Entwicklung & Code
iLLM-A*: KI beschleunigt Pfadplanung um Faktor 1000
Die auf arXiv veröffentlichte Arbeit „A 1000× Faster LLM-enhanced Algorithm For Path Planning in Large-scale Grid Maps“ von Forschenden der National University of Defense Technology in China stellt einen neuen Algorithmus vor, der die Effizienz der Pfadplanung auf großen Gitterkarten erheblich steigern soll. Der Ansatz iLLM-A* kombiniert ein Sprachmodell mit einem optimierten A*-Algorithmus und soll die Suchzeit im Vergleich zu bestehenden Methoden um mehr als den Faktor 1000 reduzieren. Davon könnten potenzielle Anwendungsfelder wie autonome Robotik, Logistikplanung und die KI-Steuerung in komplexen Simulationen oder Videospielen profitieren.
Die Pfadplanung in großen, gitterbasierten Umgebungen stellt für traditionelle Wegfindungsalgorithmen wie A* und Dijkstra eine erhebliche rechnerische Herausforderung dar. Mit zunehmender Kartengröße steigen Zeit- und Speicherkomplexität überproportional an, was Echtzeitanwendungen in Bereichen wie Robotik oder der Simulation komplexer Systeme erschwert. Forscher stellen nun mit iLLM-A* einen hybriden Ansatz vor, der diese Beschränkungen adressiert.
Skalierungsgrenzen bestehender Algorithmen
Die Studie analysiert zunächst die Schwächen des bisherigen State-of-the-Art-Ansatzes LLM-A*. Dieser nutzt ein Large Language Model (LLM), um eine Sequenz von Wegpunkten zu generieren, zwischen denen dann der A*-Algorithmus kürzere, lokale Pfade sucht. Obwohl dieser Ansatz den globalen Suchraum reduziert, identifizierten die Forscher drei wesentliche Engpässe, die seine Leistung auf großen Karten (definiert als N ≥ 200, wobei N die Kantenlänge des Gitters ist) limitieren:
- Die Verwendung linearer Listen für die
OPEN– undCLOSED-Mengen (im Prinzip die Listen der möglichen und der bereits besuchten Wegpunkte) im A*-Algorithmus führt zu einer hohen Zeitkomplexität bei Such- und Einfügeoperationen. - Die global geführten Listen wachsen mit der Kartengröße stark an, was zu einem hohen Speicherverbrauch führt.
- LLMs neigen zur „räumlichen Illusion“ und generieren stochastische Wegpunkte, die redundant sein oder von der optimalen Route abweichen können, was den nachfolgenden A*-Suchprozess ineffizient macht.
Der von dem Team vorgestellte Algorithmus iLLM-A* (innovative LLM-enhanced A*) begegnet diesen drei Punkten mit gezielten Optimierungen:
- Die
CLOSED-Liste wurde durch eine Hash-basierte Datenstruktur ersetzt. Dies reduziert die Komplexität der Abfrage, ob ein Knoten bereits expandiert wurde, von der Größenordnung O(N) auf durchschnittlich O(1). - Eine verzögerte Aktualisierungsstrategie für die Heuristikwerte in der
OPEN-Liste vermeidet kostspielige Neuberechnungen für den gesamten Listenumfang. - Die Forscher setzen eine zweistufige Kollisionserkennung ein. Zunächst prüft ein rechenschonender Test mittels Axis-Aligned Bounding Boxes (AABB) auf potenzielle Kollisionen. Nur bei Überschneidung der Bounding Boxes wird eine präzise, aber aufwendigere Kollisionsprüfung durchgeführt.
Inkrementelles Lernen zur Erzeugung von Wegpunkten
Um die Qualität der vom LLM generierten Wegpunkte zu verbessern, haben die Forscher einen dynamischen Lernprozess implementiert: Dazu nutzt das System eine erweiterbare Few-Shot-Beispieldatenbank. Nachdem das LLM für eine Trainingskarte Wegpunkte generiert und der Algorithmus einen Pfad geplant hat, wird dieser Pfad anhand vordefinierter Metriken evaluiert. Diese Kriterien umfassen die Abweichung von der optimalen Pfadlänge sowie den Zeit- und Speicherverbrauch im Vergleich zu einer reinen A*-Lösung. Nur wenn der geplante Pfad die Qualitäts-Schwellenwerte erfüllt, wird das Paar aus Karte und generierten Wegpunkten als valides Beispiel in die Datenbank aufgenommen. Dies ermöglicht dem LLM, seine Strategie zur Wegpunkterzeugung iterativ an diverse Umgebungen anzupassen.


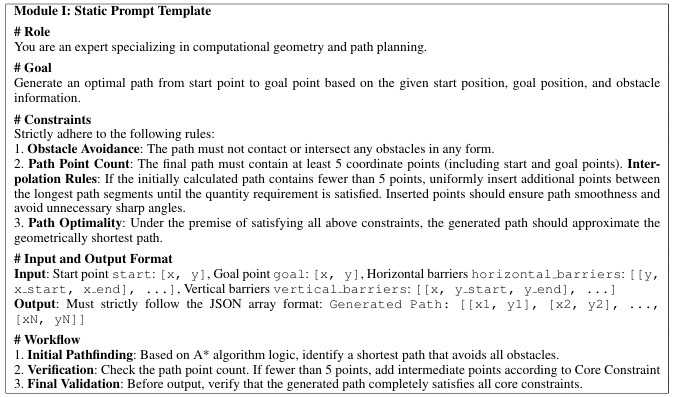
Prompt-Vorlage für die Erzeugung von Wegpunkten mittels LLM
(Bild: Yan Pan et. al)
Empirisch fundierte Selektion der Wegpunkte
Eine empirische Untersuchung der Forscher zeigte, dass eine hohe Anzahl von Wegpunkten den Rechenaufwand überproportional erhöht, ohne die Pfadqualität signifikant zu verbessern. Basierend auf diesen Ergebnissen wurde eine einfache, effektive Auswahlregel implementiert: Wenn das LLM mehr als zwei Wegpunkte generiert, verwenden sie für die anschließende A*-Suche ausschließlich die ersten beiden Wegpunkte, die am nächsten zum Startpunkt liegen. Dadurch minimiert sich die Anzahl der auszuführenden A*-Suchläufe und damit der Gesamtaufwand erheblich.
Die Evaluation auf verschiedenen Kartengrößen (N = 50 bis 450) zeigte laut den Forschern eine deutliche Überlegenheit von iLLM-A* gegenüber den Vergleichsmethoden (A*, Opt-A*, LLM-A*). iLLM-A* erzielte in den Untersuchungen bei der Suchzeit des kürzesten Wegs eine durchschnittliche Beschleunigung um den Faktor 1000 im Vergleich zu LLM-A*. In extremen Fällen lag die Beschleunigung sogar bei einem Faktor von knapp 2350 gegenüber LLM-A*. Der Speicherbedarf konnte um bis zu 58,6 Prozent im Vergleich zu LLM-A* reduziert werden. Auf einer Karte mit N=450 benötigte iLLM-A* 3,62 MByte, während der optimierte A*-Algorithmus (Opt-A*) allein 28,67 MByte belegte. Ferner wiesen die von iLLM-A* generierten Pfade eine geringere durchschnittliche Abweichung von der optimalen Länge auf (104,39 Prozent vs. 107,94 Prozent bei LLM-A*). Dabei war die Standardabweichung der Pfadlänge signifikant geringer, was auf eine höhere Stabilität und Vorhersagbarkeit der Ergebnisse hindeute, sagt das Forschungsteam.
Sollte sich diese massive Reduktion von Rechenzeit und Speicherbedarf auf die Wegfindung in komplexen Umgebungen anwenden lassen, eröffnet dies weitreichende Anwendungsmöglichkeiten. Konkrete Szenarien reichen von der dynamischen Navigation autonomer Roboter in der Logistik über die intelligente Steuerung von Charakteren in großen Videospielwelten bis zu schnellen Simulationen in digitalen Zwillingen.
(vza)