Künstliche Intelligenz
Über den Chat hinaus: Mit LLMs echte Nutzerprobleme lösen
Seit dem Erscheinen von ChatGPT ist das Chat-Fenster das zentrale User-Interface für die Interaktion mit künstlicher Intelligenz. Doch ist ein Chat tatsächlich die optimale Möglichkeit zur Interaktion – oder gibt es möglicherweise besser geeignete Wege, KI in Anwendungen zu integrieren?


Sascha Lehmann war mit seinem ersten PC schon klar, in welche Richtung die Reise geht. Durch Desktop- und Backend-Entwicklung im .NET-Umfeld fand er über die Jahre hinweg zu seiner wahren Leidenschaft, der Webentwicklung. Als Experte im Angular- und im UI/UX-Umfeld hilft er bei der Thinktecture AG in Karlsruhe tagtäglich Kunden bei ihren Herausforderungen und Vorhaben.
In den vergangenen Jahren haben KI-Werkzeuge die Welt im Sturm erobert. KI-Funktionen hielten Einzug in alltäglich genutzte Software – sei es in Entwicklungsumgebungen (IDEs), Office-Programmen oder sogar bei der Erstellung der Steuererklärung. Und fast überall kann man mit der Software chatten. Doch warum eigentlich?
Warum Chat als Interface so gut funktioniert
Die Stärken großer Sprachmodelle liegen insbesondere darin, unterschiedlichste Arten von Informationen zu verarbeiten und in natürlicher Sprache mit Nutzerinnen und Nutzern zu kommunizieren. Dafür benötigen sie Eingaben – ebenfalls in natürlicher Sprache. Was läge also näher, als per Texteingabe mit ihnen zu interagieren?
Auch aus Sicht der User-Experience (UX) bietet sich der Chat als Interface zunächst an. Nahezu jede und jeder kennt dieses mentale Modell – also die grundsätzliche Funktionsweise und das Erscheinungsbild eines Chatfensters – und kann es intuitiv nutzen, ohne vorherige Schulung. Gerade diese Niedrigschwelligkeit war einer der entscheidenden Faktoren für den durchschlagenden Erfolg von ChatGPT und vergleichbaren Anwendungen.
Mehrwert statt Selbstzweck: Was gute KI-Features ausmacht
Bei genauerer Betrachtung kann das Interaktionsmodell „Chat“ jedoch nicht ohne Weiteres ebenso erfolgreich auf andere Einsatzbereiche übertragen werden. So hilfreich es sein kann, beliebige Fragestellungen in einem offenen Chat mit einer KI zu diskutieren, umso schneller verliert dieses Modell seinen Reiz, sobald es in einem klar definierten Anwendungskontext zum Einsatz kommt. Der Rahmen ist dort meist deutlich enger gesteckt, was neue Herausforderungen aufwirft – beispielsweise:
- Wie kann ein Chat sinnvoll in den Anwendungskontext integriert werden?
- Welchen konkreten Mehrwert bietet die KI-Funktion gegenüber etablierten Arbeitsabläufen?
- Wie können fachspezifische Informationen kontextbezogen eingebunden werden?
Ohne gezielte Unterstützung – etwa Hinweise zu möglichen Interaktionen oder zum verfügbaren Domänenwissen und dessen Nutzung im Chat – fühlen sich viele Nutzerinnen und Nutzer schnell überfordert. Bleiben erste Interaktionen zudem erfolglos, führt das häufig zu Frustration – und das beworbene KI-Feature wird nur noch zögerlich oder gar nicht mehr verwendet. Es entsteht der Eindruck, die neue Technologie sei lediglich um ihrer selbst willen integriert worden.
Ein solches Nutzungserlebnis gilt es unbedingt zu vermeiden. KI-Funktionen – wie auch alle anderen Features – müssen einen klaren Mehrwert bieten. Sei es durch eine Erweiterung des Funktionsumfangs oder durch die Vereinfachung zuvor mühsamer Aufgaben.
UX-Patterns gegen kognitive Überforderung
Ein blanker Chat erzeugt – ähnlich wie die berüchtigte leere Seite beim Schreiben einer Hausarbeit – eine zu hohe kognitive Last, also eine Art Überforderungs- oder Lähmungszustand. Um dem entgegenzuwirken, können Vorschläge (Suggestions), hilfreich sein: kleine Container mit konkreten Prompt-Hinweisen.

„Vorschlagskarten“ (hier für Chat-GPT) helfen, die anfängliche Überforderung zu reduzieren und Interaktionshinweise zu geben.
(Bild: Shape of AI)
Diese Suggestions sind Teil einer Sammlung von UX-Patterns (Shape of AI) rund um den Einsatz von KI- und Chat-Integrationen. Da künstliche Intelligenz nach wie vor ein junges Themenfeld ist, werden in den kommenden Jahren zunehmend weitere dieser Gestaltungsmuster entstehen, auf die Entwicklerinnen und Entwickler bei der Konzeption und Entwicklung zurückgreifen können. Dennoch empfiehlt es sich, bereits heute solche Patterns zu nutzen, um Usern einen einfachen und intuitiven Einstieg zu ermöglichen.
Tu, was ich will – nicht, was ich sage
Die kognitive Last ist nicht die einzige Schwachstelle von Chat-basierten Interfaces. Bei längeren Konversationen kann es dazu kommen, dass das Kontextfenster – sozusagen das Kurzzeitgedächtnis des LLM, um Informationen der Konversation zu halten – des aktuell verwendeten Sprachmodells ausgeschöpft ist. In solchen Fällen müssen User auf einen neuen Chat ausweichen. Da LLMs jedoch über kein dauerhaftes Gedächtnis verfügen, ist es notwendig, bei diesem Wechsel eine Zusammenfassung des bisher Gesagten mitzugeben – nur so kann an vorherige Ergebnisse angeknüpft werden.
Zudem neigen LLMs in Konversationen gelegentlich zu Halluzinationen oder verlieren sich bei unpräzisen Eingaben in einem ineffizienten Hin und Her. Besonders problematisch wird das, wenn die Nutzerin oder der Nutzer bereits eine klare Vorstellung vom gewünschten Ergebnis hat. Die Herausforderung liegt darin, die eigene Intention so klar zu formulieren, dass das Modell sie korrekt interpretiert – ganz nach dem Motto: „Tu, was ich will – nicht, was ich sage.“
Formulare automatisch verstehen und ausfüllen
Gibt es also jenseits des klassischen Chat-Interfaces klügere Wege, Nutzerinnen und Nutzern KI-Funktionen zugänglich zu machen – möglichst in kleinen, leicht verdaulichen Einheiten, sodass Überforderung gar nicht erst entsteht?
Ein genauer Blick auf die Stärken großer Sprachmodelle zeigt Fähigkeiten, die im Alltag besonders hilfreich sein können:
- Verständnis und Verarbeitung natürlicher Sprache
- umfangreiches Weltwissen
- vielfältige Einsatzgebiete und enorme Anpassbarkeit
- Multimodalität – Verarbeitung von Text-, Audio- und Bilddaten (ohne Modellwechsel)
- Echtzeitsprachverarbeitung
- Erkennung und Analyse von Patterns
Immer wieder gibt es Anwendungsszenarien, in denen Daten aus Dokumenten, Bildern oder Videos zu extrahieren und in strukturierter Form weiterzuverarbeiten sind – etwa bei Formularen. Das Ausfüllen langer Formulare zählt in der Regel nicht zu den beliebtesten Aufgaben im Alltag.
Gerade hier besteht deutliches Potenzial zur Verbesserung der User-Experience. Doch wie könnte ein optimierter „Befüllungs-Workflow“ konkret aussehen?
Von Text zu JSON: Daten intelligent befüllen
Für die Arbeit mit Formularen stehen im Web und in etablierten Frameworks umfangreiche Schnittstellen (Application Programming Interfaces, APIs) zur Verfügung. Die zugrunde liegende Struktur eines Formulars wird dabei häufig in Form eines JSON-Objekts (JavaScript Object Notation) definiert.
Das Listing zeigt eine exemplarische Deklaration einer FormGroup (inklusive Validatoren) innerhalb einer Angular-Anwendung.
personalData: this.fb.group({
firstName: ['', Validators.required],
lastName: ['', Validators.required],
street: ['', Validators.required],
zipCode: ['', Validators.required],
location: ['', Validators.required],
insuranceId: ['', Validators.required],
dateOfBirth: [null as Date | null, Validators.required],
telephone: ['', Validators.required],
email: ['', [Validators.required, Validators.email]],
licensePlate: ['', Validators.required],
}),
Dieses JSON-Objekt stellt den ersten Baustein des Workflows dar und definiert zugleich die Zielstruktur, in die das System die extrahierten Informationen überführt. Den zweiten Baustein bilden die Quelldaten in Form von Text, Bildern oder Audio. Zur vereinfachten Darstellung liegen sie im folgenden Szenario in Textform vor und sollen über die Zwischenablage in das System übertragen werden.
Bleibt noch ein dritter Aspekt: Entwicklerinnen und Entwickler müssen das Sprachmodell instruieren – sie müssen ihm eine präzise Aufgabenbeschreibung geben, um den gewünschten Verarbeitungsschritt korrekt durchzuführen. Diese Instruktion erfolgt im Hintergrund, vor dem User versteckt.
Versteckte Prompts: KI steuern ohne Chatfenster
Auch wenn Entwicklerinnen und Entwickler bewusst auf ein Chat-Interface verzichten, arbeiten Sprachmodelle weiterhin auf Basis von Instruktionen in natürlicher Sprache. Um Usern die Formulierungs- und Eingrenzungsarbeit abzunehmen, können diese Anweisungen vorab als sogenannte System-Messages oder System-Prompts im Programmcode hinterlegt werden.
Der Vorteil dieses Ansatzes liegt darin, dass die Befehle standardisiert und in konsistenter Qualität an das LLM übermittelt werden können. Zudem ist es möglich, diese Prompts mit Guards zu versehen – ergänzenden Anweisungen, die Halluzinationen vorbeugen oder potenziellem Missbrauch entgegenwirken sollen.
Nachfolgend eine exemplarische Darstellung eines System Prompt mit einer gezielten Aufgabe für das LLM:
Each response line must follow this format:
FIELD identifier^^^value
Provide a response consisting only of the following lines and values derived from USER_DATA:
${fieldString}END_RESPONSE
Do not explain how the values are determined.
For fields without corresponding information in USER_DATA, use the value NO_DATA.
For fields of type number, use only digits and an optional decimal separator.
In modernen Frontend-Applikationen ist es üblich, dass Schnittstellen ihre Antworten im JSON-Format liefern, da diese Datenstruktur leicht weiterverarbeitet werden kann.
Für möglichst präzise und verlässliche Ergebnisse kann die erwartete Zielstruktur mithilfe des JSON Mode definiert werden – in Form eines JSON-Schemas. Es beschreibt die Felder nicht nur strukturell, sondern auch mit genauen Typinformationen. Das erspart ausführliche textuelle Erläuterungen und erleichtert die Verarbeitung der Ergebnisse im Frontend.
Um Typsicherheit in der Anwendung sicherzustellen, kommt häufig Zod zum Einsatz – eine auf TypeScript ausgerichtete Validierungsbibliothek, mit der Datenstrukturen, von einfachen Strings bis hin zu komplexen geschachtelten Objekten, deklarativ definiert und zuverlässig geprüft werden können.
Das folgende Listing von OpenAI zeigt einen exemplarischen Aufruf der OpenAI-API, um Daten in einem bestimmten JSON Format zu extrahieren.
import OpenAI from "openai";
import { zodTextFormat } from "openai/helpers/zod";
import { z } from "zod";
const openai = new OpenAI();
// JSON-Schema-Definition mithilfe von Zod
const CalendarEvent = z.object({
name: z.string(),
date: z.string(),
participants: z.array(z.string()),
});
const response = await openai.responses.parse({
model: "gpt-4o-2024-08-06",
input: [
{ role: "system", content: "Extract the event information." },
{
role: "user",
content: "Alice and Bob are going to a science fair on Friday.",
},
],
text: {
format: zodTextFormat(CalendarEvent, "event"),
},
});
const event = response.output_parsed;
So kommunizieren Anwendungen mit dem LLM
Um System-Prompts und Quelldaten an ein LLM zu übermitteln, stehen je nach Anbieter verschiedene SDKs (Software Development Kits) zur Verfügung. Das obige Listing zeigt beispielsweise die Verwendung des OpenAI-SDK. Weitere Beispiele führender Anbieter sind Anthropic und Google. Sie bieten jeweils umfangreiche Funktionen, hohe Performance und eine benutzerfreundliche Developer-Experience, die den Einsatz der SDKs erleichtert.
Selbstverständlich ist die Nutzung von KI-Modellen nicht auf webbasierte Angebote großer Anbieter beschränkt. Wer mit kleineren Modellen für seine Aufgaben auskommt, kann ebenso lokal laufende Modelle verwenden oder auf im Browser integrierte Modelle wie WebLLM zurückgreifen.
Nach der erfolgreichen Implementierung und Abstraktion der SDK-Aufrufe genügt bereits ein Dreizeiler für das vollständige Parsing.
Es folgt eine exemplarische Darstellung des Ablaufs eines Extraktionsvorgangs anhand einer in Angular definierten FormGroup:
/* User Message – Datenquelle, aus der Daten zum Befüllen des Formulars extrahiert werden sollen. Diese werden in die Zwischenablage kopiert
Max Mustermann
77777 Musterstadt
Kfz-Kennzeichen: KA-SL-1234
Versicherungsnummer: VL-123456
*/
// Angular FormGroup zum Erfassen persönlicher Daten
personalData: this.fb.group({
firstName: ['', Validators.required],
lastName: ['', Validators.required],
street: ['', Validators.required],
zipCode: ['', Validators.required],
location: ['', Validators.required],
insuranceId: ['', Validators.required],
dateOfBirth: [null as Date | null, Validators.required],
telephone: ['', Validators.required],
email: ['', [Validators.required, Validators.email]],
licensePlate: ['', Validators.required],
}),
// JSON-Schema, das mit Zod anhand der FormGroup erstellt wurde
{
"firstName": {
"type": "string"
},
"lastName": {
"type": "string"
},
"street": {
"type": "string"
},
"zipCode": {
"type": "string"
},
"location": {
"type": "string"
},
"insuranceId": {
"type": "string"
},
"dateOfBirth": {
"type": "object"
},
"telephone": {
"type": "string"
},
"email": {
"type": "string"
},
"licensePlate": {
"type": "string"
}
}
// Antwort des LLM
[
{
"key": "firstName",
"value": "Max"
},
{
"key": "lastName",
"value": "Mustermann"
},
{
"key": "location",
"value": "Musterstadt"
},
{
"key": "zipCode",
"value": "77777"
},
{
"key": "licensePlate",
"value": "KA-SL-1234"
},
{
"key": "insuranceId",
"value": "VL-123456"
}
]
// Befüllen des Formulars mit den Ergebnissen (hier eine Angular FormGroup --> personalData)
try {
const text = await navigator.clipboard.readText();
const completions = await this.openAiBackend.getCompletions(fields, text);
completions.forEach(({ key, value }) => this.personalData.get(key)?.setValue(value));
} catch (err) {
console.error(err);
}
Aufwendige Ausfüllarbeiten gehören von nun an der Vergangenheit an und können dank geschickt eingesetzter KI-Unterstützung mühelos erledigt werden.
Dieses Beispiel zeigt einen ausgeführten Extraktionsvorgang: Zunächst wird der Text mit Informationen in die Zwischenablage kopiert, dann der Extraktionsvorgang gestartet, und schließlich stehen automatisch befüllte Formularfelder anhand der Textinformation bereit.

Darstellung des Ablaufs eines Extraktionsvorgangs aus Sicht der User (in drei Schritten, von oben nach unten).
Mehr Transparenz bei KI-generierten Inhalten
Diese Integration allein verbessert die UX enorm. Bei genauerer Betrachtung fallen aus UX-Designer-Sicht allerdings noch weitere Möglichkeiten auf:
Wie steht es etwa um die Nachvollziehbarkeit? Aktuell werden anhand des übermittelten Textes oder Bildes die Felder des Formulars automatisch befüllt. Zudem kann der Nutzer oder die Nutzerin das Formular nach Belieben selbst anpassen und editieren. Das mag in den meisten Fällen ausreichend und unproblematisch sein. Doch in bestimmten Kontexten reicht das allein nicht aus – beispielsweise bei rechtlich verbindlichen Themen wie Versicherungen oder Banking. Hier muss unter Umständen ersichtlich sein, welche Felder von einem Menschen und welche mithilfe von KI-Unterstützung befüllt wurden. Aus UX-Gründen ist es außerdem sinnvoll, Nutzern transparent zu vermitteln, wie einzelne Feldwerte zustande gekommen sind.
Nachvollziehbarkeit sichtbar machen
Ein Blick auf die großen Player zeigt: Wenn es um die Visualisierung von KI-generierten Inhalten geht, kommen oftmals Farbverläufe, Leucht- und Glitzereffekte zum Einsatz. Die folgenden Beispiele zeigen die visuelle Gestaltung von KI-Inhalten anhand der Designsprache von Apple und Google.

Beispiele für die Designsprachen von Apple (oben) und Google (unten) in Bezug auf deren AI-Produkte.
Warum also nicht dieses Pattern aufgreifen und für eigene Integrationen nutzen? Die großen Anbieter verfügen über UI/UX-Research-Budgets, von denen kleinere Unternehmen nur träumen können. Es liegt nahe, sich hier inspirieren zu lassen, zumal die hohe Reichweite bereits neue visuelle Standards prägt – Nutzer sind mit derartigen Darstellungen zunehmend vertraut.
Eine exemplarische Umsetzung im gezeigten Formularszenario könnte darin bestehen, automatisch befüllte Felder mit einem leuchtenden Rahmen (Glow-Effekt) zu versehen. Diese einfache Maßnahme schafft eine klare visuelle Unterscheidbarkeit – und verbessert gleichzeitig die User-Experience.

Automatisch befüllte Felder sind durch einen leuchtenden Rahmen (Glow-Effekt) hervorgehoben.
Um die Nachvollziehbarkeit weiter zu verbessern, können Entwickler eine History-Funktion einbauen: Sie zeigt, welche automatischen Extraktionen wann passiert sind – inklusive der genutzten Quellen (Texte, Sprache oder Bilder). So haben User jederzeit den Überblick und können bei Bedarf einfach per Undo/Redo zu einem früheren Zustand zurückspringen.










Künstliche Intelligenz
Samsung Galaxy S25 Edge gefloppt: S26 Edge offenbar gestrichen
Samsung hat offenbar das Galaxy S26 Edge gestrichen. Das berichten sowohl die koreanische Website Newspim als auch das Samsung-Blog SamMobile. Älteren Gerüchten zufolge wollte Samsung ursprünglich das Galaxy-Plus- im nächsten Jahr durch ein Edge-Modell ersetzen. Schwache Absatzzahlen des ersten schlanken Smartphones, dem im Mai gestarteten Galaxy S25 Edge, könnten die Pläne des koreanischen Techriesen umgeworfen haben. Nun heißt es, dass das Plus-Modell weiterhin der Produktpalette erhalten bleibt.
Weiterlesen nach der Anzeige
Produktion des S25 Edge wohl schon eingestellt
Laut Newspim soll Samsung seine Mitarbeiter erst kürzlich über die Einstellung der Edge-Reihe informiert und die Einstellung des Galaxy S26 Edge bekannt gegeben haben. Zudem berichtet die koreanische Webseite, dass das im Mai erschienene Galaxy S25 Edge voraussichtlich eingestellt werde, sobald die Lagerbestände ausverkauft seien. Die Wahrscheinlichkeit einer Rückkehr der Edge-Reihe werde ebenfalls als gering eingeschätzt.
Nach Informationen von Sammobile soll Samsung vier S26-Modelle in Arbeit gehabt haben – das Basisgerät Galaxy S26, ein Plus, ein Ultra und das Edge. Nach den schlechten Verkaufszahlen des Galaxy S25 Edge habe Samsung sich entschieden, das Galaxy S26 Edge nicht zusammen mit dem Galaxy S26 und dem Galaxy S26 Ultra auf den Markt zu bringen.
Die Absatzzahlen der S25-Reihe von Hana Investment & Securities, die Newspim vorliegen, sprechen eine klare Sprache: Demnach wurden im ersten Monat nach Markteinführung des Galaxy S25 Edge nur 190.000 Geräte verkauft. Das ist deutlich weniger als die Verkaufszahlen des Galaxy S25 (1,17 Millionen Geräte), des S25 Plus (840.000 Geräte) und des S25 Ultra (2,55 Millionen Geräte) im gleichen Zeitraum.
Lesen Sie auch
Laut Sammobile wurden bis August vom Edge 1,31 Millionen Geräte verkauft, während im gleichen Zeitraum das Galaxy S25, Plus und Ultra mit 8,28 Millionen, 5,05 Millionen beziehungsweise 12,18 Millionen Einheiten deutlich darüber lagen.
Weiterlesen nach der Anzeige
Auf Anfrage von heise online zu den Berichten über eine mögliche Einstellung der Edge-Reihe wollte sich Samsung Deutschland nicht äußern: „Spekulationen zum Produktportfolio kommentiert Samsung nicht.“
Insider: Dünnes Galaxy-Smartphone wegen Apple
Gegenüber Newspim sagte ein nicht näher genannter Vertreter der Mobilfunkbranche: „Das Edge wurde nicht entwickelt, weil man von vornherein ein schlankes Gehäuse brauchte, sondern weil ein Konkurrent (Apple) versprochen hatte, eines zu produzieren.“ Er ergänzte, dass dieses Produkt bestätigte, „dass Leistung und Akkukapazität wichtigere Faktoren sind, da die bestehenden Premium-Smartphones bereits immer dünner werden“.
Neben Apple und Samsung wird im November auch Motorola auf den Zug der dünnen Smartphones aufspringen. Das als Moto Edge 70 bezeichnete Modell wird beim Akku jedoch weniger Opfer bringen als die Modelle der Konkurrenz: Dank eines Silizium-Carbon-Akkus, der eine hohe Energiedichte besitzt, wird die Kapazität bei 4800 mAh liegen, während die der Mitbewerber nur 3900 mAh (S25 Edge) beziehungsweise 3149 mAh (Air) groß sind. Ob das ein Kaufgrund für Verbraucherinnen und Verbraucher sein wird, bleibt jedoch abzuwarten.
(afl)
Künstliche Intelligenz
Lithografie-Systeme: ASMLs China-Umsatz soll 2026 wegbrechen
ASML hat im dritten Quartal 2025 gut 7,5 Milliarden Euro umgesetzt, minimal weniger als noch die drei Monate zuvor (7,7 Milliarden). Analog sanken auch der Betriebs- und Nettogewinn minimal auf knapp 2,5 Milliarden beziehungsweise gut 2,1 Milliarden Euro.
Weiterlesen nach der Anzeige
Im Vergleich zum Vorjahr herrscht nahezu Stillstand. Die sequenziellen Vergleiche sind allerdings sinnvoller, weil ASML kein traditionell saisonabhängiges Geschäft hat.
Kein Rückgang im Jahr 2026 erwartet
Für das gesamte Jahr 2025 erwartet ASML jetzt rund 15 Prozent Wachstum, also rund 32,5 Milliarden Euro Umsatz. Das entspricht der nach unten korrigierten Prognose vom Jahresbeginn. Wichtig ist allerdings vor allem ein Satz im Geschäftsbericht: „ASML geht nicht davon aus, dass der Gesamtumsatz 2026 unter dem Wert von 2025 liegen wird.“
Im Juli 2025 zeigte sich der Hersteller noch unsicherer: „Gleichzeitig beobachten wir weiterhin eine zunehmende Unsicherheit aufgrund makroökonomischer und geopolitischer Entwicklungen. Daher bereiten wir uns zwar weiterhin auf ein Wachstum im Jahr 2026 vor, können dies jedoch zum jetzigen Zeitpunkt noch nicht bestätigen.“
Der letzte Satz sorgte damals für einen deutlichen Kursrutsch an der Börse. Das Update bringt nun offenbar Sicherheit zurück, sodass ASMLs Aktie seit Veröffentlichung des Geschäftsberichts um etwa fünf Prozent gestiegen ist. Das Allzeithoch vom Sommer 2024 von gut 1000 Euro bleibt allerdings unerreicht.
China-Geschäft soll signifikant fallen
Weiterlesen nach der Anzeige
Die Aussicht berücksichtigt bereits einen deutlichen Umsatzrückgang beim Umsatz mit chinesischen Chipfertigern im Jahr 2026. ASML spielt die Signifikanz herunter: Der Hersteller habe den chinesischen Markt vor 2022 „unterbedient“, sodass über die letzten Jahre ein großer Bestellrückstand entstanden sei. Der Umschwung kam vor der Verschärfung von Exporteinschränkungen nach China; der Umsatz schoss da schlagartig hoch.
Demnach sollen sich die Verkäufe 2026 normalisieren. Chinesische Firmen kommen allerdings auch allmählich bei heimischen Lithografie-Systemen voran, könnten dort also mehr Geld investieren. Gleichzeitig wollen die USA die Exporteinschränkungen nach China weiter verschärfen.
Im dritten Quartal stieg der chinesische Umsatzanteil noch mal deutlich an. Weltweit hat ASML fast 5,6 Milliarden Euro mit dem Verkauf von Lithografie-Systemen eingenommen. 42 Prozent davon kamen aus China.

Aktuell macht China noch einen großen Anteil von ASMLs Umsatz aus. 2026 soll sich das ändern.
(Bild: ASML)
Insgesamt 66 neue Lithografie-Systeme und sechs wieder aufbereitete verbuchte ASML auf das dritte Quartal. Die restlichen knapp zwei Milliarden Euro Umsatz machte die Firma mit der Wartung bestehender Systeme sowie dem Einbau von Upgrades.
Temporäres Wachstum erwartet
Im jetzt laufenden vierten Quartal erwartet ASML 9,2–9,8 Milliarden Euro Umsatz. Mit dem oberen Ende der Prognose würde der Hersteller an seinem Umsatzrekord von Ende 2024 kratzen. Anhand der Erwartung ans kommende Jahr wird der Umsatz Anfang 2026 wieder sinken.
(mma)
Künstliche Intelligenz
Balkonkraftwerk Priwatt Duo mit Speicher Avocado Orbit im Test: günstig und gut
Das Balkonkraftwerk von Priwatt kommt mit einem eigenen Speicher und zwei 450-Watt-Modulen. Wie gut die Lösung in der Praxis funktioniert, zeigt unser Test.
Mit einem Balkonkraftwerk lässt sich eine große Menge an Strom sparen. Aufgrund stark gefallener Preise für einen Speicher und hohen Energiepreisen von etwa 35 Cent pro kWh lohnt sich die Anschaffung eines solchen. Zwar verlängert sich die Amortisationszeit, doch über einen Zeitraum von 20 Jahren erwirtschaftet das Balkonkraftwerk mit Speicher einen höheren Gewinn als das gleiche Modell ohne Speicher. Siehe dazu auch Balkonkraftwerk & Amortisation: Gewinn maximieren mit der richtigen Auswahl.
Mit dem Avocado Orbit M liefert BKW-Fachhändler Priwatt seinen ersten eigenen Speicher, der in Zusammenarbeit mit dem chinesischen Konzern Fox ESS entstanden ist. Auch Solakon (Testbericht) und Tepto bieten einen OEM-Speicher von Fox ESS an. Technisch unterscheiden sich die Lösungen nur im Detail. Während Solakon einen Ausbau auf bis zu 12,66 kWh erlaubt, ist bei Priwatt und Tepto bei 10,55 kWh Schluss. Tepto hat außerdem ein Brandschutzsystem integriert, ähnlich wie bei Zendure-Lösungen.
Ansonsten sind die Funktionen der auf Fox ESS basierten Speichermodelle identisch:
- Grundeinheit mit bidirektionaler Lademöglichkeit mit bis zu 1200 Watt und 2,11 kWh Kapazität auf Basis von LiFePO4-Batteriezellen
- vier MPP-Tracker mit 2600 Watt PV-Eingangsleistung
- Notstromsteckdose mit 1200 Watt im Off-Grid-Betrieb und 2200 Watt bei Netzanschluss
- Über steckbare Erweiterungseinheiten mit je 2,11 kWh Ausbau bis zu 12,26 kWh Gesamtkapazität (Solakon) oder 10,55 kWh (Priwatt, Tepto)
- Ethernet-Port
- WLAN
- USB-Ladeport
- Heizfunktion (betriebsbereit zwischen –20 °C bis +55 °C)
- wetterfest nach IP65
- Info-Display
- Smart-Meter-Unterstützung für Nulleinspeisung: Shelly Pro 3EM, Everhome Ecotracker (Solakon, Tepto; Priwatt nur Shelly, Ecotracker geplant)
Der folgende Test zeigt, wie das Priwatt-BKW Duo mit dem Speicher Avocado Orbit M in Betrieb genommen wird, wie man den Speicher für eine Nulleinspeisung konfiguriert und wie die Anlage in Home Assistant integriert wird. Begutachtet wird dabei auch die Zuverlässigkeit und die Effizienz des Systems.
Bilder: Priwatt Avocado Orbit M
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.
Balkonkraftwerk Priwatt Duo mit 900 Watt Solarleistung und Speicher Avocado Orbit M mit 2,11 kWh, vier MPPTs mit einer Eingangsleistung von bis zu 2600 Watt.

Priwatt-App Orbit
Priwatt-App Orbit

Priwatt-App Orbit

Priwatt-App Orbit

Priwatt-App Orbit
Priwatt-App Orbit

Priwatt-App Orbit
Priwatt-App Orbit
Priwatt-App Orbit
Priwatt-App Orbit
Priwatt-App Orbit
Priwatt-App Orbit
Priwatt-App Orbit
Priwatt-App Orbit
Priwatt-App Orbit
Die Inbetriebnahme des Speichers erfolgt mit der App Fox Cloud 2.0 des Herstellers Fox ESS. Dieser bietet auch eine informative Web-Ansicht.
Die Inbetriebnahme des Speichers erfolgt mit der App Fox Cloud 2.0 des Herstellers Fox ESS. Dieser bietet auch eine informative Web-Ansicht.
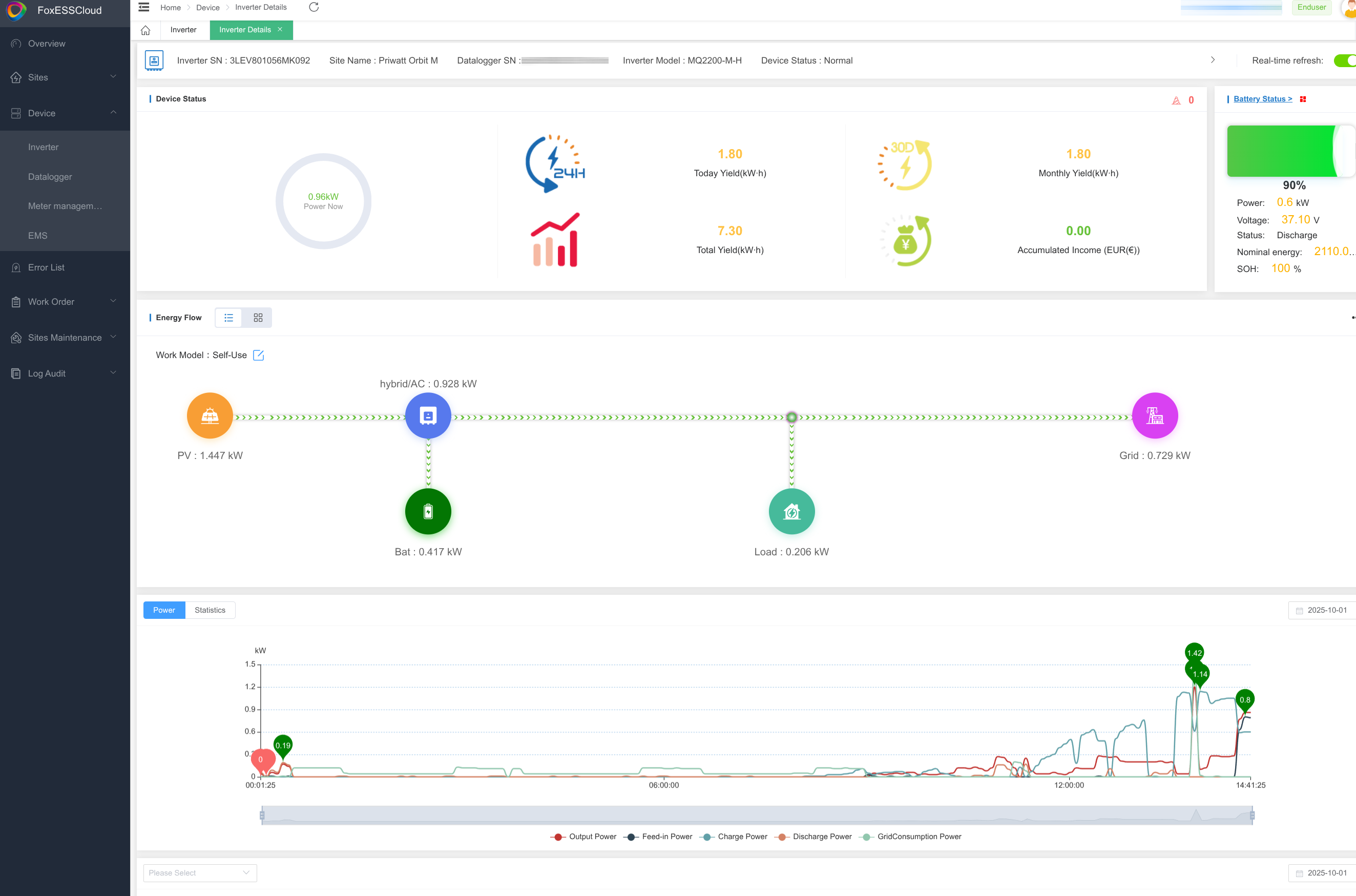
Die Inbetriebnahme des Speichers erfolgt mit der App Fox Cloud 2.0 des Herstellers Fox ESS. Dieser bietet auch eine informative Web-Ansicht.
Die Inbetriebnahme des Speichers erfolgt mit der App Fox Cloud 2.0 des Herstellers Fox ESS. Dieser bietet auch eine informative Web-Ansicht.
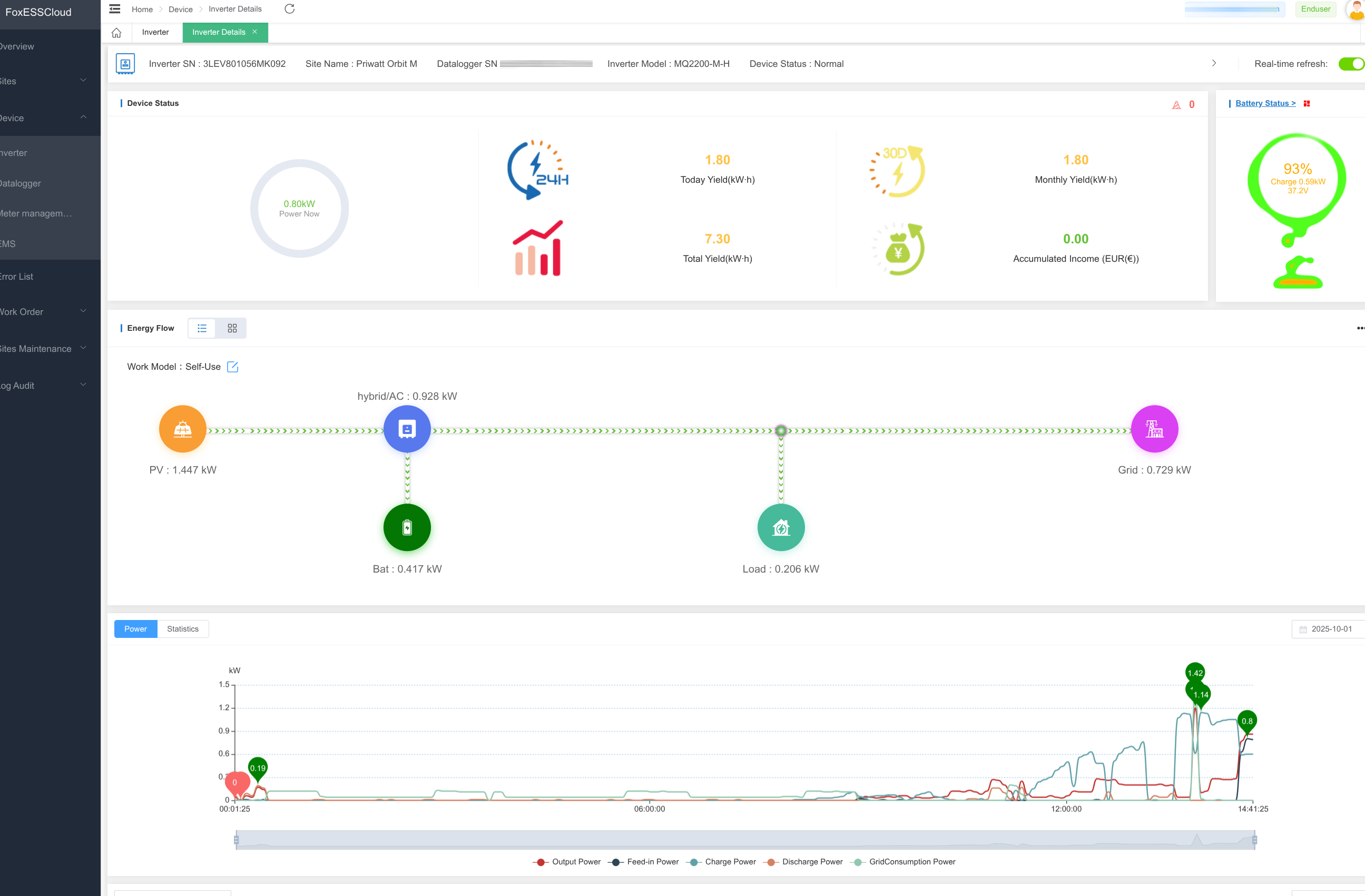
Lieferumfang: Priwatt Duo mit Avocado Orbit M und 2,11 kWh
Für den Test hat uns Priwatt das Balkonkraftwerk Duo mit zwei 450-Watt-Solarmodulen inklusive des Speichers Avocado Orbit M mit 2,11 kWh zur Verfügung gestellt. Da wir außerdem noch zwei 500-Watt-Module im Einsatz haben, schließen wir auch diese an den Speicher an, um zu testen, ob alle vier MPP-Tracker problemlos funktionieren.
Im Lieferumfang befinden sich zum Anschluss der Solarmodule an den Speicher vier MC4-Anschlusskabel mit jeweils zwei Meter Länge. Für die Installation an einem Balkon kann die Länge ausreichen. Aber wer das BKW im Garten aufstellt oder an einem angrenzenden Zaun montiert, benötigt längere MC4-Kabel. Diese hat Priwatt zwar auch im Programm, aktuell aber bisher nicht auf der Bestellseite für das BKW integriert. Stattdessen muss man diese im Bereich Zubehör bestellen.
Halterungen für die Solarmodule bietet Priwatt für Balkon, Flachdach, Garten, Fassade und Schrägdach an. Wer die Anlage auf einem Balkon installieren möchte, kann aber nicht die 500-Watt-Module auswählen, da diese offenbar zu groß respektive zu schwer dafür sind. Alternativ stehen aber in derselben Größe wie die 450-Watt-Module noch 475-Watt-Varianten zur Auswahl, die dank ABC-Technik eine bessere Leistung bei Verschattung bieten und einen Wirkungsgrad von 24 Prozent aufweisen sollen.
Der Speicher und die Notstromsteckdose werden über die Power-Taste links oben eingeschaltet. Relevante Betriebsdaten können Anwender am kleinen Display an der Oberseite rechts ablesen. Dazu zählen Gesamtsolarleistung sowie die Eingangsleistung der einzelnen MPPT-Eingänge in Watt, Ladeleistung, Spannung und Strom der Batterie, Leistung des Wechselrichters, sowie Spannung und Strom, Firmwareversion von Wechselrichter, Batteriemanagementsystem und PV-Eingang und Ladestatus des Speichers in Prozent. Um zwischen den einzelnen Anzeigen zu wechseln, drückt man links neben dem Display auf den Schalter mit zwei gekrümmten Pfeilen. Drückt man diesen für 20 Sekunden, wird WLAN und Bluetooth zurückgesetzt. Anders als beim Marstek Jupiter C Plus können Anwender über das Display allerdings keine Einspeisepläne anlegen. Dafür wird die Orbit-App respektive das Pendant des Speicherherstellers Fox Cloud 2.0 benötigt.
Inbetriebnahme mit Orbit-App
Für die Nutzung der Orbit-App muss man sich per E-Mail registrieren. Aktuell bietet die App noch keine Steuerungsmöglichkeit für den Speicher. Allerdings soll diese Funktion noch in diesem Jahr integriert werden. Die Einrichtung des Avocado Orbit M erfolgt daher zunächst mit der App des Speicherherstellers Fox Cloud 2.0. Beide Apps sind nur für Smartphones optimiert und profitieren daher nicht von dem größeren Bildschirm eines iPads oder Tablets. Schade.
Auch die App des Speicherherstellers erfordert eine Registrierung. Nach der Anmeldung fügt man den Speicher Avocado Orbit M hinzu und in unserem Fall auch den Smart Meter Shelly Pro 3EM, der in der Stromverteilung installiert ist und mithilfe von drei Induktionsspulen den aktuellen Strombedarf ermittelt. Die Einrichtung ist relativ einfach. Wer dennoch Schwierigkeiten hat, geht nach der Anleitung (PDF) von Priwatt vor.
Ist der Avocado Orbit M in der App des Speichers vollständig konfiguriert, kann man nun die Orbit-App verwenden und Speicher sowie Shelly Pro 3EM dort integrieren. Warum sollte man das tun? Die Benutzerführung der App des Speicherherstellers ist nicht gerade intuitiv. Sie bietet zwar eine große Menge an Informationen zu den Leistungsdaten des Speichers und der PV-Module, doch weder Zugang noch deren Präsentation sind besonders gelungen. Leistungsangaben erfolgen etwa in kW. Das ist bei Balkonkraftwerken nicht optimal und zeigt, dass Fox ESS eher mit großen Anlagen zu tun hat. Wie bereits erwähnt, will Priwatt die Steuerung des Speichers noch in diesem Jahr über die Orbit-App bereitstellen. Damit sollten Nutzer deutlich besser klarkommen. Aber schon jetzt bietet die App von Priwatt eine bessere Übersicht.
In der Orbit-App hat Priwatt außerdem seinen eigenen dynamischen Stromtarif Orbit Energy integriert, sodass der Speicher auch bei schlechtem Wetter oder der kommenden Dunkelflaute im Winter profitabel genutzt werden kann. Damit sich das Laden des Speichers mit Strom aus dem Netz lohnt, muss der Preisunterschied zwischen hohem und niedrigem Tarif wegen der Umwandlungsverluste aber deutlich über 20 Prozent liegen. Und noch eine Voraussetzung muss erfüllt sein: Ohne ein sogenanntes intelligentes Messsystem (iMSys) am Hausanschluss gibt es keinen dynamischen Stromtarif, sondern nur einen Durchschnittstarif. Bis ein solches Gerät eingebaut ist, kann es aber dauern: Wir warten seit April auf den Einbau, nachdem wir zu einem dynamischen Stromtarif von Rabot Energy gewechselt sind. Nachdem ein Termin im Juli abgesagt wurde, sollte der Smart Meter am 8.10. eingebaut werden. Dieses Mal kam zwar der Techniker, doch ein Einbau konnte wegen fehlender Ethernetverbindung und unzureichendem Mobilfunkempfang nicht erfolgen.
Einspeiseleistung festlegen: Zeitpläne oder Smart Meter
Anhand des realen Strombedarfs, der vom Shelly Pro 3EM ermittelt wird, speist der Avocado Orbit M bedarfsgerecht ein, sodass in der Theorie weder Strom verschenkt noch unnötig bezogen wird. In der Praxis vergehen allerdings einige Sekunden, bis die Regelung einsetzt. Wie auch schon beim Solakon One (Testbericht), dauert es auch beim Avocado M etwas länger, bis die Einspeiseleistung den tatsächlichen Strombedarf trifft. Dabei reagieren die beiden OEM-Speicher von Fox ESS nach wenigen Sekunden auf den veränderten Verbrauch, schließlich ist der Shelly lokal angebunden und nicht über die Cloud, doch die Regelung arbeitet offensichtlich noch nicht optimal. Das funktioniert bei anderen Herstellern wie Anker, Marstek, Hoymiles und Zendure deutlich besser. Und so zeigt die Shelly-App bei der Gesamtleistung selten die 0 an. Die Abweichung davon beträgt nach oben und unten bis zu 60 Watt, meistens aber zwischen -20 und +20 Watt. Diese Flatterhaftigkeit macht über den Tag betrachtet jedoch wenig aus. Zu bemängeln ist sie aber trotzdem.
Alternativ zur dynamischen Einspeisung mithilfe eines Smart Meters wie dem Shelly Pro 3EM, können Anwender auch traditionell Einspeisepläne nach bestimmten Zeiten mit der App Fox Cloud 2.0 definieren, um so den tagesaktuellen Strombedarf annähernd zu treffen. Dafür ist es natürlich von Vorteil, wenn man die Grundlast kennt. Das ist der Strombedarf, der von dauernd aktiven Geräten wie Router, Kühlschrank, Smart-Home-Zentralen, NAS und anderen Gerätschaften erzeugt wird. Um diese herauszufinden, sollte man einen Blick auf den Stromzähler am Hausanschluss werfen. Etwa kurz vor der Schlafenszeit, wenn Geräte wie TV und PC und andere Verbraucher, die während des Tages aktiv sind, ausgeschaltet sind. Kurz nach dem Aufstehen zeigt der Blick auf den Stromzähler, wie hoch der Verbrauch von Geräten, die dauernd aktiv sind, ausfällt.
In einem modernen Haushalt dürfte sich die Grundlast zwischen 50 Watt und 150 Watt bewegen. Diesen Wert trägt man dann in den Zeitplan ein. Hat man abends häufiger den TV samt Soundbar in Betrieb, kann man den zusätzlichen Bedarf anhand einer smarten Stromsteckdose (Bestenliste) ermitteln oder wieder den Gang zum Stromzähler antreten, um anhand der Werte den Strombedarf zu ermitteln. Ähnlich kann man tagsüber verfahren, wenn etwa im Homeoffice dauerhaft ein PC und Monitor in Betrieb sind. Anhand dieser Daten kann man dann Einspeisepläne anfertigen.
Die Nutzung eines Smart Meters ist in jedem Fall die bessere Lösung, da dadurch die Einspeiseleistung dynamisch nach dem aktuellen Strombedarf erfolgt, was die Eigenverbrauchsquote und damit gleichzeitig auch die Rentabilität erhöht.
Während der Einbau des Shelly Pro 3EM in die Stromverteilung nur durch eine Fachkraft erfolgen sollte, erfordert das Anbringen eines Infrarot-Lesegeräts wie dem Everhome Ecotracker am Stromzähler kein Fachpersonal. Die Frage ist allerdings, ob am Hausanschluss die nötige Netzwerkverbindung sichergestellt ist. Das sollte im Eigenheim kein Problem sein, aber in einer Eigentumswohnanlage dürfte eine Netzwerkverbindung zum Stromzähler im Keller in den seltensten Fällen möglich sein.
Notstromsteckdose
Wie der Solakon One bietet auch der Avocado Orbit M eine als Notstromsteckdose (EPS, Emergency Power Supply) bezeichnete Schuko-Steckdose. Sie bietet im Offgrid-Betrieb eine Leistung von 1200 Watt. Das ist etwa bei einem Stromausfall (siehe auch Betreiber: Längster Stromausfall der Nachkriegszeit beendet) interessant. So kann man an dieser Steckdose etwa eine Kühlgefrier-Kombination betreiben. Im Regelbetrieb, wenn der Speicher mit dem Stromnetz verbunden ist, liegt die Leistung bei 2200 Watt. Dann werden allerdings 1000 Watt aus dem Netz bezogen.
Im Alltag erweist sich die Steckdose bereits ohne Stromausfall als ungemein praktisch. Etwa dann, wenn auf der Terrasse oder dem Balkon nur eine Außensteckdose zur Verfügung steht und man neben dem Balkonkraftwerk noch Strom für weitere Verbraucher wie Leuchten oder eine Ladestation für einen Mähroboter benötigt.
Wie effizient arbeitet der Priwatt Avocado Orbit M?
Der Priwatt Avocado M bietet eine Bruttokapazität von 2,11 kWh. Die maximale Entladetiefe liegt bei 10 %, also 1,9 kWh. Wer den Speicher besonders schonend betreiben möchte, stellt diesen Wert auf 20 %. Leider gibt es keine obere Begrenzung, sodass er immer voll aufgeladen wird.
Bei einer Einspeiseleistung von 800 Watt kommen aus dem Avocado Orbit M etwa 1,7 kWh Wechselstrom, was einer Effizienz von über 89 Prozent entspricht. Beim Entladen mit 150 Watt sinkt diese auf etwa 75 Prozent. In puncto Effizienz gehört der Avocado Orbit M von Priwatt wie das technisch nahezu identische Konkurrenzmodell Solakon One damit zur Spitze der aktuellen Speicherlösungen.
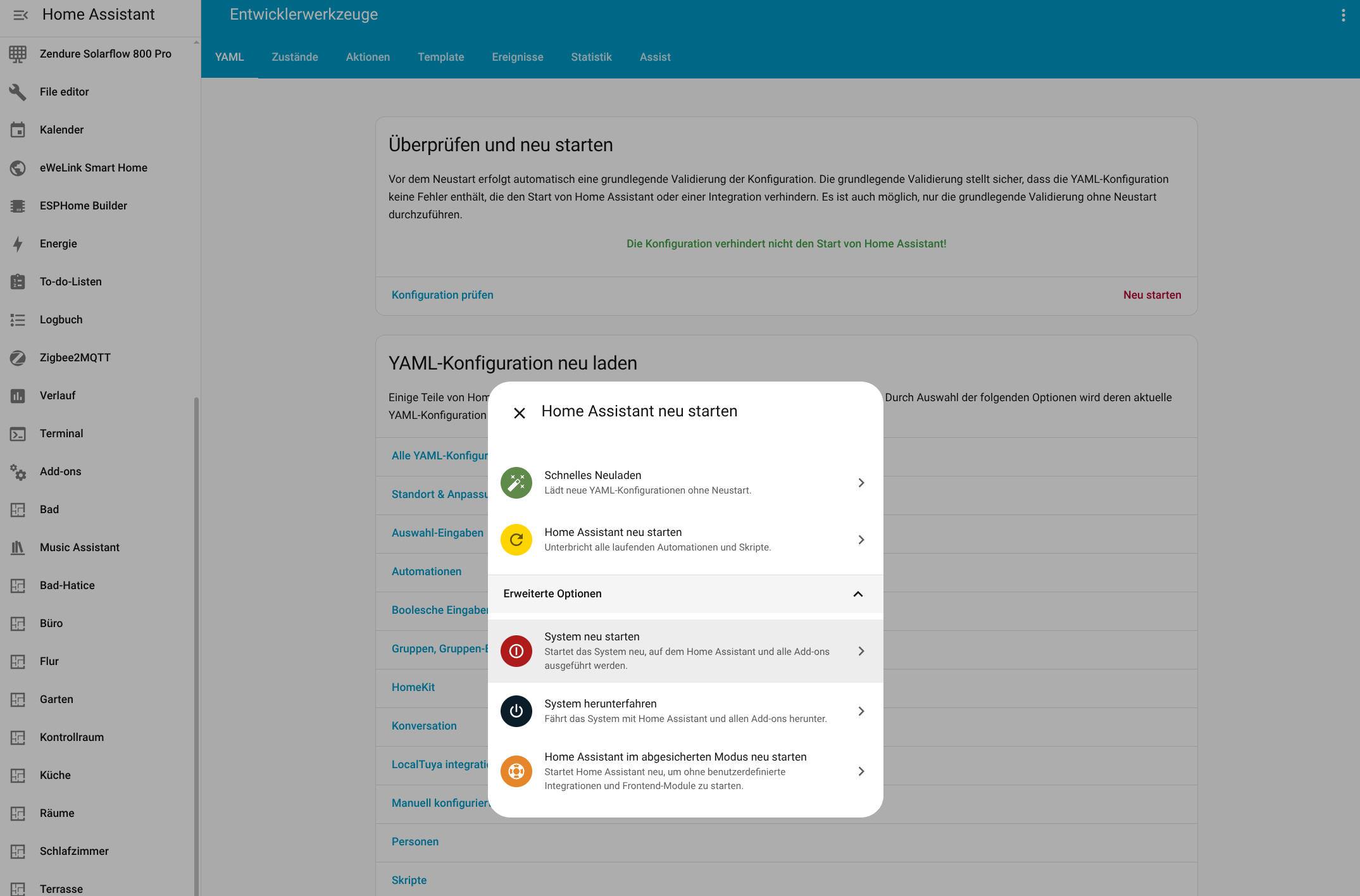
Kann man das Priwatt-BKW in Home Assistant einbinden?
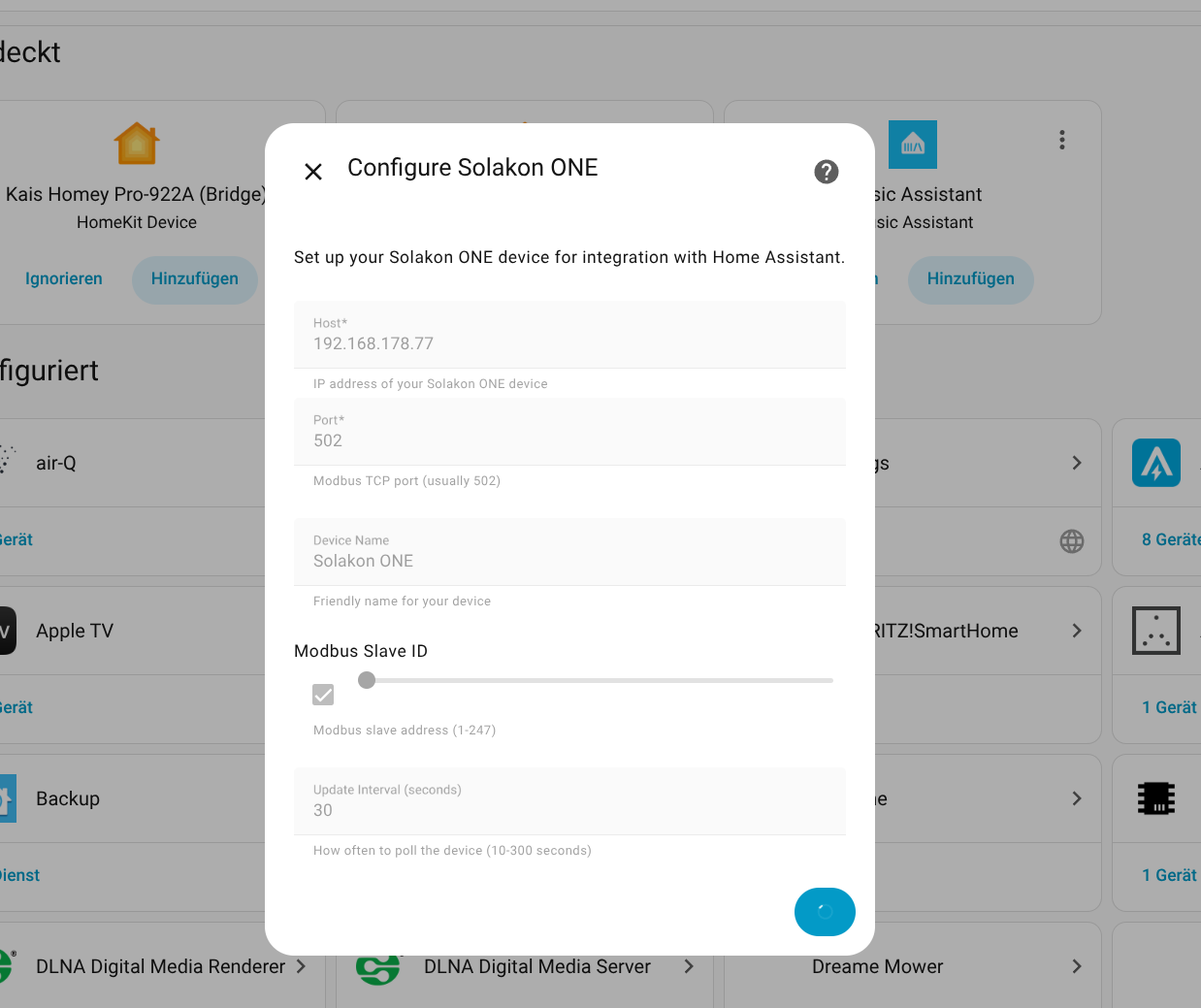
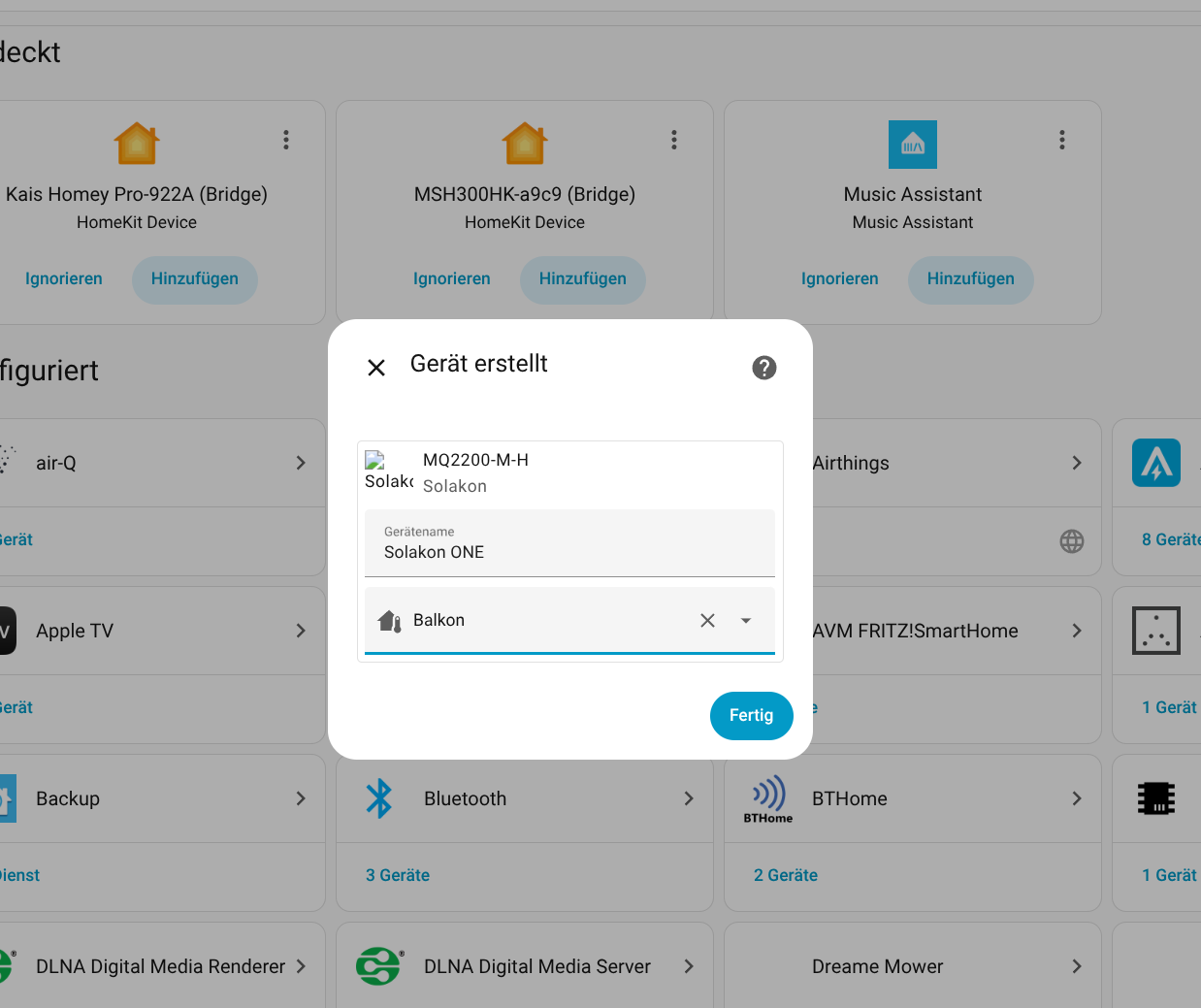
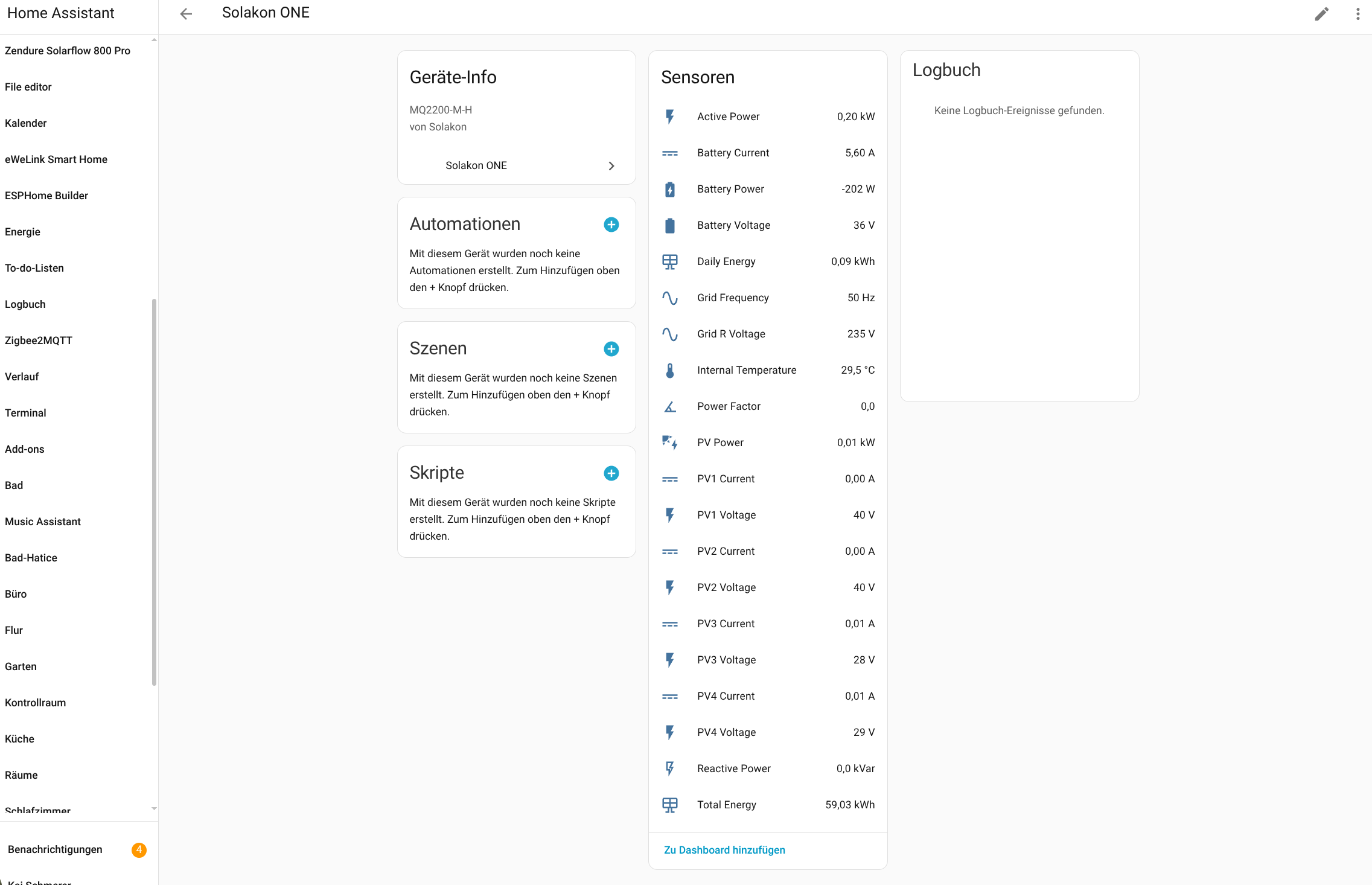
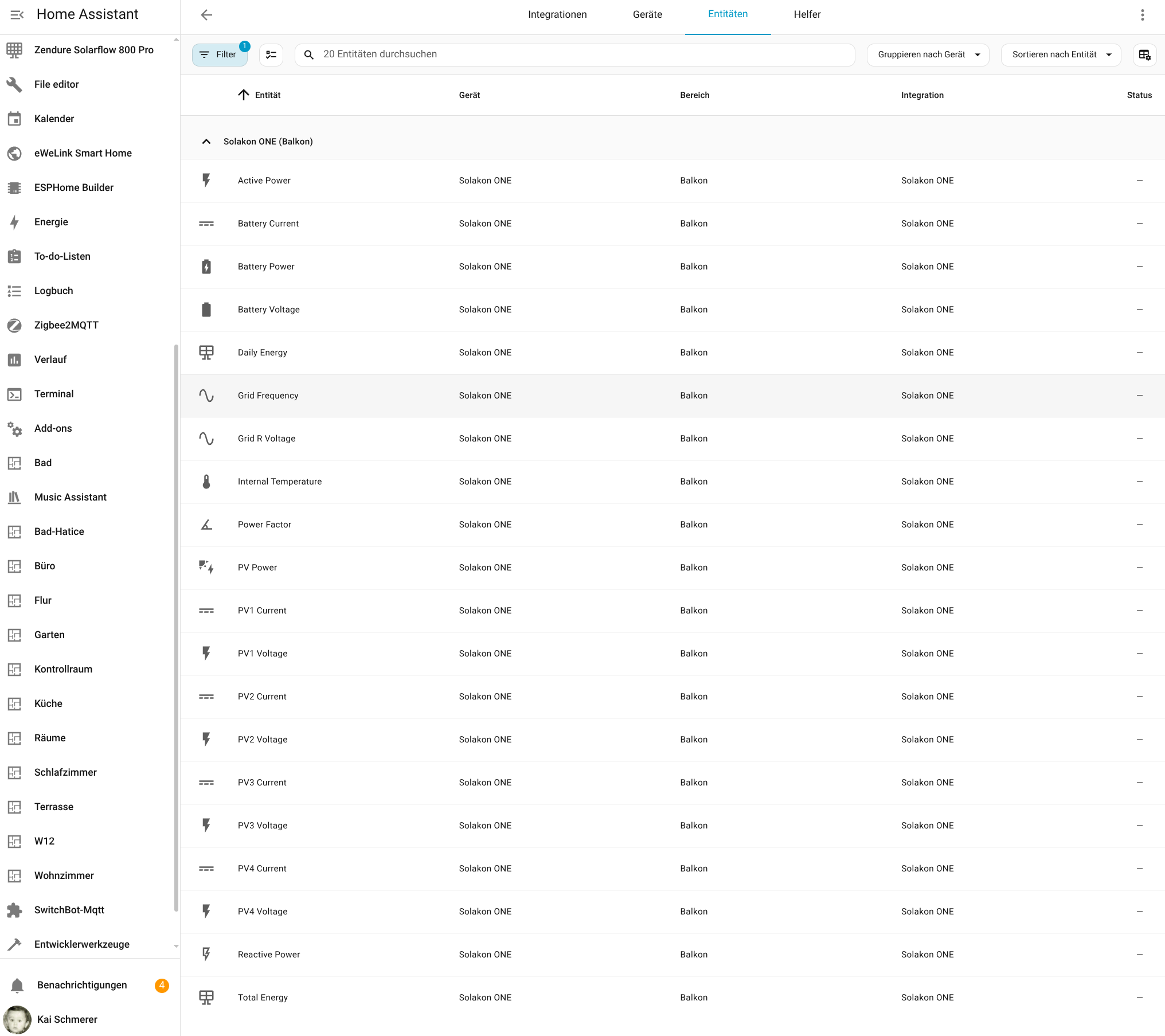
Die Einbindung des Avocado Orbit M in Home Assistant (Testbericht) ist dank einer offiziell von Solakon bereitgestellten Integration derzeit möglich. Allerdings ist diese bislang nicht final. Seit Kurzem stehen unter Home Assistant zwar relevante Betriebsparameter zur Verfügung, doch steuern lässt sich die Anlage mit Home Assistant bislang nicht.
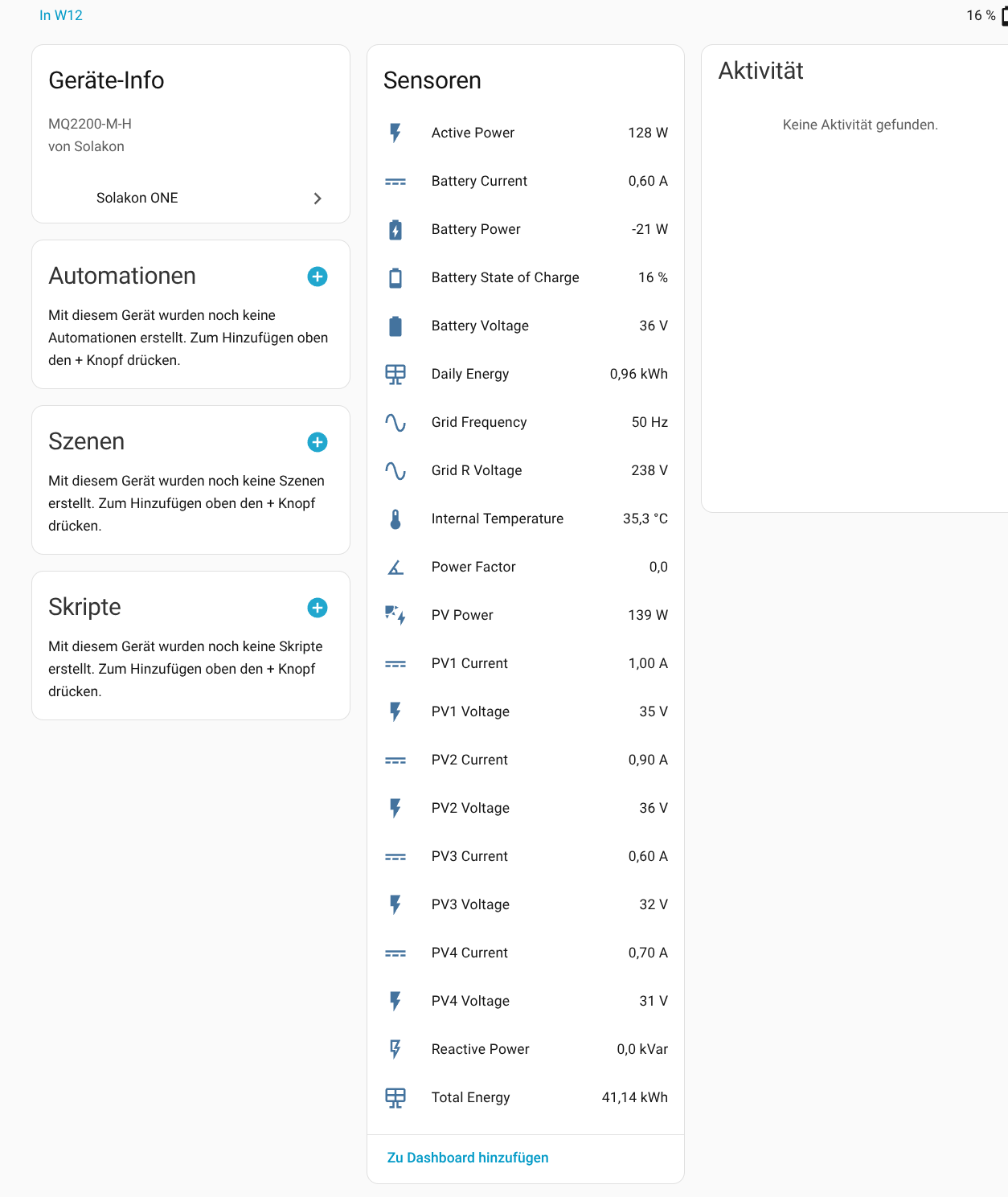
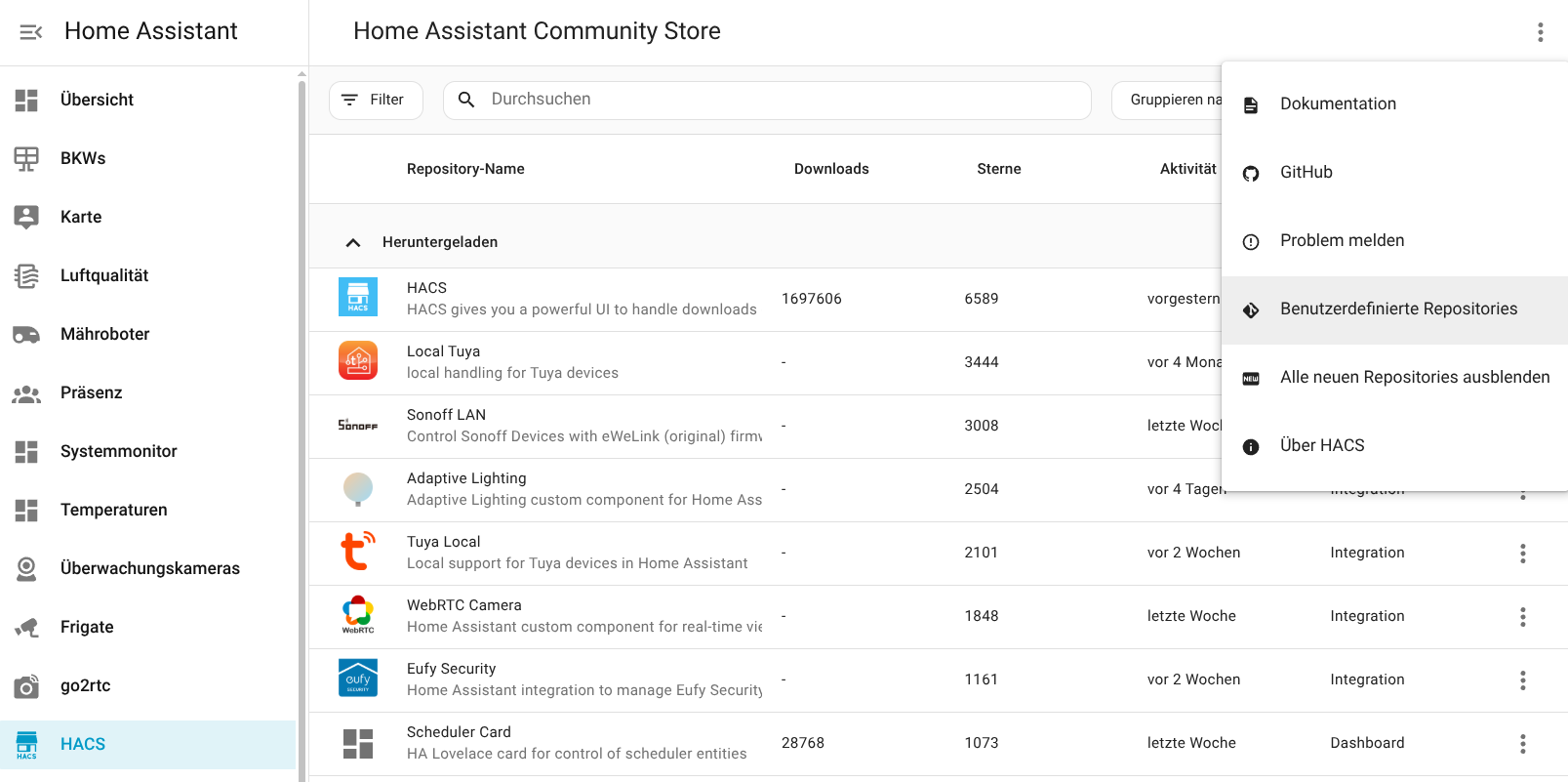
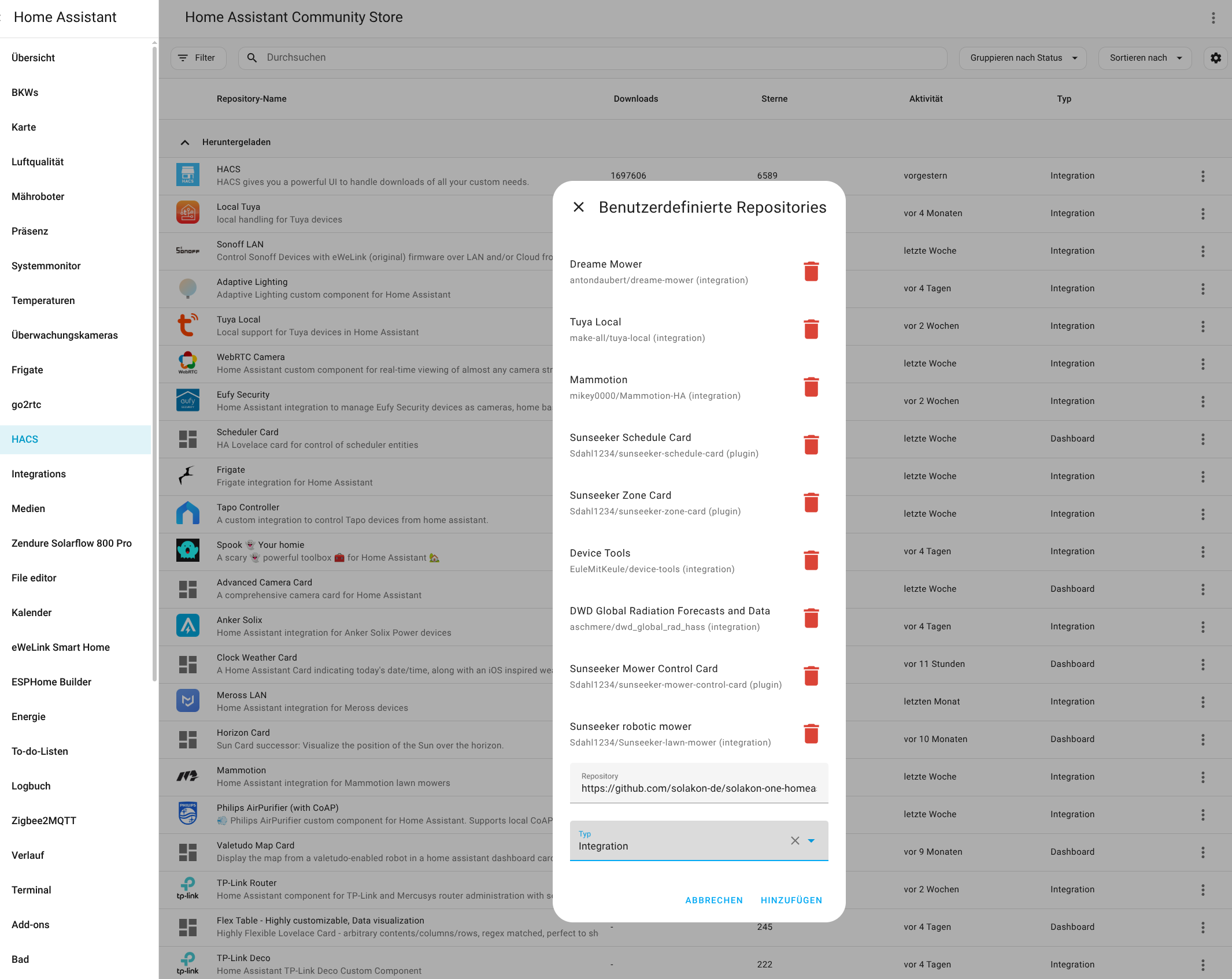
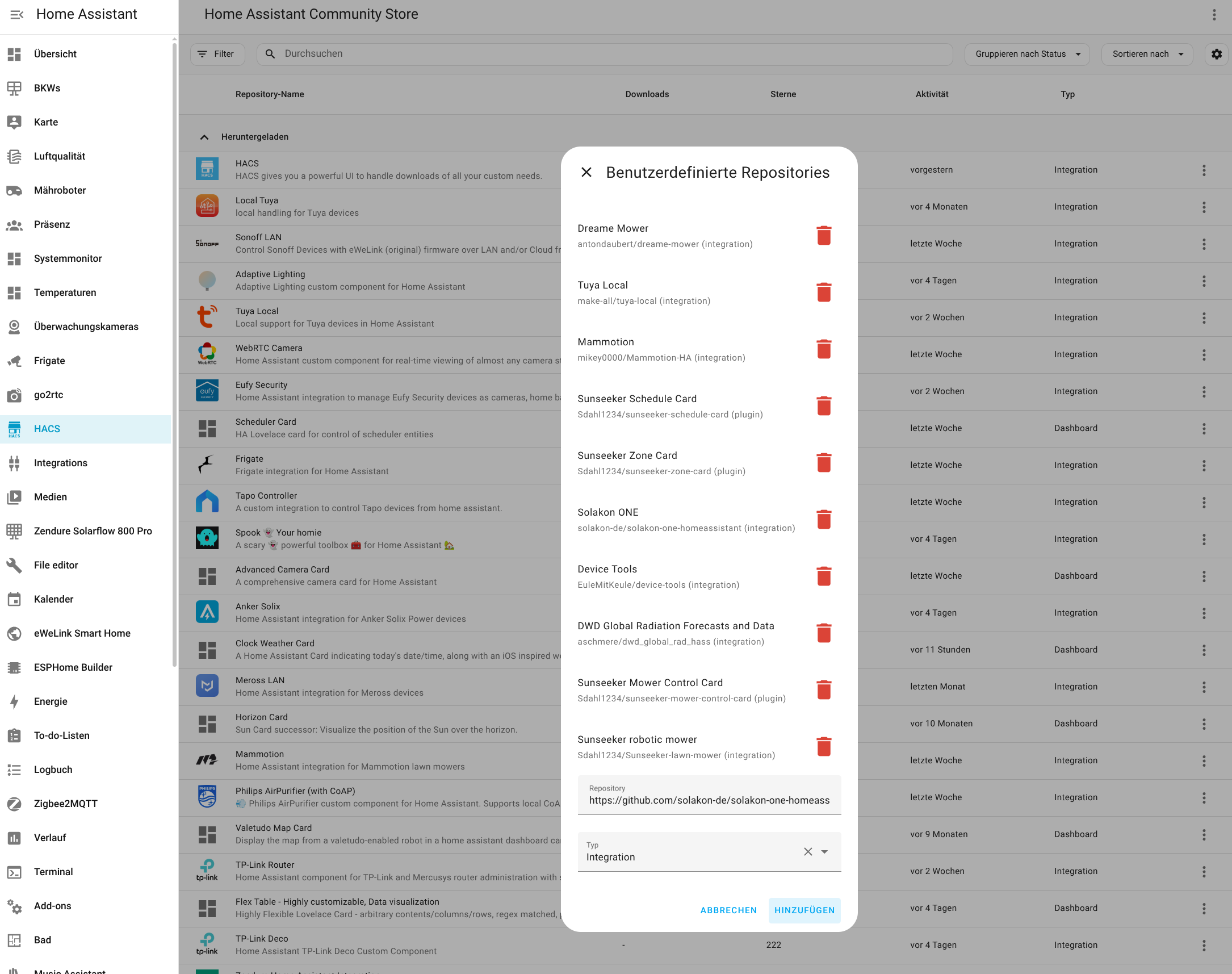
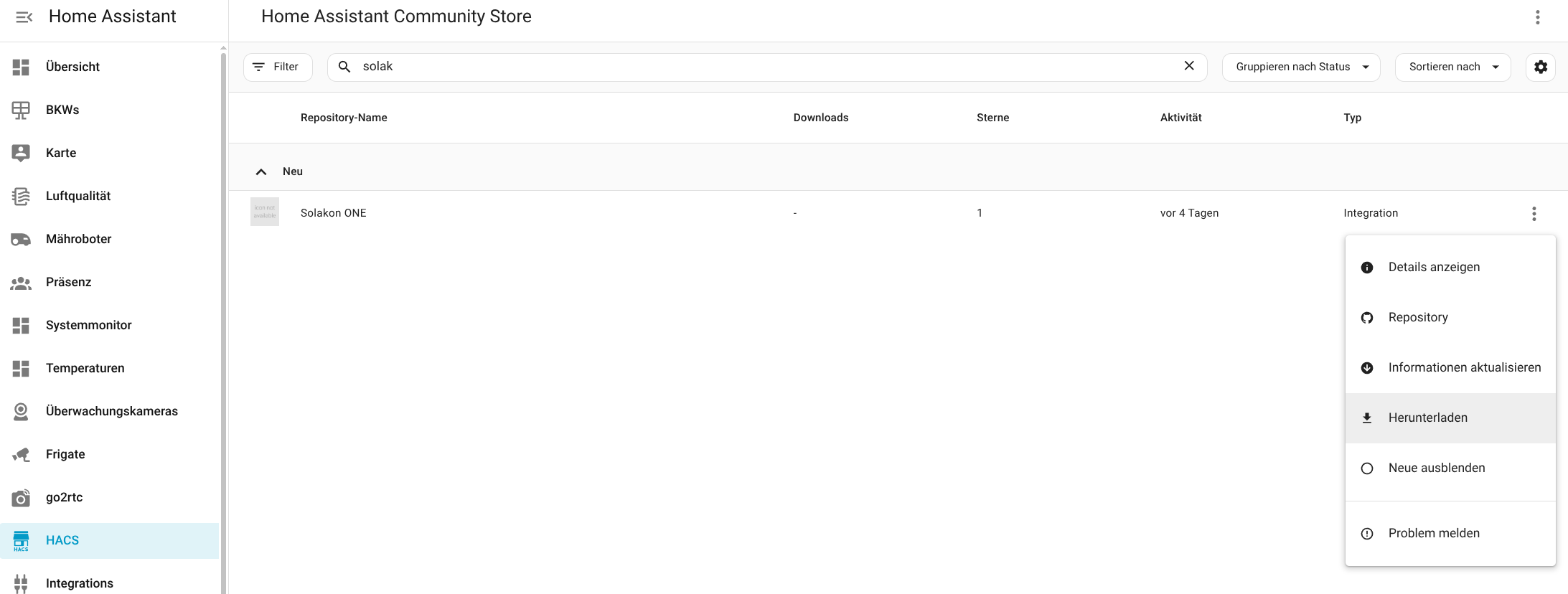
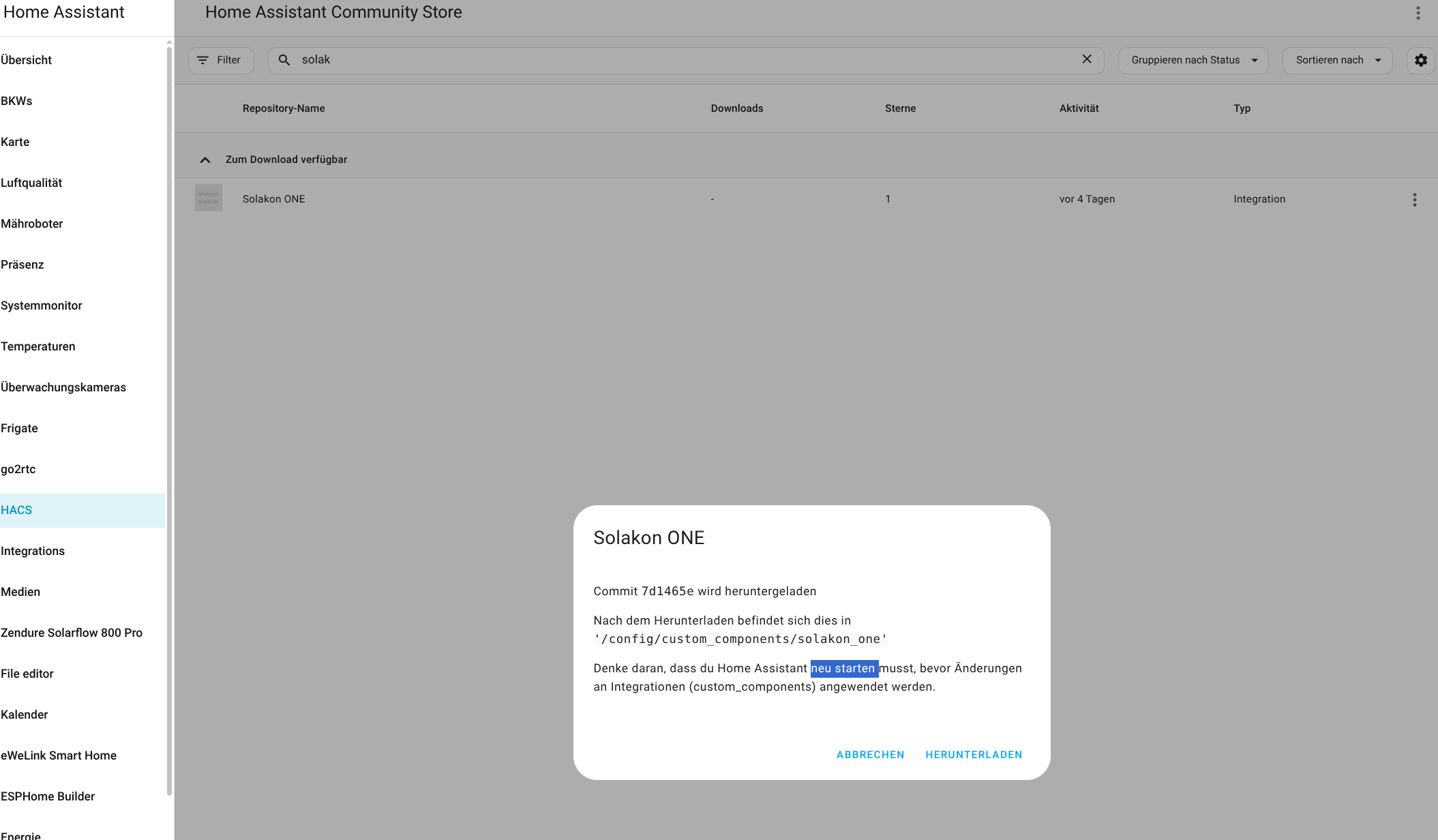
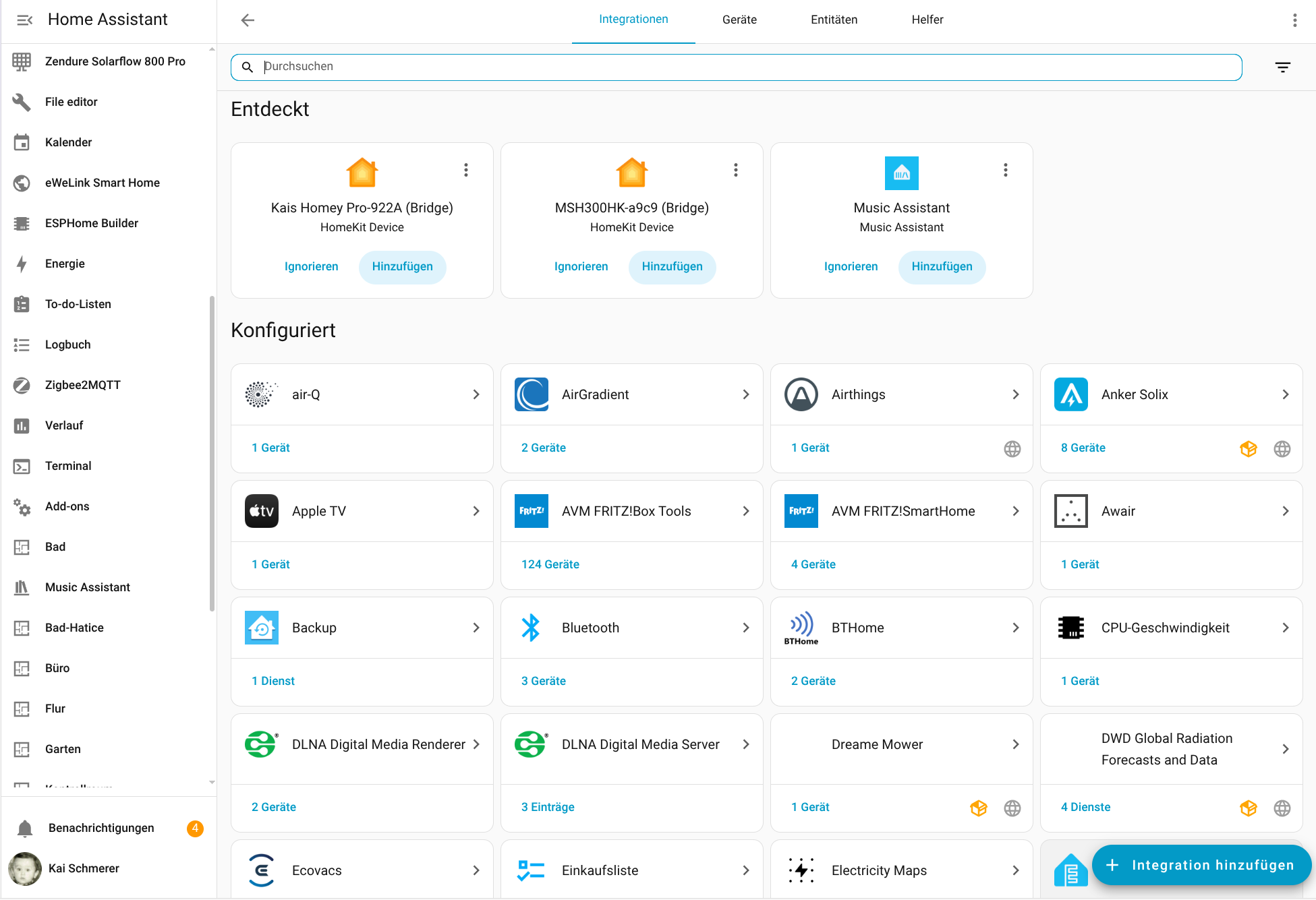
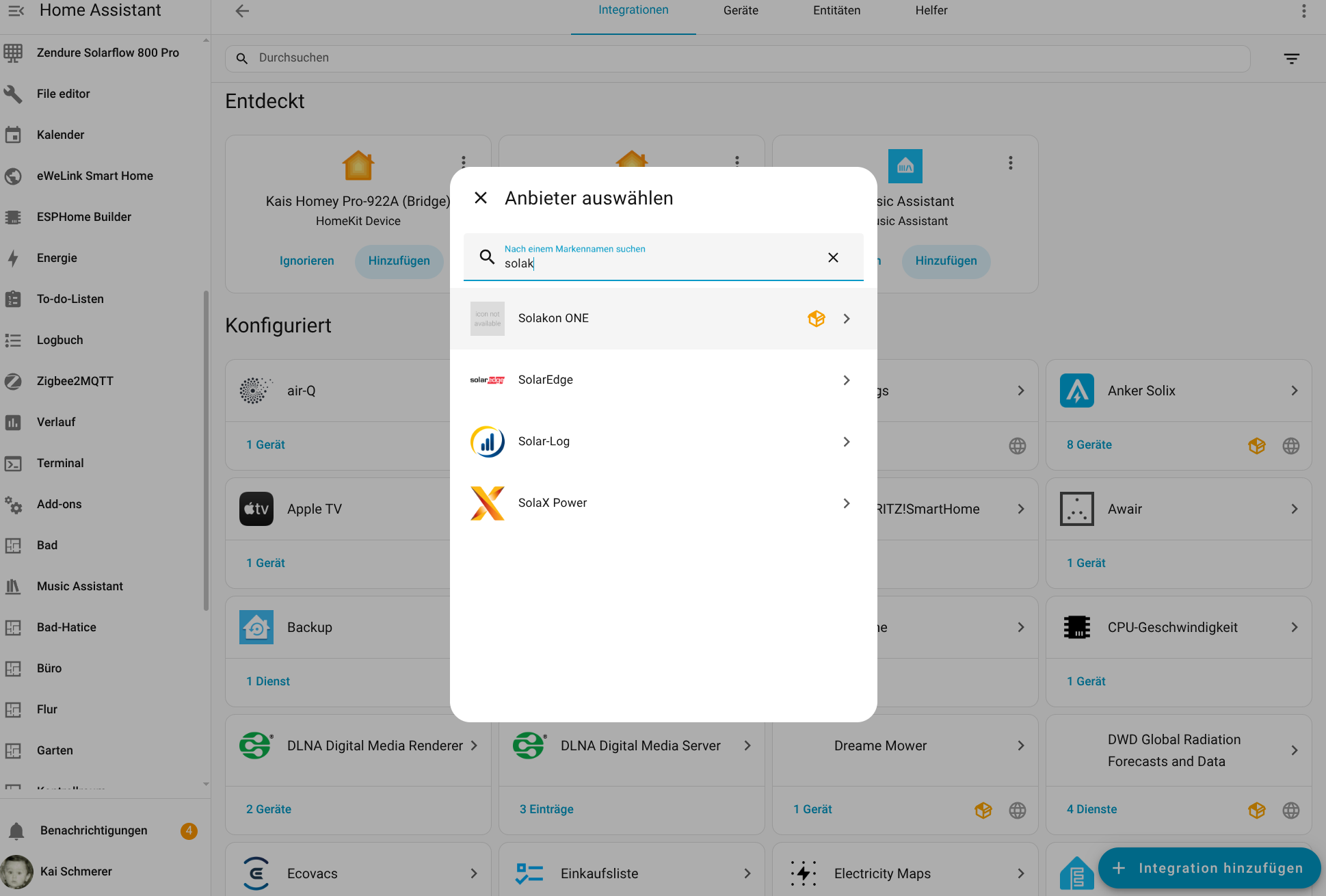
Für die Konfiguration der Integration wird die IP-Adresse des Speichers benötigt. Da die App darüber noch keine Auskunft gibt, muss man sie mit einem IP-Scanner wie Angry IP (Heise Download) ermitteln. Der Speicher meldet sich im Netzwerk mit Inverter, gefolgt von der Seriennummer, die man in der App ablesen kann. Außerdem steht die Integration bisher nicht im Home Assistant Community Store zur Verfügung, sodass man das Repository manuell hinzufügen muss. Wie man dabei vorgeht, zeigt die folgende Bildergalerie.
Solakon One: Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
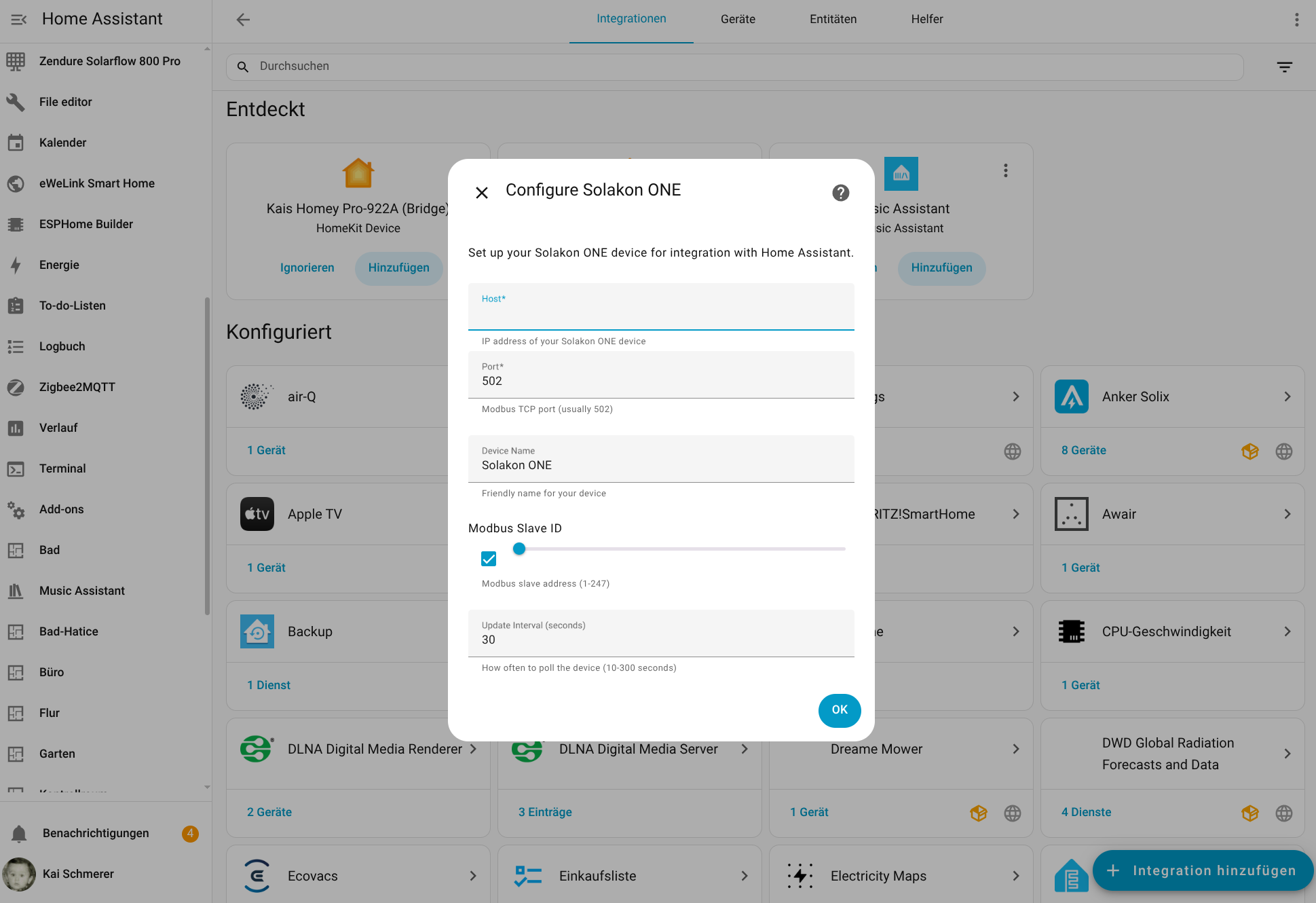
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
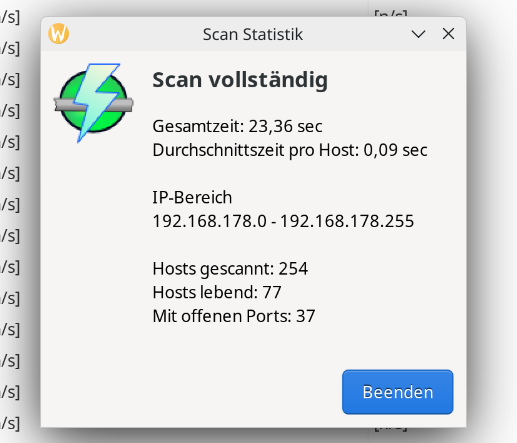
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant

Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
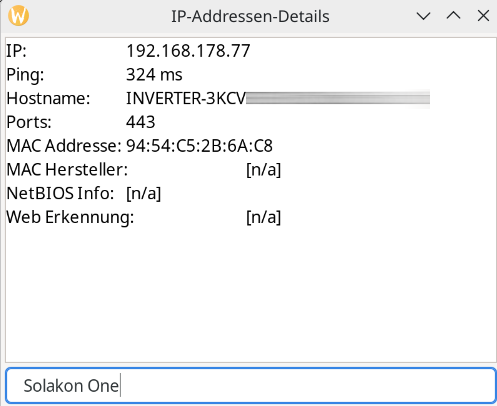
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
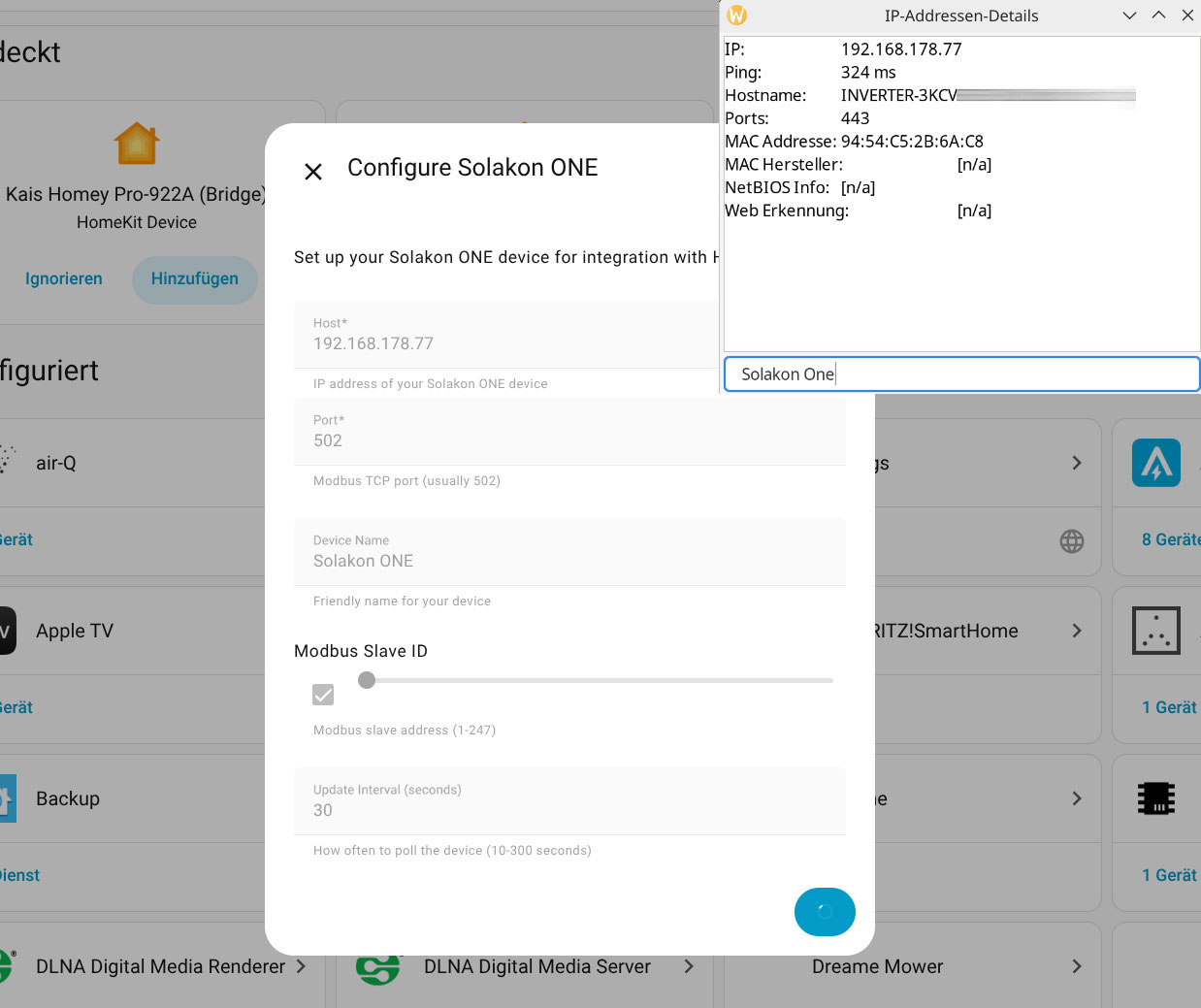
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
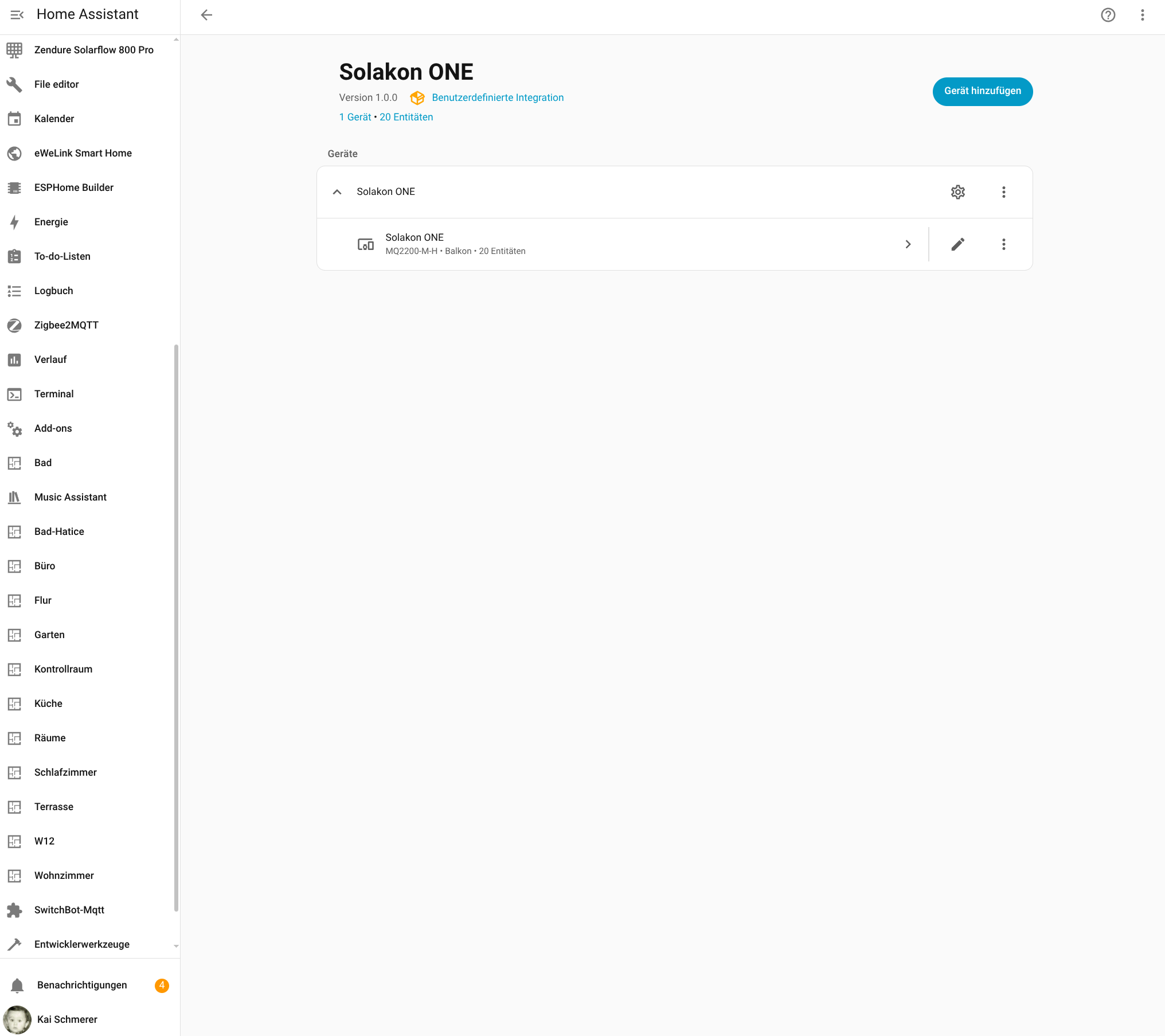
Solakon One: Integration in Home Assistant
Solakon One: Integration in Home Assistant
Was kostet der Priwatt Avocado Orbit M?
Priwatt verkauft den Stromspeicher Avocado Orbit M einzeln oder im Set. Die Basiseinheit mit 2,11 kWh kostet regulär 699 Euro. Aktuell gibt es mit dem Code SAVE8 acht Prozent Rabatt, sodass der Speicher bereits für 643 Euro den Besitzer wechselt. Mit einer Zusatzeinheit, die regulär für 599 Euro erhältlich ist, steigt die Speicherkapazität auf 4,22 kWh und der Preis auf 1102 Euro. Pro kWh zahlt man für diese Kombination 261 Euro, was im Vergleich zum Mitbewerb wie Anker Solarbank 3 mit 5,38 kWh, Zendure Solarflow 800 Pro mit 3,84 kWh und Ecoflow Stream Ultra X mit 3,92 kWh relativ günstig ist. Bei diesen Lösungen kostet die kWh zwischen 276 Euro (Anker) und 284 Euro (Zendure).
Noch günstiger pro kWh sind die Sets mit größerer Speicherkapazität. Mit 6,33 kWh (Basiseinheit + 2 Erweiterungen) kostet der Avocado Orbit M 1561 Euro (Rabattcode SAVE8 an der Kasse eingeben). Dann kostet die kWh nur noch 247 Euro.
| kWh | kWh | kWh | kWh | kWh | |
| Priwatt Avocado Orbit M | 2,11 | 4,22 | 6,33 | 8,44 | 10,55 |
| Preis | 699 € | 1.198 € | 1.697 € | 2.196 € | 2.695 € |
| Rabatt 8 Prozent (SAVE8) | 643 € | 1.102 € | 1.561 € | 2.020 € | 2.479 € |
| Preis pro Einheit | 643 € | 551 € | 520 € | 505 € | 496 € |
| Preis pro kWh | 305 € | 261 € | 247 € | 239 € | 235 € |
Unser Test-Komplettset mit zwei 450-Watt-Modulen, Avocado Orbit M mit 2,11 kWh, Balkonhalterung und Versand kostet mit dem Rabattcode SAVE8 1016 Euro. Die gleiche Anlage mit zwei effizienteren 475-Watt-Modulen (ABC-Technik) kostet 1081 Euro. Etwas günstiger sind die Varianten mit einfacher Flachdachhalterung. Für das Modell mit zwei 450-Watt-Modulen zahlt man mit 2,11-kWh-Speicher nur 980 Euro und für das Set mit zwei 500-Watt-Panels 989 Euro.
Wer ein leistungsfähigeres Balkonkraftwerk mit 2000 Watt wünscht, zahlt mit 2,11-kWh-Speicher, Flachdach-Halterung und Versand 1256 Euro und mit 4,22-kWh-Speicher 1716 Euro.
Wenn die mitgelieferten zwei Meter langen MC4-Kabel zum Anschluss an den Speicher nicht ausreichen, gibt es im Priwatt-Shop unter Zubehör Verlängerungskabel. Mit fünf Meter Länge kostet ein Paar 22,50 Euro.
Wer mit dem Priwatt-Speicher eine an den tatsächlichen Strombedarf angepasste Einspeiseleistung umsetzen möchte, muss einen Smart Meter verwenden. Dafür kommt derzeit nur der Shelly Pro 3EM für aktuell 80 Euro infrage. An der Unterstützung des für digitale Stromzähler geeigneten Everhome Ecotracker für aktuell rund 70 Euro arbeitet Priwatt noch. Während der Shelly von einem Elektriker in der Stromverteilung eingebaut werden muss, kann man den Ecotracker selbst an einem kompatiblen digitalen Zähler anbringen. Passende Modelle listet Everhome in einem PDF.
Wann rechnet sich der Priwatt Avocado Orbit M und wie viel spart man damit?
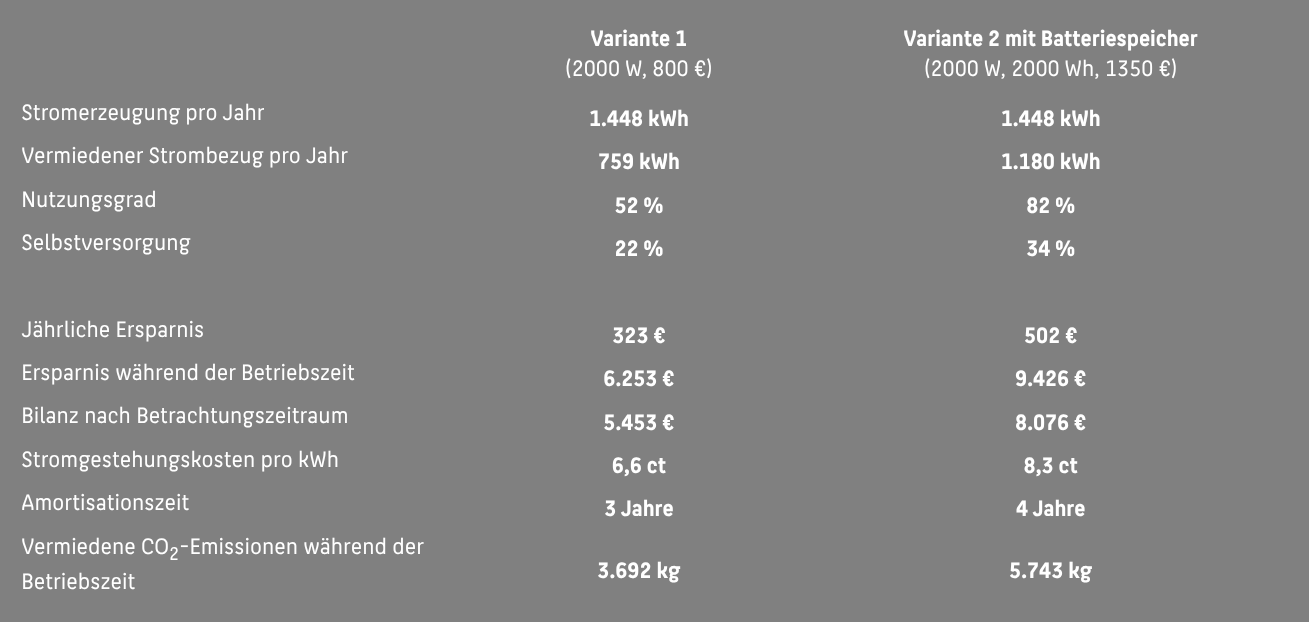
Für die Wirtschaftlichkeitsrechnung mit dem Stecker-Solar-Simulator der HTW Berlin nehmen wir einen Stromverbrauch eines Zwei-Personen-Haushalts in Höhe von 3500 kWh an und betrachten einen Zeitraum von 20 Jahren. Der Stecker-Solar-Simulator ermöglicht auch, die Ersatzkosten für Wechselrichter und Speicher zu berücksichtigen. Das ist zwar für die Amortisationszeit nicht entscheidend, wohl aber für die Gesamtbilanz. Dabei fallen Ersatzkosten für den Wechselrichter nach 15 Jahren und für die Batterie nach 10 Jahren an. Für letztere kalkuliert er einen Wiederbeschaffungswert von 75 Prozent der ursprünglichen Investitionssumme, während diese für den Wechselrichter auf ein Drittel taxiert wird. Die Stromkosten setzen wir mit 35 Cent pro kWh an und gehen von einer Verteuerung von 2 Prozent pro Jahr aus.
Laut Stecker-Solar-Simulator ist die Amortisationszeit beim Priwatt-BKW mit 2000 Watt und dem Speicher Avocado Orbit M genauso lange wie das Pendant ohne Speicher. Über die gesamte Laufzeit erzielt das BKW mit Speicher allerdings einen um 2623 Euro höheren Gewinn. Dabei hat der Simulator auch die Ersatzkosten für Speicher und Wechselrichter berücksichtigt.
Fazit
Wie Solakon und Tepto basiert der von Priwatt angebotene Speicher auf einem Modell des chinesischen Herstellers Fox ESS. Die Modelle arbeiten effizient, bieten mithilfe eines Smart Meters wie dem Shelly Pro 3EM eine bedarfsgerechte Einspeisung, was Eigenverbrauch und Rentabilität erhöht und lassen sich bidirektional laden. Während Solakon mit der besten App aufwartet, ist der Priwatt-Speicher am günstigsten, hauptsächlich dann, wenn man mehr als eine Einheit davon verwendet. Und mit der Solakon-Integration für Home Assistant kann man auch den Priwatt-Speicher in das beliebte Smart-Home-System einbinden.
Last but not least integriert Priwatt außerdem seinen eigenen dynamischen Stromtarif in der Orbit-App, sodass man den Speicher auch während der Dunkelflaute im Winter lukrativ betreiben kann. Dafür wird allerdings ein intelligentes Messsystem (iMSys) am Stromanschluss benötigt. Mehr Informationen dazu bietet der Beitrag xxx.

Samsung Galaxy S25 Edge gefloppt: S26 Edge offenbar gestrichen

Surviving Mars: Relaunched: Neuauflage des Mars-Aufbauspiels erscheint am 10. November

Lithografie-Systeme: ASMLs China-Umsatz soll 2026 wegbrechen

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenFirefox-Update 141.0: KI-gestützte Tab‑Gruppen und Einheitenumrechner kommen
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenSo baut Googles NotebookLM aus deinen Notizen KI‑Diashows