Entwicklung & Code
.NET 10.0 ist fertig | heise online
Die fertige Version von .NET 10.0 steht seit den Abendstunden des 11. November 2025 auf der Downloadseite kostenfrei zur Verfügung. Für .NET 10.0 benötigen Entwicklerinnen und Entwickler die Entwicklungsumgebung Visual Studio 2026 (alias Version 18.0), die ebenfalls gestern erstmals in einer stabilen Version erschienen ist.
Weiterlesen nach der Anzeige
Support für 36 Monate
Microsoft gewährt für .NET 10.0 einen Long-Term Support (LTS) von 36 Monaten, also von November 2025 bis November 2028. Für die vorherige Version .NET 9.0 endet der Support ebenfalls im November 2028, nachdem Microsoft im September bekanntgab, den ursprünglich auf 18 Monate begrenzten Support auf 24 Monate zu erweitern.
Diese Erweiterung gilt ab .NET 9.0 für alle Versionen mit Standard-Term Support (STS). .NET 11.0, das im November 2026 erscheinen soll (voraussichtlich wieder am zweiten Dienstag im November, also am 10.11.2026), wird wieder eine solche Version mit Standard-Term Support sein.


Der aktuelle Standard-Term und Long-Term Support für .NET
(Bild: Microsoft)
.NET für Android läuft auch auf .NET Core Runtime
Der Aufbau von .NET 10.0 ist fast der gleiche wie bei .NET 9.0 (siehe Abbildung): zahlreiche Anwendungsarten laufen auf Basis eines gemeinsamen Software Development Kit (SDK), einer gemeinsamen Basisklassenbibliothek, den Sprachen C#, F# und Visual Basic .NET sowie dem in (fast) allen Anwendungsarten verwendbaren objektrelationalen Mapper Entity Framework Core. Anders als der Vorgänger Entity Framework Core 9.0, der auf .NET 8.0 und .NET 9.0 nutzbar war, läuft die Version 10.0 des objektrelationalen Mappers ausschließlich auf .NET 10.0. Im Untergrund von .NET 10.0 wirken weiterhin zwei verschiedene Runtimes, abhängig von Anwendungsart und Betriebssystem: die .NET Core Runtime und die Mono Runtime.
Weiterlesen nach der Anzeige
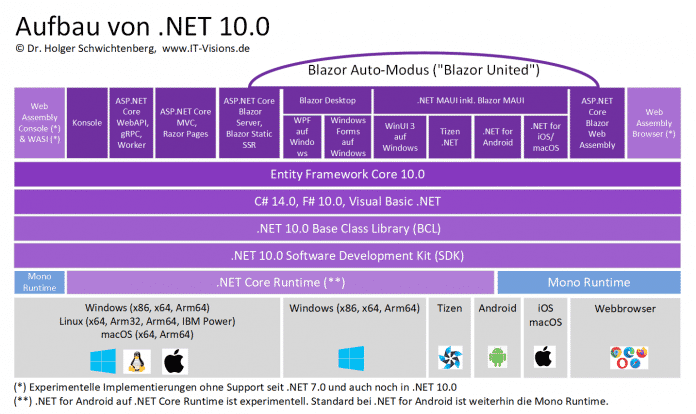
Aufbau von .NET 10.0
(Bild: Dr. Holger Schwichtenberg)
Neu in .NET 10.0 ist, dass Android-Anwendungen nicht nur wie bisher auf der Mono Runtime, sondern auch auf der .NET Core Runtime laufen können. Dieses Feature gilt aber in .NET 10.0 als experimentell. Ebenso gilt die Kompilierung von Konsolenanwendungen und Browseranwendungen (außer innerhalb von Blazor) zu WebAssembly weiterhin als experimentelles Feature.
Wieder zahlreiche Breaking Changes
Umsteiger von älteren .NET-Versionen auf .NET 10.0 müssen nicht nur das Target-Framework in der Projektdatei bzw. zentralen Build-Konfigurationsdatei Directory.Build.props auf
Die Breaking Changes, von denen es in .NET 10.0 weniger als in den letzten Versionen gibt, dokumentiert Microsoft in drei Listen:
.NET 10.0 läuft schneller
Wie in den letzten Versionen hat Microsoft zahlreiche Leistungsverbesserungen eingebaut. Insbesondere sind das in .NET 10.0 Verbesserungen der Ausführungszeit und Speicherallokation bei zahlreichen .NET-Basisklassen, was sich positiv auf viele Anwendungen auswirkt. Erläuterungen zu den Performance- und Speicherverbrauchsverbesserungen und genaue Zahlen findet man in einem sehr langen Dokument.
(Bild: coffeemill/123rf.com)

Verbesserte Klassen in .NET 10.0, Native AOT mit Entity Framework Core 10.0 und mehr: Darüber informieren Dr. Holger Schwichtenberg und weitere Speaker der Online-Konferenz betterCode() .NET 10.0 am 18. November 2025. Nachgelagert gibt es sechs ganztägige Workshops zu Themen wie C# 14.0, KI-Einsatz und Web-APIs.
