Entwicklung & Code
Docker Inc. macht gehärtete Abbilder kostenlos verfügbar
Docker Inc. hat angekündigt, ein bisher kostenpflichtiges Produkt fortan kostenlos anzubieten: Docker Hardened Images (DHI). Der Erfinder der Software Docker und Betreiber des Docker Hubs erklärt, damit auf Lieferkettenangriffe zu reagieren, die auch im Containerumfeld vorkommen. Die gehärteten Abbilder enthalten ein aufs absolut Nötige reduziertes Userland einer Distribution und unterscheiden sich dadurch von den sogenannten „Official Images“, die man ohne Login im Docker Hub (hub.docker.com) für viele Anwendungen findet.
Weiterlesen nach der Anzeige
Weniger Spuren der Distribution
Als Beispiel reicht ein Blick auf den Webserver Nginx und dessen Abbild: Im öffentlichen Hub gibt es Abbilder mit dem Namen nginx, die auf den Distributionen Alpine oder Debian aufbauen. Neben dem Webserver selbst stecken Teile der Distribution darin. Die meisten Komponenten sind für den Betrieb des Webservers gar nicht nötig und allenfalls hilfreich, wenn man mit Werkzeugen wie docker exec in einen Container springt und darin Fehler sucht. Über den eingebauten Paketmanager (apt oder apk) kann man beispielsweise einen Texteditor nachinstallieren und auf Fehlersuche im Container gehen. Solche Werkzeuge können aber auch zum Einfallstor für Angreifer werden.
Die gehärteten Abbilder enthalten weniger Spuren der Distribution und damit weniger Einfallstore – im Gegenzug aber auch keine Werkzeuge für die spontane Fehlersuche. Zum Vergleich: Das offizielle Nginx-Abbild auf Alpine-Basis (nginx:alpine) ist 21 MByte groß und kommt mit einer bekannten mittelschweren Sicherheitslücke, für die es einen CVE-Eintrag gibt. Die Debian-Variante (nginx:stable-bookworm) ist sogar 67 MByte groß, hat drei Lücken mit hoher Dringlichkeit, drei mittelschwere und ganze 61 mit der Einstufung „low“. Die gehärtete Version auf Alpine-Basis (dhi.io/nginx:1-alpine3.21) ist nur 4 MByte groß und Docker listet keine einzige bekannte Sicherheitslücke. Ein Blick in den Container zeigt: Der Paketmanager apk, der zu Alpine gehört, fehlt im Abbild.


Kompakt und ohne bekannte Lücken: Das gehärtete Nginx-Abbild auf Alpine-Basis ist nur 4 MByte groß.
Die gehärteten Abbilder gibt es für viele Anwendungen, für die es auch offizielle Abbilder gibt – darunter MySQL, PHP, Node.js, Traefik und MongoDB. Kein gehärtetes Abbild fanden wir für die MySQL-Alternative MariaDB. Um die Abbilder zu finden, müssen Sie sich im Docker Hub mit einem kostenlosen Account anmelden, über den öffentlichen Bereich des Hubs sind sie aktuell nicht zu finden. Sie landen nach dem Login in einer Übersicht namens „My Hub“ und finden links im Menü den Punkt „Hardened Images“. Um die Abbilder auf einem Server, einer Entwicklermaschine oder in einer CI/CD-Umgebung zu nutzen, müssen Sie dort zuerst den Befehl docker login dhi.io ausführen und sich mit Benutzernamen und einem persönlichen Zugangstoken anmelden. Ein solches Token erzeugen Sie, indem Sie oben rechts auf Ihre Initialen klicken, die „Account Settings“ öffnen und links unter „Personal access tokens“ ein Token erzeugen, das Leserechte hat.
Mehr Service gegen Geld
Neben den Abbildern hat Docker Inc. auch Helm-Charts für Kubernetes-Nutzer veröffentlicht, in denen die gehärteten Abbilder zum Einsatz kommen.
Weiterlesen nach der Anzeige
Auch in Zukunft möchte Docker Inc. mit den gehärteten Abbildern Geld verdienen, wie der Blogpost zur Ankündigung erklärt. Wer regulatorische Anforderungen hat und beispielsweise FIPS-konforme Abbilder braucht oder sich eine Reaktion auf kritische CVEs innerhalb von sieben Tagen vertraglich zusichern lassen muss, greift zu den kostenpflichtigen „Docker Hardened Images Enterprise“. Außerdem verspricht Docker erweiterten Support für Anwendungen in Versionen, die von den Entwicklern der Anwendungen nicht mehr unterstützt werden („DHI Extended Lifecycle Support“).
(jam)










Entwicklung & Code
Windows-XP-Nachbau ReactOS wird 30 | heise online
Das ReactOS-Projekt feiert seinen 30. Geburtstag. Ende Januar 1996 gab es den ersten Commit zum ReactOS-Quellcode. In einem Blog-Beitrag würdigen die derzeitigen Projekt-Maintainer das Ereignis. Sie überreißen grob die Entwicklungsgeschichte des Windows-XP-kompatiblen Betriebssystems.
Weiterlesen nach der Anzeige
ReactOS-Geschichte: Aus Windows-95-Alternative entstanden
Zwischen 1996 und 2003 begannen die Entwickler, aus dem nicht so richtig vorwärtskommenden „FreeWin95“-Projekt ReactOS zu schmieden, das als Ziel keine DOS-Erweiterung, sondern die Binärkompatibilität für Apps zum Windows-NT-Kernel hat. Das zog sich allerdings hin, da sie zunächst einen NT-artigen Kernel entwickeln mussten, bevor sie Treiber programmieren konnten. Am 1. Februar 2003 veröffentlichte das Projekt schließlich ReactOS 0.1.0. Das war die erste Version, die von einer CD starten konnte. Allerdings beschränkte die sich noch auf eine Eingabeaufforderung, es gab keinen Desktop.
Zwischen 2003 und 2006 nahm die Entwicklung von ReactOS 0.2.x rapide an Fahrt auf. „Ständig wurden neue Treiber entwickelt, ein einfacher Desktop gebaut und ReactOS wurde zunehmend stabil und benutzbar“, schreiben die Entwickler. Ende 2005 trat der bis dahin amtierende Projekt-Koordinator Jason Filby zurück und übergab an Steven Edwards. Im Dezember 2005 erschien ReactOS 0.2.9, über das heise online erstmals berichtete. Anfang 2006 gab es jedoch Befürchtungen, einige Projektbeteiligte könnten Zugriff auf geleakten, originalen Windows-Quellcode gehabt und diesen für ihre Beiträge zum ReactOS-Code genutzt haben. Ein „Kriegsrat“ entschied daraufhin, die Entwicklung einzufrieren und mit dem Team den bestehenden Code zu überprüfen.
Zwischen 2006 und 2016 lief die Entwicklung an ReactOS 0.3.x. Die andauernde Code-Prüfung und der Stopp von neuen Code-Beiträgen gegen Ende der ReactOS 0.2.x-Ära haben der Entwicklung deutlich Schwung entzogen. Steven Edwards trat im August 2006 als Projekt-Koordinator zurück und übergab an Aleksey Bragin. Ende desselben Monats erschien dann ReactOS 0.3.0, dessen erster Release-Kandidat Mitte Juni verfügbar wurde, und brachte Netzwerkunterstützung und einen Paketmanager namens „Download!“ mit.
Seit 2016 findet die Entwicklung am ReactOS-0.4.x-Zweig statt. Im Februar 2016 verbesserte ReactOS 0.4.0 etwa die 16-Bit-Emulation für DOS-Anwendungen, ergänzte aber auch Unterstützung für NTFS und das Ext2-Dateisystem. Die eingeführte Unterstützung für den Kernel-Debugger WinDbg hat die Entwicklung spürbar vorangetrieben. Seit März vergangenen Jahres stellt ReactOS 0.4.15 den derzeit aktuellen Stand der Entwicklung dar.
Aber auch zur Zukunft des Projekts äußern sich die derzeitigen Projekt-Entwickler. „Hinter dem Vorhang befinden sich einige Projekte jenseits des offiziellen Software-Zweigs in Entwicklung“, schreiben sie, etwa eine neue Build-Umgebung, ein neuer NTFS-Treiber, ebenso neue ATA-Treiber sowie Multi-Prozessor-Unterstützung (SMP). Auch Klasse-3-UEFI-Systeme sollen unterstützt werden, also solche, die keine Kompatibilität mit altem BIOS mehr anbieten. Adress Space Layout Randomization (ASLR) zum Erschweren des Missbrauchs von Speicherfehlern zum Schadcodeschmuggel befindet sich ebenfalls in Entwicklung. Wichtig ist zudem die kommende Unterstützung moderner Grafikkartentreiber, basierend auf WDDM.
Weiterlesen nach der Anzeige
(dmk)
Entwicklung & Code
Die vier Apokalyptischen Reiter der Aufwandsschätzung von Cloud-Legacy-Projekten
Viele ältere Anwendungen profitieren deutlich von einer Modernisierung zu einer Cloud‑Native‑Architektur. Dieser Ansatz löst bestehende Probleme durch neue Technologien, bietet Entwicklerinnen und Entwicklern eine moderne Arbeitsumgebung und eröffnet neue Absatzchancen als Software‑as‑a‑Service. Verschiedenen Studien zufolge ist Modernisierung bei einer Mehrheit der Unternehmen unvermeidlich, weil deren Altanwendungen geschäftskritisch sind (siehe Lünendonk: Unternehmen ringen mit der IT-Modernisierung und Thinkwise: Legacy-Modernisierung – Warnsignale ernst nehmen). Daher wächst das Interesse, bestehende Kernsysteme zu modernisieren und fit für die Cloud zu machen.
Weiterlesen nach der Anzeige

Thomas Zühlke ist Cloud-Architekt bei adesso SE mit fast 20 Jahren Berufserfahrung, davon die letzten neun Jahre ausschließlich im Cloud-Umfeld. Er berät Kunden bei der Adaption der Azure Cloud, erstellt Roadmaps, entwirft Migrationsstrategie und Modernisierungskonzepte. Trotz vorwiegender Konzeptionsarbeit begeistert er sich weiterhin für die technische Umsetzung der entworfenen Lösungen.
Die DOAG Cloud Native Community (DCNC) vernetzt Interessierte und Anwender aus Deutschland, Österreich und der Schweiz für den Informations- und Erfahrungsaustausch zu Themen rund um Cloud Native. Gemeinsam organisieren sie überregionale Veranstaltungen wie die CloudLand („Das Cloud Native Festival“), die sich wichtigen Themen widmet: AI & ML, DevOps, Compute / Storage / Network, Data & BI, Security & Compliance, Public Cloud, Architecture, Organization & Culture, Customer Stories, Sovereign Cloud und Cloud-native Software Engineering.
Im Rahmen der Cloud Native Kolumne beleuchten Expertinnen und Experten aus der Community regelmäßig die verschiedensten Trends und Aspekte Cloud-nativer Softwareentwicklung und -bereitstellung.
Vorbereitung: Konzeptionsphase
Einer Modernisierung geht meist ein Konzept voraus. Dieses analysiert alte und neue Anforderungen und beschreibt, wie sie umgesetzt werden sollen. Es benennt betriebliche Anpassungen und konzipiert neue Teamstrukturen. Auf dieser Basis erstellt das Unternehmen Schulungspläne für die beteiligten Mitarbeitenden. Alle Änderungen fließen in eine Roadmap ein, die sowohl verpflichtende als auch optionale Schritte mit ihren jeweiligen Kosten abbildet.
Frühe Aufwandsschätzung
Oft ist schon vor dem Modernisierungskonzept eine erste Aufwandsschätzung nötig, etwa für die Budgetplanung. Diese Schätzung ist schwierig, weil Anwendungen komplex sind und sich konkrete Änderungen erst nach einer Analyse bestimmen lassen. Manchmal stehen mehrere Systeme zur Auswahl. Dann müssen Architektinnen und Architekten den geeignetsten Kandidaten identifizieren und eine grobe Kostenschätzung für die kommenden Jahre entwickeln. Unternehmen erwarten in dieser Phase häufig eine schnelle Einschätzung mit nachvollziehbaren Zahlen – quasi ein fundiertes Bauchgefühl.
