Künstliche Intelligenz
4chan will in Großbritannien verhängte Strafen nicht bezahlen
Ein Anwalt von 4chan hat angekündigt, dass das berüchtigte Image-Board von der britischen Medienaufsicht verhängte Strafen nicht bezahlen werde. Das sagte er der BBC und erklärte, Mitteilungen der Behörde namens Ofcom „begründen keine rechtlichen Verpflichtungen in den Vereinigten Staaten“. Obendrein nannte er die Ermittlungen der Aufsichtsbehörde Teil einer „illegalen Belästigungskampagne“ gegen US-amerikanische Tech-Firmen. Dem Anwalt zufolge hat das Ofcom eine vorläufige Strafe in Höhe von 20.000 Pfund (etwa 23.000 Euro) gegen 4chan verhängt, bei Nichtbefolgung der Vorgaben sollen demnach tägliche Strafzahlungen verfügt werden.
Ermittlungen nach Beschwerden
Hintergrund der Auseinandersetzung ist eine Untersuchung, die das Office of Communications im Juni eingeleitet hat. Anlass waren Beschwerden über angebliche illegale Aktivitäten, hieß es damals. Herausfinden wollte das Ofcom, wie 4chan mit illegalen Inhalten umgeht und ob der Dienste „angemessene Sicherheitsmaßnahmen“ umgesetzt hat, um User in Großbritannien vor illegalen Inhalten und Aktivitäten zu schützen. Im August hat die Behörde 4chan dann laut der BBC darüber informiert, dass die Plattform zwei Informationsersuchen nicht beantwortet hat. In der Folge wurde nun offenbar die Strafzahlung verhängt.
4chan ist seit Jahren berüchtigt für seine kontroversen Inhalte. Beiträge werden dort standardmäßig anonym abgegeben, Urheberrechte ignoriert und Beiträge mit politisch extremen und antisemitischen Inhalten toleriert. 4chan ist Quelle vieler Memes, aber auch Ausgangspunkt zahlreicher problematischer Internet-Phänomene – etwa die Verschwörungserzählung rund um „QAnon“. Auf dem Kurznachrichtendienst X erklärte die Anwaltskanzlei des Dienstes jetzt, dass US-Unternehmen ihre von der US-Verfassung garantierten Rechte nicht einfach aufgebe, nur weil ein „ausländischer Bürokrat ihnen eine E-Mail sendet“. Man werde alle Versuche, 4chan zu bestrafen, vor einem US-Bundesgericht bekämpfen.
(mho)












Künstliche Intelligenz
c’t Fotografie: Fototouren Deutschland V
Die Welt unter Wasser: Das Meeresmuseum in Stralsund
Weiterlesen nach der Anzeige
Das Deutsche Meeresmuseum lockt mit spektakulären Unterwasserwelten und einer faszinierenden Vielfalt an Aquarien. Wer hier in Stralsund jedoch mit der Kamera auf Entdeckungsreise geht, wird schnell mit den erheblichen technischen Herausforderungen konfrontiert. Die fotografische Abbildung weicht oft deutlich von der visuellen Wahrnehmung des menschlichen Auges ab.


In den Ausstellungen und Aquarien des Deutschen Meeresmuseums dreht sich alles um unsere Ozeane und ihre Bewohner. Darin mit der Kamera abzutauchen ist so lehrreich wie herausfordernd.
(Bild: Sandra Petrowitz)
In dieser Ausgabe der c’t Fotografie Fototouren „Deutschland V“ stellen wir Ihnen die zwei Standorte des Museums in Stralsund vor: das futuristische Ozeaneum auf der Hafeninsel und das historische Meeresmuseum im ehemaligen Dominikanerkloster. Beide bieten grundlegend verschiedene fotografische Motive, teilen jedoch eine zentrale Schwierigkeit – ungünstige Lichtverhältnisse. Die Realität vor Ort ist oft ernüchternd, da viele Fotografen die technischen Anforderungen unterschätzen.
Die Ausstellungsräume sind bewusst abgedunkelt, um durch gezielte, meist blaue Lichtspots eine besondere Atmosphäre zu schaffen. Was für das Auge reizvoll wirkt, zwingt die Kameratechnik an ihre Grenzen und treibt die ISO-Werte in extreme Höhen. Während der Besucher farbenprächtige Korallen und Fische erkennt, herrscht für den Kamerasensor beinahe Dunkelheit. Die effektvolle Beleuchtung betont zwar die Farbenpracht der Meeresbewohner, täuscht aber über die tatsächlich sehr geringe Lichtmenge hinweg. Blitzgeräte sind zum Schutz der Tiere grundsätzlich untersagt.
In den Aquarien selbst erhöht sich der Schwierigkeitsgrad weiter, denn zur Dunkelheit gesellt sich die ständige Bewegung der Bewohner. Selbst vermeintlich statische Korallen pulsieren mit ihren winzigen Polypen, und Clownfische huschen unablässig zwischen den Tentakeln der Anemonen hin und her. Dieser Umstand schafft ein klassisches Dilemma: Längere Verschlusszeiten führen unweigerlich zu Bewegungsunschärfe, während eine kurze Belichtung das Bildrauschen drastisch erhöht. Erfolgreiche Aquarienfotografie ist dennoch möglich. Sie erfordert jedoch vor allem Geduld und eine gute Vorbereitung. Einige Tricks helfen, die Aufnahmen zu optimieren.
Als reizvollen Kontrast bietet das historische Meeresmuseum architektonische Motive. Hier treffen gotische Spitzbogenfenster auf moderne Vitrinen, das Rot der Backsteine kontrastiert mit dem Grau von Stahlkonstruktionen. Seit 1974 dominiert das 15 Meter lange Skelett eines Finnwals den ehemaligen Kirchenchor. Diese statischen Objekte sind fotografisch deutlich dankbarer als die agilen Bewohner der Aquarien.
Weitere Fototouren im Heft
Weiterlesen nach der Anzeige
Direkt vor den Toren Bremens wartet ein außergewöhnliches Naturparadies auf Entdeckung: Das Bremer Blockland vereint auf faszinierende Weise jahrhundertealte Kulturlandschaften mit einem der wertvollsten Naturschutzgebiete Norddeutschlands. In diesem Artikel nehmen wir Sie mit auf eine fotografische Reise durch eine Region, die trotz ihrer Nähe zur Großstadt eine erstaunliche Artenvielfalt beherbergt.
Erfahren Sie, wie niederländische Siedler bereits im 12. Jahrhundert diese einzigartige Marschlandschaft prägten und warum das Zusammenspiel von Gezeiten, Deichen und Wiesen heute ein Refugium für seltene Wiesenvögel und majestätische Greifvögel schafft. Wir zeigen Ihnen die besten Fotospots für stimmungsvolle Landschaftsaufnahmen bei Sonnenaufgang, verraten Ihnen, wann und wo Sie Rohrweihen bei ihren spektakulären Flugmanövern beobachten können, und geben praktische Tipps für die Tierfotografie in diesem besonderen Habitat.
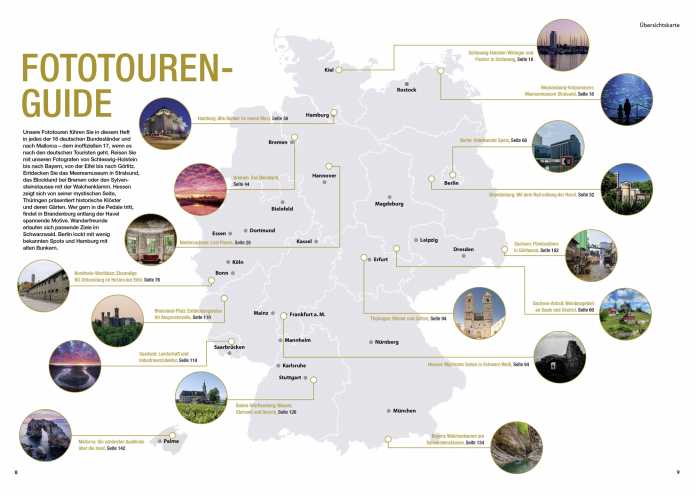
Übersicht der Fototouren
Wer durch Thüringen reist, begegnet nicht nur einer reich bewaldeten, sanft hügeligen Landschaft, sondern auch Orten, an denen die Zeit stillzustehen scheint. Klöster, Ruinen und verwunschene Gärten erzählen von jahrhundertealter Geschichte und bieten fotografisch Interessierten eine wahre Schatztruhe voller stiller Entdeckungen.
Fotograf Paul Hentschel nimmt Sie mit auf eine besondere Fototour zu sieben außergewöhnlichen Orten, wo Architektur und christliche Geschichte zu einer faszinierenden Einheit verschmelzen. Von den bizarren Mauerwinkeln der verfallenen Klosterruine Göllingen über die meditativen Kräutergärten in Veßra bis hin zum spektakulären Kontrast zwischen jahrhundertealten Gemäuern und moderner Glasarchitektur im Kloster Volkenroda – diese Orte leben von Dramatik, Licht und Geschichte.
Unser Beitrag zeigt Ihnen nicht nur, wo Sie die schönsten Motive finden, sondern auch, wie Sie fotografisch das Beste aus ihnen herausholen – respektvoll, achtsam und mit Blick für die Details, die diese besonderen Orte zu fotografischen Paradiesen machen.
Das Saarland – ein kleines Bundesland mit großer Wirkung für Fotografen! Zwischen der legendären Saarschleife und imposanten Industriedenkmälern erwartet Sie eine faszinierende Reise durch Kontraste, die es so nur hier gibt. In diesem fotografischen Reiseführer entdecken Sie fünf außergewöhnliche Locations, die das Saarland zu einem echten Geheimtipp für Naturfotografen machen. Von den dampfenden Wassergärten Landsweiler-Reden, wo sich Graureiher im warmen Nebel des Grubenwassers tummeln, bis hin zur weltberühmten Saarschleife, die bei Sonnenaufgang in mystischen Nebelschwaden versinkt.
Erleben Sie, wie sich Industriekultur und Natur zu einzigartigen Motiven verbinden: Besuchen Sie die Völklinger Hütte, ein UNESCO-Weltkulturerbe mit gigantischen Hochöfen und labyrinthartigen Rohrsystemen, wandern Sie durch die märchenhaften Sandsteinformationen des Kirkeler Felsenpfads oder lassen Sie sich vom romantischen Schiessentümpel in Luxemburg verzaubern.

