Entwicklung & Code
Visual Studio Code 1.102 bringt neue Features für Copilot Chat und MCP-Support
Microsofts freier Sourcecode-Editor Visual Studio Code hat in Version 1.102 einige Neuerungen zu bieten. Das Juni-Release bringt zusätzliche Funktionen für den KI-basierten GitHub Copilot Chat, allgemeinen Support für das Model Context Protocol (MCP) und Updates für die Barrierefreiheit.
GitHub Copilot Chat: Open Source und mit LLM-Auswahl
Kürzlich hat Microsoft verkündet, seine KI-Funktionen für Visual Studio Code (VS Code) quelloffen verfügbar zu machen. Im Rahmen dessen hat das Unternehmen bereits die Copilot-Chat-Erweiterung Open Source gestellt. In diesem Release von VS Code stehen außerdem neue Funktionen bereit.
Neben den vordefinierten Chatmodi „Ask“, „Edit“ und „Agent“ können Entwicklerinnen und Entwickler seit dem letzten Release als Preview eigene Modi mit spezifischen Anweisungen und einem Set erlaubter Tools erstellen, nach denen sich das Large Language Model (LLM) richten soll. Nun können sie auch festlegen, welches Sprachmodell für den Chatmodus eingesetzt werden soll, indem sie die model-Metdateneigenschaft zur Datei chatmode.md hinzufügen und den Model Identifier angeben. Die Modellinfos sind mithilfe des Autovervollständigungs-Tools IntelliSense verfügbar.

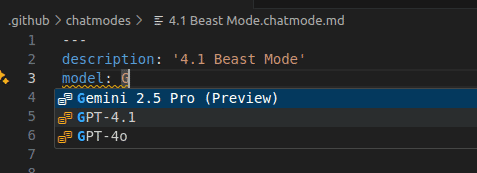
Auswahl des gewünschten LLM im benutzerdefinierten Chatmodus
(Bild: Microsoft)
Daneben bietet der Editor für Chatmodi, Prompts und Anweisungsdateien nun Vervollständigung, Validierung und Hovern für alle unterstützten Metadateneigenschaften. Das Einstellungs-Icon Configure Chat in der Chat-View-Toolbar erlaubt das Verwalten benutzerdefinierter Modi sowie wiederverwendbarer Anweisungen, Prompts und Toolsets:
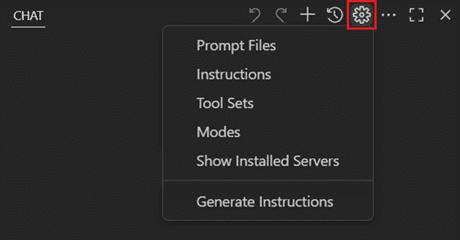
In der Toolbar der Chat-Ansicht erscheint das Icon „Configure Chat“.
(Bild: Microsoft)
Die Auswahl von Modes zeigt dabei alle aktuell installierten benutzerdefinierten Modi und ermöglicht das Öffnen, Erstellen oder Löschen eines Modus. Zahlreiche weitere Updates zum Copilot Chat lassen sich im Ankündigungsbeitrag der neuen VS-Code-Version einsehen.
MCP-Support für den Agentenmodus
Der Support für das Model Context Protocol ist nun in VS Code allgemein verfügbar. Mit diesem Standard, der KI-Modellen die Interaktion mit externen Tools und Services durch ein einheitliches Interface erlaubt, lässt sich der in VS Code verfügbare Agent Mode erweitern – etwa um eine Anbindung an Datenbanken oder um das Aufrufen von APIs. Zudem können Unternehmen nun die Verfügbarkeit von MCP-Servern mithilfe einer GitHub-Copilot-Richtlinie kontrollieren.
Um direkt loszulegen, stellt das VS-Code-Team eine kuratierte Liste beliebter MCP-Server für den Agent Mode bereit.
Erhöhte Barrierefreiheit
Regelmäßig führt VS Code neue Features ein, die die Barrierefreiheit verbessern sollen. In diesem Release sind drei entsprechende Neuerungen an Bord:
Der Befehl Keep All Edits zum Annehmen aller Änderungen lässt sich auch dann ausführen, während der Fokus auf dem Editor liegt. Bisher musste dafür der Fokus auf der Chatansicht liegen. Bei einem Rendering-Fehler im Chat werden Screenreader-User nun benachrichtigt und können diese Information mittels Keyboard fokussieren, und wenn der Chat eine User-Aktion benötigt, ertönt ein akustisches Signal.
Weitere Details zum Juni-Update VS Code 1.102 lassen sich dem Ankündigungsbeitrag entnehmen. Ebenfalls aktualisiert wurden die VS-Code-Erweiterungen für Python, Pylance and Jupyter, wie ein dedizierter Blogeintrag informiert.
(mai)











Entwicklung & Code
Künstliche Neuronale Netze im Überblick 7: Rekursive neuronale Netze
Neuronale Netze sind der Motor vieler Anwendungen in KI und GenAI. Diese Artikelserie gibt einen Einblick in die einzelnen Elemente. Der siebte Teil widmet sich rekursiven neuronalen Netzen, nachdem der sechste Teil der Serie Convolutional Neural Networks vorgestellt hat.

Prof. Dr. Michael Stal arbeitet seit 1991 bei Siemens Technology. Seine Forschungsschwerpunkte umfassen Softwarearchitekturen für große komplexe Systeme (Verteilte Systeme, Cloud Computing, IIoT), Eingebettte Systeme und Künstliche Intelligenz.
Er berät Geschäftsbereiche in Softwarearchitekturfragen und ist für die Architekturausbildung der Senior-Software-Architekten bei Siemens verantwortlich.
Rekursive neuronale Netze sind für die Verarbeitung sequenzieller Daten ausgelegt, indem sie einen versteckten Zustand aufrechterhalten, der sich im Laufe der Zeit weiterentwickelt. Im Gegensatz zu Feedforward-Netzwerken, die davon ausgehen, dass jede Eingabe unabhängig von allen anderen ist, ermöglichen rekursive Netzwerke das Speichern von Informationen über Zeiträume hinweg. Bei jedem Schritt t empfängt eine rekurrente Zelle sowohl den neuen Eingabevektor xₜ als auch den vorherigen versteckten Zustand hₜ₋₁. Die Zelle berechnet einen neuen versteckten Zustand hₜ gemäß einer gelernten Transformation und erzeugt (optional) eine Ausgabe yₜ.
In ihrer einfachsten Form berechnet eine Vanilla-RNN-Zelle einen Präaktivierungsvektor zₜ als Summe einer Eingabetransformation und einer versteckten Zustandstransformation plus einer Verzerrung:
zₜ = Wₓ · xₜ + Wₕ · hₜ₋₁ + b
Der neue Zustand entsteht durch elementweise Anwendung einer nicht linearen Aktivierung σ:
hₜ = σ(zₜ)
Wenn bei jedem Zeitschritt eine Ausgabe yₜ erforderlich ist, kann eine Ausleseschicht hinzugefügt werden:
yₜ = V · hₜ + c
wobei V und c eine Ausgabegewichtungsmatrix und ein Bias-Vektor sind.
In PyTorch kapselt die Klasse torch.nn.RNN dieses Verhalten und verarbeitet das Stapeln mehrerer Schichten und Batches nahtlos. Das folgende Beispiel zeigt, wie man eine einlagige RNN-Zelle erstellt, ihr einen Stapel von Sequenzen zuführt und den endgültigen versteckten Zustand extrahiert:
import torch
import torch.nn as nn
# Angenommen, wir haben Sequenzen der Länge 100, jedes Element ist ein 20-dimensionaler Vektor,
# und wir verarbeiten sie in Batches der Größe 16.
seq_len, batch_size, input_size = 100, 16, 20
hidden_size = 50
# Erstellen Sie einen zufälligen Stapel von Eingabesequenzen: Form (seq_len, batch_size, input_size)
inputs = torch.randn(seq_len, batch_size, input_size)
# Instanziieren Sie ein einlagiges RNN mit tanh-Aktivierung (Standard)
rnn = nn.RNN(input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
nonlinearity='tanh',
batch_first=False)
# Initialisiere den versteckten Zustand: Form (Anzahl_Schichten, Batchgröße, versteckte Größe)
h0 = torch.zeros(1, batch_size, hidden_size)
# Vorwärtspropagierung durch das RNN
outputs, hn = rnn(inputs, h0)
# `outputs` hat die Form (seq_len, batch_size, hidden_size)
# `hn` ist der versteckte Zustand beim letzten Zeitschritt, Form (1, batch_size, hidden_size)
Jede Zeile dieses Ausschnitts hat eine klare Aufgabe. Durch das Erstellen von Eingaben simuliert man ein Batch von Zeitreihendaten. Das RNN-Modul weist zwei Parametermatrizen zu: eine mit der Form (hidden_size, input_size) für Wₓ und eine mit der Form (hidden_size, hidden_size) für Wₕ sowie einen Bias-Vektor der Länge hidden_size. Beim Aufrufen des Moduls für Eingaben und den Anfangszustand h0 durchläuft es die 100 Zeitschritte und berechnet bei jedem Schritt die Rekursionsbeziehung. Der Ausgabetensor sammelt alle Zwischenzustände, während hn nur den letzten zurückgibt.
Obwohl Vanilla-RNNs konzeptionell einfach sind, haben sie Schwierigkeiten, langfristige Abhängigkeiten zu lernen, da über viele Zeitschritte zurückfließende Gradienten dazu neigen, zu verschwinden oder zu explodieren. Um das abzumildern, führen Gated Recurrent Units wie LSTM und GRU interne Gates ein, die steuern, wie stark die Eingabe und der vorherige Zustand den neuen Zustand beeinflussen sollen.
Die LSTM-Zelle (Long Short-Term Memory) verwaltet sowohl einen versteckten Zustand hₜ als auch einen Zellzustand cₜ. Sie verwendet drei Gates – Forget Gate fₜ, Input Gate iₜ und Output Gate oₜ –, die als Sigmoid-Aktivierungen berechnet werden, sowie eine Kandidaten-Zellaktualisierung ĉₜ, die sich mit einer Tanh-Aktivierung berechnen lässt. Konkret:
fₜ = σ( W_f · xₜ + U_f · hₜ₋₁ + b_f )
iₜ = σ( W_i · xₜ + U_i · hₜ₋₁ + b_i )
oₜ = σ( W_o · xₜ + U_o · hₜ₋₁ + b_o )
ĉₜ = tanh( W_c · xₜ + U_c · hₜ₋₁ + b_c )
Der Zellzustand wird dann durch Kombination des vorherigen Zellzustands und des Kandidaten aktualisiert, gewichtet durch die Vergessens- und Eingangsgatter:
cₜ = fₜ * cₜ₋₁ + iₜ * ĉₜ
Schließlich erstellt das System den neuen versteckten Zustand, indem es das Ausgangs-Gate auf die Nichtlinearität des Zellzustands anwendet:
hₜ = oₜ * tanh(cₜ)
PyTorchs torch.nn.LSTM kapselt all diese Berechnungen unter der Haube. Folgender Code zeigt ein Beispiel für eine Reihe von Sequenzen:
import torch
import torch.nn as nn
# Sequenzparameter wie zuvor
seq_len, batch_size, input_size = 100, 16, 20
hidden_size, num_layers = 50, 2
# Zufälliger Eingabebatch
inputs = torch.randn(seq_len, batch_size, input_size)
# Instanziieren eines zweischichtigen LSTM
lstm = nn.LSTM(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=False)
# Initialisiere versteckte und Zellzustände: jeweils mit der Form (Anzahl_Schichten, Batchgröße, versteckte Größe)
h0 = torch.zeros(num_layers, batch_size, hidden_size)
c0 = torch.zeros(num_layers, batch_size, hidden_size)
# Vorwärtsdurchlauf durch das LSTM
outputs, (hn, cn) = lstm(inputs, (h0, c0))
# `outputs` hat die Form (seq_len, batch_size, hidden_size)
# `hn` und `cn` haben jeweils die Form (num_layers, batch_size, hidden_size)
Die Gated Recurrent Unit (GRU) vereinfacht das LSTM, indem sie die Vergessens- und Eingangsgatter zu einem einzigen Aktualisierungsgatter zₜ kombiniert und die Zell- und versteckten Zustände zusammenführt. Die Gleichungen lauten:
zₜ = σ( W_z · xₜ + U_z · hₜ₋₁ + b_z )
rₜ = σ( W_r · xₜ + U_r · hₜ₋₁ + b_r )
ħₜ = tanh( W · xₜ + U · ( rₜ * hₜ₋₁ ) + b )
hₜ = (1 − zₜ) * hₜ₋₁ + zₜ * ħₜ
In PyTorch bietet torch.nn.GRU diese Funktionalität mit derselben Schnittstelle wie nn.LSTM, außer dass nur die versteckten Zustände zurückgegeben werden.
Bei der Arbeit mit Sequenzen variabler Länge benötigt man häufig torch.nn.utils.rnn.pack_padded_sequence und pad_packed_sequence, um Sequenzen effizient im Batch zu verarbeiten, ohne Rechenleistung für das Auffüllen von Tokens zu verschwenden.
Rekursive Netzwerke eignen sich hervorragend für Aufgaben wie Sprachmodellierung, Zeitreihenprognosen und Sequenz-zu-Sequenz-Übersetzungen, wurden jedoch in vielen Anwendungsbereichen von aufmerksamkeitsbasierten Modellen übertroffen.
Zunächst widmet sich der nächste Teil dieser Serie jedoch der Kombination aus konvolutionalen und rekursiven Schichten, um Daten mit sowohl räumlicher als auch zeitlicher Struktur zu verarbeiten. Bei der Videoklassifizierung kann ein Convolutional Neural Network beispielsweise Merkmale auf Frame-Ebene extrahieren, die dann in ein LSTM eingespeist werden, um Bewegungsdynamiken zu erfassen.
(rme)
Entwicklung & Code
EventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
Version 1.1 der auf Event Sourcing spezialisierten Datenbank EventSourcingDB flexibilisiert die Konsistenzsteuerung und erhöht die Sicherheit mit digitalen Signaturen für Events. Event Sourcing ist ein Architekturverfahren, das alle Veränderungen des Zustands einer Anwendung als Sequenz von Events abbildet.
In der neuen Version der EventSourcingDB lassen Konsistenzgrenzen nicht nur über Aggregate festlegen, sondern auch flexibel über EventQL-Abfragen beschreiben. Mit diesen Dynamic Consistency Boundaries (DCBs) definieren Teams genau, wann strikte Konsistenz notwendig ist und wo Eventual Consistency konform zur offiziellen Spezifikation genügt. Dazu implementierte der Freiburger Hersteller the native web eine neue Precondition, die die Datenbank vor dem Schreiben von Events prüft.
Ebenfalls neu sind per Ed25519 signierte Events. Die Datenbank erzeugt die Signaturen on-the-fly, was Schlüsselwechsel ermöglicht, ohne bestehende Events anpassen zu müssen. Client-SDKs unterstützen die Verifikation inklusive Hash-Prüfung in Go und JavaScript, weitere Sprachen sollen folgen. Damit lassen sich Integrität und Authentizität von Events gegenüber Auditoren und Regulatoren zuverlässig nachweisen.
Im Detail gibt es weitere Verbesserungen: Der integrierte EventQL-Editor bietet Autovervollständigung für Event-Typen, neue sowie konsistentere API-Endpunkte erleichtern den Zugriff, und das Management-UI wurde leicht überarbeitet. Zahlreiche Optimierungen im Hintergrund sollen Stabilität und Entwicklerfreundlichkeit erhöhen.

Die Abfragen in der EventSourcingDB erfolgen über die Sprache EventQL.
(Bild: the native web)
Die EventSourcingDB steht als Docker-Image und als Binary für Linux, macOS und Windows bereit. Offizielle SDKs existieren für Go, JavaScript/TypeScript, .NET, PHP, Python, Rust und die JVM. Die Nutzung ist bis 25.000 Events pro Instanz kostenlos. Zudem startet der Anbieter eine gemanagte Version als private Beta. Sie richtet sich an Teams, die die Datenbank nutzen möchten, ohne selbst Infrastruktur betreiben zu müssen.
(who)
Entwicklung & Code
programmier.bar: Cloud-Exit mit Andreas Lehr
Cloud-Exit ist aktuell ein heiß diskutiertes Thema – spätestens seit Firmen wie Basecamp angekündigt haben, die Cloud zu verlassen und wieder auf eigene Infrastruktur zu setzen.
In dieser Podcastfolge sprechen Dennis Becker und Jan Gregor Emge-Triebel mit Andreas Lehr, Berater für Cloud- und DevOps-Themen und Herausgeber des Podcasts „Happy Bootstrapping“ sowie des Newsletters „Alles nur gecloud“. Gemeinsam diskutieren sie, was neben hohen Kosten noch für einen Cloud-Exit spricht: von Vendor-Lock-ins über Datenschutz bis hin zu Performance und digitaler Souveränität. Dabei berichtet Andreas Lehr von realen Erfahrungen aus der Praxis.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externer Inhalt geladen.
Einig sind sich die drei, dass Hyperscaler durchaus weiter ihre Berechtigung haben – aber wo genau fängt ein Cloud-Exit an, und wie nah muss ein Unternehmen seinen eigenen Servern wieder kommen, damit sich der Schritt lohnt?
Die aktuelle Ausgabe des Podcasts steht auch im Blog der programmier.bar bereit: „Cloud-Exit mit Andreas Lehr„. Fragen und Anregungen gerne per Mail oder via Mastodon, Bluesky, LinkedIn oder Instagram.
(mai)

Der Cube-Look lebt: Harman/Kardon legt Soundsticks in Version 5 auf

DeepL: Deutsches Start-up bringt KI-Agenten an den Start

Apples AI-Suche als Angriff auf OpenAI

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

Der ultimative Guide für eine unvergessliche Customer Experience

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-

 UX/UI & Webdesignvor 5 Tagen
UX/UI & Webdesignvor 5 TagenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist")
eine gute Nachricht ist") Social Mediavor 2 Wochen
Social Mediavor 2 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Wochen
Entwicklung & Codevor 2 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick