Künstliche Intelligenz
Missing Link: Machtzentrale Palantir – eine Software lenkt Organisationen
Kaum ein Technologieunternehmen polarisiert so stark wie Palantir Technologies. Das 2003 gegründete US-Unternehmen hat sich vom geheimnisvollen Start-up mit CIA-Verbindungen zu einem börsennotierten Konzern entwickelt, der Regierungen und Großkonzerne weltweit beliefert. Palantir verspricht, aus den Daten moderner Organisationen verwertbare Erkenntnisse zu gewinnen. Während Befürworter die Software als revolutionäres Werkzeug für datenbasierte Entscheidungen preisen, warnen Kritiker vor Überwachung, Intransparenz und Vendor-Lock-in-Effekten. Doch was steckt technisch dahinter?
„Palantir ist keine Datenfirma, sondern eine Softwarefirma“ betont das US-Technologie-Unternehmen seit Jahren. Dabei will Palantir mit seiner Software die zentrale Infrastruktur zur Entscheidungsunterstützung für jede Organisation sein. Um das zu erreichen, müsse man „Ordnung ins Datenchaos“ bei den Kunden bringen und eine vernetzte Organisation schaffen. Das Geschäftsmodell von Palantir beruht auf Software-as-a-Service, zu den Lizenzkosten kommen Servicegebühren und Schulungskosten. Wer sich für Palantir entscheidet, macht sich abhängig und verlagert seine digitale Infrastruktur in ein proprietäres Ökosystem.
Der Einsatz von Palantir bedeutet nicht nur eine technische, sondern auch eine strukturelle Bindung der eigenen Organisation an das US-Unternehmen. Ein späterer Systemwechsel ist aufwendig. Zwar bietet Palantir zahlreiche Schnittstellen, um bestehende Systeme und Datenquellen zu integrieren, aber keine Möglichkeit das einmal aufgebaute System zu einem anderen Anbieter umzuziehen. Bestimmte Daten lassen sich exportieren, doch das eigentliche Kapital – die semantischen Strukturen, Logiken, Interaktionen – sind tief mit Palantirs System verknüpft und funktionieren nur dort. Im Zentrum der Architektur steht eine einheitliche Ontologie – ein formales Bedeutungsmodell, das festlegt, wie Daten der Organisation verstanden, verknüpft und operational nutzbar gemacht werden. Auf einem solchen System basierende datengetriebene Entscheidungen und Prozesse können die Arbeitsweise einer Organisation verändern.


Was fehlt: In der rapiden Technikwelt häufig die Zeit, die vielen News und Hintergründe neu zu sortieren. Am Wochenende wollen wir sie uns nehmen, die Seitenwege abseits des Aktuellen verfolgen, andere Blickwinkel probieren und Zwischentöne hörbar machen.
Palantir verändert Organisationen
Ob sich Palantir als bundesweite Interimslösung für die Polizei eignet und eingeführt werden soll, wie es der Bundesrat im März 2025 gefordert hat und sich einige Innenminister wünschen, erscheint fraglich. Inzwischen zeigt sich wachsender Widerstand gegen die US-Big-Data-Software für die Polizei und bei der Innenministerkonferenz (IMK) konnte keine Einigung für die bundesweite Einführung von Palantir erzielt werden. Stattdessen stellte die IMK in ihrem Beschluss vom 18. Juni 25 fest, „dass die Fähigkeit der automatisierten Datenanalyse als ein Schlüsselelement der künftigen digitalen Sicherheitsinfrastruktur hinsichtlich Verfügbarkeit, Vertraulichkeit, Integrität und ihrer Rechtskonformität keiner strukturellen Einflussmöglichkeit durch außereuropäische Staaten ausgesetzt sein darf“ und „vor diesem Hintergrund die Entwicklung einer digital souveränen Lösung anzustreben ist“.
Den Bundesländern steht es nach wie vor frei, (weiter) mit Palantir zusammenzuarbeiten. Baden-Württemberg plant bereits seit Längerem die Einführung einer Landes-VeRA und hat dafür nach Rücksprache mit Bayern 18,5 Millionen Euro an Haushaltsmittel für 2025/2026 veranschlagt. Auch Sachsen-Anhalt möchte Palantir einführen, berichtet der MDR.
