Entwicklung & Code
Die Produktwerker: Designprinzipien für bessere Entscheidungen
Tanja Heyken ist zu Gast bei den Produktwerkern, um gemeinsam auf das Thema „Designprinzipien“ zu schauen, und was diese im Alltag von Produktteams tatsächlich bewirken können. Dabei bringt Tanja Heyken ihre doppelte Perspektive als UX-Professional und Product Owner mit, die sie bei Checkmk täglich lebt. Ihr Ziel ist es, Entscheidungsprozesse zu vereinfachen, Konsistenz zu schaffen und die User Experience (UX) zu verbessern, ohne dafür jedes Mal von vorn zu diskutieren. Designprinzipien versteht sie dabei als konkrete, nutzerzentrierte Leitplanken. Sie helfen Teams, bessere Entscheidungen zu treffen – auch dann, wenn gerade niemand aus UX oder dem Produktmanagement dabei ist.

(Bild: deagreez/123rf.com)

So geht Produktmanagement: Auf der Online-Konferenz Product Owner Day von dpunkt.verlag und iX am 13. November 2025 können Product Owner, Produktmanagerinnen und Service Request Manager ihren Methodenkoffer erweitern, sich vernetzen und von den Good Practices anderer Unternehmen inspirieren lassen.
Im iterativen Prozess zu Designprinzipien
Die wichtige Grundlage dafür sind Daten: Wer mit Designprinzipien arbeiten möchte, sollte die Perspektive der Nutzerinnen und Nutzer ernst nehmen. Heyken empfiehlt den UEQ+ – eine modulare Erweiterung des User Experience Questionnaire (UEQ) – als kompaktes Instrument, um herauszufinden, welche Eigenschaften den Nutzenden wichtig sind und wie das Produkt aktuell wahrgenommen wird. Daraus lassen sich Designprinzipien ableiten, die zur Realität der Nutzerinnen und Nutzer passen, nicht nur zu den Annahmen im Team.
Doch wie kommt man von ersten Erkenntnissen zu Prinzipien, die im Alltag wirklich nützlich sind? Für Tanja Heyken beginnt alles mit einem interdisziplinären Workshop. Entscheidend sind UX, Product, Entwicklung, Support, Sales; also möglichst viele Sichtweisen an einen Tisch holen, um gemeinsames Verständnis zu schaffen. Ziel ist nicht die perfekte Formulierung im ersten Anlauf, sondern die Entwicklung von sogenannten Proto-Prinzipien, die sich dann im Team schrittweise verfeinern und gegen reale Entscheidungen testen lassen. Dieser iterative Prozess sichert nicht nur Qualität, sondern stärkt auch die Akzeptanz im Unternehmen.
Designprinzipien müssen einfach und greifbar sein. Drei bis fünf gut formulierte Prinzipien lassen sich besser merken und leben als zwölf ambitionierte. Spotify zeigt, wie es geht: Relevant, Human, Unified. Auch bei Figma sieht man, wie Eigenschaften wie „Thoughtful“ oder „Approachable“ Orientierung bieten können. Entscheidend ist aber nicht nur die Kürze, sondern das gemeinsame Verständnis dahinter: Was bedeutet etwa „Human“ konkret im Produkt? Welche Sprache, welche Gestaltung, welche Entscheidungen zahlen darauf ein?
Die Prinzipien im Alltag einsetzen
Damit Designprinzipien im Alltag wirken, braucht es mehr als ein PDF oder einen Eintrag im Wiki. Prinzipien müssen kontinuierlich sichtbar gemacht werden, etwa durch Beispiele in Reviews, durch Argumentation im Daily oder durch Verankerung im Onboarding neuer Teammitglieder. Designprinzipien sind keine Regeln, sondern Orientierung. Sie ersetzen kein User Research, kein Testing und keine Interviews, aber sie geben Teams Sicherheit in Entscheidungen, die jeden Tag getroffen werden müssen.
Die große Stärke von Designprinzipien liegt darin, dass sie helfen, auch in wachsenden Teams mit immer mehr Beteiligten eine konsistente UX sicherzustellen. Die Verknüpfung zu anderen Artefakten in der Produktentwicklung, etwa der Produktvision, dem Product Goal oder Sprintziel ist auch sehr spannend. Selbst wenn Designprinzipien keine direkten Bestandteile von Scrum sind, lassen sie sich gut als tägliche Entscheidungshilfe für alle, die das Produkt gestalten, in diese Strukturen einbetten. Wer Designprinzipien im Team etablieren möchte, sollte aber auch nicht zu perfektionistisch starten, sondern lieber loslegen, lernen und iterieren. Denn die besten Prinzipien entstehen nicht auf dem Papier, sondern in der echten Zusammenarbeit.
Weitererführende Links
Die aktuelle Ausgabe des Podcasts steht auch im Blog der Produktwerker bereit: „Die Produktwerker: Designprinzipien„.
(mai)









