Entwicklung & Code
Warum viele Teams mit Monolithen besser fahren als mit Micro-Frontends
Softwarearchitektur kennt Moden und Gegenbewegungen. Frontends in winzige unabhängige Teile zu zerschneiden, galt in den letzten Jahren als modern: Micro-Frontends und Microservices. Heute zeigt sich: Der Ansatz bleibt wertvoll. Aber nur dort, wo er die organisatorische Realität tatsächlich abbildet. Für viele kleine bis mittlere Teams ist ein modularer Monolith oft die robustere Startarchitektur.


Nicolai Wolko ist Softwarearchitekt, Consultant und Mitgründer der WBK Consulting AG. Er unterstützt Unternehmen bei komplexen Web- und Cloudprojekten und wirkt als Sparringspartner sowie Gutachter für CTOs. Fachbeiträge zur modernen Softwarearchitektur veröffentlicht er regelmäßig in Fachmedien und auf seinem Blog.
State of Frontend
Die internationale Umfrage State of Frontend des Unternehmens The Software House zeigt eine klare Bewegung: 2022 gaben 75,4 Prozent der Befragten an, Micro‑Frontends zu nutzen. 2024 waren es nur noch 23,6 Prozent. Das klingt auf den ersten Blick dramatisch, ist aber kein Tod der Idee. Der Rückgang zeigt, dass viele Teams Micro-Frontends nicht mehr als Standardlösung betrachten, sondern selektiv dort einsetzen, wo organisatorische oder architektonische Gründe es rechtfertigen. Denn parallel dazu steigt die Popularität von Module Federation, und zwar nicht nur für Micro‑Frontends: 2024 berichten 51,8 Prozent die Nutzung, oft auch in monolithischen Anwendungen, um Teile unabhängig zu aktualisieren. Das stützt die These einer Konsolidierung auf weniger Deployment-Einheiten bei weiterhin modularer Struktur.
Bemerkenswert ist, dass auch KI Microservices favorisiert: Fragt man ChatGPT ohne Kontext nach Architekturmustern, empfiehlt es fast immer Microservices und oft auch Micro-Frontends. Das ist kein Indiz für universelle Richtigkeit, sondern für den Hype-Bias in den Trainingsdaten. Ohne fachliche Einordnung bleibt es eine Wahrscheinlichkeitsaussage und ersetzt nicht die Analyse eines erfahrenen Architekten oder einer erfahrenen Architektin.
Warum der Micro-Frontend-Hype abkühlt
Micro-Frontends entstanden als Analogie zu Microservices und erfreuen sich nicht ohne Grund großer Beliebtheit. Die Idee besteht darin, schwerfällige SPAs oder Webportale in kleine, autonome Apps aufzuteilen. Jedes Team kann sein Stück mit dem Lieblingsframework entwickeln und unabhängig deployen. Das reduziert den Koordinationsaufwand, vermeidet monolithische Rebuilds und erlaubt, Teile des Frontends asynchron zu laden.
In der Praxis führt diese Freiheit jedoch auch oft zu neuen Problemen: Mehrere Frameworks oder UI-Bibliotheken erhöhen die Downloadgröße und verlängern die Time to Interactive, globale Stores oder Shells schaffen den berüchtigten Hidden Monolith oder verteilten Monolithen, in dem Micro-Apps weiterhin denselben Zustand teilen, und zusätzliche Deployments erzeugen Overhead bei CI/CD, Feature Flags und Versionierung.
Micro‑Frontends eignen sich, wenn wirklich unabhängige Teams und heterogene Stacks aufeinandertreffen, etwa bei Tech‑Riesen wie Amazon oder Spotify. In sehr vielen Projekten erzeugt die zusätzliche Orchestrierung jedoch mehr Probleme, als sie löst und sorgt schnell für komplexe Builds und längere Ladezeiten. Gerade bei kleineren Teams und klar abgegrenzten Produkten übersteigt der Aufwand den Nutzen, und die erhoffte Entkopplung bleibt aus. Oft entsteht faktisch ein verteilter Monolith mit zahlreichen Teilprojekten, die doch nur gemeinsam leben können. Eine fatale Entwicklung, denn der verteilte Monolith vereint oft die schlechtesten Eigenschaften beider Welten in sich.
Monolith vs. Microservices vs. Serverless
Die Debatte über Monolithen und Microservices krankt oft daran, dass Begriffe nicht klar sind. Ein Beitrag auf dem Dev-Details-Blog erläutert anschaulich, dass die Einordnung nicht von der Anzahl der Repositories, Container oder Teams abhängt:
- Ein Monolith entsteht, wenn mehrere Teile so eng gekoppelt sind, dass sie nur gemeinsam deployt werden können.
- Microservices wiederum zeichnen sich durch lose Kopplung und hohe Kohäsion aus. Sie können Daten und Ressourcen mit anderen Diensten teilen, solange jede Komponente ihre eigene Verantwortung behält.
- Serverless bedeutet nur, dass die Infrastrukturverwaltung abstrahiert wird. Es ist kein Synonym für Function as a Service. Entscheidend ist, dass sich die Teams nicht um Server kümmern müssen und nur für tatsächliche Nutzung bezahlen.
Diese Perspektive hilft, Modebegriffe zu entmystifizieren. Man kann monolithische, Microservices‑basierte oder Serverless-Architekturen mischen – entscheidend ist, wie stark die Komponenten voneinander abhängen. Wenn mehrere Services stets gemeinsam deployt werden müssen, entsteht faktisch wieder ein „verteilter Monolith“.
Das Fallbeispiel Amazon Prime Video
Oft zitiert wird das Team hinter Amazon Prime Video, wie auch bereits auf heise berichtet. Es hat 2023 die Audio/Video-Monitoring-Komponente von einem Step-Functions-getriebenen verteilten Design auf ein monolithisches Prozessdesign umgestellt, was zu über 90 Prozent geringeren Kosten und höherer Skalierbarkeit für diese Komponente führte.
Das ist keine Abkehr von Microservices im gesamten Produkt, aber eine klare kontextspezifische Optimierung: weniger Netzwerk-Hops, wegfallender S3-Zwischenspeicher und weniger Orchestrierungs-Overhead.
Ein hervorragendes Beispiel dafür, dass Architektur keinem Etikett folgen sollte, sondern in diesem Fall dem Lastprofil und Coupling. Microservices und Serverless sind Werkzeuge, die bei passender Problemklasse hervorragend funktionieren; andernfalls ist ein enger gekoppelter Entwurf aber günstiger und einfacher zu betreiben.
Einfachheit schlägt Cleverness: Lehren aus Code‑Audits
Praktische Erfahrungen bestätigen diese Sicht: Ken Kantzer, VP Engineering bei FiscalNote und Gründer der Sicherheits- und Architekturberatung PKC Security, hat in über zwanzig Code-Audits von Start-ups wiederkehrende Muster identifiziert. Sein Befund: Die erfolgreichsten Unternehmen hielten ihre Architektur bewusst einfach. Teams, die konsequent nach dem Prinzip „Keep it simple“ arbeiteten, dominierten später ihre Märkte.
Demgegenüber verschwanden viele Firmen, die sich früh in komplexe Architekturexperimente stürzten. Kantzer hält die vorzeitige Umstellung auf Microservices, stark verteilte Systeme und Messaging-lastige Designs für eine eine selbst verschuldete Falle, die Teams in unnötige Betriebs- und Entwicklungsprobleme manövriert. In seinen Audits zeigte sich, dass solche Systeme einen Großteil der Entwicklerzeit mit Queue-Fehlern, Versionsinkompatibilitäten und Netzwerk-Latenzen blockierten, während die eigentliche Produktentwicklung ins Stocken geriet.
Die Lehre: Komplexität ist keine Investition in Zukunftsfähigkeit, wenn sie dem Kontext vorauseilt – sie ist ein Kostenfaktor, der den Markterfolg gefährden kann.
Modularer Monolith: Bewährtes Konzept mit Renaissance
Der modulare Monolith oder auch Modulith vereint die Vorteile von Monolith und Microservices: Die Anwendung wird in klar abgegrenzte Module unterteilt, die sich intern unabhängig entwickeln, testen und versionieren lassen, aber gemeinsam deployed werden. Thoughtworks beschreibt ihn als „best of both worlds“: Es gibt weniger bewegliche Teile, einfache Deployments und geringere Infrastrukturkosten, während eine klare Aufteilung in Module dennoch möglich ist. Durch die gemeinsame Deployment-Einheit entfallen Gateways, Service Discovery und verteiltes Logging. Das verbessert die Performance, da Module über Funktionsaufrufe statt über das Netzwerk kommunizieren und das System bei Ausfall eines Moduls nicht sofort fragmentiert. Gleichzeitig lassen sich klare Teamgrenzen und Domänen definieren, sodass Entwickler ein Modul später relativ leicht ausgliedern können.
Eine praktische Entscheidungshilfe in Tabellenform stellen die Architekturexperten hinter der Toolsuite Ptidej zur Verfügung. Microservices bieten Vorteile, wenn autonome Teams mit eigenen Releasezyklen an unterschiedlichen Teilen eines großen Systems arbeiten, wenn einzelne Komponenten sehr unterschiedlich skalieren oder wenn verschiedene Technologien notwendig sind. Ein Monolith hingegen genügt, wenn das Team überschaubar ist, die Domäne klar umrissen und die Skalierungsanforderungen homogen sind. Wichtig ist, dass das System modular bleibt, damit es sich bei Bedarf später in Microservices zerlegen lässt.
Der modulare Monolith bietet somit einen pragmatischen Mittelweg: Er teilt eine Anwendung in klar abgegrenzte Module, deployt sie aber gemeinsam. Im Python/Django-Umfeld ist das Prinzip seit Jahren gelebte Praxis („Apps“ als Modulgrenzen), auch wenn es dort nicht Modulith heißt.
Thoughtworks empfiehlt, mit einem solchen Monolithen zu starten und erst nach gründlichem Verständnis der Geschäftsprozesse einzelne Module auszulagern. Die Vorteile sind klar: einfache Deployments, gute Performance, niedrigere Betriebskosten und weniger Latenz.
Monorepos: Modularisieren ohne Zerreißen
Moderne Monorepo‑Werkzeuge senken die Reibung größerer Codebasen: Nx etwa bietet Computation Caching (lokal und remote) und „Affected“‑Mechaniken, sodass bei Änderungen nur die betroffenen Projekte gebaut und getestet werden. Das senkt Build‑ und CI‑Zeiten drastisch und macht ein Repo mit vielen Modulen praktikabel.
Interessant ist, dass Nx explizit dokumentiert, dass Micro‑Frontends vor allem dann empfehlenswert sind, wenn unabhängiges Deployment wirklich notwendig ist. Andernfalls lassen sich dieselben Build‑Effekte zunehmend auch ohne Micro-Frontend‑Architektur erzielen (etwa Module Federation nur zur Build‑Beschleunigung).
Entscheidungsrahmen: Architektur vom Kopplungsgrad ableiten
Aus Daten, Praxisberichten und Werkzeugtrends lassen sich pragmatische Leitlinien ableiten:
- Für die meisten kleinen bis mittleren Teams ist ein modularer Monolith der schnellste Weg zu Features und Feedback. Er reduziert Kosten, minimiert Betriebsrisiken und bleibt evaluierbar.
- Wenn Komponenten immer gemeinsam deployt werden müssen, ist die Anwendung monolithisch – unabhängig davon, auf wie viele Container oder Repos sie verteilt ist. Umgekehrt sind Microservices erst dann sinnvoll, wenn Deployments wirklich unabhängig sind.
- Verteilte Systeme erkauft man sich mit Betriebskosten: Observability, Versionierung, Backward Compatibility, Netzwerklatenz, CAP‑Trade‑offs (Abwägungen zwischen Konsistenz, Verfügbarkeit und Partitionstoleranz). Wer diese Reife nicht hat oder nicht braucht, verliert Zeit und Fokus aufs Produkt. Genau das zeigen Code‑Audits aus der Start‑up‑Praxis.
- Was in einem Konzern mit Dutzenden Teams sinnvoll ist, ist für ein Team mit zehn Leuten häufig Overkill. Architektur folgt Teamschnitt und Geschäftsprozess, nicht dem Blog‑Hype. Der Artikel auf Heise hat das am Prime‑Video‑Beispiel sorgfältig eingeordnet (Stichwort Modulith).
- Werden einzelne Module zu Engpässen (abweichender Release‑Rhythmus, stark abweichende Last, anderes Team), lassen sie sich sauber herauslösen. Ohne vorzeitige Zersplitterung bleibt die Komplexität beherrschbar.












Entwicklung & Code
Kafka in Blau: IBM kauft Confluent
Für rund elf Milliarden US-Dollar will IBM Confluent kaufen. Big Blue bietet den Aktionären des kalifornischen Anbieters einer Data Streaming-Plattform je 31 Dollar pro Papier – ein Aufschlag von deutlich über dreißig Prozent zum Kurs vor Bekanntgabe der anstehenden Übernahme. Die größten Aktionäre und Investoren von Confluent, die zusammen etwa 62 Prozent der Stimmrechte ausgegebener Stammaktien halten, haben dem Deal bereits zugestimmt. Vorbehaltlich der üblichen Abschlussbedingungen rechnet das Management beider Firmen, den Kauf bis Mitte 2026 abzuschließen.
Weiterlesen nach der Anzeige
Umsatzrekord bei Confluent erwartet
Confluent, vor elf Jahren im kalifornischen Mountain View gegründet und seit 2021 an der Nasdaq gelistet, wird im Geschäftsjahr 2025 voraussichtlich erstmals die Umsatzmarke von einer Milliarde Dollar knacken. Die gleichnamige Software basiert auf der Open-Source-Daten- und Event-Streaming-Plattform Apache Kafka, die heute mehr oder minder als Standard auf diesem Gebiet gilt. Der Confluent-Funktionsumfang spannt sich über Daten-Streaming, Connectors, Stream Governance, Stream-Verarbeitung, Tableflow, Confluent Intelligence und Streaming-Agenten. Die Software wird als Cloud-Dienst, aber auch zum Einsatz auf on Premises oder hybriden Infrastrukturen vermarktet.
Für IBM stellt Confluent nach Red Hat und Hashicorp die dritte große Akquise im Open-Source-Segment dar. Stoßrichtung ist – natürlich – Künstliche Intelligenz. Im konkreten Fall dreht es sich zuvorderst um die Versorgung generativer und agentischer KI mit den über öffentliche und private Clouds, Rechenzentren und unzählige Technologieanbieter verteilten Daten. Die Echtzeit-Daten- und Event-Streaming-Funktionen von Confluent in Kombination mit KI-Infrastruktursoftware und Automatisierungsangeboten von Hashicorp und in Teilen Red Hat sollen IBMs Angebot vervollständigen. Die Einbindung der Streaming-Plattform in das Portfolio des neuen Eigners soll zudem zu Synergien von rund 500 Millionen Dollar bei den Betriebskosten führen. IBM rechnet mit der Steigerung des bereinigten Betriebsgewinns vor Zinsen, Steuern, und Abschreibungen (EBITDA) im ersten vollen Geschäftsjahr nach Abschluss der Transaktion.
(fo)
Entwicklung & Code
Wendet man DDD auf DDD an, bleibt kein Domain-Driven Design übrig
Domain-Driven Design (DDD) verspricht bessere Software durch Fokus auf die Fachdomäne und ein gemeinsames Verständnis zwischen Developern und Fachleuten. Das ist die Essenz, verdichtet auf einen Satz. Aber wenn Sie dieses Prinzip tatsächlich auf DDD selbst anwenden (also fragen, was die Domäne ist, was wichtig ist, was man weglassen kann, …), dann landen Sie nicht bei dem, was wir heute „DDD“ nennen. Sie landen bei etwas viel Einfacherem.
Weiterlesen nach der Anzeige

Golo Roden ist Gründer und CTO von the native web GmbH. Er beschäftigt sich mit der Konzeption und Entwicklung von Web- und Cloud-Anwendungen sowie -APIs, mit einem Schwerpunkt auf Event-getriebenen und Service-basierten verteilten Architekturen. Sein Leitsatz lautet, dass Softwareentwicklung kein Selbstzweck ist, sondern immer einer zugrundeliegenden Fachlichkeit folgen muss.
Warum also hat DDD nach mehr als zwei Jahrzehnten nie seine Nische verlassen? Warum fühlen sich so viele Entwicklerinnen und Entwickler davon überfordert, verwirrt, oder glauben, sie seien nicht schlau genug dafür? Die Antwort ist unbequem, aber klar: DDD scheitert an seinem eigenen Anspruch.
Das Problem: DDD schreckt Menschen ab
DDD gibt es seit 2003. Das Buch „Domain-Driven Design: Tackling Complexity in the Heart of Software“ von Eric Evans gilt als Klassiker, und die darin enthaltenen Ideen sind mächtig. Trotzdem bleibt DDD auf eine relativ kleine Gemeinschaft beschränkt. Es ist nicht Mainstream geworden. Es hat nicht revolutioniert, wie die meisten Teams Software bauen. Und ein wesentlicher Grund dafür ist: Wir verlieren die Leute, bevor sie überhaupt die Kernidee verstanden haben.
Statt Entwicklerinnen und Entwickler dort abzuholen, wo sie stehen, erschlagen wir sie mit einer Unmenge an Theorie: Aggregates, Bounded-Contexts, Value Objects, Entities, Repositories, Anti-Corruption Layers, Ubiquitous Language, Strategic Design, Tactical Design und so weiter. Allein die Terminologie ist einschüchternd. Die Konzepte sind abstrakt. Die Beispiele bleiben oft akademisch. Und wenn jemand sich durch all das durchgearbeitet hat, ist er entweder erschöpft oder überzeugt davon, dass DDD nur etwas für Enterprise-Architektinnen und -Architekten mit jahrzehntelanger Erfahrung ist.
Das ist kein Zufall. DDD wurde akademisiert. Es wurde zu einem Framework gemacht, einer Methodik, einem Zertifizierungspfad. Es wurde in Jargon gehüllt und unter Schichten von Pattern-Katalogen begraben. Was als einfache, menschenzentrierte Idee begann („verstehe die Domäne und sprich die Sprache des Business“) ist zu etwas geworden, das sich für die meisten unerreichbar anfühlt.
Und das ist das Paradox: DDD soll Softwareentwicklung erleichtern und besser an der Realität ausrichten. Aber die Art, wie wir es lehren, wie wir darüber sprechen, wie wir es praktizieren: All das macht es schwieriger.
Weiterlesen nach der Anzeige
Intention vs. Implementierung: Eine bekannte Geschichte
Das ist kein neues Problem. Dasselbe ist mit den Design-Pattern der „Gang of Four“ passiert.
Nehmen Sie beispielsweise das Singleton-Pattern. Die Intention ist einfach: Man will sicherstellen, dass eine Klasse genau eine Instanz hat. Das ist alles. Das ist das Problem, das das Pattern löst. Aber was haben die meisten Entwicklerinnen und Entwickler gelernt? Die Implementierung: einen privaten Konstruktor und eine statische getInstance()-Methode. Sie haben den Code auswendig gelernt. Sie haben ihn mechanisch angewendet. Und (zu) viele von ihnen haben nie verstanden, dass die Implementierung nur ein Weg ist, die Intention zu erreichen. Die Implementierung wurde zum Pattern selbst.
Dasselbe ist mit DDD passiert. Die Intention ist klar: Man will bessere Software bauen, indem man sich auf die Fachdomäne konzentriert und eine gemeinsame Sprache mit Fachleuten entwickelt. Aber was lernen Entwicklerinnen und Entwickler? Sie lernen die Implementierung: eine lange Liste von Pattern und (technischen) Konzepten. Und genau wie beim Singleton glauben viele, dass das Anwenden dieser Pattern DDD ist. Sie behandeln es wie eine Checkliste.
„Haben wir Aggregates? Check. Haben wir Value Objects? Check. Haben wir Bounded Contexts? Check.“
Aber das ist nicht DDD. Das ist Pattern-Theater. Es ist Form ohne Substanz. Es ist wie Daily Stand-ups, Sprints und Retrospektiven abzuhalten und sich agil zu nennen, obwohl sich an der Kultur, Kommunikation oder Entscheidungsfindung des Teams nichts geändert hat. Man führt die Rituale durch, aber man verfehlt den Punkt.
Die große Flucht: Sich hinter Pattern verstecken
Hier ist die unbequeme Wahrheit: DDD ist im Kern nicht technisch. Was es wirklich von Ihnen verlangt, ist Folgendes: Verlassen Sie Ihre Komfortzone. Sprechen Sie mit Fachexpertinnen und Fachexperten. Nicht nur, um Anforderungen zu sammeln, sondern um ihre Welt wirklich zu verstehen. Hören Sie zu. Stellen Sie Fragen. Halten Sie Unsicherheit aus. Geben Sie zu, wenn Sie etwas nicht verstehen. Entwickeln Sie eine gemeinsame Sprache, iterativ und kollaborativ – und damit vor allem auch ein gemeinsames Verständnis.
Das ist harte Arbeit. Es ist Arbeit mit Menschen. Es ist unbequeme Arbeit. Sie erfordert Demut, Geduld und Kommunikationsfähigkeiten, in denen viele Entwicklerinnen und Entwickler, mich eingeschlossen, nicht ausgebildet wurden. Es ist viel einfacher, im technischen Bereich zu bleiben, wo Dinge vorhersagbar und kontrollierbar sind.
Und hier ist die Falle: Die Pattern bieten Ihnen ein perfektes Versteck.
Statt mit Menschen zu reden, können Sie darüber diskutieren, ob etwas ein Aggregate oder eine Entity sein sollte. Statt die Domäne zu verstehen, können Sie Bounded-Context-Diagramme zeichnen. Statt Fachexpertinnen und Fachexperten zu fragen „Wie nennt ihr das?“, können Sie Ihre Kolleginnen und Kollegen fragen „Ist das ein Value Object?“. Sie fühlen sich produktiv. Sie schaffen Struktur, zeichnen Diagramme, wenden Pattern an. Aber die eigentliche Arbeit, die harte, menschliche, domänenfokussierte Arbeit, wird beiseitegeschoben.
Deshalb sehen so viele DDD-Projekte technisch ausgereift aus, fühlen sich aber vom Business abgekoppelt an. Der Code ist voll von den richtigen Pattern, aber er spricht nicht die Sprache der Domäne. Die Architektur ist sauber, aber die Entwicklerinnen und Entwickler verstehen immer noch nicht wirklich, was die Software tun soll oder warum.
„Ich bin zu dumm für DDD“
Leider hat das einen sehr traurigen, oft persönlichen Grund. Denn das Gefühl, das die Beschäftigung mit DDD bei vielen hinterlässt, ist Unsicherheit. Ich selbst dachte jahrelang, ich sei zu dumm für DDD, weil ich nicht das Gefühl hatte, es wirklich verstanden zu haben. Natürlich habe ich das Blue Book gelesen. Ich habe mir Vorträge angeschaut. Und das große Ganze ergab durchaus Sinn: Fokussiere dich auf die Domäne, baue ein gemeinsames Verständnis auf! Aber bei den Details verlor ich mich. Aggregates, Bounded Contexts, Anti-Corruption Layers. Ich verstand sie in der Theorie, aber ich fühlte mich nie sicher, sie anzuwenden. Ich dachte, alle anderen „kapieren“ es einfach, und ich nicht.
Dann wurde mir klar: Das Problem war nicht ich. Das Problem war die Art, wie DDD gelehrt wird.
DDD wurde unnötig verkompliziert. Es wurde in akademische Sprache gekleidet, unter Abstraktionsschichten begraben und so präsentiert, als bräuchte man einen Doktor in Softwarearchitektur, um es zu verstehen. Aber das ist nicht, was DDD ist. DDD ist nicht kompliziert. Wir haben es kompliziert gemacht.
Wenn Sie sich jemals genauso gefühlt haben, wenn Sie jemals dachten, Sie seien nicht schlau genug für DDD, oder dass es nur für bestimmte Arten von Projekten sei, oder dass es einfach zu abstrakt sei, um nützlich zu sein, dann kann ich Ihnen versichern: Sie sind nicht allein. Und Sie sind nicht das Problem.
Worum es bei DDD wirklich geht
Streifen wir die Komplexität ab und kommen zur Essenz. Hier ist DDD in einem Satz:
Bauen Sie bessere Software, indem Sie die Fachdomäne verstehen und eine gemeinsame Sprache mit den Menschen sprechen, die darin arbeiten.
Das ist alles. Alles andere – all die Pattern, all die Diagramme, all die Terminologie – ist sekundär. Die Pattern sind Werkzeuge. Sie können Ihnen helfen, die Domäne klarer im Code auszudrücken. Aber sie sind nicht das Ziel. Das Ziel ist Verstehen.
Wie sieht das also in der Praxis aus?
Erstens: Reden Sie mit Menschen, nicht mit Diagrammen. Die wichtigste Frage, die Sie stellen können, ist nicht „Ist das eine Entity oder ein Value Object?“, sondern sie lautet „Wie nennt ihr das?“. Verbringen Sie Zeit mit Fachexpertinnen und Fachexperten. Hören Sie zu, wie sie ihre Arbeit beschreiben. Achten Sie auf die Wörter, die sie benutzen, die Unterscheidungen, die sie machen, die Dinge, die ihnen wichtig sind. Daher kommt die gemeinsame Sprache. Nicht aus UML-Diagrammen, sondern aus echten Gesprächen.
Zweitens: Benutzen Sie die Sprache der Domäne, nicht die Sprache der Technik. Wenn die Fachleute von Kundinnen und Kunden, Gästen und Benutzerinnen und Benutzern als drei verschiedenen Konzepten sprechen, dann sollte Ihr Code das widerspiegeln. Fassen Sie sie nicht alle in einer einzigen User-Klasse zusammen, nur weil es einfacher ist. Nennen Sie etwas nicht UserEntity, wenn das Business es Customer nennt. Die Präzision der Sprache ist wichtig. Das ist nicht pedantisch, es ist vielmehr der Kern von DDD.
Drittens: Benennen Sie Dinge exakt. Ist es „stornieren“ oder „erstatten“? Ist es eine „Rechnung“ oder ein „Beleg“? Ist es „zurückgeben“ oder „widerrufen“? Das sind keine trivialen Unterscheidungen. Sie repräsentieren verschiedene Geschäftsprozesse, verschiedene Regeln, verschiedene Bedeutungen. Wenn Sie die Namen falsch wählen, haben Sie bereits die Ausrichtung mit der Domäne verloren.
Viertens: Weg von CRUD. Create, Read, Update, Delete – das sind technische Operationen, keine Geschäftsprozesse. Sie erfassen nicht, was tatsächlich in der Domäne passiert. Denken Sie stattdessen in Verben, die aus dem Business kommen: confirmOrder(), cancelOrder(), changeDeliveryAddress(). Diese Namen sagen Ihnen, was das System tut und warum.
Schließlich: Pattern sind Werkzeuge, keine Ziele. Wenn Ihnen ein Aggregate-Pattern hilft, ein Geschäftskonzept klarer auszudrücken, benutzen Sie es. Wenn nicht, lassen Sie es weg. Lassen Sie die Domäne Ihre Struktur leiten, nicht Pattern-Kataloge. Die Pattern existieren, um der Domäne zu dienen, nicht umgekehrt.
Warum sich Event Sourcing natürlich anfühlt
Tatsächlich gibt es etwas, das mir über die Jahre aufgefallen ist, was enorm helfen kann: Menschen verstehen Events intuitiv.
Events sind, wie wir natürlich über die Welt denken. Wir erzählen Geschichten als Abfolge von Dingen, die passiert sind. Wir beschreiben unseren Tag in Events: Ich bin aufgewacht, ich habe gefrühstückt, ich bin zur Arbeit gefahren, ich war in einem Meeting. Wenn wir Geschichte erzählen, sprechen wir über Events: Die Mauer fiel, der Vertrag wurde unterzeichnet, die Entdeckung wurde gemacht. Das ist keine technische Abstraktion. Es ist, wie Menschen Informationen verarbeiten und kommunizieren.
Stellen Sie sich vor, Sie erzählen die Geschichte von Rotkäppchen. Sie würden es nicht so machen:
UPDATE Rotkäppchen SET ort = 'Wald' UPDATE Wolf SET ort = 'Wald' UPDATE Rotkäppchen SET emotion = 'verängstigt' DELETE Großmutter UPDATE Wolf SET verkleidung = 'Großmutter'
Das ist absurd. Es streift alle Bedeutung ab, alle Kausalität, alle Erzählung. Sie würden es als Abfolge von Events erzählen:
RotkäppchenBetratDenWald RotkäppchenTrafDenWolf WolfGingZumHausDerGroßmutter WolfVerschlangDieGroßmutter WolfVerkleideteSichAlsGroßmutter
So funktionieren Geschichten. So verstehen wir, was passiert ist und warum. Und genau so funktioniert Event Sourcing.