Wie sich die Arbeitsweise mit Palantir ändert, zeigen die Erfahrungen bei der Landespolizei Hessen, die Palantir Gotham als „HessenData“ seit 2017 einsetzt. Jährlich werden mehrere Tausend Abfragen mit dem System durchgeführt, das von jedem Arbeitsplatz aus erreichbar ist. Als im Februar 2023 das Bundesverfassungsgericht die Regeln zur Datenanalyse bei der Polizei beanstandete, wurde dem Land Hessen eine Frist für die Gesetzesänderung eingeräumt, in der die Nutzung von HessenData unter Auflagen weiter erlaubt war. Hessen passte seine Rechtsgrundlage an, weshalb HessenData weiter in Betrieb ist. Das System sorge für mehr Effizienz und „eigentlich ist jede Nutzung im Alltag der Kollegen schon ein Riesenerfolg“, zitiert die SZ in einem aktuellen Beitrag eine Polizistin aus dem Innovation Hub 110, die für den Betrieb der Plattform verantwortlich ist. Palantir scheint fester Bestandteil der hessischen Ermittlungsarbeit zu sein und Hessen ist auch an einem Ausbau der Analysefähigkeiten mit KI interessiert. So nahmen Mitarbeiter des Innovation Hub 110 im Mai 2025 mit einer eigenen Live-Demo an einer AIP Expo von Palantir in München teil, wie sie auf LinkedIn mitteilten. Palantir veranstaltet solche AIP Expos als geschlossenes Networking-Event für Führungskräfte aus seinem Kundenstamm, um die Integration von KI in seine Produkte in der Praxis durch einzelne Kunden selbst vorführen zu lassen.
Um die dahinterliegende Systemarchitektur besser einordnen zu können, lohnt sich ein Blick auf die zentralen Palantir-Produkte – insbesondere auf die modular aufgebauten Plattformen Foundry und Gotham. Sie bilden die technische Grundlage für Anwendungen wie HessenData , DAR (NRW) oder VeRA (Bayern), die sich mittels AIP (Artificial Intelligence Platform) leicht mit KI-Funktionalitäten ergänzen lassen könnten.
Keine Datenplattform, sondern ein Betriebssystem
Die Hauptprodukte sind Palantir Foundry und Palantir Gotham, dazu kommen Palantir AIP und Palantir Apollo. Alle Produkte werden als „Plattformen“ beworben, wobei betont wird, dass sie keine Datenplattform, sondern eine modular aufgebaute Betriebsplattform sind, und als OS dienen sollen.
Foundry wird als „Ontologie-basierte Betriebssystem für das moderne Unternehmen“ beworben; während der Slogan „Deine Software ist das Waffensystem“ für Gotham als „Betriebssystem für die globale Entscheidungsfindung“ bei Behörden und Organisationen im Sicherheitsbereich wirbt.
Das Betriebssystem setzt sich in seiner Basis aus dem „Palantir Data Store“ als physische/technische Ebene der Speicherstruktur für Roh- und Transformationsdaten und der Ontologie als logischer Bedeutungsebene für die Daten zusammen. Der „Palantir Data Store“ ist Bestandteil von Foundry. In Foundry erfolgt die Datenintegration, -modellierung und -analyse.
Von 100 fragmentierten zu einem Palantir-System
Die Ontologie ist als zentrales Struktur- und Organisationsprinzip das Herzstück des Palantir-Systems, das zum semantischen Rückgrat der das System nutzenden Organisation wird.
Eine Ontologie ist ein formales Modell, das Konzepte, Entitäten und ihre Eigenschaften und Beziehungen zueinander einheitlich und strukturiert beschreibt.
So wird eine gemeinsame Bedeutungswelt in einem zentralen System geschaffen, in dem Daten quer über Systeme hinweg aus unterschiedlichsten Quellen und Formaten zusammenfließen, vereinheitlicht, kontextualisiert und analysierbar werden.
Über heterogene IT-Systemlandschaften einer Organisation und ihrer Daten hinweg wird mit der Ontologie eine gemeinsame Sprache als semantische Zwischenebene (Semantic Layer) geschaffen. Und diese Sprache kann auch in der Zusammenarbeit mit anderen Organisationen genutzt werden, wenn sie dieselbe Ontologie nutzen.
Mit Palantirs Ontologie wird ein digitaler Zwilling einer Organisation erstellt. Daten, Prozesse, Regeln und Nutzerinteraktionen werden in einem einheitlichen Modell strukturiert zentral zusammengeführt – dieses Wissen lässt sich maschinell verarbeiten, durchsuchen und logisch verknüpfen. Es lassen sich nicht nur Zusammenhänge verstehen und Rückschlüsse ziehen, sondern auch steuerbare Aktionen durchführen.
Diese Ontologie ist vollständig anpassbar und erweiterbar – sie bildet die Struktur, auf der alle Analysen, Datenflüsse und Benutzeroberflächen in Palantir-Produkten aufbauen. Über die Ontologie wird bestimmt, was sichtbar wird, was verknüpft wird, was als relevant gilt.
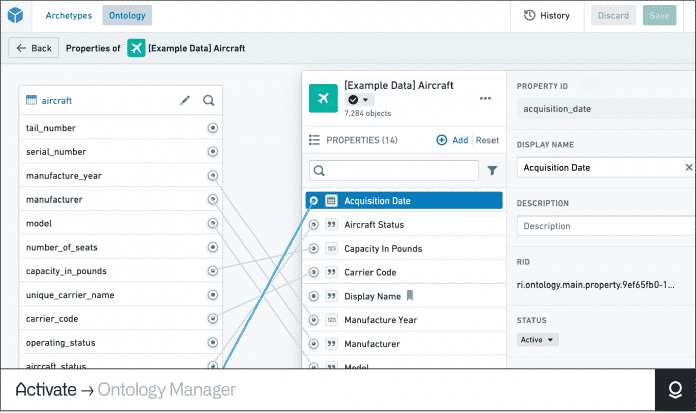
Im „Ontology Manager“ definiert man Entitäten – im Beispiel ein Passagierflugzeug – und weist ihnen Eigenschaften zu. Die Ontologie verknüpft diese mit (Echtzeit-)Daten, Prozessen, Regeln und führt sie in einem einheitlichen Modell strukturiert zentral zusammen.
(Bild: Screenshot/Palantir)
Die Kern-Komponenten der Palantir-Ontologie
- Object Types – definieren Entitäten wie zum Beispiel „Person“, „Sache“, „Ereignis“, „Vorfall“, „Produktionslinie“, „Konzept“
- Properties – beschreiben Eigenschaften/Attribute dieser Entitäten, etwa „Name“, „Kennzeichen“, „Ort“, „Datum“, „Zeitstempel“
- Shared Properties – beschreibt eine Eigenschaft, die auf mehreren Objekttypen verwendet wird, so lassen sich Eigenschaftsmetadaten zentral verwalten
- Link Types – repräsentieren Beziehungen zwischen Entitäten, zum Beispiel „enthält“, „war bei“, „kennt“, „verwendet“, „wohnt“, „Fahrer“, „Mitfahrer“, „ist Mitglied bei“, „Zeuge“, „Beschuldigter“, „Tatverdächtiger“
- Action Types – ermöglicht Änderungen an den Entitäten, ihren Eigenschaften und Beziehungen. Dabei können nach Durchführung der Aktion auch (automatisiert) weitere Aktionen folgen, die in den jeweiligen Aktions-Schemata hinterlegt sind.
- Functions – ermöglichen die Interaktion mit den Entitäten in Form von Logiken, die ausgeführt werden
- Object Views – Darstellung von Informationen und Arbeitsabläufen, die sich auf ein bestimmtes Objekt beziehen, es könnte etwa ein Steckbrief angezeigt werden oder eine detaillierte Darstellung aller mit einem Objekt zusammenhängenden Informationen
- Rollen – die direkte Anwendung von Rollen auf jede Ontologie-Ressource, unabhängig von den Berechtigungen auf die ursprüngliche Datenquelle
- Interfaces – abstraktes Schema für Schnittstellen ist ein Ontologietyp, der die Form eines Objekttyps und seine Funktionen beschreibt. Schnittstellen ermöglichen eine konsistente Modellierung und Interaktion mit Objekttypen, die eine gemeinsame Form haben.








")
")
Künstliche Intelligenz
Forschungspreis „Wissen der Vielen“ würdigt wissenschaftliche Leistungen
Der 2023 ins Leben gerufene „Wissen der Vielen – Forschungspreis für Citizen Science“ zeichnet herausragende wissenschaftliche Beiträge von Projekten im Bereich Bürgerwissenschaften (Citizen Science) mit Preisgeldern von insgesamt 35.000 Euro aus. Er fördert die Anerkennung von Citizen Science in der Forschung und motiviert Bürgerinnen und Bürger, sich aktiv an wissenschaftlichen Projekten zu beteiligen.
Bei Citizen Science kann jeder Mensch mitmachen. Weltweit laden zahlreiche Projekte aus verschiedenen Lebensbereichen zum Mitforschen ein, viele davon kommen aus Deutschland, Österreich und der Schweiz. Jeder kann dabei aktiv an wissenschaftlichen Projekten teilnehmen.
Die besten drei Projekte 2025
Drei zukunftsweisende Projekte gewinnen 2025 den Forschungspreis „Wissen der Vielen“: Ein Team untersucht Birken als Habitat für Baumpilze, ein anderes entwickelt 3D-gedruckte Prothesen für Kinder, und ein drittes schafft eine Plattform für den Austausch zwischen Forschern und DIY-Wissenschaftlern. Die Preisträger erhalten zusammen 35.000 Euro für ihre erstklassigen Arbeiten, die durch Citizen Science – also Wissenschaft mit Bürgerbeteiligung – entstanden sind. Wissenschaft im Dialog und das Museum für Naturkunde Berlin verleihen die Preise im Rahmen des Projekts „mit:forschen!“ zum dritten Mal.
1. Platz
Dr. Dirk Knoche vom Forschungsinstitut für Bergbaufolgelandschaften e.V. in Finsterwalde (Brandenburg) landete auf dem 1. Platz (Preisgeld: 20.000 Euro) für die Publikation „Gemeinsam die Birke erforschen: Bürgerforschung zum Waldwandel: Wasserhaushalt, Biodiversität & Klimawirksamkeit“. Im Projekt „PlanBirke plus C“ sammelten Citizen Scientists eigenständig Messdaten oder nahmen an Bürgerlabor-Tagen im Wald teil. So verglichen Forscher erstmals den Wasserhaushalt verschiedener Birkenmischwälder in Mitteleuropa. Zudem erfassten sie umfassende Daten zur Kohlenstoffspeicherung – vom Stamm bis zu den Blättern. Ein weiteres zentrales Ergebnis: Die Birke bietet gefährdeten Baumpilzarten in Deutschland einen wichtigen Lebensraum.
2. Platz
Diplom-Wirtschaftsinformatiker Sven Bittenbinder nahm den mit 10.000 Euro dotierten Preis für den zweiten Platz für sein Team mit der Publikation „Research Buddy – From a Framework for Overcoming Language Barriers to the Development of a Qualitative Citizen Science Platform“ entgegen. Die Forschungsarbeit aus der Mensch-Computer-Interaktion zeigt, wie Studierende, Senioren und Forscher gemeinsam technische Anforderungen für eine Citizen-Science-Plattform erarbeiten. Ihr Ergebnis: ein Prototyp einer kollaborativ entwickelten Plattform, die Forschern und Bürgern ermöglicht, Projektideen auszutauschen oder Mitforschende zu finden.
3. Platz
Dr. Melike Şahinol, Soziologin, sicherte sich und dem Team den mit 5000 Euro dotierten dritten Platz mit der Publikation „3D-gedruckte Kinderprothesen als befähigende Technologie? Erfahrungen von Kindern mit Oberkörperunterschieden“. Sie zeigt, wie partizipative Ansätze vulnerable Gruppen erfolgreich in die Technikentwicklung einbinden. Im Fokus steht die Frage, ob 3D-gedruckte Prothesen Kindern neue Handlungsmöglichkeiten eröffnen. Dafür arbeitete Şahinol mit Familien, Kindern und Ehrenamtlichen zusammen. Mit einem eigens entwickelten Erkundungs-Toolkit dokumentierten die Kinder ihre körperlichen, emotionalen und sozialen Erfahrungen mit den Prothesen. Die Ergebnisse zeigen, dass die Prothesen die Identität und soziale Teilhabe der Kinder stärken, aber auch Herausforderungen bei der Nutzung aufzeigen.
Die Preisverleihung findet am 12. November während der Konferenz PartWiss in Leipzig statt. Die Preise sollen die Bürgerwissenschaft würdigen und DIY-Enthusiasten motivieren, aktiv an Forschungsprojekten teilzunehmen. Das Bundesministerium für Forschung, Technologie und Raumfahrt unterstützt die Initiative. Weitere Details, auch zu vergangenen Wettbewerben, bietet die Veranstaltungswebseite.
(usz)
Künstliche Intelligenz
Kurz erklärt: Confidential Computing und wie es funktioniert
Die Sicherheitsarchitekturen heutiger IT-Systeme basieren auf einem fundamentalen Vertrauensmodell: Verschlüsselt sind Daten immer dann, wenn sie gespeichert oder übertragen werden – „Data at Rest“ und „Data in Transit“. Während der Verarbeitung liegen sie aber unverschlüsselt im Arbeitsspeicher vor, wo sie ausgelesen werden können – Angreifer bewerkstelligen das zum Beispiel über Seitenkanalattacken.
Confidential Computing schließt diese Lücke mit einer hardwarebasierten Ausführungsumgebung (Trusted Execution Environment, TEE). Sie soll die Daten auch während der Ausführung (Data in Use) vor unbefugtem Zugriff schützen. Das ist insbesondere dann relevant, wenn Cloud-Computing im Spiel ist und es dadurch notwendig wird, dem Cloud-Anbieter zu vertrauen, dass keine sensiblen Daten abfließen.
- Ein Confidential-Computing-fähiger Prozessor kann geschützte Ausführungsumgebungen – Enklaven – erstellen, um den Zugriff auf Daten während ihrer Verarbeitung zu unterbinden.
- Enklaven können weder durch Software- noch durch Hardware-Debugger analysiert werden. Nur der in der Enklave vorhandene Code kann mit den Daten darin interagieren. Zur Verschlüsselung dienen Schlüssel, die direkt in die CPU-Hardware geschrieben sind.
- Enklaven verfügen über Einschränkungen, sowohl in der Funktion als auch in der Performance. Einschlägige SDKs und Frameworks wie SCONE dienen dazu, Software für die entsprechenden Anforderungen aufzubereiten.
Dafür braucht es bestimmte CPUs mit Confidential-Computing-Fähigkeiten. 2015 implementierte Intel die Funktion unter dem Namen SGX (Software Guard Extension) als erster Hersteller in seinen x86-Skylake-Prozessoren. Mittlerweile haben auch andere Hersteller vergleichbare Ansätze – ARM mit TrustZone und AMD mit Secure Processor.
Das war die Leseprobe unseres heise-Plus-Artikels „Kurz erklärt: Confidential Computing und wie es funktioniert“.
Mit einem heise-Plus-Abo können Sie den ganzen Artikel lesen.
Künstliche Intelligenz
TSMC widerspricht Intel-Gerüchten | heise online
Der weltweit größte Chipauftragsfertiger TSMC plant weiterhin keine Partnerschaft mit Intel. Das machte TSMC ein weiteres Mal gegenüber taiwanischen Medien wie Taipei Times klar. Zuvor hatte das Wall Street Journal berichtet, dass Intel wegen möglicher Investitionen auf TSMC zugegangen sei.
TSMC hat laut eigenen Aussagen niemals Gespräche mit einem anderen Unternehmen über Investitionen oder die Gründung einer gemeinsamen Tochterfirma (Joint Venture) geführt – abseits der bestehenden Joint Ventures in Japan (JASM) und Deutschland (ESMC). Auch soll es keine Gespräche über die Vergabe von Lizenzen oder den Transfer von Technologien gegeben haben.
Dementis häufen sich
Gerüchte und Spekulationen über einen TSMC-Einstieg bei Intel halten sich hartnäckig. Zum Jahresanfang erschienen Berichte, wonach sich die US-Regierung verschiedene Kooperationsmodelle gewünscht hätte. Die Spekulationen gingen so weit, dass TSMC den Betrieb von Intels Halbleiterwerken zur Chipproduktion hätte übernehmen können. Im April folgten Gerüchte über ein Joint Venture. TSMC widersprach stets.
Ausgangslage ist Intels wirtschaftlich schlechte Lage. Insbesondere die Halbleiterwerke machen momentan jedes Quartal Verlust in Milliardenhöhe. Aktuell sucht Intel nach Großinvestoren, um sich mehr Zeit zur Rückkehr in die grünen Zahlen zu verschaffen. Erst sollte die Fertigungsgeneration 18A neue Chipkunden anlocken, inzwischen vertröstet Intel auf den Nachfolger 14A fürs Jahr 2027.
Die US-Regierung ist mit einem Anteil von 9,9 Prozent bei Intel eingestiegen. Dafür hat sie zusätzlich zu vorherigen Subventionen 5,7 Milliarden US-Dollar gezahlt. Der japanische Investor Softbank steigt mit zwei Milliarden Dollar ein. Zudem kommt eine Milliarde durch den Teilverkauf der Automotive-Sparte Mobileye rein, weitere 4,5 Milliarden folgen durch den anstehenden Teilverkauf des FPGA-Designers Altera.
Intels Aktie profitiert derweil deutlich von Investitionsgerüchten. Insbesondere Meldungen über einen Apple-Stieg ließen das Wertpapier kürzlich hochschießen. Seit TSMCs Stellungnahme sank der Wert moderat um etwa zwei Prozent.
(mma)

Nur Amazon, Alphabet und Meta profitieren: Social-Media-Boom: WARC hebt Prognose für den Werbemarkt an

Steam Sale: Der Herbst bringt Rabatte für Spiele und ein Steam Deck

Forschungspreis „Wissen der Vielen“ würdigt wissenschaftliche Leistungen

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 1 Monat
Social Mediavor 1 MonatRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 1 Monat
Entwicklung & Codevor 1 MonatPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenFirefox-Update 141.0: KI-gestützte Tab‑Gruppen und Einheitenumrechner kommen