Entwicklung & Code
Die Produktwerker: Designprinzipien für bessere Entscheidungen
Tanja Heyken ist zu Gast bei den Produktwerkern, um gemeinsam auf das Thema „Designprinzipien“ zu schauen, und was diese im Alltag von Produktteams tatsächlich bewirken können. Dabei bringt Tanja Heyken ihre doppelte Perspektive als UX-Professional und Product Owner mit, die sie bei Checkmk täglich lebt. Ihr Ziel ist es, Entscheidungsprozesse zu vereinfachen, Konsistenz zu schaffen und die User Experience (UX) zu verbessern, ohne dafür jedes Mal von vorn zu diskutieren. Designprinzipien versteht sie dabei als konkrete, nutzerzentrierte Leitplanken. Sie helfen Teams, bessere Entscheidungen zu treffen – auch dann, wenn gerade niemand aus UX oder dem Produktmanagement dabei ist.

(Bild: deagreez/123rf.com)

So geht Produktmanagement: Auf der Online-Konferenz Product Owner Day von dpunkt.verlag und iX am 13. November 2025 können Product Owner, Produktmanagerinnen und Service Request Manager ihren Methodenkoffer erweitern, sich vernetzen und von den Good Practices anderer Unternehmen inspirieren lassen.
Im iterativen Prozess zu Designprinzipien
Die wichtige Grundlage dafür sind Daten: Wer mit Designprinzipien arbeiten möchte, sollte die Perspektive der Nutzerinnen und Nutzer ernst nehmen. Heyken empfiehlt den UEQ+ – eine modulare Erweiterung des User Experience Questionnaire (UEQ) – als kompaktes Instrument, um herauszufinden, welche Eigenschaften den Nutzenden wichtig sind und wie das Produkt aktuell wahrgenommen wird. Daraus lassen sich Designprinzipien ableiten, die zur Realität der Nutzerinnen und Nutzer passen, nicht nur zu den Annahmen im Team.
Doch wie kommt man von ersten Erkenntnissen zu Prinzipien, die im Alltag wirklich nützlich sind? Für Tanja Heyken beginnt alles mit einem interdisziplinären Workshop. Entscheidend sind UX, Product, Entwicklung, Support, Sales; also möglichst viele Sichtweisen an einen Tisch holen, um gemeinsames Verständnis zu schaffen. Ziel ist nicht die perfekte Formulierung im ersten Anlauf, sondern die Entwicklung von sogenannten Proto-Prinzipien, die sich dann im Team schrittweise verfeinern und gegen reale Entscheidungen testen lassen. Dieser iterative Prozess sichert nicht nur Qualität, sondern stärkt auch die Akzeptanz im Unternehmen.
Designprinzipien müssen einfach und greifbar sein. Drei bis fünf gut formulierte Prinzipien lassen sich besser merken und leben als zwölf ambitionierte. Spotify zeigt, wie es geht: Relevant, Human, Unified. Auch bei Figma sieht man, wie Eigenschaften wie „Thoughtful“ oder „Approachable“ Orientierung bieten können. Entscheidend ist aber nicht nur die Kürze, sondern das gemeinsame Verständnis dahinter: Was bedeutet etwa „Human“ konkret im Produkt? Welche Sprache, welche Gestaltung, welche Entscheidungen zahlen darauf ein?
Die Prinzipien im Alltag einsetzen
Damit Designprinzipien im Alltag wirken, braucht es mehr als ein PDF oder einen Eintrag im Wiki. Prinzipien müssen kontinuierlich sichtbar gemacht werden, etwa durch Beispiele in Reviews, durch Argumentation im Daily oder durch Verankerung im Onboarding neuer Teammitglieder. Designprinzipien sind keine Regeln, sondern Orientierung. Sie ersetzen kein User Research, kein Testing und keine Interviews, aber sie geben Teams Sicherheit in Entscheidungen, die jeden Tag getroffen werden müssen.
Die große Stärke von Designprinzipien liegt darin, dass sie helfen, auch in wachsenden Teams mit immer mehr Beteiligten eine konsistente UX sicherzustellen. Die Verknüpfung zu anderen Artefakten in der Produktentwicklung, etwa der Produktvision, dem Product Goal oder Sprintziel ist auch sehr spannend. Selbst wenn Designprinzipien keine direkten Bestandteile von Scrum sind, lassen sie sich gut als tägliche Entscheidungshilfe für alle, die das Produkt gestalten, in diese Strukturen einbetten. Wer Designprinzipien im Team etablieren möchte, sollte aber auch nicht zu perfektionistisch starten, sondern lieber loslegen, lernen und iterieren. Denn die besten Prinzipien entstehen nicht auf dem Papier, sondern in der echten Zusammenarbeit.
Weitererführende Links
Die aktuelle Ausgabe des Podcasts steht auch im Blog der Produktwerker bereit: „Die Produktwerker: Designprinzipien„.
(mai)











