Apps & Mobile Entwicklung
AI-Suchmaschinen: Google AI vs. ChatGPT, Perplexity & Copilot
Was Google mit dem AI Mode präsentiert, ist ein Paradigmenwechsel: Die herkömmliche Suche tritt immer mehr in den Hintergrund, AI übernimmt. Wie zuverlässig die KI-Suchen Perplexity, Copilot Search, ChatGPT Search und der AI Overview mittlerweile arbeiten, analysiert ComputerBase.
Von einem Plattformwandel hin zu KI sprach Google-CEO Sundar Pichai bei der Entwicklerkonferenz I/O – eine alltägliche Phrase im AI-Marketing, doch Google macht dieses Mal ernst. Der Startschuss fiel bereits letztes Jahr mit dem AI Overview, der Auftakt war für Google aber ein Desaster. Statt hilfreicher Zusammenfassungen generierte der Suchassistent zu oft hanebüchene Antworten, viral gingen Tipps wie ein Pizza-Rezept mit Klebstoff und Ernährungsratgeber für Steine. Enshittification – also der dauerhafte Abstieg – war wieder ein Stichwort.
Der neue AI Mode übertrifft den AI Overview nun nochmals, die KI-Suche entspricht damit eher Diensten wie Perplexity oder ChatGPT Search. Was diese Modi von den normalen AI-Chatbots unterscheidet: Der Fokus liegt auf aktuellen Daten, die über Suchdienste erfasst werden. Die Antworten erhalten zudem Quellen, je nach Anfrage auch Produktempfehlungen und mehr weitergehende Fragen – man will also den Suchprozess optimieren, die Nutzer im Dienst halten.
Perplexity war so etwas wie das Role Model für diese Dienste, bei denen zwar immer noch Quellen und Link-Listen existieren, die generierten Antworten aber wesentlich mehr Raum einnehmen. Die Frage ist nur: Wie zuverlässig laufen die Dienste mittlerweile?
Leicht zu erfassen ist Qualität nicht. Eine vielzitierte Studie des Columbia Journalism Review vom März 2025 zeigte, dass KI-Suchen damit kämpfen, Zitate einer Quelle zuzuordnen. In 60 Prozent der Fälle komme es zu Fehlern, lauteten die Schlagzeilen. Die Frage bei dieser Vorgehensweise ist aber: Wie oft sucht man anhand von Zitaten nach konkreten Medienartikeln? Vermutlich eher selten.
Vertrauenswürdig sind die generierten Antworten deswegen aber auch nicht. „Diese KI-generierten Zusammenfassungen sind oft unzuverlässig können komplett falsche oder irreführende Informationen beinhalten“, sagte AdGuard-Mitgründer Andrey Meshkov im Februar der Huffington Post. Er verwies dabei etwa auf medizinische Fragestellungen, also ein Bereich, in dem Fehler besonders dramatisch sind. Auch darüber hinaus muss man immer mit den typischen AI-Fehlern rechnen:
- Die Antworten sind komplett falsch und irreführend, präsentieren die Ergebnisse aber mit großer Selbstsicherheit.
- Fast noch schlimmer: Generell sind die Antworten korrekt, es hakt aber an einigen Details.
- Kleinere Fehler und Ungereimtheiten, die sich aber ohne Fachwissen kaum entdecken lassen.
Der Haken beim Bewerten: Allein aufgrund der schieren Menge an Suchanfragen lässt sich kaum quantifizieren, wie viele Antworten stimmen. Selbst wenn Experten sich äußern, ist es daher vor allem anekdotische Evidenz. Aus einem Sammelsurium an Einzelfällen entwickelt sich ein Gefühl, wie adäquat die Ergebnisse sind.
Unterscheiden kann sich die Qualität der generierten Antworten zudem von Bereich zu Bereich. Wie die Qualität im Tech-Bereich ausfällt, analysiert ComputerBase.
Test: KI-Suchen im Tech-Alltag
Um einen Überblick zu bieten, werden typische Suchanfragen abgehandelt. Die Liste umfasst aktuelle Nachrichten samt Zahlen, Grafikkarten-Kaufberatung, Fehlersuche, Wissen, Spieleempfehlung – und Bundesliga-Ergebnisse. Inhaltlich ein Ausreißer, in der Vergangenheit hatten sich diese aber schon als erstaunliche Fehlerquelle offenbart.
Der Test umfasst die vier generative KI-Suchen:
- ChatGPT Search: Der Marktführer, getestet wird mit der kostenfreien Variante des Chatbots, die GPT-4o mit aktivierten Suchmodus verwendet.
- Perplexity: Wegbereiter der KI-Suchen. Getestet wird in der kostenlosen Variante, die allerdings auch einige Pro-Suchen pro Tag zulässt – bei diesen kommt dann ebenfalls GPT-4o zum Einsatz.
