Künstliche Intelligenz
Aus Softwarefehlern lernen – Teil 1: Einheiten. Wenn Zahlen irreführend werden
Wenn Softwarefehler auftreten, passiert das meistens unbemerkt und unauffällig, gelegentlich aber auch höchst spektakulär und kostspielig. Von fehlgeschlagenen Raumfahrtmissionen über Börsencrashs bis hin zu fehlerhaften medizinischen Geräten gibt es eine lange Liste berühmter Softwarepannen. Wer sie studiert, stellt schnell fest: Die meisten dieser Fehler wirken auf den ersten Blick wie einmalige Katastrophen, sind in Wahrheit aber Wiederholungen bekannter Muster.


Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Die Teile der Serie „Aus Softwarefehlern lernen“:
Diese Artikelserie stellt neun dieser typischen Fehlerklassen vor, die in der Praxis immer wieder auftauchen – unabhängig von Branche oder Technologie. In jeder Kategorie wird die Serie ein konkretes Beispiel vorstellen, dessen Ursachen analysieren und daraus ableiten, was Softwareentwicklerinnen und Softwareentwickler langfristig lernen können.
Der Bug in der Rechenanlage
Eine der beliebtesten Anekdoten der Softwaregeschichte ist die von Grace Hopper und der berühmten Motte. 1947 arbeitete Grace Hopper an der Harvard-Mark-II-Rechenanlage, in der sich eine echte Motte in einem Relais verfangen hatte. Nachdem ein Teammitglied sie gefunden und entfernt hatte, klebte dieser sie mit dem Kommentar „first actual case of bug being found“ ins Protokollbuch. Dieses Protokollbuch wird heute in einem Smithsonian Museum in Washington ausgestellt.
Diese Episode ist zu einer Legende der IT-Kultur geworden – das Wort „Bug“ wurde damals aber nicht erfunden. Schon Thomas Edison sprach 1878 in Briefen über „Bugs“ in Maschinen, also kleine, schwer zu findende Fehler. Trotzdem prägte Grace Hopper die Vorstellung, dass Softwarefehler etwas sind, das man wie ein Insekt finden und entfernen kann.
Doch die Realität ist oft subtiler: Bugs sind meist Symptome systematischer Schwächen. Hinter fast jeder spektakulären Panne steckt ein Muster, das sich in abgewandelter Form immer und immer wieder findet. Deshalb lohnt sich ein Blick nicht nur auf die einzelnen Vorfälle, sondern vor allem auf die Fehlerkategorien, die sie repräsentieren.
Teil 1: Einheiten und Maße: Wenn Zahlen irreführend werden
Am Beginn dieser Serie steht ein Thema, mit dem Entwicklerinnen und Entwickler jeden Tag wie selbstverständlich hantieren – und das vielleicht gerade deshalb so gefährlich ist. Es wird allzu leicht unterschätzt: Die Rede ist vom Umgang mit Zahlen.
Kaum ein Beispiel für Softwarefehler wird so häufig genannt wie der Verlust der NASA-Sonde Mars Climate Orbiter im Jahr 1999. Ziel der Mission war es, die Marsatmosphäre zu untersuchen. Nach einer monatelangen Reise näherte sich die Sonde dem Planeten – und verglühte. Die Ursache war fast grotesk simpel: Die Entwickler hatten in der Software metrische und imperiale Maßeinheiten verwechselt. Das Ergebnis war ein systematischer Navigationsfehler, der die Sonde auf eine zu niedrige Umlaufbahn führte.
Dieser Vorfall zeigt, dass Zahlen ohne Kontext gefährlich sind. Eine Zahl wie 350 kann das Maß einer Geschwindigkeit, einer Kraft oder einer Energie bedeuten – oder eben etwas ganz anderes. Solange eine Software Daten als rohe Zahlen behandelt, besteht die Gefahr, dass jemand sie falsch missinterpretiert. In großen Projekten mit mehreren Teams potenziert sich dieses Risiko, wenn jede Seite implizite Annahmen trifft, die niemand irgendwo explizit dokumentiert oder technisch abgesichert hat.
Aus Sicht der Qualitätssicherung sind solche Fehler besonders tückisch, denn Unit Tests können ebenso wie Integrationstests durchaus korrekt durchlaufen – solange die falschen Einheiten konsistent falsch sind. Das Problem zeigt sich oft erst in der Realität, wenn Sensoren, Aktoren oder externe Systeme ins Spiel kommen, deren Daten den zuvor getroffenen Annahmen nicht entsprechen. Die Lehre aus diesem Vorfall ist klar: Zahlen brauchen Bedeutung. Moderne Programmiersprachen und Frameworks bieten verschiedene Möglichkeiten, diese Bedeutung explizit zu machen:
- Value Objects oder Wrapper-Typen: Statt
doubleoderfloatkommt ein eigener Typ wieForceInNewtonoderVelocityInMetersPerSecondzum Einsatz. Damit wird die Einheit Teil der Typinformation. Manche Programmiersprachen, beispielsweise F#, bieten Unterstützung für Einheiten sogar bereits als Teil der Sprache an. - Bibliotheken für physikalische Einheiten: Sie ermöglichen automatische Umrechnungen und erzwingen korrekte Kombinationen.
- Schnittstellenverträge und End-to-End-Tests: API-Definitionen sollten Einheiten benennen. Tests mit echten Daten decken Diskrepanzen auf, bevor sie zu Katastrophen führen.
Neben diesen technischen Maßnahmen spielt außerdem auch die Teamkultur eine große Rolle. Projekte, die früh auf eine gemeinsame Sprache für ihre Daten achten – sei es durch Domain-Driven Design (DDD) oder einfach durch konsequente Dokumentation –, vermeiden solche Fehler deutlich häufiger.
Der Verlust des Mars Climate Orbiter hat die NASA hart getroffen. Doch er hat auch dazu geführt, dass Entwicklerinnen und Entwickler zumindest in manchen Projekten stärker auf Einheitenfehler achten und diese Fehlerklasse seither (hoffentlich) ernster nehmen. Für Softwareteams im Alltag gilt dasselbe: Wer Zahlen ohne Kontext weitergibt, lädt zum nächsten Bug geradezu ein.
Im nächsten Teil lesen Sie: Überlauf, Arithmetik und Präzision: Wenn Zahlen kippen
(who)











Künstliche Intelligenz
Kommentar zur KI-Blase: Sam Altman mimt den Oppenheimer des 21. Jahrhunderts
Weltweit reiben sich Ökonomen und Anleger die Augen: OpenAI meldet zweistellige Milliardenverluste pro Quartal, und jeder noch so kleine YouTuber mit Anlegertipps warnt inzwischen vor dem Platzen der KI-Blase. Und doch pumpen Investoren weiter Geld in KI, während OpenAI-Chef Sam Altman erklärt, die Betriebskosten interessierten ihn nicht im Geringsten. Wie ist diese Diskrepanz zwischen Horrorzahlen und ungebrochener Investitionsfreude zu erklären?
Weiterlesen nach der Anzeige
Die Strategie des „Wachstums, koste es, was es wolle“ ist altbekannt: Amazon, Uber, Netflix – sie alle verbrannten in den ersten Jahren Kapital, um Märkte zu erobern. Aber ihre Verluste bewegten sich im einstelligen Milliardenbereich pro Jahr, nicht bei über elf Milliarden in einem einzigen Quartal. Und sie hatten Geschäftsmodelle, bei denen Skaleneffekte irgendwann die Kosten drückten.

