Datenschutz & Sicherheit
Comeback von Lumma und NoName057(16): Cybercrime-Zerschlagung misslungen
Gelingt Strafverfolgungsbehörden ein größerer Schlag gegen Akteure und Infrastrukturen des Cybercrime, so ist der Rückgang der verbrecherischen Aktivitäten selten von Dauer: Nach ein paar internen Umbauten setzen sie ihre Angriffe häufig fort, als sei (fast) nichts geschehen.
So auch im Falle zweier Gruppen, die erst kürzlich zum Ziel internationaler Operationen wurden: Sicherheitsforscher haben neue Aktivitäten des berüchtigten Infostealers Lumma beobachtet, und auch die politisch motivierte russische dDoS-Gruppe (distributed Denial-of-Service) NoName057(16) attackierte schon nach wenigen Tagen Funkstille wieder munter deutsche Websites.
Parallel dazu wächst offenbar eine neue Bedrohung heran: US-Behörden haben eine gemeinsame Warnmeldung zu einer Ransomware namens Interlock veröffentlicht. Die ist zwar schon länger aktiv, soll nun jedoch ihre Aktivitäten ausgeweitet haben.
Lumma: wieder voll im Geschäft
Erst Ende Mai dieses Jahres war einem Kollektiv aus Cloud- und Sicherheitsunternehmen, angeführt von Europol und Microsoft, ein empfindlicher Schlag gegen Lumma gelungen. Nachdem Microsoft allein zwischen Mitte März und Mitte Mai rund 400.000 infizierte Windows-Rechner registriert hatte, schlug das Unternehmen zu: Es leitete die Kommunikation zwischen dem Schadprogramm und den Command-and-Control-Servern (C2) der Angreifer zu eigenen Servern um (Sinkholing) und unterband so die kriminellen Aktivitäten. Außerdem wurden nach Angaben Microsofts im Austausch mit Europol ermittelte Angreifer-Domains identifiziert und beschlagnahmt.
Zur „Zerschlagung“ des Lumma-Stealers, der auf infizierten Rechnern unter anderem Browserdaten, Krypto-Wallets, VPN-Konfigurationen und Dokumente im PDF- oder Word-Format abgreift, reichte das aber nicht. Sicherheitsforscher von Trend Micro haben beim gezielten Monitoring von Lumma-Aktivitäten festgestellt, dass der Informationsdiebstahl mittlerweile wieder in vollem Gange ist.

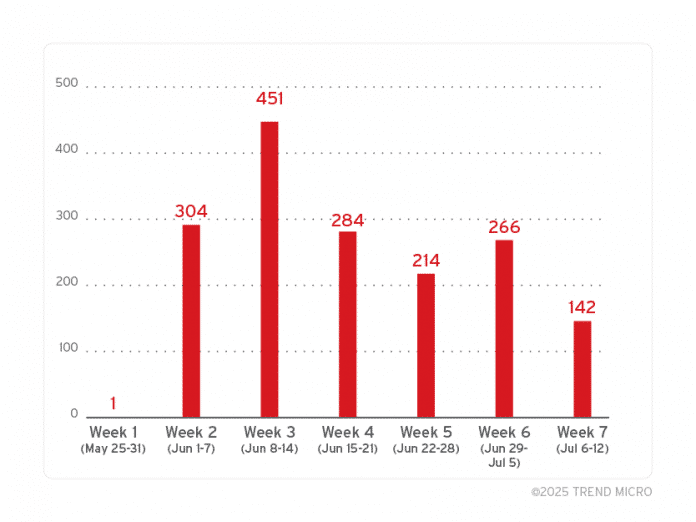
Automatisiert von Trend Micro erfasste Lumma-C2-URLs zeigen den Rückgang nach dem Takedown und die anschließende Wiederaufnahme der Aktivitäten.
(Bild: Trend Micro)
Gegenüber heise security bestätigte ein Experte von Trend Micro, dass es sich bei dem beobachteten Infostealer wahrscheinlich um Lumma handele: „We are sure that this resurgence is Lumma because we have our own automated process of sourcing (through internal rules) and validation of Lumma Stealer samples and Command and Control URLs“.
