Entwicklung & Code
Clean Architecture und Co.: Softwarearchitektur mit Mustern strukturieren
Strukturierte Software basiert auf einem Plan, der die spezifischen Anforderungen an ein System berücksichtigt und in lose gekoppelte Bausteine überführt. In der arbeitsteiligen Softwareentwicklung benötigen Entwicklungsteams solche gemeinsamen Pläne, um eine harmonische und einheitliche Architektur zu entwickeln, ohne jedes Detail vorab miteinander abstimmen zu müssen. Bewähren sich die Pläne, entwickeln sich daraus Muster und Prinzipien auf unterschiedlichen Architekturebenen.
Weiterlesen nach der Anzeige


Matthias Eschhold ist Lead-Architekt der E-Mobilität bei der EnBW AG. Als Experte für Domain-driven Design gestaltet er die IT-Landschaft und Team-Topologien der E-Mobilität. Trotz strategischer Schwerpunkte bleibt er mit Java und Spring Boot nah am Code, entwickelt Prototypen und führt Refactorings durch. Als Trainer vermittelt er seit Jahren praxisnahe Softwarearchitektur, die Theorie und Projektrealität verbindet.
Bei der grundlegenden Strukturierung eines Systems muss man zwischen Architekturstilen und Architekturmustern unterscheiden, wobei sie sich nicht immer sauber abgrenzen. Ein Architekturstil ist ein Mittel, das dem System eine grundlegende Struktur verleiht. Beim Stil Event-driven Architecture basiert die Anwendung beispielsweise auf asynchroner Kommunikation, und Events beeinflussen die Architektur und den Code an vielen Stellen. Gleiches gilt für REST, das eine ressourcenorientierte Struktur vorgibt.
Entscheidet sich ein Entwicklungsteam für Microservices als Architekturstil, wählt es eine verteilte Systemarchitektur, beim Stil Modularer Monolith ist das Gegenteil der Fall. In komplexen Systemen kombinieren Architektinnen und Architekten in der Regel mehrere Stile. Manche Architekturstile ergänzen sich, etwa REST und Microservices, während sich andere gegenseitig ausschließen, wie Microservices und der Modulare Monolith.
Ob Microservices oder Modularer Monolith – beides sagt wenig über die Gestaltung der internen Strukturen aus. Auf dieser inneren Architekturebene, der Anwendungsarchitektur, kommen Muster zum Einsatz, die Entwurfsprinzipien und -regeln kombinieren und eine Basisstruktur der Anwendung prägen. Architekturmuster der Anwendungsarchitektur nutzen Verantwortungsbereiche und Beziehungsregeln als Strukturierungsmittel. Im Muster Clean Architecture sind dies beispielsweise konzentrische Ringe, wobei die Beziehungsrichtung stets zum inneren Kern des Ringmodells führt. Die geschichtete Architektur (Layered Architecture) hingegen unterteilt die Verantwortungsbereiche in hierarchische Schichten, wobei jede Schicht nur mit der darunter liegenden kommunizieren darf (siehe Abbildung 1).

Vergleich zwischen Clean Architecture und Schichtenarchitektur (Abb. 1).
Mustersprache als Fundament
Eine Mustersprache ergänzt Architekturmuster für einen ganzheitlichen Konstruktionsplan – von Modulen und Paketen bis hin zum Klassendesign. Sie bildet das Fundament für eine konsistente und verständliche Umsetzung der Muster und beschreibt eine Reihe von Entwurfsmustern für die Programmierung auf der Klassenebene.
Weiterlesen nach der Anzeige
Die Klassen der Mustersprache bilden Geschäftsobjekte, Fachlogik und technische Komponenten ab. Sie werden unter Einhaltung der definierten Beziehungsregeln in einem Klassenverbund implementiert. Diese Regeln bestimmen, wie die Klassen miteinander interagieren, wie sie voneinander abhängen und welche Aufgaben sie haben. Ein Geschäftsobjekt ist charakterisiert durch seine Eigenschaften und sein Verhalten, während ein Service Geschäftslogik und fachliche Ablaufsteuerung implementiert. Eine derartige, genaue Differenzierung gestaltet Architektur klar und nachvollziehbar.
