Entwicklung & Code
Wie KI die Fähigkeiten von Entwicklerinnen und Entwicklern untergräbt
Mir ist vor Kurzem etwas passiert, das ich sehr erschreckend fand. Ich wurde gebeten, einen Pull Request zu reviewen, und bin dabei auf eine Codezeile gestoßen, die ich nicht verstanden habe und die für mein Verständnis keinen wirklichen Sinn ergeben hat. Da ich kein Freund davon bin, in einem Review vorschnell mit einem harschen
„Das ist falsch!“
zu reagieren, sondern stets versuche, auch die Option in Betracht zu ziehen, dass ich vielleicht etwas missverstanden habe, dass mir eventuell der Kontext fehlt oder dass ich noch nicht das gesamte Bild überblicke, habe ich den Entwickler, der diesen Pull Request verfasst hat, gefragt, was es mit dieser Zeile auf sich habe. Ich würde sie nicht verstehen. Die Antwort lautete:
„Das weiß ich leider auch nicht, ich habe das nicht so wirklich verstanden, aber ChatGPT hat gesagt, dass das so sein muss.“
Ich war sprachlos.


Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Meiner Meinung nach sollte man niemals und unter keinen Umständen Code als „fertig“ deklarieren, den man nicht verstanden hat. Ich habe mich über diesen Vorfall dann mit einer Reihe von befreundeten Entwicklerinnen und Entwicklern ausgetauscht. Das Erschreckende ist: Die meisten von ihnen haben diese Erfahrung auch schon gemacht. Es handelt sich also nicht um einen Einzelfall, sondern das scheint inzwischen eine durchaus gängige Normalität zu sein. Und das ist ein Problem, auf ganz vielen verschiedenen Ebenen.
Kein Mehrwert gegenüber der KI
Fangen wir mit dem offensichtlichsten Punkt an: Wenn Sie als Entwicklerin oder als Entwickler nicht in der Lage sind, Ihre Arbeit und Ihre Ergebnisse zu erklären, weil Sie Ihre Arbeit von einer KI erledigen lassen und mehr oder weniger einfach nur das durchwinken, was Ihnen die KI generiert hat, dann stellt sich die Frage: Welchen Mehrwert liefern Sie?
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
KI zerstört Deine Intelligenz // deutsch
Anders formuliert: Sie sind deutlich teurer als die KI. Wenn Ihre gesamte Leistung lediglich darin besteht, einen (hoffentlich) passenden Prompt zu formulieren und dann das KI-generierte Ergebnis unhinterfragt und unverstanden einfach nur weiterzugeben, dann wäre es objektiv betrachtet günstiger und auch effizienter, die Aufgabe direkt der KI zu geben. Denn auch Ihnen muss zunächst jemand die Aufgabe erklären, zum Beispiel in Form einer Anforderung. Das ist aber letztlich nichts anderes als ein Prompt, und diesen könnte man theoretisch auch direkt an die KI übergeben und das Ergebnis 1:1 übernehmen. Das ginge nicht nur deutlich schneller, sondern wäre vor allem deutlich günstiger. Die Frage ist also: Womit ist Ihr Job gerechtfertigt?
Natürlich kann man nun einwenden:
„Entwicklerinnen und Entwickler sehen sich das Ergebnis aber noch einmal genau an und validieren es, und damit ist das Ergebnis am Ende dann viel besser!“
Der Punkt dabei ist nur: Genau das erfordert, dass man verstanden hat und nachvollziehen kann, was die KI generiert hat. Und genau das war im besagten Fall eben nicht gegeben. Insofern stellt sich durchaus die Frage: Wenn Sie regelmäßig so arbeiten, untergraben Sie damit nicht langfristig Ihren eigenen Job? Das ist vermutlich nicht in Ihrem Interesse.
Papa, darf ich Instagram haben?