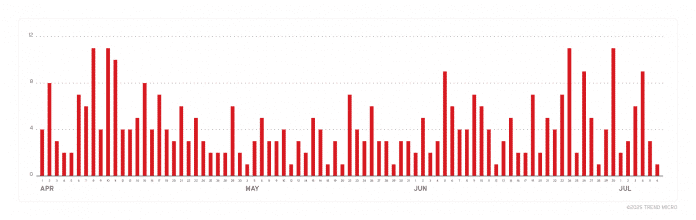
Eine Timeline der Lumma-Angriffe illustriert die Rückkehr zur Infostealer-„Normalität“.
(Bild: Trend Micro)
Statistiken aus Trend Micros Blogeintrag zur Lumma-Rückkehr bilden einen nahezu kompletten Stopp der Malware-Aktivitäten nach Microsofts am 21. Mai 2025 publik gemachten Sinkholing-Aktion ab. Doch bereits ab Anfang Juni kehrten die Gangster allmählich zum „business as usual“ zurück und erreichten im Laufe des Juli wieder ihr vorheriges Aktivitätsniveau.
Auffällig seien damit einhergehende Umbauten der C2-Struktur: Während Lumma zuvor stark auf das Hosting bei Cloudflare gesetzt habe, hätten die Kriminellen ihre Infrastruktur nun stärker diversifiziert. Zur neuen Mischung alternativer Provider zählten verstärkt auch legitime Data Center und Cloud-Infrastruktur-Anbieter mit Sitz in Russland.
NoName057(16): Vergeltungsaufrufe via Telegram
Noch schneller als die Lumma-Gang ließen die Drahtzieher hinter „NoName057(16)“ wieder von sich hören – nämlich schon wenige Tage nach der „Operation Eastwood“ internationaler Strafverfolger vergangene Woche. Laut Bundeskriminalamt (BKA) wurde bei besagter Aktion das Botnetz der Gruppierung abgeschaltet. Außerdem wurden drei Objekte durchsucht und sechs internationale Haftbefehle erlassen; die Fahndung läuft.
Grund für die seit November 2023 laufenden und in die Operation mündenden Ermittlungen waren zahlreiche dDos-Angriffswellen, in deren Zuge deutsche Firmen- und Behörden-Websites lahmgelegt wurden. Aber auch andere Länder wie etwa die Schweiz waren Ziel der Attacken, mit denen die Gruppe eine prorussische politische Botschaft aussenden wollte.
In ihrem Propagandakanal beim Messengerdienst Telegram zeigten sich die Russen unbeeindruckt von den Strafverfolgungsmaßnahmen. Sie bezeichneten die „Operation Eastwood“ als wertlos und riefen ihre Unterstützer zu Vergeltung auf. Nach eigener Aussage setzten sie am gestrigen Mittwoch die Website des Bundesministeriums für Digitalisierung und Staatsmodernisierung, verschiedene Polizeibehörden und die Internetpräsenz des Bundespräsidenten außer Gefecht.
Die Attacken dürften außerhalb der Telegram-Echokammer der Hacktivisten aber großteils unbemerkt geblieben sein – alle genannten Webseiten waren nach kurzer Zeit wieder problemlos abrufbar. Weitere Angriffe auf Websites deutscher Städte und Behörden wurden bereits vollmundig bei Telegram angekündigt.
Interlock: Der nächste Big (Ransomware) Player?
Zu den bereits vorhandenen Bedrohungen hat sich eine weitere gesellt, die IT-Verteidiger im Blick behalten sollten: Die US-Behörde CISA (Cybersecurity and Infrastructure Security Agency) hat gemeinsam mit dem FBI und weiteren Beteiligten einen Sicherheitshinweis zur Ransomware Interlock veröffentlicht. Die ist bereits seit September 2024 aktiv und soll laut CISA auf Unternehmen und Organisationen, aber auch auf Kritische Infrastrukturen abzielen – und zwar sowohl in Nordamerika als auch in Europa.
Interlocks Strategie der doppelten Erpressung (Double Extortion) mit Verschlüsselung, aber auch Exfiltrierung sensibler Daten ist mittlerweile Standard in der Ransomware-Szene. Bemerkenswert ist, dass laut CISA sowohl Interlock-Versionen für Windows- als auch für Linux-Systeme existieren. Dort zielen sie jeweils primär auf die Verschlüsselung installierter virtueller Maschinen (VMs) ab.