Entwicklung & Code
Genkit Go 1.0: Google bringt stabiles KI-Framework ins Go-Ökosystem
Google hat mit Genkit Go 1.0 die erste stabile Version seines Open-Source-Frameworks für KI-Entwicklung im Go-Ökosystem veröffentlicht. Entwicklerinnen und Entwickler können damit ab sofort produktionsreife KI-Anwendungen erstellen und deployen. Gleichzeitig bringt Google mit dem neuen CLI-Befehl genkit init:ai-tools eine direkte Integration für gängige KI-Coding-Assistenten.
Typsichere KI-Flows erstellen
Eine der spannendsten Neuerungen in Genkit Go 1.0 ist die Möglichkeit, typensichere KI-Flows mit Go-Structs und JSON-Schema-Validierung zu erstellen. Dadurch lassen sich Modellantworten offenbar zuverlässig strukturieren und einfacher testen.
Im folgenden Beispiel aus dem Ankündigungsbeitrag generiert ein Flow ein strukturiertes Rezept:
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/firebase/genkit/go/ai"
"github.com/firebase/genkit/go/genkit"
"github.com/firebase/genkit/go/plugins/googlegenai"
)
// Define your data structures
type RecipeInput struct {
Ingredient string `json:"ingredient" jsonschema:"description=Main ingredient or cuisine type"`
DietaryRestrictions string `json:"dietaryRestrictions,omitempty" jsonschema:"description=Any dietary restrictions"`
}
type Recipe struct {
Title string `json:"title"`
Description string `json:"description"`
PrepTime string `json:"prepTime"`
CookTime string `json:"cookTime"`
Servings int `json:"servings"`
Ingredients []string `json:"ingredients"`
Instructions []string `json:"instructions"`
Tips []string `json:"tips,omitempty"`
}
func main() {
ctx := context.Background()
// Initialize Genkit with plugins
g := genkit.Init(ctx,
genkit.WithPlugins(&googlegenai.GoogleAI{}),
genkit.WithDefaultModel("googleai/gemini-2.5-flash"),
)
// Define a type-safe flow
recipeFlow := genkit.DefineFlow(g, "recipeGeneratorFlow",
func(ctx context.Context, input *RecipeInput) (*Recipe, error) {
dietaryRestrictions := input.DietaryRestrictions
if dietaryRestrictions == "" {
dietaryRestrictions = "none"
}
prompt := fmt.Sprintf(`Create a recipe with the following requirements:
Main ingredient: %s
Dietary restrictions: %s`, input.Ingredient, dietaryRestrictions)
// Generate structured data with type safety
recipe, _, err := genkit.GenerateData[Recipe](ctx, g,
ai.WithPrompt(prompt),
)
if err != nil {
return nil, fmt.Errorf("failed to generate recipe: %w", err)
}
return recipe, nil
})
// Run the flow
recipe, err := recipeFlow.Run(ctx, &RecipeInput{
Ingredient: "avocado",
DietaryRestrictions: "vegetarian",
})
if err != nil {
log.Fatalf("could not generate recipe: %v", err)
}
// Print the structured recipe
recipeJSON, _ := json.MarshalIndent(recipe, "", " ")
fmt.Println("Sample recipe generated:")
fmt.Println(string(recipeJSON))
<-ctx.Done() // Used for local testing only
}
Hier wird ein Flow (recipeGeneratorFlow) definiert, der Rezepte auf Basis einer Hauptzutat und optionaler Ernährungsvorgaben wie „vegetarian“ generiert. Der Prompt wird dynamisch gebaut, ans KI-Modell (Google Gemini) übergeben und die Antwort in eine klar definierte Go-Datenstruktur (Recipe) zurückgeschrieben. Am Ende läuft der Flow mit der Eingabe „avocado, vegetarisch“ und gibt ein komplettes JSON-Rezept mit Zutaten, Kochzeit und Tipps zurück.
Anbindung an gängige Sprachmodelle
Darüber hinaus haben Developer mit Genkit Go 1.0 die Möglichkeit, externe APIs über Tool Calling einzubinden und Modelle von Google AI, Vertex AI, OpenAI, Anthropic und Ollama über eine einheitliche Schnittstelle zu nutzen. Die Bereitstellung soll unkompliziert als HTTP-Endpoint erfolgen. Eine Standalone-CLI sowie eine interaktive Developer UI unterstützen beim Schreiben von Tests, Debugging und Monitoring.
Der neue Befehl genkit init:ai-tools richtet automatisch KI-Assistenztools wie Gemini CLI, Firebase Studio, Claude Code und Cursor ein. Somit können Entwicklerinnen und Entwickler damit direkt die Genkit-Dokumentation durchsuchen, Flows testen, Debug-Traces ausführen und Go-Code nach Best Practices generieren.
(mdo)
Entwicklung & Code
Vorstellung Studie Cupra Tindaya: Betont unruhig
In den Weiten des Volkswagen-Konzerns darf sich kaum eine Marke optisch so weit vorwagen wie Cupra. Tatsächlich seriennah dürfte die Studie Tindaya kaum sein, und doch ist die spektakuläre Formgebung mehr als nur ein Blickfang auf der IAA. Der Name Tindaya, nach einem Vulkan auf der Insel Fuerteventura, ist dabei durchaus Programm.
Terramar, Tavascan, Formentor und auch noch der Ateca, dessen Produktion absehbar ausläuft: An SUVs mangelt es der Marke Cupra derzeit wahrlich nicht. Ist dort perspektivisch Platz für ein weiteres Modell mit rund 4,7 m Länge? Ja, befanden offenbar die Verantwortlichen. Die Studie Tindaya ist 4,72 m lang und ausschließlich auf batterieelektrische Antriebe ausgerichtet. Welche Plattform in einem Serienmodell genutzt werden würde, ist aktuell noch zweitrangig. Viel spricht dafür, dass es die Basis des kommenden VW ID.4 sein könnte.
23-Zoll-Felgen
Das kantig-faltige Design ist bewusst überzeichnet. Allein schon der gesetzliche Fußgängerschutz würde einem Serieneinsatz dieser Front vermutlich entgegenstehen. Riesige Radhäuser, in denen selbst 23-Zoll-Felgen samt Reifen mit geringer Flankenhöhe nicht übertrieben scheinen, haben da vermutlich bessere Chancen. Innen gibt es vier Einzelsitze, ein 24-Zoll-Display, ein Lenkrad im Gaming-Stil und eine Mittelkonsole, die an die 2023er-Studie des Lamborghini Lanzador erinnert. In der Mitte der bis in den Fond durchgehenden Konsole befindet sich ein Zentralknopf, mit dem sich verschiedene Funktionen ansteuern lassen.
250 kW Leistung im Spitzenmodell – mindestens
Ein aufregend gestaltetes Serienmodell würde sich bei den Antriebskomponenten vermutlich im Baukasten des Konzerns bedienen. Hinter- wie Allradantrieb wären damit möglich. Das Leistungsangebot dürfte sich zwischen 210 und 250 kW bewegen, wobei wir damit rechnen, dass sich Volkswagen irgendwann genötigt sehen könnte, in dieser Hinsicht nachzulegen. Ein Ende des Wettrüstens ist schließlich nicht abzusehen – ganz im Gegenteil: Der Umstieg auf Elektromobilität macht mehr Leistung vergleichsweise problemlos möglich, was eher Folgen für die Verkehrssicherheit haben wird als auf den Bedarf an Fahrenergie.

Cupra
)
Unter anderem Volkswagen hat mit dem E-Motor APP550 gezeigt, dass sich selbst 210 kW Spitzenleistung potenziell mitführen lassen, ohne beim Verbrauch dramatisch über dem zu liegen, was ein elektrischer Kleinwagen wie der Opel Corsa-e auch braucht. Auch in dieser Hinsicht unterscheiden sich Verbrenner und batterieelektrischer Antrieb enorm. Das Potenzial eines aufgeladenen V8 wird auch bei gemäßigter Fahrweise immer ein Stück weit zu füttern sein. Beim ungleich effizienteren E-Motor steigt der Verbrauch erst dann, wenn die Leistung abgerufen wird.
Ladeleistung: 200 kW plus X
Zweigeteilt ist die Welt bei Volkswagen hinsichtlich der Ladeleistung. Audi und Porsche haben schon Modelle mit 800 Volt Spannungsebene, was Ladeleistung von deutlich mehr als 200 kW an der gängigen, mit 500 Ampere abgesicherten Ladeinfrastruktur erlaubt. Marken wie Skoda, VW und eben auch Cupra nutzen derzeit ein 400-Volt-System. Damit ist an Ladesäulen mit 500 A bei 200 kW die Spitze erreicht. Mittelfristig werden auch andere Konzernmarken Elektroautos mit 800 Volt ins Sortiment aufnehmen. Ob ein Serienableger der Studie Tindaya dazu gehören könnte, ist ungewiss.
Lesen Sie mehr zur Marke Cupra
(mfz)
Entwicklung & Code
Docker Image Security – Teil 2: Minimale und sichere Docker Images
Viele Softwareentwicklungsteams verwenden Container-Images aus offiziellen Registries wie Docker Hub. Diese Images enthalten häufig viele Komponenten. Scanner wie Trivy oder Grype finden dann sehr viele CVEs (siehe Teil 1 dieser Serie), ob zu Recht (True Positives) oder als Fehlalarme (False Positives). Obgleich offizielle Images meist kostenlos sind, kann die Prüfung (Triage) aller gemeldeten CVE darin ein Kostentreiber sein – sofern das Team nicht riskieren will, auf die Suche tatsächlich ausnutzbarer CVEs zu verzichten.

Dr. Marius Shekow war über 10 Jahre als Forscher und Softwareentwickler bei Fraunhofer tätig. Seit 2022 ist er Lead DevOps- & Cloud-Engineer bei SprintEins in Bonn. Dort baut er für Konzerne und KMUs individuelle Cloud-Umgebungen, inkl. CI/CD-Automatisierung, Observability und Security-Absicherung.
Minimale Container-Images – auch als „distroless“, „gehärtete“ oder „chiseled“ bekannt – bieten eine Lösung für dieses Problem. Unter dem Motto „weniger Komponenten bedeuten weniger Schwachstellen“ verzichten sie auf alle Komponenten (etwa Shells oder Paketmanager), die zur Laufzeit normalerweise nicht gebraucht werden, um die Angriffsfläche zu reduzieren.
Anhand einer Gegenüberstellung der Vor- und Nachteile sowie einer Liste von kostenlosen und kostenpflichtigen minimalen Images für die Anwendungsfälle Basis-Linux, PHP, Python, Java, C#/.NET und Node.js, soll dieser Artikel DevOps-Teams bei der Auswahl geeigneter Container-Images helfen.
Was sind minimale Images?
Minimale Images enthalten nur die absolut notwendigen Komponenten, um die eigentlichen Basis-Funktionen auszuführen (beim postgres-Image ist etwa der PostgreSQL-Server die Basis-Komponente). Ziel ist, die Angriffsfläche für Hacker so weit wie möglich zu reduzieren (siehe Abbildung 1) und Komponenten auszuschließen, etwa:
- Distro-spezifische Paketmanager, z.B. apt für Debian/Ubuntu, apk für Alpine oder dnf/yum für Red Hat
- Verschiedene Linux-Distro-spezifische Pakete, die normalerweise standardmäßig installiert, aber nicht erforderlich sind, um eine Anwendung auszuführen, z.B. Binärdateien und Bibliotheken für perl, grep oder gzip. Lässt man solche Komponenten weg, hat man ein „distroless“ Image ohne Färbung von Distro-Vorlieben.
- Eine Shell (z.B. /bin/bash oder /bin/sh)
- Debugging-Werkzeuge, beispielsweise curl zur Diagnose von Verbindungsproblemen
Während Slim Images (z.B. python:3.13-slim) in der Regel kleiner als die regulären Image-Varianten sind (z.B. python:3.13), enthalten sie dennoch eine Shell und einen Paketmanager und erleichtern es daher einem Angreifer, tiefer in ein System einzudringen!
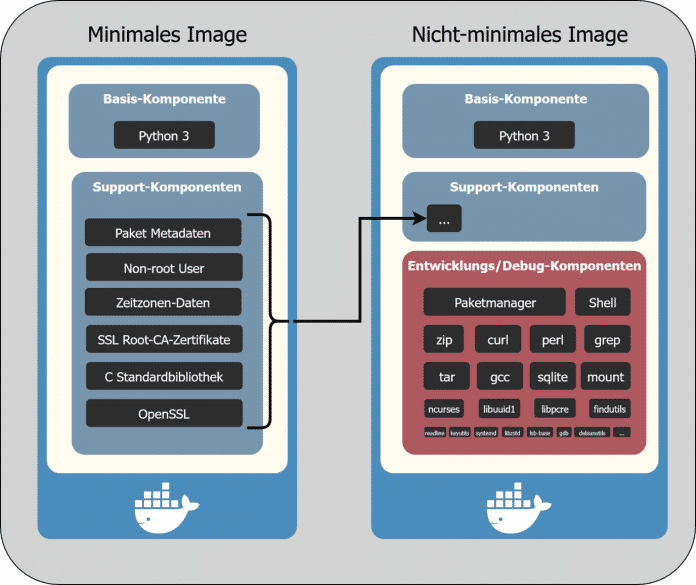
Komponenten-Vergleich: minimale vs. nicht-minimale Images (Abb. 1)
| Vor- und Nachteile von minimalen Images | |
| Vorteile | Nachteile |
| ✅ Reduzierte Startdauer | ❌ Schwieriger zu debuggen |
| ✅ Weniger Sicherheitslücken und Triage-Arbeit | ❌ Erhöhter Testaufwand |
| ✅ Verbesserte Sicherheit | ❌ Erhöhter Rechercheaufwand |
Ein Blick auf die Details der in der Tabelle gegenübergestellten Vor- und Nachteile macht deutlich, warum minimale Images nicht zwangsläufig immer die beste Wahl sind.
Vorteile:
- Reduzierte Startdauer: Minimale Images sind sehr klein und starten daher schneller, da das Herunterladen und Entpacken weniger Zeit benötigen.
- Weniger Sicherheitslücken und Triage-Arbeit: Schwachstellenscanner wie Trivy oder Grype melden für minimale Images (im Durchschnitt) deutlich weniger Schwachstellen als für nicht-minimale Images. Daher kann das Team sich auf die Softwareentwicklung konzentrieren, anstatt potenzielle False-Positive-Funde der Scanner zu untersuchen (siehe Teil 1 dieser Serie).
- Verbesserte Sicherheit: Falls ein Angreifer es schafft, eine Schwachstelle der in dem Image laufenden Software auszunutzen (z.B. eine PostgreSQL-Schwachstelle in einem PostgreSQL-Image), wird er keine beliebigen Shell-Befehle ausführen können. Denn im minimalen Image gibt es keine Shell. Er kann also keine zusätzliche Software herunterladen, um damit die (virtuelle) Infrastruktur weiter zu infiltrieren. Ein weiterer Vorteil ist, dass Schwachstellenscanner wie Trivy in den meisten minimalen Images alle vorhandenen Komponenten korrekt identifizieren, was False Negatives vermeidet.
Nachteile:
- Schwieriger zu debuggen: Wenn es Probleme im Produktivbetrieb gibt, greifen Entwickler- oder Betriebsteams häufig direkt auf die Shell im Container zu, um darin Debug-Befehle auszuführen. Bei minimalen Images funktioniert dies mangels Shell nicht mehr. Es gibt jedoch Workarounds, wie kubectl debug oder das bessere cdebug. Beide starten einen kurzlebigen (ephemeral) Sidecar-Container, der den Prozess-Namespace und das Filesystem mit dem zu debuggenden Container teilt.
