Entwicklung & Code
Künstliche Neuronale Netze im Überblick 7: Rekursive neuronale Netze
Neuronale Netze sind der Motor vieler Anwendungen in KI und GenAI. Diese Artikelserie gibt einen Einblick in die einzelnen Elemente. Der siebte Teil widmet sich rekursiven neuronalen Netzen, nachdem der sechste Teil der Serie Convolutional Neural Networks vorgestellt hat.


Prof. Dr. Michael Stal arbeitet seit 1991 bei Siemens Technology. Seine Forschungsschwerpunkte umfassen Softwarearchitekturen für große komplexe Systeme (Verteilte Systeme, Cloud Computing, IIoT), Eingebettte Systeme und Künstliche Intelligenz.
Er berät Geschäftsbereiche in Softwarearchitekturfragen und ist für die Architekturausbildung der Senior-Software-Architekten bei Siemens verantwortlich.
Rekursive neuronale Netze sind für die Verarbeitung sequenzieller Daten ausgelegt, indem sie einen versteckten Zustand aufrechterhalten, der sich im Laufe der Zeit weiterentwickelt. Im Gegensatz zu Feedforward-Netzwerken, die davon ausgehen, dass jede Eingabe unabhängig von allen anderen ist, ermöglichen rekursive Netzwerke das Speichern von Informationen über Zeiträume hinweg. Bei jedem Schritt t empfängt eine rekurrente Zelle sowohl den neuen Eingabevektor xₜ als auch den vorherigen versteckten Zustand hₜ₋₁. Die Zelle berechnet einen neuen versteckten Zustand hₜ gemäß einer gelernten Transformation und erzeugt (optional) eine Ausgabe yₜ.
In ihrer einfachsten Form berechnet eine Vanilla-RNN-Zelle einen Präaktivierungsvektor zₜ als Summe einer Eingabetransformation und einer versteckten Zustandstransformation plus einer Verzerrung:
zₜ = Wₓ · xₜ + Wₕ · hₜ₋₁ + b
Der neue Zustand entsteht durch elementweise Anwendung einer nicht linearen Aktivierung σ:
hₜ = σ(zₜ)
Wenn bei jedem Zeitschritt eine Ausgabe yₜ erforderlich ist, kann eine Ausleseschicht hinzugefügt werden:
yₜ = V · hₜ + c
wobei V und c eine Ausgabegewichtungsmatrix und ein Bias-Vektor sind.
In PyTorch kapselt die Klasse torch.nn.RNN dieses Verhalten und verarbeitet das Stapeln mehrerer Schichten und Batches nahtlos. Das folgende Beispiel zeigt, wie man eine einlagige RNN-Zelle erstellt, ihr einen Stapel von Sequenzen zuführt und den endgültigen versteckten Zustand extrahiert:
import torch
import torch.nn as nn
# Angenommen, wir haben Sequenzen der Länge 100, jedes Element ist ein 20-dimensionaler Vektor,
# und wir verarbeiten sie in Batches der Größe 16.
seq_len, batch_size, input_size = 100, 16, 20
hidden_size = 50
# Erstellen Sie einen zufälligen Stapel von Eingabesequenzen: Form (seq_len, batch_size, input_size)
inputs = torch.randn(seq_len, batch_size, input_size)
# Instanziieren Sie ein einlagiges RNN mit tanh-Aktivierung (Standard)
rnn = nn.RNN(input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
nonlinearity='tanh',
batch_first=False)
# Initialisiere den versteckten Zustand: Form (Anzahl_Schichten, Batchgröße, versteckte Größe)
h0 = torch.zeros(1, batch_size, hidden_size)
# Vorwärtspropagierung durch das RNN
outputs, hn = rnn(inputs, h0)
# `outputs` hat die Form (seq_len, batch_size, hidden_size)
# `hn` ist der versteckte Zustand beim letzten Zeitschritt, Form (1, batch_size, hidden_size)
Jede Zeile dieses Ausschnitts hat eine klare Aufgabe. Durch das Erstellen von Eingaben simuliert man ein Batch von Zeitreihendaten. Das RNN-Modul weist zwei Parametermatrizen zu: eine mit der Form (hidden_size, input_size) für Wₓ und eine mit der Form (hidden_size, hidden_size) für Wₕ sowie einen Bias-Vektor der Länge hidden_size. Beim Aufrufen des Moduls für Eingaben und den Anfangszustand h0 durchläuft es die 100 Zeitschritte und berechnet bei jedem Schritt die Rekursionsbeziehung. Der Ausgabetensor sammelt alle Zwischenzustände, während hn nur den letzten zurückgibt.
Obwohl Vanilla-RNNs konzeptionell einfach sind, haben sie Schwierigkeiten, langfristige Abhängigkeiten zu lernen, da über viele Zeitschritte zurückfließende Gradienten dazu neigen, zu verschwinden oder zu explodieren. Um das abzumildern, führen Gated Recurrent Units wie LSTM und GRU interne Gates ein, die steuern, wie stark die Eingabe und der vorherige Zustand den neuen Zustand beeinflussen sollen.
Die LSTM-Zelle (Long Short-Term Memory) verwaltet sowohl einen versteckten Zustand hₜ als auch einen Zellzustand cₜ. Sie verwendet drei Gates – Forget Gate fₜ, Input Gate iₜ und Output Gate oₜ –, die als Sigmoid-Aktivierungen berechnet werden, sowie eine Kandidaten-Zellaktualisierung ĉₜ, die sich mit einer Tanh-Aktivierung berechnen lässt. Konkret:
fₜ = σ( W_f · xₜ + U_f · hₜ₋₁ + b_f )
iₜ = σ( W_i · xₜ + U_i · hₜ₋₁ + b_i )
oₜ = σ( W_o · xₜ + U_o · hₜ₋₁ + b_o )
ĉₜ = tanh( W_c · xₜ + U_c · hₜ₋₁ + b_c )
Der Zellzustand wird dann durch Kombination des vorherigen Zellzustands und des Kandidaten aktualisiert, gewichtet durch die Vergessens- und Eingangsgatter:
cₜ = fₜ * cₜ₋₁ + iₜ * ĉₜ
Schließlich erstellt das System den neuen versteckten Zustand, indem es das Ausgangs-Gate auf die Nichtlinearität des Zellzustands anwendet:
hₜ = oₜ * tanh(cₜ)
PyTorchs torch.nn.LSTM kapselt all diese Berechnungen unter der Haube. Folgender Code zeigt ein Beispiel für eine Reihe von Sequenzen:
import torch
import torch.nn as nn
# Sequenzparameter wie zuvor
seq_len, batch_size, input_size = 100, 16, 20
hidden_size, num_layers = 50, 2
# Zufälliger Eingabebatch
inputs = torch.randn(seq_len, batch_size, input_size)
# Instanziieren eines zweischichtigen LSTM
lstm = nn.LSTM(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=False)
# Initialisiere versteckte und Zellzustände: jeweils mit der Form (Anzahl_Schichten, Batchgröße, versteckte Größe)
h0 = torch.zeros(num_layers, batch_size, hidden_size)
c0 = torch.zeros(num_layers, batch_size, hidden_size)
# Vorwärtsdurchlauf durch das LSTM
outputs, (hn, cn) = lstm(inputs, (h0, c0))
# `outputs` hat die Form (seq_len, batch_size, hidden_size)
# `hn` und `cn` haben jeweils die Form (num_layers, batch_size, hidden_size)
Die Gated Recurrent Unit (GRU) vereinfacht das LSTM, indem sie die Vergessens- und Eingangsgatter zu einem einzigen Aktualisierungsgatter zₜ kombiniert und die Zell- und versteckten Zustände zusammenführt. Die Gleichungen lauten:
zₜ = σ( W_z · xₜ + U_z · hₜ₋₁ + b_z )
rₜ = σ( W_r · xₜ + U_r · hₜ₋₁ + b_r )
ħₜ = tanh( W · xₜ + U · ( rₜ * hₜ₋₁ ) + b )
hₜ = (1 − zₜ) * hₜ₋₁ + zₜ * ħₜ
In PyTorch bietet torch.nn.GRU diese Funktionalität mit derselben Schnittstelle wie nn.LSTM, außer dass nur die versteckten Zustände zurückgegeben werden.