Wie reagiert man auf einen solchen Vorfall? Eine Möglichkeit wäre, pauschal den Einsatz von KI zu verbieten. Das Problem dabei ist allerdings, dass Verbote in der Regel wenig bis gar nichts nützen. Das ist genauso wie bei einem Teenager, der fragt, ob er einen Instagram-Account haben dürfe, und Sie als Elternteil sagen dann „nein“.
Das Ergebnis ist mit hoher Wahrscheinlichkeit nicht, dass der Teenager dann keinen Instagram-Account haben wird, sondern dass er relativ bald stattdessen heimlich einen erstellt. Das kann natürlich nicht das Argument sein, um als Eltern allem einfach zuzustimmen, und letztlich muss den richtigen Weg hierfür auch jede Familie für sich entscheiden, aber ich persönlich denke mir: Es ist durchaus ein Vertrauensbeweis und etwas Besonderes, wenn Ihr Kind Sie das fragt. Vielleicht ist es sinnvoll(er), das Positive zu sehen und zu versuchen, gemeinsam einen Weg zu finden, statt ein pauschales Verbot auszusprechen, das ohnehin nicht greift.
So ähnlich ist es auch, wenn man in einem Unternehmen versucht, künstliche Intelligenz zu verbieten. Das kann man machen – aber es wird vermutlich nicht besonders gut funktionieren, weil die Versuchung, sich das Leben leichter zu machen, sehr groß ist.
KI ist verführerisch
Damit kommen wir zu dem Punkt, warum so viele Entwicklerinnen und Entwickler überhaupt auf künstliche Intelligenz zurückgreifen. Denn eigentlich müsste man annehmen, dass, wenn man das zu lösende Problem verstanden hat, es in der Mehrzahl der Fälle nicht so schwierig sein dürfte, den passenden Code selbst zu schreiben. Warum macht man das also?
Künstliche Intelligenz macht das Leben leichter, zumindest auf den ersten Blick. Man muss nicht mehr so viel über das Problem und die Lösung nachdenken, man kann mögliche Stolpersteine umgehen und mit weniger Aufwand zu einem guten Ergebnis kommen. Warum also sollte man das nicht nutzen?
Das lässt sich recht einfach beantworten, wenn man sich fragt, warum wir Kindern in der Grundschule nicht einfach einen Taschenrechner in die Hand drücken, sondern ihnen mühsam zunächst schriftliches Addieren und andere Grundrechenarten beibringen. Der Taschenrechner wird üblicherweise erst am Ende der Unterstufe oder am Anfang der Mittelstufe eingeführt, wenn das Kind die Grundrechenarten von Hand beherrscht.
Würden Sie es für eine gute Idee halten, wenn wir Kindern nun nicht mehr das Rechnen an sich, sondern nur noch das Bedienen eines Taschenrechners beibringen würden? Vermutlich nicht. Denn ein gewisses Grundverständnis ist zwingend erforderlich, um später komplexere Probleme lösen zu können.
Wissen …
Der Taschenrechner in der ersten Klasse ist jedoch nur ein Beispiel von vielen. Man könnte auch sagen: 99 Prozent der alltäglichen Kommunikation findet über gesprochene Sprache statt. Eigentlich muss man dafür auch nicht mehr unbedingt lesen und schreiben lernen. Das mag provokant klingen, aber wenn Sie sich fragen, wo Sie in Ihrem Alltag wirklich auf geschriebene Sprache angewiesen sind, dann ist das nicht allzu häufig der Fall. Alexa liest die Nachrichten vor, Tomaten und Gurken können Sie im Supermarkt vermutlich auch dann voneinander unterscheiden, wenn Sie das zugehörige Schild nicht lesen können, und in der Apotheke geben Sie ohnehin das Rezept ab, das Ihnen Ihre Ärztin oder Ihr Arzt ausgestellt hat. Wozu also noch lesen und schreiben lernen?
Wie gesagt: Das ist ein provokantes Beispiel. Der Punkt ist jedoch: Wenn wir grundlegende Fähigkeiten entweder nie erlernen oder sie durch Nichtnutzung wieder verlernen, fehlt uns die Basis für komplexeres Denken. Und genauso ist das beim Entwickeln: Wenn Sie nie gelernt haben – oder zunehmend verlernen – Probleme selbst zu analysieren, Fehler zu suchen, unterschiedliche Lösungsstrategien zu entwickeln, Vor- und Nachteile abzuwägen, Dinge auszuprobieren, kurz: Erfahrung zu sammeln, dann werden Sie nie an Ihren Aufgaben wachsen. Dann sind Sie nämlich dauerhaft darauf angewiesen, dass jemand anders Ihnen sagt, wie Sie etwas besser lösen sollten.
… und Erfahrung
Ich kann mir denken, welches Gegenargument an dieser Stelle kommen wird:
„Das kann mir doch aber auch die KI sagen. Ich muss nur fragen.“
Das Problem daran: Sie wissen nicht, was und wann Sie fragen müssen, weil Sie gar nicht wissen, was in der jeweiligen Situation relevant ist und worauf Sie achten müssten. Um ein Beispiel zu nennen: Wenn Sie eine Datei speichern möchten, und dabei sicherstellen wollen, dass sie auch dann vollständig geschrieben wird, wenn beispielsweise der Strom ausfällt, dann dürfen Sie die Datei nicht einfach so schreiben. Sonst haben Sie möglicherweise eine halbe Datei.
Stattdessen müssen Sie den Inhalt zunächst in eine temporäre Datei schreiben und diese dann umbenennen. Das Umbenennen ist nämlich (meistens) ein atomarer Vorgang. Unter macOS und Linux funktioniert das allerdings wiederum etwas anders als unter Windows. Wenn Sie dieses Problem lösen sollen, müssen Sie also all das wissen. Wenn Sie das nicht wissen, weil Sie nie gelernt haben, wie SSDs funktionieren, was Blöcke sind, wie ein Dateisystem funktioniert, was „atomar“ bedeutet, was eine Transaktion ist, welchen Einfluss Partitionen haben, was der POSIX-Standard ist, und so weiter – dann werden Sie den Vorschlag der KI auch nicht hinterfragen, sondern ihn direkt übernehmen. Und genau das ist das Problem.
KI funktioniert, bis sie nicht mehr funktioniert
Was Sie in solchen Situationen brauchen, ist also nicht nur Wissen, sondern vor allem auch Erfahrung. Wissen kann man nachschlagen. Erfahrung hingegen kann man nicht nachschlagen – die muss man machen: Sie müssen Fehler machen, Sie müssen herausfinden, wo die Ursachen liegen und wie man sie behebt, und das kostet Zeit. Wenn Sie das nicht tun, verlernen Sie – oder lernen gar nicht erst –, wie man komplexe Probleme löst.
Insofern fördert der Einsatz von künstlicher Intelligenz ein sehr oberflächliches Entwickeln: Auf den ersten Blick scheint alles korrekt. Wenn Sie kein tieferes Wissen haben, denken Sie schnell, dass alles zu passen scheint. Aber Sie können es nicht wirklich beurteilen. Sie erkennen nicht die Konsequenzen, kennen keine Alternativen, denken nicht aktiv über Codequalität, Performance oder Architektur nach, und Sie prüfen nichts mehr, weil Sie sich daran gewöhnt haben, dass die KI in der Regel richtig liegt. Doch KI-generierter Code – sofern er nicht trivial ist – enthält gerne subtile Fehler.
Das Beispiel mit dem atomaren Schreiben ist mein üblicher Test: Kein Sprachmodell, das ich bisher ausprobiert habe, liefert auf Anhieb eine korrekte Lösung – im Gegenteil. Und hakt man nach, nähert es sich einer korrekten Lösung nach und nach an, bleibt aber erschreckend lange fehlerhaft. Und Sie merken das nicht, wenn Sie die Grundlagen nicht selbst verstanden haben.
Auf dem Weg in eine Zwei-Klassen-Gesellschaft
Kurz gesagt: Wissen und Erfahrung schwinden – und damit auch Ihre Fähigkeit, echte Probleme zu lösen. KI macht Sie dümmer. Und je mehr Sie sie einsetzen, desto schneller tritt dieser Effekt ein.