Entwicklung & Code
Software Testing: Mehr Qualität durch Product Discovery
In dieser Episode des Pocasts Software Tesing tauschen sich Richard Seidl und Curie Kure über die Kunst der Product Discovery aus. Sie zeigen, wie wichtig es ist, schon zu Beginn eines Projekts alle relevanten Informationen zu sammeln, um klare Produktvisionen zu schaffen.
Curie Kure erklärt, wie Workshops helfen, unentdeckte Herausforderungen aufzudecken und warum die Nutzerperspektive entscheidend ist, bevor Code entsteht. Das Duo geht der Frage nach: Wie kann ein User Research dazu beitragen, den richtigen Weg einzuschlagen und Unsicherheiten zu minimieren?
„Es lohnt sich auf jeden Fall, das zu machen, weil man sehr, sehr früh Fehler vermeidet. Man holt sich ja sehr früh schon Feedback rein mit Dingen, die gar nicht programmiert sind.“ – Curie Kure
Bei diesem Podcast dreht sich alles um Softwarequalität: Ob Testautomatisierung, Qualität in agilen Projekten, Testdaten oder Testteams – Richard Seidl und seine Gäste schauen sich Dinge an, die mehr Qualität in die Softwareentwicklung bringen.
Die aktuelle Ausgabe ist auch auf Richard Seidls Blog verfügbar: „Mehr Qualität durch Product Discovery – Curie Kure“ und steht auf YouTube bereit.
(mdo)
Entwicklung & Code
Datenparallele Datentypen in C++26: Reduktion eines SIMD-Vektors
Nach der Vorstellung der datenparallelen Datentypen in C++26 und einem praktischen Beispiel behandle ich in diesem Artikel die Reduktion und Maskenreduktion für datenparallele Datentypen.

Rainer Grimm ist seit vielen Jahren als Softwarearchitekt, Team- und Schulungsleiter tätig. Er schreibt gerne Artikel zu den Programmiersprachen C++, Python und Haskell, spricht aber auch gerne und häufig auf Fachkonferenzen. Auf seinem Blog Modernes C++ beschäftigt er sich intensiv mit seiner Leidenschaft C++.
Funktionen zur Reduktion
Eine Reduktion reduziert den SIMD-Vektor auf ein einzelnes Element. Die Bibliothek stellt drei Funktionen für diesen Zweck zur Verfügung: reduce, hmin und hmax.
Das folgende Programm zeigt, wie diese Funktionen verwendet werden:
// reduction.cpp
#include
#include
#include
#include
#include
namespace stdx = std::experimental;
void println(std::string_view name, auto const& a) {
std::cout << name << ": ";
for (std::size_t i{}; i != std::size(a); ++i)
std::cout << a[i] << ' ';
std::cout << '\n';
}
int main() {
const stdx::fixed_size_simd a([](int i) { return i; });
println("a", a);
auto sum = stdx::reduce(a);
std::cout << "sum: " << sum << "\n\n";
const stdx::fixed_size_simd b([](int i) { return i + 1; });
println("b", b);
auto product = stdx::reduce(b, std::multiplies<>());
std::cout << "product: " << product << "\n\n";
auto maximum = stdx::hmax(b);
std::cout << "maximum: " << maximum << "\n\n";
auto minimum = stdx::hmin(b);
std::cout << "minimum: " << minimum << "\n\n";
}
Zunächst kommt die Funktion reduce zum Einsatz. Standardmäßig wird der Operator + wie gewohnt angewendet. Diese Funktion kann jedoch auch mit einem beliebigen binären Operator parametrisiert werden. Der Ausdruck stdx::reduce(b, std::multiplies<>()) wendet das Funktionsobjekt std::multiplies aus dem Header functional an. Die Funktionen hmax und hmin bestimmen das Maximum und Minimum des SIMD-Vektors b.

Die Ausgabe zeigt die Reduktion auf die Summe, das Produkt, das Minimum und das Maximum.
Maskenreduktion auf true oder false
Bei der Reduktion einer Maske wird die SIMD-Maske entweder auf den Wert true oder auf den Wert false reduziert.
Hier begegnen wir einigen alten Bekannten aus C++: all_of, any_of, none_of und some_of.
all_of: Gibttruezurück, wenn alle Werte in der SIMD-Masketrueany_of: Gibttruezurück, wenn mindestens ein Wert in der SIMD-Masketruenone_of: Gibttruezurück, wenn alle Werte in der SIMD-Maskefalsesome_of: Gibttruezurück, wenn mindestens ein Wert in der SIMD-Masketrueist, aber nicht alle Werte darintrue
cppreference.com enthält ein schönes Beispiel für diese Funktionen:
// reductionWithMask.cpp
#include
#include
namespace stq = std::experimental;
int main()
{
using mask = stq::fixed_size_simd_mask;
mask mask1{false}; // = {0, 0, 0, 0}
assert
(
stq::none_of(mask1) == true &&
stq::any_of(mask1) == false &&
stq::some_of(mask1) == false &&
stq::all_of(mask1) == false
);
mask mask2{true}; // = {1, 1, 1, 1}
assert
(
stq::none_of(mask2) == false &&
stq::any_of(mask2) == true &&
stq::some_of(mask2) == false &&
stq::all_of(mask2) == true
);
mask mask3{true};
mask3[0] = mask3[1] = false; // mask3 = {0, 0, 1, 1}
assert
(
stq::none_of(mask3) == false &&
stq::any_of(mask3) == true &&
stq::some_of(mask3) == true &&
stq::all_of(mask3) == false
);
}
popcount bestimmt, wie viele Werte in einer SIMD-Maske true sind. Ein Programm, das dies ausführt, lässt sich schnell schreiben:
// popcount.cpp
#include
#include
#include
namespace stdx = std::experimental;
void println(std::string_view name, auto const& a) {
std::cout << std::boolalpha << name << ": ";
for (std::size_t i{}; i != std::size(a); ++i)
std::cout << a[i] << ' ';
std::cout << '\n';
}
int main() {
const stdx::native_simd a = 1;
println("a", a);
const stdx::native_simd b([](int i) { return i - 2; });
println("b", b);
const auto c = a + b;
println("c", c);
const stdx::native_simd_mask x = c < 0;
println("x", x);
auto cnt = popcount(x);
std::cout << "cnt: " << cnt << '\n';
}

Die Programmausgabe des popcount-Beispiels ist selbsterklärend.
Darüber hinaus gibt es zwei weitere weitere Funktionen:
find_first_set: Gibt den niedrigsten Indexizurück, bei dem die SIMD-Masketrueist.find_last_set: Gibt den größten Indexizurück, bei dem die SIMD-Masketrueist.
Das folgende Programm demonstriert die Verwendung der beiden Funktionen:
// find_first_set.cpp
#include
#include
#include
namespace stdx = std::experimental;
void println(std::string_view name, auto const& a) {
std::cout << std::boolalpha << name << ": ";
for (std::size_t i{}; i != std::size(a); ++i)
std::cout << a[i] << ' ';
std::cout << '\n';
}
int main() {
stdx::simd_mask x{0};
println("x", x);
x[1] = true;
x[x.size() - 1] = true;
println("x", x);
auto first = stdx::find_first_set(x);
std::cout << "find_first_set(x): " << first << '\n';
auto last = stdx::find_last_set(x);
std::cout << "find_last_set(x): " << last<< '\n';
}

Die Ausgabe zeigt die Suche nach dem ersten und letzten true im Vektor.
Wie geht‘s weiter?
In meinem nächsten Artikel werde ich mich auf die Algorithmen datenparalleler Datentypen konzentrieren.
(rme)
Entwicklung & Code
.NET 10.0 Preview 6 bringt persistierte Circuits und Passkeys für Blazor
.NET 10.0 Preview 6 steht zum Download auf der .NET-Downloadseite bereit. Von Visual Studio 2022 gab es nur ein Bugfixing-Update von Version 17.14.8 auf 17.14.9. Weiterhin ist .NET 10.0 nicht direkt über das Visual-Studio-Setupprogramm installierbar. Wenn das .NET 10.0 SDK getrennt installiert wurde, kann man aber „.NET 10.0 Preview“ in den Auswahlmasken finden.

Dr. Holger Schwichtenberg ist Chief Technology Expert bei der MAXIMAGO-Softwareentwicklung. Mit dem Expertenteam bei www.IT-Visions.de bietet er zudem Beratung und Schulungen im Umfeld von Microsoft-, Java- und Webtechniken an. Er hält Vorträge auf Fachkonferenzen und ist Autor zahlreicher Fachbücher.
Persistenz für Circuit-Zustände bei Blazor Server
Blazor Server besitzt für jeden per Websocket angeschlossenen Browser einen sogenannten Circuit mit dem HTML-Inhalt und den Werten aller Variablen aller aktiven Razor Components. Bisher ging der Circuit komplett verloren, wenn die Verbindung mehrere Sekunden abreißt oder der Browser die Anwendung schlafen legt (z. B. bei mobilen Geräten), denn der Webserver erwartet zum Beibehalten des Circuits eine regelmäßige kurze Keep-Alive-Nachricht über die Websocket-Verbindung.
(Bild: coffeemill/123rf.com)