Ein beliebtes Einfallstor sind laut CISA unter anderem kompromittierte legitime Websites, auf denen ein Drive-by-Download lauert – laut Sicherheitshinweis eine eher ungewöhnliche Infektionsmethode für Ransomware. Die Bande hinter Interlock setzt zudem (wie auch Lumma) auf Social Engineering in Gestalt gefälschter Captchas mit Nutzerinteraktion („ClickFix“). Weitere Informationen sowie Kompromittierungsindikatoren (Indicators of Compromise, IoC) sind dem Sicherheitshinweis zu entnehmen.
Übrigens haben die CISA-Analysten beobachtet, dass im Zuge von Interlock-Infektionen hin und wieder auch Lumma auf die Systeme geschleust wurde. Eine ungute Allianz, die sich nun fortsetzen könnte. Bis zur nächsten Cybercrime-Zerschlagung – und der sich (mit hoher Wahrscheinlichkeit) anschließenden „Wiederauferstehung“.
(ovw)












Datenschutz & Sicherheit
EU-Kommission bemängelt Verstöße bei Instagram, Facebook und TikTok

Im Frühjahr 2024 hat die EU-Kommission die jeweils ersten Verfahren nach dem Gesetz über digitale Dienste (DSA) für Meta (Instagram, Facebook) und für TikTok eröffnet. Seitdem hat die Behörde vorläufig mehrere Verstöße festgestellt, etwa im Bereich des Jugendschutzes und der Desinformation vor Wahlen. Heute hat sie weitere Untersuchungsergebnisse geteilt.
Alle drei Plattformen – also TikTok, Instagram und Facebook – setzen demnach den Zugang zu Daten für Forschende nicht ausreichend um. Es sei sehr umständlich, die Daten zu beantragen und es gebe Probleme im Überprüfungsprozess der Forschenden. Und auch wenn die Daten bereitgestellt würden, seien diese oft unvollständig und nicht zuverlässig. Ähnliche Punkte hatte die Kommission bereits vor einem Jahr bei X bemängelt. Laut DSA ist die Kommission die zuständige Aufsichtsbehörde für „sehr große Plattformen“ (VLOPs).
Die weiteren der heute vorgestellten Ergebnisse betreffen nur Instagram und Facebook. Die Meldewege seien zu kompliziert, sagte eine Kommissionsbeamtin heute in einem Pressebriefing. Wenn Nutzende auf den Plattformen auf illegale Inhalte stoßen, etwa die Darstellung von Missbrauch oder Betrugsmaschen, sollen sie diese selbst möglichst einfach bei den Plattformen melden können. Der DSA will so die Nutzendenrechte stärken und ein System schaffen, das sich quasi “selbst reinigt”.
Manipulative Designs beim Meldeweg
Doch in der Realität sei der Weg so anspruchsvoll und lang, dass viele Nutzende die Meldungen abbrechen würden, heißt es aus der Kommission. Außerdem kämen hier manipulative Designs zum Einsatz. Das bedeutet, dass Meldewege etwa irreführend oder kompliziert gestaltet sind, zum Beispiel über schwer auffindbare Buttons oder unnötig viele Klicks.
Wir sind ein spendenfinanziertes Medium
Unterstütze auch Du unsere Arbeit mit einer Spende.
In der Folge würden Inhalte nicht gemeldet, Plattformen also nicht darauf aufmerksam gemacht, und es könnten entsprechend auch keine Maßnahmen ergriffen werden, um die Inhalte zu entfernen. Hierzu hätten die Kommission viele Beschwerden erreicht. Es sei klar, dass Meta hier nachbessern müsse.
Darüber hinaus kritisiert die Kommission den Mechanismus zum Umgang mit Beschwerden zur Inhaltsmoderation. Wenn Plattformen Inhalte oder Accounts sperren, können sich betroffene Nutzende an die Plattformen wenden und Beschwerde einreichen. Allerdings laufe auch das bei Meta nicht zufriedenstellend ab, so die Kommission. Zum Beispiel sei es nicht möglich, in der Kommunikation mit den Plattformen Dokumente anzuhängen, um etwa zu beweisen, dass eine Facebook-Seite einem selbst gehöre. In der Konsequenz würden Beschwerden nicht beantwortet.
So geht es jetzt weiter
Meta und TikTok können nun die Dokumente der Kommission einsehen und schriftlich auf die Kritikpunkte antworten – etwas, das nach Einschätzung der Kommissionsbeamtin zwei bis drei Monate in Anspruch nehmen könne. Im nächsten Schritt soll es weitere Gespräche zwischen Kommission und betroffenen Unternehmen geben. Die Hoffnung der Kommission dabei ist, dass die Plattformen ihre Mechanismen anpassen und damit die Vorgaben des DSA erfüllen.
Sollte dies nicht passieren, könnte die Kommission abschließend feststellen, dass sich die Plattformen nicht an den DSA halten und eine Geldstrafe verhängen – in Höhe von bis zu sechs Prozent des jährlichen weltweiten Umsatzes. Auch dann hätten die Plattformen noch die Möglichkeit, diese Entscheidung vor Gericht anzufechten.
Datenschutz & Sicherheit
AWS-Ausfall: Amazon legt vollständigen Ursachenbericht vor
Der Ausfall von Amazons AWS-Cloud-Diensten am Montag dieser Woche bereitete nicht nur IT-Experten schlaflose Nächte, sondern etwa auch Besitzern von vernetzten Matratzen. Nun haben Amazons Techniker eine vollständige Analyse der Vorfälle veröffentlicht, die erklärt, wie es zu so weitreichenden Störungen kommen konnte.
Weiterlesen nach der Anzeige
Bereits der Titel der Amazon-Analyse weist auf einen Single-Point-of-Failure: „Zusammenfassung der Amazon DynamoDB-Dienst-Störung in der Region Nord Virginia (US-EAST-1)“. Der dort aufgetretene Fehler sorgte nicht nur für Ausfälle von Amazon-Diensten wie Streaming mit Prime oder Amazon Music, sondern legte etwa den Messenger Signal über Stunden lahm. Umso spannender ist, wie es dazu kommen konnte.
AWS-Ausfall: Detaillierter Fehlerverlauf
Während die Techniker bei Wiederherstellung des Normalbetriebs, den Amazon gegen kurz nach Mitternacht zum Dienstag, 21. Oktober, verkündete, bereits eine erste knappe Zusammenfassung des Vorfalls bereitgestellt haben, geht die jetzige Analyse deutlich in die Tiefe. Aus Amazons Sicht hat sich die Fehlerkaskade in drei Etappen abgespielt. Zwischen 8:48 Uhr mitteleuropäischer Sommerzeit am 20. Oktober 2025 und 11:40 Uhr lieferte Amazons DynamoDB erhöhte Fehlerraten bei API-Zugriffen in der Region Nord Virginia (US-EAST-1). Das war laut Amazon die erste Phase der Störung.
Die zweite Phase folgte zwischen 14:30 Uhr und 23:09 Uhr, während der der Network Load Balancer (NLB) erhöhte Verbindungsfehler bei einigen Load Balancern in Nord Virginia aufwies. Dies ging auf Health-Check-Fehler in der NLB-Flotte zurück, die zu diesen erhöhten Verbindungsfehlern führten. Zudem kam die dritte Phase von 11:25 Uhr bis 19:36 Uhr, in der das Starten neuer EC2-Instanzen nicht klappte. Bei einigen der EC2-Instanzen, die ab 19:37 Uhr anliefen, kam es jedoch zu Verbindungsproblemen, die ihrerseits bis 22:50 Uhr andauerten.
DynamoDB-Fehler
Die Probleme mit der DynamoDB erklärt Amazon mit „einem latenten Defekt“ im automatischen DNS-Management, wodurch die Namensauflösung der Endpunkte für die DynamoDB fehlschlug. „Viele der größten AWS-Dienste stützen sich in hohem Ausmaß auf DNS, um nahtlose Skalierbarkeit, Fehlerisolierung und -behebung, geringe Latenz und Lokalität zu gewährleisten. Dienste wie DynamoDB verwalten Hunderttausende von DNS-Einträgen, um eine sehr große heterogene Flotte von Load Balancern in jeder Region zu betreiben“, schreiben die Techniker. Automatisierung ist nötig, um zusätzliche Kapazitäten hinzuzufügen, sofern sie verfügbar sind, und um etwa korrekt mit Hardwarefehlern umzugehen. Zwar sei das System auf Resilienz ausgelegt, jedoch war die Ursache für die Probleme eine latente Race-Condition im DynamoDB-DNS-Management-System, die in einen leeren Eintrag für den regionalen Endpunkt „dynamodb.us-east-1.amazonaws.com“ mündete. Interessierte erhalten in der Analyse dazu einen tiefen Einblick in die DNS-Management-Struktur.
Sowohl der eigene als auch der Traffic von Kunden, die auf DynamoDB aufsetzen, war davon betroffen, da diese mangels korrekter Namensauflösung nicht mehr zu der DynamoDB verbinden konnten. Um 9:38 Uhr haben die ITler den Fehler im DNS-Management gefunden. Erste temporäre Gegenmaßnahmen griffen um 10:15 Uhr und ermöglichten die weitere Reparatur, sodass gegen 11:25 Uhr alle DNS-Informationen wiederhergestellt wurden.
Weiterlesen nach der Anzeige
Nicht startende EC2-Instanzen
Die EC2-Instanzen starteten ab 8:48 Uhr nicht mehr, da dieser von sogenannten DropletWorkflow Manager (DWFM) auf verschiedene Server verteilt werden. Die DWFM überwachen den Status der EC2-Instanzen und prüfen, ob etwa Shutdown- oer Reboot-Operationen korrekt verliefen in sogenannten Leases. Diese Prüfungen erfolgen alle paar Minuten. Dieser Prozess hängt jedoch von der DynamoDB ab und konnte aufgrund deren Störung nicht erfolgreich abschließen. Statusänderungen benötigen einen neuen Lease. Die DWFM versuchten, neue Leases zu erstellen, die jedoch zwischen 8:48 Uhr und 11:24 Uhr zunehmend in Time-Outs liefen. Nachdem die DynamoDB wieder erreichbar war, konnten die EC2-Instanzen jedoch mit dem Fehler „insufficient capacity errors“ nicht starten. Das Backlog der ausstehenden Leases erzeugte einen Flaschenhals, sodass neue Anfragen dennoch in Time-Out-Situationen kamen. Gegen 14:28 Uhr konnten die DWFM alle Leases zu allen Droplets genannten Instanzen wieder herstellen, nachdem Neustarts der DWFMs die Warteschlangen geleert hatte. Aufgrund einer temporären Anfragendrosselung, die die IT-Mitarbeiter zur Reduktion der Gesamtlast eingerichtet hatten, kam es jedoch etwa zu Fehlermeldungen der Art „equest limit exceeded“.
Die Droplets/EC2-Instanzen erhalten von einem Network Manager Konfigurationsinformationen, die ihnen die Kommunikation mit anderen Instanzen in der gleichen Virtual Private Cloud (VPC), mit VPC-Appliances und dem Internet erlaubt. Die Verteilung hatte durch die Probleme mit den DWFM ein großes Backlog erzeugt. Ab 15:21 Uhr kam es dadurch zu größeren Latenzen. Zwar starteten neue EC2-Instanzen, sie konnten mangels gültiger Netzwerkkonfigurationen jedoch nicht im Netzwerk kommunizieren. Das haben die ITler gegen 19:36 Uhr in den Griff bekommen, sodass EC2-Starts wieder „normal“ verliefen.
Verbindungsfehler durch Network Load Balancer
Die Network Load Balancer (NLB) von AWS nutzen ein Überwachungssystem (Health-Check-System). Sie umfassen Lastverteilung-Endpoints und verteilen Traffic auf die Backend-Systeme, bei denen es sich typischerweise um EC2-Instanzen handelt. Das Health-Check-System überprüft regelmäßig alle NLB-Knoten und entfernt alle Systeme, die dabei als „ungesund“ auffallen. Die Prüfungen schlugen bei der Störung jedoch zunehmend fehl, da die vom Health-Check-System neu gestarteten EC2-Instanzen keinen Netzwerk-Status melden konnten. Die Prüfungen schlugen in einigen Fällen fehl, obwohl NLB-Knoten und die Backen-Systeme korrekt funktionierten. Die Ergebnisse der Prüfung lieferten abwechselnd korrekten Status und Fehler zurück, wodurch NLB-Knoten und Backend-Systeme aus dem DNS entfernt wurden, um beim nächsten erfolgreichen Durchlauf wieder hinzugefügt zu werden. Das fiel in der Netzwerküberwachung gegen 15:52 Uhr auf.
Die Last im Health-Check-System stieg durch die alternierenden Prüfergebnisse an, wodurch es langsamer wurde und Verzögerungen bei Health-Checks auftraten. Dadurch wurden schließlich Lord-Balance-Kapazitäten reduziert, da diese außer Dienst gestellt wurden. Dadurch kam es zu vermehrten Verbindungsfehlern von Anwendungen, wenn die übriggebliebene noch laufende Kapazität nicht zum Verarbeiten der Anwendungslast ausreichte. Um 18:36 Uhr hat das IT-Team die automatischen Prüfungen für die NLB deaktiviert, wodurch alle verfügbaren, noch in Funktion befindlichen NLB-Knoten und Backend-Systeme wieder in Dienst gestellt werden konnten. Nachdem auch die EC2-Systeme sich erholt hatten, konnten die Health-Checks gegen 23:09 Uhr wieder aktiviert werden.
Im Weiteren erörtert Amazon noch, wie von den gestörten Hauptsystemen abhängige Amazon-Services der zeitliche Störungsverlauf aussah. Das IT-Team will einige Änderungen als Folge der größeren Cloud-Störungen umsetzen. Etwa der DynamoDB „DNS Planner“ und „DNS Enactor“-Automatismus wurde weltweit deaktiviert. Das soll so bleiben, bis unter anderem die aufgetretene Race-Condition gelöst wurde. Die Network Load Balancer sollen eine Geschwindigkeitskontrolle erhalten, die begrenzt, wie viele Kapazitäten ein einzelner NLB nach fehlschlagenden Health-Checks entfernen kann. Für die EC2-Systeme entwickelt Amazon zusätzliche Test-Suites, um etwa den DWFM-Workflow zu analysieren und künftige Regressionen zu vermeiden.
(dmk)
Datenschutz & Sicherheit
Atlassian Jira Data Center: Angreifer können Daten abgreifen
Admins von Atlassian-Software sollten zeitnah Confluence Data Center und Jira Data Center auf den aktuellen Stand bringen. Geschieht das nicht, können Angreifer an zwei Sicherheitslücken ansetzen, um Systeme zu attackieren.
Weiterlesen nach der Anzeige
Jetzt Systeme schützen
Eine Schwachstelle (CVE-2025-22167 „hoch„) betrifft Jira Software Data Center und Jira Software Server. An dieser Stelle können Angreifer im Zuge einer Path-Traversal-Attacke unrechtmäßig auf Daten zugreifen. In einer Warnmeldung versichern die Entwickler, dass sie die Lücke in den Versionen 9.12.28, 10.3.12 und 11.1.0 geschlossen haben.
Die Schwachstelle (CVE-2025-22166 „hoch„) in Confluence Data Center dient einem Beitrag zufolge als Ansatzpunkt für DoS-Attacken. An dieser Stelle schaffen die Ausgaben 8.5.25, 9.2.7 und 10.0.2 Abhilfe.
Auch wenn es noch keine Berichte zu laufenden Angriffen gibt, sollten Admins mit der Installation der Sicherheitsupdates nicht zu lange warten.
(des)

Revolut-Gründer sollte offenbar entführt werden – im Auftrag der Wagner-Söldner

Help Me Decide: Amazon AI Tool trifft Kaufentscheidung für dich

Smart Delivery Glasses: Amazon stattet Fahrer mit AR-Brillen aus

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 UX/UI & Webdesignvor 6 Tagen
UX/UI & Webdesignvor 6 TagenIllustrierte Reise nach New York City › PAGE online
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatSchluss mit FOMO im Social Media Marketing – Welche Trends und Features sind für Social Media Manager*innen wirklich relevant?