Künstliche Intelligenz
Kinderarzt zur ePA und Co.: Warum Eltern nicht alles wissen dürfen
Elektronische Patientenakten, E-Rezepte, Apps und Künstliche Intelligenz sollen die medizinische Versorgung moderner und effizienter machen. Gleichzeitig wächst die Sorge um Datenschutz und Vertraulichkeit – auch bei sensiblen Gesundheitsdaten von Kindern und Jugendlichen.
Weiterlesen nach der Anzeige
Nach Kritik aus der Praxis wurden inzwischen erste Verbesserungen auf den Weg gebracht: So müssen Kinderärzte besonders heikle Informationen, etwa aus psychotherapeutischen oder sexualmedizinischen Behandlungen, künftig nicht mehr verpflichtend in die elektronische Patientenakte eintragen, „sofern dem erhebliche therapeutische Gründe entgegenstehen“ oder „gewichtige Anhaltspunkte für die Gefährdung des Wohles eines Kindes oder eines Jugendlichen vorliegen und die Befüllung der elektronischen Patientenakte den wirksamen Schutz des Kindes oder Jugendlichen in Frage stellen würde“.
Und auch die Abrechnungsdaten sollen mit Änderungen am Gesetz zur Befugniserweiterung und Entbürokratisierung in der Pflege nicht mehr automatisch für alle am Behandlungsprozess Beteiligten sichtbar sein.


Michael Achenbach ist Kinderarzt und Vorstandsmitglied im Landesverband der Kinder- und Jugendärzt*innen (BVKJ) Westfalen Lippe und hat unter anderem Technik in der Medizin studiert.
(Bild: BVKJ)
Warum das so wichtig ist und über Chancen, Grenzen und offene Fragen bei der Digitalisierung spricht Dr. Achenbach mit heise online. Er ist Kinder- und Jugendarzt sowie langjährig engagierter Experte für digitale Gesundheitsanwendungen.
Besteht die Sorge zu Recht, dass sensible Daten in der elektronischen Patientenakte (ePA) zu leicht und unkontrolliert zur Verfügung stehen?
Ja, und das gilt besonders bei Jugendlichen. Viele denken, Eltern dürften alles wissen, was ihre jugendlichen Kinder betrifft. Dem ist aber nicht so. Sobald man einsichtsfähig ist – und das kann schon vor dem 15. Geburtstag sein –, gilt die ärztliche Schweigepflicht auch gegenüber den Eltern. Wenn dann sensible Daten, etwa aus psychotherapeutischen Behandlungen oder welche, die die sexuelle Gesundheit betreffen, automatisch in der ePA landen, kann das fatale Folgen haben. Dann sehen Eltern mit Zugriff Dinge, die vertraulich bleiben müssten. Ärztliche Schweigepflicht bedeutet eben auch, den Kindern Schutz gegenüber den Eltern zu ermöglichen, sobald das Kind reif genug ist, eigenständig über Behandlungen zu entscheiden.
Die Patienten sollen ihre Gesundheitsinformationen dank der ePA selbst verwalten können. Ist das Ihrer Meinung nach realistisch?
Grundsätzlich ja, aber nur, wenn die Rahmenbedingungen stimmen. Momentan fehlt die Möglichkeit, alte oder überholte Daten wirklich zu löschen. Das sogenannte Recht auf Vergessenwerden existiert für die ePA bislang nur sehr eingeschränkt. Wenn beispielsweise ein Kind wegen einer psychischen oder sozialen Auffälligkeit behandelt wurde – sagen wir, einer Störung des Sozialverhaltens – bleibt diese Diagnose in der Akte stehen, selbst wenn sie Jahre später keinerlei Relevanz mehr hat – sofern sie niemand selbst löscht oder löschen lässt. Solche Einträge können später bei Versicherungen oder Bewerbungen problematisch werden. Da braucht es klare, rechtlich abgesicherte Löschmechanismen – auch für Kinder, deren Eltern das vielleicht gar nicht bedenken. Wer sich selbst um seine Akte oder im Bedarfsfall die seiner Angehörigen kümmert, den betrifft das selbstverständlich nicht.
Weiterlesen nach der Anzeige
Die Versicherungen können unter bestimmten Umständen aber auch Daten austauschen?
Versicherungen tauschen Daten aber nicht über die ePA untereinander aus, das ist ein Trugschluss. Die Krankenkassen haben nämlich gar keinen direkten Zugriff auf die Inhalte der ePA; sie können zwar Dokumente einstellen, sie aber nicht betrachten. Ein eventueller Datenaustausch unter den Kassen läuft an der ePA vorbei, ist also davon gar nicht betroffen.
Ärzte sind gesetzlich zur Befüllung der ePA, aber auch zur Dokumentation verpflichtet. Gibt es da Herausforderungen?
Die ePA ersetzt die herkömmlichen Patientenakten nicht, sondern ist lediglich aus Informationen aus den herkömmlichen Patientenakten, die Ärztinnen führen müssen, gespeist. Daher eignet sich die ePA nicht, um gesetzliche Aufbewahrungserfordernisse der Ärzte zu erfüllen. Diese haben gesetzliche Aufbewahrungspflichten, Patienten dagegen ein Löschrecht in ihrer ePA – das passt schlicht nicht zusammen. Wenn Behandlungsunterlagen vom Patienten gelöscht werden können, kann die Ärztin ihre Dokumentationspflicht nicht mehr erfüllen. Die ePA ist daher nur ein zusätzliches Instrument, um Informationen abzubilden, nicht aber dazu geeignet, die originäre ärztliche Dokumentation zu ersetzen oder aufzubewahren.
Die Aufbewahrungspflichten sind umfangreich: Sie betragen meist zehn, teils bis zu 30 Jahre, bei Minderjährigen oft noch länger. Die Archive dürfen zwar elektronisch geführt werden, doch wer garantiert, dass Daten auch nach Jahrzehnten noch zugänglich sind? Die sichere elektronische Langzeitarchivierung ist bisher kaum etabliert. Eine Herausforderung dabei ist auch die Findbarkeit der Daten, die entsprechend – je nach Archivierungszeitraum – gekennzeichnet sein müssen, damit diese auch ordnungsgemäß gelöscht werden können.
Die ärztliche Dokumentation ist ein rechtsverbindlicher Teil des Behandlungsvertrags und dient im Streitfall auch der Beweissicherung – etwa wenn Jahre später Behandlungsfehler behauptet werden. Patientinnen und Patienten hingegen sollen in ihrer ePA frei entscheiden dürfen, welche Daten sie behalten oder löschen. Deshalb brauchen wir zwei getrennte Systeme: eines für die rechtssichere medizinische Dokumentation und ein zweites, flexibles für den patientengesteuerten Informationsaustausch.
Hinzu kommen gesetzliche Regelungen wie im Gendiagnostikgesetz, das nach zehn Jahren sogar eine Vernichtungspflicht vorsieht. Das zeigt, wie widersprüchlich und komplex der Umgang mit medizinischen Daten in der Praxis geworden ist. Wie man Daten aus Backups tatsächlich löscht oder durch Schlüsselvernichtung unzugänglich macht, ist technisch und organisatorisch noch wenig durchdacht – sowohl in vielen Praxen als auch bei den Softwareanbietern.
Besonders diskutiert werden regelmäßig die sogenannten F-Diagnosen, also Diagnosen aus dem psychiatrischen ICD-Kapitel. Dies betrifft uns Kinder- und Jugendärzte ebenfalls, denn in diesem Kapitel finden sich auch die kindlichen Entwicklungsstörungen. Also nicht nur die eben schon genannte Störung des Sozialverhaltens, sondern zum Beispiel auch die Entwicklungsstörung der Fein- und Graphomotorik, die Artikulationsstörung und so weiter. Diagnosen, die also bei Kindern oft über Jahre – korrekterweise – in der arztgeführten Patientenakte dokumentiert sind, somit klassische Dauerdiagnosen. Wenn aber Patienten die Problematik überwunden haben, bleiben die Diagnosen dennoch in der Akte – denn sie wirken sich oftmals auf die weitere Betreuung aus. Viele Studien zu Entwicklungsstörungen zeigen longitudinale Zusammenhänge zwischen Problemen im frühen Kindesalter und späteren Problemstellungen, zum Beispiel im Jugendalter.
Ist die ePA rechtlich genauso geschützt wie die klassische Patientenakte?
Nein. Die ePA ist eine patientengeführte Akte und fällt damit nicht unter den ärztlichen Beschlagnahmeschutz. Man kann sie sich wie einen privaten Ordner vorstellen – auch der darf von Ermittlungsbehörden beschlagnahmt werden. Eine arztgeführte Fallakte dagegen wäre vor dem Zugriff durch Behörden geschützt. Das ist ein gravierender Unterschied, über den viele gar nicht Bescheid wissen.
Wie erleben Sie die Technik im Alltag?
Das E-Rezept funktioniert inzwischen halbwegs zuverlässig. Die Einlösung über die Versichertenkarte hat sich durchgesetzt. Aber die dazugehörige App spielt in der Praxis kaum eine Rolle. Die meisten nutzen sie gar nicht – sie gehen einfach mit der Karte in die Apotheke. Das bedeutet aber auch, dass sie oft nicht wissen, was auf dem Rezept steht, zum Beispiel oder wie das Medikament dosiert werden soll. Der Informationsvorteil für die Patientinnen und Patienten, den man sich mit der Einführung des E-Rezepts erhofft hatte, ist also ausgeblieben.
Die Systeme, sowohl für das E-Rezept als auch für die ePA, sind allerdings immer noch nicht stabil. Wenn man sieht, wie selten Kartenterminals im Supermarkt ausfallen, ist der Unterschied frappierend. In der Medizin tragen die Praxen die finanziellen Auswirkungen der durch Dritte ausgelösten Ausfälle selbst, obwohl sie die Technik nicht einmal frei wählen konnten. Das ist teuer, frustrierend und innovationsfeindlich. Ein konkretes Beispiel ist unser Kartenlesegerät in der Praxis. Ich habe noch keine einzige Arbeitswoche erlebt, in der es ohne Absturz durchgelaufen wäre.
Dabei haben Sie sich in der Vergangenheit immer sehr begeistert für die Digitalisierung gezeigt, beispielsweise für die App „Meine pädiatrische Praxis“. Was macht diese Anwendung anders?
Diese App ist tatsächlich ein gutes Beispiel dafür, wie Digitalisierung im Arzt-Patienten-Alltag funktionieren kann, wenn sie sinnvoll umgesetzt wird. Sie wurde vom Berufsverband der Kinder- und Jugendärzt*innen e.V. herausgegeben und dient als direkter Kommunikationskanal zwischen Praxis und Familien. Eltern können darüber Termine buchen, Erinnerungen an Vorsorgeuntersuchungen oder Impfungen erhalten und sogar Videosprechstunden starten. Ich kann Push-Nachrichten an bestimmte Altersgruppen oder Patientinnen und Patienten schicken, zum Beispiel, um über Grippeimpfungen zu informieren oder geänderte Sprechzeiten weiterzugeben.
Das System ist bewusst geschlossen und datensparsam aufgebaut – keine Cloud, keine unnötigen Drittanbieter. Die Nutzenden entscheiden selbst, welche Funktionen sie nutzen. So habe ich ein digitales Werkzeug, das zur Versorgung beiträgt, ohne den Datenschutz zu gefährden. Für mich ist das ein Schritt in die richtige Richtung: Digitalisierung nahe am praktischen Nutzen, nicht als bürokratische Pflichtübung.
Sie experimentieren außerdem mit KI-Modellen. Was genau testen Sie da?
Ich probiere zurzeit an Dummy-Daten aus, ob eine KI Dokumenttypen automatisch erkennen kann – also ob sie unterscheiden kann, ob ein Schreiben ein Arztbrief, ein Therapiebericht oder etwa ein Versicherungsnachweis ist. Das alles geschieht lokal, auf eigenen Servern, ohne Patientendaten im Netz. Ich nutze aktuelle Modelle, wie zum Beispiel „Qwen 3“ von Alibaba oder „gpt-oss“ von OpenAI. Sie arbeiten verhältnismäßig effizient und kommen mit wenig Rechenleistung aus, also ideal für den lokalen Einsatz. Wichtig ist mir dabei nämlich vor allem, dass ich die volle Kontrolle über die Daten habe und sie nicht an unbekannte Dritte weitergebe. Deshalb kommt Cloud-Computing für medizinische Informationen aktuell für mich nicht infrage.
Ist KI Ihrer Einschätzung nach reif für den Einsatz in Praxen?
Ja, mit Einschränkungen. In kritischen Bereichen – etwa bei Diagnosen oder Therapieentscheidungen – darf sie keine autonome Rolle spielen. Aber sie kann Prozesse erleichtern: zum Beispiel Arztbriefe vorsortieren oder Gesprächsnotizen zusammenfassen. Wichtig ist, dass ich als Arzt jederzeit kontrollieren kann, was die KI macht. Wenn ich selbst im Gespräch dabei bin, erkenne ich sofort, ob eine Zusammenfassung richtig ist. Wenn die KI dagegen fremde Texte auswertet, verliere ich diese Kontrolle. Dann wird’s riskant.
Ein anderes Thema, das beschäftigt, sind medizinische Register, wozu ein Registergesetz geplant ist. Warum ist das in Deutschland eine Herausforderung?
Wir haben über 400 verschiedene Register, aber alle sind freiwillig und voneinander isoliert. Länder wie Dänemark oder Schweden machen das besser – dort gibt es eine einheitliche Identifikationsnummer, über die Gesundheitsdaten pseudonymisiert zusammengeführt werden können. So konnten sie – die Dänen, nicht die Deutschen – zum Beispiel nachweisen, dass die Masernimpfung kein Autismusrisiko verursacht. Solche Erkenntnisse sind bei uns in Deutschland kaum möglich, weil die Datenbasis fehlt.
Würden Sie also sagen, ein zentrales Gesundheitsregister wäre der ePA vorzuziehen?
Für Forschungszwecke: ja, sofern der Datenschutz stimmt. Für die individuelle Versorgung: nein, da sollte alles freiwillig sein. Ich halte nichts von einer automatischen Befüllung der Patientenakte. Gesundheitsdaten sind persönlichstes Eigentum. Wenn jemand sie speichern will – gerne. Wenn nicht, dann eben nicht.
Sehen Sie bei seltenen Krankheiten Chancen in der Mustererkennung?
Ja, absolut. Wir Ärztinnen und Ärzte erkennen im besten Fall ein paar Hundert Krankheitsmuster, vielleicht 500. Es gibt aber mehrere Tausende seltener Erkrankungen. Eine gut trainierte KI kann helfen, Muster zu finden, die wir übersehen würden. Das erweitert unseren Blick. Ich habe das in meiner eigenen Familie erlebt. Eine nahe Verwandte litt jahrelang an Schmerzen, bis ich – durch Zufall – erkannte, dass sie an einer seltenen Bindegewebsschwäche erkrankt ist. Eine KI mit entsprechender Datenbasis hätte diesen Zusammenhang vielleicht früher erkannt.
Wie sehen Sie persönlich die digitale Zukunft der Medizin?
Ich finde die Zeit unglaublich spannend. Wir haben gewaltige Chancen – etwa durch offene KI-Modelle oder smarte Praxislösungen. Aber wir müssen sie sicher und verantwortungsvoll nutzen. Die ärztliche Schweigepflicht muss auch im digitalen Zeitalter gelten und die Daten der Patientinnen und Patienten dürfen nie heimlich zum Rohstoff für Dritte werden. Heimlichkeit umgeht das Recht auf selbstbestimmte Entscheidungen. Wenn Digitalisierung den Alltag wirklich erleichtert und die Versorgung verbessert, bin ich sofort dabei. Aber sie darf kein Selbstzweck sein.
(mack)










Künstliche Intelligenz
Deutsche eID-Karte als Geldwäsche-Hilfe kritisiert
Seit 2021 gibt es in Deutschland eID-Karten, die zum Online-Nachweis der eigenen Identität und Adresse gereichen. Sie kosten 37 Euro, gelten zehn Jahre und können von nicht-deutschen EWR-Bürgern ab 16 Jahren bei Einwohnermeldeämtern gelöst werden. Ein Bericht der Süddeutschen Zeitung (SZ) übt nun Kritik an der Handhabe der Ausstellung: Viele Ämter prüfen demnach die Identität der Antragsteller unzureichend, sodass sich Geldwäscher und anderen Kriminelle mit gefälschten oder gestohlenen ausländischen Ausweisen eID-Karten lösen könnten.
Weiterlesen nach der Anzeige

Muster einer eID-Karte
(Bild: Bundesministerium des Innern)
Antragsteller müssen für eine deutsche eID-Karte persönlich auf einem Einwohnermeldeamt vorsprechen und sich ausweisen. Allerdings hätten viele Meldeämter keine Prüfgeräte, um die Echtheit des vorgelegten Ausweises zu prüfen, weil diese Geräte teuer sind. Auch biometrische Abgleiche oder die Überprüfung, ob der vorgelegte Ausweis als gestohlen gemeldet ist, gehören nicht zum notwendigen Prüfregime, schließlich handelt es sich nicht um ein Reisedokument.
Der SZ-Bericht zitiert als Beispiel die Polizei Berlins: „Ein Abgleich biometrischer Daten oder ein Abgleich mit dem europäischen Dokumenten-Fahndungsbestand findet nicht statt. Nicht alle Meldebehörden sind mit Dokumentenprüfgeräten ausgestattet.“ Das Bundesinnenministerium hat die Zeitung darauf hingewiesen, dass diese Regelungen Aufgabe der Länder seien, die das sicherlich gewissenhaft erledigen würden.
Unzulässige Einsatzszenarien
Ist die Karte einmal ausgestellt, kann sie beispielsweise zur Online-Eröffnung von Bankkonten genutzt werden. Einfache Kriminelle würden mit gefälschten oder gestohlenen Dokumenten eID-Karten unter falscher Identität lösen, um damit Bankkonten mit Überziehungsrahmen zu eröffnen. Der Rahmen wird ausgereizt, dann verschwindet der virtuelle Kunde, die Bank bleibt auf dem Schaden sitzen.
Fortgeschrittenere Kriminelle würden unter fremder Identität Bankkonten und Firmengeflechte für Geldwäsche oder komplexere Betrugsmodelle hochziehen. Da die eID-Karten für den Online-Einsatz konzipiert sind, können sie einfach weitergegeben werden. Foto oder biometrische Daten sind nicht enthalten, zumal deren Abgleich online schwierig ist.
Der Inhalt der eID-Karte:
Weiterlesen nach der Anzeige
Auf der eID-Karte werden folgende Daten sowohl aufgedruckt als auch auf dem enthaltenen Chip gespeichert: Kartennummern, Familienname, Geburtsname, Vornamen, etwaige Doktorgrade, Tag und Ort der Geburt, Anschrift, oder, falls zutreffend, die Angabe „keine Wohnung in Deutschland“, Staatsangehörigkeit, gegebenenfalls Ordensname oder Künstlername, die Art des vorgelegten Ausweisdokuments sowie das Ablaufdatum der eID-Karte.
Die Ausstellung an Personen ohne deutschen Wohnsitz ist gewollt, weil gerade diese mithilfe der eID-Karte deutsche Behördenwege bewältigen können sollen. Der Chip kann mittels Lesegerät oder NFC-fähigem Smartphone ausgelesen werden, wobei eine sechsstelligen Nummer (PIN) eingegeben werden muss.
(ds)
Künstliche Intelligenz
Generative KI: Disney wirft Google massive Copyright-Verletzung vor
Der Disney-Konzern setzt auf OpenAI und lizenziert für drei Jahre mehr als 200 Charaktere für die Nutzung mit dem KI-Videogenerator Sora. Andere generative Künstliche Intelligenzen sollen hingegen die Finger von copyrightgeschützten Disney-Charakteren lassen. Dahingehende Gespräche mit Google hätten nichts gebracht, sagt Disney-Chef Bob Iger. Daher hat er Google jetzt ein geharnischtes Unterlassungsbegehren zugemittelt.
Weiterlesen nach der Anzeige
„Wir waren im Gespräch mit Google, haben unsere Bedenken geäußert”, berichtet Iger in einem Fernsehinterview, „Letztendlich, weil wir keine Fortschritte gemacht und unsere Gespräche keinen Erfolg gezeigt haben, haben wir das Gefühlt bekommen, dass wir keine andere Wahl haben, als eine Unterlassungsaufforderungen zu schicken.” Es ist nicht der erste solche Fall: „Wir haben andere Firmen verfolgt, die unsere Rechte nicht geachtet haben”, sagte der Disney-CEO zu CNBC. Tatsächlich hat sein Konzern bereits ähnliche Unterlassungsbegehren an Meta Platforms und Character.AI geschickt. Zudem Disney, gemeinsam mit anderen Rechteinhabern, Klage gegen die KI-Firmen Midjourney und Minimax.
„Google verletzt Disneys Copyright in massivem Ausmaß, indem es einen großen Korpus aus Disneys copyrightgeschützten Werken ohne Genehmigung für Training und Entwicklung von KI-Modellen und Diensten kopiert hat”, heißt es laut Variety in dem Anwaltsschreiben, „und indem es KI-Modelle und -Dienste kommerziell verwertet sowie Kopien geschützter Werke an Verbraucher verbreitet”. Erschwerend komme hinzu, dass viele der rechtsverletzenden Bilder mit Google-Logos gekennzeichnet werden, was den falschen Eindruck vermittle, Disney habe das genehmigt und unterstützt.
Disney verlangt, dass Google sofort aufhört, weitere Kopien von oder derivative Werke mit geschützten Disney-Charakteren anzufertigen, aufzuführen oder zu verbreiten. Das bezieht sich ausdrücklich auch auf Youtube. Zudem verlangt Disney, dass Google sofort technische Maßnahmen ergreift, um sicherzustellen, dass Google-Produkte mit KI-Integration nicht länger zur Erzeugung von Disney-Inhalten genutzt werden.
heise online hat Google zu einer Stellungnahme eingeladen.
(ds)
Künstliche Intelligenz
Top 10: Das beste Mittelklasse-Smartphone mit guter Kamera im Vergleich
Ein Flaggschiff sprengt das Budget? Dann lohnt sich ein Mittelklasse-Smartphone. Wir zeigen die besten Handys bis 600 Euro mit Top-Kamera und starker Hardware.
Die Top-Smartphones namhafter Hersteller stehen im Rampenlicht. Modelle wie das Samsung Galaxy S25 Ultra oder iPhone 17 Pro wecken Begehrlichkeiten, schließlich vereinen sie aktuelle Spitzen-Technik in edlem Design. Der Preis sorgt jedoch schnell für Ernüchterung: Über 1000 Euro für ein Mobilgerät, das meist nur wenige Jahre hält, ist für viele keine Option.
Zum Glück geht es günstiger. Mit etwas Recherche finden sich gehobene Mittelklasse-Smartphones, die technisch nah an Flaggschiff-Modelle herankommen – und dabei oft nur die Hälfte kosten.
Der Begriff Mittelklasse ist weit gefasst. In dieser Bestenliste konzentrieren wir uns daher auf aktuelle Smartphones, die wir selbst getestet haben, die technisch nah an der Oberklasse liegen und preislich etwa zwischen 400 und etwas über 600 Euro angesiedelt sind. Modelle, die älter als zwei Jahre sind, berücksichtigen wir nicht. Auch aktuelle iPhones sucht man in diesem Preissegment vergeblich – deshalb liegt der Fokus hier ausschließlich auf Android-Geräten.
Welches ist aktuell das beste Mittelklasse-Smartphone?
Testsieger der Mittelklasse-Smartphones ist das Xiaomi 15T Pro für aktuell nur 497 Euro (inklusive Versand). Es überzeugt mit einem starken Gesamtpaket und insbesondere mit seiner hervorragenden Kamera samt leistungsstarker Telelinse.
Technologiesieger ist das Poco F8 Pro von Xiaomi ab 524 Euro (inklusive Versand). Auch dieses Modell bietet ein überzeugendes Gesamtpaket zu einem fairen Preis. Mit an Bord sind eine gute Kamera mit Teleobjektiv sowie der leistungsstärkste Prozessor im Testfeld.
Den Titel Preis-Leistungs-Sieger sichert sich das Motorola Edge 60 Pro ab 399 Euro (inklusive Versand). Es punktet mit einer starken Telekamera, einem robusten Gehäuse und einer ausdauernden Akkulaufzeit.
Hinweis: Wie all unsere Bestenlisten sind die genannten Preise immer Momentaufnahmen.
Das Xiaomi 15T Pro überzeugt mit einer tollen Kamera, besonders die Telelinse sticht hervor. Leistung, Display und Verarbeitung liegen nahe am Flaggschiff-Niveau, und der Akku bietet lange Laufzeiten und 90-W-Schnellladen. Auch die Software-Pflege mit fünf Android-Upgrades und sechs Jahren Sicherheits-Updates ist vorbildlich.
- exzellente Kamera mit optischem 5-fach-Zoom
- schickes Design
- starke Performance
- lange Akkulaufzeit
- USB-C 2.0
- Display ohne LTPO
Technologiesieger ist das Poco F8 Pro. Es bietet ein exzellentes Preis-Leistungs-Verhältnis mit der besten Performance dieser Bestenliste. Dazu kommt eine richtig gute Kamera samt Telezoom, ein brillantes Display und ein besonders ausdauernder Akku.
- starke Performance
- gute Kamera mit Telelinse
- schickes und hochwertiges Design
- schnelles Laden
- kein kabelloses Laden
- eher schwache Ultraweitwinkellinse
Das Motorola Edge 60 Pro bietet ein elegantes Design mit exzellenter Verarbeitung und hochwertiger Haptik. Ausgestattet mit einem hellen OLED‑Display, einer leistungsstarken Triple-Kamera, 12 GB RAM und großzügigen 512 GB Speicher zeigt es sich rundum modern und alltagstauglich.
Der 6000‑mAh‑Akku sorgt für lange Laufzeiten und lädt wahlweise schnell per Kabel oder kabellos. Mit 396 Euro hat es auch noch hervorragendes Preis-Leistungs-Verhältnis.
- tolles Display
- schickes Design
- IP69 und MIL-STD-810H
- gute Kamera mit Telelinse
- starker Akku
- nur USB 2.0
- kein microSD-Slot
- Software-Updates nur bis 2029
Ratgeber
Günstige Alternativen
Bei begrenztem Budget empfehlen wir aus dieser Bestenliste den Preis-Leistungs-Sieger Motorola Edge 60 Pro sowie das Xiaomi 14T Pro als eines der besten Smartphone bis 500 Euro.
So testen wir
Die Hersteller stellen uns die Geräte für einen begrenzten Zeitraum kostenfrei zur Verfügung. Während dieser Zeit nutzen wir die Mobilgeräte im Alltag mit einer Zweit-SIM-Karte für einen Zeitraum von mehreren Wochen. Ergänzend fließt unsere Praxiserfahrung in die Bewertung ein. Wir schießen Fotos unter verschiedenen Lichtbedingungen an möglichst gleichen Orten, um vergleichbare Ergebnisse zu erhalten.
Die Display-Helligkeit messen wir in Nits (cd/m²) und probieren das dann auch bei Sonnenschein – sofern das Wetter mitspielt – im Freien aus. Spitzenwerte oberhalb von rund 2000 Nits lassen sich mit unseren Messmethoden nur eingeschränkt erfassen. Die Performance ermitteln wir mit PCMark Work sowie 3DMark Wild Life und Wild Life Extreme.
Für die Akkulaufzeit stellen wir die Helligkeit auf 200 cd/m² ein und verwenden den simulierten Battery Test von PCMark. Das Tool führt verschiedene Aufgaben in einer Endlosschleife aus, bis der Akkustand auf 20 Prozent fällt. Daraus ergibt sich eine durchschnittliche Laufzeit – kein absoluter, aber ein gut vergleichbarer Richtwert. Zusätzlich tauschen wir uns regelmäßig mit den Kolleginnen und Kollegen der c’t aus, die eigene Akkutests durchführen.
Display-Technologie
In der Preisklasse bis 600 Euro sind Auflösungen mit weniger als FHD+ nicht mehr zu finden. Bei durchschnittlichen Diagonalen von etwa 6,5 Zoll ergibt FHD+ etwas mehr als 400 Pixel pro Zoll (PPI), was entsprechend für eine scharfe Darstellung sorgt. Die höchste Auflösung im Vergleich hat das Poco F7 mit beeindruckenden 3200 × 1440 Pixeln.
Als Technologie steht ein AMOLED-Display ganz oben auf der Wunschliste – das bedeutet nicht, dass IPS-LCDs schlecht wären. AMOLED bietet aber deutlich bessere Schwarzwerte, Kontraste sowie Farbintensität und höhere Blickwinkelstabilität. Zudem ist ein OLED-Display bei Smartphones auch für unter 600 Euro inzwischen richtig hell und mittlerweile in diesem Preisrahmen auch der Standard, abgesehen von Outdoor-Handys (Bestenliste).
Inzwischen schaffen die Panels in dieser Preisklasse üblicherweise eine Bildwiederholrate von 120 Hz oder sogar 144 Hz für flüssigere Darstellung von Inhalten. Einige Geräte bieten sogar LTPO-Technik (Low-Temperature Polycrystalline Oxide) mit variablen Bildwiederholraten von 1 bis 120 Hz, was für mehr Effizienz sorgt. Stellenweise gibt es auch Geräte mit 144 Hz. Mindestens 120 Hz bieten alle Modelle in dieser Bestenliste.
Mit 60 Hz sollte sich bei so viel Geld niemand mehr zufriedengeben. Wer einmal das flüssigere Erlebnis beim Scrollen in Menüs oder Browser erlebt hat, will nicht mehr zurück auf 60 Hz.
Leistung & Prozessoren
In der Mittelklasse steckt heute deutlich mehr Power als noch vor wenigen Jahren. Viele Modelle unserer Bestenliste nutzen Chipsätze der oberen Mittelklasse wie den Qualcomm Snapdragon 7 Gen 3 oder Snapdragon 7s Gen 3. Im Alltag macht das kaum einen Unterschied zu teureren High-End-Prozessoren – für alltägliche Aufgaben wie Surfen, Messaging oder Videostreaming reicht die Leistung locker aus.
Besonders für Gaming sind aus dieser Bestenliste Geräte mit Snapdragon 8 Gen 3 sowie Mediatek Dimensity 9400+ empfehlenswert. Die stärkste Leistungsfähigkeit bietet das Poco F8 Pro mit Snapdragon 8 Elite Gen 4.
Einige Hersteller verbauen leicht abgespeckte Spitzenchips, wie den Snapdragon 8s Gen 3, der in puncto Performance bereits nahe an die Flaggschiff-Serie heranreicht. Dazu kommen Alternativen wie der Samsung Exynos 2400. Die Chips von Mediatek der Reihe Dimensity 8300‑Ultra oder 9300+ bieten ein hervorragendes Verhältnis aus Leistung und Effizienz.
Wer hauptsächlich anspruchsvolle 3D-Spiele spielt, ist mit echten Oberklasse-Chips der Snapdragon-8-Serie besser bedient – sie liefern die höchste CPU- und GPU-Leistung. Für den Alltag und gelegentliches Gaming reicht die Rechenleistung der hier gelisteten Smartphones jedoch vollkommen aus.
Kamera
Viele Hersteller sparen bei der Kamera. In der gehobenen Mittelklasse bieten aber inzwischen fast alle Smartphones einen optischen Bildstabilisator (OIS). Immer mehr Modelle verfügen zudem über eine leistungsstarke Telelinse – teils sogar mit Periskop-Technik.
In dieser Top 10 nutzen acht von zehn Geräten eine Telelinse. Das Xiaomi 15T Pro bringt eine Periskop-Telelinse mit starkem Zoom mit. Es gibt Modelle mit OIS für Haupt- und Telelinse, entsprechend sind die Aufnahmen damit besser – teils auch bei Nacht.
Bei Videos gibt es zwar 4K-Aufnahmen, allerdings ist meistens bei 30 Bildern pro Sekunde Schluss. Das führt dazu, dass Schwenks etwas ruckelig wirken, weil die Bildwiederholungsrate zu niedrig ist. 4K mit 60 FPS behebt dieses Problem. Frontkameras bieten heute fast immer hohe Auflösungen, haben aber oft Schwierigkeiten mit der Bilddynamik. Für Videochats und Social Media reicht das allemal.

Speicher & RAM
Bei Android-Smartphones gelten 4 bis 6 GB RAM inzwischen als absolute Untergrenze. Empfehlenswert sind mindestens 8 GB – das ist mittlerweile auch der Standard in der Mittelklasse. Immer häufiger tauchen sogar Modelle mit 12 GB RAM auf – ein Wert, der bis in jüngster Vergangenheit der Oberklasse vorbehalten war.
Beim Speicher sieht es ähnlich aus: 128 GB sind das Minimum, 256 GB die sinnvollere Wahl. Selbst 512 GB sind längst keine Exoten mehr. Wir empfehlen klar 256 GB als Untergrenze, denn microSD-Steckplätze verschwinden zusehends. In dieser Bestenliste berücksichtigen wir daher nur Modelle mit mindestens 256 GB. Technisch ist ansonsten alles an Bord, was ein modernes Smartphone auszeichnet – von 5G bis NFC.
Langsamer interner Speicher macht sich anders bemerkbar. Wenn man „eben schnell“ das neueste Foto aus dem Speicher des Mittelklasse-Smartphones herunterladen möchte und schon Hunderte im Speicher hat, dauert es anfangs lange, bis alle Bilder angezeigt werden. Inzwischen verwenden aber alle Modelle in dieser Bestenliste schnellen UFS-Speicher – je höher die Version, desto besser.
Akku & Laden
Ein wichtiges Kriterium beim Kauf sollte der Akku sein. Die Spanne reicht im Testfeld von 4500 mAh bis 5500 mAh. Bei gewöhnlicher Nutzung, bestehend aus gelegentlicher Nutzung von Chat-Apps, Social Media oder dem Lesen von Artikeln, halten alle hier gezeigten Geräte gut einen Tag lang durch. Wer jedoch damit für längere Zeit Spiele zockt, navigiert oder Videos streamt, muss damit leben, dass das Smartphone nicht ganz bis zum Abend durchhält. Im Zweifel raten wir hier zu kompakten Powerbanks fürs Smartphone (Bestenliste).
Die Ladegeschwindigkeit variiert stark, von gemächlichen 25 Watt bis zu flotten 90 Watt. Interessant sind auch Schnellladen sowie kabelloses Laden, das in dieser Preisklasse noch selten zu finden ist.
Software
Bei der Aktualität der Android-Version steht es bei den meisten Geräten in unserer Top 10 gut. Das Xiaomi 15T Pro erhält fünf Android-Updates sowie Sicherheits-Patches für sechs Jahre. Honor bietet drei große Updates und vier Jahre Software-Support. Beim Samsung Galaxy S25 FE gibt es sieben Jahre lang Android-Updates. Der Zeitraum gilt allerdings nicht ab dem Kaufdatum, sondern ab der Veröffentlichung des Geräts.
Wie wichtig sind KI-Funktionen? Tatsächlich ziehen die immer mehr in den Alltag und damit auch in Smartphones bis 600 Euro ein. Aufwändige KI-Funktionen wie intelligente Bildbearbeitung, die etwa Gegenstände oder Personen virtuell hinzugefügt oder entfernt, sind derzeit noch hochpreisigen Modellen vorbehalten.
Konnektivität & Schnittstellen
5G gehört in dieser Preisklasse inzwischen zum Standard – überwiegend im Sub-6-GHz-Bereich, seltener im besonders flotten mmWave-Spektrum. Auch Dual-SIM-Support ist selbstverständlich, häufig in Kombination mit eSIM-Unterstützung, die immer mehr Geräte bietet.
Mangels flächendeckenden Netzausbaus ist 5G in Deutschland jedoch bisher nicht überall verfügbar. In Städten bringt der Standard klare Vorteile bei Datendurchsatz und Latenz, während er auf dem Land oft Lücken im 4G‑Netz schließt. Für die Zukunftssicherheit lohnt sich der 5G‑Support aber in jedem Fall.
Neben Mobilfunk spielt die WLAN‑Leistung eine wachsende Rolle: Moderne Geräte setzen auf Wi-Fi 6 oder Wi-Fi 6E, teils sogar schon auf Wi-Fi 7. Das sorgt für stabilere Verbindungen und höhere Geschwindigkeiten – etwa beim Streamen oder bei Cloud‑Gaming.
Auch Bluetooth 5.3 ist mittlerweile die Regel, was niedrigere Latenzen und Energieverbrauch bedeutet. Für Musikfans sind unterstützte Audio‑Codecs wie aptX HD, LDAC oder AAC entscheidend – sie ermöglichen kabellosen Sound in Hi‑Res-Qualität.
Beim USB‑Anschluss sparen einige Hersteller leider weiterhin: Viele Modelle setzen noch auf USB 2.0, was beim Übertragen großer Dateien oder bei der Nutzung im Desktop‑Modus (etwa Samsung DeX) zum Flaschenhals werden kann. Geräte mit USB‑C 3.1 oder USB‑C 3.2 punkten hier deutlich, da sie schnellere Datenraten und bessere Kompatibilität bieten.
Ein gutes Mittelklasse‑Smartphone sollte heute 5G, Wi-Fi 6 oder 6E, Bluetooth 5.3 und eSIM‑Support bieten. Wer häufig Daten überträgt oder externe Geräte anschließt, sollte zudem auf USB 3.x achten – das steigert Komfort und Zukunftssicherheit spürbar.
Schutz vor Wasser & Staub
Eine IP-Zertifizierung gibt Aufschluss darüber, wie gut ein Smartphone gegen Staub und Wasser geschützt ist. Je höher die zweite Ziffer, desto besser der Schutz. IP54 bedeutet Spritzwasserschutz – etwa gegen Regen. IP68 hingegen schützt das Gerät auch für kurzes Untertauchen bis zu 30 Minuten in maximal 1,5 Meter Tiefe, was aber nur für Süßwasser gilt. In der Mittelklasse sind wasserdichte Smartphones nicht selbstverständlich, aber immer häufiger.
In der Mittelklasse schützt meist Gorilla Glass 5, 7 oder Victus 2 das Display vor Kratzern und Stürzen – gänzlich bruchsicher ist aber kein Glas. Besonders flache Displays ohne starke Krümmung gelten als widerstandsfähiger. Nur das Motorola Edge 60 Pro bietet in dieser Preisklasse eine MIL-STD-810H-Zertifizierung, die dessen hohe Robustheit bescheinigt.

Sonstige Ausstattung
Alle Smartphones in dieser Bestenliste bieten eine Entsperrung per Fingerabdrucksensor, der überwiegend unter dem Display sitzt, seltener seitlich im Power-Button. Alternativ steht eine Gesichtserkennung über die Frontkamera zur Verfügung, die jedoch nur auf 2D-Technik basiert und daher weniger sicher gegen Täuschungsversuche ist.
Der Klang der Geräte ist für Videos, Social Media oder Spiele vollkommen ausreichend – klar, laut und teilweise sogar mit Dolby Atmos. Für längeres Musikhören fehlt den Lautsprechern allerdings häufig die Balance: Der Sound wirkt leicht schrill und höhenlastig, was im Alltag aber kaum stört.
Fazit
Beachtlich, was man für unter 600 Euro an Technik bekommt. Groß ist der Unterschied zur absoluten Spitze teilweise nicht mehr, sofern man den Preis in Relation zum Mehrwert setzt. Ansonsten sind die neuesten Spitzenmodelle etablierter Hersteller natürlich doch noch einmal besser – allein schon, weil dort fast immer optische Teleobjektive angeboten werden. Dazu kommen Merkmale wie USB-C 3.0, kabelloses Laden und meistens auch Wasserdichtigkeit. Bei der Leistung sind aber bei einigen Smartphones bis 600 Euro – primär im „normalen“ Alltag – so gut wie keine Unterschiede mehr zu spüren.
Wer mit anderen Preisklassen vergleichen möchte, sollte einen Blick in unsere weiteren Top 10 der besten Smartphones werfen, die regelmäßig aktualisiert werden:
Übrigens: Wer zu seinem neuen Smartphone einen passenden Tarif sucht, wird vielleicht im Tarifrechner von heise.de fündig. Hier gibt es verschiedene Vergleichsrechner für Prepaid, monatlich kündbare und sogar kostenlose Tarife. Der Rechner umfasst dabei übergreifend alle Angebote, die derzeit in Deutschland verfügbar sind.
Xiaomi 15T Pro
Das Xiaomi 15T Pro vereint Top-Kamera, starke Performance und lange Akkulaufzeit zum fairen Preis. Ist das der neue Underdog unter den Smartphones?
- exzellente Kamera mit optischem 5-fach-Zoom
- schickes Design
- starke Performance
- lange Akkulaufzeit
- USB-C 2.0
- Display ohne LTPO
Xiaomi 15T Pro im Test: Dieses Smartphone ist der Geheimtipp des Jahres
Das Xiaomi 15T Pro vereint Top-Kamera, starke Performance und lange Akkulaufzeit zum fairen Preis. Ist das der neue Underdog unter den Smartphones?
Wer sagt denn, dass man über 1000 Euro auf den Tisch legen muss, um ein schnelles, stilvolles Smartphone mit Top-Kamera und ordentlichem Zoom zu bekommen? Xiaomi zeigt mit seiner T‑Serie regelmäßig, dass es auch eine Nummer bodenständiger geht – ohne langweilig zu sein.
Das neue Xiaomi 15T Pro demonstriert eindrucksvoll, wie das klappt: Im Prinzip ist es eine clever abgestimmte Mischung aus dem Xiaomi 15 und dem Ultra-Modell, behält dabei aber einen eigenständigen Charakter. Der Star ist die Kamera mit fünffachem optischem Zoom und starken Ergebnissen – und das zu einem fairen Preis. Damit stiehlt das T‑Modell der großen Ultra‑Serie fast ein wenig die Show.
Auch sonst gibt es wenig zu meckern: Der Prozessor liefert reichlich Power, auch wenn dieses Mal kein Snapdragon verbaut ist, und der Akku hält beeindruckend lange durch. Warum das Xiaomi 15T Pro vielleicht die spannendste Oberklasse-Alternative des Jahres 2025 ist, klären wir im Detail im Testbericht.
Design
Beim Design geht Xiaomi beim 15T Pro seinen eigenen Weg. Mit dem Vorgänger oder den Schwestermodellen 15 und 15 Ultra hat es stilistisch nur wenig gemeinsam. Auffälligstes Merkmal ist das große Kameraelement, das in einem Rechteck mit stark abgerundeten Ecken sitzt. Es ragt deutlich hervor und beherbergt drei Linsen plus LED-Blitz.
Das Gehäuse wirkt hochwertig und ist mit seinem Metallrahmen und der griffigen Rückseite aus Glasfaserverbundstoff wie aus einem Guss gefertigt. Anders als bei vielen Top-Smartphones verzichtet Xiaomi hier also auf eine Glasrückseite. Die Oberfläche ist dabei erfreulich unempfindlich gegenüber Fingerabdrücken. Die Ecken sind deutlich abgerundet, das Format wirkt insgesamt wuchtig. Mit 162,7 × 77,9 × 8 mm übertrifft es in der Breite sogar das Ultra-Modell. Für die Einhandbedienung und kleine Hände ist es also weniger geeignet, liegt dank der sanften Form aber trotzdem gut in der Hand.
Die Verarbeitung ist erstklassig, klar auf Flaggschiff-Niveau. Xiaomi bietet drei Farben an: Schwarz, Grau und ein edles Dunkelbraun, das der Hersteller „Mocha Gold“ nennt. Dazu kommt IP68-Schutz gegen Staub und Wasser. Mit 210 g bleibt das Gewicht für diese Größe absolut im Rahmen. Das Xiaomi 15T Pro hat Stil – und eine ordentliche Portion Eleganz gleich dazu.
Xiaomi 15T Pro – Bilderstrecke
Xiaomi 15T Pro

Xiaomi 15T Pro

Xiaomi 15T Pro

Xiaomi 15T Pro

Xiaomi 15T Pro

Xiaomi 15T Pro

Xiaomi 15T Pro

Xiaomi 15T Pro

Xiaomi 15T Pro

Display
Der Bildschirm des Xiaomi 15T Pro ist mit einer Diagonale von 6,83 Zoll riesig bei einem Seitenverhältnis von 19,5:9. Es zeigt eine messerscharfe Auflösung von 2772 × 1280 Pixeln und erreicht damit eine hohe Pixeldichte von 447 PPI. Das AMOLED-Panel liefert eine hervorragende Bildqualität. Mit einer Bildwiederholrate von bis zu 144 Hz wirkt das Bild beim Spielen und Scrollen besonders flüssig.
Gorilla Glass 7i schützt den Bildschirm und soll Stürze aus etwa einem Meter Höhe abfedern – wir haben es aber nicht übers Herz gebracht, das auszuprobieren. Die Anzeige leuchtet zudem äußerst hell und bleibt bei Sonnenlicht stets ablesbar. Laut Hersteller erreicht das Display bis zu 3200 Nits. Die Abtastrate von 480 Hz und die Touch-Abtastrate von 2560 Hz sind ebenfalls hoch. Eine hohe Abtastrate lässt Eingaben schneller erkennen, was die Bedienung flüssiger und direkter macht. Ein Always-On-Display steht ebenfalls zur Verfügung.
Einziger Nachteil: Das Display nutzt keine LTPO-Technologie. Diese Technik passt die Bildwiederholrate in 1-Hz-Schritten automatisch an, um Energie zu sparen. Das Xiaomi 15T Pro kann die Frequenz zwar auch anpassen, wechselt aber nur zwischen 144, 120 und 60 Hz. Am Ende ist das aber Jammern auf hohem Niveau.
Kamera
Der Star des Xiaomi 15T Pro ist die Kamera – vorrangig die Telelinse. Die Zusammenarbeit mit Leica zahlt sich erneut aus. Xiaomi verbaut ein Hauptobjektiv mit 50 Megapixeln (f/1.62) und optischer Bildstabilisierung (OIS), dazu eine Periskop-Telelinse mit ebenfalls 50 Megapixeln (f/3.0), OIS und fünffachem optischen Zoom. Ergänzt wird das Setup durch ein Ultraweitwinkelobjektiv mit 12 Megapixeln. Für Selfies gibt es eine Frontkamera mit 32 Megapixeln.
Bei Tageslicht liefert die Kamera ausgezeichnete Fotos mit hohem Detailgrad, großem Dynamikumfang und kräftigen Kontrasten. Auch bei wenig Licht entstehen richtig gute Aufnahmen mit geringem Bildrauschen, die fast an das Level des Xiaomi 15 Ultra heranreichen. Das Ultraweitwinkelobjektiv fällt bei Details und Dynamik leicht ab, bleibt aber farblich sehr nah an den übrigen Linsen.
Besonders stark ist die Telelinse mit fünffachem optischem Zoom. Selbst bei zehnfacher Vergrößerung entstehen detailreiche und verlustfreie Aufnahmen. Auch 30-fach gezoomte Bilder bleiben brauchbar. Der digitale Zoom reicht bis 100-fach, dann nimmt die Schärfe trotz KI-Unterstützung sichtbar ab – diese Stufe hat aber eher experimentellen Charakter. Kleine Schwäche: Für Zoomstufen unter dem Faktor fünf kommt nur die Hauptkamera zum Einsatz.
Nutzer können zwischen zwei Farbmodi wählen: Leica Vibrant („lebendig“) liefert kräftige Farben und starke Kontraste, während Leica Authentic („authentisch“) dezenter wirkt und eine etwas dunklere Stimmung erzeugt. Im Alltag überzeugt der lebendige Modus am meisten, auch wenn Farben oft etwas intensiv wirken. Der authentische Stil eignet sich dagegen gut für stimmungsvolle, leicht düstere Szenen.
Auch Selfies gelingen scharf und farblich ausgewogen, das Bokeh im Porträtmodus wirkt natürlich und sauber. Videos überzeugen ebenfalls mit hoher Schärfe und guter Stabilisierung. Möglich sind Aufnahmen in 4K mit bis zu 120 FPS oder sogar in 8K mit 30 FPS. Insgesamt bietet das Xiaomi 15T Pro eine hervorragende Kamera, die fast das Niveau des 15 Ultra erreicht und den Fokus klar auf die starke Telelinse legt.
Xiaomi 15T Pro – Originalaufnahmen
Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Xiaomi 15T Pro – Originalaufnahmen

Ausstattung
Statt eines Snapdragon-Chips wie in den Top-Modellen setzt Xiaomi beim 15T Pro auf den Mediatek Dimensity 9400+. Er ist zwar etwas schwächer als Qualcomms aktuelles Elite-Modell, bietet aber ebenfalls enorme Leistungsreserven. Im Alltag läuft das Smartphone sehr flüssig und reagiert ohne spürbare Verzögerungen.
Beim Benchmark PCMark Work erreichten wir starke 16.500 Punkte, und auch die Grafikleistung überzeugt mit 6000 Punkten im 3DMark Wild Life Extreme – damit eignet sich das Xiaomi 15T Pro auch zum Spielen grafisch aufwendiger Titel. Unter Volllast im Stresstest wird das Gerät allerdings recht warm. Aufgrund der Wärmedrosselung erreicht es lediglich eine Effizienz von rund 60 Prozent. Das Xiaomi 15 Ultra kommt hier auf über 70 Prozent.
Der Arbeitsspeicher ist mit 12 GB RAM großzügig bemessen, dazu kommen 256 GB, 512 GB oder sogar 1 TB Speicher nach schnellem UFS-4.1-Standard. Bei den kabellosen Schnittstellen ist das Gerät auf neuestem Stand: 5G, Wi-Fi 7, Bluetooth 6.0, NFC und der typische Infrarot-Port von Xiaomi sind vorhanden. Auf UWB verzichtet Xiaomi allerdings.
Einen großen Schwachpunkt gibt es aber: Der USB-C-Anschluss unterstützt nur USB 2.0 – bei diesem Preis wäre USB 3.2 angemessen gewesen, da kabelgebundene Datenübertragungen so recht langsam ausfallen. Das ist schon frech für den Preis.
Die Ortung über GPS, Glonass, Beidou, Galileo, QZSS und Navic arbeitet sehr präzise. Im Test erreichten wir eine Genauigkeit von rund zwei Metern. Das Smartphone kann zwei physische SIM-Karten aufnehmen und zusätzlich bis zu zwei eSIMs unterstützen. Die Telefonqualität überzeugt, und auch das 5G im E-Netz wurde vollständig ausgereizt.
Eine Besonderheit bringt das Xiaomi 15T Pro mit: die Offline-Walkie-Talkie-Funktion „Xiaomi Astral Communication“. Sie ermöglicht Kommunikation ohne Mobilfunknetz über eine optimierte Bluetooth-Direktverbindung mit einer Reichweite von knapp 2 km zwischen zwei kompatiblen Geräten – praktisch etwa beim Wandern oder in Gebieten mit schlechtem Empfang. Aktuell unterstützen nur das Xiaomi 15T und 15T Pro die Funktion, weitere Modelle sollen folgen.
Die Stereo-Lautsprecher klingen klar und bleiben auch bei hoher Lautstärke verzerrungsfrei. Der Bass ist etwas zurückhaltend, was in dieser Klasse normal ist. Über die Dolby-Atmos-Software lässt sich der Klang leicht anpassen. Der Fingerabdruckscanner unter dem Display arbeitet zuverlässig und schnell.
Software
Das Xiaomi 15T Pro läuft mit Android 15 und der Bedienoberfläche Hyper OS 2. Der Sicherheits-Patch stammt zum Testzeitpunkt aus August, was noch in Ordnung ist. Ein Update auf Hyper OS 3 auf Basis von Android 16 soll bald folgen.
Xiaomi hat zudem seine Update-Politik verbessert: Das 15T Pro soll insgesamt fünf große Android-Upgrades und sechs Jahre Sicherheits-Updates erhalten. Das ist zwar nicht ganz auf dem Niveau von Samsung oder Google, geht aber in die richtige Richtung und dürfte für die meisten Nutzer ausreichen.
Hyper OS wirkt im Vergleich zu früheren Versionen deutlich aufgeräumter und übersichtlicher. Künstliche Intelligenz spielt hier eine geringere Rolle als bei der Konkurrenz – Xiaomi setzt hier vorwiegend auf Google Gemini.
Akku
Der Akku bietet eine stattliche Kapazität von 5500 mAh. Das ergibt in Kombination mit dem effizienten Prozessor eine lange Akkulaufzeit. Im PCMark Battery Test erreichte das Xiaomi 15T Pro einen guten Wert von 15,5 Stunden – damit liegt es fast auf Augenhöhe mit vielen anderen Top-Smartphones, auch wenn einige Geräte noch länger durchhalten. Regelt man das Display fest auf 60 Hz, hält das Smartphone gut drei Stunden länger durch.
Einen vollen Tag übersteht das Smartphone problemlos, bei sparsamer Nutzung sogar zwei. Es lässt sich mit bis zu 90 W schnell laden und ist in etwa einer halben Stunde vollständig aufgeladen – vorausgesetzt, man besitzt ein entsprechendes Ladegerät, denn ein Netzteil liegt nicht bei. Kabelloses Laden ist ebenfalls möglich. Das passende Ladegerät Xiaomi 90W Hypercharge Combo kostet rund 25 Euro.
Preis
Die UVP des Xiaomi 15T Pro liegt bei 800 Euro für die Version mit 256 GB, bei 900 Euro für 512 GB und bei 1000 Euro für 1 TB Speicher. Das ist ziemlich hoch, womit das Gerät den Preisrahmen der Mittelklasse eigentlich sprengt. Aber schon kurz nach dem Marktstart sind die Preise spürbar gefallen.
Aktuell kostet die Variante mit 256 GB nur 491 Euro. Das Modell mit 512 GB liegt bei knapp 541 Euro. Die Version mit 1 TB kostet etwa 674 Euro.
Fazit
Das Xiaomi 15T Pro zeigt eindrucksvoll, wie gut ein Smartphone für rund 600 Euro sein kann. Die Kamera überzeugt auf ganzer Linie, besonders die starke Telelinse hat uns begeistert. Auch die Leistung ist hoch, wenn auch nicht ganz auf Flaggschiff-Niveau eines Snapdragon 8 Elite. Für den Alltag bietet das Gerät jedoch reichlich Reserven für viele Jahre. Das edle Design gefällt und verleiht dem 15T Pro einen eigenständigen Charakter. Xiaomi bietet jetzt sechs Jahre Sicherheits-Updates und fünf große Android-Upgrades, was ein klarer Fortschritt ist.
Schwächen gibt es nur wenige: LTPO wäre schön gewesen für eine noch längere Akkulaufzeit. Ärgerlich ist der veraltete USB‑2.0‑Standard des Anschlusses, obwohl die restliche Ausstattung auf Top-Niveau liegt. Bei Nachtaufnahmen erreicht die Kamera nicht ganz das Niveau von Top-Modellen wie dem Xiaomi 15 Ultra oder dem Google Pixel 10 Pro – dennoch liefert sie hervorragende Ergebnisse.
Wer ein leistungsstarkes Smartphone mit Fokus auf Fotografie sucht und sich nicht an der Größe stört, bekommt mit dem Xiaomi 15T Pro ein rundum gelungenes Paket. Man muss also nicht zum Flaggschiff für über 1000 Euro greifen, um starke Fotos und hohe Qualität zu bekommen.
Poco F8 Pro
Das Poco F8 Pro bietet Flaggschiff-Leistung mit starker Kamera samt Telelinse – und das für knapp über 500 Euro. Ist das zu gut, um wahr zu sein?
- starke Performance
- gute Kamera mit Telelinse
- schickes und hochwertiges Design
- schnelles Laden
- kein kabelloses Laden
- eher schwache Ultraweitwinkellinse
Xiaomi Poco F8 Pro im Test: High-End-Smartphone zum Mittelklasse-Preis
Das Poco F8 Pro bietet Flaggschiff-Leistung mit starker Kamera samt Telelinse – und das für knapp über 500 Euro. Ist das zu gut, um wahr zu sein?
Mit der F-Reihe bietet Poco von Xiaomi vergleichsweise günstige Smartphones aus der Mittelklasse an, die mit High-End-Features aufwarten – allen voran einem starken Prozessor. Mit dem F8 Pro geht Xiaomi in diesem Jahr jedoch einen Schritt weiter. Im Kern handelt es sich um eine an den europäischen Markt angepasste Version des in Asien erhältlichen Redmi K90.
Das Smartphone bietet eine Ausstattung, die man sonst nur in der Oberklasse findet – inklusive einer Telekamera. Diese war im Vorjahr noch dem F7 Ultra vorbehalten, nun erhält auch das Pro-Modell ein echtes Zoom-Objektiv. Das Poco F8 Pro verspricht dementsprechend Top-Leistung zu einem exzellenten Preis-Leistungs-Verhältnis – ob es dennoch einen Haken gibt, klärt unser Test.
Design
Verglichen mit anderen Smartphones der oberen Mittel- und Oberklasse fällt das Poco F8 Pro relativ kompakt aus. Es positioniert sich zwischen handlichen Geräten und großen High-End-Modellen. Mit Abmessungen von 157,5 × 75,3 × 8 mm passt es problemlos in die Hosentasche, und auch die einhändige Bedienung ist – zumindest für Nutzer mit größeren Händen – gut machbar. Das Gewicht von 199 g wirkt moderat. Der Formfaktor ist für uns ein idealer Kompromiss.
Optisch erinnert das Modell an das Xiaomi 14T Pro aus dem Vorjahr – mit einem Schuss aktueller iPhone-Ästhetik. Vier runde Linsen mit Metallringen sitzen quadratisch angeordnet auf einem quaderförmigen Modul aus Kunststoff mit abgerundeten Ecken. Dort findet sich auch der Schriftzug „Sound by Bose“. Der Audio-Spezialist war an der Optimierung der Lautsprecher beteiligt.
Bei der Materialwahl zeigt sich das Poco F8 Pro erwachsen: Ein Metallrahmen und eine Glasrückseite verleihen dem Smartphone eine hochwertige Haptik. Zudem ist es nach IP68 staub- und wasserdicht. Die Verarbeitungsqualität liegt insgesamt auf Premium-Niveau.
Poco F8 Pro – Bilderstrecke
Poco F8 Pro