- Erhöhter Testaufwand: Tauscht man bei einer containerisierten Anwendung das offizielle durch ein minimales Image aus, muss das Team manuell testen, ob es zu Kompatibilitätsproblemen kommt. Insbesondere Multi-Stage-Builds für Runtimes wie Python muss man genau betrachten. Dort kompiliert man die Anwendung in einer „Build“-Stage und kopiert sie dann in die „Final“-Stage, die das minimale Basis-Image verwendet. Verwendet man in der Build-Stage jedoch das offizielle (nicht-minimale) Image, treten oft subtile, implementierungsspezifische Inkompatibilitäten zwischen beiden Stages auf. Beispielsweise fehlen in der minimalen Final-Stage bestimmte (native) Bibliotheken oder Binärdateien. Oder der Pfad zur Runtime ist unterschiedlich, sodass der Container-Start fehlschlägt. Der Python-spezifische Abschnitt verlinkt ein konkretes Beispiel.
Zudem ist es bei der Verwendung eines minimalen Image aufgrund der fehlenden Shell nicht möglich, mehrere Befehle (oder Shell-Entrypoint-Scripte) beim Start des Containers auszuführen. - Erhöhter Rechercheaufwand: Auch wenn dieser Artikel die Recherchezeit reduziert, um das beste minimale Image zu finden, fällt trotzdem immer der Rechercheaufwand an. Es könnte sich beispielsweise zeigen, dass es kein geeignetes minimales Image gibt, sodass Interessenten ein eigenes erstellen müssen, was nicht trivial und Thema von Teil 3 der Artikelserie ist.
Verfügbare minimale (Base-) Images
Derzeit sind minimale Images nach wie vor ein Nischenmarkt. Die Maintainer von offiziellen Base-Images (z.B. des Python-Interpreters) oder von Stand-alone-Software wie PostgreSQL sehen aus unersichtlichen Gründen bisher davon ab, minimale Images zu erstellen.Stattdessen haben sich Drittanbieter darauf spezialisiert – wie Chainguard, Rapidfort, Docker, SecureBuild, Minimus und Bitnami.
Der folgende Abschnitt stellt verschiedene Alternativen zu Base-Image-Alternativen für diverse Runtimes sowie ein schlichtes Basis-Linux vor. Es handelt sich um typische Images, die Anwender im FROM-Statement im Dockerfile angeben, um eigene Anwendungen darauf aufzubauen.
Bei der Recherche nach Alternativen empfiehlt es sich, folgende Auswahlkriterien zu berücksichtigen:
- Baut der Image-Maintainer die minimalen Images regelmäßig neu, z.B. alle paar Tage? Images, bei denen dies nicht der Fall ist, sollte man ignorieren. Der Docker Tag Monitor hilft dabei, die Rebuild-Frequenz bestimmter Image-Tags zu ermitteln (weitere Details finden sich in diesem Blogeintrag des Autors).
- Sind die Images kryptografisch signiert, z. B. mit Cosign? Falls nicht, lässt sich nicht überprüfen, ob das Image manipuliert wurde.
- Können Schwachstellenscanner (wie Trivy) die Komponenten korrekt identifizieren und mit Schwachstellendatenbanken abgleichen? Falls nicht, bleibt unklar, ob das minimale Image etwaige Schwachstellen enthält (siehe Teil 1 dieser Serie).
Alle im Folgenden vorgestellten Images erfüllen die Kriterien – andernfalls weist der Artikel auf Ausnahmen explizit hin. Die Tabelle unten bietet eine Übersicht der auf dem Markt verfügbaren Hersteller (Spalten 2-4) für die verschiedenen Use Cases (Spalte 1):
| Image-Anbieter und Anwendungsfälle im Vergleich | ||||
| Use case | Google Distroless | WolfiOS / Chainguard | Ubuntu Chiseled | Weitere |
| Basis-Linux | ✅ (4 Varianten) | ✅ (2 gratis Varianten, 1 Bezahl-Variante die aber gratis selbst gebaut werden kann) | ⚠️ (nur bei Eigenbau) | — |
| PHP | ❌ | ✅ (neueste Upstream-Version) | ❌ | — |
| Python | ✅ (v3.11, kein ctypes Support) | ✅ (neueste Upstream-Version) |
✅ (v3.10, v3.12) ⚠️ (v3.13 bei Eigenbau für Ubuntu 25.04) |
— |
| Java | ✅ (v17, v21) | ✅ (neueste Upstream-Version) | ✅ (v8, v11, v17, v21) | jlink |
| C# / .NET | ❌ | ✅ (neueste Upstream-Version) | ✅ (.NET v6-10, von Microsoft) | — |
| Node.js | ✅ (v20, v22) | ✅ (neueste Upstream-Version) |
⚠️ (v18, ist End-Of-Life ⚠️ (v20.18.1 bei Eigenbau für Ubuntu 25.04) |
— |

