Entwicklung & Code
Model Context Protocol: Anwendungsbeispiel in TypeScript
Das KI-Unternehmen Anthropic, das 2021 von ehemaligen OpenAI-Mitarbeitern gegründet wurde, hat das Model Context Protocol (MCP) mit dem Ziel einer Standardisierung der Kommunikation zwischen Large Language Models und externen Datenquellen entwickelt. Beim sogenannten Tool Calling hat das LLM die Möglichkeit, auf vordefinierte Schnittstellen zuzugreifen. Diese lassen sich parametrisieren und erlauben so große Flexibilität. Die meisten LLM-Anbieter unterstützen dieses Feature. Jede Datenquelle braucht dabei eine Verknüpfung über eine eigene Funktion, was in der Regel eine Anpassung am Programmcode erforderlich macht.


Sebastian Springer weckt als Dozent für JavaScript, Sprecher auf zahlreichen Konferenzen und Autor die Begeisterung für professionelle Entwicklung mit JavaScript.
Das Model Context Protocol soll die Verknüpfung externer Datenquellen deutlich vereinfachen und es erlauben, externe Schnittstellen, Datenbanken, Unternehmenssysteme oder Dateisysteme ohne zusätzliche Anpassung direkt anzubinden. Dieser Artikel widmet sich den technischen Details der Funktionsweise des MCP und zeigt anhand eines konkreten Beispiels mit dem MCP-TypeScript-SDK, wie eine Integration in eine Applikation gelingen kann.
Die zentrale Anlaufstelle für Ressourcen zum Thema MCP sind zum einen die offizielle Website des Projekts und zum anderen das GitHub-Repo. Dort stehen die Dokumentation, die Spezifikation und eine ganze Reihe von Software Development Kits (SDKs) für verschiedene Programmiersprachen wie Python, TypeScript, C# oder Kotlin zur Verfügung.
Die Architektur einer MCP-Applikation
Eine Applikation, die das MCP nutzt, besteht aus verschiedenen Komponenten:
- MCP-Server: Der Server ist die Stelle bei MCP, die ihre Funktionalität über das MCP zur Verfügung stellt. Das können Daten aus einer Datenbank, aber auch Suchergebnisse aus dem Internet sein. Die Schnittstellen des Servers sind exakt definiert und lassen sich von der Clientseite verwenden.
- MCP-Client: Die Gegenseite zum Server ist der Client. Er kommuniziert mit dem Server und führt die verfügbaren Operationen über die Schnittstellen aus. Dabei gibt es sowohl lesende als auch schreibende Operationen.
- MCP-Host: Die Applikation, mit der die Benutzer interagieren. Das kann eine Web-Applikation, eine klassische Desktop-Applikation (wie Claude Desktop), eine Entwicklungsumgebung (wie Cursor) oder ein eigener, auf Frameworks wie Langchain basierender Agent sein. In diese Applikation ist der Client eingebettet, sodass der Host nicht direkt über MCP mit dem Server, sondern über den Umweg des Clients kommuniziert.
MCP-Server
Ein MCP-Server kann direkt in eine Applikation integriert, aber auch, und das wird der häufigere Fall sein, ein eigenständiger Dienst sein. Die MCP-Initiative stellt eine Reihe von SDKs in unterschiedlichen Programmiersprachen bereit, die die Grundlage für die Serverimplementierung bilden. Der Server selbst ist modular aufgebaut und erlaubt verschiedene Transportmechanismen, über die er mit den Clients kommuniziert. Das TypeScript-SDK sieht aktuell die Transportmechanismen Streamable HTTP, SSE und stdio vor. Streamable HTTP und SSE basieren auf HTTP, wobei die MCP-Spezifikation vom 26.03.2025 den SSE-Transport als veraltet (deprecated) markierte und die Version vom 18.06.2025 (latest) SSE bereits nicht mehr erwähnt.
Ein MCP-Client kann die HTTP-basierten Transportmechanismen verwenden, um sich mit einem entfernten Server zu verbinden. Der stdio-Transport ist für lokale Anwendungen gedacht. Hierbei verbindet sich der Client über die Standard-Ein- und -Ausgabe mit dem Server. Dieser Weg arbeitet deutlich schneller, ist jedoch nur für die Verwendung auf einem System geeignet. Das Python-SDK definiert zusätzlich zu diesen Transporttypen noch weitere wie den ASGI-Transport (Asynchronous Server Gateway Interface), eine Schnittstelle aus der Python-Welt, die neben der Kommunikation über HTTP noch weitere Protokolle wie WebSockets oder benutzerdefinierte Protokolle unterstützt.