Poco F8 Pro

Poco F8 Pro

Poco F8 Pro

Poco F8 Pro

Poco F8 Pro

Poco F8 Pro

Poco F8 Pro

Poco F8 Pro

Display
Das Poco F8 Pro setzt auf ein 6,59-Zoll-Display und liegt damit größenmäßig zwischen kompakten Geräten wie dem Xiaomi 15 und größeren Ultra-Modellen des Herstellers. Das OLED-Display überzeugt mit hervorragender Bildqualität: starke Kontraste, tiefes Schwarz und lebendige, aber nicht übertrieben gesättigte Farben. Auch die Blickwinkelstabilität ist einwandfrei.
Mit einer Auflösung von 2510 × 1156 Pixeln erreicht das Panel eine hohe Schärfe von 419 PPI. Die Bildwiederholrate passt sich automatisch zwischen 60 und 120 Hz an, was flüssige Animationen ermöglicht. Die Touch-Abtastrate von 2560 Hz erlaubt zudem äußerst präzise Eingaben.
Auch die Helligkeit liegt auf Spitzenniveau. Selbst bei direkter Sonneneinstrahlung bleibt die Anzeige gut ablesbar. Im HDR-Modus erreicht es laut Hersteller bis zu 3200 Nits – ein beeindruckender Wert für diese Preisklasse.
Kamera
Musste sich das Vorgänger-Modell Poco F7 Pro noch mit einer Dual-Kamera begnügen, bietet das Poco F8 Pro jetzt ein echtes Triple-Kamerasystem. Es besteht aus einer Hauptkamera mit 50 Megapixeln (f/1.88) und optischer Bildstabilisierung, einer 8-Megapixel-Ultraweitwinkelkamera sowie einer Telelinse mit 50 Megapixeln. In der Punch-Hole-Notch auf der Front sitzt eine 20-Megapixel-Selfiekamera.
Im Test überzeugte die Hauptkamera mit detailreichen Aufnahmen und einem hohen Dynamikumfang. Farben wirken kräftig, aber natürlich. Auch bei Dunkelheit hellt die Kamera Szenen effektiv auf – das Bildrauschen ist zwar sichtbar, bleibt aber gut kontrolliert.
Die Telelinse liefert einen 2,5-fachen optischen Zoom und sorgt auch bei fünffacher Vergrößerung noch für ordentliche Ergebnisse. Bis zu 30-fach ist möglich, dann wird es allerdings sichtbar pixelig. Bei Nachtaufnahmen steigt das Rauschen, bleibt bei 2,5-fachem Zoom jedoch auf akzeptablem Niveau.
Etwas schwächer schneidet die Ultraweitwinkelkamera ab. Sie bringt es nur auf 8 Megapixel, liefert bei Tageslicht aber brauchbare Ergebnisse. Die Detailtiefe ist geringer als bei der Hauptkamera, farblich stimmt das Bild jedoch gut überein. Auf Leica-Farbmodi müssen Nutzer verzichten – sie gibt es beim Poco F8 Pro nicht.
Der Supermakromodus nutzt die Telelinse, verlangt jedoch einen Abstand von etwa 50 cm. Die Ergebnisse wirken oft etwas unscharf und weniger überzeugend. Bessere Resultate können erzielt werden, wenn man näher an das Motiv herangeht und manuell fokussiert. Bei der Schärfe ist insgesamt noch etwas Luft nach oben.
Selfies gelingen solide, setzen aber keine neuen Maßstäbe. Videos nimmt das Poco F8 Pro dank des leistungsstarken Prozessors in bis zu 8K mit 30 FPS oder in 4K mit 60 FPS auf. Die Frontkamera schafft Aufnahmen in Full-HD mit 60 FPS.
Poco F8 Pro – Originalaufnahmen
Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen
Poco F8 Pro – Originalaufnahmen

Poco F8 Pro – Originalaufnahmen

Ausstattung
Das Poco F8 Pro bietet viel Leistung. Unter der Haube arbeitet der Snapdragon 8 Elite Gen 4, einer der stärksten Qualcomm-Chips des Jahres. Der Prozessor sorgt für eine spürbare Leistungssteigerung – egal ob beim Gaming, Surfen oder Medienkonsum. Der absolute Top-Chip bleibt zwar dem Poco F8 Ultra vorbehalten, doch das Pro-Modell liefert trotzdem Oberklasse-Power.
Im Benchmark 3DMark Wild Life Extreme erreicht das F8 Pro rund 6400 Punkte und liegt damit leicht unter Geräten wie dem Galaxy S25 Ultra. Eine Schwachstelle zeigt sich bei der Effizienz: Im Stresstest von Wild Life Extreme hält das Gerät nur etwa 50 Prozent seiner Leistung dauerhaft und wird dabei spürbar warm. Bei PCMark stehen rund 20.000 Punkte zu Buche.
Zur Ausstattung gehören je nach Version 256 oder 512 GB UFS-4.1-Speicher und stets 12 GB RAM, was auch bei Multitasking für flüssige Performance sorgt. Bei der Konnektivität ist alles auf dem neuesten Stand: Wi-Fi 7, Bluetooth 5.4 (mit aptX Adaptive, LDAC, LHDC, AAC, SBC und LC3), NFC, Infrarot-Port und 5G.
Die Ortung erfolgt über GPS, Glonass, Beidou, Galileo, QZSS und Navic – mit einer Genauigkeit von etwa drei Metern. Einziger Wermutstropfen: Der USB-C-Anschluss unterstützt nur den USB-2.0-Standard und bremst damit kabelgebundene Datenübertragungen – ein häufiges Manko in dieser Preisklasse.
Die Stereo-Lautsprecher liefern soliden Klang für Videos und Spiele. Trotz Bose-Unterstützung ist der Unterschied zu anderen Xiaomi-Modellen gering. Der Fingerabdrucksensor unter dem Display arbeitet schnell und zuverlässig.
Software
Das Poco F8 Pro läuft ab Werk bereits mit Hyper OS 3 auf Basis von Android 16. Zum Testzeitpunkt Mitte Dezember war der Sicherheitspatch von November installiert – noch ausreichend aktuell. Xiaomi verspricht vier große Android-Upgrades, also Updates bis Android 20. Überdies sind sechs Jahre Sicherheitsupdates geplant, voraussichtlich bis 2031. Das ist solide, liegt aber leicht unter dem Niveau von Samsung oder Google, die inzwischen rund sieben Jahre Software-Support bieten.
Die Oberfläche wirkt aufgeräumt. Ob man einen App-Drawer nutzt oder nicht, lässt sich frei wählen. Xiaomi installiert allerdings etwas mehr Bloatware als bei seinen Geräten der Zahlenreihe, diese lässt sich jedoch problemlos entfernen. Etwas lästig ist der integrierte Xiaomi-App-Store: Beim ersten Start schlägt er zahlreiche zusätzliche Apps zur Installation vor, die man manuell abwählen muss. Auch Werbung ist im Store sehr präsent.
Akku
Trotz der vergleichsweise kompakten Bauform verbaut Poco im F8 Pro einen üppigen 6210-mAh-Akku. Möglich wird das durch moderne Carbon-Silizium-Technologie. In Kombination mit dem effizienten Snapdragon-Chip liefert das Smartphone eine beeindruckende Ausdauer. Im PCMark Battery Test erreichten wir rund 17 Stunden Laufzeit – das ist ein starker Wert in dieser Geräteklasse.
Im Alltag hält das Poco F8 Pro problemlos einen vollen Tag durch, selbst bei intensiver Nutzung. Bei moderatem Gebrauch sind auch zwei Tage ohne Nachladen realistisch. Aufgeladen wird der Akku mit bis zu 100 W, sofern man ein Xiaomi-Netzteil hat (Hypercharge). Nach etwa 45 Minuten ist der Energiespeicher wieder voll. Andere Geräte lädt das Smartphone wie eine Powerbank mit 22,5 W. Auf kabelloses Laden verzichtet Xiaomi beim Poco F8 Pro allerdings. Für dieses Feature müssen Interessenten schon zum Poco F8 Ultra greifen.
Preis
Das Poco F8 Pro startet bei rund 520 Euro für die Version mit 256 GB Speicher. Empfehlenswerter ist das Modell mit 512 GB, das ab etwa 540 Euro erhältlich ist. Angesichts der Ausstattung ist das ein fairer Preis – und es dürfte nur eine Frage der Zeit sein, bis das Gerät unter die 500-Euro-Marke fällt.
Fazit
Das Poco F8 Pro bietet ein beeindruckendes Preis-Leistungs-Verhältnis. Wer kein teures Flaggschiff benötigt, aber trotzdem Wert auf Leistung und Ausstattung legt – etwa auf einen schnellen Prozessor oder eine starke Kamera mit Telezoom – bekommt hier für etwas über 500 Euro ein rundum überzeugendes Paket. Das Display überzeugt, der mittelgroße Formfaktor gefällt, und die Akkulaufzeit ist hervorragend.
Größere Schwächen leistet sich das Gerät kaum – und die vorhandenen sind für den Preis leicht zu verschmerzen. Die Telelinse verliert bei hohen Zoomstufen und schwachem Licht etwas an Schärfe, Weitwinkel- und Selfiekamera erreichen solides Mittelklasse-Niveau. Beim Software-Support liegt Xiaomi im guten Mittelfeld, die Konkurrenz ist hier jedoch mittlerweile etwas weiter.
Insgesamt ist das Poco F8 Pro eines der besten Smartphones seiner Preisklasse – ein stimmiger Kompromiss aus Leistung, Ausstattung und Kamera zum fairen Preis.
Motorola Edge 60 Pro
Helles OLED, schickes Design, vielseitige Kamera und massenhaft Speicher: Das Motorola Edge 60 Pro bringt Premium-Flair zum fairen Preis.
- tolles Display
- schickes Design
- IP69 und MIL-STD-810H
- gute Kamera mit Telelinse
- starker Akku
- nur USB 2.0
- kein microSD-Slot
- Software-Updates nur bis 2029
Motorola Edge 60 Pro im Test: Die Smartphone-Überraschung
Helles OLED, schickes Design, vielseitige Kamera und massenhaft Speicher: Das Motorola Edge 60 Pro bringt Premium-Flair zum fairen Preis.
Das Motorola Edge 60 Pro will Oberklasse-Features zum Mittelklasse-Preis bieten. Es punktet mit einem strahlend hellen OLED-Display mit 120 Hz, einem trotz des schlanken Gehäuses großzügigen 6000‑mAh‑Akku, 12 GB RAM und 512 GB internem Speicher. Hinzu kommt eine Hauptkamera mit 50 Megapixeln sowie optischer Bildstabilisierung (OIS) und eine Weitwinkelkamera mit ebenfalls 50 Megapixeln. Dazu kommt ein Teleobjektiv mit 10 Megapixeln sowie 3-fachem optischen Zoom.
Gegenüber dem Edge 50 Pro (Testbericht) steigt auf dem Papier die Ausdauer deutlich, die maximale Bildwiederholrate sinkt hingegen moderat. Wir haben im Test überprüft, wie sich das hübsche Gerät abseits der Theorie in der Praxis schlägt.
Design
Eines kann Motorola: Design. Das Gehäuse des Edge 60 Pro ist extrem dünn und wirkt hochwertig sowie elegant. Mit kaum mehr als 8 mm Bautiefe ist das Gerät fast schon das Leichtgewicht unter den Oberklasse-Smartphones. Auch das Gewicht von 186 g sorgt dafür, dass es angenehm in der Hand liegt und den fast schon filigranen Eindruck verstärkt.
Sorgen müssen sich Nutzer jedoch nicht machen: Das Gerät wirkt zwar auf den ersten Blick zerbrechlich, liegt aber solide und stabil in der Hand. Die Verarbeitung ist hervorragend – die Spaltmaße stimmen, nichts knarzt. Die Tasten im Metallrahmen sitzen fest und bieten einen festen Druckpunkt. Insgesamt wirkt alles hochwertig, und wer sein Smartphone gerne einhändig bedient, profitiert von der schmalen Bauform und der griffigen Rückseite.
Ein Highlight: Das Chassis ist gegen Staub und sogar Strahlwasser abgedichtet. Motorola verweist auf Prüfungen nach IP69 und MIL-STD-810H. Das ist ungewöhnlich für ein Smartphone ohne den Zusatz „Outdoor“ – zumal es so grazil daherkommt. Allerdings ist beim Militärstandard nicht exakt festgelegt, welche Tests für die Zertifizierung tatsächlich absolviert werden müssen. Einen freiwilligen Härtetest würden wir diesem schicken Gerät daher dennoch besser nicht zumuten.
Die Rückseite ist entweder Lederoptik („veganes Leder“) oder mit texturierter Oberfläche erhältlich. Beide Varianten sehen edel aus, sorgen für guten Halt und verhindern weitgehend Fingerabdrücke. Wie gewohnt arbeitet Motorola dabei mit dem Farbspezialisten Pantone zusammen, was sich in auffälligen, aber nicht aufdringlichen Farbvarianten bemerkbar macht.
Die drei Kameralinsen sowie der LED-Blitz sitzen in einer dezenten, minimal erhöhten Fläche in der oberen linken Ecke der Rückseite. Ihre gleich großen, runden Einfassungen betonen das modulare Design, stehen leicht hervor und erinnern entfernt an einen klassischen Herd. Durch die Symmetrie und die feine Ausarbeitung wirkt das Ganze aber modern und ansprechend statt altmodisch.
Die Ränder des Displays sind sanft gekrümmt und verstärken den hochwertigen Gesamteindruck des Geräts zusätzlich. Gleichzeitig lässt das die Front schmaler wirken und verbessert die Ergonomie. Geschützt wird der Bildschirm von Corning Gorilla Glas 7i der aktuellen Generation. Zwar handelt es sich nicht um das Topglas des Herstellers, doch bietet auch 7i einen ordentlichen Schutz vor Kratzern und bei Stürzen.
Motorola Edge 60 Pro – Bilderstrecke
Motorola Edge 60 Pro

Motorola Edge 60 Pro

Motorola Edge 60 Pro

Motorola Edge 60 Pro

Motorola Edge 60 Pro
Motorola Edge 60 Pro

Motorola Edge 60 Pro

Motorola Edge 60 Pro
Motorola Edge 60 Pro
Display
Das knapp 6,7 Zoll große POLED-Display des Motorola Edge 60 Pro bietet eine Auflösung von 2712 × 1220 Pixeln. Damit kommt es auf knackig-scharfe 446 Pixel pro Zoll (PPI) – mehr ist in Kombination mit den tollen Kontrasten, dem hervorragenden Schwarzwert und der Pantone-getreuen Farbwiedergabe für eine herausragende Darstellung definitiv nicht nötig.
Farben wirken satt, aber im Modus „natürlich“ nicht zu knallig. Wer es kräftiger mag, stellt auf „leuchtend“ um. Weiß bleibt neutral, Hauttöne wirken stimmig. Bemerkenswert ist die Spitzenhelligkeit: Laut Hersteller sind partiell bis zu 4500 cd/m² bei HDR-Inhalten möglich, im Alltag haben wir exzellente 1480 cd/m² gemessen – das ist stark! Inhalte bleiben damit selbst im direkten Sonnenlicht einwandfrei ablesbar.
Einen Rückschritt – zumindest auf dem Papier – stellt die Bildwiederholrate von jetzt „nur noch“ 120 Hz dar. Zwar konnte der Vorgänger Edge 50 Pro mit 144 Hz noch mehr, aber nicht erst bei dem haben wir angemerkt, dass der Unterschied von 120 zu 144 Hz kaum sichtbar, stattdessen aber eher unnötig energieintensiv ist. Das sieht Motorola jetzt offenbar ähnlich.
Die seitlichen Krümmungen sehen edel aus und eventuelle Spiegelungen stören im Alltag kaum. Motorolas Palm-Rejection, also die Erkennung von versehentlichen Berührungen des Touchscreens mit den Fingerspitzen oder dem Handballen beim Halten des Geräts, arbeitet zuverlässig, sodass es bei der Nutzung nicht zu Fehlbedienungen kommt. Schade: Ein echtes Always-on-Display gibt es weiterhin nicht. Dennoch ist das Display ein Highlight des Edge 60 Pro.
Kamera
Motorola setzt beim Edge 60 Pro auf eine Triple-Cam und technische Finesse. Als Hauptkamera verwendet der Hersteller ein Modul von Sony (Lytia 700 C, basiert auf IMX896 ) mit 50 Megapixeln und lichtstarker f/1.8-Blende samt optischer Stabilisierung (OIS). Dazu kommt eine Kamera von Samsung mit 50 Megapixeln als Weitwinkel und Makro mit Autofokus. Abgerundet wird das Set von einer Tele-Kamera mit 10 Megapixeln, 3-fachem optischem Zoom und OIS, die ebenfalls von Samsung stammt. Vorn steckt eine Kamera mit 50 Megapixeln und f/2.0, erneut von Samsung.
Bei Tageslicht liefert die Hauptkamera detailreiche, scharfe Fotos mit ausgeprägter Bilddynamik, guten Kontrasten und natürlichen, aber intensiven Farben. Bei wenig Licht hellt die Software nur dezent und damit natürlich auf. Dadurch wirken entsprechende Aufnahmen natürlich und bei ausreichender Beleuchtung dennoch hell genug. Bildrauschen tritt wie bei der Konkurrenz dann trotzdem etwas stärker auf. Feine Texturen und Details leiden entsprechend eher als bei den Klassenbesten, insgesamt sind aber auch Nachtaufnahmen richtig gut. Das gilt auch für das Teleobjektiv.
Schwierige Lichtsituationen wie Gegenlicht meistert die Hauptkamera ebenfalls solide, die Zusatzobjektive – vorrangig das Weitwinkel – etwas schwächer. Die Weitwinkeloptik hält dafür bei gutem Licht bei Schärfe und generellem Eindruck ordentlich mit und punktet dank Autofokus auch im Nahbereich. Das Teleobjektiv sorgt bei 3-facher Vergrößerung für stimmige Porträts und gelungene Tiefenwirkung. Die Bildqualität ist mit ausreichendem Licht ebenfalls klasse. Bis zum 5-fachen Zoom ist das Ergebnis gut nutzbar, darüber sieht man zunehmend den Eingriff der Software.
Als störend empfanden wir während des Fotografierens den zu hektischen Wechsel zwischen den Objektiven bei nahen Motiven. Kaum hat man gerade ein Objekt im Fokus, springt auch schon die Ansicht um und selbst auf dem Display ist dabei häufig die Bildqualität schlechter als zuvor. Das nervt. Abhilfe schafft zum Glück das Deaktivieren der Funktion „automatisches Makro“ in den Kamera-Einstellungen.
Die Videoauflösung endet bei 4K mit 30 FPS – eine echte Enttäuschung, da Kameraschwenks so immer ruckelig wirken. Das passt nicht zur restlichen Qualität von aufgenommenen Videos, bei denen die Stabilisierung zuverlässig, wenn auch nicht spektakulär arbeitet. Auch Tonaufnahmen sind klar verständlich, der Windfilter verrichtet seine Arbeit ordentlich.
Motorola Edge 60 Pro – Originalaufnahmen
Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Motorola Edge 60 Pro – Originalaufnahmen

Ausstattung
Im Inneren steckt ein Mediatek Dimensity 8350, der für die obere Mittelklasse gedacht ist. Zielsetzung bei seiner Entwicklung war in erster Linie Energieeffizienz, Leistung stand erst an zweiter Stelle. Entsprechend bleibt das Edge 60 Pro in Benchmarks hinter aktuellen Spitzen-Chips wie einem Snapdragon 8 Elite deutlich zurück, liegt aber spürbar vor Geräten mit Snapdragon 7 Gen 4. In 3Dmark Wild Life Extreme erreicht das Handy etwa 3000 Punkte, in PCmark Work 3.0 knapp 20.000 Punkte.
Im Alltag geht alles flott von der Hand. Apps starten schnell, auch bei vielen offenen Apps im Hintergrund ist Multitasking dank 12 GB LPDDR5X-RAM kein Problem und selbst anfordernde Spiele laufen stabil mit hohen Details. Bei langen Sessions wird das Gerät dabei allerdings spürbar warm. Auch große Spiele und speicherintensive Dateien finden im internen Speicher problemlos Platz. 512 GB UFS-4.0-Speicher sind üppig, schnell und damit zukunftssicher.
Bluetooth 5.4, NFC, Wi-Fi 6E und 5G sind natürlich ebenfalls mit dabei. Dank Dual-SIM-Fähigkeit dürfen Nutzer zwei Nano-SIMs einlegen, hinzu kommt eSIM-Support. Eine microSD-Erweiterung gibt es nicht. Schade: Motorola verbaut beim Edge 60 Pro lediglich USB‑C 2.0. Der Standard erlaubt nur eine langsame Datenübertragung und gilt längst als nicht mehr zeitgemäß.
Die Stereo-Lautsprecher mit Dolby Atmos liefern dafür klare Stimmen und ordentlichen Druck für solch ein dünnes Handy. Der In-Display-Fingerabdrucksensor reagiert zügig und zuverlässig, ist für unseren Geschmack allerdings etwas zu weit nach unten an den Display-Rand gewandert.
Software
Ab Werk läuft Android 15 mit schlanker Motorola-Oberfläche. Das System wirkt aufgeräumt. Bloatware ist kaum vorhanden und lässt sich bei Bedarf deinstallieren. Die bekannten Moto-Gesten bleiben ein praktisches Plus: Die Taschenlampe lässt sich per doppelter Hackbewegung aktivieren, die Kamera per Drehbewegung öffnen und Screenshots per Drei-Finger-Touch aufnehmen.
Neu ist eine dedizierte AI-Taste. Sie startet Motor AI mit Funktionen wie Transkription, Zusammenfassung und Bildwerkzeugen. Notizen lassen sich automatisiert strukturieren, Googles Circle to Search zur Bildsuche ist ebenfalls integriert. Smart Connect bindet PC, Tablet und TV ein und erlaubt schnelle Übergaben von Inhalten untereinander, Benachrichtigungsspiegelung und Drag-and-drop. Für manche AI-Dienste ist ein Motorola-Konto nötig.
Das Update-Versprechen bleibt eher konservativ. Motorola nennt drei große Android-Versionen und vier Jahre Sicherheits-Patches. Damit reicht der Support nach heutigem Stand bis 2029. Das ist in Ordnung, mancher Konkurrent verspricht inzwischen aber bis zu sieben Jahre.
Akku
Trotz der schlanken Bauform des Motorola Edge 60 Pro verbaut der Hersteller einen großzügigen Akku mit 6000 mAh. Offizielle Details zur Technologie gibt es zwar nicht, doch wahrscheinlich handelt es sich um einen Lithium-Ionen-Akku mit spezieller Silizium-Kohlenstoff-Anode. Diese ermöglicht eine höhere Energiedichte als herkömmliche Grafit-Anoden – und erklärt die für ein so dünnes Smartphone beachtliche Kapazität.
Im Alltag schlägt sich das Gerät dank des großen Akkus überdurchschnittlich gut: Ein Tag intensiver Nutzung ist problemlos möglich, bei moderatem Betrieb hält es meist zwei bis drei Tage durch. Das kann sich sehen lassen – zumal man dies einem so schlanken Smartphone kaum zutrauen würde.
Aufgeladen wird kabelgebunden mit bis zu 90 W, sofern ein kompatibles Motorola-Netzteil oder ein Ladegerät mit USB Power Delivery 3.0 zur Verfügung steht. Im Lieferumfang liegt allerdings keines bei. Bereits nach rund 15 Minuten ist der Akku etwa zur Hälfte gefüllt, nach etwa 50 Minuten vollständig. Kabelloses Laden wird mit bis zu 15 W unterstützt, kabelgebundenes Reverse Charging mit bis zu 5 W.
Preis
Die unverbindliche Preisempfehlung liegt bei 600 Euro. Bei Drittanbietern gibt es das Gerät bereits für knapp über 396 Euro. Als Farben stehen Grau, Blau und Violett zur Wahl.
Fazit
Das Motorola Edge 60 Pro überzeugt mit hochwertiger Haptik, exzellenter Verarbeitung und einem Auftritt, der an ein echtes High-End-Smartphone erinnert. Dazu passen die Ausstattungspunkte wie Schutz nach IP69 und MIL‑STD‑810H, das starke OLED‑Display, eine Kamera, die fast auf Augenhöhe mit der Smartphone-Elite agiert, sowie der großzügige Speicher. Auch der Akku weiß zu gefallen: Er hält lange durch und lässt sich schnell laden – auf Wunsch sogar kabellos. Ebenso macht die Alltags‑Performance einen rundum überzeugenden Eindruck.
Dennoch gibt es Punkte, die den vergleichsweise niedrigen Preis erklären: Software‑Updates könnten länger garantiert sein, USB 2.0 ist nicht mehr zeitgemäß, und reine Benchmark-Enthusiasten werden mit dem Edge 60 Pro kaum glücklich. Letztlich bietet das Gerät jedoch viel Oberklasse-Feeling zum fairen Preis – mit Kompromissen, die im Alltag leicht zu verschmerzen sind.
Xiaomi 15
Klein, stark, edel: Das Xiaomi 15 ist ein kompaktes High-End-Smartphone mit Spitzen-Kamera, hoher Leistung und exzellenter Verarbeitung.
- Top-Performance
- hervorragende Kamera
- lange Akkulaufzeit & schnelles Laden
- handlich & hochwertig
- Leica-Profile wirken teils unnatürlich
- kürzerer Update-Support als bei Google, Samsung und Honor
Xiaomi 15 im Test: Das beste kleine Android-Smartphone 2025
Klein, stark, edel: Das Xiaomi 15 ist ein kompaktes High-End-Smartphone mit Spitzen-Kamera, hoher Leistung und exzellenter Verarbeitung.
Mit dem Xiaomi 15 bringt der Hersteller ein kompaktes, aber vollwertiges Flaggschiff-Handy auf den Markt. Trotz seiner handlichen Abmessungen bietet das Gerät starke Performance, eine hochwertige Kamera-Ausstattung und eine erstklassige Verarbeitung.
Während Modelle wie das Xiaomi 15 Ultra (Testbericht) oder das Samsung Galaxy S25 Ultra (Testbericht) mit riesigen Displays und üppigen Gehäusen punkten, richtet sich das Xiaomi 15 an Nutzerinnen und Nutzer, die ein leistungsstarkes, aber kompaktes Premium-Smartphone suchen. Trotz der geringen Größe macht Xiaomi keine technischen Kompromisse – es bietet einen High-End-SoC, ein hochauflösendes AMOLED-Display mit LTPO-Technologie, schnelle Ladeleistung sowie eine überzeugende Leica-Kamera.
Wie gut das kompakte Flaggschiff im Alltag tatsächlich abschneidet, klären wir im ausführlichen Praxistest des Xiaomi 15.
Design
Mit seinem kantigen Design wirkt das Xiaomi 15 modern, edel und zugleich elegant. Das Gehäuse folgt einer klaren, geometrischen Formsprache. Auf der Rückseite befindet sich ein quadratisches Kameramodul mit leicht abgerundeten Ecken – im selben Designstil wie das Gerät selbst. Darin sind drei Linsen und ein LED-Blitz symmetrisch angeordnet.
Mit Abmessungen von 152,3 × 71,2 × 8,1 mm und einem Gewicht von 191 g liegt das Xiaomi 15 angenehm in der Hand und lässt sich auch mit einer Hand bedienen. Es passt so problemlos in eine Hosentasche und bleibt dabei handlich. Neben klassischem Schwarz und Weiß gibt es eine Variante in hellem Grün.
Die matte Glasrückseite ist weitgehend unempfindlich gegenüber Fingerabdrücken, allerdings etwas rutschig, weshalb sich eine Schutzhülle empfiehlt. Der Rahmen besteht aus Metall und vermittelt zusammen mit der Glasrückseite ein hochwertiges Flaggschiff-Gefühl. Auch die Tasten bieten einen präzisen, angenehmen Druckpunkt. Das Xiaomi 15 ist nach IP68 gegen Wasser und Staub geschützt.
Xiaomi 15 – Bilderstrecke
Xiaomi 15

Xiaomi 15

Xiaomi 15

Xiaomi 15

Xiaomi 15

Xiaomi 15

Xiaomi 15

Xiaomi 15

Display
Das Xiaomi 15 ist mit einem 6,36 Zoll großen AMOLED-Display mit LTPO-Technologie ausgestattet, das mit 2670 × 1200 Pixeln eine hohe Pixeldichte von 460 PPI erreicht. Der Bildschirm ist flach gestaltet, verfügt über ein mittig angeordnetes Kameraloch und bietet eine hervorragende Screen-to-Body-Ratio von rund 90 Prozent. Dank einer adaptiven Bildwiederholrate von 1 bis 120 Hz wirkt die Darstellung stets flüssig, während die Touch-Abtastrate von 300 Hz Eingaben präzise umsetzt.
Mit einer Spitzenhelligkeit von bis zu 3200 Nits ist das Display auch bei direktem Sonnenlicht einwandfrei ablesbar. Unterstützung für HDR10+ und Dolby Vision sorgt zudem für intensive Farben und starken Kontrast – ideal zum Streamen oder Fotografieren. In der Praxis überzeugt der Bildschirm mit exzellenter Bildqualität, stabilen Blickwinkeln und natürlichen Farben, was ihn zu einem der besten Panels seiner Größenklasse macht.
Kamera
Das Xiaomi 15 setzt auf eine vielseitige Triple-Kamera mit durchweg 50-Megapixel-Sensoren. Die Hauptkamera (f/1.62) verfügt über einen optischen Bildstabilisator (OIS) und liefert detailreiche, scharfe Aufnahmen mit hohem Dynamikumfang. Dazu kommt eine Ultraweitwinkelkamera (f/2.2), die auch für Makroaufnahmen genutzt wird, sowie eine Telelinse mit OIS und 2,6-fachem optischem Zoom (f/2.6). Für Selbstporträts ist eine 32-Megapixel-Frontkamera integriert.
Wie schon bei früheren Modellen wurde das Kamerasystem in Kooperation mit Leica entwickelt. Die Traditionsmarke war erneut für die Optimierung von Optik und Bildsoftware verantwortlich. Nutzer können zwischen zwei Leica-Farbmodi wählen: Vibrant liefert kräftige, kontrastreiche Farben, während Authentic auf eine natürlichere, etwas gedämpfte Darstellung setzt. Im Alltag wirken Aufnahmen mit Vibrant teils etwas übersättigt, Authentic hingegen leicht düster – beide Varianten verleihen den Bildern jedoch einen charakteristischen, aber nicht immer ganz natürlichen Leica-Look.
Bei Tageslicht überzeugt das Xiaomi 15 mit sehr detailreichen, scharfen Fotos, natürlicher Farbwiedergabe und ausgewogenem Kontrast. Auch bei zweifachem Zoom bleiben die Aufnahmen klar und weitgehend rauschfrei. Im Nachtmodus sorgt die Kamera für gut belichtete, aufgehellte Szenen, muss jedoch bei Detailtiefe und Dynamik leichte Abstriche hinnehmen.
Die Ultraweitwinkelkamera stimmt farblich gut mit der Hauptlinse überein und liefert ähnlich scharfe, detailreiche Aufnahmen. Lediglich bei Dunkelheit zeigt sie leichte Schwächen. Die Telekamera überzeugt mit verlustfreiem 2,6-fach-Zoom, und selbst bei fünffacher Vergrößerung bleiben die Bilder erstaunlich scharf. Bis zu einer 30-fachen Vergrößerung sind die Ergebnisse noch akzeptabel, darüber hinaus – bis zum maximalen 60-fach-Zoom – nimmt die Schärfe deutlich ab.
Selfies gelingen mit hoher Bildschärfe, natürlicher Farbwiedergabe und präziser Belichtung. Auch Videos überzeugen: Sie wirken scharf, farbecht und hervorragend stabilisiert – in 4K sind bis zu 60 FPS, in 8K maximal 30 FPS möglich.
Xiaomi 15 – Originalaufnahmen
Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Xiaomi 15 – Originalaufnahmen

Ausstattung
Mit dem Qualcomm Snapdragon 8 Elite liefert das Xiaomi 15 reichlich Leistung – genug, um auch in den kommenden Jahren problemlos mitzuhalten. Ob im Alltag oder bei anspruchsvollen Spielen, Rechen- und Grafikleistung sind stets im Überfluss vorhanden. Das belegen auch die starken Benchmark-Ergebnisse: rund 17.000 Punkte im PCMark und 6.500 Punkte im 3DMark Wild Life Extreme.
Unterstützt wird der SoC von 12 GB RAM sowie schneller UFS-4.0-Speicher mit wahlweise 256 oder 512 GB Kapazität. Eine Erweiterung per microSD-Karte ist nicht vorgesehen. Die Stereo-Lautsprecher liefern einen ordentlichen, klaren Klang – ideal für Videos oder Streams, weniger bei Musik.
Bei der Konnektivität zeigt sich das Gerät auf aktuellem Stand: Wi-Fi 7, 5G, Bluetooth 6.0 (inklusive aptX Adaptive, LDAC, LHDC, AAC, SBC und LC3), USB-C 3.2 mit DisplayPort, NFC und Infrarot sind an Bord. Dual-SIM wird ebenso unterstützt wie der gleichzeitige Betrieb von bis zu zwei eSIMs.
Der im Display integrierte Ultraschall-Fingerabdrucksensor reagiert flott und präzise. Bei der Ortung greift das Xiaomi 15 auf alle relevanten Satellitensysteme zurück – GPS, Glonass, Beidou, Galileo, QZSS und Navic – mit einer Genauigkeit von etwa drei Metern laut GPS-Test.
Software
Ausgeliefert wird das Xiaomi 15 mit Hyper OS 2 auf Basis von Android 15. Mittlerweile steht ein Update auf Hyper OS 3 mit Android 16 zur Verfügung. Die Oberfläche erinnert optisch eher an iOS als an klassisches Android und bietet zahlreiche Möglichkeiten zur Anpassung – von Hintergründen über App-Icons bis zu Schriftarten. Themes gibt es teils kostenlos, teils gegen Gebühr, der App-Drawer lässt sich je nach Geschmack aktivieren oder ausblenden.
Die Update-Politik hat Xiaomi deutlich verbessert: Sechs Jahre Sicherheitsupdates (bis 2031) und vier große Android-Versionen (bis 2029) sind zugesagt. Das ist gut, aber Samsung, Google und Honor machen das besser, mit garantierten Updates und Patches für sieben Jahre. Zum Testzeitpunkt im November war der Sicherheitspatch noch recht aktuell und stammte aus Oktober 2025.
Neben den Google-Apps installiert Xiaomi viele eigene Anwendungen sowie den alternativen App-Store App Mall. Das vergrößert die Auswahl, führt aber teilweise zu doppelten Funktionen, auch wenn viele dieser Apps deinstalliert werden können. Immerhin hält sich die Zahl der vorinstallierten Drittanbieter-Apps mittlerweile in Grenzen.
Bei den KI-Funktionen setzt Xiaomi vorrangig auf Google Gemini, ergänzt durch eigene Features unter dem Namen Hyper AI. Dazu gehören dynamische Hintergrundbilder, ein Schreibassistent, Textzusammenfassungen und ein Sprachrekorder mit Übersetzungsfunktion. In der Galerie lassen sich – ähnlich wie bei Google oder Samsung – Objekte und Spiegelungen entfernen.
Akku
Eine typische Schwachstelle kleiner Smartphones ist oft der begrenzte Akku – nicht so beim Xiaomi 15. Dank Silizium-Karbon-Technologie bringt der kompakte und leichte Bolide eine beachtliche Kapazität von 5240 mAh mit. Zum Vergleich: Das ähnlich kleine Samsung Galaxy S25 begnügt sich mit 4000 mAh.
In Kombination mit dem effizienten Snapdragon-Chip und dem sparsamen LTPO-Display sorgt das im Alltag für beeindruckende Laufzeiten. Im Battery Test von PCMark erzielte das Xiaomi 15 eine Laufzeit von über 17 Stunden – ein Spitzenwert in dieser Größenklasse. Damit kommt man bei intensiver Nutzung problemlos durch den Tag, bei moderatem Gebrauch sogar bis zu zwei Tage ohne Nachladen aus.
Aufgeladen wird das Gerät per Xiaomis Hypercharge mit bis zu 90 W. Dafür ist allerdings ein kompatibles Netzteil notwendig, das aufgrund von EU-Vorgaben nicht im Lieferumfang enthalten ist. Mit einem passenden Ladegerät ist das Xiaomi 15 in rund 35 Minuten wieder vollständig geladen. Kabelloses Laden wird ebenfalls unterstützt – mit bis zu 50 W.
Preis
Beim Marktstart Anfang des Jahres lag die UVP des Xiaomi 15 noch bei rund 1000 Euro. Inzwischen ist das Modell mit 256 GB Speicher meist für etwa 650 Euro erhältlich. Aktuell wird die weiße Variante bei NBB für rund 545 Euro angeboten. Die Version mit 512 GB startet derzeit bei etwa 640 Euro. Original-Netzteile von Xiaomi kosten etwa 18 Euro, bei Online-Händlern wie Aliexpress sind sie teils ab 13 Euro.
Fazit
Das Xiaomi 15 ist ein ausgezeichnetes und zugleich handliches Smartphone. Technisch bewegt es sich klar auf Flaggschiff-Niveau und leistet sich kaum Schwächen. Der Snapdragon-Prozessor bietet enorme Leistung bei hoher Effizienz, das LTPO-Display überzeugt mit brillanter Darstellung und variabler Bildwiederholrate zwischen 1 und 120 Hz. Besonders beeindruckt hat die starke Ausdauer – bis zu zwei Tage Laufzeit ist realistisch.
Schwächen muss man mit der Lupe suchen. Die Leica-Farbmodi wirken nicht immer gänzlich natürlich, wer Wert auf neutrale Aufnahmen legt, greift besser zu einem Pixel-Modell. Xiaomi installiert zudem recht viele eigene Apps neben den Google-Varianten. Auch bei der Update-Versorgung liegt der Hersteller leicht hinter Samsung, Google oder Honor zurück.
Letztlich ist das Xiaomi 15 eines der besten kompakten Top-Smartphones auf dem Markt. Samsung mit dem Galaxy S25 und auch Apple mit dem iPhone 16 Pro oder iPhone 17 Pro müssen sich hier warm anziehen.
Honor 400 Pro
Das Honor 400 Pro mit starker Kamera, Snapdragon 8 Gen 3 und KI-Features ist beinahe ein Flaggschiff. Wie gut das Smartphone für knapp 800 Euro ist, zeigt der Test.
- schnelle CPU
- lange Akkulaufzeit
- Top-Kamera mit starker Telelinse
- 6 Jahre Software-Updates
- nur USB-C 2.0
- Fotos wirken teilweise zu knallig
- viele zusätzliche Apps
Honor 400 Pro im Test: Hervorragendes Smartphone mit Top-Kamera
Das Honor 400 Pro mit starker Kamera, Snapdragon 8 Gen 3 und KI-Features ist beinahe ein Flaggschiff. Wie gut das Smartphone für knapp 800 Euro ist, zeigt der Test.
Die Number-Reihe steht bei Honor traditionell für gut ausgestattete Smartphones der Mittel- und Oberklasse. Das Pro-Modell legt dabei einmal mehr den Schwerpunkt auf die Kamera. Mit dem Honor 400 Pro bringt der Hersteller ein nahezu vollwertiges Flaggschiff auf den Markt, das nur knapp hinter den aktuellen Geräten der Magic-Serie zurückbleibt. Allerdings kratzt die UVP auch an der Premiumklasse.
Als Prozessor kommt der flotte Snapdragon 8 Gen 3 aus dem Vorjahr zum Einsatz. Die Triple-Kamera mit Teleobjektiv liefert solide Ergebnisse, ergänzt um einige spannende KI-Funktionen. Wie gut das abgespeckte Flaggschiff im Alltag wirklich abschneidet, klärt unser Test.
Design
Das Honor 400 Pro bietet ein sehr elegantes Design. Die Verarbeitung ist erstklassig: Die Tasten sitzen fest und bieten einen klar definierten Druckpunkt. Die Linienführung des Gehäuses ist sauber, ohne scharfe Kanten, und die leicht abgerundeten Ränder sowie das 2,5D-Display sorgen für eine angenehme Haptik. Es liegt gut in der Hand, verrutscht nicht so leicht und ist relativ unempfindlich gegenüber Fingerabdrücken.
Die Rückseite besteht aus Glas, der Rahmen aus Metall – beides verleiht dem Gerät eine edle Anmutung. Trotz seiner wuchtigen Abmessungen von 160,8 × 76,1 × 8,1 mm liegt das Smartphone mit 205 g noch vergleichsweise leicht in der Hand. Auffällig ist das markante Kameraelement auf der Rückseite: In einem umgedrehten Trapez mit abgerundeten Kanten sind die drei Objektive samt LED-Blitz untergebracht – sehr präsent, aber stilvoll integriert.
Hervorzuheben ist die IP69-Zertifizierung. Diese Schutzklasse ist bei Smartphones noch selten und bedeutet, dass das Gerät nicht nur gegen Staub, sondern auch gegen starkes Strahlwasser und sogar Hochdruckreinigung geschützt ist – ideal für besonders anspruchsvolle Einsatzbedingungen.
Honor 400 Pro – Bilder
Honor 400 Pro
Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Honor 400 Pro

Display
Das Honor 400 Pro verfügt über ein 6,7 Zoll großes AMOLED-Display mit einer Auflösung von 2800 × 1280 Pixeln. Mit einer Pixeldichte von 460 PPI bietet es eine messerscharfe Darstellung. Die adaptive Bildwiederholrate liegt zwischen 60 und 120 Hz und passt sich automatisch an die jeweilige Nutzungssituation an.
Laut Hersteller erreicht das Display eine maximale Helligkeit von bis zu 5000 Nits, was auch bei direkter Sonneneinstrahlung eine einwandfreie Ablesbarkeit gewährleistet. Hohe Kontraste, satte Schwarzwerte und eine ausgewogene Farbdarstellung runden den positiven Gesamteindruck ab.
Die Frontkamera sitzt in einer etwas breiteren, ovalen Punch-Hole-Notch, da sie neben der Selfie-Kamera eine zweite Linse für eine verbesserte 3D-Gesichtserkennung integriert. Das Design erinnert in Ansätzen an Apples Dynamic Island, fällt jedoch kompakter aus. Im Android-Umfeld stellt diese Lösung eine Besonderheit dar.
Kamera
Das Honor 400 Pro ist mit einem leistungsstarken Triple-Kamera-System ausgestattet. Die Hauptkamera bietet eine Auflösung von 200 Megapixeln (f/1.9) und verfügt über optische Bildstabilisierung (OIS) sowie Phasenvergleichs-Autofokus. Ergänzt wird sie durch ein 50-Megapixel-Teleobjektiv (f/2.4) mit ebenfalls OIS und eine 12-Megapixel-Ultraweitwinkelkamera (f/2.2).
Bei Tageslicht liefert die Hauptkamera exzellente Aufnahmen mit hoher Detailtreue, ausgewogener Dynamik und realistischen Farben. Auch die Telelinse überzeugt mit scharfen, kontrastreichen Bildern und ist für Porträts und entfernte Motive gut geeignet. Nachtaufnahmen gelingen ebenfalls – trotz gelegentlichem Bildrauschen bleibt die Bildqualität insgesamt überzeugend. Die Ultraweitwinkelkamera kann in puncto Schärfe, Bilddetails und Farbdynamik nicht ganz mit den beiden anderen Modulen mithalten, liefert aber dennoch brauchbare Ergebnisse.
Nutzer können zwischen drei Bildprofilen wählen: „Natürlich“, „Dynamisch“ und „Authentisch“. Diese beeinflussen Farbsättigung, Kontraste sowie die Wiedergabe von hellen und dunklen Bildbereichen. Manchmal wirken Fotos aber nicht mehr natürlich. Für Porträtaufnahmen stehen zudem drei Filter des bekannten Fotostudios Harcourt zur Verfügung, die bereits aus dem Vorgänger Honor 200 Pro bekannt sind. Eine KI-gestützte Optimierung sorgt zusätzlich für verbesserte Hauttöne und feinere Details bei Gesichtern.
Videos sind in 4K mit bis zu 60 Bildern pro Sekunde möglich. Auch HDR-Modi für kontrastreiche Szenen sind integriert. Damit bietet das Honor 400 Pro eine Kameraausstattung, die sich in der oberen Mittelklasse sehen lassen kann.
Honor 400 Pro – Originalaufnahmen
Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen
Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen
Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Honor 400 Pro – Originalaufnahmen

Ausstattung
Das Honor 400 Pro ist mit dem Qualcomm Snapdragon 8 Gen 3 ausgestattet, einem High-End-Prozessor aus dem Jahr 2024. Trotz der inzwischen verfügbaren Nachfolgegeneration liefert der Chip noch immer mehr als genügend Leistung für alle Aufgaben – ob im Alltag, beim Multitasking oder bei grafikintensiven Spielen. Das System reagiert im Test durchweg flüssig und verzögerungsfrei.
In den Benchmarks bestätigt das Gerät seine starke Performance: Bei PCmark erreicht es rund 18.000 Punkte, bei 3DMark Wild Life Extreme knapp 4500 Punkte – Werte, die es für die kommenden Jahre zukunftssicher machen.
Auch bei Speicher und Arbeitsspeicher zeigt sich das Honor 400 Pro großzügig. Es ist standardmäßig mit 512 GB internem Speicher ausgestattet, eine Erweiterung per microSD ist allerdings nicht möglich. Hinzu kommen 12 GB RAM, die für eine reibungslose Nutzung sorgen.
Zur biometrischen Entsperrung bietet das Honor 400 Pro zwei schnelle und zuverlässige Optionen: Dazu gehört ein im Display integrierter Fingerabdrucksensor sowie eine 3D-Gesichtserkennung, die mithilfe einer zweiten Frontkamera umgesetzt wird. Letztere ist deutlich sicherer als die herkömmliche 2D-Gesichtserkennung, wie sie bei vielen anderen Android-Smartphones zum Einsatz kommt.
Bei den Schnittstellen zeigt sich das Gerät auf der Höhe der Zeit: Wi-Fi 7, Bluetooth 5.4, NFC und 5G gehören zur Ausstattung. Die Stereo-Lautsprecher liefern einen klaren und kräftigen Klang – für ein Smartphone dieser Klasse absolut angemessen.
Ein großer Schwachpunkt bleibt jedoch: Honor setzt beim USB-Anschluss lediglich auf USB-C 2.0. Angesichts der ansonsten hochwertigen Ausstattung ist das kaum nachvollziehbar – insbesondere im Hinblick auf Datentransferraten.
Honor-Smartphones unterstützen ferner den BMW Digital Key nicht. Dieser ist ausschließlich mit bestimmten Modellen kompatibel, etwa von Herstellern wie Apple, Samsung, Google, Motorola, Oneplus oder Xiaomi.
Software
Auf dem Honor 400 Pro läuft Android 15 mit der Bedienoberfläche Magic OS in Version 9, die optisch stark an iOS und Huaweis EMUI erinnert. Der App-Drawer ist standardmäßig deaktiviert, lässt sich aber über die Startbildschirm- und Wallpaper-Einstellungen aktivieren. Das Einstellungsmenü ist zweigeteilt: Benachrichtigungen werden zentral von oben, das Kontrollzentrum vom rechten oberen Rand aufgerufen.
Zum Testzeitpunkt stammt der Sicherheits-Patch aus dem Mai und ist somit noch hinreichend aktuell. Honor verspricht sechs Jahre lang Software- und Sicherheits-Updates – ein erfreulich langer Zeitraum für ein Android-Gerät.
Magic OS bietet zudem praktische Funktionen wie eine Multi-Windows-Ansicht, eine seitliche App-Leiste für Schnellzugriffe sowie das „Magic Portal“, mit dem sich Inhalte wie Adressen oder Texte direkt in passende Apps übertragen lassen, etwa in Google Maps oder Messenger. Auch die „Knöchel-Geste“ zur Markierung von Bildausschnitten ist an Bord – ähnlich wie „Circle to Search“ von Samsung, in der Praxis aber weniger zuverlässig.
Ein Highlight ist das neue KI-Foto-Feature, das aus einem einzelnen Bild ein kurzes animiertes Video erzeugt – etwa im Stil von Stop-Motion. Besonders bei Nahaufnahmen, etwa von Miniaturfiguren, entstehen beeindruckende Effekte: Die KI simuliert sogar einen Finger, der die Figuren scheinbar bewegt. Ergänzt wird das durch weitere KI-Funktionen wie Google Gemini, einen Fotoradierer, Nachschärfung von Zoomaufnahmen und automatische Zusammenfassungen in der Notizen-App.
Es gibt jedoch eine Vielzahl vorinstallierter Honor-Apps, um die Google-Lösungen zu verdrängen. So ist etwa die hauseigene Kalender-App weniger ausgereift als das Google-Pendant, und Synchronisierungen funktionieren teilweise verzögert.
Akku
Der Silizium-Kohlenstoff-Akku des Honor 400 Pro bietet trotz des schlanken Gehäuses eine beeindruckende Kapazität von 5300 mAh – ein guter Indikator für lange Laufzeiten. Diese Technologie ermöglicht kompaktere Akkus, weil diese eine höhere Energiedichte haben und somit mehr Energie auf gleichem Raum speichern können.
Unsere Messungen bestätigen diesen Eindruck: Im PCMark Battery Test erreichte das Gerät eine Laufzeit von über 14 Stunden im simulierten Dauerbetrieb – ein ausgezeichnetes Ergebnis für ein Smartphone dieser Leistungsklasse. Einen Tag sollte es also problemlos ohne Netzteil schaffen.
Das Honor 400 Pro bietet beeindruckende Ladeleistungen: Über Kabel sind mit Honor Supercharge bis zu 100 Watt möglich, kabelloses Laden wird mit bis zu 50 Watt unterstützt (Honor Wireless Supercharge). Ein Netzteil liegt dem Gerät jedoch nicht bei – wer die volle Ladegeschwindigkeit nutzen möchte, muss entsprechendes Zubehör separat erwerben. Mit dem passenden Ladegerät ist der Akku kabelgebunden in knapp über 30 Minuten vollständig geladen, kabellos dauert es bei 50 Watt etwa eine Stunde.
Preis
Die UVP liegt – wie schon beim Vorgänger – bei stolzen 799 Euro und sprengt damit den Rahmen der gehobenen Mittelklasse. Die Preise dürften jedoch weiter fallen: Aktuell ist das Honor 400 Pro bereits ab etwa 534 Euro erhältlich. Verfügbar ist das Gerät in den Farben Anthrazit und Grau.
Fazit
Mit dem Honor 400 Pro ist dem chinesischen Hersteller ein überzeugendes Oberklasse-Smartphone gelungen. Die hochwertige Verarbeitung, die starke Triple-Kamera und die hervorragende Akkulaufzeit sprechen für sich. Auch wenn der verbaute Snapdragon 8 Gen 3 nicht mehr der neueste High-End-Chip ist, liefert er weiterhin für die nächsten Jahre mehr als genug Leistung für alle Anwendungen – vom Alltag bis zum Gaming.
Besonders gefallen haben uns die KI-Funktionen, etwa das neue Feature, das aus einem einzigen Foto animierte Kurzvideos erstellt – kreativ und beeindruckend umgesetzt. Wer nicht über 1000 Euro für ein Flaggschiff ausgeben möchte, findet im Honor 400 Pro eine attraktive Alternative für unter 800 Euro.
Abzüge gibt es für die veraltete USB-C-2.0-Schnittstelle – in diesem Preisbereich kaum nachvollziehbar. Auch die Vielzahl vorinstallierter Apps stört etwas – viele davon können qualitativ nicht mit den Google-Originalen mithalten. Perfekt ist das Honor 400 Pro also nicht, doch es bietet ein starkes Gesamtpaket und präsentiert sich als gelungenes Sub-Flaggschiff. Eine clevere Wahl für alle, die Wert auf Design, Kamera und Performance legen, ohne dafür vierstellige Beträge ausgeben zu wollen.
Samsung Galaxy S25 FE
Das Galaxy S25 FE verspricht Flaggschiff-Technik zum Mittelklassepreis. Im Vergleich zum Vorgänger scheint sich aber nur wenig geändert zu haben.
- tolle Bildqualität des AMOLED-Displays
- gute Triple-Kamera bei Tag und Nacht mit optischem Zoom
- 7 Jahre Software-Support
- hochwertige Verarbeitung
- sinkende Preise
- hohe UVP
- mäßige Akkulaufzeit
- ohne LTPO-Technologie
- niedriges PWM-Dimming
- CPU mit Schwächen bei Effizienz
Samsung Galaxy S25 FE im Test: Top-Smartphone als Kompromiss oder Mogelpackung?
Das Galaxy S25 FE verspricht Flaggschiff-Technik zum Mittelklassepreis. Im Vergleich zum Vorgänger scheint sich aber nur wenig geändert zu haben.
Zum fünften Mal bringt Samsung eine Fan-Edition seiner Galaxy‑S‑Reihe auf den Markt. Die Modelle kombinieren High-End-Features mit gezielten Abstrichen, um Flaggschiff-Technik zum Mittelklassepreis anzubieten – zumindest in der Theorie.
Auch beim Galaxy S25 FE bleibt die UVP zunächst hoch, sinkt jedoch traditionell schnell. Optisch wirkt das Smartphone hochwertig und schlanker als der Vorgänger, technisch erinnert jedoch vieles an das S24 FE. Wir klären im Test, ob die neue Fan-Edition ein gelungener Kompromiss oder eher ein lauer Aufguss ist.
Design
Das Design des Samsung Galaxy S25 FE zeigt sich vertraut – auf den ersten Blick könnte man es leicht mit dem Galaxy S25+ oder dem S24 FE verwechseln. Samsung bleibt seiner klaren, minimalistischen Formensprache treu: Auf der Rückseite finden sich drei einzeln eingefasste Kameralinsen, eingebettet in ein kantiges Gehäuse mit Metallrahmen sowie Glasrückseite.
Die Verarbeitung überzeugt durchweg. Von der früheren Kunststoffanmutung älterer FE-Modelle ist nichts mehr zu spüren – das S25 FE wirkt solide, hochwertig und elegant. Gleichzeitig ist die Optik, gerade im direkten Vergleich zu neueren Konkurrenten, etwas konservativ und nur dezent modernisiert.
Mit Abmessungen von 161,3 × 76,6 × 7,4 mm liegt das Smartphone nahezu auf dem Niveau seines Vorgängers und ist nur minimal größer als das S25+. Das Gewicht bleibt mit 190 g angenehm im Rahmen. Positiv: Die Display-Ränder sind etwas schmaler geworden, das Gehäuse ist zudem dünner, was für einen edleren Look sorgt.
Wie schon beim Vorgänger ist das Gehäuse nach IP68 zertifiziert und damit gegen Staub und Wasser geschützt – ein Detail, das man in dieser Preisklasse keineswegs als selbstverständlich ansehen kann.
Samsung Galaxy S25 FE – Bilderstrecke
Samsung Galaxy S25 FE