Deutschland spart am falschen Ende – und gefährdet so die Verkehrswende

Gemini überholt ChatGPT in App Store Charts
Dieser Hersteller wächst schneller als Apple und Samsung

Der ultimative Guide für eine unvergessliche Customer Experience
eine gute Nachricht ist")
Relatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist

Adobe Firefly Boards › PAGE online
-
 UX/UI & Webdesignvor 4 Wochen
UX/UI & Webdesignvor 4 WochenDer ultimative Guide für eine unvergessliche Customer Experience
-
eine gute Nachricht ist") Social Mediavor 4 Wochen
Social Mediavor 4 WochenRelatable, relevant, viral? Wer heute auf Social Media zum Vorbild wird – und warum das für Marken (k)eine gute Nachricht ist
-
 UX/UI & Webdesignvor 2 Wochen
UX/UI & Webdesignvor 2 WochenAdobe Firefly Boards › PAGE online
-

 Entwicklung & Codevor 4 Wochen
Entwicklung & Codevor 4 WochenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R
-

 Entwicklung & Codevor 2 Wochen
Entwicklung & Codevor 2 WochenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events
-

 Digital Business & Startupsvor 2 Monaten
Digital Business & Startupsvor 2 Monaten10.000 Euro Tickets? Kann man machen – aber nur mit diesem Trick
-

 Digital Business & Startupsvor 3 Monaten
Digital Business & Startupsvor 3 Monaten80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen