Künstliche Intelligenz
Nvidia DGX Spark: Ist das wirklich der KI-„Supercomputer“?
Er wird als „KI-Supercomputer auf dem Schreibtisch“ beworben; aber kann Nvidias DGX Spark halten, was er verspricht? Wir haben die OEM-Variante Gigabyte AI Top Atom auf Herz und Nieren getestet und sie gegen die AMD-Strix-Halo-Konkurrenz (AI Max+ 395) antreten lassen.
Der Video-Test folgt unten, die Textvariante ist hier (heise+).
Weiterlesen nach der Anzeige
Transkript des Videos
(Hinweis: Dieses Transkript ist für Menschen gedacht, die das Video oben nicht schauen können oder wollen. Der Text gibt nicht alle Informationen der Bildspur wieder.)
Guckt mal hier, ich habe ihn endlich, den KI-Supercomputer für den Schreibtisch. Also zumindest bezeichnet Nvidia den DGX Spark so. Mein Testgerät kommt von Gigabyte und heißt AI Top Atom. Kostenpunkt: 4.300 Euro. Naja, das ist ja quasi nichts für so einen richtigen Supercomputer, oder?
Wir haben das Ding auf jeden Fall mit der Konkurrenz von AMD verglichen, also der Strix Halo Plattform, die ja in Vollausstattung AMD Ryzen AI Max+ 395 heißt. Konkret ist das der Framework Desktop. Darüber haben wir schon mal ein Video gemacht. Beide Rechner haben 128 Gigabyte schnellen Speicher. Und ich sage euch, ich fand die Ergebnisse richtig interessant. Und kleiner Spoiler: In vielen Benchmarks ist die AMD-Plattform tatsächlich schneller, obwohl die Geräte deutlich günstiger sind als die mit Nvidia-Technik. Und ja, meinen Gaming-PC haben wir auch mit in den Vergleich genommen. Bleibt dran.
Liebe Hackerinnen, liebe Internetsurfer, herzlich willkommen hier bei…
Also, da ist er nun, der Nvidia DGX Spark, beziehungsweise in meinem Fall der Gigabyte AI Top Atom. Und das kann man auf jeden Fall schon mal sagen: Das ist ein sehr ungewöhnliches Gerät. Angekündigt von Nvidia im Januar 2025 als KI-Supercomputer für den Schreibtisch, gibt es das Teil eben nicht nur von Nvidia im Goldgehäuse, sondern auch leicht modifiziert von Acer, Asus, Dell, HP, Lenovo und MSI. Und eben wie gesagt von Gigabyte, die uns als Erste ein Testgerät geschickt haben. Vielen Dank dafür.
Hätte man mich allerdings gefragt, hätte ich vielleicht den Begriff Atom vermieden, weil das ja nun der Markenname von Intels Billig-Prozessoren ist, die ich eher mit wenig Rechenpower assoziiere. Aber okay, der Gigabyte AI Top Atom kostet auf jeden Fall 4.300 Euro und hat wie alle DGX Spark-Varianten zwei wesentliche Besonderheiten. Einmal den Nvidia-Kombiprozessor GB10. GB steht für Grace Blackwell mit eingebauter Nvidia-GPU als CUDA-kompatiblen KI-Beschleuniger und zweitens viel, viel, viel schnellen Speicher, nämlich 128 Gigabyte LPDDR5X-RAM.
Weiterlesen nach der Anzeige
Aber wenn man sich diese Tabelle ja mal anguckt, ist die Geschwindigkeit zwar deutlich schneller als normales DDR5-RAM, aber eben auch bei Weitem nicht so schnell wie das Video-RAM auf aktuellen Grafikkarten. Und das sehen wir auch bei unseren Geschwindigkeitsmessungen, aber dazu später mehr.
Erst mal noch mal kurz, was die sonst noch so mitbringen, die Hardware. Am auffälligsten ist wohl der ziemlich exotische 200-Gigabit-Netzwerkadapter ConnectX-7, mit dem man mehrere dieser Rechner verkoppeln kann. Aber es gibt auch noch einen normalen RJ45-Port mit 10-Gigabit-Ethernet. Ansonsten halt einfach nur einen HDMI-2.1a-Port und vier USB-C-Ports, einer davon für die Stromversorgung. Ja, die läuft tatsächlich über USB Power Delivery und das Teil zieht unter Volllast auch maximal nur 216 Watt.
Hier seht ihr auch noch unsere anderen Messwerte, die meine Kollegen aus dem Hardwareressort der c’t ermittelt haben. Interessant dabei ist, dass der GPU-Teil des GB10-Kombiprozessors genauso viele Shader-Einheiten respektive CUDA-Kerne hat wie die GPU der Gaming-Grafikkarte RTX 5070, nämlich 6.144 Stück. Aber die sind bei der DGX Spark anders strukturiert, nämlich für KI-Algorithmen optimiert. Beispielsweise hat die GB10-GPU doppelt so viele Tensorkerne wie die 5070, nämlich 384 statt 192, aber weniger Render Output Units, 49 statt 80.
Kann man also genauso gut eine Grafikkarte nehmen, vor allem wenn da ja, wie gesagt, auch noch viel schnellerer Speicher drin ist? Ja, nee, denn Consumer-Grafikkarten haben zurzeit maximal 32 Gigabyte Speicher. Die 5070 hat sogar nur 16 und unser Testgerät halt 128 Gigabyte. Aber so Geräte mit 128 Gigabyte schnellem Unified Speicher gibt es ja auch noch mit anderen Architekturen, zum Beispiel von Apple oder von AMD.
Praktischerweise habe ich direkt so einen AMD Ryzen AI Max+ 395 da, also die Strix-Halo-Plattform und zwar den Framework Desktop. Was tatsächlich ein bisschen lustig ist: Strix Halo sollte ja die Antwort auf Nvidias DGX Spark sein, weil da bei der CES im Januar diesen Jahres viele Leute darüber gesprochen haben, war dann aber am Ende tatsächlich deutlich früher im Handel als das, worauf eigentlich reagiert werden sollte.
Auf alle Fälle sind vergleichbare Geräte mit AMD-Technik deutlich preisgünstiger. Also den Framework Desktop gibt es mit gleicher Ausstattung wie der DGX Spark, also mit 4 Terabyte SSD, für 2.800 Euro, also 1.500 Euro günstiger als die Nvidia-Variante. Von zum Beispiel GMKtec gibt es sogar einen AI Max+ 395 mit 128 Gigabyte für 1.999 Euro. Der hat dann allerdings nur 2 Terabyte SSD. Und ja, dazu kann ich im Moment auch noch nichts sagen, weil ich den noch nicht getestet habe.
Aber jetzt wird es auf jeden Fall interessant. Wie schneiden die beiden Kontrahenten denn jetzt ab mit so lokalen KI-Anwendungen? Ja, da habe ich nun versucht, den Vergleich so gerecht wie möglich aufzubauen. Also der Nvidia-Rechner läuft ja mit dem selbst benannten Nvidia DGX OS. Das ist aber eigentlich nur ein Ubuntu Linux mit einem angepassten Kernel. Und zwar ist der Kernel auch noch alt. Er hat Version 6.11. Das Ding ist über ein Jahr alt. Aktuell ist 6.17. Naja, aber dieses DGX OS ist eben das offiziell empfohlene Betriebssystem für DGX Spark-Computer. Deshalb nehmen wir das natürlich.
Bei dem Framework Desktop hier nennt Framework zwei offiziell unterstützte Linux-Varianten, einmal Fedora und einmal Beside. Beside ist ja eher so Gaming-orientiert. Deshalb habe ich einfach Fedora Workstation 43 installiert. Bei meinem Vergleichs-Gaming-PC läuft CachyOS.
Ja, und der erste Benchmark war natürlich LLM-Abzapfen aka Inferenz. Da habe ich auf allen Rechnern LM Studio in der aktuellen Version 0.3.31 verwendet. Als Runtime natürlich CUDA für Nvidia und Vulkan für das AMD-System. ROCm kann LM Studio eigentlich auch, aber das lief bei uns nicht. Und ram tam tam tam – hier sind die Ergebnisse.
Ja, ich würde sagen, das nimmt sich nicht viel. Beziehungsweise bei dem wichtigen Modell GPT-OSS:120B ist der günstigere AMD-Rechner sogar 11 Prozent schneller. Generell kann man auf jeden Fall sagen: Wenn ihr nur LLM-Inferenz machen wollt, könnt ihr gut das AMD-Modell nehmen.
Fernab von den Vergleichen: Es ist auf jeden Fall beeindruckend, mit GPT-OSS ein 63 GB großes Modell mit 120 Milliarden Parametern mit fast 50 Token die Sekunde laufen zu lassen auf so einem kleinen Ding. Das ist tatsächlich besonders. Allerdings gibt es auch nicht so viele Open-Source-Modelle, die so groß sind.
Und da kommt jetzt mein Gaming-PC mit RTX 4090 ins Spiel. Guckt mal hier, der ist mit den meisten von mir getesteten aktuell populären Sprachmodellen ungefähr dreimal so schnell, weil die halt klein sind und in den 24-Gigabyte großen Speicher meiner 4090 passen. Nur halt GPT-OSS 120B nicht. Das muss ich in meinen langsamen, normalen DDR5-Arbeitsspeicher auslagern. Und deshalb schaffe ich damit dann nur 16,9 Token.
So, jetzt sind mir aber noch andere interessante Unterschiede aufgefallen. So lädt GPT-OSS:120B bei der Nvidia-Kiste viel länger, nämlich anderthalb Minuten. Gleichzeitig friert auch der Bildschirm jedes Mal für ein paar Sekunden ein. Also ich kann auch die Maus einige Sekunden lang nicht bewegen. Mit den anderen beiden Rechnern lädt das Modell deutlich schneller, in weniger als 20 Sekunden.
So, aber wir können jetzt auch RAG machen, also eigene Dateien mit dem Sprachmodell analysieren. Ich habe hier mal das Programm des sogenannten Entdeckertags der Region Hannover reingeschmissen und dann Fragen dazu gestellt. Damit das ganze PDF in den Kontext passt, muss man das Kontextfenster manuell hochziehen auf mindestens 20.000 Token.
Ja, das Ding ist jetzt, dass die Nvidia-Workstation nur 14 Sekunden braucht, um das alles zu verarbeiten. Die AMD-Konkurrenz braucht fast vier Minuten und mein Gaming-PC 46 Sekunden. Also der Teufel steckt bei solchen Sachen wirklich im Detail. Müsst ihr wirklich überlegen, was ihr machen wollt, was da die richtige Hardware für euch ist.
Übrigens habe ich auch alles mal testweise mit Ollama gemessen, und da kann ich euch sagen: LM Studio ist auf allen drei Systemen immer schneller gewesen. Hier die Zahlen dazu.
Ja, aber man will ja vielleicht mit so einer Workstation nicht nur LLMs anzapfen, sondern vielleicht auch Bilder, Videos oder Musik generieren. Und das machen inzwischen viele Leute mit ComfyUI. Das ist so eine Node-basierte GenAI-Umgebung. Und ja, die lässt sich bei Nvidia wunderbar einfach installieren. Es gibt da nämlich sogenannte Playbooks, und das sind so recht übersichtlich gemachte Tutorials, wie man bestimmte Dinge zum Laufen bringt. Und da gibt es ziemlich viele dieser Playbooks von Nvidia, also auch für so Feintuning-Sachen, zum Beispiel Anbindungen in VSCode und natürlich wie gesagt auch ComfyUI.
Das Playbook sagt, die Installation dauert 45 Minuten. Das ist aber wirklich sehr pessimistisch. Das hat in meinem Fall nicht mal 15 Minuten gedauert. Auf dem Framework Desktop sah die Sache dann schon wirklich anders aus. Da habe ich mich leider stundenlang festgefrickelt, weil ich es lange nicht hinbekommen habe, dass ComfyUI meine ROCm-Installation akzeptiert. Und da merkt man dann halt deutlich, dass viele Sachen eben mit Nvidia CUDA im Kopf entwickelt wurden. Also ROCm ist quasi die AMD-Variante von CUDA, aber eben ein bisschen weniger populär.
Ja, und am Ende habe ich es hinbekommen. Aber mein Benchmark hier, das ist einfach das Bildgenerierungsmodell FLUX.1-dev-fp8. Da habe ich einfach das Standard-Template mit einem eigenen Prompt genommen. Und da braucht das Generieren eines 1024×1024 Pixel großen Bildes mit dem Nvidia DGX Spark-System 38 Sekunden, bei dem AMD-System 89 Sekunden, also mehr als doppelt so lange. Mein Gaming-PC mit RTX 4090 schafft es in 12 Sekunden.
Wenn ihr jetzt aufgepasst habt, dann habt ihr vielleicht gemerkt, dass es eine einzige Sache gab bislang, die mein Gaming-PC nicht deutlich besser gemacht hat als die beiden speziellen KI-PCs. Und das ist tatsächlich das Abzapfen des einen großen LLMs GPT-OSS:120B, weil das eben nicht in die 24 Gigabyte Speicher meiner RTX 4090 passt. Aber der ganze andere Kram eben schon. Also gerade diese Bild- und Video-Generierungssachen, die sind halt auf kleinere RAM-Größen ausgelegt.
Okay, ja gut, man könnte natürlich von den offenen Sprachmodellen statt mit 4-Bit quantisierte Modelle irgendwie, keine Ahnung, 8-Bit quantisierte Modelle nutzen. Die würden auch nicht in den Speicher meiner Grafikkarte passen. Und natürlich schon in die AMD-Workstation, in die Nvidia-Workstation. Das würde schon gehen. Aber ob das so viel bringt, ist die Frage.
Aber generell kann man auf jeden Fall sagen: Es fehlen die Inferenz-KI-Killer-Applikationen für diese Speichergröße, weil dann am Ende 128 Gigabyte dann doch zu wenig sind, um zum Beispiel so etwas wie DeepSeek zu laden, was also wirklich ein ernsthafter Wettbewerber zu den großen kommerziellen Cloud-Modellen ist. Aber das braucht halt einfach mindestens das Fünffache an Speicher.
Und deshalb muss man sagen, dass die KI-Workstations wirklich für ordentliche normale KI-Anwender wahrscheinlich nichts sind und dass am Ende die Nützlichkeit sehr, sehr, sehr, sehr spezifisch ist. Also zum Beispiel, das ist für Leute, die irgendwelche KI-Software in Rechenzentren deployen wollen und die vorher auf der gleichen Architektur testen wollen. Also ein ganz spezielles Entwicklergerät für die Nvidia-Serverplattform DGX.
Wenn ich mir jetzt aber angucke, wie viele Hersteller diese sehr, sehr speziellen Rechner verkaufen, da denke ich schon, da scheint der KI-Hype dann doch schon mit reinzuspielen. Denn gibt es wirklich so viele Entwickler, die einen so speziellen Rechner brauchen? Weiß nicht.
Beim Framework ist es ja so, dass der Rechner primär als Gaming-PC vermarktet wird. Also zumindest steht hier auf der Website Gaming noch vor KI und auch die Produktfotos, die sehen mir sehr nach Gaming aus. Aber auch hier ist es so: Das Preis-Leistungs-Verhältnis ist, wenn man damit nur spielen will, ziemlich schlecht.
Ja, also wenn jemand von euch da draußen mit diesen Geräten liebäugelt: Ich hoffe, dieses Video hat euch ein bisschen geholfen, das Thema besser einzuschätzen. Ich jedenfalls, der sehr gerne mit lokalen KI-Sachen herumexperimentiert, kann für mich auf jeden Fall sagen, dass ich mit meinem PC mit RTX 4090 und 128 GB langsamem DDR5-RAM als Backup-Notlösungsspeicher Stand heute mehr anfangen kann als mit diesen beiden spezialisierten Geräten. Aber ich bin auch kein Entwickler, der irgendwelche Modelle fine-tuned – bisher jedenfalls nicht – oder Anwendungen für DGX-Systeme baut.
Ja, wie seht ihr das? Bin ich da total auf der falschen Spur? Gerne in die Kommentare schreiben und tschüss.
c’t 3003 ist der YouTube-Channel von c’t. Die Videos auf c’t 3003 sind eigenständige Inhalte und unabhängig von den Artikeln im c’t Magazin. Die Redakteure Jan-Keno Janssen, Lukas Rumpler, Sahin Erengil und Pascal Schewe veröffentlichen jede Woche ein Video.
(jkj)











Künstliche Intelligenz
Nachhaltige Baustoffe: Mit einem Pilz veredeltes Holz sieht aus wie Marmor
In Wald und Garten kann es jeder beobachten: Baumpilze zersetzen Holz zu unansehnlichen Resten. Wird der Prozess aber gezielt gesteuert und der richtige Pilz gewählt, kann ein edel aussehender Werkstoff entstehen: Holz mit Marmor-Look. Das ist, in Kurzform, die Geschäftsidee des Schweizers Jakob Koster. Unter dem Namen Myrai soll das Produkt schon bald zu kaufen sein.
Weiterlesen nach der Anzeige
Als Grundlage dienen lokale Laubholzarten, die laut Koster üblicherweise verheizt werden. Das Produkt tauge zudem als nachhaltige Alternative zu exotischen Importhölzern, sagt er.
Die Idee dafür entstand durch einen Zufall. Koster, damals Chef der Schreinerei Koster Holzwelten in Arnegg bei St. Gallen, entdeckte auf einem Holzstück ungewöhnliche schwarze Linien. Er fragte bei dem Schweizer Materialforschungsinstitut EMPA nach und erfuhr, dass es sich um einen ganz besonderen Baumschädling handelte.
Der Schlauchpilz produziert das schwarze Pigment Melanin. Beim Besiedeln des Holzes erzeugt er ein marmorähnliches Muster. Koster hatte Glück, ihn zu finden, denn er ist selten. „Früher hat man Baumstämme für mehrere Monate in den Wald gelegt und gehofft, dass sie vom richtigen Pilz besiedelt werden“, erzählt ihm der Empa-Forscher Francis Schwarze.
Koster und Schwarze taten sich zusammen, um die „Holzmalerei“ des Pilzes gezielt zu steuern. In die luftige Schreinereihalle bei St. Gallen zogen Edelstahlcontainer mit Laboren und Klima- sowie Vakuumkammern ein. Die Agentur für Innovationsförderung Innosuisse unterstützte das Vorhaben.
Marmormuster aus der Klimakammer
Mittlerweile haben die Männer eine funktionstüchtige Vorgehensweise gefunden. Sie bringen bis zu zweieinhalb Meter lange Bretter in einer Klimakammer auf eine geeignete Feuchtigkeit. Anschließend werden die Bretter sterilisiert und dann mit Sporen des Schlauchpilzes geimpft.
Mehrere Wochen dauert es, bis der Pilz die gewünschten Muster ins Holz gezeichnet hat. Unter anderem die Wahl des Holzes und Änderungen der Produktionsbedingungen beeinflussen das Aussehen der Marmorierung. Am Ende des Prozesses wird das Holz in einer Kammer getrocknet. Der Pilz stirbt ab.
Weiterlesen nach der Anzeige
Für Bauplatten, Möbel und Musikinstrumente
„Das Besondere an dem Schlauchpilz ist, dass er nur die stark lignifizierten Bereiche der Zellwand nicht abbaut und das Holz eine hohe Biegesteifigkeit beibehält“, berichtet Francis. Das marmorierte Holz eignet sich für den Innenausbau, für Möbel, Musikinstrumente und für Schmuck. Wann genau es zu kaufen sein wird, steht bislang nicht fest.
Die neue Holzveredlung erweitert das Potenzial von Pilzen für die Produktion nachhaltiger Baustoffe. Myzelien etwa, fadenartige Pilzzellen-Geflechte, eignen sich unter anderem als Dämmstoff und für Bauplatten. Auch Möbel sind daraus schon entstanden. Ob die Melanin-Malerei des Schlauchpilzes auch hier für Verschönerung sorgen kann, ist unbekannt.
Dieser Beitrag ist zuerst auf t3n.de erschienen.
(jle)
Künstliche Intelligenz
Expertenforderung: OpenDesk sollte für Unis gratis sein
Der deutsche Hochschulsektor steuert im Bereich Office-Software auf eine strategische Sackgasse zu. Davor warnen zumindest führende IT-Experten in einem heise online vorliegenden Brief an Bundesdigitalminister Karsten Wildberger (CDU): Während der US-Gigant Microsoft seine Office-Suite für Studierende kostenlos anbietet, kostet die staatseigene deutsche Alternative OpenDesk 45 Euro netto pro Nutzer und Jahr.
Weiterlesen nach der Anzeige
Dass eine Open-Source-Lösung teurer ist als das proprietäre Konkurrenzprodukt, liegt vor allem an den Kosten für den sicheren Betrieb und die Wartung in zertifizierten deutschen Rechenzentren. Während Microsoft den Gratis-Zugang als Marketinginstrument zur langfristigen Bindung nutzt, muss die souveräne Lösung ihre Infrastruktur real finanzieren.
Für eine mittelgroße Universität mit 30.000 Studierenden bedeutet dies jährliche Mehrkosten von über 1,6 Millionen Euro, geben die Autoren zu bedenken. Diese finanzielle Hürde mache den politisch gewünschten Wechsel zur digitalen Eigenständigkeit praktisch unmöglich. Die Unterzeichner, zu denen Torsten Prill vom Verband der Hochschulrechenzentren (ZKI) und Vertreter der Gesellschaft für Informatik (GI) gehören, kritisieren diesen Zustand als absurden Wettbewerbsnachteil für eine bundeseigene Entwicklung.
Strategische Abhängigkeit statt digitaler Eigenständigkeit
Dabei steht weit mehr auf dem Spiel als nur das Budget. Die Verfasser befürchten, dass Deutschland die Kontrolle über seine Bildungs- und Forschungsinfrastruktur an nicht souveräne Ökosysteme verliert. Während das vom Zentrum für digitale Souveränität (Zendis) bereitgestellte OpenDesk auf volle Datenhoheit und offene Standards setze, führe der Weg über Microsoft in einen „Cloud-Lock-in“. Selbst bei Speicherung in der EU unterlägen die Daten etwa durch den Cloud Act dem Zugriff von US-Behörden.
Der Appell erhält Brisanz durch den Verweis auf die nationale Sicherheitsstrategie der USA. Die zielt den Experten zufolge darauf ab, monopolistische Positionen für US-Technologien global auszubauen. Gleichzeitig explodierten die Ausgaben des Bundes für Microsoft-Produkte: Sie sind von 274 Millionen Euro im Jahr 2023 auf rund 481,4 Millionen Euro im vorigen Jahr gestiegen.
Die Forderung an das Ministerium lautet daher: Bis Mitte 2026 soll eine Lösung her, die OpenDesk für alle Studierenden kostenfrei verfügbar macht. Nur so könne sich digitale Unabhängigkeit im Bildungsbereich gegen die Marktmacht der US-Konzerne durchsetzen. Es sei an der Zeit, in die Souveränität künftiger Fachkräfte zu investieren, statt lediglich wachsende Abhängigkeiten zu finanzieren.
Weiterlesen nach der Anzeige
(cku)
Künstliche Intelligenz
Mit 3D-Drucker mehrfarbig drucken: Bambu Lab, Snapmaker & Co. im Vergleich
Seit dem AMS-Materialwechsler von Bambu Lab ist farbiges 3D-Drucken massentauglich. Die nächste Revolution startet jetzt – und spart Zeit, Filament und Geld.
Die meisten 3D-Drucker im Hobbykeller arbeiten nach dem FDM-Verfahren. Der zu verarbeitende Kunststoff liegt als Filament auf Rollen vor, wird geschmolzen und mit einer feinen Düse Schicht für Schicht zum zu druckenden Objekt zusammengesetzt. Moderne Drucker sind sehr einsteigerfreundlich und ab etwa 180 Euro zu bekommen. Die besten 3D-Drucker zeigen wir in unserer Bestenliste.
Bei dieser Drucktechnik ist das Filament – und damit das Druckergebnis – in der Regel einfarbig. Wer seinen R2D2 grau drucken will, legt entsprechendes Filament ein. Ein Farbwechsel oder gar das Mischen von Farben erfolgt im Drucker normalerweise nicht. Stattdessen kann man mit Pinsel oder Airbrush-Set nacharbeiten.
Es gibt aber verschiedene Ansätze, die mehrfarbiges 3D-Drucken ermöglichen. Wir werfen einen kurzen Blick in die Vergangenheit des Multi-Color-Printings und zeigen die aktuellen Möglichkeiten und neuen Entwicklungen im Hobbyumfeld.

Tintenstrahldruck
Der taiwanesische Hersteller XYZ Printing hatte mit seinem Da Vinci Color bereits vor über fünf Jahren ein fertiges Gerät im Programm, das Farbdrucken Out-of-the-Box verspricht. Das Prinzip ist einfach: Der Drucker verarbeitet weißes Filament und färbt die äußeren Schichten der Objekte mit einer Art integriertem Tintenstrahldrucker ein. Das erlaubt echten Vollfarbdruck, allerdings ist nur die Oberfläche eingefärbt.
Die Technik hat sich nicht durchgesetzt und ist aktuell vollständig vom Markt verschwunden. Der Grund dafür dürfte der hohe Preis sein. Für den Drucker selbst verlangte der Hersteller mindestens 2700 Euro. Das größere Problem war aber das Verbrauchsmaterial. Zum einen musste man das weiße Kunststoff-Filament teuer vom Hersteller kaufen: XYZ Printing setzte auf einen Chip in der Filamentrolle, um die Nutzung von günstigerem Fremdfilament auszuschließen. Zum anderen war die Tinte zum Einfärben ein Kostentreiber, den man nirgendwo anders bekommen konnte. Der Hersteller hat sich 2023 vom Markt zurückgezogen, seitdem gab es auch keinen anderen Drucker mit dieser Technik mehr.
Palette
Ein früher externer Ansatz der heutigen Materialwechsler dürfte ein Gerät namens „Palette“ sein. Vier verschiedenfarbige Filamente werden in einen Kasten eingespannt, auf der anderen Seite kommt nur noch ein Filament heraus, das zum Drucker führt. Im Inneren trennen Messer die farbigen Filamente an den richtigen Stellen ab, mit Hitze werden sie wieder zusammengeschmolzen – und am Drucker kommt jeweils die Farbe an, die gerade nötig ist.

Prinzipbedingt ist die Farbauflösung dabei nicht hoch. Echtes Mischen von Farben ist nicht möglich, wohl aber das Drucken unterschiedlicher Segmente in unterschiedlichen Farben. Mit dem anfangs erwähnten R2D2 klappt es gut, wenn man weißes, blaues, graues und schwarzes Filament einspannt. Echter Vollfarbdruck ist das aber nicht; auch das Mischen von Farben ist nicht möglich.
Die Nachteile waren erhöhter Filamentverbrauch, weil der Drucker die Mischfarbe beim Wechsel der Filamente an der Seite ausspült, sprich: wegwirft. Dazu kommen die Kosten des Geräts, das mit 599 Dollar damals teurer war als heute ein guter, anfängertauglicher 3D-Drucker samt Filamentwechselsystem.
Dual-Extruder
Ein bewährter Weg zum Mehrfarbdruck sind Drucker mit zwei Extrudern. Sie können zwei unterschiedliche Filamente mehr oder weniger gleichzeitig verarbeiten; in der Praxis laufen beide Extruder auf der gleichen Achse und geben abwechselnd Filament aus. Damit lässt sich schon einiges realisieren, das Drucken von Logos in Vereinsfarben beispielsweise – aber ein Mischen der beiden Farben ist nicht möglich. Dafür entfällt der Spülvorgang beim Farbwechsel, da es eine eigene Düse für jede Farbe gibt.

Das hat andere Haken: So muss der Druckerhersteller beispielsweise dafür sorgen, dass aus der gerade nicht genutzten Düse kein geschmolzenes Filament austritt und das Druckobjekt versaut. Aktuell gibt es diese Technik beispielsweise bei Bambus Top-Modell H2D (das D steht für Dual). Hier sitzen auf dem beweglichen Druckkopf zwei Extruder und zwei Düsen, wobei die eine hoch- oder heruntergefahren und die jeweils nicht genutzte Düse von einem Kunststoff-Schieber abgedeckt wird. Das ist optimal, wenn es beispielsweise um Beschriftungen geht, da der Wechsel zwischen den beiden Düsen in Sekundenschnelle stattfindet und es keine Materialverschwendung durch Spülen gibt.

Außerdem auf der Habenseite: Das gleichzeitige Drucken unterschiedlicher Materialien ist mit dieser Technik möglich, da die beiden Hot-Ends unterschiedliche Temperaturen haben können. Anwendungsbeispiele sind das Drucken von Scharnieren aus dem gummiartigen TPU bei einer Kiste aus hartem Kunststoff wie PLA oder ABS, aber auch der Einsatz von speziellen Support-Filamenten, die sich leichter ablösen oder in Wasser auflösen lassen.
Farben mischen: two in, one out
Eine Variante des Dual-Extruders nennt sich Two in, one out. Technisch gibt es wie beim Dual-Extruder zwei getrennte Filamente mit jeweils eigenem Antrieb, die aber in diesem Fall nicht in jeweils einem Druckkopf enden, sondern in einem Hot-End zusammengeführt werden. Unten gibt es nur einen Auslass. Auf diese Weise ist ein beliebiges Mischen der Filamente möglich, etwa 10 Prozent Anteil des einen und 90 Prozent des anderen. Im Gegensatz zum Dual-Extruder gibt es hier aber auch nur eine Temperatureinstellung. Damit ist das Verarbeiten von zwei unterschiedlichen Materialien nicht möglich.
Auch in der Praxis ist dieses Verfahren fummelig, weil die meisten Slicer-Programme nur mit zwei Farben (respektive Extrudern) zurechtkommen. Der „klassische“ Zweifarbdruck ist hier ohne weiteres möglich, allerdings nicht mit sauberer Trennung: Schaltet der Drucker von der einen auf die andere Farbe um, wird zunächst noch etwas Mischfarbe ausgegeben. Wer bereit ist, sich tiefer in das Thema einzuarbeiten, kann damit tolle Effekte erzielen. Aktuell gibt es keine kommerziellen Drucker mit dieser Technik, Bastler können die entsprechende Technik aber an Geräten mit Open-Source-Firmware nachrüsten.
Eine Sonderform sind die Diamond Extruder (three in, one out), die das gleiche Prinzip mit drei Filamenten anwenden. Entsprechende Extruder kann man noch kaufen, sie sind aber eine totale Randerscheinung.
Materialwechsler wie MMU oder AMS
In der Praxis haben sich die sogenannten Materialwechsler durchgesetzt. Je nach Hersteller haben sie andere Namen. Bei Prusa nennt sich das System beispielsweise MMU (Multi Material Upgrade), bei Bambu Lab AMS (Automatic Material System), bei Anycubic ACE Pro (Anycubic Color Engine).

Das Prinzip ist ähnlich: Mehrere Filamentrollen – meist vier – sitzen in einem geschlossenen Kasten oder offenen System. Von dort führen PTFE-Schläuche zum Druckkopf, wo jeweils nur ein Filament aktiv ist. Eine Schneide-Mechanik im Feeder oder Materialwechsler – vornehmlich ein Messer – trennt das zuletzt verwendete Filament vor dem Hot-End ab. Der Wechsler zieht es zurück und schiebt das nächste vor. Übergangsreste der Mischfarbe werden als „Poop“ ausgetragen. Der günstigste (und gute) Einstieg in den mehrfarbigen Druck ist der Bambu Lab A1 Mini (Testbericht), den es mit Materialwechselsystem A1 Lite aktuell ab 300 Euro gibt.
3D-Druck in Farbe
Der Bambu Lab A1 Mini wirft das Spülfilament auf den Boden.

Für Beschriftungen wie diese sind Materialwechsler gut geeignet, da sie hier nur selten die Farbe wechseln müssen.

Direkt am Druckkopf laufen die vier Filamente zusammen. Die nicht verwendeten werden in den PTFE-Schlauch zurückgezogen, das zu druckende Filament wird bis zum Extruder vorgeschoben.

Hier sind CMYK-Farben für ein farbiges Lithopane eingelegt.

Hier druckt der Bambu H2D ein CMYK-Bild. Wie beim Druck auf Papier werden die Farbpunkte hier nebeneinander gesetzt.

Wird das Lithophane von hinten beleuchtet, erscheint ein Farbfoto. Je dicker das Material, um so dunkler wird es, die Farben werden aus den CMYK-Punkten zusammengesetzt.

Für Beschriftungen wie hier eignen sich Drucker mit Dual Nozzlse perfekt, da sie die Beschriftung ohne Spülvorgang setzen können.

Hier ist eine mehrfarbige Beschriftung aus dem AMS zu sehen.

Im AMS sind die Filamentspulen gut verräumt. Geschlossene Systeme schützen auch vor Staub und Feuchtigkeit.

Der Anycubic Kobra 3 konnte uns als Prototyp noch nicht überzeugen, da in der Software das „Abstreifen“ des gespülten Filaments gefehlt hat.

Die Zuordnung der zu druckenden Farben kann direkt auf dem Display des Druckers erfolgen. Die grundlegenden Farbeinstellungen setzt man aber in der Slicing Sofwtare.

Der Bambu P1S wirft sein Poop hinten aus.

Zum Vergleich: Das linke Benchy haben wir mit dem Bambu AMS auf dem P1S gedruckt, das rechte auf dem Snapmaker U1. Gerade das Benchy verlangt aufgrund seiner vielen schiefen Ebenen viele Farbwechsel. Der Drucker muss fast die zehnfache Menge Filament aus Abfall auswerfen, als das eigentliche Druckobjekt wiegt. Das rechte Benchy haben wir auf dem Snapmaker U1 mit Werkzeugwechsler gedruckt, hier fällt fast kein Abfall an.
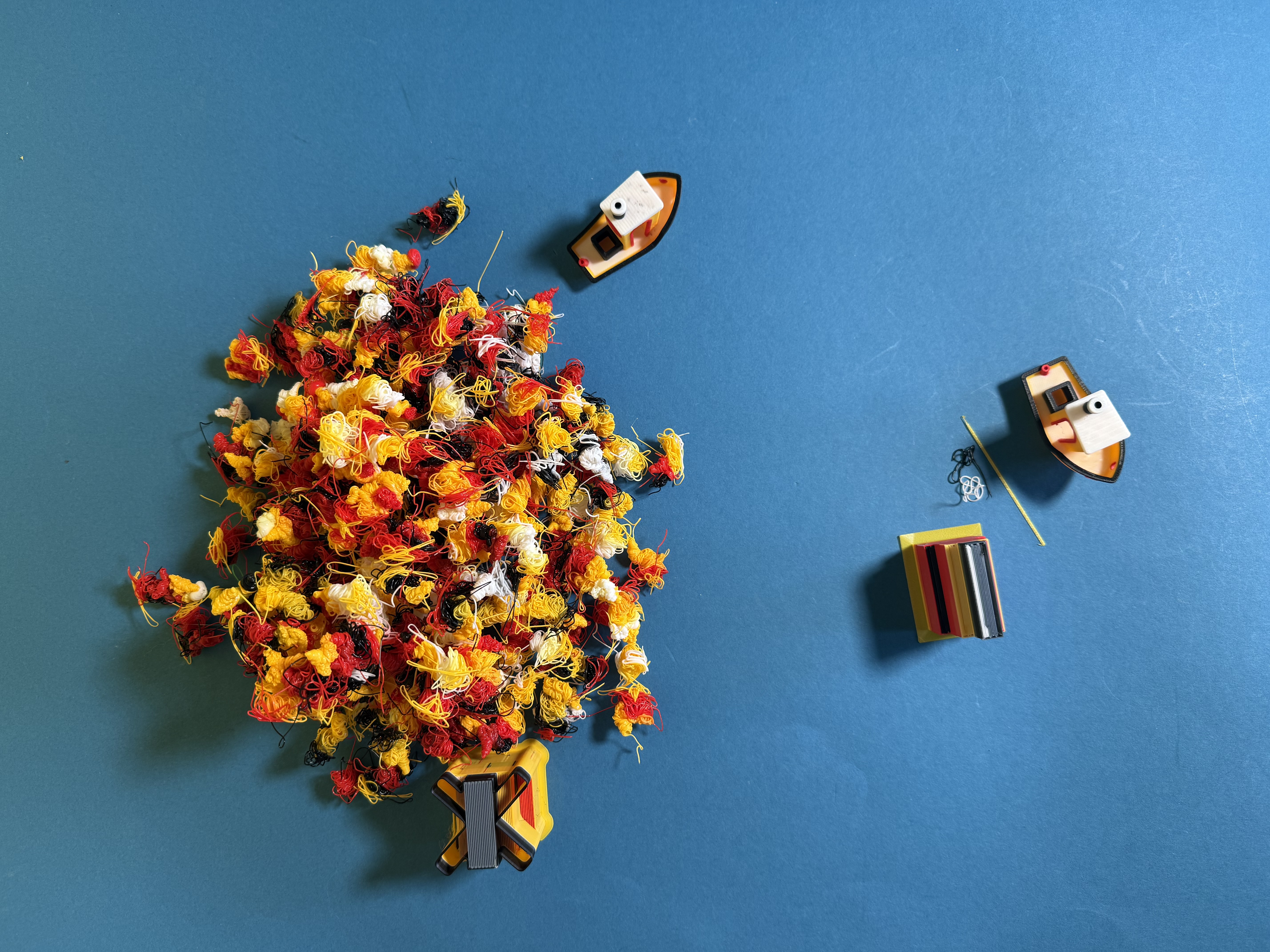
Wer noch mehr Filament sparen möchte, lässt den Wipe Tower weg – doch der Preis dafür ist zu hoch, dann sieht der Druck nicht mehr sauber aus.

Wer viel mehrfarbig drucken möchte, sollte sich einen Drucker mit Werkzeugwechselsystem ansehen.

Vor allem bei Prusa und Bambu Lab ist die Technik sehr ausgereift. Bei anderen Herstellern empfehlen wir vor dem Kauf das Lesen von Testberichten. Aktuell haben wir in der Redaktion insbesondere den Elegoo Centauri Carbon 2 mit Canvas-Farbwechselsystem und den Qidi Q2 mit Qidi Box. Testberichte zu beiden Geräten haben wir noch nicht veröffentlicht, da wir derzeit aufgrund diverser Probleme beim Mehrfarbdruck mit den Herstellern im Austausch stehen.
Die Technik ist günstig und funktioniert zuverlässig, ist je nach Einsatzzweck aber langwierig und verschwenderisch, da im Extremfall auf jedem Layer mehrere Farbwechsel samt Spülvorgang stattfinden. Zum Test haben wir mehrfach vierfarbige Benchys gedruckt. Das eigentliche Modell kommt auf ein Gewicht von 12 Gramm, aber das Zehnfache dieses Filaments wurde „gespült“ und somit als Abfall entsorgt – und die Druckzeit verlängert sich extrem. Für Modelle mit wenigen Farbwechseln eignet sich das Prinzip hervorragend. Zudem ist es komfortabel, mehrere Filamente im Drucker einsatzbereit zu haben und je nach Bedarf mit PLA, ABS oder TPU zu drucken.
Werkzeugwechsler
Der neueste Schrei im Hinblick auf Mehrfarbdruck sind 3D-Drucker mit mehreren Köpfen, die bei Bedarf durchgewechselt werden. Beispiel dafür ist der kürzlich von uns getestete Snapmaker U1 (Testbericht). Er hat einen beweglichen Kopf, aber vier Einheiten aus Hot-End und Extruder, die er bei Bedarf mit dem Kopf verbindet. So entfällt der Spülvorgang, da die verschiedenen Farben jeweils direkt einsatzbereit sind. Für echten Mehrfarbdruck im großen Stil ist das die optimale Drucktechnik, weil sie schneller arbeitet und fast kein Material verschwendet.

Auch von Bambu Lab gibt es mit dem H2C (Testbericht) einen Drucker, der auf dieses Prinzip setzt. Für andere Drucker, etwa von Prusa, kommt demnächst mit dem Bondtech Index eine Nachrüstlösung auf den Markt.
Fazit
Die entscheidende Frage ist: Wie viel Mehrfarbdruck wird man in der Praxis wirklich machen? Ein guter Drucker mit Materialwechsler ist eine tolle Option für die meisten Fälle. Je häufiger man diese Technik einsetzt, umso eher fallen aber die Haken ins Gewicht – die lange Druckzeit und die Materialverschwendung.
Ein guter Kompromiss sind Dual-Nozzle-Drucker wie der Bambu H2D, der übrigens zusätzlich zu seiner zweiten Düse auch noch mit einem Materialwechselsystem verbunden werden kann. Und wer wirklich viel farbig druckt, sollte sich aktuell den Snapmaker U1 ansehen, den wir im Test als den derzeit besten Mehrfarbdrucker bezeichnet haben.

Nachhaltige Baustoffe: Mit einem Pilz veredeltes Holz sieht aus wie Marmor

Shu On Kwok

Expertenforderung: OpenDesk sollte für Unis gratis sein

Kommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac

Schnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt

Huawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-
 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-
 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-
 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenFast 5 GB pro mm²: Sandisk und Kioxia kommen mit höchster Bitdichte zum ISSCC
-

 Social Mediavor 3 Tagen
Social Mediavor 3 TagenCommunity Management zwischen Reichweite und Verantwortung
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights