Künstliche Intelligenz
DeepSeek-OCR: Bilder vereinfachen Texte für große Sprachmodelle
Viele Unternehmensdokumente liegen zwar als PDFs vor, sind aber häufig gescannt. Obwohl es simpel klingt, können diese Dokumente oftmals nur unter großen Mühen in Text gewandelt werden, insbesondere wenn die Struktur der Dokumente komplexer ist und erhalten bleiben soll. Auch Bilder, Tabellen und Grafiken sind häufige Fehlerquellen. In den letzten Monaten gab es daher eine wahre Flut von OCR-Software, die auf großen Sprachmodelle (LLMs) setzt.
Weiterlesen nach der Anzeige
Auch der chinesische KI-Entwickler DeepSeek steigt nun in diesen Bereich ein und veröffentlicht nach dem Reasoning-Modell R1 ein experimentelles OCR-Modell unter MIT-Lizenz. Auf den ersten Blick mag das verblüffen, denn OCR schien bisher nicht die Kernkompetenz von DeepSeek zu sein. Und tatsächlich ist das neue Modell erstmal eine Technikdemo für einen neuen Ansatz in der Dokumentenverarbeitung von großen Sprachmodellen.


Prof. Dr. Christian Winkler beschäftigt sich speziell mit der automatisierten Analyse natürlichsprachiger Texte (NLP). Als Professor an der TH Nürnberg konzentriert er sich bei seiner Forschung auf die Optimierung der User Experience.
DeepSeek versucht, lange Textkontexte in Bildern zu komprimieren, da sich hierdurch eine höhere Informationsdichte mit weniger Token darstellen lässt. DeepSeek legt die Messlatte für die Erwartungen hoch und berichtet, dass das Modell bei hohen Kompressionsraten (Faktor 10) noch eine Genauigkeit von 97 Prozent erreicht, bei einer noch stärkeren Kompression fällt zwar die Genauigkeit, bleibt dabei aber relativ hoch. Das alles soll schneller funktionieren als bei anderen OCR-Modellen und auf einer Nvidia A100-GPU bis zu 200.000 Seiten pro Tag verarbeiten.
Das Kontext-Problem
Large Language Models haben Speicherprobleme, wenn der Kontext von Prompts sehr groß wird. Das ist der Fall, wenn das Modell lange Texte oder mehrere Dokumente verarbeiten soll. Grund dafür ist der für effiziente Berechnungen wichtige Key-Value-Cache, der quadratisch mit der Kontextgröße wächst. Die Kosten der GPUs steigen stark mit dem Speicher, was dazu führt, dass lange Texte sehr teuer in der Verarbeitung sind. Auch das Training solcher Modelle ist aufwendig. Das liegt allerdings weniger am Speicherplatz, sondern auch an der quadratisch wachsenden Komplexität der Berechnungen. Daher forschen die LLM-Anbieter intensiv daran, wie sich man diesen Kontext effizienter darstellen kann.
Hier bringt DeepSeek die Idee ins Spiel, den Kontext als Bild darzustellen: Bilder haben eine hohe Informationsdichte und Vision Token zur optischen Kompression könnten einen langen Text durch weniger Token. Mit DeepSeek-OCR haben die Entwickler diese Grundidee überprüft – es ist also ein Experiment zu verstehen, das zeigen soll, wie gut die optische Kompression funktioniert.
Weiterlesen nach der Anzeige
Die Modellarchitektur
Der dazugehörige Preprint besteht aus drei Teilen: einer quantitativen Analyse, wie gut die optische Kompression funktioniert, einem neuen Encoder-Modell und dem eigentlichen OCR-Modell. Das Ergebnis der Analyse zeigt, dass kleine Sprachmodelle lernen können, wie sie komprimierte visuelle Darstellungen in Text umwandeln.
Dazu haben die Forscher mit DeepEncoder ein Modell entwickelt, das auch bei hochaufgelösten Bildern mit wenig Aktivierungen auskommt. Der Encoder nutzt eine Mischung aus Window und Global Attention verbunden mit einem Kompressor, der Konvolutionen einsetzt (Convolutional Compressor). Die schnellere Window Attention sieht nur einzelne Teile der Dokumente und bereitet die Daten vor, die langsamere Global Attention berücksichtigt den gesamten Kontext, arbeitet nur noch mit den komprimierten Daten. Die Konvolutionen reduzieren die Auflösung der Vision Token, wodurch sich der Speicherbedarf verringert.
DeepSeek-OCR kombiniert den DeepEncoder mit DeepSeek-3B-MoE. Dieses LLM setzt jeweils sechs von 64 Experten und zwei geteilte Experten ein, was sich zu 570 Millionen aktiven Parametern addiert. Im Gegensatz zu vielen anderen OCR-Modellen wie MinerU, docling, Nanonets, PaddleOCR kann DeepSeek-OCR auch Charts in Daten wandeln, chemische Formeln und geometrische Figuren erkennen. Mathematische Formeln beherrscht es ebenfalls, das funktioniert zum Teil aber auch mit den anderen Modellen.
Die DeepSeek-Entwickler betonen allerdings, dass es sich um eine vorläufige Analyse und um ebensolche Ergebnisse handelt. Es wird spannend, wie sich diese Technologie weiterentwickelt und wo sie überall zum Einsatz kommen kann. Das DeepSeek-OCR-Modell unterscheidet sich jedenfalls beträchtlich von allen anderen. Um zu wissen, wie gut und schnell es funktioniert, muss man das Modell jedoch selbst ausprobieren.
DeepSeek-OCR ausprobiert
Als Testobjekt dient eine Seite aus einer iX, die im JPEG-Format vorliegt. DeepSeek-OCR kann in unterschiedlichen Konfigurationen arbeiten: Gundam, Large und Tiny. Im Gundam-Modus findet ein automatisches Resizing statt. Im Moment funktioniert das noch etwas instabil, bringt man die Parameter durcheinander, produziert man CUDA-Kernel-Fehler und muss von vorne starten.
Möchte man den Text aus Dokumenten extrahieren, muss man das Modell geeignet prompten. DeepSeek empfiehlt dazu den Befehl

Im Gundam-Modus erkennt DeepSeek-OCR den gesamten Text und alle relevanten Elemente und kann auch Textfluss des Magazins rekonstruieren.
Den Text hat das Modell praktisch fehlerfrei erkannt und dazu auf einer RTX 4090 etwa 40 Sekunden benötigt. Das ist noch weit entfernt von den angepriesenen 200.000 Seiten pro Tag, allerdings verwendet Gundam auch nur ein Kompressionsfaktor von zwei: 791 Image Token entsprechen 1.580 Text Token. Immerhin erkennt das Modell den Textfluss im Artikel richtig. Das ist bei anderen Modellen ein gängiges Problem.
Mit etwa 50 Sekunden rechnet die Large-Variante nur wenig länger als Gundam, allerdings sind die Ergebnisse viel schlechter, was möglicherweise auch dem größeren Kompressionsfaktor geschuldet ist: 299 Image-Token entsprechen 2068 Text-Token. Im Bild verdeutlichen das die ungenauer erkannten Boxen um den Text – hier gibt es noch Optimierungsbedarf. Außerdem erkennt das Modell die Texte nicht sauber, teilweise erscheinen nur unleserliche Zeichen wie „¡ ¢“, was möglicherweise auf Kodierungsfehler und eigentlich chinesische Schriftzeichen hindeuten könnte.

Der Large-Modus komprimiert die Bilder stärker als Gundam, was zu einer ungenaueren Erkennung führt. Die Textboxen sind unschärfer abgegrenzt und es erscheinen unleserliche Zeichen, die auf eine fehlerhafte Kodierung hinweisen.
Fehler mit unleserlichen Zeichen gibt es beim Tiny-Modell nicht. Das rechnet mit einer Dauer von 40 Sekunden wieder etwas schneller und nutzt einen Kompressionsfaktor von 25,8 – 64 Image-Token entsprechen 1652 Text-Token. Durch die hohe Kompression halluziniert das Modell allerdings stark und erzeugt Text wie „Erweist, bei der Formulierung der Ab- fragen kann ein KI-Assistent helfen. Bis Start gilt es auf Caffès offiziell die Gewicht 50 Prozent der Früh-, der Prüfung und 50 Prozent für den Arzt- und NEUT und in Kürze folgen. (Spezielle)“. Das hat nichts mit dem Inhalt zu tun – auf diese Modellvariante kann man sich also nicht verlassen.

Die Tiny-Variante hat den höchsten Kompressionsfaktor für die Bilder und halluziniert bei der Text-Ausgabe stark. Hier sollte man sich also nicht auf die Ergebnisse verlassen.
Neben der Markdown-Konvertierung lässt DeepSeek-OCR auch ein Free OCR zu, das das Layout nicht berücksichtigt. Damit funktioniert das Modell sehr viel schneller und produziert auch in der Large-Version mit hoher Kompression noch gute Resultate. Diese Variante ist aber nur sinnvoll, wenn man weiß, dass es sich um Fließtexte ohne schwieriges Layout handelt.
Informationen aus Grafiken extrahieren
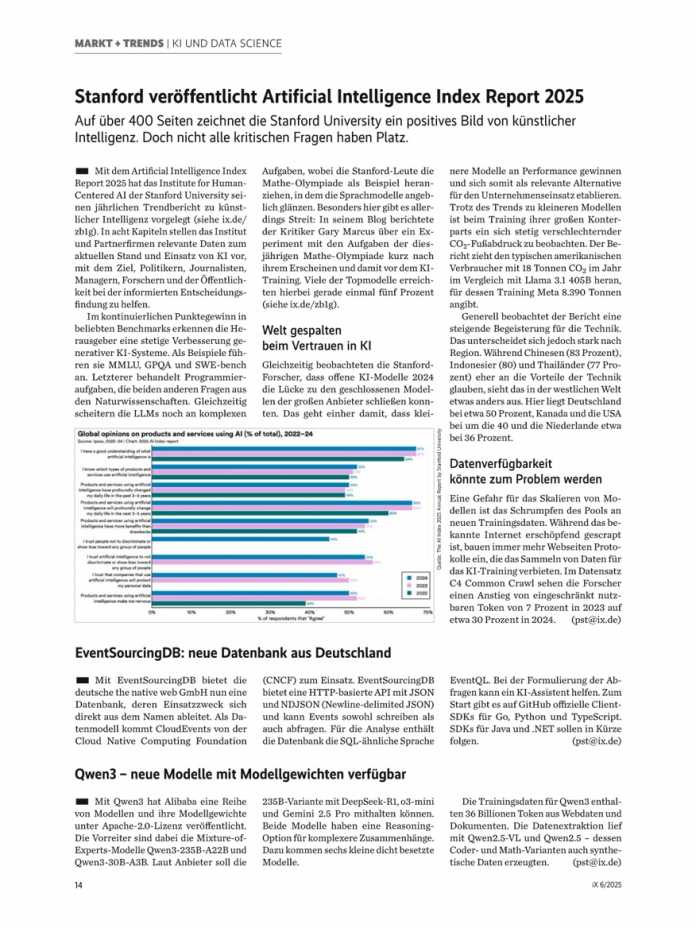
DeepSeek-OCR hat beim Parsing die im Artikel enthaltenen Bilder erkannt und separat abgelegt. Das Diagramm speichert das Modell dabei in einer schlecht lesbaren Auflösung.
Das mit Gundam extrahierte Diagramm ist verschwommen und lässt sich mit bloßem Auge nur noch schlecht entziffern.
Jetzt wird es spannend, denn DeepSeek-OCR soll aus diesem Diagramm auch Daten extrahieren können, das geht mit dem Prompt
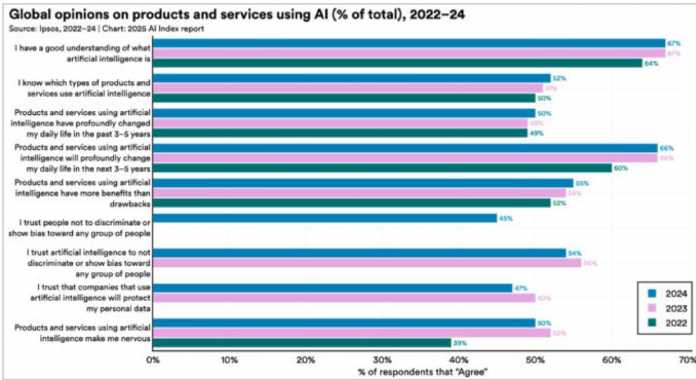
| 2024 | 2023 | 2022 | |
| I have a good understanding of what artificial intelligence is | 67% | 67% | 64% |
| I know which types of products and services use artificial intelligence | 52% | 51% | 50% |
| Products and services using artificial intelligence have profoundly changed my daily life in the past 3-5 years | 50% | 50% | 49% |
| Products and services using artificial intelligence will profoundly change my daily life in the next 3-5 years | 66% | 66% | 60% |
| Products and services using artificial intelligence have more benefits than drawbacks | 55% | 54% | 52% |
| I trust people not to discriminate or show bias toward any group of people | 45% | 45% | 44% |
| I trust artificial intelligence to not discriminate or show bias toward any group of people | 54% | 54% | 50% |
| I trust that companies that use artificial intelligence will protect my personal data | 47% | 50% | 50% |
| Products and services using artificial intelligence make me nervous | 39% | 39% | 39% |
Offenbar haben sich Fehler in die Tabelle eingeschlichen, aber zumindest hat das Modell den verwaschenen Text richtig erkannt. Hier zeigt sich die Stärke des Encoders, aber auch die englische Beschriftung vereinfacht den Prozess für das Modell. Die meisten Prozentwerte stimmen, ebenso die Struktur der Daten. Verwendet man eine höhere Auflösung, verbessern sich die Ergebnisse allerdings nur marginal.
Neben Diagrammen kann DeepSeek-OCR auch mathematische Formeln erkennen und sie in LaTeX-Syntax wandeln. Chemische Strukturformeln hat es auch im Repertoire und wandelt sie in das SMILES-Format.
Fazit
DeepSeek hat sich erneut einen spannenden technischen Ansatz ausgedacht und mit DeepSeek-OCR überzeugend demonstriert. Die Erkennung von Texten funktioniert besonders im Gundam-Modus schon gut, auch das Parsing der Diagramme ist überzeugend. Allerdings sind andere Modelle wie MinerU, Nanonets und PaddleOCR-VL besonders bei der reinen Texterkennung ebenfalls sehr gut und liefern teilweise sogar bessere Ergebnisse, da sie etwa getrennte Wörter zusammenführen. Besonders das ebenso nagelneue PaddleOCR-VL ist hervorzuheben, das Daten aus Diagrammen verlässlich extrahiert und in eigenen Tests sogar besser als DeepSeek-OCR funktionierte. Um OCR ist ein wahres Wettrennen entbrannt.
DeepSeek scheint mit dem Modell jedoch nicht nur auf OCR zu setzen, sondern möchte zeigen, dass die Vision Token eine gute Darstellung sind, um den Kontext in großen Sprachmodellen besonders kompakt zu speichern. Mit einer geringen Kompression funktioniert das schon gut, mit höherer Kompression leiden die Ergebnisse aber spürbar. Dieser Ansatz steht allerdings noch ganz am Anfang.
DeepSeek-OCR ist in allen Konfigurationen verhältnismäßig schnell. Experimente mit MinerU, Nanonets und PaddleOCR-VL waren alle mindestens 50 Prozent langsamer. Nanonets erzeugte immerhin eine Tabelle aus dem Diagramm, aber ohne die Jahreszahlen, dafür war der Fließtext sehr viel besser erkannt. Das nagelneue PaddleOCR-VL konnte das Diagramm sogar besser als DeepSeek-OCR erkennen, ist aber nicht auf chemische Strukturformeln und ähnliche Inhalte trainiert.
DeepSeek-OCR ist – wie von den Entwicklern deutlich vermerkt – eine Technologiedemonstration, die dafür schon äußerst gut funktioniert. Es bleibt abzuwarten, wie sich die Technologie in klassische LLMs integrieren lässt und dort zur effizienteren Verarbeitung von längeren Kontexten genutzt werden kann.
Weitere Informationen finden sich auf GitHub, Hugging Face und im arXiv-Preprint.
(pst)












Künstliche Intelligenz
Intel macht weniger Minus als erwartet
Umsatz am oberen Ende der selbstgesteckten Erwartungen, aber weniger Nettoverlust als befürchtet: Intel liefert im Rahmen der eigenen Möglichkeiten einen passablen Jahresabschluss ab. Knapp 13,7 Milliarden US-Dollar hat das Unternehmen im vierten Quartal 2025 umgesetzt. Das sind vier Prozent weniger als im Vorjahreszeitraum. Unterm Strich stehen 591 Millionen Dollar Nettoverlust und damit etwa 14 Prozent weniger Miese als erwartet.
Weiterlesen nach der Anzeige
Über das komplette Jahr hat Intel knapp 52,9 Milliarden Dollar umgesetzt und damit fast genauso viel wie 2024. Auf dem Papier sinkt der Jahresverlust von 18,8 Milliarden auf 267 Millionen Dollar. Die Differenz ist allerdings nur so groß, weil Intel 2024 hohe Milliardensummen abschreiben musste. Das betriebliche Jahresergebnis schießt von -11,7 Milliarden auf -2,2 Millionen Dollar hoch, weil Intel insgesamt über fünf Milliarden Dollar bei Forschung, Entwicklung, Marketing und Administrativem spart und längst nicht mehr so viele Kosten für die Umstrukturierung anfallen. Sie sinken von knapp sieben Milliarden auf 2,2 Milliarden Dollar. Der betriebliche Jahres-Cashflow hat sich von 8,3 Milliarden auf 9,7 Milliarden Dollar verbessert.
Operativ bleibt zumindest für das vierte Quartal 2025 sogar ein Plus von 580 Millionen Dollar stehen, ein Wachstum von 41 Prozent gegenüber dem Vorjahreszeitraum. Vor Steuern bleiben davon 338 Millionen Dollar übrig; die 671 Millionen Dollar Steuern schießen Intel dann ins Minus.
Chipfertigung über 10 Milliarden Dollar im Minus
Das Sorgenkind bleibt die eigene Chipfertigung (Intel Foundry), die über das komplette Jahr 10,3 Milliarden Dollar Verlust gemacht hat. Das sind immerhin drei Milliarden weniger Minus als noch 2024.
Das Defizit ist so hoch, seitdem Intel die Foundry als eigenständigen Chipauftragsfertiger betrachtet, bei dem die Prozessorsparten zu branchenüblichen Preisen CPUs produzieren lassen. Die Umsätze reichen bislang nicht, um die Sparte nachhaltig über Wasser zu halten.
Es gibt allerdings einen allerersten, wenn auch kleinen Lichtblick: Die Intel Foundry hat im vierten Quartal 2025 offenbar 170 Millionen Dollar Umsatz mit externen Kunden gemacht. Das entspricht einem Anteil von 3,8 Prozent der insgesamt 4,5 Milliarden Dollar Umsatz. Ein Jahr zuvor waren es noch 27 Millionen Dollar externer Umsatz von gut 4,3 Milliarden Dollar.
Zu den Kundeneinnahmen der Foundry äußert sich Intel wie branchenüblich nicht. Aufgrund früherer Ankündigung wäre denkbar, dass Amazon (AWS) oder Microsoft KI-Chips mit Intels Fertigungstechnik testen oder in Kleinserie fertigen lassen.
Weiterlesen nach der Anzeige
Prozessoren bleiben stark
Intels unangefochtenes Zugpferd bleibt die sogenannte Client Computing Group rund um Core-Prozessoren für Notebooks und Desktop-PCs. 32,2 Milliarden Dollar hat sie 2025 umgesetzt, gut drei Prozent weniger als 2024. Sie macht 9,3 Milliarden Dollar Operativgewinn.

Intel
)
Serverprodukte sind mit 16,9 Milliarden Dollar Jahresumsatz weit abgeschlagen. Trotz des KI-Booms und der irrsinnigen Investitionen von Hyperscalern in Rechenzentren wächst Intels Serversparte nur um knapp fünf Prozent.
Intel hat weiterhin keine KI-Beschleuniger, die gut bei Hyperscalern ankommen. CEO Lip-Bu Tan sagt deswegen: „Unsere Überzeugung, dass CPUs in der KI-Ära eine wesentliche Rolle spielen, wächst weiter.“
Alle anderen Geschäftsbereiche haben knapp 3,6 Milliarden Dollar umgesetzt. Dazu zählen maßgeblich die Automotive-Sparte Mobileye und bis zum dritten Quartal der FPGA-Hersteller Altera, den Intel da mehrteilig verkauft hat.
Trüber Ausblick betrübt Börse
Im angelaufenen ersten Quartal 2026 erwartet Intel 11,7 Milliarden bis 12,7 Milliarden Dollar Umsatz und damit im besten Fall Stillstand gegenüber Anfang 2025. Die Bruttomarge soll von aktuell 36,1 auf nur noch 32,3 Prozent fallen. Der Nettoverlust soll Richtung zwei Milliarden Dollar steigen.
Gerade der letzte Punkt dürfte die Börse abgeschreckt haben: Im nachbörslichen Handel fiel Intels Aktie um etwa sechs Prozent. Damit steht das Wertpapier allerdings immer noch besser da als in den zwei Jahren zuvor.
(mma)
Künstliche Intelligenz
Kernfusion: Kanadisches Start-up General Fusion findet neue Investoren
An kontrollierte Kernfusion zu einem Bruchteil der Kosten anderer Projekte arbeitet General Fusion seit über 20 Jahren. 2009 hieß es, das werde binnen zehn Jahren fertig. Ausgegangen ist sich das nicht. Immerhin erzeugt der Reaktor Lawson Machine 26 (LM26) seit Februar 2025 Plasma, im kommenden Jahrzehnt soll Fusionsenergie kommerziell nutzbar sein. Damit auf dem Weg dorthin das Geld nicht ausgeht, geht General Fusion nun an die New Yorker Börse NASDAQ.
Weiterlesen nach der Anzeige
Das Management hofft auf gut 300 Millionen US-Dollar für die Firmenkasse. Allerdings ist es kein klassischer Börsengang. Vielmehr hat General Fusion das Interesse eines SPAC geweckt.
Ein SPAC namens SVAC III
SPAC steht für Special Purpose Acquisition Company. So eine Firma wird nur dazu gegründet, Geld von Investoren einzusammeln, dann ohne eigentliche Geschäftstätigkeit an der Börse zu notieren, um schließlich binnen zweier Jahre mit einer noch nicht börsennotierten Firma – hier: General Fusion – zu verschmelzen. Das war um das Jahr 2020 en vogue; für den übernommenen Betrieb ist das ein schneller und günstigerer Weg an die Börse. General Fusion wird im Zuge der Fusion mit 600 Millionen US-Dollar bewertet.
Viele solcher SPAC-Konstrukte haben ihren Anlegern wenig Freude bereitet. Der Zwang, binnen zweier Jahre viele Millionen für irgendeine Akquisition ausgeben zu müssen, ist womöglich nicht der ideale Anreiz für die beste Investitionsentscheidung.
Das konkrete SPAC-Vehikel heißt Spring Valley Acquisition Corp. III (SVAC III). Es hat 230 Millionen US-Dollar von Spekulanten eingesammelt, die ihr Geld allerdings vor der Übernahme zurückziehen könnten. Die Organisatoren eines SPAC heißen „Sponsoren”. Das gleiche Team hat unter dem Namen Spring Valley Acquisition Corp. (ohne „III”) 2022 die Firma Nuscale Power mittels SPAC-Fusion an die Börse gebracht. Dieses US-Start-up entwickelt proprietäre kleine modulare Atomreaktoren (SMR). Der Aktienkurs hat in den letzten Monaten eine Achterbahnfahrt gemacht, liegt nach einem herben Kurssturz aber immer noch beim etwa Doppelten des Übernahmekurses.
Zusätzliche Investoren
Weiterlesen nach der Anzeige
Parallel zur Fusion mit SVAC III hat General Fusion noch andere Investoren gefunden, die 105 Millionen Dollar für Vorzugswandelaktien hinlegen. Sie sollen pro Aktie 20 Prozent mehr zahlen, als SVAC III bietet.
Der Plan sieht vor, dass General Fusion insgesamt 335 Millionen Dollar erhält: Die 230 Millionen Dollar, die derzeit in der SVACIII-Kasse liegen, und die 105 Millionen Dollar von den zusätzlichen Investoren. Abzüglich Transaktionskosten winken damit bis zu 311 Millionen Dollar Liquidität.
Die bisherigen Eigentümer General Fusions behalten 58 Prozent der Anteile. Die SVACIII-Aktionäre bekommen 22 Prozent, die zusätzliche Investoren Gruppe gut 13 Prozent. Als Belohnung für die Einfädelung der ganzen Sache gehen knapp sieben Prozent an den SPAC-Sponsor. Dieser Anteil verdreifacht sich ungefähr, sollte sich der Aktienkurs gut entwickeln (sogenanntes earnout im Gegenwert von 135 Millionen Dollar).
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
So soll das funktionieren
General Fusion setzt auf das exotische Konzept der Magnetized Target Fusion (MTF), eine Art Mittelding anderer Fusion-Konzepte (Magneteinschluss und Trägheitsfusion). Bei General Fusion dient ein rotierender Zylinder aus flüssigem Metall als Brennkammer, in den heißes Wasserstoff-Plasma eingebracht wird. Mittels Hochleistungssprengstoff wird das Plasma verdichtet und auf etwa 100 Millionen Grad erhitzt. Bei dieser Temperatur können Wasserstoffatome verschmelzen und Energie freisetzen. Das könnte sogar funktionieren.
(ds)
Künstliche Intelligenz
ESA-Sonden Proba-3: Zeitraffer zeigt drei heftige Sonneneruptionen nacheinander
Die ESA-Weltraumsonden Proba-3 haben am 21. September innerhalb von fünf Stunden gleich drei heftige Materieausbrüche auf der Sonne beobachtet, und jetzt hat die Weltraumagentur einen Zeitraffer davon veröffentlicht. Der wurde aus Aufnahmen unseres Sterns zusammengesetzt, die im Abstand von fünf Minuten von Proba-3 und dem Solar Dynamics Observatory der NASA aufgenommen wurden. Zuerst sieht man darauf oben rechts eine noch vergleichsweise kleine Protuberanz, es folgt eine größere links oben und schließlich die heftigste unten rechts. Solch ein Zusammenfall von mehreren Materieausbrüchen sei ziemlich selten, erklärt Andrei Zhukov vom Königlichen Observatorium von Belgien, der die Forschung mit dem eingesetzten Koronagrafen leitet.
Weiterlesen nach der Anzeige

Der Zeitraffer
(Bild: ESA/Proba-3/ASPIICS, NASA/SDO/AIA)
Auf den zusammengesetzten Aufnahmen stammt der äußere (gelbe) Teil aus den Sensoren von Proba-3, er zeigt die innere Sonnenkorona. Dort sei es etwa zweihundertmal heißer als auf der Sonnenoberfläche, erklärt die ESA. Wenn deutlich kälteres Plasma von dort heraufgeschleudert werde, spreche man von einer aktiven Protuberanz. Bei solch einer Sonneneruption wird das Plasma in unterschiedliche Richtungen gestoßen. Weil die Sonnenkorona vom strahlend hellen Licht der Sonne überstrahlt wird, kann das nur mit Hilfsmitteln sichtbar gemacht werden. Gleichzeitig sind die Eruptionen aber für die Forschung von hohem Wert, da sie auf Vorgänge unter der Sonnenoberfläche schließen lassen.
Proba-3 besteht aus zwei Satelliten, die in höchster Präzision zusammenarbeiten, um die Sonnenkorona sichtbar zu machen. Dabei wirft einer der beiden einen Schatten auf den zweiten, der damit in den Genuss einer künstlichen Sonnenfinsternis kommt. Die immens helle Sonnenscheibe wird also verdeckt und nur die Korona bleibt sichtbar. Die dann gesammelten Daten sollen Einblicke in das Weltraumwetter, koronale Massenauswürfe und Sonnenstürme geben, die Satelliten beeinträchtigen und sich auch auf die Kommunikation auf der Erde auswirken können. Ergründen wollen die Verantwortlichen auch, warum die Korona überhaupt so viel heißer ist als die Sonnenoberfläche. Und nebenbei kommen dann immer wieder solche beeindruckenden Aufnahmen heraus.
(mho)


-

 Entwicklung & Codevor 2 Monaten
Entwicklung & Codevor 2 MonatenKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 UX/UI & Webdesignvor 3 Monaten
UX/UI & Webdesignvor 3 MonatenArndt Benedikt rebranded GreatVita › PAGE online
-

 Künstliche Intelligenzvor 3 Wochen
Künstliche Intelligenzvor 3 WochenSchnelles Boot statt Bus und Bahn: Was sich von London und New York lernen lässt
-

 Entwicklung & Codevor 1 Monat
Entwicklung & Codevor 1 MonatKommentar: Anthropic verschenkt MCP – mit fragwürdigen Hintertüren
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenGoogle „Broadwing“: 400-MW-Gaskraftwerk speichert CO₂ tief unter der Erde
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenHuawei Mate 80 Pro Max: Tandem-OLED mit 8.000 cd/m² für das Flaggschiff-Smartphone
-

 Apps & Mobile Entwicklungvor 2 Monaten
Apps & Mobile Entwicklungvor 2 MonatenFast 5 GB pro mm²: Sandisk und Kioxia kommen mit höchster Bitdichte zum ISSCC
-

 Social Mediavor 1 Monat
Social Mediavor 1 MonatDie meistgehörten Gastfolgen 2025 im Feed & Fudder Podcast – Social Media, Recruiting und Karriere-Insights