Bei der Arbeit mit Sequenzen variabler Länge benötigt man häufig torch.nn.utils.rnn.pack_padded_sequence und pad_packed_sequence, um Sequenzen effizient im Batch zu verarbeiten, ohne Rechenleistung für das Auffüllen von Tokens zu verschwenden.
Rekursive Netzwerke eignen sich hervorragend für Aufgaben wie Sprachmodellierung, Zeitreihenprognosen und Sequenz-zu-Sequenz-Übersetzungen, wurden jedoch in vielen Anwendungsbereichen von aufmerksamkeitsbasierten Modellen übertroffen.
Zunächst widmet sich der nächste Teil dieser Serie jedoch der Kombination aus konvolutionalen und rekursiven Schichten, um Daten mit sowohl räumlicher als auch zeitlicher Struktur zu verarbeiten. Bei der Videoklassifizierung kann ein Convolutional Neural Network beispielsweise Merkmale auf Frame-Ebene extrahieren, die dann in ein LSTM eingespeist werden, um Bewegungsdynamiken zu erfassen.
(rme)












Entwicklung & Code
.NET: Ein Herz und Sponsoring für NuGet-Maintainer
Microsoft hat verkündet, dass für Package-Maintainer im NuGet.org-Ökosystem – dem Paketmanager für .NET – das neue Sponsorship-Feature zur Verfügung steht. Es erlaubt ihnen das Hinterlegen von Sponsorship-URLs, unter der User ihnen finanzielle Unterstützung zukommen lassen können.
Weiterlesen nach der Anzeige
Der Link zu den Sponsorship-URLs erscheint als Herz-Emoji beziehungsweise „Sponsor“-Button auf der jeweiligen Paketseite. Nach einem Klick darauf können User mittels einer Plattform wie GitHub Sponsors oder Patreon ihre gewünschte Zahlung tätigen. Wie Microsoft betont, können auch kleine Beiträge einen großen Unterschied machen, um zur Verwaltung und Sicherheit kritischer Pakete beizutragen.
(Bild: coffeemill/123rf.com)

Verbesserte Klassen in .NET 10.0, Native AOT mit Entity Framework Core 10.0 und mehr: Darüber informieren .NET-Profis auf der Online-Konferenz betterCode() .NET 10.0 am 18. November 2025. Nachgelagert gibt es sechs ganztägige Workshops zu Themen wie C# 14.0, künstliche Intelligenz und Web-APIs.
Eintragen von Sponsorship-Links
Entwicklerinnen und Entwickler, die einen Link zum Sponsoring einfügen möchten, müssen Besitzer oder Co-Besitzer des betreffenden NuGet-Pakets sein. Der Link muss zu einer der folgenden zugelassenen Plattformen führen: GitHub Sponsors, Patreon, Open Collective, Ko-fi, Tidelift oder Liberapay.
Auf der Paketmanagement-Seite des jeweiligen Pakets müssen Developer dafür zum Abschnitt „Sponsorship Links“ herunterscrollen und dort in das Formular einen oder mehrere Links eintragen, zum Beispiel Es lassen sich je Package-ID bis zu zehn URLs hinterlegen und per „Remove“-Button bei Bedarf wieder entfernen.
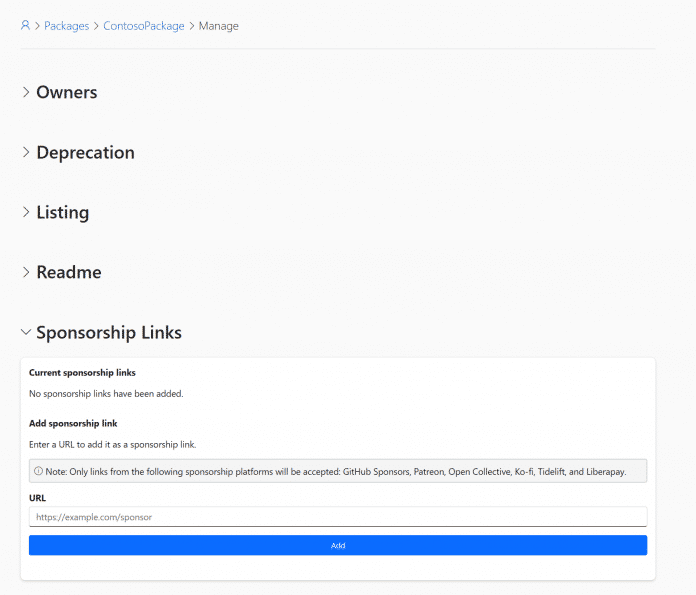
Im Formular lassen sich Sponsorship-Links einfügen.