Samsung Galaxy S25 FE

Samsung Galaxy S25 FE

Samsung Galaxy S25 FE

Samsung Galaxy S25 FE

Samsung Galaxy S25 FE

Samsung Galaxy S25 FE

Samsung Galaxy S25 FE
Samsung Galaxy S25 FE

Samsung Galaxy S25 FE

Display
Das AMOLED-Display des Samsung Galaxy S25 FE wird nun durch widerstandsfähiges Gorilla Glass Victus+ geschützt, was die Alltagstauglichkeit erhöht und Kratzern besser vorbeugt. An den grundlegenden Spezifikationen hat sich gegenüber dem S24 FE allerdings wenig verändert: Die Bilddiagonale beträgt 6,7 Zoll bei einer Auflösung von 2340 × 1080 Pixeln, was eine scharfe Darstellung mit rund 385 PPI ermöglicht. Zum Vergleich: Das S25+ bietet hier eine 3K-Auflösung.
Die Screen-to-Body-Ratio liegt bei starken 89 Prozent – ein ausgezeichnetes Verhältnis. Deutliche Fortschritte zeigt Samsung bei der Displayhelligkeit: Mit bis zu 1900 Nits Spitzenwert bleibt der Bildschirm auch bei direkter Sonneneinstrahlung hervorragend ablesbar.
Auf die LTPO-Technologie der teureren S25-Modelle muss das FE allerdings verzichten. Die Bildwiederholrate erreicht zwar bis zu 120 Hz, lässt sich jedoch nicht stufenlos anpassen, sondern wechselt lediglich zwischen festen Stufen. Das PWM-Dimming liegt bei vergleichsweise niedrigen 240 Hz, was bei empfindlichen Nutzern zu Unwohlsein führen könnte.
Wie gewohnt liefert das AMOLED-Panel eine exzellente Bildqualität mit kräftigen Farben, satten Kontrasten und ausgezeichneter Blickwinkelstabilität. Insgesamt präsentiert sich der Bildschirm also als eine der klaren Stärken des Galaxy S25 FE – typisch Samsung.
Kamera
Auch beim Kamera-Setup bleibt Samsung beim Galaxy S25 FE der bisherigen Linie treu. Auf der Rückseite sitzt eine Triple-Kamera, bestehend aus einer 50-Megapixel-Hauptlinse mit optischer Bildstabilisierung (OIS), einer 12-Megapixel-Ultraweitwinkelkamera sowie einer 8-Megapixel-Telelinse mit dreifachem optischem Zoom – exakt die gleiche Kombination wie beim Vorgängermodell. Dazu kommt wieder eine Frontkamera mit 12 Megapixeln.
Im Vergleich zum S25+ fällt vorwiegend die Telekamera etwas ab, da sie eine geringere Auflösung bietet. Hier hätte sich Samsung etwas mehr Innovation erlauben dürfen, beispielsweise durch die stärkere Telelinse aus dem größeren Modell. Insgesamt liefert das Kamera-Setup solide Ergebnisse, bleibt aber eher evolutionär als revolutionär – bewährt, aber ohne echte Neuerungen. Gefühlt tut sich hier seit Jahren wenig.
Dennoch liefert auch das S25 FE beeindruckende Fotos. Die Bildqualität überzeugt mit klaren Details, hohem Dynamikumfang und natürlichen Farben – auch wenn diese manchmal etwas zurückhaltend wirken. Die Telelinse bietet einen dreifachen optischen Zoom. Bis zu einer zehnfachen Vergrößerung lassen sich noch gute Ergebnisse erzielen, darüber hinaus nimmt das Bildrauschen stark zu. Bis zu 30-fach ist möglich.
Der Nachtmodus arbeitet zuverlässig: Er hellt dunkle Szenen spürbar auf und sorgt für sehenswerte Aufnahmen, ohne dass das Bildrauschen störend auffällt. Am besten schneidet hier das Hauptobjektiv ab. Die KI greift dabei gelegentlich unterstützend ein – so entstehen mit der Telelinse beeindruckende Mondaufnahmen, die jedoch softwareseitig nachbearbeitet werden.
Im direkten Vergleich zeigen vorwiegend das Galaxy S25 und S25+ bei schwierigen Lichtbedingungen und Teleaufnahmen noch einmal bessere Resultate – sie holen feinere Details heraus und rauschen weniger. Für den Alltag und die meisten Anwendungsfälle liefert das S25 FE dennoch rundum gute Fotos und ein verlässliches Kameraerlebnis. Auch Selfies sehen klasse aus, Videos sind bei 4K-Auflösung mit 60 FPS (Frames pro Sekunde) möglich oder bei 8K mit 30 FPS.
Samsung Galaxy S25 FE – Originalaufnahmen
Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Samsung Galaxy S25 FE – Originalaufnahmen

Ausstattung
Beim Prozessor geht das Galaxy S25 FE innerhalb der neuen S25-Reihe den deutlichsten Kompromiss ein. Statt eines Qualcomm-Chips verbaut Samsung den Exynos 2400, der bereits im Galaxy S24 und S24+ zum Einsatz kam. Im Vergleich zum S24 FE mit dem leicht abgespeckten Exynos 2400e bedeutet das immerhin einen kleinen Fortschritt. Die Performance passt im Alltag: Das System läuft flüssig und stabil, Apps starten schnell, und auch anspruchsvollere Spiele sind problemlos spielbar.
In der Grafikleistung liegt das FE jedoch etwas hinter dem S25 und S25+, die mit dem stärkeren Snapdragon 8 Elite ausgestattet sind. Mit rund 4200 Punkten im 3DMark Wild Life Extreme bewegt sich das S25 FE aber weiterhin im oberen Mittelfeld – nicht ganz Flaggschiff-Niveau, aber mehr als ausreichend für die meisten Nutzer. Allerdings wird das Smartphone unter hoher Auslastung spürbar warm, dann drosselt die CPU die Leistung.
Beim Speicher stehen 128, 256 oder 512 GB zur Wahl. Da eine microSD-Erweiterung nicht möglich ist, empfiehlt sich mindestens die 256-GB-Variante. Der Arbeitsspeicher umfasst 8 GB RAM und liegt damit leicht unter dem Niveau der größeren S25-Modelle.
Die Ausstattung ist auf modernem Stand: USB-C 3.2, Wi-Fi 6E, Bluetooth 5.4, NFC und 5G sind an Bord, ebenso eSIM-Unterstützung. Der Fingerabdruckscanner unter dem Display arbeitet schnell und zuverlässig. Wi-Fi 7 wäre allerdings schön gewesen, UWB (Ultra-Wideband) fehlt.
Auch der Stereo-Sound kann überzeugen – klar, laut und ausgewogen. Zusätzlich bietet Samsung die Funktion Adapt Sound, die nach einem kurzen Hörtest die Klangwiedergabe individuell anpasst. So werden hohe Frequenzen oder leise Passagen gezielt verstärkt, was vor allem älteren oder hörgeschwächten Nutzern zugutekommt. Die Funktion wirkt jedoch nur bei der Nutzung von Kopfhörern.
Software
Eine der größten Stärken des Galaxy S25 FE bleibt – typisch für Samsung – die Software, sofern man sich mit der eigenständigen Optik von One UI anfreundet. Das Smartphone wird mit Android 16 und One UI 8 ausgeliefert. Samsung garantiert für 7 Jahre Software- und Sicherheits-Updates, was im Android-Bereich immer noch vorbildlich ist. Zum Testzeitpunkt war der Sicherheitspatch aktuell.
Das neue „Now Brief“-Widget bündelt auf dem Homescreen Wetter, Termine und Verkehrsinformationen, während die „Now Bar“ Live-Infos wie Stoppuhren oder Erinnerungen bietet. Wie gewohnt installiert Samsung zahlreiche eigene Apps neben den Google-Diensten, die sich bei Bedarf deaktivieren, aber nicht vollständig deinstallieren lassen.
Das S25 FE unterstützt die kompletten Galaxy-AI-Funktionen der S25-Serie. Statt Bixby greift Samsung dabei stärker auf Googles Gemini zurück, das mit seinen AI Agents App-übergreifende Aufgaben übernimmt – etwa die Suche nach Sport-Events mit automatischem Kalendereintrag oder die Restaurantwahl nach persönlichen Vorlieben.
Weitere KI-Features sind die sprachgesteuerte Suche in den Einstellungen, AI Select zum Zuschneiden von Bildschirminhalten und Circle to Search, das nun auch Musik erkennen kann. Der integrierte Dolmetscher übersetzt Gespräche und Telefonate in Echtzeit, wenn auch mit leichter Verzögerung. Hinzu kommen KI-gestützte Fotofunktionen wie der Radierer oder das Entfernen von Spiegelungen, die im Test erstaunlich zuverlässig arbeiten.
Akku
Der Akku des Galaxy S25 FE bietet jetzt eine Kapazität von 4900 mAh und liegt damit auf dem Niveau des S25+, was gegenüber dem Vorgänger ein kleiner Zugewinn ist. Unser üblicher Battery Test von PCMark ließ sich allerdings aufgrund von Kompatibilitätsproblemen mit One UI 8 und Android 16 nicht durchführen.
Im Praxistest zeigte sich, dass die Akkulaufzeit etwas kürzer ausfällt als beim S25+. Grund dafür ist die geringere Effizienz des Exynos-Chips. In der Regel schafft das S25 FE zwar locker einen Tag, hält aber im Durchschnitt rund zwei Stunden weniger durch als das Plus-Modell mit Qualcomm-Prozessor – einer der wenigen echten Schwachpunkte des abgespeckten Premium-Geräts.
Positiv: Samsung hat das Laden deutlich verbessert. Das S25 FE unterstützt jetzt 45 W Schnellladen – allerdings messen wir in der Praxis hier eher 30 W. Damit ist eine vollständige Ladung in etwa einer Stunde möglich. Auch kabelloses Laden mit 15 W ist möglich, ebenso wie das Reverse-Wireless-Charging anderer Geräte mit bis zu 4,5 W.
Preis
Die UVP des Galaxy S25 FE ist mit 749 Euro für 128 GB, 809 Euro für 256 GB und 929 Euro für 512 GB eindeutig zu hoch angesetzt. Inzwischen sind die Preise jedoch deutlich gefallen: Aktuell ist das Modell mit 128 GB schon ab etwa 474 Euro erhältlich. Empfehlenswerter ist jedoch die 256-GB-Variante, die bei rund 559 Euro liegt. Die Ausführung mit 512 GB Speicher kostet aktuell 659 Euro.
Fazit
Das Samsung Galaxy S25 FE überzeugt mit einem tollen Display, starker Performance und einer guten Kamera. Die Verarbeitung mit Metallrahmen und Glasrückseite ist wie gewohnt exzellent, optisch ist das Modell kaum vom regulären S25+ zu unterscheiden. Der Akku ist leicht gewachsen, und der Prozessor bietet im Vergleich zum S24 FE ein kleines Leistungsplus.
Allerdings wirkt es, als hätte sich Samsung in diesem Jahr etwas weniger Mühe gegeben. Das Kamera-Setup entspricht weitgehend dem der letzten FE-Generationen, und der Exynos 2400 bleibt im Hinblick auf Grafikleistung und Energieeffizienz klar hinter den Snapdragon-Chips der teureren Modelle zurück. Die Akkulaufzeit fällt entsprechend etwas kürzer aus als beim S25+.
Zum Marktstart war der Preis in unseren Augen zu hoch – ein reguläres S25+ bot kurzzeitig das bessere Gesamtpaket zum nahezu gleichen Preis. Inzwischen sind die Preise spürbar gefallen. Bald könnte die 500-Euro-Grenze in Reichweite liegen. Dann wird aus der Fan-Edition auch ein echter Preis-Leistungs-Tipp.
Wer ein möglichst komplettes Smartphone mit starker Kamera und optischem Zoom sowie langjährigem Software-Support sucht, findet im S25 FE weiterhin einen soliden Kompromiss – auch wenn der Mehrwert gegenüber dem Vorgänger kleiner ausfällt als in früheren Jahren.
Xiaomi 14T Pro
Ein Smartphone wie ein Flagship, ohne eines zu sein? Das neue Xiaomi 14T Pro verspricht starke Hardware zum vergleichsweise niedrigen Preis. Ob das gelingt, zeigt der Test.
- lädt rasant
- tolle Kamera
- hervorragendes Display
- gute Akkulaufzeit
Xiaomi 14T Pro im Test: Top-Smartphone lädt in 25 Minuten
Ein Smartphone wie ein Flagship, ohne eines zu sein? Das neue Xiaomi 14T Pro verspricht starke Hardware zum vergleichsweise niedrigen Preis. Ob das gelingt, zeigt der Test.
Das neue Xiaomi 14T Pro folgt auf das Xiaomi 13T Pro. Mit der T-Reihe bietet Xiaomi jährlich je zwei Modelle, die man als abgespeckte oder zumindest überarbeitete Varianten seiner aktuellen Flagship-Smartphones betrachtet. Diese bieten dennoch hochwertige Technologie, schnelle Prozessoren und Telelinsen zu einem vergleichsweise niedrigen Preis.
Auf den ersten Blick verspricht das Gerät einige Highlights: eine 50-Megapixel-Telelinse, einen starken Prozessor, IP68 und ein ansprechendes Design. Damit bietet es Flagship-Features zum vergleichsweise niedrigen Preis. Ob es hält, was es verspricht, zeigt dieser Testbericht.
Design: Ist das Xiaomi 14T Pro wasserdicht?
Das Xiaomi 14T Pro gehört mit Abmessungen von 160,4 × 75,1 × 8,4 mm bei einem Gewicht von 209 g zu den größeren Smartphones. Einhändiges Bedienen ist hier nicht drin. Die Verarbeitung mit Metallrahmen und Glasrückseite wirkt sehr hochwertig und folgt einem klassischen sowie eleganten Design. Das Kameramodul mit seinen präsenten Ringen rund um die drei Linsen und dem LED-Blitz verbreitet Vintage-Charme. An die Eleganz der Top-Modelle Xiaomi 14 sowie Xiaomi 14 Ultra reicht die T-Reihe jedoch nicht heran.
Trotz der Größe liegt es gut in der Hand. Die Oberfläche ist recht unempfindlich gegenüber Fingerabdrücken. Eine etwas schnöde, dunkelgraue Schutzhülle legt Xiaomi von Haus aus bei. Gegen Wasser ist das Xiaomi 14T Pro effektiv nach IP68 geschützt. Damit übersteht das Smartphone den Aufenthalt in Süßwasser für 30 Minuten in knapp einem Meter Tiefe.
Display: Wie hell ist der Bildschirm des Xiaomi 14T Pro?
In der Diagonale misst der Bildschirm wie beim Vorgänger 6,67 Zoll. Das OLED-Panel löst messerscharf mit 2712 × 1220 Pixel auf und zaubert dabei eine tolle Bildqualität auf die Anzeige. Farben wirken sehr lebendig, Kontraste sind ausgeprägt und Schwarzwerte tief wie die Nacht. Die Blickwinkelstabilität ist zudem aus allen Lagen gegeben.
Beachtlich ist die Aktualisierungsrate von 30 bis 144 Hz. Das liefert ein äußert geschmeidiges Bild ab, was besonders bei Spielen von Vorteil ist, aber auch beim Scrollen. Strahlend hell wird das Display – Xiaomi spricht hier von bis zu 4000 Nits im HDR-Modus bei aktiver Helligkeitsanpassung. Im Test konnten wir die Anzeige im Freien immer ablesen – auch bei Sonnenschein. Damit ist der Bildschirm absolut Flagship-tauglich.
Kamera: Wie gut sind Fotos mit dem Xiaomi 14T Pro
Neben der Hauptlinse mit 50 Megapixeln und f/1.6-Blende sowie optischer Bildstabilisierung (OIS) kommt eine Telelinse mit ebenfalls 50 Megapixeln und f/1.9-Blende sowie ein Ultraweitwinkelobjektiv mit 12 Megapixeln und f/2.2 zum Einsatz. Die Selfie-Kamera in der Punch-Hole-Notch vorn löst mit 32 Megapixeln auf.
Es stehen grundsätzlich zwei Modi zur Auswahl: Leica Authentic und Leica Lebendig. Die erste Variante wirkt natürlicher und weniger kräftig bei den Farben. Der lebendige Modus bietet höhere Kontraste und sattere Farben mit stärkerer Sättigung. Im Porträtmodus wiederum emuliert die Kamera-App vier Festbrennweiten von Leica (35, 50, 75 und 90 mm). Dazu kommen noch zahlreiche Farbfilter von Leica, die man über die Bilder legen kann. Zudem gibt es viele Einstellungsmöglichkeiten für Experten.
Das Ergebnis kann sich wirklich sehen lassen. Das Xiaomi 14T Pro schießt richtig gute Fotos mit der Hauptkamera, bei Tag wie bei Nacht. Bilddetails sind ausgeprägt, der Dynamikumfang hoch. Selbst Aufnahmen mit zweifachem digitalem Zoom sehen noch sehr detailliert aus. Bei Dunkelheit hilft der Nachtmodus – zudem macht sich dann der OIS positiv bemerkbar.
Die Telelinse bietet einen 2,6-fachen optischen Zoom, der detaillierte Bilder hervorzaubert. Bei Dunkelheit lässt dieser jedoch deutlich nach, da die Blende nicht lichtempfindlich genug ist. Das Ultraweitwinkelobjektiv fällt da nicht nur bei der Auflösung etwas zurück, sondern weicht farblich etwas ab im Vergleich zur Hauptlinse. Selfies sehen ebenfalls sehr detailreich und scharf, zudem gelingt das Bokeh im Porträtmodus hervorragend.
Videos sind mit der Hauptkamera mit 8K bei 30 FPS oder 4K bei 60 FPS möglich. Die Selfie-Kamera schafft hier 4K mit 30 FPS oder Full-HD mit 60 FPS.
Xiaomi 14T Pro – Originalaufnahmen
Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Xiaomi 14T Pro – Originalaufnahmen

Ausstattung: Wie stark ist der Prozessor des Xiaomi 14T Pro?
Einer der größeren Unterschiede der T-Reihe ist der Prozessor. Statt Snapdragon 8 Gen 3 von Qualcomm gibt es den Dimensity 9300+ von Mediatek. Dieser liefert starke Leistung, kann aber nicht ganz mit dem Pendant von Qualcomm mithalten. Bei PCmark kommen wir auf starke 15.500 Punkte, bei Wild Life Extreme von 3Dmark auf 3700 Punkte. Damit entspricht die Performance etwa dem Stand eines Snapdragon 8 Gen 2. Das ist für die meisten Anwendungsfälle, inklusive Gaming, auch mehr als genug. Der Prozessor zeigt sich erfreulich resilient und erreicht beim Stresstest von Wild Life Extreme hohe Stabilität von 69 Prozent.
Serienmäßig hat das 14T Pro 12 GB RAM und wird mit internem Speicher zu je 256 GB, 512 GB sowie 1 TB angeboten. Nachrüsten per microSD-Karte ist nicht möglich, bei der Menge an internem Speicher aber auch nicht unbedingt nötig. Die Schnittstellen für kabellose Konnektivität sind auf dem neuesten Stand: 5G, Wi-Fi 7 sowie Bluetooth 5.4 (LDAC, LHDC, AAC), NFC und Infrarot-Port. Zwei Schwachstellen fallen aber auf, die in der Reizblase wirklich nicht sein müssen: Der Anschluss bietet nur langsames USB-C 2.0, Ultra Wide Band (UWB) fehlt.
Die Navigation per Multiband-Funktion erfolgt mittels GPS, Glonass, Beidou, Galileo und Navic. Die Genauigkeit ist mit knapp zwei Metern laut GPS-Test sehr gut. Der Fingerabdruckleser sitzt unten im Display und arbeitet flott und verlässlich. Die Lautsprecher liefern zudem einen klaren und deutlichen Klang.
Software: Wie lange gibt es Updates?
Das Xiaomi 14T Pro kommt mit Android 14 und der Bedienoberfläche Hyper OS zum Kunden, diese erinnert stark an iOS oder EMUI. Einen App-Drawer kann man auf Wunsch aktivieren sowie auf Gesten-Steuerung oder klassische Android-Icons setzen. Käufer können mit vier Android-Updates und für fünf Jahre Sicherheits-Patches rechnen. Zum Testzeitpunkt (27.09.2024) stammt der Patch aus September – das ist auf dem neuesten Stand.
Akku: Wie lange läuft das Xiaomi 14T Pro?
Zum Einsatz kommt ein üppiger Akku mit rund 5000 mAh. Wir erreichen im Battery Test von PCmark im simulierten Betrieb bei 200 cd/m² Helligkeit rund 13 Stunden. Das ist ein starker Wert. Über einen Tag kommt man mit dem Xiaomi 14T Pro gut – bei spärlicher Nutzung sind auch zwei Tage drin. Letzten Endes hängt die Akkulaufzeit immer stark von der Nutzung ab. Wer zockt, bei Sonnenschein das Gerät nutzt oder viel navigiert, verkürzt die Laufzeit deutlich.
Richtig flott kann das Xiaomi 14T Pro laden. Bis 120 Watt sind mit PD+ möglich. Damit ist das Smartphone in 25 Minuten vollständig aufgeladen. Nach 10 Minuten hat man bereits rund 50 Prozent nachgeladen. Allerdings legt Xiaomi kein Ladegerät bei. Natürlich kann man mit jedem Netzteil laden, wer aber dieses Tempo nutzen möchte, benötigt ein passendes und kompatibles Gerät dafür. Im Test klappte das einwandfrei mit einem 120-Watt-Netzteil mit PD+ von Ulefone. Mit anderen Ladegeräten vergingen aber fast zwei Stunden, bis der Akku voll war.
Immerhin kann man das Netzteil direkt bei Xiaomi für einen symbolischen Preis von einem Euro ordern. Da wirkt der Hinweis auf Müllvermeidung gleich glaubhafter, als wenn man den vollen Preis aufrufen würde. Eine große Verbesserung zum Vorgänger: Induktives Laden per Qi ist jetzt möglich – und zwar mit bis zu 50 Watt.
Preis: Wie viel kostet das Xiaomi 14T Pro?
Die UVP liegt bei 800 Euro. Das Xiaomi 14T Pro mit 512 GB kostet mittlerweile nur noch 499 Euro. Erhältlich ist es jeweils in den Farben: Schwarz, Grau und Blau.
Fazit: Lohnt sich der Kauf?
Mit dem Xiaomi 14T Pro bringen die Chinesen einen richtig starken Nachfolger des Pro-Modells der T-Reihe. Das Gerät ist nicht nur deutlich schicker, sondern auch schneller und schießt richtig gute Fotos – eigentlich wie ein Flagship, ohne eins zu sein.
Schwächen hat das Smartphone wenige: Klar, Geräte mit aktuellem Snapdragon-Chip sind noch performanter, aber der Mediatek-Chip des Xiaomi 14T Pro liefert genug Reserven auch für die Zukunft. Nicht ganz überzeugt sind wir von der Bedienoberfläche, die Bloatware und teils Werbung mit sich bringt. USB-C 2.0 in dieser Preisklasse darf ebenfalls nicht mehr sein. Dennoch, wer Top-Technik bei Android sucht, ohne in den vierstelligen Preisbereich gehen zu müssen, wird beim Xiaomi 14T Pro fündig. Das Gerät ist sehr nah am Flagship-Niveau.
Samsung Galaxy S24
Das Galaxy S24 bietet auf den ersten Blick wenig Neues, hat aber starke Verbesserungen im Detail. Knapp ein Jahr nach Release ist es mit unter 500 Euro günstig wie nie.
- starke CPU-Leistung
- helles Display
- Software-Updates für 7 Jahre
- kein Ladegerät, lädt langsam
- AI-Funktionen sind bisher nicht ausgereift
- wenig Neues bei Hardware
Samsung Galaxy S24 im Test: Kompaktes Top-Smartphone jetzt für unter 500 Euro
Das Galaxy S24 bietet auf den ersten Blick wenig Neues, hat aber starke Verbesserungen im Detail. Knapp ein Jahr nach Release ist es mit unter 500 Euro günstig wie nie.
Kleine Smartphones sind selten geworden in der Android-Welt. Eine der wenigen Ausnahmen ist die S-Reihe ohne Zusatz, die verglichen mit anderen Mobilgeräten noch eine sehr kompakte Form hat und in etwa gleich groß ist wie das iPhone. Auf Technik muss hier niemand verzichten: So bietet das Samsung Galaxy S24 als Nachfolger des Galaxy S23 (Testbericht) Top-Technologie der Koreaner – auch wenn es mit dem Samsung Galaxy S24 Ultra (Testbericht) nicht ganz mithalten kann. Nicht nur das Format ist kleiner, auch der Preis mit einer UVP im hohen dreistelligen Bereich macht es zu einer interessanten Alternative unter den High-End-Smartphones.
Bei der Generation des Jahres 2024 fallen die Änderungen auf den ersten Blick minimal aus. Samsung legt hingegen großen Wert auf die Software und baut zahlreiche KI-Funktionen in das handliche Smartphone ein. Wie gut sich das S24 schlägt, zeigt unser Test.
Hinweis: Der Testbericht stammt vom 14.02.2024, das letzte Preis-Update vom 03.06.2025.
Was ist neu beim Galaxy S24?
Das Display ist dank noch schmalerer Ränder minimal größer. Die wichtigste Neuerung ist neben den umfangreichen AI-Funktionen, auf die wir noch eingehen, der neue Octa-Core-Prozessor. Statt eines Qualcomm Snapdragon 8 Gen 3 wie im Galaxy S24 Ultra (Testbericht) kommt der hauseigene Exynos 2400 zum Einsatz. Die Akkukapazität ist zudem geringfügig auf 4000 mAh angewachsen.
Design: Wie groß ist das Samsung Galaxy S24?
Auf den ersten Blick merkt man kaum einen Unterschied zum Vorgänger Galaxy S23 (Testbericht). Das Design ist gleich, Abmessungen (147 × 70,6 × 7,6 mm) und Gewicht (167 g) sind nahezu identisch zum Vorgänger. Damit gehrt es zu den kleinsten, modernen Top-Smartphones mit Android, die man bekommen kann und ist in etwa so groß wie das iPhone 15. Einhändiges Bedienen ist damit möglich, es passt zudem gut in kleinere Handtaschen, was es zu einer geeigneten Option für Frauen macht.
Das Display ist dank eines noch dünneren Rands in der Diagonale um 0,25 cm auf 6,2 Zoll (15,75 cm) gewachsen. Die Anzeige ist absolut top und bietet eine grandiose Bildqualität. Das OLED-Display ist zudem hell genug, um auch bei Sonnenschein ablesbar zu sein. Samsung spricht hier von bis zu 2600 Nits bei automatischer Helligkeitsanpassung. Die Auflösung beträgt wieder 2340 × 1080 Pixel bei einer adaptiven Bildwiederholrate von 1 bis 120 Hertz.
Samsung Galaxy S24 – Bilderstrecke
Samsung Galaxy S24

Samsung Galaxy S24

Samsung Galaxy S24

Samsung Galaxy S24

Samsung Galaxy S24

Samsung Galaxy S24

Samsung Galaxy S24

Samsung Galaxy S24

Samsung Galaxy S24

Samsung Galaxy S24

Kamera: Wie gut sind die Fotos?
Das Kamera-Setup entspricht mit einer Hauptkamera von 50 Megapixeln sowie einer Weitwinkellinse mit 12 Megapixel und einem Teleobjektiv mit 10 Megapixeln dem Vorgänger. Große Überraschungen bleiben aus. Das Galaxy S24 schießt schöne, scharfe Fotos mit stimmigem Dynamikumfang und ausgeprägten Bilddetails, sowohl am Tag als auch in den Abendstunden. Speziell bei Dunkelheit und etwas Umgebungslicht erweist sich der Nachtmodus als große Hilfe – eine ruhige Hand vorausgesetzt. Die optische Bildstabilisierung sorgt dafür, dass Videoaufnahmen mit bis zu 8K bei 30 FPS oder in 4K mit 60 FPS sehr stabil wirken.
Samsung Galaxy S24 – Originalaufnahmen
Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Samsung Galaxy S24 – Originalaufnahmen

Austattung: Wie gut ist der Exynos 2400?
Der Samsung Exynos 2400 ist ein erstaunlich guter Prozessor. Mit dem Snapdragon 8 Gen 3 aus dem Galaxy S24 Ultra (Testbericht) ist er zwar leicht unterlegen, aber er schlägt bezüglich Performance den Snapdragon 8 Gen 2 aus dem Vorgänger. Bei PCmark Work 3.0 erreichten wir damit starke 17000 Punkte, bei Wild Life Extreme von 3Dmark waren es satte 4200 Punkte. Im Alltag oder beim Gaming bedeutet es: Es ist immer genügend Power vorhanden, Ruckler sind ein Fremdwort. Bei hoher Auslastung wird das Gerät allerdings spürbar warm, auch wenn man sich keine Finger verbrennt.
Als Premium-Gerät bietet das S24 eine Top-Ausstattung – mit Wi-Fi 6E, USB-C 3.2, 8 GB RAM sowie bis zu 256 GB Speicher. Achtung: Die kleine Version mit 128 GB bietet „nur“ UFS 3.2, UFS 4.0 gibt es erst bei 256 GB. Wir raten gleich zur größeren Variante, da der Platz knapp werden könnte bei der ganzen Bloatware, die Samsung mitliefert.
Software: Was bieten die KI-Funktionen?
Das Augenmerk bei der gesamten S24-Serie liegt in den neuen KI-Features, die Samsung Galaxy AI nennt. Zu den spannendsten Features gehört etwa eine Live-Übersetzung bei Telefonaten in mehreren Sprachen. Diese ist auf dem Gerät integriert, funktioniert also auch offline. Die Übersetzung benötigt aber Zeit, was zu Überlappungen mit neuen Aussagen führen kann. Teilweise klappte das gut, in anderen Fällen kam noch viel Blödsinn heraus. Potenzial für Feinabstimmung ist also vorhanden.
Ein Feature, das Pixel-Kunden in ähnlicher Form erkennen, ist die Suche anhand von Bildern. Hierzu direkt man den Home-Button und kreist mit dem Finger auf dem Display ein bestimmtes Objekt ein – etwa auf einem Foto oder einer Webseite. Das Smartphone sucht dann entsprechend nach dem Objekt und erklärt, worum es sich handelt. Das funktioniert erstaunlich gut.
Weniger gelungen ist das Zusammenfassen von Texten sowie die Textformatierung, die selten den wirklichen Kern des Haupttextes findet, sowie die inkonsistente Rechtschreibprüfung. Weitere Erfahrungen mit Galaxy AI schildern wir im Testbericht zum Galaxy S24 Ultra.
Den Vogel schießt Samsung bei den Updates ab: Die gesamte S24-Reihe kann künftig für 7 Jahre mit Patches und Android-Updates rechnen. Damit zieht Samsung mit Google gleich. Die 5-Jahre-Software-Garantie beim Vorgänger war schon gut, der längere Zeitraum sollte jetzt ausreichen, dass die Software mit der Lebenszeit der Hardware gleichzieht.
Akku: Wie lange läuft das Galaxy S24?
Laut unseres üblichen Benchmarks Battery Test von PCmark kommt das S24 auf rund 12 Stunden. Das liegt rund zwei Stunden hinter dem Vorgänger – ist aber für ein kompaktes Gerät mit einem Li-Ion-Akku mit 4000 mAh noch ein ordentlicher Wert. Über einen Tag, vielleicht sogar zwei, sollte man mit dem Gerät problemlos kommen, sofern man nicht stündig spielt, viel navigiert oder das Display ständig im Freien nutzt. Der Exynos scheint hier nicht ganz so effizient zu laufen wie der Snapdragon, hat aber große Fortschritte gemacht im Vergleich zu früheren Samsung-Chips.
Aus Gründen der Nachhaltigkeit legt Samsung kein Netzteil bei. Da ohnehin nur maximal 25 Watt unterstützt werden, eignet sich ein entsprechendes Ladegerät eines älteren Smartphones. Ein vollständiger Ladevorgang dauert damit knapp über eine Stunde. Kabelloses Laden beherrscht das S24 bis 15 Watt.
Preis: Wie viel kostet das Samsung Galaxy S24?
Überraschenderweise liegt die UVP des S24 mit 849 Euro unter dem Vorgänger. Mittlerweile bekommt man die Variante mit 128 GB schon für 489 Euro. Das Modell mit 256 GB liegt bei 550 Euro.
Fazit
Klein, aber oho, gilt seit jeher für das kleine Modell der S-Reihe von Samsung. Viel Neues hat das Galaxy S24 abgesehen von den AI-Features nicht zu bieten. Der neue Exynos 2400 liefert überraschend gut ab, das Display ist gewohnt gut und hell.
An der Kamera hat sich wenig getan – vielleicht der einzige Punkt, wo die Konkurrenz zeitweise weiter ist. Das langsame Laden kann zudem nerven, wenn man von Xiaomi und Co. stärkere Netzteile gewohnt ist. Die Koreaner liefern dennoch ein stimmiges Gesamtpaket und eines der besten kompakten Android-Smartphones.
Xiaomi 15T
Starke CPU, Telekamera und Top-Display zum fairen Preis: Das Xiaomi 15T bietet viel Ausstattung für wenig Geld – wenn auch nicht ohne Abstriche.
- gute Kamera
- starke Performance
- helles und scharfes Display
- fairer Preis
- lediglich USB 2.0
- nur zweifacher optischer Zoom bei Telelinse
- kein kabelloses Laden
- aus Kunststoff
Xiaomi 15T im Test: Smartphone mit richtig guter Kamera ab 400 Euro
Starke CPU, Telekamera und Top-Display zum fairen Preis: Das Xiaomi 15T bietet viel Ausstattung für wenig Geld – wenn auch nicht ohne Abstriche.
Ein leistungsfähiges Mittelklasse-Smartphone mit guter Kamera muss nicht teuer sein. Das zeigt seit einiger Zeit die T-Variante der Xiaomi-Number-Reihe. Nachdem uns das Xiaomi 14T mit seiner Telelinse zum kleinen Preis überzeugen konnte, steht nun der Nachfolger auf dem Prüfstand: das Xiaomi 15T. Im Test klären wir, ob das neue Modell die hohen Erwartungen erfüllt.
Design
Rein optisch lässt sich das Xiaomi 15T kaum von seinem großen Bruder unterscheiden. Spätestens in der Hand wird der Unterschied jedoch spürbar: Statt auf Metall und Glas setzt Xiaomi beim 15T auf Kunststoff. Das wirkt weniger hochwertig, ist in dieser Preisklasse aber nicht ungewöhnlich.
Das Gehäuse ist kantig, die Ecken sind stark abgerundet. Auf der Rückseite sitzen drei Linsen samt LED-Blitz in einem rechteckigen Kameramodul, das sich optisch an das Pro-Modell anlehnt. Ein metallisch eingefasster Rahmen fehlt hier allerdings. Mit Abmessungen von 163 × 78 × 7,5 mm bleibt das Gerät dennoch sehr nah am Pro, fällt aber durch den Kunststoff mit 194 g etwas leichter aus. Das Xiaomi 15T ist ebenfalls nach IP68 gegen Staub und Wasser geschützt.
Xiaomi 15T – Bilder
Xiaomi 15T

Xiaomi 15T

Xiaomi 15T

Xiaomi 15T

Xiaomi 15T

Xiaomi 15T

Xiaomi 15T

Xiaomi 15T

Display
Das Xiaomi 15T setzt wie das 15T Pro auf ein 6,83 Zoll großes OLED-Panel mit einer Auflösung von 2772 × 1280 Pixeln. Die resultierende Pixeldichte von 446 PPI sorgt für ein sehr scharfes Bild, das selbst kleine Schriften klar darstellt. Farben wirken kräftig, Schwarzwerte sind OLED-typisch tief und Kontraste hoch.
Im Alltag überzeugt das Display mit einer hohen Maximalhelligkeit, die auch bei direkter Sonneneinstrahlung eine gute Ablesbarkeit ermöglicht. Laut Hersteller erreicht das Panel im HDR-Modus mit adaptiver Helligkeitsregelung bis zu 3200 Nits – ein Spitzenwert, der auch über viele Konkurrenten in dieser Preisklasse hinausgeht.
Die Bildwiederholrate wird automatisch zwischen 60 Hz und maximal 120 Hz an den Inhalt angepasst. Auf LTPO-Technik verzichtet Xiaomi jedoch, sodass die Anpassung nicht stufenlos erfolgt. Gegenüber dem Vorgänger Xiaomi 14T mit bis zu 144 Hz ist das ein leichter Rückschritt, der im Alltag aber kaum spürbar sein dürfte. Die Touch-Abtastrate von 2560 Hz sorgt zudem für eine schnelle Reaktionszeit bei Eingaben. Die Blickwinkelstabilität überzeugt ebenfalls.
Kamera
Das Kamerasystem des Xiaomi 15T orientiert sich weitgehend am Vorgänger. Es besteht aus einer 50-Megapixel-Hauptkamera (f/1.7) mit optischer Bildstabilisierung (OIS), einem 50-Megapixel-Teleobjektiv (f/1.9) mit zweifachem optischem Zoom sowie einer 12-Megapixel-Ultraweitwinkelkamera (f/2.2). Die Frontkamera löst mit 32 Megapixeln auf.
Im Vergleich zum Pro-Modell fällt das Teleobjektiv deutlich ab. Der zweifache optische Zoom ist im Klassenvergleich zurückhaltend – viele Konkurrenten bieten 2,5- oder 3-fache Vergrößerung. Bis zur zweifachen Stufe bleiben Teleaufnahmen scharf und detailreich, auch beim fünffachen Zoom ist die Qualität noch akzeptabel. Bei höheren Stufen nimmt die Bildschärfe dann spürbar ab, die Farbgebung weicht dabei minimal von der Hauptkamera ab.
Bei Tageslicht liefert die Hauptkamera kontrast- und detailreiche sowie scharfe Bilder mit stimmigem Dynamikumfang. Die Ultraweitwinkelkamera bietet farblich stimmige, aber weniger detailreiche Ergebnisse. Selfies zeigen gute Schärfe und Detailzeichnung, tendieren aber zu einem leicht rötlichen Hautton. Der Porträtmodus erzeugt ein ansprechendes, sauber getrenntes Bokeh.
Xiaomi integriert erneut die beiden Leica-Farbprofile Vibrant und Authentic. Vibrant liefert kräftige, aber natürliche Farben, während Authentic mit höherem Kontrast und kühlerer Abstimmung einen düsteren Look erzeugt, der aber nicht mehr ganz natürlich wirkt – letztlich eine Frage des Geschmacks.
Videos zeichnet die Hauptkamera in 4K mit bis zu 60 fps auf. Dank OIS bleiben Aufnahmen stabil und klar, ohne die Detailpräzision eines Flaggschiffs zu erreichen. Die Frontkamera schafft 4K mit 30 fps oder Full-HD mit 60 fps. Letztere reagiert schneller, zeigt bei Bewegung aber sichtbares Verwackeln.
Bei Dämmerung stößt die Hauptkamera an physikalische Grenzen: Details und Dynamikumfang gehen zurück, während das Rauschen zunimmt. Das 15T hellt Szenen weniger effektiv auf als das 15T Pro, liefert aber immer noch ordentliche Nachtaufnahmen für seine Preisklasse.
Xiaomi 15T – Originalaufnahmen
Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen
Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Xiaomi 15T – Originalaufnahmen

Ausstattung
Im Inneren des Xiaomi 15T arbeitet der Mediatek Dimensity 8400‑Ultra, ein leistungsstarker Achtkern‑SoC der oberen Mittelklasse. Im Benchmark PCMark erreicht das Smartphone rund 15.500 Punkte und liegt damit leicht über dem Niveau des Vorgängers. Das System läuft damit stets geschmeidig und ruckelfrei.
Deutlich verbessert zeigt sich die Grafikleistung: Bei 3DMark Wild Life Extreme erzielt das 15T rund 4000 Punkte, was auf eine Gaming-Tauglichkeit hinweist. Auch unter Dauerlast bleibt der Chip effizient. Im Stresstest hält das System rund 75 Prozent seiner Ausgangsleistung und erwärmt sich nur moderat – ein angemessenes Ergebnis für die Preisklasse.
Die Speicherausstattung fällt großzügig aus: Xiaomi bietet das 15T mit 12 GB RAM und wahlweise 256 oder 512 GB mit flottem UFS-4.1-Speicher an. Zur weiteren Ausstattung gehören 5G, Wi-Fi 6E, Bluetooth 6.0, NFC und ein Infrarotsender. Der USB-C-Anschluss ist allerdings nur nach dem älteren USB-2.0-Standard angebunden – in dieser Klasse üblich, aber ein kleiner Nachteil bei der Datenübertragung.
Die Standortbestimmung erfolgt präzise per Dual-GNSS mit GPS, Galileo, Beidou, QZSS und Navic. Der optische Fingerabdrucksensor unter dem Display arbeitet zügig und zuverlässig. Auch die Stereo-Lautsprecher gefallen mit klarem Klang, auch wenn es etwas an Kraft bei den Tiefen fehlt.
Software
Ab Werk läuft das Xiaomi 15T mit Hyper OS 2 auf Basis von Android 15, inzwischen steht aber das Update auf Hyper OS 3 mit Android 16 bereit. Zum Testzeitpunkt Anfang Dezember trug das Gerät den Sicherheits-Patch vom Oktober – das ist noch akzeptabel.
Bei den Updates zeigt sich Xiaomi solide, wenn auch nicht auf dem Niveau von Google oder Samsung. Der Hersteller verspricht vier große Android-Upgrades, also voraussichtlich bis Android 19, sowie Sicherheits-Updates bis 2031 – das entspricht rund sechs Jahren Support.
Beim Einrichten lässt sich wählen, ob das System einen App-Drawer verwendet oder alle Apps direkt auf dem Startbildschirm platziert. Auch die Bedienung kann zwischen klassischer Tastensteuerung und Gestensteuerung umgestellt werden.
Neben den Google-Apps installiert Xiaomi mehrere eigene Anwendungen als Alternative sowie den eigenen App-Store App Mall. Drittanbieter-Software ist nur in geringer Zahl vorinstalliert und deinstallierbar. Beim ersten Start der App Mall versucht das System, zahlreiche Spiele und Tools zur Installation vorzuschlagen – diese lassen sich manuell abwählen.
Bei den KI-Funktionen kombiniert Xiaomi Googles Gemini mit eigenen Hyper-AI-Features. Dazu gehören ein Schreibassistent, automatische Textzusammenfassungen, dynamische Hintergrundbilder sowie ein Sprachrekorder mit Übersetzungsfunktion. In der Galerie lassen sich zudem Objekte oder Spiegelungen nachträglich entfernen.
Akku
Der Akku des Xiaomi 15T fällt mit 5500 mAh großzügig aus. Im PCMark Battery Test erreichte das Smartphone rund 13 Stunden Laufzeit – ein starkes, wenn auch nicht herausragendes Ergebnis. Das Xiaomi 15T Pro sowie weitere Konkurrenten im gleichen Segment halten etwas länger durch. Über den Tag sollte man aber problemlos kommen.
Per Kabel lädt das Xiaomi 15T mit bis zu 67 Watt und ist in rund einer Stunde vollständig aufgeladen. Kabelloses Laden unterstützt das Gerät dagegen nicht.
Preis
Zur Markteinführung im Spätsommer lag die UVP des Xiaomi 15T bei rund 650 Euro für die Variante mit 12 GB RAM und 256 GB Speicher. Inzwischen sind die Preise deutlich gefallen: Zwischenzeitlich war das Modell bereits für unter 400 Euro zu haben, aktuell liegt es bei knapp über 405 Euro (12/256 GB) oder 450 Euro (12/512 GB) – ein fairer Preis für die gebotene Ausstattung.
Fazit
Das Xiaomi 15T bietet – ähnlich wie sein Vorgänger – ein stimmiges Gesamtpaket aus starkem Display, hoher Systemleistung und vielseitiger Triple-Kamera mit Telelinse. Für rund 400 Euro erhält man ein leistungsfähiges Smartphone, das auch Fotofans zufriedenstellen dürfte.
Optisch ähnelt das 15T stark dem Pro-Modell, wirkt aber durch das Kunststoffgehäuse weniger hochwertig. Technisch bleibt der Fortschritt gegenüber dem Vorgänger überschaubar: Das Teleobjektiv bietet nur zweifachen optischen Zoom, während viele Konkurrenten hier mehr bieten. Auch beim Software-Support kann Xiaomi nicht ganz mit den Updatestrategien von Google, Samsung oder OnePlus mithalten.
Wer jedoch ein schnelles, gut ausgestattetes Smartphone mit brillantem Display und solider Kamera sucht, bekommt mit dem Xiaomi 15T ein empfehlenswertes Gerät zu einem sehr fairen Preis.
Sony Xperia 10 VII
Kompakt und ausdauernd: Das neue Xperia 10 VII bietet 6,1-Zoll-OLED, eine bessere Kamera, lange Akkulaufzeit und längere Update-Garantie – reicht das zum Erfolg?
- gute Akkulaufzeit
- Klinkenanschluss und microSD-Erweiterbarkeit
- gute Update-Versorgung
- IP68
- wenig Speicher
- kein Teleobjektiv
- altbackenes Design
- zu teuer
Sony Xperia 10 VII im Test: Kleines Smartphone mit guter Kamera
Kompakt und ausdauernd: Das neue Xperia 10 VII bietet 6,1-Zoll-OLED, eine bessere Kamera, lange Akkulaufzeit und längere Update-Garantie – reicht das zum Erfolg?
Mit dem Xperia 10 VII frischt Sony trotz schrumpfender Marktanteile seine Mittelklasse erneut auf. Statt des extrem schmalen 21:9-Formats früherer Modelle setzt der Hersteller dieses Mal mit 6,1-Zoll-Display auf ein handlicheres Design im 19,5:9-Verhältnis und endlich 120 Hertz. Neu sind auch der überarbeitete Kamerabalken, eine 50-Megapixel-Hauptkamera und ein 5000-mAh-Akku. Wie gewohnt gibt es einen dedizierten Kameraauslöser und einen Klinkenanschluss.
Im Inneren arbeitet ein Snapdragon 6 Gen 3 mit 8 GB RAM und 128 GB Speicher, der sich – selten in dieser Preisklasse über 300 Euro – per microSD erweitern lässt. Zusammen mit dem langen Update-Versprechen soll das Xperia 10 VII attraktiver sein als sein Vorgänger Xperia 10 VI. Ob das gelingt, klärt der Test.
Design
Optisch bricht das Xperia 10 VII an zwei Punkten mit der bisherigen Designsprache der Serie: Die bisher vertikal angeordnete Kamera weicht einem breiten, pillenförmigen Kamerabalken, der sich fast über die gesamte Rückseite zieht – optisch klar an Googles aktuellen Pixel-Modellen angelehnt. Trotz der hervorstehenden Kameraeinheit liegt das Smartphone eben auf dem Tisch, ohne zu wackeln. Die matte Kunststoffrückseite mit leicht weicher, griffiger Oberfläche verhindert Fingerabdrücke, wirkt aber etwas weniger hochwertig als Glas oder Metall – vorrangig angesichts des Preises.
Das Design bleibt Sony-typisch kantig, wirkt aber durch den abgerundeten Rahmen angenehm handlich. Auf der rechten Seite sitzen Lautstärkewippe, Power-Taste mit integriertem Fingerabdrucksensor und der markentypische Kameraauslöser. Mit 153 × 72 × 8,3 mm und 168 g bleibt das Xperia 10 VII kompakt und auffallend leicht – gerade im Vergleich zu größeren Mittelklassemodellen. Gorilla Glass Victus 2 schützt die Front, IP68-Zertifizierung bietet Schutz gegen Staub und zeitweiliges Untertauchen. Dennoch weist Sony auf seiner Website wieder einmal darauf hin, dass „das Gerät […] nicht vollständig in Wasser eingetaucht werden“ dürfe – ein unnötiger Widerspruch.
Auf eine Notch verzichtet Sony weiterhin. Stattdessen behält das Xperia die typischen, etwas breiteren Ränder ober- und unterhalb des Displays. Das mag altmodisch wirken, hat aber praktische Vorteile: Die Frontlautsprecher strahlen direkt nach vorn, und es gibt keine störende Aussparung in Videos oder Spielen. Insgesamt überzeugt das Design durch Eigenständigkeit – es polarisiert, dürfte aber gerade eingefleischte Xperia-Fans ansprechen.
Sony Xperia 10 VII – Bilder
Sony Xperia 10 VII