Damit steuern wir auf eine Zwei-Klassen-Gesellschaft zu: Es gibt Entwicklerinnen und Entwickler, die den steinigen Weg gehen, langsam vorankommen, die Grundlagen verstehen und sich mit Details befassen. Und es gibt jene, die sich auf KI verlassen. Letztere werden aber langfristig keinen Erfolg haben, denn Sie sind nicht in der Lage, einen echten Mehrwert zu leisten. Ihr Job kann über kurz oder lang automatisiert werden.
Das ist überraschenderweise kein neues Phänomen. Schon vor KI gab es diese Unterschiede. Ich habe in einer Zeit programmieren gelernt, in der es (für mich) kein Internet gab. Daher war ich auf Bücher, Zeitschriften und vor allem auf logisches Denken angewiesen. Diese Zeit war mühsam, aber ich bin dankbar dafür. Sie hat mir beigebracht, ein Problem im Kern verstehen zu wollen – oder zu müssen.
Wer schon einmal mit mir im Pair Programming gearbeitet hat, weiß, dass ich ständig frage:
„Warum ist das so?“
Ich will verstehen, bevor ich handle. Aber ich habe oft das Gefühl, damit allein zu sein.
Bei der Fehlersuche beobachte ich zum Beispiel oft, dass viele Entwicklerinnen und Entwickler nicht gründlich den Code und die Fehlermeldung lesen und nachdenken, sondern mehr oder weniger blind und wahllos herumprobieren, was ihnen naheliegend erscheint. Ich hingegen analysiere den Code und finde so meist schnell die Ursache. Nicht, weil ich besonders klug bin, sondern weil ich mich auf das Problem einlasse und versuche, es zu durchdringen.
Tiefes Wissen ist selten
Viele machen sich meiner Meinung nach dabei das Leben zu leicht. Sie verlassen sich auf Assistenten, Frameworks – und heute eben auf KI, ohne sich mit den Grundlagen zu befassen. Das hat in den 1990er-Jahren schon nicht funktioniert, und heute funktioniert es immer noch nicht. Tiefes Wissen ist selten und wird durch KI noch seltener. KI verstärkt die Spaltung. Es gibt eine kleine Elite, die Systeme versteht. Und eine große Masse, die KI-Code validiert, ohne ihn zu verstehen. Diese Masse erlebt aktuell die Illusion von Beschleunigung und Befähigung, doch in Wahrheit schaufelt sie sich ihr eigenes Grab.
Unternehmen glauben, sie könnten künftig ohne Entwicklerinnen und Entwickler auskommen – bis irgendwann niemand mehr da ist, der komplexe Probleme lösen und die KI noch hinterfragen kann. Die wenigen, die das dann noch können, werden sehr, sehr teuer sein. Und dann ist das Gejammer groß …
Was tun?
Ich hatte eingangs gefragt, wie man mit dem Thema umgehen sollte. Ein Verbot wird nicht funktionieren, KI lässt sich nicht mehr aufhalten. Die Frage lautet also vielmehr: Wie arrangiert man sich mit KI?
Ich glaube, die Lösung muss sein: Nutzen Sie KI als Werkzeug, aber behalten Sie die Kontrolle. Die KI darf keine Entscheidung treffen, die Sie nicht auch selbst hätten treffen können. Wenn Sie die KI nicht mehr hinterfragen können, dann haben Sie die Kontrolle verloren. Meine persönliche Faustregel lautet daher: Wenn Sie es nicht selbst schreiben könnten, dann nutzen Sie es nicht. KI darf helfen, aber nie Ihre einzige Wissensquelle sein. Und vor allem: Sie darf Ihnen nicht das Denken abnehmen, sonst verlernen Sie, selbst zu denken.
Wenn Sie nicht mehr verstehen, was passiert, haben Sie ein Problem. Der falsche Ansatz ist also zu sagen, dass es schon irgendwie passen wird. Der richtige ist, herauszufinden, was passiert und warum. Heute gilt dasselbe wie vor 30 Jahren: Tiefer Einstieg in die Materie ist anstrengend, aber lohnenswert. Er kostet Zeit, Disziplin und Ausdauer. Doch genau das unterscheidet Austauschbarkeit von Exzellenz. Wer sich dem KI-Trend einfach hingibt, wird untergehen. Echte Entwicklerinnen und Entwickler hingegen werden die neue Elite der IT-Welt sein.
Was bedeutet das nun für Sie? Ganz einfach: Verlassen Sie sich nicht auf KI. Wählen Sie nicht den bequemen Weg. Dieser führt in die Abhängigkeit. Wollen Sie langfristig gefragt sein? Dann denken Sie selbst. Die Frage, die Sie sich heute stellen müssen, lautet: Wollen Sie langfristig erfolgreich sein oder nur kurzfristig bequem?
(mai)











Entwicklung & Code
Angular Signals: Elegante Reaktivität als Architekturfalle
Mit Angular 17 hielten Signals 2023 offiziell Einzug in das Framework. Sie versprechen eine modernere, klarere Reaktivität: weniger Boilerplate-Code, bessere Performance. Gerade im Template- und Komponentenbereich lösen sie viele Probleme eleganter als klassische Observable-basierte Ansätze.

Nicolai Wolko ist Softwarearchitekt, Consultant und Mitgründer der WBK Consulting AG. Er unterstützt Unternehmen bei komplexen Web- und Cloudprojekten und wirkt als Sparringspartner sowie Gutachter für CTOs. Fachbeiträge zur modernen Softwarearchitektur veröffentlicht er regelmäßig in Fachmedien und auf seinem Blog.
Statt Subscriptions, pipe() und komplexen Streams genügen nun wenige Zeilen mit signal(), computed() und effect(). Der Code wirkt schlanker, intuitiver und näher am User Interface (UI).
Da liegt die Idee nahe: Wenn Signals im UI überzeugen, warum nicht auch in der Applikationslogik? Warum nicht RxJS vollständig ersetzen? Ein Application Store ohne Actions, Meta-Framework und Observable: direkt, deklarativ, minimalistisch.
Ein Ansatz, der im Folgenden anhand eines konkreten Fallbeispiels analysiert und kritisch hinterfragt wird. Anschließend wird behandelt, in welchen Kontexten sich Signals sinnvoll einsetzen lassen.
Aufbau des Fallbeispiels
Auf den ersten Blick besitzt dieses Beispiel einen klar strukturierten Architekturansatz. Doch der Wandel beginnt unauffällig. RxJS bleibt zunächst außen vor. Das UI reagiert flüssig, der Code bleibt übersichtlich. Komplexe Streams, verschachtelte Operatoren oder eigenes Subscription Handling entfallen. Stattdessen kommen Signals zum Einsatz. Es liegt nahe, diese unkomplizierte Herangehensweise auch für die Applikationslogik zu übernehmen. Im folgenden Beispiel übernimmt ein ProductStore die Zustandslogik. Signals organisieren Kategorien, Filter und Produktdaten – reaktiv und direkt.
@Injectable({ providedIn: 'root' })
export class ProductStore {
private allProducts = signal([]);
readonly selectedCategory = signal('Bücher');
readonly onlyAvailable = signal(false);
readonly productList = computed(() => {
return this.allProducts().filter(p =>
this.onlyAvailable() ? p.available : true
);
});
selectCategory(category: string) {
this.selectedCategory.set(category);
}
toggleAvailabilityFilter() {
this.onlyAvailable.set(!this.onlyAvailable());
}
constructor(private api: ProductApiService) {
effect(() => {
const category = this.selectedCategory();
const onlyAvailable = this.onlyAvailable();
this.api.getProducts(category, onlyAvailable).then(products => {
this.allProducts.set(products);
});
});
}
}
Die Struktur überzeugt zunächst durch Klarheit. Die Komponente konsumiert productList direkt, ohne eigene Logik. Der Store verwaltet den Zustand, Signals sorgen für die Weitergabe von Änderungen.
Doch mit der nächsten Anforderung ändert sich das Bild: Bestimmte Produkte sollen zwar im Katalog verbleiben, aber im UI nicht mehr erscheinen. Da auch andere Systeme die bestehende API verwenden, ist eine Anpassung nicht möglich. Stattdessen liefert das Backend eine Liste freigegebener Produkt-IDs, anhand derer das UI filtert.
@Injectable({ providedIn: 'root' })
export class ProductStore {
// [...]
readonly backendEnabledProductIds = signal>(new Set());
readonly productList = computed(() => {
return this.allProducts().filter(p =>
this.onlyAvailable() ? p.available : true
).filter(p => this.backendEnabledProductIds().has(p.id));
});
constructor(private api: ProductApiService) {
effect(() => {
const category = this.selectedCategory();
const onlyAvailable = this.onlyAvailable();
this.api.getProducts(category, onlyAvailable).then(products => {
this.allProducts.set(products);
});
});
effect(() => {
this.api.getEnabledProductIds().then(ids => {
this.backendEnabledProductIds.set(new Set(ids));
});
});
}
// [...]
}
Nach außen bleibt die Architektur zunächst unverändert. Die Komponente enthält weiterhin keine eigene Logik, Subscriptions sind nicht notwendig, und die Reaktivität scheint erhalten zu bleiben. Im Service jedoch nimmt die Zahl der effect()s zu, Abhängigkeiten werden vielfältiger, und die Übersichtlichkeit leidet.
Nach und nach wandert Logik in verteilte effect()s, bis ihre Zuständigkeiten kaum noch greifbar sind. Aus einem überschaubaren ViewModel entsteht ein Gebilde mit immer mehr impliziten Reaktionen – eine Entwicklung, die ein waches Auge für Architektur erfordert.
Wenn reaktive Systeme entgleisen
Das Setup wirkt zunächst unspektakulär. Die Produktliste wird über ein computed() erstellt, gefiltert nach Verfügbarkeit und den vom Backend freigegebenen IDs. Zwei effect()s laden die Daten.
Der Code wirkt aufgeräumt und lässt sich modular erweitern. Doch der nächste Feature-Wunsch stellt das System auf die Probe: Die Stakeholder möchten wissen, wie oft bestimmte Kategorien angesehen werden. Die Entwicklerinnen und Entwickler entscheiden sich für einen naheliegenden Ansatz. Eine Änderung der Kategorie löst ein Tracking-Event aus. Ein effect() scheint dafür perfekt geeignet – unkompliziert und ohne erkennbare Nebenwirkungen:
effect(() => {
const category = this.selectedCategory();
this.analytics.trackCategoryView(category);
});
Schnell eingebaut, kein zusätzlicher State, keine neue Subscription. Eine Reaktion auf das bestehende Signal, unkompliziert und ohne erkennbare Nebenwirkungen. Doch damit verlässt der Code den Bereich kontrollierter Reaktivität.
Der Kipppunkt
Die Annahme ist klar: Ändert sich die Kategorie, wird ein Tracking ausgelöst. Was dabei leicht zu übersehen ist: Signals reagieren nicht auf Bedeutung, sondern auf jede Mutation. Auch wenn set() denselben Wert schreibt oder zwei Komponenten nacheinander dieselbe Auswahl treffen, passiert zwar technisch etwas, semantisch aber nicht. Das Ergebnis sind doppelte Events und verzerrte Metriken, ohne dass der Code einen Hinweis darauf gibt. Alles sieht korrekt aus.
Das Tracking erfolgt unmittelbar im selben Ausführungstakt (Tick), ohne Möglichkeit zur Entkopplung. Wenn parallel ein weiterer effect() ausgelöst wird – etwa durch ein zweites Signal –, fehlt jegliche Koordination.
Die Reihenfolge ist nicht vorhersehbar, und das UI kann in einen inkonsistenten Zustand geraten: Daten werden mehrfach geladen, Reaktionen überschneiden sich, Seiteneffekte sind nicht mehr eindeutig zuzuordnen. Mit jedem zusätzlichen effect() steigt die Zahl impliziter Wechselwirkungen. Was wie ein reagierendes System wirkt, ist längst nicht mehr entscheidungsfähig.
In einem Kundenprojekt führte genau dieser Zustand dazu, dass ein effect() mehrfach pro Sekunde auslöste. Nicht wegen einer echten Änderung, sondern weil derselbe Wert mehrfach gesetzt wurde. Das UI zeigte korrekte Daten, aber das Backend war mit redundanten Anfragen überlastet.
Das Missverständnis
effect() wirkt wie ein deklarativer Controller: „Wenn sich X ändert, tue Y.“ Doch in Wirklichkeit ist es ein reaktiver Spion. Er beobachtet jedes Signal, das gelesen wird, unabhängig von der semantischen Bedeutung. Er feuert sogar dann, wenn niemand es erwartet. Und er ist nicht koordiniert. Jeder effect() lebt in seiner eigenen Welt, ohne zentrale Regie.
Was als architektonische Vereinfachung begann, endet in einer Blackbox aus Zuständen, Reaktionen und Nebenwirkungen. Mit jedem weiteren Feature wächst diese Komplexität. Es gibt keinen großen Knall, aber eine zuvor elegant erscheinende Struktur driftet leise auseinander.
Entwicklung & Code
KubeSphere entfernt Open-Source-Dateien und stellt Support ein
Die chinesische Kubernetes-Plattform KubeSphere hat auf GitHub angekündigt, die Open-Source-Version des Produkts zurückzuziehen und den kostenlosen Support einzustellen: „Ab dem Datum dieser Ankündigung werden die Download-Links für die Open-Source-Version von KubeSphere deaktiviert und der kostenlose technische Support eingestellt.“
Das Kernprojekt von KubeSphere auf GitHub bleibt jedoch Open Source unter Apache-2-Lizenz. Als Grund für den Wechsel nennt der Hersteller die Änderung der Digitalisierung mit Gen AI, wodurch auch die Infrastruktur-Branche tiefgreifende Veränderungen erfahren hat. „Um sich an die neue Ära anzupassen, die Produktkapazitäten und die Servicequalität weiter zu verbessern und sich auf die Forschung und Entwicklung von Kerntechnologien sowie die Optimierung kommerzieller Lösungen zu konzentrieren, hat das Unternehmen nach mehrjähriger Planung und sorgfältiger Prüfung beschlossen, die folgenden Anpassungen am Open-Source-Projekt KubeSphere vorzunehmen.“ Es folgt die oben genannte Ankündigung.
Welche aktuellen oder künftigen Produkte konkret nicht mehr Open Source sind, ist der Ankündigung nicht zu entnehmen. Auf der Webseite weist der Hersteller derzeit sogar noch auf die CNCF-Zertifizierung hin. Nutzern von KubeSphere rät der Diskussionsbeitrag, sich für eine kommerzielle Version an den Support zu wenden.
Der Beitrag ist auf Chinesisch, darunter findet sich eine englische Übersetzung. Wir haben mit KI-Hilfe direkt aus dem Chinesischen übersetzt.
(who)
Entwicklung & Code
JetBrains: Preissprung bei Entwicklungsumgebungen ab 1. Oktober
Das tschechische Softwareunternehmen JetBrains hat angekündigt, seine Preise am 1. Oktober 2025 anzuziehen. Nach drei Jahren der Preisstabilität sieht sich der Hersteller beliebter Entwicklungsumgebungen (Integrated Development Environments, IDEs) aufgrund der Inflation gezwungen, die Preise für Abonnements zu erhöhen. Wer im Voraus zahlt, kann die bisherigen Preise noch für eine begrenzte Zeitdauer über den 1. Oktober hinaus beibehalten.
Preissteigerungen für IDEs, .NET-Tools, dotUltimate und All Products Pack
Betroffen sind die Abos für die JetBrains-Entwicklungsumgebungen – wie IntelliJ IDEA, WebStorm oder PhpStorm –, die .NET-Tools, das .NET-Toolkit dotUltimate und die IDE-Sammlung All Products Pack. Auf einer Webseite informiert JetBrains über die Preisänderungen. Beispielsweise erhöhen sich die Kosten der IDE IntelliJ IDEA Ultimate für den individuellen Einsatz bei jährlicher Zahlweise von 169 Euro auf 199 Euro (plus Mehrwertsteuer), bei monatlicher Zahlung von 16,90 Euro auf 19,90 Euro – jeweils auf das erste Nutzungsjahr bezogen. Für Unternehmen fallen die Steigerungen happiger aus: Das gleiche Produkt kostet pro User und Jahr derzeit 599 Euro (oder 59,90 Euro monatlich), ab dem 1. Oktober 719 Euro (oder 71,90 Euro monatlich) – eine Erhöhung um rund 20 Prozent.

Kosten für IntelliJ IDEA Ultimate für die individuelle Nutzung
(Bild: JetBrains)
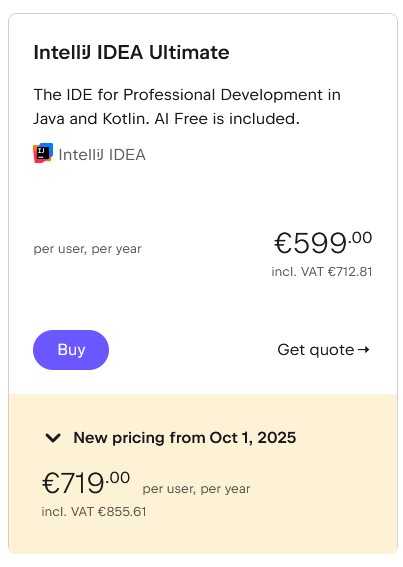
Kosten für IntelliJ IDEA Ultimate für Unternehmen
(Bild: JetBrains)
Beim All Products Pack, das aus elf Entwicklungsumgebungen und weiteren Inhalten besteht, steigen die Preise für den individuellen Einsatz von 289 Euro auf 299 Euro pro Jahr an, für den Einsatz in Unternehmen pro Jahr und User von 779 Euro auf 979 Euro.
Für bestimmte Nutzergruppen wie Lehrkräfte, Schülerinnen und Schüler oder Core Maintainer von Open-Source-Projekten sind weiterhin kostenfreie Angebote aufgeführt.
Alternative: Im Voraus bezahlen und sparen
JetBrains bietet seinen bestehenden sowie neuen Kundinnen und Kunden die Möglichkeit, im Voraus noch zu den derzeitigen Preisen zu bezahlen: Für individuelle Abos gilt dieser dann bis zu drei Jahre lang, für kommerzielle bis zu zwei Jahre. Dann wird die entsprechende Zahlung jedoch auf einen Schlag vor dem 1. Oktober 2025 fällig.
Weitere Details bieten der JetBrains-Blog und die Preisübersichtsseite.
(mai)

Vodafone: Wacken ist das Festival mit dem meisten Datenverkehr

Wirklich besser als der Arztbesuch?

Microsoft: Das sind die Jobs, bei denen KI am stärksten zum Einsatz kommt

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

TikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 Online Marketing & SEOvor 2 Monaten
Online Marketing & SEOvor 2 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenPhilip Bürli › PAGE online
-

 Digital Business & Startupsvor 1 Monat
Digital Business & Startupsvor 1 Monat10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Digital Business & Startupsvor 1 Monat
Digital Business & Startupsvor 1 Monat80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Apps & Mobile Entwicklungvor 1 Monat
Apps & Mobile Entwicklungvor 1 MonatPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenLinkedIn Feature-Update 2025: Aktuelle Neuigkeiten