(Bild: Microsoft)
Nach dem Eintragen der URLs können Developer verifizieren, dass das Hinterlegen funktioniert hat, indem sie die öffentliche Seite ihres Pakets aufrufen. Dort sollte im „About“-Abschnitt der „Sponsor“-Button erscheinen und beim Klick darauf ein Pop-up zu den hinterlegten URLs anzeigen.
Weiterlesen nach der Anzeige
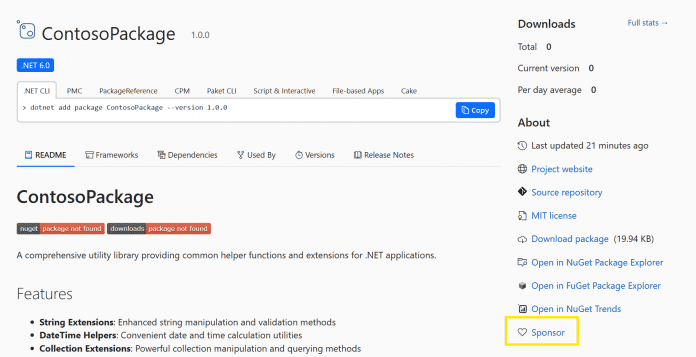
NuGet-Paket mit Sponsoring-Button
(Bild: Microsoft)
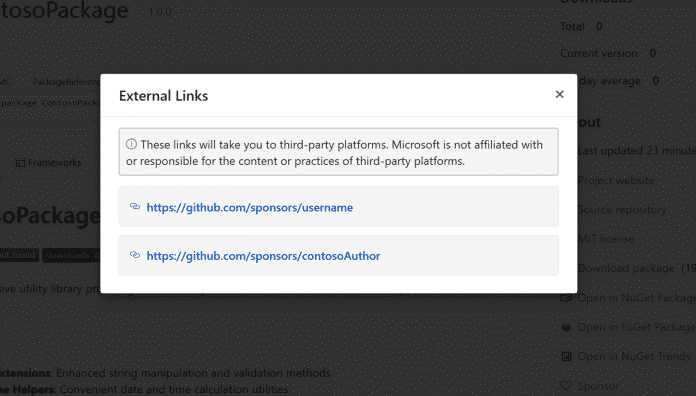
Das Pop-up nach Klick auf den Button zeigt die hinterlegten URLs an.
(Bild: Microsoft)
Im Rahmen des Sponsorship-Features werden auf NuGet.org keine persönlichen oder Zahlungsinformationen gespeichert, denn die Transaktionen geschehen auf den gewählten externen Plattformen, wie Microsoft betont.
Weitere Informationen und ein FAQ-Abschnitt finden sich in der Ankündigung auf Microsofts Entwicklerblog.
(mai)
Entwicklung & Code
Projektmanagement: Wir sind eine große Familie
Weiterlesen nach der Anzeige
Moin.
Wir sind eine große Familie, sang Peter Alexander 1973, und mancher Chef holt den Schlager auch heute nochmal heraus. Während das Lied eine Geschmacksfrage ist, lädt der Satz im Firmenkontext dazu ein, aufmerksam zu werden. „Wir sind eine große Familie“, sagt der Chef. Klingt super, finde ich. Oder doch nicht?
(Bild: Stefan Mintert )
Stefan Mintert arbeitet mit seinen Kunden daran, die Unternehmenskultur in der Softwareentwicklung zu verbessern. Das derzeit größte Potenzial sieht er in der Leadership; unabhängig von einer Hierarchieebene.