Event Sourcing fragt nicht „Was ist der aktuelle Zustand?“, sondern „Was ist passiert?“. Es speichert ein chronologisches Protokoll von Fakten und Geschehnissen in der Vergangenheit, unveränderlich und unbestreitbar. Und aus diesem Protokoll können Sie den aktuellen Zustand rekonstruieren, die Historie abspielen, Kausalität verstehen und ein vollständiges Bild davon aufbauen, was zu dem geführt hat, wo Sie jetzt sind.
Event Sourcing als leichtgewichtiger Weg zu DDD
Event Sourcing ist nicht nur eine Art, Daten zu speichern. Es ist auch ein überraschend effektiver, leichtgewichtiger Einstieg in die Welt von DDD, weil es Sie natürlich in die richtige Richtung schiebt.
Erstens zwingt es Sie, in Verben zu denken, nicht in CRUD. Events haben Namen wie OrderPlaced, PaymentReceived oder ItemShipped. Nicht createOrder, updatePayment oder deleteItem. Sie können nicht auf generische CRUD-Operationen zurückfallen. Sie müssen beschreiben, was tatsächlich im Business passiert ist. Das bringt Sie sofort näher an die Domänensprache.
Zweitens: Events nach Subjekten zu organisieren, ist die halbe Aggregate-Diskussion. Welche Events gehören zusammen? Alle Events für eine bestimmte Bestellung landen unter /orders/42. Alle Events für eine bestimmte Kundin oder einen bestimmten Kunden vielleicht unter /customers/23. Oder Sie strukturieren es anders: /customers/23/orders/42. Die Art, wie Sie Events gruppieren, spiegelt die Struktur der Domäne wider. Sie machen die Arbeit, Aggregates zu definieren, aber Sie machen es konkret, indem Sie entscheiden, welche Events zusammengehören, nicht indem Sie abstrakte Konzepte debattieren.
Drittens: Zu entscheiden, welcher Service welche Events verarbeitet, ist die Bounded-Context-Diskussion. Soll der Order-Service PaymentReceived verarbeiten, oder sollte das der Billing-Service sein? Was gehört zu Inventory versus Fulfillment? Das sind Bounded-Context-Fragen. Aber Sie zeichnen keine Diagramme. Sie treffen konkrete Entscheidungen darüber, welcher Teil Ihres Systems für welche Events verantwortlich ist. Die Domäne entsteht natürlich aus diesen Entscheidungen.
Schließlich: Events sind selbsterklärend. Sie müssen keine Aggregates, Entities oder Value Objects verstehen, um zu wissen, was CustomerRegistered bedeutet. Sie brauchen keinen Abschluss in DDD, um herauszufinden, was BookBorrowed darstellt. Events sprechen die Sprache des Business. Sie sind zugänglich. Sie sind konkret. Sie sind sofort verständlich.
Schauen wir uns ein einfaches Beispiel aus einem Bibliothekssystem an. Statt darüber nachzudenken, ob ein Buch eine Entity oder ein Aggregate ist, fragen Sie zunächst: Was kann mit einem Buch passieren?
BookAcquired: Die Bibliothek bekommt ein neues Buch.BookBorrowed: Jemand leiht es aus.BookReturned: Es wird zurückgebracht.LateFeeCharged: Es wurde zu spät zurückgebracht und daher eine Strafe berechnet.BookRemoved: Die Bibliothek sortiert es aus.
Diese Events erzählen die Geschichte. Sie erfassen den Geschäftsprozess. Und wenn Sie sie nach Subjekt organisieren, sagen wir /books/42 für Buch Nummer 42, haben Sie gerade definiert, was in DDD-Begriffen ein Aggregate genannt würde. Sie haben die Theorie nicht gebraucht. Sie haben einfach gefragt: Was passiert, und was gehört zusammen?
Ein Plädoyer für pragmatisches DDD
Vielleicht brauchen wir nicht mehr DDD. Vielleicht brauchen wir pragmatischeres DDD.
Streifen Sie die akademische Sprache ab! Hören Sie auf, Pattern als Ziel zu behandeln! Hören Sie auf, Menschen mit Theorie zu überwältigen, bevor sie auch nur eine Zeile Code geschrieben haben! Kommen Sie zurück zur Essenz: Fokussieren Sie sich auf die Domäne, sprechen Sie die Sprache des Business, bauen Sie ein gemeinsames Verständnis auf!
Wenn Sie DDD lernen wollen, fangen Sie hier an:
- Vergessen Sie die Pattern zunächst. Lernen Sie, gute Gespräche mit Fachexpertinnen und Fachexperten zu führen.
- Lernen Sie, aufmerksam zuzuhören, die richtigen Fragen zu stellen und Unsicherheit auszuhalten.
- Lernen Sie, in Events zu denken: Was ist passiert, und warum?
- Lassen Sie die Domäne Ihren Code leiten, nicht umgekehrt.
Wenn Sie DDD bereits praktizieren, fragen Sie sich ehrlich:
- Verstecke ich mich hinter Pattern, statt die schwierige Arbeit auf mich zu nehmen, die Domäne zu verstehen?
- Wie viel Zeit verbringe ich mit Fachexpertinnen und Fachexperten im Vergleich dazu, wie viel Zeit ich mit dem Zeichnen von Diagrammen verbringe?
- Spricht mein Code die Sprache des Business, oder spricht er die Sprache der Technik?
- Benutze ich CRUD, oder benutze ich Events und Domänen-Verben?
DDD war nie dazu gedacht, kompliziert zu sein. Wir haben es kompliziert gemacht. Wenn wir DDD ernst nehmen, wenn wir seine eigenen Prinzipien auf DDD selbst anwenden, dann müssen wir zugeben: Wir sind vom Kern abgedriftet. Wir haben Abstraktionsschichten gebaut, die die darunter liegende Einfachheit verdecken.
Event Sourcing kann helfen. Es ist konkret. Es ist intuitiv. Es passt natürlich dazu, wie Menschen denken. Und es schiebt Sie, fast mühelos, zu den Praktiken, um die es bei DDD schon immer ging: verstehen, was passiert ist, es präzise benennen und die Sprache der Domäne sprechen.
Wenn Sie Event Sourcing interessiert und Sie sehen wollen, wie es Sie zu besserer Domänenmodellierung führen kann, ohne den Overhead, fangen Sie mit einer Einführung in Event Sourcing an. Vielleicht stellen Sie fest, dass der Weg zu DDD einfacher ist, als Sie dachten.
(rme)
Entwicklung & Code
Babelfisch für Softwarearchitekten – Kommunikation mit den Stakeholdern
In der praktischen Arbeit müssen Softwarearchitektinnen und -architekten mit Personen in vielen unterschiedlichen Positionen und Rollen zusammenarbeiten. Dabei agieren sie überwiegend ohne Macht, sie müssen also kommunikativ eher mit Motivation arbeiten statt mit der Autorität einer Führungsposition. Abbildung 1 zeigt eine Auswahl der wichtigsten Kommunikationspartner.
Weiterlesen nach der Anzeige

Prof. Dr. Michael Stal arbeitet seit 1991 bei Siemens Technology. Seine Forschungsschwerpunkte umfassen Softwarearchitekturen für große komplexe Systeme (Verteilte Systeme, Cloud Computing, IIoT), Eingebettte Systeme und Künstliche Intelligenz.
Er berät Geschäftsbereiche in Softwarearchitekturfragen und ist für die Architekturausbildung der Senior-Software-Architekten bei Siemens verantwortlich.
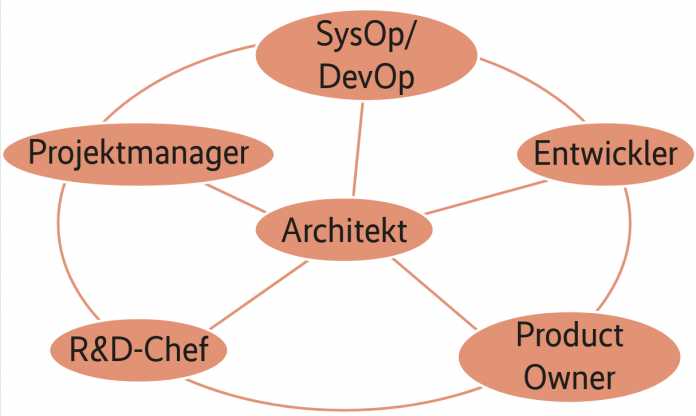
Softwarearchitekten kommunizieren in ihrer Tätigkeit mit unterschiedlichsten Rollen und Personen (Abb. 1).
Natürlich sollten Softwarearchitekten darauf achten, keinen Tod durch Meetings zu erleiden. Diese sollten sich auf das notwendige Minimum beschränken, denn Überkommunikation ist genauso kontraproduktiv wie Unterkommunikation. Das Wasserfallmodell tendiert anfangs oft zu Unterkommunikation, aber in späteren Phasen, bisweilen auch Panikmodus genannt, zu Überkommunikation. In agilen Umgebungen verteilen sich im Idealfall die Kommunikationsaufwände gleichmäßig über die Projektlaufzeit.
Architektur als Kommunikationsmittel
Die Softwarearchitektur dient als verpflichtende Guideline zur Umsetzung des Problems, sprich der Anforderungen. Daher ist deren Kommunikation nicht nur für Entwickler essenziell. Für die Kommunikation empfehlen sich folgende Mittel:
Die Architekturdokumentation darf nicht nur das Was und das Wie berücksichtigen, sondern muss auch das Warum der getroffenen Architekturentscheidungen abdecken. Manchen Architekturdokumenten ist anzusehen, dass die Architekten unmotiviert ihrer Dokumentationspflicht nachgekommen sind, was die Sache für die Zielgruppen und letztendlich auch die Architekten selbst schwierig macht. Daher sollten sie sich vorher genau überlegen, welche Informationen Stakeholder wie zum Beispiel Produktmanagerinnen, Tester oder Entwickler benötigen.
Zur Strukturierung und Komplettierung dieser Dokumente empfiehlt es sich, auf ein vorhandenes Template wie arc42 zuzugreifen. Abbildung 2 zeigt die Vorgaben von arc42 mit Ebene 1 (Whitebox-Beschreibung des Gesamtsystems und Blackbox-Beschreibungen der darin enthaltenen Bausteine) und Ebene 2 (Hineinzoomen in einige Bausteine der Ebene 1). Ebene 3 würde wiederum in Ebene 2 hineinzoomen und so weiter.
Weiterlesen nach der Anzeige
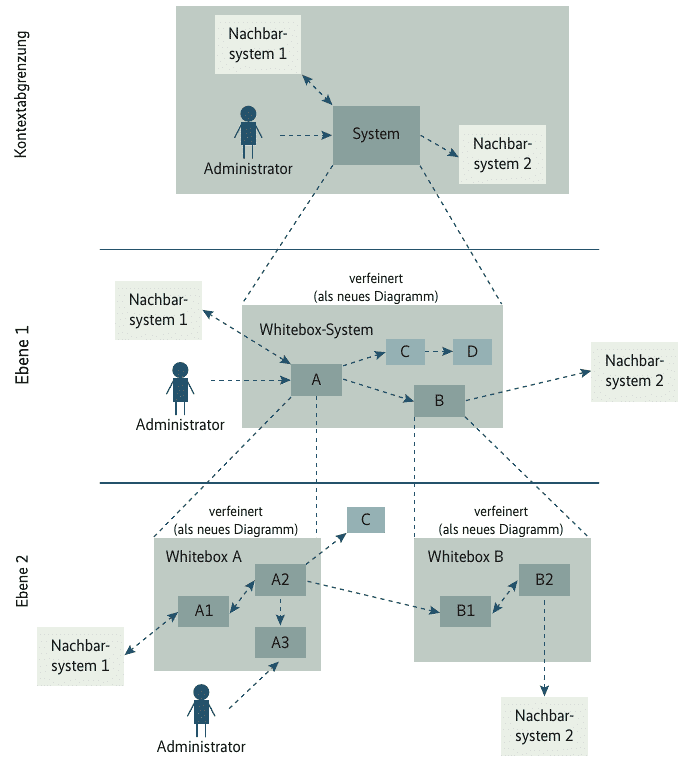
Das Dokumentationstemplate arc42 enthält Vorgaben für eine geeignete und gut strukturierte Architekturdokumentation (Abb. 2).
(Bild: arc42)
Solche Templates basieren auf jahrzehntelangen Erfahrungen und weisen in der Regel einen Topdown-Ansatz auf, um Leser nicht zu überfordern. Natürlich dürfen die Dokumente nicht zu umfangreich sein, sondern sollten für Detailinformationen auf entsprechende Dokumente zu Subsystemen oder Komponenten verweisen. Ein Umfang von maximal 60 bis 80 Seiten pro Dokument erweist sich in der Praxis als zielführend.
Erfolgreiche Kommunikation darf sich nicht im Austausch von Dokumenten erschöpfen, sondern sollte als Multi-Channel Communication auch über Präsentationen und Workshops erfolgen. Es hat sich als vorteilhaft herausgestellt, vor der Übergabe des Architekturdokuments eine Präsentation mit den wichtigsten Kernelementen zu zeigen. Einige Unternehmen organisieren zu diesem Zweck sogar Workshops mit Nutzern und Kunden.
Um Kommunikationspartner zu überzeugen, müssen Architekten ihre Entscheidungen begründen können. Architecture Decision Records (siehe Abbildung 3) helfen dabei. Sie geben das Thema der Entscheidung an, zeigen mögliche Alternativen und erläutern, weshalb eine Alternative den Vorrang bekommen hat. Ihre Speicherung erfolgt zusammen mit der Codebasis in Source-Management-Systemen wie GitHub. Davon profitieren nicht nur Newbies, sondern alle Stakeholder, die sich über Entscheidungen informieren wollen.

Architecture Decision Records helfen, Architekturentscheidungen zu dokumentieren (Abb. 3).
Aus Software-Pattern (siehe Abbildung 4) entsteht eine idiomatische Sprache für effektivere Kommunikation, von der alle Beteiligten profitieren. Statt beispielsweise von einer Ereignisquelle, einer Ereignisschnittstelle und Ereignisnutzern zu sprechen, reicht die Nennung des Observer-Pattern aus. Dadurch ist es überflüssig, einzelne Klassen und Schnittstellen zu erläutern, sondern man nutzt eine höhere Abstraktionsebene. Das gilt auch für DDD-Pattern (Domain-driven Design) auf Fachdomänenebene.
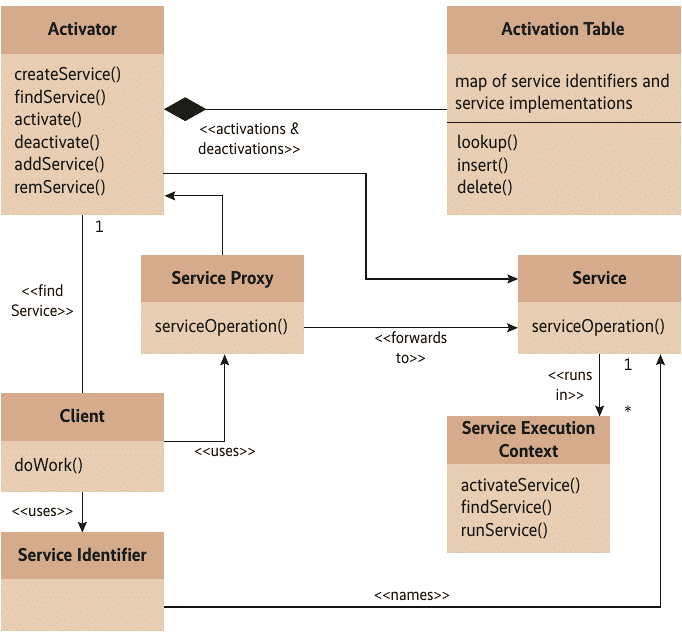
Pattern wie der Activator können die Kommunikation zwischen Softwareentwicklern beträchtlich vereinfachen, weil sie auf einer höheren Abstraktionsebene aufbauen als Programmstrukturen (Abb. 4).
Das Nutzen einfacher Arbeitsmittel wie Whiteboards, Blackboards oder Flipcharts in einem Low-Tech-First-Ansatz hat viele Vorteile. Sie erlauben eine freiere und interaktivere Kommunikation sowie Zusammenarbeit und helfen, für jeden Zweck ein adäquates Mittel zu verwenden. Ohnehin erhöht häufiger Medienwechsel die Aufmerksamkeit. Ein relativ simples Verfahren besteht in Karteikärtchen, die in drei Bereiche unterteilt sind. Im oberen schlanken horizontalen Segment schreibt man einen Klassen- oder Komponentennamen (siehe Abbildung 5), darunter auf der linken Seite folgt eine Spalte „Responsibilities“ mit den Verantwortlichkeiten der Komponente und rechts daneben die Spalte „Collaborators“, also anderen Komponenten, mit denen die vorliegende zusammenarbeitet.
Mit CRC-Karten lassen sich auf einer Pinnwand sehr einfach architektonische Entwürfe durchsprechen (Abb. 5).
Diese CRC-Karten (Class-Responsibilities-Collaborators) lassen sich einfach erstellen, auf einer Pinnwand befestigen, gruppieren oder über Fäden verbinden. Auf diese Weise erhalten Entwurfsdiskussionen ein adäquates Tool zur Kommunikation. UML-Tools dokumentieren anschließend die Arbeitsergebnisse solcher Diskussionen in einem elektronischen Format.
Es hat sich bewährt, dass Softwarearchitektinnen und Entwickler mit Fachdomänenexperten getreu dem Ansatz des Domain-driven Design (DDD) eine Ubiquitous Language entwerfen, die die Fachkonzepte und ihre Beziehungen definiert. Dadurch lassen sich später Missverständnisse vermeiden. Die Entwicklung und Verbesserung dieser Sprache erfolgt kontinuierlich. Zusätzlich bietet DDD einen von der Problemdomäne gesteuerten Ansatz, der verhindert, dass sich Entwicklerinnen und Entwickler zu schnell auf die Lösungsdomäne stürzen. So konzentrieren sich Softwarearchitekten bei DDD auf die Entwicklung einer geeigneten Sprache für die Fachdomäne und befassen sich zu Beginn ausschließlich mit dem Problemraum beziehungsweise der Fachdomäne.
Wenn Architekten anderen Beteiligten die Dokumentation nur hinwerfen, sich aber danach nicht mehr darum kümmern, kommt es fast immer zu einer Architekturdrift. Das heißt, die Implementierung entspricht nicht dem Entwurf. Die Gründe dafür können vielfältig sein: Möglicherweise waren Entwickler unter Zeitdruck, haben die Architektur nicht verstanden oder haben aus ihrer Sicht unsinnige Entscheidungen durch eigene Alternativen ersetzt.
Daher ist es ratsam, Management by Walking zu betreiben, sich also kontinuierlich unter die Developer zu mischen, deren Feedback einzuholen und Fragen zu klären. Ebenso sollten Architekten an der Implementierung mitarbeiten, und zwar nicht nur, um der „Eat your own dog food!“-Regel zu folgen, sondern um in Kontakt mit Entwicklern zu bleiben. Es wäre allerdings kontraproduktiv, wenn Architekten im kritischen Pfad arbeiten.
Reviews besitzen neben Optimierungsaspekten auch Kommunikationsaspekte. Durch ein Architektur-Review lassen sich erfahrungsgemäß sowohl Fragen klären als auch Problematiken und Risiken aufspüren. Zudem erhöht sich das Verständnis aller Beteiligten von Problemen und der Architektur. Diesen Aspekt unterschätzen viele Projekte. Reviews sollten bei jedem Inkrement beziehungsweise Sprint erfolgen, um frühzeitig Probleme zu beheben. Das gilt selbstverständlich auch für Code oder Design Reviews.
Als leichtgewichtige Methode bieten sich Architecture Design Reviews an, um kurzfristig Feedback von Kundinnen oder Nutzern zu erhalten. Dazu stellt die Architektin Dokumente oder Entwicklungsartefakte und einen Fragebogen mit Aufgaben zusammen. Zum Beispiel hat das Entwicklungsteam eine Cloud-basierte Persistenzlösung mit AWS S3 erstellt und benötigt Feedback zur Nutzerfreundlichkeit. Die Architektin stellt die Implementierung samt Dokumentation zur Verfügung oder liefert eine URL, über die Reviewer den Dienst nutzen. Hinzu fügt sie für die Reviewer einen Fragebogen, der unter anderem abfragt: „Wie viel Zeit haben Sie benötigt, um über die API ein Verzeichnis zu kreieren und ein neues Objekt dort abzulegen?“ oder „Ist die Dokumentation aus Ihrer Sicht angemessen? Falls nein, tragen Sie bitte Verbesserungsvorschläge ein.“ Der Aufwand für solche Reviews hält sich in Grenzen, der Nutzen ist trotzdem groß. Ratsam ist, für den Verfasser des Reviews einen Tag einzuplanen und für den oder die Reviewer je einen weiteren Tag.
Knowledge Replicas: In einigen Projekten ergeben sich dadurch Stolperfallen, dass gewisse Kompetenzen nur in einzelnen Köpfen vorhanden sind. Verlässt eine Person das Unternehmen, entstehen Probleme. Daher empfiehlt sich eine Information-Sharing-Kultur, zu der auch Softwarearchitekten beitragen. Über jedes kritische Wissen sollten mehrere Personen verfügen. Die Informationen lassen sich via Coaching oder Mentoring teilen. Das gilt insbesondere für das von externen Beratern eingebrachte Wissen. Derartige Wünsche stoßen mitunter auf den Widerstand der Wissensträger, die ihren Wissensvorsprung und ihre Bedeutung für das Unternehmen dadurch sichern wollen, weshalb es entsprechender Anreize bedarf, etwa zusätzliche monetäre Vergütungen oder sichtbare Wertschätzung.
Metriken und Qualitätsprüfung durch Architekturevaluierungswerkzeuge (siehe Abbildung 6) ermöglichen die Bewertung der Architekturqualität, beispielsweise hinsichtlich Abhängigkeitszyklen, Größe der Codebasis, Fehlerbrennpunkten oder Komplexitätsaspekten. Was zunächst wie eine rein technische Facette erscheinen mag, bewährt sich auch für die Kommunikation, da reines Bauchgefühl oft nicht überzeugt. Durch handfeste Zahlen lassen sich andere Beteiligte eher dazu motivieren, Verbesserungsmaßnahmen vorzunehmen und zu finanzieren.
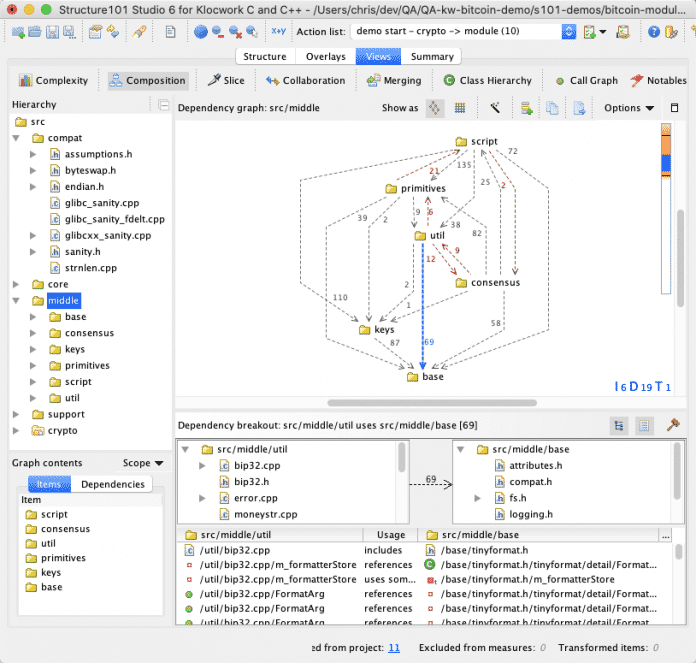
Architekturwerkzeuge wie Structure 101 ermöglichen die Qualitätsanalyse der eigenen Softwarearchitektur und Codebasis (Abb. 6).
Frühzeitige Klärung offener Fragen spielt beim Projektstart eine wichtige Rolle. Softwarearchitekten sollten gezielt auf andere Beteiligte zugehen, um geschäftliche Aspekte, Anforderungen oder die Teststrategie zu klären. Das gilt selbst dann, wenn andere Rollen für diese Aktivität verantwortlich sind. Oft ist beispielsweise der Anforderungskatalog verbesserungswürdig, weil wichtige Informationen oder eindeutige Prioritäten fehlen, insbesondere in Bezug auf Qualitätsattribute. Im letzteren Fall erstellen Softwarearchitekten einen Utility Tree mit selbst eingeschätzten Prioritäten. Den diskutieren sie dann mit den verantwortlichen Rollen und ergreifen so die Initiative.
Softwarearchitekten und -entwickler stehen in Projekten häufig einem nebulösen und dynamischen Umfeld gegenüber. Der Anforderungskatalog ist nicht fertiggestellt oder besitzt mangelnde Qualität. Es fehlt an Erfahrungen mit neuen Technologien, das Team verfügt über zu wenig Wissen oder Ressourcen und vieles mehr. Zwei Faktoren helfen in solchen Situationen. Zum einen bietet ein agiler Prozess mit hintereinander folgenden Sprints und dadurch schnellem Feedback Vorteile. Zum anderen müssen Architektinnen und Architekten mit der entsprechenden Courage Sachverhalte aktiv klären (siehe vorhergehender Aspekt). Sind die Anforderungen unvollständig, sorgen Softwarearchitekten im Idealfall dafür, dass zumindest die wichtigsten 20 bis 30 Prozent der Anforderungen zeitnah vorliegen. Damit können sie eine ausreichende Architecture Baseline (Basisarchitektur) gewährleisten.
Parallel zur Klärungsphase lassen sich zum einen technische Prototypen erstellen, um die Brauchbarkeit und Eigenschaften neuer oder bisher nicht verwendeter Technologien zu eruieren, und zum anderen die dafür notwendigen Fortbildungsmaßnahmen organisieren und durchführen. Dieser Ansatz stammt vom sogenannten Twin-Peaks-Modell. Auch hierfür ist die Überzeugung anderer Beteiligter notwendig.
Blinde Flecke: Wer schon einmal ein Dokument oder ein Programm erstellt und einen darin befindlichen Fehler trotz mehrfacher Prüfung einfach nicht gefunden hat, weiß, dass das Gehirn Details unbewusst verdrängen oder zu falschen Kontexten vervollständigen kann. Ein berühmtes Beispiel ist das vermeintliche Gesicht auf der Mondoberfläche. Hier können andere Mitarbeiter gut unterstützen, weshalb Pair Programming oder Pair Designing hilfreich sind.
Retrospektiven beziehen sich auf die häufig unterschätzte Aktivität, auf die Vergangenheit zurückzublicken, um daraus für die Zukunft zu lernen. Treiber sind die Fragen „Was waren die Ursachen für Fehlschläge oder Probleme?“ und „Was waren die wichtigsten Erfolgsfaktoren?“. Neben technischen Aspekten ergeben sich oft auch kommunikative Defizite, die für Unheil gesorgt haben. Wer in der Rolle des Softwarearchitekten die Vergangenheit retrospektiv analysiert, sollte sich die Frage stellen, wo er oder sie besser hätten agieren können.
Wichtige Fragen der Kommunikation
Natürlich kann dieser Artikel nicht alle Eventualitäten abdecken, doch vor jeder Art von Kommunikation können sich Softwarearchitektinnen und -architekten beispielsweise folgende Fragen stellen:
- Warum/wozu ist das wichtig?
- Für wen ist das wichtig?
- Was will ich erreichen?
- Wie will ich es erreichen?
- Was erwarten oder benötigen die Kommunikationspartner (Zuhörerkontext)?
- Welche Persönlichkeitstypen liegen vor?
- Was ist das notwendige und hinreichende Minimum an Kommunikation beziehungsweise wie lässt sich Communication Overflow vermeiden?
- Welche Aufmerksamkeitsspannen haben meine Gesprächspartner?
Dazu kommt ein entscheidender und oft unterschätzter Faktor, der immer in das Kommunikationsverhalten hineinspielt: Wie schaffe ich es, einen guten Eindruck zu hinterlassen?


-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenIllustrierte Reise nach New York City › PAGE online
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenJetzt patchen! Erneut Attacken auf SonicWall-Firewalls beobachtet
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenAus Softwarefehlern lernen – Teil 3: Eine Marssonde gerät außer Kontrolle
-
Künstliche Intelligenzvor 2 Monaten
Top 10: Die beste kabellose Überwachungskamera im Test
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenFake It Untlil You Make It? Trifft diese Kampagne den Nerv der Zeit? › PAGE online
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenSK Rapid Wien erneuert visuelle Identität
-

 Entwicklung & Codevor 3 Wochen
Entwicklung & Codevor 3 WochenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 Social Mediavor 3 Monaten
Social Mediavor 3 MonatenSchluss mit FOMO im Social Media Marketing – Welche Trends und Features sind für Social Media Manager*innen wirklich relevant?

