Online Marketing & SEO
Instagram-Algorithmus selbst steuern – so geht’s
Endlich bietet Meta den Usern mehr Kontrolle über den Algorithmus. Denn auf Instagram und Threads kannst du künftig selbst entscheiden, welche Themen deinen Feed dominieren. Wir zeigen dir, welche Features die Plattformen derzeit testen.
Mit der Möglichkeit, eigene Kommentare in Posts anzupinnen, hat Instagram Creatorn und Brands kürzlich neue Optionen für Storytelling und Community Management geliefert. Denn mit der neuen Funktion lassen sich beispielsweise kurze Updates zu Ankündigungen, Antworten auf häufige Fragen oder zusätzliche Hintergrundinfos direkt unter dem Beitrag hinzufügen.
Instagram erlaubt jetzt das Anheften eigener Kommentare
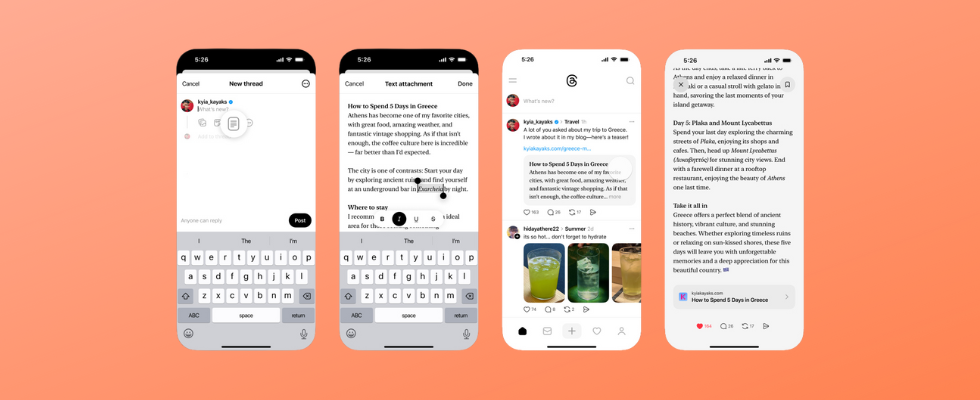
Jetzt erhalten auch die User ein Feature, das ihnen mehr Kontrolle auf Instagram bietet: Die Plattform arbeitet an einer Funktion, die dich deinen Algorithmus steuern lässt. Social-Media-Experte Alessandro Paluzzi hat erste Hinweise auf das Feature entdeckt und in einem Threads Post geteilt.
Wie der Screenshot zeigt, kannst du Instagram mitteilen, wovon du mehr und wovon du weniger auf der Plattform sehen willst. Tippe einfach in einer der Kategorien auf das Plussymbol. Anschließend beschreibst du Instagram deine Interessen, zum Beispiel „Ich liebe Fußball“, und die Plattform fügt alle relevanten Keywords zum Dashboard hinzu. Mit dieser Funktion bietet Instagram den Usern neben bekannten Features wie dem „Interessiert mich nicht“-Button oder der Reset-Funktion eine weitere Möglichkeit, ihre App Experience zu steuern.
Neues Threads Feature: Take control of your feed
Auch auf Threads hat Paluzzi ein neues Algorithmus-Feature entdeckt: Unter dem Motto „Übernimm die Kontrolle über deinen Feed“ kannst du künftig – ähnlich wie auf Instagram – mehr oder weniger Posts zu einem bestimmten Thema sehen, indem du @threads.algo in einem Beitrag markierst. Unklar ist bislang, wie du spezifizieren kannst, ob dich das Thema besonders oder nicht interessiert (etwa durch den Zusatz „mehr“ oder „weniger“ hinter der Markierung). Eine offizielle Ankündigung der Funktion mit weiteren Informationen steht bislang aus.
Die Benachrichtigung zum neuen Feature lässt dich über eine integrierte Schaltfläche direkt einen neuen Post erstellen – das deutet darauf hin, dass die Markierung bei eigenen Beiträgen gesetzt werden kann. Möglicherweise kannst du aber auch in Kommentaren unter den Posts anderer Nutzer:innen @threads.algo taggen, um den Algorithmus zu beeinflussen, wenn dich ein Thema sehr oder gar nicht interessiert.
Beide neuen Meta Features befinden sich derzeit noch in der limitierten Testphase. Ob und wann der umfassende Roll-out folgt, wird sich zeigen. Schon jetzt kostenlos für alle User verfügbar ist derweil das neue Text Attachment Feature, mit dem du Textbeiträge mit bis zu 10.000 Zeichen deinen Threads Posts hinzufügen kannst.
Threads erlaubt längere Texte mit 10.000 Zeichen
– kostenlos für alle












Online Marketing & SEO
Katharina Wildau: Warum jetzt der richtige Moment für mutige Media-Entscheidungen im Mittelstand ist
Katharina Wildau
Auch 2026 dürfte ein Jahr werden, das nicht zuletzt den Mittelstand vor Herausforderungen stellt. Oft geraten dann auch die Werbeinvestitionen unter Druck. In ihrer neuesten Talking-Heads-Kolumne richtet Katharina Wildau daher einen Appell an mittelständische Marken, die Wirkung wollen – und Orientierung suchen.
Der deutsche Mittelstand steht vor einem Jahr, das vieles entscheiden wird – nicht nur in der Bilanz, sondern auch in der strategischen Ausricht
Jetzt Angebot wählen und weiterlesen!
HORIZONT Digital
- Vollzugriff auf HORIZONT Online mit allen Artikeln
- E-Paper der Zeitung und Magazine
- Online-Printarchiv
HORIZONT Digital-Mehrplatzlizenz für Ihr Team
Online Marketing & SEO
Denkanstöße-Umfrage – Teil 1: Worauf es 2026 für CMOs ankommt
Das kommende Jahr wird für Marketer wieder viele Herausforderungen bereithalten – aber auch Chancen
Ein ereignisreiches und herausforderndes Jahr 2025 geht zu Ende. Und 2026 dürfte kaum weniger Challenges für Marketer bereithalten. HORIZONT hat sich bei Branchenköpfen umgehört: Was wird im kommenden Jahr für CMOs wichtig? Welche Trends setzen sich durch – und worauf sollten CMOs jetzt schon achten?
Jasmin Seitel, Managing Director von Diffferent: Beidhändige Markenführung für zukü
Jetzt Angebot wählen und weiterlesen!
HORIZONT Digital
- Vollzugriff auf HORIZONT Online mit allen Artikeln
- E-Paper der Zeitung und Magazine
- Online-Printarchiv
HORIZONT Digital-Mehrplatzlizenz für Ihr Team
Online Marketing & SEO
How-to: Community Building: In 10 Schritten zur loyalen Community
Durch Googles AI-Offensive und strenge Algorithmen auf Social-Media-Plattformen wird der Dialog zwischen Marken und Nutzern zunehmend erschwert. Innovative Community-Strategien werden für Brands deshalb immer wichtiger. Mandy Schamber, Geschäftsführerin von Ferret Go, erklärt anhand von zehn Schritten, wie Marken erfolgreich und nachhaltig Community Building betreiben.
1. Schaffe einen Safer Space mit echter Wertschätzung
Um deine Zielgruppe aus der Komfortzone zu
Jetzt Angebot wählen und weiterlesen!
HORIZONT Digital
- Vollzugriff auf HORIZONT Online mit allen Artikeln
- E-Paper der Zeitung und Magazine
- Online-Printarchiv
HORIZONT Digital-Mehrplatzlizenz für Ihr Team

Elektrostimulation gegen VR-Übelkeit: Stimbox sagt Motion Sickness den Kampf an

Windows: Microsoft will SSD-Performance massiv verbessern
Framework SGLang für schnelle LLM-Inferenz kurz vorgestellt

-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenIllustrierte Reise nach New York City › PAGE online
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAus Softwarefehlern lernen – Teil 3: Eine Marssonde gerät außer Kontrolle
-
Künstliche Intelligenzvor 2 Monaten
Top 10: Die beste kabellose Überwachungskamera im Test
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenSK Rapid Wien erneuert visuelle Identität
-

 Entwicklung & Codevor 1 Monat
Entwicklung & Codevor 1 MonatKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenNeue PC-Spiele im November 2025: „Anno 117: Pax Romana“
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenDonnerstag: Deutsches Flugtaxi-Start-up am Ende, KI-Rechenzentren mit ARM-Chips
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenArndt Benedikt rebranded GreatVita › PAGE online