Weiterlesen nach der Anzeige
Zur Veranschaulichung dient ein reales Beispielprojekt. Das Produkt läuft seit acht Jahren und umfasst ein Team aus einem Frontend-Entwickler, einem Backend-Entwickler und einem Architekten, die sich um die Weiterentwicklung kümmern – alle in Vollzeit. Pro Jahr entstehen rund 600 Personentage an Aufwand; über acht Jahre summiert sich das auf 4800 Personentage. Das Team war zu Beginn möglicherweise größer, dieser Effekt ist über die lange Laufzeit jedoch vernachlässigbar. Der Projektleiter bzw. Product Owner ist in dieser Betrachtung nicht enthalten, da der Fokus für die Berechnung auf den Entwicklungsaufwänden liegen soll.
Aufwandsschätzung Reifegrad 1 – Faustformel
Erfahrungen der vergangenen Jahre zeigen im Allgemeinen, dass für eine minimale Modernisierung und Cloud‑Readiness etwa 10 bis 30 Prozent der ursprünglichen Entwicklungskosten anfallen. Dieser Aufwand umfasst Änderungen an Konfigurationen, den Austausch einzelner Komponenten durch höherwertige Dienste sowie die Anpassung von Querschnittsthemen. Er gilt nicht für reine Lift‑and‑Shift‑Szenarien oder vollständige Neuimplementierungen, da jene deutlich weniger beziehungsweise diese erheblich mehr Aufwand erfordern.
Die Berechnungen setzen voraus, dass das bestehende Team die Modernisierung eigenständig durchführt – ohne externe Unterstützung und zusätzlichen Schulungsbedarf. Für das Beispielprodukt ergibt sich ein Aufwand zwischen 480 und 1440 Personentagen. Diese Spanne ist groß, insbesondere bei älteren Produkten. Je länger ein System läuft, desto größer ist der Anteil der Wartungsphase, die keine neuen Funktionen schafft und dadurch die ursprünglichen Entwicklungsaufwände verwässert. Zudem bleibt unklar, welche Softwareteile konkret angepasst oder modernisiert werden müssen. Der nächste Abschnitt zeigt, wie sich diese Werte genauer herleiten lassen, und nennt die wichtigsten Kostentreiber.
Aufwandsschätzung Reifegrad 2 – Entwickleraufwände
Mehrere Studien haben untersucht, wie sich Ressourcen im Lebenszyklus eines Softwareprojekts verteilen. Sie zeigen ähnliche Ergebnisse, setzen jedoch unterschiedliche Schwerpunkte. Ein bekanntes Beispiel ist „The Staged Model of the Software Lifecycle: A New Perspective on Software Evolution“.
Es gliedert den Lebenszyklus in folgende Phasen (siehe Abbildung unten):
- Initial Development
- Evolution
- Servicing
- Phase‑Out
- Close‑Down
Das Modell unterscheidet zwischen aktiver (Evolution) und passiver Wartung (Servicing). Aktive Wartung gilt als Entwicklungsaufwand, da sie Erweiterungen durch neue Features, regulatorische Anforderungen oder Mandantenanpassungen umfasst. Passive Wartung betrifft ausschließlich erhaltende Maßnahmen wie Bugfixes oder Bibliotheksupdates und fließt nicht in die Modernisierungskosten ein. Weitergehende Informationen zu Modellen, die unter anderem auch die mit der Zeit steigenden Wartungskosten berücksichtigen, finden sich in: How much does software development cost? In-depth guide for 2025; Lebenszyklus-Kosten von IT Produkten und IT Project Outsourcing In 2025 – A Comprehensive Guide.
Aus der Erfahrung haben sich folgende, in der Abbildung hervorgehobenen Werte bewährt:
- Initial Development ≈ 15 Prozent
- Evolution ≈ 25 Prozent
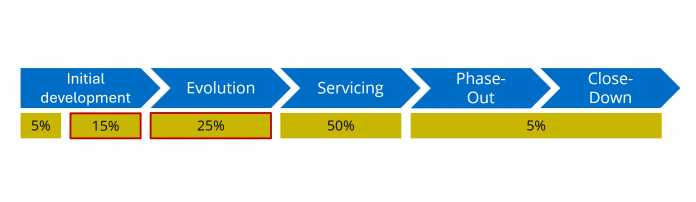
Verteilung von Aufwänden auf die Phasen des Software-Lebenszyklus
Die Phasen Phase‑Out, Close‑Down und Servicing bleiben unberücksichtigt, da sie keine relevante Entwicklungstätigkeit enthalten. Der Entwicklungsanteil der Software beträgt (inklusive etwa 5 Prozent für die zu Beginn häufig erhöhte Lernkurve und eventuell benötigte Proof-of-Concepts) somit 40 Prozent von 4800 Personentagen, also 1920 Personentage. Davon entfallen 10 bis 30 Prozent auf die Modernisierung, also 192 bis 576 Personentage. Diese Werte sind realistisch, doch bleibt die Bandbreite groß. Um sie zu verfeinern, müssen die größten Aufwandstreiber identifiziert werden.
(Bild: cloudland.org)

Vom 19. bis 22. Mai 2026 finden Interessierte beim Cloud Native Festival CloudLand ein prall gefülltes Line-up mit mehr als 200 Highlights – darunter die beiden neuen Themenbereiche „Open Source“ und „Platform Engineering“. Besucherinnen und Besucher erwartet eine bunte Mischung überwiegend interaktiver Sessions, Hands-ons und Workshops, begleitet von einem umfassenden Rahmenprogramm, das zum aktiven Mitmachen einlädt.
Tickets für das Festival und Unterkünfte im Heide Park Soltau lassen sich über die Festival-Homepage buchen.
Aufwandsschätzung Reifegrad 3 – Apokalyptische Reiter
Je gründlicher die Analyse einer Modernisierung, desto genauer wird die Schätzung. Für eine solide Näherung genügt es, die zentralen Aufwandstreiber zu erkennen und zu prüfen, ob sie im Projekt relevant sind. Einige Basisbausteine müssen bei jeder Modernisierung angepasst werden, etwa CI/CD‑Pipelines oder Logging‑Mechanismen. Solche Arbeiten lassen sich pauschal mit rund 5 Prozent der Entwicklungsaufwände veranschlagen.
Daneben existieren optionale Basisbausteine, die den Aufwand erheblich steigern können. Diese entscheidenden Faktoren werden sinnbildlich als apokalyptische Reiter bezeichnet. Jeder dieser vier Treiber kann mit etwa 5 Prozent der Entwickleraufwände bewertet werden:
Architektur der Geschäftslogik
Häufig erfolgt eine Umstellung auf Microservices oder Self‑Contained Systems. Dadurch entstehen neue System‑Schnitte, Kommunikationswege und Skalierungsmechanismen, während die Business‑Logik selbst unverändert bleibt.
Architektur des Speicherkonzepts
Ein Wechsel von relationalen Datenbanken zu Dokumenten‑ oder Graphenmodellen oder die Einführung von Event Sourcing/CQRS erfordert umfassende Anpassungen an Persistenz, Migration und Nachrichtenverarbeitung.
Mandantenkonzept
SaaS‑Lösungen verlangen Multi‑Tenant‑Fähigkeit. Altanwendungen nutzen häufig getrennte Installationen je Mandant und sind nicht auf zentrale Datenhaltung oder gemeinsame Berechtigungsmodelle ausgelegt.
Authentifizierung und Autorisierung (AuthN/AuthZ)
Viele Systeme verwenden noch eine eigene Benutzerverwaltung oder veraltete Identity‑Provider. Die Migration zu Cloud‑Providern (z. B. Azure Entra ID) sowie die Einführung verschlüsselter Kommunikation und zentraler Token‑Validierung erhöhen den Aufwand deutlich.
Selten umfasst die Modernisierung zusätzlich ein Redesign des GUI‑Konzepts oder den Wechsel zu einem neuen Frontend‑Framework. Auch dafür kann ein pauschaler Mehraufwand von 5 Prozent angesetzt werden. Darüber hinaus entstehen gelegentlich parallele Projekte für Infrastruktur und Governance (Landing Zones), um die modernisierte Lösung sicher betreiben zu können.
Im Beispielprojekt greifen drei dieser Reiter: die Umstellung auf Microservices (+ 5 %), die Einführung eines Mandantenkonzepts (+ 5 %) und die Modernisierung des Security‑Konzepts (+ 5 %). Zusammen mit der Basisanpassung ergibt sich ein Gesamtaufwand von 20 Prozent der 1920 Entwicklungs‑Personentage, also etwa 384 Personentage.
Fazit: Eine gute Schätzung ersetzt kein Konzept – aber sie zeigt, wo sich Aufwand wirklich lohnt
Die Kombination aus Entwicklungsaufwandsanalyse und Bewertung einzelner Änderungsbausteine liefert eine ausreichend präzise Schätzung. Da genaue Prozentwerte schwer festzulegen sind, empfiehlt sich eine Unterteilung in Fünf‑Prozent‑Schritte, sofern keine detaillierteren Informationen vorliegen. Eine Schätzung bleibt jedoch stets eine Annäherung.
Vor jeder Modernisierung ist deshalb ein detailliertes Konzept unverzichtbar. Es identifiziert obligatorische und optionale Änderungen, bewertet deren Aufwand und legt einen konkreten Umsetzungsplan fest. Fehlt dieses Konzept, scheitert die Modernisierung oft schon vor dem Projektstart.
(map)
Entwicklung & Code
Kuratierte KI-Agenten-Sammlung von JetBrains und Zed
Der IDE-Anbieter JetBrains und das Unternehmen hinter dem Sourcecode-Editor Zed, Zed Industries, haben gemeinsam die ACP Registry veröffentlicht. Diese soll es Entwicklerinnen und Entwicklern vereinfachen, mit dem Agent Client Protocol (ACP) kompatible KI-Coding Agenten bereitzustellen, aufzufinden und in Entwicklungsumgebungen zu installieren.
Weiterlesen nach der Anzeige
Die ACP Registry: KI-Agenten per Klick installieren
In der ACP Registry finden sich derzeit ausschließlich kuratierte KI-Agenten und -Extensions, die Authentifizierung unterstützen. Sie folgen dem Agent Client Protocol (ACP), einem standardisierten, offenen Protokoll für das Zusammenspiel von KI-Agenten und Editoren. ACP wurde von JetBrains und Zed Industries erstmals im Oktober 2025 vorgestellt.
Laut den Herstellern war das Protokoll bereits ein großer Schritt nach vorn, doch die Distribution war bisher fragmentiert. Agenten mussten für jeden Client als Extension verfügbar gemacht oder manuell durch User installiert werden. Hier setzt die ACP Registry an: Entwicklerinnen und Entwickler können ihre geeignete Implementierung eines Agenten oder einer Extension einmal registrieren, und diese wird dann für jeden ACP-kompatiblen Client verfügbar.
Sowohl Zed als auch die Entwicklungsumgebungen von JetBrains besitzen integrierten ACP-Registry-Support, um die Agenten auf einfache Weise zu installieren und ihre jeweils aktuellste Version zu verwenden. In JetBrains-IDEs – ab Version 2025.3.2 und mit JetBrains AI (253.30387.147) – lassen sich Agenten beispielsweise im Agent-Picker-Menü unter „Install From ACP Registry…“ auswählen und installieren. In Zed sieht die ACP-Registry-Seite wie folgt aus:

Zed bietet eine integrierte Anbindung an die ACP Registry.
(Bild: Zed Industries)
Das aktuelle Portfolio
Weiterlesen nach der Anzeige
Die kuratierte ACP Registry enthält aktuell die folgenden neun Agenten und Extensions:
- Auggie CLI
- Claude Code
- Codex CLI
- Factory Droid
- Gemini CLI
- GitHub Copilot
- Mistral Vibe
- OpenCode
- Qwen Code
Weitere Informationen zur ACP Registry finden sich auf der offiziellen Website und im GitHub-Repository sowie in den Ankündigungen von JetBrains und Zed Industries.
Lesen Sie auch
(mai)

Glasfaserausbau und DSL-Abschaltung | c’t uplink

GPT-5, 4o und mehr: OpenAI schaltet alte ChatGPT-Modelle im Februar ab

Milliarden-Übernahme: Q.AI gehört jetzt Apple

Kommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Huawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-
 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-
 Künstliche Intelligenzvor 1 Monat
Künstliche Intelligenzvor 1 MonatSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenFast 5 GB pro mm²: Sandisk und Kioxia kommen mit höchster Bitdichte zum ISSCC
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenWeiter billig Tanken und Heizen: Koalition will CO₂-Preis für 2027 nicht erhöhen