Redakteur Hartmut Gieselmann, Jahrgang 1971, ist seit 2001 bei c’t. Er leitet das Ressort Anwendungen, Datenschutz & Internet und bearbeitet unter anderem aktuelle Themen rund um die Bereiche Medizin-IT, Netzpolitik und Datenschutz.
OpenAI dagegen betreibt eine Technologie, deren variable Kosten – Chips, Strom, Rechenzentren – mit jeder Generationsstufe steigen. Laut einer Analyse der Unternehmensberatung Bain wäre bis 2030 in der KI-Branche ein globaler Jahresumsatz von zwei Billionen Dollar (sic!) nötig, um die benötigte Rechenleistung zu finanzieren. Die Lücke ist so groß, dass sie mit Abomodellen schlicht nicht zu schließen ist. Sie ist ein klares Signal an alle potenziellen Konkurrenten: Ihr könnt hier nicht mitspielen, ohne euch zu ruinieren.
Trotzdem zieht niemand den Stecker. Warum?
OpenAI geht es nicht darum, bloß ein neuer Player der globalen Plattformökonomie zu werden. Es geht vielmehr um geopolitische Machtsicherung. Die USA behandeln fortgeschrittene KI inzwischen wie ein nationales Infrastrukturprojekt. Es ist für sie das geopolitische Großprojekt des 21. Jahrhunderts, mit dem sie ihre Dominanz sichern wollen.
Palantir-Chef Alexander Karp hat eine solche nationale Großanstrengung in seinem Buch „The Technological Republic“ offen gefordert. Und Trumps Entscheidung, die leistungsfähigsten Nvidia-Chips exklusiv in den USA zu halten, zeigt das unverblümt. Das Weiße Haus hat im Herbst bereits angekündigt, den Ausbau von Rechenzentren als „kritische Infrastruktur“ zu priorisieren. Was hier entsteht, ähnelt eher dem Manhattan-Projekt als dem nächsten iPhone aus dem Silicon Valley.
Wie beim Atomprogramm der 40er Jahre entsteht eine technologisch, politisch und finanziell abgeschirmte Großstruktur, die nur unter staatlicher Protektion funktionsfähig ist. Es gelten dann andere Regeln: Nvidia, Microsoft, OpenAI und Co. werden gegen ausländische Konkurrenz abgeschirmt, rechtlich privilegiert und politisch getragen. Die Verluste sind keine betriebswirtschaftlichen Fehlplanungen, sondern Vorleistungen für ein Machtinstrument, das später kaum noch einholbar ist. Deshalb verwundert es nicht, dass Altman mit seinen nationalen Ausbauplänen und seiner demonstrativen Gleichgültigkeit gegenüber den gigantischen Kosten auftritt, als stünde er an der Spitze eines neuen Manhattan-Projekts.
Weiterlesen nach der Anzeige
Wer die technologische Infrastruktur kontrolliert, bestimmt die Standards, Protokolle und Abhängigkeiten der nächsten Jahrzehnte. Und die USA haben in ihrer Geschichte mehrfach bewiesen, dass sie zur Absicherung technologischer und wirtschaftlicher Vorherrschaft selbst vor gravierenden Kollateralschäden nicht zurückschrecken und geopolitische Prioritäten über ökologische und gesellschaftliche Folgen stellen. Die absehbaren Schäden des KI-Ausbaus für Umwelt und Klima gelten in Washington als verkraftbarer Preis.
Strategische Warnungen vor dem Crash
Die offenen Anspielungen der CEOs wie Mark Zuckerberg auf das mögliche Platzen der KI-Blase sind in diesem Kontext kein Alarmruf, sondern strategisch platzierte PR. Wer öffentlich vor einer Überbewertung warnt, signalisiert Investoren, dass nur die größten Player stabil genug sind, um einen Crash zu überstehen. Das erschwert kleineren Konkurrenten die Finanzierung und senkt deren Übernahmepreis, sobald die Kurse in den Keller rauschen.
Angesichts dieses Gigantismus muss Europa einen anderen Weg einschlagen als die USA. Weder Gigawatt-Rechenzentren noch milliardenschwere Chipfabriken sind eine realistische Option; ökologisch wären sie ein Desaster. Souveränität heißt stattdessen, die Kontrolle über Standards, Schnittstellen und Zugänge zu behalten: offene Modelle, offene Daten, gemeinsame europäische Compute-Cluster, klare Interoperabilitätsvorgaben und eine demokratische Aufsicht über die KI-Systeme, die in Wirtschaft und Verwaltung eingesetzt werden.
Die Schweiz zeigt mit dem Apertus-Programm, dass ein solcher Weg möglich ist. So könnte sich Europa langfristig vom KI-Tropf der USA abnabeln, ohne den Kontinent in eine zweite Rechenzentrumswüste nach dem Vorbild Arizonas zu verwandeln.
(hag)
Künstliche Intelligenz
Amazfit T-Rex 3 Pro im Test: Robuste Sportuhr mit GPS-Navigation zum Top-Preis
Amazfit schickt mit der T‑Rex 3 Pro eine spürbar verbesserte Version seiner Outdoor-Sportuhr ins Rennen und sagt damit Konkurrenten wie Garmin den Kampf an.
Die Amazfit T‑Rex 3 überzeugte im Test bereits als robuste Sportuhr und preiswerte Alternative zu Garmin, Polar & Co., offenbarte jedoch einige Schwächen. Mit der T‑Rex 3 Pro möchte Amazfit diese ausbügeln und legt technisch wie funktional nach. Wir haben das Pro-Modell getestet und geprüft, ob sich der Aufpreis lohnt.
Design & Bedienung
Optisch unterscheidet sich die Amazfit T‑Rex 3 Pro nur geringfügig von der normalen T‑Rex 3. Beide Modelle setzen auf dieselbe achteckige Form, ein wuchtiges Gehäuse (48 × 48 × 14 mm) und ein 1,5‑Zoll‑AMOLED‑Display mit einer gestochen scharfen Auflösung von 480 × 480 Pixeln. Bei der Lünette zeigt sich jedoch ein wichtiger Unterschied: Die Pro-Version nutzt eine Titanlegierung und Saphirglas, was das Gewicht von 68 g auf 52 g reduziert. Damit ist sie deutlich leichter als etwa eine Garmin Fenix 8.
Es gibt inzwischen zudem eine etwas kompaktere Variante mit einem Durchmesser von 44 mm, die auch an schmaleren Handgelenken gut sitzt. Wir haben das größere Modell mit 48 mm getestet.
Wie schon beim Standardmodell überzeugt das Gehäuse der Pro-Variante durch eine robuste und saubere Verarbeitung. Beim Silikonarmband bleibt hingegen alles beim Alten – es wirkt etwas billig, und die Kunststoffschließe beißt sich optisch mit dem sonst hochwertigen Auftritt der Smartwatch.
Die T-Rex 3 Pro erfüllt wie ihr Schwestermodell die US-Militärnorm MIL-STD-810H und ist bis zu 10 ATM (100 Meter Wassersäule) wasserdicht. Das Saphirglas zeigt im Test eine sehr hohe Kratzfestigkeit: Weder ein Sturz aus 1,5 Metern auf Fliesen noch Kontakt mit einer Kettlebell hinterließen sichtbare Spuren.
Bei der Bedienung gibt es kaum Neuerungen. Die vier Bedientasten sind identisch angeordnet und erinnern an das Layout einer Garmin-Uhr. Wer möchte, kann die obere oder untere Taste auf der rechten Seite individuell belegen, etwa zum direkten Start eines Trainings. Auch die vom Standardmodell bekannten Wischgesten sind an Bord: Sie erlauben die Navigation durch Menüs und Widgets – im Test stets flüssig und ohne Ruckler. Selbst leicht verschmutzte oder feuchte Finger beeinträchtigen die Touch-Erkennung kaum.
Amazfit T-Rex 3 Pro – Bilder
Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

Amazfit T-Rex 3 Pro

App & Einrichtung
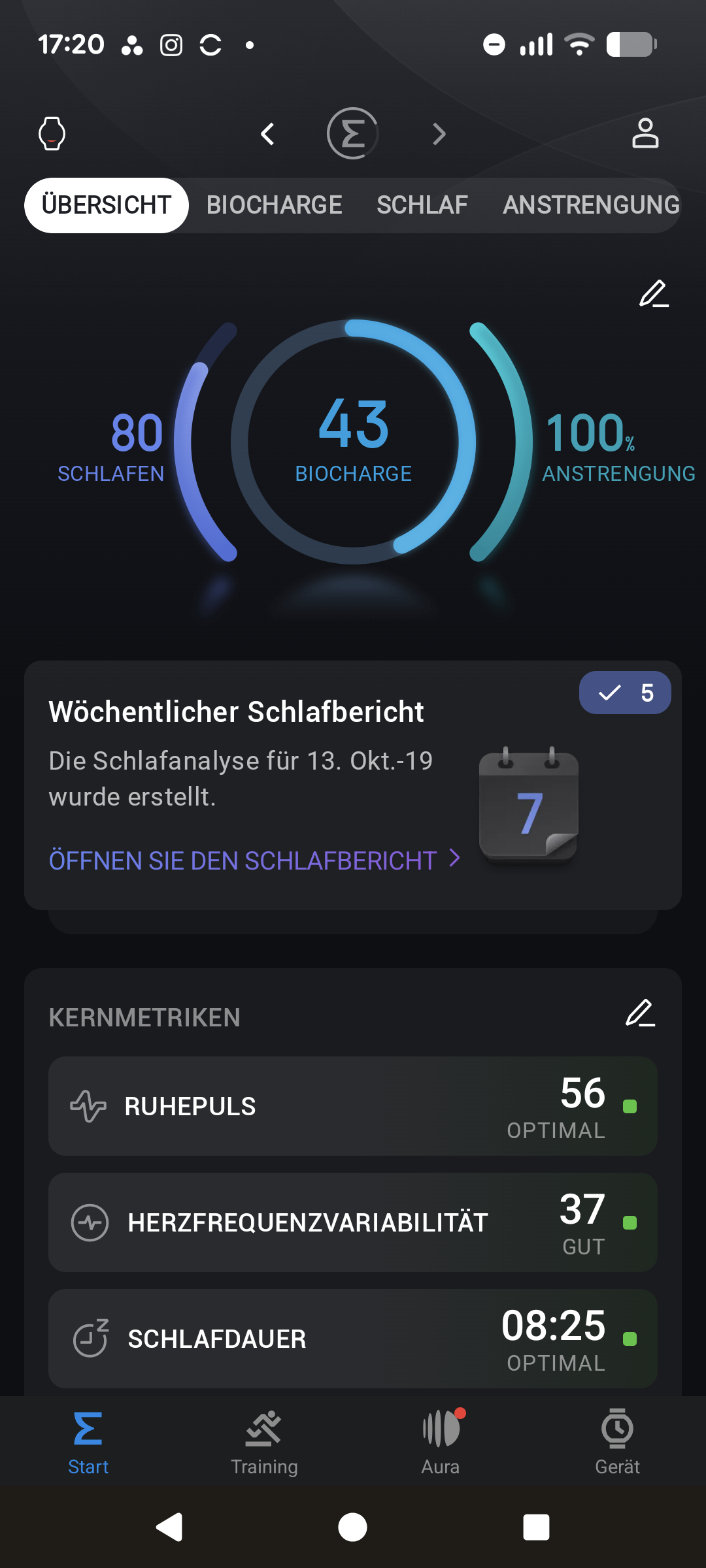
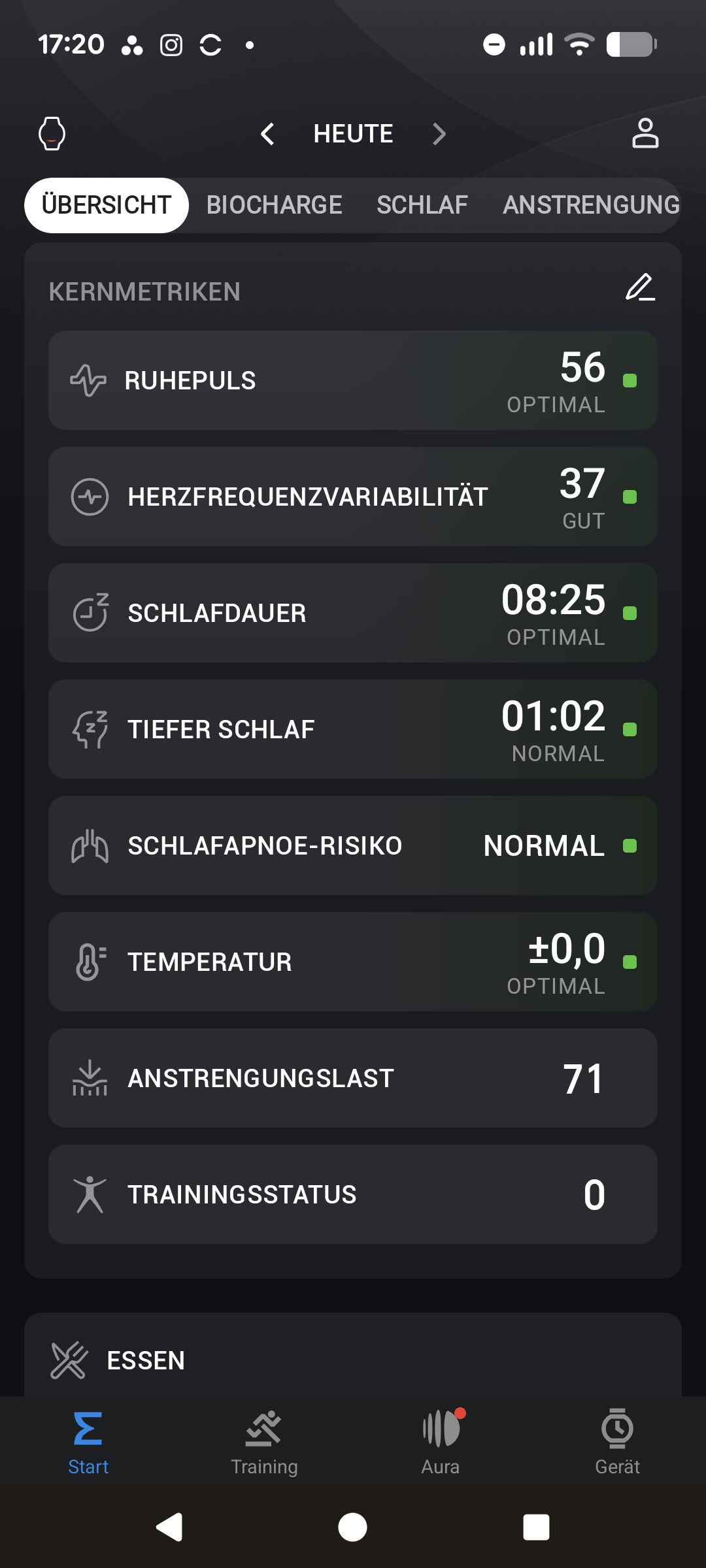
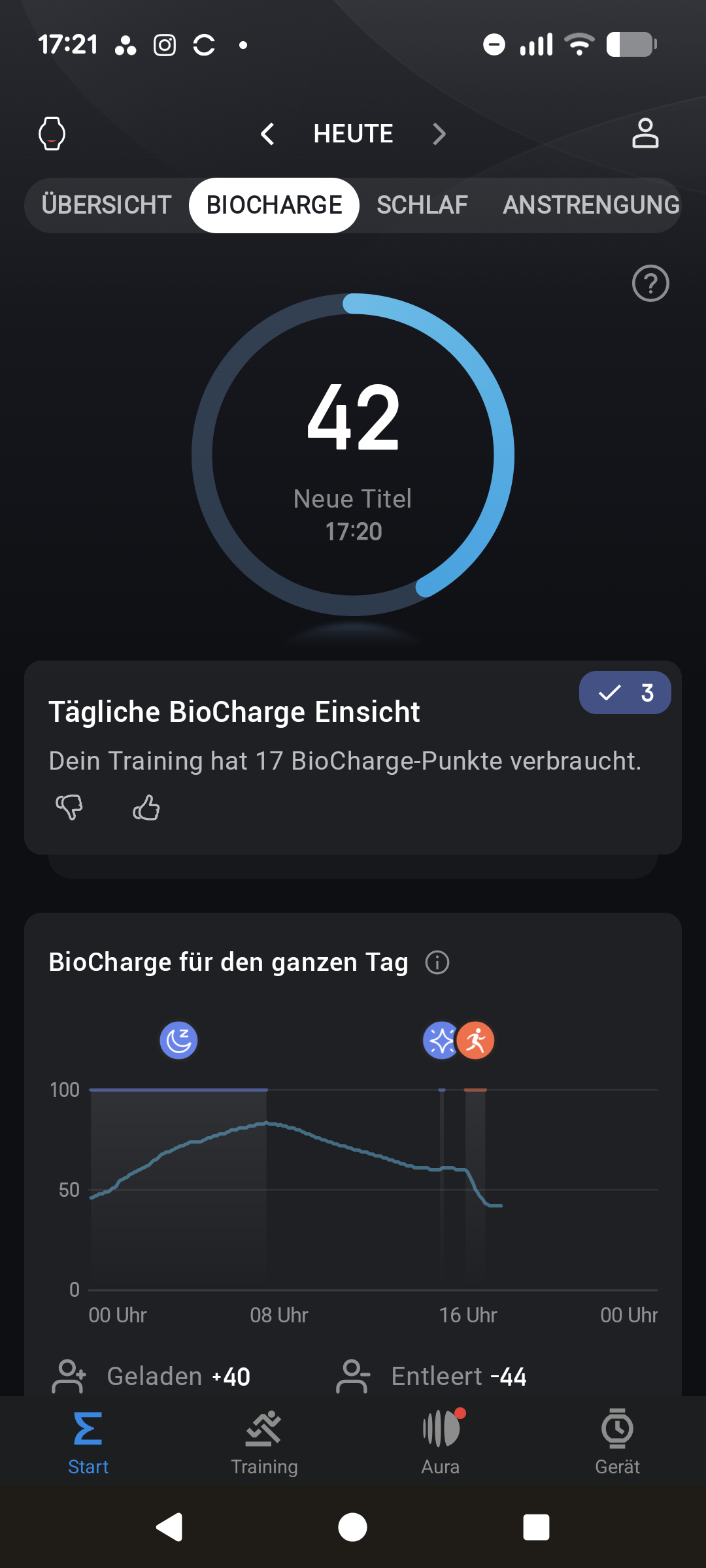
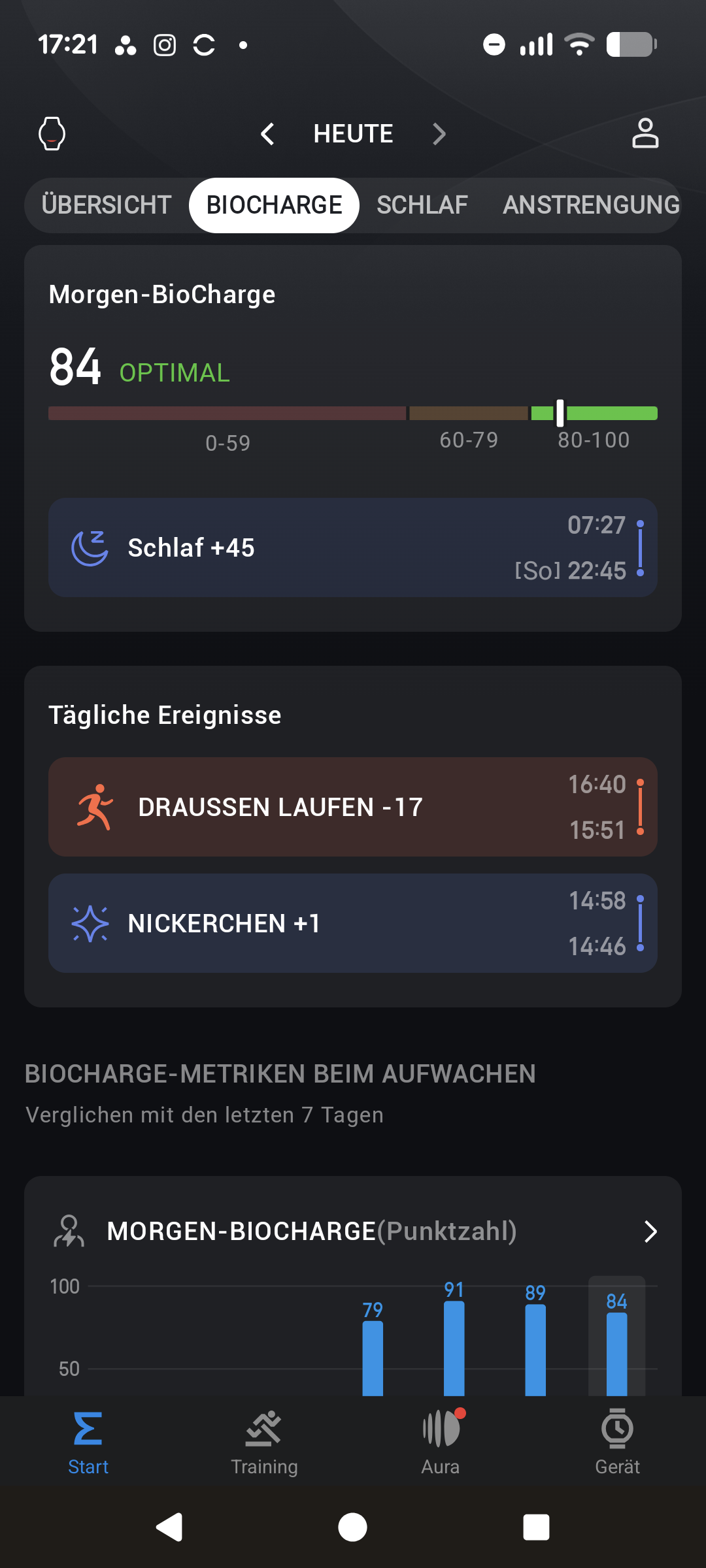
Die Einrichtung der Amazfit T‑Rex 3 Pro läuft identisch zur herkömmlichen T‑Rex 3 ab. Nach der Installation der Zepp‑App verbinden wir die Uhr per Bluetooth mit dem Smartphone. Ab jetzt stellt die App alle gesammelten Daten der Uhr übersichtlich in Diagrammen dar. Auf der Startseite erscheinen Kennzahlen zur Herzfrequenz, Training und Schlaf, für die es zusätzlich eigene Detailmenüs mit Tabellen und Verlaufsdaten gibt.
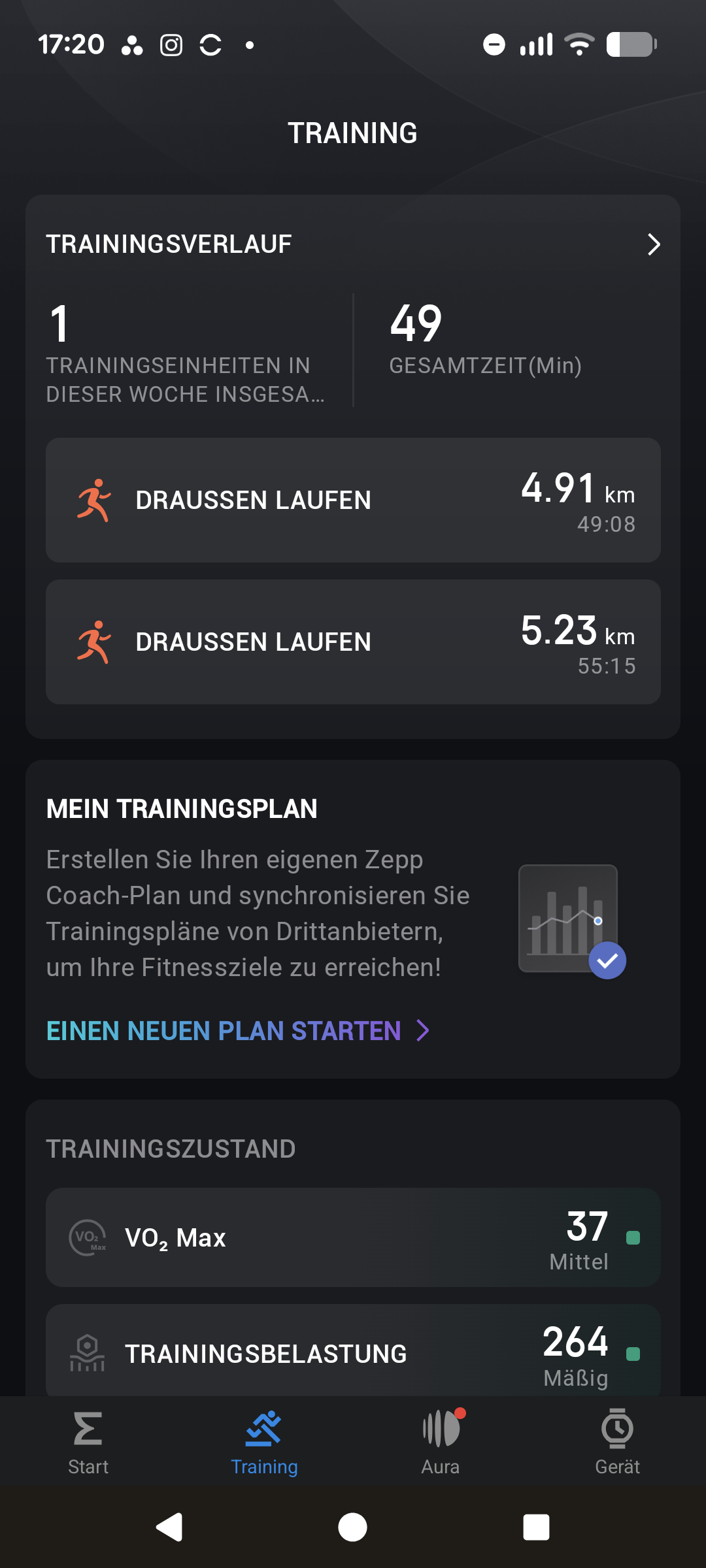
Im Bereich Training startet man Sporteinheiten manuell, ruft Workouts ab und verwaltet Trainingspläne. Ebenfalls integriert ist der kostenpflichtige Zepp‑Coach, ein KI-Assistent, der die Trainingsdaten genauer analysiert als die kostenlose App-Version. Hinzu kommt das Abo‑Feature Aura mit erweiterten Schlafanalysen, geführten Meditationen und einem KI‑Schlaftrainer.
Unter dem Menüpunkt Gerät passt man die verschiedenen Systemeinstellungen der T‑Rex 3 Pro bei Bedarf an. Dazu gehören die Konfiguration von Menüs und Widgets, Benachrichtigungen sowie die optionale Verknüpfung mit dem Google‑Kalender.
Tracking & Training
Bei den Trainings- und Trackingfunktionen unterscheiden sich die T-Rex 3 und T-Rex 3 Pro nur geringfügig. Beide messen im Schlaftracking die verschiedenen Phasen (Leicht-, Tief- und REM-Schlaf) und berechnen daraus einen Index, der den Erholungszustand widerspiegeln soll. Das Problem der ungenauen Erkennung von Wachphasen bleibt jedoch bestehen, wodurch die Aussagekraft eingeschränkt ist. Wie bei den meisten Wearables verbessert sich die Genauigkeit mit regelmäßigem Tragen.
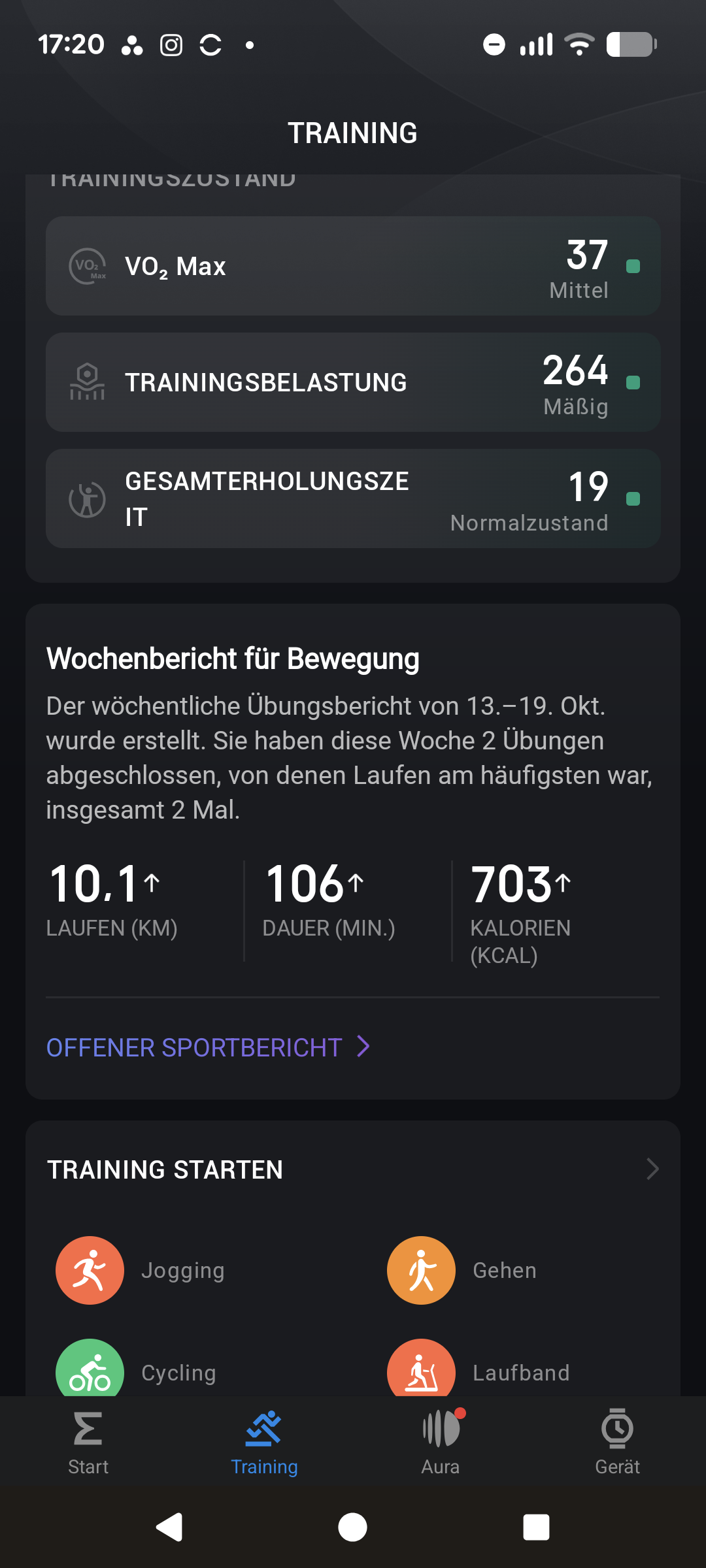
Amazfit hat mit der T-Rex 3 Pro die Anzahl der Sportmodi auf über 180 verschiedene Profile erweitert. Über die App erstellt man eigene Trainingseinheiten und kann diese auf die Uhr übertragen, etwa im Bereich Kraftsport oder Hyrox-Training. Positiv fällt die Vielzahl zusätzlicher Daten auf, die die Uhr je nach Sportart erfasst: Beim Laufen und Radfahren werden etwa Herzfrequenz, Dauer und Strecke aufgezeichnet, beim Outdoor-Klettern zudem die Höhe. Beim Krafttraining können Sätze und Gewichte manuell gespeichert werden – ein Funktionsumfang, den kaum ein Konkurrenzprodukt bietet.
Ein Alleinstellungsmerkmal der T-Rex-Serie ist der Hyrox-Race-Modus. Er kombiniert alle Stationen eines Hyrox-Wettkampfs – vom Lauf über Ski-Ergometer, Sled-Push und Sled-Pull bis zum Ziel – in einem Profil und zeichnet die Dauer jeder Disziplin separat auf. So behält man den Überblick über den gesamten Trainingsablauf.
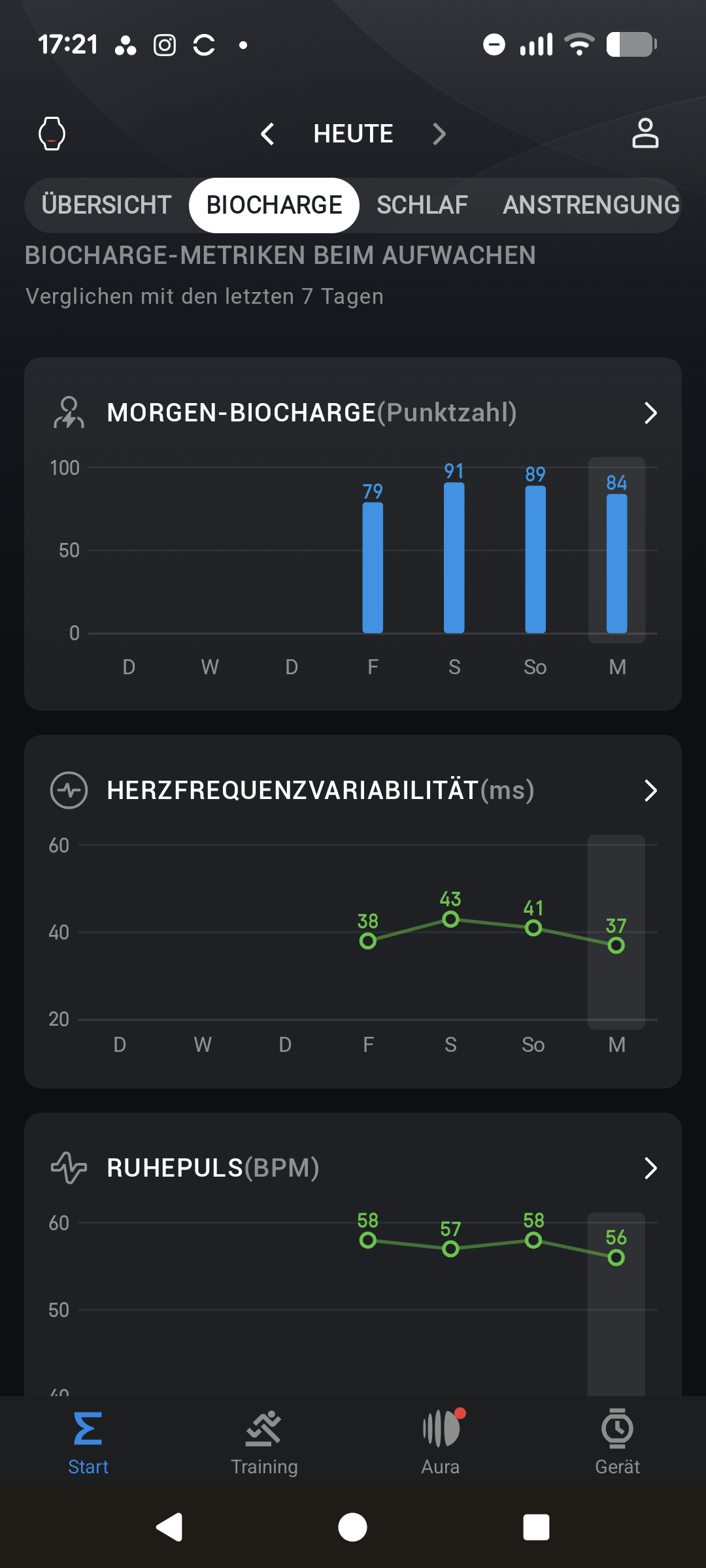
Wie schon bei der Standardversion nutzt auch die T-Rex 3 Pro die Auswertung von Aktivitätsdaten über die PAI (Persönliche Aktivitätsintelligenz). Dieser Wert berücksichtigt Alter, Geschlecht, Ruhepuls und Pulsverlauf der letzten sieben Tage und steigt bei intensiver Belastung entsprechend an.
Die Uhr erkennt Trainingseinheiten wie Laufen, Radfahren, Schwimmen, Crosstrainer- und Rudertraining automatisch. Die Empfindlichkeit der Erkennung kann in drei Stufen angepasst werden. Auf der höchsten Stufe registriert die T-Rex 3 Pro nahezu jede Bewegung, während Standard- und Niedrig-Einstellungen eine längere oder intensivere Aktivität erfordern. Im Praxistest funktioniert das zuverlässig.
Das Herzstück des Trackings ist die Pulsmessung, die im Test sehr präzise arbeitet. Die Abweichungen zu unseren Referenzmessungen mit Brustgurt bewegen sich im niedrigen einstelligen Prozentbereich – typisch für optische Sensoren.
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Amazfit T-Rex 3 Pro – Zepp App
Weitere Features
Neben den bereits von der T-Rex 3 bekannten Funktionen wie Zepp Pay, dem Amazfit-Sprachassistenten und integriertem Musikspeicher bietet die T-Rex 3 Pro mehrere sinnvolle Neuerungen. Besonders erfreulich: Über das integrierte Mikrofon nimmt man nun auch eingehende Anrufe entgegen. Ein eSIM-Slot fehlt allerdings weiterhin, sodass das Smartphone zum Telefonieren in Reichweite bleiben muss.
Ein wesentlicher Fortschritt gegenüber dem Standardmodell ist das auch zur Navigation nutzbare GPS. Beide Varianten verfügen zwar über ein präzises Ortungsmodul inklusive Höhenbarometer, doch die Pro-Version bringt zusätzliche Funktionen mit: Routenplanung, Round-Trip-Routing und automatische Routenanpassung. Damit gleicht Amazfit eines der größten Defizite des Vorgängers aus und schließt funktional zur deutlich teureren Garmin Fenix 8 auf. Die Uhr unterstützt sowohl GPX-Tracks als auch Navigationsziele auf der Karte und eignet sich damit hervorragend für Outdoor-Touren, Läufe und Radtouren.
Akku
Der einzige spürbare Nachteil der T-Rex 3 Pro mit 48 mm gegenüber dem Basismodell liegt in der Akkulaufzeit. Statt 27 erreicht sie laut Hersteller im typischen Alltag 25 Tage. Faktoren wie Always-on-Display und GPS-Nutzung wirken sich deutlich auf die Laufzeit aus. Im Test lag der Akkustand nach acht Tagen mit drei jeweils anderthalbstündigen GPS-Trainingseinheiten bei rund 50 Prozent – ein ordentlicher Wert.
Damit hält die T-Rex 3 Pro zwar etwas kürzer durch als ihr Vorgänger, bleibt im Vergleich zur Konkurrenz aber weiterhin ausdauernd.
Geladen wird die Smartwatch wie gewohnt über die beiliegende Ladeschale, die man per USB-C-Kabel (nicht im Lieferumfang enthalten) verbindet. Eine vollständige Ladung dauert rund drei Stunden.
Preis
Die T-Rex 3 Pro mit 48 mm kostet laut UVP offiziell 400 Euro und ist in den Farben Schwarz sowie Schwarz-Gold verfügbar. Derzeit kostet das Modell mit 48 mm in der Farbvariante Tactical Black 341 Euro bei Ebay mit dem Code PRESALE25. Die kompaktere Variante in 44 mm kostet rund 400 Euro.
Fazit
Nachdem die Amazfit T‑Rex 3 im Test bereits überzeugt hatte, legt der Hersteller mit der T‑Rex 3 Pro spürbar nach. Fast alle Schwächen des Standardmodells hat Amazfit ausgebessert – und das zu einem weiterhin fairen Preis. Das Ergebnis ist eine robuste Outdoor-Smartwatch mit starkem Preis-Leistungs-Verhältnis.
Display und Akkulaufzeit gehören weiterhin zu den größten Stärken, auch wenn der Akku beim Pro-Modell etwas kürzer durchhält. Neu hinzugekommen sind eine Telefonfunktion und eine solide Routennavigation. Lediglich die beschränkte App-Auswahl bleibt ein kleiner Wermutstropfen.
Wer eine preisgünstige Alternative zur Garmin Fenix 8 sucht und dabei nicht auf Navigation verzichten möchte, findet in der Amazfit T‑Rex 3 Pro einen echten Outdoor-Geheimtipp.
Künstliche Intelligenz
KI-Update: US-Jobless-Boom, Meta will bauen, DSGVO in Gefahr, Siri mit Gemini
Entlassungswellen und Rekordgewinne in den USA – der „Jobless Boom“ durch KI
Weiterlesen nach der Anzeige
Die US-Wirtschaft streicht dieses Jahr fast eine Million Jobs, während die Unternehmensgewinne sprunghaft steigen und die Aktienmärkte neue Höchststände erreichen. Experten nennen dies den „Jobless Boom“. Chen Zhao von Alpine Macro, einem Investment-Forschungshaus, macht den zunehmenden Einsatz von KI dafür verantwortlich. Die Technik steigere die Produktivität, drücke aber die Nachfrage nach Arbeitskräften. Amazon etwa entließ 14.000 Mitarbeiter trotz hoher Gewinne. Der Trend, der zunächst die Tech-Branche traf, breitet sich nun aus.

Trotz der Entlassungen bleibt die Arbeitslosenquote mit 4,3 Prozent niedrig. Zhao erklärt dies mit einer schrumpfenden Zahl verfügbarer Arbeitskräfte: Baby-Boomer scheiden aus dem Berufsleben aus, und die restriktive Einwanderungspolitik der Trump-Regierung verringert die Zuwanderung. Andere Experten sehen nicht die KI als Hauptursache, sondern eine Korrektur nach übermäßigen Einstellungen während der Pandemie.
Meta kündigt 600 Milliarden US-Dollar KI-Investitionen an
Meta, ein Social-Media-Konzern, will 600 Milliarden Dollar investieren, um neue Rechenzentren in den USA zu bauen. Chef Mark Zuckerberg spricht von einer „persönlichen Superintelligenz für jeden“, bleibt aber vage, was das bedeuten soll. Woher die riesige Summe kommen soll, verrät Meta nicht. Im dritten Quartal 2025 erzielte der Konzern 51 Milliarden Dollar Umsatz, 26 Prozent mehr als im Vorjahr.
Vieles deutet darauf hin, dass Meta auf externe Geldgeber setzt. Im Oktober einigte sich der Konzern mit Blue Owl, einem Investmentunternehmen, auf ein 27 Milliarden Dollar teures Rechenzentrum in Louisiana, das bisher größte seiner Art. Im selben Monat kündigte Meta eine 1,5-Milliarden-Dollar-Investition in ein Rechenzentrum in Texas an.
Anthropic will Umsatz bis 2028 auf 70 Milliarden Dollar steigern
Weiterlesen nach der Anzeige
Anthropic, ein KI-Unternehmen, das das Modell Claude entwickelt, will seinen Umsatz von 4,7 Milliarden Dollar im Jahr 2025 auf 70 Milliarden Dollar im Jahr 2028 steigern. Das wäre eine Verfünfzehnfachung in drei Jahren. Die größte Hürde: Derzeit arbeitet Anthropic mit einer Bruttomarge von minus 94 Prozent. Für jeden Dollar Umsatz entstehen fast zwei Dollar Serverkosten. Bis 2025 soll die Marge auf 50 Prozent steigen, bis 2028 auf 77 Prozent. Den Großteil seiner Einnahmen erzielt Anthropic über API-Zugänge für Unternehmen, die bis 2028 mehr als 80 Prozent des Umsatzes ausmachen sollen.
Zum Vergleich: OpenAI, ein KI-Modellhersteller, rechnet für Ende 2025 mit einem Umsatz von 20 Milliarden Dollar, fast dem Vierfachen von Anthropics Prognose für das Gesamtjahr. OpenAI will bis 2028 einen Jahresumsatz von 100 Milliarden Dollar erreichen, bei einem Verlust von 50 Milliarden Dollar. Beide Firmen müssen massiv wachsen und gleichzeitig ihre Kosten senken. Ob die Nachfrage nach KI-Diensten tatsächlich so stark steigt, bleibt offen.
EU will Training von KI-Modellen erleichtern
Die EU-Kommission plant umfangreiche Änderungen an der Datenschutz-Grundverordnung durch den Digital-Omnibus. Das Ziel: digitale Vorschriften vereinfachen, Verwaltungsaufwand und Kosten für Unternehmen senken und so die Wettbewerbsfähigkeit Europas stärken. Kritiker befürchten, dass dies auf Kosten bestehender Datenschutzstandards geschieht. Im Fokus steht die Ausweitung des „berechtigten Interesses“ als Rechtsgrundlage für Datenverarbeitung. Mit dem neuen Entwurf könnte das Speichern und Auslesen von Tracking-Cookies bereits aufgrund unternehmerischer Ziele erfolgen. Nutzer hätten nur noch die Möglichkeit eines nachträglichen Widerspruchs, eines Opt-outs.
Die Kommission plant zudem, das Training von KI-Systemen mit personenbezogenen Daten auf Basis des berechtigten Interesses zu ermöglichen. Dies würde die oft nötige Einholung von Einwilligungen erübrigen. Die Aufsicht über KI soll in einem „AI Office“ gebündelt werden, eine zentralisierte Kontrollstruktur, von der vor allem große Online-Plattformen profitieren würden. Paul Nemitz, früherer EU-Kommissionsdirektor, warnt, dass mit dem neuen Entwurf vom Datenschutz nichts mehr übrig bleibe.

Wie intelligent ist Künstliche Intelligenz eigentlich? Welche Folgen hat generative KI für unsere Arbeit, unsere Freizeit und die Gesellschaft? Im „KI-Update“ von Heise bringen wir Euch gemeinsam mit The Decoder werktäglich Updates zu den wichtigsten KI-Entwicklungen. Freitags beleuchten wir mit Experten die unterschiedlichen Aspekte der KI-Revolution.
ChatGPT empfiehlt je nach Zugang unterschiedliche Nachrichtenquellen
ChatGPT verhält sich nicht einheitlich bei Nachrichtenempfehlungen. Eine Studie der Universität Hamburg und des Leibniz-Instituts für Medienforschung fand systematische Unterschiede zwischen dem Web-Interface und der API-Schnittstelle. Die Forschenden analysierten über fünf Wochen mehr als 24.000 Antworten auf nachrichtenbezogene Anfragen im deutschen Sprachraum. Im Web-Interface dominieren Medien des Axel-Springer-Verlags, mit dem OpenAI einen Lizenzvertrag hat. Die Webseiten welt.de und bild.de machten dort etwa 13 Prozent aller Quellenverweise aus. Über die API waren es nur rund 2 Prozent. Die API bevorzugt stattdessen Wikipedia und kleinere lokale Medien.
Besonders problematisch wird es, wenn Nutzer explizit nach Quellenvielfalt fragen. ChatGPT listete dann zwar mehr unterschiedliche Quellen auf, darunter aber auch stark politisch gefärbte Seiten, propagandistische Medien und sogar nicht existierende Domains. OpenAI gibt keine Informationen zu den Unterschieden zwischen Web-Interface und API preis. Nutzer müssen daher kritisch bleiben und Quellen selbst prüfen.
Siri setzt auf Gemini und Apple zahlt kräftig
Apple hat laut Bloomberg einen Partner für KI gefunden: Googles Gemini. Das KI-Modell soll künftig das Herz einer kommenden LLM-Serie sein, die Fragen so gut beantworten kann wie ChatGPT, Claude oder Gemini. Mit einer Implementierung wird im kommenden Jahr gerechnet. Apple hat seit Jahren Probleme, mit seiner KI-Technik zu OpenAI, Anthropic oder Google aufzuschließen. Gemini soll angeblich auf Apples eigenen Servern laufen, eine offizielle Ankündigung ist nicht geplant.
Ein Preis für den Deal wurde ebenfalls genannt: eine Milliarde Dollar im Jahr. Apple verdient von Google bereits jetzt deutlich mehr. Rund 20 Milliarden Dollar sollen nur dafür fließen, dass Google seine Suchmaschine als Standard auf iPhone, Mac und iPad platzieren darf. Weder Google noch Apple haben sich zu dem Bericht geäußert. Vor Frühjahr 2026 ist mit offiziellen Informationen nichts zu rechnen.
Inception setzt auf Diffusion statt LLMs
Inception, ein KI-Start-up, hat 50 Millionen Dollar Kapital eingesammelt, angeführt von Menlo Ventures, einem Risikokapitalgeber. Beteiligt sind auch Microsoft, Nvidia, Databricks und Snowflake. Inception setzt auf Diffusionsmodelle für Text und Code. Diese Technik, bekannt aus der Bildgenerierung, erstellt komplette Inhalte wie Code-Blöcke oder Essays auf einmal und verfeinert sie dann stufenweise, statt sie Wort für Wort zu generieren.
Das Ergebnis: deutlich höhere Geschwindigkeit. Das hauseigene Modell Mercury schafft mehr als 1.000 Token pro Sekunde. Herkömmliche Modelle wie GPT-4 erreichen nur 40 bis 60 Token. An die Qualität dieser Modelle reicht Mercury aber nicht heran.
Fendt Xaver GT: Autonomer Roboter für Unkrautbekämpfung ohne Fahrer
Fendt, ein Landmaschinenhersteller, hat auf der Agritechnica in Hannover den vollautonomen Feldroboter Xaver GT vorgestellt. Das System arbeitet komplett ohne menschliche Bedienperson und soll Landwirten helfen, den Pestizideinsatz zu reduzieren. Die mechanische Unkrautbekämpfung erlebt laut Fendt eine Renaissance. Resistenzen von Beikräutern gegen Herbizide und der gesellschaftliche Druck zur Pestizidreduktion treiben diese Entwicklung voran.
Der autonome Xaver GT nutzt Sensortechnik sowie KI-gestützte Bildverarbeitung für die Navigation. Für die exakte Reihenführung wird eine kamerabasierte Pflanzenreihenerkennung eingesetzt. Die KI des „RowPilot“ soll zwischen Kulturpflanzen und Beikräutern unterscheiden und die Hackgeräte entsprechend steuern. Das könnte vor allem für ökologisch wirtschaftende Betriebe interessant sein, da mechanische Unkrautbekämpfung dort die einzige Option darstellt. Aber auch konventionelle Betriebe nutzen zunehmend mechanische Verfahren.

(mali)

BCG-Umfrage in zehn Ländern: So verändert KI das Kaufverhalten an Black Friday, Cyber Monday und Co

Neue WhatsApp-Funktion kommt: Ändert sich jetzt alles?

Kommentar zur KI-Blase: Sam Altman mimt den Oppenheimer des 21. Jahrhunderts
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenDer ultimative Guide für eine unvergessliche Customer Experience
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenAdobe Firefly Boards › PAGE online
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets
-
eine gute Nachricht ist")
eine gute Nachricht ist") Social Mediavor 3 Monaten
Social Mediavor 3 MonatenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-

 UX/UI & Webdesignvor 3 Wochen
UX/UI & Webdesignvor 3 WochenIllustrierte Reise nach New York City › PAGE online
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenHarte Zeiten für den demokratischen Rechtsstaat
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events