Alle Themen der Ausgabe auf einen Blick.
Sie erhalten die Sonderausgabe der c’t Fotografie Fototouren Deutschland V für 12,90 Euro im heise shop. Dort finden Sie eine komplette Inhaltsübersicht und Informationen über das Online Zusatz-Material als c’t Fotografie-Download, dazu Vorschaubilder und das Editorial.
(tho)
Künstliche Intelligenz
Gehaltserhöhungen: Was ITler gern hätten und wozu Chefs bereit sind
Bei der Gehaltsentwicklung könnten für ITler bescheidenere Zeiten anstehen. Das geht aus der aktuellen Marktstudie der Personalberatung Robert Walters hervor, die der iX-Redaktion exklusiv vorliegt. Unternehmen agierten zunehmend wirtschaftlicher und können nicht mehr jährlich mit Gehaltssteigerungen mithalten, erklären die Personalexperten. Das bedeutet noch keine Einbußen, aber eine „Stabilisierung der Gehälter“.
Weiterlesen nach der Anzeige
Im Schnitt um 3,6 Prozent könnten laut den für die Studie befragten Personalverantwortlichen die Gehälter im IT-Bereich steigen, was die derzeitige Inflationsrate von 2,3 Prozent übersteigen würde. Die Steigerung liegt leicht unter dem Durchschnittswert von 3,74 Prozent für alle befragten Branchen. Und deutlich unter dem, was die befragten ITler gerne hätten. Im Schnitt möchten sie 6,94 Prozent Zuschlag auf ihr Gehalt. 2024 lag der Zuwachs für ITler laut Zahlen der Bundesagentur für Arbeit bei 3,85 Prozent.
Erhöhungen nicht überall wahrscheinlich
Durchschnittswert heißt aber nicht, dass in jedem Unternehmen mit solchen Steigerungen zu rechnen ist. 71 Prozent der Befragten im IT-Feld gaben immerhin an, dass es in ihren Unternehmen wahrscheinlich (46 Prozent) oder sehr wahrscheinlich (25 Prozent) zu Gehaltserhöhungen komme. Bei 29 Prozent sei das aber unwahrscheinlich oder sehr unwahrscheinlich.
Wichtigster Faktor bei Gehaltsentscheidungen sei für die meisten Personalverantwortlichen (43 Prozent) die Geschäftsentwicklung und finanzielle Lage des Unternehmens. Für rund ein Viertel sei es der Mangel an Fachkräften und der Wettbewerb um diese. Nur rund 17 Prozent hätten die Gehaltsvorstellungen der Angestellten als stärksten Faktor genannt.
Die Chance auf gute Gehälter sei aber auch eine Frage der jeweiligen Spezialisierung. Die Nachfrage nach klassischen Softwareentwicklern sinke etwa, da viele Projekte eingestellt wurden, wie Arne Fietz, Manager IT bei Robert Walters, erklärt. Attraktive Vergütungsmöglichkeiten bieten sich aus seiner Sicht etwa für Solution Architects, Data- und KI-Spezialisten sowie Infrastruktur-Experten. Auch krisenfeste Branchen wie Banken, Immobilien oder Rüstung investierten weiterhin in ihre IT-Infrastruktur und seien so Garant für überdurchschnittliche Gehälter.
Recruiting und Bindung: Gehalt entscheidet
Weiterlesen nach der Anzeige
Die Gehaltsfrage zeigt sich der Studie nach auch immer wieder als wesentliches Hindernis, um Personal zu gewinnen oder zu halten. 62 Prozent der Personaler berichteten von zu hohen Gehaltserwartungen, die Einstellungen verhinderten – lediglich fehlende Qualifikationen auf dem Markt seien mit 65 Prozent ein noch größeres Recruiting-Hindernis. Und bei den Faktoren, die es für Firmen schwieriger machten, ihre Fachleute zu binden, rangieren zu geringe Gehaltssteigerungen oder Boni aufgrund der wirtschaftlichen Lage mit 55 Prozent weit vorn. Nur erhöhte Arbeitsbelastung aufgrund von Personalknappheit scheint mit 60 Prozent noch mehr Leute aus den Unternehmen zu scheuchen.
Für die Angestellten ist das Gehalt ohnehin das wichtigste Argument für ihren Arbeitgeber. 40,4 Prozent gaben das an – von allen anderen Faktoren hatte nur die Möglichkeit zur eigenständigen Arbeit genauso viele Nennungen.
Die Gehaltsstudie 2026 von Robert Walters basiert eigenen Angaben nach auf einer Auswertung interner Gehaltsdaten sowie einer Befragung von 644 Personalverantwortlichen und 856 Fach- und Führungskräften aus verschiedenen Branchen in Deutschland. Für den Bereich der IT wurden demnach 136 Kandidaten und 250 Personalverantwortliche befragt.
(axk)
Künstliche Intelligenz
Mountainbiker springt durch offene Ladeflächen zweier fahrender autonomer Lkw
Red Bulls Profi-Mountainbiker Matt Jones ist mit seinem Mountainbike durch die seitlich offenen Ladeflächen zweier sich kreuzender selbstfahrender Scania-Lkw gesprungen. Die autonomen Lkw erreichten dazu fast auf die Sekunde genau die gleiche Stelle, damit der Mountainbiker durch sie hindurchspringen konnte.
Weiterlesen nach der Anzeige
Um den Stunt zu schaffen, müssen die beiden autonom fahrenden Lkw zeitgleich die Sprungrampe passieren, damit Jones durch die seitlich geöffneten Ladeflächen der Trucks springen kann. Diese Präzision sei ausschließlich durch KI-gesteuerte selbstfahrende Lkw zu erreichen, die reproduzierbar immer wieder zum gleichen Zeitpunkt die Absprungstelle gemeinsam erreichen, heißt es von Scania Autonomous Solutions. Dem Mountainbiker bleibt durch die beiden in Bewegung befindlichen Lkw allerdings nur ein schmales Zeitfenster von etwa einer Sekunde, bevor sich die Lücke für das Durchspringen schließt. Hinzu kommt, dass der Mountainbiker ebenfalls in Bewegung ist und zum exakten Zeitfenster die Absprungrampe treffen muss.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
Das Video zeigt den Prozess, bis der Mountainbiker Matt Jones durch die beiden autonomen Scania-Lkw springen konnte.
Um das zu gewährleisten, haben die Ingenieure von Scania ein System ersonnen, das dem von einem Auto gezogenen und auf Absprunggeschwindigkeit gebrachten Mountainbiker signalisiert, ob der Sprung möglich ist oder nicht. Das System erfasst dazu über GPS die Position und Geschwindigkeit der beiden Lkw und übermittelt sie an das Zugfahrzeug des Mountainbikers. Aus den Positionen und Geschwindigkeiten der Fahrzeuge berechnet das System, ob das Absprungzeitfenster passt und der Sprung „sicher“ möglich ist.
Signal für einen „sicheren“ Sprung
Dem Mountainbiker wird das über einen Monitor am Heck des ziehenden Fahrzeugs signalisiert: Rot bedeutet, dass der Sprung nicht möglich ist und abgebrochen werden sollte. Im gelben Status ist das noch nicht klar. Grün signalisiert, dass der Sprung durchgeführt werden kann.
Es waren lange Trainingseinheiten und letztlich mehrere Versuche nötig, bis Jones durch die beiden Lkw springen konnte. Die beiden autonomen Lkw schafften es dabei konstant, so aneinander vorbeizufahren, dass die beiden offenen Ladeflächen an der Absprungrampe deckungsgleich waren. Schwieriger war es dagegen, den Mountainbiker für den Absprung zum richtigen Zeitfenster auf die Rampe zu bringen.
Weiterlesen nach der Anzeige
(olb)

c’t Fotografie: Fototouren Deutschland V

+++ voize +++ Peec AI +++ Albatross +++ Pionix +++ Integral +++ Mirantus Health +++ German Bionic +++

Schlagt schnell zu! Diese 8 Apps für Android & iOS sind jetzt gratis » nextpit
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenAdobe Firefly Boards › PAGE online
-

 UX/UI & Webdesignvor 1 Monat
UX/UI & Webdesignvor 1 MonatIllustrierte Reise nach New York City › PAGE online
-

 Apps & Mobile Entwicklungvor 3 Monaten
Apps & Mobile Entwicklungvor 3 MonatenGalaxy Tab S10 Lite: Günstiger Einstieg in Samsungs Premium-Tablets
-

 Datenschutz & Sicherheitvor 3 Monaten
Datenschutz & Sicherheitvor 3 MonatenHarte Zeiten für den demokratischen Rechtsstaat
-

 Datenschutz & Sicherheitvor 2 Monaten
Datenschutz & Sicherheitvor 2 MonatenJetzt patchen! Erneut Attacken auf SonicWall-Firewalls beobachtet
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 Monaten„Buongiorno Brad“: Warum Brad Pitt für seinen Werbejob bei De’Longhi Italienisch büffeln muss
-

 Online Marketing & SEOvor 3 Monaten
Online Marketing & SEOvor 3 MonatenCreator und Communities: Das plant der neue Threads-Chef
-

 Entwicklung & Codevor 3 Monaten
Entwicklung & Codevor 3 MonatenEventSourcingDB 1.1 bietet flexiblere Konsistenzsteuerung und signierte Events