Die MCP-Spezifikation unterteilt die Features, die ein Server seinen Clients bietet, in drei Kategorien: Resources, Tools und Prompts.
Resources
Mit der Feature-Kategorie Resources stellt ein MCP-Server Daten zur Verfügung. Ein typisches Beispiel ist die Anbindung an eine Datenbank. Resources sollten Daten nur lesend zur Verfügung stellen, keine komplexen Berechnungen durchführen und keine Seiteneffekte wie Datenmanipulationen aufweisen. Sie sind parametrisierbar, um die Abfrage zu beeinflussen und eine höhere Flexibilität zu erreichen.
Die MCP-Spezifikation sieht vor, dass das Format [protocol]://[host]/[path] Resources spezifiziert. Ein Beispiel könnte folgendermaßen aussehen: postgres://database/users. Die Antwort auf eine Resources-Anfrage kann entweder im Textformat wie beispielsweise JSON oder als Binärdaten wie PDFs oder Bilder erfolgen.
Der MCP-Server stellt über den Endpunkt resources/list eine Liste der verfügbaren Resources zur Verfügung. Jeder Datensatz weist mindestens die URL der jeweiligen Resource und einen menschenlesbaren Namen auf. Hinzu kommen noch eine optionale Beschreibung und ein ebenfalls optionaler MIME-Type, der das Format der Rückmeldung spezifiziert.
Die Spezifikation sieht nicht nur den lesenden Zugriff auf Ressourcen vor, sondern auch einen Benachrichtigungsmechanismus, über den der Server registrierte Clients über Änderungen der verfügbaren sowie Datenänderungen einer einzelnen Resource benachrichtigen kann.
Tools
Die Features der Kategorie Tools dürfen Berechnungen durchführen und Seiteneffekte aufweisen. Clients müssen berücksichtigen, dass eine Toolausführung im Vergleich zu einer Ressourcenabfrage länger dauern kann. Diese Werkzeuge können Funktionen sein, die aufgrund einer Eingabe eine bestimmte Ausgabe produzieren, aber auch Schnittstellen zu Datenbanken und anderen Systemen, um dort gespeicherte Informationen zu manipulieren. Ähnlich wie Resources können Clients auch die verfügbaren Tools eines Servers über einen Endpunkt auslesen. Dieser lautet tools/list.
Die Beschreibung eines MCP-Tools ist etwas umfangreicher als die einer Resource. Sie enthält einen Namen und ein Input-Schema, um die Parameter des Tools zu beschreiben. Hinzu kommen noch dessen optionale Beschreibung und optionale Metadaten über die Tool-Annotations. Die Annotations liefern Clients beziehungsweise Hinweise für Entwicklerinnen und Entwicklern über das Verhalten eines Tools. Die meisten vordefinierten Annotations der MCP-Spezifikation sind Boolean-Werte. So sagt beispielsweise die readOnlyHint-Annotation aus, dass das Tool sein Umfeld nicht modifiziert. Wie auch bei den Resources kann ein Client sich beim Server registrieren, um über Änderungen benachrichtigt zu werden.
Prompts
Prompts sind Vorlagen, die dem MCP-Host die Arbeit mit dem Large Language Model (LLM) erleichtern. Damit kann eine MCP-Applikation nicht nur die Kommunikation zwischen Client und Server, sondern auch zum LLM hin standardisieren. Bei einer Applikation, die ein Code-Review-Feature anbietet, dient der Prompt beispielsweise dazu, den zu überprüfenden Code korrekt einzubetten. Laut der MCP-Spezifikation besitzen die Prompt-Templates einen eindeutigen Namen. Zusätzlich sieht die Spezifikation noch die optionalen Felder description für eine menschenlesbare Beschreibung und arguments mit einer Liste der unterstützten Argumente des Schemas vor.
Die Prompt-Endpunkte eines MCP-Servers kommen ähnlich wie Tools zum Einsatz. Der Client fragt nach dem eindeutigen Identifier und übermittelt die benötigten Werte. Der Server antwortet mit dem Prompt, in den die Werte integriert sind, sodass der Client beziehungsweise die Host-Applikation den Prompt direkt verwenden kann.Für eine Liste aller verfügbaren Prompts bietet der MCP-Server den Endpunkt prompts/list an.
Die SDKs, die die MCP-Initiative zur Verfügung stellt, implementieren die Spezifikation und dienen als Grundlage für die Implementierung von MCP-Servern und MCP-Clients. Das folgende Beispiel implementiert einen einfachen MCP-Server mit je einer Resource, einem Tool und einem Prompt mit dem TypeScript-SDK.
import {
McpServer,
ResourceTemplate,
} from '@modelcontextprotocol/sdk/server/mcp.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
import { z } from 'zod';
const server = new McpServer({
name: 'mcp-server',
version: '1.0.0',
});
server.tool(
'currency-converter',
'Convert currency between EUR and USD',
{
amount: z.number(),
from: z.enum(['EUR', 'USD']),
to: z.enum(['EUR', 'USD']),
},
async ({ amount, from, to }) => {
const exchangeRate =
from === 'EUR' && to === 'USD'
? 1.1
: from === 'USD' && to === 'EUR'
? 0.91
: 1;
const convertedAmount = amount * exchangeRate;
return {
content: [
{
type: 'text',
text: `${amount} ${from} is ${convertedAmount.toFixed(2)} ${to}`,
},
],
};
}
);
server.resource(
'price-list',
new ResourceTemplate('price-list://products/{category}', {
list: undefined,
}),
async (uri, { category }) => {
const priceList = [
{ name: 'Apple', category: 'Fruit', price: 1.2 },
{ name: 'Banana', category: 'Fruit', price: 0.8 },
{ name: 'Carrot', category: 'Vegetable', price: 0.5 },
{ name: 'Bread', category: 'Bakery', price: 2.5 },
{ name: 'Milk', category: 'Dairy', price: 1.5 },
];
const filteredList =
category !== 'all'
? priceList.filter(
(item) => item.category.toLowerCase() === category.toLowerCase()
)
: priceList;
return {
contents: [
{
uri: uri.href,
text: JSON.stringify(filteredList),
json: filteredList,
},
],
};
}
);
server.prompt(
'get-product-description-prompt',
{
productName: z.string().describe('The name of the product.'),
length: z
.enum(['short', 'medium', 'long'])
.optional()
.describe('The desired length of the description.'),
},
async (input) => {
const { productName, length } = input;
let promptInstructions = `Please generate a compelling product description.`;
let promptCore = `The product is named "${productName}". `;
promptCore += `Focus on its general benefits and appeal. `;
let refinements = '';
if (length) {
let lengthGuidance = '';
if (length === 'short')
lengthGuidance = 'Keep it concise, around 1-2 sentences. ';
if (length === 'medium')
lengthGuidance = 'Aim for a paragraph of about 3-5 sentences. ';
if (length === 'long')
lengthGuidance =
'Provide a detailed description, potentially multiple paragraphs. ';
refinements += lengthGuidance;
}
const fullPrompt = `${promptInstructions}\n\nProduct Details:\n${promptCore}\n\nStyle and Constraints:\n${refinements.trim()}`;
return {
messages: [
{
role: 'user',
content: {
type: 'text',
text: fullPrompt,
},
},
],
};
}
);
const transport = new StdioServerTransport();
await server.connect(transport);
Listing 1: MCP-Serverimplementierung
Die Grundlage für das Beispiel bildet das TypeScript-SDK, das mit dem Kommando npm install @modelcontextprotocol/sdk installiert wird. Das Paket stellt mit der McpServer-Klasse die Grundlage für die Serverimplementierung zur Verfügung. Auf der Server-Instanz sind die Methoden tool, resource und prompt implementiert, die die Schnittstelle zur Registrierung der verschiedenen MCP-Features darstellen. Nachdem die Applikation alle Features registriert hat, ruft sie die connect-Methode der Serverinstanz auf und übergibt ein Transport-Objekt. Das kann wie im Beispiel eine Instanz der StdioServerTransport-Klasse für den Stdio-Transport sein oder auch eine Instanz der StreamableHTTPServerTransport-Klasse für eine Remote-Schnittstelle über Streamable-HTTP. Alternativ dazu unterstützt das TypeScript-SDK auch noch die SSEServerTransport-Klasse für Server Sent Events als Transportmethode.
Für die Implementierung der einzelnen Features des MCP-Servers gelten einige Regeln, die das SDK mit einer sehr strikten Schemavalidierung absichert. Folgt die Implementierung nicht diesen Regeln, lässt sich der Serverprozess nicht starten. Die Validierung stellt auch die Konsistenz der Argumente beim Aufruf sicher und spielt damit eine wichtige Rolle bei der Sicherheit in der Applikation.
Resource im Beispiel
Zur Definition von Resources sieht das SDK die resource-Methode des Serverobjekts vor. Diese Methode akzeptiert die Bezeichnung der Resource, die zugehörige URL und eine Callback-Funktion, die das Ergebnis produziert. Die Callback-Funktion darf asynchron sein, sodass auch der Anbindung einer Datenbank nichts im Wege steht. Eine Besonderheit gibt es bei der Registrierung von Resources allerdings: Ist die URL als Zeichenkette angegeben, darf sie keine dynamischen Parameter enthalten. Für diesen Fall akzeptiert die resource-Methode eine ResourceTemplate-Instanz. Hier werden die Parameter im Pfad mit geschweiften Klammern gekennzeichnet. Die Callback-Funktion kann über ihr zweites Argument auf die Parameter der URL zugreifen und das Ergebnis entsprechend modifizieren.
Im Beispiel ist die Resource eine statische Preisliste für eine Reihe von Produkten. Sie trägt die Bezeichnung price-list und ist über die URL price-list://products/{category} erreichbar, wobei category für eine Kategorie steht, nach der die Callback-Funktion die Datensätze filtert. Das TypeScript-SDK arbeitet mit Zod als Validierungsbibliothek und nutzt diese beispielsweise für die Überprüfung des Rückgabewerts der Resource-Callback-Funktion, sodass diese verpflichtend eine gewisse Struktur zurückgeben muss. Das contents-Array im Rückgabewert kann eine Reihe von Objekten aufweisen, die mindestens über die Eigenschaften uri und text verfügen müssen. Zusätzlich akzeptiert das SDK noch weitere Eigenschaften wie json, in der die Daten als JSON-Objekt vorliegen dürfen.











Entwicklung & Code
Stack Overflow: Kuratierte Knowledge Base für KI-Agenten im Unternehmen
Das Entwicklerforum Stack Overflow stellt ein Knowledge-Base-Tool für Unternehmen vor. Es verbindet kuratiertes Wissen mit KI-Unterstützung und Microsoft-365-Anbindung. So soll es als zuverlässiger Informations-Pool im Unternehmen dienen.
Weiterlesen nach der Anzeige
Stack Internal soll das verteilte Wissen im Unternehmen in einer einheitlichen, von Menschen geprüften Basis zusammenführen, die den Qualitätsansprüchen und Compliance-Regeln der Firma entspricht. KI kommt beim Zusammenstellen der Informationen aus Quellen wie Confluence oder Teams zum Einsatz. Die Maschine klassifiziert die Daten beim Einlesen und präsentiert sie den menschlichen Prüferinnen und Prüfern in sortierter und vorbewerteter Form. Die Kuratoren korrigieren die Vorschläge und geben sie frei.
Enge Verknüpfung mit Microsoft 365
Die Inhalte von Stack Internal dienen einerseits als Basis für den KI-Chat in Microsoft-Tools, also Office 365, Teams und dem Coding-Copiloten für Entwicklerinnen und Entwickler. Ein MCP-Server ermöglicht andererseits die Anbindung an weitere GenAI-Modelle und Agenten. Umgekehrt sollen Interaktionen mit der Knowledge Base das Wissen darin verbessern und erweitern. Auf welche Art das geschehen soll, erklärt der Anbieter nicht.
Stack Internal ist eine Weiterentwicklung von Stack Overflow for Teams und läuft auf Azure. Es gibt Cloud- und On-Premises-Varianten, darunter eine kostenlose für bis zu fünfzig Mitglieder.
Stack Overflow macht mit Stack Internal aus der Not eine Tugend: Gestartet als Forum für Entwicklerinnen und Entwickler, war Stack Overflow mit der Verbreitung von Coding-Assistenten zu einer reinen Trainingsfundgrube für KI-Modelle abgesunken. Dass solide Trainingsdaten aber einen Wert eigener Art darstellen, vermarktet der Anbieter Stack Exchange nun.
(who)
Entwicklung & Code
Kommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
Ein neues, kostenloses Git-Management-Tool vereinfacht die Arbeit mit der Versionierungssoftware Git. Viele Funktionen lassen sich zusammenfassen oder schnell und übersichtlich ausführen, auch in älteren Commits. Dabei verwaltet es mehrere lokale Repositories gleichzeitig.
Weiterlesen nach der Anzeige
Anbieter RemObjects schreibt im Blog, dass das macOS-Tool GitBrowser die Alltagsaufgaben von Entwicklerinnen und Entwicklern beim Versionsmanagement beschleunigen soll. Das Fenster des Tools ist dreigeteilt: In der linken Sidebar findet sich eine Liste der Repos, die sich gruppieren und umbenennen lassen. Entwickler führen hier Aktionen über das Kontextmenü aus – auch in nicht aktiven Projekten.
Der Mittelteil zeigt die Versionen eines Repos, und zwar noch zu pushende in Fett, noch zu pullende kursiv und noch zu mergende blau. Auch die verschiedenen Autoren sind farblich unterschiedlich gekennzeichnet. Rechts im Fenster finden sich die betroffenen Dateien eines Commits und darunter eine Diff-Ansicht. Bei Doppelklick auf einen Commit öffnet sich ein Diff-Tool des Anwenders, derzeit Araxis Merge oder BBEdit. Weitere sollen laut Anbieter hinzukommen.
Ganz oben im Fenster steht der lokale Status, beim Klick darauf öffnet sich rechts die Bühne mit Checkboxen zum Hinzufügen oder Entfernen von Dateien. Darunter steht ein dreifach Diff: eine originale, lokale und auf der Stage liegende Variante.
Commiten und Pushen lässt sich mit einem Klick, und die Commit-Nachricht lässt sich auf Wunsch bereits beim Stagen von einer KI erzeugen. Möglich sind hier OpenAI, Claude, Gemini, Grok, Mistral oder eine lokale Verknüpfung mit LM Studio. Wer selbst die Nachricht schreibt, kann mit Pfeiltasten in älteren Ausgaben blättern.
Pullen lassen sich alle Repos auf einen Schlag oder alle einer Gruppe. Anwender ziehen Dateien, auch aus älteren Commits, per Drag-and-drop in andere Tools – ohne Checkout – GitBrowser extrahiert sie automatisch. Der Wechsel zwischen Zweigen erfolgt einfach über einen Popup-Button.
Der Anbieter betont im Blog, dass GitBrowser nicht für tiefergehende Funktionen gedacht sei, sondern alltägliche Verwaltungsvorgänge erleichtern soll. Anspruchsvolle Anwenderinnen und Anwender werden ganz ohne Kommandozeile also doch nicht auskommen.
Weiterlesen nach der Anzeige
Lesen Sie auch
(who)
Entwicklung & Code
Clean Architecture und Co.: Softwarearchitektur mit Mustern strukturieren
Strukturierte Software basiert auf einem Plan, der die spezifischen Anforderungen an ein System berücksichtigt und in lose gekoppelte Bausteine überführt. In der arbeitsteiligen Softwareentwicklung benötigen Entwicklungsteams solche gemeinsamen Pläne, um eine harmonische und einheitliche Architektur zu entwickeln, ohne jedes Detail vorab miteinander abstimmen zu müssen. Bewähren sich die Pläne, entwickeln sich daraus Muster und Prinzipien auf unterschiedlichen Architekturebenen.
Weiterlesen nach der Anzeige

Matthias Eschhold ist Lead-Architekt der E-Mobilität bei der EnBW AG. Als Experte für Domain-driven Design gestaltet er die IT-Landschaft und Team-Topologien der E-Mobilität. Trotz strategischer Schwerpunkte bleibt er mit Java und Spring Boot nah am Code, entwickelt Prototypen und führt Refactorings durch. Als Trainer vermittelt er seit Jahren praxisnahe Softwarearchitektur, die Theorie und Projektrealität verbindet.
Bei der grundlegenden Strukturierung eines Systems muss man zwischen Architekturstilen und Architekturmustern unterscheiden, wobei sie sich nicht immer sauber abgrenzen. Ein Architekturstil ist ein Mittel, das dem System eine grundlegende Struktur verleiht. Beim Stil Event-driven Architecture basiert die Anwendung beispielsweise auf asynchroner Kommunikation, und Events beeinflussen die Architektur und den Code an vielen Stellen. Gleiches gilt für REST, das eine ressourcenorientierte Struktur vorgibt.
Entscheidet sich ein Entwicklungsteam für Microservices als Architekturstil, wählt es eine verteilte Systemarchitektur, beim Stil Modularer Monolith ist das Gegenteil der Fall. In komplexen Systemen kombinieren Architektinnen und Architekten in der Regel mehrere Stile. Manche Architekturstile ergänzen sich, etwa REST und Microservices, während sich andere gegenseitig ausschließen, wie Microservices und der Modulare Monolith.
Ob Microservices oder Modularer Monolith – beides sagt wenig über die Gestaltung der internen Strukturen aus. Auf dieser inneren Architekturebene, der Anwendungsarchitektur, kommen Muster zum Einsatz, die Entwurfsprinzipien und -regeln kombinieren und eine Basisstruktur der Anwendung prägen. Architekturmuster der Anwendungsarchitektur nutzen Verantwortungsbereiche und Beziehungsregeln als Strukturierungsmittel. Im Muster Clean Architecture sind dies beispielsweise konzentrische Ringe, wobei die Beziehungsrichtung stets zum inneren Kern des Ringmodells führt. Die geschichtete Architektur (Layered Architecture) hingegen unterteilt die Verantwortungsbereiche in hierarchische Schichten, wobei jede Schicht nur mit der darunter liegenden kommunizieren darf (siehe Abbildung 1).

Vergleich zwischen Clean Architecture und Schichtenarchitektur (Abb. 1).
Mustersprache als Fundament
Eine Mustersprache ergänzt Architekturmuster für einen ganzheitlichen Konstruktionsplan – von Modulen und Paketen bis hin zum Klassendesign. Sie bildet das Fundament für eine konsistente und verständliche Umsetzung der Muster und beschreibt eine Reihe von Entwurfsmustern für die Programmierung auf der Klassenebene.
Weiterlesen nach der Anzeige
Die Klassen der Mustersprache bilden Geschäftsobjekte, Fachlogik und technische Komponenten ab. Sie werden unter Einhaltung der definierten Beziehungsregeln in einem Klassenverbund implementiert. Diese Regeln bestimmen, wie die Klassen miteinander interagieren, wie sie voneinander abhängen und welche Aufgaben sie haben. Ein Geschäftsobjekt ist charakterisiert durch seine Eigenschaften und sein Verhalten, während ein Service Geschäftslogik und fachliche Ablaufsteuerung implementiert. Eine derartige, genaue Differenzierung gestaltet Architektur klar und nachvollziehbar.
Ein wichtiger Aspekt einer Mustersprache ist die Organisation des Codes in einer gut verständlichen Hierarchie. Dadurch fördert sie die Verteilung von Verantwortlichkeiten auf unterschiedliche Klassen. Prinzipiell kann jedes Projekt seine eigene Mustersprache definieren oder eine bestehende als Basis verwenden und mit individuellen Anforderungen ausbauen. Eine Mustersprache sorgt auch im Team dafür, dass alle Mitglieder dieselben Begriffe und Prinzipien verwenden.
Dieser Artikel wählt die DDD Building Blocks als Grundlage für eine Mustersprache, wie die folgende Tabelle und Abbildung 2 zeigen.
| Value Object | Ein Value Object repräsentiert einen unveränderlichen Fachwert ohne eigene Entität. Das Value Object ist verantwortlich für die Validierung des fachlichen Werts und sollte nur in einem validen Zustand erzeugt werden können. Ferner implementiert ein Value Object dazugehörige Fachlogik. |
| Entity | Eine Entity ist ein Objekt mit einer eindeutigen Identität und einem Lebenszyklus. Die Entität wird beschrieben durch Value Objects und ist verantwortlich für die Validierung fachwertübergreifender Geschäftsregeln sowie die Implementierung dazugehöriger Fachlogik. |
| Aggregate | Ein Aggregate ist eine Sammlung von Entitäten und Value Objects, die durch eine Root Entity (oder Aggregate Root bzw. vereinfacht Aggregate) zusammengehalten werden. Die Root Entity definiert eine fachliche Konsistenzgrenze, klar abgegrenzt zu anderen Root Entities (oder Aggregates). |
| Domain Service | Ein Domain Service implementiert Geschäftslogik, die nicht zu einer Entität oder einem Value Object gehört. Weiter steuert der Domain Service den Ablauf eines Anwendungsfalls. Ein Domain Service ist zustandslos zu implementieren. |
| Factory | Eine Factory ist für die Erstellung von Aggregates, Entitäten oder Value Objects verantwortlich. Die Factory kapselt die Erstellungslogik komplexer Domänenobjekte. |
| Repository | Ein Repository ist verantwortlich für die Speicherung und das Abrufen von Aggregaten und Entitäten aus einer Datenquelle. Das Repository kapselt den Zugriff auf eine Datenbank oder auch andere technische Komponenten. |

Mustersprache des taktischen Domain-driven Design (Abb. 2).
Ein Beispiel verdeutlicht den Unterschied zwischen einem Value Object und einer Entity: Eine Entity könnte ein bestimmtes Elektrofahrzeug sein. Entities sind also eindeutig und unverwechselbar. In der realen Welt zeigt sich das an der global eindeutigen Fahrgestellnummer (VIN). Der aktuelle Zustand eines E-Fahrzeugs wird zu einem bestimmten Zeitpunkt beispielsweise durch seinen Ladezustand beschrieben, ein Wert, der sich im Laufe der Nutzung des Fahrzeugs verändert. Der Ladezustand entspricht einem Value Object. Er verfügt über keine eigene Identität, sondern definiert sich ausschließlich durch seinen Wert.
Erweiterung der Mustersprache auf Basis der Stile und Muster
Die Mustersprache der Building Blocks ist nicht vollständig. Sie benötigt weitere Elemente, die von den eingesetzten Architekturstilen und -mustern abhängen. REST als Architekturstil führt beispielsweise zwei Elemente in die Mustersprache ein: Controller und Resource. Bei der Integration von REST als Provider liegt der Fokus auf der Resource, die als Datentransferobjekt (DTO) über den API-Endpunkt bereitsteht. Der Controller fungiert als Schnittstelle zwischen der Anfrage des Konsumenten und der Fachlogik des Systems. Das heißt, der Controller nutzt den bereits eingeführten Domain Service und delegiert die Ausführung von Fachlogik an diesen.
Bei der Integration von REST als Consumer erhält die Mustersprache das Element Service Client, das dem Abrufen von Daten oder Ausführen von Funktionen über einen externen API-Endpunkt dient. Der Domain Service triggert dies als Teil der Fachlogik über den Service Client.
Der Stil Event-driven Architecture erweitert die Mustersprache um die Elemente Event Listener, Event Publisher und das Event selbst. Ein Event Listener hört auf Ereignisse und ruft den entsprechenden Domain Service auf, um die Ausführung der Geschäftslogik auszulösen. Der Event Publisher veröffentlicht eine Zustandsveränderung in der Fachlichkeit über ein Event. Der Domain Service triggert die Event-Veröffentlichung als Teil seiner Fachlogik und nutzt hierfür den Event Publisher.
Die in diesen Beispielen aufgeführten Begriffe sind im Vergleich zu den DDD Building Blocks nicht in der Literatur definiert und entstammen der Praxis. Abbildung 3 zeigt die Klassen der erweiterten Mustersprache.

Elemente der Mustersprache des taktischen Domain-driven Design (Abb. 3).
Architekturmuster kombinieren Regeln, Entwurfsmuster und Prinzipien. Muster wie Clean Architecture, die sich besonders für komplexe Systeme mit hohen Anforderungen an den Lebenszyklus eignen, bündeln mehrere Konzepte und beeinflussen daher die Mustersprache stärker als andere Muster. Ein Beispiel ist das Konzept Use Case in der Clean Architecture, das ein zentrales Element darstellt und die Mustersprache um die Elemente Use Case Input Port, Use Case Output Port und Use Case Interactor erweitert. Ein weiteres Beispiel ist die Anwendung des Dependency Inversion Principle (DIP) in der Clean Architecture, das zu dem Musterelement Mapper führt.
Nach dem Exkurs über die Mustersprachen stellt dieser Artikel verschiedene Architekturmuster vor, die sich in schichten- und domänenbasierende unterteilen.
Schichtenbasierende Architekturmuster
Schichtenbasierende Architekturmuster sind datenzentrisch strukturiert. Je nach Muster ist dieser Aspekt mehr oder weniger ausgeprägt. Die Schichtung unterscheidet sich in technischer (horizontal geschnitten) und fachlicher (vertikal geschnitten) Hinsicht. Für die weitere Beschreibung eignet sich die Begriffswelt von Simon Brown mit „Package by …“ .
Package by Layer: Dieses Muster organisiert die Anwendung nach technischen Aspekten, zum Beispiel nach Controller, Service und Repository (Abbildung 4). Es kommt jedoch schnell an seine Grenzen: Mittlere und große Systeme mit komplizierter Fachlichkeit erfordern eine vertikale Schichtung anhand fachlicher Aspekte, andernfalls enden die Projekte erfahrungsgemäß in komplizierten Monolithen mit vielen Architekturverletzungen.
Vorteile:
- Bekannt und verbreitet
- Einfach zu verstehen und anzuwenden
- In kleinen Projekten praktikabel
Nachteile:
- Enge Kopplung zwischen Schichten, mit der Gefahr chaotischer Abhängigkeiten bei Wachstum des Systems
- Fachlich zusammenhängende Funktionalitäten sind über viele Pakete verteilt
- Schwer wartbar und erweiterbar bei mittleren bis großen Anwendungen

Das Architekturmuster Package by Layer (Abb. 4).
Package by Feature: Der Code organisiert sich vertikal anhand fachlicher Aspekte. Eine Schnitt-Heuristik, wie genau das Feature von den fachlichen Anforderungen abzuleiten ist, definiert das Architekturmuster nicht. Es definiert nur, dass dieser fachliche Schnitt zu erfolgen hat. Wird das taktische DDD angewendet, erfolgt der Schnitt entlang der Aggregates (siehe Abbildung 5).
Vorteile:
- Fachlich kohäsiver Code ist lokal zusammengefasst, was zu hoher Wartbarkeit und Erweiterbarkeit führt.
- Modularisierung ermöglicht die unabhängige Entwicklung fachlicher Module.
- Fachliche Ende-zu-Ende-Komponenten sind lose gekoppelt.
- Abhängigkeiten zwischen fachlichen Modulen müssen explizit gehandhabt werden, was die Robustheit der Architektur gegenüber ungewünschten Abhängigkeiten erhöht.
- Fachlich komplexe, mittelgroße bis große Anwendungen lassen sich mit vertikalen Schichten besser beherrschen als mit Package by Layer und Package by Component.
Nachteile:
- Abhängigkeiten zwischen fachlichen Modulen erfordern fortgeschrittene Kommunikationsmuster (zum Beispiel Events), was die architektonische Komplexität erhöht.
- Vertikale Modularisierung muss gut durchdacht werden, um enge Kopplung zwischen Modulen zu vermeiden.

Das Architekturmuster Package by Feature (Abb. 5).
Package by Component: Das Muster strukturiert die Anwendung sowohl fachlich (vertikal) als auch technisch (horizontal), wobei sich ein fachliches Feature in eine Inbound-Komponente und eine Domain-Komponente aufteilt (siehe Abbildung 6). Die Domain-Komponente kapselt Geschäftslogik und die dazugehörige Persistenzschicht. Diese Unterteilung in fachliche Module ist ein entscheidender Unterschied zu Package by Layer.
Vorteile:
- Gute Modularisierung durch fachliche Grenzen zwischen Komponenten
- Hohe Wiederverwendbarkeit der Domain-Komponenten, durch unterschiedliche Inbound-Komponenten
- Erleichterte Testbarkeit durch gesteigerte Modularisierung im Vergleich zu Package by Layer
Nachteile:
- Enge Kopplung zwischen Inbound- und Domain-Schicht, mit dem Risiko indirekter Abhängigkeiten und Seiteneffekten bei Änderungen, insbesondere wenn die Anwendung wächst
- Komponentenkommunikation schwer beherrschbar bei erhöhter fachlicher Komplexität
- Schwerer erweiterbar für mittlere bis große Anwendungen mit höherer fachlicher Komplexität
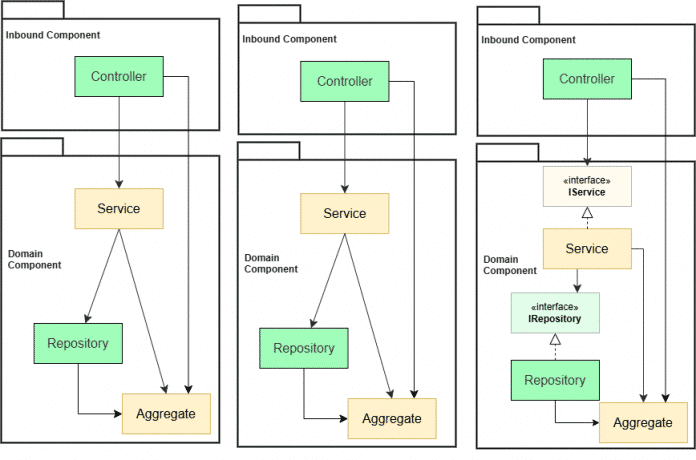
Das Architekturmuster in Package by Component (Abb. 6).

BYD Atto 2: E-SUV bekommt mehr Reichweite und höhere Ladeleistung

DeepSeek-R1 erzeugt unsicheren Code bei politisch sensiblen Begriffen

+++ Keen Venture Partners +++ State of European Tech +++ Trade Republic +++ Flix +++
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenAdobe Firefly Boards › PAGE online
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatIllustrierte Reise nach New York City › PAGE online
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenHarte Zeiten für den demokratischen Rechtsstaat
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenJetzt patchen! Erneut Attacken auf SonicWall-Firewalls beobachtet
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 Monaten„Buongiorno Brad“: Warum Brad Pitt für seinen Werbejob bei De’Longhi Italienisch büffeln muss
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenCreator und Communities: Das plant der neue Threads-Chef
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenPosit stellt Positron vor: Neue IDE für Data Science mit Python und R