Apps & Mobile Entwicklung
Tensordyne: KI-Start-up will mit TDN Math Nvidias Dominanz brechen
Das in Kalifornien und München ansässige KI-Start-up Tensordyne schickt sich an, mit einer eigens entwickelten logarithmische Zahlen- und Rechenarchitektur für KI-Inferenz sowie entsprechender eigener Hardware den Markt aufzurollen. Tensordyne wirbt mit vielfach höherer Leistung und niedrigerem Verbrauch im Vergleich zu Nvidia.
Gegründet im Jahr 2017
Tensordyne wurde 2017 unter dem Namen Recogni gegründet. Das Unternehmen konzentrierte sich von Beginn an auf die Entwicklung energieeffizienter KI-Hardware und spezieller Chiparchitekturen, die komplexe KI-Berechnungen mit geringerem Energieverbrauch ermöglichen sollten. In den folgenden Jahren entwickelte Recogni eigene Technologien für KI-Inferenz und konnte umfangreiche Investitionen einholen, um die Forschungs- und Entwicklungsaktivitäten in den USA und Europa auszubauen.
Im Jahr 2024 erfolgte die Umbenennung in Tensordyne, verbunden mit einer strategischen Neuausrichtung vom reinen Chipentwickler hin zum Anbieter kompletter KI-Inferenzsysteme für Rechenzentren. Heute entwickelt das Unternehmen nicht nur eigene Prozessoren, sondern auch die zugehörige Hardware, Software und mathematische Grundlagen, um leistungsstarke und energieeffiziente KI-Lösungen bereitzustellen. Mit Standorten in Sunnyvale (Kalifornien) und München positioniert sich Tensordyne als innovativer Anbieter im Markt für KI-Infrastruktur. Passend dazu hat das Unternehmen jetzt den Tape-out und eigenen „TDN72 Inference Pod“ sowie das erste Rack-System angekündigt.

TDN Math sei der große Vorteil von Tensordyne
Die „DNA“ von Tensordyne ist in der eigens entwickelten logarithmischen Zahlen- und Rechenarchitektur für KI-Inferenz zu finden, vom Unternehmen „TDN Math“ oder „Logarithmic Mathematics“ genannt. Die Grundidee besteht darin, Zahlen nicht wie üblich im Floating-Point-Format (FP16, FP8 usw.) darzustellen, sondern in einer logarithmischen Form. Dadurch können viele Multiplikationen durch wesentlich einfachere Additionen ersetzt werden. Mathematisch basiert das auf der Eigenschaft:
log(A×B)=log(A)+log(B)
Da KI-Modelle den Großteil ihrer Rechenleistung für Matrixmultiplikationen benötigen, können spezialisierte Chips mit logarithmischer Mathematik deutlich weniger Transistoren für Recheneinheiten benötigen. Der frei werdende Chipplatz kann stattdessen für mehr Speicher (SRAM), zusätzliche Tensor-Einheiten oder schnellere Datenverbindungen genutzt werden. Laut Tensordyne führt das zu höherer Energieeffizienz und besserer Ausnutzung der Hardware im Vergleich zu etablierten Lösungen.
Der eigentliche technische Knackpunkt ist jedoch die Addition. Während Multiplikationen im logarithmischen Raum einfach werden, sind Additionen dort deutlich komplizierter. Nach Angaben des Unternehmens liegt die eigentliche Innovation in einer sehr effizienten und präzisen Umwandlung bzw. Behandlung dieser Operationen, sodass die Vorteile des logarithmischen Rechnens erhalten bleiben. Genau diese Verfahren sind Teil des proprietären Know-hows von Tensordyne. Das Unternehmen gibt an, damit eine Genauigkeit von über 99,9 Prozent gegenüber den ursprünglichen KI-Modellen zu erreichen und gleichzeitig den Energieverbrauch sowie die Chipfläche gegenüber herkömmlichen FP8-/FP16-Lösungen zu reduzieren.
TDN72 Inference Pod and Rack System
Die Plattform von Tensordyne besteht neben der TDN Math aus dem TDN AIP (Artificial Intelligence Processor) sowie dem TDN Link (Any-to-Any Scale-Up Interconnect) und lässt sich im „TDN72 Inference Pod and Rack System“ zusammenführen. Dabei handelt es sich um einen Inference Pod mit 72 Chips pro Compute-Tray, der es mit Nvidias NVL72 auf Basis von Grace Blackwell aufnehmen und dabei gleichzeitig deutlich weniger Energie verbrauchen soll. Vier TDN72 Pods ergeben dabei ein vollständiges „Tensordyne Napier“-Rack, das im Vergleich zu Nvidia beworben wird mit:
- 17 Mal mehr Tokens pro Watt
- 13 Mal mehr Tokens pro Sekunde
- Bis zu 33 Millionen USD mehr Jahresumsatz pro Rack
Tensordyne argumentiert, dass die KI-Branche vor einem grundlegenden Infrastrukturwandel stehe. Da die Nachfrage nach KI-Inferenz stark wachse, würden Hyperscaler und Cloud-Anbieter dieses Jahr voraussichtlich mehr als 700 Milliarden US-Dollar in Infrastruktur investieren. Bestehende Systeme würden Betreiber jedoch weiterhin zu Kompromissen zwischen Geschwindigkeit, Packungsdichte und Betriebskosten zwingen.

Nach Angaben des Unternehmens wurde das Napier-System speziell entwickelt, um diese Zielkonflikte aufzulösen. Durch die gemeinsame Optimierung von Mathematik, Prozessorarchitektur, Speicher und Netzwerk soll hohe Inferenz-Geschwindigkeiten mit deutlich besserer Energie- und Kosteneffizienz als bei Nvidia kombiniert werden.
Tensordyne Napier kommt 288 KI-Prozessoren
Tensordyne Napier ist ein Rack, das wiederum aus vier TDN72 Pods besteht, in denen jeweils 72 Tensordyne Napier AI-Prozessoren zum Einsatz kommen. Der Chip wird in 3 nm bei TSMC (N3P) gefertigt, weist 138 Milliarden Transistoren auf und ist mit 300 Watt TDP spezifiziert. Jeder AI-Prozessor kommt mit 256 MB SRAM (40 TB/s) und 144 GB HBM3e (4,7 TB/s) und soll damit eine Rechenleistung von 2,1 PFLOPS für Dense FP8 erreichen. Ein Compute-Tray im TDN72 Pod nimmt neun Napier-Chips für dann 2,3 GB SRAM und 1,3 TB HBM3e auf. Verbaut ist außerdem ein Intel Xeon für die Runtime API, zudem sind 8 TB NVMe SSD und zweimal 200 Gbit/s Ethernet als Front I/O an Bord. Für den Scale-up im Rack mit vier Pods setzt Tensordyne auf den eigenen TDN Link mit 1 TB/s bidirektionaler Bandbreite.
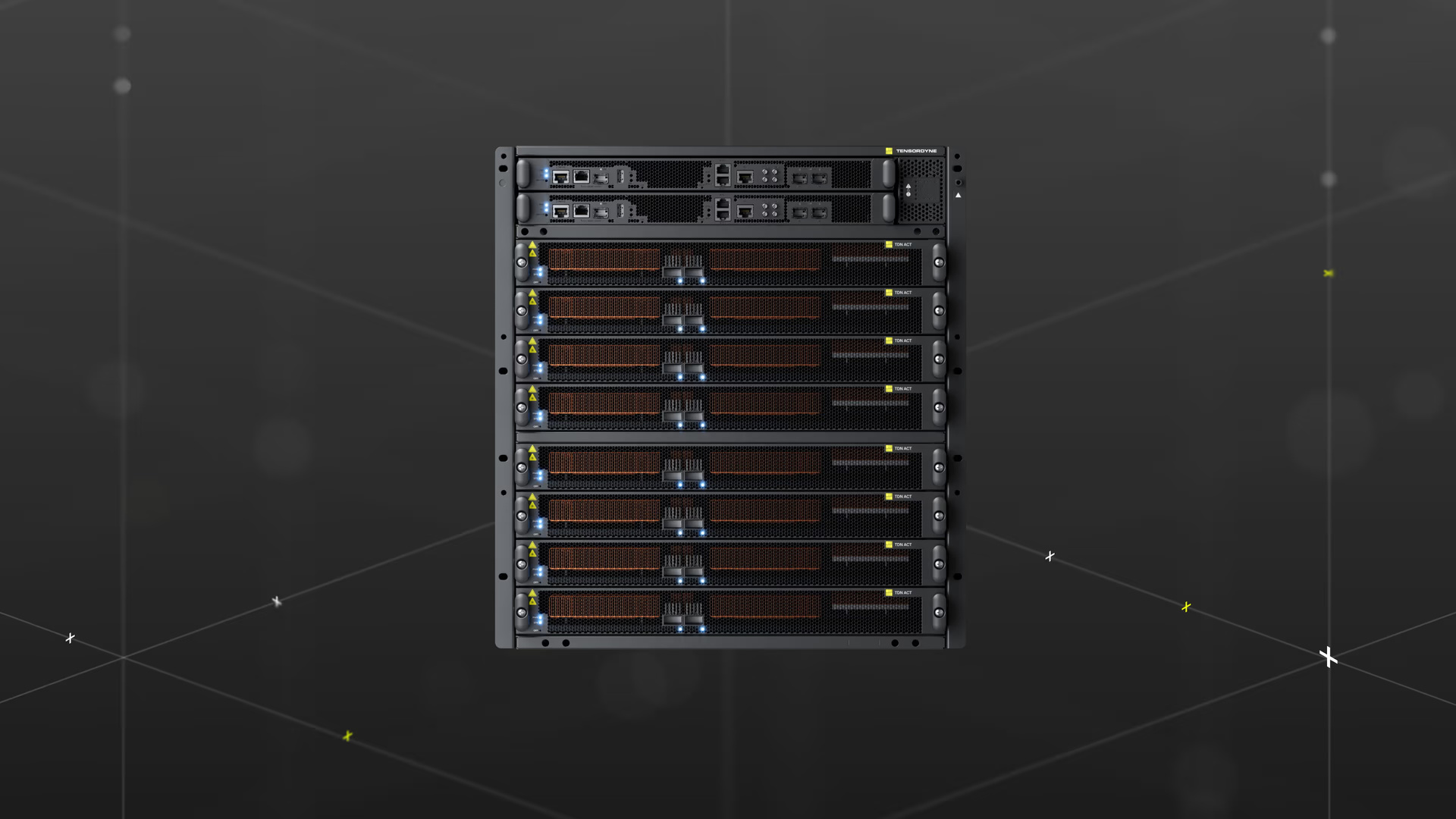

Das TDN-Rack könne dabei Tokens standardmäßig ausliefern, sodass ein Modell die gesamte Inferenz (Prefill und Decode) auf derselben Infrastruktur ausführt und Tokens sequenziell erzeugt, oder sogenannte „disaggregated Inference“ ausführen, also diese Schritte systemisch trennen, sodass Prefill und Decode auf unterschiedlichen Trays laufen. Beim Prefill verarbeitet ein KI-Modell den gesamten eingegebenen Prompt auf einmal und erstellt dabei den Kontext (z. B. Key-Value-Cache), der alle bisherigen Informationen enthält; das ist rechenintensiv, passiert aber nur einmal. Beim Decode wird anschließend die Antwort Token für Token generiert, wobei das Modell jeweils auf den gespeicherten Kontext zugreift, wodurch jeder einzelne Generationsschritt effizienter ist, aber viele Wiederholungen nötig sind.
Erste Systeme ab Mitte 2027
Nachdem jetzt der Tape-out der eigenen Hardware erfolgreich war, sollen gegen Ende dieses Jahres die Chips in den eigenen Laboren getestet und validiert werden. Mitte des nächsten Jahres sei laut Tensordyne mit der Verfügbarkeit von fertigen Systemen zu rechnen, sodass bis dahin auch mit entsprechend neuerer Konkurrenz von (unter anderem) Amazon, AMD, Cerebras, Google oder Nvidia gerechnet werden muss.