Künstliche Intelligenz
iPad mit Faltung könnte 2028 erscheinen
Für manchen Nutzer wäre es ein Traum: ein faltbares iPad, das gleichzeitig ein Mac ist. Diese Idee scheint Apple schon seit längerem zu verfolgen, Gerüchte gibt es bereits seit Jahren. Doch nun sieht es danach aus, dass es noch bis mindestens 2028 dauert. Diese Nachricht kommt vom üblicherweise gut informierten Analysten Ming-Chi Kuo vom taiwanischen Investmenthaus TF International Securities. In einer in dieser Woche erschienenen Notiz an Investoren schreibt er, mit dem Gerät sei im Jahr 2028 zu rechnen.
Ein möglicher Lieferant ist schon bekannt
Einer der Lieferanten von Komponenten ist demnach General Interface Solution (GIS), wo man auch schon an der Vision Pro mitgearbeitet hatte. Sogenanntes Ultra-Thin Glass (UTG) wird die Firma aus Taiwan angeblich in Zusammenarbeit mit Apples Stammlieferanten Corning bauen – wobei GIS für Kantenbehandlung, Zuschnitt, Inspektion und Packaging zuständig sein soll. Kuo bestätigte in seiner Notiz den Termin eines iPhone Foldable für 2026. Es wird zusammen mit dem iPhone 18 im Herbst erwartet, sollte nicht noch etwas dazwischenkommen.
In Sachen iPad Foldable ist Kuo aber wie erwähnt pessimistischer. Zuletzt hatte ein anderer als zuverlässig geltender Analyst, Jeff Pu von GF Securities aus Hongkong, behauptet, Apple werde 2027 damit herauskommen. Schon das war eine Verschiebung, nachdem einige Gerüchteköche gar gehofft hatten, faltbares iPad und faltbares iPhone könnten im Herbst 2026 erscheinen. Auch ein anderer Apple-Beobachter, Mark Gurman von Bloomberg, tippt eher auf 2028 statt auf 2027. Eine Art „gigantisches iPad“, das so groß wie zwei iPad-Pro-Modelle nebeneinander sei, werde geplant.
Kitzlige Glas-Angelegenheit
Laut Kuo bereitet sich GIS darauf vor, sein Backend-Processing für das ultradünne iPad-Foldable-Glas vorzubereiten. Damit könne dann zwischen Ende 2027 und Anfang 2028 geliefert werden. Die Firma spielt eine wichtige Rolle, da UTG sehr bruchanfällig für Mikrorisse ist. Im Gegensatz zu gewöhnlichem Smartphone-Glas ist es bis zu viermal teurer. Sinn ist offensichtlich, das iPad Foldable besonders haltbar zu machen. Erste faltbare Smartphones hatten anfangs mit großen Haltbarkeitsschwierigkeiten gekämpft. Bei einem großen iPad ist das noch ein größeres Thema.
Ob es sich bei dem Gerät nun wirklich um ein iPad oder ein MacBook mit Falt-Bildschirm handelt, bleibt ungewiss. Apple betont stets, beide Produktlinien auseinanderhalten zu wollen, nähert das Design von macOS und iPadOS einander allerdings immer mehr an.
(bsc)











Künstliche Intelligenz
Der neue c’t Fotografie-Fotowettbewerb: Die Farbe Blau
Das kommende Winterhalbjahr steht nicht unbedingt für blauen Himmel oder paradiesische Strände. Doch gerade darin liegt die Herausforderung des neuen c’t-Fotografie-Wettbewerbs, denn er steht unter dem Thema Die Farbe Blau. Bestimmt fallen Ihnen auch im Alltag ein paar Dinge ins fotografische Auge, die das Motto treffen. Wie wäre es mit zwei Freunden mit blauen Sonnenbrillen, mit blauem Eis in einer Gletscherhöhle oder einem blau gestrichenen Haus, das zwischen tristen Gebäuden Ruhe oder Fröhlichkeit ausstrahlt? Gehen Sie mit Ihrer Kamera auf Jagd nach einem passenden Motiv, alternativ: Erschaffen Sie eines! Oder durchforsten Sie Ihr Archiv. Wer weiß, welche Schätze vergangener Reisen Sie dort noch heben können. Wir sind gespannt auf Ihre Ideen und darauf, wie Sie uns und die Mitglieder der heise-Fotogalerie mit Ihrem Motiv überzeugen können.
Weiterlesen nach der Anzeige


Reichen Sie Ihr bestes Bild bitte zwischen dem 24. Oktober 2025 ab 13.00 Uhr und dem 24. November 2025 bis 12.00 Uhr über die Galerie von c’t Fotografie online ein. Anschließend läuft die Bewertungsphase zwischen dem 24. November ab 12.00 Uhr und dem 05. Januar 2026 bis 12.00 Uhr.
c’t Fotografie Zoom In abonnieren
Ihr Newsletter mit exklusiven Foto-Tipps, spannenden News, Profi-Einblicken und Inspirationen – jeden Samstag neu.
E-Mail-Adresse
Ausführliche Informationen zum Versandverfahren und zu Ihren Widerrufsmöglichkeiten erhalten Sie in unserer Datenschutzerklärung.
Am Wettbewerb und an der Bewertung können alle registrierten User der Galerie teilnehmen. Die zehn bestplatzierten Bilder stellen wir in der Ausgabe 02/26 vor. Sie haben noch keinen Galerie-Account? Hier können Sie sich kostenlos anmelden. Der erste Platz gewinnt ein 2-Jahres-Abo der c’t Fotografie, der 2. und 3. Platz erhalten jeweils einen Bildband. Wir wünschen viel Freude bei der Teilnahme.
(cbr)
Künstliche Intelligenz
#TGIQF: Das Quiz rund um Tabellenkalkulationen
Die Arbeitsmappen von Tabellenkalkulationen sind im Arbeitsalltag auf den ersten Blick nicht besonders sexy: Ihre Attraktivität ziehen sie vor allem aus dem Vergleich zur Erinnerung, wie kompliziert es war, die gleiche Arbeit auf Papier zu bringen, was der Rechner heutzutage mit einem Tastendruck erledigt.
Weiterlesen nach der Anzeige
Nicht umsonst gelten Tabellenkalkulationen als wichtigste Tools in der IT: Für jedes relevante Computersystem wurden eigene Tabellenkalkulationen entwickelt.

„Thank God It’s Quiz Friday!“ Jeden Freitag gibts ein neues Quiz aus den Themenbereichen IT, Technik, Entertainment oder Nerd-Wissen:
Dabei war Microsofts marktbeherrschender Dauerbrenner Excel nicht immer die Nummer 1 – man war eigentlich eher spät dran. Im Oktober 1979 brachten die US-Softwareentwickler Dan Bricklin und Bob Frankston VisiCalc auf den Markt. Microsofts Excel erschien erstmals 1985. Dabei hatte der Konzern aus Redmond einen Vorläufer, der im Gegensatz zu den USA hierzulande ein großer Erfolg war – Doch wie hieß er? Das wollen wir von Ihnen in unserem kleinen Nerdquiz zu Tabellenkaluationen wissen.
Eines vorweg: Nicht wundern! Beim letzten Freitagsquiz wurde der Wechsel zu einem neuen Quiz-Tool eingeleitet. Für dieses Quiz haben wir uns jedoch entschieden, noch einmal das alte Tool zu verwenden. Wie so oft bei Neustarts kann es stellenweise zu Problemen kommen – Ausgerechnet bei der App-Integration hat es gehakt. Wir sind dran und möchten die Übertragung weiter optimieren, damit Sie perfekt ins Wochenende starten können. Wir bedanken uns auch fürs Feedback. Betrachten Sie das Quiz der letzten Woche also als Sneak Preview.
In der heiseshow stellte Anna Bicker den Redakteuren Malte Kirchner und Ben Schwan drei Fragen vorab: Die meisten Antworten schüttelten sie aus dem Ärmel wie die Excel eine einfache Addition.
Die Uhr läuft mit und belohnt schnelles Raten in 10 Fragen mit maximal-satten 200 Punkten. Die Punktzahl kann gern im Forum mit anderen Mitspielern verglichen werden. Halten Sie sich dabei aber bitte mit Spoilern zurück, um anderen Teilnehmern nicht die Freude am Quiz zu verhageln. Lob und Kritik ist wie immer gern genommen.
Weiterlesen nach der Anzeige
Bleiben Sie zudem auf dem Laufenden und erfahren Sie das Neueste aus der IT-Welt: Folgen Sie uns bei Mastodon, auf Facebook oder Instagram. Und schauen Sie auch gern beim Redaktionsbot Botti vorbei.
Und falls Sie Ideen für eigene Quizze haben, schreiben Sie einfach eine Mail an den Quizmaster aka Herr der fiesen Fragen.
(mawi)
Künstliche Intelligenz
DeepSeek-OCR: Bilder vereinfachen Texte für große Sprachmodelle
Viele Unternehmensdokumente liegen zwar als PDFs vor, sind aber häufig gescannt. Obwohl es simpel klingt, können diese Dokumente oftmals nur unter großen Mühen in Text gewandelt werden, insbesondere wenn die Struktur der Dokumente komplexer ist und erhalten bleiben soll. Auch Bilder, Tabellen und Grafiken sind häufige Fehlerquellen. In den letzten Monaten gab es daher eine wahre Flut von OCR-Software, die auf großen Sprachmodelle (LLMs) setzt.
Weiterlesen nach der Anzeige
Auch der chinesische KI-Entwickler DeepSeek steigt nun in diesen Bereich ein und veröffentlicht nach dem Reasoning-Modell R1 ein experimentelles OCR-Modell unter MIT-Lizenz. Auf den ersten Blick mag das verblüffen, denn OCR schien bisher nicht die Kernkompetenz von DeepSeek zu sein. Und tatsächlich ist das neue Modell erstmal eine Technikdemo für einen neuen Ansatz in der Dokumentenverarbeitung von großen Sprachmodellen.

Prof. Dr. Christian Winkler beschäftigt sich speziell mit der automatisierten Analyse natürlichsprachiger Texte (NLP). Als Professor an der TH Nürnberg konzentriert er sich bei seiner Forschung auf die Optimierung der User Experience.
DeepSeek versucht, lange Textkontexte in Bildern zu komprimieren, da sich hierdurch eine höhere Informationsdichte mit weniger Token darstellen lässt. DeepSeek legt die Messlatte für die Erwartungen hoch und berichtet, dass das Modell bei hohen Kompressionsraten (Faktor 10) noch eine Genauigkeit von 97 Prozent erreicht, bei einer noch stärkeren Kompression fällt zwar die Genauigkeit, bleibt dabei aber relativ hoch. Das alles soll schneller funktionieren als bei anderen OCR-Modellen und auf einer Nvidia A100-GPU bis zu 200.000 Seiten pro Tag verarbeiten.
Das Kontext-Problem
Large Language Models haben Speicherprobleme, wenn der Kontext von Prompts sehr groß wird. Das ist der Fall, wenn das Modell lange Texte oder mehrere Dokumente verarbeiten soll. Grund dafür ist der für effiziente Berechnungen wichtige Key-Value-Cache, der quadratisch mit der Kontextgröße wächst. Die Kosten der GPUs steigen stark mit dem Speicher, was dazu führt, dass lange Texte sehr teuer in der Verarbeitung sind. Auch das Training solcher Modelle ist aufwendig. Das liegt allerdings weniger am Speicherplatz, sondern auch an der quadratisch wachsenden Komplexität der Berechnungen. Daher forschen die LLM-Anbieter intensiv daran, wie sich man diesen Kontext effizienter darstellen kann.
Hier bringt DeepSeek die Idee ins Spiel, den Kontext als Bild darzustellen: Bilder haben eine hohe Informationsdichte und Vision Token zur optischen Kompression könnten einen langen Text durch weniger Token. Mit DeepSeek-OCR haben die Entwickler diese Grundidee überprüft – es ist also ein Experiment zu verstehen, das zeigen soll, wie gut die optische Kompression funktioniert.
Weiterlesen nach der Anzeige
Die Modellarchitektur
Der dazugehörige Preprint besteht aus drei Teilen: einer quantitativen Analyse, wie gut die optische Kompression funktioniert, einem neuen Encoder-Modell und dem eigentlichen OCR-Modell. Das Ergebnis der Analyse zeigt, dass kleine Sprachmodelle lernen können, wie sie komprimierte visuelle Darstellungen in Text umwandeln.
Dazu haben die Forscher mit DeepEncoder ein Modell entwickelt, das auch bei hochaufgelösten Bildern mit wenig Aktivierungen auskommt. Der Encoder nutzt eine Mischung aus Window und Global Attention verbunden mit einem Kompressor, der Konvolutionen einsetzt (Convolutional Compressor). Die schnellere Window Attention sieht nur einzelne Teile der Dokumente und bereitet die Daten vor, die langsamere Global Attention berücksichtigt den gesamten Kontext, arbeitet nur noch mit den komprimierten Daten. Die Konvolutionen reduzieren die Auflösung der Vision Token, wodurch sich der Speicherbedarf verringert.
DeepSeek-OCR kombiniert den DeepEncoder mit DeepSeek-3B-MoE. Dieses LLM setzt jeweils sechs von 64 Experten und zwei geteilte Experten ein, was sich zu 570 Millionen aktiven Parametern addiert. Im Gegensatz zu vielen anderen OCR-Modellen wie MinerU, docling, Nanonets, PaddleOCR kann DeepSeek-OCR auch Charts in Daten wandeln, chemische Formeln und geometrische Figuren erkennen. Mathematische Formeln beherrscht es ebenfalls, das funktioniert zum Teil aber auch mit den anderen Modellen.
Die DeepSeek-Entwickler betonen allerdings, dass es sich um eine vorläufige Analyse und um ebensolche Ergebnisse handelt. Es wird spannend, wie sich diese Technologie weiterentwickelt und wo sie überall zum Einsatz kommen kann. Das DeepSeek-OCR-Modell unterscheidet sich jedenfalls beträchtlich von allen anderen. Um zu wissen, wie gut und schnell es funktioniert, muss man das Modell jedoch selbst ausprobieren.
DeepSeek-OCR ausprobiert
Als Testobjekt dient eine Seite aus einer iX, die im JPEG-Format vorliegt. DeepSeek-OCR kann in unterschiedlichen Konfigurationen arbeiten: Gundam, Large und Tiny. Im Gundam-Modus findet ein automatisches Resizing statt. Im Moment funktioniert das noch etwas instabil, bringt man die Parameter durcheinander, produziert man CUDA-Kernel-Fehler und muss von vorne starten.
Möchte man den Text aus Dokumenten extrahieren, muss man das Modell geeignet prompten. DeepSeek empfiehlt dazu den Befehl

Im Gundam-Modus erkennt DeepSeek-OCR den gesamten Text und alle relevanten Elemente und kann auch Textfluss des Magazins rekonstruieren.
Den Text hat das Modell praktisch fehlerfrei erkannt und dazu auf einer RTX 4090 etwa 40 Sekunden benötigt. Das ist noch weit entfernt von den angepriesenen 200.000 Seiten pro Tag, allerdings verwendet Gundam auch nur ein Kompressionsfaktor von zwei: 791 Image Token entsprechen 1.580 Text Token. Immerhin erkennt das Modell den Textfluss im Artikel richtig. Das ist bei anderen Modellen ein gängiges Problem.
Mit etwa 50 Sekunden rechnet die Large-Variante nur wenig länger als Gundam, allerdings sind die Ergebnisse viel schlechter, was möglicherweise auch dem größeren Kompressionsfaktor geschuldet ist: 299 Image-Token entsprechen 2068 Text-Token. Im Bild verdeutlichen das die ungenauer erkannten Boxen um den Text – hier gibt es noch Optimierungsbedarf. Außerdem erkennt das Modell die Texte nicht sauber, teilweise erscheinen nur unleserliche Zeichen wie „¡ ¢“, was möglicherweise auf Kodierungsfehler und eigentlich chinesische Schriftzeichen hindeuten könnte.

Der Large-Modus komprimiert die Bilder stärker als Gundam, was zu einer ungenaueren Erkennung führt. Die Textboxen sind unschärfer abgegrenzt und es erscheinen unleserliche Zeichen, die auf eine fehlerhafte Kodierung hinweisen.
Fehler mit unleserlichen Zeichen gibt es beim Tiny-Modell nicht. Das rechnet mit einer Dauer von 40 Sekunden wieder etwas schneller und nutzt einen Kompressionsfaktor von 25,8 – 64 Image-Token entsprechen 1652 Text-Token. Durch die hohe Kompression halluziniert das Modell allerdings stark und erzeugt Text wie „Erweist, bei der Formulierung der Ab- fragen kann ein KI-Assistent helfen. Bis Start gilt es auf Caffès offiziell die Gewicht 50 Prozent der Früh-, der Prüfung und 50 Prozent für den Arzt- und NEUT und in Kürze folgen. (Spezielle)“. Das hat nichts mit dem Inhalt zu tun – auf diese Modellvariante kann man sich also nicht verlassen.

Die Tiny-Variante hat den höchsten Kompressionsfaktor für die Bilder und halluziniert bei der Text-Ausgabe stark. Hier sollte man sich also nicht auf die Ergebnisse verlassen.
Neben der Markdown-Konvertierung lässt DeepSeek-OCR auch ein Free OCR zu, das das Layout nicht berücksichtigt. Damit funktioniert das Modell sehr viel schneller und produziert auch in der Large-Version mit hoher Kompression noch gute Resultate. Diese Variante ist aber nur sinnvoll, wenn man weiß, dass es sich um Fließtexte ohne schwieriges Layout handelt.
Informationen aus Grafiken extrahieren
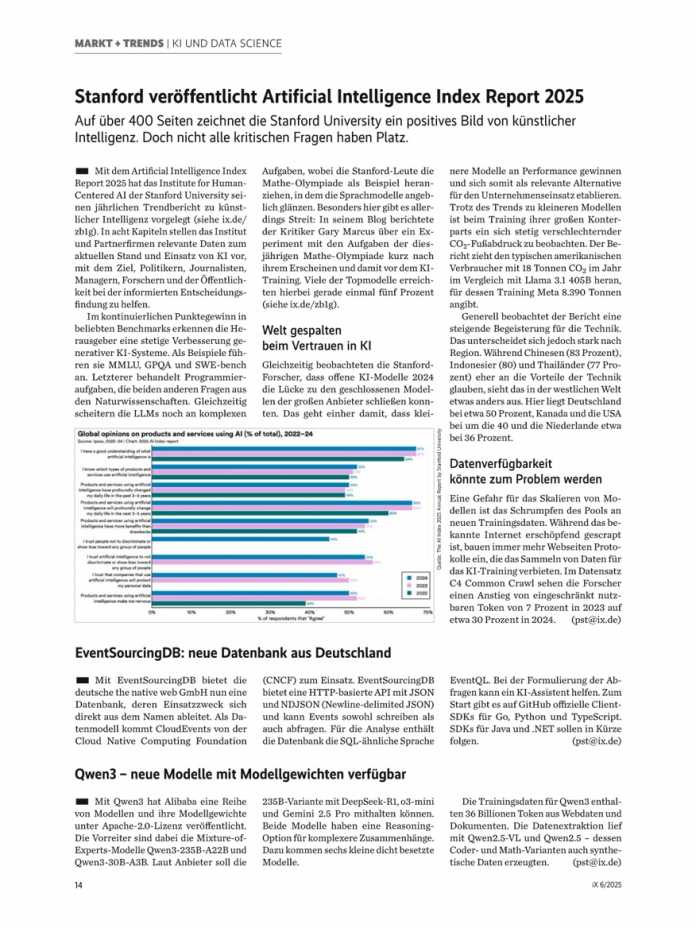
DeepSeek-OCR hat beim Parsing die im Artikel enthaltenen Bilder erkannt und separat abgelegt. Das Diagramm speichert das Modell dabei in einer schlecht lesbaren Auflösung.
Das mit Gundam extrahierte Diagramm ist verschwommen und lässt sich mit bloßem Auge nur noch schlecht entziffern.
Jetzt wird es spannend, denn DeepSeek-OCR soll aus diesem Diagramm auch Daten extrahieren können, das geht mit dem Prompt
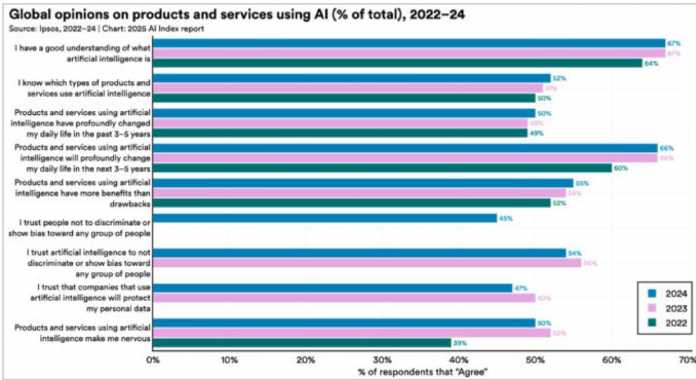
| 2024 | 2023 | 2022 | |
| I have a good understanding of what artificial intelligence is | 67% | 67% | 64% |
| I know which types of products and services use artificial intelligence | 52% | 51% | 50% |
| Products and services using artificial intelligence have profoundly changed my daily life in the past 3-5 years | 50% | 50% | 49% |
| Products and services using artificial intelligence will profoundly change my daily life in the next 3-5 years | 66% | 66% | 60% |
| Products and services using artificial intelligence have more benefits than drawbacks | 55% | 54% | 52% |
| I trust people not to discriminate or show bias toward any group of people | 45% | 45% | 44% |
| I trust artificial intelligence to not discriminate or show bias toward any group of people | 54% | 54% | 50% |
| I trust that companies that use artificial intelligence will protect my personal data | 47% | 50% | 50% |
| Products and services using artificial intelligence make me nervous | 39% | 39% | 39% |
Offenbar haben sich Fehler in die Tabelle eingeschlichen, aber zumindest hat das Modell den verwaschenen Text richtig erkannt. Hier zeigt sich die Stärke des Encoders, aber auch die englische Beschriftung vereinfacht den Prozess für das Modell. Die meisten Prozentwerte stimmen, ebenso die Struktur der Daten. Verwendet man eine höhere Auflösung, verbessern sich die Ergebnisse allerdings nur marginal.
Neben Diagrammen kann DeepSeek-OCR auch mathematische Formeln erkennen und sie in LaTeX-Syntax wandeln. Chemische Strukturformeln hat es auch im Repertoire und wandelt sie in das SMILES-Format.
Fazit
DeepSeek hat sich erneut einen spannenden technischen Ansatz ausgedacht und mit DeepSeek-OCR überzeugend demonstriert. Die Erkennung von Texten funktioniert besonders im Gundam-Modus schon gut, auch das Parsing der Diagramme ist überzeugend. Allerdings sind andere Modelle wie MinerU, Nanonets und PaddleOCR-VL besonders bei der reinen Texterkennung ebenfalls sehr gut und liefern teilweise sogar bessere Ergebnisse, da sie etwa getrennte Wörter zusammenführen. Besonders das ebenso nagelneue PaddleOCR-VL ist hervorzuheben, das Daten aus Diagrammen verlässlich extrahiert und in eigenen Tests sogar besser als DeepSeek-OCR funktionierte. Um OCR ist ein wahres Wettrennen entbrannt.
DeepSeek scheint mit dem Modell jedoch nicht nur auf OCR zu setzen, sondern möchte zeigen, dass die Vision Token eine gute Darstellung sind, um den Kontext in großen Sprachmodellen besonders kompakt zu speichern. Mit einer geringen Kompression funktioniert das schon gut, mit höherer Kompression leiden die Ergebnisse aber spürbar. Dieser Ansatz steht allerdings noch ganz am Anfang.
DeepSeek-OCR ist in allen Konfigurationen verhältnismäßig schnell. Experimente mit MinerU, Nanonets und PaddleOCR-VL waren alle mindestens 50 Prozent langsamer. Nanonets erzeugte immerhin eine Tabelle aus dem Diagramm, aber ohne die Jahreszahlen, dafür war der Fließtext sehr viel besser erkannt. Das nagelneue PaddleOCR-VL konnte das Diagramm sogar besser als DeepSeek-OCR erkennen, ist aber nicht auf chemische Strukturformeln und ähnliche Inhalte trainiert.
DeepSeek-OCR ist – wie von den Entwicklern deutlich vermerkt – eine Technologiedemonstration, die dafür schon äußerst gut funktioniert. Es bleibt abzuwarten, wie sich die Technologie in klassische LLMs integrieren lässt und dort zur effizienteren Verarbeitung von längeren Kontexten genutzt werden kann.
Weitere Informationen finden sich auf GitHub, Hugging Face und im arXiv-Preprint.
(pst)

Der neue c’t Fotografie-Fotowettbewerb: Die Farbe Blau

Atlassian Jira Data Center: Angreifer können Daten abgreifen

+++ Pitch it! +++ Formel Skin +++ Manual +++ BlueYard Capital +++ Michael Wax +++ Hello Inside +++

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 UX/UI & Webdesignvor 6 Tagen
UX/UI & Webdesignvor 6 TagenIllustrierte Reise nach New York City › PAGE online
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatSchluss mit FOMO im Social Media Marketing – Welche Trends und Features sind für Social Media Manager*innen wirklich relevant?