Neuerungen in allen Bereichen
In .NET 10.0 gibt es viele neue Funktionen in allen Bereichen: bei der Programmiersprache C#, in der Basisklassenbibliothek, beim objektrelationalen Mapping mit Entity Framework Core, bei der JSON-Serialisierung mit System.Text.Json, den Webframeworks ASP.NET Core und Blazor sowie bei dem Cross-Platform-UI .NET MAUI. Auch bei den alten Windows-Desktop-Frameworks Windows Forms und WPF gibt es einzelne Verbesserungen.
heise Developer hatte über die Neuerungen in .NET 10.0 jeweils anhand der Preview- und Release-Candidate-1-Versionen berichtet, sofern es dort signifikante Neuerungen gab.
Lesen Sie auch












Entwicklung & Code
Integration-Tests mit TestContainers: Von der Theorie zur Praxis
Wer Integration-Tests schreibt, kennt das Problem: Entweder man arbeitet mit Mocks, die nur begrenzt die Realität abbilden, oder man kämpft mit langsamen, schwer wartbaren Testumgebungen. Mocks haben den Charme, dass Tests schnell durchlaufen und keine externe Infrastruktur benötigen. Doch sie bergen eine Gefahr: Die Tests werden grün, weil die Mocks perfekt zu den Tests passen. Das heißt nicht unbedingt, dass der Code mit echten Systemen funktioniert. Wer garantiert, dass der Mock das Verhalten einer PostgreSQL-Datenbank oder einer Kafka-Queue korrekt abbildet?
Weiterlesen nach der Anzeige
Die Alternative in Form einer dedizierten Testumgebung mit echten Diensten bringt andere Probleme mit sich: Wie setzt man den Zustand zwischen Tests zurück? Wie verhindert man, dass Tests sich gegenseitig beeinflussen? Und wie stellt man sicher, dass die Testumgebung exakt der Produktionsumgebung entspricht?
Mit TestContainers gibt es einen pragmatischen Ausweg: Die Bibliothek startet echte Dienste in wegwerfbaren Docker-Containern. Jeder Test bekommt seine eigene, frische Instanz – komplett isoliert, mit definiertem Startzustand – und nach Testende automatisch aufgeräumt. Der Ansatz ist allerdings nur dann praktikabel, wenn die containerisierten Dienste schnell genug starten. Bei einer Datenbank, die in weniger als einer Sekunde bereit ist, lässt sich für jeden einzelnen Test ein neuer Container hochfahren. Bei Diensten mit mehreren Minuten Startzeit muss man hingegen zu Shared Containers greifen.
Die Idee hinter TestContainers
TestContainers ist ein Projekt zur programmatischen Steuerung von Docker-Containern in Tests. Der Kerngedanke ist simpel: Statt Mocks zu schreiben oder manuelle Testumgebungen zu pflegen, lässt man den Test selbst die benötigte Infrastruktur hochfahren. Nach Testende räumt TestContainers automatisch auf – kein manuelles Stoppen von Containern, keine vergessenen Ressourcen.
Die konzeptionelle Funktionsweise ist schnell erklärt: Ein Test startet einen oder mehrere Container, wartet, bis sie bereit sind, führt die eigentlichen Testschritte durch und stoppt zum Schluss die Container. TestContainers übernimmt dabei die dynamische Portzuordnung, sodass der Test sich nicht um Portkonflikte kümmern muss. Ein integrierter Reaper-Mechanismus sorgt dafür, dass Container auch dann aufgeräumt werden, wenn ein Test abstürzt oder abbricht.
Besonders wichtig sind die Wait Strategies. Ein gestarteter Container ist nämlich nicht automatisch sofort bereit, Anfragen zu verarbeiten. Eine Datenbank braucht beispielsweise Zeit zum Initialisieren, ein Webserver muss zunächst hochfahren. Wait Strategies definieren, wann ein Container als bereit gilt – etwa wenn ein bestimmter Port lauscht, eine HTTP-Anfrage erfolgreich ist oder eine spezifische Logzeile erscheint.
Weiterlesen nach der Anzeige
TestContainers bietet dabei bereits für viele gängige Anwendungen und Dienste vorgefertigte Module wie PostgreSQL, MySQL, Redis, MongoDB und Kafka. Diese Module sind Wrapper-Klassen um die generische Container-API, die bereits sinnvolle Defaults mitbringen, etwa Standardports, typische Umgebungsvariablen und passende Wait Strategies.
Für weniger verbreitete Dienste oder eigene Systeme kann man eigene Wrapper schreiben. Sie bauen auf dem GenericContainer auf und kapseln domänenspezifische Konfiguration. Das praktische Beispiel im Folgenden zeigt, wie unkompliziert die Umsetzung ist: eine Klasse, die das Image, Ports und Kommandozeilenparameter konfiguriert und eine Client-Instanz zurückgibt. Der Wrapper abstrahiert die TestContainers-API und bietet eine auf den konkreten Dienst zugeschnittene Schnittstelle.
Auf den ersten Blick scheint Docker Compose eine Alternative zu sein, das ebenfalls Container für Tests starten kann. Der Unterschied liegt jedoch in der Herangehensweise: Docker Compose arbeitet deklarativ mit YAML-Dateien und richtet typischerweise eine geteilte Umgebung für mehrere Tests ein. TestContainers hingegen ist programmatisch und integriert sich direkt in den Testcode. Jeder Test kann seine eigene Containerkonfiguration haben, Container werden im laufenden Betrieb gestartet und wieder gestoppt.
Ein weiterer Unterschied: Bei Compose muss man explizit darauf achten, Container zwischen verschiedenen Tests zurückzusetzen. Bei TestContainers ist das Design von Anfang an auf Isolation ausgelegt. Jeder Test bekommt neue Container, was sie robuster und unabhängiger voneinander macht.
Mehr Idee als Projekt
TestContainers ist kein monolithisches Open-Source-Projekt, sondern eher eine Idee, die in verschiedenen Programmiersprachen umgesetzt wurde. Es gibt TestContainers für Java, Go, .NET, Node.js, Python, PHP, Rust und zahlreiche weitere Sprachen – entwickelt von verschiedenen Maintainer-Teams mit unterschiedlichen Schwerpunkten.
Das bedeutet, dass beispielsweise Features, die in der Java-Implementierung selbstverständlich sind, in der Python-Version fehlen können – und umgekehrt. Auch die API-Gestaltung unterscheidet sich zwischen den Programmiersprachen, selbst wenn die Konzepte gleich bleiben. Die Dokumentationsqualität variiert und die Reife der Implementierungen ebenso.
Die Community und der Support sind pro Sprache organisiert: Hilfe zur Go-Implementierung findet man in anderen Foren als Hilfe zur PHP-Version.
Man sollte nicht davon ausgehen, dass ein bestimmtes Feature existiert, nur weil man es aus einer anderen Sprache kennt. Ein Blick in die Dokumentation der jeweiligen Implementierung ist unerlässlich. Die gute Nachricht: Die Grundkonzepte sind überall gleich. Wer das Prinzip verstanden hat, findet sich grundsätzlich auch in anderen Implementierungen zügig zurecht.
Ein Praxisbeispiel
Um die Unterschiede zwischen TestContainers-Implementierungen konkret zu zeigen, dient die Datenbank EventSourcingDB als Beispiel. Dabei handelt es sich um eine auf Event Sourcing spezialisierte, von the native web entwickelte Datenbank. Sie ist Closed Source, aber die zugehörigen Client-SDKs (Software Development Kits) sind Open Source auf GitHub verfügbar.
EventSourcingDB steht dabei exemplarisch für einen typischen Service, den man in Anwendungen benötigt – sei es eine Datenbank, eine Message-Queue oder ein anderer Infrastrukturdienst. Der entscheidende Vorteil für unser Beispiel: EventSourcingDB startet in weniger als einer Sekunde, was den „Container pro Test“-Ansatz praktikabel macht. Die Client-SDKs für verschiedene Sprachen enthalten jeweils eine eigene TestContainers-Integration, deren Implementierung sich lohnt anzuschauen.
Dieser Artikel betrachtet die Go- und PHP-Implementierung im Detail. Beide verfolgen konzeptionell den gleichen Ansatz, unterscheiden sich aber in wichtigen Details. Daher eignen sich die Implementierungen gut, um die Unterschiede zwischen TestContainers-Implementierungen zu illustrieren.
Entwicklung & Code
Nun auch Gmail: Nutzer dürfen bald ihre Mail-Adresse ändern
Im Netz sind Hinweise aufgetaucht, dass nun bald auch Gmail-Nutzer die Mail-Adresse für ihren Google-Account ändern dürfen. Bislang konnten Anwender die Adresse nur wechseln, sofern es sich nicht um eine @gmail.com handelte. Auf einer indischen Supportseite kündigt Google jetzt jedoch an, dass sich das ändern soll.
Weiterlesen nach der Anzeige
Auf der Seite in Hindi heißt es: „Wichtiger Hinweis: Die Funktion zum Ändern der E-Mail-Adresse eines Google-Kontos wird schrittweise für alle Nutzer eingeführt. Daher ist diese Option möglicherweise derzeit für Sie nicht verfügbar.“ (übersetzt mit DeepL). Eine Änderung von einer @gmail.com- ist nur in eine andere @gmail.com-Adresse möglich. Die alte Adresse bleibt als Alias bestehen und kann weiter Nachrichten empfangen sowie für das Login verwendet werden.
Auch bereits vorhandene Daten und Nachrichten bleiben erhalten. Eine Änderung ist einmal im Jahr möglich. Dass das Dokument derzeit nur in Indien erscheint, könnte darauf hindeuten, dass Google die Funktion dort vor einem weltweiten Start testen möchte.
(who)
Entwicklung & Code
Ruby 4.0: Viel Umbau unter der Haube, wenig neue Features
Am 21. Dezember 2025 wurde die Sprache Ruby 30 Jahre alt – und seit rund 20 Jahren veröffentlicht ihr Schöpfer, Yukihiro Matsumoto (Matz), jedes Jahr zu Weihnachten eine neue größere Version, am 25. Dezember 2025 sogar eine mit der runden Versionsnummer 4.0. Die ist, soviel sei vorweggenommen, eher Dekoration und dem Jubiläum geschuldet als tatsächlich durch zahlreiche neue Features gerechtfertigt. Doch da Ruby ohnehin keiner strengen semantischen Versionierung folgt und größere Breaking Changes meidet wie der Teufel das Weihwasser (zumindest seit Ruby 1.9), ist das legitim.
Weiterlesen nach der Anzeige

Stefan Wintermeyer ist freier Consultant und Trainer. Er beschäftigt sich mit Phoenix Framework, Ruby on Rails, Webperformance und Asterisk.
Andererseits war 2025 ein spannendes Jahr für Ruby und die Ruby-on-Rails-Welt, so dass dieser Artikel neben dem Blick nach vorn auf Ruby 4 auch auf das zurückblickt, was Ruby in den letzten Monaten technisch erreicht hat und die jetzt erschienene Version in diesem Kontext stellt. Denn obwohl das Vorurteil von Ruby als langsamer Sprache schwer auszurotten ist, hat die Sprache durch langjährige, fortdauernde Entwicklung eine beeindruckende Performance entwickelt.
Der mit Ruby 3.4 noch einmal deutlich optimierte Just-in-Time-Compiler YJIT erreicht in Benchmarks von Shopify eine Leistungssteigerung von 92 Prozent gegenüber dem Interpreter. Der Praxisbeweis kam am Black Friday 2025: Shopify wickelte mit seiner Ruby-on-Rails-Infrastruktur Einkäufe von 81 Millionen Kunden ab. Die Spitzenlast betrug 117 Millionen Requests pro Minute auf den Applikationsservern, während die Datenbanken 53 Millionen Lesezugriffe und 2 Millionen Schreibzugriffe pro Sekunde bewältigten.
Doch auch die Arbeiten an künftigen Performance-Optimierungen gehen weiter voran. Die technisch bedeutendste Neuerung in Ruby 4 ist ZJIT, ein experimenteller Method-Based-JIT-Compiler, den das gleiche Team bei Shopify entwickelt wie YJIT. ZJIT wurde im Mai 2025 nach Matz‘ Zustimmung auf der Konferenz RubyKaigi in den Master-Branch gemerged.
ZJIT unterscheidet sich architektonisch fundamental von YJIT. Während YJIT den Bytecode der Ruby-VM YARV direkt in Low-Level-IR kompiliert und dabei einen Basic-Block nach dem anderen verarbeitet (Lazy Basic Block Versioning), verwendet ZJIT die Static Single Assignment Form (SSA) als High-Level Intermediate Representation (HIR) und kompiliert komplette Methoden auf einmal. Diese Architektur soll breiteren Community-Beiträgen den Weg ebnen und langfristig die Speicherung kompilierten Codes zwischen Programmausführungen ermöglichen.
Der Name ZJIT hat übrigens keine bestimmte Bedeutung, sondern steht einfach für den Nachfolger von YJIT. Intern wird ZJIT als der „wissenschaftliche Nachfolger“ bezeichnet, da die Architektur klassischen Compiler-Lehrbüchern entspricht und damit leichter zu verstehen und zu erweitern ist. Der Compiler ist als experimentell eingestuft und bringt derzeit in produktiven Projekten noch keine Vorteile. Wer sich damit beschäftigen will, muss Ruby mit der Configure-Option --enable-zjit neu bauen und bei der Ausführung Ruby mit der Option --zjit aufrufen.
Syntaktische Feinheiten
Weiterlesen nach der Anzeige
Seit Ruby 3.4 gibt es mit it einen eleganten impliziten Block-Parameter für Einzeiler. Er ist lesbarer als die nummerierten Parameter (_1, _2), die seit Ruby 2.7 existieren, und spart die explizite Parameterdeklaration. Die klassische Deklaration mit explizitem Parameter
users.map { |user| user.name }
und mit impliziten nummeriertem Parameter
users.map { _1.name }
wird also ergänzt durch
users.map { it.name }
Besonders intuitiv und praktisch ist das beim Method Chaining:
files
.select { it.size > 1024 }
.map { it.basename }
.sort { it.downcase }
Der Bezeichner it liest sich wie natürliche Sprache und macht den Code selbstdokumentierend. Wichtig: it funktioniert nur in Blöcken mit genau einem Parameter. Bei mehreren Parametern bleiben _1, _2 oder explizite Namen die richtige Wahl.
Der Splat-Operator (*) entpackt Arrays in einzelne Elemente – etwa um die Elemente aus [1, 2, 3] als drei separate Argumente an eine Methode zu übergeben. Ab Ruby 4.0 ruft der Ausdruck *nil nun nicht mehr nil.to_a auf, sondern liefert direkt ein leeres Array. Das entspricht dem Verhalten des Double-Splat-Operators (**) für Hashes, bei dem **nil bereits seit längerem nil.to_hash nicht mehr aufruft. Diese Vereinheitlichung macht das Verhalten konsistenter und weniger überraschend. Das zeigt sich zum Beispiel, wenn man optionale Elemente, zum Beispiel aus einer Datenbank-Abfrage, in ein Array einfügen will:
optional_tags = nil
Mit Ruby 4.0 funktioniert das sauber – *nil wird zu nichts und muss nicht explizit abgefangen werden:
post = { title: "Ruby 4.0", tags: ["news", *optional_tags, "ruby"] }
#=> { title: "Ruby 4.0", tags: ["news", "ruby"] }
Die binären logischen Operatoren ||, &&, and und or am Zeilenanfang setzen nun die vorherige Zeile fort – analog zum Fluent-Dot-Stil bei Methodenketten. Das ermöglicht elegantere Formatierung von Bedingungen, analog zum Method Chaining:
result = first_condition
second_condition
&& third_condition
Diese Änderung erlaubt bessere Lesbarkeit bei längeren logischen Ausdrücken, ohne Backslashes oder Klammern zur Zeilenfortsetzung verwenden zu müssen.
Ractors: Echte Parallelität für Ruby
Ractors sind Rubys Antwort auf das Problem der echten Parallelität. Anders als Threads, die durch den Global VM Lock (GVL) serialisiert werden, können Ractors tatsächlich parallel auf mehreren CPU-Kernen laufen. Der Name ist ein Kofferwort aus Ruby und Actor – das Konzept basiert auf dem Actor-Modell, bei dem isolierte Einheiten ausschließlich über Nachrichten kommunizieren. Ractors gelten auch in Ruby 4.0 noch als experimentell. Der IRB zeigt eine entsprechende Warnung an.
Der GVL war lange Zeit Rubys größte Schwäche bei CPU-intensiven Aufgaben. Zwar konnten Threads I/O-Operationen parallelisieren, da der Lock bei I/O freigegeben wird, aber Berechnungen liefen immer sequentiell. Ractors umgehen dieses Problem, da sie sich keinen gemeinsamen GVL mehr teilen; jeder Ractor führt den Code unabhängig aus. Ruby synchronisiert intern nur noch an spezifischen Punkten.
Jeder Ractor besitzt seinen eigenen Speicherbereich. Objekte können nicht zwischen Ractors geteilt werden – außer sie sind unveränderlich. Diese strikte Isolation eliminiert Race Conditions by Design (siehe Listing 1):
Listing 1: Lebenszyklus eines Ractor im IRB
$ irb
irb(main):001> r = Ractor.new { 2 + 2 }
(irb):1: warning: Ractor is experimental, and the behavior may change in future versions of Ruby! Also there are many implementation issues.
=> #
irb(main):002> r.join
=> #
irb(main):003> puts r.value
4
=> nil
Das Beispiel zeigt den typischen Ractor-Lebenszyklus: Ractor.new startet einen neuen Ractor mit dem übergebenen Block, join wartet auf dessen Beendigung, und value liefert das Ergebnis – hier die berechnete Summe 4. Bei einer so simplen Berechnung wie 2 + 2 ist der Ractor bereits beendet (terminated), bevor der Aufruf von join erfolgt. Der Vollständigkeit halber zeigt das Beispiel trotzdem den kompletten Ablauf – bei längeren Berechnungen ist join essenziell, um auf das Ergebnis zu warten.
Listing 2: Fibonacci-Zahlen mit Ractors
irb(main):004> def fib(n) = n < 2 ? n : fib(n-1) + fib(n-2)
irb(main):005* ractors = [35, 36, 37, 38].map do |n|
irb(main):006* Ractor.new(n) { fib(it) }
irb(main):007> end
=>
[#,
...
irb(main):008> results = ractors.map(&:value)
=> [9227465, 14930352, 24157817, 39088169]
Ractors zeigen ihre Stärke bei CPU-intensiven Aufgaben. Das Beispiel in Listing 2 demonstriert das. Es berechnet mittelgroße Fibonacci-Zahlen parallel. Auf einem Vier-Kern-System läuft dieses Beispiel nahezu viermal so schnell wie die sequentielle Variante. Im Tarai-Benchmark – einem klassischen Rekursions-Test – erreichen vier parallele Ractors eine 3,87-fache Beschleunigung gegenüber sequentieller Ausführung.
Ruby 4.0 überarbeitet das Ractor-API grundlegend. Die alten Methoden Ractor.yield, Ractor#take und die close_*-Methoden wurden entfernt. An ihre Stelle tritt Ractor::Port für die Kommunikation zwischen Ractors.
Die wichtigste Regel: Ein Port kann nur von dem Ractor empfangen werden, der ihn erstellt hat. Für bidirektionale Kommunikation benötigt daher jeder Ractor seinen eigenen Port (siehe Listing 3)
Listing 3: Kommunikation zwischen Ractors mittels Ports
# Port des Haupt-Ractors für Antworten
main_port = Ractor::Port.new
worker = Ractor.new(main_port) do |reply_port|
# Worker erstellt eigenen Port für eingehende Nachrichten
worker_port = Ractor::Port.new
reply_port.send(worker_port) # teilt seinen Port mit
num = worker_port.receive # empfängt von eigenem Port
reply_port.send(num * 2) # sendet Ergebnis zurück
end
worker_port = main_port.receive # erhält Worker-Port
worker_port.send(21) # sendet Aufgabe
puts main_port.receive # => 42
Nicht alles darf geteilt werden
Die strikte Isolation von Ractors bedeutet, dass nicht jedes Objekt zwischen ihnen ausgetauscht werden kann. Ruby unterscheidet zwischen teilbaren (shareable) und nicht-teilbaren Objekten. Unveränderliche Objekte sind automatisch teilbar:
Ractor.shareable?(42) #=> true
Ractor.shareable?(:symbol) #=> true
Ractor.shareable?("text") #=> false
Per Deep Freeze lassen sich aber Objekte explizit teilbar machen:
config = Ractor.make_shareable({ host: "localhost" })
Neu in Ruby 4.0 sind Shareable Procs und Ractor-lokaler Speicher. Damit lassen sich auch komplexere Szenarien umsetzen, bei denen Funktionen zwischen Ractors geteilt oder Daten innerhalb eines Ractors persistiert werden müssen.
Das Typsystem: RBS und die Zukunft
Ruby war und ist eine dynamisch typisierte Sprache und prüft Variablentypen werden erst zur Laufzeit statt bei der Kompilierung. Doch die Arbeit am optionalen Typsystem zeigt, dass statische Analyse und dynamische Flexibilität koexistieren können. Ruby 4.0 markiert einen wichtigen Meilenstein auf diesem Weg.
RBS (Ruby Signature) ist das offizielle Format für Typdefinitionen. Anders als Annotationen im Quellcode werden RBS-Definitionen in separaten .rbs-Dateien gepflegt – ähnlich wie in TypeScript die .d.ts-Dateien. Dieser Ansatz hat einen entscheidenden Vorteil: Bestehender Ruby-Code muss nicht verändert werden, Teams können Typdefinitionen schrittweise einführen (siehe Listing 4).
Listing 4: Typdefinitionen
# sig/user.rbs
class User
attr_reader name: String # Pflichtfeld: muss String sein
attr_reader age: Integer? # Optional: Integer oder nil
# Rückgabe: void (kein Rückgabewert relevant)
def initialize: (String, ?Integer) -> void
# Prädikatmethode: gibt bool zurück
def adult?: -> bool
end
Fehler finden mit Steep
Steep, der Referenz-Typchecker für RBS, findet Bugs, die sonst erst zur Laufzeit auffallen würden. Ein vollständiges Beispiel zeigen die Listings 5 und 6.
Diese Fehler würden ohne Typsystem erst zur Laufzeit auffallen. Mit RBS und Steep werden sie bereits beim Entwickeln oder spätestens in der CI-Pipeline erkannt. Das spart nicht nur Debugging-Zeit, sondern verhindert auch, dass solche Bugs überhaupt in Produktion gelangen.
Typechecks und Agentic Coding
KI-gestützte Coding-Assistenten wie GitHub Copilot, Cursor oder Claude generieren heute ganze Funktionen und Klassen auf Knopfdruck. Doch Large Language Models halluzinieren – sie erfinden Methodennamen, verwechseln Parameter-Reihenfolgen oder übergeben Strings, wo Integers erwartet werden. Bei dynamisch typisierten Sprachen wie Ruby fallen solche Fehler erst zur Laufzeit auf – im schlimmsten Fall in Produktion.
Hier entfaltet das RBS-Typsystem seinen vollen Wert: Steep fungiert beim Agentic Coding als Sicherheitsnetz. Generiert ein Assistent eine Funktion, die User.find_by_email mit einem Integer statt String aufruft, meldet Steep den Fehler sofort – noch bevor der Code ausgeführt wird. Die Feedback-Schleife verkürzt sich von „Laufzeitfehler nach Deployment“ auf „rote Unterstreichung im Editor“.
Noch wichtiger: RBS-Definitionen verbessern die Qualität der KI-Vorschläge selbst. Coding-Assistenten nutzen den Kontext – und Typsignaturen sind extrem dichter Kontext. Eine RBS-Datei dokumentiert nicht nur, welche Typen eine Methode akzeptiert, sondern kommuniziert auch die Intention des Codes. KI-Modelle, die auf Typdefinitionen trainiert wurden, generieren präziseren Code, weil sie die Constraints verstehen. Das Zusammenspiel in der Praxis:
- Entwickler schreibt RBS-Signatur für neue Methode
- KI-Assistent generiert Implementation basierend auf Signatur
- Steep validiert generierten Code gegen Typdefinition
- Fehler werden sofort sichtbar, Korrektur erfolgt vor Commit
Für Teams, die intensiv mit KI-Assistenten arbeiten, ist ein Typsystem oft keine optionale Ergänzung mehr – es ist die Qualitätssicherung, die verhindert, dass halluzinierter Code in die Codebasis gelangt. Ruby mit RBS bietet hier das Beste aus beiden Welten: die Flexibilität einer dynamischen Sprache mit der Sicherheit statischer Analyse, genau dort, wo man sie braucht.
Die Vision: Graduelle Typisierung
Das langfristige Ziel ist ein Ökosystem der graduellen Typisierung. Entwickler sollen selbst entscheiden können, wie viel statische Analyse sie wünschen – von gar keine bis strikt überall. Anders als TypeScript, das JavaScript mit Typen erweitert, bleibt Ruby syntaktisch unverändert. Die Typen leben in separaten Dateien und sind vollständig optional.
Die Bausteine für dieses Ökosystem sind bereits vorhanden:
- RBS Collection: Eine wachsende Bibliothek von Typdefinitionen für populäre Gems. Die IDE RubyMine lädt diese automatisch herunter und nutzt sie für Autovervollständigung und Fehlerprüfung. In VS Code ist die manuelle Einrichtung via
rbs collection installnötig, danach funktioniert die Autovervollständigung mit der Ruby LSP Extension. - Steep: Der offizielle statische Typchecker, der RBS-Definitionen gegen den Quellcode prüft und in CI-Pipelines integriert werden kann.
- TypeProf: Ein Inferenz-Tool, das aus bestehendem Code automatisch RBS-Definitionen generiert – ideal für die schrittweise Einführung von Typen in Legacy-Projekten.
- Sorbet-Integration: Stripes alternativer Type-Checker erhöht die RBS-Kompatibilität, was die Interoperabilität zwischen beiden Systemen verbessert.
Prism: Der neue Standard-Parser
Ein Parser ist das Programm, das Quellcode liest und in eine strukturierte Darstellung übersetzt – den Abstract Syntax Tree (AST). Erst durch diese Baumstruktur kann der Interpreter verstehen, was der Code bedeutet. Seit Ruby 3.4 ist Prism der Standard-Parser und ersetzt den 30 Jahre alten parse.y. Prism wurde in C99 ohne externe Abhängigkeiten geschrieben, ist fehlertolerant und portabel.
Die Benchmarks sprechen für sich: Prism ist 2,56-mal schneller beim Parsen zu C-Structs gegenüber parse.y und zwölfmal schneller als das Parser-Gem beim AST-Walk. Für Entwickler bedeutet das schnellere IDE-Reaktionen und kürzere CI-Zeiten. Bei Kompatibilitätsproblemen kann der klassische Parser weiterhin aktiviert werden:
ruby --parser=parse.y script.rb
Für die meisten Projekte sollte Prism jedoch problemlos funktionieren.
Ruby-Versionen verwalten – von RVM zu mise
Wer Ruby 4.0 parallel zu älteren Versionen betreiben möchte, braucht einen Version Manager. Diese Tools lösen ein grundlegendes Problem: Jedes Ruby-Projekt kann eine andere Ruby-Version erfordern, und Gems sind nicht zwischen Ruby-Versionen kompatibel.
Version Manager installieren mehrere Ruby-Versionen isoliert voneinander – typischerweise unter ~/.rvm, ~/.asdf oder ~/.local/share/mise. Jede Ruby-Version erhält ihr eigenes Verzeichnis mit einem eigenen gem-Ordner. Fürht man also gem install rails unter Ruby 3.3 aus, landet Rails in einem anderen Verzeichnis als unter Ruby 4.0. Gems müssen daher für jede Ruby-Version separat installiert werden. Bundler (bundle install) erledigt das automatisch basierend auf dem Gemfile.
Welche Ruby-Version für ein Projekt gilt, bestimmt eine Datei im Projektverzeichnis: .ruby-version (einfacher Standard) oder .tool-versions (für asdf und mise, kann auch Node, Python etc. definieren). Wechselt man ins Projektverzeichnis, aktiviert der Version Manager automatisch die richtige Ruby-Version.
Der erste populäre Ruby Version Manager war RVM. Er modifiziert die Shell-Umgebung tiefgreifend und verwaltet zusätzlich Gemsets – isolierte Gem-Umgebungen pro Projekt. Das war vor Bundler (2010) revolutionär, da es keine andere Möglichkeit gab, Gem-Abhängigkeiten pro Projekt zu isolieren. Heute sind Gemsets obsolet, da Bundler diese Aufgabe besser löst.
asdf löste RVM für viele Teams ab. Der entscheidende Vorteil: Ein Tool für alle Sprachen. Über Plugins verwaltet asdf Ruby, Node.js, Python, Elixir und dutzende weitere Runtimes einheitlich. Die .tool-versions-Datei im Projektverzeichnis definiert alle benötigten Versionen. asdf ist weniger invasiv als RVM, in Bash geschrieben und integriert sich sauber in die Shell.
Der aktuelle Trend geht zu mise, benannt nach dem Mise en place bei Köchen. Entwickelt vom asdf-Maintainer Jeff Dickey, ist mise ein kompletter Rewrite in Rust. Die Vorteile: deutlich schneller (Rust statt Bash), kompatibel mit asdf-Plugins und .tool-versions-Dateien, aber auch mit eigenen Backends. mise aktiviert Versionen ohne Shell-Hooks über Shims – ein einfaches mise activate in der Shell-Konfiguration genügt. Zudem kann mise Umgebungsvariablen und Tasks verwalten, was es zu einem universellen Manager für Entwicklungsumgebungen macht. So wird Ruby 4 mit mise installiert:
mise install ruby@4.0.0
mise use ruby@4.0.0
mise activate # einmalig in .bashrc/.zshrc
Für neue Projekte ist mise die beste Wahl. Es ist schnell, modern und vielseitig. Bestehende asdf-Setups funktionieren weiter, mise liest deren Konfiguration. RVM-Nutzer sollten den Umstieg erwägen.
Breaking Changes im Detail
Die praktische Breaking-Change-Bilanz von Ruby 4.0 ist moderat. Fedora bewertet: Da sich mit Ruby 4.0 der soname, also der Bezeichner für Shared Libraries ändert, müssen Pakete mit binären Erweiterungen neu gebaut werden. Da aber große Aufmerksamkeit auf Quellkompatibilität gelegt wurde, sind keine Code-Änderungen nötig. Weitere Breaking Changes sind:
- Binding#local_variables enthält keine nummerierten Parameter mehr
- ObjectSpace._id2ref ist deprecated
- CGI-Library aus Default Gems entfernt (nur cgi/escape bleibt)
- SortedSet entfernt und erfordert die Gem sorted_set
- String-Literal-Warnung: In Dateien ohne frozen_string_literal-Kommentar erzeugt Mutation eine Deprecation-Warnung
Problematisch bleibt die Pessimistic-Constraint-Praxis vieler Gems: ~> 3.x in required_ruby_version verhindert die Installation unter Ruby 4.0, auch wenn der Code ohne Änderungen laufen würde.
Fazit: Evolution statt Revolution
Für Entwickler bedeutet Ruby 4.0 vor allem Kontinuität: Bestehender Code läuft weiter, die Performance verbessert sich weiter (YJIT bietet 92 Prozent Speedup gegenüber dem Interpreter), und das Typsystem reift. Die eigentliche Innovation liegt in der Infrastruktur für die nächste Dekade – ZJIT, Modular GC und die verbesserten Ractors werden Ruby für die kommenden Jahre wettbewerbsfähig halten.
(ulw)


-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenIllustrierte Reise nach New York City › PAGE online
-

 Künstliche Intelligenzvor 3 Monaten
Künstliche Intelligenzvor 3 MonatenAus Softwarefehlern lernen – Teil 3: Eine Marssonde gerät außer Kontrolle
-
Künstliche Intelligenzvor 3 Monaten
Top 10: Die beste kabellose Überwachungskamera im Test
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenSK Rapid Wien erneuert visuelle Identität
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenNeue PC-Spiele im November 2025: „Anno 117: Pax Romana“
-

 Entwicklung & Codevor 1 Monat
Entwicklung & Codevor 1 MonatKommandozeile adé: Praktische, grafische Git-Verwaltung für den Mac
-

 Künstliche Intelligenzvor 2 Monaten
Künstliche Intelligenzvor 2 MonatenDonnerstag: Deutsches Flugtaxi-Start-up am Ende, KI-Rechenzentren mit ARM-Chips
-

 UX/UI & Webdesignvor 2 Monaten
UX/UI & Webdesignvor 2 MonatenArndt Benedikt rebranded GreatVita › PAGE online