Die Aufgabe, dieses Potenzial zu heben, hat er sich nach einem beruflichen Weg mit einigen Kurswechseln gegeben. Ursprünglich aus der Informatik kommend, mit mehreren Jahren Consulting-Erfahrung, hatte er zunächst eine eigene Softwareentwicklungsfirma gegründet. Dabei stellte er fest, dass Führung gelernt sein will und gute Vorbilder selten sind.
Es zeichnete sich ab, dass der größte Unterstützungsbedarf bei seinen Kunden in der Softwareentwicklung nicht im Produzieren von Code liegt, sondern in der Führung. So war es für ihn klar, wohin die Reise mit seiner Firma Kutura geht: Führung verbessern, damit die Menschen, die die Produkte entwickeln, sich selbst entwickeln und wachsen können.
Für Heise schreibt Stefan als langjähriger, freier Mitarbeiter der iX seit 1994.
Auch Familien haben ihre Schattenseiten. So wurden 2023 mehr als 250.000 Menschen das Opfer häuslicher Gewalt. Davon sind mehr als 78.000 Opfer innerfamiliärer Gewalt zwischen nahen Angehörigen. (Quelle: BKA-Lagebild, BMFSFJ)
Vermutlich meint mein Chef das nicht, wenn er von Familie spricht, aber was denn dann? Welchen Zweck verfolgt er mit seiner Aussage? Was will er von mir? Welches Verhalten soll meinerseits hervorgerufen werden? Und, last, but not least: Wie gehe ich damit um?
Am liebsten würde ich es bei den Fragen belassen, weil Ihr bestimmt auch eigene Antworten parat habt. Dann wäre der Beitrag allerdings sehr kurz. Deshalb ein Vorschlag: Macht beim Lesen eine Pause, denkt über die Fragen nach und schreibt Antworten in die Kommentare. Danach könnt Ihr meine Antworten lesen. Ich bedanke mich im Voraus für Eure Beiträge.
Ein Märchen
Weiterlesen nach der Anzeige
Zum Zweck der Äußerung: Meine beste Antwort lautet „Bindung“. Wer das sagt, möchte andere an sich binden; möglicherweise vor dem Hintergrund einer unangenehmen Aufgabe oder bevorstehenden negativen Veränderung. Zumindest denke ich, dass es nicht nötig ist, bei der Bindung nachzuhelfen, wenn das Arbeitsleben im Augenblick das reinste Paradies ist. Wer sollte dann gehen wollen?
Bindung an sich ist ja nicht so schlecht, allerdings stellt sich eine weitere Frage: Was ist, wenn die wirtschaftliche Lage für die Firma schlechter wird? Wir sind doch eine große Familie, oder? Hier wird doch niemand gefeuert, oder? Wir alle kennen die Wahrheit und das genügt, um die Mär der großen Familie als genau das zu entlarven: ein Märchen. Es gibt Firmen, die eine Ausnahme darstellen, aber dort ist es vermutlich nicht nötig, auf die starke Bindung mit der Familienaussage hinzuweisen.
Damit kommen wir zur wichtigsten Frage: Wie gehe ich damit um? Das hängt natürlich stark vom Einzelfall ab, sodass ich hier keine universelle Antwort anbieten kann. Mein Vorschlag ist, klar zu kommunizieren, wie das, was man gerade hört, ankommt.
Zum Einstieg vielleicht eine Erwiderung der Art: „Wenn ich höre, dass wir eine Familie sind, habe ich den Eindruck/bekomme ich das Gefühl, dass …“
(Bild: Katsiaryna/stock.adobe.com)

Die Agile Leadership Conference 2025 findet im November und Dezember statt. Der Leadership Day (27.11.25) behandelt das Führen von Teams und Organisationen, während sich der Self Leadership Day (3.12.25) mit Selbstführung und dem aktiven Selbst als Führungskraft beschäftigt.