Verbesserte Klassen in .NET 10.0, Native AOT mit Entity Framework Core 10.0 und mehr: Darüber informieren Dr. Holger Schwichtenberg und weitere Speaker der Online-Konferenz betterCode() .NET 10.0 am 18. November 2025. Nachgelagert gibt es sechs ganztägige Workshops zu Themen wie C# 14.0, KI-Einsatz und Web-APIs.
In .NET 10.0 Preview 6 können Entwicklerinnen und Entwickler nun erstmalig, was das Konkurrenzprodukt Wisej.NET schon lange kann: Zustände über solche Abbrüche hinweg persistieren. Während dies in Wisej.NET jedoch automatisch erfolgt, müssen sie bei Blazor Server selbst etwas implementieren.
Die Persistenz von Circuit-Zuständen bei Blazor Server erfolgt im Standard nur im RAM des Webservers, kann aber optional auch in getrennten Cache-Prozessen (z. B. Redis) oder in einem Datenbankmanagementsystem (z. B. Microsoft SQL Server) erfolgen.
Blazor Server persistiert dabei nicht den kompletten Circuit und auch nicht alle Variablen einer Razor Component, sondern nur diejenigen Werte, die explizit in den Persistent Component State gelegt werden. Den gibt es in Blazor schon länger, um Werte vom Pre-Rendering an das interaktive Rendering zu übergeben. Vor .NET 10.0 mussten Entwicklerinnen und Entwickler den Persistent Component State aufwendig per Code setzen und lesen. Seit .NET 10.0 Preview 3 können sie die zu persistierenden Variablen einfach mit [SupplyParameterFromPersistentComponentState] annotieren.
Lesen Sie auch
Das folgende Listing zeigt ein aussagekräftiges Beispiel. Die Razor Component „State.razor“ persistiert via [SupplyParameterFromPersistentComponentState] eine Instanz der eigenen Klasse PageState. Die Klasse PageState umfasst eine aus einem Datenbankmanagementsystem via Entity Framework Core in OnInitialized() geladene Menge von Flugdaten sowie die Anzahl der Flüge, die angezeigt werden sollen. Zudem gibt es auf der Seite eine laufend aktualisierte Zeitanzeige. Zu Demonstrationszwecken wird jeweils beim Aktualisieren der Zeit die aktuelle Zeit auch in die Browserkonsole geschrieben.
Für .NET 10.0 Preview 7 hat Microsoft angekündigt, [SupplyParameterFromPersistentComponentState] in [PersistentState] umzubenennen. Im gleichen Ankündigungskasten steht auch „Blazor.pauseCircuit will be renamed to Blazor.pause. Blazor.resumeCircuit will be renamed to Blazor.resume.“. Im Praxistest zeigt sich aber, dass die neuen Namen schon in Preview 6 gelten.
@page "/State"
@using BO.WWWings
@using ITVisions
@inject ITVisions.Blazor.BlazorUtil util
Counter
Aktuelle Uhrzeit: @currentTime.ToString("HH:mm:ss")
Anzahl Flüge: @pageState.CurrentCount
@if (this.pageState?.FlightSet != null)
{
@foreach (Flight f in this.pageState.FlightSet.Take(this.pageState.CurrentCount))
{
- Flug #@f.FlightNo @f.FlightDate.ToShortTimeString() @f.Departure ⟶ @f.Destination
}
}
@code {
[SupplyParameterFromPersistentComponentState] // NEU ab .NET 10.0
public PageState pageState { get; set; } = null;
private DateTime currentTime = DateTime.Now;
private System.Timers.Timer? timer;
private void IncrementCount()
{
if (pageState.CurrentCount < maxCount) pageState.CurrentCount++;
}
private void DecrementCount()
{
if (pageState.CurrentCount > 0) pageState.CurrentCount--;
}
int maxCount = 50; // > 58 Führt zum Absturz von Blazor Server (Stand Preview 5)
protected override void OnInitialized()
{
// Uhrzeit-Timer starten
timer = new System.Timers.Timer(1000);
timer.Elapsed += (s, e) => {
currentTime = DateTime.Now;
InvokeAsync(StateHasChanged);
util.Log(currentTime);
};
timer.Start();
if (pageState == null)
{
// Lade Daten
var renderMode = this.RendererInfo.Name;
var logMessage = "Lade bis zu " + maxCount + " Flugdatensätze im Blazor-Rendermode=" + renderMode;
DA.WWWings.WwwingsV1EnContext ctx = new();
var data = ctx.Flights.Take(maxCount).ToList(); // LINQ --> SQL
pageState = new()
{
FlightSet = data,
CurrentCount = 20,
Created = DateTime.Now
};
}
}
public void Dispose()
{
timer?.Dispose();
}
///
/// Beliebige eigene Klasse mit dem zu persistierenden Zustand der Seite.
///
public class PageState
{
public DateTime Created { get; set; }
public DateTime LastChange { get; set; }
public int _CurrentCount;
public int CurrentCount
{
get
{
return _CurrentCount;
}
set
{
_CurrentCount = value;
LastChange = DateTime.Now;
}
}
public List FlightSet { get; set; }
}
}
Listing: State.razor
In App.razor wird zudem der folgende JavaScript-Code hinterlegt, der dafür sorgt, dass Circuits und die zugehörige Websocket-Verbindung beendet werden, wann immer die Webanwendung nicht mehr sichtbar ist und eine Wiederherstellung des Circuits und der Websocket-Verbindung erfolgen, sobald die Webanwendung wieder sichtbar wird. Auf diese Weise kann man bei Blazor Server einige Ressourcen (RAM und Rechenzeit) auf dem Webserver sparen und damit die Skalierbarkeit verbessern.
Listing: Pausieren und Wiederaufnahme von Circuits und zugehöriger Websocket-Verbindung
Die folgende Abbildung zeigt das Verhalten der Razor Component, die für kurze Zeit unsichtbar gemacht wurde (z. B. durch Öffnen eines anderen Browser-Tags oder Minimieren des Browsers). Zunächst gibt es im Sekundentakt eine Ausgabe in die Browserkonsole, jeweils beim Aktualisieren der Uhrzeit auf dem Bildschirm. Sobald die Razor Component nicht mehr sichtbar ist, wird der Circuit-Zustand mit dem JavaScript-Aufruf blazor.pause() persistiert und die Websocket-Verbindung beendet. 23 Sekunden später wird die Webseite wieder sichtbar. Via Blazor.resume() in JavaScript wird ein neuer Circuit erstellt, der persistente Zustand des Circuits geladen und die Websocket-Verbindung wieder aufgebaut. Die Razor Component wird neu gerendert und macht aus Benutzersicht dort weiter, wo sie aufgehört hat: Sie besitzt noch die gleichen Flugdaten wie zuvor (ohne diese neu aus dem Datenbankmanagementsystem laden zu müssen) und zeigt die gleiche Anzahl von Flügen. Die Uhrzeitausgabe in der Webseite und der Browserkonsole läuft weiter. Dass die Uhrzeitausgabe in der Browserkonsole unterbrochen ist, beweist, dass die Webanwendung zwischenzeitlich tatsächlich inaktiv war.
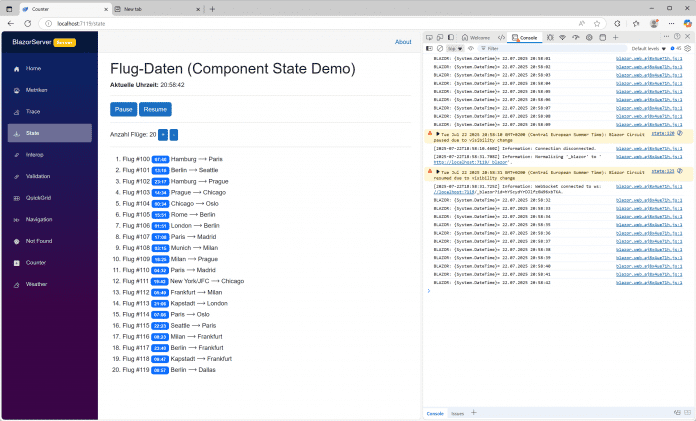
Persistierung eines Blazor-Server-Circuits
Im Startcode der Blazor-Server-Anwendung können Entwicklerinnen und Entwickler die Persistierung konfigurieren. Das folgende Listing zeigt die Festlegung der maximalen Anzahl der persistierten Circuits-Zustände auf 500 (Standard ist 1000), die Dauer der Persistierung im RAM auf 10 Sekunden (der Standard ist zwei Stunden) und die Dauer der Persistierung im Second-Level-Cache auf eine Stunde (der Standard ist zwei Stunden) sowie die Festlegung eines Microsoft SQL Servers als Second-Level-Cache zusätzlich zum RAM-Cache. Einen Hybrid Cache muss man dabei auch hinzufügen, denn Microsoft verwendet die Hybrid-Cache-Bibliothek (eingeführt in .NET 9.0) als Abstraktion.
Der Second-Level-Cache soll eine serverübergreifende Nutzung der persistierten Circuit-Daten erlauben, wenn man dem Tooltip der neuen Eigenschaft HybridPersistenceCache in der Klasse CircuitOptions glauben will: „Gets or sets the HybridCache instance to use for persisting circuit state across servers.“ Mangels Dokumentation zu dieser Aussage wurde die serverübergreifende Nutzung vom Autor dieses Beitrags aber bisher noch nicht getestet.
builder.Services.Configure(options =>
{
options.PersistedCircuitInMemoryMaxRetained = 500; // The maximum number of circuits to retain. The default is 1,000 circuits.
options.PersistedCircuitInMemoryRetentionPeriod = TimeSpan.FromSeconds(1); // The maximum retention period as a TimeSpan. The default is two hours.
options.PersistedCircuitDistributedRetentionPeriod = TimeSpan.FromSeconds(60); // The maximum retention period for distributed circuits. The default is two hours.
options.DetailedErrors = true;
});
// --------------------- Hybrid Cache konfigurieren
var hyb = builder.Services.AddHybridCache(options => // optionale Einstellungen
{
options.DefaultEntryOptions = new HybridCacheEntryOptions
{
Flags = HybridCacheEntryFlags.DisableCompression // nur als Beispiel für Einstellungen
};
});
// --------------------- Second-Level-Cache konfigurieren
builder.Services.AddDistributedSqlServerCache(options =>
{
options.ConnectionString = "Data Source=" + DB_SERVERNAME + ";Initial Catalog=NET_Cache;Integrated Security=True;Connect Timeout=30;Encrypt=False;Trust Server Certificate=True;Application Intent=ReadWrite;Multi Subnet Failover=False";
options.SchemaName = "dbo";
options.TableName = "Cache2";
});
Listing: Circuit-Zustandspersistenz konfigurieren
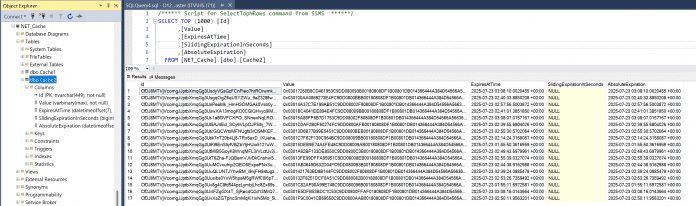
Persistierte Circuit-Zustände in einer Microsoft-SQL-Server-Tabelle, deren Aufbau durch den Distributed Cache Provider (SqlServerCache) vorgegeben ist.
Die hier beschriebene Persistenz funktioniert nur bei Blazor Server. Bei einem manuellen Browser-Refresh (Wisej.NET behält dabei den Zustand) oder manuellen Schließen des Browserfensters funktioniert die Persistenz nicht. Diese und weitere Einschränkungen dokumentiert Microsoft in den Release Notes. Dort findet man ebenso Hinweise, wie man Daten in per Dependency Injection injizierten Diensten (sofern es ein „Scoped Service“ ist) persistieren kann.
Validierung für Unterobjekte in Blazor
Die in Blazor eingebauten Eingabesteuerelemente (Company-Objekt ein Contact-Objekt und dieses wieder ein Address-Objekt enthält, wurden nur die Datenvalidierungsannotationen in der Klasse Company verwendet.
using System.ComponentModel.DataAnnotations;
using Microsoft.Extensions.Validation;
namespace NET10_BlazorServer.Model;
#pragma warning disable ASP0029 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
[ValidatableType]
#pragma warning restore ASP0029 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
public class Company
{
public int CompanyID { get; set; }
[Required(ErrorMessage = "Firmenname ist Pflichtfeld")]
public string CompanyName { get; set; }
[Required(ErrorMessage = "Gründungsdatum ist Pflichtfeld")]
[Range(typeof(DateTime), "01/01/1900", "31/12/2024", ErrorMessage = "Datum muss zwischen 1900 und 2024 liegen.")]
public DateTime Foundation { get; set; }
public Contact Contact { get; set; } = new Contact();
}
public class Contact
{
[Required(ErrorMessage = "Website ist Pflichtfeld")]
public string Website { get; set; }
[Required(ErrorMessage = "E-Mail ist Pflichtfeld")]
[EmailAddress(ErrorMessage = "Ungültige E-Mail-Adresse")]
public string Email { get; set; }
public Address Address { get; set; } = new Address();
}
public class Address
{
[Required(ErrorMessage = "Adresse ist Pflichtfeld")]
public string AddressText { get; set; }
}
Listing: Datenmodell Company mit Unterobjekt Contact
In dem im nächsten Listing gezeigten Formular wurde daher bisher nur geprüft, ob die Eingaben bei Firma und Gründungsdatum stimmen, nicht aber bei Website und E-Mail sowie Adresse.
@page "/Validation"
@using BO.WWWings
@using ITVisions
@using System.ComponentModel.DataAnnotations
@using NET10_BlazorServer.Model
@inject ITVisions.Blazor.BlazorUtil util
Eingabevalidierung für komplexe Objekte in Blazor 10.0
company.CompanyName)" />
company.Foundation)" />
company.Contact.Website)" />
company.Contact.Email)" />
company.Contact.Address.AddressText)" />
@code {
private Company company = new Company();
private EditContext editContext;
protected override void OnInitialized()
{
editContext = new EditContext(company);
}
void Submit()
{
if (editContext.Validate())
{
// Formular ist gültig
util.Log("Formular ist gültig!");
}
else
{
// Formular ist NICHT gültig
util.Log("Formular ist NICHT gültig!");
}
}
}
Listing: Eingabeformular für das obige Datenmodell
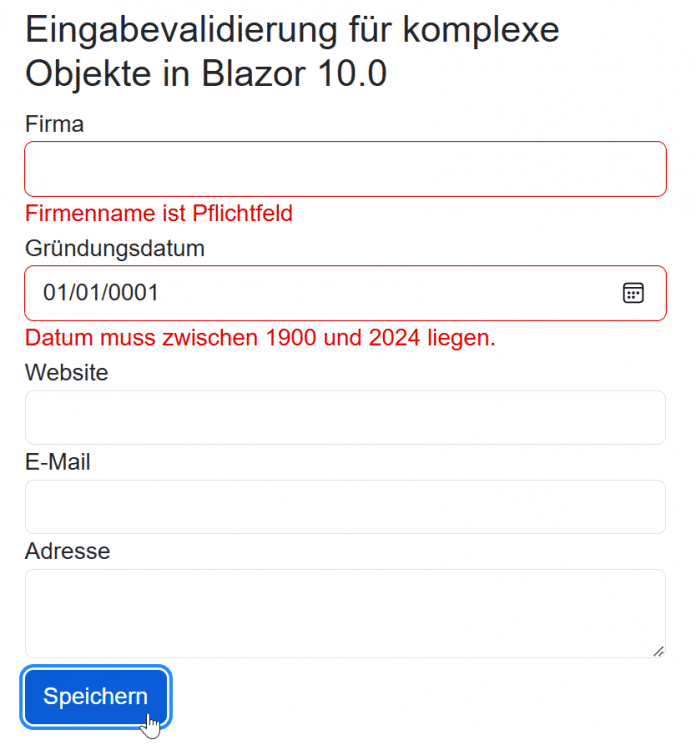
Die Validierung findet bei Blazor 9.0 nur auf der obersten Ebene in der Objekthierarchie statt.
Ab .NET 10.0 Preview 6 können nun auch Unterobjekte (komplexe Objekte bzw. Objekthierarchien) validiert werden. Blazor verwendet dabei die gleiche Implementierung wie ASP.NET Core Minimal WebAPIs seit .NET 10.0 Preview 3. Die Implementierung liegt seit Preview 6 im neuen NuGet-Paket „Microsoft.Extensions.Validation„.
Dazu müssen Entwicklerinnen und Entwickler zwei Dinge hinzufügen: erstens einen Aufruf von builder.Services.AddValidation() im Startcode der Anwendung in Program.cs und zweitens müssen sie diese Zeilen in der Datei ergänzen, in der die Modellklassen stehen, wobei dies eine .cs-Datei sein muss. Es funktioniert nicht, wenn die Modellklassen in .razor-Dateien liegen:
#pragma warning disable ASP0029 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
[ValidatableType]
#pragma warning restore ASP0029 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
Da ein Teil der Funktionen noch als „experimentell“ gilt, braucht man die Deaktivierung der Warnung.
Dies führt dazu, dass zur Entwicklungszeit ein Source Code Generator den Validierungscode erzeugt. Einsehen kann man den generierten Programmcode im Projekt im Ast „Dependencies/Analyzers/Microsoft.Extensions.Validation.ValidationsGenerator“.

In Blazor 10.0 können auch die Benutzereingaben für das Unterobjekt Contact validiert werden.
Passkeys in ASP.NET Core Identity
ASP.NET Core Identity ist eine von Microsoft vordefinierte Benutzerverwaltung mit Weboberfläche und REST-Diensten. Ab .NET 10.0 Preview 6 unterstützt ASP.NET Core Identity nun auch die Web Authentication (WebAuthn) API alias Passkeys.
Der einfachste Weg zur Passkey-Unterstützung führt über das Anlegen eines neuen Blazor-Projekts mit dem Authentifizierungstyp „Individual Accounts“. Man findet dann zusätzliche Dateien wie PasskeyOperation.cs, PasskeyInputModel.cs, Passkeys.razor und PasskeySubmit.razor im Projekt in den Ordnern /Component/Account, /Component/Account/Shared und /Component/Account/Pages/Manage. Diese Dateien kann man (wie bei ASP.NET Core üblich) an eigene Bedürfnisse anpassen. Die Passkey-Daten speichert ASP.NET Core Identity im Standard in seiner Microsoft-SQL-Server-Datenbank in der neuen Tabelle „AspNetUserPasskeys“.
Wie man bestehende Projekte und Datenbankschemata nachrüsten kann, will Microsoft laut „What’s new„-Dokument Mitte August 2025 zusammen mit .NET 10.0 Preview 7 veröffentlichen.
Die Passkey-Implementierung in .NET 10.0 unterstützt Resident Keys (Discoverable Credentials) und Non-Resident Keys, allerdings keine Attestation.

Anlegen eines neuen Blazor-Projekts mit dem Authentifizierungstyp „Individual Accounts“

Anlegen eines Passkeys innerhalb der Benutzerverwaltung
Man muss dem Passkey einen Namen geben.
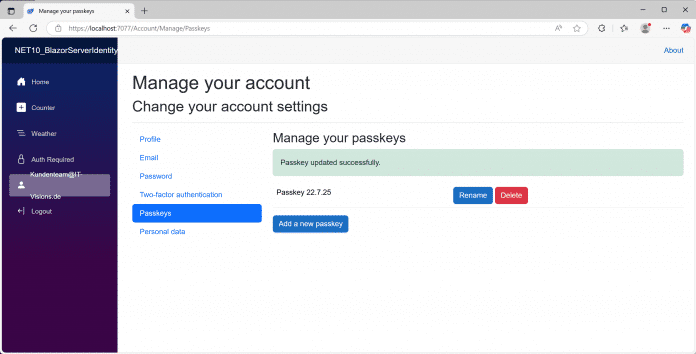
Der Passkey wurde gespeichert.
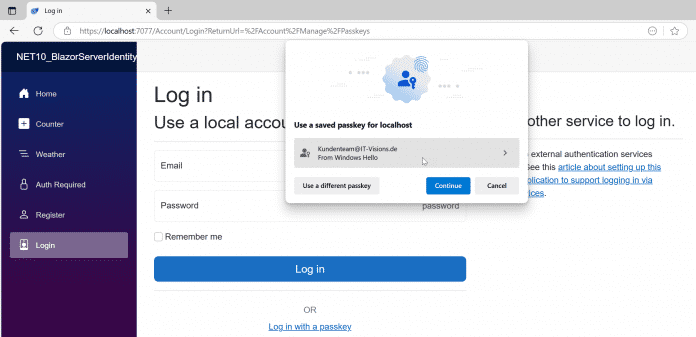
Mit dem gespeicherten Passkey kann man sich wieder anmelden.

Tabelle „AspNetUserPasskeys“ im Microsoft SQL Server

Zukunftsfähige Krankenhaus-IT: Digitalisierung, Sicherheit und Cloud

25 aufstrebende Startups, die nicht aus Berlin sind

Wie jung ist zu jung für ein Smartphone? Diese Studie gibt eine eindeutige Antwort

Geschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken

TikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings

Metal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-
 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenGeschichten aus dem DSC-Beirat: Einreisebeschränkungen und Zugriffsschranken
-
 Online Marketing & SEOvor 2 Monaten
Online Marketing & SEOvor 2 MonatenTikTok trackt CO₂ von Ads – und Mitarbeitende intern mit Ratings
-
 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenMetal Gear Solid Δ: Snake Eater: Ein Multiplayer-Modus für Fans von Versteckenspielen
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenPhilip Bürli › PAGE online
-

 Digital Business & Startupsvor 1 Monat
Digital Business & Startupsvor 1 Monat80 % günstiger dank KI – Startup vereinfacht Klinikstudien: Pitchdeck hier
-

 Apps & Mobile Entwicklungvor 1 Monat
Apps & Mobile Entwicklungvor 1 MonatPatentstreit: Western Digital muss 1 US-Dollar Schadenersatz zahlen
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatLinkedIn Feature-Update 2025: Aktuelle Neuigkeiten
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenAktuelle Trends, Studien und Statistiken