Apps & Mobile Entwicklung
TSMC in Europa: Eine französische AI-GPU als Aushängeschild
ComputerBase war auf dem TSMC OIP Ecosystem Forum in Amsterdam und konnte vor Ort einen Eindruck davon gewinnen, welche Themen TSMC, aber auch europäische Partner aktuell beschäftigen: Effizienz, Packaging – und einseitig mehr Unabhängigkeit. Ein AI-Beschleuniger mit 288 GB HBM3e aus Frankreich war hingegen für TSMC ein Vorbild.
ComputerBase trifft TSMCs Europa-Chef in Amsterdam
750 Milliarden US-Dollar schwer, so groß ist der Halbleitermarkt im Jahr 2025. Damit liegt er über allen Prognosen, selbst über denen, die erst wenige Jahre alt sind. Das Wachstum wird weltweit primär über Cloud und Datacenter realisiert.
In Europa sind es noch vorrangig klassische Themen wie IoT und Automotive, doch auch Datacenter darf inzwischen nicht mehr vergessen werden. Und bei Robotics hat Europa einen ziemlich guten Stand, erklärt Paul de Bot, TSMCs Europa-Chef, zum Auftakt des 2025 TSMC Europe Open Innovation Platform Ecosystem Forum.

TSMC trägt einen großen Anteil am weltweiten Halbleitermarkt. Die Veranstaltung in Amsterdam war dafür gedacht, den Auftragsfertiger mit Partnern und Kunden zusammenzuführen. Für Europa heißt dies vor allem zu zeigen, dass das Rad nicht noch einmal neu erfunden werden muss, es darf Know-how genutzt werden, welches bereits verfügbar ist. Das Motto: TSMC ist hier um zu helfen.
Klingt gut, ist für ein Europa, das eigenständiger werden möchte, aber durchaus auch ein Hindernis – das wurde in Amsterdam in Gesprächen klar. Die Kehrseite der Medaille: Allein dauert der Weg viel zu lange und die vermutete Kostenersparnis, die zu Anfang oft ein ausschlaggebendes Thema war, führte am Ende oft dazu, dass Produkte viel zu spät fertig geworden sind und dann eventuell überhaupt keine Chance mehr am Markt hatten. Denn wie umfangreich allein das Thema 3D-Stacking ist, zeigten weit über 200 Dokumente im EDA-Segment der Veranstaltung, die sich nur darum drehten.
„Think big, innovate fast .. and use our OIP ecosystem“, lautete daher der Aufruf von Paul de Bot. Auch das Verbleiben in einem Nischenmarkt sei keine Lösung, erläutert Bot im Gespräch mit ComputerBase weiter. Die Unterscheidung von anderen ist freilich weiterhin wichtig, aber ohne eine entsprechend schnelle Umsetzung sei sie am Ende wertlos.

AI-Beschleuniger mit 288 GB HBM3e aus Frankreich
Ein Beispiel ist das Unternehmen Vsora, dem TSMC in Amsterdam sogar die große Bühne als Teil der Keynote gab. Das französische Unternehmen war bisher eher IP-Lieferant für die Automotive-Industrie, hat dadurch aber so viel Wissen angesammelt, dass binnen kurzer Zeit ein eigener AI-Inference-Chip entwickelt wurde und dank des Ökosystems von TSMC nicht nur als 144 Milliarden Transistoren schwerer Chip in 5 nm bei TSMC gefertigt, sondern auch mittels CoWoS-S komplex in einem Package integriert wird: Acht Stacks HBM3e mit insgesamt 288 GByte inklusive.
Das Tape-out ist bereits erfolgt – andere Unternehmen wie Tachyum schaffen dies seit Jahren nicht. Nun soll schnellstmöglich die Marktreife erreicht werden.