Sony Xperia 10 VII
Sony Xperia 10 VII
Sony Xperia 10 VII

Sony Xperia 10 VII

Sony Xperia 10 VII

Sony Xperia 10 VII

Sony Xperia 10 VII

Sony Xperia 10 VII

Sony Xperia 10 VII

Sony Xperia 10 VII

Sony Xperia 10 VII

Sony Xperia 10 VII

Display
Sony verbaut im Xperia 10 VII ein HDR-fähiges OLED-Display mit 6,1 Zoll und einer Auflösung von 2340 × 1080 Pixeln. Das neue Format im Verhältnis 19,5:9 liegt deutlich näher am Standard als das extrem schmale 21:9 des Vorgängers. Inhalte wirken mit über 420 PPI gestochen scharf, das Panel überzeugt mit kräftigen, aber natürlichen Farben und starken Kontrasten. Eine zentrale Verbesserung gegenüber dem Xperia 10 VI ist die Bildwiederholrate: Statt 60 Hertz bietet das Panel jetzt bis zu 120 Hertz. Das sorgt für spürbar flüssigeres Scrollen, weichere Animationen und ein insgesamt moderneres Bediengefühl.
Die maximale Helligkeit von bis zu 890 cd/m² reicht aus, um den Screen im Freien gut ablesbar zu halten, solange keine direkte Sonneneinstrahlung vorliegt. Insgesamt ist die Display-Qualität deutlich besser, als es die breiten Ränder vermuten lassen – sie wirken auf den ersten Blick etwas altmodisch. Ein echtes Always-on-Display bietet Sony weiterhin nicht.
Kamera
Die Kameras des Xperia 10 VII wurden im Vergleich zum Vorgänger leicht verbessert. Die Hauptkamera bietet jetzt 50 statt 48 Megapixel, allerdings mit einer minimal kleineren Blende von f/1.9 statt f/1.8. Ebenso bleibt die optische Bildstabilisierung (OIS) erhalten sowie der Phasenautofokus und die 4K-Videoaufnahme – allerdings weiterhin nur mit 30 Bildern pro Sekunde. Die zweite Kamera liefert 13 statt zuvor 8 Megapixel und dient als Weitwinkel. Einen optischen Zoom gibt es leider nicht.
Im Alltag entstehen mit der Hauptkamera detailreiche Aufnahmen mit natürlicher Farbwiedergabe. Dynamikumfang und Belichtungsautomatik liegen auf ausgeprägtem Mittelklasseniveau, auch Gegenlicht begegnet die Software mit zuverlässig arbeitendem Auto-HDR. Bei schwachem Licht hilft die OIS, Verwacklungen zu minimieren. Das Bildrauschen wird effektiv unterdrückt, teils aber zu aggressiv, wodurch feine Details verloren gehen. Insgesamt positioniert sich die Kamera im oberen Mittelfeld der Mittelklasse – von Sony als Kamerapionier dürfte man dennoch etwas mehr erwarten.
Die Weitwinkelkamera liefert bei Tageslicht ordentliche Ergebnisse, zeigt jedoch weniger Schärfe und Details als die Hauptkamera. An den Rändern sind leichte Unschärfen sichtbar, bei schwierigem Licht nimmt die Qualität deutlich ab. Für gelegentliche Landschafts- oder Gruppenaufnahmen reicht sie aus, für mehr nicht. Die 8-Megapixel-Frontkamera ist solide und liefert bei gutem Licht ansprechende Selfies sowie klare Bilder für Videoanrufe.
Die Kamera-App präsentiert sich im gewohnten Sony-Stil: übersichtlich im Automatikmodus, mit umfangreichen Optionen in den Pro-Modi und separaten Foto-Apps. Features wie Fokus-Peaking und manuelle Einstellungen bieten Fotoenthusiasten mehr Kontrolle als bei vielen Konkurrenten. Hier zeigt Sony seine Kamera-Expertise – schade nur, dass die Bildqualität, vorwiegend bei schwachem Licht, nicht ganz diesem Anspruch gerecht wird. Videos wirken insgesamt gut, allerdings führen die auf 30 FPS in 4K begrenzte Bildrate und daraus resultierende Ruckler bei Schwenks zu Abzügen.
Sony Xperia 10 VII – Originalaufnahmen
Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Sony Xperia 10 VII – Originalaufnahmen

Ausstattung
Im Inneren des Xperia 10 VII arbeitet Qualcomms Snapdragon 6 Gen 3, ein aktueller Mittelklasse-Chip mit acht Kernen, gefertigt im 4-Nanometer-Verfahren. Dazu kommen 8 GB RAM und 128 GB interner Speicher – angesichts einer UVP von über 400 Euro eher knapp bemessen. Immerhin lässt sich der Speicher per microSD-Karte um bis zu 2 TB erweitern. Dual-SIM-Betrieb mit eSIM und einer physischen Nano-SIM ist ebenfalls möglich – ein inzwischen seltenes Feature.
Im Alltag reicht die Leistung für typische Aufgaben wie Social Media, Streaming und alltägliche Apps problemlos aus. Die Bedienung läuft flüssig, doch bei grafisch anspruchsvollen Spielen müssen die Nutzer Details reduzieren, um stabile Bildraten zu erzielen. In 3DMark Wild Life Extreme erreicht das Xperia 10 VII 870 Punkte, im PCMark Work 3.0 rund 10.675 Punkte.
Im Vergleich zum Vorgänger Xperia 10 VI mit Snapdragon 6 Gen 1 arbeitet der neue Chip spürbar schneller und effizienter. Im Benchmark-Vergleich bleibt das Smartphone aber weiterhin im unteren Bereich der aktuellen Mittelklasse – bei einem gemessen am Leistungsniveau recht hohen Preis.
Bei der Konnektivität zeigt sich Sony großzügig: 5G, Wi-Fi 6E, Bluetooth 5.4 mit aptX Adaptive und LDAC, NFC sowie GPS mit Glonass, Galileo, Beidou und QZSS sind an Bord. Dazu kommen ein klassischer 3,5-mm-Klinkenanschluss und USB-C, allerdings nur in der Version 2.0. Die nach vorn gerichteten Stereo-Lautsprecher klingen klar und werden ausreichend laut, allerdings mit wenig Bass. Dank der Ausrichtung profitieren Sprachverständlichkeit und Medienwiedergabe. Der seitlich integrierte Fingerabdrucksensor in der Power-Taste reagiert zuverlässig und schnell – ein Sensor im Display würde aber moderner wirken.
Software
Auf dem Xperia 10 VII läuft ab Werk Android 15 mit Sonys gewohnt schlanker Bedienoberfläche. Optisch bleibt vieles nah an reinem Android, ergänzt um typische Xperia-Elemente wie spezielle Kamera-Apps, Audio-Optimierungen und Komfortfeatures wie das Seitenleisten-Menü. Neu hinzukommen KI-Funktionen wie Circle to Search und die Integration von Google Gemini. Überflüssige Drittanbieter-Apps sind erfreulicherweise kaum vorinstalliert.
Ein großes Plus ist die Update-Politik: Sony garantiert vier große Android-Upgrades und sechs Jahre Sicherheits-Patches. Damit dürfte das Xperia 10 VII voraussichtlich bis etwa 2031 mit Updates versorgt werden – ein starkes Versprechen für ein Mittelklassemodell und auf Augenhöhe mit den Update-Vorreitern der Branche.
Angesichts der seit Jahren schrumpfenden Marktanteile von Sony im Smartphone-Geschäft bleibt jedoch die Frage, was länger Bestand hat: das zugesagte Software-Versprechen oder Sonys Engagement im Mobilmarkt selbst. Gerüchte über einen möglichen Rückzug kursieren schon länger – besonders nach den Problemen rund um das Xperia 1 VII.
Preis
Sony ruft für das Xperia 10 VII eine unverbindliche Preisempfehlung von 449 Euro auf. Im Rahmen des Black Friday liegt der aktuelle Straßenpreis bei 379 Euro. Erhältlich ist das Gerät in drei Farbvarianten: Schwarz, Weiß und Türkis. Alle Ausführungen bieten die gleiche Speicherausstattung.
Fazit
Das Sony Xperia 10 VII ist ein eigenständiges Mittelklasse-Smartphone, das bewusst nicht jedem gefallen will. Es punktet mit kompaktem, kantigem Design, klassisch breiten Display-Rändern, microSD-Slot, IP68-Schutz, Kopfhörerbuchse und dediziertem Kameraauslöser. Positiv fallen die gute Akkulaufzeit und das neue, lange Update-Versprechen auf, mit dem Sony endlich zur Konkurrenz aufschließt. Wirklich neu ist allerdings nur der quer verlaufende Kamerabalken – etwas wenig für eine neue Generation.
Die Ausstattung ist solide, gemessen am Preis jedoch teils knapp. Das 6,1-Zoll-OLED-Display mit 120 Hertz und kräftigen Farben überzeugt, dürfte aber heller sein. Die Hauptkamera mit optischer Stabilisierung liefert bei Tageslicht gute Bilder, schwächelt jedoch bei wenig Licht, während der Weitwinkel kaum zu gebrauchen ist. Ein Teleobjektiv fehlt, und 4K-Videos mit nur 30 fps sind in dieser Preisklasse zu wenig – dem Snapdragon-Chip geschuldet, der eher der unteren Mittelklasse entspricht. Seine Leistung genügt im Alltag, wirkt aber angesichts des Preises schwach. Auch das rein kabelgebundene, langsame Laden passt 2025 nicht mehr ganz in die Zeit – zumal weder Netzteil noch Kabel beiliegen.
Im Endeffekt richtet sich das Xperia 10 VII an eine kleine Zielgruppe, die klassische Anschlüsse, microSD-Erweiterung und flexible Kamerasteuerung schätzt. Wer mehr Leistung, ein Teleobjektiv oder ein rundum stärkeres Gesamtpaket sucht, wird bei der Konkurrenz leichter fündig.
ZUSÄTZLICH GETESTET
Nubia Redmagic 10 Air
Nubia Redmagic 10 Air
Das Redmagic 10 Air will Gaming-Performance mit einem leichten, dünnen Design kombinieren. Unser Test wird zeigen, wie gut das funktioniert.
- starke Performance
- schlankes, leichtes Design (für ein Gaming-Smartphone)
- viele tolle Gaming-Features
- schnelles 80-W-Laden
- Display ohne Notch
- schwache Akkulaufzeit
- mittelmäßige Kamera
- nur IP54-Schutzklasse
- ohne eSIM-Unterstützung
- kein kabelloses Laden
Redmagic 10 Air im Test: Ein ultradünnes Gaming-Smartphone
Das Redmagic 10 Air will Gaming-Performance mit einem leichten, dünnen Design kombinieren. Unser Test wird zeigen, wie gut das funktioniert.
Smartphone-Hersteller Nubia erweitert seine speziell auf Gaming ausgerichtete Redmagic-Reihe um ein neues Modell: das Redmagic 10 Air. Es ist weniger leistungsstark und opulent als die beiden Flaggschiffe Redmagic 10 Pro (Testbericht) und 10S Pro, dafür aber deutlich schlanker, leichter und günstiger. Für eine UVP von 499 Euro zielt das Redmagic 10 Air auf die Mittelklasse – als kompaktes Gaming-Smartphone, das mit seinem schlichten Design kaum als solches erkennbar ist. Ein spannender Ansatz, der sich im Test beweisen muss.
Design
So wie die aktuellen Redmagic-Pro-Modelle bleibt auch das Redmagic 10 Air der kantigen Designsprache treu und weckt bei manchen Erinnerungen an frühere Sony-Xperia- oder Galaxy-Note-Modelle. Optisch gefällt uns das richtig gut. Hinzu kommt das – für ein Gaming-Smartphone – überraschend schlichte Design, das in unserer schwarzen Testvariante nur durch eine rote „Magic-Key“-Taste an der linken Seite Akzente setzt. Diese dient standardmäßig als Shortcut für das Gaming-Center.
Durch die kantige Bauweise liegt das Smartphone allerdings nicht ganz so geschmeidig in der Hand wie Modelle mit stärker abgerundeten Rändern – Geschmackssache. Bei der Haptik punktet das Air-Modell mit einem matten Finish, das sich angenehm anfühlt und Fingerabdrücken kaum Chancen lässt. Besonders gelungen ist die Rückseite aus Glas, die täuschend echt wie gebürstetes Metall wirkt.
Mit seinen Maßen von 164,3 × 76,6 × 7,85 mm und einem Gewicht von nur 205 g ist das Redmagic 10 Air deutlich leichter und rund einen Millimeter dünner als die Pro-Modelle. Zum Vergleich: Diese bringen 229 g auf die Waage und messen 8,9 mm in der Tiefe. Das Air-Prädikat hat sich unser Testkandidat im eigenen Haus also verdient – auch wenn er nicht zu den leichtesten Smartphones auf dem Markt gehört. Das Samsung Galaxy S25 Edge (Testbericht) wiegt nur 163 g. Mit Blick auf die aktuellen Gaming-Smartphones am Markt darf man beim Redmagic 10 Air dennoch von einem Leichtgewicht sprechen.
Bei der Verarbeitungsqualität zeigt das Redmagic 10 Air keine echten Schwächen. Der Mittelrahmen besteht aus leichtem Aluminium in Luftfahrtqualität, die Vorder- und Rückseite aus Glas – das sorgt insgesamt für einen hochwertigen Eindruck.
Enttäuschend ist jedoch die Zertifizierung nach IP54: Das Smartphone ist damit nur eingeschränkt gegen Staub und Spritzwasser geschützt. Während das bei den Pro-Modellen aufgrund des offenen Lüftersystems noch nachvollziehbar ist, hätte Nubia beim Redmagic 10 Air mehr Schutz bieten können – zumal hier eine passive Flüssigmetallkühlung zum Einsatz kommt und der 3,5-mm-Klinkenanschluss entfällt.
Redmagic 10 Air – Bilder
Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Redmagic 10 Air

Display
Das 6,8-Zoll-AMOLED-Display des Redmagic 10 Air löst mit 2480 × 1116 Pixeln auf und bietet eine Bildwiederholrate von bis zu 120 Hertz. Im Vergleich zu den hauseigenen Pro-Modellen ist das zwar etwas abgespeckt, überzeugt trotzdem mit starker Darstellung. Mit rund 400 ppi wirkt das Bild knackscharf, zeigt kräftige Kontraste, natürliche Farben und ein tiefes Schwarz.
Die maximale Helligkeit von 1600 Nits reicht aus, um Inhalte auch bei Tageslicht gut zu erkennen. Unter direkter Sonne wird es allerdings etwas schwieriger – Geräte mit 2000 Nits und mehr, wie die Pro-Varianten, sind hier klar im Vorteil. Erfreulich: Die Frontkamera sitzt unauffällig unter dem Display – ohne störende Notch.
Kamera
Das Dual-Kamerasystem auf der Rückseite des Redmagic 10 Air besteht aus zwei 50-Megapixel-Sensoren von Omnivision. Die Hauptkamera bietet eine Brennweite von 24 mm, eine f/1.88-Blende und eine optische Bildstabilisierung (OIS). Die Ultraweitwinkelkamera arbeitet mit 14 mm Brennweite und einer f/2.05-Blende. Auf die 2-Megapixel-Telelinse der Pro-Modelle wurde verzichtet, dafür kommt auf der Vorderseite die gleiche 16-Megapixel-Kamera mit f/2.0-Blende und KI-Unterstützung zum Einsatz. Einen optischen Zoom gibt es nicht, digital lässt sich aber bis zu zehnfach vergrößern.
In der Mittelklasse um 500 Euro liefert das Redmagic 10 Air solide Ergebnisse. Bei Tageslicht überzeugen die Aufnahmen mit guter Schärfe und natürlicher Farbwiedergabe. Bei Dämmerung, Nachtaufnahmen oder starkem Zoom nimmt die Bildqualität allerdings merklich ab – hier sind Modelle von Samsung, Google oder Xiaomi klar überlegen.
Die Frontkamera liefert ordentliche Fotos, schwächelt aber ebenfalls bei wenig Licht. Positiv hingegen: Die Hauptkamera nimmt Videos in 4K mit 60 Bildern pro Sekunde und sogar in 8K mit 30 FPS auf. Bis 4K lässt sich zudem eine digitale Stabilisierung aktivieren, die für ruhige und saubere Aufnahmen sorgt.
Redmagic 10 Air – Originalaufnahmen
Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen

Redmagic 10 Air – Originalaufnahmen
Ausstattung
Wie bereits erwähnt, fällt das Redmagic 10 Air in puncto Hardware etwas weniger leistungsstark aus als die Pro-Modelle. Statt des Snapdragon 8 Elite verbaut Nubia den Snapdragon 8 Gen 3 von Qualcomm – ein Chip, der dennoch mehr als genug Power für alltägliche Anwendungen und anspruchsvolles Gaming bietet. Unterstützt wird er vom hauseigenen Red Core R3-Chip, der speziell für optimiertes Gaming-Tuning und bessere Reaktionszeiten entwickelt wurde.
Das Gerät ist wahlweise mit 12 GB LPDDR5X-RAM und 256 GB UFS-4.0-Speicher (Testgerät) oder 16 GB RAM und 512 GB Speicher erhältlich.
Statt der typischen aktiven Lüfterkühlung, für die Redmagic bekannt ist, setzt das Air-Modell auf ein passives ICE-X-Kühlsystem. Dieses nutzt eine Kombination aus Flüssigmetall und einer 6100 mm² großen Dampfkammer, um die Abwärme effizient zu verteilen. In der Praxis bleibt das Smartphone selbst bei langen Gaming-Sessions angenehm kühl – nur bei sehr hohen Umgebungstemperaturen oder direkter Sonneneinstrahlung stößt das System an seine Grenzen.
Zur tatsächlichen Performance: Das Redmagic 10 Air schafft es im Benchmark „PCMark Work 3.0“ auf sehr starke 18.000 Punkte. Das Smartphone arbeitet stets geschmeidig und ohne spürbare Ladezeiten. Zum Vergleich: Den bisherigen Rekord schaffte das Redmagic 10 Pro (Testbericht) mit 25.000 Punkten. Im Benchmark „Wild Life Extreme“ von 3DMark erreicht das 10 Air mit insgesamt 4700 Punkten ebenfalls einen starken Wert und ist damit voll Gaming-tauglich. Auch hier liegt der Rekord mit 7.000 Punkten beim Redmagic 10 Pro. Im Stresstest bei hoher Dauerbelastung wird das Air-Modell spürbar warm und die Effizienz sinkt auf 80 Prozent. Für ein so leistungsfähiges Gerät ist das ebenfalls ein guter Wert!
Im Hinblick auf Anschlüsse und Konnektivität muss sich das Redmagic 10 Air einige Kritik gefallen lassen. Der verbaute USB-2.0-Port wirkt nicht mehr zeitgemäß, eSIM-Unterstützung fehlt, und auch der 3,5-mm-Klinkenanschluss wurde gestrichen.
Abseits davon ist die Ausstattung aber solide: Bluetooth 5.4, Wi-Fi 7 (ohne HBS), Dual-GPS, NFC, 5G und Platz für zwei Nano-SIM-Karten sorgen für eine moderne Grundausstattung. Der optische Fingerabdrucksensor unter dem Display reagiert zuverlässig und schnell.
Ein Highlight für Gamer sind die Touch-Schultertasten an der rechten Seite mit 520 Hz Abtastrate – sie bieten im Querformat spürbare Vorteile beim Spielen. Die DTS-X-zertifizierten Stereo-Lautsprecher liefern einen klaren und kräftigen Klang, neigen bei maximaler Lautstärke jedoch leicht zum Übersteuern.
Software
Das Redmagic 10 Air läuft mit dem hauseigenen Redmagic OS 10, das auf Android 15 basiert. Nubia verspricht fünf Jahre Software-Support, einschließlich wichtiger Android-Updates – ein starkes Zeichen für ein Gaming-Smartphone der Mittelklasse. Die Bedienoberfläche wirkt modern, aufgeräumt und bietet viele Anpassungsmöglichkeiten. Etwas störend ist allerdings die Menge an Bloatware, also vorinstallierten Apps, die man aber problemlos deinstallieren kann. Weiterhin fallen teils unsaubere Übersetzungen im Menü auf – besonders im Gaming-Center. So verbirgt sich hinter dem Punkt „Spiel Raum Tapete“ schlicht die Option, das Hintergrundbild zu ändern. Das sorgt gelegentlich für Verwirrung.
Bei den KI-Funktionen greift das Redmagic 10 Air größtenteils auf die bekannten Google-AI-Features inklusive Gemini zurück. Ergänzend integriert Nubia eigene Werkzeuge unter dem Label Redmagic AI+. Dazu zählen etwa eine Echtzeit-Sprachübersetzung für Gespräche oder eine intelligente Antennensteuerung, die die Signalqualität verbessern soll. Eine zusätzliche Shortcut-Seitenleiste wird ebenfalls als KI-Funktion geführt – warum, bleibt allerdings unklar. Nützlich ist sie dennoch, etwa für den Schnellzugriff auf häufig genutzte Tools.
Das Herzstück der Oberfläche bildet das Gaming-Center X-Gravity, das über die „Magic-Key“-Taste oder per Shortcut geöffnet wird. Hier lassen sich zahlreiche spielrelevante Einstellungen vornehmen: von der individuellen Performance-Anpassung über Makro-Funktionen hin zu Bildfiltern, die Gegner in dunklen Szenen besser sichtbar machen. Auch die Schultertasten können hier frei belegt und konfiguriert werden – ein klarer Pluspunkt für ambitionierte Mobile-Gamer.
Akku
Im Redmagic 10 Air verbaut Nubia einen 6000-mAh-Akku – deutlich kleiner als der 7050-mAh-Energiespeicher der Pro-Modelle. Irgendwo musste das geringere Gewicht schließlich herkommen. Im „Battery Test“ von PCMark erreicht das Smartphone damit jedoch nur etwa 9 Stunden Laufzeit.
Zum Vergleich: Die meisten Geräte dieser Klasse schaffen 10 bis 12 Stunden, Spitzenmodelle sogar bis zu 14 Stunden. Im Alltag heißt das: Das Redmagic 10 Air hält bei normaler Nutzung knapp einen Tag durch – wer viel spielt, dürfte bereits nach rund vier Stunden an die Steckdose müssen.
Positiv: Das 80-W-Schnellladen funktioniert zuverlässig. In nur etwa 52 Minuten ist der Akku wieder komplett voll. Eine Option für kabelloses Laden bietet das Gerät jedoch nicht.
Preis
Direkt beim Hersteller kostet das Redmagic 10 Air mit 12/256 GB etwa 499 Euro. Damit positioniert sich das Redmagic 10 Air klar in der Mittelklasse. Mit 16/512 GB sind es 649 Euro. Am günstigsten ist es derzeit bei 449 Euro bei Amazon für 12/256 GB und 519 Euro für 16/512 GB.
Beide Speicher-Varianten sind in den Farben Twilight (Schwarz) und Hailstone (Weiß) erhältlich. Eine deutlich auffälligere Sonderedition namens Flare in Orange und Schwarz, die den Gaming-Charakter durch zusätzliche Designakzente betont, gibt es ausschließlich in der größten Speicherausführung.
Fazit
Das Redmagic 10 Air richtet sich an Nutzer, die ein voll spieletaugliches Gaming-Smartphone suchen, das zugleich kompakt und alltagstauglich bleibt. Diesen Spagat hat Nubia weitgehend überzeugend gemeistert. Besonders gefallen das schlanke Design, das Notch-freie Display, die starke Performance, die zahlreichen Gaming-Funktionen und nicht zuletzt der deutlich günstigere Preis im Vergleich zu den Pro-Modellen.
Für das schlanke Gehäuse waren allerdings Kompromisse nötig: Die schwache Akkulaufzeit dürfte für viele der größte Kritikpunkt sein. Das mittelmäßige Kamerasystem und kleine Abstriche bei der Ausstattung fallen im Alltag hingegen weniger ins Gewicht. Schlussendlich positioniert sich das Redmagic 10 Air mit solidem Preis-Leistungs-Verhältnis in einer Mittelklasse-Nische, in der echte Gaming-Smartphones bislang rar sind.
Google Pixel 8a
Google Pixel 8a
Das Google Pixel 8a kostet nur 469 Euro und bietet trotzdem mehr als manch anderes deutlich teureres Smartphone. Neben der Software, der langen Akkulaufzeit und dem guten Display gefällt uns im Test vorwiegend die Kamera.
- beste Kamera unter 500 Euro
- viele sinnvolle Software-Funktionen
- lange Akkulaufzeit, helles Display
- breiter Displayrand
- langsames Laden
- keine Makroaufnahmen möglich
Google Pixel 8a im Test
Das Google Pixel 8a kostet nur 469 Euro und bietet trotzdem mehr als manch anderes deutlich teureres Smartphone. Neben der Software, der langen Akkulaufzeit und dem guten Display gefällt uns im Test vorwiegend die Kamera.
Die Google-Pixel-Reihe hat sich vom reinen Nerd-Produkt zu einer der beliebtesten Mainstream-Marken am Smartphone-Markt gemausert. Traditionell zeigt Google im Herbst zwei High-End-Modelle und etwa ein halbes Jahr danach deren Budget-Variante. Im Herbst 2023 waren das die Smartphones Google Pixel 8 und Google Pixel 8 Pro. Beide räumten in unseren Tests hervorragende Wertungen ab. Wie bereits die Jahre davor glänzen die Pixel wieder mit einer fantastischen Kamera und vielen sinnvollen Software-Features.
Das Google Pixel 8a ist das günstigste Smartphone der 8er-Reihe. Trotzdem bietet es vieles, was man sonst nur in teureren Modellen findet. Dazu gehört neben der guten Verarbeitung, dem schnellen und hellen Display, den umfassenden Software-Features primär die exzellente Kameraeinheit. Besseres gibt es in der Preisklasse außerhalb der Pixel-Familie nicht. Google verspricht nun beim Pixel 8a vergleichbar gute Bilder, eine ähnlich hohe Performance und den vollen Zugriff auf alle KI-Funktionen. Richtig gut ist auch, dass Google ganze 7 Jahre Android-Updates verspricht. Wie gut das Google Pixel 8a wirklich ist, zeigt dieser Testbericht.
Design: Ist das Google Pixel 8a wasserdicht?
Das Google Pixel 8a ist mit seinen Maßen von 152 × 73 × 9 mm nur minimal kleiner als das Google Pixel 7a (Testbericht). Auch das Gewicht ist mit 188 g beinahe identisch. Trotzdem ist es etwas breiter als das Pixel 8. Das liegt auch am deutlich sichtbaren Displayrand, der in der Größe etwas aus der Zeit gefallen scheint.
Wie bereits der Vorgänger ist auch das Pixel 8a nach IP67 gegen das Eindringen von Wasser und Staub geschützt. Es kann sich damit für maximal 30 Minuten bis in eine Tiefe von 0,5 m in Süßwasser aufhalten. Noch besser sind hier das Google Pixel 8 und Google Pixel 8 Pro (Testbericht) mit IP68.
Die Rückseite besteht aus einem matten Kunststoff, der sich fantastisch anfühlt. Rein haptisch empfinden wir ihn gar angenehmer als die edleren Glasrückseiten der Pixel 8 und Pixel 8 Pro. Die Kameraeinheit kommt wieder in einem etwa einen Millimeter herausragenden Visier unter, welches sich komplett vom linken zum rechten Rand zieht. So wackelt das Smartphone nicht, wenn es auf dem Rücken liegt.
Display: Wie groß ist der Bildschirm des Pixel 8a?
Das durch Gorilla Glass 3 geschützte, 6,1 Zoll große OLED-Display löst mit 2400 × 1080 Pixel auf und kommt so auf eine Pixeldichte von 430 PPI. Soweit gleichen sich die Werte mit denen des Pixel 7a. Allerdings strahlt es heller. Das fällt vorwiegend im HDR-Modus auf. Das Ablesen des Displays ist auch bei direkter Sonneneinstrahlung kein Problem.
Auch hat Google an der Bildwiederholungsrate geschraubt. Das Pixel 8a kann 120 Bilder pro Sekunde darstellen, beim Vorgänger waren es noch 90 Hz. Wie bei Pixel-Modellen üblich sind die Farben knackig, der Kontrast hoch und die Blickwinkel stabil.
Kamera: Wie gut sind die Fotos des Pixel 8a?
Das Google Pixel 8a hat die gleiche Kameraeinheit wie das Google Pixel 7a. Auf dem Datenblatt kann sie also nicht mit den Pixel 8 und Pixel 8 Pro mithalten. Trotzdem sorgt die Hauptkamera (f/1,89) mit 64 Megapixeln für beeindruckende Ergebnisse. Per Pixel-Binning fasst es vier Bildpunkte zu einem zusammen, weshalb das fertige Bild dann 16 Megapixel bietet. Erst, wenn man weit in das fertige Bild hineinzoomt, fallen Unterschiede zu den beiden Pixel-Platzhirschen auf. Die Selfie-Kamera mit 13 Megapixeln gehört ebenfalls zu den besten am Markt.
An seine Grenzen stößt das Pixel 8a beim von Google getauften „Super Resolution Zoom“, welcher einer achtfachen Vergrößerung entspricht. Hier kommt es zu deutlichen Unschärfen. Diese sind jedoch bei einem Digital-Zoom üblich und nur bei Kameraeinheiten mit Telelinse wirklich gut wie beim Pixel 8 Pro.
Die Ultraweitwinkellinse (f/2,2) löst mit 13 Megapixeln auf und zeigt hervorragende Ergebnisse. Zwar gibt es wie üblich an den Rändern Verzerrungen, doch das Bild zeigt in allen Bereichen eine beeindruckende Schärfe. Allerdings verzichtet die Weitwinkellinse auf einen Autofokus, weshalb mit dem Pixel 8a keine sinnvollen Makroaufnahmen möglich sind.
Google Pixel 8a Fotos
Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Google Pixel 8a Foto

Ausstattung: Wie schnell ist das Pixel 8a?
Im Smartphones wirkt wie beim Pixel 8 und 8 Pro der selbst designte SoC Tensor G3. Dieser soll primär KI-Anwendungen beschleunigen. Ihm stehen 8 GB RAM (LPDDR5X) und 128 GB oder 256 GB Speicher (UFS 3.1) zur Seite. Es erreicht bei „Wild Life Extreme“ von 3Dmark gut 2300 Punkte und bei Work 3.0 von PCmark rund 11500 Punkte. Das ist vergleichbar mit den anderen 8er-Modellen und für ein Handy für den Preis eine adäquate Leistung. Es gibt allerdings günstigere Smartphones wie das Redmi Note 13 Pro 5G, die mehr schaffen.
Im Alltag reagiert es jedoch auf alle Eingaben ausgesprochen schnell. Neben der Nano-SIM unterstützt das Pixel 8a auch eine eSIM. Außerdem kann es Wi-Fi 6E und Bluetooth 5.3. Einen Klinkenstecker hat es nicht. Der Fingerabdrucksensor ist flott und auch das Entsperren per Kamera funktioniert zuverlässig. Die Kamera lässt sich nicht mit einem Bild austricksen.
Google Pixel 8a Bilder
Google Pixel 8a

Google Pixel 8a

Google Pixel 8a

Google Pixel 8a

Google Pixel 8a

Google Pixel 8a

Google Pixel 8a

Google Pixel 8a

Google Pixel 8a

Google Pixel 8a

Software: Was kann das Pixel 8a und wie lange gibt es Updates?
Wie üblich wirkt die Software des Telefons zunächst minimalistisch. Bloatware gibt es keine. Bemerkenswert: Google verspricht auch hier 7 Jahre lang Android-Updates. Unter der Haube gibt es jedoch zahlreiche Funktionen zu entdecken.
Android bietet eine Vielzahl neuer Funktionen, darunter die Aktivierung eines eigenen VPN-Dienstes, das Teilen einzelner Apps statt des gesamten Bildschirms sowie die Einblendung von Untertiteln oder Audio-Emojis während Telefonaten. Inhalte lassen sich per KI analysieren, Webseiten vorlesen, Nachrichten übersetzen und Musik automatisch erkennen. Dokumente können gescannt, bearbeitet und die Kamera als Webcam verwendet werden. Die Recorder-App transkribiert und archiviert Sprache. In der Foto- und Videobearbeitung ermöglichen KI-gestützte Tools das Entfernen von Störgeräuschen, das Optimieren von Porträts, das Kombinieren von Gesichtsausdrücken und das Hervorheben des Sternenhimmels im Zeitraffer.
Dabei ist das längst nicht alles, diese Liste ließe sich deutlich erweitern. Uns sind mit den aktuellen Samsung-Phones wie dem Samsung S24 Ultra nur wenige weitere Smartphones bekannt, welche vergleichbar viele KI-Funktionen bietet.
Google Pixel 8a Screenshots
Google Pixel 8a Screenshot
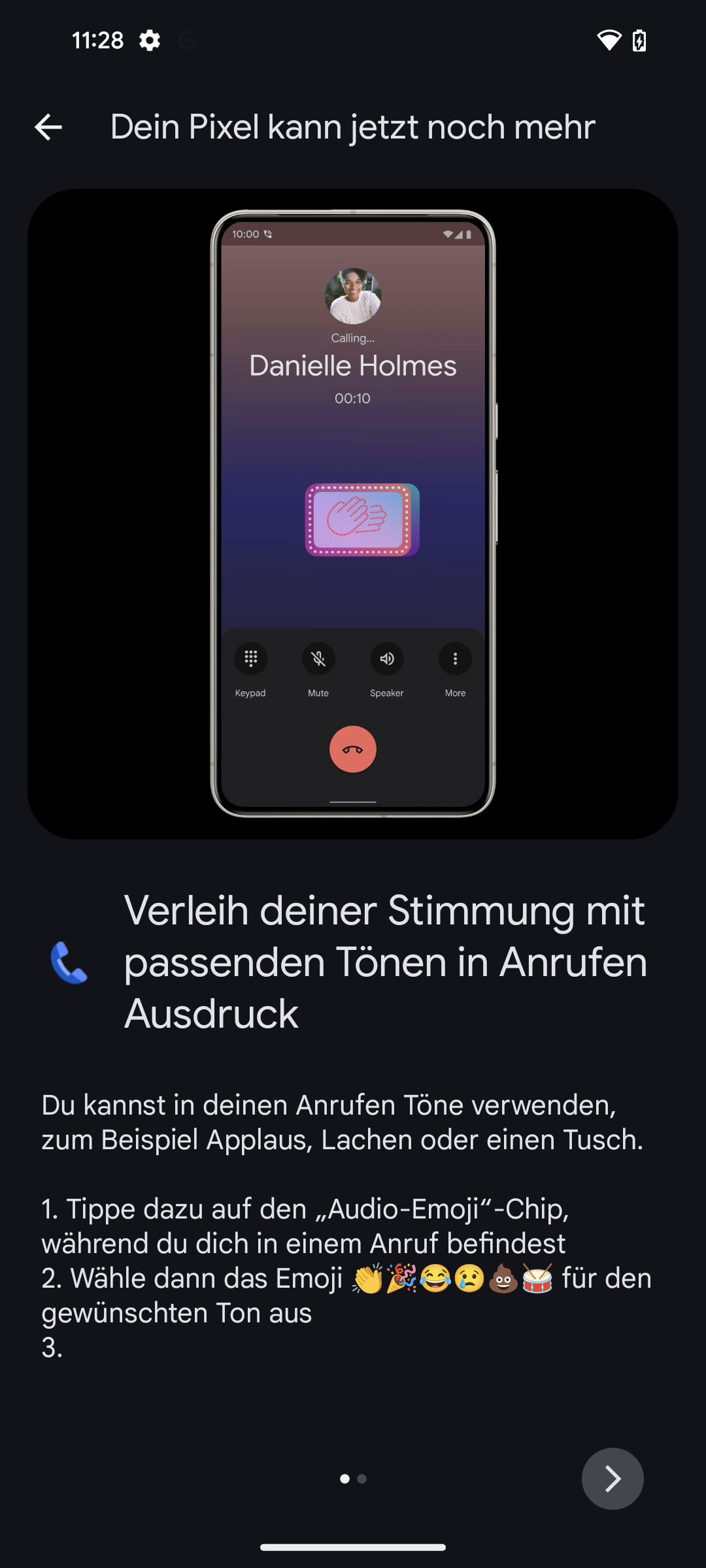
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
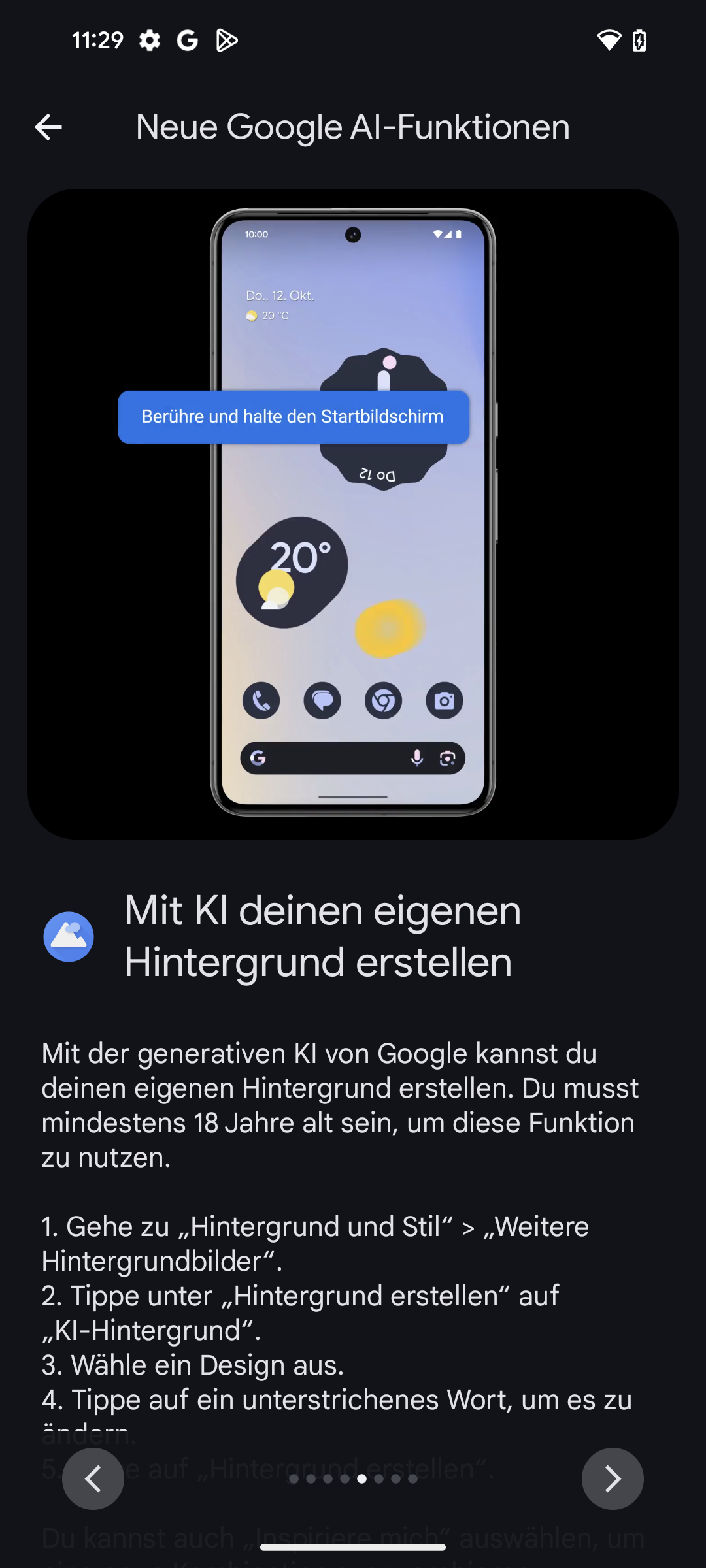
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
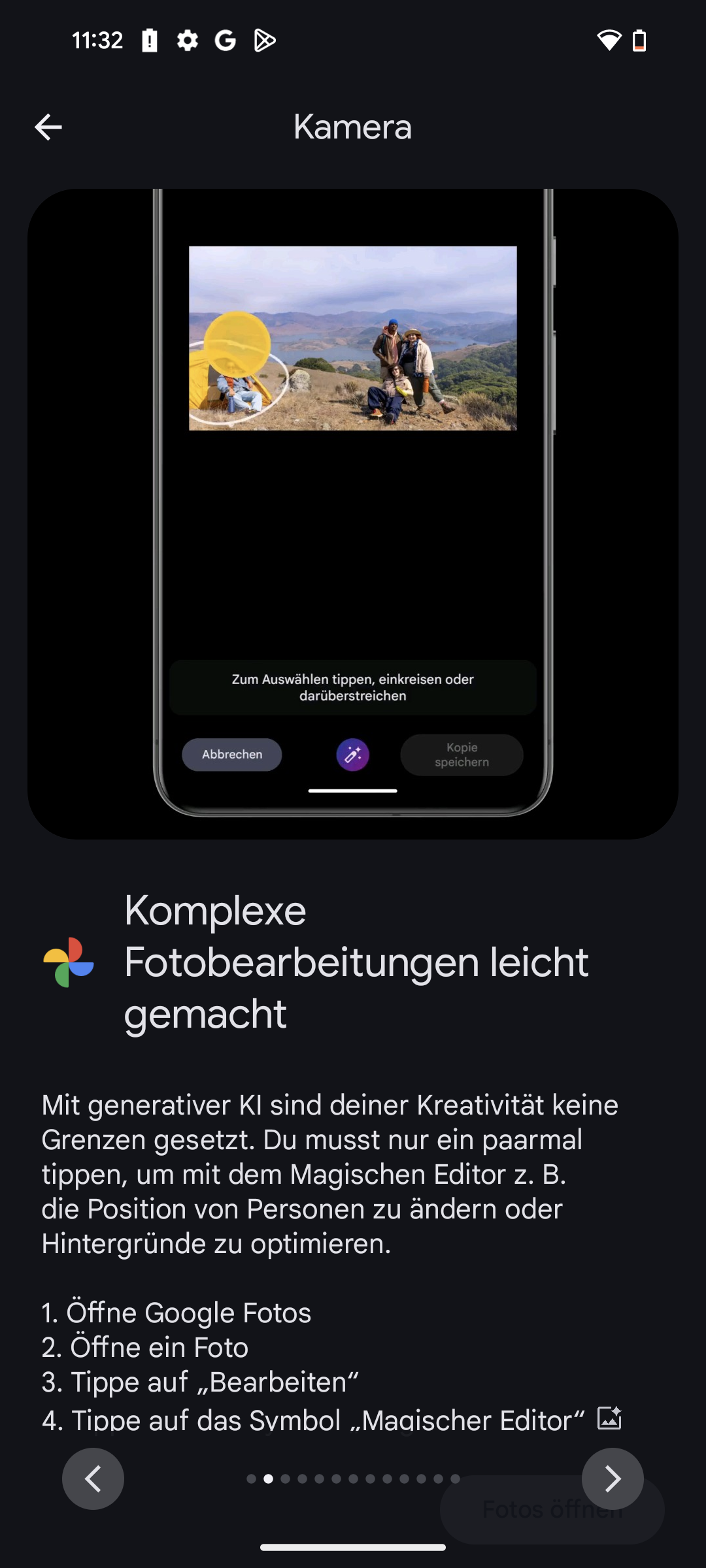
Google Pixel 8a Screenshot
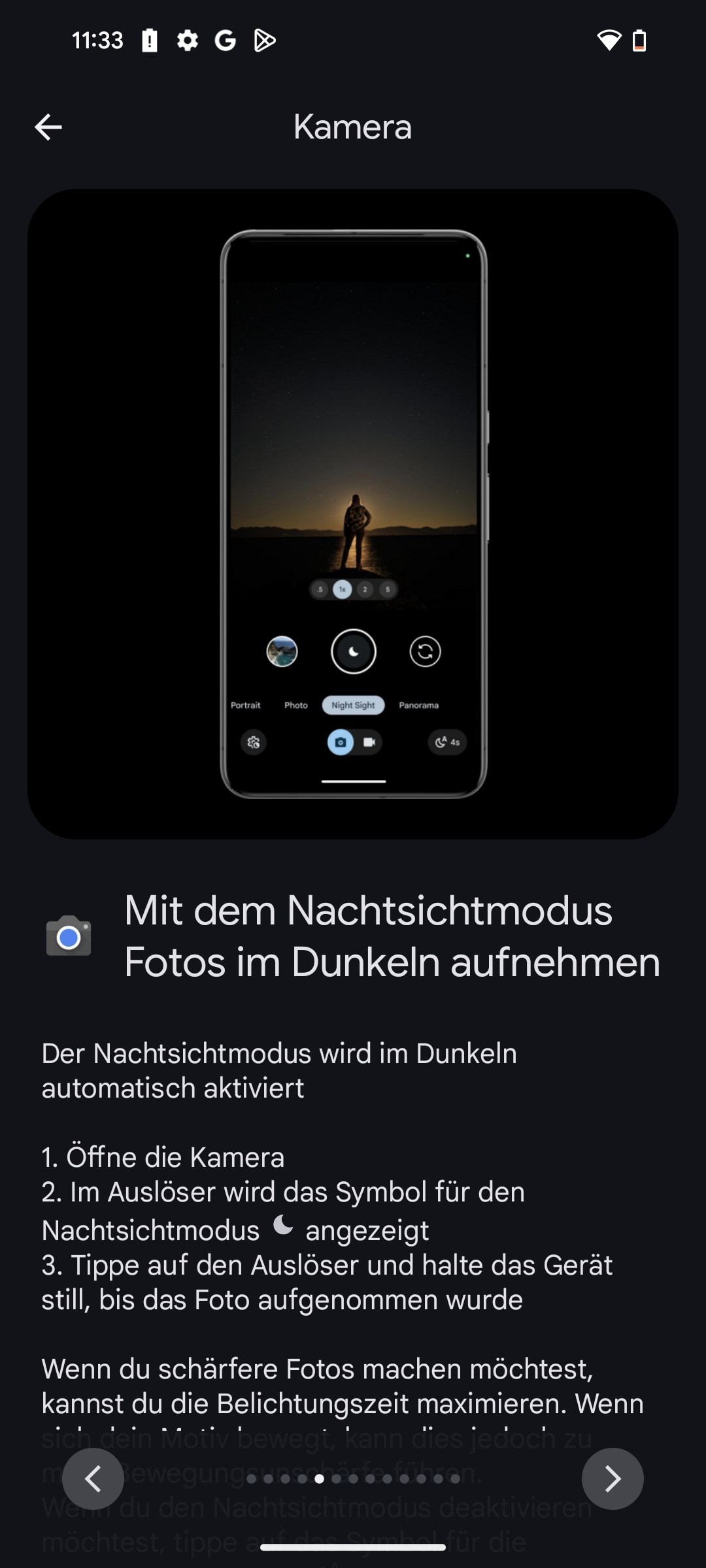
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
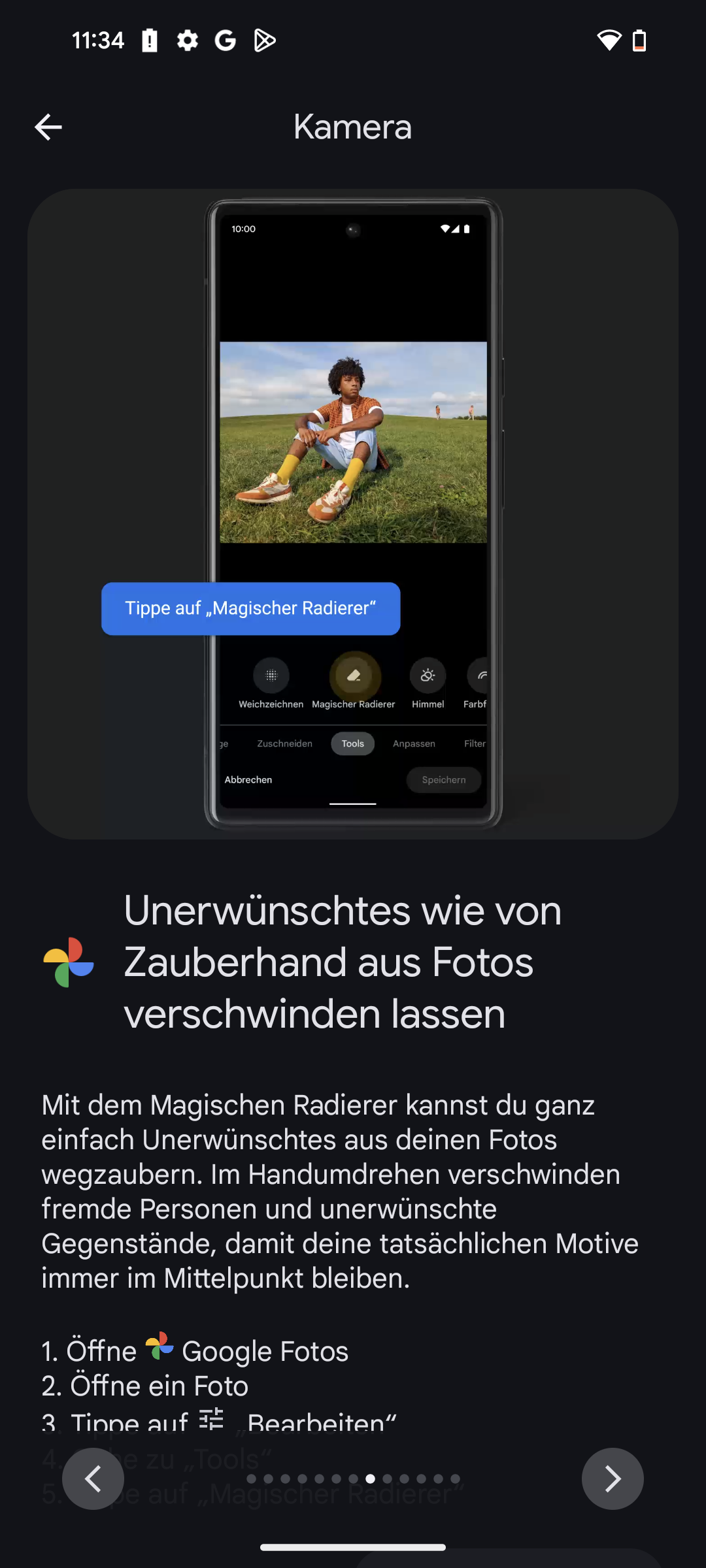
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
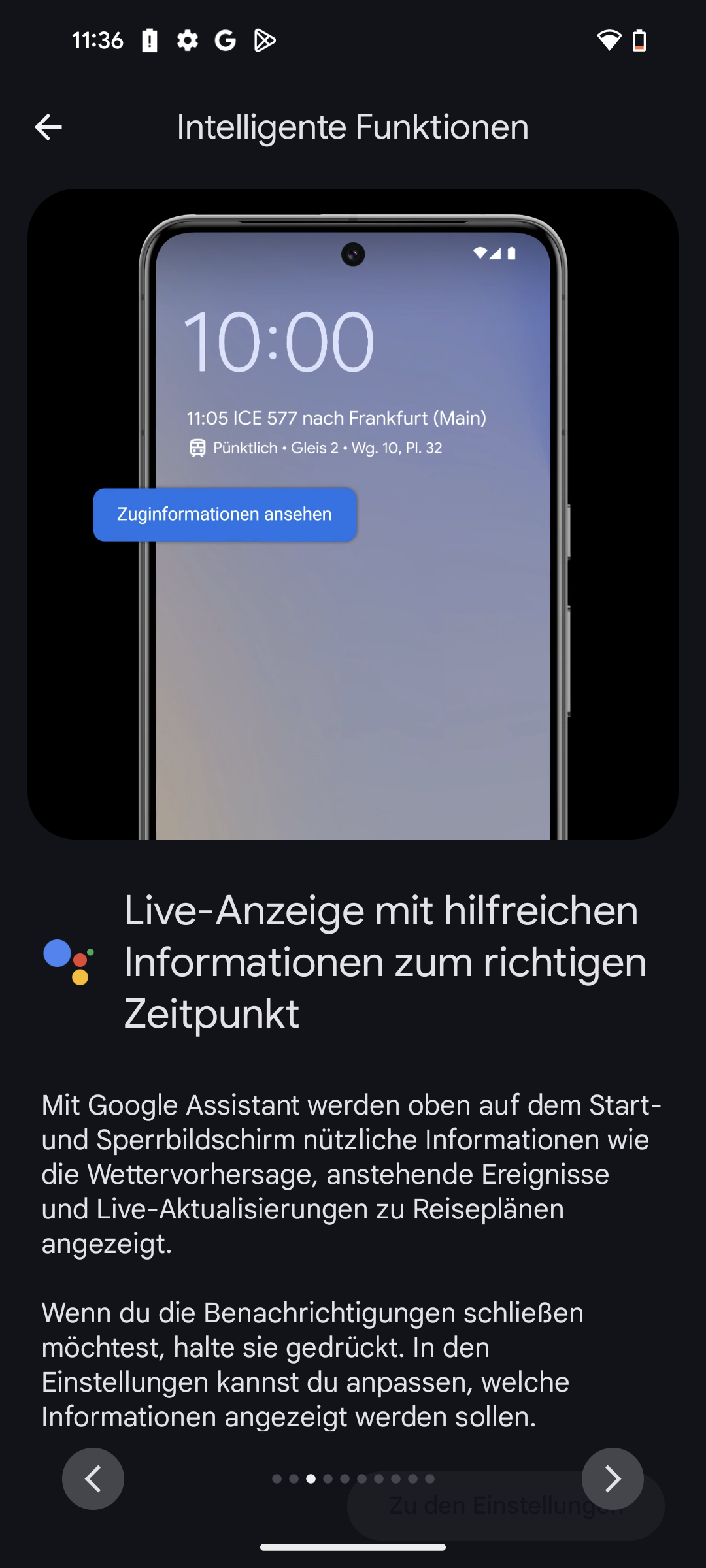
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot

Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
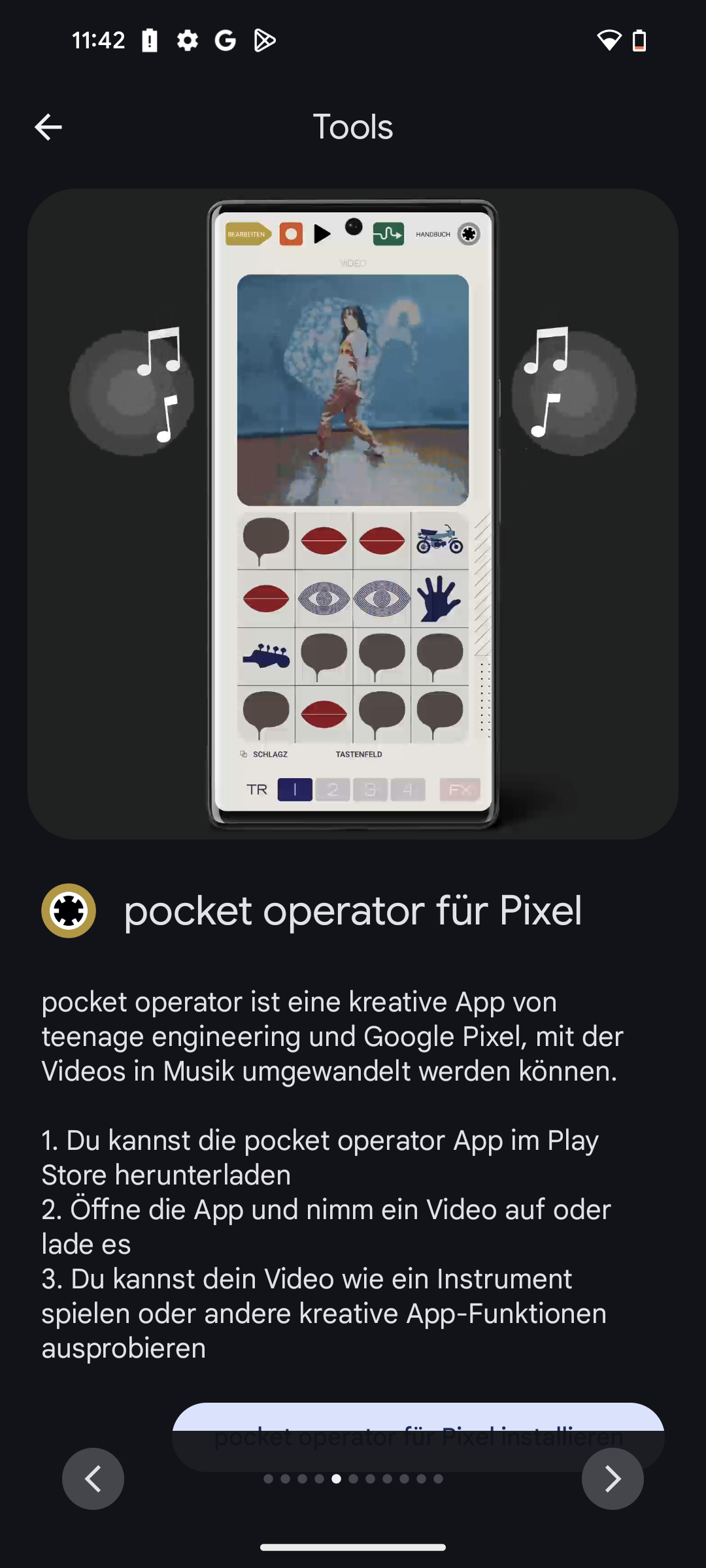
Google Pixel 8a Screenshot
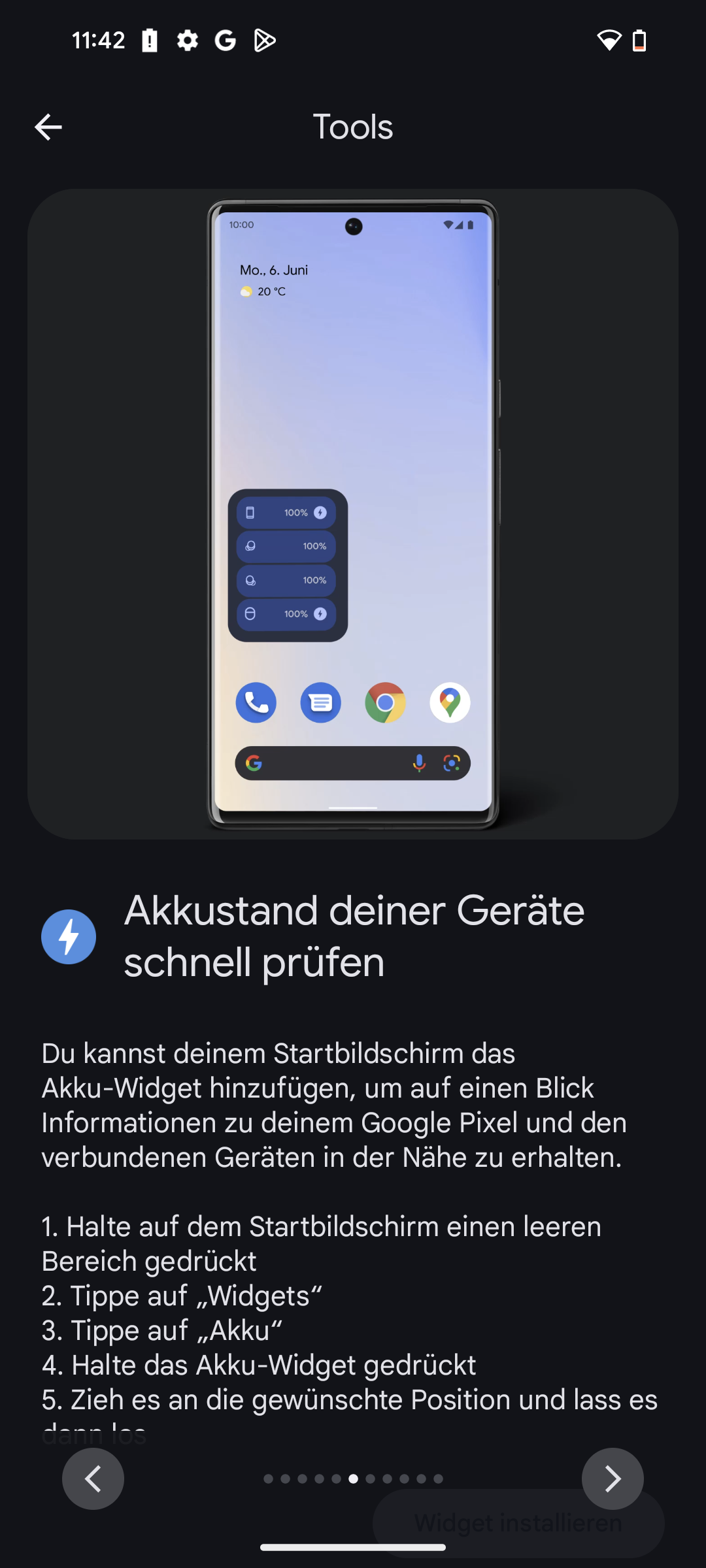
Google Pixel 8a Screenshot
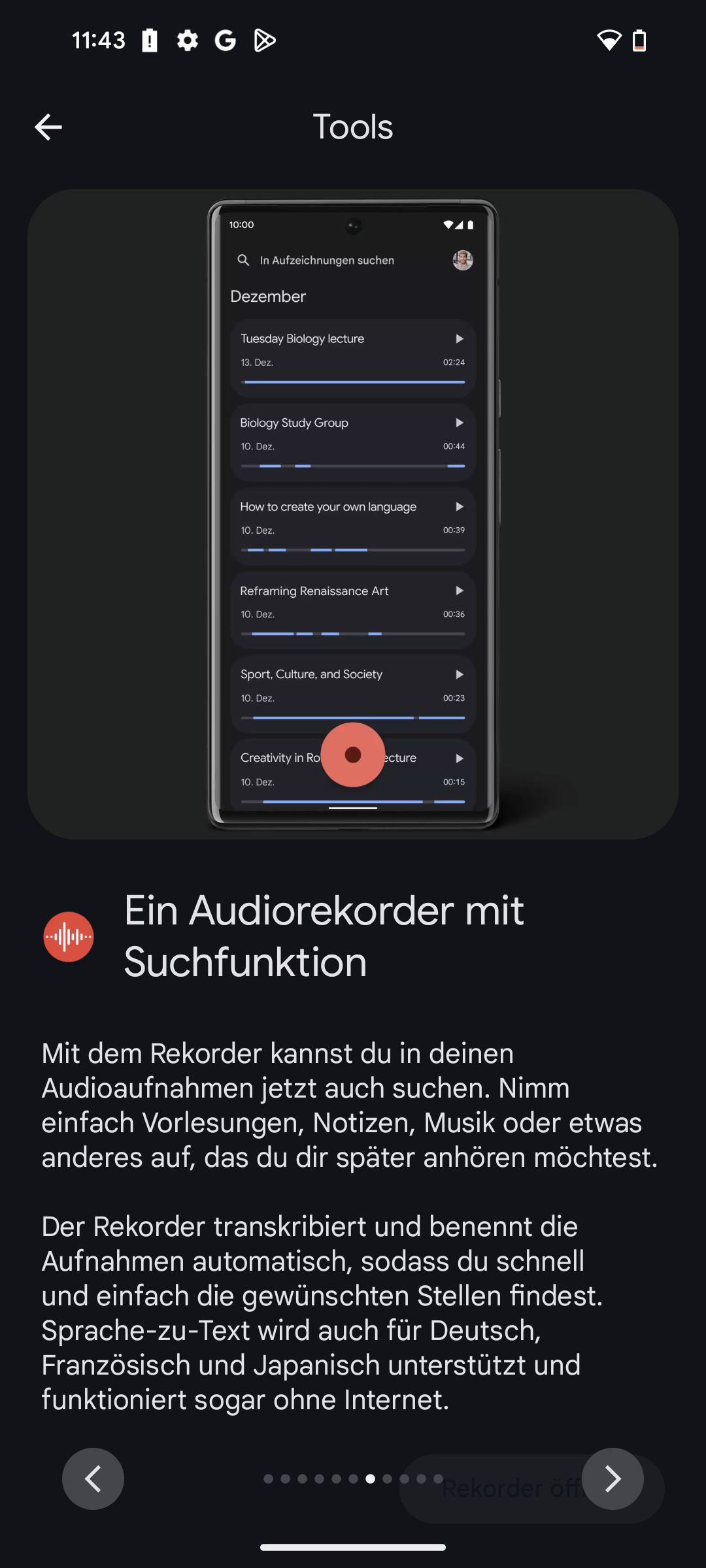
Google Pixel 8a Screenshot
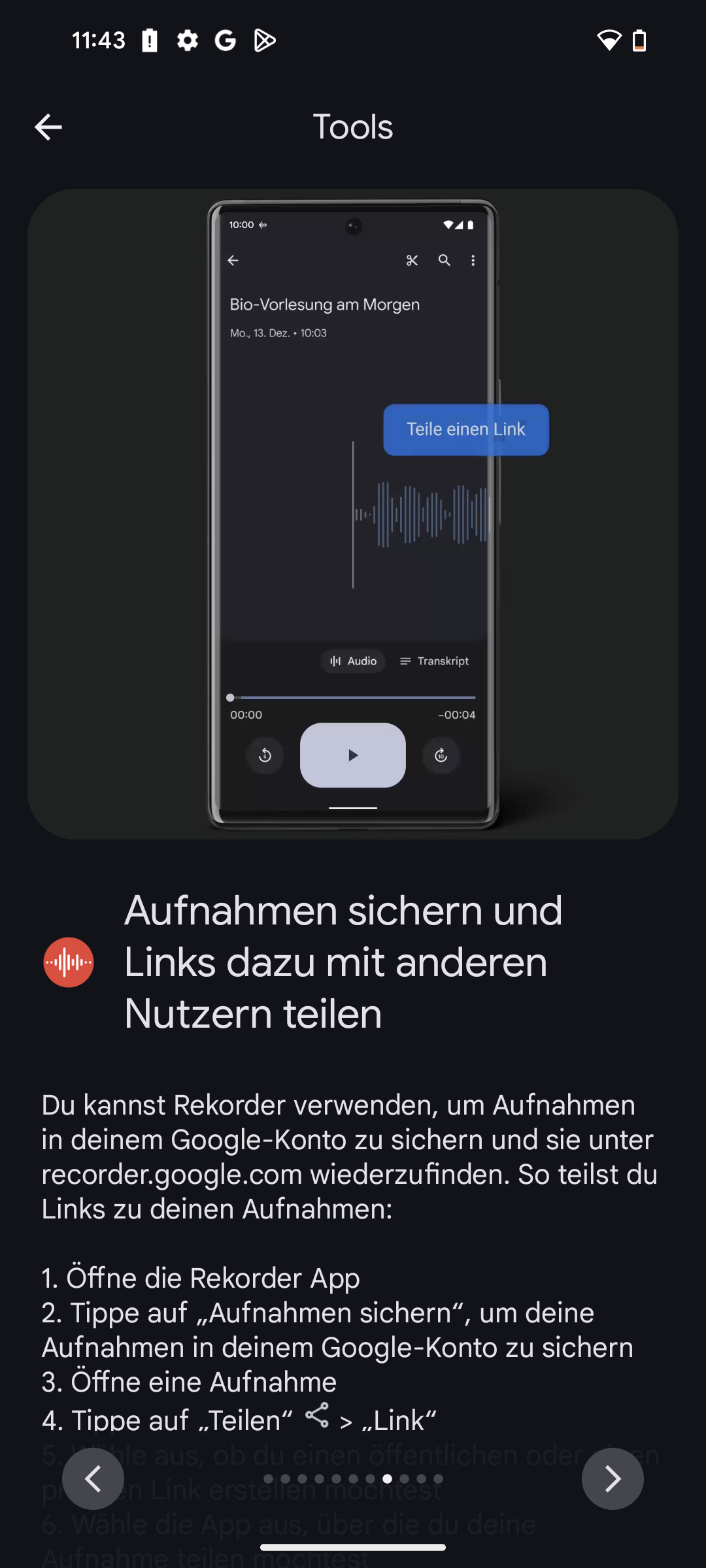
Google Pixel 8a Screenshot
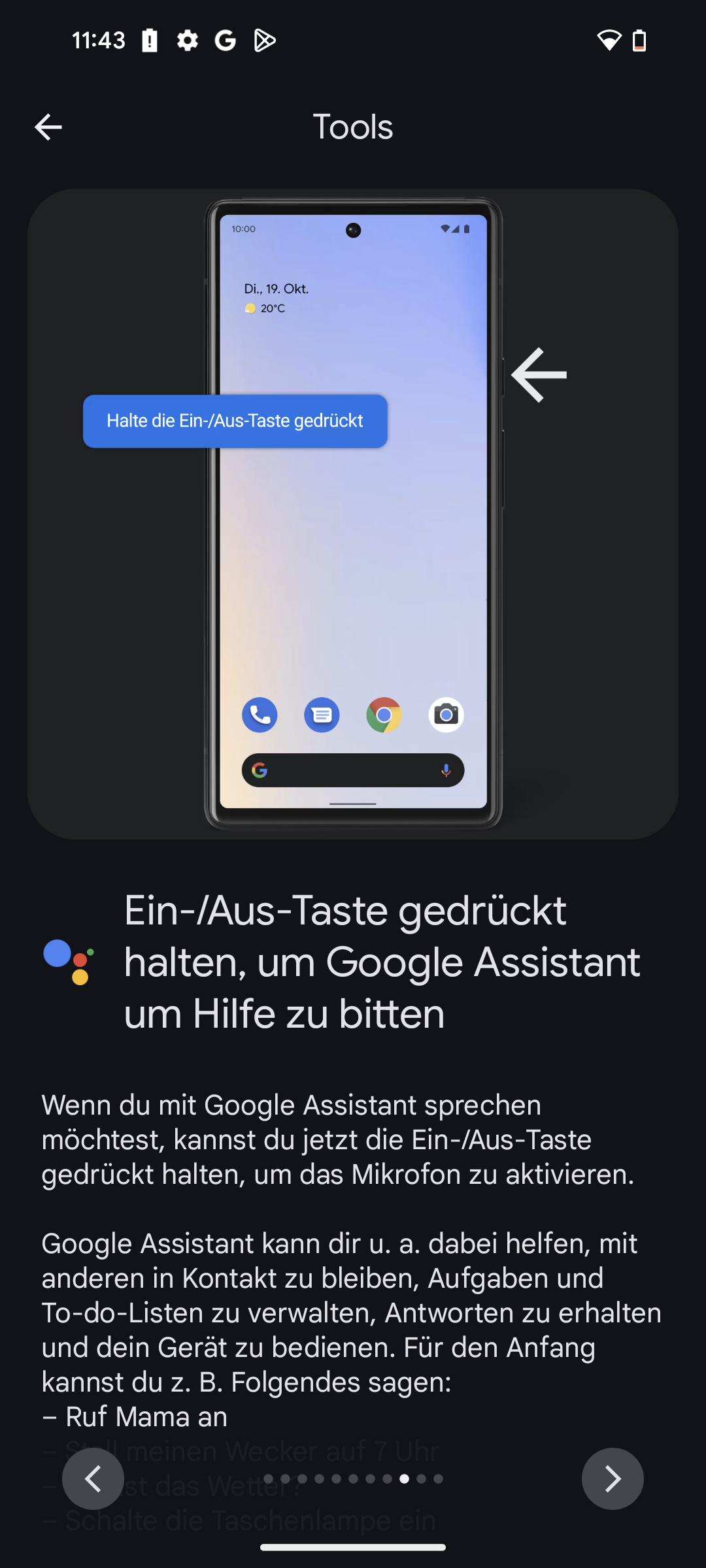
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
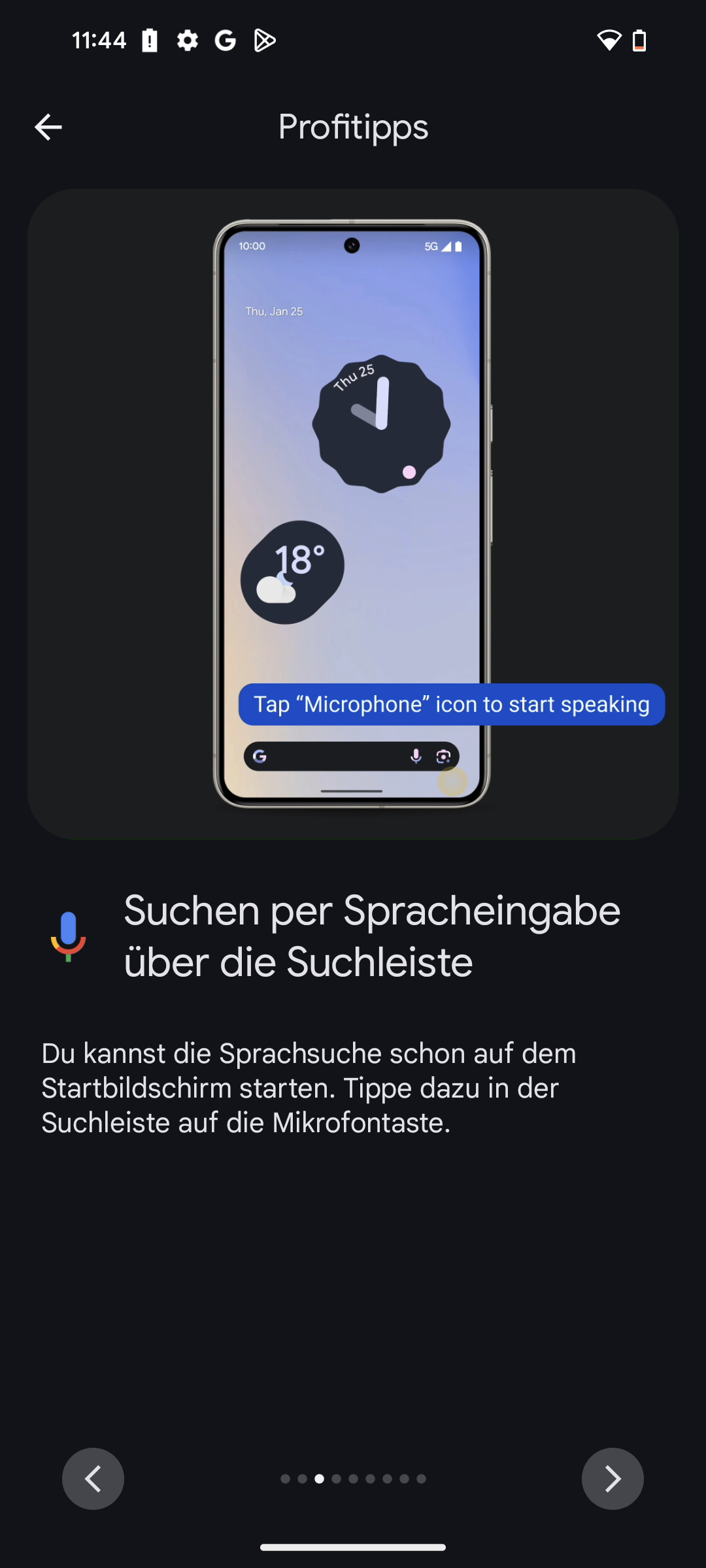
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
Google Pixel 8a Screenshot
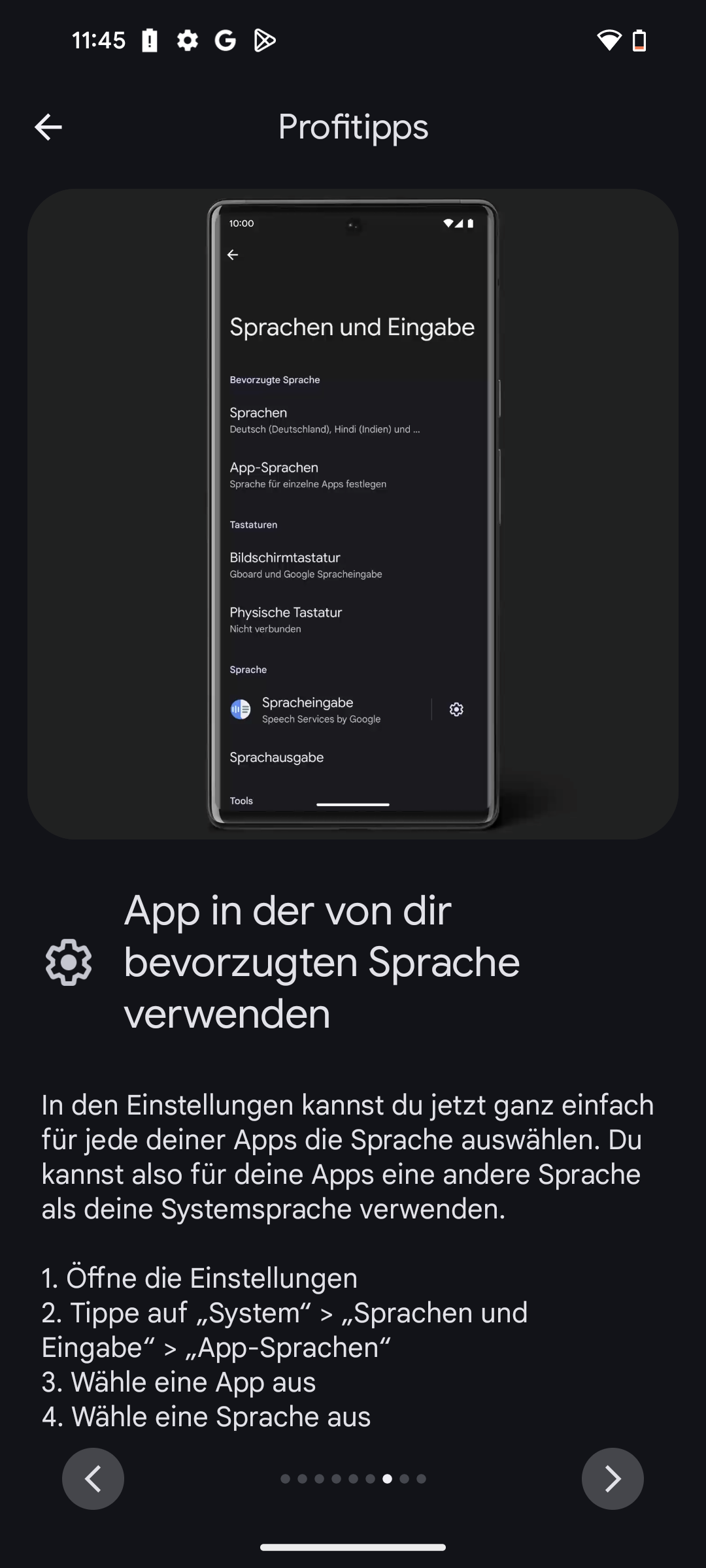
Google Pixel 8a Screenshot
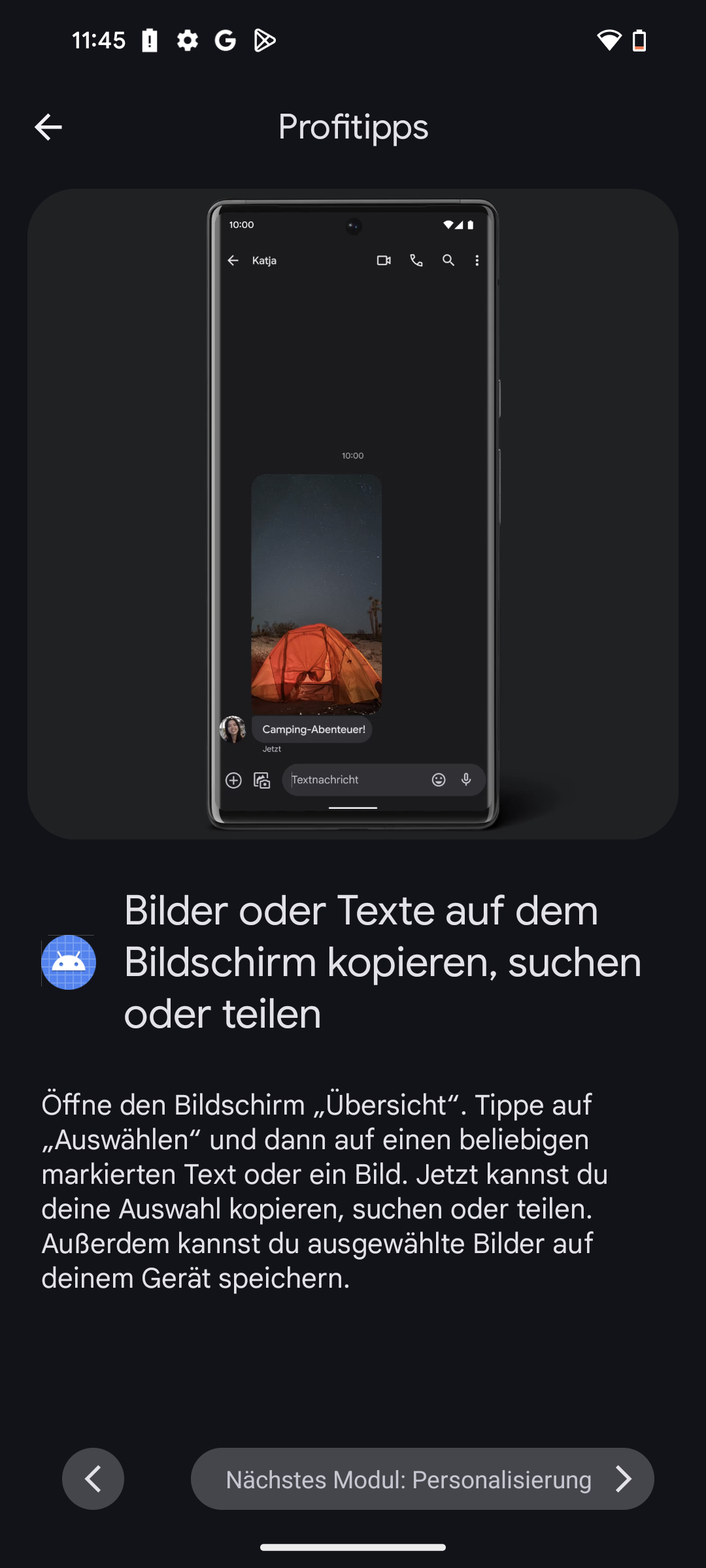
Google Pixel 8a Screenshot
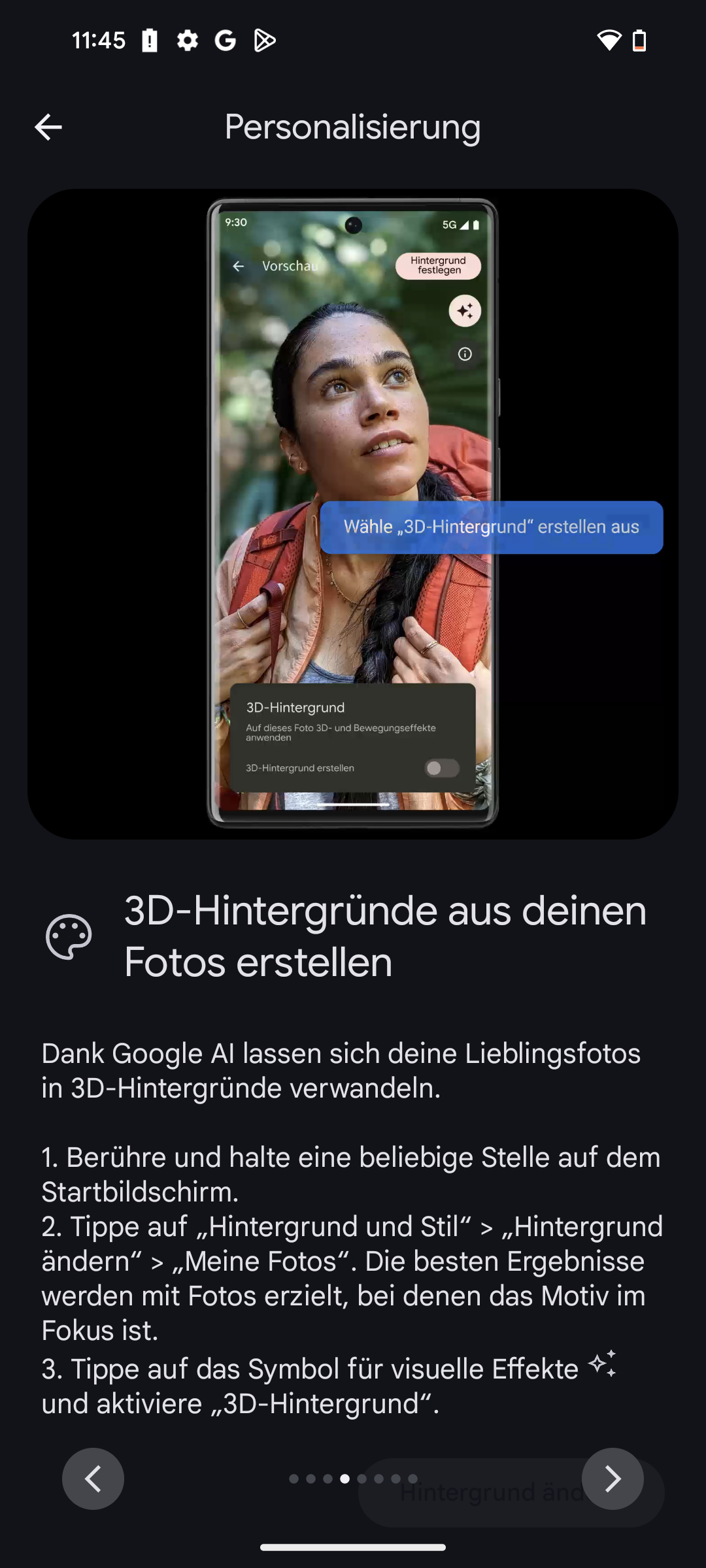
Google Pixel 8a Screenshot
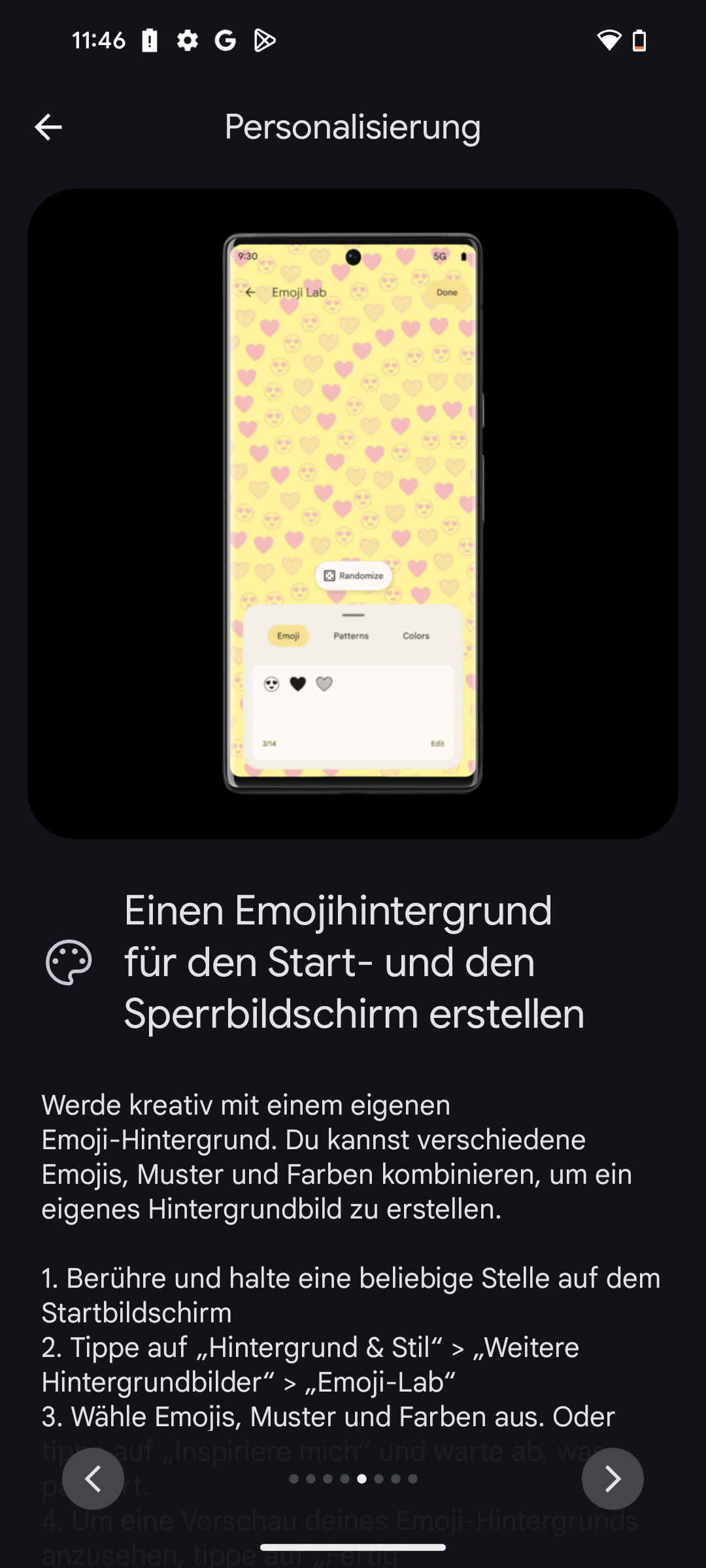
Google Pixel 8a Screenshot
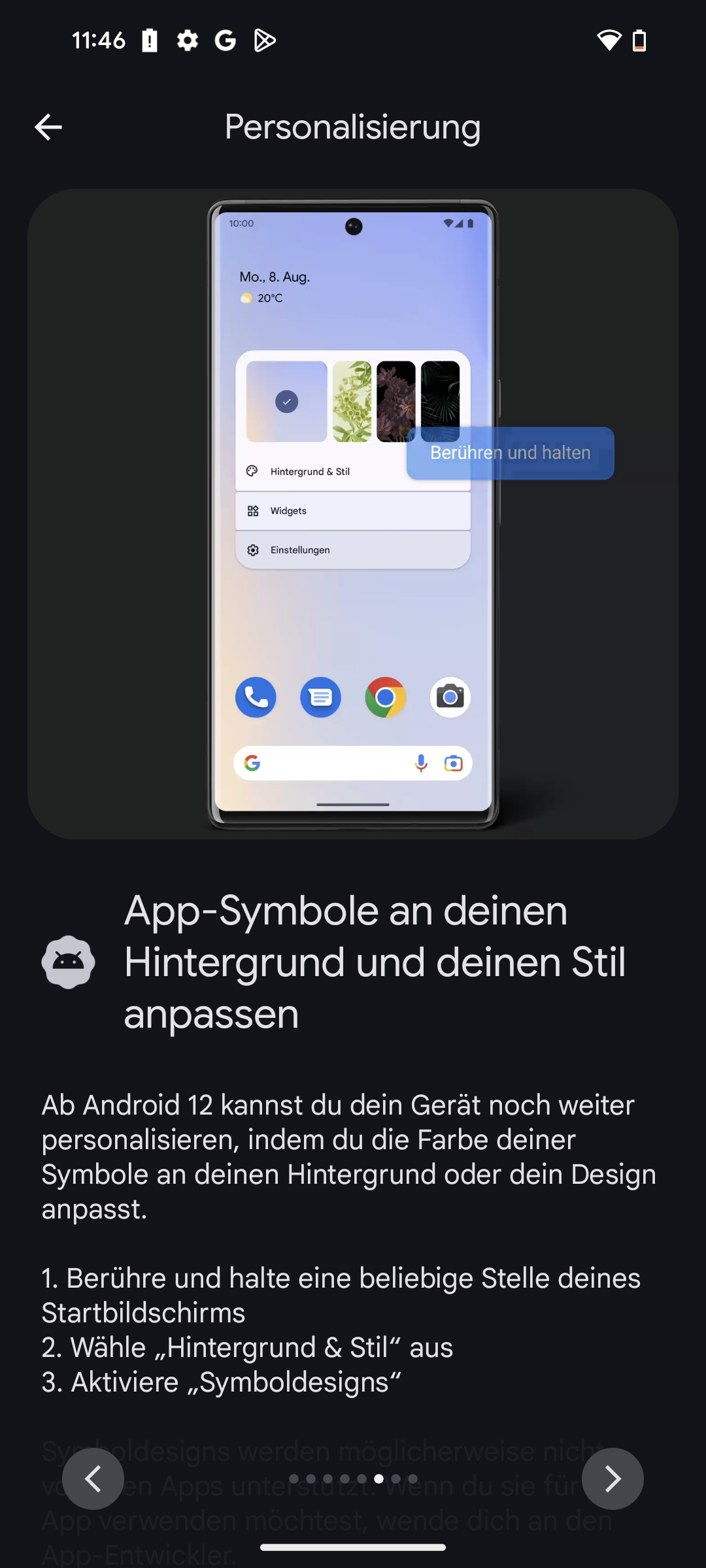
Laufzeit: Wie lang hält der Akku des Pixel 8a?
Der Akku hat eine Kapazität von 4404 mAh. Das ist etwas weniger als beim Pixel 8, aber mehr als noch beim Pixel 7a. Schon das Pixel 7a schaffte es, mit einer Akkuladung länger zu laufen als das Pixel 7 und 7 Pro. Bezogen auf das Pixel 8 und das 8 Pro gelingt auch dem Pixel 8a das gleiche Kunststück. Beim Battery Test von PCmark schaffte das Smartphone mehr als 15 Stunden, das ist hervorragend.
An einem unserer Kritikpunkte am Pixel 7a hat Google jedoch nicht geschraubt: Die Ladegeschwindigkeit ist mit 18 W zu niedrig und wirkt aus der Zeit gefallen. So benötigt das Pixel 8a für eine komplette Ladung fast 2,5 Stunden. Kabelloses Qi-Laden überträgt mit bis zu 7,5 W. Reverse-Charge, etwa zum Laden von Kopfhörern, gibt es nicht.
Preis: Was kostet das Google Pixel 8a?
Das Google Pixel 8a ist seit dem 5. Mai verfügbar. Zunächst kostete es mindestens 550 Euro. Mittlerweile ist der Preis für die Variante mit 128 GB auf 389 Euro gefallen. Die Version mit 256 GB kostet 516 Euro. Es ist in den Farben Blau, Grün und Weiß erhältlich.
Fazit
Das Google Pixel 8a beeindruckt im Test. Mit einer Vielzahl an Features, die man sonst oft nur in deutlich teureren Geräten findet, wie der langen Akkulaufzeit, der schnellen Performance und vor allem einer herausragenden Kamera, setzt es sich deutlich von anderen Smartphones der 500-Euro-Klasse ab. Toll ist auch, dass es eine vergleichbar hohe Software-Qualität und anspruchsvolle KI-Funktionalitäten bietet wie die teureren Google Pixel 8 und Google Pixel 8 Pro.
Auch das kompakte Gehäuse, die hochwertige Verarbeitung und der Schutz gegen Wasser und Staub gemäß IP67 stehen auf der Haben-Seite. Das OLED-Display hat nun eine Bildwiederholrate von 120 Hz. Allerdings ist der Displayrand zu dick. Der Tensor G3 SoC liefert eine solide Performance, die den alltäglichen Anforderungen gerecht wird.
Die Kamera des Pixel 8a bleibt auf dem Papier hinter einem High-End-Modell zurück. In der Praxis liefert sie jedoch gerade am Tag und in der Nacht hervorragende Ergebnisse. Erst bei genauem Betrachten von Details fallen Unterschiede zum Pixel 8 und 8 Pro auf. Eine Zoomlinse hat das Pixel 8a jedoch nicht. Schade, dass die Weitwinkellinse keinen Autofokus kennt, dadurch sind keine Makroaufnahmen möglich.
Samsung Galaxy S23
Samsung Galaxy S23
Das kleinste Modell der neuen Galaxy-S-Reihe macht vieles wett, was der Vorgänger versäumt hat. Wie gut das Samsung Galaxy S23 wirklich ist, zeigt der TechStage-Test.
- extrem starke Leistung
- hervorragendes Display
- tolle Kamera
- elegantes Design
- teuer
- kein Netzteil
- lädt langsamer als Konkurrenz
Samsung Galaxy S23 im Test
Das kleinste Modell der neuen Galaxy-S-Reihe macht vieles wett, was der Vorgänger versäumt hat. Wie gut das Samsung Galaxy S23 wirklich ist, zeigt der TechStage-Test.
In diesem Testbericht widmen wir uns dem kleinsten Modell der Reihe – dem Samsung Galaxy S23. Auf den ersten Blick scheinen die Unterschiede zum Vorgänger nur minimal zu sein. Der Teufel steckt wie immer im Detail und hat es in sich – um schon ein wenig vorwegzunehmen. Das Galaxy S22 war ein tolles Smartphone, allerdings waren wir enttäuscht von der Akkulaufzeit, zudem konnte der Exynos 2200 nicht mit dem Snapdragon 8 Gen 1 aus anderen Top-Smartphones mithalten.
Den größten Fortschritt verspricht der neue Chipsatz. Samsung verzichtet endlich auf einen eigenen Prozessor und arbeitet bei seinem Flaggschiff eng mit Qualcomm zusammen. Zum Einsatz kommt der brandneue Snapdragon 8 Gen 2 in einer auf das Gerät zugeschnittenen Ausführung mit dem Namenszusatz „for Galaxy“. Wie stark dieser Chip ist und wo Samsung sonst noch beim Galaxy S23 nachgebessert hat, zeigt unser Test.
Design
Geht es um die Größe, hat sich nichts geändert. Das Samsung Galaxy S23 bietet erneut ein Display mit 6,1 Zoll und kommt auf nahezu die gleichen Abmessungen wie der Vorgänger: 146,3 × 70,9 × 7,6 mm bei einem Gewicht von 167 g. Damit liegt es gut in der Hand, dank der kompakten Ausmaße kann man es auch einhändig bedienen. Die Power-Taste sowie die Lautstärkewippe rechts sind wie der Fingerabdrucksensor im Display gut erreichbar.
Der Rahmen ist erneut aus Metall, die Rückseite besteht aus Glas. Lackiert ist das Testgerät, das uns Gomibo zur Verfügung gestellt hat, in einem matten Schwarz („Phantom Black“). Die Oberfläche zeigt sich erfreulich unempfindlich für Fingerabdrücke. Damit wirkt das Galaxy S23 für unseren Geschmack noch eine Spur edler als der Vorgänger.
Die Verarbeitung ist tadellos. Weder Spaltmaße noch wackelige Komponenten stören das Erlebnis – was bei dem Preis auch inakzeptabel wäre. Das Galaxy S23 wirkt allerdings fast schon zerbrechlich, sodass wir den Kauf einer Schutzhülle nahelegen. Dabei dürfte das Galaxy S23 mehr einstecken können als bisherige Generationen. Samsung schützt das Display und die Rückseite mit dem neuen Gorilla Glass Victus 2 von Corning. Laut Hersteller übersteht das Display den Sturz auf Asphalt auch noch aus 2 Meter Höhe – sogar bei ungünstigen Aufprallwinkeln. Wir haben es aber nicht übers Herz gebracht, das auszuprobieren. Vor Staub und Wasser ist es erneut nach IP68 geschützt.
Die größte sichtbare Änderung betrifft das Design der Kameralinsen auf der Rückseite. Diese ragen nun jeweils einzeln von einem Ring umfasst hervor. In diesem Jahr orientiert sich der kompakte Vertreter der Reihe damit am Design des Ultra-Modells. Dadurch wirkt das S23 nochmals filigraner. Beim Galaxy S22 waren die drei Linsen noch in einem größeren Element eingefasst. An der Anordnung selbst hat sich nichts geändert.
Display
Wie bereits angesprochen, bleibt es bei 6,1 Zoll. Die Auflösung des OLED-Displays beträgt erneut 2340 × 1080 Pixel, was auf der kompakten Anzeige zu einer hohen Pixeldichte von 423 Pixel pro Zoll (ppi) führt. Das Bild ist bei der Größe stets messerscharf, Farben erscheinen kräftig und Schwarzwerte dunkel wie die Nacht. Kontraste sind perfekt abgestimmt und die Blickwinkelstabilität ist ebenfalls toll. Noch besser ist hier nur das Top-Modell Samsung Galaxy S23 Ultra (Testbericht) dank weiterer automatischer Optimierungen.
Die maximale Bildwiederholrate beträgt 120 Hz. Es gibt die Wahl zwischen „Standard“ mit 60 Hz oder „Adaptiv“ mit einer automatischen Anpassung zwischen 48 und 120 Hz. Höhere Bildwiederholraten erlauben flüssigere Animationen beim Scrollen oder bei Spielen, erhöhen aber den Stromverbrauch.
Hell genug ist das Display, um bei Sonnenlicht im Freien ablesbar zu sein. Stellt man die Helligkeit manuell aufs Maximum, leuchtet es noch zurückhaltend mit 465 cd/m². Bei aktiver Helligkeitsanpassung schnellt dieser Wert aber auf etwa 885 cd/m² hoch. Das ist ein starker Wert, auch wenn es nicht an die 1350 cd/m² des Ultra-Modells heranreicht.
Samsung Galaxy S23 – Bilderstrecke
Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Samsung Galaxy S23

Kamera
Allein vom Datenblatt her hat sich wenig getan bei der Kamera des Galaxy S23. Die Hauptkamera bietet erneut 50 Megapixel mit f/1.8-Blende, Phasenvergleich-Autofokus und optischer Bildstabilisierung (OIS). Das Objektiv fasst vier Pixel in einem Raster zu einem zusammen (Pixel Binning) – die späteren Bilder entsprechen also 12,5 Megapixel. Durch das Zusammenfassen der Bildpunkte erlangen die Aufnahmen eine bessere Bildschärfe und höheren Detailgrad, gerade bei schlechten Lichtbedingungen. Auf Wunsch kann man auch die vollen 50 Megapixel für ein Bild abrufen.
Identisch erscheinen zudem das Weitwinkelobjektiv mit 12 Megapixeln und f/2.2-Blende sowie die Telelinse mit 10 Megapixeln, OIS und F/2.4-Blende. Der einzige auf den ersten Blick erkennbare Fortschritt betrifft die Frontkamera. Diese hat jetzt 12 statt 10 Megapixel. Die übrigen Verbesserungen stecken im Detail. So hat Samsung die Kamera-Software optimiert und die optische Bildstabilisierung wurde ebenfalls verbessert. Sie stabilisiert Bewegungen nur bis zu 3 Grad statt zuvor 1,5 Grad.
Das Ergebnis kann sich sehen lassen. Der Vorgänger war schon exzellent, aber das Galaxy S23 ist nochmals besser geworden. Trotz trister Lichtverhältnisse eines wolkenverhangenen Winterhimmels bieten unsere Test-Schnappschüsse eine ausgeprägte Dynamik, Bildschärfe und hohe Bilddetails. Die Farbgebung und der Weißabgleich bei den Aufnahmen sind ansprechend, wirken aber stets natürlich. Weitwinkelaufnahmen weichen bei der Farbgebung so gut wie gar nicht von der Hauptlinse ab.
Das Teleobjektiv bietet einen dreifachen optischen Zoom mit hervorragenden Ergebnissen. Wer es noch näher benötigt, kombiniert den Digitalzoom mit der optischen Vergrößerung. Selbst bei 30-facher Vergrößerung erkennt man noch, was die Kamera da eingefangen hat – auch wenn hier Bildrauschen nicht zu verhindern ist und etwas Schärfe verloren geht. Bis zu einer zehnfachen Vergrößerung bekommt man noch brauchbare Aufnahmen mit wenig Qualitätsverlust. Selfies mit der Frontkamera sind zudem scharf und natürlich, mit ausgeprägtem Dynamikumfang.
Sehr beeindruckend ist die Kamera des Galaxy S23 bei Nachtaufnahmen – hier ist das Ergebnis dank Software-Optimierung noch besser geworden. Wenn genügend Restlicht vorhanden ist, etwa durch eine Laterne, wirken Fotos im Nachtmodus fast wie bei Tag. Lediglich mit der Telelinse oder dem Weitwinkelobjektiv kommt es zu stärkerem Bildrauschen bei Dunkelheit. Dank des starken Prozessors sind sogar Videos mit 8K bei 30 fps (Frames pro Sekunde) möglich. Wir raten eher zu 4K mit 60 fps – die Hi-Res-Videos wirken knackscharf, stabil und geschmeidig.
Samsung Galaxy S23 – Originalaufnahmen
Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Samsung Galaxy S23 – Originalaufnahmen

Ausstattung
Endlich der Top-Prozessor, den ein Flagship verdient: Samsung setzt bei der Galaxy-S23-Reihe auf den Qualcomm Snapdragon 8 Gen 2. Der Exynos 2200 beim Vorgänger konnte späteren Smartphones mit Snapdragon 8 Gen 1 im Hinblick auf Top-Performance nicht das Wasser reichen. Jetzt feiert der Nachfolger des Super-Chipsatzes Premiere und wurde mit einem etwas höheren Takt für den Hochleistungs-Kern sowie die integrierte GPU nochmals für die Modelle optimiert.
Für den digitalen Vortrieb sorgen acht Kerne. Das Zugpferd ist der Hauptkern (Kryo Prime) mit 3,2 GHz, der von vier Kernen (Kryo Gold) mit 2,8 GHz und drei Kernen (Kryo Silver) mit 2 GHz flankiert wird. Für die Grafik ist die neue Adreno 740 als GPU zuständig. Zudem beträgt der Arbeitsspeicher 8 GB. Für Laien ausgedrückt: Das Galaxy S23 bietet Leistung satt – mehr, als die meisten Menschen vermutlich benötigen. Das Smartphone reagiert super flott und geschmeidig. Mit dieser Ausstattung ist das Galaxy S23 sogar ein echtes Gaming-Smartphone.
Die großen Leistungsreserven bestätigen auch die Benchmarks. Bei Work 3.0 von PCmark erreicht unser Galaxy S23 etwa 15.000 Punkte – was ein bärenstarker Wert ist. Das Samsung Galaxy S23 Ultra (Testbericht) war hier nochmals besser – bei gleicher RAM-Größe. Top ist auch die Grafikleistung. Bei 3Dmark musste der Test „Wild Life Extreme“ herhalten, da der Prozessor für unseren Standard-Benchmark „Wild Life“ zu schnell ist. Das war aber auch schon bei der ersten Generation des Snapdragon 8 so. Die Animationen aus dem Benchmark flitzen einfach nur geschmeidig über die Anzeige. Satte 3800 Punkte hat das S23 hier erreicht – gemeinsam mit dem Ultra-Modell der beste bisher gemessene Wert.
Die restliche Ausstattung lässt ebenfalls wenig Wünsche offen. Die Datenübertragung über den Typ-C-Steckplatz ist flott dank USB 3.2, der interne Speicher beträgt wahlweise 128 GB nach UFS 3.1 oder 256 GB nach UFS 4.0. Eine Erweiterung über Micro-SD-Karte ist aber nicht möglich. Der Rest ist auf dem neuesten Stand: Bluetooth 5.3, Wi-Fi 6E sowie NFC. Richtig gut klingen die Stereolautsprecher, sie wirken nochmals voluminöser als beim Vorgänger.
Software & Updates
Samsung ist mittlerweile der Klassenprimus in Hinblick auf Software. Ausgeliefert wird das Samsung Galaxy S23 mit Android 13. Die Koreaner versprechen monatliche Sicherheits-Patches für 5 Jahre sowie bis zu vier Version-Upgrades – das beinhaltet also auch noch Android 17.
Als Bedienoberfläche kommt One UI 5.1 zum Einsatz. Wer schon ein Samsung-Handy genutzt hat, wird sich sofort heimisch fühlen. Im Vergleich zu Stock-Android weicht One UI stärker ab, für nahezu jeden Google-Dienst bietet Samsung eine eigene Alternative. Ab Werk kommen dazu noch ein paar Microsoft-Anwendungen.
Größere Neuheiten gibt es bei Bixby – im Prinzip Samsungs Antwort auf Alexa, Siri und Google Assistant. Dafür benötigt man zum Google-Konto noch einen Samsung-Account. Neu sind die Bixby-Routinen, mit denen man das Verhalten des Smartphones wie von Smart Home gewohnt für bestimmte Situationen programmieren kann. Das Smartphone schlägt automatisch neue Routinen vor, Nutzer können aber auch selbst welche anstoßen. Den Sprachassistenten von Bixby hat Samsung ebenfalls erweitert.
Akku
Die vielleicht größte Schwachstelle des Galaxy S22 war die nur mittelmäßige Akkulaufzeit. Samsung hat hier nachgebessert – auf den ersten Blick allerdings moderat. Der Akku bietet jetzt eine Kapazität von 3900 mAh statt 3700 mAh. Zugegeben: Wir waren zunächst etwas skeptisch, ob die 200 mAh so viel bewirken.
Glücklicherweise hat Samsung viel Arbeit in die Optimierung der Software gesteckt. Wir vermuten auch, dass der Snapdragon 8 Gen 2 eher auf Effizienz, denn bloße Leistung getrimmt ist. Denn das Ergebnis war eine unerwartet positive Überraschung: Beim Battery Test erreicht das Gerät eine Akkulaufzeit von fast 14 Stunden. Der Test ermittelt diesen in einem simulierten Dauerbetrieb mit verschiedenen Anwendungen bei einer fest eingestellten Bildhelligkeit.
Das Galaxy S23 übertrifft damit sogar noch das Ultra-Modell – eine echte Überraschung. Der Vorgänger erreichte beim gleichen Test nur eine halb so lange Akkulaufzeit von etwa 7 Stunden. Wie lange der Akku wirklich durchhält, hängt natürlich vom Nutzerverhalten ab. Spiele oder Videos verbrauchen mehr Energie. Im Alltag dürfte das Galaxy S23 aber zwei Tage locker durchhalten.
Einziger Kritikpunkt wäre hier das Fehlen eines Netzteils im Lieferumfang – sowie die im Vergleich zur chinesischen Konkurrenz relativ langsame Ladegeschwindigkeit. Mit Netzteil lädt das Galaxy S23 maximal mit 25 Watt. Per Induktion sind 10 Watt möglich. Anker hat uns als Ladegerät das neue Power Port III zur Verfügung gestellt, das für die Galaxy-S-Reihe optimiert wurde. Damit war der Akku von 20 auf 100 Prozent in exakt einer Stunde aufgeladen. Weitere Ladegeräte zeigen wir in der Top 10: Die besten USB-C-Ladegeräte – billig lädt schneller als teuer.
Preis
Die UVP ist gegenüber dem Vorgängermodell um etwa 100 Euro gestiegen. Die Basis-Version mit 128 GB hat eine UVP von 949 Euro, mit 256 GB sind es 1009 Euro. Größere Speichervarianten gibt es nicht. Zu haben ist das Galaxy S23 mit 128 GB mittlerweile schon ab 500 Euro. Die Version mit 256 GB kostet rund 560 Euro.
Als Farben stehen Schwarz („Phantom Black“), Grün („Green“), Flieder („Lavender“) sowie Weiß („Cream“) zur Auswahl. Exklusiv im Online-Shop von Samsung gibt es noch die Farben Anthrazit („Graphite“), Rot („Red“), Gelb („Lime“) und Hellblau („Skye Blue“).
Fazit
Samsung ist mit dem Galaxy S23 ein wirklich großer Wurf gelungen. Es ist das derzeit beste kompakte Smartphone und bügelt nahezu alle Ärgernisse des Vorgängers aus. Die Leistung wirkt schier unerschöpflich, das OLED-Display ist brillant und die Kamera ist vorwiegend dank Software-Optimierungen noch mal ein bisschen besser geworden.
Es gibt nur wenig zu beanstanden, etwa den Preisanstieg, der aber auch bei der Konkurrenz zu erwarten ist sowie das Fehlen eines Netzteils. Zudem lädt das Galaxy S23 verglichen mit der Konkurrenz deutlich langsamer. Das wäre es aber auch schon mit den Schwächen.
Google Pixel 8
Google Pixel 8
Das Google Pixel 8 ist kompakt, bringt viele sinnvolle KI-Features und eine Kamera, die für 750 Euro ungeschlagen ist. Wir haben das Smartphone getestet.
- geniale Kamera mit sinnvollen KI-Funktionen
- sehr helles Display mit 120 Hz
- kompakt und trotzdem High-End
- keine Telelinse
- lädt nur mit maximal 27 Watt
- CPU nicht so schnell wie Snapdragon 8 Gen 2
Google Pixel 8 im Test: Der Kamera-Sieger der Mittelklasse
Das Google Pixel 8 ist kompakt, bringt viele sinnvolle KI-Features und eine Kamera, die für 750 Euro ungeschlagen ist. Wir haben das Smartphone getestet.
Die Google-Pixel-Reihe gehört neben den Apple iPhones und den Samsung Galaxys zu den beliebtesten Smartphones am Markt. Besonders Software und Kamera überzeugten in der Vergangenheit. Auch das aktuelle Google Pixel 8 Pro (Testbericht) schlägt in diese Kerbe und gefällt uns im Test. Allerdings kostet es über 1000 Euro. Dem etwa 300 Euro günstigeren Google Pixel 8 fehlt im Vergleich im Grunde hauptsächlich die Telelinse. Dafür ist es deutlich kompakter. Wir haben es getestet. Dazu empfehlen wir auch unsere Top 10: Die besten Smartphones – Samsung vorn, Apple nur Mittelfeld.
Design
Das Google Pixel 8 ist verhältnismäßig kompakt. Im Vergleich zum Google Pixel 7 (Testbericht) und Google Pixel 7a (Testbericht) ist es an den Ecken abgerundet und etwas geschrumpft. Ein schlauer Schachzug. Schließlich gibt es auf dem Markt nur wenige High-End-Smartphones, welche die neueste Technik in ein schlankes Gehäuse packen. Während die Maße geschrumpft sind, ist das Kameravisier, welches sich wieder über die komplette Breite zieht, etwas gewachsen. Das liegt vor allem daran, dass Google hier seine neue und etwas größere Kameraeinheit unterbringt.
Das Kameravisier kommt in einem matten, gebürsteten Metall. Das gefällt uns besser als die Hochglanzvariante am Pixel 8 Pro. Dafür ist der Rest der Rückseite hochglanz. Bei der uns vorliegenden schwarzen Variante sorgt das für eine recht hohe Fingerabdruckanfälligkeit. Halb so wild, schließlich sollte man sein teures Pixel 8 ohnehin mit einer Hülle schützen. Neben der schwarzen Version gib es das Smartphone außerdem in einer Art Beige-Grau und Rosé.
Die Verarbeitungsqualität ist hochwertig. Es ist nach IP68 gegen das Eindringen von Staub und Wasser geschützt, nichts knarzt oder wackeln und der Druckpunkt der drei Taster ist straff.

Display
Das Display ist im Vergleich zum Pixel 7 von 6,3 auf 6,2 Zoll geschrumpft. Dafür ist die Bildwiederholungsrate von 90 Herzt auf 120 Hertz angestiegen. Außerdem ist seine maximale Helligkeit nun viel höher – wenn auch nicht ganz so hoch wie die des Pixel 8 Pro. Trotzdem ist es eine wahre Freude, das Pixel 8 in direkter Sonne zu nutzen. Auch unter normalen Lichtverhältnissen wirkt bei voll aufgedrehtem Display alles einen Tick knackiger. Farben und Blickwinkelstabilität sind Oberklasse.
Die Auflösung von 1080 x 2400 Pixel ist für die Displaygröße mehr als ausreichend. Dank OLED-Technik kennt das Pixel 8 einen Always-On-Modus, zeigt also stets relevante Informationen wie Uhrzeit, Datum, Temperatur und auf Wunsch App-Benachrichtigungen an.
Google Pixel 8 Bilder
Google Pixel 8
Google Pixel 8

Google Pixel 8

Google Pixel 8

Google Pixel 8

Google Pixel 8

Google Pixel 8

Google Pixel 8

Google Pixel 8
Google Pixel 8

Kamera
Die mit dem Pixel 8 Pro geschossenen Bilder sind phänomenal gut und auf einem Level mit dem 300 Euro teureren Google Pixel 8 Pro. Kein Wunder, schließlich nutzen die beiden Smartphones die gleiche Hardware mit der gleichen Software. Einziger Unterschied ist das Fehlen der 5-fach-Telelinse. Auch hat die Frontkamera keinen automatischen, sondern einen fixen Fokus.
Insgesamt sind wir von der Fotoqualität begeistert. Die 48-Megapixel-Hauptkamera liefert in Verbindung mit der digitalen Nachbearbeitung auch in schummrigen Umgebungen scharfe, farbechte und rauscharme Bilder ab. Selbst im Vergleich mit teureren Smartphones wie dem iPhone 15 muss es sich nicht verstecken. Auch die Qualität der Weitwinkellinse ist auf einem hohen Niveau. Wer Videos aufnehmen will, kann dies mit bis zu 4k bei 60 Bildern pro Sekunde tun. Bei Full-HD sind gar 240 Bilder pro Sekunde möglich. Außerdem gibt es einen anständigen 10-bit-HDR-Modus.
Die Frontkamera kann nicht mit der Qualität der rückseitigen Kameraeinheit mithalten. Wir vermissen zwar den Autofokus des Pixel 8 Pro nicht, schließlich kommen Selfies meist mit einem fixen Abstand, allerdings wirken die Farben nicht immer ganz korrekt und auch die Schärfe dürfte etwas höher sein.
Google Pixel 8 Fotos
Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Google Pixel 8 Fotos

Äquivalent zum Google Pixel 8 Pro sind die Nachbearbeitungsmöglichkeiten enorm hoch und nützlich. So kann jedes Bild individuell bezüglich Farbe und Belichtung angepasst werden – das kennen wir so schon von den Vorgängern. Auch der magische Radierer, der unerwünschte Objekte aus dem Bild entfernt, ist wieder mit dabei. Diesmal geht die KI-Spielerei aber noch einen Schritt weiter. Google nennt sie magischer Editor. Dort gewählte Bildelemente lassen sich verschieben oder in ihrer Größe anpassen. Auch ganze Bildbereiche können gelöscht werden. Die Google KI überlegt sich daraufhin, womit sie den leeren Bereich ersetzen will. Das gelingt in den meisten Fällen überraschend gut.
Der magische Editor ermöglicht es uns, mit wenigen Fingerbewegungen Dinge zu tun, für die wir zuvor Photoshop und Spezialkenntnisse benötigt hätten. Ein Beispiel vom Google Pixel 8 Pro, dessen Software weitestgehend identisch ist: Wir sehen im Fernsehen ein Bild eines Künstlers, welches uns gefällt. Also fotografieren wir den Fernseher, optimieren Farbe und Belichtung, löschen mit Googles KI Personen, die das Bild teilweise verdecken, schneiden einen zu großen Bildausschnitt zu und lassen Googles Künstliche Intelligenz die unpassenden Bereiche erweitern. Das Ganze dauert zehn Minuten – mit beeindruckendem Ergebnis. Was hier nervt, sind die langen Wartezeiten. So benötigt die Google-KI je nach gewähltem Bereich, der gelöscht und ersetzt werden soll, bis zu 13 Sekunden.
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung

Google Pixel 8 Bildbearbeitung

Google Pixel 8 Bildbearbeitung

Google Pixel 8 Bildbearbeitung

Google Pixel 8 Bildbearbeitung

Google Pixel 8 Bildbearbeitung

Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung

Google Pixel 8 Bildbearbeitung

Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Hardware
Der Tensor 2 SoC im Vorgängermodell Pixel 7, Pixel 7a und Pixel 7 Pro war unserer Meinung nach schon zügig, auch wenn es gelegentlich zu kleinen Verzögerungen kam. Der jetzt verwendete Tensor 3 ist schneller, was vor allem beim Fotografieren auffällt. Bilder sind sofort nach dem Aufnehmen fertig, während man beim Vorgängermodell manchmal auf die Nachbearbeitung warten musste. Zudem bleibt der Tensor 3 auch unter Höchstlast kühler.
Obwohl High-End-SoCs von Qualcomm, Apple und Mediatek schneller sind, erledigt der Tensor 3 im Alltag alle Aufgaben zügig. Die Benchmark-Ergebnisse sind stark, aber nicht herausragend. Das Pixel 8 erreicht in „Wild Life Extreme“ von 3Dmark vergleichbar mit dem Pixel 8 Pro etwa 2300 Punkte und bei Work 3.0 von PCmark rund 11000 Punkte. Das geht besser. So erreicht das Xiaomi 13 bei PCmark 14.000 Punkte und bei 3Dmark rund 3000 Punkte. Allerdings gibt es Situationen, wie im magischen Editor, in denen wir uns über lange Wartezeiten ärgern.
Software
Das Google Pixel 8 wird mit Android 14 ausgeliefert. Google verspricht Updates bis 2030 – also bis Android 21. Das ist ein bemerkenswert langes Update-Versprechen, das kein anderer Smartphone-Hersteller übertrifft. Doch wir sind skeptisch, ob dies realistisch und überhaupt sinnvoll ist. So ist die Hardware in sieben Jahren hoffnungslos veraltet und auch der Akku benötigt spätestens dann einen Austausch.
Android auf dem Pixel 8 Pro ist übersichtlich, sauber und schnell. Es bietet nützliche Alltagsfunktionen wie Face Unlock, das Übersetzen und Vorlesen von Webseiten sowie quellenunabhängige Sprach-zu-Text-Übersetzungen von Audio- und Video-Inhalten.
Die Now-Playing-Funktion, die automatisch Musik erkennt und Title sowie Interpret in einer Liste speichert, sowie die hervorragende Text-to-Speech-Funktion und der nützliche Sprachassistent sind weitere Highlights. Aber es gibt auch Aspekte, die uns stören. Dazu gehört das umständliche Ein- und Ausschalten des WLANs über das Drop-Down-Menü.
Akku
Die Akkukapazität im Pixel 8 beträgt 4575 mAh. Beim Vorgänger mit größerem Display waren das noch 4355 mAh. Trotzdem sinkt die Akkulaufzeit von 11 Stunden 40 Minuten auf knapp 11 Stunden. Das wird den allermeisten Nutzern reichen, um über den Tag zu kommen. Trotzdem ist die Akkulaufzeit insgesamt – gerade für den aufgerufenen Preis – zu gering.
Auch beim Laden glänzt das Pixel 8 nicht. So ist die maximale Ladegeschwindigkeit gegenüber dem Vorgänger leicht von maximal 25 Watt auf 27 Watt gestiegen. Für eine volle Ladung benötigt es gut 1,5 Stunden. Das ist zu langsam. So lädt etwa das Motorola Edge 40 Pro (Testbericht) gut viermal so schnell. Immerhin ist der kabellose Ladestandard Qi wieder mit dabei.
Preis
Das Google Pixel 8 hatte zum Testzeitpunkt am 12. November 2023 mit 128 GB eine UVP von 799 Euro und mit 256 GB etwa 859 Euro. Eine 512-GB-Variante wie beim Pixel 8 pro gibt es nicht. Mittlerweile ist der Preis aber stark gefallen. Schon ab 450 Euro geht es los.
Fazit
Das Google Pixel 8 ist vor allem für jene interessant, die ein hervorragendes Kamera-Smartphone im kompakten Gehäuse suchen. Die damit geschossenen Bilder suchen in der Preisklasse um die 750 Euro ihresgleichen. Dazu kommen die zahlreichen KI-Funktionen, die bei der Bildbearbeitung mehr als nur eine Spielerei sind. Auch das Display hat einen deutlichen Sprung nach vorn gemacht und bietet nun 120 Hertz sowie eine enorme maximale Helligkeit. Der Akku dagegen enttäuscht, Heavy-User werden mit ihm nicht immer über den Tag kommen. Auch die Ladegeschwindigkeit ist nicht mehr zeitgemäß.
Wer ein gutes Kamera-Smartphone der Oberklasse zu gerade noch bezahlbarem Preis sucht, ist beim Pixel 8 goldrichtig. Abgesehen von der fehlenden Telelinse und der guten, aber nicht perfekten Selfiekamera, spielt das Kamera-Setup ganz weit oben mit und lässt sogar den ein anderen teureren Konkurrenten hinter sich.
Das größte Problem des Pixel 8 kommt aus dem eigenen Haus. So ist das Google Pixel 7 Pro (Testbericht) richtig gut und kostet aktuell genauso viel. Für viele Smartphone-Nutzer ist es wohl die vernünftigere Wahl. Noch günstiger wird es mit dem Google Pixel 7 (Testbericht) für 490 Euro. Dagegen lohnt sich das Google Pixel 7a (Testbericht) für 450 Euro weniger. Es ist zwar abermals etwas günstiger, aber im Vergleich zum Pixel 7 auch abgespeckt.
Samsung Galaxy S24+
Samsung Galaxy S24+
Das Samsung Galaxy S24+ ist ein guter Kompromiss aus S24 und Ultra. Was das Smartphone mit 6,7-Zoll-Display und KI-Funktionen zu bieten hat, zeigt der Test.
- starke CPU
- tolles Design
- helles und messerscharfes Display
- gute Akkulaufzeit
- Software-Updates für 7 Jahre
- kein Ladegerät, lädt langsam
- AI-Funktionen sind nicht ganz ausgereift
- wenig Neuheiten bei Hardware
Samsung Galaxy S24+ im Test
Das Samsung Galaxy S24+ ist ein guter Kompromiss aus S24 und Ultra. Was das Smartphone mit 6,7-Zoll-Display und KI-Funktionen zu bieten hat, zeigt der Test.
Als mittleres Modell komplettiert das Galaxy S24+ neben dem Galaxy S24 (Testbericht) und Galaxy S24 Ultra (Testbericht) das Trio der neuen Samsung-Flagship. Im Vergleich zum Vorgänger Samsung Galaxy S23+ (Testbericht) hat sich auf den ersten Blick wenig getan, was die technische Ausstattung angeht. Neu ist die CPU, die Samsung selbst beisteuert. Optisch ähnelt das Plus-Modell dem kleinen S24, fällt aber deutlich größer aus. Im Vordergrund stehen auch bei diesem Modell die erweiterten und neuen KI-Funktionen von Galaxy AI.
Im Rampenlicht von Werbung und Berichterstattung steht meistens das Ultra-Modell als Top-Flagship, viele begeistern sich zudem für das kompakte S24, das preislich den Einstieg markiert. Stellt sich die Frage, ob das Plus-Modell dann eher zwischen den Stühlen steht oder die goldene Mitte ist? Wie gut das S24+ ist und ob es als die „goldene Mitte“ durchgehen kann, zeigt der Testbericht.
Das ist neu beim Galaxy S24+
Schmale Ränder führen dazu, dass das Display in der Diagonale jetzt 6,7 Zoll statt 6,6 Zoll misst. Als Antrieb dient ein Exynos 2400 von Samsung. Dieser übertrifft den Chip von Qualcomm aus dem Vorgängermodell um rund 10 Prozent, kann aber nicht ganz mit dem Snapdragon 8 Gen 3 des S24 Ultra mithalten. Die Leistung ist dennoch top und sollte für die nächsten Jahre genügend Reserven bereithalten.
Größte Neuerungen sind die als Galaxy AI bezeichneten KI-Funktionen, die aus dem S24+ unter anderem einen virtuellen Dolmetscher machen. Der Akku hat zudem um 200 mAh an Kapazität hinzugewonnen und bietet jetzt 4900 mAh.
Wie groß ist das Samsung Galaxy S24+?
Die Abmessungen entsprechen weitgehend dem Vorgänger und betragen: 158,5 × 75,9 × 7,7 mm bei einem Gewicht von 196 g. Das Design mit den drei markanten Kameralinsen und dem kantigen Gehäuse ist in etwa gleich wie beim S24. Allerdings ist das Plus-Modell deutlich größer, aber etwas schlanker und kürzer als das Ultra-Modell. Zum einhändigen Bedienen ist das S24+ jedoch zu groß.

Absolut überzeugend ist das große OLED-Display mit einer messerscharfen Auflösung von 3120 × 1440 Pixel bei einer variablen Aktualisierungsrate von 1 bis 120 Hertz. Auch bei Sonnenschein ist die Anzeige immer ablesbar. Samsung spricht hier von bis zu 2600 Nits.
Wie gut ist die Kamera?
Hier gibt es wenig Neues, das Setup ist wie beim Vorgänger: Hauptkamera mit 50 Megapixel, Weitwinkellinse mit 12 Megapixel und Teleobjektiv mit 10 Megapixel. Die Kamera liefert Fotos mit hohen Details, guter Schärfe und ausgewogenem Dynamikumfang, sowohl bei Tag als auch abends oder nachts. Der Nachtmodus gepaart mit dem OIS machen dann einen guten Job. Videos sind bis in 8K bei 30 FPS oder in 4K bei 60 FPS möglich und sind hervorragend stabilisiert.
Samsung Galaxy S24+ – Originalaufnahmen
Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen
Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Samsung Galaxy S24+ – Originalaufnahmen

Wie gut ist die Ausstattung?
Der Exynos 2400 erweist sich als positive Überraschung, nachdem gerade die S22-Reihe mit dem Samsung-eigenen Chip noch für große Ernüchterung gesorgt hat. Die Koreaner haben offenbar dazu gelernt. Der Chip übertrifft den Snapdragon 8 Gen 2 aus dem Vorgänger. Bei PCmark erreichten wir 17.400 Punkte, bei „Wild Life Extreme“ von 3Dmark sind es stolze 4250 Punkte. Noch stärker ist nur der Snapdragon 8 Gen 3 aus dem Galaxy S24 Ultra (Testbericht). Im Alltag bedeutet das ein rasend schnelles Smartphone mit geschmeidiger Bedienoberfläche.
Alles andere ist auf Top-Niveau. Der Arbeitsspeicher beträgt 12 GB RAM, als interner Speicher stehen wahlweise 256 GB oder 512 GB mit dem schnellsten Typ UFS 4.0 zur Auswahl. Das Gehäuse ist erneut nach IP68 wasserdicht. An Bord sind zudem UWB, NFC, Bluetooth 5.3, Wi-Fi 6E sowie USB-C 3.2 und Multi-Band-GNSS zur Navigation.
Samsung Galaxy S24+ – Bilderstrecke
Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+
Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+

Samsung Galaxy S24+

Was kostet das Samsung Galaxy S24+?
Die UVP für das Modell mit 12/256 GB liegt bei 1149 Euro. Preislich geht es mittlerweile schon ab knapp über 1000 Euro los. Die Variante mit 512 GB liegt bei mindestens 1079 Euro bei einer UVP von 1249 Euro. Es stehen zahlreiche Farben zur Auswahl: Schwarz, Hellgrau, Violett, Gelb, Orange oder Hellgrün.
In Kombination mit einem neuen Vertrag bekommt man das Smartphone erschwinglich im Bundle bei Freenet ab 100 Euro. Ohne Vertrag gibt es ebenfalls gute Optionen. So kann man sein altes Smartphone für 100 Euro einschicken und dann das S24+ in 36 Raten à 33,59 Euro abzahlen.
Wie gut sind die KI-Funktionen?
Spannend wird es mit KI-Features bei der Kamera. Diese können etwa Schatten oder Spiegelungen aus Fotos entfernen oder auch schiefe Motive gerade stellen. Das klappt einwandfrei. Nicht ganz so gut sehen umfassend veränderte Aufnahmen aus, wenn man etwa Menschen verschwinden lassen will auf Motiven. Die per KI bearbeiten Fotos erhalten dann einen Stern als Markierung – als Vorbeugung gegen „Deepfakes“.
Ein herausragendes Feature ist die Live-Übersetzung bei Telefonaten in mehreren Sprachen. Allerdings benötigt die Übersetzung Zeit, was zu Überlappungen mit neuen Aussagen führen kann. Die Genauigkeit variiert, und es besteht Potenzial für Feinabstimmung. Das S24+ eignet sich auch als Übersetzungsgerät – sogar offline.
Das Zusammenfassen von Texten und die Textformatierung ist weniger überzeugend, da sie selten den wirklichen Kern des Haupttextes treffen. Die Rechtschreibprüfung ist zudem inkonsistent. Ein weiteres interessantes Feature ist die Bildsuche. Drückt man den Home-Button und kreist dann einen bestimmten Bereich auf dem Display ein, etwa ein Foto, wird eine Suche danach ausgelöst. Die funktioniert erstaunlich gut.
Wie lange gibt es Updates?
Samsung hat nochmals nachgebessert und bietet jetzt die gleichen Konditionen wie Google: Künftig gibt es für 7 Jahre Sicherheits-Patches sowie Android-Updates. Ab Werk läuft bereits Android 14. Software-Updates gibt es auf monatlicher Basis, die zeitnah und zuverlässig zur Verfügung stehen.
Wie lange hält der Akku?
Wie schon der Vorgänger kommt das S24+ auf eine hervorragende Akkulaufzeit von 13,5 Stunden im Battery Test von PCmark. Damit kommt das Handy locker über einen, wenn nicht gar zwei Tage. Weniger schnell ist das Laden: Es stehen maximal 45 Watt zur Verfügung, ein Netzteil legt Samsung aus „Gründen der Nachhaltigkeit“ nicht bei. Kabelloses Laden ist bis 15 Watt möglich.
Technische Daten
Preis
Die UVP startet bei 1149 Euro. Die Preise sind aber mittlerweile gefallen: Ab knapp unter 600 Euro geht es mit 256 GB los, die Variante mit 512 GB kostet rund 660 Euro.
Fazit
Das Samsung Galaxy S24+ gehört definitiv zu den besten Android-Smartphones. Die Änderungen mögen eher klein sein – abgesehen von den neuen, umfangreichen KI-Funktionen. Im Detail stecken aber sinnvolle Verbesserungen. Für wen das Samsung Galaxy S24 (Testbericht) zu klein, das Samsung Galaxy S24 Ultra (Testbericht) aber zu teuer ist, findet im S24+ den perfekten Kompromiss.
Wirklich gut und strahlend hell ist das Display, das jetzt sogar auf 6,7 Zoll kommt – bei gleicher Gehäusegröße wie beim Vorgänger. Die Verarbeitung und das Design sind wieder tadellos und auf Top-Niveau. Dabei entspricht die technische Ausstattung weitgehend dem Galaxy S24. Sprich: Der Exynos sorgt für rund 10 Prozent mehr Power im Vergleich zum Chip aus dem Samsung Galaxy S23+ (Testbericht).
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Die Fan-Edition steht vorrangig für eine Sache: Highlights der Serie zum deutlich geringeren Preis. Ob das mit dem S23 FE erneut gelungen ist, zeigt unser Test.
- hervorragendes Display
- exzellente Kamera
- tolles Design
- lädt langsam
- kein Netzteil
- mittelmäßige Akkulaufzeit
Samsung Galaxy S23 FE im Test
Die Fan-Edition steht vorrangig für eine Sache: Highlights der Serie zum deutlich geringeren Preis. Ob das mit dem S23 FE erneut gelungen ist, zeigt unser Test.
Nach einer einjährigen Pause ist die Fan-Edition endlich zurück. Das Galaxy S23 FE folgt auf das mittlerweile etwa betagte Samsung Galaxy S21 FE. Da stellt sich die Frage, ob auch dieses Jahr die Highlights der S23-Serie, wie Kamera und Prozessor, zu einem guten Preis geboten werden.
Ein erster Blick aufs Datenblatt zeigt, dass die Kamera größtenteils vom S23 übernommen wurde und Grund zur Vorfreude bietet. Betrachtet man jedoch den Prozessor Exynos 2200, ist unklar, ob Samsung hier die Erwartungen an die Fan-Edition erfüllt. Wie gut der Prozessor tatsächlich ist und wo Stärken sowie Schwächen des Samsung Galaxy S23 FE liegen, zeigt unser Test.
Design
Die Fan-Edition bekommt nun das neue, kantige Design der Galaxy-S23-Reihe. Der Vorgänger musste noch mit einer unschönen Kunststoff-Optik vorliebnehmen. Dadurch sieht es nicht nur edel aus, sondern fühlt sich auch sehr robust und hochwertig an. Nur die Display-Ränder sind etwas dicker als beim S23 und zudem unsymmetrisch. So ist der untere Rand sichtbar breiter als der obere. Die Verarbeitung des Gerätes ist wie erwartet makellos. Das Display ist wie beim S21 FE rund 6,4 Zoll groß. Einhändiges Bedienen ist damit nicht mehr ohne Weiteres möglich.
Die Power-Taste und Lautstärkewippe sind weiterhin gut erreichbar auf der rechten Seite platziert. Der Rahmen mit Unterbrechungen für die Antennen ist aus Aluminium. Vorder- und Rückseite sind aus Glas. Vor allem auf der Vorderseite wurde gespart, da statt Gorilla Glas Victus 2 wie bei der S23-Reihe nur Gorilla Glas 5 zum Einsatz kommt, das weniger robust gegen Kratzer und Display-Brüche ist. Die violettfarbene Rückseite unseres Testgerätes sieht ansprechend aus, Fingerabdrücke sind jedoch deutlich sichtbar.
Die Kameras sind einzeln angeordnet wie bei der S23-Reihe und stehen deutlich aus dem Gehäuse hervor. Auf der Unterseite liegt der USB-C-Anschluss verbaut. Beim Gewicht hat die Fan-Edition ein wenig zugelegt und bringt 209 g auf die Waage. Das Gerät ist 8,2 mm dick und hat Außenmaße von 158 × 76,5 mm. Das ist in etwa so groß wie das Samsung Galaxy S23+ bei minimal kleinerem Display. Außerdem ist das S23 FE nach IP68 effektiv vor Staub und Wasser geschützt.
Samsung Galaxy S23 FE – Bilderstrecke
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Samsung Galaxy S23 FE
Display
Beim Display enttäuscht Samsung nicht. Das 6,4-Zoll-große OLED-Display ist mit 403 PPI (Pixel per Inch) bei einer Auflösung von 2310 × 1080 Pixeln gestochen scharf und liefert hervorragende Kontraste. Wie zu erwarten, ist das Display aus jedem Winkel gut abzulesen. Überdies wird es mit bis zu 1450 Nits strahlend hell. So bleibt es im Freien immer ablesbar und ist optisch ein Hingucker. Die Bildwiederholrate wird dynamisch zwischen 60 Hz und 120 Hz geregelt, kann aber auch dauerhaft auf 120 Hz eingestellt werden. So gestalten sich Animationen und das Scrollen immer ruckelfrei.
Kamera
Ein erster Blick ins Datenblatt lässt vermuten, dass die gleiche Hardware wie beim Vorgänger S23 verbaut ist. Eine 50-Megapixel-Hauptkamera mit Bildstabilisierung (OIS) und f/1,8-Blende, 12-Megapixel-Weitwinkelkamera mit f/2,2-Blende und einer 8-Megapixel-Telekamera mit f/2,4. Doch der Teufel steckt im Detail.
Wohingegen die Fotoqualität nahezu gleichgeblieben ist, gibt es bei den Videos einen Rückschritt: weniger Bilder pro Sekunde (FPS). Das dürfte den meisten jedoch nicht wirklich auffallen. Ein weiterer Rückschritt ist bei der Telekamera festzustellen, die jetzt nur noch 8 Megapixel statt 10 Megapixel bietet. Die Ergebnisse können sich dennoch sehen lassen. Auch wenn die Kamera nicht mehr ganz auf dem Niveau des Galaxy S23 ist, kann sie Samsung-typisch voll überzeugen und wird gerade für Hobby-Fotografen mehr als ausreichend sein.
Ein starker Zoom darf natürlich auch nicht bei der Fan-Edition fehlen, so vergrößert das Handy dreifach optisch und dann noch einmal zehnfach digital. Die Bilder aller Kameras können mit einem hervorragenden Dynamikumfang glänzen. Erst beim starken Heranzoomen fällt die Bildqualität ab. Auch bei der Selfie-Kamera gibt es einen Rückschritt. Diese hat jetzt nur noch 10 Megapixel mit einer f/2,4-Blende.
Samsung Galaxy S23 FE – Originalaufnahmen
Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Samsung Galaxy S23 FE – Originalaufnahmen

Ausstattung
Nun zur Achillesferse des S23 FE: dem Prozessor. Hier setzt Samsung auf die Eigenkreation Exynos 2200. Dieser kann jegliche Alltagsaufgaben zwar einwandfrei bewältigen, wie das Ergebnis von 13.300 Punkten im Benchmark Work 3.0 von PCmark zeigt. Dennoch ist es ein Nachteil gegenüber der restlichen S23er-Serie mit Snapdragon 8 Gen 2. Der Exynos 2200 ist deutlich schwächer und vor allem weniger energieeffizient, wie es sich noch bei der Akkulaufzeit zeigen wird. Gegenüber der S23-Reihe bietet der Chip rund 40 Prozent weniger Leistung bei grafiklastigen Anwendungen und liegt in etwa auf dem Niveau eines Tensor 3 von Google.
Als Speicher stehen 128 GB oder 256 GB zur Auswahl, gepaart mit 8 GB RAM. Der Speicher ist dabei nicht per Micro-SD-Karte erweiterbar. Wir raten deshalb gleich zur größeren Variante. Der Anschluss ist dank USB-C 3.2 sehr schnell bei der Datenübertragung. Es gibt zudem Platz für zwei Nano-SIM-Karten, eine E-SIM wird ebenfalls unterstützt. Die kabellosen Verbindungs-Standards sind auf aktuellem Stand: Wi-Fi 6E, Bluetooth 5.3 und NFC. Die Stereo-Lautsprecher klingen wieder hervorragend. Der Fingerabdrucksensor liegt unter dem Display, ist gut zu erreichen und reagiert schnell.
Software & Updates
Auch die Fan-Edition kommt wieder mit Samsungs angepasster Bedienoberfläche „One UI“, mittlerweile per Update in der Version 6.0. Ab Werk ist Android 13 vorinstalliert, kann aber per Software-Update auf die Version 14 aktualisiert werden. Samsung bietet hier verglichen mit dem S23 nur Android-Updates für 4 Jahre sowie Sicherheits-Patches für 5 Jahre.
Die Software umfasst alle Samsung Funktionen wie Bixby-Routinen und den entsprechenden Sprachassistenten. Auch der „Dex“-Modus wird wieder unterstützt, womit sich das Smartphone in einen richtigen Computer verwandelt. Dazu muss nur ein Monitor über USB-C mit dem Handy verbunden werden. Vorinstalliert sind Samsung Apps, einige Anwendungen von Microsoft sowie Netflix und Facebook.
Akku
Eine weitere Schwachstelle des Smartphones ist weiterhin die Ladeleistung. Die Ladegeschwindigkeit beträgt nur 25 Watt – das ist längst nicht mehr zeitgemäß. Der 4500-mAh-große Akku wird dabei in rund 60 Minuten von 20 auf 100 Prozent geladen. Kabellos wird maximal mit 15 Watt geladen, was den Ladevorgang nochmals verlängert. In der gleichen Zeit füllt sich das Smartphone von 20 auf 80 Prozent.
Eine der größten Schwächen ist wie erwähnt der Prozessor. Das zeigt sich auch bei der Effizienz. So erreicht das S23 FE im Battery Test von PCmark nur einen Wert von rund 10 Stunden durch. Das Galaxy S23+ kommt hier aber auf 13,5 Stunden. Das sind Einbußen von über 25 Prozent. Einen Tag hält das S23 FE im Alltag durch, für mehr reichen die Reserven aber nicht. Bei starker Nutzung muss es vermutlich auch bis zu zweimal am Tag ans Netzteil. Umgekehrtes kabelloses Laden ist mit 4,5 Watt wieder möglich. Samsung verzichtet bei der Fan-Edition auf ein mitgeliefertes Netzteil. Wer noch ein passendes Gerät sucht, dem raten wir zu unserer Top 10: Die besten USB-C-Ladegeräte bis 65 Watt – billig lädt schneller.
Preis
Seit der Markteinführung ist die unverbindliche Preisempfehlung von 700 Euro deutlich gesunken. Aktuell ist das Testgerät mit 128 GB Speicher und 8 GB RAM für knapp 400 Euro zu bekommen. 256 GB Speicher sind ab 480 Euro zu haben. Damit liegt das Smartphone in einer stark umkämpften Preisklasse. Sollte es die Fan-Edition sein, ist das Upgrade zu 256 GB angesichts des minimalen Aufpreises ein Muss.
Fazit
Keine Frage, das Samsung Galaxy S23 FE ist ein wirklich gutes Smartphone, jedoch mit ein paar kleinen Schwächen. Gerade bei der Ladeleistung und beim Prozessor ist noch Luft nach oben. Display, Verarbeitung und Kamera sind einfach nur erstklassig, die Software muss man mögen. Aufgrund der starken Konkurrenz ist das Smartphone jedoch nur an echte Samsung- und FE-Fans zu empfehlen. Wer nicht den Aufpreis zum S23 zahlen will, bekommt mit dem S23 FE dennoch ein hervorragendes Handy, das wenige Wünsche offenlässt.
Google Pixel 7 Pro
Google Pixel 7 Pro
Schon das Google Pixel 7 überzeugte uns im Test. Doch das Google Pixel 7 Pro steckt den kleinen Bruder locker in die Tasche, wie unser Test zeigt.
- fast perfektes Display
- eines der besten Kamerasysteme
- tolle Software mit exklusiven Funktionen
Google Pixel 7 Pro im Test: Ein großartiges Smartphone
Schon das Google Pixel 7 überzeugte uns im Test. Doch das Google Pixel 7 Pro steckt den kleinen Bruder locker in die Tasche, wie unser Test zeigt.
Bereits seit ihrem Erscheinen genießt die Pixel-Reihe unter Android-Enthusiasten Kultstatus. Denn gerade zu Beginn waren sie die Einzigen, auf denen Android in seiner reinen Form und ohne Anpassungen der Smartphone-Hersteller lief. Mittlerweile gibt es jedoch jede Menge andere Smartphones, die ebenfalls mehr oder weniger Vanilla-Android bieten.
Doch Software ist nach wie vor eines der wichtigsten Kaufargumente für ein Google Pixel. Denn die Pixel-Smartphones haben nützliche Software-Features, die man so auf keinem anderen Smartphone findet.
Jedoch waren wir – ironischerweise aus Software-Gründen – vom Google Pixel 6 (Testbericht) und Google Pixel 6 Pro (Testbericht) zunächst wenig begeistert. Denn die beiden Smartphones zeigten auch wegen der eigenen, erstmals eingesetzten SoC-Architektur Tensor massive Bugs. In den folgenden Monaten beseitigte Google die Software-Probleme. Seitdem gehört ihre Software auch wegen vieler tollen Zusatzfeatures mit zu der besten, die man auf Android-Phones findet.
Beim Google Pixel 7 (Testbericht) schraubt Google weiter an der Software, diesmal gleich zum Marktstart ohne Bugs, aber auch an der Hardware. Im Test räumt es 5/5 Sternen ab. Das hier getestete Google Pixel 7 Pro kostet etwa 200 Euro mehr, schlägt seinen kleinen Bruder aber in vielen wichtigen Hardware-Kategorien. Warum es für uns zur Android-Elite gehört, verraten wir im Testbericht des Google Pixel 7 Pro.
Design & Verarbeitung
Wie schon das Google Pixel 7, bleibt auch das Google Pixel 7 Pro der Design-Sprache der 6er-Reihe treu. Es ist 163 Millimeter hoch, 77 Millimeter breit und knapp 9 Millimeter tief. Sein Gewicht beträgt 212 Gramm. Damit ist es minimal kleiner und leichter als das Pixel 6 Pro, gehört aber dennoch zu den größeren Smartphones am Markt. Das einhändige Bedienen fällt wie bei den meisten Smartphones mit großen Displays schwer. Wer ein kleines und trotzdem potentes Smartphone sucht, dem empfehlen wir unsere Bestenliste Top 10: Klein und trotzdem stark – die besten Mini-Smartphones.

Wie beim Google Pixel 7 besteht das Visier mit der Kameraeinheit nun aus Metall. Wo das 7-er jedoch auf ein mattes Finish setzt, glänzt und spiegelt es bei Pixel 7 Pro. Eine Design-Entscheidung, die wir nicht nachvollziehen können, denn im Gegensatz zum Pixel 7 zeigen sich beim Visier des 7 Pro Fingerabdrücke.
Die Verarbeitungsqualität ist hoch. Wir können dem Smartphone kein Knacken oder Knarzen entlocken. Auch die Knöpfe sitzen perfekt. Es ist nach IP68 staub- und wasserdicht.
Der Hybrid-Stereo-Lautsprecher ist vergleichbar mit dem des Google Pixel 7, Google Pixel 6 und Google Pixel 6 Pro. Er ist laut und bietet im Landscape-Modus einen dezenten Stereo-Effekt.
Der interne Speicher des 7 Pro beträgt 128 GByte, gegen Aufpreis verdoppelt Google ihn. Es gibt Pixel-typisch keine Möglichkeit, ihn etwa über eine Micro-SD-Karte zu erweitern. Google spendiert dem 7 Pro zusätzlich zum physischen SIM-Kartenslot eine eSIM.
Google Pixel 7 Pro Bilder
Google Pixel 7 Pro

Google Pixel 7 Pro

Google Pixel 7 Pro

Google Pixel 7 Pro
Google Pixel 7 Pro

Google Pixel 7 Pro

Google Pixel 7 Pro
Google Pixel 7 Pro

Google Pixel 7 Pro

Display
Das AMOLED-Display ähnelt dem Display des Google Pixel 6 Pro (Testbericht) stark. Es hat wieder eine Diagonale von 6,7 Zoll, bietet eine Auflösung von 3120 x 1440 Pixel, kann 120 Hertz und HDR10+. Jedoch beherrscht es diesmal LTPO. Damit kann es die Bildwiederholungsrate auf 10 Bilder pro Sekunde absenken, um etwa den Akku zu schonen. Bemerkt haben wir davon im Test nichts. Allerdings setzt Google hier auf LTPO 1.0, während andere Top-Smartphones wie das Samsung Galaxy S22 Ultra (Testbericht) bereits LTPO 2.0 verwenden.
Verbessert wurde außerdem die Helligkeit. Schon manuell lässt sie sich auf gut 1000 Nits schrauben. Bei direkter Sonneneinstrahlung wächst sie gar auf über 1700 Nits. Auch wenn unter der extremen Helligkeit die Akkulaufzeit leidet, ist so das Display stets gut ablesbar. Positiv sind uns auch die im Gegensatz zum Pixel 6 Pro weniger stark abgerundeten Seiten des Displays aufgefallen.
Das Display des Pixel 7 Pro ist dem Display des Pixel 7 vor allem bezüglich der höheren Bildwiederholungsrate und der Auflösung überlegen. Aber auch DC-Dimming soll besser sein, was das Display-Flackern reduziert. Insgesamt ist das Display des Google Pixel 7 Pro über alle Zweifel erhaben. Es ist schlicht eines der besten Smartphone-Displays am Markt.
Kamera
Zunächst die Spezifikationen: Die Hauptkamera löst mit 50 Megapixel auf (2×2 Binning), hat eine f/1.85 Blende und 1,2 μm große Pixel. Die Weitwinkelkamera bietet 10 Megapixel, f/2.2 und 1,25 μm Pixel. Sichtfeld: 125,8 Grad. Die 5-fach-Telekamera bietet 48 Megapixel, hat eine f/3.5 Blende und 0,7 μm große Pixel. Alle drei Kameras bieten einen Laser-Autofokus sowie optische Bildstabilisierung. Die Frontkamera löst mit 10,8 Megapixel auf, hat eine f/2.2 Blende, 1,22 μm große Pixel und einen fixen Fokus.
Damit hat das 7 Pro beinahe die gleichen Kamera-Spezifikationen wie das Google Pixel 6 Pro (Testbericht). Wenig überraschend ähneln sich damit auch viele der mit den Geräten geschossenen Fotos. Das gilt jedoch nicht immer. So sind etwa die Nachtaufnahmen des 7 Pro dank des neuen Tensor-G2-SoCs besser, da schneller. Bilder verwackeln weniger und holen mehr Details aus dunklen Umgebungen.
Google Pixel 7 Pro Fotos
Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos
Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos
Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Google Pixel 7 Pro Fotos

Die Weitwinkelkamera kommt mit einer spannenden neuen Funktion: Sie besitzt nun einen Autofokus und eignet sich dadurch für Makrofotografie. Die so geschossenen Bilder können sich sehen lassen. Beim Fotografieren selbst kann es jedoch zuweilen verwirren, wenn plötzlich die Kamera wechselt und damit eine neue Perspektive bietet. Hier hätten wir uns gewünscht, dass der Fotograf manuell seine bevorzugte Kameraeinheit wählen kann.
Die Telekamera bietet nun im Vergleich zum 6 Pro einen 5-fach- statt 4-fach-Zoom. Im direkten Vergleich ist der damit implizierte Qualitätssprung aber nicht wirklich groß. Dennoch liefert die Telekamera beeindruckende Bilder. Gerade Aufnahmen mit 10x-Zoom wirken natürlich, auch wenn sie im Detail gerne etwas schärfer hätten sein dürfen. Dafür versteht es Google beim 7 Pro hervorragend, die Zwischenzoomstufen, etwa wenn der Nutzer mit den Fingern auf dem Display die Vergrößerung wählt, abzudecken. Google nennt das SuperResZoom.
Auch die Video-Funktionen sind wie schon bei der 6-er-Reihe richtig gut. Auf allen Kameras – auch der Frontkamera – kann das 7 Pro 4K bei 60 Hertz. Sollen die Aufnahmen dann noch 10-Bit-HDR-Inhalte darstellen, sinkt die Bildwiederholungsrate auf 30 Hertz. Im Cinematic Mode macht die Software bei 24 Bildern pro Sekunde in Echtzeit den Hintergrund unscharf. Das Ergebnis sieht in den meisten Fällen richtig gut aus. Die Bildstabilisierung arbeitet in allen Modi auf höchstem Niveau.
Ausstattung
Beim 7 Pro kommt genauso wie beim Google Pixel 7 (Testbericht) der neue Tensor G2 zum Einsatz. Diesmal sind jedoch 12 statt 8 GByte RAM an Bord. Bezüglich der allgemeinen gefühlten Geschwindigkeit verrichtet der Tensor G2 einen hervorragenden Job. Es gibt auch nach nun zwei Monaten der Nutzung keinen Augenblick, in dem der G2 zu lange nachdenken muss. Wer jedoch großen Wert auf maximale Gaming-Performance legt, sollte vielleicht eher zu einem anderen Modell wie dem Asus ROG Phone 5 (Testbericht) greifen.
In Benchmarks erreicht das Google Pixel 7 Pro gute, aber keine überragenden Werte. Sie sind in etwa mit denen des Google Pixel 7 vergleichbar. Im Work-3.0-Benchmarkt git es 11.250 Punkte, im Wildlife-Benchmark 6500 Punkte und im Wildlife-Extreme-Benchmark 1820 Punkte. Wie wir schon beim Google Pixel 7 feststellten, scheint Google mit dem Tensor G2 nicht unbedingt Benchmark-Rekorde brechen zu wollen. Vielmehr legt das Unternehmen Wert auf die Optimierung der Pixel-KI-Features.
Der Fingerabdrucksensor arbeitet schneller als noch bei der 6-er-Reihe. Allerdings gibt es auch Sensoren anderer Hersteller, die noch einmal flotter sind. Dafür gibt diesmal wieder eine Gesichtserkennung zum Entsperren des Smartphones. Die funktioniert unter normalen Lichtbedingungen gut, ist allerdings nicht sicher. Für sensible Funktionen wie Bezahlvorgänge ist die Gesichtserkennung deswegen nicht nutzbar.
Das Pixel 7 unterstützt Wi-Fi 6E, NFC, 5G und Bluetooth 5.2. Im Telefontest verstand uns das Gegenüber auch in lauten Umgebungen hervorragend. Google filtert effizient Umgebungsgeräusche heraus. Auch die von vielen beim Pixel 6 bemängelten Verbindungsprobleme hatten wir in den ersten Tagen der Nutzung nicht.
Software
Auf dem Google Pixel 7 Pro läuft bereits Android 13. Das Betriebssystem läuft sauber und flott. Wir konnten im Nutzungszeitraum keine Bugs feststellen. Bezüglich Software-Updates verspricht Google, das Telefon fünf Jahre lang mit Sicherheits-Updates und drei Jahre lang mit Major-Android-Updates zu versorgen.
Das Besonderes am Google Pixel 7 Pro sind seine vielen wirklich nützlichen Software-Funktionen. Diese reichen von offensichtlich bis versteckt. Eher versteckt ist etwa die sehr hohe Geschwindigkeit der Sprache-zu-Text-Funktion. Auch Emojis können jetzt angesagt werden. Offensichtlicher: Wer will, kann nun seine Bilder digital nachschärfen. Dank viel KI-Einsatz geht das besser, als wir es für möglich gehalten hätten – auch bei alten, nicht mit dem Smartphone geschossenen Bildern.
Sehr nützlich: Sprachnachrichten im Google Messenger wandeln sich auf Wunsch direkt in Text um. Hoffentlich kommt dieses nützliche Feature per Software-Update auch bald für weitere Messenger wie Whatsapp. Beeindruckend: Die Rekorder-App transkribiert Gesprochenes in Echtzeit. Bald soll die Software sogar verschiedene Sprecher unterscheiden können. Das Google Pixel 7 Pro ist sogar in der Lage, den Schlaf des Nutzers über die Mikrofone zu tracken.
Was sich sonst noch alle getan hat, zeigt unsere Bildergalerie.
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
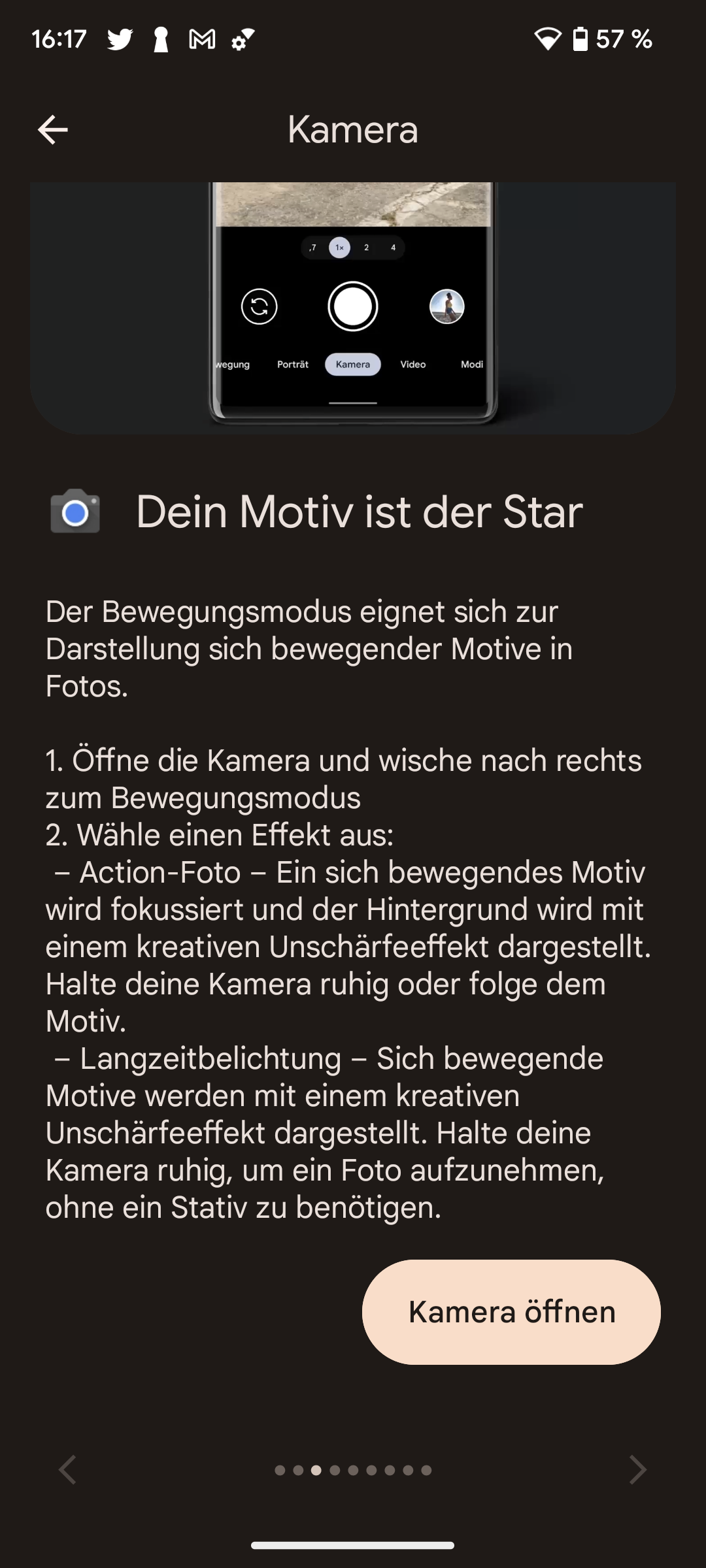
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
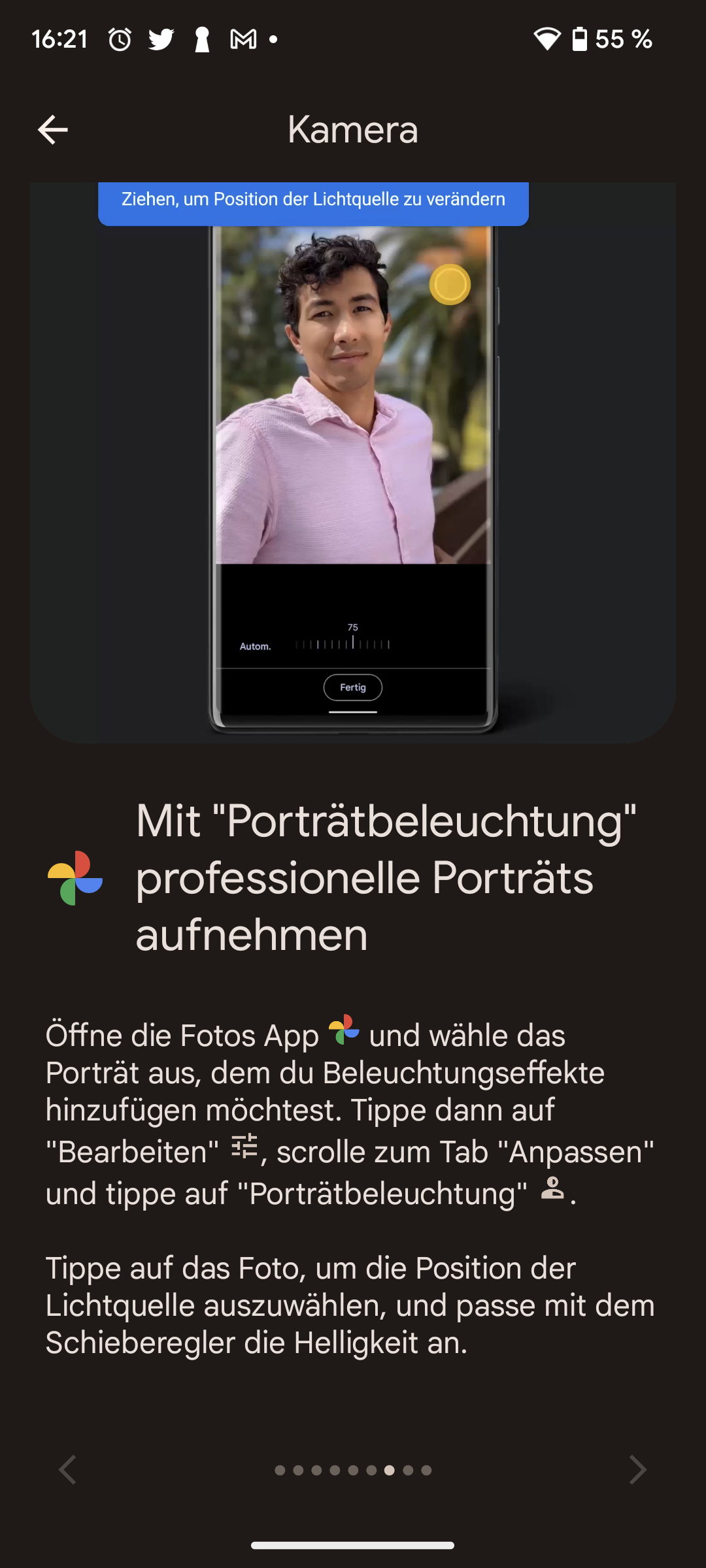
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
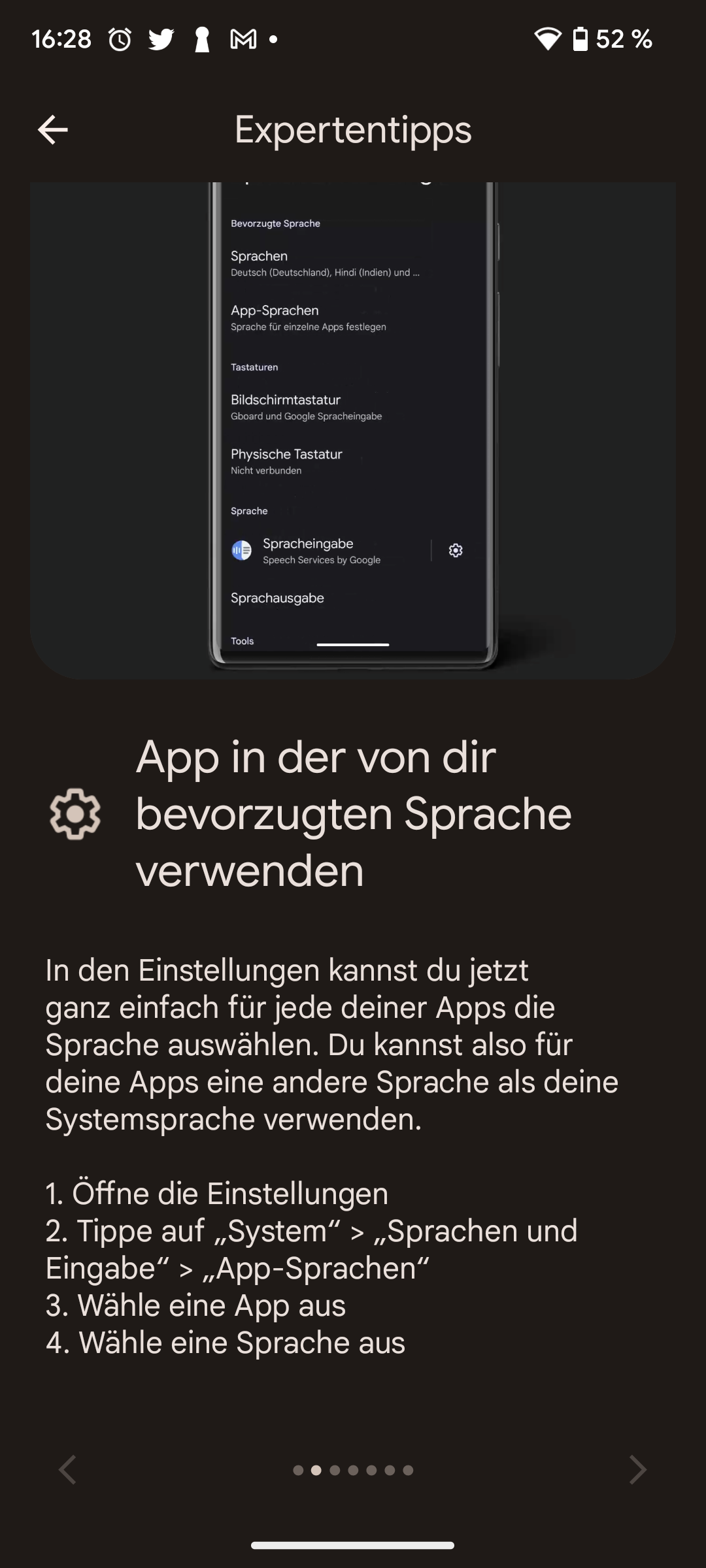
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
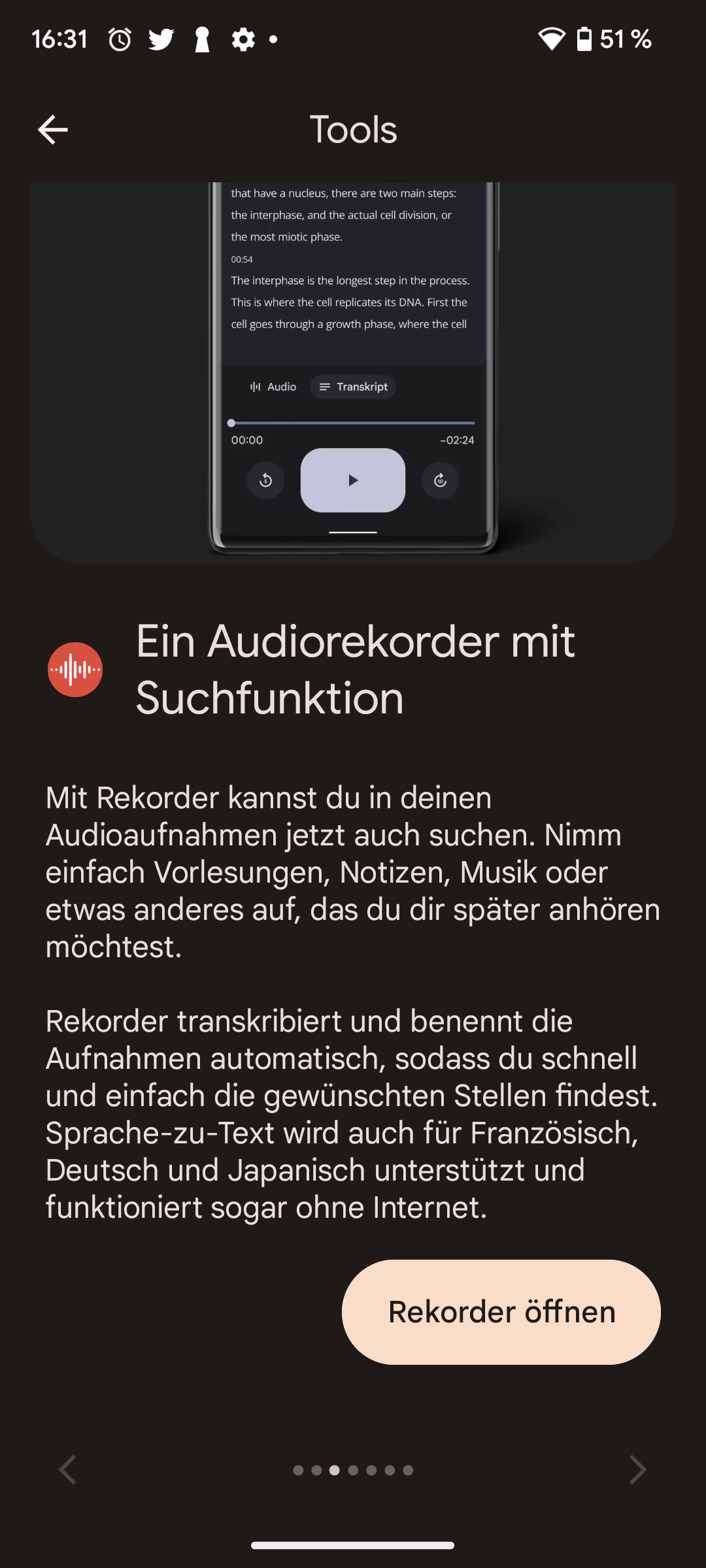
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen

Google Pixel 7 Software-Funktionen
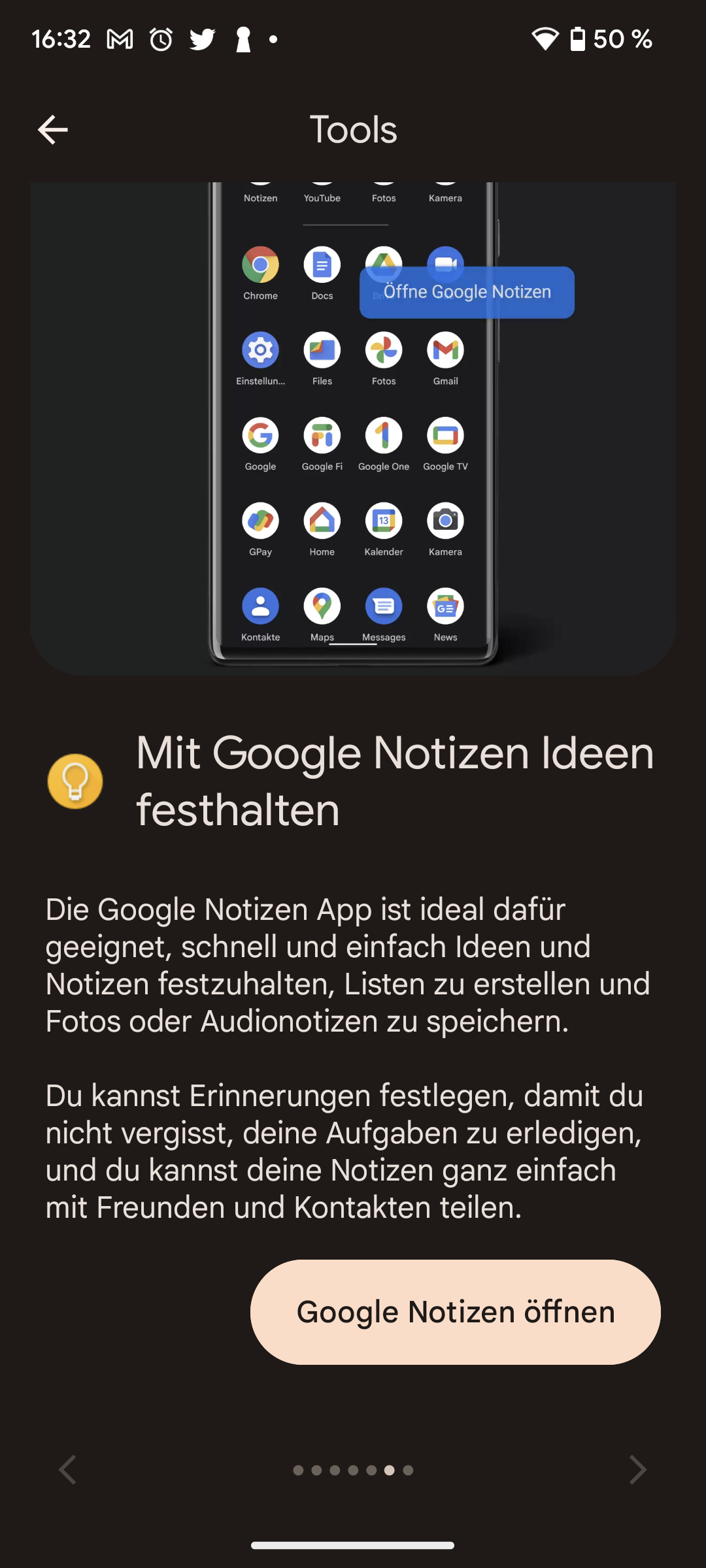
Google Pixel 7 Software-Funktionen

Google Pixel 7 Software-Funktionen

Google Pixel 7 Software-Funktionen

Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen

Google Pixel 7 Software-Funktionen

Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen

Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
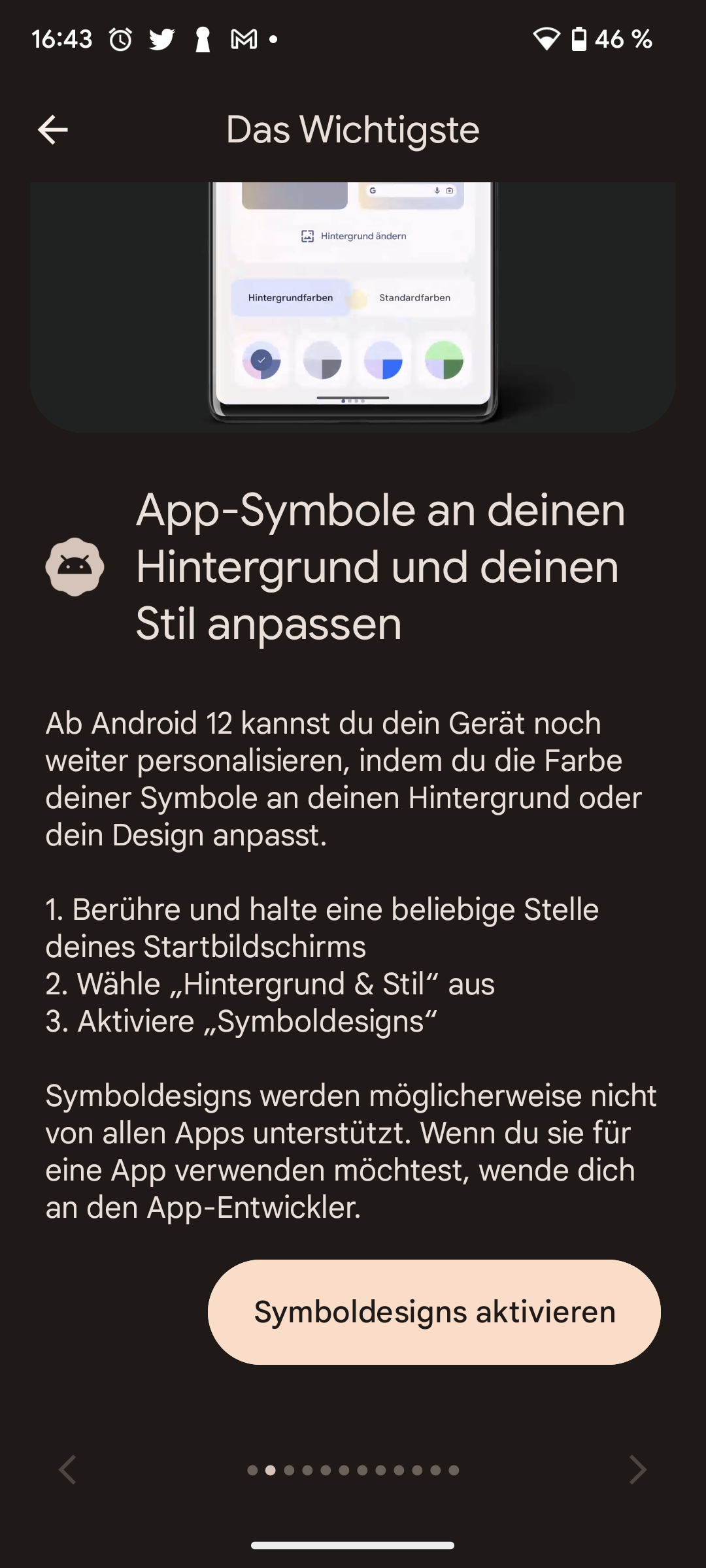
Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen

Google Pixel 7 Software-Funktionen
Google Pixel 7 Software-Funktionen
Akku
Der Akku hat eine Kapazität von 5000 Milliamperestunden und damit ähnlich viel wie der Akku des Google Pixel 6 Pro. Trotzdem hält das neue 7 Pro deutlich länger durch als sein Vorgänger. Wir messen beim PCMark Battery Test 12,5 Stunden. Beim 6 Pro waren es noch 10 Stunden. Das 7 Pro hält damit auch länger durch als das 7 und das 6. Lediglich das 6a kommt mit 13,5 Stunden auf einen noch mal höheren Wert. Insgesamt ist die Akkulaufzeit des Google Pixel 7 pro gut.
Preis
Das Google Pixel 7 Pro kommt zu einer UVP von 899 Euro. Wie unsere Preisverlaufskurve zeigt, sank sein Preis bereits auf 779 Euro, bevor er wieder auf 849 Euro stieg. Wir gehen äquivalant zum Preisverlauf des Google Pixel 6 Pro davon aus, dass sich der Preis des 7 Pro weiter nach unten bewegen wird. Das Google Pixel 6 Pro war teilweise bereits für unter 600 Euro zu haben.
Fazit
Das Google Pixel 7 Pro ist das beste Smartphone, dass Google je auf dem Markt gebracht hat. Es gehört sogar zu den allerbesten Smartphones überhaupt. Diesen Status erreicht es durch seine Kombination vieler hervorragender Funktionen und Hardware-Features. Die Optik ist gut, die Verarbeitung perfekt. Der Prozessor ist schnell genug für alle neuen und alten Funktionen des Smartphones, auch wenn es für Gamer durchaus bessere Optionen gibt. Die Software-Funktionen sind allesamt durchdacht und nützlich. Egal ob Foto oder Video, Nacht oder greller Sonnenschein, Tele oder Makro: Das Kamerasystem gehört zu den allerbesten. Auch das Display kratzt an der Perfektion. Selbst bei der Akkulaufzeit gibt sich das 7 Pro diesmal keine Blöße. Weniger gut gefällt uns, dass das Google Pixel 7 Pro lediglich mit maximal 23 Watt geladen werden kann.
Rieten wir beim Vergleich der Vorgänger noch eher zum Google Pixel 6 (Testbericht) statt zum Google Pixel 6 Pro (Testbericht), sieht es nun anders aus. Wer für das Pro-Modell etwa 200 Euro mehr investieren will, kann das mit gutem Gewissen tun. Denn im Gegensatz zum Google Pixel 7 (Testbericht) bietet das Pixel 7 Pro deutlich mehr. Das Display ist heller, schneller und hochauflösender. Die Telelinse bietet mehr Flexibilität. Auch der neue Makromodus ist ein echter Mehrwert. Noch dazugibt es mehr Arbeitsspeicher und der Akku hält etwas länger durch.
Google Pixel 9a
Google Pixel 9a
Das Google Pixel 9a bringt Premium in die Mittelklasse. Mit neuem Design, starkem Akku und einer grandiosen Kamera für etwa 500 Euro überzeugt es im Test in fast allen Bereichen.
- hervorragende Kameraqualität
- sehr lange Akkulaufzeit
- sieben Jahre Software-Updates
- umfangreiche KI-Funktionen
- IP68-Zertifizierung
- dicke Displayränder
- keine Telelinse
- vergleichsweise langsames Laden (23W)
- weniger RAM als Premium-Modelle
- einige KI-Funktionen eingeschränkt
Google Pixel 9a im Test
Das Google Pixel 9a bringt Premium in die Mittelklasse. Mit neuem Design, starkem Akku und einer grandiosen Kamera für etwa 500 Euro überzeugt es im Test in fast allen Bereichen.
Die „a“-Serie ist Googles Antwort auf die Frage nach einem Pixel-Smartphone ohne Premium-Preisschild. In der Vergangenheit erwies sich das als Erfolgsrezept – die Vorgänger lancierten durchgängig zu Bestsellern, was Google zuletzt wieder mit dem Google Pixel 8a unter Beweis stellte. Das Pixel 9a positioniert sich mit einem Straßenpreis von etwa 470 Euro (Computeruniverse) zwischen dem Samsung Galaxy A55 und dem Nothing Phone (2a), verspricht aber viele Funktionen der teureren Geschwistermodelle.
Besonders interessant: Das 9a nutzt denselben Tensor G4 Prozessor wie die teuren Modelle und bringt fast alle KI-Funktionen mit. Dazu kommen eine verbesserte Kamera, ein größerer Akku und das gleiche Update-Versprechen. Kann man damit die doppelt so teuren Flaggschiffe links liegen lassen? Unser Test gibt Antworten.
Design und Verarbeitung
Das Pixel 9a verabschiedet sich vom ikonischen Kamera-Visier der Vorgängermodelle. Der hohe Wiedererkennungswert geht damit verloren, dafür ragt die Kameraeinheit kaum noch aus dem Gehäuse. Mit Abmessungen von 73,3 × 154,7 × 8,9 mm und 186 g bleibt es recht kompakt und liegt hervorragend in der Hand.
Die matte Metallumrandung und Kunststoffrückseite fühlen sich überraschend hochwertig an. Zwar fehlt das Glas der teureren Modelle, doch der Materialmix überzeugt. Bei den Farben stehen Schwarz, Weiß, Flieder und ein intensives Rosa zur Auswahl. Die uns vorliegende dunkle Variante wirkt etwas austauschbar und zeigt Fingerabdrücke deutlicher als die helleren Optionen. Wer eine Schutzhülle verwendet, für den ist die Farbwahl ohnehin meist zweitrangig.
Der größte Kritikpunkt im Design sind die vergleichsweise dicken Displayränder, die das Gerät weniger modern erscheinen lassen. Die IP68-Zertifizierung bietet vollständigen Schutz gegen Staub und zeitweiliges Untertauchen – ein Feature, das in dieser Preisklasse nicht selbstverständlich ist.
Google Pixel 9a Bilder
Google Pixel 9a

Google Pixel 9a

Google Pixel 9a

Google Pixel 9a

Google Pixel 9a

Google Pixel 9a

Google Pixel 9a

Google Pixel 9a

Google Pixel 9a

Google Pixel 9a

Display: Wie gut ist der Bildschirm des Google Pixel 9a?
Das 6,3-Zoll-OLED-Display löst mit 1080 × 2424 Pixeln auf, was einer Pixeldichte von 421 ppi entspricht. Texte und Bilder werden scharf dargestellt, die Farben sind satt, und die Blickwinkelstabilität überzeugt. Mit 120 Hz Bildwiederholrate scrollt alles flüssig – allerdings nur, wenn man die standardmäßig deaktivierte „Smooth Display“-Funktion aktiviert.
Die maximale Helligkeit erreicht beeindruckende 1900 cd/m² im Vollbildmodus und sogar bis zu 2650 cd/m² bei direkter Sonneneinstrahlung. Damit bleibt das Display stets gut ablesbar. Geschützt wird es durch Gorilla Glass 3, das zwar nicht mehr dem neuesten Stand entspricht, aber ausreichenden Kratzschutz bietet.
Im Vergleich zu Premium-Modellen fehlt dem Display ein LTPO-Panel für stufenlose Anpassung der Bildwiederholrate zwischen 1 und 120 Hz. Das Pixel 9a kann nur zwischen 60 und 120 Hz wechseln. Für die Preisklasse ist das Display dennoch überraschend gut.
Kamera: Wie gut sind Fotos mit dem Google Pixel 9a?
Das Kamerasystem des Pixel 9a besteht aus einer 48-Megapixel-Hauptkamera (f/1.7) mit optischer Bildstabilisierung und einer 13-Megapixel-Ultraweitwinkelkamera (f/2.2). Die Frontkamera löst mit 13 Megapixeln (f/2.2) auf und unterstützt 4K-Videoaufnahmen.
Bei guten Lichtverhältnissen liefert die Hauptkamera beeindruckende Ergebnisse mit hohem Detailreichtum und natürlichen Farben. Auch bei Nachtaufnahmen überzeugt die Kamera mit rauscharmen und detaillierten Bildern. Die Ultraweitwinkelkamera schlägt sich ebenfalls gut und liefert Aufnahmen mit zur Hauptkamera vergleichbar konsistenten Farben.
Für Nahaufnahmen bietet das Pixel 9a einen Makromodus über die Hauptkamera. Zwar kann man nicht extrem nah an Objekte herangehen, dafür überzeugt die Bildqualität mit hoher Schärfe und vielen Details. Die größte Einschränkung des Kamerasystems ist das Fehlen einer Telelinse – der digitale Zoom liefert bei stärkerer Vergrößerung deutlich schlechtere Ergebnisse.
Bei Videoaufnahmen kann das Pixel 9a mit 4K-Auflösung bei 60 FPS punkten. Die Stabilisierung arbeitet zuverlässig, und die Bildqualität ist durchweg gut. Wie von Pixel-Smartphones gewohnt, stehen auch beim 9a zahlreiche KI-gestützte Nachbearbeitungstools zur Verfügung, darunter der magische Radierer zum Entfernen unerwünschter Objekte und Funktionen zur Optimierung von Gruppenfotos.
Insgesamt bietet das Pixel 9a eine Kameraqualität, die in dieser Preisklasse heraussticht und selbst mit deutlich teureren Smartphones mithalten kann.
Google Pixel 9a Fotos
Google Pixel 9a Foto

Google Pixel 9a Foto

Google Pixel 9a Foto

Google Pixel 9a Foto

Google Pixel 9a Foto

Google Pixel 9a Foto

Google Pixel 9a Foto

Google Pixel 9a Foto

Hardware: Wie stark ist das Google Pixel 9a?
Das Google Pixel 9a wird vom hauseigenen Tensor G4 SoC angetrieben – dem gleichen Chip, der auch in den teureren Pixel 9 und 9 Pro zum Einsatz kommt. Allerdings stehen hier nur 8 GB LPDDR5X RAM zur Verfügung, während die Premium-Modelle mit 12 GB ausgestattet sind. Der interne Speicher beträgt je nach Variante 128 oder 256 GB, eine Erweiterung per microSD-Karte ist wie gewohnt nicht möglich.
Im 3DMark Wild Life Extreme Benchmark erreicht das Pixel 9a einen Score von 2568 Punkten. Dieser Wert liegt zwar wie von anderen Tensor-SoC gewohnt etwas hinter den Spitzenwerten aktueller Flaggschiff-Chips, im Alltag läuft das Smartphone dennoch flüssig und schnell. Bei anspruchsvollen Anwendungen erwärmt sich das Gerät spürbar, wird aber nicht übermäßig heiß.
Die Konnektivität ist zeitgemäß: USB-C 3.2, NFC für kontaktloses Bezahlen, Bluetooth 5.3 und Wi-Fi 6E sind an Bord. Auch die Mobilfunkausstattung ist vollständig mit Dual-SIM-Unterstützung (Nano-SIM und eSIM) und 5G-Kompatibilität. Die Satellitennavigation unterstützt alle gängigen Standards (GPS, GLONASS, BeiDou, Galileo, QZSS und NavIC) für präzise Ortung.
Der Fingerabdrucksensor ist unter dem Display verbaut und arbeitet nach dem optischen Prinzip. Er funktioniert zuverlässig, reagiert aber etwas langsamer als die Ultraschall-Sensoren in Premium-Modellen. Die Stereo-Lautsprecher liefern einen guten Klang mit klarer Sprachverständlichkeit und ordentlicher Lautstärke, auch wenn der Bass wie bei den quasi allen Smartphones schwach ausfällt.
Software
Das Pixel 9a kommt mit Android 15 und bietet die für Google-Geräte typische aufgeräumte Material-You-Benutzeroberfläche ohne Bloatware. Das herausragende Merkmal ist das Update-Versprechen: Google garantiert sieben Jahre lang Software-Updates, was das Gerät bis 2032 mit aktueller Software versorgen wird – ein Versprechen, das in der Mittelklasse selten ist.
Ein besonderer Fokus liegt wieder auf den KI-Funktionen. Dazu gehören Gemini Live für Echtzeitübersetzungen, Circle to Search zum Suchen von Objekten durch einfaches Einkreisen auf dem Bildschirm, Pixel Studio für Bildbearbeitung und der Google Recorder für automatische Transkriptionen.
Allerdings gibt es im Vergleich zu den teureren Pixel-Modellen einige Einschränkungen: So fehlt unter anderem die KI-gestützte Screenshot-Analyse. Für KI-Enthusiasten ist zu bedenken, dass der geringere RAM-Speicher (8 GB statt 12 GB) zukünftige KI-Funktionen möglicherweise einschränken könnte. Aktuelle Anwendungen laufen jedoch problemlos, und die vorhandenen KI-Tools bieten bereits einen deutlichen Mehrwert gegenüber der KI-Konkurrenz in dieser Preisklasse.
Akku: Wie lange hält das Google Pixel 9a durch?
Mit einer Kapazität von 5100 mAh bietet das Pixel 9a den größten Akku der aktuellen Google-Smartphone-Generation – mehr als das Pixel 9 (4700 mAh) und deutlich mehr als das Vorgängermodell Pixel 8a (4500 mAh). Diese großzügige Dimensionierung macht sich bemerkbar.
Im PCMark Battery Test erreicht das Gerät bei einer Bildwiederholrate von 60 Hz beeindruckende 21 Stunden Laufzeit. Selbst mit aktivierten 120 Hz sind es noch 17 Stunden – Werte, die die meisten Flaggschiff-Modelle übertreffen. Im Alltag bedeutet das: Selbst intensive Nutzung mit viel Kameraeinsatz, Navigation und Streaming bringt das Pixel 9a problemlos durch den Tag, bei moderater Nutzung sind auch zwei Tage ohne Ladegerät möglich.
Das kabelgebundene Laden erfolgt mit maximal 23 Watt, was nicht zu den schnellsten Ladegeschwindigkeiten zählt. Von 0 auf 50 Prozent benötigt das Pixel 9a etwa 30 Minuten, eine vollständige Ladung dauert rund 90 Minuten. Kabelloses Laden via Qi wird unterstützt, allerdings mit geringerer Leistung. Ein Ladegerät ist nicht im Lieferumfang enthalten.
Preis: Wie viel kostet das Google Pixel 9a?
Die UVP liegt für die Variante mit 128 GB Speicher bei 549 Euro. Schon nach wenigen Wochen liegt der niedrigste Straßenpreis derzeit bei gut 419 Euro. Wir gehen davon aus, dass der Preis innerhalb der nächsten Monate weiter auf die 400-Euro-Marke zuläuft. Mit 256 GB sind es knapp 549 Euro.
Fazit
Das Google Pixel 9a ist ein überzeugendes Mittelklasse-Smartphone, das in vielen Bereichen über seine Preisklasse hinausragt. Die hervorragende Kamera, der starke Akku und das siebenjährige Update-Versprechen sind die größten Stärken des Geräts. Auch die Integration von KI-Funktionen, die sonst eher in Premium-Modellen zu finden sind, ist ein klares Verkaufsargument.
Abstriche muss man beim Design mit den etwas dicken Displayrändern, dem fehlenden optischen Zoom und der vergleichsweise langsamen Ladegeschwindigkeit machen. Für viele Nutzer dürften diese Nachteile jedoch durch die Stärken ausgeglichen werden.
Google Pixel 8
Google Pixel 8
Das Google Pixel 8 ist kompakt, bringt viele sinnvolle KI-Features und eine Kamera, die für 750 Euro ungeschlagen ist. Wir haben das Smartphone getestet.
- geniale Kamera mit sinnvollen KI-Funktionen
- sehr helles Display mit 120 Hz
- kompakt und trotzdem High-End
- keine Telelinse
- lädt nur mit maximal 27 Watt
- CPU nicht so schnell wie Snapdragon 8 Gen 2
Google Pixel 8 im Test: Der Kamera-Sieger der Mittelklasse
Das Google Pixel 8 ist kompakt, bringt viele sinnvolle KI-Features und eine Kamera, die für 750 Euro ungeschlagen ist. Wir haben das Smartphone getestet.
Die Google-Pixel-Reihe gehört neben den Apple iPhones und den Samsung Galaxys zu den beliebtesten Smartphones am Markt. Besonders Software und Kamera überzeugten in der Vergangenheit. Auch das aktuelle Google Pixel 8 Pro (Testbericht) schlägt in diese Kerbe und gefällt uns im Test. Allerdings kostet es über 1000 Euro. Dem etwa 300 Euro günstigeren Google Pixel 8 fehlt im Vergleich im Grunde hauptsächlich die Telelinse. Dafür ist es deutlich kompakter. Wir haben es getestet. Dazu empfehlen wir auch unsere Top 10: Die besten Smartphones – Samsung vorn, Apple nur Mittelfeld.
Design
Das Google Pixel 8 ist verhältnismäßig kompakt. Im Vergleich zum Google Pixel 7 (Testbericht) und Google Pixel 7a (Testbericht) ist es an den Ecken abgerundet und etwas geschrumpft. Ein schlauer Schachzug. Schließlich gibt es auf dem Markt nur wenige High-End-Smartphones, welche die neueste Technik in ein schlankes Gehäuse packen. Während die Maße geschrumpft sind, ist das Kameravisier, welches sich wieder über die komplette Breite zieht, etwas gewachsen. Das liegt vor allem daran, dass Google hier seine neue und etwas größere Kameraeinheit unterbringt.
Das Kameravisier kommt in einem matten, gebürsteten Metall. Das gefällt uns besser als die Hochglanzvariante am Pixel 8 Pro. Dafür ist der Rest der Rückseite hochglanz. Bei der uns vorliegenden schwarzen Variante sorgt das für eine recht hohe Fingerabdruckanfälligkeit. Halb so wild, schließlich sollte man sein teures Pixel 8 ohnehin mit einer Hülle schützen. Neben der schwarzen Version gib es das Smartphone außerdem in einer Art Beige-Grau und Rosé.
Die Verarbeitungsqualität ist hochwertig. Es ist nach IP68 gegen das Eindringen von Staub und Wasser geschützt, nichts knarzt oder wackeln und der Druckpunkt der drei Taster ist straff.
Display
Das Display ist im Vergleich zum Pixel 7 von 6,3 auf 6,2 Zoll geschrumpft. Dafür ist die Bildwiederholungsrate von 90 Herzt auf 120 Hertz angestiegen. Außerdem ist seine maximale Helligkeit nun viel höher – wenn auch nicht ganz so hoch wie die des Pixel 8 Pro. Trotzdem ist es eine wahre Freude, das Pixel 8 in direkter Sonne zu nutzen. Auch unter normalen Lichtverhältnissen wirkt bei voll aufgedrehtem Display alles einen Tick knackiger. Farben und Blickwinkelstabilität sind Oberklasse.
Die Auflösung von 1080 x 2400 Pixel ist für die Displaygröße mehr als ausreichend. Dank OLED-Technik kennt das Pixel 8 einen Always-On-Modus, zeigt also stets relevante Informationen wie Uhrzeit, Datum, Temperatur und auf Wunsch App-Benachrichtigungen an.
Google Pixel 8 Bilder
Google Pixel 8
Google Pixel 8
Google Pixel 8
Google Pixel 8
Google Pixel 8
Google Pixel 8
Google Pixel 8
Google Pixel 8
Google Pixel 8
Google Pixel 8
Kamera
Die mit dem Pixel 8 Pro geschossenen Bilder sind phänomenal gut und auf einem Level mit dem 300 Euro teureren Google Pixel 8 Pro. Kein Wunder, schließlich nutzen die beiden Smartphones die gleiche Hardware mit der gleichen Software. Einziger Unterschied ist das Fehlen der 5-fach-Telelinse. Auch hat die Frontkamera keinen automatischen, sondern einen fixen Fokus.
Insgesamt sind wir von der Fotoqualität begeistert. Die 48-Megapixel-Hauptkamera liefert in Verbindung mit der digitalen Nachbearbeitung auch in schummrigen Umgebungen scharfe, farbechte und rauscharme Bilder ab. Selbst im Vergleich mit teureren Smartphones wie dem iPhone 15 muss es sich nicht verstecken. Auch die Qualität der Weitwinkellinse ist auf einem hohen Niveau. Wer Videos aufnehmen will, kann dies mit bis zu 4k bei 60 Bildern pro Sekunde tun. Bei Full-HD sind gar 240 Bilder pro Sekunde möglich. Außerdem gibt es einen anständigen 10-bit-HDR-Modus.
Die Frontkamera kann nicht mit der Qualität der rückseitigen Kameraeinheit mithalten. Wir vermissen zwar den Autofokus des Pixel 8 Pro nicht, schließlich kommen Selfies meist mit einem fixen Abstand, allerdings wirken die Farben nicht immer ganz korrekt und auch die Schärfe dürfte etwas höher sein.
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Google Pixel 8 Fotos
Äquivalent zum Google Pixel 8 Pro sind die Nachbearbeitungsmöglichkeiten enorm hoch und nützlich. So kann jedes Bild individuell bezüglich Farbe und Belichtung angepasst werden – das kennen wir so schon von den Vorgängern. Auch der magische Radierer, der unerwünschte Objekte aus dem Bild entfernt, ist wieder mit dabei. Diesmal geht die KI-Spielerei aber noch einen Schritt weiter. Google nennt sie magischer Editor. Dort gewählte Bildelemente lassen sich verschieben oder in ihrer Größe anpassen. Auch ganze Bildbereiche können gelöscht werden. Die Google KI überlegt sich daraufhin, womit sie den leeren Bereich ersetzen will. Das gelingt in den meisten Fällen überraschend gut.
Der magische Editor ermöglicht es uns, mit wenigen Fingerbewegungen Dinge zu tun, für die wir zuvor Photoshop und Spezialkenntnisse benötigt hätten. Ein Beispiel vom Google Pixel 8 Pro, dessen Software weitestgehend identisch ist: Wir sehen im Fernsehen ein Bild eines Künstlers, welches uns gefällt. Also fotografieren wir den Fernseher, optimieren Farbe und Belichtung, löschen mit Googles KI Personen, die das Bild teilweise verdecken, schneiden einen zu großen Bildausschnitt zu und lassen Googles Künstliche Intelligenz die unpassenden Bereiche erweitern. Das Ganze dauert zehn Minuten – mit beeindruckendem Ergebnis. Was hier nervt, sind die langen Wartezeiten. So benötigt die Google-KI je nach gewähltem Bereich, der gelöscht und ersetzt werden soll, bis zu 13 Sekunden.
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Google Pixel 8 Bildbearbeitung
Hardware
Der Tensor 2 SoC im Vorgängermodell Pixel 7, Pixel 7a und Pixel 7 Pro war unserer Meinung nach schon zügig, auch wenn es gelegentlich zu kleinen Verzögerungen kam. Der jetzt verwendete Tensor 3 ist schneller, was vor allem beim Fotografieren auffällt. Bilder sind sofort nach dem Aufnehmen fertig, während man beim Vorgängermodell manchmal auf die Nachbearbeitung warten musste. Zudem bleibt der Tensor 3 auch unter Höchstlast kühler.
Obwohl High-End-SoCs von Qualcomm, Apple und Mediatek schneller sind, erledigt der Tensor 3 im Alltag alle Aufgaben zügig. Die Benchmark-Ergebnisse sind stark, aber nicht herausragend. Das Pixel 8 erreicht in „Wild Life Extreme“ von 3Dmark vergleichbar mit dem Pixel 8 Pro etwa 2300 Punkte und bei Work 3.0 von PCmark rund 11000 Punkte. Das geht besser. So erreicht das Xiaomi 13 bei PCmark 14.000 Punkte und bei 3Dmark rund 3000 Punkte. Allerdings gibt es Situationen, wie im magischen Editor, in denen wir uns über lange Wartezeiten ärgern.
Software
Das Google Pixel 8 wird mit Android 14 ausgeliefert. Google verspricht Updates bis 2030 – also bis Android 21. Das ist ein bemerkenswert langes Update-Versprechen, das kein anderer Smartphone-Hersteller übertrifft. Doch wir sind skeptisch, ob dies realistisch und überhaupt sinnvoll ist. So ist die Hardware in sieben Jahren hoffnungslos veraltet und auch der Akku benötigt spätestens dann einen Austausch.
Android auf dem Pixel 8 Pro ist übersichtlich, sauber und schnell. Es bietet nützliche Alltagsfunktionen wie Face Unlock, das Übersetzen und Vorlesen von Webseiten sowie quellenunabhängige Sprach-zu-Text-Übersetzungen von Audio- und Video-Inhalten.
Die Now-Playing-Funktion, die automatisch Musik erkennt und Title sowie Interpret in einer Liste speichert, sowie die hervorragende Text-to-Speech-Funktion und der nützliche Sprachassistent sind weitere Highlights. Aber es gibt auch Aspekte, die uns stören. Dazu gehört das umständliche Ein- und Ausschalten des WLANs über das Drop-Down-Menü.
Akku
Die Akkukapazität im Pixel 8 beträgt 4575 mAh. Beim Vorgänger mit größerem Display waren das noch 4355 mAh. Trotzdem sinkt die Akkulaufzeit von 11 Stunden 40 Minuten auf knapp 11 Stunden. Das wird den allermeisten Nutzern reichen, um über den Tag zu kommen. Trotzdem ist die Akkulaufzeit insgesamt – gerade für den aufgerufenen Preis – zu gering.
Auch beim Laden glänzt das Pixel 8 nicht. So ist die maximale Ladegeschwindigkeit gegenüber dem Vorgänger leicht von maximal 25 Watt auf 27 Watt gestiegen. Für eine volle Ladung benötigt es gut 1,5 Stunden. Das ist zu langsam. So lädt etwa das Motorola Edge 40 Pro (Testbericht) gut viermal so schnell. Immerhin ist der kabellose Ladestandard Qi wieder mit dabei.
Preis
Das Google Pixel 8 hatte zum Testzeitpunkt am 12. November 2023 mit 128 GB eine UVP von 799 Euro und mit 256 GB etwa 859 Euro. Eine 512-GB-Variante wie beim Pixel 8 pro gibt es nicht. Mittlerweile ist der Preis aber stark gefallen. Schon ab 450 Euro geht es los.
Fazit
Das Google Pixel 8 ist vor allem für jene interessant, die ein hervorragendes Kamera-Smartphone im kompakten Gehäuse suchen. Die damit geschossenen Bilder suchen in der Preisklasse um die 750 Euro ihresgleichen. Dazu kommen die zahlreichen KI-Funktionen, die bei der Bildbearbeitung mehr als nur eine Spielerei sind. Auch das Display hat einen deutlichen Sprung nach vorn gemacht und bietet nun 120 Hertz sowie eine enorme maximale Helligkeit. Der Akku dagegen enttäuscht, Heavy-User werden mit ihm nicht immer über den Tag kommen. Auch die Ladegeschwindigkeit ist nicht mehr zeitgemäß.
Wer ein gutes Kamera-Smartphone der Oberklasse zu gerade noch bezahlbarem Preis sucht, ist beim Pixel 8 goldrichtig. Abgesehen von der fehlenden Telelinse und der guten, aber nicht perfekten Selfiekamera, spielt das Kamera-Setup ganz weit oben mit und lässt sogar den ein anderen teureren Konkurrenten hinter sich.
Vivo V50 5G
Vivo V50 5G
Das Vivo V50 5G will in der Mittelklasse mitmischen und tritt gegen Galaxy A56 und Pixel 9a an. Wir haben Kamera, Display, Leistung und Akkulaufzeit getestet.
- IP69
- gute Kamera
- Top-Display
- lange Akkulaufzeit & schnelles Laden
- für das Gebotene zu teuer
- keine Telelinse
- kein kabelloses Laden
- nur Wifi 5 und USB-C 2.0
Vivo V50 5G im Test: Smartphone mit Top-Akkulaufzeit und guter Kamera
Das Vivo V50 5G will in der Mittelklasse mitmischen und tritt gegen Galaxy A56 und Pixel 9a an. Wir haben Kamera, Display, Leistung und Akkulaufzeit getestet.
Mit dem Vivo V50 5G bringt der chinesische Hersteller ein Smartphone in der hart umkämpften oberen Mittelklasse auf den Markt – preislich knapp über 500 Euro. Aufgrund früherer Verkaufsverbote in Deutschland hatten wir längere Zeit kein Gerät von Vivo im Test. Anders als die Modelle der X-Reihe handelt es sich beim V50 um ein Mittelklasse-Gerät, das in Konkurrenz mit dem Samsung Galaxy A56 oder dem Google Pixel 9a steht.
Wie sich das Vivo V50 5G mit seiner Dual-Kamera, dem AMOLED-Display und der Schnellladefunktion im Alltag schlägt, klären wir in unserem ausführlichen Test.
Design
Das Vivo V50 5G zeigt sich im Test mit einem ansprechend schlanken Design. Trotz der recht großzügigen Abmessungen von 163,3 × 76,7 × 7,4 mm bringt es nur 189 g auf die Waage. Es liegt damit angenehm in der Hand, auch wenn einhändiges Bedienen eher schwierig ist. Das Gerät ist aber gut ausbalanciert und rutscht nicht so leicht aus der Hand. Die Vorder- und Rückseite sind leicht abgerundet, was die Handhabung zusätzlich verbessert.
Die Verarbeitung macht insgesamt einen hochwertigen Eindruck, auch wenn Rahmen und Rückseite aus Kunststoff bestehen. In dieser Preisklasse sind zunehmend Materialien wie Glas und Metall üblich, die oft deutlich edler wirken. Hier hat die Konkurrenz die Nase vorn.
Auf der Rückseite sticht das markante Kameramodul ins Auge: Zwei mit Carl Zeiss entwickelte Linsen sitzen in einem runden Element, das in ein größeres Oval eingebettet ist – darunter befindet sich ein weiterer, nicht näher erklärter Kreis. Dieses auffällige Design sorgt für Wiedererkennungswert, lässt das Gerät jedoch leicht kippeln, wenn es auf dem Rücken liegt.
Ein praktisches Highlight ist die IP69-Zertifizierung: Das Vivo V50 5G ist nicht nur gegen Staub und zeitweiliges Untertauchen geschützt, wie bei IP68, sondern widersteht auch Hochdruck- und Heißwasserstrahlen.
Vivo V50 5G – Bilder
Vivo V50 5G

Vivo V50 5G

Vivo V50 5G

Vivo V50 5G

Vivo V50 5G

Vivo V50 5G

Vivo V50 5G

Vivo V50 5G

Display
Der Bildschirm des Vivo V50 5G überzeugt mit sehr dünnem Rand und starker Bildqualität. Dank der AMOLED-Technologie wirken Farben und Kontraste satt und kräftig. Die große 6,77-Zoll-Anzeige bietet mit 2392 × 1080 Pixeln (Full-HD+) eine ausreichend scharfe Darstellung bei 388 ppi.
Auch bei direkter Sonneneinstrahlung bleibt der Bildschirm ablesbar, und die Blickwinkelstabilität ist wie gewohnt hoch. Für flüssige Animationen unterstützt das Display bis zu 120 Hz, alternativ lässt sich zur Akkuschonung auch auf 60 Hz umschalten.
Kamera
Das Kamera-Setup ist recht einfach gehalten: Zum Einsatz kommt eine Dual-Linse, die wieder in Zusammenarbeit mit Carl Zeiss entstanden ist. Die Hauptkamera bietet 50 Megapixel bei f/1.88 mit optischer Bildstabilisierung. Das Weitwinkelobjektiv löst ebenfalls mit 50 Megapixel bei f/2.0 auf. Das Gleiche gilt für die Selfie-Linse vorn.
Bei Tageslicht liefert das Vivo V50 5G erfreulich gute Fotos. Der Dynamikumfang ist groß, wodurch selbst bei schwierigen Lichtverhältnissen lebendige und kontrastreiche Aufnahmen entstehen. Nutzer können zwischen drei Farbprofilen wählen: „Lebendig“, „Strukturiert“ und „Zeiss Naturfarbe“. Während der Modus „Lebendig“ kräftig gesättigte Farben erzeugt, verstärkt „Strukturiert“ die Kontraste – das führt zu dunkleren, aber detailreicheren Bildern. „Zeiss Naturfarbe“ zielt auf eine möglichst realistische Farbwiedergabe ab.
Die Bildschärfe und Detailtreue sind ordentlich, aber nicht überragend. In dieser Preisklasse hätten wir uns ein Teleobjektiv gewünscht. Zwar sehen Fotos mit zweifachem und teilweise auch vierfachem Digitalzoom noch überraschend gut aus, darüber hinaus nimmt die Bildqualität jedoch sichtbar ab – Aufnahmen wirken dann zunehmend pixelig.
Die Ultraweitwinkelkamera ist farblich gut auf die Hauptkamera abgestimmt, wodurch sich die Ergebnisse beider Linsen harmonisch in Bildserien einfügen. Farbabweichungen sind nur minimal. Zudem macht diese Linse auch gute Makroaufnahmen.
Bei Dunkelheit lässt die Bildqualität rapide nach. Ist noch genügend Restlicht vorhanden, gelingen brauchbare Aufnahmen, auch wenn Bildrauschen deutlich sichtbar ist. Bei sehr wenig Licht sind ohne Blitz nur noch rudimentäre Strukturen erkennbar.
Vivo V50 5G – Originalaufnahmen
Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Vivo V50 5G – Originalaufnahmen

Selfies gelingen ebenfalls gut. Im Porträtmodus erzeugt das Vivo V50 5G ein ansprechendes Bokeh mit sauberer Kantentrennung. Videos lassen sich mit der Hauptkamera in 4K bei 30 FPS oder in Full-HD mit bis zu 60 FPS aufnehmen. Die Bildqualität ist dabei gut, die elektronische Stabilisierung arbeitet zuverlässig.
Insgesamt liefert die Kamera des Vivo V50 5G eine solide Leistung für die Mittelklasse. Ein optischer Zoom fehlt allerdings, und an das Niveau eines Google Pixel 9a (Testbericht) reicht Vivo im Hinblick auf Bildqualität nicht ganz heran.
Ausstattung
Das Vivo V50 5G ist mit dem Qualcomm Snapdragon 7 Gen 3 ausgestattet und bietet damit eine mehr als solide Performance in der gehobenen Mittelklasse. Beim Benchmark von PCmark erreicht das Gerät rund 11.000 Punkte, was auf eine gute Alltagstauglichkeit hinweist.
Auch für das Gaming ist es mit leichten Abstrichen nutzbar. Bei 3Dmark Wildlife Extreme erzielt das Smartphone 1500 Punkte, bei Wildlife sind es 5300 – grafisch anspruchsvolle Spiele laufen also, allerdings raten wir zu mittleren Grafikdetails. Im Alltag überzeugt das Gerät meistens mit flüssiger und flotter Bedienung.
Der interne Speicher mit 512 GB sowie der Arbeitsspeicher mit 12 GB RAM sind großzügig bemessen, verwendet allerdings nur den langsameren UFS-2.2-Standard. Zur Ausstattung gehören ein schneller und zuverlässiger Fingerabdrucksensor unter dem Display, 5G, NFC sowie Bluetooth 5.4. Für die Ortung werden alle gängigen Systeme wie GPS, Glonass, Beidou, Galileo und QZSS unterstützt – mit einer üblichen Genauigkeit von rund 3 Metern.
Kritikwürdig sind der veraltete USB-C-2.0-Anschluss und nur WLAN nach Wifi 5 – das wirkt in dieser Preisklasse überholt. Der Klang der Lautsprecher ist insgesamt klar und ordentlich, tendiert jedoch stellenweise zu überbetonten Höhen, was zuweilen leicht scheppernd klingt.
Software
Das Vivo V50 5G läuft mit Android 15 und der hauseigenen Bedienoberfläche Funtouch OS. Diese weicht kaum vom klassischen „Vanilla“-Android ab – inklusive App-Drawer und einzeiligem Einstellungsmenü, das sich per Wischgeste öffnen lässt. Optisch bringt Funtouch OS mit seinen Farben dennoch eine frische Note ins System. Nützliche Zusatzfunktionen wie ein Objektradierer für Fotos oder ein Textgenerator in der Notizen-App runden das Softwarepaket ab.
Zum Testzeitpunkt stammt der Sicherheits-Patch vom 1. Mai – das ist noch aktuell, ein Update sollte aber bald folgen. Vivo verspricht fünf Jahre Sicherheits-Updates, das ist positiv. Weniger schön: Neue Android-Versionen werden nur dreimal bis 2028 ausgeliefert, also voraussichtlich bis Android 18.
Akku
Trotz des schlanken Gehäuses bietet das Vivo V50 5G eine ordentliche Akkukapazität von 5260 mAh. In Kombination mit der guten Energieeffizienz erreicht das Smartphone eine herausragende Akkulaufzeit. Im simulierten Battery-Test von PCmark erzielte das Gerät beeindruckende 15 Stunden und liegt damit auf Augenhöhe mit aktuellen Flaggschiff-Smartphones. Über den Tag kommt es problemlos, bei sparsamer Nutzung ist auch ein weiterer halber Tag drin.
Schnelles Laden ist ebenfalls an Bord – mit bis zu 90 Watt. Damit ist das Smartphone in weniger als einer Stunde vollständig aufgeladen. Nach einer halben Stunde erreicht es schon über 75 Prozent. Einen Abstrich gibt es im Vergleich zu Top-Geräten jedoch: Kabelloses Laden wird nicht unterstützt.
Preis
Die UVP ist angesichts der Ausstattung etwas hoch gegriffen. Mittlerweile nähert sich das Smartphone aber der 500-Euro-Grenze. Zu haben ist es bereits ab 508 Euro bei Alza in den Farben Dunkelgrau (Satin Black) sowie Lila (Mist Purple). Andere Händler verlangen meistens um die 570 Euro.
Fazit
Mit dem V50 5G liefert Vivo ein insgesamt überzeugendes Mittelklasse-Smartphone ab. Besonders positiv stechen die sehr lange Akkulaufzeit und das schnelle Laden mit bis zu 90 Watt hervor – ein echtes Plus im Alltag. Auch das helle OLED-Display überzeugt mit starker Bildqualität und guter Ablesbarkeit. Die Dual-Kamera liefert ordentliche Ergebnisse, auch wenn wir in dieser Preisklasse ein Teleobjektiv vermissen. Manche Konkurrenten sind hier besser aufgestellt. Die Systemleistung ist für nahezu alle Anwendungsbereiche absolut ausreichend.
Allerdings wirkt der Preis mit knapp über 500 Euro angesichts der Ausstattung etwas ambitioniert. Einschränkungen wie Speicher nach UFS 2.2, lediglich Wi-Fi 5 und USB-C 2.0 wirken im Jahr 2024 nicht mehr zeitgemäß. In einem stark umkämpften Marktsegment fehlt dem schicken Vivo V50 5G letztlich ein echtes Alleinstellungsmerkmal – und ein konkurrenzfähigerer Preis.
Poco F6 Pro
Poco F6 Pro
Richtig viel Leistung für vergleichsweise wenig Geld bietet das Poco F6 Pro. Wir haben das Budget-Smartphone mit Top-Prozessor von Xiaomi getestet.
- schnelle CPU
- tolles Display
- schnelles Laden mit 120 Watt
- gute Hauptkamera
- nicht wasserfest
- mäßige Weitwinkel- und Makrolinse
- nur USB 2.0
- kein induktives Laden
Poco F6 Pro im Test
Richtig viel Leistung für vergleichsweise wenig Geld bietet das Poco F6 Pro. Wir haben das Budget-Smartphone mit Top-Prozessor von Xiaomi getestet.
Unter der Marke Poco vermarktet Xiaomi gute Smartphones zum günstigen Preis. Während Modelle wie das Poco X6 (Testbericht) oder Poco X6 Pro (Testbericht) vorwiegend durch das Preis-Leistung-Verhältnis glänzen, bietet die F-Reihe der Marke viel Power für relativ wenig Geld. Neben dem preiswerten Poco F6 (Testbericht) gibt es mit dem Poco F6 Pro eine besonders starke Variante. Sie folgt auf das Poco F5 Pro (Testbericht), das uns letztes Jahr mit guter Leistung zum fairen Preis überzeugt hat.
Design: Ist das Poco F6 Pro wasserdicht?
Anders als das preiswertere Poco F6 (Testbericht), das immerhin über IP64 verfügt und somit spritzwassergeschützt ist, hat das Poco F6 Pro keine IP-Zertifizierung. Es ist also nicht wasserdicht, entsprechend vorsichtig sollte man sein. Das ist schade, denn die Konkurrenz bietet mittlerweile in dieser Preisklasse IP67 und teilweise sogar IP68.
Das Poco F6 Pro von Xiaomi ist definitiv ein Hingucker. Verglichen mit den preiswerteren Poco-Modellen aus Kunststoff kommen hier hochwertiges Glas und Metall zum Einsatz. Das große Smartphone wirkt schlank und filigran und ist zudem relativ leicht (209 g) für die dann schon recht wuchtigen Abmessungen (160,9 × 75 × 8,2 mm). Einhändiges Bedienen ist nicht so ohne Weiteres möglich.
Sehr präsent ist das Kameramodul im oberen Drittel auf der Rückseite. Vier Ringe beherbergen die drei Linsen sowie den LED-Blitz auf einem rechteckigen Element. Der übrige Bereich der Rückseite ist aus Glas. Unser Testgerät ist mit einer sehr edlen Schraffierung versehen. Der Rahmen besteht aus Metall. Die Verarbeitung ist erstklassig, der Druckpunkt der Tasten ist solide und Spaltmaße gibt es keine.
Display: Wie hell ist der Bildschirm des Poco F6 Pro?
Nichts zu meckern gibt es am messerscharfen und strahlend hellen Display. Das OLED-Panel hat eine Diagonale von 6,67 Zoll. Die Auflösung fällt mit 3200 × 1440 Pixel sehr hoch aus, das führt zu einer ausgesprochen scharfen Bildgebung mit 525 PPI (Pixel per Inch). Die Bildqualität überzeugt mit lebendigen Farben und perfekt abgestimmten Kontrasten. Zudem ist die Anzeige bei adaptiver Anpassung immer hell genug, um auch bei starkem Sonnenschein ablesbar zu sein. Wir konnten über 1000 Nits messen, laut Xiaomi sind bis zu 4000 Nits im HDR-Modus möglich.
Fotos: Wie gut ist die Kamera des Poco F6 Pro?
Als Kamera dient eine Hauptlinse mit 50 Megapixel (f/1.6) sowie optischer Bildstabilisierung (OIS). Dazu kommt jeweils eine Weitwinkellinse mit 8 Megapixel (f/2.2) sowie eine Makrolinse mit 2 Megapixel (f/2.4). Für Selfies steht eine Frontkamera mit 16 Megapixeln in einer Punch-Hole-Notch zur Verfügung.
Wie so oft bei Smartphones dieser Klasse gilt auch hier: Hauptkamera hui, Weitwinkel und Makro pfui. Die 50-Megapixel-Linse liefert tolle Aufnahmen bei Tag und macht dank des Nachtmodus in Verbindung mit OIS auch bei Dunkelheit noch eine gute Figur. Üblicherweise fasst die Linse per Pixel Binnning vier Bildpunkte zu einem zusammen, somit entstehen Aufnahmen mit 12,5 Megapixel. Die Methode reduziert zwar die Auflösung, verbessert aber wiederum die Lichtempfindlichkeit. Auf Wunsch kann man auch die volle Auflösung von 50 Megapixel abrufen.
Fotos wirken sehr lebendig dank eines großen Dynamikumfangs, der ein gutes Zusammenspiel aus Licht und Schatten bietet. Bilddetails sind ausgeprägt, der Zoom ist bei zweifacher Vergrößerung noch fast verlustfrei nutzbar, ab fünffacher Vergrößerung neigen die Bilder aber zu grobkörniger Darstellung.
Aufnahmen mit der Weitwinkellinse gehen in Ordnung, offenbaren aber deutlich weniger Bilddetails aufgrund der niedrigen Auflösung. Bei Dunkelheit sollte man den Weitwinkel nicht nutzen, er zeigt dann ohnehin nur dunkles Bildrauschen. Die Makrolinse wiederum hätte man sich auch sparen können. Eine Telelinse wäre uns hier lieber gewesen, diese sind allerdings teurer. Selfies sehen wiederum gut aus, auch das Bokeh im Porträtmodus ist gelungen.
Videos sind mit der Hauptkamera mit bis zu 4K bei 60 FPS (Frames pro Sekunde) möglich. Hier zeigt der OIS sein Können, die Clips sehen flüssig und stabil aus und überzeugen mit hoher Bildschärfe und lebendigen Farben. Das gefällt uns gut. Videos mit der Selfie-Cam gelingen in Full-HD bei 60 FPS.
Poco F6 Pro – Originalaufnahmen
Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen
Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Poco F6 Pro – Originalaufnahmen

Ausstattung: Wie gut ist das Poco F6 Pro?
Angetrieben wird das Poco F6 Pro vom Snapdragon 8 Gen 2 – dem Flagship-Prozessor aus dem Vorjahr. Dieser ist nicht mehr ganz neu, bietet aber noch immer eine enorme Leistung für alle Anforderungen. Selbst Gaming ist kein Problem, was die starken Benchmark-Werte bei 3Dmark Wild Life Extreme mit 3500 Punkten sowie PCmark Work 3.0 mit 15.000 Punkten verdeutlichen.
Der RAM beträgt immer 12 GB und als interner Speicher stehen 256 GB, 512 GB sowie 1 TB zur Auswahl – und zwar von der schnellen Sorte mit UFS 4.0. Eine Erweiterung per microSD-Karte ist aber nicht möglich. Wi-Fi 7, 5G und Bluetooth 5.3 sowie NFC und ein Infrarot-Port sind auch an Bord. Schwach ist der Typ-C-Anschluss, der nur USB 2.0 liefert und damit eine langsame Datenübertragung per Kabel ermöglicht. Für den Preis wäre mehr zu erwarten. Zur Ortung nutzt das Poco F6 Pro Multiband-Technologie via GPS, Glonass, Beidou, Galileo, QZSS und Navic. Laut GPS-Test kommen wir auf eine Genauigkeit von rund 3 Metern.
Poco F6 Pro – Bilderstrecke
Poco F6 Pro

Poco F6 Pro

Poco F6 Pro

Poco F6 Pro

Poco F6 Pro

Poco F6 Pro

Poco F6 Pro

Poco F6 Pro

Poco F6 Pro

Software: Wie lange gibt es Updates?
Das Poco F6 Pro läuft mit Hyper OS 1.0.5 auf Basis von Android 14. Die Änderungen gegenüber der früheren Bedienoberfläche MIUI 14 fallen auf den ersten Blick nur marginal aus. Wie immer ist zu viel Bloatware vorhanden. Zum Testzeitpunkt Ende August stammte der Sicherheits-Patch aus Juli, hier wäre also langsam ein Update fällig. Xiaomi verspricht Sicherheits-Patches für vier Jahre und drei große Android-Updates, also bis Version 17.
Akku: Wie lange hält das Poco F6 Pro durch?
Der Akku hat üppige 5000 mAh. Zum Laufzeitwunder wird das F6 Pro damit aber eher nicht, so konnten wir im Battery Test von PCmark rund 10,5 Stunden festhalten. Das liegt nur im Mittelfeld unseres Testfelds. Über den Tag sollte man mit dem F6 Pro aber problemlos kommen. Das Laden geht dann erfreulich schnell – mit 120 Watt ist das leere Handy in weniger als 30 Minuten voll aufgeladen. Kabellose Laden gibt es aber nicht.
Preis: Wie viel kostet das Poco F6 Pro?
Das Poco F6 Pro ist mit Abstand das teuerste Modell der Reihe. Die UVP für das Modell mit 12/256 GB liegt bei 599 Euro. Mittlerweile ist der Preis aber deutlich gesunken. Die Variante mit 12/256 GB startet bei 389 Euro. Unser Tipp ist das Modell mit 12/512 GB, das mit 445 Euro nur minimal teurer ist.
Fazit
Das Poco F6 Pro bietet als Top-Gerät der preiswerten Marke von Xiaomi viel Performance und ein fabelhaftes Display auf Flagship-Niveau. Anders als sonst bei Poco-Modellen wirkt auch die Verarbeitung mit Glas und Metall statt Kunststoff sehr hochwertig. Per 120-Watt-Netzteil ist das Smartphone rasant geladen. Die Hauptkamera überzeugt ferner am Tag und weitgehend bei Nacht.
Allerdings fehlen einige Merkmale, die sie Top-Smartphones heutzutage bieten. So gibt es keine Telelinse, die Weitwinkellinse ist nur Durchschnitt und die Makrolinse hätte sich Xiaomi sparen können. Einen Schutz vor Wasser samt Zertifikat gibt es nicht – nicht mal bei Spritzwasser. Wenn das nicht stört, bekommt man ein gutes Smartphone, das aber nicht so günstig ist, wie man es von anderen Modellen der Marke her gewohnt ist. Naheliegend ist aus diesem Grund das Poco F6 als günstige Alternative.
Honor 200 Pro
Honor 200 Pro
Das Honor 200 Pro möchte mit einem besonderen Kamera-Setup Porträtfotografen ersetzen. Ist das der neue Flagship-Killer? Die Frage klärt der Testbericht.
- tolle Kamera
- schickes Design
- flotter Prozessor
- hervorragendes Display
- kein Netzteil im Lieferumfang
- nur USB-C 2.0
- wirkt fragil & ist nicht wirklich wasserdicht
- Akkulaufzeit mit Luft nach oben
Honor 200 Pro im Test
Das Honor 200 Pro möchte mit einem besonderen Kamera-Setup Porträtfotografen ersetzen. Ist das der neue Flagship-Killer? Die Frage klärt der Testbericht.
Smartphones haben die digitale Kamera weitestgehend verdrängt. Für Schnappschüsse im Urlaub oder bei geselligen Anlässen hat man ohnehin ein Handy dabei, das schnell griffbereit ist. Smartphones mit Telelinse wiederum eignen sich gut für Landschaftsaufnahmen. Mit dem Honor 200 Pro bietet der chinesische Hersteller jetzt ein Mobilgerät für einen weiteren Einsatzzweck der Fotografie an: Porträtaufnahmen.
Gemeinsam mit dem berühmten Fotostudio Harcourt aus Paris wurden Kamera und Software samt KI-Funktionen speziell für Porträtfotos optimiert. Das Studio hat sich in den 1930er-Jahren einen Namen für hochwertige Porträts von berühmten Persönlichkeiten aus Film, Sport und Politik geschaffen. Zur Handschrift des Studio Harcourt gehört die Arbeit mit Schatten, die ein möglichst plastisches Erscheinungsbild erzeugt. Hierzu nutzen die Fotografen des Studios ein aufwendiges Setting aus sorgfältig ausgewählter Beleuchtung, Make-up sowie der nötigen Fotoapparatur samt Nachbearbeitung.
Die Erfahrung des Studios gepaart mit dem Know-how von Honor floss bei der Entwicklung des 200 Pro mit ein. Der jüngste Spross der Number-Reihe, die unterhalb der Flaggschiffe der Magic-Serie angesiedelt ist, bringt neben der Triple-Kamera noch weitere Highlights mit sich. Dazu gehört der flotte Snapdragon 8s Gen 3 – eine leicht abgespeckte Variante des High-End-Chipsatzes von Qualcomm, sowie ein schickes Design. Ob der Nachfolger des Honor 90 hält, was er verspricht, zeigt dieser Test.
Design: Ist das Honor 200 Pro wasserdicht?
Auffälligstes Design-Merkmal gegenüber dem Vorgänger ist die neugestaltete Triple-Kamera auf der Rückseite. Diese befindet sich jetzt in einem ovalen, schwarzen Element, das deutlich hervorsteht. Die Rückseite aus aufgerautem Glas gibt es in zwei Farbvarianten: Schwarz und Weiß – letztere mit auffälliger Marmorierung. Erfreulich: Fingerabdrücke sind kaum sichtbar. Die Verarbeitung wirkt sehr hochwertig, lediglich die aufgeklebte Displayschutzfolie wirft nach einer Weile leichte Blasen.
Das Honor 200 Pro ist sehr dünn und leicht für die sonst wuchtigen Ausmaße. Es liegt gut in der Hand und ist auf jeden Fall ein Hingucker. Allerdings raten wir zum Kauf einer Schutzhülle, denn das Smartphone wirkt nicht gerade widerstandsfähig. Immerhin ist es nicht wasserscheu, mit einer Zertifizierung nach IP65 (Spritzwasserschutz) übersteht es zumindest ein Missgeschick mit einem Glas Wasser oder Regentropfen. Länger unter Wasser tauchen sollte man es aber nicht.
Display: Wie gut ist die Anzeige?
Das große OLED-Display mit 6,78 Zoll in der Diagonale ist eine Augenweide. Inhalte sind knackig scharf bei 2700 × 1200 Pixeln, 120 Hertz sorgen für eine flüssige Bilddarstellung und die Helligkeit ist ebenfalls top. Selbst bei strahlendem Sonnenschein konnten wir die Anzeige gut ablesen. Kontraste sind gut abgestimmt und Farben sind kraftvoll, aber nicht unnatürlich. Hier gibt es nichts zu meckern.
Kamera: Wie gut sind Fotos mit dem Honor 200 Pro?
Beim Honor 200 Pro kommt eine Triple-Kamera zum Einsatz: Die Hauptlinse (f/1.9) löst mit bis zu 50 Megapixel auf, fasst standardmäßig vier Pixel zu einem zusammen, was Fotos mit 12,5 Megapixel liefert. Zum Einsatz kommt ein großer Sensor mit lichtstarker Blende sowie eine optische Bildstabilisierung (OIS).
Das Teleobjektiv (f/2.4) mit OIS kommt ebenfalls auf 50 Megapixel mit einem Pixel-Binning-Verhältnis von 4:1. Die Weitwinkellinse (f/2.2) mit 12 Megapixeln dient auch als Makroobjektiv. Für Selfies kommt eine Dual-Kamera mit 50 Megapixeln zum Einsatz, wobei die zweite Linse mit 2 Megapixeln die Tiefenschärfe erzeugt.
Die Fotos mit der Hauptlinse sind scharf und sehen einfach klasse aus, sowohl bei tollem Wetter als auch schwierigen Lichtverhältnissen. Hier kann das Honor 200 Pro locker mit dem Honor Magic 6 Pro mithalten. Dynamikumfang wie auch Bilddetails sind sehr ausgeprägt. Videos sind in filmreifer Qualität mit 4K-Auflösung bei 60 Bildern pro Sekunde (FPS) möglich.
Die Telelinse überzeugt ebenfalls, kann aber nicht ganz mit dem Objektiv aus dem Magic 6 Pro mithalten. Diese bietet einen optischen Zoom bis zu einer 2,5-fachen Vergrößerung ohne nennenswerte Verluste. Digital verstärkt ist ein bis zu 50-facher Zoom möglich, aber wenig sinnvoll. Bis zu einer fünffachen Vergrößerung sind Aufnahmen noch gut zu gebrauchen, kann man mit Bildrauschen leben, geht auch der zehnfache Zoom in Ordnung.
Die große Besonderheit ist der Porträtmodus beim Honor 200 Pro. Dieser nutzt die Telelinse bei zweifacher Vergrößerung und setzt KI-Funktionen ein, um die Studiobedingungen nachzustellen. Es stehen neben der normalen Ansicht auch drei Filter des Studio Harcourt zur Auswahl: Dynamisch, Farbe und Klassisch (Schwarz-Weiß). Die Filter sehen toll auch, achtet man dabei auf Perspektive, Belichtung und nutzt etwa Make-up, kann man sich eigentlich den Weg zu einem professionellen Fotografen sparen.
Die Weitwinkellinse weicht farblich minimal ab von den übrigen Objektiven und tendiert stärker in Richtung Gelb. Bilddetails sind etwas weniger ausgeprägt, dennoch gelingen auch damit gute Aufnahmen. Gleichzeitig kommt das Weitwinkelobjektiv bei Nahaufnahmen zum Einsatz. Die Software der Kamera-App schaltet hier automatisch um, sobald man sehr nahe an einem Objekt ist.
Ebenfalls mehr als gelungen sind Selfies, Videos mit der Frontlinse sind in Full-HD bei 60 FPS oder in 4K bei 30 FPS möglich. Ersteres sieht geschmeidiger aus. Auch ein Multivideo aus beiden Linsen zeichnet das Honor 200 Pro auf.
Honor 200 Pro – Originalaufnahmen
Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen
Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Honor 200 Pro – Originalaufnahmen

Ausstattung: Wie schnell ist der Snapdragon 8s Gen 3?
Honor setzt beim 200 Pro auf den Qualcomm Snapdragon 8s Gen 3. Die abgespeckte Variante des aktuellen High-End-Chipsatzes entspricht in etwa der zweiten Generation der Reihe. Damit ist das 200 Pro nicht so stark wie aktuelle Flagship-Smartphones, bietet aber dennoch eine bärenstarke Leistung. Egal, ob beim Gaming, Videoaufnahmen in hoher Auflösung oder Medienkonsum: Das Honor 200 Pro hat immer genug Power und läuft stets rund. Bei PCmark erreicht es stolze 17.300 Punkte, bei 3Dmark „Wild Life Extreme“ sind es starke 3000 Punkte.
Üppig ist zudem die Speicherausstattung: 512 GB interner Speicher und 12 GB RAM. Da kann man auch darüber hinwegsehen, dass es keine Aufrüstungsmöglichkeit per microSD-Karte gibt. Enttäuschend dagegen ist der Übertragungsstandard des Anschlusses: Wegen USB-C 2.0 gestaltet sich die kabelgebundene Datenübertagung unnötig zeitintensiv. Bei dem Preis hätte eigentlich mehr drin sein müssen – auch wenn andere chinesische Anbieter das ähnlich handhaben.
Auf einem aktuellen Stand hingegen ist die kabellose Konnektivität mit Bluetooth 5.3, NFC, Infrarot-Port sowie 5G und Wi-Fi 6. Zur Ortung nutzt das Smartphone GPS, Glonass, Beidou und Galileo mit einer hohen Genauigkeit von 3 Metern laut GPS-Test.
Honor 200 Pro – Bilderstrecke
Honor 200 Pro

Honor 200 Pro

Honor 200 Pro

Honor 200 Pro

Honor 200 Pro

Honor 200 Pro

Honor 200 Pro

Honor 200 Pro

Honor 200 Pro

Honor 200 Pro

Software: Wie lange gibt es Updates?
Das Honor 200 Pro läuft mit Android 14 mit der Bedienoberfläche Magic OS 8. Diese verzichtet standardmäßig auf einen App-Drawer und nutzt die für Android typischen Gesten. Honor packt eine Menge eigener Apps als Alternative zu Google-Anwendungen auf das Handy, etwa für den Kalender, Tools sowie einen eigenen Apps-Store zusätzlich zum Google Play Store.
Der Sicherheits-Patch stammt zum Testzeitpunkt aus Mai und ist noch aktuell. Honor hat Software-Patches für einen Zeitraum von vier Jahren angekündigt, zudem soll es drei große Android-Updates geben.
Akku: Wie lange läuft das Honor 200 Pro?
Für ein so schlankes Gerät sind 5200 mAh beim Akku eine echte Ansage. Das Ergebnis beim Battery Test von PCmark war dagegen mit rund 10 Stunden enttäuschend. Flaggschiff-Smartphones kommen dagegen auf längere Laufzeiten. Damit kommt das Smartphone knapp über den Tag – viele Reserven bleiben dann aber nicht.
Ein weiteres Ärgernis: Honor legt wie schon beim Vorgänger kein Netzteil mehr bei. Was etwa bei Samsung aufgrund des ohnehin nur langsamen Ladetempos der Koreaner eigentlich egal ist, stört beim Chinesen. Denn möglich sind bis zu 100 Watt, was rasantes Laden erlaubt. Dafür muss aber ein spezielles Netzteil von Honor her. Damit ist der Akku in rund 30 Minuten aufgeladen. Mit anderen Ladegeräten ist das natürlich über USB-C möglich, aber langsamer. Mit einem 66-Watt-Netzteil etwa klappt es in knapp 45 Minuten. Laden per Induktion ist mit bis zu 66 Watt möglich.
Preis: Was kostet das Honor 200 Pro?
Die UVP für das Honor 200 Pro liegt zum Marktstart bei 799 Euro. Mittlerweile sind die Preise weitgehend auf unter 500 Euro gefallen. Den besten Deal gibt es derzeit bei Amazon für 470 Euro.
Fazit
Das Honor 200 Pro ist eine spannende und sehr schicke Alternative zu Flagship-Smartphones. Damit gehört es zu den Anwärtern auf das beste Smartphone der gehobenen Mittelklasse. Die Kamera überzeugt bei den meisten Anwendungsfällen – insbesondere Porträtfotos. Klasse ist auch das OLED-Display und richtig schnell ist der Prozessor, auch wenn er nicht ganz mit der neuesten Generation mithalten kann – was aber im Alltag kaum jemand merken dürfte.
Luft nach oben ist bei der Akkulaufzeit, der Schutz vor Wasser könnte besser sein und warum ein Anschluss mit USB-C 2.0 zum Einsatz kommt, ist uns schleierhaft. Zum schnellen Laden braucht es ein Netzteil, das nicht standardmäßig im Lieferumfang enthalten ist. Zum Marktstart bekommt man es aber häufig geschenkt dazu.
Wer ein schnelles Smartphone sucht und sehr gerne Fotos macht, den hohen Preis von High-End-Smartphones aber nicht mitmachen will, bekommt mit dem Honor 200 Pro eine exzellente Option.
Poco F7 Pro
Poco F7 Pro
Snapdragon 8 Gen 3, 90-Watt-Laden und 3K-OLED – das Poco F7 Pro bietet Oberklasse-Technik zum fairen Preis. Der Test zeigt, ob es der Mittelklasse-König ist.
- starke Prozessorleistung
- fairer Preis
- gute Verarbeitung & IP68
- ordentliche Hauptkamera
- Top-Display
- keine Telelinse
- kein Qi
- ohne eSIM
- nur USB-C 2.0
- mäßige Weitwinkellinse
Xiaomi Poco F7 Pro im Test
Snapdragon 8 Gen 3, 90-Watt-Laden und 3K-OLED – das Poco F7 Pro bietet Oberklasse-Technik zum fairen Preis. Der Test zeigt, ob es der Mittelklasse-König ist.
Poco steht seit Jahren für starke Technik zum fairen Preis – vorrangig bei der F-Reihe, die traditionell auf Leistung getrimmt ist. Mit dem F7 Pro bringt die Submarke von Xiaomi ein Smartphone mit dem Snapdragon 8 Gen 3, einem strahlend hellen 3K-OLED-Display und flachem, schickem Design auf den Markt – zum Einstiegspreis ab 430 Euro.
Nur bei der Kameraausstattung, etwa durch den Verzicht auf eine Telelinse, zeigt sich die Mittelklasse. Wie sich das F7 Pro im Alltag und unter Last schlägt, klärt unser Test.
Design
Optisch hebt sich das Poco F7 Pro von typischer Mittelklasseware ab. Der kantige Look erinnert an aktuelle iPhones, das flache Gehäuse wirkt elegant und hochwertig. Die Verarbeitung ist tadellos: Ein Rahmen aus Metall trifft auf eine Rückseite aus Glas – erstmals in der F-Reihe sogar mit IP68-Zertifizierung gegen Wasser und Staub.
Mit 8,1 mm Bautiefe zählt das F7 Pro zu den schlanken Vertretern seiner Klasse. Die Abmessungen von 160,3 × 75 × 8,1 mm und das Gewicht von g machen es zwar nicht zum Kompaktgerät, doch für seine Größe wirkt es angenehm leicht. Einhändige Bedienung ist dennoch kaum praktikabel.
Auffällig ist das große, runde Kameraelement mit zwei Linsen und LED – es sorgt für einen gewissen Wiedererkennungswert, lässt das Gerät aber auf dem Tisch leicht kippeln. Die Tasten sitzen sauber im Gehäuse und bieten einen klar definierten Druckpunkt. Eine transparente Schutzhülle legt Poco gleich bei.
Xiaomi Poco F7 Pro – Bilder
Xiaomi Poco F7 Pro

Xiaomi Poco F7 Pro

Xiaomi Poco F7 Pro

Xiaomi Poco F7 Pro

Xiaomi Poco F7 Pro

Xiaomi Poco F7 Pro

Xiaomi Poco F7 Pro

Xiaomi Poco F7 Pro

Display
Das Poco F7 Pro bietet ein beeindruckendes AMOLED-Display, das sich nicht hinter deutlich teureren Geräten verstecken muss und sich auf Flaggschiff-Niveau bewegt. Die hohe Auflösung von 3200 × 1440 Pixeln sorgt bei einer Diagonale von 6,67 Zoll für eine gestochen scharfe Darstellung mit 526 PPI. Farben wirken kräftig und Kontraste sind mit tiefstem Schwarz ausgeprägt – typisch OLED.
Mit einer maximalen Helligkeit von bis zu 3200 Nits bleibt der Bildschirm selbst bei direkter Sonneneinstrahlung ablesbar. Die variable Bildwiederholrate von 60 bis 120 Hz sorgt für flüssige Darstellungen, etwa beim Scrollen oder Gaming. Die Touch-Abtastrate liegt bei schnellen 480 Hz – das kommt primär schnellen Reaktionen in Spielen zugute. Geschützt wird das Panel durch Gorilla Glass 7i, die Frontkamera sitzt unauffällig in einer kleinen Punch-Hole-Notch.
Kamera
Bei der Kamera zeigt das Poco F7 Pro seine Mittelklasse-Herkunft. Statt vielseitigem Triple-Setup verbaut der Hersteller eine Dual-Kamera auf der Rückseite – mit starker Haupt- und schwächerer Weitwinkellinse.
Die 50-Megapixel-Hauptkamera (f/1.6) mit optischer Bildstabilisierung (OIS) liefert bei Tageslicht detailreiche Aufnahmen mit natürlicher Farbwiedergabe und guter Dynamik. Per Software lassen sich Farbstil und Kontrast auf Wunsch anpassen. Selbst digitaler Zoom bei vierfacher Vergrößerung funktioniert mit nur geringen Qualitätseinbußen, bis zehnfach sind die Bilder noch brauchbar. Bei Nacht überrascht das Poco mit hellen, gut abgestimmten Fotos – das Rauschen ist zwar sichtbar, bleibt in dieser Preisklasse aber im Rahmen.
Weniger überzeugt die 8-Megapixel-Weitwinkelkamera (f/2.2). Die Bilddynamik ist eingeschränkt, Details wirken schnell verwaschen. Einen dedizierten Makromodus gibt es nicht. Die 20-Megapixel-Frontkamera schießt hingegen scharfe Selfies und erzeugt im Porträtmodus ein natürliches Bokeh.
Videos nimmt das F7 Pro mit der Hauptkamera in bis zu 4K bei FPS auf – stabilisiert, detailreich und farbtreu. Die Frontkamera filmt maximal in Full-HD mit 60 FPS, liefert aber ebenfalls solide Ergebnisse.
Unterm Strich: Die Kameraausstattung reicht für Alltag und soziale Medien völlig aus, ambitionierte Fotografen müssen aber auf Telezoom und mehr Flexibilität verzichten.
Xiaomi Poco F7 Pro – Originalaufnahmen
Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Xiaomi Poco F7 Pro – Originalaufnahmen

Ausstattung
Im Poco F7 Pro arbeitet Qualcomms Top-Prozessor aus 2024 – der Snapdragon 8 Gen 3. Die Leistung reicht problemlos für alle Aufgaben, vom Alltag hin zu anspruchsvollem Gaming. Damit positioniert sich das Gerät an der oberen Grenze der Mittelklasse.
Im Benchmark überzeugt das F7 Pro mit starken Ergebnissen: Über 17.000 Punkte bei PCmark und rund 4200 Punkte im 3Dmark Wild Life Extreme belegen das. Im Stresstest blieb die Performance relativ stabil bei rund 68 Prozent.
Zur Seite stehen 12 GB RAM sowie wahlweise 256 GB oder 512 GB Speicher nach dem schnellen Standard UFS 4.1. Eine Erweiterung per microSD-Karte ist allerdings nicht vorgesehen. Dual-SIM wird unterstützt (zweimal Nano-SIM). Support für eine eSIM gibt es aber nicht.
Auch bei den Schnittstellen zeigt sich das F7 Pro gut ausgestattet: Wifi 7, Bluetooth 5.4, NFC und ein Infrarot-Port sind mit an Bord. Einziger Wermutstropfen: Der USB-C-Port unterstützt nur USB 2.0, was zu langsameren Datenübertragungen führt – in dieser Preisklasse aber noch üblich.
Die Stereo-Lautsprecher liefern einen guten Klang bei der Medienwiedergabe. Die akustische Qualität beim Telefonieren überzeugt ebenfalls. Der Fingerabdrucksensor ist ins Display integriert und reagiert zuverlässig.
Software
Auf dem Poco F7 Pro läuft Hyper OS 2, Xiaomis Bedienoberfläche auf Basis von Android 15. Bei der Einrichtung lässt sich zwischen App-Drawer und klassischem Startbildschirm wählen, ebenso zwischen Gestensteuerung und Navigationstasten. Die grafische Oberfläche wirkt aufgeräumt, allerdings ist werksseitig recht viel Bloatware vorinstalliert, die sich aber entfernen lässt. Praktisch: Xiaomi integriert einige KI-Funktionen zur Bildbearbeitung, darunter einen intelligenten Radierer oder eine Entspiegelung.
Zum Testzeitpunkt war der Sicherheits-Patch vom 1. April 2025 installiert – nicht mehr ganz aktuell, aber noch im grünen Bereich. Positiv: Xiaomi hat bei der Update-Politik stark nachgebessert. Sicherheits-Updates soll es nun ganze sechs Jahre lang geben, also bis 2031. Neue Android-Versionen sind für vier Jahre zugesichert – bis einschließlich Android 19. Das ist in dieser Preisklasse bislang eine Seltenheit.
Akku
Trotz des schlanken Gehäuses verbaut Poco im F7 Pro einen kräftigen 6000-mAh-Akku. Damit hat das Smartphone mehr als genug Reserven. Im Battery Test von PCmark erzielte das Gerät einen hervorragenden Wert von knapp 14,5 Stunden – genug für einen langen Tag, bei moderater Nutzung sind sogar bis zu zwei Tage drin.
Auch beim Laden zeigt sich das Poco F7 Pro von der schnellen Seite: Mit dem beiliegenden 90-Watt-Netzteil springt der Akkustand in nur 10 Minuten von 20 auf 40 Prozent. Die vollständige Ladung von 20 auf 100 Prozent dauert knapp 30 Minuten, ein kompletter Ladevorgang ist in rund 40 Minuten erledigt. Einziger Wermutstropfen: Kabelloses Laden wird nicht unterstützt.
Preis
Das Poco F7 Pro startete mit einer UVP von 600 Euro für die Variante mit 12/256 GB Speicher, das Modell mit 12/512 GB lag zum Marktstart bei 650 Euro. Inzwischen sind die Preise deutlich gesunken: Die Version mit 256 GB ist aktuell ab rund 430 Euro erhältlich, für die 512-GB-Variante werden etwa 500 Euro fällig. Zur Auswahl stehen die Farben Silber, Schwarz und Blau.
Fazit
Das Poco F7 Pro bietet ein exzellentes Preis-Leistungs-Verhältnis und ist somit ein echter No-Brainer. Die Performance liegt auf Flaggschiff-Niveau von 2024. Das schlanke Gehäuse ist hochwertig verarbeitet, der große Akku sorgt zudem für starke Laufzeiten. Hinzu kommt ein erstklassiges OLED-Display, das kaum Wünsche offenlässt.
Wer auf eine Telekamera verzichten kann und nicht den höchsten Wert auf Fotografie legt, erhält mit dem Poco F7 Pro ein äußerst leistungsstarkes Smartphone für unter 500 Euro – ein echter Geheimtipp. Der König der Mittelklasse ist es zwar nicht wegen der fehlenden Telelinse – aber so etwas wie ein Sportwagen unter den erschwinglichen Smartphones.
Samsung Galaxy S24 FE
Samsung Galaxy S24 FE
Samsung bietet mit der Fan Edition des Galaxy S24 wieder Top-Technik zum günstigeren Preis. Wie viel Premium steckt in der abgespeckten Version? Das zeigt der Test.
- starke Leistung
- hervorragende Kamera mit Telelinse
- lange Akkulaufzeit
- Software-Updates bis 2031
- größer als Vorgänger
- breite Display-Ränder
- Alleinstellungsmerkmal fehlt
Samsung Galaxy S24 FE im Test
Samsung bietet mit der Fan Edition des Galaxy S24 wieder Top-Technik zum günstigeren Preis. Wie viel Premium steckt in der abgespeckten Version? Das zeigt der Test.
Mit der „Fan Edition“ bietet Samsung wieder eine leicht abgespeckte Variante seiner Galaxy-S-Smartphones an, die erstklassige Technik zum erschwinglichen Preis bieten möchte. Gegenüber dem Vorgänger Samsung Galaxy S23 FE macht das S24 FE einen deutlichen technischen Sprung nach vorn. Allerdings wächst das Smartphone deutlich und ähnelt nun stark dem Samsung Galaxy S24+.
Angesichts der ähnlichen Ausstattung und hohen unverbindlichen Preisempfehlung (UVP) stellt sich die Frage nach dem Alleinstellungsmerkmal der Fan Edition. Ob hier ein Schnäppchen mit Top-Technik angeboten wird oder eine nur Mogelpackung, offenbart der Testbericht.
Design: Was ist der Unterschied zwischen Galaxy S24+ und S24 FE?
Bisher nahm das FE-Modell bei einer Größe von 6,4 Zoll eine Sonderstellung bei der Galaxy-S-Reihe zwischen dem kompakten Modell mit 6,1 Zoll und der Plus-Variante mit 6,7 Zoll ein. Das Samsung Galaxy S24 FE ist aber deutlich gewachsen und misst jetzt 6,7 Zoll in der Diagonale. Schade, der Autor dieses Testberichts wusste die Zwischengröße sehr zu schätzen.
Auf den ersten Blick ist das Galaxy S24 FE nur schwer vom Galaxy S24+ (Testbericht) zu unterscheiden. Die Fan-Edition des S24 setzt auf fast identisches Design mit einer Rückseite aus Glas und mattem Metallrahmen. Dazu kommen die seit dem S23 bekannten drei in einer Linie angeordneten Kameralinsen mit Metallrand.
Erst bei genauerem Hinsehen und direktem Vergleich mit dem Plus-Modell offenbaren sich einige Unterschiede. So ist das FE-Modell trotz gleicher Bildschirmdiagonale mit 162 × 77,3 × 8 mm etwas größer geraten. Es ist damit etwa 4 mm länger und 2 mm breiter, was an den breiteren Display-Rändern liegt. Zudem ist es etwas schwerer mit 213 g. Ein Zertifikat für IP68 ist vorhanden, womit das Handy den Aufenthalt in Süßwasser für 30 Minuten bis in 150 cm Tiefe überstehen sollte. Die Verarbeitung ist tadellos.
Display: Wie sind Helligkeit und Auflösung beim S24 FE?
Wie bereits erwähnt, beträgt die Diagonale des OLED-Displays 6,7 Zoll. Die Auflösung fällt mit 2340 × 1080 Pixel allerdings niedriger aus als beim S24+ mit 3K. Dennoch bleibt die Anzeige mit einer Pixeldichte von 385 PPI (Pixel per Inch) scharf genug, dass Pixel mit dem bloßen Auge nicht zu erkennen sind. Geschützt wird das Display durch Gorilla Glass Victus+ und nicht Victus 2 wie beim S24+.
Die Bildwiederholrate regelt sich automatisch zwischen 60 und 120 Hz. Das Galaxy S24+ regelt im Gegensatz dazu von 1 bis 120 Hz. Die Bildqualität ist auch beim FE-Modell gewohnt hervorragend. Bei der maximalen Helligkeit kann das S24 FE nicht ganz mit dem S24+ mithalten, bleibt aber bei rund 1600 Nits laut Samsung auf einem hohen Niveau. Im Test konnten wir es im Freien auch bei gutem Wetter ablesen. Das Spiegeln scheint etwas ausgeprägter als bei den übrigen Modellen der S24-Reihe.
Samsung Galaxy S24 FE – Bilderstrecke
Samsung Galaxy S24 FE

Samsung Galaxy S24 FE

Samsung Galaxy S24 FE

Samsung Galaxy S24 FE

Samsung Galaxy S24 FE

Samsung Galaxy S24 FE

Samsung Galaxy S24 FE

Samsung Galaxy S24 FE

Kamera: Wie gut sind Fotos mit dem Galaxy S24 FE?
Die Triple-Kamera bietet eine Hauptlinse (f/1.8) mit 50 Megapixeln und optischer Bildstabilisierung (OIS) ein Weitwinkelobjektiv (f/2.2) mit 12 Megapixel sowie eine Telelinse mit OIS und lediglich 8 Megapixel (f/2.4). Das S24+ hat im Vergleich dazu eine Telelinse mit 10 Megapixeln. Abgespeckt ist auch die Selfie-Kamera mit 10 Megapixeln.
Mit dem Galaxy S24 FE gelingen bei Tag fantastische Aufnahmen. Bilddetails sind ausgeprägt und der Dynamikumfang hoch. Farben wirken natürlich, auch wenn sie für unseren Geschmack teils etwas blass erscheinen. Der Nachtmodus hellt bei Dunkelheit effektiv die Motive auf und liefert gute Fotos. Bildrauschen ist sichtbar, hält sich aber noch in Grenzen. An das Niveau des Galaxy S24 und S24+ reicht die Kamera bei schwierigen Lichtverhältnissen nicht ganz heran, bleibt aber verdammt nah dran.
Der Ultraweitwinkel ist verglichen mit dem Vorgänger Galaxy S23 FE etwas verbessert worden und weicht farblich kaum ab von der Hauptlinse. Die Telelinse bietet einen dreifachen optischen Zoom mit ansprechenden Aufnahmen, auch wenn Bilddetails etwas weniger ausgeprägt sind als beim S24+. Digital unterstützt ist damit bis zu 30-facher Zoom möglich. Auch Selfies überzeugen. Videos machen einen ausgezeichneten Eindruck und sind bei 4K-Auflösung mit bis zu 60 FPS (Frames pro Sekunde) möglich oder bei 8K mit 30 FPS.
Samsung Galaxy S24 FE – Originalaufnahmen
Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Samsung Galaxy S24 FE – Originalaufnahmen

Ausstattung: Wie stark ist das Galaxy S24 FE?
Als Prozessor kommt mit dem Samsung Exynos 2400e eine leicht heruntergetaktete Variante des Chips aus dem S24 und S24+ zum Einsatz. Dieser ist aber nur minimal schwächer bei der Performance, wie Benchmarks zeigen: 17.000 Punkte bei PCmark sowie 3900 Punkte bei „Wild Life Extreme“ von 3Dmark sind eine Ansage auf Flagship-Niveau. Das Betriebssystem reagiert flott, auch Gaming ist mit dem S24 FE auf hohem Niveau drin. Bei Dauerbelastung im Stresstest mit „Wild Life Extreme“ wird das S24 FE allerdings ziemlich heiß und büßt nach mehreren Durchläufen rund 50 Prozent der anfänglichen Leistung ein.
Abgespeckt wurde im Vergleich zum S24 und S24+ beim Speicher: Es stehen 8 GB RAM sowie 128 GB oder 256 GB interner Speicher zur Verfügung, eine Erweiterungsmöglichkeit fehlt. Von ersterer Variante raten wir daher entschieden ab, da der Platz knapp werden könnte. Die übrige Ausstattung ist auf Top-Niveau: Wi-Fi 6E, USB-C 3.2, Bluetooth 5.3 und NFC lassen wenig Wünsche offen. Die Navigation nutzt GPS, Glonass, Beidou, Galileo, QZSS sowie Navic.
Software: Wie lange gibt es Updates für das Galaxy S24 FE?
Das S24 FE läuft mit Android 14 und der Samsung-Bedienoberfläche One UI 6.1. Vorbildlich sind die Koreaner wie immer bei den Updates, der Sicherheits-Patch war zum Testzeitpunkt aktuell – Updates gibt es monatlich für stolze sieben Jahre, inklusive Versions-Upgrades für Android! Besser geht es kaum.
Samsung liefert die Fan-Edition mit den neuesten Diensten von Galaxy AI aus. Dazu gehören etwa Tools zum Bearbeiten von Fotos. So kann man Objekte oder Personen auf Fotos verwinden lassen. Das gelingt zum Teil erstaunlich gut, je umfangreicher und gewagter die Änderungen, desto künstlicher sieht das Ergebnis aus, wie ein Beispiel in unserer Bildergalerie zeigt. Schatten oder Spiegelungen entfernt die KI aus Fotos ebenfalls oder begradigt schiefe Motive automatisch. KI-bearbeitete Fotos werden zur Kennzeichnung mit einem Stern versehen, um Missbrauch wie „Deepfakes“ vorzubeugen. Das AI-Feature „Portrait-Studio“ erstellt aus einem Selfie einen Avatar, der wahlweise als 3D-Cartoon, Comic-Zeichnung, Gemälde oder Bleistiftskizze dargestellt werden kann.
Ein bekanntes Feature ist die Live-Übersetzung bei Telefonaten in mehreren Sprachen. Die Übersetzung benötigt jedoch Zeit, was zu Überschneidungen bei neuen Gesprächsbeiträgen führen kann. Die Genauigkeit ist unterschiedlich, und es gibt noch Raum für Optimierung. Das S24 FE kann auch offline als Übersetzungsgerät arbeiten.
Nicht ideal ist die Textzusammenfassung, da sie nicht immer den wesentlichen Inhalt des Textes korrekt wiedergibt. Die Rechtschreibprüfung ist teils inkonsistent. Eine interessante Funktion ist hingegen die Bildsuche: Durch das Drücken des Home-Buttons und Markieren eines Bildbereichs auf dem Display kann eine Suche ausgelöst werden – und das funktioniert erstaunlich gut, ist aber eigentlich ein Google-Feature.
Akku: Wie lange hält das Galaxy S24 FE durch?
Der Akku fällt mit 4700 mAh gegenüber dem S24+ minimal kleiner aus. Die Akkulaufzeit ist mit 12 Stunden laut Battery Test von PCmark dennoch stark – auch wenn sie fast 2 Stunden unter dem Niveau des Galaxy S24+ bleibt. Damit sollte das Smartphone trotzdem locker über den Tag mit Reserven kommen. Geladen wird gemächlich per Kabel mit 25 Watt oder Qi mit 15 Watt.
Preis: Wie viel kostet das Galaxy S24 FE?
Die UVP ist mit 749 Euro für 8/128 GB und 809 Euro für 8/256 GB entschieden zu hoch. Zum Zeitpunkt der Veröffentlichung war der Unterschied zum S24+ zu gering, um einen Kauf zu rechtfertigen. Teilweise gab es das Plus-Modell sogar preiswerter.
Mittlerweile ist der Preis der Fan Edition aber spürbar gesunken. Die Variante mit kleinem Speicher gibt es mittlerweile ab 401 Euro, wir raten aber gleich zur Variante mit 256 GB ab 490 Euro. Als Farben stehen Anthrazit, Hellblau, Hellgrün und Gelb zur Auswahl.
Fazit
Das Galaxy S24 FE macht einen deutlichen Leistungssprung gegenüber dem Vorgänger und ist wohl die bisher beste Fan Edition. Die Performance ist ganz nah am Level des Galaxy S24+, Kamera, Akkulaufzeit sowie das Display und Design überzeugen – bleiben nur minimal hinter den anderen Modellen der aktuellen S-Reihe zurück.
Allerdings fehlt in gewisser Hinsicht ein echtes Alleinstellungsmerkmal, seit das S24 FE die Dimensionen des Plus-Modells angenommen hat. Nach einer anfangs zu hohen UVP sinken derzeit die Preise, was es das Mobilgerät dennoch zu einer preiswerten Alternative mit hervorragender Technik zu den Samsung-Flagships macht – wie auch schon die Vorgängermodelle.
Xiaomi 13T
Xiaomi 13T
Xiaomis T-Serie folgt immer zum Jahresende und ist dabei günstiger, aber oftmals auch abgespeckt im Vergleich zur eigentlichen Spitzenserie. Beim neuen Xiaomi 13T ist das anders.
- hervorragendes Display
- tolle Kamera mit Telelinse
- schick und schnell
- wasserdicht
- guter Preis
- kein kabelloses Laden
- wieder nur USB 2.0
Xiaomi 13T im Test
Xiaomis T-Serie folgt immer zum Jahresende und ist dabei günstiger, aber oftmals auch abgespeckt im Vergleich zur eigentlichen Spitzenserie. Beim neuen Xiaomi 13T ist das anders.
Xiaomi 13T und Xiaomi 13T Pro erweitern auch in diesem Jahr die High-End-Serie, die bis jetzt aus Xiaomi 13 und Xiaomi 13 Pro bestand. Im Gegensatz zu den letzten Jahren ist der Unterschied der T-Modelle zur Spitze aber deutlich geringer, klar günstiger als die Top-Modelle bleiben sie trotzdem. Klingt klasse – wir wollten im Test des Xiaomi 13 wissen, ob es das auch ist.
Design und Verarbeitung
Bei der Optik orientiert sich das Xiaomi 13T stark am Xiaomi 13. Unser Testmodell kommt im gleichen Farbton (Schwarz), bietet eine fast identische, spiegelnde Glasrückseite mit stark gerundeten Seiten und selbst die Kamera weist eine deutliche Ähnlichkeit auf. Das ist einerseits etwas langweilig, andererseits wirkt das T-Modell dadurch genauso edel wie die Oberklasse. Auch bei der Verarbeitung gibt es nichts zu meckern, sie ist vorbildlich. Ebenfalls schön: Eine IP68-Zertifizierung, die Schutz vor Staub und Wasser bescheinigt, ist wie bei den „großen“ auch beim 13T mit dabei. Wegen des größeren Displays und des etwas zu dicken Rahmens ist das T-Modell insgesamt spürbar größer und etwas schwerer geworden.
Alle Bilder zum Xiaomi 13T
Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T
Xiaomi 13T

Xiaomi 13T

Display
War der Bildschirm und damit das Xiaomi 13 noch recht handlich, wächst das Display beim Xiaomi 13T auf stolze 6,67 Zoll an. Gleichzeitig steigt die Auflösung, so kommt der Bildschirm im T-Modell auf knapp 450 Pixel pro Zoll und ist somit sogar schärfer als im Xiaomi 13. Auch bei den restlichen Werten zeigt sich das Panel des 13T vorbildlich. Es punktet dank OLED-Technik und Unterstützung von HDR10+ und Dolby Vision mit bis zu 68 Mrd. Farben. Es ist nicht nur sehr kontraststark, sondern stellt Farben zudem auf Wunsch intensiv, aber ausreichend farbtreu dar.
Die Helligkeit ist ebenfalls vorbildlich, wir konnten über 1100 cd/m² messen, der Bildschirm liegt somit auf dem Niveau des kleinen Flagship-Smartphones. Zugelegt hat das Xiaomi 13T bei der Bildwiederholungsrate: Sie steigt auf satte 144 Hz – nötig ist das unserer Ansicht nach aber nicht. Im Gegensatz zum günstigeren Poco F5 bietet das Xiaomi 13T ein echtes Always-on-Display und rundet damit die positive Leistung des Displays ab.
Kamera
Das neue Xiaomi 13T setzt auf eine Triple-Cam mit Haupt-, Weitwinkel- und Telelinse. Mit 50, 50 und 12 Megapixel ist die Auflösung der Linsen bis auf die der Hauptkamera sogar deutlich höher als beim Xiaomi 13. Dafür wird beim 13T nur noch die Hauptkamera von einem optischen Bildstabilisator (OIS) unterstützt. Tatsächlich merkt man das im direkten Vergleich auch, wenn nur etwas.
Zwar ist die Bildqualität von Xiaomi 13 und 13T insgesamt ähnlich hoch, im Detail gibt es dann aber doch ein paar Unterschiede. So gefallen uns Haupt- und Weitwinkelkamera des neuen 13T bei Tageslicht mindestens genauso gut wie beim Xiaomi 13, in manchen Situationen sogar noch etwas besser.
Bei Nachtaufnahmen liegt hingegen das kleine Top-Modell leicht vor dem 13T. Außerdem hat das Xiaomi 13 beim Teleobjektiv die Nase vorn. Insgesamt sind die Unterschiede aber selten der Rede wert und auch das Xiaomi 13T bietet Fotoqualität auf sehr hohem Niveau. Die Frontkamera macht ebenfalls ordentliche Bilder, die auf dem Niveau der Xiaomi-13-Modelle sind, die Konkurrenz macht das aber bisweilen noch besser. Etwas schade: Bei Videos ist die Hauptkamera zwar eigentlich ebenfalls ordentlich, allerdings ist hier bei 4K/30 schon Feierabend. Das führt etwa bei schnellen Schwenks zu Rucklern.
Alle Bilder mit dem Xiaomi 13T
Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Xiaomi 13T

Ausstattung
Xiaomi 13T und das ebenfalls neue Xiaomi 13T Pro sind technisch weitestgehend gleich aufgestellt. Hauptunterschied ist der eingebaute Chipsatz: Während im Pro-Modell der Spitzenchip Snapdragon 8 Gen 2 steckt, der auch Xiaomi 13 und Xiaomi 13 Pro zu Spitzenleistung verhilft, arbeitet im Xiaomi 13T „nur“ ein Dimensity 8200 Ultra von Mediatek. Der schlägt sich im Alltag trotzdem richtig gut und Unterschiede zu den Modellen mit stärkerem Chipsatz sind allenfalls im direkten Vergleich zu bemerken. Und in Benchmarks und sehr anfordernden Games. Denn hier zeigt der Dimensity-Chip, dass in PCmark Work 3.0 mit 13.300 Punkten und in 3Dmark Wildlife Extreme mit 1750 Punkten ein respektabler Unterschied besteht. Zum Vergleich: Das Xiaomi 13 schaffte 14.800 und 2950 Punkte. In den meisten Spielen wird der Leistungsunterschied normalerweise ebenso wenig wie im sonstigen Alltag bemerkt, bei viel 3D-Grafikpracht haben Gamer mit dem 13T aber das Nachsehen.
Ansonsten ist vieles gleich oder zumindest nahezu gleichwertig. Speicher gibt es bis 8/256 GB, erweiterbar ist er erneut nicht. Allerdings bietet das Xiaomi 13 UFS 4.0, beim 13T ist es „nur“ UFS 3.1. Außerdem bietet das kleine Top-Modell Wi-Fi 7, beim 13T gibt es nur Wi-Fi 6. Bei Bluetooth hat das neue 13T mit Version 5.4 sogar die Nase vorn, der Rest ist gleich. Das betrifft leider auch den USB-C-Port, der wieder nur mit Version 2.0 daherkommt. Das sollte im Jahr 2023 auch in der oberen Mittelklasse langsam aber sicher mal zugunsten des schnelleren 3er-Standards aussterben. Einwandfrei funktioniert der Fingerabdrucksensor im Display, der hybride Stereolautsprecher klingt ausreichend laut und voll.
Android 13 und MIUI 14 sind installiert, hinzu sollen mindestens vier Android-Upgrades und 5 Jahre Sicherheits-Patches kommen. Das ist ordentlich. Wie immer installiert Xiaomi recht viel Bloatware, vieles davon lässt sich aber deinstallieren.
Akku
5000 mAh bietet der Akku des Xiaomi 13T, das ist guter Standard bei einem so großen Display. Dennoch schneidet das Modell etwas schlechter als das Xiaomi 13 mit nur 4500 mAh ab. Schlussendlich sind 11,5 Stunden im Battery Test von PCmark aber ein ordentlicher Wert, der für gute 2 Tage Laufzeit spricht – je nach Nutzung versteht sich. Bei der anschließenden Ladegeschwindigkeit sind Xiaomi 13 und 13T auf dem Papier gleichauf, beide laden am Kabel mit 67 Watt. Wegen des größeren Akkus dauert das beim 13T mit etwa 45 Minuten aber minimal länger. Kabelloses Laden fehlt hier.
Preis
Das Xiaomi 13T gibt es in Schwarz, Blau und Grün. Die UVP für die Variante mit 8/256 GB lag zum Testzeitpunkt bei 650 Euro. Mittlerweile sind die Preise stark gesunken, das Modell mit 8/256 GB kostet 324 Euro, mit 12/256 GB sind es 408 Euro.
Fazit
Eigentlich ist die T-Version immer die jüngere, aber schon mehr oder weniger klar schwächere Version des jeweiligen Spitzenmodells. Vor allem der Preis macht da die Wahl zugunsten des T-Modells oft schwer. Beim Xiaomi 13T ist das anders, denn technisch sind die Abstriche überschaubar und im Alltag dürfte weder der schwächere Chipsatz noch der im Detail niedrigere Standard einiger technischer Komponenten weiter auffallen. Im Gegenteil: Display, Kamera und generelle Leistung überzeugen, das Design stammt von den Top-Modellen und ist hochwertig.
Die Akkuausdauer ist insgesamt ebenfalls auf gutem Kurs, am schlimmsten wiegt hier der Wegfall der kabellosen Lademöglichkeit. Dafür kostet das T-Modell aber auch mal locker 100 Euro weniger als das Xiaomi 13 – das ist schon eine Hausnummer. Wer mit den genannten Nachteilen leben kann, sollte daher zum neuen 13T greifen.

Nachlässigkeiten in der Verwaltung: Wie ehemalige Behörden-Domains zu Sicherheitsrisiken werden

Deutsche eID-Karte als Geldwäsche-Hilfe kritisiert

Gerüchte zu Studio Display 2: Neuer Monitor von Apple mit 120Hz, Mini-LED und A19-Chip
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenIllustrierte Reise nach New York City › PAGE online
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenJetzt patchen! Erneut Attacken auf SonicWall-Firewalls beobachtet
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAus Softwarefehlern lernen – Teil 3: Eine Marssonde gerät außer Kontrolle
-
Künstliche Intelligenzvor 2 Monaten
Top 10: Die beste kabellose Überwachungskamera im Test
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenSK Rapid Wien erneuert visuelle Identität
-

 Entwicklung & Codevor 3 Wochen
Entwicklung & Codevor 3 WochenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenNeue PC-Spiele im November 2025: „Anno 117: Pax Romana“