- Copilot Search: Neuste Ausbaustufe für Microsofts KI-Suche in Bing, die zum 50-jährigen Jubiläum im April präsentiert wurde. Microsoft verwendet ebenfalls die OpenAI-Modelle.
- AI Overview: Googles KI-Update für die reguläre Suche ergänzt das Testfeld, basiert technisch auf den Gemini-Modellen.
Von den Standard-Chatbots wie ChatGPT und Gemini unterscheiden sich die KI-Suchen durch den Zugriff auf Suchmaschinen-Daten, die jeweils die Grundlage für die generierten Antworten sind. Nutzer bleiben aber in einer Chat-Oberfläche und haben daher etwa die Möglichkeit, Folgefragen zu stellen.
Der AI Overview hebt sich von den vollständigen KI-Suchen ab, weil die generierten Antworten im Kern nur die herkömmlichen Suchergebnisse ergänzen. Wer eine neue Anfrage stellt, startet also eine neue Suche. Mit dem AI Mode – der bislang nur in den USA verfügbar ist – bringt auch Google eine vollständige KI-Suche. Ausgehend von SmiliarWeb-Daten laufen bislang aber nur ein Prozent der Google-Anfragen über den AI Mode, erklärt der SEO-Analyst Barry Adams. AI-Overview-Antworten sind also die relevantesten, weil sämtliche Google-Nutzer diese zu Gesicht bekommen.
Zum Vorgehen: Es wurden bewusst einfache Prompt-Eingaben verwendet, um alltägliches Suchen zu simulieren. Der Test 1 wurde am 4. Juni durchgeführt, die übrigen Testläufe fanden am 1. Juni statt, Test 6 bereits am 27. April.
Test 1: Was ist das wertvollste Unternehmen der Welt?
Prompt: Was ist aktuell das wertvollste Unternehmen der Welt und welchen Börsenwert hat es?
Eine aktuelle News-Suche zum Auftakt, denn am 3. Juni 2025 übernahm Nvidia von Microsoft, den ersten Platz im Ranking der wertvollsten Unternehmen der Welt. Der Test wurde am 4. Juni gegen 10 Uhr durchgeführt, der Marktwert von Nvidia lag zu diesem Zeitpunkt laut Companies Market Cap bei 3,44 Billionen US-Dollar.
Von den KI-Suchen war nun ChatGPT Search die einzige, die die korrekte Antwort lieferte. Googles AI Overview nennt Nvidia und einen Börsenwert von 3,3 Billionen US-Dollar, verweist in den Quellen aber auf einen Tagesschau-Artikel vom Juni 2024 (!). Microsofts Copilot Search schafft es zwar, eine aktuelle Quelle zu finden, nutzt diese aber nicht. Stattdessen setzt man Apple auf Rang 1, die Zahlen stammen offenbar aus dem August 2024. Perplexity scheitert ebenfalls. Obwohl der Juni 2025 als Zeitraum genannt wird, Microsoft liegt mit einem Marktwert von 2,6 Billionen auf Rang 1. Dieser Wert scheint aus dem April oder Anfang Mai zu stammen, als die Börsenkurse aufgrund von Trumps Zollpolitik auf dem Tiefpunkt waren.
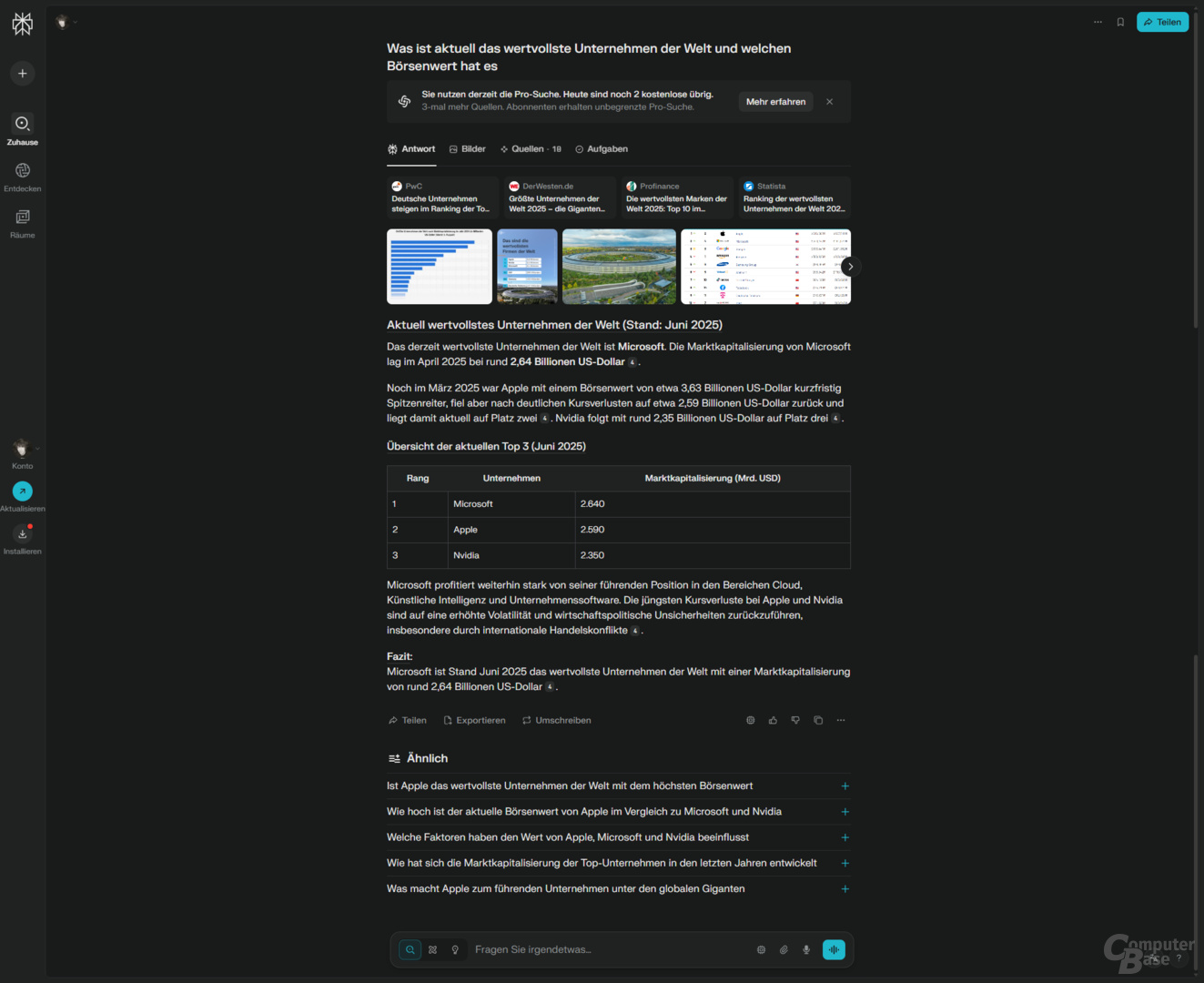
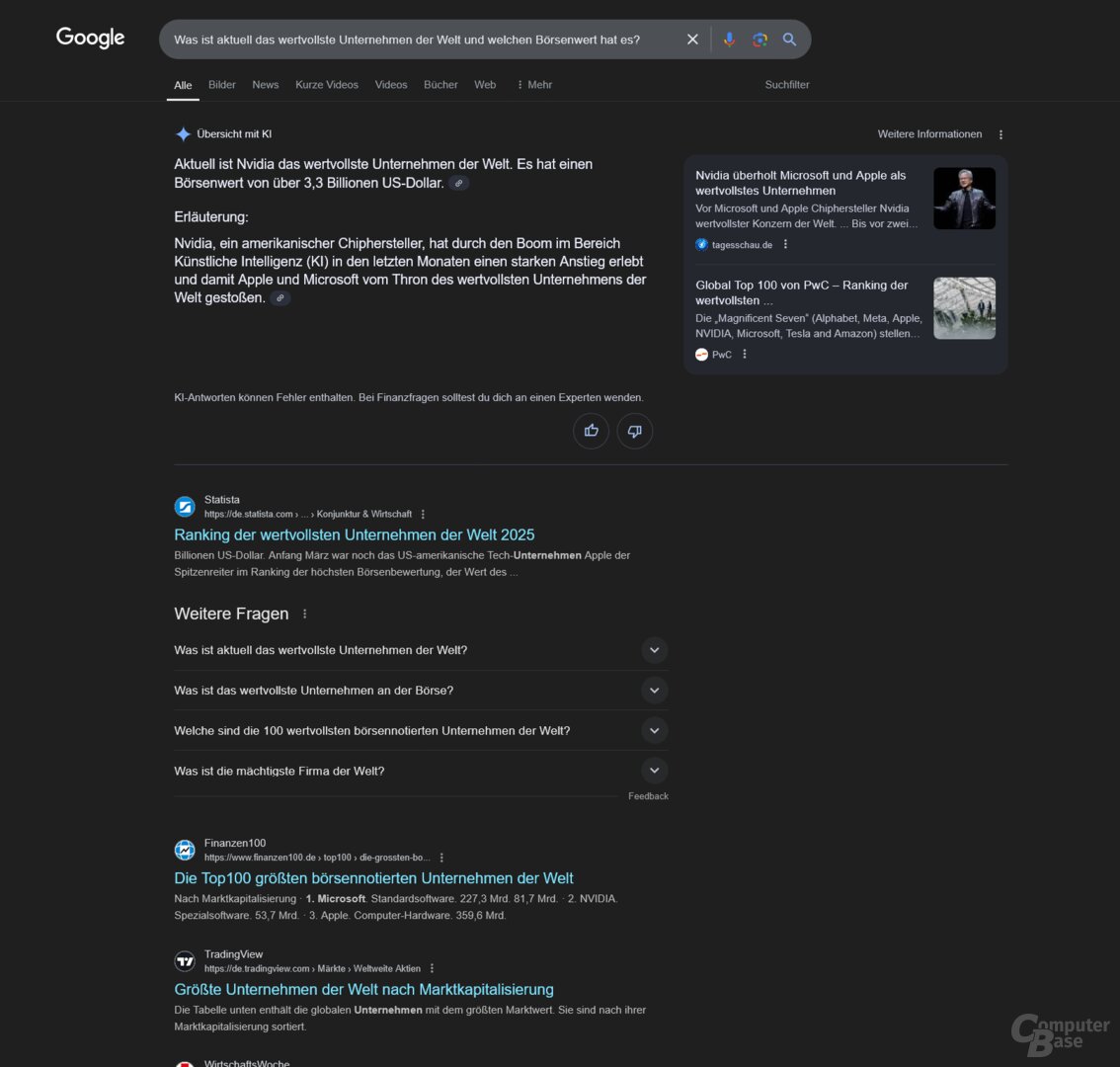
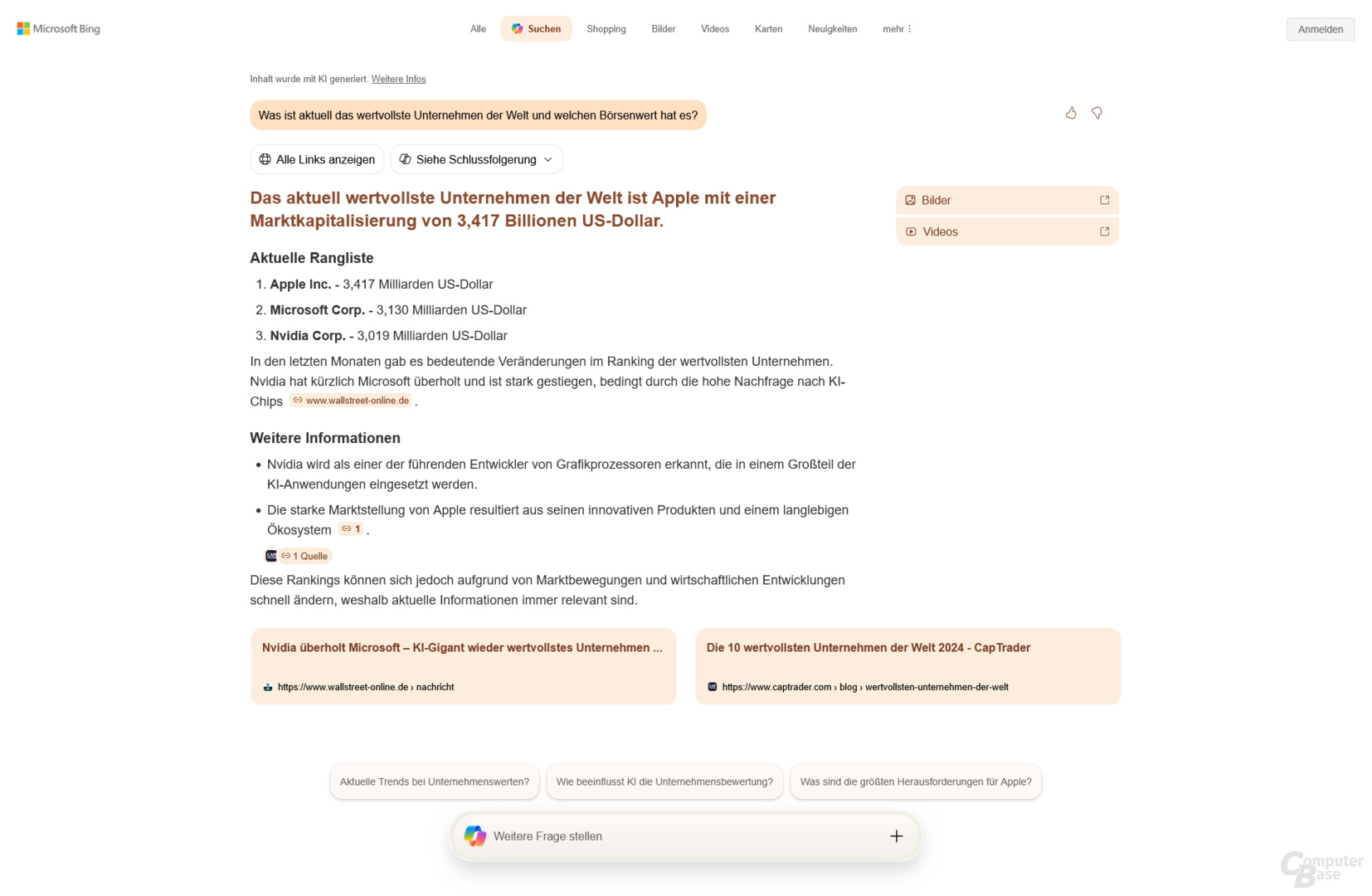
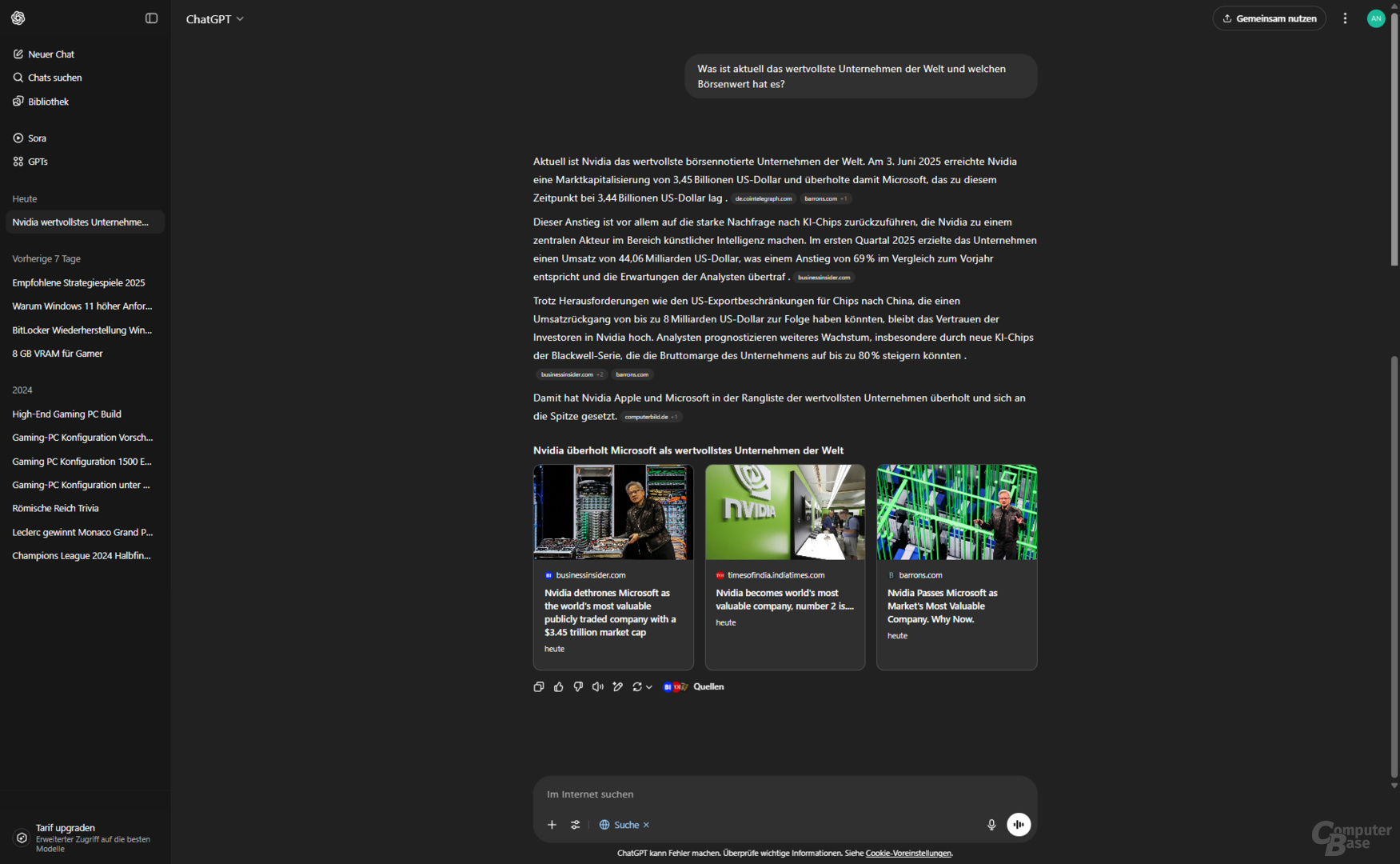
Kurzum: Bis auf die Antwort von ChatGPT Search sind die Ergebnisse falsch. Offenbar schaffen es die KI-Suchen nicht, die Antwort ausschließlich auf aktuelle Nachrichten zu beziehen.
Erwähnenswert ist aber: Wie die Antworten ausfallen, hängt maßgeblich vom Prompt ab. Fragt man nach dem wertvollsten Unternehmen der Welt samt Börsenkurs, ist die Antwort von Perplexity falsch. Fragt man hingegen nur „Was ist das wertvollste Unternehmen der Welt“, ist die Antwort korrekt.
Noch sind die Systeme fragil, aktuelle Zahlen und Informationen können immer wieder zu Bruchlandungen führen. Beobachten lässt sich das bei allen Anbietern, generell scheint ChatGPT Search der KI-Dienst zu sein, der am robustesten im Umgang mit Prompt-Eingaben ist.
Test 2: Wie sinnvoll ist eine Grafikkarte mit 8 GB Grafikspeicher für Gamer?
Prompt 1: Wie sinnvoll ist momentan eine Grafikkarte mit 8 GB Grafikspeicher für Gamer?
Prompt 2: Welche Grafikkarte ist aktuell empfehlenswert, wenn ich auf Zukunftssicherheit und Leistung bei höheren Auflösungen oder anspruchsvolleren Spielen Wert lege?
Wie viel Grafikspeicher nötig ist, ist auch bei ComputerBase eines der großen Diskussionsthemen. Vor allem Nvidias GeForce 5060 mit 8 GB steht für die mangelnde VRAM-Ausstattung in der Kritik, selbst in Full HD kann es damit heute schon zu Problemen kommen. Dasselbe gilt für die AMD Radeon RX 9600 XT (Test), die erschien aber erst, nachdem die KI-Suchen getestet worden sind.
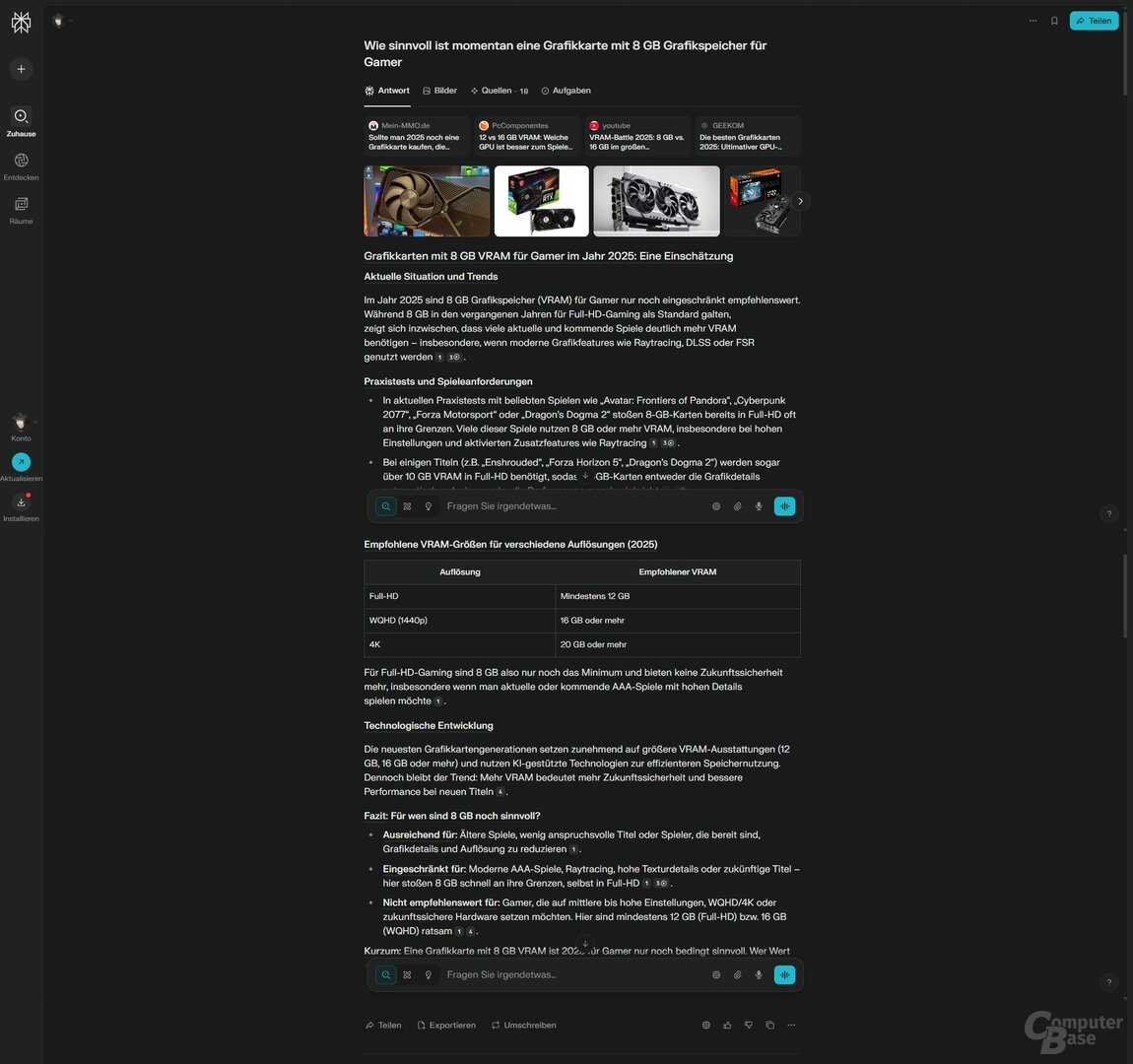
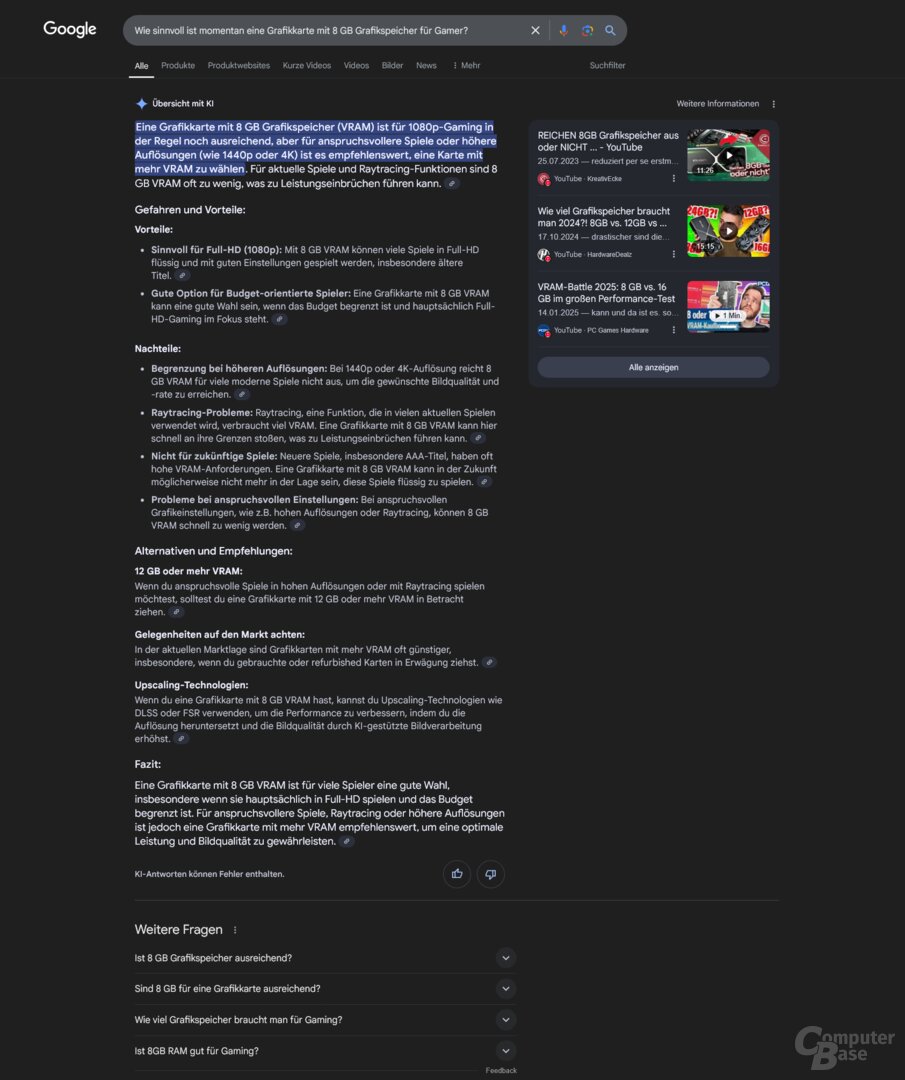
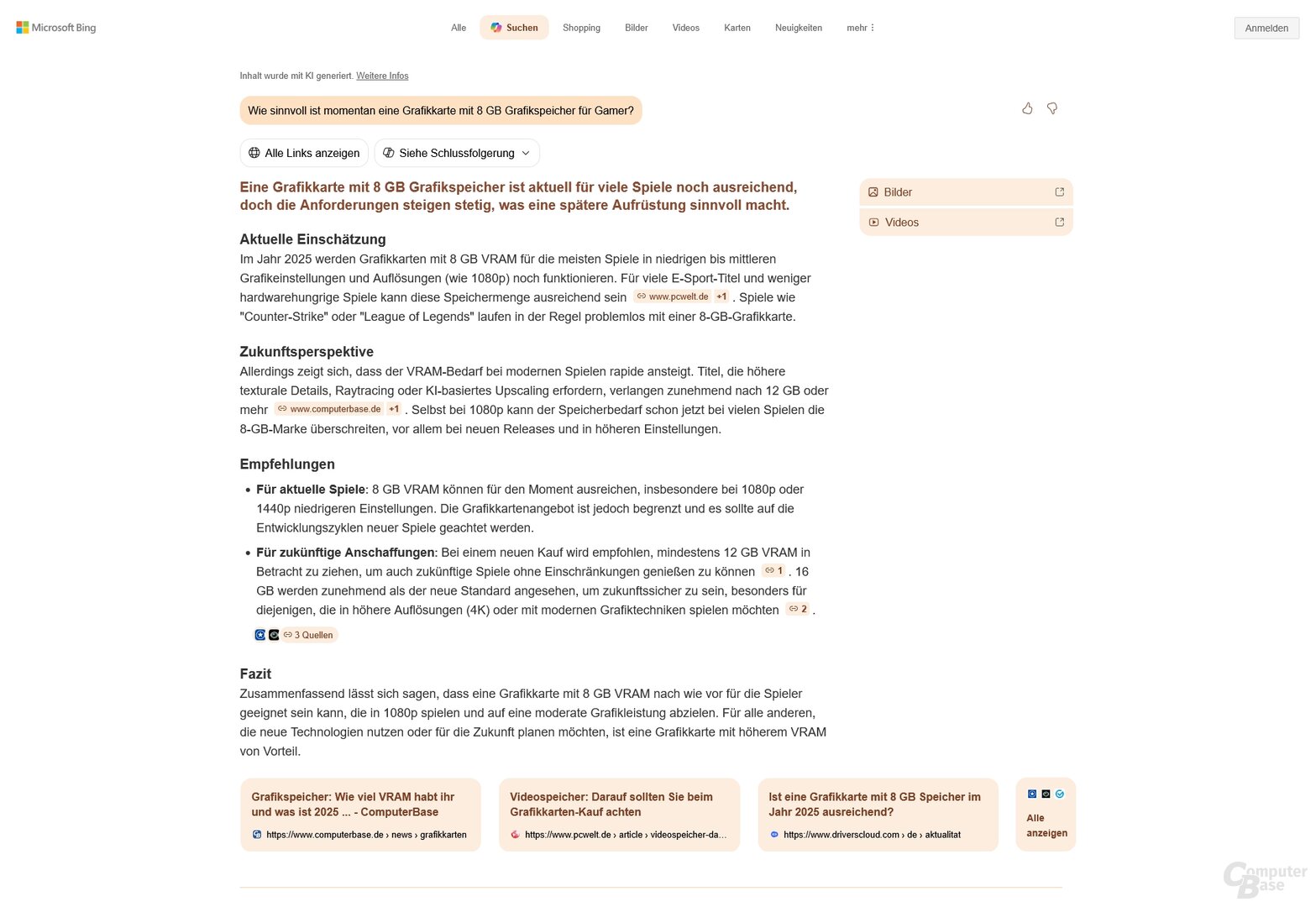
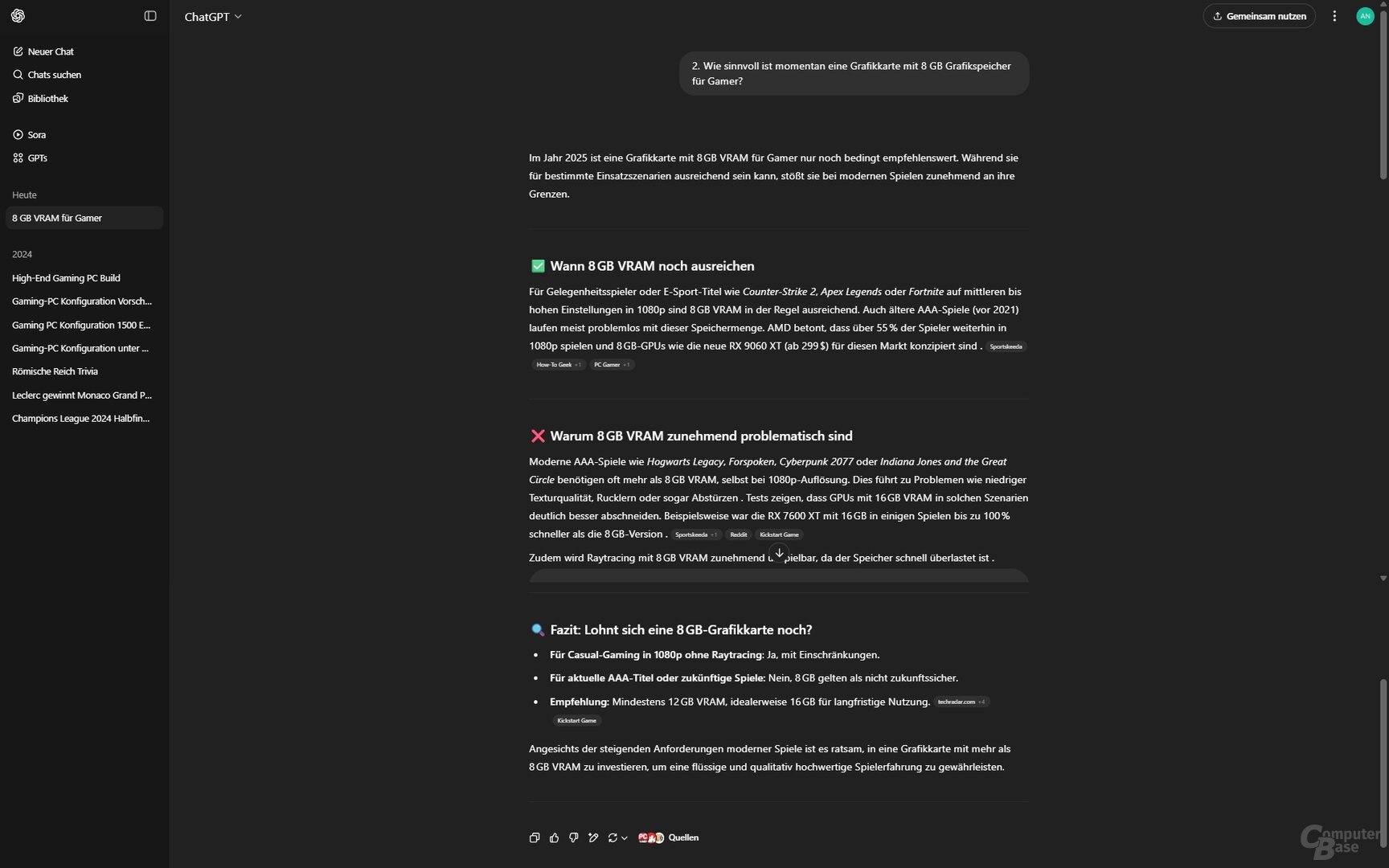
Dass diese Menge an VRAM kritisch ist, ordnen alle KI-Suchen ordentlich ein. Der Tenor: Für Full HD und Gelegenheitsspieler mag es derzeit noch ausreichen, mehr wäre indes besser. So weit sind die Ergebnisse also passabel. Wilder wird es indes bei der Folgefrage nach einer Grafikkarten-Empfehlung, die zukunftssicher ist.
Ein Problem ergibt sich zunächst aus der Suchanfrage, die generell viel zu allgemein ist. Im Kontext mit der vorausgehenden Frage nach den 8 GB VRAM sollte aber naheliegend sein, dass man das Preisleistungsverhältnis im Blick hat. Sinnvoll wäre daher vor allem eine Antwort, die auf aktuelle Ranglisten wie die von ComputerBase verweist.
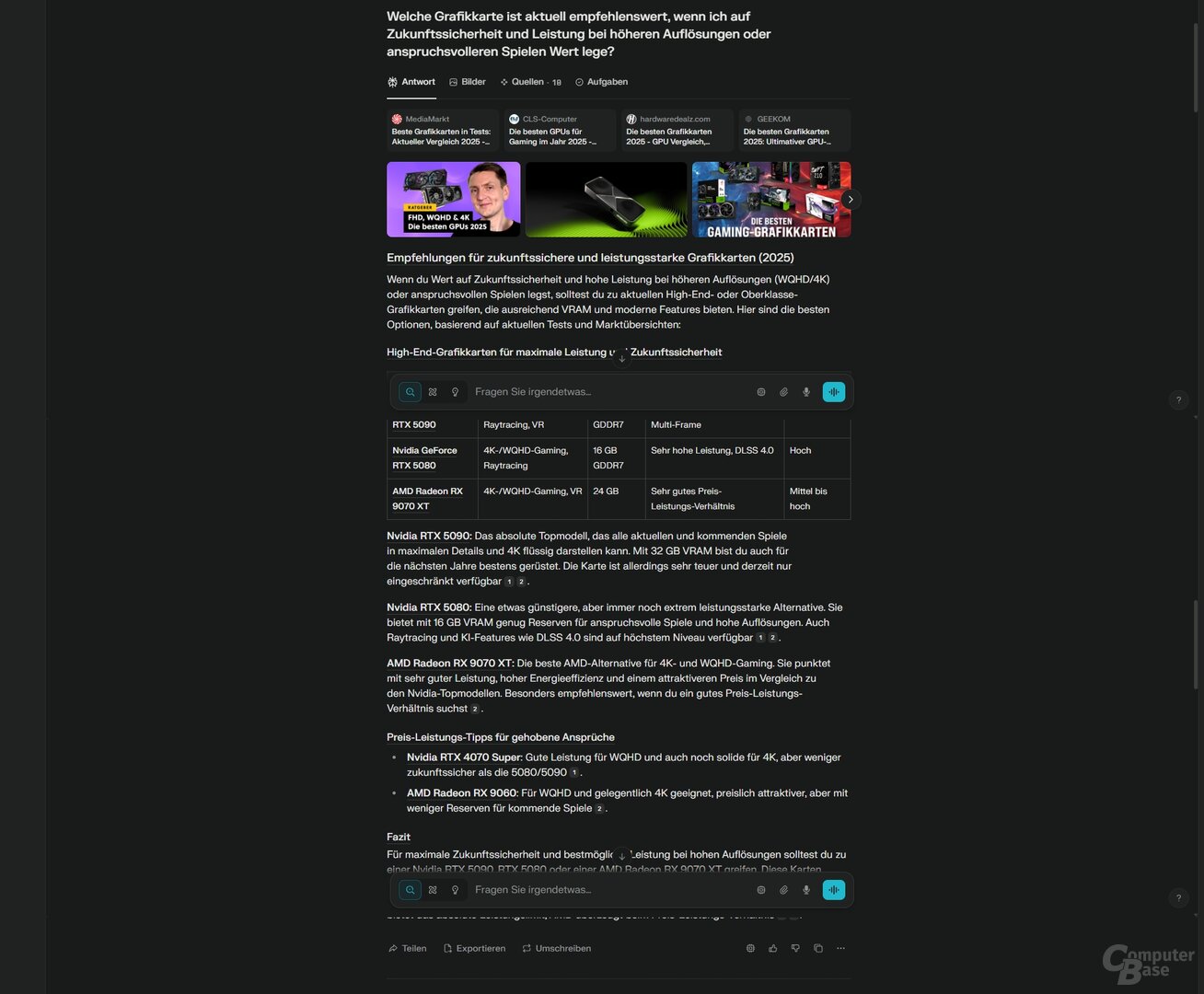
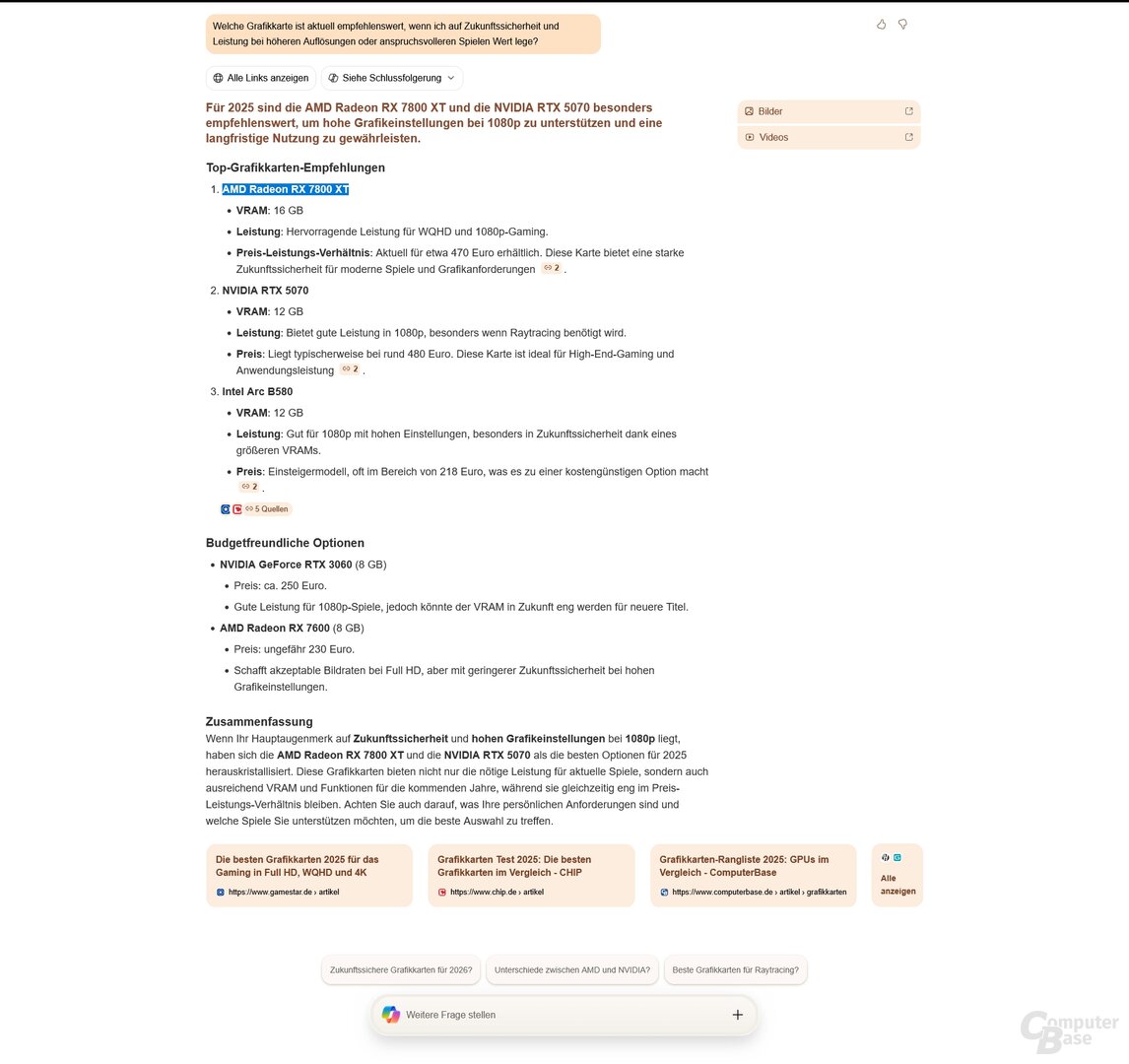
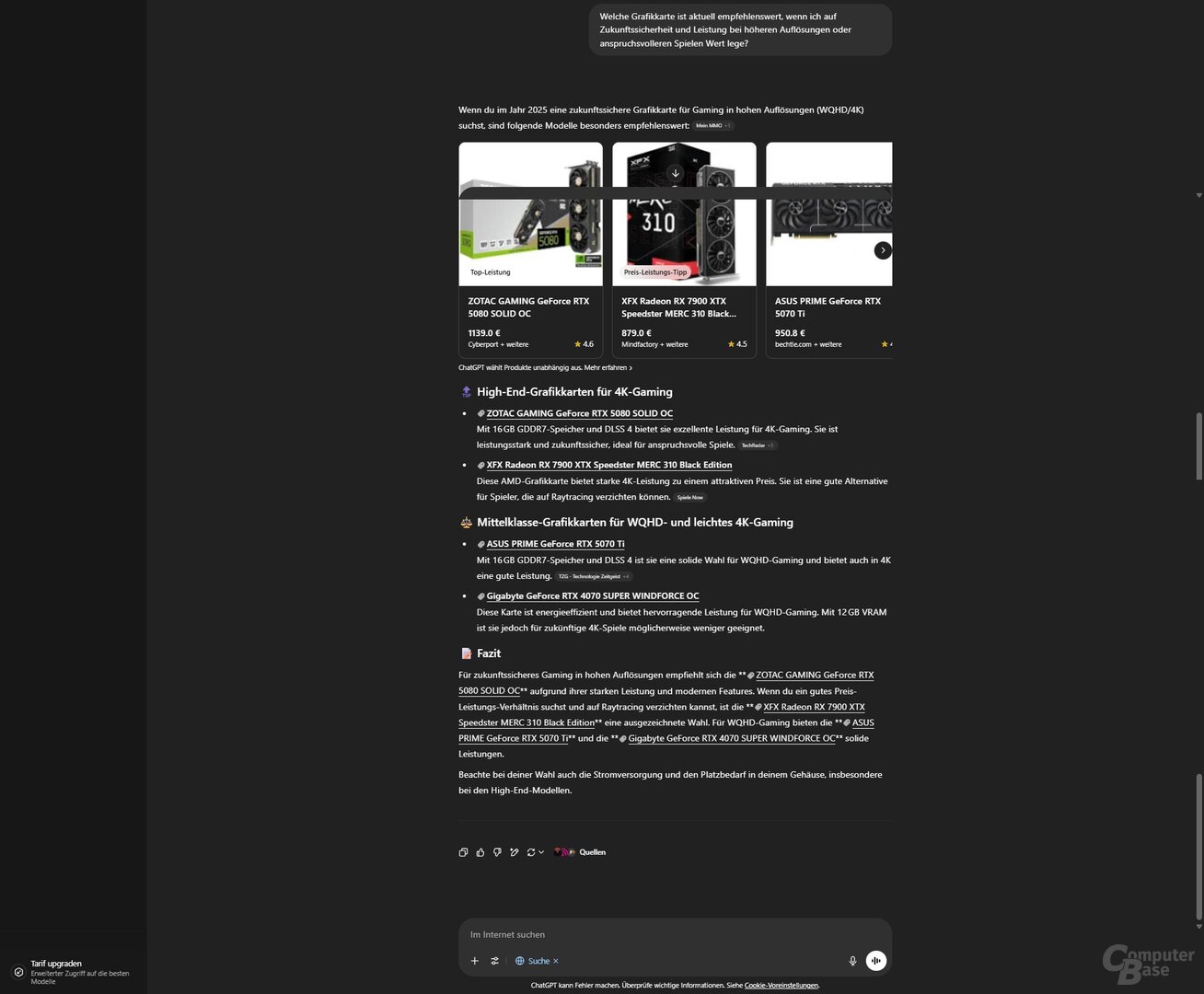
Das machen die KI-Suchen aber nicht. Stattdessen versuchen diese, einzelne Modelle zu empfehlen. Nur sind diese Empfehlungen in der Regel schlicht Top-Modelle oder Mittelklasse-Modelle, bei denen die Auswahl relativ zufällig wirkt. Auch bei den Preisen wirkt es bisweilen konfus. So empfiehlt ChatGPT Search etwa eine Zotac GeForce RTX 5080 Solid OC für 1.139 Euro, in der verlinkten Quellen-Liste findet sich konkret dieser Preis aber nicht. Immerhin: Der Marktpreis passt in etwa. Copilot Search hat eine Radeon RX 7800 XT für rund 470 Euro in der Liste, was sich mit den Ergebnissen von Geizhals deckt. Die GeForce RTX 5070 wurde aber mit rund 100 Euro zu günstig bepreist.
Anmerkung: AI Overview wurde nicht erfasst, weil dort ohne Chatbot-Interface keine Folgefragen möglich sind. Und einen Maßstab für Grafikkarten-Empfehlungen liefert etwa der Ratgeber Der Ideale Gaming-PC.
Konkret und einordnend sind die KI-Tipps jedoch nicht. Nachfragen ist aber immer möglich, was generell einer der Vorteile ist. Man kann sich etwa schnell eine tabellarische Übersicht von allen Grafikkarten mit 16 GB VRAM samt Preis erstellen lassen. Angesichts der Probleme mit Preisen und Zahlen mangelt es bei solchen Ergebnissen aber an der Qualität – ein Link auf Preisvergleich-Suchmaschinen wäre hier die adäquate Antwort.
Test 3: IT-Fehler – wie lässt sich eine BitLocker-Schleife erkennen?
Prompt: Ich nutze Windows 11 24H2 und habe gerade ein Windows-Update installiert. Wenn ich den Rechner starte, lande ich jetzt im BitLocker-Recovery-Menü. Egal was ich mache, der Rechner bleibt hängen. Was kann ich tun?
Die Anfrage zielt auf den BitLocker-Fehler, bei dem sich Windows-11-Rechner aufgrund eines Bugs im Mai-Update in einer Recovery-Schleife aufhängen konnten. Für betroffene Systeme gab es einen Workaround, man musste die Virtualisierungsfunktion TXT im BIOS vorübergehend deaktivieren. Mittlerweile steht ein Update bereit.
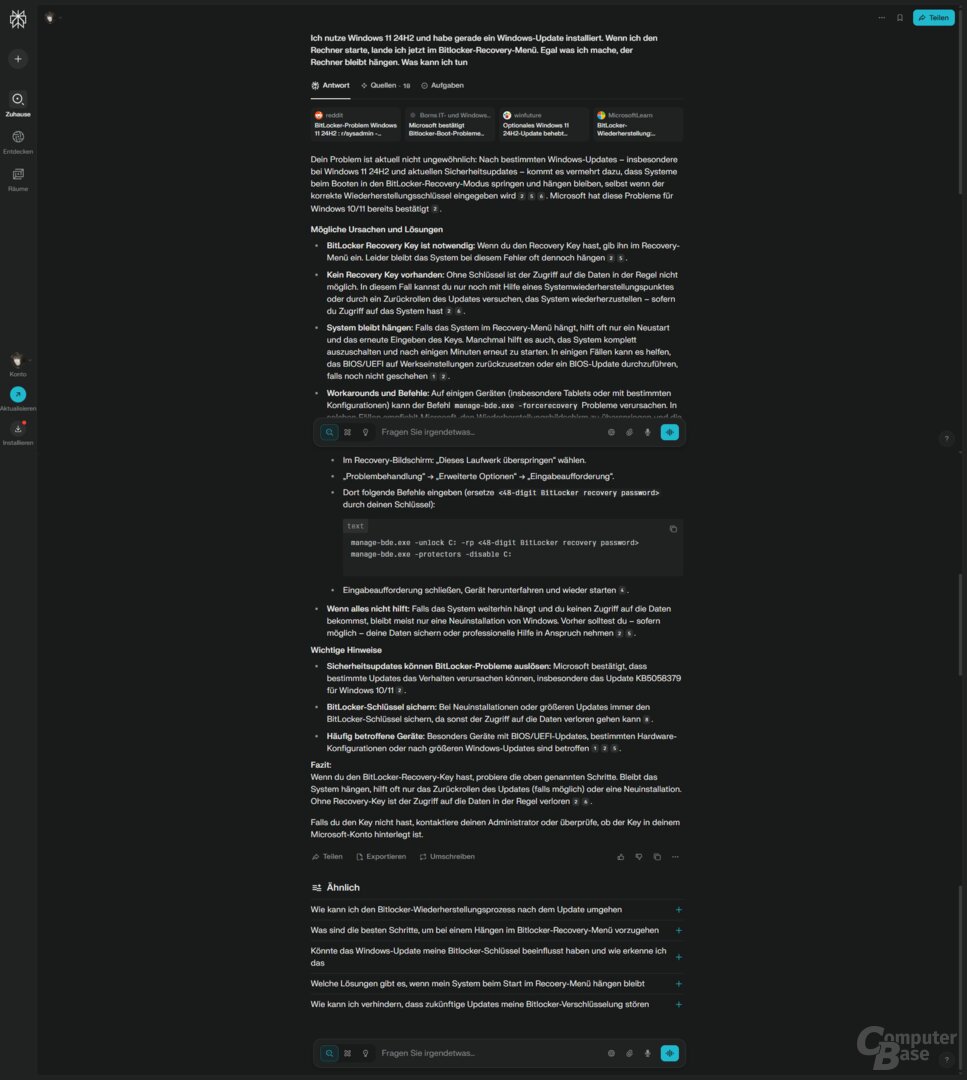
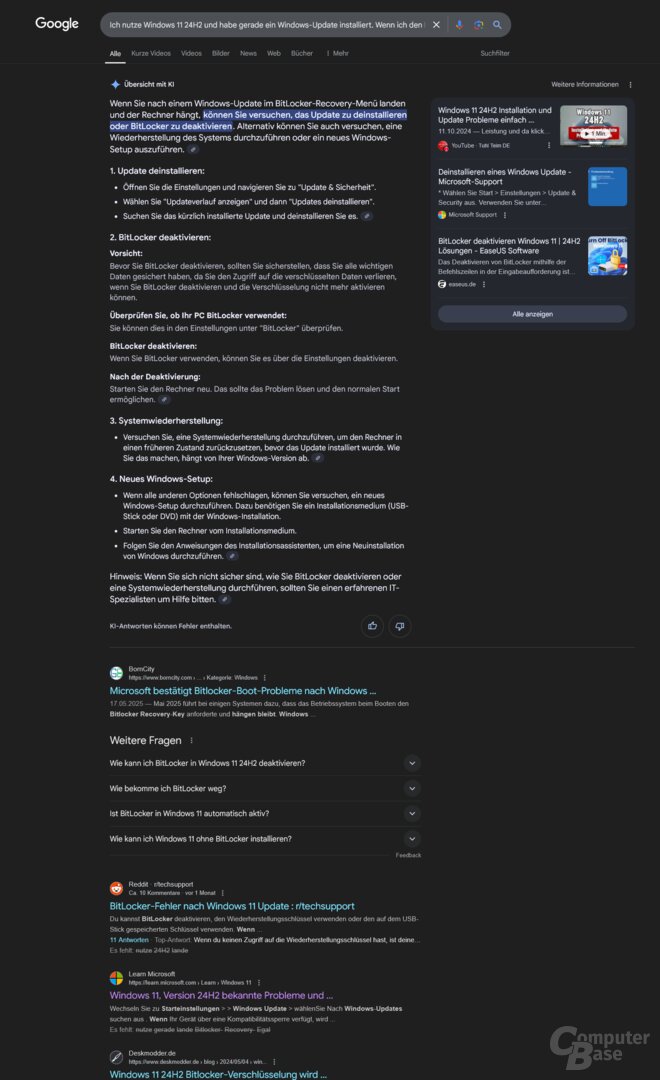

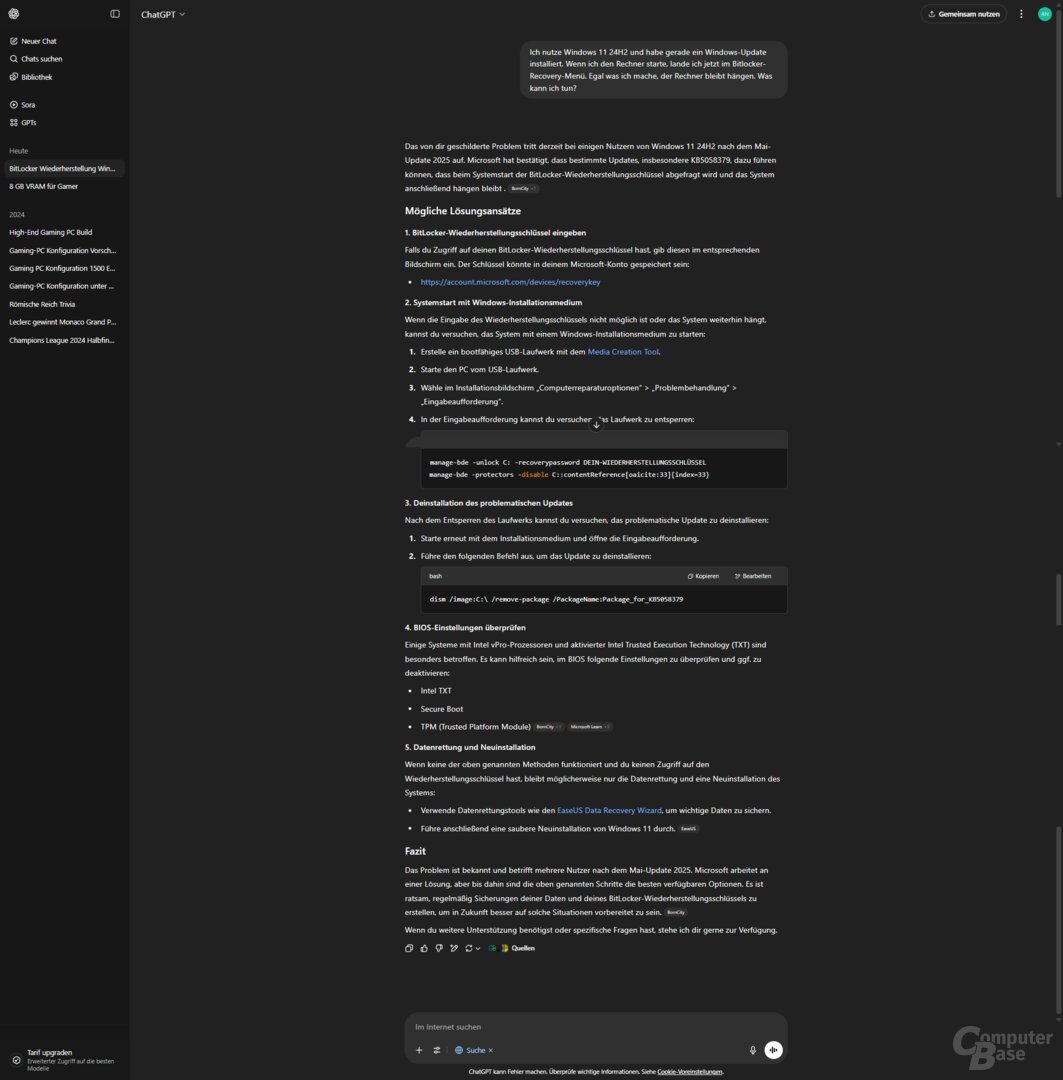
Korrekt beantwortet wurde die Anfrage nur von ChatGPT Search, verwiesen wird sowohl auf den konkreten Bug als auch die Möglichkeiten, um diesen zu umgehen. Copilot Search bleibt allgemeiner, verweist aber ebenfalls auf das Mai-Update und den Workaround. Bei Perplexity geht es allgemein um BitLocker-Probleme, das Mai-Update erscheint nur als Hinweis im Kleingedruckten. Und beim AI Overview tauchen die aktuellen Probleme überhaupt nicht auf, obwohl der erste Artikel in den Suchergebnissen die passende Antwort liefert – nur eben nicht an erster Stelle auf der Webseite, sondern erst nach der generierten Antwort.
Test 4: Warum hat Windows 11 höhere Hardware-Anforderungen?
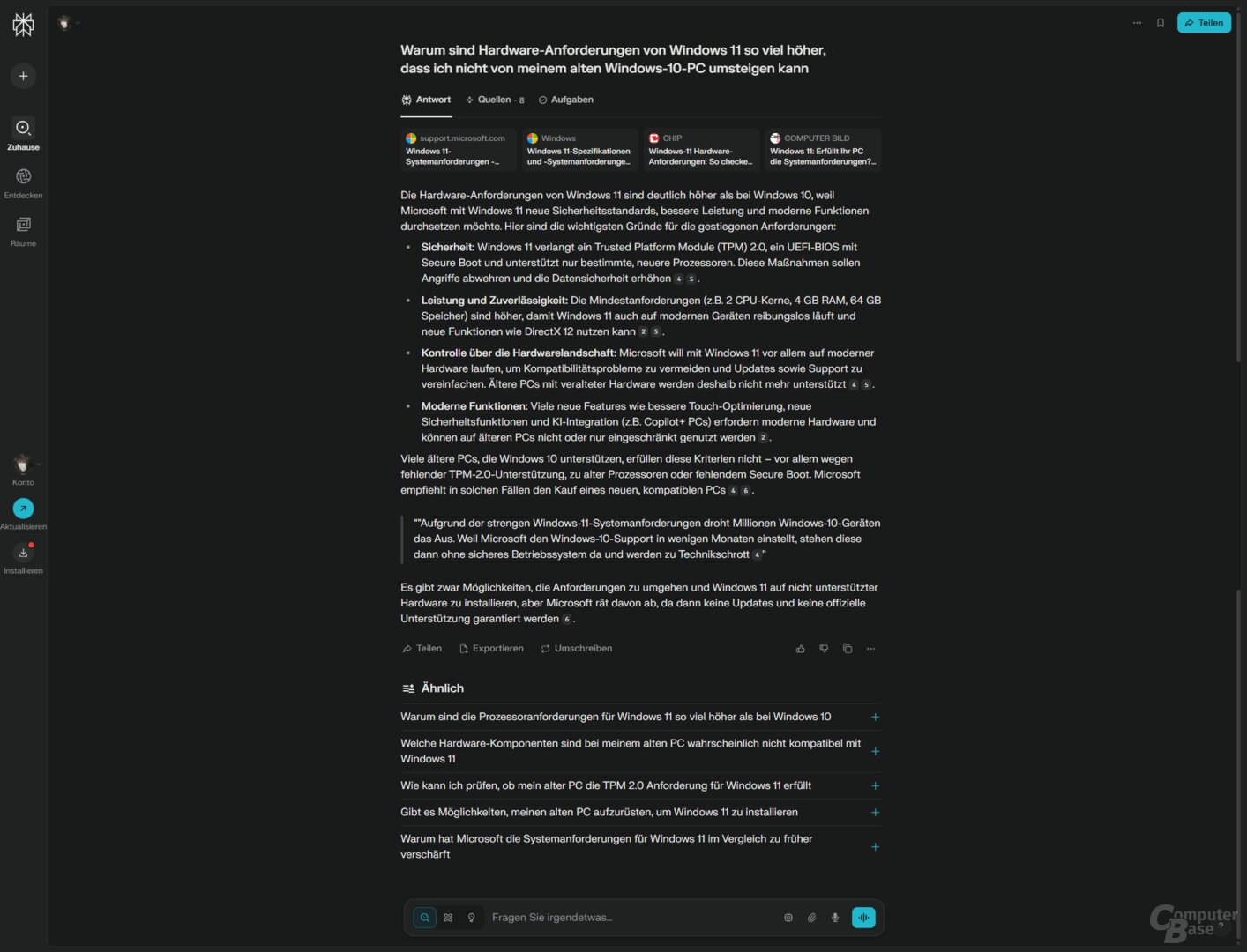
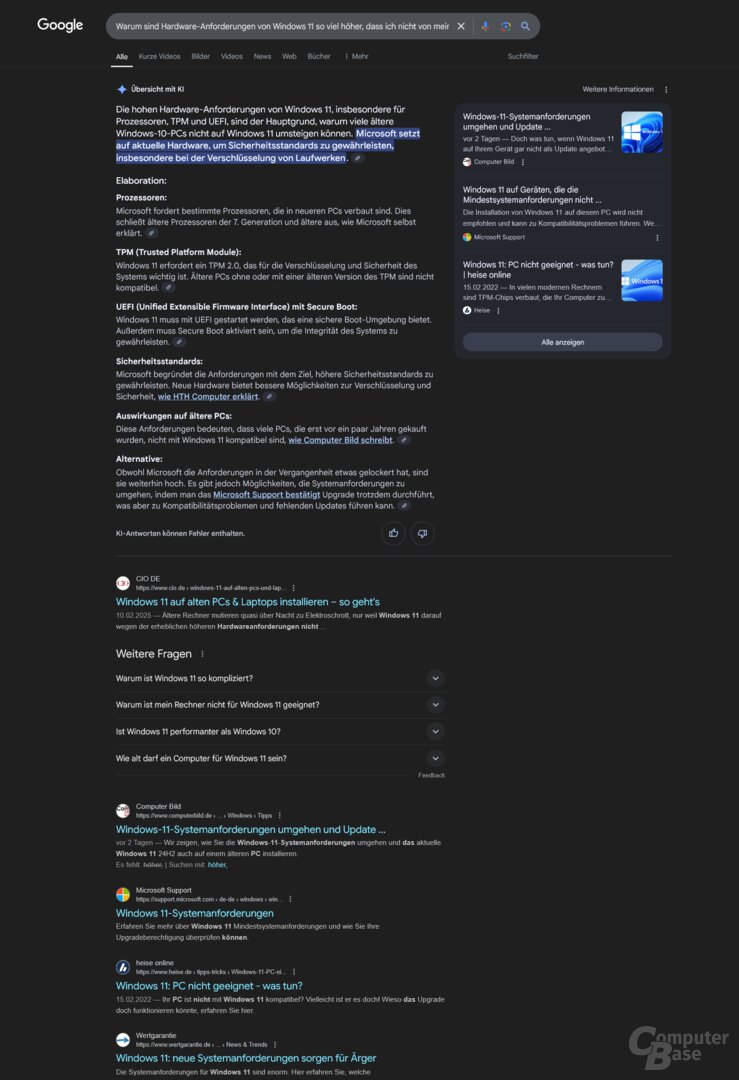
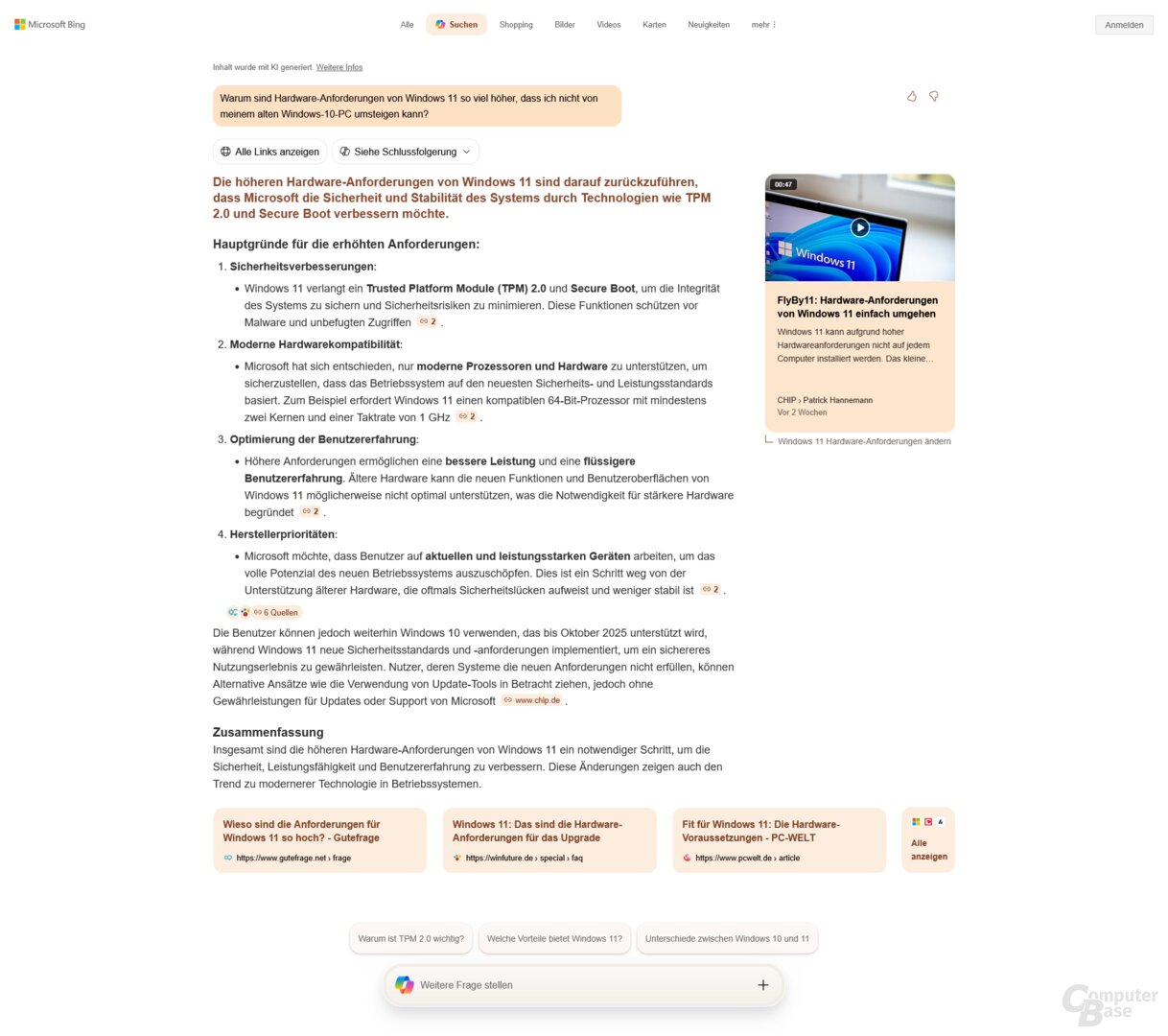
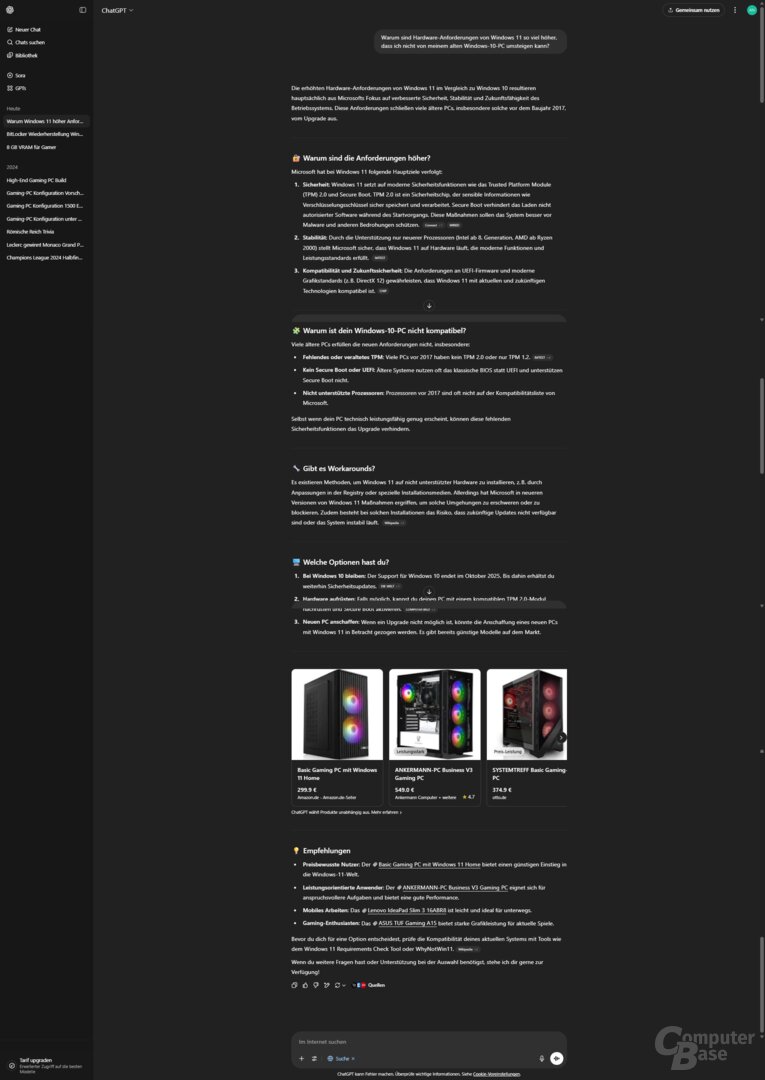
Prompt: Warum sind die Hardware-Anforderungen von Windows 11 so viel höher, dass ich nicht von meinem alten Windows-10-PC wechseln kann?
Eine klassische Wissensfrage, bei der die KI-Suchen ihre Stärken ausspielen können. Alle erklären, höhere Sicherheitsanforderungen wie TPM 2.0 und Secure Boot führen dazu, dass ältere CPU-Generationen nicht mehr unterstützt werden; zusätzlich liefern diese noch weitere Hinweise. Dass es bei den vollständigen KI-Suchen möglich ist, Folgefragen zu stellen, ist in diesem Fall ein enormer Vorteil – die wenigsten Nutzer werden sich im Alltag mit Aspekten wie TPM befasst haben und ihren Prozessor einer bestimmten Generation zuordnen können.
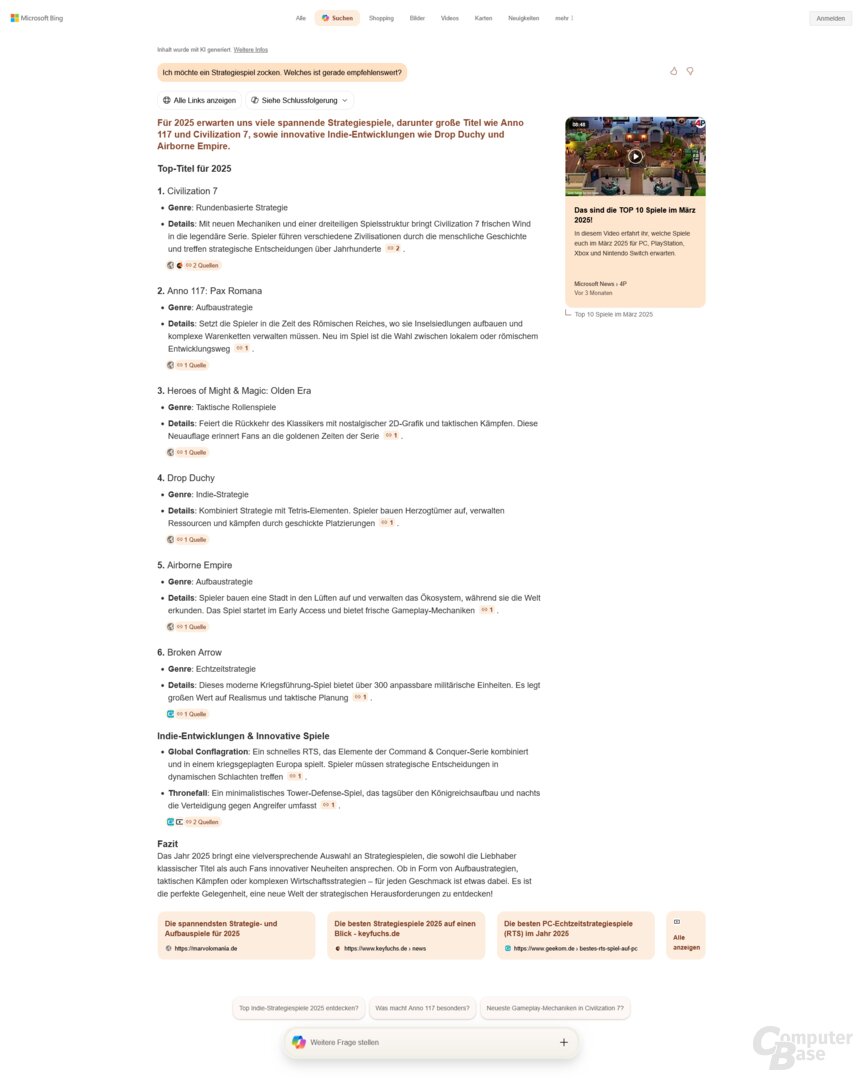
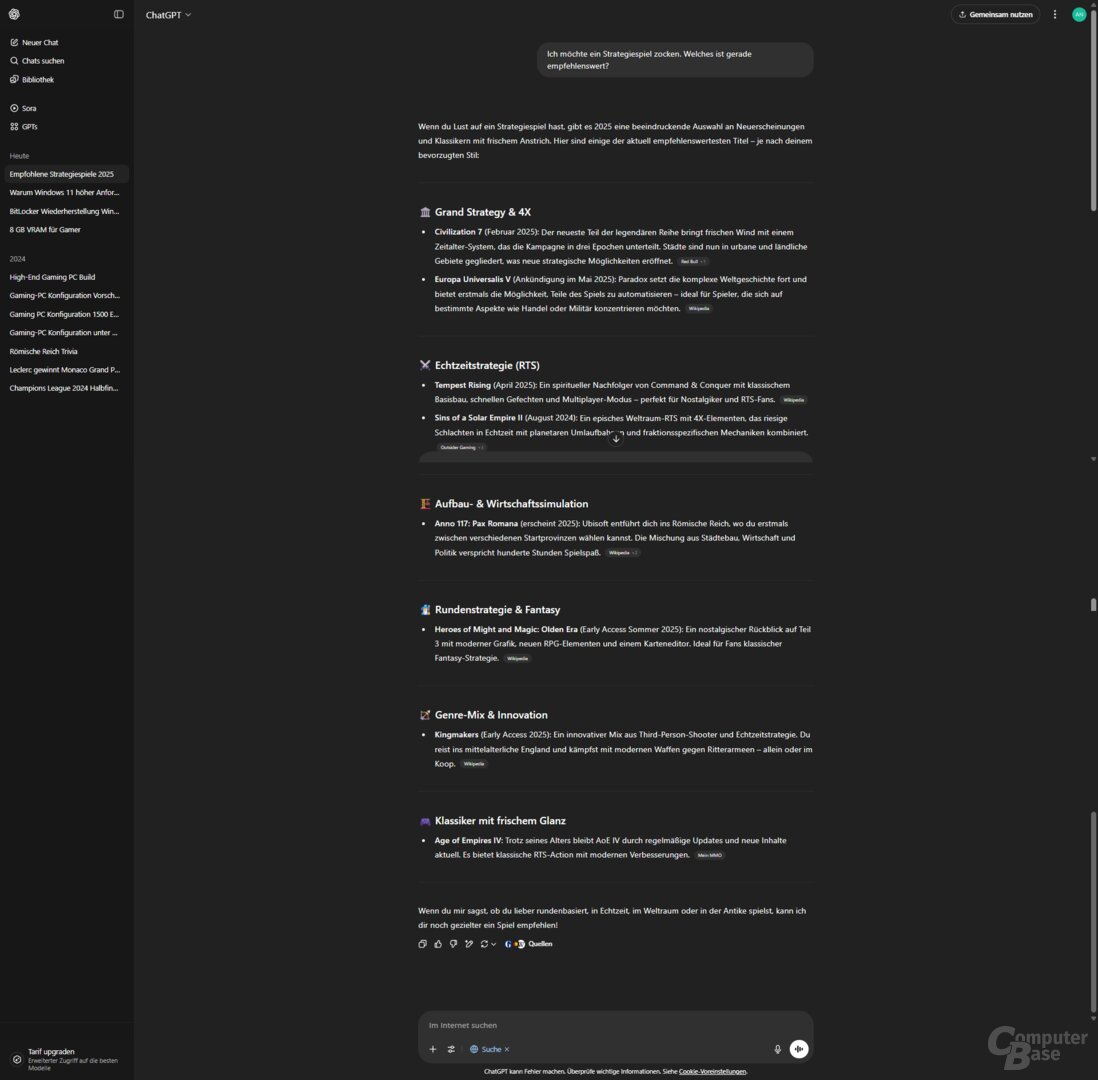
Test 5: Welches Strategiespiel ist empfehlenswert?
Prompt: Ich möchte ein Strategiespiel zocken. Welches ist gerade empfehlenswert?
Erneut eine vage Anfrage, die KI-Suchen sollen also eine Übersicht liefern. Das klappt mal besser und mal schlechter. Während AI Overview als erstes Civilization VI sowie StarCraft II nennt und bei der Antwort generell keine gute Figur macht, gibt ChatGPT Search konkrete Tipps, unterteilt nach Genres. Was erstaunt: Mal sind Spiele bereits erschienen, mal handelt es sich um Titel, die erst im Laufe des Jahres veröffentlicht werden. Generell ist die Auswahl aber solide. Dasselbe gilt für die Übersicht von Copilot Search.
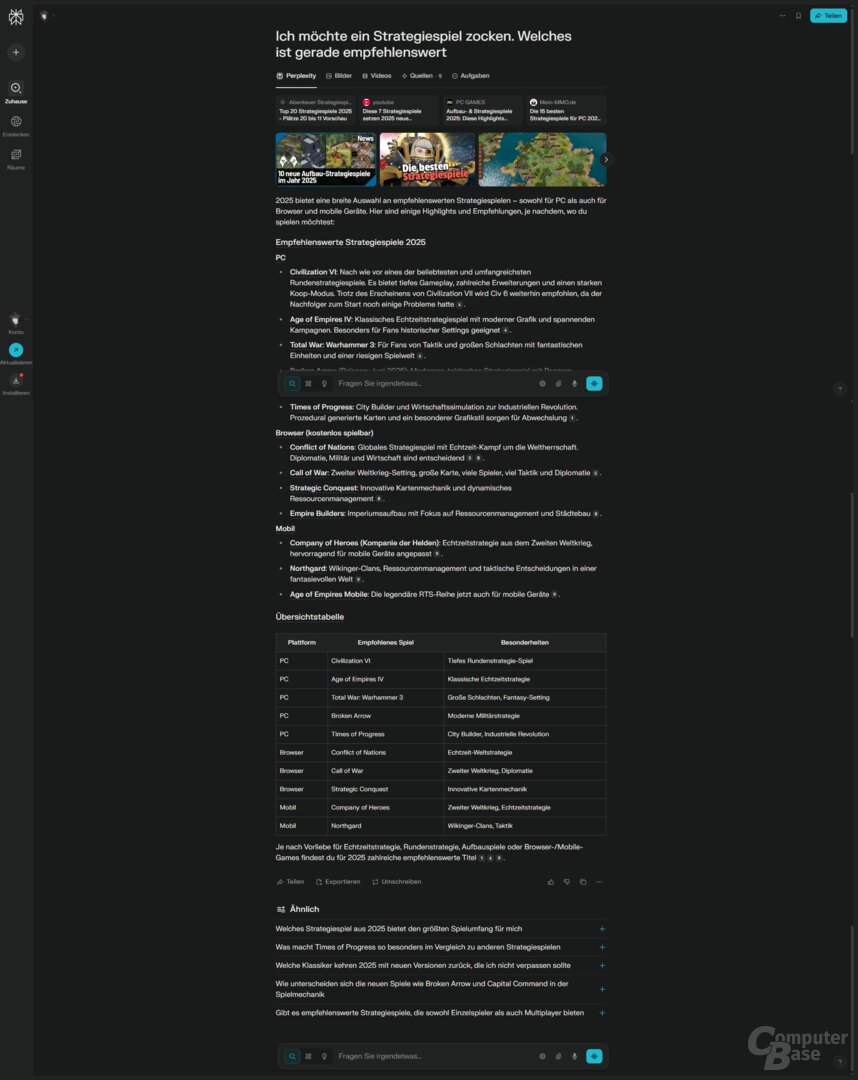
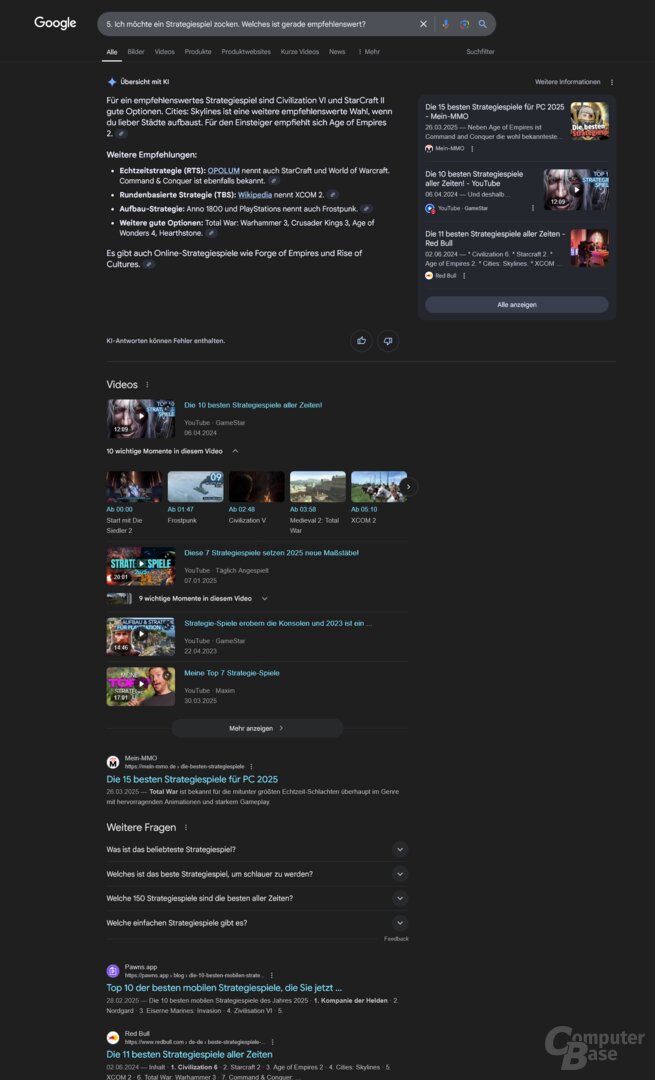
Perplexity fällt hingegen zurück. Die ersten Tipps sind Civilization VI, Age of Empires 4 und Warhammer 3 – viel uninspirierter geht es kaum. Weitere Empfehlungen wie Times of Progress sind hingegen Nischentitel. Separat werden noch Browser- und Mobil-Spiele genannt, was grundsätzlich zwar ein Pluspunkt ist, jedoch schwächelt die KI-Suche in diesem Bereich ebenfalls bei der Auswahl. Einer von drei Tipps ist Strategic Conquest – ein Spiel aus den 1980ern, das sich mittlerweile über den Browser spielen lässt. Generell scheiterte Perplexity wieder daran, passende Quellen zu wählen.
Test 6: Wie lauten die aktuellen Bundesligaergebnisse?
Prompt: Wie lauten die Ergebnisse vom aktuellen Bundesligaspieltag?
Die Bundesligaergebnisse wurden bereits am 31. Spieltag abgefragt, der Zeitpunkt war der 27. April (Sonntag) gegen 13 Uhr. Die Freitag- und Samstagspiele haben also schon stattgefunden, die Sonntagspiele standen noch aus. Es ist ein ähnliches Testszenario wie bei der Anfrage zum DFB-Pokal im Dezember 2024, als ChatGPT Search Ergebnisse erfand – und zwar sogar von Spielen, die noch nicht stattgefunden haben.
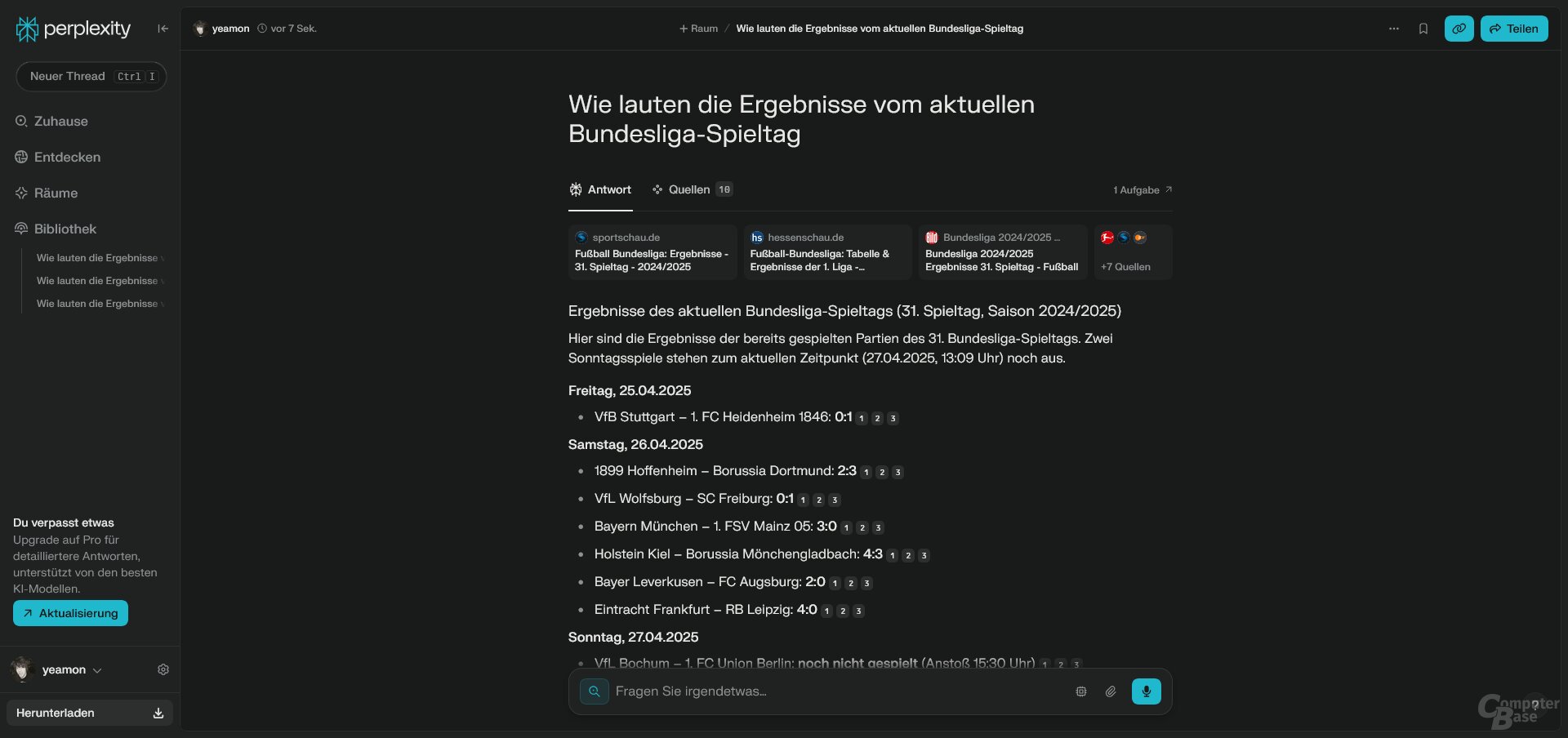
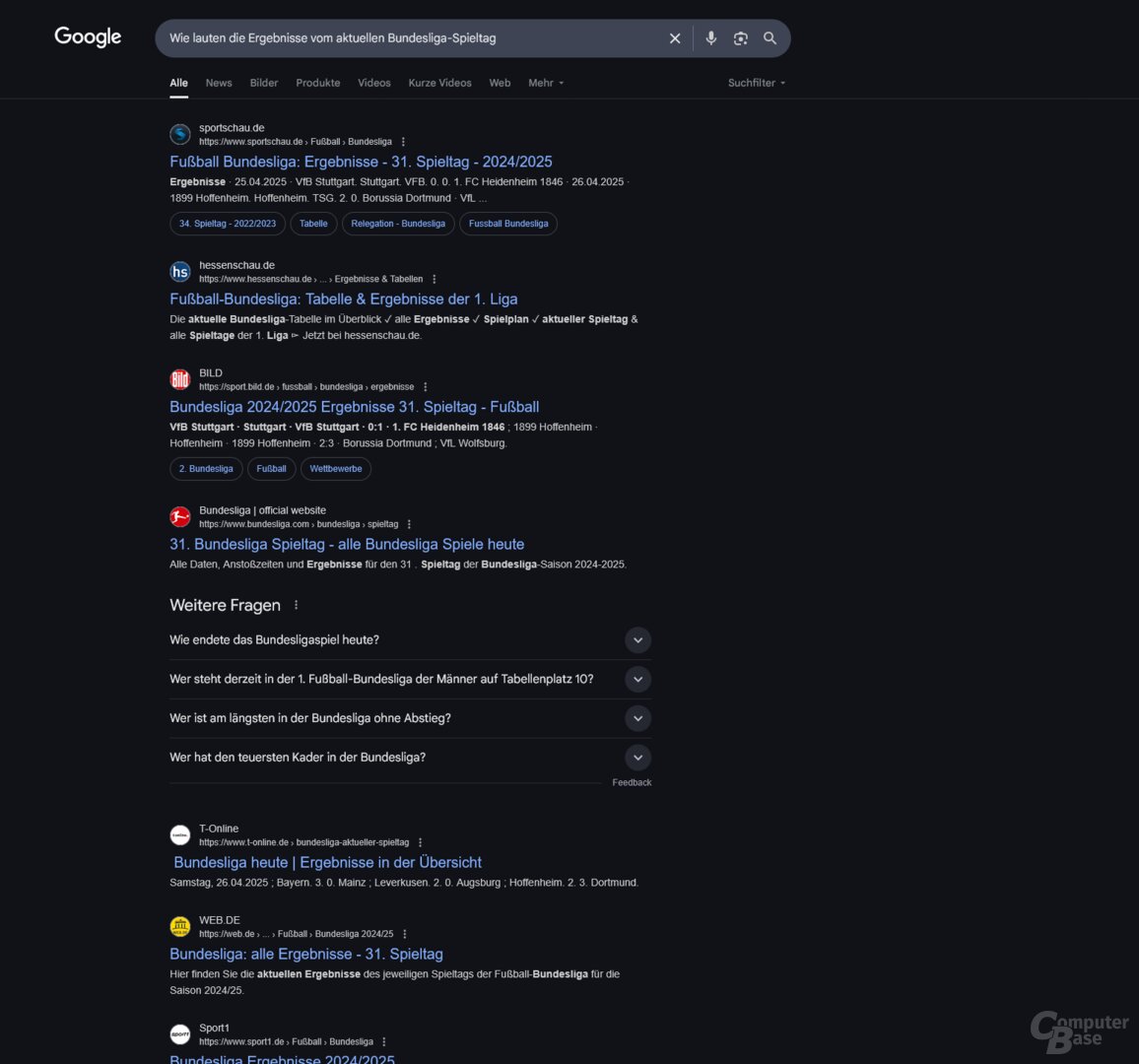
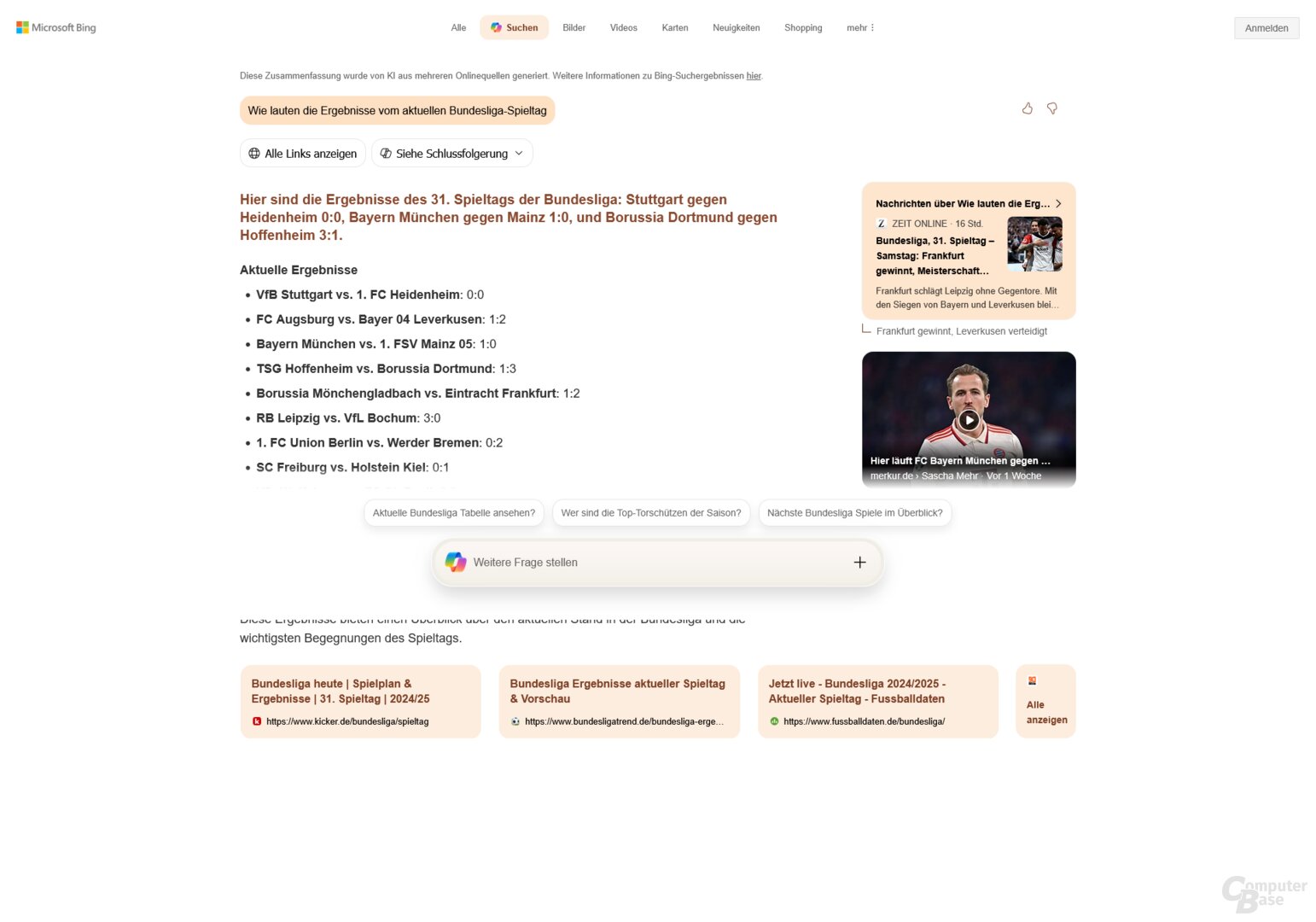
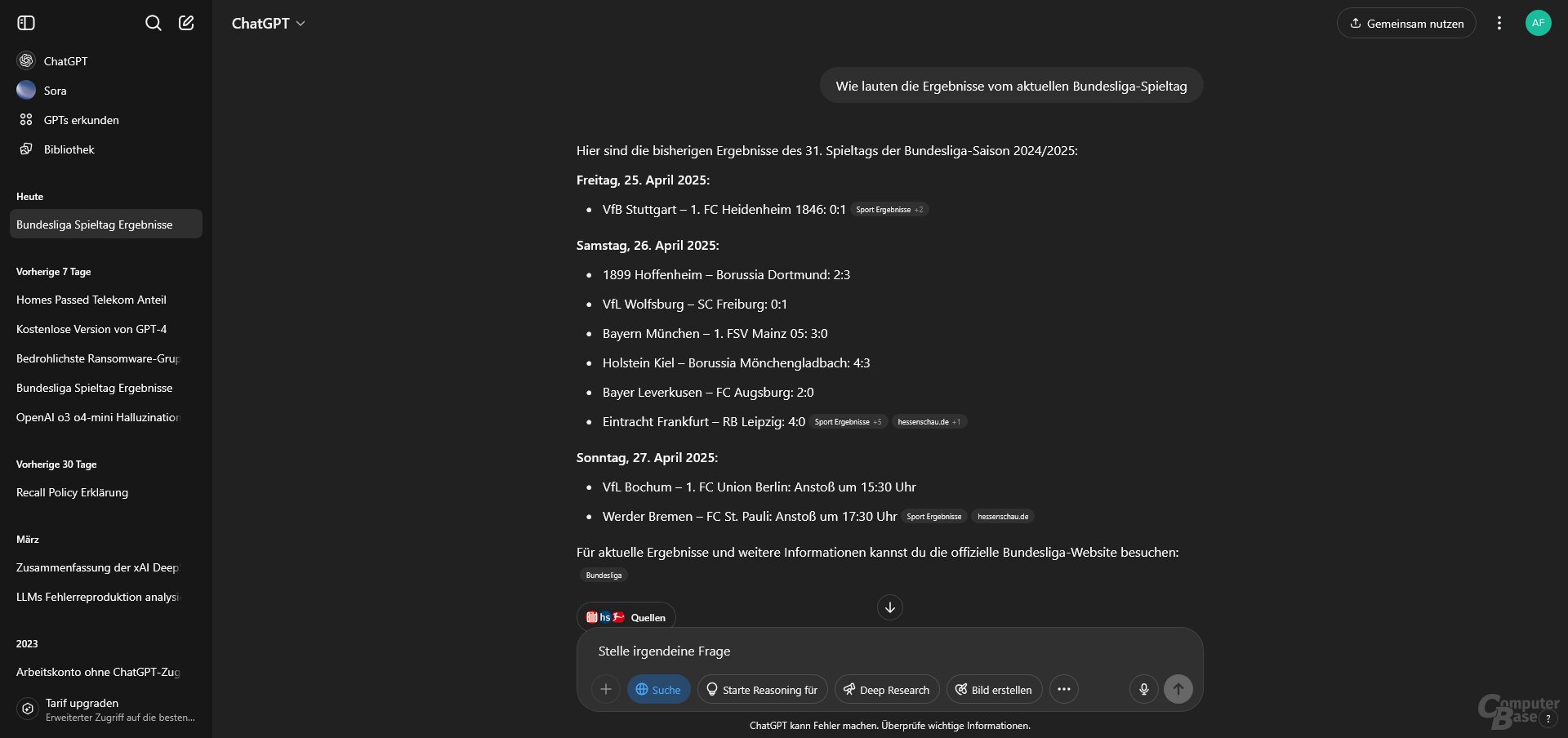
OpenAI scheint die Probleme mittlerweile im Griff zu haben, ChatGPT Search liefert ebenso wie Perplexity die korrekten Ergebnisse. Google generierte bei dieser Anfrage keine AI-Overview-Antwort, Aussetzer hatte hingegen Copilot Search. Falsche Ergebnisse, falsche Paarungen, erfundene Ergebnisse – Microsofts KI-Suche scheiterte bei dieser Anfrage voll und ganz.
Fazit: Wo es noch hakt
Selbst wenn es nur ein kleiner Testlauf in Tech-relevanten Themen ist, verraten die Ergebnisse schon etwas: KI-Suchen haben unbestreitbare Vorteile. Wer in ein Thema einsteigen will, kann sich wesentlich leichter einen Überblick verschaffen, weil man direkt eine Antwort auf spezifische Fragen erhält. Insbesondere bei Wissensfragen klappt es auch gut. Doch Schwächen sind noch da und diese sind nach wie vor erstaunlich:
- Je aktueller das abgefragte Wissen ist, desto eher kann es zu Problemen kommen. Dass nur ein Dienst das aktuell wertvollste Unternehmen korrekt benennen konnte, ist dafür symptomatisch.
- Zahlen bleiben ein Problem, das zeigte sich etwa schon beim Test von OpenAIs Recherche-Tools Deep Research. Im Fall der KI-Suche gilt das etwa für Produkt-Preise.
- Je konkreter man nach einem Produkt fragt, desto besser ist die Einordnung. Allgemeine Übersichten gelingen noch nicht, die Ergebnisse wirken oftmals wie ausgewürfelt oder sind uninspiriert.
- Typische KI-Probleme: Irreführende Antworten und kleine Fehler sind nur schwer zu erkennen – vor allem, wenn man selbst nicht tief in der Materie steckt.
Wie gut die KI-Suche abschneidet, hängt auch vom Anbieter ab. ChatGPT Search macht mittlerweile den ausgereiftesten Eindruck, Perplexity zeigt Licht und Schatten, Copilot Search wirkt bisweilen erstaunlich unfertig. Beim AI Overview bemerkt man die Zwischenlösung, das System generiert kürzere Antworten und man landet als Nutzer eher noch bei den herkömmlichen Suchergebnissen – ein Aspekt, der nicht unbedingt ein Kritikpunkt ist.
Unbefriedigend bleiben die Antworten generell, wenn es um allgemeine Empfehlungen wie zukunftsfähige Grafikkarten oder aktuelle Strategiespiele geht. Eine adäquate Antwort wäre, wenn die Suchmaschine in diesem Fall auf aktuelle Ranglisten verweisen würden, die Fachmedien bereitstellen. Das passiert eher nicht, die Quellenauswahl ist bisweilen wild.
Zu viel Einfluss hat auch noch die Prompt-Formulierung. Wie schon seit Jahrzehnten bei der Google-Suche gibt es auch bei den AI-Chatbots zahlreiche Ratgeber, die erklären, wie man mit den richtigen Eingaben die Antworten optimiert. Und wie schon seit Jahrzehnten bei der Google-Suche kann man davon ausgehen, dass Menschen in der Regel einfach direkt eine Anfrage stellen, ohne auf spezifische Vorgaben zu achten. Daher müssen die Dienste auch mit solchen Eingaben umgehen können. Dass insbesondere Perplexity immer wieder Probleme hat, wenn der Prompt nicht passt, ist ernüchternd.
Die neuen KI-Suchen verändern nicht nur die Art, wie man im Internet nach Informationen sucht, sondern haben massiven Einfluss auf das Ökosystem. Wie dieser sich auswirkt, beschreibt ComputerBase in einer separaten Analyse.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.