CEO Khaled Maalej erklärt auf der Bühne, dass dies mit dem TSMC-Ökosystem mit Partnern wie Cadence, Synopsys, GUC und weiteren „einfach“ möglich sei. Entscheidender Faktor für einen AI-Beschleuniger dieser Art war das Packaging, erläuterte er. Dennoch ermutigte er, dass auch andere Unternehmen den Weg gehen können: Es brauche keine hunderte Millionen für die Entwicklung und viele hunderte Leute in einem Designteam um ein solches Produkt – mit TSMC – umzusetzen.
Über 11.000 Produkte von über 500 Kunden
TSMCs PR-Chefin ergänzt dazu, dass TSMCs Kundschaft auf über 500 Unternehmen angewachsen ist, also nicht nur aus Apple, Nvidia oder Qualcomm besteht. Nach wie vor sei das Unternehmen aktiv bestrebt, auch kleinen Firmen Platz einzuräumen, damit sie ihre Lösungen auf den Markt bringen können. Und schließlich hat Nvidia vor 27 Jahren auch einmal klein angefangen und bei TSMC als Neukunde angefragt. Über 11.000 verschiedene Produkte fertige TSMC derzeit.
Europa braucht aber dennoch ein, zwei oder drei große Firmen, nicht 27 kleine, die an der Weltspitze mitspielen wollen, betonte Paul de Bot. Wenn diese dann eine entsprechende Nachfrage erzeugen können, dann folgt auch der Rest. Dies schließt auch Produktionsstätten ein, wie bei TSMC aktuell sichtbar wird: Die Ausbauten in den USA und Japan, aber auch Deutschland sind Teil dieses Weges: Die Nachfrage ist da, also kommt auch die Produktion.
Für Deutschland bedeutet die Speciality-Fab, die TSMC zusammen mit Partnern in Dresden errichtet, ein Schritt in die Zukunft. Noch sind bei Automotive & Co primär 2D-Transistoren an der Tagesordnung, doch die klassischen Chips für die Branche entwickeln sich langsam von 65 nm über 40 nm zu 28 nm, 22 nm und noch kleineren Strukturen. Damit hält auch in diesem Bereich erstmals FinFET Einzug – ein Novum.
Die Lehre muss aufholen
Apropos FinFET. Wie TSMC im Gespräch ebenfalls deutlich machte, kommen auch auf die Universitäten und Lehranstalten neue Aufgaben zu. Viele lehren noch planare Transistoren, während TSMC im High-End-Bereich zu Nanosheets alias Gate all around übergeht und FinFETs seit über zehn Jahren an der Tagesordnung sind. Auch hier sei eine Aufholjagd nötig.
Hier setzt TSMC bereits auf AI
Über allem schwebte auch in Amsterdam AI, allerdings mit einem Fokus auf den Einsatz bei TSMC inklusive der Anmerkung, dass „AI“ als Machine Learning schon länger in den eigenen Prozessoren Verwendung findet. Aber der Einsatz von AI wird aktuell mit Hochdruck voran getrieben und hilft auch TSMC und Partnern, Produkte und Prozesse mitunter viel effizienter zu gestalten. Bei absoluten High-End-Chips ist das noch nur geringfügig der Fall, aber das Routing durch das Substrat via AI zu optimieren, kann laut TSMC bereits eine Steigerung um den Faktor 100 bei der Produktivität im Designprozess bedeuten. Für die kritische „time to market“ sei das extrem von Vorteil.

TSMCs Fokus rückt auf Effizienz
Die Welt lechzt nach mehr Leistung, gleichzeitig kommt dem Thema Effizienz – nicht zu verwechseln mit einer auch absolut sinkenden Leistungsaufnahme – eine stetig wichtigere Rolle zuteil. Denn wenn ein Bestandteil etwas weniger Strom verbraucht, lässt sich aus einem Gesamtpaket mehr Leistung herausholen.
Und das gilt nicht nur für AI-Beschleuniger in „Gigafabriken“, sondern beispielsweise auch für Chips für den Automotive-Markt. Dort werden mit fortschreitender Automatisierung Chips gefragt sein, die über 1000 TOPS an Leistung bieten, um Autonomes Fahren nach Level 4+ zu ermöglichen (siehe Nvidias Thor-Chip). Und dass die Ausstattung für Cockpit auf 300+ TOPS mitwächst, überrascht auch nicht.
Super Power Rail (Backside Power Delivery)
Die Roadmap, die TSMC in Amsterdam erneut bestätigt, geht mit dem Eintritt in das GAA-Zeitalter mit TSMC N2 derzeit einen weiteren Schritt in Richtung Effizienz, mit dem darauf folgenden A16 soll die Effizienz hingegen signifikante Fortschritte machen: Super Power Rail heißt die dafür eingesetzte Technologie bei TSMC und steht für die rückseitige Stromversorgung der Transistoren.
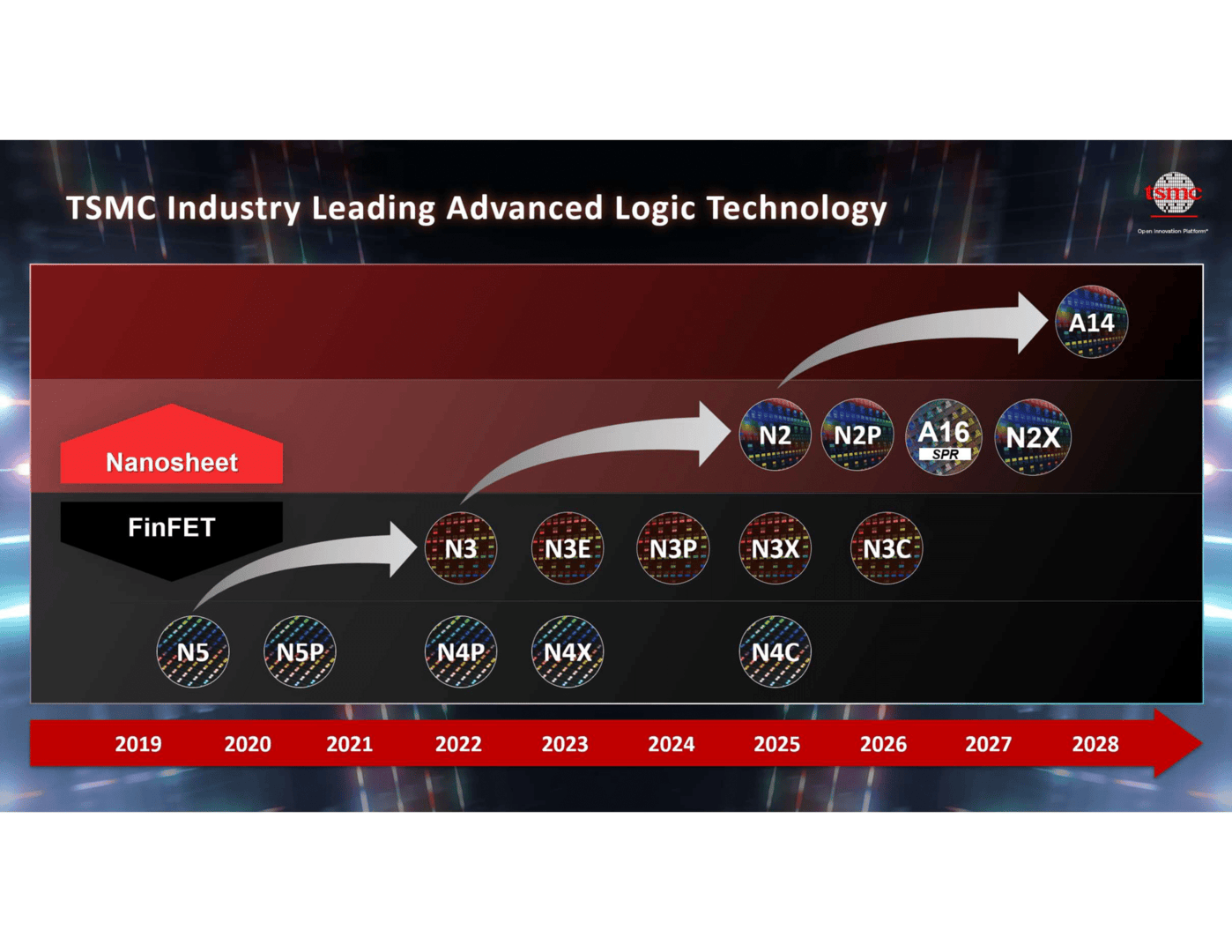

Packaging bleibt ein Erfolgsfaktor
Immer mehr Chips im Packaging zu stapeln, bleibt die zweite große Herausforderung und ein entscheidender Erfolgsfaktor der kommenden Jahre. Immer größere Interposer („Basisplatten“) mit zusätzlichem Platz für Chips und Speicher werden benötigt und auch von TSMC angeboten. Immer größere und immer bessere Interposer zu liefern, wird für den Erfolg eines Auftragsfertigers immer wichtiger werden.

CoWoS-L als aktuell fortschrittlichste Ausbaustufe für „Chips on Wafer on Substrate“ kann über diverse Parameter wie integrierte Spannungsregler (IVR) bereits angepasst werden. Dazu wird die Kapazität der Embedded Deep Trench Capacitors (eDTC) direkt im Silizium oder Interposer stetig erhöht, die Fluktuationen abfangen. Und wenn CoWoS nicht reicht, bleibt auch das System on Wafer (SoW) eine Option für die Zukunft, die eventuell bald öfter anzutreffen sein könnte.

TSMCs Interposer sind gefragt
TSMC hat auf diesem Feld in der Tat viel Expertise vorzuweisen. So kommt es letztlich nicht von ungefähr, dass Speicherhersteller in Kürze ihre Base-Dies (Interposer) für HBM wohl fast alle von TSMC beziehen werden. Vor allem die zweite Generation HBM4 als Custom-Lösung (C-HBM4E) verspricht viel Potenzial um Kundenwünsche noch spezifischer umzusetzen – und alle Speicherhersteller haben diese Technologie deshalb auf ihren Roadmaps. Auch Compute in Memory (CIM) wird in Zukunft deutlich effizienter und so vielleicht etwas für einen breiteren Markt.

Silicon Photonics
Neben der „Memory Wall“, also der Speicherbandbreite als ein Hindernis bei der AI-Skalierung, ist Silicon Photonics eines der Zukunftsthemen – und deshalb auch in Amsterdam bei TSMC wieder präsent. Silicon Photonics (die Verbindung von Chips über Lichtleiter) hat noch viel Optimierungsspielraum in Hinblick auf die Effizienz. Es kommt dabei sehr auf die Umsetzung an. Wird es nur angeflanscht, oder direkt auf dem Package oder ist es gar voll integriert? Die Antwort auf die Frage macht durchaus einen gewaltigen Unterschied bei der Effizienz.

Die Komplexität wächst enorm
Der Komplexitätszugewinn bei neuen Produkten, die auf derartige Technologien setzen, ist jedoch nicht zu unterschätzen, erklärten führende TSMC-Ingenieure auf der Bühne: Noch mehr Integration, höhere Stromstärken und dadurch Wärmequellen, die Stromversorgung durch mehrere Lagen Chips – Standardisierung kann helfen, der Komplexität Herr zu werden und TSMC arbeitet mit Partnern unter Hochdruck daran.
Denn vor allem sind es Partnerlösungen, mit denen es am Ende Probleme geben kann, weil Grenzfälle auftauchen, die zuvor ohne Gesamtkonstrukt nicht zu sehen waren oder limitierten. In einem Partnergespräch wurde hier unter anderem AMDs X3D-Lösung genannt. Das Stapeln der Chips war im Endeffekt – einmal gelöst – kein Problem, doch dann kam das Problem der thermischen Isolation des CPU-Dies durch den L3-Cache-Die bei der 1. und 2. Generation X3D-CPUs auf. Die Problemlösung ab der neuen Generation in Ryzen 9000 war bekanntlich, den L3-Cache von der Ober- auf die Unterseite zu legen, der Hotspot CPU wurde nun nicht mehr nach oben hin zum Kühler abgeschirmt.
Weitere Vorträge in Amsterdam deckten ein breites Feld ab, in denen Partner über ihre Möglichkeiten und Herangehensweise an bestimmte Probleme sprachen und sie zumindest zum Teil auch offenlegten. Dabei ging es von kleinsten Schnittstellen noch im Designprozess bis hin zum Finalisieren eines zukünftigen Produkts, welches bald in den Markt eintritt, wie beispielsweise LPDDR6-14400 oder auch Qualcomms Ausführungen zur Entwicklung eines kommenden Chips der die N2/N2P-Fertigungstechnologie nutzt, die sich von bisherigen FinFETs eben mitunter doch deutlich unterscheidet.
An TSMC führt aktuell kaum ein Weg vorbei
Alles in allem wurde in Amsterdam einmal mehr das Offensichtliche sichtbar: TSMC ist derzeit der unangefochtene Platzhirsch unter den Chip-Auftragsfertigern. Und das gilt inzwischen nicht mehr nur für die reine Belichtung der Wafer, sondern auch und insbesondere für das, was mit den einzelnen Chips auf einem Package dann noch umgesetzt werden kann.
ComputerBase wurde von TSMC zum Europe Open Innovation Platform Ecosystem Forum in Amsterdam eingeladen. Das Unternehmen übernahm dabei die Reisekosten. Eine Einflussnahme des Unternehmens auf den Bericht fand nur insofern statt, dass keine eigenen Fotos und Videos erstellt werden durften. Im Nachgang sollte Material durch TSMC bereitgestellt werden. Dazu kam es mit Verweis auf „Qualitätsprobleme“ am Ende nicht. Der Bericht muss daher ohne Fotos von der Veranstaltung auskommen. Eine Verpflichtung zur Veröffentlichung bestand nicht.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.













Apps & Mobile Entwicklung
Günstiger war die Smartwatch nie
Die Google Pixel Watch 4 ist das aktuellste Modell der Smartwatch-Serie. Mit neuen Rekordwerten und einem echten Upgrade im Vergleich zu den Vorgängermodellen galt sie lange als äußerst preisstabil. Dank eines aktuellen Deals könnte sich dies jedoch ändern.
Seit einigen Wochen zeichnet sich bereits ein Preisabfall der Google Pixel Watch 4 ab. Während sie im November noch für deutlich über 400 Euro erhältlich war, sind Angebote unter dieser Preisgrenze im Januar 2026 keine Seltenheit mehr. Dem setzt der niederländische Online-Shop Gomibo jetzt allerdings die Krone auf und reduziert die beliebte Android-Smartwatch auf ein neues Rekordtief.
Google Pixel Watch 4 zum Bestpeis: Lohnt sich der Deal?
Die Google-Uhr ist in zwei verschiedenen Größen erhältlich. Die größere, mit einem Gehäusedurchmesser von 45 mm, könnt Ihr Euch jetzt mit einem ordentlichen Rabatt schnappen. Gerade einmal 339 Euro verlangt Gomibo derzeit für die Pixel Watch 4. Ein Blick in den Preisverlauf zeigt: So günstig war die Smartwatch bisher nie. Der nächstbeste Anbieter verlangt zudem noch mindestens 369,99 Euro. Allerdings müsst Ihr noch Versandkosten in Höhe von 1,95 Euro zahlen, erhaltet die Smartwatch jedoch bereits am Folgetag, wenn Ihr bis um 17:30 Uhr bestellt. Als Teil der Gomibo Deal Days ist jedoch nur eine begrenzte Stückzahl verfügbar – wer zuerst kommt mahlt zuerst.
Das bietet Euch die Smartwatch
Natürlich sollt Ihr auch erfahren, für was Ihr hier Euer Geld ausgebt. Während das Design der Pixel Watches auf den ersten Blick recht ähnlich ist, verbergen sich die Upgrades etwas. So setzt Google seit zwei Generationen auf zwei verschiedene Größenvarianten, wobei die aktuellere Version dünnere Ränder erhielt und zusätzlich auf bis zu 3000 nits aufhellen kann. Zusätzlich nutzte die Pixel Watch 3 noch den Chip der Vorgänger-Variante, was sich mit der neuen Iteration ändert. Hier kommt (endlich) der frischere Snapdragon W5 Gen 2 zum Einsatz. Dies verspricht neben einer höheren Gesamtleistung auch eine effizientere KI-Verarbeitung und präzsisere GPS-Genauigkeit.
Zusätzlich wurde die Akkulaufzeit auf bis zu 40 Stunden erhöht und die Ladezeit deutlich verkürzt. So stehen Euch nach rund 15 Minuten wieder 50 Prozent Leistung zur Verfügung. Welche Änderungen es im Tracking gibt und worauf Ihr unbedingt noch achten solltet, könnt Ihr übrigens in unserem ersten Test zur Pixel Watch 4 nachlesen. Habt Ihr das Wearable schon länger ins Auge gefasst, möchtet Euer Google-Ökosystem erweitern oder seid einfach auf der Suche nach einer schicken und leistungsfähigen Android-Smartwatch, können wir Euch diesen Deal von Gomibo definitiv empfehlen.
Was haltet Ihr von dem Angebot? Ist die Pixel Watch 4 interessant für Euch oder greift Ihr lieber zu Apple/Samsung? Lasst es uns in den Kommentaren wissen!
Mit diesem Symbol kennzeichnen wir Partner-Links. Wenn du so einen Link oder Button anklickst oder darüber einkaufst, erhalten wir eine kleine Vergütung vom jeweiligen Website-Betreiber. Auf den Preis eines Kaufs hat das keine Auswirkung. Du hilfst uns aber, nextpit weiterhin kostenlos anbieten zu können. Vielen Dank!
Apps & Mobile Entwicklung
Zotac MAGNUS EAMAX: AMD Strix Halo als 2,65 Liter kleiner Mini-PC verpackt

AMDs APU-Serie Strix Halo mit starker GPU und NPU gibt es bald besonders kompakt. Zotac hat nämlich einen Mini-PC mit Ryzen AI Max vorgestellt, dessen Gehäuse ein Volumen von nur 2,65 Liter besitzt. Das Spitzenmodell nutzt den Ryzen AI Max+ 395 mit 128 GB LPDDR5X.
Zbox Magnus EAMAX
In der E-Serie erscheint die Zbox Magnus EAMAX mit AMD Strix Halo, der bisher größten APU von AMD. Die SoCs liefern nicht nur bis zu 16 Zen-5-CPU-Kerne und die bisher stärkste integrierte GPU, sondern bieten neben I/O-Schnittstellen auch den Arbeitsspeicher gleich mit. Dabei handelt es sich um schnellen LPDDR5X-DRAM, der sich allerdings nicht nachträglich aufrüsten lässt.
Das Gehäuse der Zbox Magnus EAMAX misst 210 × 203 × 62,2 mm (L×B×H) und besitzt einen Kühler mit Lüfter, um die Prozessoren, die normal mit bis zu 120 Watt TDP agieren, im Zaum zu halten. Die Stromversorgung erfolgt über ein externes Netzteil mit 240 Watt.
Zur Bildausgabe stehen jeweils DisplayPort 1.4 und HDMI 2.1 im Doppelpack bereit. Diese liegen auf der Rückseite, wo sich zudem vier USB-A-Anschlüsse, gleich zwei Netzwerk-Ports (2,5 Gbit/s LAN) sowie die Antennenbuchsen für das integrierte WiFi 7 und Bluetooth 5.4 befinden. An der Hochglanzfront gibt es noch einmal USB-A sowie einmal schnelles USB4 über den C-Stecker und einen herkömmlichen Kopfhörerausgang.
Vom Innenleben fehlen bisher Abbildungen, doch sollen dort noch drei M.2-SSDs mit PCIe 4.0 x4 unterkommen. Dabei werden die Formate M.2 2280 und M.2 2242 angeführt.
Drei Varianten plus Windows-Versionen
Die Zbox Magnus EAMAX wird in drei Versionen angeboten, die sich in der eingesetzten APU unterscheiden. Das Spitzenmodell EAMAX395C nutzt den AMD Ryzen AI MAX+ 395 mit 128 GB LPDDR5X und Radeon 8060S. Beim EAMAX390C gibt es bereits deutliche Abstriche, denn der Ryzen AI MAX 390 bietet hier nur 32 GB LPDDR5X und eine langsamere Radeon 8050S. Den Einstieg gibt es mit der EAMAX385C, mit Ryzen AI MAX 385, Radeon 8050S und 32 GB LPDDR5X.
Die drei Modelle gibt es wahlweise als Barebone ohne Massenspeicher und Betriebssystem oder als Windows-Variante mit 1 TB SSD und vorinstalliertem Windows 11 Home.
Informationen zum Marktstart liegen allerdings noch nicht vor, sodass abzuwarten bleibt, wann die neue Serie erhältlich ist und was sie kosten wird. Bekanntlich ist AMD Strix Halo ein teures Unterfangen, was sich wegen steigender RAM-Preise sicher nicht geändert hat. Komplettsysteme (Desktop) mit diesen Chips starten erst bei rund 2.000 Euro und auch die Notebooks sind kaum günstiger.
Apps & Mobile Entwicklung
Doch nicht kostenpflichtig: Samsung macht Rückzieher
Gute Nachrichten für Samsung-Nutzer: Mehrere Funktionen, die ursprünglich nur für eine begrenzte Zeit kostenlos sein sollten, werden nun dauerhaft ohne Zusatzkosten angeboten. Doch welche Features betrifft das genau? Und weshalb ändert Samsung seine Strategie?
Als Samsung vor rund zwei Jahren die Galaxy‑S24‑Reihe präsentierte, standen die neuen KI‑Werkzeuge klar im Mittelpunkt. Erstmals waren smarte Funktionen tief ins System integriert und konnten Notizen automatisch zusammenfassen, Fotos optimieren oder Gespräche in Echtzeit übersetzen, zunächst ohne Gebühren.
Samsung bestätigt: „Basisfunktionen bleiben kostenlos“
In den Nutzungsbedingungen der generativen Bildbearbeitung und anderer Galaxy‑AI‑Features war ursprünglich vermerkt, dass nach einer kostenlosen Einführungsphase möglicherweise ein kostenpflichtiges Abo nötig wird. Später wurde dieser Zeitraum bis Ende 2025 verlängert, ohne konkrete Angaben zu späteren Preisen.
Nun sorgt Samsung für Klarheit: Hinweise auf mögliche Kosten wurden entfernt. Stattdessen heißt es jetzt, dass die „Galaxy‑AI‑Basisfunktionen“ dauerhaft gratis bleiben. Voraussetzung ist lediglich ein aktiver Samsung‑Account. Viele Funktionen benötigen zudem eine Internetverbindung, da die Verarbeitung nicht lokal, sondern auf Servern von Samsung und Google erfolgt.
Damit erhalten Nutzer eines Galaxy S24, S25 sowie zahlreicher günstiger A‑Modelle langfristig kostenlosen Zugriff auf alle betroffenen Features. Dazu zählen unter anderem der Anruf‑Assistent, Schreib‑Assistent, Foto‑Assistent, der Dolmetscher, der Notizen‑Assistent, Health Assist sowie der Sprachdienst Bixby.
Warum die Kehrtwende?
Als das Galaxy S24 im Jahr 2024 erschien, gehörte Samsung zu den ersten Herstellern, die KI‑Funktionen fest ins Betriebssystem integrierten. Mittlerweile hat sich der Markt jedoch stark verändert: Apple bietet ähnliche Möglichkeiten auf dem iPhone, und auch Marken wie Honor setzen auf beeindruckende KI‑Bildbearbeitung und smarte Tools.
Was einst ein echtes Alleinstellungsmerkmal war, gilt heute als Standard. Nutzer erwarten schlicht, dass ihr Smartphone störende Objekte aus Fotos entfernen kann oder einen intelligenten Sprachassistenten mitbringt – ohne zusätzliche Kosten.
Ganz ohne Einschränkungen ist Samsungs Versprechen jedoch nicht. Das Unternehmen spricht explizit von „Basisfunktionen“. In einer Fußnote weist Samsung darauf hin, dass zukünftige Softwareversionen zusätzliche oder erweiterte KI‑Dienste enthalten könnten, die nicht mehr kostenlos angeboten werden. Für solche Neuerungen wäre Samsung gut beraten, mögliche Kosten frühzeitig und transparent zu kommunizieren.
Günstiger war die Smartwatch nie

TikTok USA: Behördliche Genehmigungen für Verkauf sollen fertig sein

Mit diesem Auto startet Audi erstmals in der Formel 1 – mit Fintech an der Seite
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenArndt Benedikt rebranded GreatVita › PAGE online
-

 Künstliche Intelligenzvor 3 Wochen
Künstliche Intelligenzvor 3 WochenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-

 Entwicklung & Codevor 1 Monat
Entwicklung & Codevor 1 MonatKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGoogle „Broadwing“: 400-MW-Gaskraftwerk speichert CO₂ tief unter der Erde
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenFast 5 GB pro mm²: Sandisk und Kioxia kommen mit höchster Bitdichte zum ISSCC
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights