvor 1 Monat
Digital Business & Startupsvor 1 Monat80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Digital Business & Startupsvor 1 Monat
Digital Business & Startupsvor 1 Monat10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Apps & Mobile Entwicklungvor 1 Monat
Apps & Mobile Entwicklungvor 1 MonatPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenLinkedIn Feature-Update 2025: Aktuelle Neuigkeiten