Ein wichtiger Aspekt einer Mustersprache ist die Organisation des Codes in einer gut verständlichen Hierarchie. Dadurch fördert sie die Verteilung von Verantwortlichkeiten auf unterschiedliche Klassen. Prinzipiell kann jedes Projekt seine eigene Mustersprache definieren oder eine bestehende als Basis verwenden und mit individuellen Anforderungen ausbauen. Eine Mustersprache sorgt auch im Team dafür, dass alle Mitglieder dieselben Begriffe und Prinzipien verwenden.
Dieser Artikel wählt die DDD Building Blocks als Grundlage für eine Mustersprache, wie die folgende Tabelle und Abbildung 2 zeigen.
| Value Object | Ein Value Object repräsentiert einen unveränderlichen Fachwert ohne eigene Entität. Das Value Object ist verantwortlich für die Validierung des fachlichen Werts und sollte nur in einem validen Zustand erzeugt werden können. Ferner implementiert ein Value Object dazugehörige Fachlogik. |
| Entity | Eine Entity ist ein Objekt mit einer eindeutigen Identität und einem Lebenszyklus. Die Entität wird beschrieben durch Value Objects und ist verantwortlich für die Validierung fachwertübergreifender Geschäftsregeln sowie die Implementierung dazugehöriger Fachlogik. |
| Aggregate | Ein Aggregate ist eine Sammlung von Entitäten und Value Objects, die durch eine Root Entity (oder Aggregate Root bzw. vereinfacht Aggregate) zusammengehalten werden. Die Root Entity definiert eine fachliche Konsistenzgrenze, klar abgegrenzt zu anderen Root Entities (oder Aggregates). |
| Domain Service | Ein Domain Service implementiert Geschäftslogik, die nicht zu einer Entität oder einem Value Object gehört. Weiter steuert der Domain Service den Ablauf eines Anwendungsfalls. Ein Domain Service ist zustandslos zu implementieren. |
| Factory | Eine Factory ist für die Erstellung von Aggregates, Entitäten oder Value Objects verantwortlich. Die Factory kapselt die Erstellungslogik komplexer Domänenobjekte. |
| Repository | Ein Repository ist verantwortlich für die Speicherung und das Abrufen von Aggregaten und Entitäten aus einer Datenquelle. Das Repository kapselt den Zugriff auf eine Datenbank oder auch andere technische Komponenten. |

Mustersprache des taktischen Domain-driven Design (Abb. 2).
Ein Beispiel verdeutlicht den Unterschied zwischen einem Value Object und einer Entity: Eine Entity könnte ein bestimmtes Elektrofahrzeug sein. Entities sind also eindeutig und unverwechselbar. In der realen Welt zeigt sich das an der global eindeutigen Fahrgestellnummer (VIN). Der aktuelle Zustand eines E-Fahrzeugs wird zu einem bestimmten Zeitpunkt beispielsweise durch seinen Ladezustand beschrieben, ein Wert, der sich im Laufe der Nutzung des Fahrzeugs verändert. Der Ladezustand entspricht einem Value Object. Er verfügt über keine eigene Identität, sondern definiert sich ausschließlich durch seinen Wert.
Erweiterung der Mustersprache auf Basis der Stile und Muster
Die Mustersprache der Building Blocks ist nicht vollständig. Sie benötigt weitere Elemente, die von den eingesetzten Architekturstilen und -mustern abhängen. REST als Architekturstil führt beispielsweise zwei Elemente in die Mustersprache ein: Controller und Resource. Bei der Integration von REST als Provider liegt der Fokus auf der Resource, die als Datentransferobjekt (DTO) über den API-Endpunkt bereitsteht. Der Controller fungiert als Schnittstelle zwischen der Anfrage des Konsumenten und der Fachlogik des Systems. Das heißt, der Controller nutzt den bereits eingeführten Domain Service und delegiert die Ausführung von Fachlogik an diesen.
Bei der Integration von REST als Consumer erhält die Mustersprache das Element Service Client, das dem Abrufen von Daten oder Ausführen von Funktionen über einen externen API-Endpunkt dient. Der Domain Service triggert dies als Teil der Fachlogik über den Service Client.
Der Stil Event-driven Architecture erweitert die Mustersprache um die Elemente Event Listener, Event Publisher und das Event selbst. Ein Event Listener hört auf Ereignisse und ruft den entsprechenden Domain Service auf, um die Ausführung der Geschäftslogik auszulösen. Der Event Publisher veröffentlicht eine Zustandsveränderung in der Fachlichkeit über ein Event. Der Domain Service triggert die Event-Veröffentlichung als Teil seiner Fachlogik und nutzt hierfür den Event Publisher.
Die in diesen Beispielen aufgeführten Begriffe sind im Vergleich zu den DDD Building Blocks nicht in der Literatur definiert und entstammen der Praxis. Abbildung 3 zeigt die Klassen der erweiterten Mustersprache.

Elemente der Mustersprache des taktischen Domain-driven Design (Abb. 3).
Architekturmuster kombinieren Regeln, Entwurfsmuster und Prinzipien. Muster wie Clean Architecture, die sich besonders für komplexe Systeme mit hohen Anforderungen an den Lebenszyklus eignen, bündeln mehrere Konzepte und beeinflussen daher die Mustersprache stärker als andere Muster. Ein Beispiel ist das Konzept Use Case in der Clean Architecture, das ein zentrales Element darstellt und die Mustersprache um die Elemente Use Case Input Port, Use Case Output Port und Use Case Interactor erweitert. Ein weiteres Beispiel ist die Anwendung des Dependency Inversion Principle (DIP) in der Clean Architecture, das zu dem Musterelement Mapper führt.
Nach dem Exkurs über die Mustersprachen stellt dieser Artikel verschiedene Architekturmuster vor, die sich in schichten- und domänenbasierende unterteilen.
Schichtenbasierende Architekturmuster
Schichtenbasierende Architekturmuster sind datenzentrisch strukturiert. Je nach Muster ist dieser Aspekt mehr oder weniger ausgeprägt. Die Schichtung unterscheidet sich in technischer (horizontal geschnitten) und fachlicher (vertikal geschnitten) Hinsicht. Für die weitere Beschreibung eignet sich die Begriffswelt von Simon Brown mit „Package by …“ .
Package by Layer: Dieses Muster organisiert die Anwendung nach technischen Aspekten, zum Beispiel nach Controller, Service und Repository (Abbildung 4). Es kommt jedoch schnell an seine Grenzen: Mittlere und große Systeme mit komplizierter Fachlichkeit erfordern eine vertikale Schichtung anhand fachlicher Aspekte, andernfalls enden die Projekte erfahrungsgemäß in komplizierten Monolithen mit vielen Architekturverletzungen.
Vorteile:
- Bekannt und verbreitet
- Einfach zu verstehen und anzuwenden
- In kleinen Projekten praktikabel
Nachteile:
- Enge Kopplung zwischen Schichten, mit der Gefahr chaotischer Abhängigkeiten bei Wachstum des Systems
- Fachlich zusammenhängende Funktionalitäten sind über viele Pakete verteilt
- Schwer wartbar und erweiterbar bei mittleren bis großen Anwendungen

Das Architekturmuster Package by Layer (Abb. 4).
Package by Feature: Der Code organisiert sich vertikal anhand fachlicher Aspekte. Eine Schnitt-Heuristik, wie genau das Feature von den fachlichen Anforderungen abzuleiten ist, definiert das Architekturmuster nicht. Es definiert nur, dass dieser fachliche Schnitt zu erfolgen hat. Wird das taktische DDD angewendet, erfolgt der Schnitt entlang der Aggregates (siehe Abbildung 5).
Vorteile:
- Fachlich kohäsiver Code ist lokal zusammengefasst, was zu hoher Wartbarkeit und Erweiterbarkeit führt.
- Modularisierung ermöglicht die unabhängige Entwicklung fachlicher Module.
- Fachliche Ende-zu-Ende-Komponenten sind lose gekoppelt.
- Abhängigkeiten zwischen fachlichen Modulen müssen explizit gehandhabt werden, was die Robustheit der Architektur gegenüber ungewünschten Abhängigkeiten erhöht.
- Fachlich komplexe, mittelgroße bis große Anwendungen lassen sich mit vertikalen Schichten besser beherrschen als mit Package by Layer und Package by Component.
Nachteile:
- Abhängigkeiten zwischen fachlichen Modulen erfordern fortgeschrittene Kommunikationsmuster (zum Beispiel Events), was die architektonische Komplexität erhöht.
- Vertikale Modularisierung muss gut durchdacht werden, um enge Kopplung zwischen Modulen zu vermeiden.

Das Architekturmuster Package by Feature (Abb. 5).
Package by Component: Das Muster strukturiert die Anwendung sowohl fachlich (vertikal) als auch technisch (horizontal), wobei sich ein fachliches Feature in eine Inbound-Komponente und eine Domain-Komponente aufteilt (siehe Abbildung 6). Die Domain-Komponente kapselt Geschäftslogik und die dazugehörige Persistenzschicht. Diese Unterteilung in fachliche Module ist ein entscheidender Unterschied zu Package by Layer.
Vorteile:
- Gute Modularisierung durch fachliche Grenzen zwischen Komponenten
- Hohe Wiederverwendbarkeit der Domain-Komponenten, durch unterschiedliche Inbound-Komponenten
- Erleichterte Testbarkeit durch gesteigerte Modularisierung im Vergleich zu Package by Layer
Nachteile:
- Enge Kopplung zwischen Inbound- und Domain-Schicht, mit dem Risiko indirekter Abhängigkeiten und Seiteneffekten bei Änderungen, insbesondere wenn die Anwendung wächst
- Komponentenkommunikation schwer beherrschbar bei erhöhter fachlicher Komplexität
- Schwerer erweiterbar für mittlere bis große Anwendungen mit höherer fachlicher Komplexität
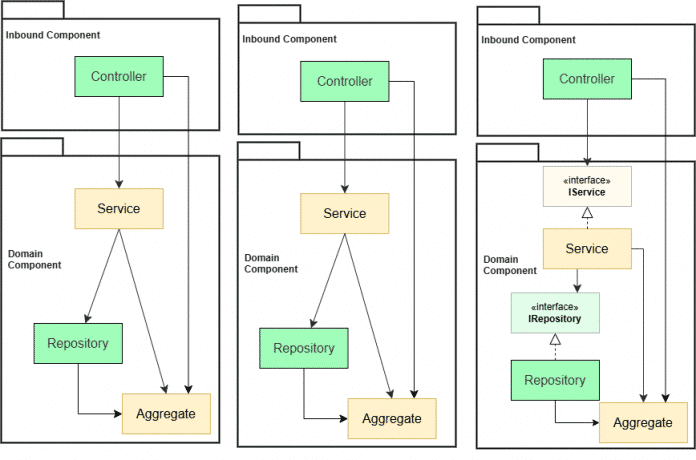
Das Architekturmuster in Package by Component (Abb. 6).










Entwicklung & Code
Rue statt Rust: Genauso sicher, aber leichter zugänglich
Rue, eine neue, kurz vor Weihnachten vorgestellte Programmiersprache, kombiniert Speichersicherheit mit guter Performance ohne Garbage Collector. Es handelt sich um eine Weiterentwicklung von Rust, die ein ähnliches Konzept verfolgt. Rue soll jedoch gerade für Einsteiger einfacher zugänglich sein. Eine Besonderheit ist, dass der KI-Assistent Claude den Compiler (x86-64 und ARM64) für Rue entwickelt.
Weiterlesen nach der Anzeige
Konzipiert wurde Rue von Steve Klabnik, der bei Ruby on Rails und Rust maßgeblich mitgewirkt hat. Er versucht, das speichersichere Borrowing-Konzept von Rust zu vereinfachen, das vielen Rust-Neulingen schwer zu verstehen fällt.
Rue verwendet affine Typen mit veränderbarer Wertesemantik. Das heißt, Entwicklerinnen und Entwickler können affine Typen nur einmal verwenden. Der Blog zeigt ein Beispiel:
struct FileHandle { fd: i32 }
fn example() {
let handle = FileHandle { fd: 42 };
use_handle(handle); // handle moves here
use_handle(handle); // ERROR: value already moved
}
Kopieren ist jedoch möglich, wenn man es ausdrücklich deklariert:
@copy
struct Point { x: i32, y: i32 }
fn example() {
let p = Point { x: 1, y: 2 };
use_point(p); // p is copied
use_point(p); // OK, p is still valid
}
Ein Wert, der konsumiert werden muss, lässt sich mit linear markieren:
Weiterlesen nach der Anzeige
linear struct DatabaseTransaction { conn_id: i32 }
fn example() {
let tx = DatabaseTransaction { conn_id: 1 };
// ERROR: linear value dropped without being consumed
}
Von Zig übernimmt Rue das Konzept von Ausdrücken, die bereits der Compiler auswertet, mit der Eigenschaft comptime. Auch Typen lassen sich so erzeugen:
fn Pair(comptime T: type) -> type {
struct { first: T, second: T }
}
fn main() -> i32 {
let IntPair = Pair(i32);
let p: IntPair = IntPair { first: 20, second: 22 };
p.first + p.second
}
Klabnik arbeitet für das Umsetzen seiner Ideen mit Claude. Er hatte zwar eine Vorstellung davon, wie Rue aussehen soll, ihm fehlte aber die Erfahrung im Bauen von Compilern. Diese Arbeit übernimmt die künstliche Intelligenz: „And you know what? It worked.“ Der erste Versuch, ein Programm zu kompilieren, funktionierte noch nicht, aber nach einer Debugging-Runde lief es dann.
Die Rue-Website betont, dass es sich um ein Forschungsprojekt in seinen Anfängen handelt, das nicht fertig für echte Projekte ist. Wer mitmachen möchte, findet bei GitHub Gelegenheit.
Lesen Sie auch
(who)
Entwicklung & Code
Die Produktwerker: Forecasting mit der Monte-Carlo-Simulation
Die Monte-Carlo-Simulation hilft in der Produktentwicklung dabei, Prognosen realistischer zu machen. Nicht als harte Zusage, sondern als Blick auf Wahrscheinlichkeiten und damit auf das Risiko, das in komplexer Arbeit fast immer mitschwingt. Zeit also, sich tiefer damit auseinanderzusetzen, weshalb Dominique Winter in dieser Folge mit dem Flight Levels und Kanban Coach Felix Rink aus Köln spricht.
Weiterlesen nach der Anzeige
(Bild: deagreez/123rf.com)

Fachvorträge und Networking-Möglichkeiten: Die Product Owner Days am 5. und 6. Mai 2026 in Köln befassen sich in über 20 Vorträgen mit aktuellen Themen rund um Product Ownership, KI im Produktmanagement, User Research, Product Discovery und Product Economics.
Fundierte Vorhersagen in der Produktentwicklung
Gemeinsam starten sie bei der Frage, wann etwas fertig ist und wie belastbar so eine Aussage eigentlich ist, wenn Teams in unsicheren Umfeldern arbeiten. Von dort geht es zur Idee hinter der Monte-Carlo-Simulation. Sie ist überraschend simpel. Vergangene Ergebnisse geben Hinweise darauf, wie sich Arbeit vermutlich auch künftig verteilen wird. Statt eine einzelne Zahl zu versprechen, entsteht eine Bandbreite. Fertigstellungen aus der Vergangenheit werden in vielen Durchläufen immer wieder neu kombiniert, bis ein Muster sichtbar wird. Manche Ergebnisse tauchen oft auf, andere sind selten.
Genau diese Verteilung ist in der Produktentwicklung hilfreich, weil Schwankungen zum Tagesgeschäft gehören. Schnell wird klar, dass es weniger um exakte Termine geht als um ein besseres Gefühl für Risiko. Die Simulation zeigt, mit welcher Wahrscheinlichkeit ein bestimmter Arbeitsumfang in einem bestimmten Zeitraum wirklich erreichbar ist. Das verändert, wie über Planung gesprochen wird. Zusagen werden zu bewussten Entscheidungen über Risiko und nicht zu Versprechen, die später unter Druck verteidigt werden müssen. Für Product Owner ist das besonders wertvoll, weil Gespräche mit Stakeholdern dadurch sachlicher werden und Erwartungen besser eingeordnet werden können.
Ein weiterer Schwerpunkt liegt auf den Daten. Entscheidend ist nicht, möglichst weit zurückzugehen, sondern eine Vergangenheit zu wählen, die der erwarteten Zukunft ähnelt. Kurze Zeiträume mit ausreichend vielen Datenpunkten liefern oft bessere Prognosen als lange Historien, in denen Sondereffekte alles verzerren. Auch eine feinere Betrachtung auf Tagesbasis kommt zur Sprache, weil sich Forecasts damit schneller aktualisieren lassen und Veränderungen im System früher auffallen.
Monte-Carlo-Simulation als laufendes Werkzeug
Weiterlesen nach der Anzeige
Spannend wird es dort, wo die Monte-Carlo-Simulation nicht als einmaliger Schritt verstanden wird, sondern als laufendes Werkzeug. Neue Erkenntnisse, zusätzliche Arbeit oder geänderte Rahmenbedingungen fließen direkt in den nächsten Forecast ein. So entsteht ein kontinuierlicher Abgleich zwischen Realität und Erwartung. Das unterstützt aktives Risikomanagement und hilft Teams, Prioritäten immer wieder neu auszurichten, ohne jedes Mal bei null anfangen zu müssen.
Am Ende geht der Blick über die klassische Fertigstellungsfrage hinaus. Überall dort, wo vergangenes Verhalten brauchbare Hinweise auf die Zukunft gibt, kann Monte Carlo helfen, Unsicherheit greifbar zu machen. In der Produktentwicklung ist das oft genau die Art von Pragmatismus, die fehlt. Nicht kompliziert, aber deutlich verlässlicher als Bauchgefühl.
Die aktuelle Ausgabe des Podcasts steht auch im Blog der Produktwerker bereit: „Forecasting mit der Monte-Carlo-Simulation“.
(mai)
Entwicklung & Code
Neue Hauptversion Spring Shell 4.0 markiert Meilenstein
Das Spring-Team hat die neue Major-Version Spring Shell 4.0.0 veröffentlicht. Sie ist auf dem zentralen Maven-Repository Maven Central verfügbar, soll einen signifikanten Meilenstein für die Spring Shell bedeuten und ist mit den aktuellen Spring-Framework- und Spring-Boot-Versionen kompatibel. Updates gibt es unter anderem für die Architektur, Null Safety und das Erstellen von Befehlen.
Weiterlesen nach der Anzeige
Modulare Architektur und JSpecify-Anbindung
Version 4.0 der Spring Shell basiert auf dem Spring Framework 7, das im November 2025 erschien. Das quelloffene Java-Framework brachte ein neues Konzept für Null Safety: Ebenso wie das Framework nutzt die Spring Shell nun das Open-Source-Projekt JSpecify für Null Safety, was Fehler durch den Umgang mit Null-Pointern verhindern soll.
Zudem bringt die neue Spring-Shell-Version ein überarbeitetes Befehlsmodell, um das Erstellen und Verwalten von Befehlen zu vereinfachen. Eine stärker modular aufgebaute Architektur soll der benutzerdefinierten Anpassung sowie Erweiterung der Shell zugutekommen. Die Dokumentation und Beispiele wurden ebenfalls aktualisiert, um insbesondere beim Einstieg in die Arbeit mit der Spring Shell zu helfen.
Migrationshinweise
Im Projekt-Wiki findet sich ein Migrationsguide. Dabei ist zu beachten, dass Anwendungen vor der Migration auf Spring Shell 4 zunächst auf die neueste 3.4.x-Version aktualisiert werden sollten.
Zu den Moduländerungen zählt, dass das spring-shell-core-Modul nicht länger auf Spring Boot und JLine angewiesen ist. Die Module spring-shell-standard und spring-shell-standard-commands wurden in das spring-shell-core-Modul integriert.
Weiterlesen nach der Anzeige
In Spring Shell 3 als deprecated (veraltet) markierte APIs und Annotationen sind entfallen, darunter Legacy-Annotationen wie ShellComponent und ShellMethod.
Shell-Anwendungen mit Spring Shell entwickeln
Mit der Spring Shell können Entwicklerinnen und Entwickler eine Spring-basierte Shell-Anwendung erstellen. Wie das Spring-Team ausführt, kann eine solche Kommandozeilenanwendung hilfreich sein, um mit der REST-API eines Projekts zu interagieren oder mit lokalen Dateninhalten zu arbeiten. Weitere Informationen – inklusive Beispielanwendungen und Tutorials – bietet das GitHub-Repository.
(mai)




-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenIllustrierte Reise nach New York City › PAGE online
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenAus Softwarefehlern lernen – Teil 3: Eine Marssonde gerät außer Kontrolle
-
Künstliche Intelligenzvor 3 Monaten
Top 10: Die beste kabellose Überwachungskamera im Test
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenSK Rapid Wien erneuert visuelle Identität
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenNeue PC-Spiele im November 2025: „Anno 117: Pax Romana“
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenDonnerstag: Deutsches Flugtaxi-Start-up am Ende, KI-Rechenzentren mit ARM-Chips
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenArndt Benedikt rebranded GreatVita › PAGE online
