Künstliche Intelligenz
Instinct MI350X/MI355X: AMD opfert Compute- für KI-Rechenleistung
AMD hat am 12. Juni 2025 auf seiner Hausveranstaltung Advancing AI im kalifornischen San José die kommenden Instinct-Beschleuniger MI350X und MI355X offiziell vorgestellt und einen Ausblick auf MI400 im nächsten Jahr gegeben. Die beiden MI35xer-Modelle kommen mit bis zu 288 GByte HBM3e-Stapelspeicher (High-Bandwidth Memory) und nehmen im Fall der MI355X mit direkter Flüssigkühlung 1,4 bis 1,5 Kilowatt Leistung auf. Laut AMD sollen Sie gegenüber den MI300X-Vorgängern beim KI-Inferencing rund 2,6 bis 4,2 Mal so schnell sein. Nvidias CPU-GPU-Kombi GB200 sollen sie beim KI-Training Paroli bieten oder im Vergleich zum B200-Beschleuniger bis zu 30 Prozent Vorsprung bieten.
Damit will AMD sich einen Anteil am riesigen KI-Geldtopf sichern, an dem sich Nvidia seit Jahren finanziell labt und in den Börsenberichten ein Rekordquartal nach dem anderen meldet. AMD wirbt mit einer bis zu 40 Prozent höheren Durchsatzrate pro Dollar (Tokens/$), die sich aus den maximal 30 Prozent höheren Durchsatz nur zum Teil speist – zusätzlich muss AMD die MI355X auch billiger anbieten als Nvidias B200-Systeme.
AMDs Instinct-Reihe sind massiv parallele Beschleuniger, die speziell für den Einsatz in Rechenzentren vorgesehen sind; die MI350X und MI355X verwenden mit CDNA4 die vierte Generation dieser Rechenbeschleuniger. Beide haben eine Speichertransferrate von bis zu 8 TByte/s und unterscheiden sich hauptsächlich in Sachen Taktrate und Leistungsaufnahme. Die MI350X ist mit 1 kW vergleichsweise zahm. Sie ist mit einem Durchsatz von 72 zu 79 Billionen Rechenschritten bei doppeltgenauen Gleitkommazahlen (FP64-TFLOPS) auf dem Papier aber nur knapp 9 Prozent langsamer als die wesentlich stromdurstigere MI355X. Letztere soll bis zu 1,4 kW, also 40 Prozent mehr als die kleinere Schwester aufnehmen. In einer Vorschau nannte ein AMD-Sprecher sogar bis zu 1,5 kW.




Übersicht AMD Instinct MI350X und MI355X.
(Bild: AMD)
AMD sieht die MI350X für den Einsatz in luftgekühlten Serverschränken mit bis zu 64 GPUs vor. Die MI355X soll in hochdichten Racks mit bis zu 128 GPUs unterkommen, benötigt dann aber direkte Flüssigkühlung (DLC), um nicht zu überhitzen.
Dass AMD weitere Schritte in Richtung KI-Optimierung geht, überrascht indes nicht. Einerseits liegt dort gerade das große Investorengeld, andererseits hatte AMDs Technikchef Mark Papermaster auf der ISC25 in Hamburg erst vor zwei Tagen die Wichtigkeit von Berechnungen mit gemischter Präzision hervorgehoben. Eine Version mit integrierten CPU-Chiplets analog zum MI300A hat AMD vom MI350 bisher nicht erwähnt.
Ein Schritt vor, ein Schritt zurück
Der Fokus lag bei den Vorgängern aus der MI300/325-Reihe noch auf der Verwendung in Supercomputern und Rechenzentren gleichermaßen. Das hat AMD bei der MI355X geändert. Die Rechenwerke sind für den Einsatz bei KI-Aufgaben weiter optimiert, müssen dafür aber Federn bei klassischen Aufgaben lassen. Pro Takt und Rechenwerk gibt es sogar Rückschritte.
Wie schon bei den älteren Instinct-MI-Modellen verwenden die AMD-Ingenieure bei der MI355X auch 3D-Chiplets. Als Basis kommen zwei IO-Dies zum Einsatz, die in bewährter 6-Nanometer-Technik gefertigt werden. Darin sind insgesamt 256 MByte Infinity-Cache enthalten, aufgeteilt in 2-MByte-Blöcke, sowie die sieben Infinity-Fabric-Links (IF) der vierten Generation, die pro Stück jetzt 153,6 GByte/s übertragen und mit insgesamt 1075 GByte pro Sekunde bis zu acht MI35xX verbinden. Auch die 5,5 TByte/s schnelle Verbindung der beiden IO-Dies hat AMD überarbeitet: Sie ist jetzt breiter, taktet dafür aber niedriger. Dadurch lässt sich die nötige Spannung als Haupttreiber der Leistungsaufnahme senken. AMD nennt diese Verbindung der beiden IO-Dies Infinity Fabric Advanced Package (IF-AP).



Chiplet-Technik mit 3D-Stacking: Zwei IO-Dies in 6- und acht XCDs in 3-nm-Technik.
(Bild: AMD)
Auf den beiden IO-Dies sitzen die acht Accelerator Compute Dies (XCDs), die TSMC im moderneren N3P-Prozess herstellt. In jedem davon sind 32 aktive Compute-Units enthalten – vier sind zur Verbesserung der Chipausbeute deaktiviert. Wer sich gut Zahlen merken kann, dem fällt auf, dass der Vorgänger mit 304 CUs noch 48 Einheiten mehr hatte. Auch dadurch ist die Versorgung mit Daten aus dem HBM3e-Speicher nun um Faktor 1,5 besser als zuvor: 16 Prozent weniger CUs, 30 Prozent mehr Transferrate.
Das geht laut AMD auf Erfahrungen aus der Praxis zurück, die den präferierten KI-Anwendungen einen hohen Bandbreitenhunger attestieren. Ein weiterer Eingriff an der Architektur ist ein größerer schneller Zwischenspeicher innerhalb der CUs (Local Data Share, LDS) auf 160 KByte. Mit dem größeren HBM-Speicher und der Überarbeitung der Speichervirtualisierung einher geht auch die Anpassung der sogenannten Universal Translation Caches, die ähnliche Aufgaben übernehmen wie die Translation Lookaside Buffer (TLBs) in Prozessoren. Der TLB enthält oft benutzte Zuordnungen von virtuellen zu physikalischen Adressen. Bei einem Speicherzugriff wird die Zuordnung zunächst im TLB gesucht, bevor Page Directory/Table konsultiert werden. Ist sie im Cache vorhanden, spricht man von einem „Hit“, ansonsten von einem „Miss“. Die Suche im TLB ist erheblich schneller als ein Zugriff auf die Page Table.
Der größte Unterschied ist aber der Aufbau der einzelnen Rechenwerke in den Compute Units. Denen hat AMD neue Datenformate spendiert, sodass die Matrixeinheiten jetzt außer FP8 (sowohl nach OCP-FP8- als auch OCP-MX-Spezifikation wie bei Nvidia) auch FP6 und FP4 beherrschen. Der Durchsatz der beiden neuen Formate ist dabei doppelt so hoch wie der des bekannten FP8 – bei Nvidias B200 erreicht FP6 nur FP8-Geschwindigkeit.
Dafür mussten speziell die dicken Multiplizierer der Matrixeinheiten bluten. Der Durchsatz mit FP64-Datenformaten, wie sie in KI-Anwendungen allerdings nicht vorkommen, wurde gegenüber den Vorgängerbeschleunigern halbiert. Damit folgt AMD auch hier Nvidias Marschrichtung, der FP64 schon länger bedeutend niedriger priorisiert. Die Vektoreinheiten, die den klassischen Shader-SIMDs in Grafikkarten ähneln, wurden beim MI350X/MI355X allerdings nicht angetastet.

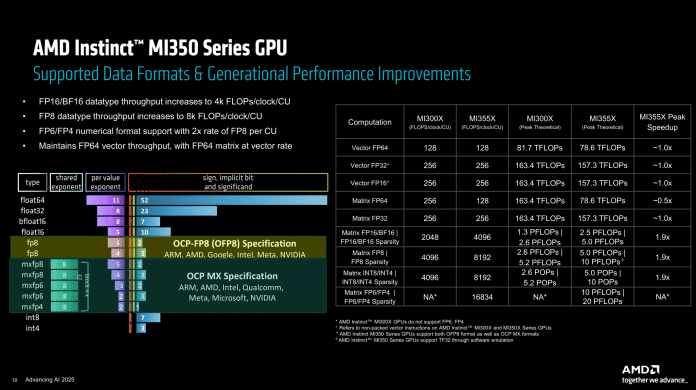
Durchsatz bei verschiedenen Datenformaten: Mit FP6 und FP4 läuft der MI350 zur Hochform auf.
(Bild: AMD)
Die kompletten Chips schaffen laut AMD daher nun einen Durchsatz von bis zu 20.000 TFLOPS bei dünn besetzten Matrizen („Sparsity“) mit FP6- oder FP4-Genauigkeit. Mit FP8 oder INT8 ist es noch die Hälfte, ebenso wie bei regulär besetzten Matrizen.


AMD will auch Racks mit MI350X anbieten.
(Bild: AMD)
„Helios“-KI-Racks und Ausblick auf MI400
AMD will mit MI355X und MI350X erstmals auch eigene KI-Racks spezifizieren. Die Basis bilden weiterhin UBB8-Formate, Universal Base Boards für acht Beschleunigermodule, die es von Partnern auch weiterhin geben wird. Neu sind die KI-Serverschränke mit bis zu 128 MI355X-Beschleunigern und Direct Liquid Cooling. Ein solcher Schrank soll dann 2,57 Exaflops an KI-Rechenleistung im FP6/FP4-Format schaffen und 36 TByte HBM3e-Speicher beherbergen. AMD betonte zudem erneut, dass die hauseigene Lösung komplett auf offene Standards wie OCP-UBBs oder Ethernet des Ultra-Ethernet-Consortiums setzt. Die Firma will sich damit von Nvidias proprietären Server-Racks mit NVLink differenzieren.
Der Nachfolger MI400 soll 2026 erscheinen und es mit dem dann erwarteten Vera Rubin von Nvidia aufnehmen, auch als Komplettlösung in neu entwickelten Helios-Racks analog zu Nvidias NVL72. AMD stellt für 72 MI400 rund 50 Prozent mehr HBM4-Speicherkapazität (31 TByte, addiert) und -Transferrate (1,4 PByte/s, addiert) sowie Scale-Out-Bandbreite (also der ins Netzwerk) in Aussicht. Einen Gleichstand erwartet die Firma bei FP4/FP8-Rechenleistung sowie bei der Scale-Up-Bandbreite der lokalen HBM-Kanäle.


Helios heißen die Rack-Designs für die 2026 erwarteten Nvidia-Rubin-Konkurrenten MI400.
(Bild: AMD)
Ein einzelner MI400 soll die FP4-Leistung gegenüber MI355X auf 40 Petaflops (40.000 Teraflops, inkl. Sparsity) verdoppeln und 432 GByte HBM4-Stapelspeicher mit bis zu 19,6 TByte/s anbinden. Jede GPU wird mit 300 GByte nach außen doppelt so schnell kommunizieren können wie MI350X/355X. Wie hoch die Leistungsaufnahme dann sein wird, hat AMD nicht verraten, wohl aber in einem irreführenden Diagramm einen enormen Performancevorsprung suggeriert. Der wurde laut der Fußnoten offenbar auf Plattformbasis errechnet: 72 MI400 gegen acht MI355X, darum geben wir ihn hier auch nicht grafisch wieder.
(csp)