Bindung funktioniert anders
Wenn es um Bindung geht, kann man deutlich machen, dass wir keine Familie sind und Bindung anders funktioniert. Das ist der richtige Zeitpunkt, die eigene Motivation auszusprechen. Was treibt Dich an und was möchtest Du demnächst oder mittelfristig erreichen? Wenn die Wir-sind-eine-Familie-Aussage mit der unangenehmen Aufgabe wie Überstunden für einen längeren Zeitraum verbunden ist, ist es ein guter Zeitpunkt, über Gegenleistungen zu sprechen. Die Palette ist breit gefächert. Man kann über Überstundenausgleich, Sonderurlaub, Fortbildungen oder natürlich Prämien sprechen. Das sind alles persönliche Benefits.
Alternativ kann man auch Veränderung in der Arbeit ansprechen. Geht es beispielsweise darum, dass ein vorgegebener Termin in der Produktentwicklung nicht ohne Überstunden des Teams gehalten werden kann, ist es vielleicht der richtige Zeitpunkt, auf die Ursache einzugehen. Eine mögliche Forderung wäre dann Mitspracherecht bei zukünftigen Terminen. Wozu sollte man für das anstehende Release Überstunden machen, wenn absehbar ist, dass es beim nächsten Release genauso läuft?
In jedem Fall verstehe ich „Wir sind eine Familie“ als Einstieg in eine Verhandlung. Wer sie als Person oder als Team nicht nutzt, verschenkt die Chance für eine Verbesserung.
Erst Lesen, dann Hören
Im Podcast Escape the Feature Factory greife ich ausgewählte Themen des Blogs auf und diskutiere sie mit einem Gast. Durch den Austausch lerne ich eine zweite Perspektive kennen. Wenn Du auch daran interessiert bist, findest Du den Podcast bei Spotify, Deezer, Amazon Music, und Apple Podcasts. Wenn Du die Themen, die ich im Blog anspreche, in Deiner Firma verbessern möchtest, komm‘ in unsere Leadership-Community für Softwareentwicklung.
(rme)
Entwicklung & Code
Aus Softwarefehlern lernen – Teil 5: 440 Millionen Dollar Verlust in Minuten
In modernen Softwareprojekten ist das Deployment längst keine einmalige Aktion mehr, sondern ein kontinuierlicher Prozess. Anwendungen bestehen aus Dutzenden oder Hunderten von Services, laufen in Containern und erhalten oft mehrmals am Tag ein Update. Um neue Funktionen schrittweise zu aktivieren, greifen Teams auf Feature Flags oder Konfigurationsschalter zurück. Diese Flexibilität ist ein Segen – und gleichzeitig eine erhebliche Gefahrenquelle.
Weiterlesen nach der Anzeige

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Die Teile der Serie „Aus Softwarefehlern lernen“:
Muster 5: Deployment, Konfiguration und Flags: Wenn ein Schalter Millionen kostet
Ein eindrückliches Beispiel liefert der Fall Knight Capital aus dem Jahr 2012. Das Unternehmen war ein Schwergewicht im elektronischen Handel an der US-Börse und wickelte täglich Millionen von Transaktionen ab. Am 1. August 2012 spielte Knight ein neues Softwareupdate aus, das eine Funktion namens „Retail Liquidity Program“ unterstützen sollte. Die Bereitstellung lief jedoch schief: Ein Feature Flag, das ursprünglich für Testzwecke existierte, wurde auf einem von acht Servern nicht korrekt aktualisiert.
Was folgte, war ein Paradebeispiel für die Kaskade aus Konfigurationsfehlern und fehlender Deployment-Sicherheit: Auf sieben Servern lief die neue Logik wie geplant, ein einzelner Server führte beim Start jedoch alten Code aus, der längst nicht mehr produktiv sein sollte – weil das Flag dort nicht korrekt gesetzt war.
Dieser alte Code enthielt eine Legacy-Routine, die fälschlicherweise massenhaft Kaufaufträge generierte. Innerhalb von nur 45 Minuten verursachte Knight Capital rund 440 Millionen US-Dollar Verlust. Das Unternehmen stand am Rand der Insolvenz, nur eine schnelle Übernahme und externe Finanzierung retteten es vor dem Aus.
Die Lehren aus diesem Vorfall sind für jede Organisation relevant – ob Börsenhandel, E-Commerce oder SaaS-Betrieb:
Weiterlesen nach der Anzeige
- Feature Flags brauchen einen Lebenszyklus: Ein Schalter, der nicht dokumentiert, nicht versioniert und nicht befristet ist, wird irgendwann zum Risiko. Flags müssen ein Ablaufdatum, einen Owner und eine Entfernungsperspektive haben.
- Deployments müssen atomar und konsistent sein: Es reicht nicht, acht Server irgendwann nacheinander zu aktualisieren. Ohne Sicherstellung, dass alle Instanzen dasselbe Release und dieselbe Konfiguration fahren, entstehen Split-Brain-Situationen. Moderne CI/CD-Pipelines oder Kubernetes-Rollouts lösen dieses Problem durch atomare Deployments und Health-Checks. „Atomar“ bedeutet hier nicht, dass alle Instanzen gleichzeitig umgestellt werden, sondern dass innerhalb eines Deployments keine Mischzustände existieren.
- Immutable Infrastructure ist die beste Versicherung: Systeme, die man nicht nachträglich verändert, sondern bei Änderungen komplett neu instanziiert, vermeiden Zombiecode. Wer ein neues Image ausrollt, kann sicher sein, dass kein Server alten Code im RAM behält.
- Staged Rollouts und Kill-Switches reduzieren den Schaden: Große Änderungen sollten zunächst bei einem Bruchteil der Instanzen aktiviert werden, am besten begleitet von automatisierten Metriken. Ein zentraler Schalter zum sofortigen Abschalten (Kill-Switch) kann Milliardenverluste verhindern. Jede Stufe eines Rollouts ist dabei für sich konsistent, aber die Ausweitung auf alle Instanzen erfolgt schrittweise.
- Runbooks und Übung unter Realbedingungen: Selbst die beste Technik hilft wenig, wenn im Ernstfall niemand weiß, wie man reagiert. Unternehmen, die Notfallprozeduren für fehlerhafte Deployments proben, reagieren schneller und souveräner.
Interessant ist, dass Knight Capital nicht am Fehlen von Technologie scheiterte. Die Tools für sichere Deployments existierten längst. Es war vielmehr ein Organisations- und Prozessversagen, bei dem technische Schulden (wie Legacy-Code und Flag-Wildwuchs) und menschliche Routine („haben wir immer so gemacht“) zusammenkamen.
Für moderne Cloud- und Webprojekte gilt übrigens dasselbe Muster: Wer Feature Flags einsetzt, ohne Lifecycle und Dokumentation zu etablieren, erzeugt unbemerkt eine tickende Zeitbombe. Und wer Deployments manuell oder halbautomatisch ausrollt, nimmt Inkonsistenzen in Kauf, die sich irgendwann rächen.
Die Lösung ist eine Kombination aus Disziplin und Automatisierung:
- Feature Flags werden wie Code behandelt, mit Versionierung, Owner und Entfernungspflicht.
- Deployments laufen atomar und reproduzierbar, am besten als Infrastructure as Code.
- Ein zentraler Kill-Switch schützt vor irreversiblen Schäden.
Knight Capital ist das prominenteste Beispiel, aber ähnliche Zwischenfälle gab es seither mehrfach – von falschen Cloudkonfigurationen bis zu versehentlich aktivierten Debug-Modi in der Produktion. Und jedes Mal zeigt sich erneut: Ein einziger vergessener Schalter kann ausreichen, um ein Unternehmen ins Wanken zu bringen.
(who)

Halo: Campaign Evolved: Master Chief ballert sich im UE5-Remake über den Ring

Mähroboter Hookii Neomow X im Test: auch ohne GPS präzise

Kostenloser 5G-Tarif: Vodafone legt beliebte Aktion neu auf!

Der ultimative Guide für eine unvergessliche Customer Experience

Adobe Firefly Boards › PAGE online
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-
 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-
eine gute Nachricht ist") Social Mediavor 2 Monaten
Social Mediavor 2 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 UX/UI & Webdesignvor 1 Woche
UX/UI & Webdesignvor 1 WocheIllustrierte Reise nach New York City › PAGE online
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatSchluss mit FOMO im Social Media Marketing – Welche Trends und Features sind für Social Media Manager*innen wirklich relevant?